Abstract
Two typical fixed-length random number generation problems in information theory are considered for general sources. One is the source resolvability problem and the other is the intrinsic randomness problem. In each of these problems, the optimum achievable rate with respect to the given approximation measure is one of our main concerns and has been characterized using two different information quantities: the information spectrum and the smooth Rényi entropy. Recently, optimum achievable rates with respect to f-divergences have been characterized using the information spectrum quantity. The f-divergence is a general non-negative measure between two probability distributions on the basis of a convex function f. The class of f-divergences includes several important measures such as the variational distance, the KL divergence, the Hellinger distance and so on. Hence, it is meaningful to consider the random number generation problems with respect to f-divergences. However, optimum achievable rates with respect to f-divergences using the smooth Rényi entropy have not been clarified yet in both problems. In this paper, we try to analyze the optimum achievable rates using the smooth Rényi entropy and to extend the class of f-divergence. To do so, we first derive general formulas of the first-order optimum achievable rates with respect to f-divergences in both problems under the same conditions as imposed by previous studies. Next, we relax the conditions on f-divergence and generalize the obtained general formulas. Then, we particularize our general formulas to several specified functions f. As a result, we reveal that it is easy to derive optimum achievable rates for several important measures from our general formulas. Furthermore, a kind of duality between the resolvability and the intrinsic randomness is revealed in terms of the smooth Rényi entropy. Second-order optimum achievable rates and optimistic achievable rates are also investigated.
1. Introduction
Two typical fixed-length random number generation problems in information theory are considered for general sources. One is the source resolvability problem (i.e., the resolvability problem), and the other is the intrinsic randomness problem. The problem setting of the resolvability problem is as follows. Given an arbitrary source (the target random number), we approximate it by using a discrete random number that is uniformly distributed, which we call the uniform random number. Here, the size of the uniform random number is requested to be as small as possible. In this setting, a degree of approximation is measured by several criteria. Han and Verdú [1] and Steinberg and Verdú [2] have determined the first-order optimum achievable rates with respect to the variational distance and the normalized Kullback–Leibler (KL) divergence. Nomura [3] has studied the first-order optimum achievable rates with respect to the KL divergence. Recently, Nomura [4] has characterized the first-order optimum achievable rates with respect to f-divergences. The class of f-divergence considered in [4] includes the variational distance and the KL divergence. Hence, the result can be considered as a generalization of the results given in [1,3]. The second-order optimum achievable rates in the resolvability problem have also been studied with respect to several approximation measures [4,5]. It should be noted that the results mentioned above are based on the information spectrum quantity. On the other hand, Uyematsu [6] has characterized the first-order optimum achievable rate with respect to the variational distance using the smooth Rényi entropy.
The intrinsic randomness problem, which is also one of typical random number generation problems, has also been studied. The problem setting of the intrinsic randomness problem is as follows. By using a given arbitrary source (the coin random number), we approximate a discrete uniform random number whose size is requested to be as large as possible. Also in the intrinsic randomness problem, optimum achievable rates with respect to various criteria have been considered. Vembu and Verdú [7] have considered the intrinsic randomness problem with respect to the variational distance as well as the normalized KL divergence and derived general formulas of the first-order optimum achievable rates (cf. Han [8]). Hayashi [9] has considered the first- and second-order optimum achievable rates with respect to the KL divergence. Recently, the first- and second-order optimum achievable rates with respect to f-divergences have been clarified in [4]. The results mentioned here are based on information spectrum quantities. On the other hand, Uyematsu and Kunimatsu [10] have characterized the first-order optimum achievable rates with respect to the variational distance using the smooth Rényi entropy.
Related works include works given by Liu, Cuff and Verdú [11], Yagi and Han [12], Kumagai and Hayashi [13,14], and Yu and Tan [15]. In [11], the channel resolvability problem with respect to the -divergence has been considered. They have applied their results to the case of the source resolvability problem. Yagi and Han [16] have determined the optimum variable-length resolvability rates with respect to the variational distance as well as the KL divergence. Kumagai and Hayashi [13,14] have determined the first- and second-order optimum achievable rates in the random number conversion problem. It should be noted that the random number conversion problem includes the resolvability and intrinsic randomness problems treated in this paper. In [13,14], an approximation measure related to the Hellinger distance has been used. Yu and Tan [15] have considered the random number conversion problem with respect to the Rényi divergence.
As we have mentioned above, in both problems of the resolvability and the intrinsic randomness, various approximation measures have been considered. Furthermore, general formulas of achievable rates have been characterized by using the information spectrum quantity and the smooth Rényi entropy. We here note that optimum achievable rates with respect to f-divergence using the smooth Rényi entropy have not been clarified yet. The smooth Rényi entropy is an information quantity that has a clear operational meaning and is easy to understand. Moreover, a class of f-divergences is a general distance measure, in which several important measures are included. In this paper, hence, we try to characterize the first- and second-order optimum achievable rates with respect to f-divergences using the smooth Rényi entropy. In addition, we also extend the class of f-divergence for which optimum achievable rates can be characterized. As a result, we find that two types of smooth Rényi entropies are useful to describe these optimum achievable rates for a wider class of f-divergence. Furthermore, a kind of duality between the resolvability and the intrinsic randomness is revealed in terms of the smooth Rényi entropy and f-divergences.
This paper is organized as follows. In Section 2, we describe the problem setting and give some definitions of the optimum first-order achievable rates. The class of f-divergences and the smooth Rényi entropy are also introduced. In Section 3 and Section 4, we show general formulas of the optimum first-order achievable rates in the resolvability problem and the intrinsic randomness problem, respectively. In Section 5, we derive the general formulas of these achievable rates for an extended class of f-divergence. In Section 6, we apply general formulas obtained in previous sections to some specified functions f and compute the optimum first-order achievable rates in each cases. In Section 7, we show general formulas of the optimum second-order achievable rates in two problems. In Section 8, optimum achievable rates in the optimistic sense are considered. Section 9 is devoted to the discussion concerning our results. Finally, we provide some concluding remarks on our results in Section 10.
2. Preliminaries
2.1. f-Divergences
The f-divergence between two probability distributions and is defined as follows [17]. Let be a convex function defined for and .
