
Information-Theoretic Modeling of Categorical Spatiotemporal GIS Data


Abstract
:1. Introduction
1.1. RA Background
1.2. Previous Work
2. Materials and Methods

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | MODEL | Level | Inf | %ΔH(DV) | ΔBIC | %C(Data) | %Cover | %C(Test) |
|---|---|---|---|---|---|---|---|---|
| 13* | IV:W1Z5:N2Z5:S3Z5:Z4Z5 | 4 | 0.723 | 44.3 | 307057 | 83.3 | 98.9 | 83.4 |
| 12* | IV:N1Z5:E2Z5:W3Z5:Z4Z5 | 4 | 0.722 | 44.3 | 306721 | 83.3 | 98.4 | 83.3 |
| 11* | IV:N1Z5:W2Z5:E3Z5:Z4Z5 | 4 | 0.722 | 44.3 | 306659 | 83.2 | 99.0 | 83.3 |
| 10* | IV:N2Z5:S3Z5:Z4Z5 | 3 | 0.697 | 42.7 | 295910 | 81.5 | 100.0 | 81.5 |
| 9* | IV:W2Z5:E3Z5:Z4Z5 | 3 | 0.694 | 42.6 | 294846 | 81.3 | 100.0 | 81.4 |
| 8* | IV:E2Z5:W3Z5:Z4Z5 | 3 | 0.694 | 42.5 | 294692 | 81.3 | 100.0 | 81.4 |
| 7* | IV:N2Z5:Z4Z5 | 2 | 0.638 | 39.1 | 271004 | 75.5 | 100.0 | 75.5 |
| 6* | IV:W2Z5:Z4Z5 | 2 | 0.636 | 39.0 | 270387 | 75.6 | 100.0 | 75.6 |
| 5* | IV:E2Z5:Z4Z5 | 2 | 0.634 | 38.9 | 269312 | 75.5 | 100.0 | 75.5 |
| 4* | IV:Z4Z5 | 1 | 0.491 | 30.1 | 208753 | 75.8 | 100.0 | 75.8 |
| 3* | IV:Z3Z5 | 1 | 0.339 | 20.8 | 143831 | 66.7 | 100.0 | 66.7 |
| 2* | IV:Z2Z5 | 1 | 0.325 | 19.9 | 138201 | 68.1 | 100.0 | 68.0 |
| 1* | IV:Z5 | 0 | 0 | 0 | 0 | 50.0 | 100.0 | 50.0 |
- Inf is the normalized information captured in the model, namely[H(pind) − (pmodel)]/[H(pind) − H(p)].
- %ΔH(DV) is the entropy reduction in the DV which indicates 2021 EFO presence or absence.
- ΔBIC is the difference in BIC from the bottom reference, namely BIC(pind) − BIC(pmodel), where
- BIC = [−2 N ∑ι∑ j p(DVi, IVj) ln pmodel (DVi, IVj) ] + ln(N) df, where N is the sample size
- %C(Data) is the %correct in the training data to which the models are fit.
- %Cover is the % of state space of predicting IVs present in the (training) data.
- %C(Test) is the %correct of the model on the test data.
3. Results
4. Discussion
- A summary of the key findings:
- Prediction of the 2021 Evergreen Forest state is ~80% accurate on test data using information from a subset of the previous years 2001 through 2016 (model 10, Table 2).
- This accuracy is obtained from a model that predicts by using the states of a specific combination of neighbors from 2001 through 2016 and the center cell from 2016. The set of neighbors for prediction were obtained by OCCAM’s Search function.
- The main finding from the analysis is that clear-cut practices are the reason that we see such dynamics in the EFO, SHB, and GRS classes from Figure 3.
- The actionable finding is that we could use these patterns to preserve forests that are nearing their harvest date. By intersecting GIS layers of land ownership with forests that are in the state of row 1 from Table 4 (all EFO), contact could be made with owners to see if preservation is an option. This could be useful under climate stress to keep wildlife corridors connected, with the additional potential for carbon sequestration.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Foody, G.M. Status of Land Cover Classification Accuracy Assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- USGS National Land Cover Database 2023. Available online: https://www.usgs.gov/data/national-land-cover-database-nlcd-2021-products (accessed on 1 January 2024).
