Abstract
Misunderstandings in dyadic interactions often persist despite our best efforts, particularly between native and non-native speakers, resembling a broken duet that refuses to harmonise. This paper delves into the computational mechanisms underpinning these misunderstandings through the lens of the broken Lorenz system—a continuous dynamical model. By manipulating a specific parameter regime, we induce bistability within the Lorenz equations, thereby confining trajectories to distinct attractors based on initial conditions. This mirrors the persistence of divergent interpretations that often result in misunderstandings. Our simulations reveal that differing prior beliefs between interlocutors result in misaligned generative models, leading to stable yet divergent states of understanding when exposed to the same percept. Specifically, native speakers equipped with precise (i.e., overconfident) priors expect inputs to align closely with their internal models, thus struggling with unexpected variations. Conversely, non-native speakers with imprecise (i.e., less confident) priors exhibit a greater capacity to adjust and accommodate unforeseen inputs. Our results underscore the important role of generative models in facilitating mutual understanding (i.e., establishing a shared narrative) and highlight the necessity of accounting for multistable dynamics in dyadic interactions.
1. Introduction
Understanding how individuals interpret the intentions of others is a fundamental challenge in studying dyadic interactions, particularly within the complex dynamics of interactions marred by linguistic differences, such as syntax and pronunciation [1,2]. These challenges are often exacerbated in interactions between native and non-native speakers, who may have significantly different prior experiences with the language in question [2,3]. Consequently, misunderstandings between native and non-native speakers can impede effective dialogue [4]. To investigate this phenomenon, we adopt a Bayesian approach, positing that misunderstandings between listeners of different proficiency levels result from asynchronous predictions about causes of outcomes under disparate model structures (or priors) [5,6].
For this, we assume that individuals model the causes of their sensory data and refine these models to maximise Bayesian model evidence [7,8,9]. Accordingly, effective exchanges manifest through generalised synchrony when individuals adopt the same generative model of communicative behaviour, thereby establishing a shared narrative [10,11,12]. This concept is grounded within the framework of predictive coding and active inference [12,13,14], where individuals are not necessarily predicting each other’s specific actions but rather predict their responses to the incoming percept under a mutually shared narrative [12,15]. Thus, synchronisation fails when there are divergences in the generative models employed by the interacting individuals [16]. Under such circumstances, the prediction mechanisms become less effective, leading to a breakdown in communication [12,17]. This breakdown can be viewed not merely as a failure of linguistic exchange but as a fundamental misalignment of the underlying model structures.
To understand how communication is hindered in the absence of an underlying shared narrative—formalised by the generative process and model—we consider dyadic interactions modelling using multistable systems [18,19]. These multistable systems are characterised by several disjoint attracting sets with different basins of attraction. Each attracting set can be seen as capturing a stable mode, i.e., an interpretation of our belief about the sensory data [20,21,22]. Under this perspective, multistable systems carry distinct interpretations (or beliefs) that can coexist based on some incoming sensory information (Figure 1). Importantly, this serves as a way to illustrate that computational mechanisms of understanding are reliant not only on appropriate perceptual inference but also on convergence towards the appropriate attractor set. This implies that the efficacy of linguistic interactions between native and non-native speakers depends on (i) the ability to infer the percept (i.e., the auditory waveform being sampled from the environment), and (ii) the capacity to assign semantic meaning to the inferred percept.
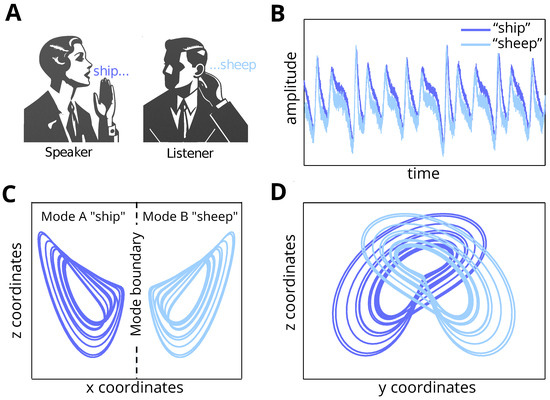
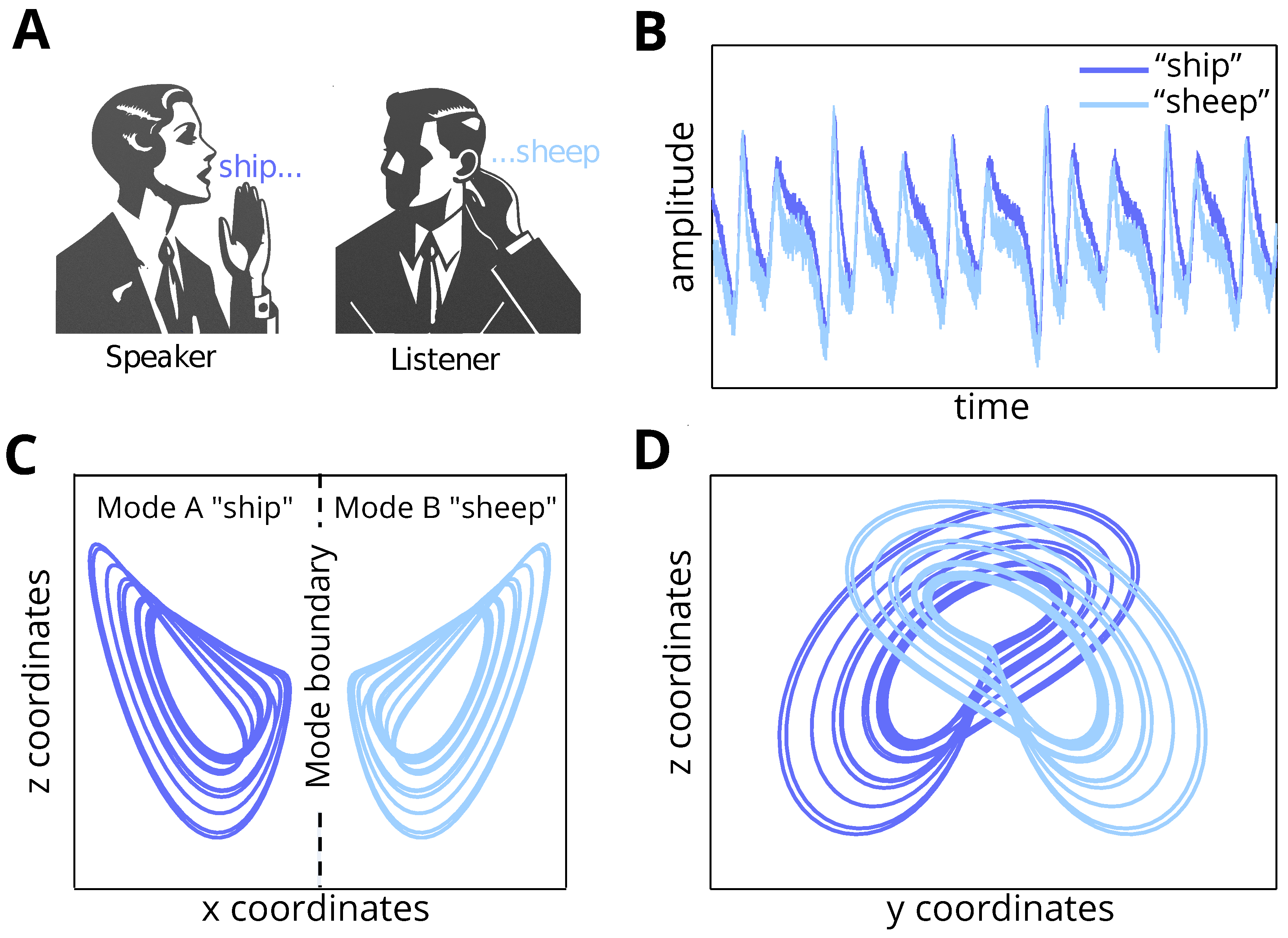
Figure 1.
Visual illustration of the problem setting. (A) Two agents (speaker and listener) are communicating, and there is a misunderstanding between them regarding the word “sheep”. (B) We present the percept measured in amplitude (y-axis) across time (x-axis) for both the pronounced word (by the speaker) and the inferred word (by the listener). (C,D) The plots illustrate the internal beliefs across the (x, y, and z) coordinate space for a broken Lorenz system. In (C), across the x (x-axis) and z (y-axis) coordinate space, the two words “sheep” and “ship” are separated along the x coordinates. Conversely, in (D), across the y (x-axis) and z (y-axis) coordinate space, the separation is less trivial. Accordingly, modelling the percept as a weighted sum of these coordinates complicates mode recognition from the percept, leading to misunderstanding of the heard word.
To elucidate our approach, we consider the communication dynamics between native and non-native speakers across two scenarios. The first scenario contends with the interaction between a native listener and a non-native speaker. For this, we introduce a ‘native listener’ model with incredibly precise (or overly confident) priors about the incoming sensory data. This model, characterised by high predictive confidence, expects inputs to conform to its beliefs (e.g., syntax, pronunciation). These lead to efficient communication in familiar contexts but introduce challenges in unexpected variations, like unconventional syntax or pronunciation errors. Thus, the native listener might experience internal confusion when hearing a non-native speaker say, “Yesterday I go to the store”, due to the rigid expectation of “went” instead of “go” despite perceptual synchronisation. For the second scenario, we consider the interaction between two non-native individuals. The non-native listener is modelled with flexible (i.e., less confident) priors that can be adjusted to accommodate unexpected inputs more effectively. Thus, the non-native listener would not experience the same internal confusion when hearing another speaker say, “Yesterday I go to the store”. The two scenarios highlight that establishing a shared narrative and avoiding linguistic misunderstandings—beyond mere perceptual inference—necessitates an appropriate amount of flexibility to enable the synchronisation of internal beliefs.
In what follows, we motivate this problem setting (Section 2), and formalise it through a dynamic systems perspective (Section 3) to simulate varying levels of miscommunication (Section 4). Our simulations illustrate that effective communication hinges on the alignment of generative models across different interlocutors. Misunderstandings arise when there is a misalignment between these models, a phenomenon often exacerbated by the linguistic differences (i.e., prior encoding) between native and non-native speakers. By examining the interplay between precise and flexible priors, we gain insight into the multistable dynamics of dyadic communication and the computational mechanisms underpinning effective exchanges. This investigation elucidates the importance of similar generative models for achieving mutual understanding. We conclude with a brief discussion on how flexible priors may alleviate communication misunderstandings by facilitating the convergence towards shared narratives (Section 5).
