

Causal Artificial Intelligence in Legal Language Processing: A Systematic Review



Abstract
1. Introduction
1.1. NLP and the Open Texture of Legal Language
1.2. Causality in Theoretical Computer Science and Its Use in NLP
1.3. The Lack of Empirical Context in Legal Texts
1.4. Relation Between Causality and Legal Language
“… blacks are almost twice as likely as whites to be labeled a higher risk but not actually re-offend, [whereas COMPAS] makes the opposite mistake among whites: They are much more likely than blacks to be labeled lower-risk but go on to commit other crimes.” [18]
1.5. Legal Assessment in Causal Models for Legal Language Processing
1.6. Objective
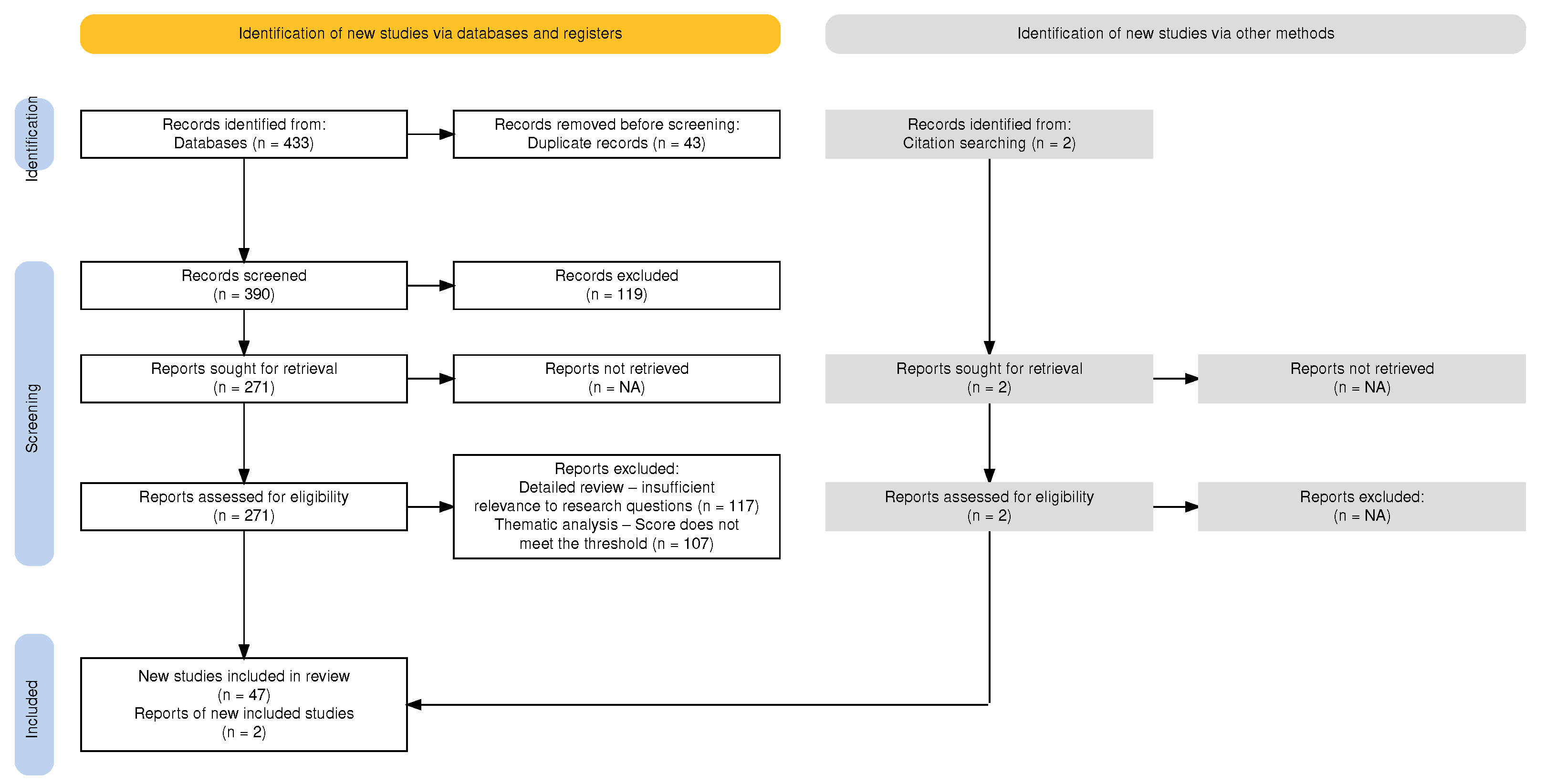
2. Materials and Methods
- What challenges do AI models face in interpreting legal language accurately?
