
Flare Removal Model Based on Sparse-UFormer Networks

Abstract
:1. Introduction
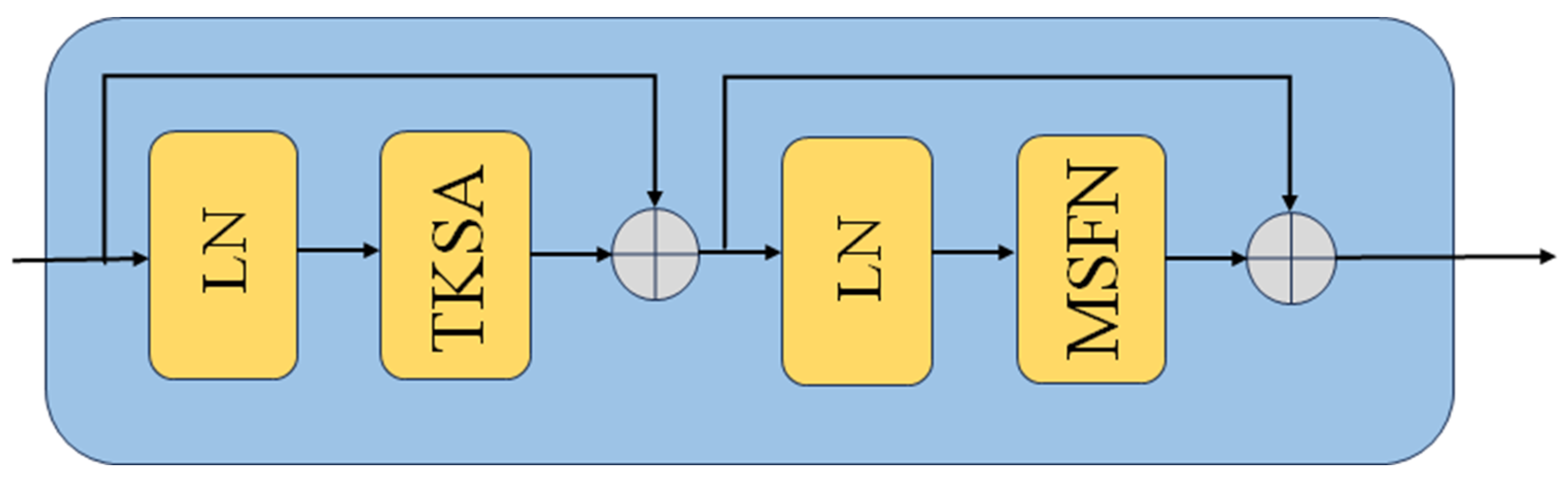
- In order to develop a novel flare removal method, we replaced the W-MSA and LeFF modules in the traditional UFormer encoding structure with the TKSA and MSFN modules.
- We design a novel loss function and achieve a significant improvement in the experimental quantitative metrics.
- We perform extensive experiments on different benchmarks to compare our method with state-of-the-art methods both qualitatively and quantitatively.
2. Model
2.1. Overall Pipeline
2.2. Sparse Transformer Block
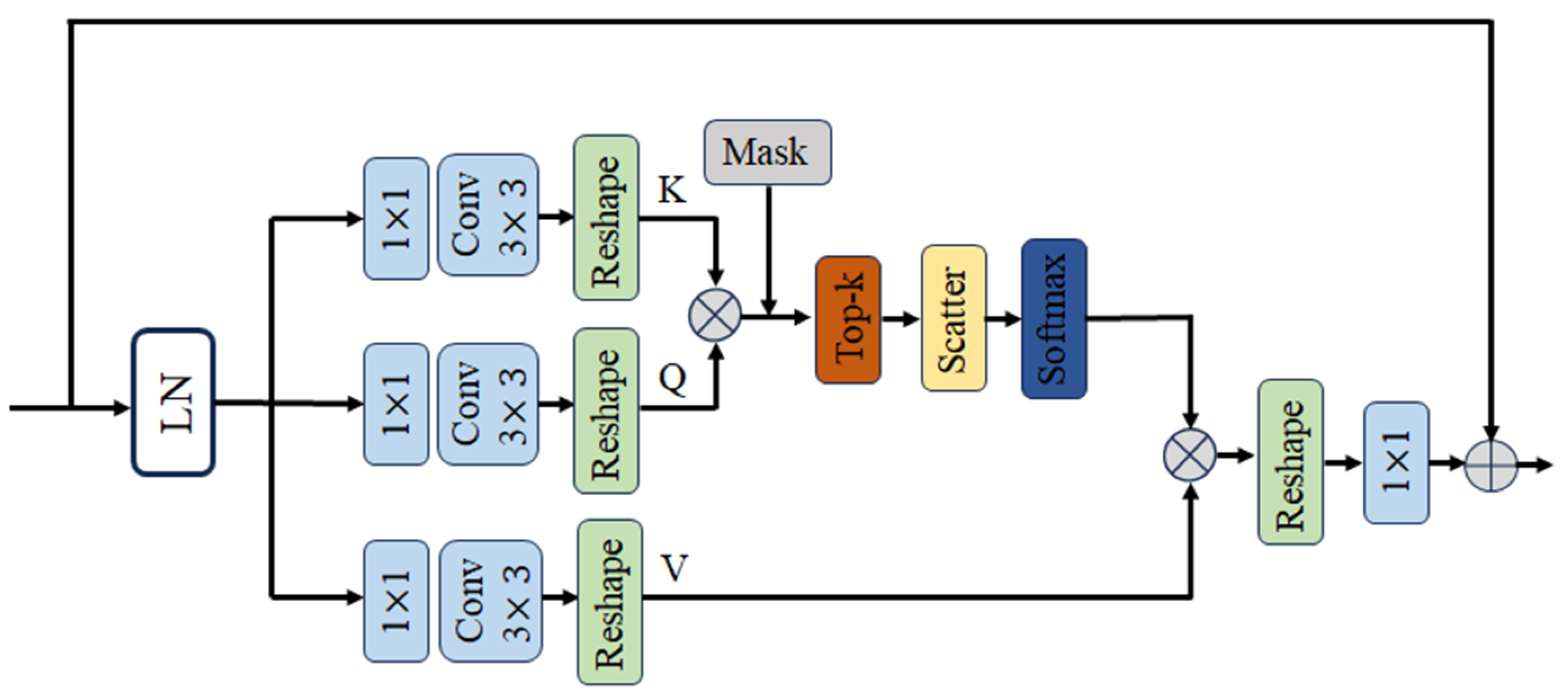
2.2.1. Top-k Sparse Attention Module
2.2.2. Multi-Scale Feedforward Convolutional Network Module
3. Loss Function
4. Dataset
5. Experiment and Result
5.1. Parameter Settings
5.2. Evaluation Metrics
5.3. Experimental Result
5.3.1. Quantitative Assessment Results
5.3.2. Qualitative Assessment Results
5.3.3. Ablation Study
5.3.4. Others’ Analyses
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Wu, Y.; He, Q.; Xue, T.; Garg, R.; Chen, J. How to Train Neural Networks for Flare Removal. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2239–2247. [Google Scholar]
