Abstract
To tackle the challenge of enhancing moving target detection performance in environments characterized by small sample sizes and non-uniformity, methods rooted in sparse signal reconstruction have been incorporated into Space-Time Adaptive Processing (STAP) algorithms. Given the prominent sparse nature of clutter spectra in the angle-Doppler domain, adopting sparse recovery algorithms has proven to be a feasible approach for accurately estimating high-resolution spatio-temporal two-dimensional clutter spectra. Sparse Bayesian Learning (SBL) is a pivotal tool in sparse signal reconstruction and has been previously utilized, yet it has demonstrated limited success in enhancing sparsity, resulting in insufficient robustness in local fitting. To significantly improve sparsity, this paper introduces a hierarchical Bayesian prior framework and derives iterative parameter update formulas through variational inference techniques. However, this algorithm encounters significant computational hurdles during the parameter update process. To overcome this obstacle, the paper proposes an enhanced Variational Bayesian Inference (VBI) method that leverages prior information on the rank of the temporal clutter covariance matrix to refine the parameter update formulas, thereby significantly reducing computational complexity. Furthermore, this method fully exploits the joint sparsity of the Multiple Measurement Vector (MMV) model to achieve greater sparsity without compromising accuracy, and employs a first-order Taylor expansion to eliminate grid mismatch in the dictionary. The research presented in this paper enhances the moving target detection capabilities of STAP algorithms in complex environments and provides new perspectives and methodologies for the application of sparse signal reconstruction in related fields.
1. Introduction
Mounted on elevated platforms, airborne radar exhibits remarkable mobility and effectively addresses the shading limitations of ground-based radar. It provides a substantially longer detection range for ground and low-altitude targets compared to ground-based radar, enjoying superior electromagnetic wave propagation conditions. Consequently, it has garnered considerable attention. Within the diverse applications of airborne radar, moving target detection holds a pivotal position. Phased array radar is frequently employed in airborne systems due to its capacity to generate multiple beams concurrently, its adaptable beam steering, and its robust anti-jamming capabilities. Nevertheless, this radar operates in a downward-facing configuration, where clutter is abundant and intense. Furthermore, the aircraft’s movement results in considerable broadening of the clutter spectrum, frequently causing targets to be obscured within the clutter, significantly hindering the effectiveness of moving target detection [1]. Hence, the foremost objective for airborne radar is clutter suppression. Space-time adaptive processing leverages a combined space-time two-dimensional strategy to devise suitable filter weight vectors, effectively mitigating clutter and preserving target energy across Doppler and angular domains, ultimately bolstering moving target detection performance. STAP technology represents an advancement of array adaptive technology [2]. In 1973, Brennan and Reed pioneered the notion of space-time two-dimensional adaptive processing [3], applying the fundamental principles of array signal processing to the two-dimensional data space of pulse and array element samples, sparking a wave of enthusiasm in STAP research. However, optimal STAP necessitates a substantial quantity of training samples that adhere to the Independent and Identically Distributed (IID) criterion, posing challenges such as elevated computational demands, clutter non-uniformity, and non-stationarity. Consequently, the direct deployment of optimal STAP technology is infeasible.
To mitigate the aforementioned computational demands, recent scholarly endeavors have introduced a diverse array of methodologies. Dimensionality reduction techniques within the space-time adaptive processing framework decrease the system’s degrees of freedom by applying clutter-independent linear transformations. This, in turn, minimizes the requisite number of training samples and lessens computational intricacy [4]. Alternatively, rank reduction STAP methodologies employ clutter-related transformations to fashion adaptive space-time filters, thereby curbing the dependency on extensive training datasets [5,6]. For both dimensionality-reduced and rank-reduced STAP strategies, the needed training samples can be diminished to twice the reduced dimension or clutter rank, respectively; however, in non-uniform settings, the sample size remains considerable. Direct digital domain methodologies [7,8] circumvent the utilization of adjacent range cell training samples by leveraging detection cell data directly to construct the STAP processor. This theoretically tackles all non-uniformity challenges but at the expense of some space-time degrees of freedom and STAP output quality due to the exclusion of samples from other range cells in weight vector formulation. Knowledge-aided STAP approaches augment STAP efficacy by incorporating prior information encompassing environmental conditions, radar system specifics, and platform motion characteristics [9]. The efficacy of this technique heavily leans on the accuracy of the preliminary knowledge. Sparse Recovery STAP (SR-STAP) methodologies exploit the sparsity of clutter distribution in the space-time domain, facilitating the recovery of high-resolution clutter power spectra with limited training samples by estimating the clutter covariance matrix (CCM). This leads to enhanced clutter suppression capabilities. For stationary radar systems, several sparse recovery methods exist, including greedy algorithms, convex optimization techniques, sparse Bayesian learning algorithms, and more. Greedy algorithms iteratively select elements from a predefined set (basis or dictionary) and compute corresponding sparse coefficients, progressively minimizing the discrepancy between the linear combination of these elements and the observed data [10]. Common greedy algorithms encompass Matching Pursuit [11], Orthogonal Matching Pursuit [12], Relaxed Greedy Algorithm [13], and -norm Greedy Algorithm, among others. These algorithms are advantageous for their flexibility in incorporating constraints [12]; however, they may yield suboptimal sparse coefficient solutions in certain scenarios [13]. Convex optimization methods recast the optimization challenge into a convex framework and solve for the sparse coefficient vector by leveraging the properties of convex functions. Prominent convex optimization algorithms include interior point methods and gradient descent-based approaches. Interior point methods, being among the earliest convex optimization techniques for sparse problems, are mature and accompanied by readily accessible software tools. They are sensitive to solution sparsity and regularization parameters but suffer from high computational complexity, especially for high-dimensional signals. Gradient descent-based algorithms, such as Iterative Splitting and Thresholding (ITS) [14], Two-step IST (TwIST), Fixed-Point Iteration (FPI), and others, closely depend on the regularization parameter’s magnitude. The burgeoning SBL approach, introduced by Tipping around 2001 [15], assumes a sparse prior distribution for the coefficient vector and employs a maximum posterior estimator to integrate prior knowledge with observations for sparse vector recovery. In noiseless conditions, SBL yields the most accurate sparse solution and maintains robustness even when the sensing matrix columns are highly correlated. However, Bayesian learning entails matrix inversion in each iteration, substantially augmenting computational complexity and posing challenges for real-time applications [16]. In recent years, the application of Bayesian methods in the field of communications has become increasingly widespread, particularly showcasing its unique advantages in channel estimation and signal processing. By incorporating prior information, Bayesian methods can effectively handle the uncertainty and sparsity in high-dimensional data, thereby enhancing estimation accuracy and computational efficiency. For example, Cheng et al. [17] proposed a Bayesian channel estimation algorithm based on irregular array manifolds, which transforms the channel estimation problem into a tensor decomposition problem under missing data scenarios and incorporates Bayesian model order selection techniques to automatically estimate the number of channel paths and significantly improve estimation accuracy. Xu et al. [18] introduced a Bayesian multiband sparsity-based channel estimation framework to address the beam squint effect in millimeter-wave massive MIMO systems. By constructing a virtual channel model and leveraging the common sparse structure across sub-bands, combined with a first-order Taylor expansion to mitigate dictionary grid mismatch, their variational Expectation-Maximization (EM) algorithm can adaptively balance the likelihood function and sparse prior information, significantly enhancing channel estimation accuracy in dual-broadband scenarios. These works highlight the unique advantages of Bayesian methods in joint sparse modeling and computational efficiency optimization, providing important insights for clutter spectrum estimation in STAP.
