
Design of Low-Latency Layered Normalized Minimum Sum Low-Density Parity-Check Decoding Based on Entropy Feature for NAND Flash-Memory Channel

Abstract
1. Introduction
1.1. Related Work
1.2. Contribution
- An LPU reliability assessment method based on the entropy feature vector of codewords is proposed. This method provides a basis for selecting the appropriate LPU for scheduling during the iteration process.
- Based on the reliability assessment of LPU, S-EFB-LNMS and P-EFB-LNMS LDPC decoding algorithms are proposed for serial and parallel architectures, respectively. These algorithms effectively optimize the transmission of redundant information in the decoding process by adjusting the scheduling strategy of LPU in each iteration, thereby reducing unnecessary calculation and decoding latency.
- A comprehensive performance evaluation of the proposed algorithm is carried out, which confirms that the algorithm can significantly reduce the average number of LPUs in each iteration and the total number of LPU executed in the decoding process, significantly improving the time efficiency of the decoding process. In addition, through a detailed space overhead analysis, it is proved that the proposed algorithm effectively reduces the additional space occupation. The complexity analysis of the algorithm reveals its linear growth characteristics, indicating that the algorithm shows the advantages of efficiency and practicality when processing large-scale data sets.
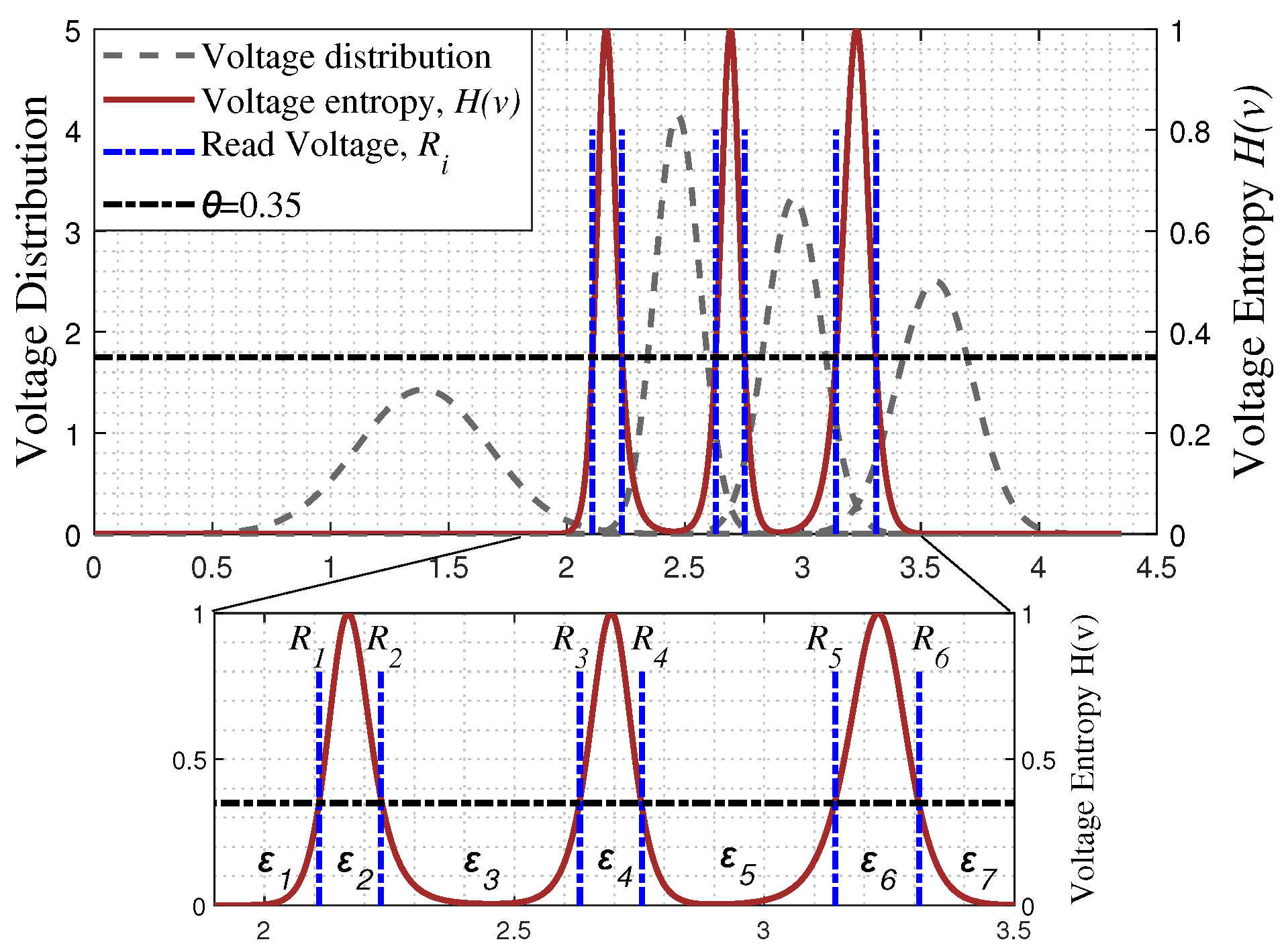
- : Voltage entropy function, where v represents the sensing threshold voltage.