- How can causal inference improve AI’s understanding of legal language compared to correlation-based methods?
- How can we address the lack of empirical data in causal analysis of legal texts?
2.1. Drafting the Protocol
2.1.1. Inclusion Criteria
2.1.2. Exclusion Criteria
2.1.3. Data Extraction
2.1.4. Data Analysis
3. Results
3.1. Trends Analysis
3.1.1. Disruption Measures
3.1.2. Causal AI Applications Trends in Legal Practice

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cluster | Method | Practical Applications | References |
|---|---|---|---|
| 1. Causal Reasoning Paradigms | Actual Causation Theory | Automated text analysis; Legal reasoning support systems | [42] |
| 2. Structural & Graphical Approaches | Bayesian Networks | Policy simulation; Legislative impact analysis; Legal argument construction; Judicial reasoning modeling; Societal value change simulation | [8] |
| Directed Acyclic Graphs (DAG) | Drug law enforcement | [43] | |
| Structural Causal Models (SCM) | Policy simulation; Legislative impact analysis; Legal argument construction; Judicial reasoning modeling; Societal value change simulation | [8] | |
| Structural Equations Model (SEM) | Drug law enforcement | [43] | |
| Structural Equations | Automated text analysis; Legal reasoning support systems | [42] | |
| Path Coefficients Analysis | Policy simulation; Legislative impact analysis; Legal argument construction; Judicial reasoning modeling; Societal value change simulation | [8] | |
| Path-Specific Effects | Drug law enforcement | [43] | |
| Causal Structural Modeling | Policy research; Legal text analysis | [44] | |
| 3. Causal Inference & Identification | Propensity Scoring/Matching | Privacy protection; Criminal justice; Policy research; Legal text analysis | [44,45] |
| Inverse Probability Weighting | Privacy protection; Criminal justice | [45] | |
| Instrumental Variable Regression | Similar charge disambiguation; Automated contract analysis; Bias detection | [37] | |
| Do-Calculus | Policy simulation; Legislative impact analysis; Legal argument construction; Judicial reasoning modeling; Societal value change simulation | [8] | |
| Intervention-Based Causal Inference | Policy simulation; Legislative impact analysis; Legal argument construction; Judicial reasoning modeling; Societal value change simulation | [8] | |
| Causal Inference Network | Electronic court records management; Online legal consulting; Digital case filing; Legal document digitization | [46] | |
| Graph-Based Causal Inference (GCI) | Automated judicial assistance; Legal advisory services; Criminal case analysis | [38] | |
| Greedy Fast Causal Inference (GFCI) | Automated judicial assistance; Legal advisory services; Criminal case analysis | [38] | |
| 4. Effect Estimation & Assessment | Average Treatment Effect (ATE) | Automated judicial assistance; Legal advisory services; Criminal case analysis | [38] |
| Causal Effect Estimation | Contract analysis; Bias detection | [47] | |
| Long-Term Causal Effect Estimation | Privacy protection; Criminal justice | [45] | |
| Causal Strength Assessment | Automated judicial assistance; Legal advisory services; Criminal case analysis | [38] | |
| 5. Mediation & Indirect Effects | Causal Mediation Analysis | Contract analysis; Bias detection; Privacy protection; Criminal justice; Policy research; Legal text analysis; Similar charge disambiguation; Automated contract analysis | [37,44,45,47] |
| 6. Counterfactual Approaches | Counterfactual Reasoning | Contract analysis; Bias detection; Privacy protection; Criminal justice; Drug law enforcement | [43,45,47,48] |
| Attentional & Counterfactual-Based NLG (AC-NLG) | Court’s view generation; Debiasing judgment narratives; Enhanced interpretability of supportive vs. non-supportive cases | [49] | |
| 7. Adversarial & Deconfounding | Adversarial Deconfounding | Litigation strategy decisions; Case outcome inference; Legal decision support systems | [50] |
| Gradient Reversal Layer | Litigation strategy decisions; Case outcome inference; Legal decision support systems | [50] | |
| 8. RL & Decision-Making | Causal Bandits | Civil litigation document review; Anti-corruption audits; Social welfare benefits adjudication | [51] |
| Causal Decision-Making Policies | Civil litigation document review; Anti-corruption audits; Social welfare benefits adjudication | [51] | |
| Constrained Reinforcement Learning | Civil litigation document review; Anti-corruption audits; Social welfare benefits adjudication | [51] | |
| 9. Representation Learning (Text/NLP) | Causal Representation Learning | Similar charge disambiguation; Automated contract analysis; Bias detection | [37] |
| BERT-Based Embeddings | General use in legal texts analysis | [52] | |
| Word2vec Adaptation | General use in legal texts analysis | [52] | |
| Deep Similarity Search | General use in legal texts analysis | [52] | |
| BERT | Personal injury cases; Patent infringement; Small claims tribunals; Legal document generation; Discovery process | [53] | |
| GIDBERT | Personal injury cases; Patent infringement; Small claims tribunals; Legal document generation; Discovery process | [53] |
- First, we explore the fundamental challenges in interpreting legal language with AI models—challenges that continue to persist despite the sophisticated nature of these emerging causal and correlation-based methods (Section 3.2).
