
An Evaluation Model for Node Influence Based on Heuristic Spatiotemporal Features

Abstract
1. Introduction
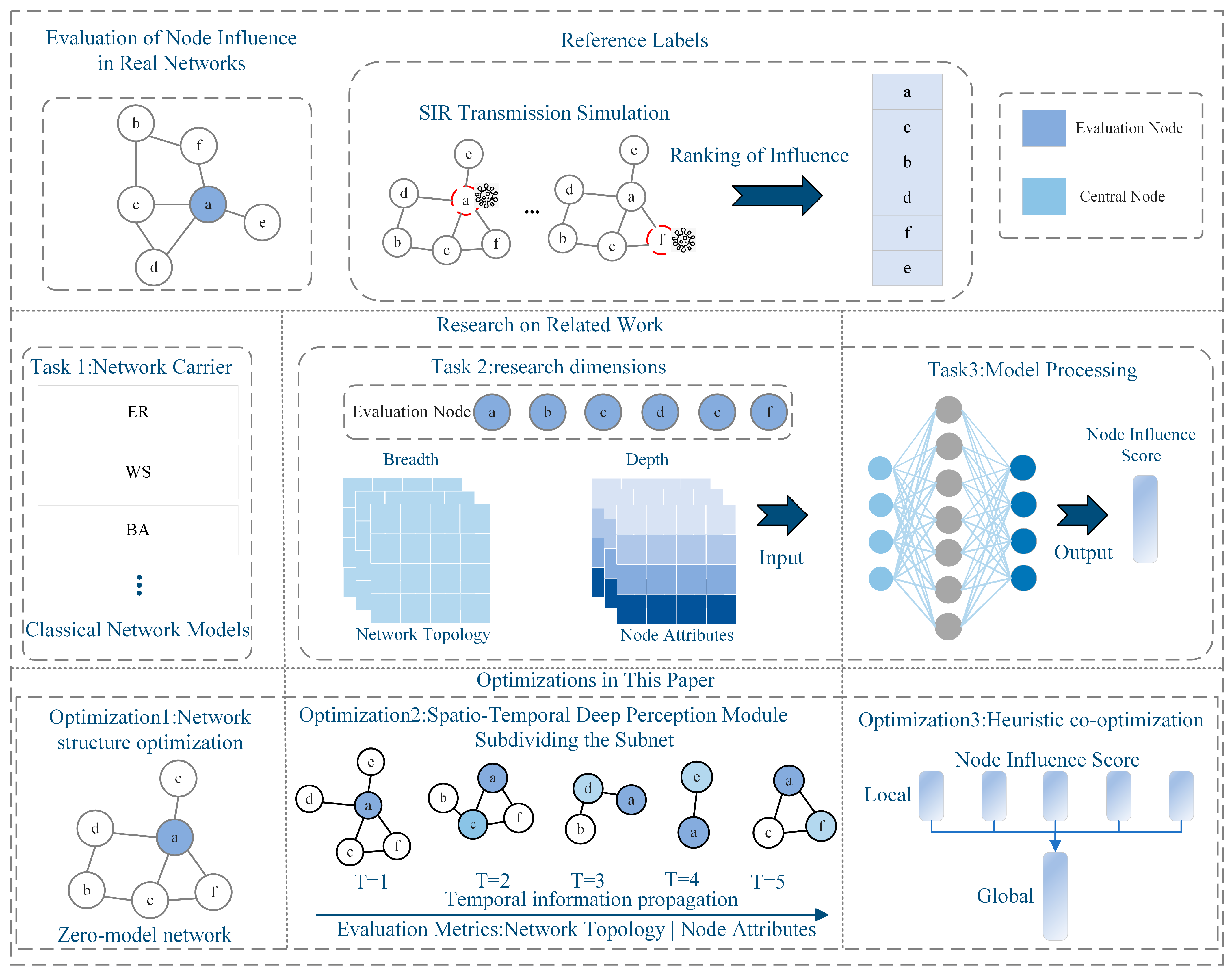
- Network structure optimization: We introduce the zero-model method to copy the empirical network topology, reduce the noise interference caused by network structure redundancy, and improve the learning ability of the assessment model for the empirical network topology characteristics.
- Spatiotemporal depth perception module: This divides the subnetwork and feature construction to enhance the differentiation of node influence, strengthens the spatiotemporal depth of node influence perception, quantifies the node influence, and improves the robustness of the assessment.
- Heuristic co-optimization: Heuristic evaluation algorithms are used to co-optimize the influence strength of nodes at different stages and quantify the influence of nodes through a nonlinear optimization function.
2. Model Description
- (1)
- Node influence label construction: Based on the SIR propagation model, the sequence of node influence scores is obtained.