- Zwick, M. Reconstructability Analysis and Its OCCAM Implementation. In Proceedings of the International Conference on Complex Systems; New England Complex Systems Institute: Cambridge, MA, USA, 2020; pp. 26–31. [Google Scholar]
- Zwick, M. An Overview of Reconstructability Analysis. Kybernetes 2004, 33, 877–905. [Google Scholar] [CrossRef]
- Altieri, L.; Cocchi, D. Entropy Measures for Environmental Data: Description, Sampling and Inference for Data with Dependence Structures; Springer: Singapore, 2024; ISBN 978-981-9725-46-5. [Google Scholar]
- Batty, M. Spatial Entropy. Geogr. Anal. 1974, 6, 1–31. [Google Scholar] [CrossRef]
- Klir, G.J. Uncertainty and Information: Foundations of Generalized Information Theory, 1st ed.; Wiley: Hoboken, NJ, USA, 2005; ISBN 978-0-471-74867-0. [Google Scholar]
- Klir, G. Reconstructability Analysis: An Offspring of Ashby’s Constraint Theory. Syst. Res. 1986, 3, 267–271. [Google Scholar] [CrossRef]
- Krippendorff, K. Information Theory: Structural Models for Qualitative Data; Sage University Paper Series on Quantitative Applications in the Social Sciences; Sage: Thousand Oaks, CA, USA, 1986. [Google Scholar]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423, 623–656. [Google Scholar] [CrossRef]
