
Information Thermodynamics: From Physics to Neuroscience


{kind=link}
{kind=link}
Abstract
“Earth, air, fire, and water in the end are all made of energy, but the different forms they take are determined by information. To do anything requires energy. To specify what is done requires information.”— Seth Lloyd (2006) [1]
1. Introduction: Information Is Physical, So Is the Brain
2. Stochastic Dynamics and Thermodynamics
2.1. Stochastic Dynamics
2.2. Stochastic Thermodynamics
3. Entropy, Information, and the Second Law of Thermodynamics
3.1. Entropy, Kullback–Leibler Divergence, and Information
3.2. Entropy Production and Flow, and the Second Law
3.3. Entropy Production and Flow for the Brownian Particle
4. Information Flow between Two Subsystems and the Maxwell Demon
5. Neural Inference
5.1. Mutual Information between Neural Activities and the Stimulus
5.2. Energy Cost of Decoding the Stimulus
6. Stochastic Dynamics of Synaptic Plasticity: Learning and Memory Storage
6.1. Dynamics of Synaptic Weights
6.2. Information Gain and Maintenance, and Associated Energy Cost
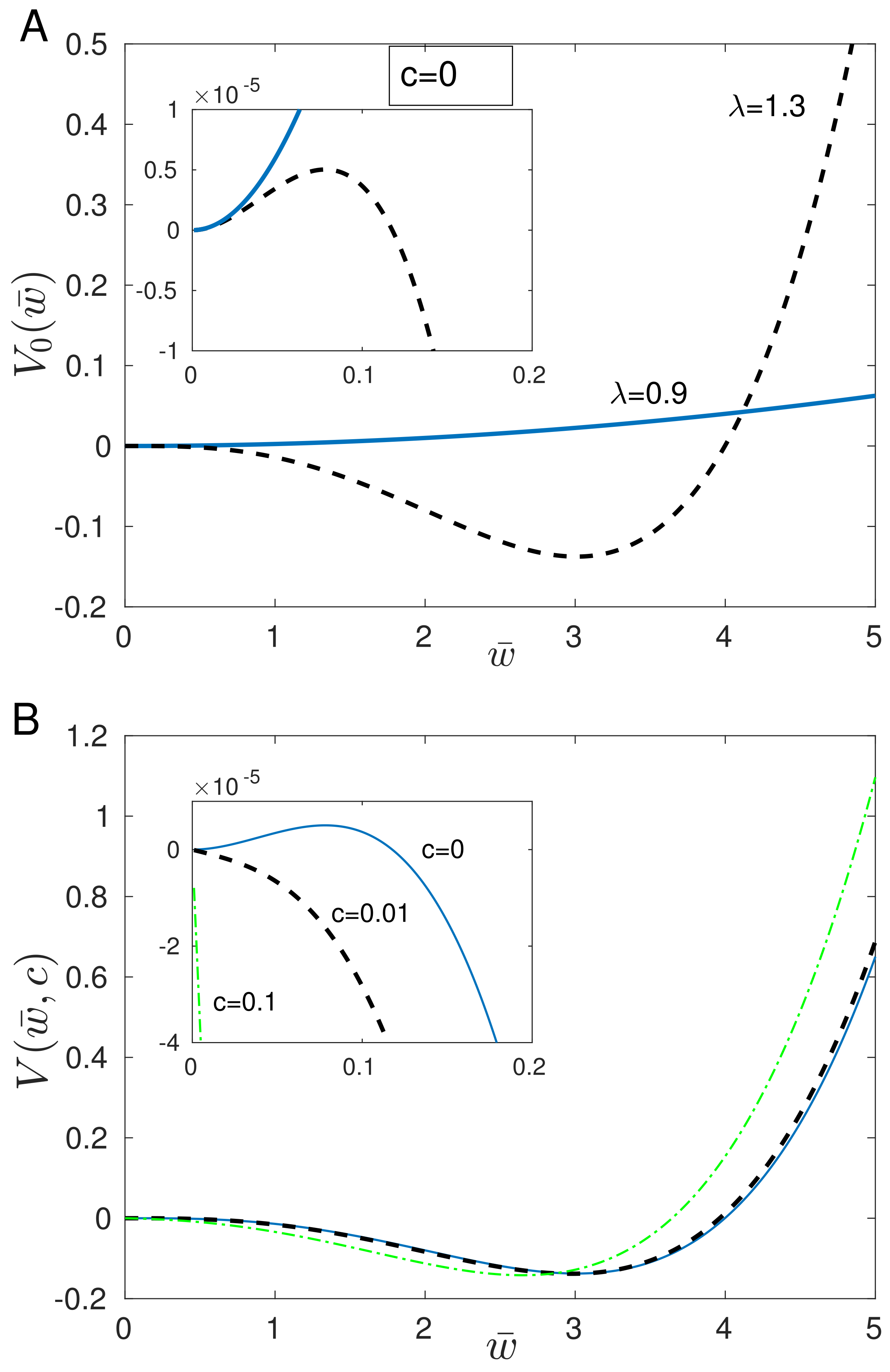
7. More General Framework for Synaptic Learning and Memory
Information Gain and Loss, and Associated Energy Cost
8. Concluding Remarks
Funding
Acknowledgments
Conflicts of Interest
Appendix A
Appendix B
References
- Lloyd, S. Programming the Universe; Knopf: New York, NY, USA, 2006. [Google Scholar]
- Levy, W.B.; Baxter, R.A. Energy efficient neural codes. Neural Comput. 1996, 8, 531–543. [Google Scholar] [CrossRef] [PubMed]
- Levy, W.B.; Baxter, R.A. Energy-efficient neuronal computation via quantal synaptic failures. J. Neurosci. 2002, 22, 4746–4755. [Google Scholar] [CrossRef] [PubMed]
- Laughlin, S.B.; de Ruyter van Steveninck, R.R.; Anderson, J.C. The metabolic cost of neural information. Nat. Neurosci. 1998, 1, 36–40. [Google Scholar] [CrossRef] [PubMed]
- Attwell, D.; Laughlin, S.B. An energy budget for signaling in the gray matter of the brain. J. Cereb. Blood Flow Metabol. 2001, 21, 1133–1145. [Google Scholar] [CrossRef]
- Karbowski, J. Thermodynamic constraints on neural dimensions, firing rates, brain temperature and size. J. Comput. Neurosci. 2009, 27, 415–436. [Google Scholar] [CrossRef]
- Karbowski, J. Approximate invariance of metabolic energy per synapse during development in mammalian brains. PLoS ONE 2012, 7, e33425. [Google Scholar] [CrossRef]
- Aiello, L.C.; Wheeler, P. The expensive-tissue hypothesis: The brain and the digestive-system in human and primate evolution. Curr. Anthropol. 1995, 36, 199–221. [Google Scholar] [CrossRef]
- Herculano-Houzel, S. Scaling of brain metabolism with a fixed energy budget per neuron: Implications for neuronal activity, plasticity, and evolution. PLoS ONE 2011, 6, e17514. [Google Scholar] [CrossRef]