The SR-STAP based on Bayesian learning necessitates matrix inversion during each iteration, resulting in a steep surge in computational complexity as the system’s dimensionality expands [19]. To mitigate this challenge, various prominent strategies have been proposed. Specifically, a rapid inversion-free approach for Sparse Bayesian Learning (SBL) was presented in [19], leveraging the fact that inverting diagonal matrices is significantly faster than traditional matrix inversion. Nonetheless, this method may suffer from performance decrement in scenarios with a relatively limited number of measurements, stemming from the relaxation of the evidence bound. In another study [20], the Spatial Alternating Variational Estimation (SAVE) method was introduced, which circumvents matrix updates by alternately optimizing each signal element. This approach significantly accelerates the reconstruction process for signals characterized by small-dimensional samples. However, its efficacy diminishes when dealing with signals of exceptionally high dimensionality. Furthermore, Al-Shoukairi et al. [21] put forward an SBL algorithm based on Generalized Approximate Message Passing (GAMP). By employing quadratic approximations and Taylor series expansions, GAMP furnishes approximations for the Maximum A Posteriori (MAP) estimates of the signal, thereby bypassing the need for matrix inversion. Nevertheless, the introduction of an iterative method to replace matrix inversion in SBL still fails to substantially alleviate the computational strain associated with large-scale datasets [22]. To address the limitations of existing methods, we introduce a novel approach that capitalizes on prior knowledge concerning the rank of the space-time clutter covariance matrix. Our contribution lies in an enhanced Variational Bayesian method, which optimizes the parameter update formulations to circumvent the inefficiencies associated with high-dimensional matrix inversion, thereby effectively minimizing computational complexity.
2. Signal Model
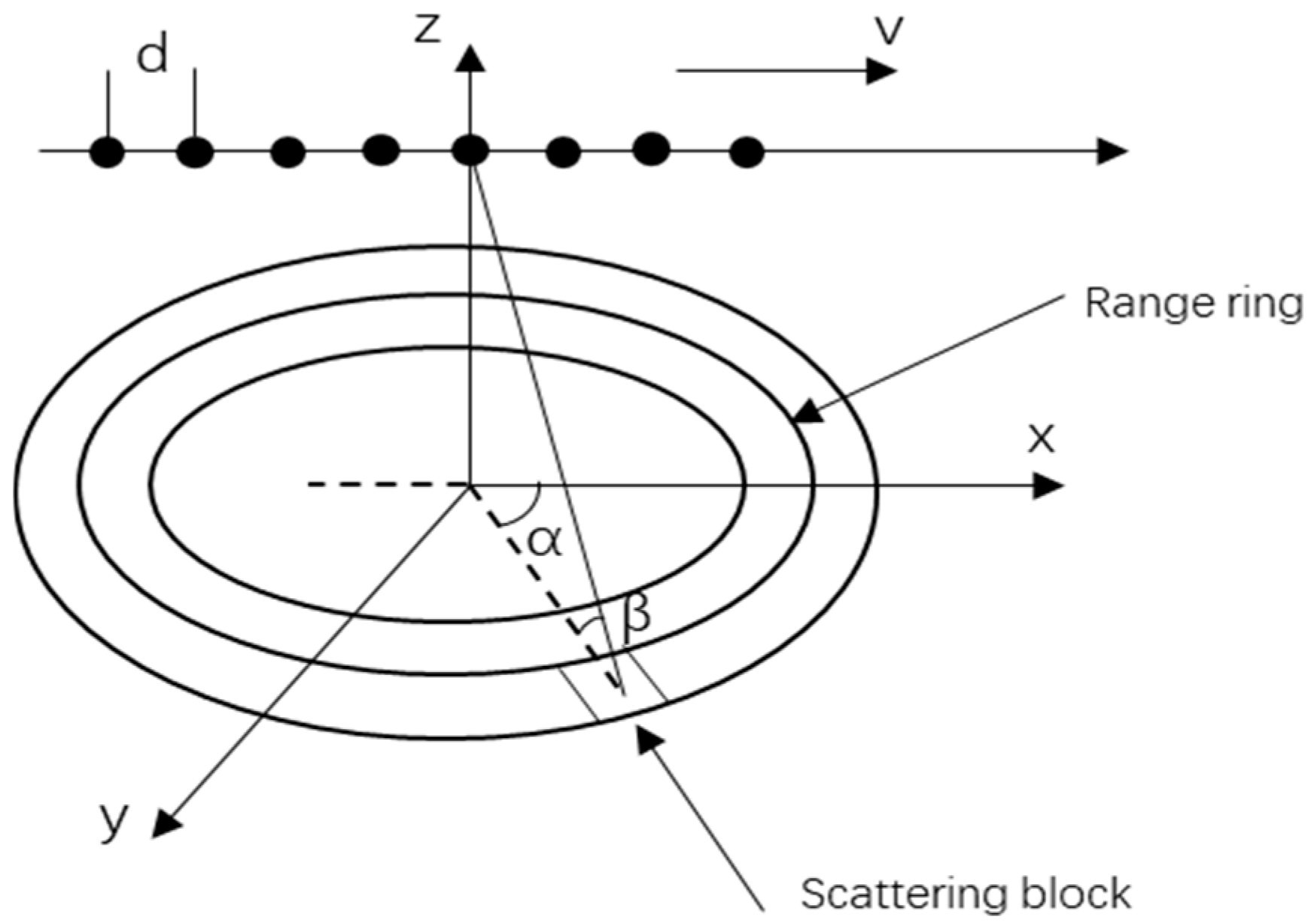
Consider an airborne side-looking uniform linear array (ULA) radar comprised of array elements, with each element spaced at a distance d, equivalent to half the radar’s operational wavelength. The height of the carrier platform is designated as , the frequency of pulse repetition is expressed as , and the count of pulses within the coherent processing interval () is indicated by . The geometrical representation of this airborne radar setup is depicted in Figure 1.
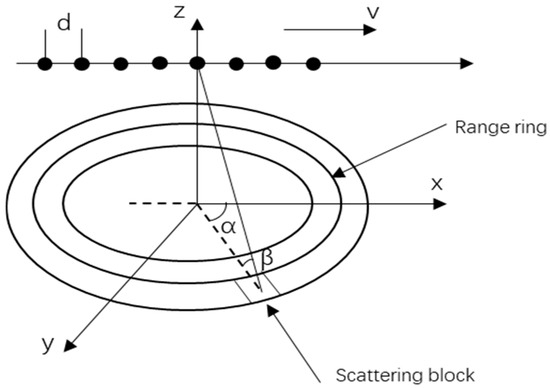
Figure 1.
Schematic diagram of airborne radar.
Considering as the velocity of the carrier platform traversing along the -axis, and and signifying the elevation and azimuth angles of the ground reflection point, respectively, the -th range ring’s space-time snapshot data, incorporating both clutter and noise, and disregarding the impact of range ambiguity, can be formulated as follows:
In the formula, denotes the count of clutter patches contained within the specific range bin, while indicates the scattering power of each individual clutter patch. , which belongs to the complex space , represents the thermal noise component. Furthermore, stands for the space-time steering vector associated with the -th clutter patch and can be formulated as follows:
While
In the formula, is used to indicate the Kronecker product, while stands for the transposition of a matrix. and represent the normalized Doppler frequency and normalized spatial frequency, respectively, corresponding to the -th clutter patch, and they can be formulated as outlined below:
In the equation, represents the wavelength.
Assuming that the snapshot data of each range bin are independent and identically distributed (IID), the covariance matrix can be expressed as follows [23]:
In the equation, denotes the mathematical expectation operation, and represents the conjugate transpose of a matrix.
Based on the Linearly Constrained Minimum Variance (LCMV) criterion, the optimal STAP weight vector can be expressed as follows:
In the equation, denotes the matrix inversion operation, and represents the space-time steering vector of the target, which can be expressed as follows:
While
While
In the equation, and represent the Doppler normalized frequency and spatial normalized frequency of the target, respectively, while and signify the elevation angle and azimuth angle of the target, respectively.