- : The i-th read reference voltage.
- : The voltage window between and . Specifically, represents a voltage interval of less than and represents a voltage interval greater than .
- : LLR obtained from the flash memory channel, where represents the LLR of the j-th bit in a codeword.
- : The entropy feature vector of a codeword, where represents the entropy feature value of the j-th bit.
- : The CN processing unit constraint vector, corresponding to a row of the LDPC matrix .
- : The cosine similarity between and .
- : Information transmitted from the i-th CN to the j-th VN at the -th decoding iteration, where . The initial value is set to .
- : Information transmitted from the j-th VN to the i-th CN at the -th decoding iteration.
- : Posterior information at the l-th decoding iteration, where represents the posterior information of the j-th bit at l-th iteration.
- : The j-th bit of the codeword after the l-th decoding iteration.
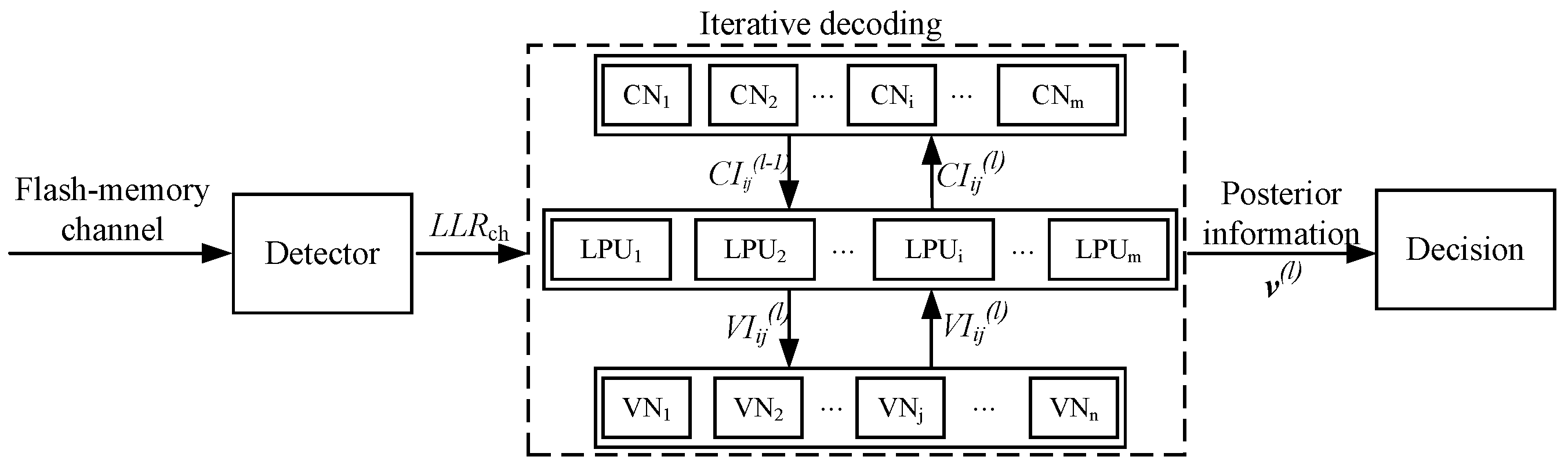
2. Design of LPU Reliability Assessment Algorithm for Flash-Memory Systems
2.1. Design of Entropy Feature Vector for Flash-Memory Channel
2.2. Cosine Similarity-Based LPU Reliability Assessment
3. Entropy Feature-Based LNMS LDPC Decoding Optimization
3.1. Generalized LNMS Decoding Algorithm
3.2. Serial Entropy Feature-Based LNMS (S-EFB-LNMS) LDPC Decoding Optimization Scheme
| Algorithm 1 Decoding Algorithm of S-EFB-LNMS |
| Input: The LLR of one codeword from the flash-memory channel , the entropy feature vector , the maximum iteration number , and the interleaving parameter . |
| Output: Decoded bits . |
| 1: Initialize the posterior information of VN to the LLR from flash-memory channel, i.e., . Clear the check-to-variable information, i.e., . |
| 2: if then |
| 3: |
| 4: else |
| 5: |
| 6: end if |
| 7: Get RLPU and URLPU with calculated by Equation (4). |
| 8: for l from 1 to do |
| 9: if % == 0 then |
| 10: Process the RLPUs. |
| 11: else |
| 12: Process the URLPUs. |
| 13: end if |
| 14: Update VN information, CN information, and posterior information calculated by Equations (5)–(7), respectively. |
| 15: if then |
| 16: |
| 17: else |
| 18: |
| 19: end if |
| 20: if then |
| 21: break |
| 22: else |
| 23: Perform an XOR operation on and to find the flipped bit, and subsequently set its corresponding entropy feature value to 0 in the . |
| 24: Refresh RLPUs and URLPUs with calculated by Equation (4). |