Definition 1
(f-divergence [17]). Let and denote probability distributions over a finite or countably infinite set . The f-divergence between and is defined by
where we set , , .
The f-divergence is a general approximation measure, which includes some important measures. We give some examples of f-divergences [17,18]:
- : (Kullback–Leibler (KL) divergence)
- : (Reverse Kullback–Leibler divergence)
- : (Hellinger distance)
- : (Squared Hellinger distance)
- : (Variational distance)
- : (Half variational distance)
- : -divergence ()
- : (-divergence) For any given ,
The -divergence is a generalization of the half variational distance defined in (7), because is arbitrary.
Remark 1.
It is known [4] that the -divergence can be expressed as an f-divergence using the function:
The following key property holds for the f-divergence from Jensen’s inequality [17]:
As we have mentioned above, the f-divergence is a general approximation measure, which includes several important measures. In this study, we first assume the following conditions on the function f that have also been imposed by previous studies [4].
- C1)
- The function is a decreasing function for with .
- C2)
- The function satisfies
- C3)
- For any pair of positive real numbers , it holds that
Remark 2.
Notice here that functions , , and satisfy the above conditions, while does not satisfy conditions C1) and C2). Moreover, it is not difficult to check that (10) satisfies these conditions.
Remark 3.
For a decreasing function , it always holds that because . Then, the condition in C1) excludes the case of for all , in which f-divergence is identically zero.
Remark 4.
Remark 5.
We will show in Section 5 that condition C1) is automatically met for the function f satisfying condition C2) (cf. claim (i) of Lemma 1).
2.2. Smooth Rényi Entropy
In what follows, we consider the case of , where is a finite or countably infinite set and n is an integer. We consider the general source defined as an infinite sequence
of n-dimensional random variables , where each component random variable takes values in a countable set . Let denote the probability distribution of the random variable X. In this paper, we assume the following condition on the source :
where
is called the spectral inf-entropy rate of the source [8]. Here, Han [8] ([Theorem 1.7.2]) has shown that
holds. Hence, the condition (15) holds for any source with a finite alphabet.
The random number which is uniformly distributed on is defined by
We next introduce the smooth Rényi entropy of the source.
Definition 2
(Smooth Rényi entropy of order [19]). For given random variables , the smooth Rényi entropy of order α given is defined by
where
Here, is a decreasing function of . The smooth Rényi entropy of order 0 and the smooth Rényi entropy of order ∞ are, respectively, called the smooth max entropy and the smooth min entropy [20].
The following theorems have shown alternative expressions of the smooth max entropy and the smooth min entropy.
Theorem 1
(Uyematsu [6,21]).
Theorem 2
(Uyematsu and Kunimatsu [10]).
where if is a countably infinite set, the infimum is taken over .
It should be noted that these alternative expressions are simple and easy to understand compared to (19). Figure 1 and Figure 2 show operational meanings of (21) and (22). As in Figure 1, the smooth max entropy is equal to the logarithm of the cardinality of the set with where each of the sequence has large probability. On the other hand, the smooth min entropy is equal to the supremum of such that the sum of probabilities of sequences that exceeds is less than or equal to (Figure 2).
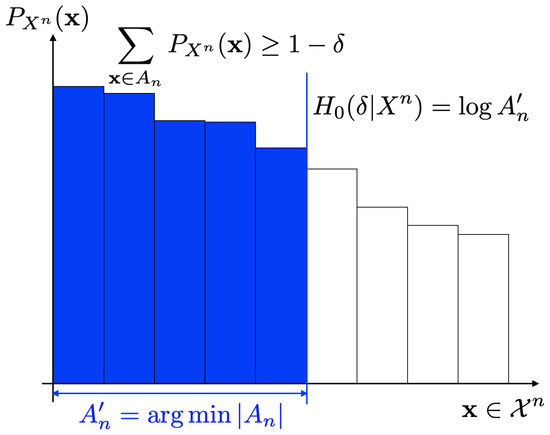
Figure 1.
Smooth max entropy .
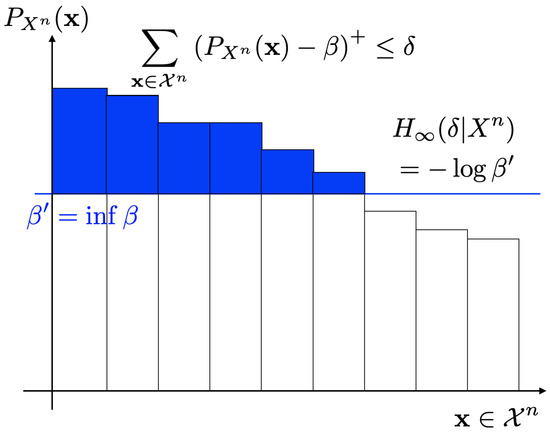
Figure 2.
Smooth min entropy .
In this paper, we use the above alternative expressions of the smooth max entropy and the smooth min entropy instead of (19).
3. Source Resolvability Problem
We consider the problem concerning how to simulate a given discrete source by using the uniform random number and the mapping . Figure 3 is an illustrative figure of this problem (the probability distribution for is depicted in black, while the one for is shown in blue). Since it is hard to simulate the exact source in general, we consider the approximation problem under some measure. This problem is called the resolvability problem. One of the main objectives in the resolvability problem is to derive the smallest value of a in the form of , which we call the optimum resolvability rate [1,8]. This is formulated as follows.
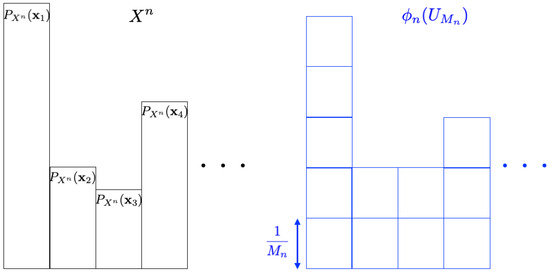
Figure 3.
Resolvability problem.
Definition 3.