2. Dyadic Exchanges and Bayesian Inference
Recent experiments have shed light on the nature of dyadic exchanges in language processing [23,24,25]. Notably, inter-subject correlations are not primarily observed in lower sensory regions but manifest across the entire hierarchy of areas involved in language processing [26,27,28]. This finding underscores the complexity of neural synchronisation during linguistic interactions, suggesting that multiple levels of cognitive processes are crucial in dyadic exchanges.
2.1. Hierarchical Processing of Speech
Understanding the hierarchical processing of speech is crucial to elucidating how the brain integrates multiple levels of linguistic information [29,30,31,32]. The primary auditory cortex is the initial cortical region that receives auditory input and is responsible for processing fundamental acoustic properties such as the frequency, intensity, and temporal aspects of sound [33]. These serve as the building blocks for more complex auditory perceptions. Information is propagated to higher-order auditory areas, including the superior temporal gyrus and superior temporal sulcus, which are involved in phoneme recognition [34]. The progression from phoneme recognition to word and sentence comprehension involves a network of regions including the inferior frontal gyrus (IFG). The IFG is critical for syntactic processing, enabling the brain to parse and understand the grammatical structure of sentences [35]. This region is also involved in managing the hierarchical structure of language, facilitating the integration of words into coherent syntactic and semantic frameworks [36]. Importantly, the hierarchical processing of speech is not linear but involves intricate feedback mechanisms. Higher-order regions send predictive signals back to lower-order areas to influence the processing of incoming auditory information [32,37,38].
2.2. Predictive Coding and Dyadic Exchanges
To formalise this hierarchical processing, we extend the Bayesian model of dyadic exchanges proposed by [10]. This model conceptualises linguistic exchange as an interplay between two agents—a speaker and a listener—who share an identical internal model of the world. The model comprises a two-level hierarchy: the first level contending with incoming sensory information, and the second level integrating and interpreting these signals within the broader context.
During an interaction, the speaker’s utterances serve as an indicator of their internal beliefs. The listener, equipped with the same model, uses the perceptual cues to align their internal beliefs with the speaker’s (i.e., internal state synchronisation) to ensure mutual understanding. This synchronisation process is grounded in hierarchical predictive coding [39], which posits that perceptual inference occurs through a cascade of predictions and prediction errors across multiple levels of processing. During dyadic exchanges, these hierarchical predictions cover many levels of speech, from low-level acoustic features, sounds, phonemes, and words, to higher-level semantic and syntactic structures. The brain then propagates these predictions backwards (i.e., top–down, from higher cognitive regions to lower sensory regions) and compares them against actual perceptual information. Any differences (i.e., prediction errors) are propagated forward (bottom–up, from lower sensory regions to higher cognitive regions) in the brain after being weighted by the precision (i.e., confidence) of the predictions (Figure 2). This ensures the continual alignment of internal models between the interacting agents, facilitating effective communication.
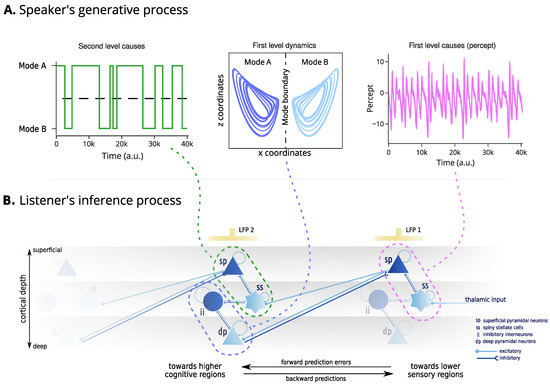
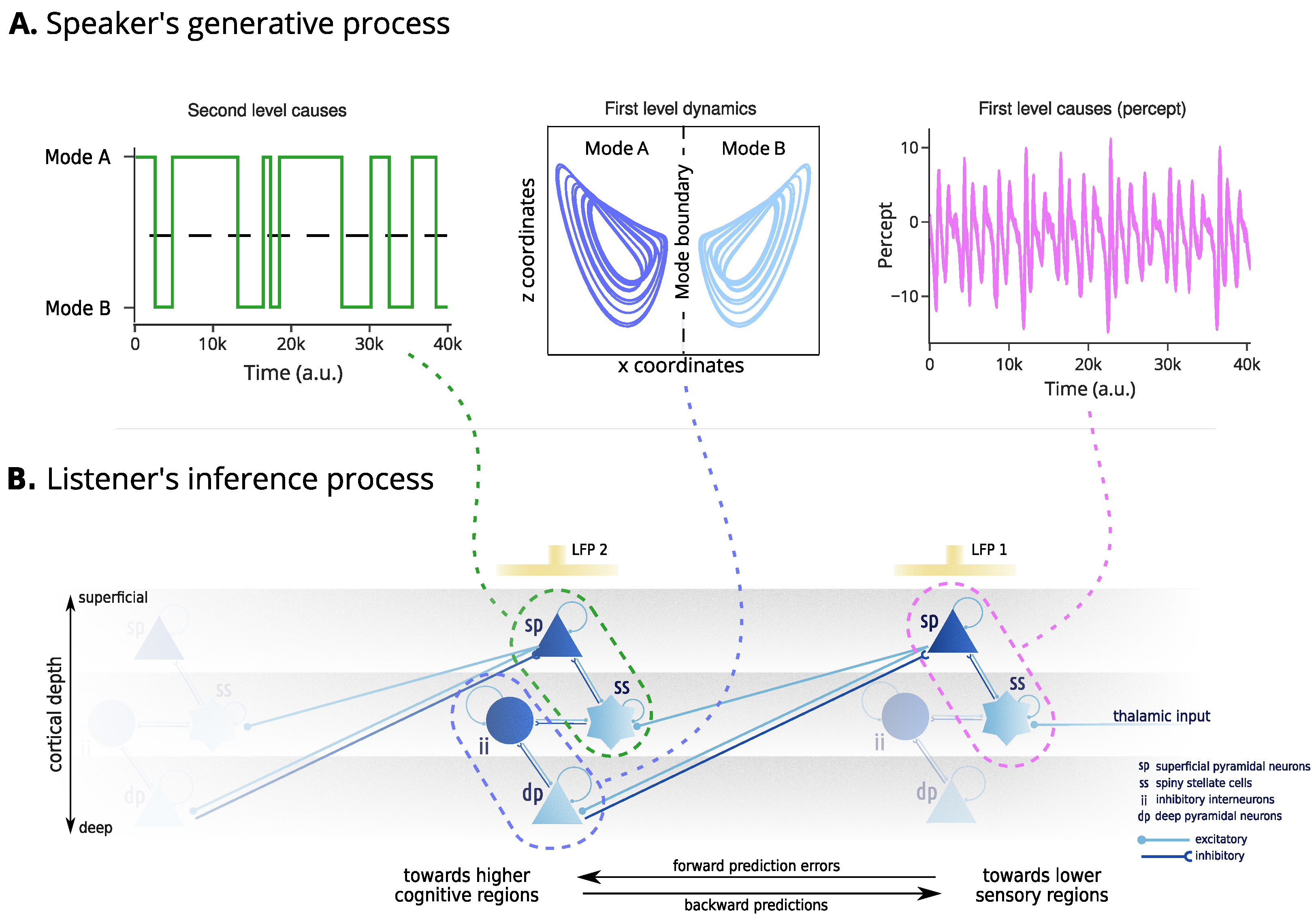
Figure 2.
Mechanisms of generation and inference. The upper panel (A) represent the speaker’s generative process. This starts from second-level outcomes, determining the mode of the broken Lorenz system. Then, the first level dynamics determines the evolution of the internal states. Finally, the first level outcomes represent the construction of the generated percepts from the internal states. The lower panel (B) denotes the assumed neurobiology of the listener’s inference process. The inference process involves two cortical regions whose activity is modelled by a canonical microcircuit capturing the local connectivity between four neuronal populations: superficial pyramidal neurons and inhibitory interneurons (dark blue), encoding prediction errors, and spiny stellate and deep pyramidal neurons (light blue), encoding predictions. The percept (e.g., auditory waveform) is assumed to be conveyed to the spiny stellate cells of a lower sensory region through a projection from the thalamus. The discrepancy with the agent’s prediction gives rise to prediction errors, encoded through the activity of the superficial pyramidal neurons. Their self-inhibition determines the excitability of the population and is assumed to encode the precision of the predictions. The electrical activity of superficial pyramidal neurons causes local fluctuations in the electromagnetic field potential, assumed to be recorded by an electrode “LFP 1”. The superficial pyramidal neurons have excitatory forward connections to higher cognitive regions. Here, the higher cognitive region is responsible for encoding the first-level dynamics of the broken Lorenz system. The prediction errors over the dynamics are encoded by the inhibitory interneurons, whose activity is modulated by the activity of the spiny stellate cells, that encode predictions about the second-level outcomes, that is, the mode of the Lorenz system. The prediction errors of the second-level model are encoded in the activity of the superficial pyramidal neurons of the second regions, and recorded through “LFP 2”.
Neurobiology Bayesian inference is realised by updating internal beliefs to explain away the prediction errors. This inference scheme can be related to the neurobiology of the cortex. The activity of superficial pyramidal neurons and inhibitory interneurons correlates with prediction errors, while corresponding predictions are assumed to be encoded by spiny stellate cells and deep pyramidal neurons. The interaction between these neuronal populations forms a canonical microcircuit, responsible for constructing and continuously updating beliefs about the dynamics and states of the world [40]. Hierarchical predictive coding emerges from the asymmetry in connections between canonical microcircuits, with superficial pyramidal neurons projecting to higher cortical regions and deep pyramidal neurons sending modulatory projections to lower sensory regions. This can be validated by recording local field potentials (LFPs) generated by superficial pyramidal neurons in the cortical or skull surface and comparing them against simulated evoked responses.
Empirical evidence Recent neuroimaging studies have provided evidence for predictive coding in speech perception [41,42]. For instance, Blank and Davis [41] demonstrated that the brain’s response to degraded speech is modulated by prior expectations, with increased activity in the frontal regions when predictions are violated. Similarly, Sohoglu et al. [42] showed that top–down predictions can override bottom–up sensory input in speech perception, providing evidence for predictive coding. Furthermore, syntactic processing also supports a predictive coding account. Hahne and Friederici [43] found that syntactic violations often elicit an early left anterior response, typically occurring between 100 and 300ms post-stimulus onset. This is thought to reflect the rapid detection of a syntactic prediction error, although its habituation has been debated [44].