| 25: end if |
| 26: end for |
3.3. Parallel Entropy Feature-Based LNMS (P-EFB-LNMS) LDPC Decoding Optimization Scheme
| Algorithm 2 Decoding Algorithm of P-EFB-LNMS |
| Input: Initial channel soft information of each bit of one frame , the entropy feature vector , the cosine similarity matrix , and the maximum iteration number . |
| Output: Decoded bits . |
| 1: Obtain RLPUs and URLPUs by using the calculated by Equation (4). |
| 2: Initialize the posterior information of j-th bit to the LLR from flash-memory channel, i.e., . Clear the check-to-variable information, i.e., . |
| 3: for l from 1 to do |
| 4: Process RLPUs and URLPUs in parallel. |
| 5: Update VN information, CN information, and posterior information calculated by Equations (5)–(7), respectively. |
| 6: if then |
| 7: |
| 8: else |
| 9: |
| 10: end if |
| 11: if then |
| 12: break |
| 13: end if |
| 14: end for |
4. Complexity and Performance
4.1. Experimental Setup
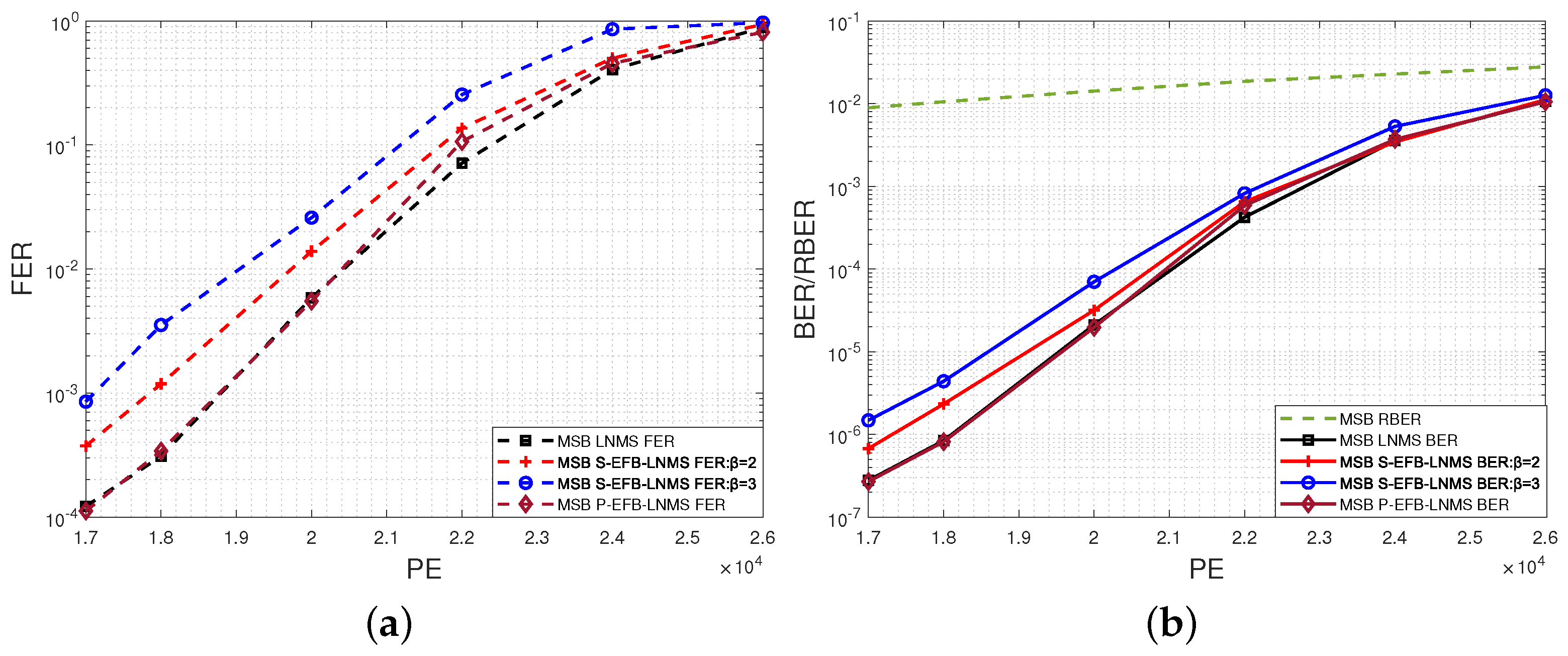
4.2. Performance Comparison
4.3. Computational Complexity
4.4. Space Overhead
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Feng, H.; Wei, D.; Gu, S.; Piao, Z.; Wang, Y.; Qiao, L. Random Flip Bit Aware Reading for Improving High-Density 3-D NAND Flash Performance. IEEE Trans. Circuits Syst. I Reg. Pap. 2024, 71, 2372–2383. [Google Scholar] [CrossRef]
- Fang, Y.; Bu, Y.; Chen, P.; Lau, F.C.M.; Otaibi, S.A. Irregular-Mapped Protograph LDPC-Coded Modulation: A Bandwidth-Efficient Solution for 6G-Enabled Mobile Networks. IEEE Trans. Intell. Trans. Syst. 2023, 24, 2060–2073. [Google Scholar] [CrossRef]
- Hu, H.; Han, G.; Wu, W.; Liu, C. Channel Parameter and Read Reference Voltages Estimation in 3D NAND Flash Memory Using Unsupervised Learning Algorithms. IEEE Trans. Comput.-Aided Design Integr. Circuits Syst. 2024, 43, 305–318. [Google Scholar] [CrossRef]
- Hwang, M.; Jee, J.; Kang, J.; Park, H.; Lee, S.; Kim, J. Dynamic Error Recovery Flow Prediction Based on Reusable Machine Learning for Low Latency NAND Flash Memory Under Process Variation. IEEE Access 2022, 10, 117715–117731. [Google Scholar] [CrossRef]
- Mei, Z.; Cai, K.; Shi, L.; Li, J.; Chen, L.; Immink, K.A.S. Deep Transfer Learning-Based Detection for Flash Memory Channels. IEEE Trans. Commun. 2024, 72, 3425–3438. [Google Scholar] [CrossRef]