- (2)
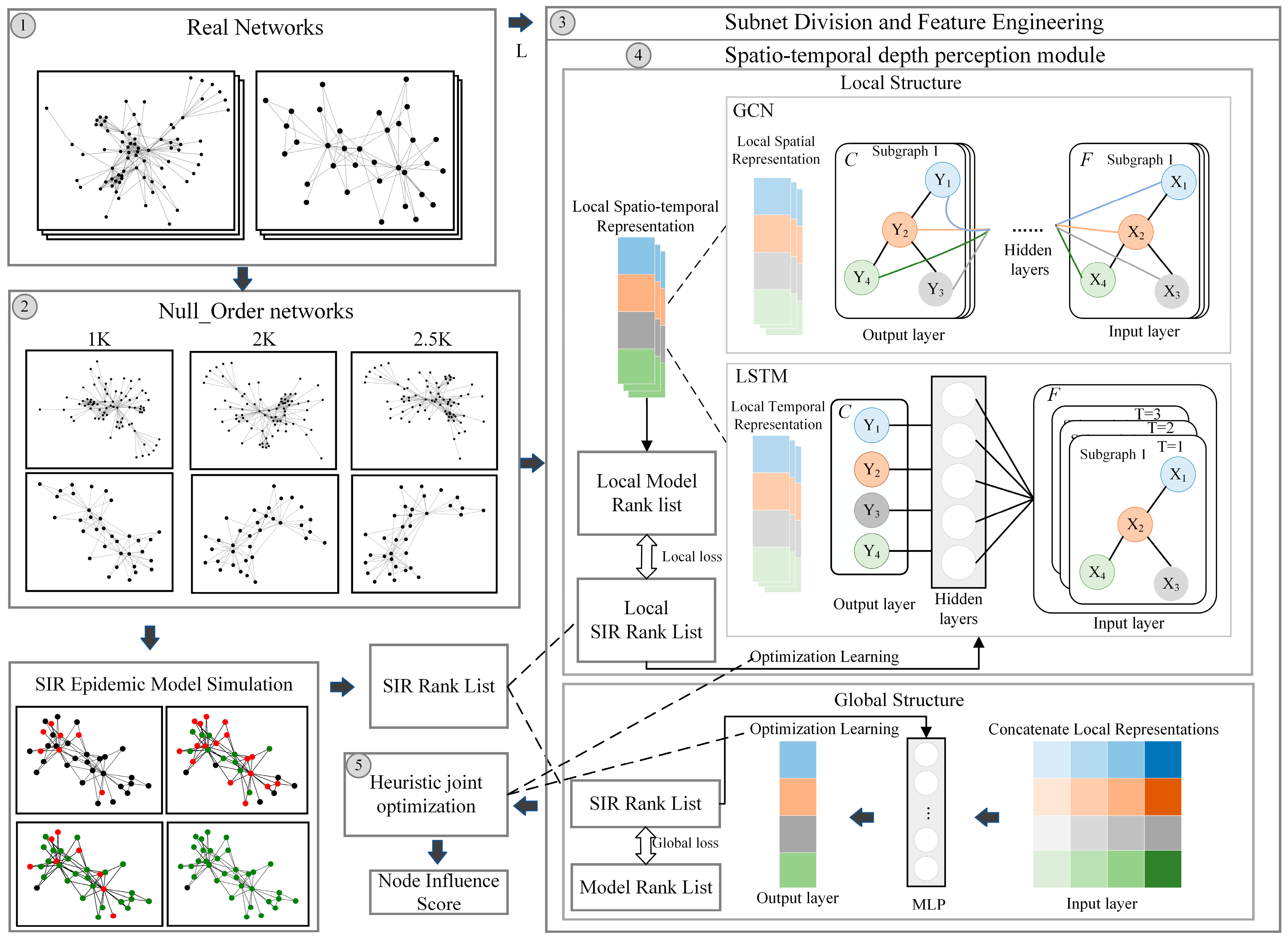
- High-order zero-model network construction: The zero-model concept is introduced, the empirical network topology is copied to generate the training network , and the noise perturbation of the network structure redundancy is reduced.
- (3)
- Subnetwork delineation: The network nodes are traversed and the temporal association subnetwork is delineated, centered on each node; is the subnetwork evaluation sequence.
- (4)
- Node feature construction: Based on the local subnetwork sequence , we use the classical centrality index to characterize the different state neighborhood structures and feature differences of the nodes as the spatial features of the nodes; at the same time, we fill in the results of the subnetwork processed at different moments as the node influence historical a priori information , which is used as the node influence temporal features.
- (5)
- Spatiotemporal depth perception module: This has a built-in local and global two-layer structure. The local structure uses the GCN network to process node spatial features and the LSTM network to obtain historical information about changes in node influence.
- (6)
- The global structure is based on a heuristic algorithm that analyzes the likelihood of the influence distribution of nodes at different assessment stages and quantifies the node influence on a weighted average basis to achieve joint local and global optimization.