Finally, the filtered snapshot data is represented as follows:
Given that the Doppler and spatial frequencies of the clutter space-time snapshot signals outlined in Equation (1) are confined within a specific range, a comprehensive set of these frequencies can be derived using an exhaustive approach, with a tolerance for a certain degree of quantization error. This set is denoted as follows:
where and , with >> 1 and >> 1 indicating the resolution scales for the Doppler frequencies and spatial frequencies, respectively. These resolution scales serve to regulate the extent of quantization error. Consequently, the space-time snapshot data pertaining to the clutter in the Equation (1) can alternatively be formulated as:
In the equation, represents the complex amplitude of the clutter space-time snapshot data on the angle-Doppler image, which can also be referred to as the angle-Doppler image.
Considering the space-time steering dictionary set in Equation (15), its column vectors correspond to discretized normalized Doppler frequencies and spatial frequencies . The actual frequencies of clutter scatterers may deviate from the predefined grid points. To address this, grid offsets and are introduced to model the true frequencies as: . During initialization, set all elements of both “δ_d” and “δ_s” to 0. Using a first-order Taylor expansion, the off-grid steering vector can be approximated as:
In the equation, the partial derivative terms are:
Therefore, the off-grid dictionary set can be rewritten as follows:
In the equation, and represent the Jacobians of with respect to and , respectively.
Then, Equation (7) can be re-expressed as:
In the equation, is the noise power, is an identity matrix of dimension NM × NM; , where , for and .
Similarly, for the Multiple Measurement Vector (MMV) scenario, the following equation applies:
In the equation, and , where L represents the number of snapshot data points, and each column of denotes the received Gaussian white noise.
Assuming that the training samples satisfy the IID condition, the implementation for solving the sparse solution using the MMV method can be expressed as follows:
In the equation, is a mixed norm defined as the number of zero elements in the vector formed by the norms of each row vector. denotes the Frobenius norm.
In Equation (21), the involvement of the norm has proven that solving the aforementioned optimization problem is NP-hard. In pursuit of sparsity, dealing with optimization problems and requiring mathematical approximations, the norm can be used as a substitute for the norm. Therefore, the above equation can be rewritten as:
In the equation, is a mixed norm defined as the norm of the vector formed by the norms of each row vector.
3. The Proposed Method
3.1. Bayesian Framework
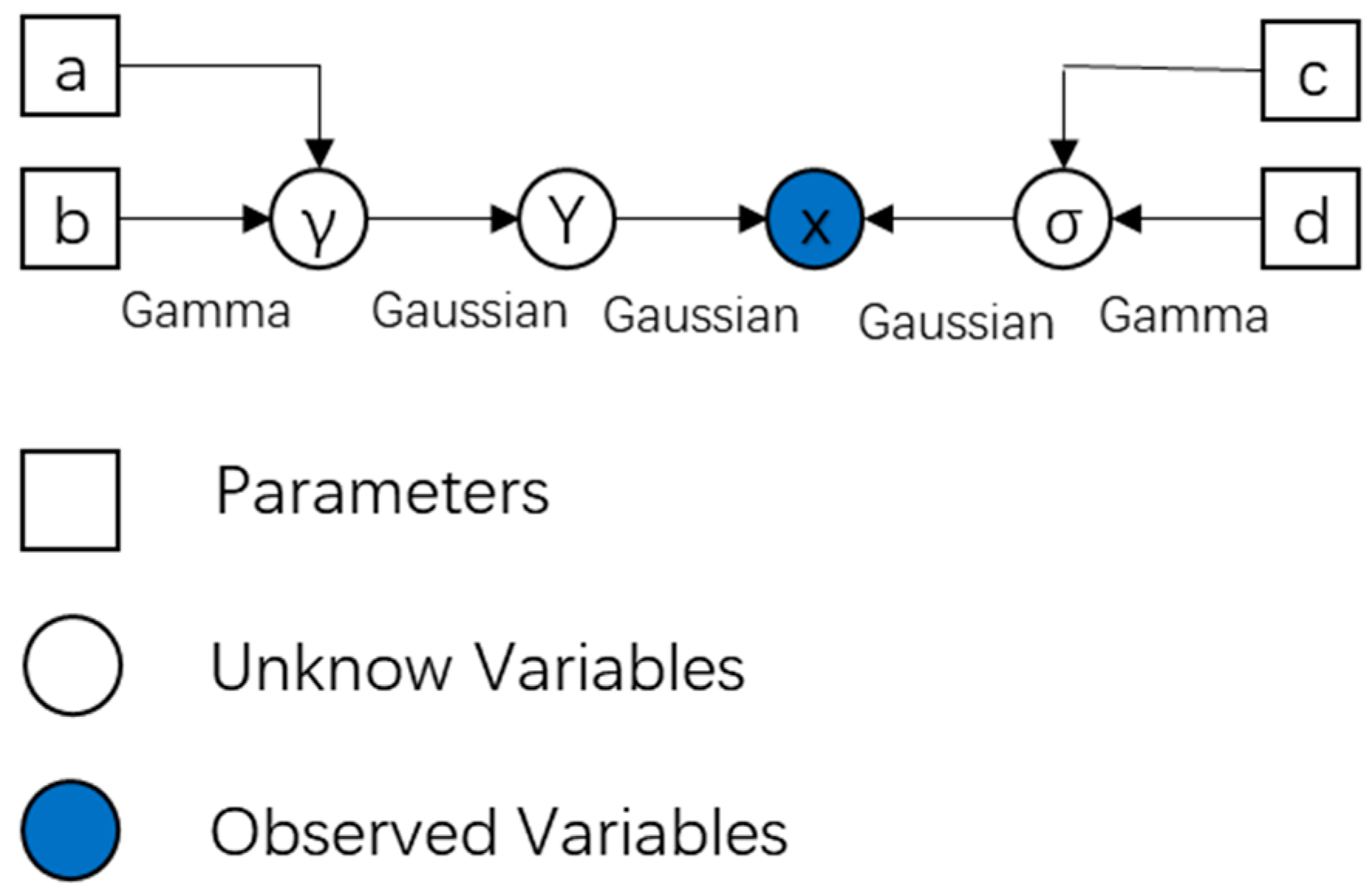
Constructing an apt Bayesian model is indispensable and pivotal for SBL. In this paper, we incorporate hierarchical prior information into the latent variables to further augment sparsity. The likelihood associated with the observed variable is expressed as follows:
In the equation, represents the noise precision.
By imposing a Gaussian distribution prior on the latent variable , we obtain:
In the equation, and . Since the inverse Gamma distribution is conjugate to the Gaussian distribution, we adopt a Gamma distribution prior for each element of , which can be expressed as:
where , with being the shape parameter and being the scale parameter. Similarly, assuming that follows a Gamma distribution, we obtain:
where and are the corresponding shape and scale parameters, respectively. The directed acyclic graph for representing the Bayesian model is shown in Figure 2.
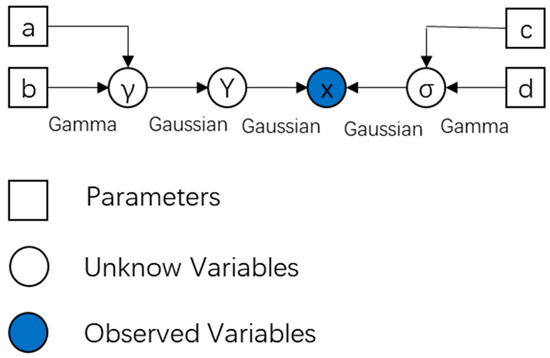
Figure 2.
Directed acyclic graph of the proposed Bayesian model.
Based on the aforementioned Bayesian hierarchical model assumptions, the joint distribution of the signals can be obtained as:
3.2. Minimization of KL Divergence (Variational E-Step)
According to Bayesian theory, the maximum posterior probability of the parameters to be estimated can be obtained, but its calculation usually involves high-dimensional and complex integrals, making it difficult to solve. Therefore, we introduce variational inference to address this issue of maximum posterior estimation.