- Dong, G.; Xie, N.; Zhang, T. On the Use of Soft-Decision Error-Correction Codes in NAND Flash Memory. IEEE Trans. Circuits Syst. I Reg. Pap. 2011, 58, 429–439. [Google Scholar] [CrossRef]
- Li, Q.; Wang, Q.; Xu, Q.; Huo, Z. A Fast Read Retry Method for 3D NAND Flash Memories Using Novel Valley Search Algorithm. IEICE Commun. Exp. 2018, 15, 20180921. [Google Scholar] [CrossRef]
- Yan, Z.; Guan, W.; Liang, L. List-Based Residual Belief-Propagation Decoding of LDPC Codes. IEEE Commun. Lett. 2024, 28, 984–988. [Google Scholar] [CrossRef]
- Li, Y.; Han, G.; Liu, C.; Zhang, M.; Wu, F. Exploiting the Single-Symbol LLR Variation to Accelerate LDPC Decoding for 3-D nand Flash Memory. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2023, 42, 5146–5150. [Google Scholar] [CrossRef]
- Li, Q.; Shi, L.; Cui, Y.; Xue, C.J. Exploiting Asymmetric Errors for LDPC Decoding Optimization on 3D NAND Flash Memory. IEEE Trans. Comput. 2020, 69, 475–488. [Google Scholar] [CrossRef]
- Zhang, M.; Wu, F.; Yu, Q.; Xie, C. PEAR: Unbalanced Inter-Page Errors Aware Read Scheme for Latency-Efficient 3-D NAND Flash. IEEE Trans. Device Mater. Reliab. 2024, 24, 49–58. [Google Scholar] [CrossRef]
- Li, Q.; Wang, Q.; Yang, L.; Yu, X.; Jiang, Y.; He, J.; Huo, Z. Optimal Read Voltages Decision Scheme Eliminating Read Retry Operations for 3D NAND Flash Memories. Microelectron. Reliab. 2022, 131, 114509. [Google Scholar] [CrossRef]
- Wang, Y.; Wei, D.; Liu, M.; Feng, H.; Qiao, L. EBDN: Entropy-Based Double Nonuniform Sensing Algorithm for LDPC Decoding in TLC NAND Flash Memory. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2024, 43, 1914–1918. [Google Scholar] [CrossRef]
- Zhao, W.; Sun, H.; Lv, M.; Dong, G.; Zheng, N.; Zhang, T. Improving Min-Sum LDPC Decoding Throughput by Exploiting Intra-Cell Bit Error Characteristic in MLC NAND Flash Memory. In Proceedings of the 2014 30th Symposium on Mass Storage Systems and Technologies (MSST), Santa Clara, CA, USA, 2–6 June 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Qiao, L.; Wu, H.; Wei, D.; Wang, S. A Joint Decoding Strategy of Non-Binary LDPC Codes Based on Retention Error Characteristics for MLC NAND Flash Memories. In Proceedings of the 2016 Sixth International Conference on Instrumentation & Measurement, Computer, Communication and Control (IMCCC), Harbin, China, 21–23 July 2016; pp. 183–188. [Google Scholar] [CrossRef]