2.1. Node Influence Label Construction
| Algorithm 1: SIR Propagation |
| Input: network |
| Output: |
| 1: for in G.nodes(): |
| 2: , , , |
| 3: while : |
| 4: while : |
| 5: Node infects neighbors with , → |
| 6: update , |
| 7: end while |
| 8: , |
| 9: end while |
| 10: append to |
| 11: end for |
2.2. Higher-Order Zero-Model Network Construction
2.3. Subnetwork Delineation
2.4. Node Feature Construction
2.5. Spatiotemporal Depth Perception Module
2.5.1. Local Structure
2.5.2. Global Structure
| Algorithm 2: Heuristic Joint Optimization |
| Input: , , |
| Output: |
| 1: while Epoch > 0: |
| 2: , |
| 3: for , , in , , : |
| 4: , , , , |
| 5: while : |
| 6: |
| 7: , |
| 8: , |
| 9: If : |
| 10: record Record , fill with . |
| 11: end if |
| 12: Backpropagate the and update model parameters. |
| 13: |
| 14: end while |
| 15: end for |
| 16: |
| 17: |
| 18: Backpropagate the and update model parameters. |
| 19: Epoch = Epoch − 1 |
| 20: end while |
2.6. Loss Function
3. Dataset
4. Experimental Analysis
4.1. Evaluation Indicators
4.2. Baseline Model
4.3. Correlation Analysis
- (1)
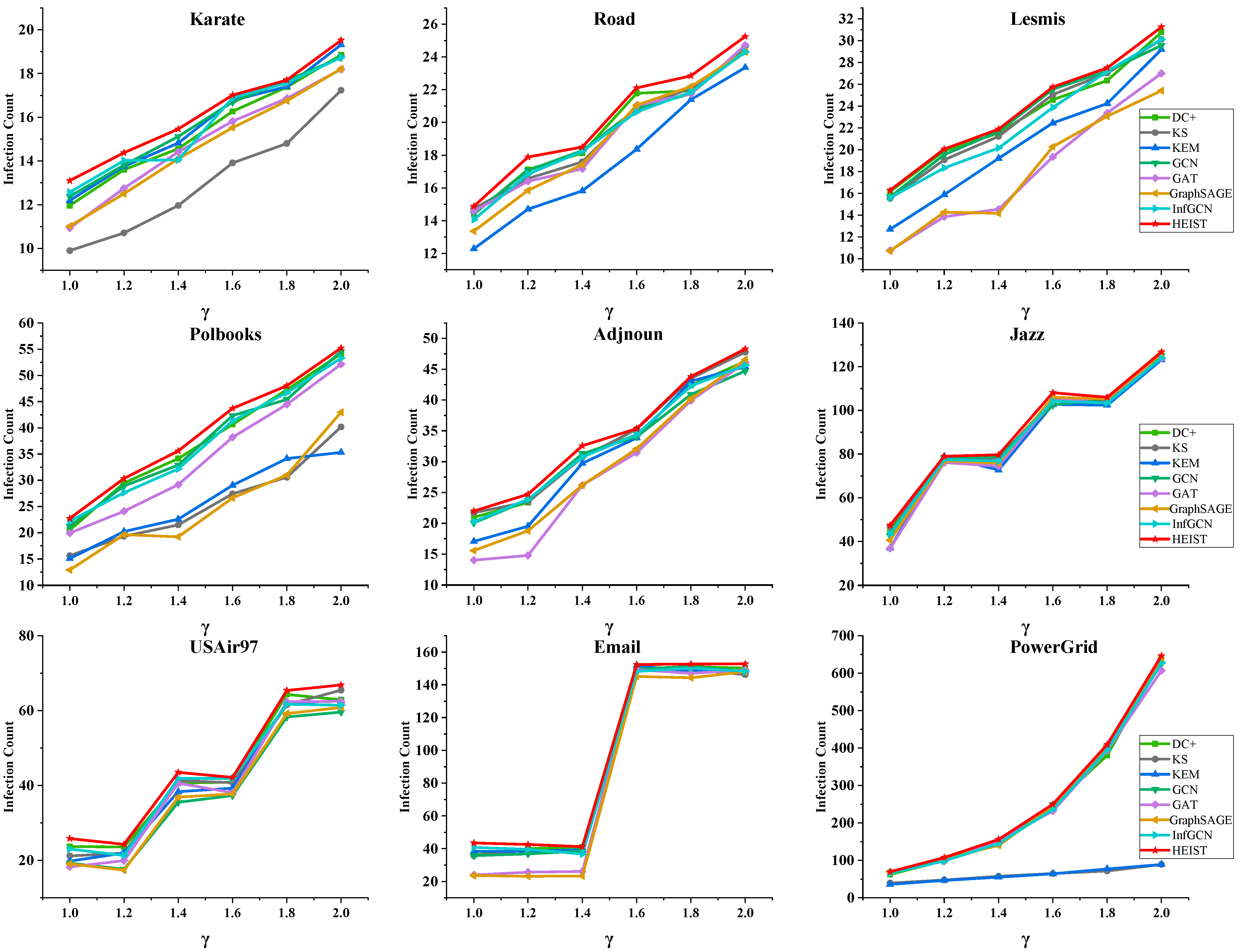
- The performance of the HEIST model is closely related to the scale of subnetwork division; it performs well on datasets such as Karate, Road, Lesmis, Polbooks, Jazz, and PowerGrid, thanks to its dense connectivity relations and high coverage of subnetworks to networks, which enable the model to comprehensively capture the spatial information within the subnetworks and the temporal variations between subnetworks. On the contrary, in scale-free networks such as USAir97 and Email, the degree of front-end nodes is extremely high, which facilitates feature learning, but the large-scale subnetwork division introduces too much filler data and interferes with the model evaluation. However, the model still has advantages over other model-like methods, with the Kendall coefficients all stable above 0.86.