Rate R is said to be D-achievable with the given f-divergence if there exists a sequence of mapping such that
Given some D, if the rate constraint R is sufficiently large, it can be shown that there exists a sequence of mappings satisfying constraints in the above definition. Conversely, if R is too small, no sequence of mappings that satisfies constraints can be found. Therefore, in the resolvability problem, the infimum of R is of particular interest.
Definition 4 (First-order optimum resolvability rate).
Remark 6.
It should be noted that we do not use but as a condition in Definition 3. This is important to consider the asymmetric measure such as the KL-divergence.
Remark 7.
We consider the case where D is in under the given f-divergence. Since is defined in the range and we assume that the function is a decreasing function of t, holds for any distributions and from the definition of f-divergence. Hence, means that there exists no restriction about the approximation error (for example, in the case of the half variational distance and in the case of the KL divergence). This case leads to the trivial result that the first-order optimum resolvability rate equals 0. Hence, we only consider the case of . A similar observation is applicable throughout the following sections.
Our main objective in this section is to derive the general formula of the first-order optimum resolvability rate. To do so, we first derive the following two theorems. We use the notation
Theorem 3.
Under conditions C1)–C3), for any and any satisfying
there exists a mapping , which satisfies
for sufficiently large n.
Proof.
We arbitrarily fix satisfying (26). We show that there exists a mapping that satisfies (27) for sufficiently large n. Let denote a set satisfying
and
The existence of the above set is guaranteed by (21). We define the probability distribution over as
Furthermore, let a set be as
and arrange elements in as
according to in ascendant order. That is, holds. Here, we define and index as arbitrarily.
Then, from the above definition, it holds that
Thus, from the assumption (15), for any small , it holds that
for sufficiently large n.
Set . For we determine such that
Secondly, we determine for such that
In a similar way, we repeat this operation to choose for as long as possible. Then, it is not difficult to check that the above procedure does not stop before .
We define a mapping as
and set .
We evaluate the performance of the mapping . From the construction of the mapping, for any i satisfying it holds that
We next evaluate . From the construction, we have . Since holds for , we obtain
for . Hence, also from the construction of the mapping, we obtain
where the second equality is from the fact that for , the first inequality is due to (39) and (40), and the last inequality is obtained from (26) and (29). Thus, we have
From the above argument, the f-divergence is given by
where the first equality is due to the condition C2) and the last inequality is due to (38) and the condition C1).
Theorem 4.
Under conditions C1) and C2), for any mapping satisfying
it holds that
Proof.
It suffices to show the fact that the relation
necessarily yields
We here denote for short. For any fixed mapping , we set and
Then, from the property of the mapping it must hold that
From the condition C2) the f-divergence between and is lower bounded by
where the first inequality is due to (11), the second inequality is due to condition C1) and (54) and the third inequality is from (51). The last inequality is from the definition of the alternative expressions given in Theorem 1. This completes the proof. □
Theorems 3 and 4 show that the smooth max entropy and the inverse function of f have important roles in the resolvability problem with respect to f-divergences. From these theorems, we obtain the following theorem, which addresses the general formula of the optimum resolvability rate. It should be noted that because of the assumption and C1), we have .
Theorem 5.
Under conditions C1)–C3), it holds that
Proof.
We here show the first equality, because the second equality can be derived from the first inequality together with the continuity of the function .
(Direct Part:) Fix arbitrarily. From Theorem 3, for any , there exists a mapping such that
and
We here use the diagonal line argument [8]. Fix a sequence such that , and we repeat the above argument as . Then, we can show that there exists a mapping satisfying
and
Here, also from the diagonal line argument with respect to , we obtain
This completes the proof of the direct part.
(Converse Part:) We fixed arbitrarily. From Theorem 4, for any mapping satisfying
it holds that
Consequently, we have
and
We also use the diagonal line argument [8]. We repeat the above argument as for a sequence such that . Then, for any mapping satisfying
it holds that
This completes the proof of the converse part. □
4. Intrinsic Randomness Problem
In the previous section, we reveal the general formula for the optimum resolvability rate. In this section, we consider how to approximate the uniform random number by using the given discrete source and the mapping . Figure 4 is an illustrative figure of the problem (the probability distribution for is depicted in blue, while the one for is shown in black). The size of the random number is requested to be as large as possible. In the intrinsic randomness problem, one of our main concerns is to derive the largest value of b in the form of under some approximation measure [7]. This problem setting is formulated as follows.
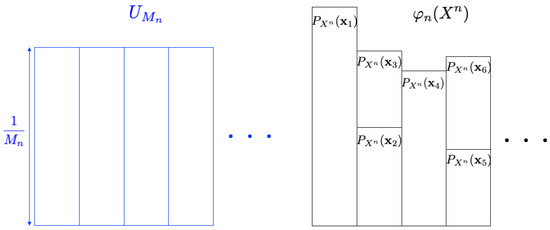
Figure 4.
Intrinsic randomness problem.
Definition 5.
R is said to be Δ-achievable with the given f-divergence if there exists a sequence of mapping such that
In this case, given , if the rate constraint R is sufficiently small, it can be shown that there exists a sequence of mappings that satisfies the constraints. On the other hand, if R is too large, no sequence of mappings that achieves the desired constraints can be found. Consequently, in this setting, the supremum of R is of particular interest.
Definition 6 (First-order optimum intrinsic randomness rate).
Remark 8.
It should be emphasized that we use the f-divergence of the form instead of (cf. Remark 6).
We also assume that in this section (cf. Remark 7). In order to analyze the general formula of the optimum intrinsic randomness rate , we first give two theorems.
Theorem 6.
Under conditions C1) and C2), for any and satisfying
there exists a mapping such that
for sufficiently large n.
Proof.
We set as
for short.
From Theorem 2, we notice that
where if holds, then . We shall show that for any satisfying
there exists a mapping such that
for sufficiently large n.
For every sequence , we define the probability distribution
Since , this probability distribution is well-defined. Then, from the definition of the smooth min entropy it holds that
Here, from (75) and the definition of the smooth min entropy it holds that
for sufficiently large n.
We next define the mapping by using . To do so, we classify the elements of into as follows.
- We choose a set arbitrarily satisfyingfor any .
- Next, we choose a set satisfyingfor any .