In variational inference, the observed data represents the data received by the array elements, and the set of latent variables consists of the parameters to be estimated. The following equation holds:
In the equation, represents the Evidence Lower Bound (ELBO), and denotes the Kullback-Leibler (KL) divergence, which measures the approximation degree between the probability distribution and the posterior distribution . The smaller the KL divergence, the higher the degree of approximation. The goal of variational inference is to maximize the lower bound of by finding the distribution of that maximizes the ELBO. At this point, can be used to approximate the posterior probability distribution of the latent variables.
To minimize KL Divergence, the probability distribution is decomposed into , and the general expression for the optimal approximate distribution is provided as follows:
In the expression, denotes the conditional expectation of the parameter under the approximate distribution , with the condition that for is held fixed.
By ignoring the terms unrelated to , the optimal approximate posterior distribution for can be obtained from Equation (29) as follows:
where denotes the expectation concerning , then can be solved as being subject to a joint complex Gaussian distribution, which is expressed as:
While
Ignoring the terms unrelated to , the optimal approximate posterior distribution for can be obtained from Equation (29) as follows:
is solved to be a Gamma distribution, with its probability distribution expressed as:
In the equation, , where denotes the -th element of the vector , and represents the element in the -th row and -th column of the matrix .
Ignoring the terms unrelated to , the optimal approximate posterior distribution for can be obtained from Equation (29) as follows:
is solved to be a Gamma distribution, with its probability distribution stated as follows:
In the equation, , where and tr() denotes the trace of a matrix.
3.3. Maximization of the Lower Bound (M-Step)
When is fixed, the maximization of the lower bound of Equation (28) is:
Ignoring the terms unrelated to and , Equation (40) can be simplified as [18]:
In the equation, R(∙) denotes taking the real part, where:
Then, by setting the derivatives of Equation (41) with respect to and to zero, the optimal solution for Equation (41) can be obtained.
The iterative algorithm for Variational Bayesian Inference is structurally simple, with the specific steps detailed in Algorithm 1.
| Algorithm 1. VB-SR-STAP algorithms. | |
| Stap1: | |
| Stap2: | respectively |
| Stap3: | respectively |
| Stap4: | |
| Stap5: | by 1 |
| Stap6: | , then return to Step 2 |
| Stap7: | Output the final result of μ(t) |
| Stap8: | |
3.4. Improved Variational Bayesian Inference
For a squint-looking uniform linear array Doppler pulse radar, assuming a constant pulse repetition frequency, constant platform velocity, and idealized clutter conditions where the clutter scatterers are stationary with no internal motion, the clutter subspace can be approximated by a subspace computed using a set of space-time steering vectors. These space-time steering vectors satisfy the following conditions:
While
In the equation, represents the rank of the clutter, which can be estimated using the well-known Brennan’s rule [23]. When is an integer less than , the rank of the clutter covariance matrix satisfies the following equation:
When is a decimal number less than , the rank of the clutter covariance matrix satisfies the following relationship:
In the formula, ⌊∙⌋ denotes the floor function. Then, the -th space-time snapshot data in Equation (1) can also be expressed as the following equation:
In the equation, , where , are complex coefficients corresponding to the space-time steering vectors . When the space-time steering dictionary includes all space-time steering vectors , the clutter space-time snapshot data represented by Equation (46) can also be expressed in the form of Equation (16). At this point, the non-zero elements in the angle-Doppler image correspond to the complex coefficients , where . This indicates that the number of non-zero elements in the clutter-Doppler spectrum, , can be much smaller than the number of clutter scatterers, . Furthermore, the space-time snapshot data of the clutter can be fully recovered using only space-time steering vectors from the dictionary.
The previous analysis shows that is a highly sparse signal, with most of its terms being close to zero. Additionally, Equation (36) indicates that when a corresponding term in is non-zero, due to the typically very small settings of parameters a and b, the corresponding term will be extremely small. Conversely, if a certain term of is large, the probability that the corresponding term in is zero is high. Since each term of corresponds to a complex coefficient of a space-time steering vector in the dictionary set, is non-zero only when clutter exists at the corresponding angle-Doppler bin. Therefore, when is small, the corresponding (clutter in the angle-Doppler image) is non-zero. Furthermore, based on the aforementioned prior knowledge that there are approximately non-zero solutions in , and inspired by a K-means clustering sparse Bayesian learning algorithm proposed in the literature [24], as well as the rank pruning techniques presented in references [17,18], combining these information allows us to significantly reduce the number of iterations by only updating the values of corresponding to the smallest values of . The update rules for each iteration can be stated as follows: (1) Record the indices of the smallest elements in the hyperparameter to form a heap set ; (2) Update the terms in whose indices are in the heap set . The corresponding update formulas then become as follows:
where denotes the -th column of matrix , and and represent the mean and variance of the complex coefficient corresponding to the -th space-time steering vector, respectively. The specific steps of the improved iterative algorithm are listed in Algorithm 2.
| Algorithm 2. IVB-SR-STAP algorithms. | |
| Stap1: | |
| Stap2: | |
| Stap3: | using Equation (47) |
| Stap4: | respectively |
| Stap5: | Update set A |
| Stap6: | |
| Stap7: | by 1 |
| Stap8: | , then return to Step 3 |
| Stap9: | Output the final result of μ(t) |
| Stap10: | |
3.5. Comparison of Computational Complexity
The main focus of this article is on the frequency of multiplication and division operations during a single iteration of an algorithm, and it conducts an in-depth analysis of its computational complexity. The proposed algorithm exhibits a computational complexity of when calculating the variables and , where . Meanwhile, the computational complexity for calculating the variable is . As a result, the total computational complexity per iteration amounts to . In comparison, the computational complexities reported in the pieces of literature [15,20] are O(Z2) and O(Z). Where , it is evident that the proposed algorithm significantly reduces computational complexity.
4. Experimental Simulation
4.1. Analysis of Clutter Power Spectrum
The performance of the IVB-SR-STAP algorithms was analyzed through simulation experiments, and compared with the Homotopy-SR-STAP [25], LMSSE-SR-STAP [26], and VB-SA-STAP algorithms [20]. Table 1 presents the simulation parameters for a radar system configured with a uniformly spaced linear array in broadside-looking configuration.

Table 1.
Simulation parameters of the radar system with a side-looking uniform linear array.