Generalised filtering in speech processing While predictive coding provides a powerful framework for understanding speech processing, implementing these ideas requires going a step further. One way to operationalise it is via generalised filtering [45,46], which offers a dynamic Bayesian inference scheme that can be applied to any hierarchical model. For this, we need to construct a hierarchy of deterministic systems that track the modes of Gaussian distributions that have fixed precision (i.e., inverse variance). The hierarchy can be formalised as a series of interconnected state space models, where each level i is characterised by:
where are states, are the outcomes, is the evolution function, is an observation function with some additive analytic Gaussian noise at level i, is the internal precision determining the confidence in internal dynamics, and is the external precision determining the confidence in the predicted outcomes. In generalised filtering, the states and outcomes are expressed in generalised coordinates, i.e., by concatenating all derivatives up to a certain order. For further technical details, see [45,46].
Happily, within the context of dyadic exchanges, generalised filtering can model how listeners continuously update their beliefs about a speaker’s internal state based on the ongoing stream of speech input. We rely on this scheme for our simulations (Section 3).
2.3. Communication between Native and Non-Native Speakers
Studies have shown that listening to accented speech accentuates activation in brain areas associated with language processing and comprehension. For instance, Adank et al. [47] observed enhanced activation in the left inferior frontal gyrus and superior temporal gyrus when native English speakers processed Dutch-accented English, compared to native English speech. This increased neural activity can be interpreted as an indicator of the greater effort required to process and understand accented speech. From a predictive coding perspective, this increased neural activity likely reflects the brain’s efforts to reconcile prediction errors arising from mismatches between the expected and actual acoustic patterns in accented speech. Furthermore, Yi et al. [48] found that native English speakers listening to Korean-accented English showed increased activation not only in classical language areas [13] but also in regions associated with attention, such as the bilateral insula and right frontal areas. This aligns with the hierarchical nature of predictive coding models. It suggests that when lower-level predictions about phonemes and acoustic features generate an increase in errors, higher-level cognitive processes engage more actively to manage these errors and guide the updating of predictive models across multiple levels of the language processing hierarchy. This cascading effect of prediction errors and model updating may explain the recruitment of additional brain regions beyond the core language network when processing accented speech, reflecting the increased computational demands of adapting to unfamiliar speech patterns.
The neural response to accented speech can differ between native and non-native listeners, potentially influencing communication dynamics. Goslin et al. [49] demonstrated that native English speakers exhibited greater activation in the left inferior frontal gyrus when processing foreign-accented speech compared to regional accents, a difference not observed in non-native listeners. From a predictive coding standpoint, this suggests that native speakers’ language models generate larger prediction errors when encountering foreign accents, necessitating increased neural activity to update these models. In contrast, the non-native listeners’ more flexible predictive models, shaped by diverse linguistic experiences, may accommodate accent variations more readily. This difference underscores how the linguistic background of the listener shapes their internal models and plays a crucial role in speech processing.
3. Methods
To investigate linguistic communication between native and non-native speakers, we explore how multistable dynamics interact with the precision of the internal model during the perception of ambiguous speech segments. For this, we employ a two-stage process to model the speaker–listener interactions: generating the speaker’s output signal, and inverting the listener’s generative model.
The speaker’s output signal is conceptualised as a generative process, governed by a hierarchical probabilistic model. This hierarchical structure reflects the nested nature of language, from phonemes to words to sentences. By integrating a set of differential equations and applying observation functions at each level, we simulate the complex, multilevel process of speech production. This approach captures the idea that speakers generate linguistic outputs based on their internal dynamics, with each level of the hierarchy influencing the levels below.
The listener’s perceptual process is modelled as inference within a similar hierarchical structure but, crucially, with its own set of priors. We construct this generative model by specifying prior distributions over internal states and outcomes at each level of the hierarchy. The generative model is the joint probability over the data and the internal states. From the listener’s perspective, the generative model describes the preferences about its internal configuration—e.g., particular patterns of neuronal activity—through priors and preferred states of the sensorium given its internal configuration through the hierarchical model described in (1).
The following sections detail the internal dynamics and the perceptual projections for this hierarchical generative model, the inference scheme, and the process for simulating in silico evoked responses.
3.1. Bistable Internal Dynamics
To simulate the internal dynamics we employ a bistable continuous dynamical system: the broken Lorenz system [19]. This model is obtained using a particular set of parameters in the equations of the classical Lorenz system [18]. The classical Lorenz system was designed to illustrate the unpredictable nature of weather patterns, but its mathematical formulation makes it suitable for exploring more general complex dynamic behaviours [50]. Briefly, the Lorenz system is governed by the following set of differential equations [18]:
where , r, and b are parameters that control the system’s dynamics.
The classical Lorenz system, for certain parameter values, exhibits chaotic behaviour characterised by its iconic butterfly-shaped attractor. This attractor consists of two lobes, with trajectories swirling around each lobe before intermittently jumping to the other lobe.
The broken Lorenz system, as investigated by [19], modifies this dynamic by introducing a regime of parameters that disrupts the connection between the two lobes of the attractor. More precisely, by letting , , and in Equation (3), the dynamics remain chaotic, but the unique attractor of the original system is divided into two unconnected attracting sets with disjoint basin of attractions. In this altered system, trajectories initialised in one lobe remain confined to that lobe, effectively disconnecting the “wings of the butterfly” (Figure 1C). This bistability creates a scenario where the system’s state is constrained to one of two possible attractors, depending on the initial conditions.
While the broken Lorenz system is not per se used by the brain in dyadic exchanges, its multistable aspect provides an ideal test-bed for investigating mutual understanding in linguistic exchanges. Indeed, each lobe of the bistable system can be seen as distinct internal “speech” models attempting to predict the hidden dynamics of the speech percept. This structural multistability could arise, for instance, from the competition for attention by two or more different neuronal populations within the same region [51,52,53]. The winning mode then constitutes an intermediate “cause”, which would need to be explained away by a higher-level region within the cortical hierarchy, evolving over a slower temporal scale [22]. Under this model, a mutual understanding between the speaker and the listener implies that both use the same internal model to predict the percept, i.e., their internal states evolve on the same lobe of the broken Lorenz system. This hierarchical synchronisation, at the level of both the internal dynamics and the attracting set, mimics the hierarchical aspect of the inter-subject synchrony between the speaker and listener observed in naturalistic neuroimaging [28,54,55]. Similarly, a misunderstanding arises from the listener predicting the speaker’s speech while being on the opposite lobe of the Lorenz system. This makes the model ideal for evaluating how the listener’s confidence—or lack thereof—over their speech predictions influences their ability to infer the lobe that generated the percept.
3.2. Ambiguous Outcome
We extend the model for our purposes by introducing an observation function that projects the 3-dimensional state-space trajectories onto a single perceptual outcome:
The projection from internal states to the percept purposely introduces perceptual ambiguity. The percept is computed as the sum of the z coordinates of internal states, over which none of the modes is distinguishable, and a down-weighted y coordinate, over which the modes are partially distinguishable. However, it does not involve the x coordinates, over which the two lobes of the broken Lorenz system are distinguishable (Figure 1D). Thus, percepts generated from different lobes of the broken Lorenz system exhibit only sensible differences. Introducing this perceptual ambiguity in the generative model is fundamental to mimic how listeners might struggle to infer the exact meaning of ambiguous spoken words, for instance, the homophones “ship” and “sheep”, when pronounced with an unfamiliar accent.
3.3. Relevance for Dyadic Exchanges
By employing this model, we simulate how different priors (i.e., generative model parametrisation) lead to distinct interpretations (i.e., different attractors) of the same sensory data. This setup allows us to explore how prior beliefs influence the alignment of generative models and the subsequent understanding of percepts. The bistable nature of the system serves as an ideal framework to investigate how misunderstandings arise when interlocutors operate under different model assumptions, akin to being on different lobes of the attractor. This is illustrated in Figure 1, which shows the projection of the Lorenz attractor and highlights the perceptual ambiguity between the speaker and listener over a particular stimulus—in this example, the word “sheep”.
Furthermore, the multistable aspect of the broken Lorenz system provides an ideal test-bed for investigating linguistic exchanges between individuals with different language proficiency. Indeed, different initial conditions mimic prior beliefs and are useful for modelling how different priors can lead to distinct, stable states of understanding. These mirror how individuals can persist in their interpretations of ambiguous linguistic inputs, leading to potential misunderstandings. For instance, two interlocutors with different native languages might interpret the same phrase in distinct ways, resulting in a stable yet divergent understanding based on their linguistic backgrounds and prior experiences. In other words, this model allows us to explore how the listener’s confidence (i.e., precision) in their language ability influences their capacity to transcend their divergent initial (i.e., prior) beliefs and synchronise to the correct mode of understanding, i.e., the same lobe as the speaker.
Interestingly, this model represents a hierarchical structure—akin to those present in linguistic communication [17,56]—with a second-level semantic encoding (i.e., lobe) and a first-level continuous encoding (i.e., the state within a lobe). This hierarchical representation is crucial for capturing the layered nature of linguistic processing, where high-level semantic meanings (corresponding to which lobe the system is in) guide the interpretation of continuous, lower-level linguistic features (corresponding to the specific state within a lobe). This structure allows us to explore how overarching semantic frameworks influence the detailed parsing and interpretation of linguistic inputs.
This formulation provides a nice opportunity to study the effect of multistability on hierarchical variational inference. In particular, it provides a computational account of how different inferences, modelled here as convergence towards different lobes of the attractor, can arise given the same percept (Figure 3).