- Ashby, W.R. Constraint Analysis of Many-Dimensional Relations. Gen. Syst. Yearb. 1964, 9, 99–105. [Google Scholar]
- Klir, G. The Architecture of Systems Problem Solving; Plenum Press: New York, NY, USA, 1985. [Google Scholar]
- Harris, M.; Zwick, M. Graphical Models in Reconstructability Analysis and Bayesian Networks. Entropy 2021, 23, 986. [Google Scholar] [CrossRef] [PubMed]
- Percy, D.; Zwick, M. Beyond Spatial Autocorrelation: A Novel Approach Using Reconstructability Analysis. In Proceedings of the International Society for the Systems Sciences 2018, Corvallis, OR, USA, 22–27 July 2018. [Google Scholar]
- Zwick, M.; Shu, H.; Koch, R. Information-Theoretic Mask Analysis of Rainfall Time Series Data. Adv. Sys Sci. Apps. 1995, 1, 154–159. [Google Scholar]
- Zwick, M.; Alexander, H.; Fusion, J.; Willett, K. OCCAM: A Reconstructability Analysis Program. Available online: https://dmit.sysc.pdx.edu/Occam_manual_v3.4.1_2021-01-19.pdf (accessed on 12 June 2024).
- Occam-RA GitHub Site 2024. Available online: https://github.com/occam-ra/occam (accessed on 1 September 2024).

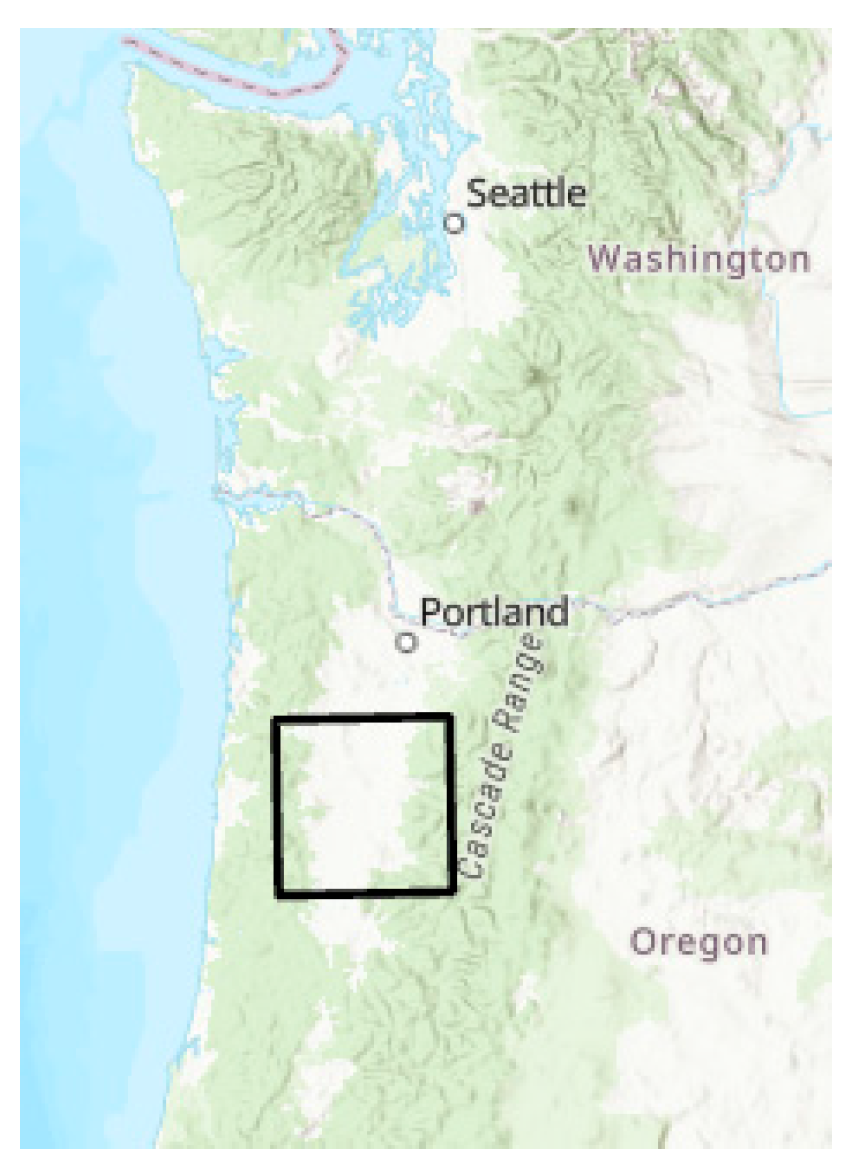
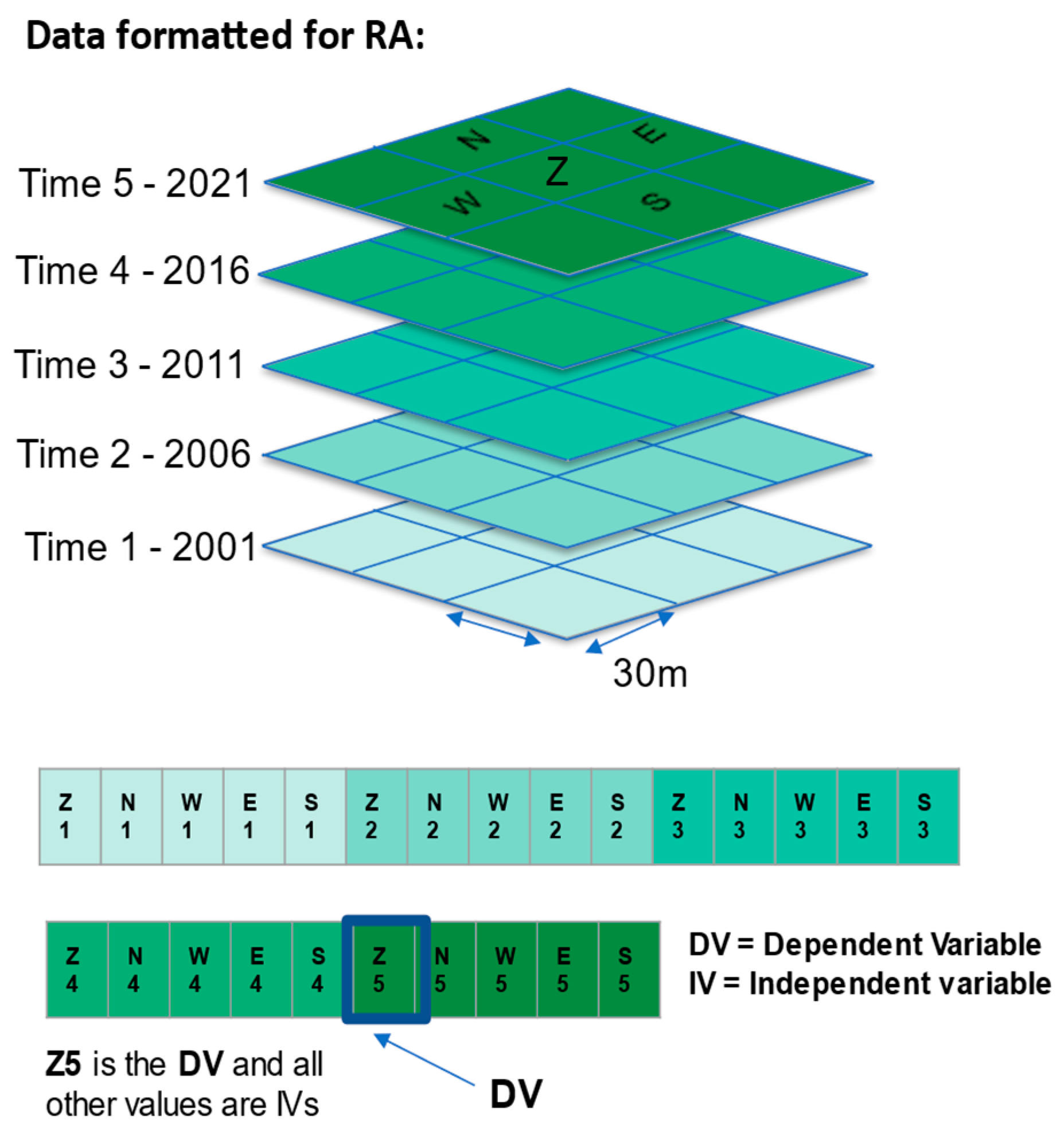
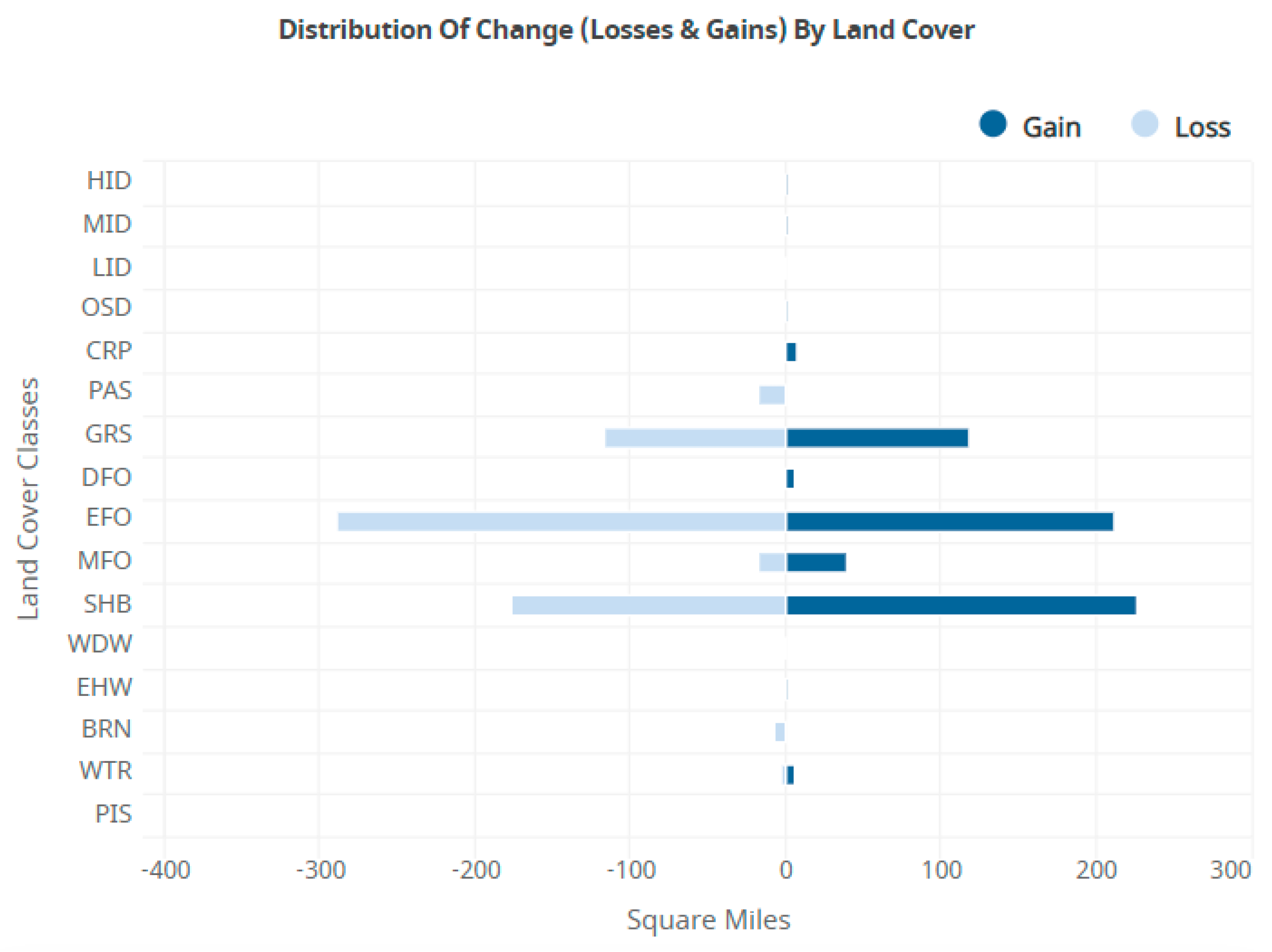
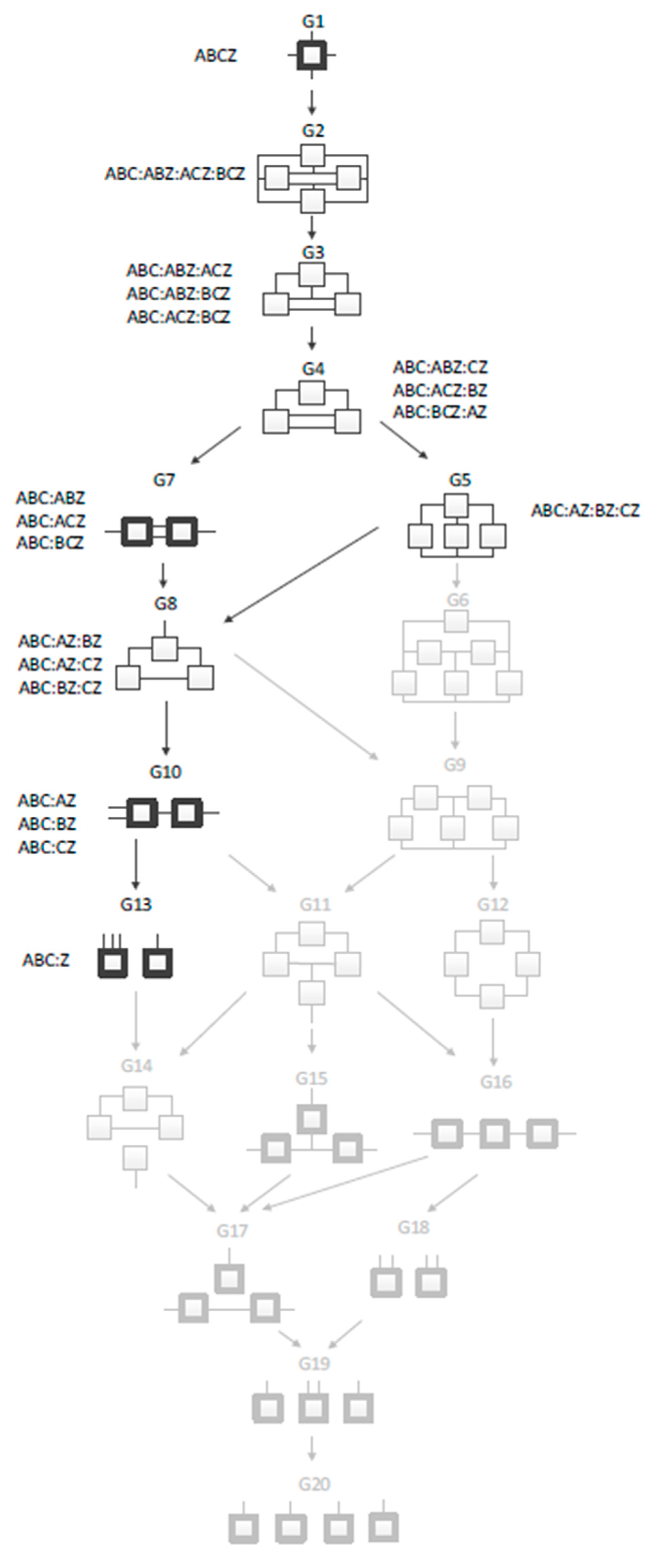


| Processing Step | Results |
|---|---|
| Extract rows that include the DV (center cell Z5) and space–time VNN neighborhood at times 1 through 4 at every location in the study area | ~11 million rows of 20 variables generated |
| Eliminate rows that have all uniform values | ~6.7 million rows retained |
| Select rows that have Evergreen Forest (NLCD code 42) anywhere in the row | ~4 million rows retained |
| Stratify data so that ½ are EFO present ½ are EFO absent, shuffle, and split into train/test sets | 500K rows in each train/test set, replicated 3 times |
| Add headers for OCCAM input file, reclassifying 15 to 5 classes with rebinning code in the variable block, also recoding Z5 to 1 for code 42, and 0 for all other values | Classes collapsed to: Water, Developed, and Agriculture, Shrubs, Grasses, Mixed/Deciduous Forest, Evergreen Forest |