- Karbowski, J. Global and regional brain metabolic scaling and its functional consequences. BMC Biol. 2007, 5, 18. [Google Scholar] [CrossRef]
- Nicolis, G.; Prigogine, I. Self-Organization in Nonequilibrium Systems; Wiley: New York, NY, USA, 1977. [Google Scholar]
- Goldt, S.; Seifert, U. Stochastic thermodynamics of learning. Phys. Rev. Lett. 2017, 11, 11601. [Google Scholar] [CrossRef]
- Karbowski, J. Metabolic constraints on synaptic learning and memory. J. Neurophysiol. 2019, 122, 1473–1490. [Google Scholar] [CrossRef] [PubMed]
- Karbowski, J. Energetics of stochastic BCM type synaptic plasticity and storing of accurate information. J. Comput. Neurosci. 2021, 49, 71–106. [Google Scholar] [CrossRef] [PubMed]
- Lynn, C.W.; Cornblath, E.J.; Papadopoulos, L.; Bertolero, M.A.; Bassett, D.S. Broken detailed balance and entropy production in the human brain. Proc. Natl. Acad. Sci. USA 2021, 118, e2109889118. [Google Scholar] [CrossRef]
- Deco, G.; Lynn, C.W.; Sanz Perl, Y.; Kringelbach, M.L. Violations of the fluctuation-dissipation theorem reveal distinct non-equilibrium dynamics of brain states. Phys. Rev E 2023, 108, 064410. [Google Scholar] [CrossRef]
- Lefebvre, B.; Maes, C. Frenetic steering in a nonequilibrium graph. J. Stat. Phys. 2023, 190, 90. [Google Scholar] [CrossRef]
- Karbowski, J.; Urban, P. Cooperativity, information gain, and energy cost during early LTP in dendritic spines. Neural Comput. 2024, 36, 271–311. [Google Scholar] [CrossRef] [PubMed]
- Dayan, P.; Abbott, L.F. Theoretical Neuroscience; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Ermentrout, G.B.; Terman, D.H. Mathematical Foundations of Neuroscience; Springer: New York, NY, USA, 2010. [Google Scholar]
- Rieke, F.; Warl, D.; de Ruyter, R.; Bialek, W. Spikes: Exploring the Neural Code; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Chaudhuri, R.; Fiete, I. Computational principles of memory. Nat. Neurosci. 2016, 19, 394–403. [Google Scholar] [CrossRef] [PubMed]
- Marblestone, A.H.; Wayne, G.; Kording, K.P. Toward an integration of deep learning and neuroscience. Front. Comput. Neurosci. 2016, 10, 94. [Google Scholar] [CrossRef]
- Markram, H.; Muller, E.; Ramaswamy, S.; Reimann, M.W.; Abdellah, M.; Sanchez, C.A.; Ailamaki, A.; Alonso-Nanclares, L.; Antille, N.; Arsever, S.; et al. Reconstruction and simulation of neocortical microcircuitry. Cell 2015, 163, 456–492. [Google Scholar] [CrossRef]
- Stiefel, K.M.; Coggan, J.S. A hard energy use limit on artificial superintelligence. TechRxiv 2023. [Google Scholar] [CrossRef]
- Landauer, R. Irreversibility and heat generation in the computing process. IBM J. Res. Dev. 1961, 5, 183–191. [Google Scholar] [CrossRef]
- Levy, W.B.; Calvert, V.G. Communication consumes 35 times more energy than computation in the human cortex, but both costs are needed to predict synapse number. Proc. Natl. Acad. Sci. USA 2021, 118, e2008173118. [Google Scholar] [CrossRef] [PubMed]