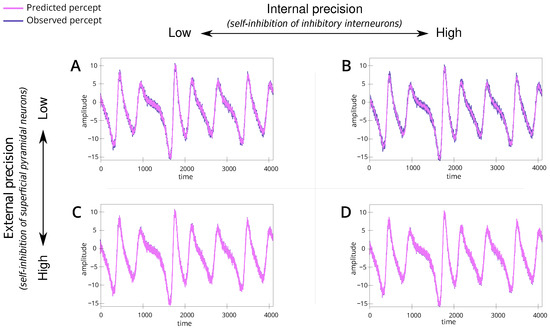
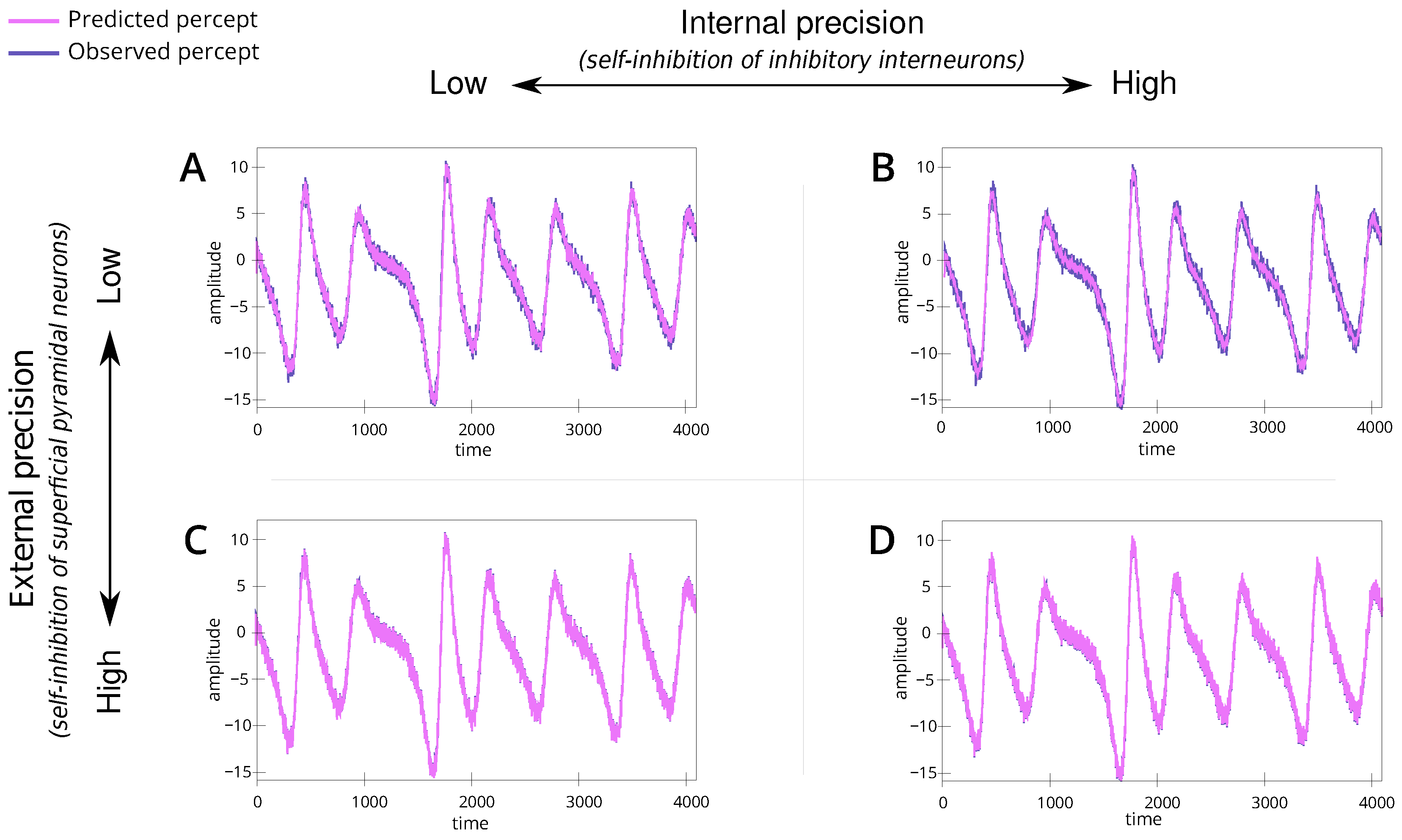
Figure 3.
Line plots (A–D) show the percept across time for the 4 simulations. (A) is the baseline simulation, (B) is the simulation with high internal precision and moderate external precision, (C) has moderate internal precision and high external precision and (D) has high internal and external precision. For each plot, the y-axis reveals the amplitude, and the x-axis is the time measured on some arbitrary scale. Here, the “observed percept” (in purple) is generated by the speaker, and the “predicted percept” (in pink) denotes the inference made by the listener. Note that the blue line (stimulus) is defined as , where and are coordinates in the speaker’s broken Lorenz system. The red line (percept) is the estimated ; inferred via generalised filtering [46].
3.4. Inversion Scheme
Having specified the generative model, one could apply Bayes rule to obtain a posterior distribution of the internal states and outcomes, i.e., their distribution refined from the sensory data. However, exact Bayes inference is computationally—or neuroanatomically—intractable, and a solution must be approximated. Thus, we rely on generalised filtering—a Bayesian filtering algorithm that enables continuous data assimilation [46] (Section 2)—to estimate the posteriors.
This is performed by constructing a hierarchical dynamical system, with the same number of levels as Equation (1), and evolving against the gradient of the generative model’s free energy F. This free energy, known as evidence lower bound (ELBO) in machine learning, scales with the distance between the approximate and exact solution to the Bayesian inference problem. The free-energy gradients correspond, under the Gaussian model, to precision-weighted prediction error. In other words, the system flows against prediction errors with a rate determined by precision. Here, the free energy minima give an approximate solution to the Bayesian inference problem. The solution is hierarchically structured, involving the construction of top–down predictions, comparison of lower-level predictions with sensory observations, and upward propagation of resulting prediction errors through the hierarchy. This update process allows for identifying the most likely cause of perceptual data under the current beliefs by solving an approximate Bayesian inference problem. Interestingly, this mathematical model yields an algorithmic construct that closely mimics aspects of hierarchical predictive coding in the brain [37,39].
3.5. Modelling In Silico Evoked Responses
We can use the connection between generalised filtering and hierarchical predictive coding to generate in silico LFPs by looking at the precision-weighted prediction errors at each level of the hierarchical model as the average activity of a population of superficial pyramidal neurons in a canonical microcircuit model, following [57] (Figure 2). This allows us to probe the mechanisms underlying linguistic misunderstandings and their neural correlates.
For this, we augment the model with a lobe variable acting as a second-level “cause” (see Figure 2). During the generation of the percept, this variable is switched between 1 and −1 and used to give the sign of the y-component in the percept equation:
This exploits the symmetry of the Lorenz system over the axes to simulate an instantaneous lobe switching.
To allow the listener to infer the lobe used by the speaker, we integrate another level that tracks the lobe variable, i.e., we let the listener hold beliefs about the current lobe. These beliefs are static (i.e., the predicted dynamics of the lobe variable is 0), and used in the first-level generative model as:
where tanh is the hyperbolic tangent function that maps a real variable between and 1, and the tilde notation is used to denote the listener’s variables. The listener’s priors on the lobe variable are Gaussian with mean 1 and log-precision . This intermediate precision allows us to model a listener who is confident that Mode A (Figure 1) was used to generate the data but is receptive to gradually revising this belief based on accumulating evidence.
Our ERP simulation of the listener’s inference process employs the following procedure. First, we generate a percept of 16,384 points using the speaker’s generative process. Next, we invert the listener’s model using DEM, producing a prediction of the percept, internal states (i.e., the location within a lobe of the broken Lorenz system) and lobe variable for each time point. The prediction error, corresponding to the difference between prior predictions and posterior estimates, is then multiplied by the precision of the internal beliefs. The precision-weighted prediction errors over the percept are taken as LFPs for the “first region”. This reflects the neurobiological assumption of canonical microcircuit models that superficial pyramidal neurons, who contribute predominantly to LFPs, encode the precision-weighted prediction errors of the outcomes. Similarly, the LFP of the ’second region’ is approximated by the precision-weighted prediction errors associated with the lobe variable. The LFPs are then extracted on a peristimulus window of −5 points to 25 points around a lobe switch, upsampled 10 times using cubic interpolation (we assumed that introduced high-frequency artefacts are attenuated by averaging as not time-locked to the stimulus onset, while low-frequency components are preserved), separated between transitions from the unexpected lobe to the expected one (from −1 to 1) from transitions to the unexpected lobe (from 1 to −1), and finally averaged over stimulus repetition.
4. Results
To simulate linguistic exchanges between native and non-native individuals, we use the broken Lorenz system introduced in the previous section (Section 3). We manipulate the precision over the prior internal states and external causes (Table 1). This allows us to explore how variations in prior beliefs influence the alignment of generative models and the resulting states of potential misunderstanding. Our simulations are designed to represent different interaction scenarios by varying the precision of priors in both internal dynamics (analogous to linguistic structure and semantics) and external causes (analogous to sensory inputs and context). By systematically adjusting these parameters, we can simulate the responses of native and non-native listeners to non-native speech under various communicative conditions. For each simulation, the model is initialised with the same conditions: for the speaker and for the listener. Data are then inverted using generalised filtering [46].

Table 1.
Overview of the prior internal and external precision.