| Upload data to OCCAM and run Search | Report generated |
| Select best model from Search and run Fit on it | Report generated |
| Extract model predictions from Fit output and analyze with R-Studio 2024, and Excel 2021 | Final results |
| Level | 500K-A | 500K-B | 500K-C |
|---|---|---|---|
| 6 | IV:N1E3Z5:W2Z5:S3Z5:Z4Z5 | IV:W1S3Z5:N2Z5:E3Z5:Z4Z5 | IV:N1E3Z5:W2Z5:S3Z5:Z4Z5 |
| 5 | IV:N1Z5:W2Z5:E3Z5:S3Z5:Z4Z5 | IV:W1Z5:N2Z5:E3Z5:S3Z5:Z4Z5 | IV:N1Z5:E2Z5:W3Z5:S3Z5:Z4Z5 |
| 4 | IV:W1Z5:S2Z5:N3Z5:Z4Z5 | IV:W1Z5:N2Z5:S3Z5:Z4Z5 | IV:W1Z5:N2Z5:S3Z5:Z4Z5 |
| Times 1 through 4 | Time 5 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| IVs | DV (Data) | DV (Model) | ||||||||
| Row | W1 | N2 | S3 | Z4 | Frequency | % Non-EFO | % EFO | % Non-EFO | % EFO | %C |
| 1 | EFO | EFO | EFO | EFO | 90363 | 68.8 | 31.2 | 59.2 | 40.8 | 68.8 |
| 2 | EFO | EFO | EFO | GRS | 28489 | 95.4 | 4.6 | 98.1 | 1.9 | 95.4 |
| 3 | EFO | EFO | GRS | SHB | 26066 | 42.4 | 57.6 | 47.2 | 52.8 | 57.6 |
| 4 | GRS | SHB | SHB | EFO | 14235 | 2.8 | 97.2 | 2.9 | 97.1 | 97.2 |
| 5 | SHB | SHB | SHB | SHB | 13144 | 19.1 | 80.9 | 9.2 | 90.8 | 80.9 |