Furthermore, we repeat this operation times so as to choose sets . Notice here that since holds, we can repeat this operation times. Thus, from the above procedure, all of are not empty. Lastly, we set .
From , we define the mapping as follows:
Furthermore, we set . Thus,
holds for every i in .
We next evaluate the above mapping . From the construction of the mapping, it holds that
for all and
Hence, for all , we have
Here, notice that for all
holds from (77). Thus, we have
for all where the first equality is due to (85), the first inequality is due to (89), the second inequality is due to (88), and the last inequality is due to (79). Hence, we obtain
where we can choose some such that , the first inequality is due to (90), and the second inequality is due to the continuity of the function f, (74) and C1). This completes the proof of the theorem. □
Theorem 7.
Under conditions C1) and C2), for any if the mapping satisfies
then it holds that
for sufficiently large n.
Proof.
Setting
we only consider the case where holds, because means the trivial result. Let be fixed arbitrarily. We show that if
holds for infinitely many then for any it holds that
From (95), there exists a positive constant satisfying
Here, for satisfying the above inequality we set as
Then, from the relation
we have
Next, we fix and a mapping satisfying (95) and set as . Using and , we set as
Thus, the set is the set of index i constructing from at least one and the set is the set of i constructing only from .
Then, from the definition of the mapping and (101), it holds that
On the other hand, from (97), we have
This means that
holds. Hence, from the condition C2), we have
From the above argument, the f-divergence between and is evaluated as
where the first inequality is due to (11), and the last inequality is due to the relation
and C1).
We next focus on the evaluation of the second term on the RHS of (107). From the definition of the smooth min entropy and Theorem 1, for any it necessarily holds that
Thus, from the definition of it holds that
Thus, we obtain
from which it holds that
Plugging the above inequality with (107), we obtain
Theorems 6 and 7 show that the smooth min entropy and the inverse function of f have important roles in the intrinsic randomness problem with respect to f-divergences, while the smooth max entropy is important in the resolvability problem. By using the above two theorems, we obtain the following theorem. It should be noted that because of the assumption and C1), we have .
Theorem 8.
Under conditions C1) and C2), it holds that
Proof.
(Direct Part:) Fix arbitrarily. From Theorem 6, for any and such that
holds, there exists a mapping satisfying
for sufficiently large n.
Since is arbitrarily, we obtain
Here, we fix a sequence such that , and we repeat the above argument as . Then, we can show that there exists a mapping satisfying
and
This completes the proof of the direct part of the theorem.
(Converse Part:) Fix arbitrarily. From Theorem 7, for any mapping satisfying
it holds that
Thus, for any , we obtain
and
Noting that is arbitrarily, we fix a sequence such that , and we repeat the above argument as . Then, we obtain
and
This completes the proof of the converse part of the theorem. □
5. Relaxation of Conditions C1) and C2)
Thus far, we have derived the general formulas for the optimum resolvability rate under conditions C1)–C3) and for the optimum intrinsic randomness rate under conditions C1) and C2). In this section, we relax conditions C1) and C2) to extend the class of f-divergence for which we can characterize these optimum rates. Hereafter, we do not consider a linear function with some a because it always gives a trivial case where .
We consider the following condition, which is a relaxation of C2):
- C2’)
- The function f satisfies
For function f satisfying condition C2’), we denote the LHS of (129) by
We give some examples of the function , which satisfies C2’) but not C2).
- : The f-divergence is variational distance, and .
- : The f-divergence is the squared Hellinger distance, and .
- (): The f-divergence is -divergence, and .
For function satisfying condition C2’), we consider its modified function
which is offset by . This function is called the offset function of f. It should be noted that under condition C2), which is a special case of C2’), it holds that and thus for all . We have the following lemma:
Lemma 1.
Assume that the function satisfies condition C2’). Then,
- (i)
- the offset function satisfies conditions C1) and (C2),
- (ii)
- for any pair of probability distributions and with the same alphabet , it holds that
Proof.
It is easily verified that is a convex function with , and claim (ii) is well-known. So, here we show claim (i). By definition, it holds that
which indicates that satisfies condition C2).
To show C1) being held, we use the left-derivative of at , denoted as
(cf. [22]). Contrary to ordinary derivatives, the left-derivative at always exists for function , which is continuous. To show that satisfies condition C1), it suffices to show that for all . Using the left-derivative , a tangent line at can be expressed as with some b, where and b correspond to the slope and intercept of this tangent line, respectively. We call this tangent line the left-tangent line at t. Fixing arbitrarily, let and be the intercept of the left-tangent line at . The convexity of implies that
Then, it follows from (133) that
Since is arbitrary, this inequality implies that is decreasing for with , completing the proof of the lemma. □
Lemma 1 indicates that if the original function f satisfies condition C2’), then its offset function satisfies conditions C1) and C2) without changing the value of f-divergence. Because condition C2) is a special instance of condition C2’) with , claim (i) of Lemma 1 implies that condition C1) is superfluous for functions satisfying C2) (cf. Remark 5). The following proposition is immediately obtained by claim (ii) of Lemma 1:
Proposition 1.
Assume that the function satisfies condition C2’). Then, we have
It is easily verified if f satisfies condition C3) as well as C2’), then so does . From this fact, Lemma 1, and Proposition 1, we have the following generalization of Theorem 5.
Theorem 9.
Under conditions C2’) and C3), it holds that
For the optimum intrinsic randomness rate, we also have the generalized result of Theorem 8.
Theorem 10.
Under condition C2’), it holds that
6. Particularization to Several Distance Measures
In previous sections, we have derived the general formula of the first-order optimum resolvability and intrinsic randomness rates with respect to f-divergences, where the smooth Rényi entropy and the inverse function of f have important roles. In this section, we first focus on several specified functions f satisfying conditions C1)–C3) and compute these rates by using Theorems 5 and 8. In addition, we consider the function f satisfying C2’) and C3) and compute the rates by using Theorems 9 and 10.
It will turn out that it is easy to derive the optimum achievable rates for specified approximation measures. We use the notation
for convenience.
Remark 9.