4.1. Low Internal and External Precision
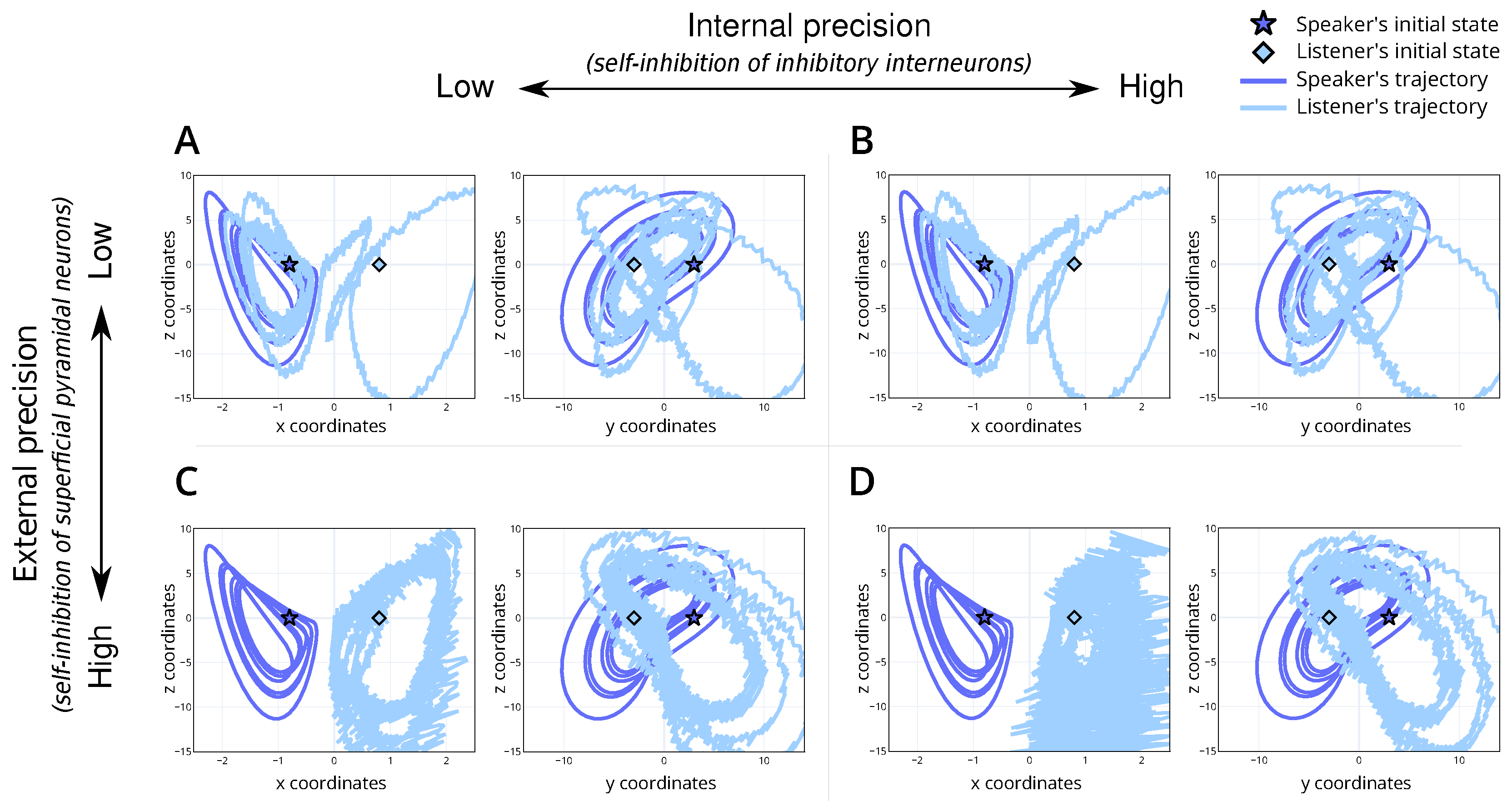
We introduce a baseline simulation (Table 1; simulation A). For this scenario, we set the internal and external precision to . This parametrisation represents a non-native listener, with low confidence in their perceptual abilities and the dynamics of the shared narrative. The simulation results show alignment between the speaker and listener (Figure 3A) and convergence to the appropriate trajectories within the attractor (Figure 4A), i.e., the correct lobe. This serves as a reference point for understanding the dynamics in subsequent simulations.
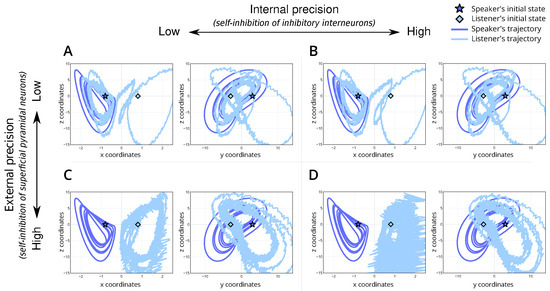
Figure 4.
Trajectory of the speaker and listener’s internal dynamics for the 4 simulations. (A) is the baseline simulation with moderate internal and external precision, (B) is the simulation with high internal precision and moderate external precision, (C) has moderate internal precision and high external precision and (D) has high internal and external precision. For each plot, the y-axis is the z-coordinate of the Lorenz system and the x-axis is the x-coordinate (left within each panel) or y-coordinate (right within each panel). Here, the dark blue line denotes the speaker’s trajectory, and the light line denotes the listener’s. The initial state of the speaker and listener are denoted by a dark blue star and a light blue diamond, respectively.
4.2. High Internal Precision with Low External Precision
We simulate a situation where a non-native listener, characterised by low confidence in their perceptual ability, has high confidence in the dynamics of the shared narrative, reflected by precise (or confident) linguistic beliefs (e.g., semantics) (Table 1; simulation B). This reflects a context where the interacting individuals understand the underlying meaning or narrative but express it differently due to linguistic variations, i.e., maybe different ways of pronouncing a particular word. To represent this, we set high internal precision () and the external precision to a low level ().
The simulation results reveal that, despite starting from different stable points within the attractor, the shared semantic understanding allows the system to converge towards a common attractor set (Figure 4B). This indicates that a shared narrative can bridge linguistic differences, facilitating mutual understanding even when vocabulary or expression varies significantly. The attractor convergence is visually represented in the trajectories within the Lorenz attractor (Figure 4B). Heuristically, this can be thought of as understanding arising from finishing the other person’s sentences by continuing the interaction, i.e., a common belief space with different outcomes or vocabulary. In terms of physiology, we would anticipate an attenuation of the prediction error as the linguistic exchange continues. This reduction reflects the system’s ability to reconcile perceptual discrepancies through a shared narrative. The dynamics observed here highlight a key aspect of bilingual communication: the ability to maintain a coherent exchange through shared semantic grounding, even when surface linguistic features differ.
4.3. Low Internal Precision with High External Precision
We simulate a situation where a native listener, characterised by precise (or confident) percepts (e.g., pronunciation), interacts with a non-native speaker (Table 1; simulation C). This reflects a context where the native listener tries to infer the underlying narrative based on the linguistic input. To simulate this, we set the internal precision to (same as baseline) while increasing the external precision to , i.e., overly confident priors of how words should be articulated.
The simulation results illustrate that the system can interpret the percept (Figure 3C) but struggles to find the correct attractor (Figure 4C). That is, there is divergence in the semantic understanding despite linguistic synchronisation. This misalignment is evident in the trajectory plots (Figure 4C), where the system fails to localise within the correct attractor basin, illustrating the native speaker’s difficulty in adjusting to unexpected linguistic inputs from the non-native speaker and inability to resolve the uncertainty over the true attractor set. Figure 4C demonstrates that the trajectories, instead of converging to a shared attractor, remain dispersed. This dispersion indicates the system’s inflexibility and the resultant divergence in understanding despite continued interaction—perhaps due to increased accumulated grammatical errors. Regarding physiology, we would anticipate a prolonged increase in the prediction error as the linguistic exchange continues. This persistent prediction error should underscore the native speaker’s ongoing struggle to integrate unexpected linguistic features with their internal model. The high external precision effectively localises the system into a rigid inference regime (i.e., the incorrect attractor set), unable to adapt to the non-native speaker’s variable inputs.
4.4. High Internal and External Precision
We simulate a scenario where the naive listener is confident about the dynamics of the shared narrative (Table 1; simulation D). For this, we parametrise internal and external precision to high levels, i.e., .
The model fails to converge to the right lobe (Figure 4D) and exhibits inaccurate internal beliefs (Figure 4D) despite its capacity to accurately infer the percept (Figure 3D). Importantly, the trajectory remains erratic and dispersed, failing to stabilise within the attractor basin (Figure 4D). This dispersion indicates that the high precision in both internal and external states leads to over-fitting and excessive sensitivity to perceptual inputs, preventing the system from achieving stable, coherent interpretations. Therefore, an overabundance of precision can be detrimental to the effective inference about the causes of the states of the world. Heuristically, this scenario could represent individuals who are overly fixated on precise linguistic rules and sensory details, leading to the constant re-evaluation and reinterpretation of inputs. Such rigidity and sensitivity hinder the establishment of a stable shared narrative, resulting in persistent misunderstandings and communication breakdowns. Physiologically, we would anticipate a persistent and elevated prediction error throughout the linguistic exchange, reflecting the system’s ongoing struggle to stabilise its internal model. This persistent prediction error underscores the interlocutors’ difficulty in integrating high-precision expectations with the variable linguistic inputs. The high internal and external precision effectively localise the system into a volatile inference regime, unable to adapt to the inherent variability in natural language exchanges.
4.5. Trade-Off between Internal and External Precision
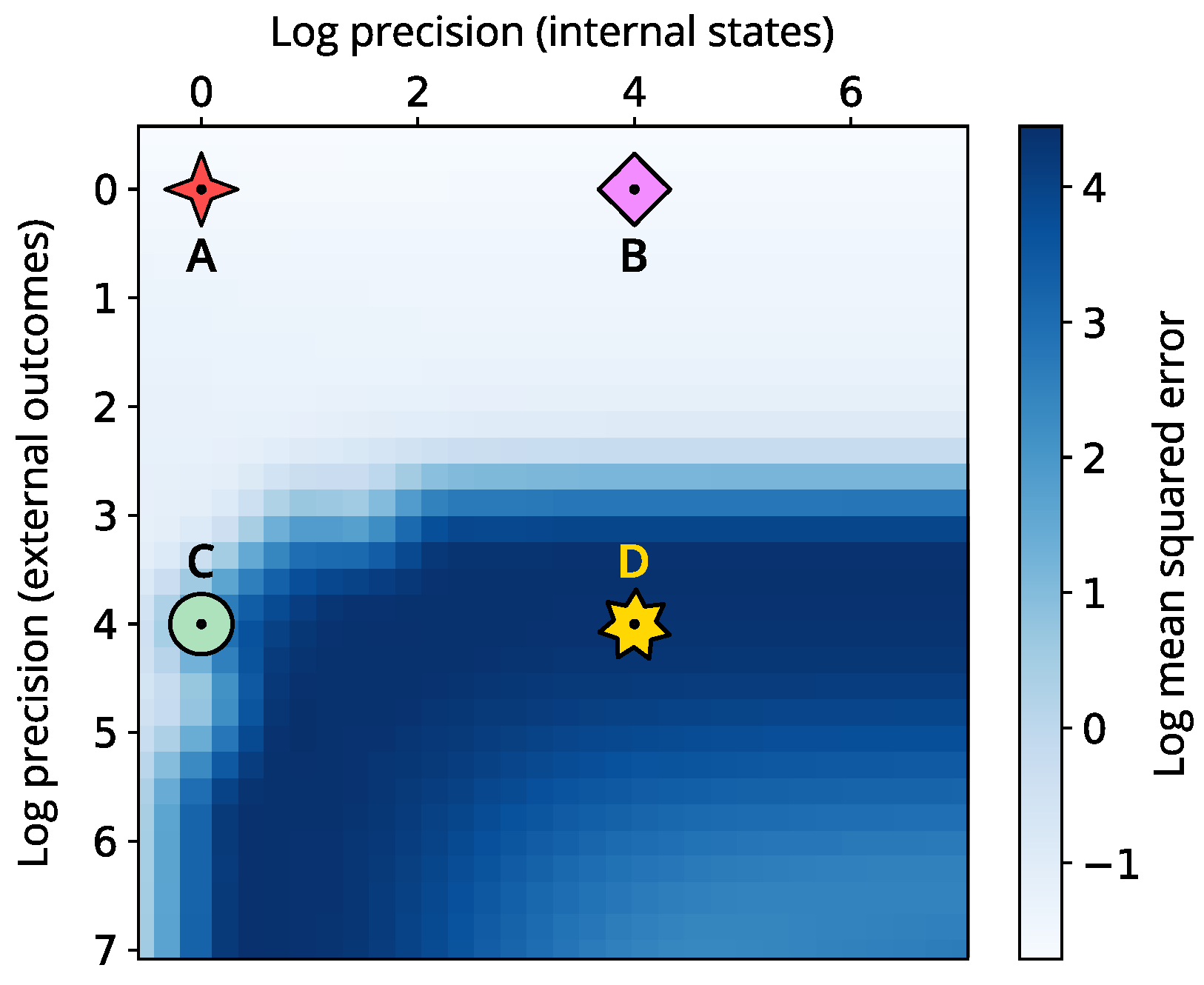
To provide a complete picture, we examine how varying internal and external precision influences the effectiveness of perceptual inference. Figure 5 presents the mean squared error (MSE) in log scale across different precision parametrisations for the internal state space. Our analysis highlights that shifts in internal precision alone have little impact on the quality of perceptual inference. Conversely, increasing external precision reveals a significant rise in MSE, indicating greater volatility and instability in the system’s internal beliefs. However, this declines for certain regimes where internal precision is also higher.