- Balasubramanian, V.; Kimber, D.; Berry, M.J. Metabolically efficient information processing. Neural. Comput. 2001, 13, 799–815. [Google Scholar] [CrossRef]
- Niven, B.; Laughlin, S.B. Energy limitation as a selective pressure on the evolution of sensory systems. J. Exp. Biol. 2008, 211, 1792–1804. [Google Scholar] [CrossRef] [PubMed]
- Maxwell, J.C. Theory of Heat; Appleton: London, UK, 1871. [Google Scholar]
- Leff, H.S.; Rex, A.F. Maxwell’s Demon: Entropy, Information, Computing; Princeton University Press: Princeton, NJ, USA, 1990. [Google Scholar]
- Maruyama, K.; Nori, F.; Vedral, V. Colloquium: The physics of Maxwell’s demon and information. Rev. Mod. Phys. 2009, 81, 1–23. [Google Scholar] [CrossRef]
- Bennett, C.H. The thermodynamics of computation—A review. Int. J. Theor. Phys. 1982, 21, 905–940. [Google Scholar] [CrossRef]
- Berut, A.; Arakelyan, A.; Petrosyan, A.; Ciliberto, S.; Dillenschneider, R.; Lutz, E. Experimental verification of Landauer’s principle linking information and thermodynamics. Nature 2012, 483, 187–190. [Google Scholar] [CrossRef] [PubMed]
- Landauer, R. Information is physical. Phys. Today 1991, 44, 23–29. [Google Scholar] [CrossRef]
- Parrondo, J.M.; Horowitz, J.M.; Sagawa, T. Thermodynamics of information. Nat. Phys. 2015, 11, 131. [Google Scholar] [CrossRef]
- Atick, J.J.; Redlich, A.N. Toward a theory of early visual processing. Neural Comput. 1990, 2, 308. [Google Scholar] [CrossRef]
- Bialek, W.; Nemenman, I.; Tishby, N. Predictability, complexity, and learning. Neural Comput. 2001, 13, 2409–2463. [Google Scholar] [CrossRef] [PubMed]
- Lang, A.H.; Fisher, C.K.; Mora, T.; Mehta, P. Thermodynamics of statistical inference by cells. Phys. Rev. Lett. 2014, 113, 148103. [Google Scholar] [CrossRef] [PubMed]
- Palmer, S.E.; Marre, O.; Berry, M.J.; Bialek, W. Predictive information in a sensory population. Proc. Natl. Acad. Sci. USA 2015, 112, 6908–6913. [Google Scholar] [CrossRef]
- Sterling, P.; Laughlin, S. Principles of Neural Design; MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Still, S.; Sivak, D.A.; Bell, A.J.; Crooks, G.E. Thermodynamics of prediction. Phys. Rev. Lett. 2012, 109, 120604. [Google Scholar] [CrossRef]
- Karbowski, J.; Urban, P. Information encoded in volumes and areas of dendritic spines is nearly maximal across mammalian brains. Sci. Rep. 2023, 13, 22207. [Google Scholar] [CrossRef] [PubMed]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Barlow, H.B. Sensory mechanisms, the reduction of redundancy, and intelligence. In Symposium on the Mechanization of Thought Processes, Volume II; Blake, D.V., Uttley, A.M., Eds.; HM Stationery Office: London, UK, 1959; pp. 537–574. [Google Scholar]
- Laughlin, S.B. A simple coding procedure enhances a neuron’s information capacity. Z. Naturforsch. C 1981, 36C, 910–912. [Google Scholar] [CrossRef]