Since the function (which indicates the KL divergence) does not satisfy C1) and C2), we can not apply Theorems 5 and 8 to the case of the KL divergence:
The resolvability problem with respect to the KL divergence of this direction has not been considered yet. On the other hand, in the intrinsic randomness problem, Hayashi [9] ([Theorem 7]) has studied the problem with respect to the normalized KL divergence: as well as .
6.1. Half Variational Distance
We first consider the case of given as , which indicates
In this special case, we obtain the following corollary:
Corollary 1.
For , it holds that
Proof.
In the case of , the inverse function becomes , because holds. Hence, from Theorems 5 and 8, we obtain the corollary. □
The former result in the above corollary coincides with the result given by Uyematsu [6] ([Theorem 6]), while the latter one coincides with the result given by Uyematsu and Kunimatsu [10] ([Theorem 6]). It is important to note that has been addressed by Steinberg [2] and Han [8] ([Theorem 2.4.1]), and has also been addressed by Vembu and Verdú [7] ([Theorem 1]), Han [8] ([Theorem 2.4.2]), and Hayashi [9] ([Theorem 2]), using different information-theoretic approaches. In particular, Hayashi [9] ([Theorem 2]) has considered various achievable rates concerning the intrinsic randomness problem with respect to the variational distance, but these are not included in our current analysis. Our work provides an alternative derivation and contextualizes these results within our framework of f-divergences.
6.2. Reverse Kullback–Leibler Divergence
Secondly, we consider the case of , which indicates
In this case, we obtain the following corollary:
Corollary 2.
For , it holds that
Proof.
The inverse function is immediately given by . Hence, from Theorems 5 and 8, we obtain the corollary. □
It is important to note that has been previously addressed by Hayashi [9] ([Theorem 7]) using different information-theoretic approaches. In particular, Vembu and Verdú [7] ([Theorem 1]) and Hayashi [9] ([Theorem 7]) have also considered the intrinsic randomness problem with respect to the normalized KL divergence, which is not included in our current analysis.
6.3. Hellinger Distance
We consider the case of , which indicates
In this case, we obtain the following corollary:
Corollary 3.
For , it holds that
Proof.
The inverse function of is given by . Hence, from Theorems 5 and 8, we obtain the corollary. Notice here that since both of D and are smaller than one, as well as are positive. □
It is worth noting that Kumagai and Hayashi [13] have analyzed this quantity for the case of i.i.d. sources. Importantly, they addressed this quantity as part of a broader problem: the random number conversion problem. On the other hand, our approach differs in that we derive this quantity from results based on f-divergences.
6.4. Eγ-Divergence
We consider the case of , which indicates
In this case, we obtain the corollary:
Corollary 4.
For , we have
Proof.
Noting that , we have . Hence, the corollary holds. □
Remark 10.
The above corollary shows that both optimum achievable rates with respect to the -divergence does not depend on γ, which means that these rates coincide with the optimum achievable rates with respect to the half variational distance (cf. Corollary 1).
6.5. Variational Distance
We next consider functions f satisfying C2’) and C3). Firstly, the function is considered:
As we have already mentioned in the previous section, does not satisfy C1). However, it satisfies C2’) and C3). Hence, from Theorems 9 and 10, we obtain the corollary:
Corollary 5.
For , we have
Proof.
Noticing that , we have , from which we obtain
Therefore, we obtain the corollary from Theorems 9 and 10. □
6.6. Squared Hellinger Distance
We consider the function , which is also satisfies C2’) and C3). It indicates
In this case, we also apply Theorems 9 and 10.
Corollary 6.
For , we have
Proof.
Noticing that , we obtain
Hence, we obtain the corollary. □
Remark 11.
The variational distance is twice the half variational distance. Consequently, the results of Corollary 5 can be trivially derived from those of Corollary 1. However, we emphasize that does not satisfy conditions C1) and C2). Therefore, to derive the results of Corollary 5, it is necessary to apply the discussion from Section 5, specifically the examination using . This underscores the importance of our theoretical framework in handling cases where the function f does not meet conditions C1) and C2). A similar relationship exists between Corollary 3 and the later-discussed Corollary 6.
6.7. α-Divergence
We consider the function (), which also satisfies C2’) and C3). The -divergence in our setting is given by
In this case, we obtain the following corollary using Theorems 9 and 10.
Corollary 7.
For , we have
Proof.
Noticing that , we obtain
Hence, we obtain the corollary. □
Let us consider the case of . In this case, the inverse function can be simply expressed as
Hence, we have
It is known that -divergence with is related to the squared Hellinger distance. In actuality, the optimum resolvability rate with respect to the squared Hellinger distance is identical to with respect to the -divergence with .
7. Second-Order Optimum Achievable Rate
Thus far, we have considered the first-order optimum resolvability rate as well as the first-order optimum intrinsic randomness rate. The rate of the second-order, which enables us to make a finer evaluation of achievable rates, has already been investigated in several information-theoretic problems [5,9,23,24,25,26,27,28,29,30]. In this section, according to these results, we also consider the second-order optimum achievable rates in random number generation problems with respect to f-divergences.
It is important to acknowledge that the second-order analysis for information-theoretic problems was initiated by Hayashi [9]. Building upon these works, Kumagai and Hayashi [13] conducted a second-order analysis for the broader random number conversion problem. They focused on i.i.d. sources and provided a more detailed analysis in this context. On the other hand, our results apply to more general sources, including but not limited to i.i.d. sources.
7.1. General Formula
We first define the second-order achievability in the resolvability problem.
Definition 7.
L is said to be -achievable with the given f-divergence if there exists a sequence mapping such that
Definition 8 (Second-order optimum resolvability rate).
In order to analyze the above quantity, we use the following condition instead of C3):
- C3’)
- For any pair of positive real numbers , it holds that
Here, functions , , , and satisfy the condition C3’). Then, the following theorem holds:
Theorem 11 (Second-order optimum resolvability rate).
In particular, under conditions C2) and C3’), it holds that
Proof.
We next consider the case of the intrinsic randomness problem.
Definition 9.
L is said to be -achievable with the given f-divergence if there exists a sequence of mapping such that
Definition 10 (Second-order optimum intrinsic randomness rate).