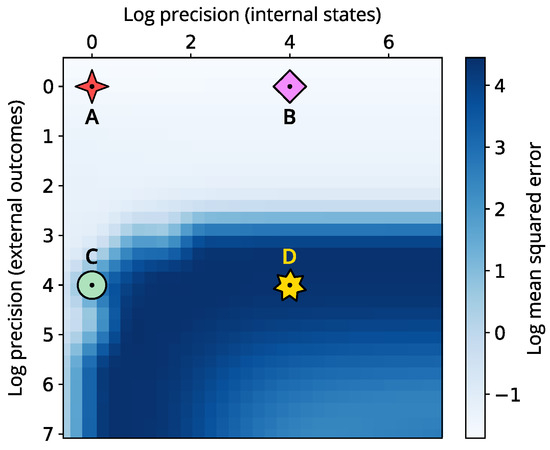
Figure 5.
Heatmap showing the log mean squared error (MSE) across varying internal and external precision (measured in log units). The MSE is over the internal states x, y and z. Here, low values denote a synchronisation to the correct lobe, while high values denote convergence towards the incorrect (initial) lobe. The four different symbols indicate the four simulations: low internal and external precision (A, red 4-branch star), high internal and low external precision (B, pink diamond), low internal and high external precision (C, green circle), and high internal and external precisions (D, yellow star).
4.6. Simulated In Silico Evoked Responses
Our simulations reveal interesting patterns in the ERPs during the listener’s inference process after switching between different “lobes” or modes (Figure 6). First, we observe that when transitioning from unexpected to expected speech patterns, the listener’s perceptual system adapts more quickly (i.e., return to 0) than when transitioning to unexpected patterns. This rapid adaptation does not necessarily mean the listener has identified the correct mode but rather that they have managed to predict the percept.
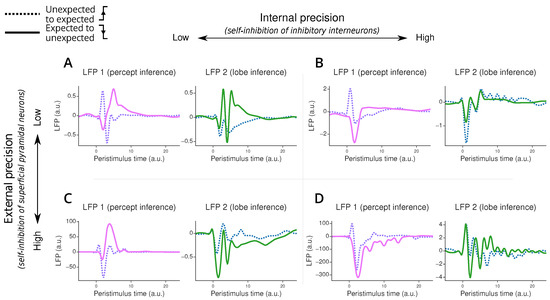
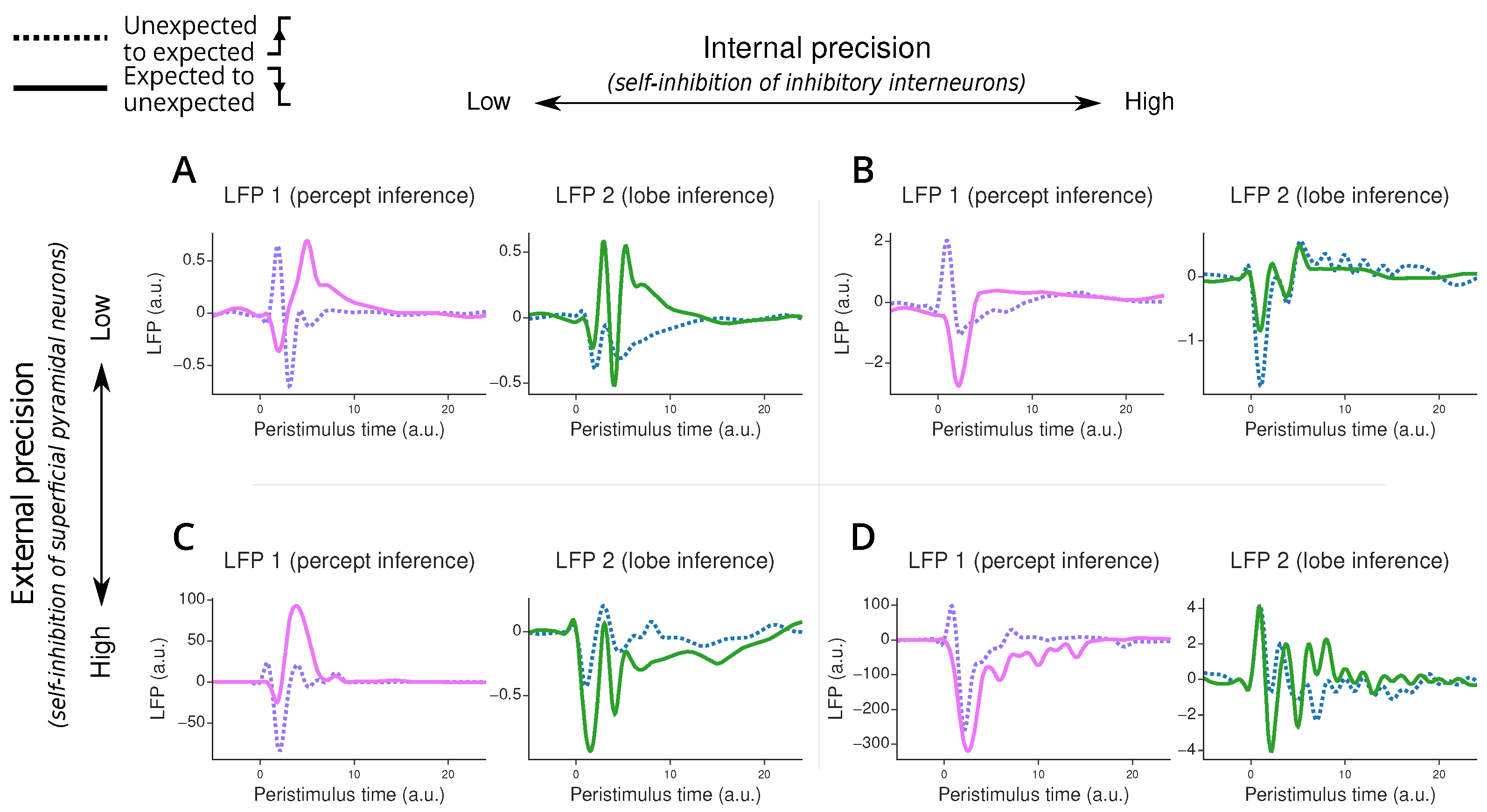
Figure 6.
Error-related potential simulated under the two-region model. Panel (A) corresponds to the model with low internal and external precision, panel (B) to the model with high internal and low external precision, panel (C) to the model with low internal and high external precision, and panel (D) to the model with high internal and external precision. Each plot displays an error-related potential as a function of peristimulus time when transitioning from the unexpected to the expected lobe (purple and blue dotted lines) or from the expected to the unexpected lobe (pink and green plain lines). The LFP value, on the y-axis, corresponds to the precision-weighted prediction error of the causes in the first region (responsible for percept inference, in pink and purple on the left plot in each panel) and the second region (responsible for lobe inference, in green and blue on the right plot in each panel). The peristimulus time corresponds to time steps after the lobe switching. The displayed ERP is upsampled 10 times using cubic interpolation.
The model’s behaviour changes significantly with different parameter settings. When we increase the external precision—which corresponds to reducing self-inhibition in superficial pyramidal neurons—we see a marked increase in the amplitude of error-related potentials in the first processing region. This effect is less pronounced in the second region, highlighting the specialised roles of different hierarchical levels. This high external precision scenario mimics a native listener’s neural response, where violations of accent or grammar typically elicit stronger ERPs compared to non-native listeners.
Interestingly, we notice that changes to the internal precision have a relatively small influence on the ERP amplitudes compared to the external precision perturbations. The difference in impact between external and internal precision arises from their distinct neural targets. External precision directly modulates the activity of superficial pyramidal neurons, which are the primary contributors to our measure of LFPs. In contrast, internal precision primarily affects inhibitory interneurons, which have minimal direct influence on LFPs. Thus, the effect on the LFP is indirect and mediated through changes in the inference processes. This is reflected through changes in the amplitudes of the ERPs in both regions, as well as a strong change in the overall shape of the ERPs.
5. Discussion
Here, we explore the computational mechanisms underlying linguistic miscommunication between native and non-native speakers using the broken Lorenz system. By manipulating internal and external precision, we simulate various scenarios reflecting different levels of linguistic proficiency. We provide insights into how generative model parametrisation may influence communication dynamics and underscore the importance of appropriate belief representations in achieving mutual understanding, i.e., convergence towards a shared narrative.
Our simulations reveal that the precision of internal and external priors significantly impacts the alignment of generative models and the resultant states of understanding. Native speakers, with highly precise external priors, exhibit rigid expectations about linguistic inputs. This rigidity leads to difficulties in adjusting to unexpected variations, such as unconventional syntax or pronunciation errors introduced by non-native speakers. Consequently, this misalignment manifests as persistent prediction errors and communication breakdowns. In contrast, non-native speakers, characterised by precise internal priors, demonstrate greater flexibility in adapting to novel inputs. This adaptability facilitates the better alignment of generative models, promoting more effective communication despite linguistic differences.
The results from simulations with high precision in both internal and external states highlight the detrimental effects of excessively high precision. This is because high precision may lead to instability and over-fitting; the system becomes overly sensitive to minor variations in perceptual inputs, preventing stable convergence and coherent understanding. This scenario underscores the importance of meta-control over precision priors to maintain stable communication dynamics.