- Yong, K.-K.; Chang, L.-P. Error Diluting: Exploiting 3-D NAND Flash Process Variation for Efficient Read on LDPC-Based SSDs. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2020, 39, 3467–3478. [Google Scholar] [CrossRef]
- Zhang, M.; Wu, F.; Du, Y.; Liu, W.; Xie, C. Pair-Bit Errors Aware LDPC Decoding in MLC NAND Flash Memory. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2019, 38, 2312–2320. [Google Scholar] [CrossRef]
- Wu, F.; Zhang, M.; Du, Y.; Liu, W.; Lu, Z.; Wan, J.; Tan, Z.; Xie, C. Using Error Modes Aware LDPC to Improve Decoding Performance of 3-D TLC NAND Flash. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2020, 39, 909–921. [Google Scholar] [CrossRef]
- Zhang, M.; Wu, F.; Yu, Q.; Liu, W.; Ma, R.; Xie, C. Exploiting Resistance Drift Characteristics to Improve Reliability of LDPC-Assisted Phase-Change Memory. IEEE Trans. Device Mater. Reliab. 2021, 21, 324–330. [Google Scholar] [CrossRef]
- Zhang, M.; Wu, F.; Yu, Q.; Fu, N.; Xie, C. eLDPC: An Efficient LDPC Coding Scheme for Phase-Change Memory. IEEE Trans. Comput.-Aided Design Integr. Circuits Syst. 2023, 42, 1978–1987. [Google Scholar] [CrossRef]
- Lian, Q.; Chen, Q.; Zhou, L.; He, Y.; Xie, X. Adaptive Decoding Algorithm with Variable Sliding Window for Double SC-LDPC Coding System. IEEE Commun. Lett. 2023, 2, 404–408. [Google Scholar] [CrossRef]
- Xu, Z.; Wang, L.; Hong, S.; Chen, G. Generalized Joint Shuffled Scheduling Decoding Algorithm for the JSCC System Based on Protograph-LDPC Codes. IEEE Access 2021, 9, 128372–128380. [Google Scholar] [CrossRef]
- Chen, Q.; Ren, Y.; Zhou, L.; Chen, C.; Liu, S. Design and Analysis of Joint Group Shuffled Scheduling Decoding Algorithm for Double LDPC Codes System. Entropy 2023, 25, 357. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Mei, Z.; Li, J.; Shu, F.; He, X.; Kong, L. Channel Modeling and Quantization Design for 3D NAND Flash Memory. Entropy 2023, 25, 965. [Google Scholar] [CrossRef] [PubMed]
- Kong, L.; Liu, H.; Hou, W.; Meng, C. Bilayer LDPC Codes Combined with Perturbed Decoding for MLC NAND Flash Memory. Entropy 2024, 26, 54. [Google Scholar] [CrossRef] [PubMed]
- Aslam, C.A.; Guan, Y.L.; Cai, K. Read and Write Voltage Signal Optimization for Multi-Level-Cell (MLC) NAND Flash Memory. IEEE Trans. Commun. 2016, 64, 1613–1623. [Google Scholar] [CrossRef]
- Zhang, M.; Wu, F.; Yu, Q.; Liu, W.; Wang, Y.; Xie, C. Exploiting Error Characteristic to Optimize Read Voltage for 3-D NAND Flash Memory. IEEE Trans. Electr. Devices 2020, 67, 5490–5496. [Google Scholar] [CrossRef]