Then, we have the theorem:
Theorem 12
(Second-order optimum intrinsic randomness rate). Under condition C2’), it holds that
where is the offset function of f.
In particular, under condition C2), it holds that
Proof.
Theorems 11 and 12 show that in both the resolvability and the intrinsic randomness, the smooth Rényi entropy and the inverse function of f also have essential roles to express second-order optimum achievable rates.
7.2. Particularizations to Several Distance Measures
Analogously to Section IV, we compute and for the specified function f satisfying C1), C2) and C3’), by using Theorems 11 and 12. We obtain the following corollary:
Corollary 8.
For , it holds that
For , it holds that
For , it holds that
For , we have
Proof.
The proof is similar to proofs of Corollaries 1–4. □
The optimum achievable rates with the variational distance in terms of the smooth Rényi entropy have already been derived. Relations (187) and (188) coincide with the result given by Tagashira and Uyematsu [31], and the result given by Namekawa and Uyematsu [32], respectively. As in the case of the first-order achievability, second-order optimum rates for the half variational distance () and the -divergence () are the same, regardless of the value of .
It is important to note that in the case of the variational distance and the reverse KL divergence has been addressed by Hayashi [9] ([Theorem 3]) and [9] ([Theorem 9]), respectively, using different information-theoretic approaches. Furthermore, , in the case of the Hellinger distance for the i.i.d. case, were studied by Kumagai and Hayashi [13] for the broader setting: the random number conversion problem. Their work focused specifically on i.i.d. sources, while our results extend to more general source models.
8. Optimistic Optimum Achievable Rates
8.1. Source Resolvability
In previous sections, we have treated general formulas of the first- and second-order optimum rates. In this section, we consider optimum achievable rates in the optimistic sense. The notion of the optimistic optimum rates was first introduced by Vembu, Verdú and Steinberg [33] in the source-channel coding problem. Several researchers have developed an optimistic coding scenario in other information-theoretic problems [4,9,34,35]. In this subsection, we also clarify the optimistic optimum resolvability rate with respect to the f-divergence using the smooth Rényi entropy.
Definition 11.
R is said to be optimistically D-achievable with the given f-divergence if there exists a sequence of mapping satisfying
Definition 12 (Optimistic first-order optimum resolvability rate).
We similarly define the second-order achievability in the optimistic scenario.
Definition 13.
L is said to be optimistically -achievable with the given f-divergence if there exists a sequence of mapping satisfying
Definition 14 (Optimistic second-order optimum resolvability rate).
Remark 12.
Conditions of optimistic D-achievability (195) can also be written as
In actuality, the optimistic first-order optimum resolvability rate on the basis of (199) coincides with the one defined by Definition 12. A similar argument is also applicable in the optimistic second-order optimum resolvability rate as well as the optimistic optimum intrinsic randomness rates.
The following theorem can be obtained by using Theorems 3 and 4.
Theorem 13.
Under conditions C2’) and C3), for any , it holds that
where is the offset function of f, defined in (131).
Proof.
The proof proceeds in parallel with proof of Theorems 5 and 9 in which
is replaced by . □
Theorem 14.
Under conditions C2’) and C3’), for any , it holds that
Proof.
The proof proceeds in parallel with the proof of Theorem 11 in which
is replaced by . □
We have revealed the first- and second-order optimum resolvability rates in the optimistic scenario. As a result, the effectiveness of Theorems 3 and 4 has also been shown.
The optimistic second-order optimum achievable rates with the half variational distance using the smooth Rényi entropy have already been derived by Tagashira and Uyematsu [31]. If we consider the case of , Theorem 14 coincides with their result.
8.2. Intrinsic Randomness
We next consider the optimum intrinsic randomness rates in the optimistic scenario.
Definition 15.
R is said to be optimistically Δ-achievable with the given f-divergence if there exists a sequence of mapping satisfying
Definition 16 (Optimistic first-order optimum intrinsic randomness rate).
Definition 17.
L is said to be optimistically -achievable with the given f-divergence if there exists a sequence of mapping satisfying
Definition 18 (Optimistic second-order optimum intrinsic randomness rate).
Then, we have the following theorem by using Theorems 6 and 7.
Theorem 15.
Under condition C2’), for any it holds that
Proof.
The proof is similar to the proof of Theorems 8 and 10 in which is replaced by . □
Theorem 16.
Under condition C2’), for any it holds that
Proof.
The proof is similar to the proof of Theorem 12 in which is replaced by . □
We have revealed the first- and second-order optimum intrinsic randomness rates in an optimistic scenario. As in the case of the resolvability problem, the effectiveness of Theorems 6 and 7 has also been shown.
The optimistic first-order optimum intrinsic randomness rate with the half variational distance using the smooth Rényi entropy has been derived by Uyematsu and Kunimatsu [10], while the second-order one has been characterized by Namekawa and Uyematsu [32]. Our results (Theorems 15 and 16) are generalizations of their results.
It is important to acknowledge that the topic of optimistic optimum achievable rates has also been previously studied in [9]. Our analysis of and relates to the optimistic optimum achievable rates for intrinsic randomness with variational distance, which were addressed in Theorems 2 and 3 of [9] using different information-theoretic quantities. It should be noted that his work encompasses the analysis of several optimal rates, including the optimistic optimum achievable rates.
9. Discussion
Theorems 5 and 8 (as well as Theorems 11 and 12) have shown a kind of duality of two optimum achievable rates in different random number generation problems in terms of the smooth Rényi entropy. It should be noted that in the case of the variational distance, Theorem 6 in [6] and Theorem 7 in [10] have implied the same duality.
As we have mentioned in Section 1, the optimum achievable rates and have already been characterized by using the information spectrum quantity.
Definition 19.
Then, using these two quantities the following theorem has already been given.
Theorem 17
(Nomura [4] ([Theorems 3.1 and 4.1])). Under conditions C1)–C3), it holds that
From the above theorem and Theorems 5 and 8, we obtain the following relationship.
Theorem 18.
Under conditions C1)–C3), it holds that
The above theorem shows equivalences between information spectrum quantities and smooth Rényi entropies.
Remark 13.