- Bialek, W.; Rieke, F.; van Steveninck, R.; Warland, D. Reading a neural code. Science 1991, 252, 1854. [Google Scholar] [CrossRef]
- Tkacik, G.; Bialek, W. Information processing in living systems. Annu. Rev. Condens. Matter Phys. 2016, 7, 12.1–12.29. [Google Scholar] [CrossRef]
- Seifert, U. Stochastic thermodynamics, fluctuation theorems and molecular machines. Rep. Prog. Phys. 2012, 75, 126001. [Google Scholar] [CrossRef]
- Peliti, L.; Pigolotti, S. Stochastic Thermodynamics: An Introduction; Princeton University Press: Princeton, NJ, USA, 2021. [Google Scholar]
- Bienenstock, E.L.; Cooper, L.N.; Munro, P.W. Theory for the development of neuron selectivity: Orientation specificity and binocular interaction in visual cortex. J. Neurosci. 1982, 2, 32–48. [Google Scholar] [CrossRef] [PubMed]
- Glauber, R.J. Time-dependent statistics of the Ising model. J. Math. Phys. 1963, 4, 294–307. [Google Scholar] [CrossRef]
- Van Kampen, N.G. Stochastic Processes in Physics and Chemistry; Elsevier: Amsterdam, The Netherlands, 2007. [Google Scholar]
- Gardiner, C.W. Handbook of Stochastic Methods; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Majumdar, S.N.; Orl, H. Effective Langevin equations for constrained stochastic processes. J. Stat. Mech. 2015, 2015, P06039. [Google Scholar] [CrossRef]
- Sekimoto, K. Langevin equation and thermodynamics. Prog. Theor. Phys. Suppl. 1998, 130, 17–27. [Google Scholar] [CrossRef]
- Sekimoto, K. Stochastic Energetics; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Novikov, E.A. Functionals and the random-force method in turbulence theory. Sov. Phys. JETP 1965, 20, 1290–1294. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley and Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Gell-Mann, M.; Lloyd, S. Information measures, effective complexity, and total information. Complexity 1996, 2, 44–52. [Google Scholar] [CrossRef]
- Renyi, A. On measures of entropy and information. In Proceedings of the 4th Berkeley Symposium on Mathematics, Statistics and Probability, Berkeley, CA, USA, 20–30 June 1961; University of California Press: Berkeley, CA, USA, 1961; pp. 547–561. [Google Scholar]
- Csiszar, I. Information-type measures of difference of probability distributions and indirect observations. Stud. Sci. Math. Hung. 1967, 2, 299–318. [Google Scholar]
- Tsallis, C. Generalized entropy-based criterion for consistent testing. Phys. Rev. E 1998, 58, 1442–1445. [Google Scholar] [CrossRef]
- Amari, S.-I.; Nagaoka, H. Methods of Information Geometry; Oxford University Press: Oxford, UK, 2000. [Google Scholar]
- Liese, F.; Vajda, I. On divergences and informations in statistics and information theory. IEEE Trans. Inform. Theory 2006, 52, 4394–4412. [Google Scholar] [CrossRef]