4.1.1. Clutter Power Spectrum Under Ideal Conditions
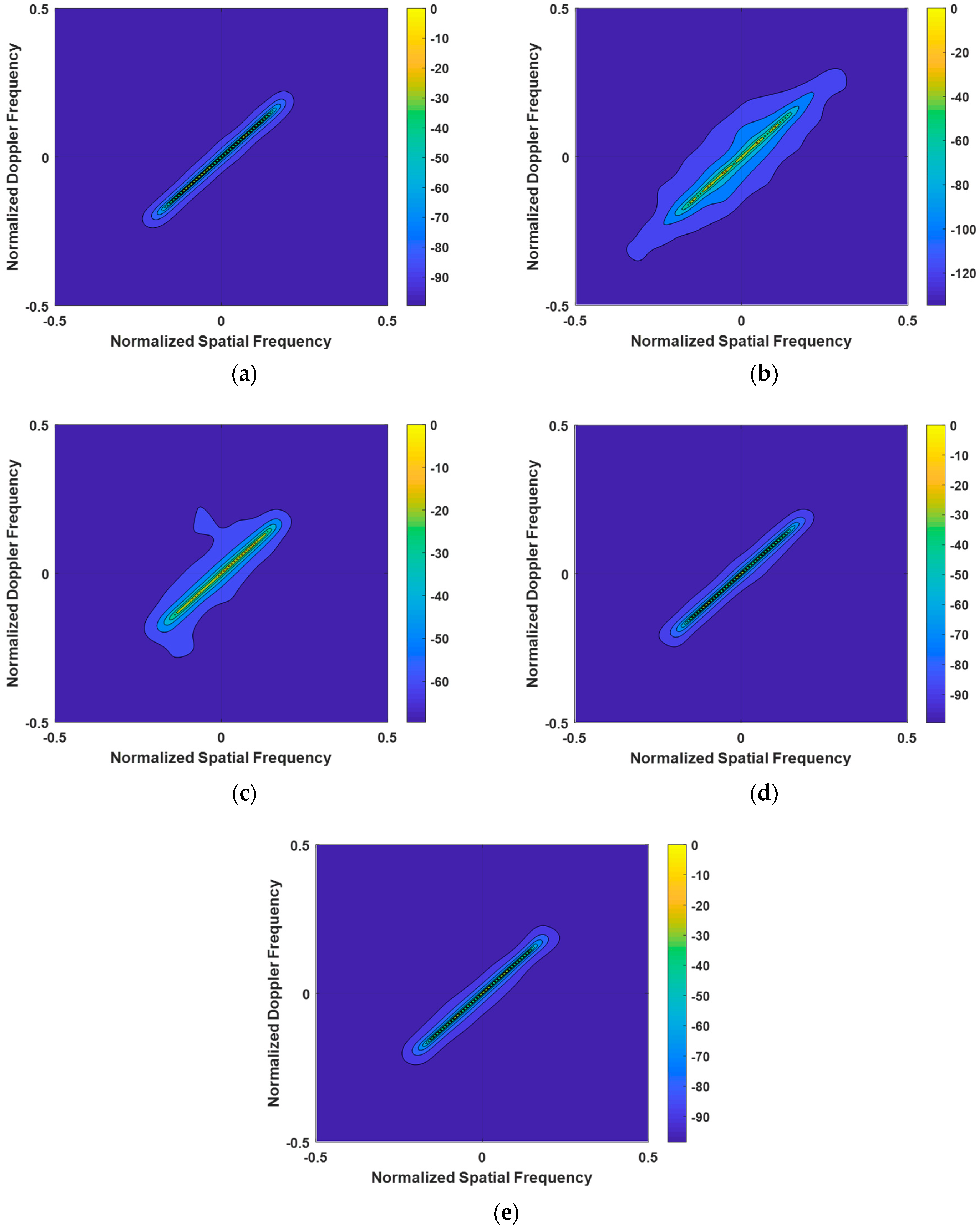
The first experiment meticulously examined the clutter power spectra of the LMSSE-SR-STAP, Homotopy-SR-STAP, VB-SR-STAP, and IVB-SR-STAP algorithms under ideal conditions, with the results presented in Figure 3. The LMSSE-SR-STAP and Homotopy-SR-STAP algorithms require the setting of regularization parameters; however, it is difficult to determine an optimal value for these parameters. This has led to a noticeable broadening phenomenon in the clutter spectrum, resulting in the dispersion of clutter energy and subsequent degradation in clutter suppression performance. In comparison, the VB-SR-STAP algorithm does not require the setting of regularization parameters, and it continuously updates Equation (18) to address quantization errors. Moreover, its recovered clutter spectrum does not show significant broadening. The clutter energy is concentrated on the clutter ridge, demonstrating its superiority in maintaining spectral integrity. The IVB-SR-STAP algorithm, by updating only a selected few key hyperparameters, is also able to produce a clutter spectrum that compares favorably with the performance of the VB-SR-STAP algorithm. Both the VB-SR-STAP and IVB-SR-STAP algorithms overcome the challenges posed by the setting of regularization parameters, and the results they produce are very close to the optimal clutter spectrum, highlighting their exceptional accuracy and efficiency.
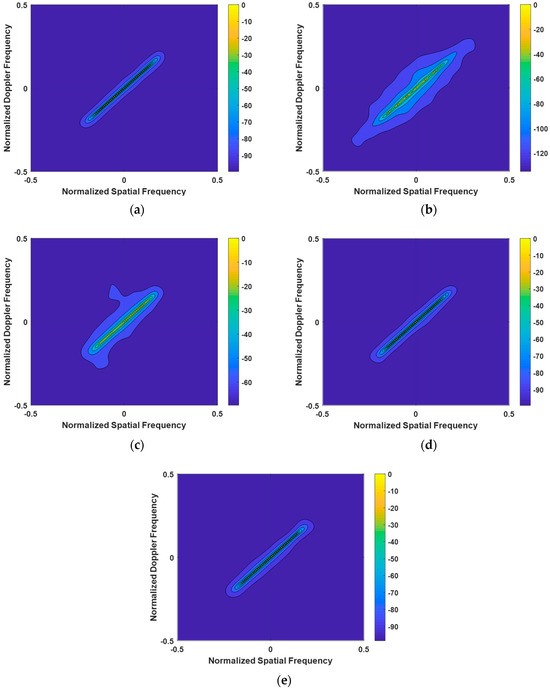
Figure 3.
Clutter Power Spectrum under Ideal Conditions. (a) OPT; (b) LSSME-SR-STAP algorithm; (c) Homotopy-SR-STAP algorithm; (d) VB-SR-STAP algorithm; (e) IVB-SR-STAP algorithm.
4.1.2. Clutter Power Spectrum Under Array Element Error Conditions
In this subsection, we consider the non-ideal scenario with gain-phase (GP) errors. GP errors arise from inconsistent amplitude and phase characteristics in the radio frequency (RF) amplifier components of the array channels. These errors manifest as variations in amplitude and phase across different channels. To describe this, we introduce an error matrix T into the steering vector modeling. By extending the signal model to account for GP errors, Equation (20) can be rewritten as follows:
where error matrix T is:
where , , i = 1, …, N represents the amplitude error and phase error of i-th element.