Theorem 18 can also be proved by using previous results and the continuity of the function f. In actuality, for , Steinberg and Verdú [2] have shown
from which together with the theorem given by Uyematsu [6] ([Theorem 6]) (Corollary 1 in this paper), we obtain
holds under conditions C1)–C3), we have (211). Equation (212) can also be derived from Corollary 1 and the result given by [8] ([Theorem 2.4.2]).
Remark 14.
From Definition 19, two quantities and are right-continuous functions of D, while
may not. The operation in Theorem 18 can be considered an operation that makes quantities in (216) to be right-continuous. Furthermore, since is a decreasing function of D, is also a decreasing function of D. This means that the relation
holds. It should be emphasized that the above inequality holds with equality except for at most countably many D. Similarly, we obtain
where the equality holds except for at most countably many Δ. A similar observation can be applied to Theorem 20 below.
The quantity on the right-hand side of Equation (214) is an information-spectrum quantity defined in [8]. This quantity has been instrumental in analyzing various problems, including source coding and resolvability. On the other hand, the following quantity is specifically used for analyzing the intrinsic randomness problem:
It is noteworthy that Hayashi [9] has defined second-order extensions of these quantities, further expanding their applicability in information theory. These extensions provide a more refined analysis of the asymptotic behavior of various information-theoretic problems.
We next consider the case of the second-order setting. We first define two quantities:
By using these quantities, the following theorem has been obtained.
Theorem 19
(Nomura [4] ([Theorems 6.1 and 6.2])). Under conditions C1), C2) and C3’), it holds that
From the above theorem and Theorems 11 and 12, we obtain:
Theorem 20.
Under conditions C1), C2) and C3’), it holds that
The above theorem also shows equivalences between information spectrum quantities and smooth Rényi entropies in the second-order sense.
We have discussed functions f under C1), C2), and C3) (or C3’)) for simplicity. We can also extend the discussions for f under C2’) and C3) (or C3’)) with due modification using .
10. Concluding Remarks
We have so far considered the optimum achievable rates in two random number generation problems with respect to a subclass of f-divergences. We have demonstrated general formulas of the first- and second-order optimum achievable rates with respect to the given f-divergence by using the smooth Rényi entropy including the inverse function of f. To our knowledge, this is the first use of the smooth Rényi entropy in information theory that contains the general function f. We believe that this is important from both the theoretical and practical viewpoints. In actuality, we have shown that we can easily derive the results on several important measures, such as the variational distance, the KL divergence, and the Hellinger distance, by substituting the specified function f into our general formulas. It should be noted that the optimum achievable rates with important measures have not been characterized before by using the smooth Rényi entropy except for the variational distance. Expressions of the smooth max entropy in Theorem 1 and the smooth min entropy in Theorem 2 are simple and easy to understand. Hence, our results using the smooth max entropy and the smooth min entropy are also comprehensive. This provides us another viewpoint to understand the mechanism of the random number generation problems compared to the results given in [4], in which the information spectrum quantities are used. In addition, we have shown that the conditions on f-divergence can be relaxed, leading to the general formulas holding for a wider class of f-divergence. These are major contributions of this paper.
As a consequence of our results and the results in [4], the equivalence of the smooth Rényi entropy and the information spectrum quantity has been clarified (Theorem 18). One may consider that if we show this equivalency first, then we can derive Theorems 5 and 8 directly. This observation is correct. That is, one simple method of deriving both of the general formulas of the optimum achievable rates (Theorems 5 and 8) is to show this equivalency (Theorem 18) first. Then, combining Theorem 18 and results in [4], we obtain Theorems 5 and 8. However, we have taken another approach to show Theorems 5 and 8 in this paper. For example, we first have shown Theorems 3 and 4 so as to establish Theorem 5. Although Theorem 5 has been established by using Theorems 3 and 4, we think that these two theorems are significant themselves. In fact, Theorem 3 provides us with how to construct an optimum mapping in the resolvability problem, and Theorem 4 shows the relationship between the rate of the random number and the smooth max entropy in terms of the finite block length. Hence, these two theorems are also significant not only for proving Theorem 5 but also for constructing the optimum mapping in the practical situation.
In this paper, we have considered the f-divergence in the case of the resolvability problem and in the case of the intrinsic randomness problem and shown a kind of duality of these problems in terms of the smooth Rényi entropy. On the other hand, we can consider the resolvability problem with respect to as well as the intrinsic randomness problem with respect to . Although these problems are also important, a similar technique in the present paper cannot be applied directly. In order to treat these problems, it seems we need some novel techniques, which remain to be studied. This is similar to the case of the information spectrum approach [4].
Finally, the condition C3) and the assumption (15) for the source, have only been needed to show Direct Part (Theorem 3) in the resolvability problem. To consider the necessity or weakening of these conditions is also a future work.