The differential effects of external and internal precision on ERPs offer a potential mechanistic explanation for the observed differences between native and non-native listeners in processing accented speech [48,49]. Native listeners, represented by high external precision in our model, show stronger error signals when encountering unexpected inputs (e.g., foreign accents). This could be interpreted as their highly tuned models generating larger prediction errors that require more neural resources to resolve [42]. Conversely, the more muted response in the model with lower external precision aligns with empirical observations that non-native listeners often show reduced sensitivity to accent-related variations [49,58].
Our model can account for well-known ERP components associated with language processing, specifically, the N400 and P600. The N400, typically linked to semantic processing, can be interpreted in our model as reflecting semantic-level prediction errors. Our framework predicts larger N400 responses in native speakers when encountering semantically incongruous words compared to non-native speakers, consistent with the empirical findings [59,60]. Similarly, the P600, associated with syntactic processing, can be viewed as reflecting syntactic prediction errors and reanalysis. Our model predicts larger P600 responses in native speakers for syntactic violations. This is consistent with studies showing larger P600 effects in native speakers compared to non-native speakers [61]. The lower external precision in non-native listeners’ models would result in smaller prediction errors overall, potentially explaining the frequently observed attenuation of both N400 and P600 effects in this population [62,63].
Our simulations highlight the hierarchical nature of linguistic processing, where high-level semantics guide the interpretation of lower-level features. This hierarchical structure is fundamental to understanding how complex language comprehension and production interact [29]. At the top of this hierarchy, high-level semantics encompasses broad, abstract concepts and contextual information, forming the cognitive backbone for interpreting incoming linguistic data [30,64]. These act as templates that shape our expectations and interpretations, ensuring that we can make sense of diverse and often ambiguous linguistic inputs. As these high-level features influence the processing of lower-level features, such as syntax, phonetics, and individual word meanings, they enable the dynamic integration of these elements into coherent, meaningful communication [12,17]. This top–down influence ensures that even when specific linguistic inputs are unclear or ambiguous, our overall understanding remains intact by relying on the broader context provided by these high-level structures.
This highlights that effective communication is not solely about the accurate inference about words or sounds but also involves the high-level alignment of underlying narratives between interlocutors. By adjusting their generative models in response to new and variable inputs, speakers can better align their internal representations, facilitating smoother and more accurate exchanges of meaning. For example, non-native speakers may rely heavily on high-level semantic frameworks to compensate for gaps in their understanding of lower-level linguistic features. Conversely, native speakers with more precise models must learn to adjust their expectations and interpretations to accommodate the linguistic variations introduced by non-native speakers.
This suggests that adjusting priors in response to new and variable inputs is important for achieving mutual understanding [29,65]. This adaptability is particularly important in multilingual contexts, where linguistic inputs are inherently diverse and unpredictable. The results emphasise that mutual understanding is facilitated by generative models that strike a balance between being sufficiently confident (precise enough) but flexible, allowing interlocutors to navigate the complexities of a particular interaction. One potential approach to enhancing this adaptability is the introduction of learning mechanisms, enabling individuals not only to infer the linguistic percept given their generative model but also to update the model in alignment with incoming inputs. For instance, native speakers exposed to a new linguistic environment, such as a native English speaker moving to France, may fine-tune their external precision to accommodate different stimuli more effectively.
Practically, this would entail equipping our current model with a learning scheme—moving beyond fixed internal and external precision. Here, we consider two different types of learning regimes that could be implemented. Under the first regime, both the speaker and listener would continuously update their precision until synchronisation of their internal beliefs is achieved. This can be seen as slowly exercising a change in the dynamical stability of the coupled system and would entail a separation of temporal scales and an abrupt switch to synchronisation [22,66,67]. The second regime would consider a slow learning procedure where updates post a particular interaction—akin to the meta-learning schemes considered in the literature [68,69]. Future research should incorporate a more sophisticated inference procedure that updates the precision over priors across time.
These precision-weighted dynamics exemplify a fundamental principle that extends across multiple domains. This balance between precise and imprecise inference reflects the brain’s inherent need to optimise its internal model while maintaining adaptability to novel inputs. This dichotomy can be understood as a trade-off between minimising prediction errors and maintaining model flexibility. Native speakers exhibit higher precision, reflecting years of experience-dependent learning. This results in more efficient processing but potentially reduced flexibility with unfamiliar inputs. Conversely, non-native speakers operate with lower precision, allowing for greater plasticity in their generative models but at the cost of increased uncertainty. This precision balancing act is ubiquitous in learning. During critical periods, sensory systems maintain low precision to facilitate rapid learning, gradually increasing precision as optimal models are established. Similarly, skill acquisition in any domain involves a progression from imprecise, attention-demanding processes to precise, automated routines [70,71].
The primary limitation of this work lies in the idealised setting provided by the broken Lorenz system. This model simplifies the complexities of real-world linguistic interactions, which involve numerous factors such as emotion and social cues not captured by our model [72]. Despite this, our study provides a step toward understanding the computational mechanisms of linguistic miscommunication through the lens of dynamic systems theory. Addressing the identified limitations in future research will be essential for understanding linguistic miscommunication. By incorporating more complex features (linguistic or otherwise), and validating with empirical data, future work can build on our findings to create a more comprehensive model of multilingual communication.
Author Contributions
Conceptualization, J.M. and N.S.; Methodology, J.M. and N.S.; Software, J.M.; Validation, J.M.; Writing—original draft, N.S.; Writing—review & editing, N.S.; Visualization, J.M. and N.S. All authors have read and agreed to the published version of the manuscript.
Funding
JM is funded by the Wellcome Trust (https://dx.doi.org/10.13039/100010269), Award ID: 203147/Z/16/Z. NS was funded by the Max Planck Society.
Data Availability Statement
The results can be reproduced using the simulations provided here: https://github.com/johmedr/dempy (accessed on 19 August 2024).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Gopnik, A.; Choi, S. Do linguistic differences lead to cognitive differences? A cross-linguistic study of semantic and cognitive development. First Lang. 1990, 10, 199–215. [Google Scholar] [CrossRef]
- Dąbrowska, E.; Street, J. Individual differences in language attainment: Comprehension of passive sentences by native and non-native English speakers. Lang. Sci. 2006, 28, 604–615. [Google Scholar] [CrossRef]
- Long, M.H. Linguistic and conversational adjustments to non-native speakers. Stud. Second Lang. Acquis. 1983, 5, 177–193. [Google Scholar] [CrossRef]
- Clahsen, H.; Felser, C. How native-like is non-native language processing? Trends Cogn. Sci. 2006, 10, 564–570. [Google Scholar] [CrossRef]
- Friston, K. The free-energy principle: A rough guide to the brain? Trends Cogn. Sci. 2009, 13, 293–301. [Google Scholar] [CrossRef]
- Penny, W. Bayesian Models of Brain and Behaviour. ISRN Biomath. 2012, 2012, 785791. [Google Scholar] [CrossRef]
- Schmidhuber, J. Learning Complex, Extended Sequences Using the Principle of History Compression. Neural Comput. 1992, 4, 234–242. [Google Scholar] [CrossRef]
- Dayan, P.; Hinton, G.E.; Neal, R.M.; Zemel, R.S. The Helmholtz machine. Neural Comput. 1995, 7, 889–904. [Google Scholar] [CrossRef]
- Knill, D.C.; Pouget, A. The Bayesian brain: The role of uncertainty in neural coding and computation. Trends Neurosci. 2004, 27, 712–719. [Google Scholar] [CrossRef]
- Friston, K.; Frith, C. A duet for one. Conscious. Cogn. 2015, 36, 390–405. [Google Scholar] [CrossRef]
- Friston, K.J.; Frith, C.D. Active inference, communication and hermeneutics. Cortex 2015, 68, 129–143. [Google Scholar] [CrossRef] [PubMed]
- Friston, K.J.; Parr, T.; Yufik, Y.; Sajid, N.; Price, C.J.; Holmes, E. Generative models, linguistic communication and active inference. Neurosci. Biobehav. Rev. 2020, 118, 42–64. [Google Scholar] [CrossRef] [PubMed]
- Sajid, N.; Da Costa, L.; Parr, T.; Friston, K. Active inference, Bayesian optimal design, and expected utility. In The Drive for Knowledge: The Science of Human Information Seeking; Cambridge University Press: Cambridge, UK, 2022; pp. 124–146. [Google Scholar]
- Friston, K.; Da Costa, L.; Sajid, N.; Heins, C.; Ueltzhöffer, K.; Pavliotis, G.A.; Parr, T. The free energy principle made simpler but not too simple. Phys. Rep. 2023, 1024, 1–29. [Google Scholar] [CrossRef]