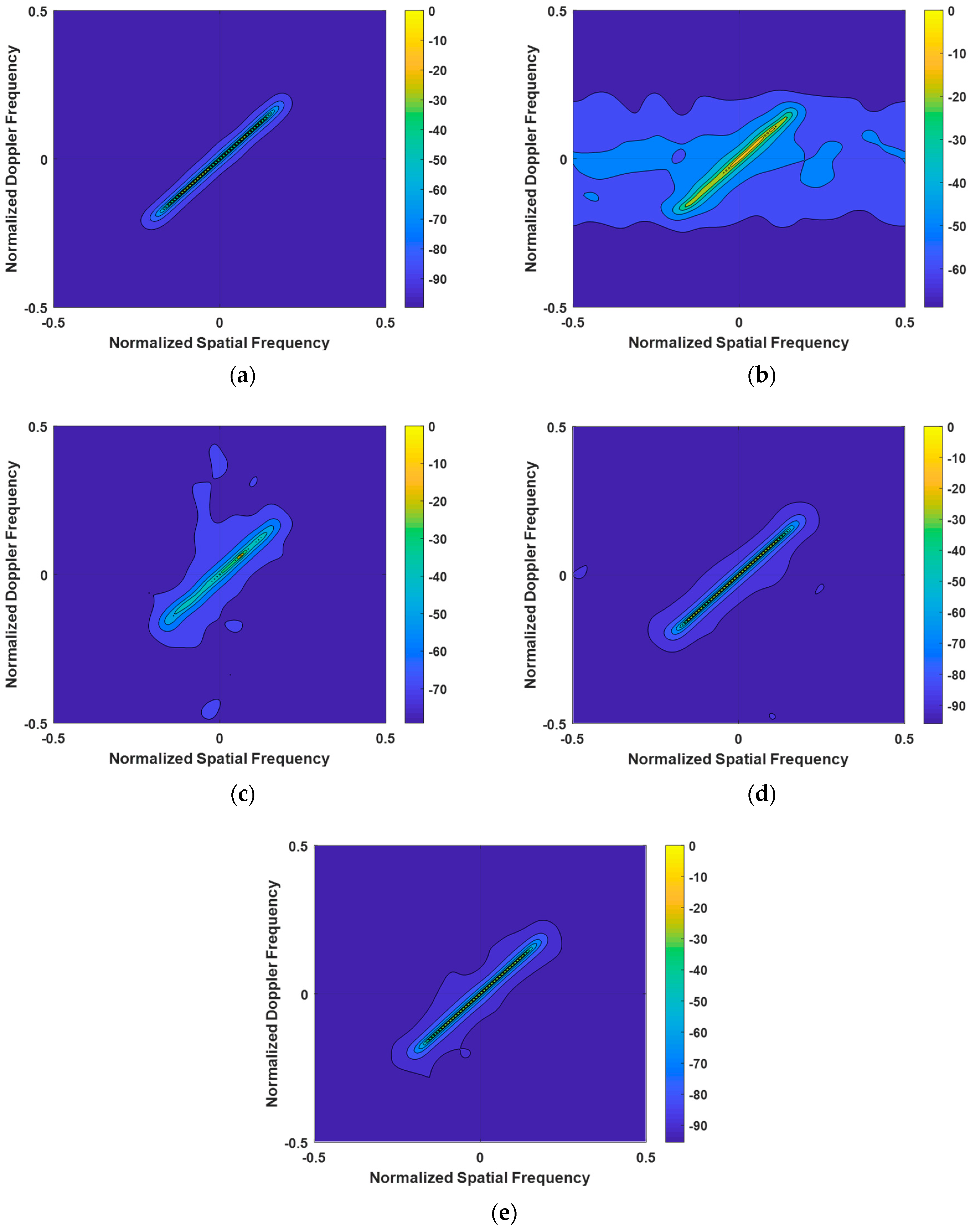
When analyzing the clutter spectra of various algorithms shown in Figure 4 under the condition of GB errors, we can draw the following conclusions: The clutter spectrum calculated by the LSSME-SR-STAP algorithm exhibits significant broadening. This indicates that, under the influence of GB errors, the performance of this algorithm in clutter suppression is greatly affected, resulting in an increased width of the clutter spectrum. Compared to the VB-SR-STAP and IVB-SR-STAP algorithms, the clutter spectrum computed by the Homotopy-SR-STAP algorithm is slightly wider. This implies that, under the same GB error conditions, the Homotopy-SR-STAP algorithm is slightly inferior in maintaining the compactness of the clutter spectrum. The performance of the VB-SR-STAP and IVB-SR-STAP algorithms is noteworthy. The clutter spectra calculated by these two algorithms are close to the optimal clutter spectrum, demonstrating their excellent clutter suppression performance even in the presence of GB errors. This shows that the VB-SR-STAP and IVB-SR-STAP algorithms exhibit greater robustness and adaptability in addressing GB errors.
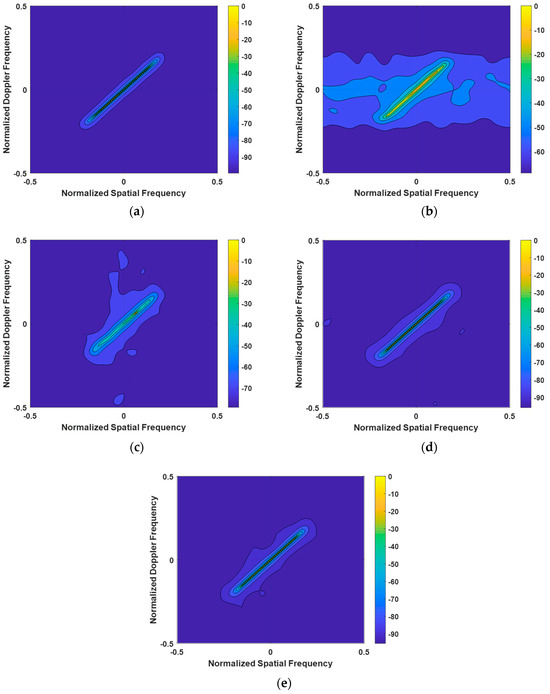
Figure 4.
Clutter Power Spectrum under Array Element Error Conditions. (a) OPT; (b) LSSME-SR-STAP algorithm; (c) Homotopy-SR-STAP algorithm; (d) VB-SR-STAP algorithm; (e) IVB-SR-STAP algorithm.
4.2. Analysis of Signal-to-Clutter-and-Noise Ratio Loss (SCNR Loss)
4.2.1. Signal-to-Clutter-and-Noise Ratio Loss Under Ideal Conditions
The second experiment compares the SCNR Loss of the LMSSE-STAP, Homotopy-SR-STAP, VB-SR-STAP, and IVB-SR-STAP algorithms to evaluate their clutter suppression performance. The SCNR Loss is calculated as follows:
In the equation, represents the noise power.
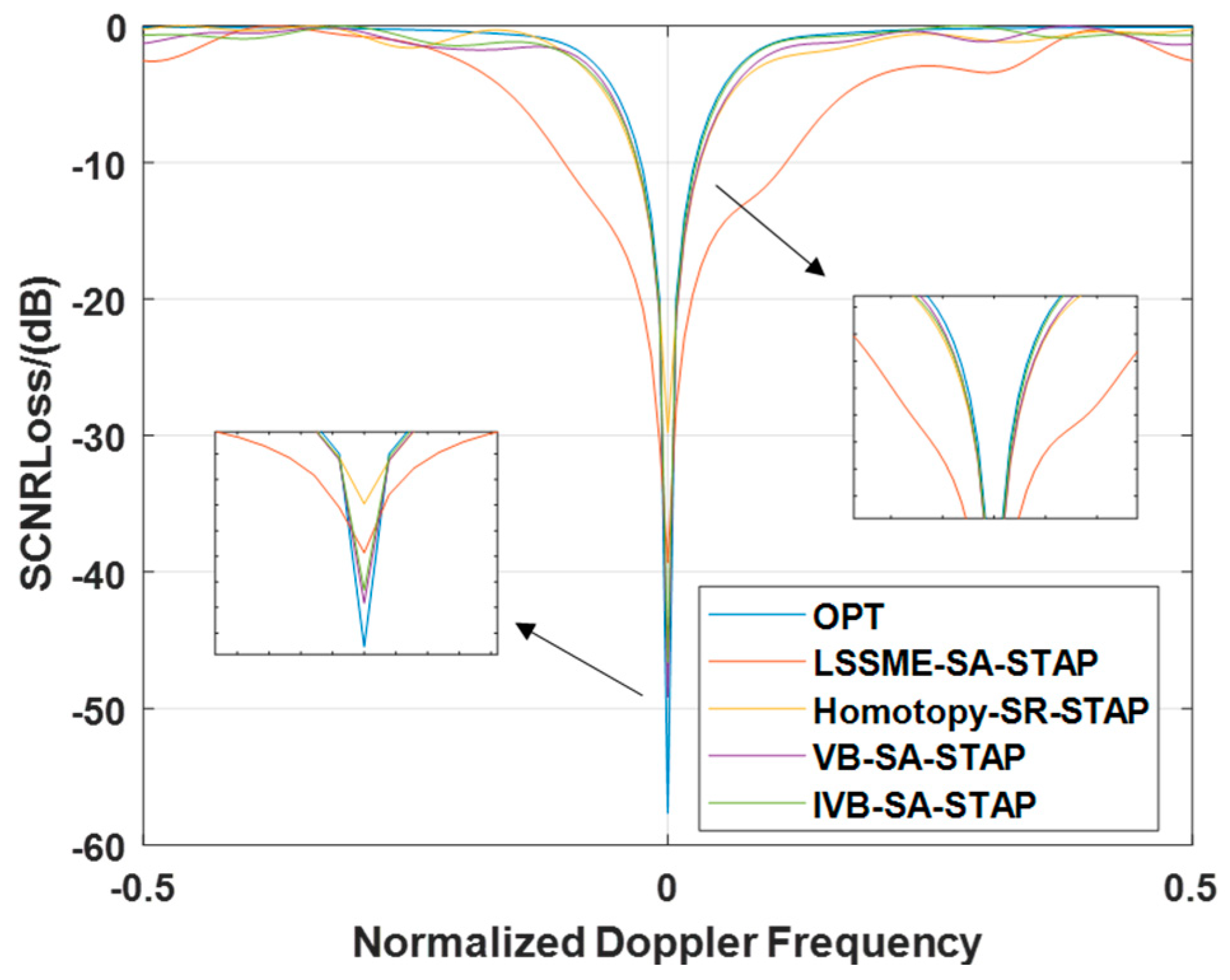
In ideal scenarios, the experimental results presented in Figure 5 reveal a compelling discovery: The SCNR Loss curve of the LMSSE-SR-STAP algorithm exhibits the most prominent notch width. Compared to the VB-SR-STAP algorithm and the IVB-SR-STAP algorithm proposed in this paper, the SCNR loss curve of the Homotopy-SR-STAP algorithm also displays a relatively wide notch, albeit less pronounced than that of the LMSSE-SR-STAP algorithm. Within the mainlobe clutter region, both the IVB-SR-STAP algorithm and the VB-SR-STAP algorithm are able to form deeper notches compared to the LMSSE-SR-STAP algorithm and the Homotopy-SR-STAP algorithm, with both trailing closely behind the optimal performance. It is worth emphasizing that the proposed new algorithm demonstrates its exceptional effectiveness and remarkable clutter suppression capabilities while significantly reducing the computational burden.