- Next, we examine how causal inference, specifically, addresses these challenges by offering a deeper structural understanding and a more law-aligned approach to reasoning, as opposed to correlation-based methods (Section 3.3).
- Finally, we discuss the scarcity of empirical data and contextual cues in legal domains and show how this gap hampers robust causal analysis (Section 3.4). In doing so, we provide an overview of existing dataset resources and highlight the methodological innovations tackling data limitations.
3.2. Challenges in Interpreting Legal Language with AI Models
3.2.1. Complexity and Ambiguity of Legal Language
3.2.2. Limitations of Current AI Techniques
3.2.3. Need for Domain-Specific Approaches and Causal Reasoning
3.2.4. Explainability and Interpretability
3.2.5. Ethical and Legal Implications
3.2.6. Potential Solutions and Future Directions
3.3. How Causal Inference Improves AI’s Understanding of Legal Language Compared to Correlation-Based Methods
3.3.1. Causal Inference as a Solution
3.3.2. Empirical Evidence Supporting Causal Approaches
3.3.3. Mathematical and Theoretical Foundations
- Keyword extraction: Key legal terms, denoted as , are extracted using the modified YAKE algorithm. This algorithm prioritizes terms based on their frequency, position, and contextual relevance within the text.
- Clustering: Keywords are grouped into q clusters, , using the k-means clustering algorithm. Each cluster represents a set of semantically related legal concepts.
- Causal graph construction: Clusters are treated as nodes in the graph, and edges are established using the Greedy Fast Causal Inference (GFCI) algorithm. Edges are classified into four types:
- : causally influences .
- : and share an unobserved confounding factor.
- : Ambiguous causation or shared confounding factor.
- : Reciprocal causation or ambiguity.
- Prediction integration: The causal graph informs the prediction model by integrating causal strength metrics, enabling the identification of applicable laws, charges, and sentences.
- It captures non-linear relationships commonly found in legal language.
- It provides a principled test for conditional independence.
- It scales effectively to high-dimensional feature spaces, typical in legal applications.
3.3.4. Implementation Challenges and Solutions
- Measurement challenges: Extracting relevant variables from legal text requires handling linguistic complexity, ambiguity, and diversity while maintaining accurate measurement.
- Legal expertise is required for annotation, making it costly to obtain large labeled datasets.
- Distribution shifts: Legal interpretations evolve over time, requiring models that are robust to changes in variable relationships.
- Legal applications demand transparent and interpretable models that can be validated by domain experts.
- Most disputes are resolved through negotiation rather than court decisions, necessitating the incorporation of settlement data for accurate modeling.
- Legal and negotiation texts vary considerably, making it difficult to structure data properly for machine learning algorithms.
- A judicial system that is too predictable may be problematic, especially if the status quo is unfair or if decision-making is heavily influenced by extraneous factors.
- Model construction: Building accurate causal models requires significant domain expertise and careful consideration of variables and relationships. The flexibility in model construction means different valid interpretations may exist.
- Data requirements: Causal inference often requires intervention data that may not be available in legal contexts. While do-calculus can help, some causal relationships may remain difficult to verify empirically.
- Computational complexity: Causal inference, especially counterfactual analysis, can be computationally intensive for complex legal scenarios with many interacting factors.
- Integration with existing systems: Most current legal AI systems are built around correlational approaches. Integrating causal reasoning capabilities requires significant architectural changes.
3.3.5. Innovations in Causal Relationship Extraction
- Directional ratio scoring: The score is computed as:where and represent the frequency of observed directional causal relations.