- Clark, A. Whatever next? Predictive brains, situated agents, and the future of cognitive science. Behav. Brain Sci. 2013, 36, 181–204. [Google Scholar] [CrossRef]
- Schwartenbeck, P.; FitzGerald, T.H.; Mathys, C.; Dolan, R.; Wurst, F.; Kronbichler, M.; Friston, K. Optimal inference with suboptimal models: Addiction and active Bayesian inference. Med. Hypotheses 2015, 84, 109–117. [Google Scholar] [CrossRef]
- Friston, K.J.; Sajid, N.; Quiroga-Martinez, D.R.; Parr, T.; Price, C.J.; Holmes, E. Active listening. Hear. Res. 2021, 399, 107998. [Google Scholar] [CrossRef] [PubMed]
- Lorenz, E.N. Deterministic nonperiodic flow. J. Atmos. Sci. 1963, 20, 130–141. [Google Scholar] [CrossRef]
- Li, C.; Sprott, J.C. Multistability in the Lorenz system: A broken butterfly. Int. J. Bifurc. Chaos 2014, 24, 1450131. [Google Scholar] [CrossRef]
- Tognoli, E.; Kelso, J.S. The metastable brain. Neuron 2014, 81, 35–48. [Google Scholar] [CrossRef]
- McIntosh, A.R.; Jirsa, V.K. The hidden repertoire of brain dynamics and dysfunction. Netw. Neurosci. 2019, 3, 994–1008. [Google Scholar] [CrossRef]
- Medrano, J.; Friston, K.; Zeidman, P. Linking fast and slow: The case for generative models. Netw. Neurosci. 2024, 8, 24–43. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Leong, Y.C.; Honey, C.J.; Yong, C.H.; Norman, K.A.; Hasson, U. Shared memories reveal shared structure in neural activity across individuals. Nat. Neurosci. 2017, 20, 115–125. [Google Scholar] [CrossRef]
- Baldassano, C.; Chen, J.; Zadbood, A.; Pillow, J.W.; Hasson, U.; Norman, K.A. Discovering event structure in continuous narrative perception and memory. Neuron 2017, 95, 709–721. [Google Scholar] [CrossRef] [PubMed]
- Zada, Z.; Goldstein, A.; Michelmann, S.; Simony, E.; Price, A.; Hasenfratz, L.; Barham, E.; Zadbood, A.; Doyle, W.; Friedman, D.; et al. A shared model-based linguistic space for transmitting our thoughts from brain to brain in natural conversations. Neuron 2024, 112, 1–12. [Google Scholar] [CrossRef]
- Stephens, G.J.; Silbert, L.J.; Hasson, U. Speaker–listener neural coupling underlies successful communication. Proc. Natl. Acad. Sci. USA 2010, 107, 14425–14430. [Google Scholar] [CrossRef] [PubMed]
- Dikker, S.; Silbert, L.J.; Hasson, U.; Zevin, J.D. On the same wavelength: Predictable language enhances speaker–listener brain-to-brain synchrony in posterior superior temporal gyrus. J. Neurosci. 2014, 34, 6267–6272. [Google Scholar] [CrossRef]
- Silbert, L.J.; Honey, C.J.; Simony, E.; Poeppel, D.; Hasson, U. Coupled neural systems underlie the production and comprehension of naturalistic narrative speech. Proc. Natl. Acad. Sci. USA 2014, 111, E4687–E4696. [Google Scholar] [CrossRef]
- Jackendoff, R. Précis of foundations of language: Brain, meaning, grammar, evolution. Behav. Brain Sci. 2003, 26, 651–665. [Google Scholar] [CrossRef]
- Friederici, A.D. Towards a neural basis of auditory sentence processing. Trends Cogn. Sci. 2002, 6, 78–84. [Google Scholar] [CrossRef]
- Price, C.J. The anatomy of language: A review of 100 fMRI studies published in 2009. Ann. N. York Acad. Sci. 2010, 1191, 62–88. [Google Scholar] [CrossRef]
- Sajid, N.; Gajardo-Vidal, A.; Ekert, J.O.; Lorca-Puls, D.L.; Hope, T.M.; Green, D.W.; Friston, K.J.; Price, C.J. Degeneracy in the neurological model of auditory speech repetition. Commun. Biol. 2023, 6, 1161. [Google Scholar] [CrossRef] [PubMed]
- Kaas, J.H. The evolution of auditory cortex: The core areas. In The Auditory Cortex; Springer: Berlin/Heidelberg, Germany, 2010; pp. 407–427. [Google Scholar]
- Hickok, G.; Poeppel, D. The cortical organization of speech processing. Nat. Rev. Neurosci. 2007, 8, 393–402. [Google Scholar] [CrossRef] [PubMed]
- Friederici, A.D. The brain basis of language processing: From structure to function. Physiol. Rev. 2011, 91, 1357–1392. [Google Scholar] [CrossRef]
- Hagoort, P. On Broca, brain, and binding: A new framework. Trends Cogn. Sci. 2005, 9, 416–423. [Google Scholar] [CrossRef] [PubMed]
- Friston, K. The free-energy principle: A unified brain theory? Nat. Rev. Neurosci. 2010, 11, 127–138. [Google Scholar] [CrossRef]
- Rao, R.; Sejnowski, T.J. Predictive sequence learning in recurrent neocortical circuits. Adv. Neural Inf. Process. Syst. 1999, 12, 164–170. [Google Scholar]
- Friston, K. Hierarchical models in the brain. PLoS Comput. Biol. 2008, 4, e1000211. [Google Scholar] [CrossRef]
- Bastos, A.M.; Usrey, W.M.; Adams, R.A.; Mangun, G.R.; Fries, P.; Friston, K.J. Canonical microcircuits for predictive coding. Neuron 2012, 76, 695–711. [Google Scholar] [CrossRef]
- Blank, H.; Davis, M.H. Prediction errors but not sharpened signals simulate multivoxel fMRI patterns during speech perception. PLoS Biol. 2016, 14, e1002577. [Google Scholar] [CrossRef]
- Sohoglu, E.; Peelle, J.E.; Carlyon, R.P.; Davis, M.H. Predictive top-down integration of prior knowledge during speech perception. J. Neurosci. 2012, 32, 8443–8453. [Google Scholar] [CrossRef]
- Hahne, A.; Friederici, A.D. Electrophysiological evidence for two steps in syntactic analysis: Early automatic and late controlled processes. J. Cogn. Neurosci. 1999, 11, 194–205. [Google Scholar] [CrossRef]
- Steinhauer, K.; Drury, J.E. On the early left-anterior negativity (ELAN) in syntax studies. Brain Lang. 2012, 120, 135–162. [Google Scholar] [CrossRef] [PubMed]
- Friston, K.J.; Trujillo-Barreto, N.; Daunizeau, J. DEM: A variational treatment of dynamic systems. Neuroimage 2008, 41, 849–885. [Google Scholar] [CrossRef]
- Friston, K.; Stephan, K.; Li, B.; Daunizeau, J. Generalised filtering. Math. Probl. Eng. 2010, 2010. [Google Scholar] [CrossRef]
- Adank, P.; Davis, M.H.; Hagoort, P. Neural dissociation in processing noise and accent in spoken language comprehension. Neuropsychologia 2012, 50, 77–84. [Google Scholar] [CrossRef]
- Yi, H.G.; Smiljanic, R.; Chandrasekaran, B. The neural processing of foreign-accented speech and its relationship to listener bias. Front. Hum. Neurosci. 2014, 8, 768. [Google Scholar] [CrossRef] [PubMed]
- Goslin, J.; Duffy, H.; Floccia, C. An ERP investigation of regional and foreign accent processing. Brain Lang. 2012, 122, 92–102. [Google Scholar] [CrossRef] [PubMed]
- Friston, K.J. Computational Nosology and Precision Psychiatry: A Proof of Concept. In Computational Psychiatry: New Perspectives on Mental Illness; Redish, A.D., Gordon, J.A., Eds.; MIT Press: Cambridge, MA, USA, 2017; Volume 20. [Google Scholar] [CrossRef]
- Pastukhov, A.; García-Rodríguez, P.E.; Haenicke, J.; Guillamon, A.; Deco, G.; Braun, J. Multi-stable perception balances stability and sensitivity. Front. Comput. Neurosci. 2013, 7, 17. [Google Scholar] [CrossRef] [PubMed]
- Gershman, S.J.; Vul, E.; Tenenbaum, J.B. Multistability and perceptual inference. Neural Comput. 2012, 24, 1–24. [Google Scholar] [CrossRef]
- Sterzer, P.; Kleinschmidt, A.; Rees, G. The neural bases of multistable perception. Trends Cogn. Sci. 2009, 13, 310–318. [Google Scholar] [CrossRef]
- Thiede, A.; Glerean, E.; Kujala, T.; Parkkonen, L. Atypical MEG inter-subject correlation during listening to continuous natural speech in dyslexia. Neuroimage 2020, 216, 116799. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Hong, B.; Nolte, G.; Engel, A.K.; Zhang, D. Speaker-listener neural coupling correlates with semantic and acoustic features of naturalistic speech. Soc. Cogn. Affect. Neurosci. 2024, 19, nsae051. [Google Scholar] [CrossRef] [PubMed]
- Sajid, N.; Holmes, E.; Costa, L.D.; Price, C.; Friston, K. A mixed generative model of auditory word repetition. bioRxiv 2022. [Google Scholar]
- Auksztulewicz, R.; Friston, K. Repetition suppression and its contextual determinants in predictive coding. Cortex 2016, 80, 125–140. [Google Scholar] [CrossRef] [PubMed]
- Bradlow, A.R.; Bent, T. Perceptual adaptation to non-native speech. Cognition 2008, 106, 707–729. [Google Scholar] [CrossRef]
- Weber-Fox, C.M.; Neville, H.J. Maturational constraints on functional specializations for language processing: ERP and behavioral evidence in bilingual speakers. J. Cogn. Neurosci. 1996, 8, 231–256. [Google Scholar] [CrossRef]
- Hahne, A. What’s different in second-language processing? Evidence from event-related brain potentials. J. Psycholinguist. Res. 2001, 30, 251–266. [Google Scholar] [CrossRef]
- Hahne, A.; Friederici, A.D. Processing a second language: Late learners’ comprehension mechanisms as revealed by event-related brain potentials. Biling. Lang. Cogn. 2001, 4, 123–141. [Google Scholar] [CrossRef]
- Ojima, S.; Nakata, H.; Kakigi, R. An ERP study of second language learning after childhood: Effects of proficiency. J. Cogn. Neurosci. 2005, 17, 1212–1228. [Google Scholar] [CrossRef]
- Steinhauer, K.; White, E.J.; Drury, J.E. Temporal dynamics of late second language acquisition: Evidence from event-related brain potentials. Second Lang. Res. 2009, 25, 13–41. [Google Scholar] [CrossRef]
- Pulvermüller, F. The Neuroscience of Language: On Brain Circuits of Words and Serial Order; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]
- Chomsky, N. Three factors in language design. Linguist. Inq. 2005, 36, 1–22. [Google Scholar] [CrossRef]
- Haken, H.; Kelso, J.S.; Bunz, H. A theoretical model of phase transitions in human hand movements. Biol. Cybern. 1985, 51, 347–356. [Google Scholar] [CrossRef]
- Haken, H.; Portugali, J. Information and self-organization II: Steady state and phase transition. Entropy 2021, 23, 707. [Google Scholar] [CrossRef] [PubMed]
- Vilalta, R.; Drissi, Y. A perspective view and survey of meta-learning. Artif. Intell. Rev. 2002, 18, 77–95. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Precup, D., Teh, Y.W., Eds.; PMLR: London, UK, 2017; Volume 70, pp. 1126–1135. [Google Scholar]
- Fountas, Z.; Sajid, N.; Mediano, P.; Friston, K. Deep active inference agents using Monte-Carlo methods. Adv. Neural Inf. Process. Syst. 2020, 33, 11662–11675. [Google Scholar]
- Yuan, K.; Sajid, N.; Friston, K.; Li, Z. Hierarchical generative modelling for autonomous robots. Nat. Mach. Intell. 2023, 5, 1402–1414. [Google Scholar] [CrossRef]
- Tanenhaus, M.K.; Trueswell, J.C. Eye movements and spoken language comprehension. In Handbook of Psycholinguistics; Elsevier: Amsterdam, The Netherlands, 2006; pp. 863–900. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).