- Gorban, A.N. General H-theorem and entropies that violate the second law. Entropy 2014, 16, 2408–2432. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Kawai, R.; Parrondo, J.M.R.; Van den Broeck, C. Dissipation: The phase-space perspective. Phys. Rev. Lett. 2007, 98, 080602. [Google Scholar] [CrossRef] [PubMed]
- Sason, I.; Verdu, S. f-Divergence inequalities. IEEE Trans. Inf. Theory 2016, 62, 5973–6006. [Google Scholar] [CrossRef]
- Karbowski, J. Bounds on the rates of statistical divergences and mutual information via stochastic thermodynamics. Phys. Rev. E 2024, 109, 054126. [Google Scholar] [CrossRef]
- Hasegawa, Y.; Vu, T.V. Uncertainty relations in stochastic processes: An information equality approach. Phys. Rev. E 2019, 99, 062126. [Google Scholar] [CrossRef]
- Tostevin, F.; Ten Wolde, P.R. Mutual information between input and output trajectories of biochemical networks. Phys. Rev. Lett. 2009, 102, 218101. [Google Scholar] [CrossRef]
- Nicoletti, G.; Busiello, D.M. Mutual information disentangles interactions from changing environments. Phys. Rev. Lett. 2021, 127, 228301. [Google Scholar] [CrossRef]
- Fagerholm, E.D.; Scott, G.; Shew, W.L.; Song, C.; Leech, R.; Knöpfel, T.; Sharp, D.J. Cortical entropy, mutual information and scale-free dynamics in waking mice. Cereb. Cortex 2016, 26, 3945–3952. [Google Scholar] [CrossRef]
- Shriki, O.; Yellin, D. Optimal information representation and criticality in an adaptive sensory recurrent neuronal network. PLoS Comput. Biol. 2016, 12, e1004698. [Google Scholar] [CrossRef]
- Schnakenberg, J. Network theory of microscopic and macroscopic behavior of master equation systems. Rev. Mod. Phys. 1976, 48, 571–585. [Google Scholar] [CrossRef]
- Maes, C.; Netocny, K. Time-reversal and entropy. J. Stat. Phys. 2003, 110, 269–310. [Google Scholar] [CrossRef]
- Esposito, M.; Van den Broeck, C. Three faces of the second law. I. Master equation formulation. Phys. Rev. E 2010, 82, 011143. [Google Scholar] [CrossRef]
- Tome, T. Entropy production in nonequilibrium systems described by a Fokker-Planck equation. Braz. J. Phys. 2006, 36, 1285–1289. [Google Scholar] [CrossRef]
- Mehta, P.; Schwab, D.J. Energetic cost of cellular computation. Proc. Natl. Acad. Sci. USA 2012, 109, 17978–17982. [Google Scholar] [CrossRef] [PubMed]
- Horowitz, J.M.; Esposito, M. Thermodynamics with continuous information flow. Phys. Rev. X 2014, 4, 031015. [Google Scholar] [CrossRef]
- Allahverdyan, A.E.; Janzing, D.; Mahler, G. Thermodynamic efficiency of information and heat flow. J. Stat. Mech. 2009, 2009, P09011. [Google Scholar] [CrossRef]
- Rodman, H.R.; Albright, T.D. Coding of visual stimulus velocity in area MT of the macaque. Vis. Res. 1987, 27, 2035–2048. [Google Scholar] [CrossRef]
- Braitenberg, V.; Schuz, A. Cortex: Statistics and Geometry of Neuronal Connectivity; Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Karbowski, J. Constancy and trade-offs in the neuroanatomical and metabolic design of the cerebral cortex. Front. Neural Circuits 2017, 8, 9. [Google Scholar] [CrossRef]