| 6 | EFO | EFO | EFO | SHB | 12886 | 71.4 | 28.6 | 77.7 | 22.3 | 71.4 |
| 7 | EFO | GRS | GRS | SHB | 12650 | 21.6 | 78.4 | 18.5 | 81.5 | 78.4 |
| 8 | SHB | SHB | EFO | EFO | 11668 | 7.5 | 92.5 | 12.2 | 87.8 | 92.5 |
| 9 | SHB | SHB | SHB | EFO | 10919 | 5.4 | 94.6 | 4.1 | 95.9 | 94.6 |
| 10 | EFO | GRS | SHB | SHB | 9047 | 15.7 | 84.3 | 21.2 | 78.8 | 84.3 |
| 11 | EFO | EFO | SHB | EFO | 8472 | 18.6 | 81.4 | 30.6 | 69.4 | 81.4 |
| 12 | EFO | SHB | EFO | EFO | 8344 | 14.8 | 85.2 | 27 | 73 | 85.2 |
| 13 | EFO | GRS | SHB | EFO | 7816 | 8.6 | 91.4 | 10.1 | 89.9 | 91.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Percy, D.; Zwick, M. Information-Theoretic Modeling of Categorical Spatiotemporal GIS Data. Entropy 2024, 26, 784. https://doi.org/10.3390/e26090784
Percy D, Zwick M. Information-Theoretic Modeling of Categorical Spatiotemporal GIS Data. Entropy. 2024; 26(9):784. https://doi.org/10.3390/e26090784
Chicago/Turabian StylePercy, David, and Martin Zwick. 2024. "Information-Theoretic Modeling of Categorical Spatiotemporal GIS Data" Entropy 26, no. 9: 784. https://doi.org/10.3390/e26090784