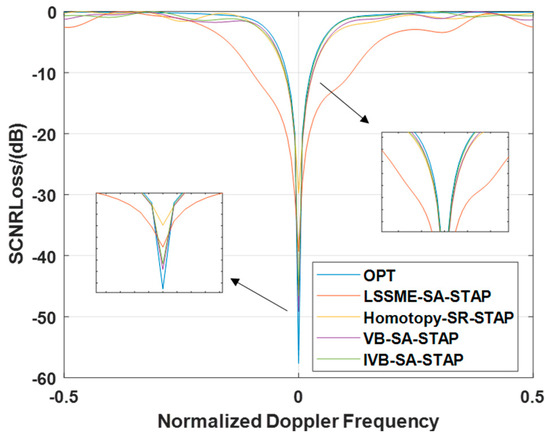
Figure 5.
Signal-to-Clutter-and-Noise Ratio Loss under Ideal Conditions.
4.2.2. Signal-to-Clutter-and-Noise Ratio Loss Under Array Element Error Conditions
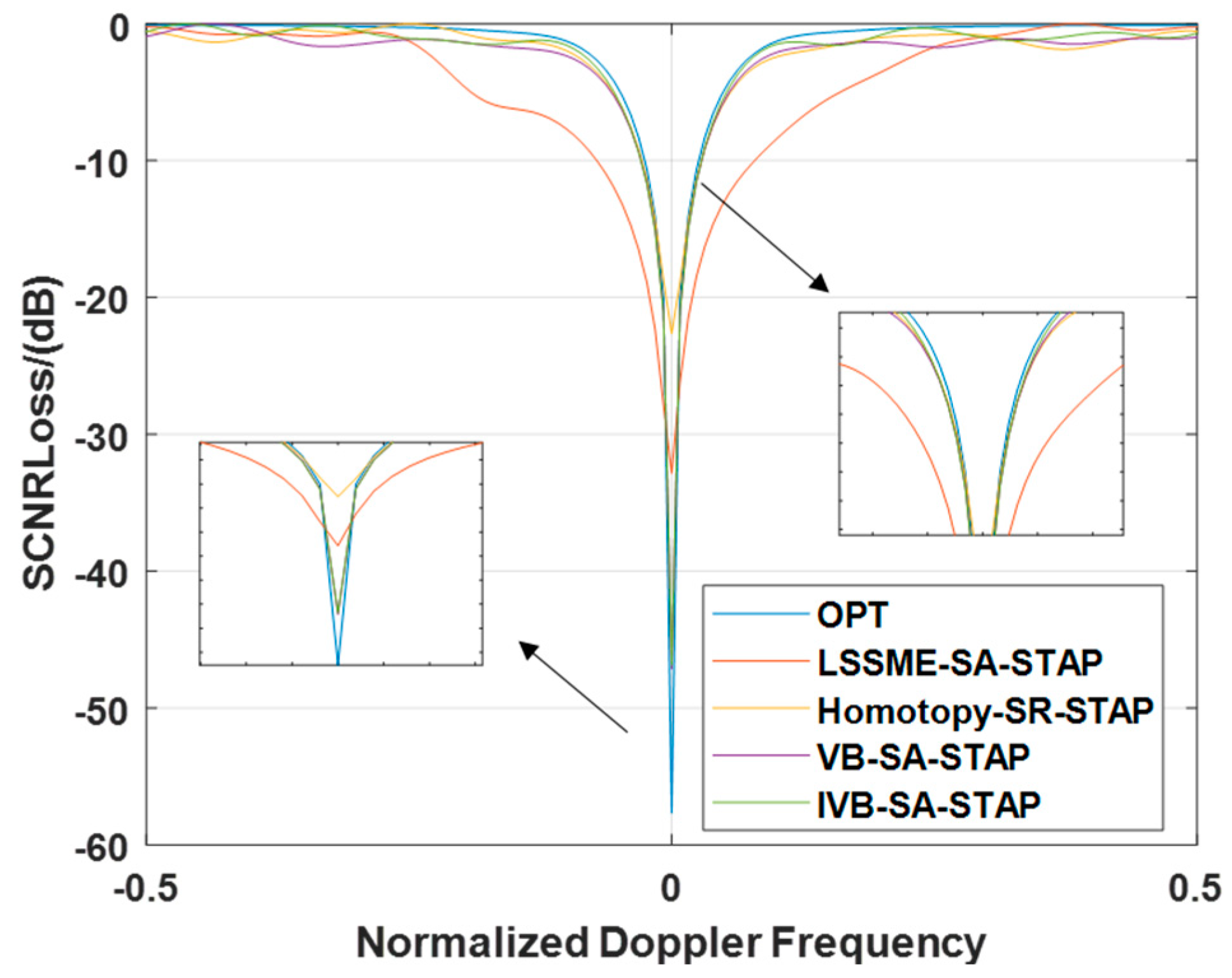
In this subsection, we delve into the specific performance of different algorithms in terms of SCNR Loss when faced with GB errors. By observing Figure 6, it is evident that the SCNR Loss notch produced by the LMSSE-SR-STAP algorithm is significantly broader than that of other algorithms. In contrast, although the Homotopy-SR-STAP algorithm is comparable to the VB-SR-STAP and IVB-SR-STAP algorithms in terms of the width of the SCNR loss notch, it falls significantly behind in the depth of the notch formed in the main clutter region, which is notably less than that of the VB-SR-STAP and IVB-SR-STAP algorithms. Based on the above analysis, we can conclude that in complex environments with array element errors, the IVB-SR-STAP algorithm proposed in this paper not only successfully reduces the computational complexity of the VB-SR-STAP algorithm but also maintains excellent clutter suppression performance. This discovery further validates the feasibility and advantages of the IVB-SR-STAP algorithm in practical applications.
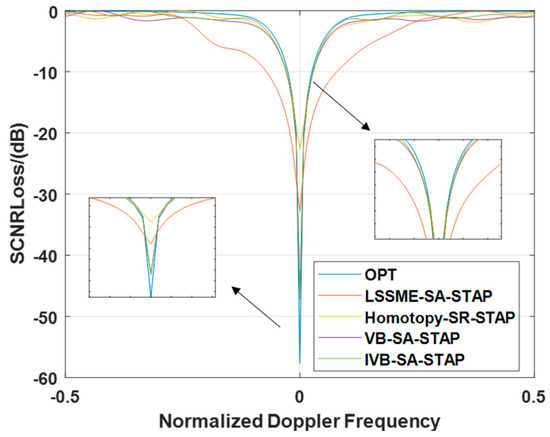
Figure 6.