- Dai, Y.; Li, C.; Zhou, S.; Feng, R.; Loy, C.C. Flare7k: A Phenomenological Nighttime Flare Removal Dataset. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: La Jolla, CA, USA, 2022; Volume 35, pp. 3926–3937. [Google Scholar]
- Blahnik, V.; Voelker, B. About the Reduction of Reflections for Camera Lenses; Zeiss: Oberkochen, Germany, 2016. [Google Scholar]
- Raut, H.K.; Ganesh, V.A.; Nair, A.S.; Ramakrishna, S. Anti-reflective Coatings: A Critical, In-depth Review. Energy Environ. Sci. 2011, 4, 3779–3804. [Google Scholar] [CrossRef]
- Faulkner, K.; Kotre, C.J.; Louka, M. Veiling Glare Deconvolution of Images Produced by X-ray Image Intensifiers. In Proceedings of the Third International Conference on Image Processing and Its Applications, Warwick, UK, 18–20 July 1989; IET: London, UK, 1989; pp. 669–673. [Google Scholar]
- Seibert, J.A.; Nalcioglu, O.; Roeck, W. Removal of Image Intensifier Veiling Glare by Mathematical Deconvolution Techniques. Med. Phys. 1985, 12, 281–288. [Google Scholar] [CrossRef] [PubMed]
- Chabert, F. Automated Lens Flare Removal; Technical Report; Department of Electrical Engineering, Stanford University: Stanford, CA, USA, 2015. [Google Scholar]
- OpenCV. Blob Detection. Available online: https://opencv.org/documentation/image-processing/blob-detection.html (accessed on 10 October 2023).