- (2)
- The performance of the HEIST model in Adjnoun networks is affected by low clustering coefficients, which leads to dispersed node relationships and limited tight group formation, which in turn challenges the effectiveness of the local unit feature learning. Nonetheless, the model still outperforms similar methods, highlighting the advantages of modeling based on subnetwork features rather than global features in enhancing the assessment.
- (3)
- When dealing with large networks such as PowerGrid, the HEIST model demonstrates significant advantages over other deep learning methods. The unique distribution of average degree and clustering coefficients in this network challenges the traditional model based on neighboring node feature evaluation, leading to a decrease in the evaluation accuracy. The HEIST model fully captures the network characteristics by setting a smaller subnetwork size and effectively aggregating the local feature information to construct the global features, which results in a better evaluation result.
4.4. Analysis of Maximum Influence Node Propagation Experiment
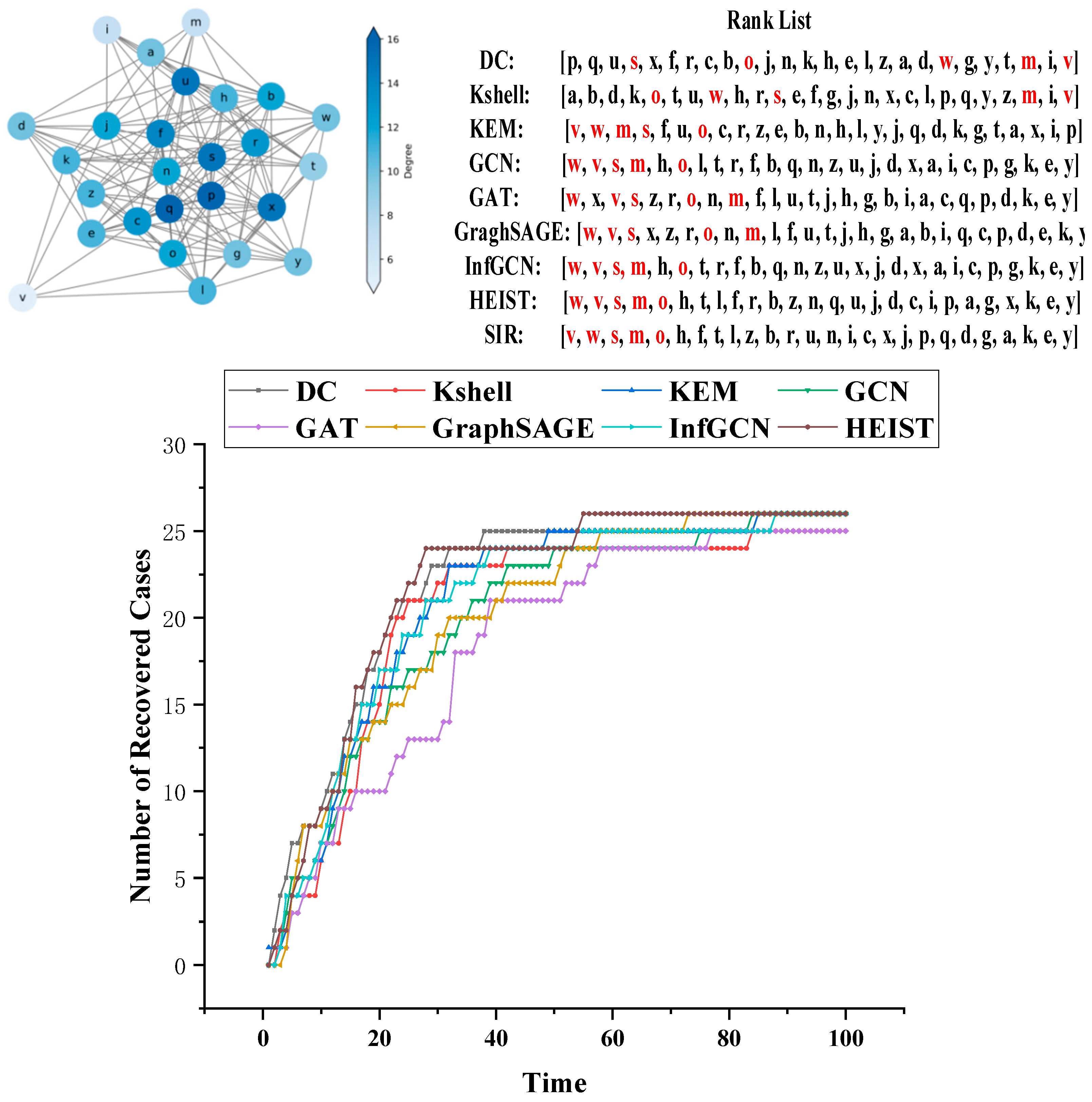
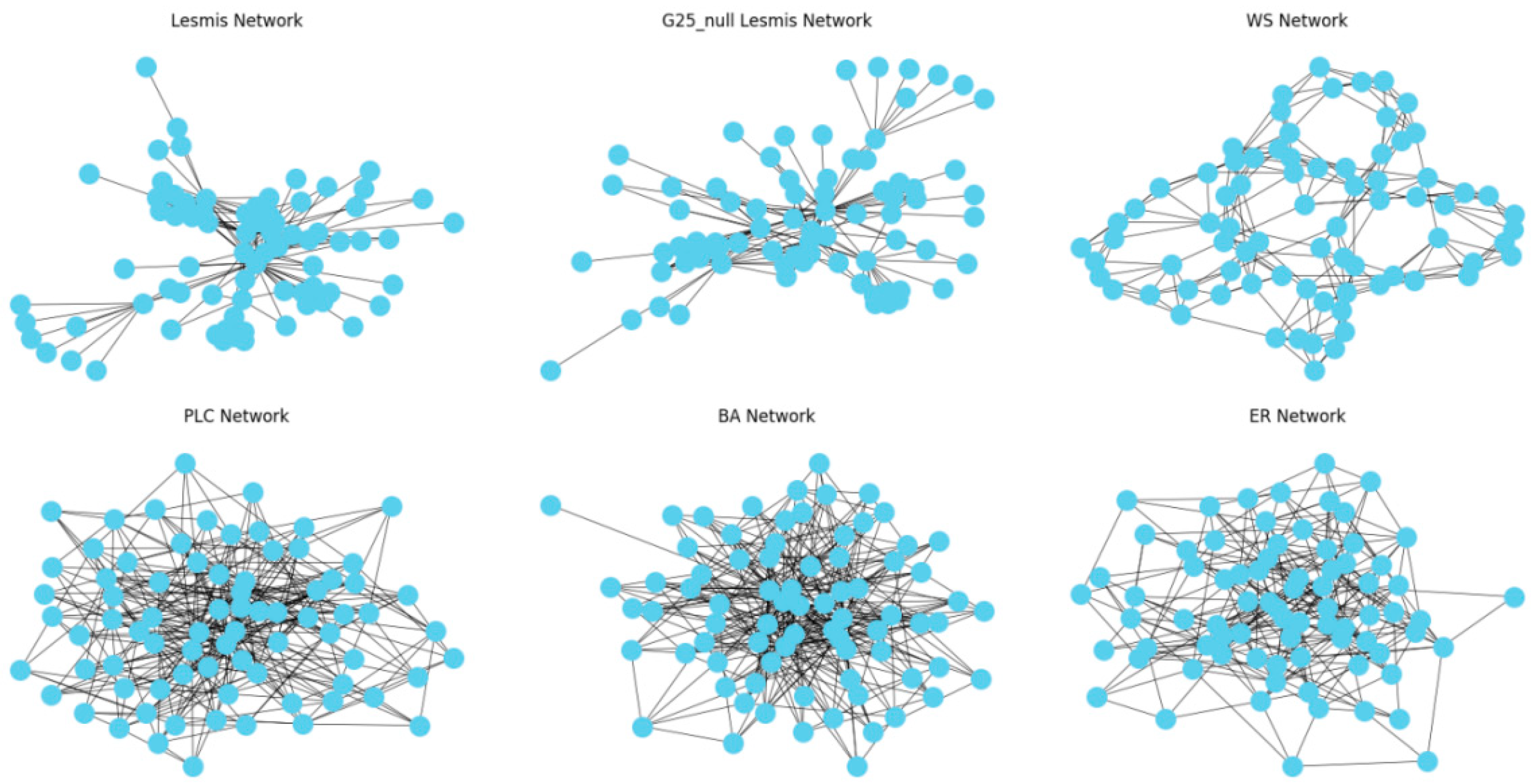
4.5. Visualization of Experiments on Small Networks
4.6. Hyperparametric Analysis
Analysis of Local Structural Parameters
4.7. Ablation Experiment
4.7.1. Training Network Ablation Experiment
- (1)
- The training results of the training networks based on ER stochastic network, BA scale-free network, WS small-world network, and PLC power-law cluster network are significantly affected by the randomness of the generation rules and show a degree of uncertainty. On the contrary, as the order of the zero-model network increases, the constraints increase, the training network gradually approaches the real network characteristics, and the training test results tend to be stable, indicating that the model learns more accurate features.
- (2)
- ER networks have limited internode variability, which limits the model’s ability to capture the subtle features of complex networks, leading to significant differences between the training and testing results. WS networks, on the other hand, exhibit clear association structures with significant internode variability, but the phenomenon of overlapping associations may increase the training complexity and be affected by the structure of the real network, e.g., in the adjnoun network (with a low clustering coefficient of 0.17). Using high-clustering WS network training may lead to poor test performance.
- (3)
- In power-law distribution networks such as BA scale-free networks and PLC power-law cluster networks, the scarcity of highly influential nodes means that the selected scale L often exceeds the average degree range when dividing the local network, resulting in a large amount of filler data, introducing noise to the model, and affecting the stability of the test results. In particular, local networks centered on end nodes may affect the overall training effect due to the loss of feature information, a phenomenon reflected in several datasets such as karate, road, polbooks, and adjnoun.