- Faisal, A.A.; White, J.A.; Laughlin, S.B. Ion-channel noise places limits on the miniaturization of the brain’s wiring. Curr. Biol. 2005, 15, 1143–1149. [Google Scholar]
- Renart, A.; Machens, C.K. Variability in neural activity and behavior. Curr. Opin. Neurobiol. 2014, 25, 211–220. [Google Scholar]
- Nicoletti, G.; Busiello, D.M. Information propagation in multilayer systems with higher-order interactions across timescales. Phys. Rev. X 2024, 14, 021007. [Google Scholar] [CrossRef]
- Kandel, E.R.; Dudai, Y.; Mayford, M.R. The molecular and systems biology of memory. Cell 2014, 157, 163–186. [Google Scholar] [CrossRef] [PubMed]
- Bourne, J.N.; Harris, K.M. Balancing structure and function at hippocampal dendritic spines. Annu. Rev. Neurosci. 2008, 31, 47–67. [Google Scholar] [CrossRef] [PubMed]
- Takeuchi, T.; Duszkiewicz, A.J.; Morris, R.G.M. The synaptic plasticity and memory hypothesis: Encoding, storage and persistence. Phil. Trans. R. Soc. B 2014, 369, 20130288. [Google Scholar] [CrossRef]
- Poo, M.M.; Pignatelli, M.; Ryan, T.J.; Tonegawa, S.; Bonhoeffer, T.; Martin, K.C.; Rudenko, A.; Tsai, L.H.; Tsien, R.W.; Fishell, G.; et al. What is memory? The present state of the engram. BMC Biol. 2016, 14, 40. [Google Scholar] [CrossRef]
- Meyer, D.; Bonhoeffer, T.; Scheuss, V. Balance and stability of synaptic structures during synaptic plasticity. Neuron 2014, 2014 82, 430–443. [Google Scholar] [CrossRef]
- Statman, A.; Kaufman, M.; Minerbi, A.; Ziv, N.E.; Brenner, N. Synaptic size dynamics as an effective stochastic process. PLoS Comput. Biol. 2014, 10, e1003846. [Google Scholar] [CrossRef]
- Petersen, C.C.; Malenka, R.C.; Nicoll, R.A.; Hopfield, J.J. All-or-none potentiation at CA3-CA1 synapses. Proc. Natl. Acad. Sci. USA 1998, 95, 4732–4737. [Google Scholar] [CrossRef]
- Montgomery, J.M.; Madison, D.V. Discrete synaptic states define a major mechanism of synaptic plasticity. Trends Neurosci. 2004, 27, 744–750. [Google Scholar] [CrossRef]
- Kasai, H.; Matsuzaki, M.; Noguchi, J.; Yasumatsu, N.; Nakahara, H. Structure-stability-function relationships of dendritic spines. Trends Neurosci. 2003, 26, 360–368. [Google Scholar] [CrossRef]
- Govindarajan, A.; Kelleher, R.J.; Tonegawa, S. A clustered plasticity model of long-term memory engrams. Nat. Rev. Neurosci. 2006, 7, 575–583. [Google Scholar] [CrossRef] [PubMed]
- Winnubst, J.; Lohmann, C.; Jontes, J.; Wang, H.; Niell, C. Synaptic clustering during development and learning: The why, when, and how. Front. Mol. Neurosci. 2012, 5, 70. [Google Scholar] [CrossRef] [PubMed]
- Yadav, A.; Gao, Y.Z.; Rodriguez, A.; Dickstein, D.L.; Wearne, S.L.; Luebke, J.I.; Hof, P.R.; Weaver, C.M. Morphologic evidence for spatially clustered spines in apical dendrites of monkey neocortical pyramidal cells. J. Comp. Neurol. 2012, 520, 2888–2902. [Google Scholar] [CrossRef] [PubMed]