Author Contributions
R.N. and H.Y. conceptualized the overall study. R.N. took the lead in writing the manuscript, with H.Y. contributing by writing Section 5. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by JSPS KAKENHI Grant Number JP20K04462, JP22K04111, JP23K10992, and Kayamori Foundation of Informational Science Advancement.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Han, T.S.; Verdú, S. Approximation theory of output statistics. IEEE Trans. Inf. Theory 1993, 39, 752–772. [Google Scholar] [CrossRef]
- Steinberg, Y.; Verdú, S. Simulation of random processes and rate-distortion theory. IEEE Trans. Inf. Theory 1996, 42, 63–86. [Google Scholar] [CrossRef]
- Nomura, R. Source resolvability with Kullback-Leibler divergence. In Proceedings of the 2018 IEEE International Symposium on Information Theory, Vail, CO, USA, 17–22 June 2018; pp. 2042–2046. [Google Scholar]
- Nomura, R. Source resolvability and intrinsic randomness: Two random number generation problems with respect to a subclass of f-divergences. IEEE Trans. Inf. Theory 2020, 66, 7588–7601. [Google Scholar] [CrossRef]
- Nomura, R.; Han, T.S. Second-order resolvability, intrinsic randomness, and fixed-length source coding for mixed sources: Information spectrum approach. IEEE Trans. Inf. Theory 2013, 59, 1–16. [Google Scholar] [CrossRef]
- Uyematsu, T. Relating source coding and resolvability: A direct approach. In Proceedings of the 2010 IEEE International Symposium on Information Theory, Austin, TX, USA, 13–18 June 2010; pp. 1350–1354. [Google Scholar]
- Vembu, S.; Verdú, S. Generating random bits from an arbitrary source: Fundamental limits. IEEE Trans. Inf. Theory 1995, 41, 1322–1332. [Google Scholar] [CrossRef]
- Han, T.S. Information-Spectrum Methods in Information Theory; Springer: New York, NY, USA, 2003. [Google Scholar]
- Hayashi, M. Second-order asymptotics in fixed-length source coding and intrinsic randomness. IEEE Trans. Inf. Theory 2008, 54, 4619–4637. [Google Scholar]
- Uyematsu, T.; Kunimatsu, S. A new unified method for intrinsic randomness problems of general sources. In Proceedings of the 2013 IEEE Information Theory Workshop (ITW), Seville, Spain, 9–13 September 2013; pp. 1–5. [Google Scholar]
- Liu, J.; Cuff, P.; Verdú, S. Eγ-resolvability. IEEE Trans. Inf. Theory 2017, 63, 2629–2658. [Google Scholar]
- Yagi, H.; Han, T.S. Variable-length resolvability for mixed sources and its application to variable-length source coding. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018. [Google Scholar]
- Kumagai, W.; Hayashi, M. Second-order asymptotics of conversions of distributions and entangled states based on rayleigh-normal probability distributions. IEEE Trans. Inf. Theory 2017, 63, 1829–1857. [Google Scholar] [CrossRef]
- Kumagai, W.; Hayashi, M. Random number conversion and LOCC conversion via restricted storage. IEEE Trans. Inf. Theory 2017, 63, 2504–2532. [Google Scholar] [CrossRef]
- Yu, L.; Tan, V.Y.F. Simulation of random variables under Rényi divergence measures of all orders. IEEE Trans. Inf. Theory 2019, 65, 3349–3383. [Google Scholar] [CrossRef]
- Yagi, H.; Han, T.S. Variable-length resolvability for general sources and channels. Entropy 2023, 25, 1466. [Google Scholar] [CrossRef] [PubMed]
- Csiszár, I.; Shields, P.C. Information theory and statistics: A tutorial. Found. Trends® Commun. Inf. Theory 2004, 1, 417–528. [Google Scholar] [CrossRef]
- Sason, I.; Verdú, S. f-divergence inequalities. IEEE Trans. Inf. Theory 2016, 62, 5973–6006. [Google Scholar] [CrossRef]
- Renner, R.; Wolf, S. Smooth Rényi entropy and applications. In Proceedings of the 2004 IEEE International Symposium on Information Theory (ISIT), Chicago, IL, USA, 27 June–2 July 2004; p. 233. [Google Scholar]
- Holenstein, T.; Renner, R. On the randomness of independent experiments. IEEE Trans. Inf. Theory 2011, 57, 1865–1871. [Google Scholar] [CrossRef]
- Uyematsu, T. A new unified method for fixed-length source coding problems of general sources. IEICE Trans. Fundam. 2010, E93-A, 1868–1877. [Google Scholar]
- Rockafellar, R.T. Convex Analysis; Princeton University Press: Princeton, NJ, USA, 1970. [Google Scholar]
- Hayashi, M. Information spectrum approach to second-order coding rate in channel coding. IEEE Trans. Inf. Theory 2009, 55, 4947–4966. [Google Scholar] [CrossRef]
- Polyanskiy, Y.; Poor, H.; Verdú, S. Channel coding rate in the finite blocklength regime. IEEE Trans. Inf. Theory 2010, 56, 2307–2359. [Google Scholar] [CrossRef]
- Ingber, A.; Kochman, Y. The dispersion of lossy source coding. In Proceedings of the Data Compression Conference (DCC), Snowbird, UT, USA, 29–31 March 2011; pp. 53–62. [Google Scholar]
- Kostina, V.; Verdú, S. Fixed-length lossy compression in the finite blocklength regime. IEEE Trans. Inf. Theory 2012, 58, 3309–3338. [Google Scholar] [CrossRef]
- Kontoyiannis, I.; Verdú, S. Optimal lossless compression: Source varentropy and despersion. In Proceedings of the 2013 IEEE International Symposium on Information Theory, Istanbul, Turkey, 7–12 July 2013; pp. 1739–1742. [Google Scholar]
- Tan, V.Y.F.; Kosut, O. On the dispersions of three network information theory problems. IEEE Trans. Inf. Theory 2014, 60, 881–903. [Google Scholar] [CrossRef]
- Yagi, H.; Han, T.S.; Nomura, R. First- and second-order coding theorems for mixed memoryless channels with general mixture. IEEE Trans. Inf. Theory 2016, 62, 4395–4412. [Google Scholar] [CrossRef]
- Watanabe, S. Second-order region for Gray-Wyner network. IEEE Trans. Inf. Theory 2017, 63, 1006–1018. [Google Scholar] [CrossRef]
- Tagashira, S.; Uyematsu, T. The second order asymptotic rates in fixed-length coding and resolvability problem in terms of smooth rényi entropy. IEICE Tech. Rep. 2013, 112, 65–70. (In Japanese) [Google Scholar]
- Namekawa, E.; Uyematsu, T. The second order asymptotic rates in intrinsic randomness problem in terms of smooth rényi entropy. IEICE Tech. Rep. 2015, 114, 1–6. (In Japanese) [Google Scholar]
- Vembu, S.; Verdú, S.; Steinberg, Y. The source-channel separation theorem revisited. IEEE Trans. Inf. Theory 1995, 41, 44–54. [Google Scholar] [CrossRef]
- Chen, P.O.; Alajaji, F. Optimistic Shannon coding theorems for arbitrary single-user systems. IEEE Trans. Inf. Theory 1999, 45, 2623–2629. [Google Scholar] [CrossRef]
- Koga, H. Four limits in probability and their roles in source coding. IEICE Trans. Fundam. 2011, 94, 2073–2082. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).