4.7.2. Spatiotemporal Feature Ablation Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Belfin, R.V.; Bródka, P. Overlapping community detection using superior seed set selection in social networks. Comput. Electr. Eng. 2018, 70, 1074–1083. [Google Scholar]
- Chandran, J.; Viswanatham, V.M. Dynamic node influence tracking based influence maximization on dynamic social networks. Microprocess. Microsyst. 2022, 95, 104689. [Google Scholar] [CrossRef]
- Huang, J.; Xiong, M.; Wang, J. Route choice and parallel routes in subway Networks: A comparative analysis of Beijing and Shanghai. Tunn. Undergr. Space Technol. 2022, 128, 104635. [Google Scholar] [CrossRef]
- Kermack, W.O.; McKendrick, A.G. Contributions to the mathematical theory of epidemics--I. 1927. Bull. Math. Biol. 1991, 53, 33–55. [Google Scholar] [CrossRef] [PubMed]
- Fu, L.; Yang, Q.; Liu, Z.; Liu, X.; Wang, Z. Risk identification of major infectious disease epidemics based on complex network theory. Int. J. Disaster Risk Reduct. 2022, 78, 103155. [Google Scholar] [CrossRef]
- Gao, S.; Ma, J.; Chen, Z.; Wang, G.; Xing, C. Ranking the spreading ability of nodes in complex networks based on local structure. Phys. A Stat. Mech. Its Appl. 2014, 403, 130–147. [Google Scholar] [CrossRef]
- Kitsak, M.; Gallos, L.K.; Havlin, S.; Liljeros, F.; Muchnik, L.; Stanley, H.E.; Makse, H.A. Identification of influential spreaders in complex networks. Nat. Phys. 2010, 6, 888–893. [Google Scholar] [CrossRef]
- Chen, D.; Su, H. Identification of influential nodes in complex networks with degree and average neighbor degree. IEEE J. Emerg. Sel. Top. Circuits Syst. 2023, 13, 734–742. [Google Scholar] [CrossRef]
- Flores, J.; Romance, M. On eigenvector-like centralities for temporal networks: Discrete vs. continuous time scales. J. Comput. Appl. Math. 2018, 330, 1041–1051. [Google Scholar] [CrossRef]
- Zhang, H.; Zhong, S.; Deng, Y.; Cheong, K.H. LFIC: Identifying influential nodes in complex networks by local fuzzy information centrality. IEEE Trans. Fuzzy Syst. 2021, 30, 3284–3296. [Google Scholar] [CrossRef]
- Yuan, H.L.; Feng, C. Ranking and Recognition of Influential Nodes Based on k-shell Entropy. Comput. Sci. 2022, 49, 226–230. [Google Scholar]
- Yang, X.; Xiao, F. An improved gravity model to identify in-fluential nodes in complex networks based on K-shell method. Knowl. Based Syst. 2021, 227, 107198. [Google Scholar] [CrossRef]
- Chawla, P.; Mangal, R.; Chandrashekar, C.M. Discrete-time quantum walk algorithm for ranking nodes on a network. Quantum Inf. Process. 2020, 19, 1–21. [Google Scholar] [CrossRef]
- Zhao, X.; Yu, H.; Huang, R.; Liu, S.; Hu, N.; Cao, X. A novel higher-order neural network framework based on motifs attention for identifying critical nodes. Phys. A Stat. Mech. Its Appl. 2023, 629, 129194. [Google Scholar] [CrossRef]
- Yang, S.; Zhu, W.; Zhang, K.; Diao, Y.; Bai, Y. Influence Maximization in Temporal Social Networks with the Mixed K-Shell Method. Electronics 2024, 13, 2533. [Google Scholar] [CrossRef]
- Xi, Y.; Cui, X. Identifying Influential Nodes in Complex Networks Based on Information Entropy and Relationship Strength. Entropy 2023, 25, 754. [Google Scholar] [CrossRef]
- Yu, Y.; Zhou, B.; Chen, L.; Gao, T.; Liu, J. Identifying Important Nodes in Complex Networks Based on Node Propagation Entropy. Entropy 2022, 24, 275. [Google Scholar] [CrossRef]
- Wu, Y.; Ren, Y.; Dong, A.; Zhou, A.; Wu, X.; Zheng, S. Key Nodes Identification Method Based on Neighborhood K-shell Distribution. Comput. Eng. Appl. 2024, 60, 87–95. [Google Scholar] [CrossRef]
- Inuwa-Dutse, I.; Liptrott, M.; Korkontzelos, I. Detection of spam-posting accounts on Twitter. Neurocomputing 2018, 315, 496–511. [Google Scholar] [CrossRef]
- Zhao, G.; Jia, P.; Huang, C.; Zhou, A.; Fang, Y. A machine learning based framework for identifying influential nodes in complex networks. IEEE Access 2020, 8, 65462–65471. [Google Scholar] [CrossRef]
- Wen, X.; Tu, C.; Wu, M.; Jiang, X. Fast ranking nodes importance in complex networks based on LS-SVM method. Phys. A Stat. Mech. Its Appl. 2018, 506, 11–23. [Google Scholar] [CrossRef]