- Turrigiano, G.G.; Nelson, S.B. Homeostatic plasticity in the developing nervous system. Nat. Rev. Neurosci. 2004, 5, 97–107. [Google Scholar] [CrossRef] [PubMed]
- Bialek, W. Ambitions for theory in the physics of life. SciPost Phys. Lect. Notes 2024, 84, 1–79. [Google Scholar] [CrossRef]
- Tkacik, G.; Mora, T.; Marre, O.; Amodei, D.; Palmer, S.E.; Berry, M.J.; Bialek, W. Thermodynamics and signatures of criticality in a network of neurons. Proc. Natl. Acad. Sci. USA 2015, 112, 11508–11513. [Google Scholar] [CrossRef]
- Holtmaat, A.J.; Trachtenberg, J.T.; Wilbrecht, L.; Shepherd, G.M.; Zhang, X.; Knott, G.W.; Svoboda, K. Transient and persistent dendritic spines in the neocortex in vivo. Neuron 2005, 45, 279–291. [Google Scholar] [CrossRef]
- Golesorkhi, M.; Gomez-Pilar, J.; Tumati, S.; Fraser, M.; Northoff, G. Temporal hierarchy of intrinsic neural timescales converges with spatial core-periphery organization. Commun. Biol. 2021, 4, 277. [Google Scholar] [CrossRef]
- Zeraati, R.; Shi, Y.L.; Steinmetz, N.A.; Gieselmann, M.A.; Thiele, A.; Moore, T.; Levina, A.; Engel, T.A. Intrinsic timescales in the visual cortex change with selective attention and reflect spatial connectivity. Nat. Commun. 2023, 14, 1858. [Google Scholar] [CrossRef]
- Honey, C.J.; Newman, E.L.; Schapiro, A.C. Switching between internal and external modes: A multiscale learning principle. Netw. Neurosci. 2017, 1, 339–356. [Google Scholar] [CrossRef]
- Beggs, J.M.; Plenz, D. Neuronal avalanches in neocortical circuits. J. Neurosci. 2003, 23, 11167–11177. [Google Scholar] [CrossRef] [PubMed]
- Chialvo, D.R. Emergent complex neural dynamics. Nat. Phys. 2010, 6, 744–750. [Google Scholar] [CrossRef]
- Das, A.; Levina, A. Critical neuronal models with relaxed timescale separation. Phys. Rev. X 2019, 9, 021062. [Google Scholar] [CrossRef]
- Kringelbach, M.L.; Perl, Y.S.; Deco, G. The thermodynamics of mind. Trends Cogn. Sci. 2024, 28, 568–581. [Google Scholar] [CrossRef] [PubMed]
- Abbott, L.F. Theoretical neuroscience rising. Neuron 2008, 60, 489–495. [Google Scholar] [CrossRef]
- Still, S. Thermodynamic cost and benefit of memory. Phys. Rev. Lett. 2020, 124, 050601. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karbowski, J. Information Thermodynamics: From Physics to Neuroscience. Entropy 2024, 26, 779. https://doi.org/10.3390/e26090779
Karbowski J. Information Thermodynamics: From Physics to Neuroscience. Entropy. 2024; 26(9):779. https://doi.org/10.3390/e26090779
Chicago/Turabian StyleKarbowski, Jan. 2024. "Information Thermodynamics: From Physics to Neuroscience" Entropy 26, no. 9: 779. https://doi.org/10.3390/e26090779
APA StyleKarbowski, J. (2024). Information Thermodynamics: From Physics to Neuroscience. Entropy, 26(9), 779. https://doi.org/10.3390/e26090779