Signal-to-Clutter-and-Noise Ratio Loss under Array Element Error Conditions.
5. Conclusions
In this paper, a hierarchical Bayesian prior framework is proposed, and iterative update formulas for parameters are derived through variational inference methods. Leveraging the prior information on the rank of the spatio-temporal clutter covariance matrix, an improved variational Bayesian approach is introduced, optimizing the updated formulas for parameters and effectively reducing computational complexity. Furthermore, this method fully exploits the joint sparsity of the multiple measurement vector model, achieving higher sparsity while maintaining high accuracy, and employs a first-order Taylor expansion to eliminate grid mismatch in the dictionary. Experimental results demonstrate that the proposed algorithm maintains excellent performance while effectively reducing computational complexity, showcasing its remarkable efficiency and effectiveness.
Author Contributions
Each author contributed to the manuscript. K.L. and J.L. wrote the manuscript; Z.H. and L.Y. derived the theoretical method; P.L. and G.L. provided raw materials. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Key Research and Development Program of Anhui Province under Grant 2023Z04020018.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Restrictions apply to the datasets.
Acknowledgments
The authors would like to thank the Editorial Board and anonymous reviewers for their careful reading and constructive comments which provide important guidance for our paper writing and research work.
Conflicts of Interest
Author Peng Li was employed by the company Sun Create Electronics Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Gao, Z.; Deng, W.; Huang, P.; Xu, W.; Tan, W. Airborne Radar Space–Time Adaptive Processing Algorithm Based on Dictionary and Clutter Power Spectrum Correction. Electronics 2024, 13, 2187. [Google Scholar] [CrossRef]
- Widrow, B.; Mantey, P.E.; Griffiths, L.J.; Goode, B.B. Adaptive antenna systems. Proc. IEEE 1967, 55, 2143–2159. [Google Scholar] [CrossRef]
- Brennan, L.E.; Reed, L.S. Theory of Adaptive Radar. IEEE Trans. Aerosp. Electron. Syst. 1973, AES-9, 237–252. [Google Scholar] [CrossRef]
- Melvin, W.L. A STAP overview. IEEE Aerosp. Electron. Syst. Mag. 2004, 19, 19–35. [Google Scholar] [CrossRef]
- Honig, M.L.; Goldstein, J.S. Adaptive reduced-rank interference suppression based on the multistage Wiener filter. IEEE Trans. Commun. 2002, 50, 986–994. [Google Scholar] [CrossRef]
- Wang, L.; Lamare, R.C.d. Adaptive reduced-rank LCMV beamforming algorithm based on the set-membership filtering framework. In Proceedings of the 2010 7th International Symposium on Wireless Communication Systems, York, UK, 19–22 September 2010; pp. 125–129. [Google Scholar]
- Cristallini, D.; Burger, W. A Robust Direct Data Domain Approach for STAP. IEEE Trans. Signal Process. 2012, 60, 1283–1294. [Google Scholar] [CrossRef]
- Cristallini, D.; Rosenberg, L.; Wojaczek, P. Complementary direct data domain STAP for multichannel airborne passive radar. In Proceedings of the 2021 IEEE Radar Conference (RadarConf21), Atlanta, GA, USA, 8–14 May 2021; pp. 1–6. [Google Scholar]
- Du, X.; Jing, Y.; Chen, X.; Cui, G.; Zheng, J. Clutter Covariance Matrix Estimation via KA-SADMM for STAP. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Tropp, J.A.; Wright, S.J. Computational Methods for Sparse Solution of Linear Inverse Problems. Proc. IEEE 2010, 98, 948–958. [Google Scholar] [CrossRef]
- Mallat, S.G.; Zhifeng, Z. Matching pursuits with time-frequency dictionaries. IEEE Trans. Signal Process. 1993, 41, 3397–3415. [Google Scholar] [CrossRef]
- Wang, J.; Shim, B. On the Recovery Limit of Sparse Signals Using Orthogonal Matching Pursuit. IEEE Trans. Signal Process. 2012, 60, 4973–4976. [Google Scholar] [CrossRef]
- Shaobo, L.; Yuanhua, R.; Xingping, S.; Zongben, X. Learning Capability of Relaxed Greedy Algorithms. IEEE Trans. Neural Networks Learn. Syst. 2013, 24, 1598–1608. [Google Scholar] [CrossRef] [PubMed]
- Zou, J.; Fu, Y.; Xie, S. A Block Fixed Point Continuation Algorithm for Block-Sparse Reconstruction. IEEE Signal Process. Lett. 2012, 19, 364–367. [Google Scholar] [CrossRef]
- Tipping, M.E. Sparse bayesian learning and the relevance vector machine. J. Mach. Learn. Res. 2001, 1, 211–244. [Google Scholar] [CrossRef]
- Zhang, L.; Dai, L. Image Reconstruction of Electrical Capacitance Tomography Based on an Efficient Sparse Bayesian Learning Algorithm. IEEE Trans. Instrum. Meas. 2022, 71, 1–14. [Google Scholar] [CrossRef]
- Cheng, L.; Xing, C.; Wu, Y.C. Irregular Array Manifold Aided Channel Estimation in Massive MIMO Communications. IEEE J. Sel. Top. Signal Process. 2019, 13, 974–988. [Google Scholar] [CrossRef]
- Xu, L.; Cheng, L.; Wong, N.; Wu, Y.C.; Poor, H.V. Overcoming Beam Squint in mmWave MIMO Channel Estimation: A Bayesian Multi-Band Sparsity Approach. IEEE Trans. Signal Process. 2024, 72, 1219–1234. [Google Scholar] [CrossRef]
- Duan, H.; Yang, L.; Fang, J.; Li, H. Fast Inverse-Free Sparse Bayesian Learning via Relaxed Evidence Lower Bound Maximization. IEEE Signal Process. Lett. 2017, 24, 774–778. [Google Scholar] [CrossRef]
- Thomas, C.K.; Slock, D. Save-space alternating variational estimation for sparse bayesian learning. In Proceedings of the 2018 IEEE Data Science Workshop (DSW), Lausanne, Switzerland, 4–6 June 2018; pp. 11–15. [Google Scholar]
- Al-Shoukairi, M.; Schniter, P.; Rao, B.D. A GAMP-Based Low Complexity Sparse Bayesian Learning Algorithm. IEEE Trans. Signal Process. 2018, 66, 294–308. [Google Scholar] [CrossRef]
- Zhou, W.; Zhang, H.-T.; Wang, J. An Efficient Sparse Bayesian Learning Algorithm Based on Gaussian-Scale Mixtures. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 3065–3078. [Google Scholar] [CrossRef] [PubMed]
- Ward, J. Space-time adaptive processing for airborne radar. In Proceedings of the 1995 International Conference on Acoustics, Speech, and Signal Processing, Detroit, MI, USA, 9–12 May 1995; Volume 2805, pp. 2809–2812. [Google Scholar]
- Lv, X.; Yuan, L.; Cheng, Z.; Zuo, L.; Yin, B.; He, Y.; Ding, C. An Improved Bayesian Learning Method for Distribution Grid Fault Location and Meter Deployment Optimization. IEEE Trans. Instrum. Meas. 2024, 73, 1–10. [Google Scholar] [CrossRef]
- Yang, Z.; Nie, L.; Huo, K.; Wang, H.; Li, X. Sparsity-based space-time adaptive processing using complex-valued homotopy technique. In Proceedings of the 2013 IEEE Radar Conference (RadarCon13), Ottawa, ON, Canada, 29 April–3 May 2013; pp. 1–6. [Google Scholar]
- Melvin, W.L.; Guerci, J.R. Knowledge-aided signal processing: A new paradigm for radar and other advanced sensors. IEEE Trans. Aerosp. Electron. Syst. 2006, 42, 983–996. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).