- Qiu, L.; Zhang, J.; Tian, X. Ranking influential nodes in complex networks based on local and global structures. Appl. Intell. 2021, 51, 4394–4407. [Google Scholar] [CrossRef]
- Zhang, M.; Wang, X.; Jin, L.; Song, M.; Li, Z. A new approach for evaluating node importance in complex networks via deep learning methods. Neurocomputing 2022, 497, 13–27. [Google Scholar] [CrossRef]
- Fan, C.; Zeng, L.; Ding, Y.; Chen, M.; Sun, Y.; Liu, Z. Learning to identify high betweenness centrality nodes from scratch: A novel graph neural network approach. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 559–568. [Google Scholar]
- Zhao, G.; Jia, P.; Zhou, A.; Zhang, B. InfGCN: Identifying influential nodes in complex networks with graph convolutional networks. Neurocomputing 2020, 414, 18–26. [Google Scholar] [CrossRef]
- Qu, H.; Song, Y.-R.; Li, R.; Li, M. GNR: A universal and efficient node ranking model for various tasks based on graph neural networks. Phys. A Stat. Mech. Its Appl. 2023, 632, 129339. [Google Scholar] [CrossRef]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive Representation Learning on Large Graphs. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; pp. 1025–1035. [Google Scholar]
- Kumar, S.; Mallik, A.; Panda, B.S. Influence maximization in social networks using transfer learning via graph-based LSTM. Expert Syst. Appl. 2023, 212, 118770. [Google Scholar] [CrossRef]
- Zhu, J.; Wang, L. Identifying influential nodes in complex networks based on node itself and neighbor layer information. Symmetry 2021, 13, 1570. [Google Scholar] [CrossRef]
- Xi, Y.; Wu, X.; Cui, X. Node Influence Ranking Model Based on Transformer. Comput. Sci. 2024, 51, 106–116. [Google Scholar]
- Gjoka, M.; Kurant, M.; Markopoulou, A. 2.5 k-graphs: From Sampling to Generation. In Proceedings of the 32nd IEEE International Conference on Computer Communications, Turin, Italy, 14–19 April 2013; pp. 1968–1976. [Google Scholar]
- Mahadevan, P.; Hubble, C.; Krioukov, D.; Huffaker, B.; Vahdat, A. Orbis: Rescaling degree correlations to generate annotated internet topologies. In Proceedings of the 2007 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, Kyoto, Japan, 27–31 August 2007; pp. 325–336. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Zero Model | Restrictive Condition |
|---|---|
| , . | |
| Features | Descriptions |
|---|---|
| Degree centrality (DC) | Measures the number of direct connections a node has in the network and reflects the direct influence and activity of the node. |
| Eigenvector centrality (EC) | Measures the pattern of connections between a node and its neighboring nodes and takes the importance of the neighboring nodes into account. |
| HITS | Measures the importance of the node as a source of information and information disseminator in the network. |
| Closeness centrality (CC) | Measures the total length of the shortest path between a node and other nodes and describes the role of a node as a broadcaster in the network. |
| Betweenness centrality (BC) | Measures the number of shortest paths through a node and describes the node’s role as a bridge in the network. |
| K-shell (Ks) | Measures the structural position of a node in the network and describes the node’s central role in the network. |
| Network | |||||||
|---|---|---|---|---|---|---|---|
| Karate | 34 | 156 | 9.18 | 15 | 0.57 | 8 | 0.13 |
| Road | 39 | 170 | 8.72 | 26 | 0.45 | 6 | 0.08 |
| Lesmis | 77 | 254 | 6.6 | 20 | 0.57 | 9 | 0.08 |
| Polbooks | 105 | 441 | 8.4 | 21 | 0.49 | 6 | 0.08 |
| Adjnoun | 112 | 850 | 15.18 | 22 | 0.17 | 12 | 0.07 |
| Jazz | 198 | 2742 | 27 | 62 | 0.62 | 30 | 0.03 |
| USAir97 | 332 | 2126 | 12.8 | 64 | 0.63 | 27 | 0.02 |
| 908 | 10430 | 22 | 117 | 0.49 | 84 | 0.01 | |
| PowerGrid | 4941 | 6594 | 2.67 | 6 | 0.08 | 5 | 0.26 |
| Baseline Model | Method Description |
|---|---|
| K-shell [7] | Quantifies the influence of a node by assigning it to different shell levels. No des within the same shell have the same core value, i.e., they have similar position and importance in the network. The higher the shell value of a node, the more significant its core position in the network structure and the higher its influence. |