- Sentence embedding similarity: Using neural sentence embeddings, the framework calculates the average similarity between the input sentence (e.g., “ may cause ”) and top-k causal sentences from the corpus.
- Combined scoring: A hybrid approach that blends directional ratio scoring and embedding-based similarity for enhanced reliability.
- : The alignment score at position , which represents the comparison of the i-th element of one sequence (or sentence structure) with the j-th element of another.
- : The score if we continue alignment without matching the current element of the second sequence.
- : The score if the i-th and j-th elements are matched.
- : The score if a new alignment starts, skipping the current element in the first sequence.
- Q: The penalty for introducing a gap (i.e., skipping elements rather than aligning them).
- : The score for matching the i-th element of one sequence () with the j-th element of the other sequence (). Higher scores indicate stronger alignment.
- 0: The decision to start fresh, ignoring previous alignments.
- Enhanced ability to represent complex legal relationships through multiple knowledge dimensions;
- Improved handling of context and source attribution—crucial for legal reasoning;
- Better integration of values and priorities, essential for ethical legal decision-making; and
- More efficient resource allocation through strategic partitioning of knowledge.
3.3.6. Integration of Domain Knowledge and Constraints
- Models trained purely on observational data often learn spurious correlations that fail to generalize to novel legal scenarios;
- Incorporating domain knowledge through explicit constraints improves model robustness;
- The effectiveness of constraints depends critically on proper formalization of legal concepts and relationships; and
- Continuous refinement and validation of constraints is essential as legal interpretations evolve.
3.4. Addressing the Lack of Empirical Context for Causal AI in Legal Texts
3.4.1. Foundational Challenges and Data Limitations
3.4.2. Core Methodological Advances
3.4.3. Implementation Strategies and Practical Applications
3.4.4. Advanced NLP and Deep Learning Applications
3.4.5. Current Limitations and Implementation Challenges
3.4.6. Theoretical Frameworks and Integration Approaches
3.4.7. Available Dataset Resources
4. General Discussion and Synthesis
4.1. Practical Implementation Guidelines
4.2. Synthesis of Findings
4.3. Future Directions and Critical Perspective