- Criminisi, A.; Pérez, P.; Toyama, K. Region Filling and Object Removal by Exemplar-based Image Inpainting. IEEE Trans. Image Process. 2004, 13, 1200–1212. [Google Scholar] [CrossRef] [PubMed]
- Fan, Q.; Yang, J.; Hua, G.; Chen, B.; Wipf, D. A Generic Deep Architecture for Single Image Reflection Removal and Image Smoothing. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3238–3247. [Google Scholar]
- Li, C.; Yang, Y.; He, K.; Lin, S.; Hopcroft, J.E. Single Image Reflection Removal through Cascaded Refinement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3565–3574. [Google Scholar]
- Zhang, X.; Ng, R.; Chen, Q. Single Image Reflection Separation with Perceptual Losses. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4786–4794. [Google Scholar]
- Qian, R.; Tan, R.T.; Yang, W.; Su, J.; Liu, J. Attentive Generative Adversarial Network for Raindrop Removal from a Single Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2482–2491. [Google Scholar]
- Wei, W.; Meng, D.; Zhao, Q.; Xu, Z.; Wu, Y. Semi-supervised Transfer Learning for Image Rain Removal. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3877–3886. [Google Scholar]
- Qiao, X.; Hancke, G.P.; Lau, R.W.H. Light Source Guided Single-image Flare Removal from Unpaired Data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4177–4185. [Google Scholar]
- Dai, Y.; Li, C.; Zhou, S.; Feng, R.; Luo, Y.; Loy, C.C. Flare7k++: Mixing Synthetic and Real Datasets for Nighttime Flare Removal and Beyond. arXiv Preprint 2023, arXiv:2306.04236. [Google Scholar]
- Chen, L.; Lu, X.; Zhang, J.; Chu, X.; Chen, C. Hinet: Half Instance Normalization Network for Image Restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 182–192. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Multi-stage Progressive Image Restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 14821–14831. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient Transformer for High-resolution Image Restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Wang, Z.; Cun, X.; Bao, J.; Zhou, W.; Liu, J.; Li, H. Uformer: A General U-shaped Transformer for Image Restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17683–17693. [Google Scholar]
- Chen, X.; Li, H.; Li, M.; Pan, J. Learning a Sparse Transformer Network for Effective Image Deraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 5896–5905. [Google Scholar]
- Xiao, J.; Fu, X.; Liu, A.; Wu, F.; Zha, Z.-J. Image De-raining Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 12978–12995. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Xing, X.; Wu, Y.; Su, Z.; Chen, J. DCSFN: Deep Cross-Scale Fusion Network for Single Image Rain Removal. In Proceedings of the ACM MM, Seattle, WA, USA, 12–16 October 2020; pp. 1643–1651. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5–9, 2015, Proceedings, Part III; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; Volume 18, pp. 234–241. [Google Scholar]
- Kotp, Y.; Torki, M. Flare-Free Vision: Empowering Uformer with Depth Insights. In Proceedings of the ICASSP 2024–2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; IEEE: New York, NY, USA, 2024; pp. 2565–2569. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Transformation Type | Transformation Range |
|---|---|
| Gamma transformation | [1.8, 2, 2] |
| Rotation | ] |
| Translation | [−300, 300] |
| Cutout | |
| Scaling | [0.8, 1.5] |
| Blurring | [0.1, 3] |
| Flip | Horizontal or vertical |
| Color shift | [−0.02, 0.02] |
| RGB adjustment | [0.5, 1.2] |
| Gaussian noise |
| Models | PSNR | SSIM | LPIPS | G-PSNR | S-PSNR |
|---|---|---|---|---|---|
| U-Net [24] | 27.189 | 0.894 | 0.0452 | 23.527 | 22.647 |
| HINet [17] | 27.548 | 0.892 | 0.0464 | 24.081 | 22.907 |
| MPRNet [18] | 27.036 | 0.893 | 0.0481 | 23.490 | 22.267 |
| Restormer [19] | 27.597 | 0.897 | 0.0447 | 23.828 | 22.452 |
| UFormer [20] | 27.633 | 0.894 | 0.0428 | 23.949 | 22.603 |
| Uformer + normalised depth [21] | 27.662 | 0.897 | 0.0422 | 23.987 | 22.847 |
| Sparse-UFormer (ours) | 27.976 | 0.906 | 0.0413 | 24.243 | 23.529 |
| Models | PSNR | SSIM | LPIPS | G-PSNR | S-PSNR |
|---|---|---|---|---|---|
| UFormer [20] | 29.498 | 0.962 | 0.0210 | 24.686 | 24.155 |
| Uformer + Normalised Depth [21] | 29.573 | 0.961 | 0.0205 | 24.879 | 24.458 |
| Sparse-UFormer (ours) | 29.717 | 0.967 | 0.0198 | 24.525 | 25.014 |
| Models | PSNR | SSIM | LPIPS | G-PSNR | S-PSNR |
|---|---|---|---|---|---|
| Base | 27.633 | 0.894 | 0.0428 | 23.949 | 22.603 |
| Without loss | 27.823 | 0.895 | 0.0418 | 24.082 | 23.120 |
| Without sparse | 27.812 | 0.902 | 0.0411 | 24.201 | 23.293 |
| Sparse-UFormer (ours) | 27.976 | 0.906 | 0.0413 | 24.243 | 23.529 |
| Pictures | Input | Base | Ours |
|---|---|---|---|
| Picture 1 | 57 | 13 | 2 |
| Picture 2 | 58 | 2 | 2 |
| Picture 3 | 59 | 1 | 4 |
| Picture 4 | 59 | 16 | 9 |
| Picture 5 | 66 | 15 | 3 |
| Avg | 60 | 9 | 4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, S.; Liu, F.; Bai, Y.; Han, H.; Wang, J.; Zhang, N. Flare Removal Model Based on Sparse-UFormer Networks. Entropy 2024, 26, 627. https://doi.org/10.3390/e26080627
Wu S, Liu F, Bai Y, Han H, Wang J, Zhang N. Flare Removal Model Based on Sparse-UFormer Networks. Entropy. 2024; 26(8):627. https://doi.org/10.3390/e26080627
Chicago/Turabian StyleWu, Siqi, Fei Liu, Yu Bai, Houzeng Han, Jian Wang, and Ning Zhang. 2024. "Flare Removal Model Based on Sparse-UFormer Networks" Entropy 26, no. 8: 627. https://doi.org/10.3390/e26080627