| DC+ [8] | Comprehensively assesses the node influence by combining the degree of the node itself and the degree of its neighboring nodes. |
| KEM [14] | Calculates the K-order information entropy of nodes in the network as the node influence score. |
| InfGCN [25] | Learns representations of nodes by combining neighboring graphs and classical structural features as input. These representations contain the structural and feature information of the nodes, which can reflect the importance and influence of the nodes in the process of virus propagation or information dissemination. |
| GCN [26] | Learns the embedding representation of a node by aggregating its neighbor information. These embedding vectors fuse the local and global information of a node, which can reflect the node’s position, role, and relationship with other nodes in the network. |
| GraphSAGE [27] | An inductive learning approach is used to generate the embedding representation of a node by sampling and aggregating the information of its neighboring nodes. This approach both considers the local information of the nodes and captures the global structure of the network. |
| Dataset | Network Characteristic | Methods | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| N | DC+ | KS | KEM | GCN | Graph SAGE | Inf GCN | HEIST | ||||
| Karate | 34 | 9.18 | 15 | 0.57 | 0.79 | 0.80 | 0.783 | 0.803 | 0.817 | 0.80 | 0.946 |
| Road | 39 | 8.72 | 26 | 0.45 | 0.89 | 0.677 | 0.908 | 0.843 | 0.873 | 0.839 | 0.924 |
| Lesmis | 77 | 6.6 | 20 | 0.57 | 0.864 | 0.801 | 0.864 | 0.878 | 0.864 | 0.868 | 0.88 |
| Polbooks | 105 | 8.4 | 21 | 0.49 | 0.841 | 0.746 | 0.859 | 0.801 | 0.854 | 0.798 | 0.873 |
| Adjnoun | 112 | 15.2 | 22 | 0.17 | 0.872 | 0.83 | 0.881 | 0.82 | 0.847 | 0.854 | 0.853 |
| Jazz | 198 | 27 | 62 | 0.62 | 0.947 | 0.81 | 0.954 | 0.74 | 0.915 | 0.925 | 0.958 |
| USAir97 | 332 | 12.8 | 64 | 0.63 | 0.899 | 0.80 | 0.913 | 0.86 | 0.861 | 0.899 | 0.886 |
| 908 | 22 | 117 | 0.49 | 0.79 | 0.736 | 0.933 | 0.764 | 0.637 | 0.788 | 0.799 | |
| PowerGrid | 4941 | 2.7 | 6 | 0.08 | 0.709 | 0.606 | 0.731 | 0.43 | 0.44 | 0.714 | 0.759 |
| Network | HEIST1 | HEIST3 | HEIST5 | HEIST7 | HEIST10 | HEIST12 | ||
|---|---|---|---|---|---|---|---|---|
| Karate | 15 | 0.13 | 0.917 | 0.946 | 0.934 | 0.938 | 0.935 | 0.938 |
| Road | 26 | 0.08 | 0.891 | 0.896 | 0.92 | 0.924 | 0.922 | 0.911 |
| Lesmis | 20 | 0.08 | 0.858 | 0.861 | 0.881 | 0.867 | 0.866 | 0.865 |
| Polbooks | 21 | 0.08 | 0.852 | 0.855 | 0.873 | 0.863 | 0.865 | 0.861 |
| Adjnoun | 22 | 0.07 | 0.819 | 0.823 | 0.824 | 0.853 | 0.843 | 0.85 |
| Jazz | 62 | 0.03 | 0.936 | 0.936 | 0.938 | 0.948 | 0.958 | 0.947 |
| USAir97 | 64 | 0.02 | 0.802 | 0.817 | 0.833 | 0.856 | 0.886 | 0.869 |
| 117 | 0.01 | 0.701 | 0.713 | 0.737 | 0.746 | 0.765 | 0.799 | |
| PowerGrid | 6 | 0.26 | 0.759 | 0.747 | 0.742 | 0.745 | 0.748 | 0.745 |
| Network | GCN | LSTM | HEIST | ||
|---|---|---|---|---|---|
| Karate | 15 | 0.13 | 0.865 | 0.9108 | 0.917 |
| Road | 26 | 0.08 | 0.8678 | 0.8866 | 0.8914 |
| Lesmis | 20 | 0.08 | 0.8421 | 0.8454 | 0.8578 |
| Polbooks | 21 | 0.08 | 0.8359 | 0.76 | 0.8520 |
| Adjnoun | 22 | 0.07 | 0.8072 | 0.8108 | 0.8191 |
| Jazz | 62 | 0.03 | 0.928 | 0.8923 | 0.9357 |
| USAir97 | 64 | 0.02 | 0.7681 | 0.7408 | 0.8015 |
| 117 | 0.01 | 0.6652 | 0.6725 | 0. 7012 | |
| PowerGrid | 6 | 0.26 | 0.7363 | 0.7215 | 0.7585 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, S.; Xiao, Y.; Han, J.; Huang, T. An Evaluation Model for Node Influence Based on Heuristic Spatiotemporal Features. Entropy 2024, 26, 676. https://doi.org/10.3390/e26080676
Jin S, Xiao Y, Han J, Huang T. An Evaluation Model for Node Influence Based on Heuristic Spatiotemporal Features. Entropy. 2024; 26(8):676. https://doi.org/10.3390/e26080676
Chicago/Turabian StyleJin, Sheng, Yuzhi Xiao, Jiaxin Han, and Tao Huang. 2024. "An Evaluation Model for Node Influence Based on Heuristic Spatiotemporal Features" Entropy 26, no. 8: 676. https://doi.org/10.3390/e26080676
APA StyleJin, S., Xiao, Y., Han, J., & Huang, T. (2024). An Evaluation Model for Node Influence Based on Heuristic Spatiotemporal Features. Entropy, 26(8), 676. https://doi.org/10.3390/e26080676