- Zhu, S.; Wu, J.; Xia, G. TOP-K Cosine Similarity Interesting Pairs Search. In Proceedings of the 2010 Seventh International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), Yantai, China, 10–12 August 2010; pp. 1479–1483. [Google Scholar] [CrossRef]
- Kim, J.; Cho, J.; Sung, W. A High-Speed Layered Min-Sum LDPC Decoder for Error Correction of NAND Flash Memories. In Proceedings of the 2011 IEEE 54th International Midwest Symposium on Circuits and Systems (MWSCAS), Seoul, Republic of Korea, 7–10 August 2011; pp. 1–4. [Google Scholar] [CrossRef]
- Mei, Z.; Cai, K.; He, X. Deep Learning-Aided Dynamic Read Thresholds Design for Multi-Level-Cell Flash Memories. IEEE Trans. Commun. 2020, 68, 2850–2862. [Google Scholar] [CrossRef]
- Nguyen, V. Design of Capacity-Approaching Protograph-Based LDPC Coding Systems. Ph.D. Dissertation, Department of Electrical & Computer Engineering, The University of Texas at Dallas, Dallas, TX, USA, 2012. [Google Scholar]
- Lv, L.; Yang, Z.; Fang, Y.; Guizani, M. Adaptive Interleaver and Rate-Compatible PLDPC Code Design for MIMO FSO-RF Systems. IEEE Trans. Veh. Technol. 2024, in press. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| of LSB | −10 | −10 | −10 | 0.00001 | 10 | 10 | 10 |
| of MSB | −10 | 0.00001 | 10 | 10 | 10 | 0.00001 | −10 |
| entropy feature value of LSB | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| entropy feature value of MSB | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Hu, H. Design of Low-Latency Layered Normalized Minimum Sum Low-Density Parity-Check Decoding Based on Entropy Feature for NAND Flash-Memory Channel. Entropy 2024, 26, 781. https://doi.org/10.3390/e26090781
Li Y, Hu H. Design of Low-Latency Layered Normalized Minimum Sum Low-Density Parity-Check Decoding Based on Entropy Feature for NAND Flash-Memory Channel. Entropy. 2024; 26(9):781. https://doi.org/10.3390/e26090781
Chicago/Turabian StyleLi, Yingge, and Haihua Hu. 2024. "Design of Low-Latency Layered Normalized Minimum Sum Low-Density Parity-Check Decoding Based on Entropy Feature for NAND Flash-Memory Channel" Entropy 26, no. 9: 781. https://doi.org/10.3390/e26090781
APA StyleLi, Y., & Hu, H. (2024). Design of Low-Latency Layered Normalized Minimum Sum Low-Density Parity-Check Decoding Based on Entropy Feature for NAND Flash-Memory Channel. Entropy, 26(9), 781. https://doi.org/10.3390/e26090781