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liddy, E.D. Natural Language Processing. In Encyclopedia of Library and Information Science, 2nd ed.; Marcel Decker, Inc.: New York, NY, USA, 2001. [Google Scholar]
- Hart, H.L.A.; Raz, J.; Bulloch, P. The Concept of Law (Clarendon Law Series), 2nd ed.; Oxford University Press: Oxford, UK, 1994. [Google Scholar]
- Sapra, R.L.; Saluja, S. Understanding statistical association and correlation. Curr. Med. Res. Pract. 2021, 11, 31–38. [Google Scholar] [CrossRef]
- Feder, A.; Keith, K.A.; Manzoor, E.; Pryzant, R.; Sridhar, D.; Wood-Doughty, Z.; Eisenstein, J.; Grimmer, J.; Reichart, R.; Roberts, M.E.; et al. Causal inference in natural language processing: Estimation, prediction, interpretation and beyond. Trans. Assoc. Comput. Linguist. 2022, 10, 1138–1158. [Google Scholar] [CrossRef]
- Rubin, D.B. Estimating causal effects of treatments in randomized and nonrandomized studies. J. Educ. Psychol. 1974, 66, 688. [Google Scholar] [CrossRef]
- Sekhon, J. 271 The Neyman— Rubin Model of Causal Inference and Estimation Via Matching Methods. In The Oxford Handbook of Political Methodology; Oxford University Press: Oxford, UK, 2008. [Google Scholar] [CrossRef]
- Pearl, J. Models, Reasoning and Inference; Cambridge University Press: Cambridge, UK, 2000; Volume 19, p. 3. [Google Scholar]
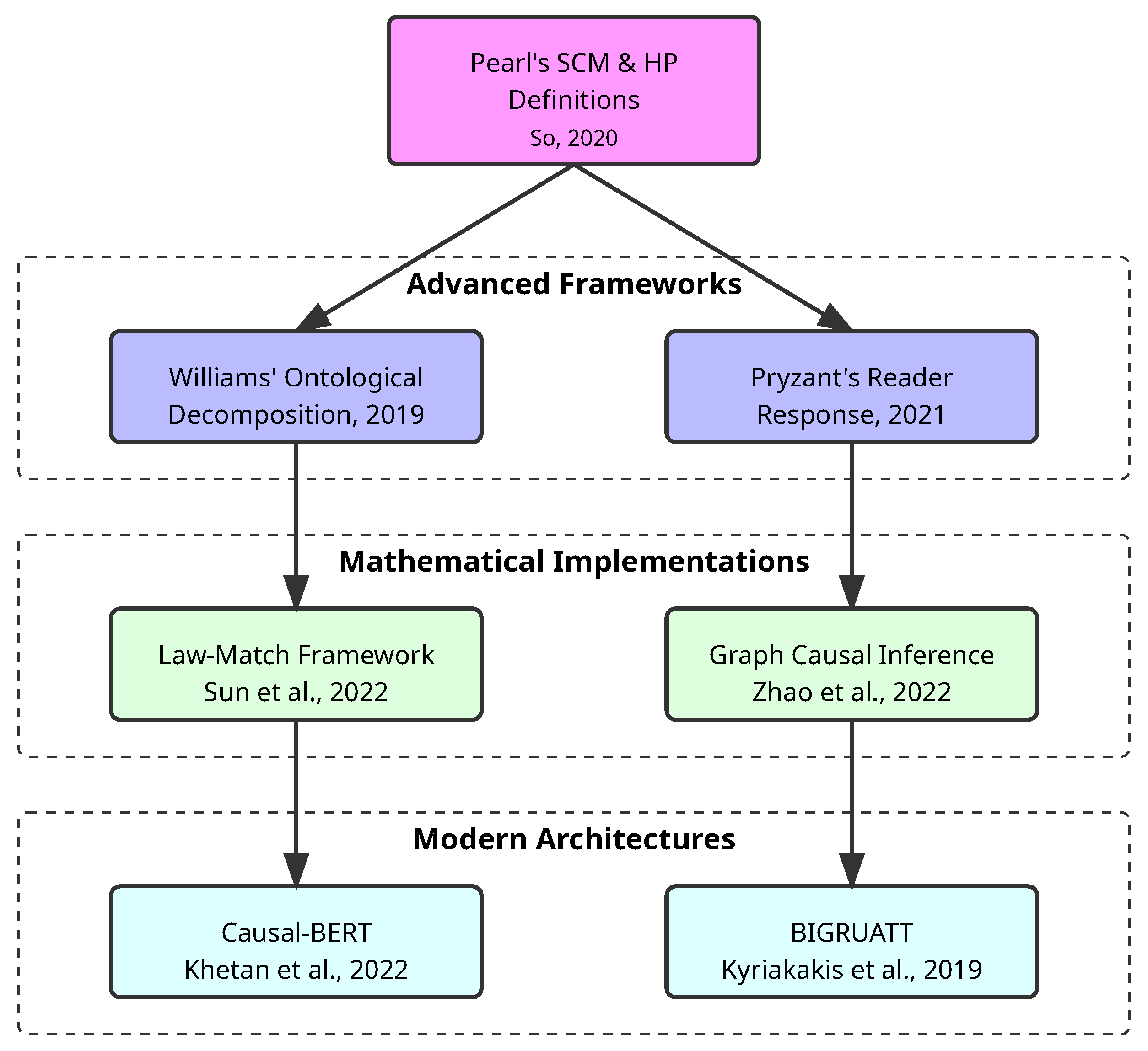
- So, F. Modelling Causality in Law = Modélisation de la Causalité en Droit. Ph.D. Thesis, University of Montreal, Montreal, QC, Canada, 2020. [Google Scholar]
- Ness, R. Causal AI; Manning Early Access Program (MEAP); Manning Publications: Boston, MA, USA, 2024. [Google Scholar]
- Kaddour, J.; Lynch, A.; Liu, Q.; Kusner, M.J.; Silva, R. Causal machine learning: A survey and open problems. arXiv 2022, arXiv:2206.15475. [Google Scholar]
- Pearl, J. Causal diagrams for empirical research. Biometrika 1995, 82, 669–688. [Google Scholar] [CrossRef]
- Powell, S. The Book of Why: The New Science of Cause and Effect. Pearl, Judea, and Dana Mackenzie. 2018. Hachette UK. J. MultiDiscip. Eval. 2018, 14, 47–54. [Google Scholar] [CrossRef]
- Harriman, D. The Logical Leap: Induction in Physics; Penguin: New York, NY, USA, 2010. [Google Scholar]
- Firth, J. Papers in Linguistics 1934–1951; Oxford University Press: London, UK, 1957. [Google Scholar]
- Marcos, H. Can large language models apply the law? AI Soc. 2024, 1–10. [Google Scholar] [CrossRef]
- Marcus, G. The Next Decade in AI: Four Steps Towards Robust Artificial Intelligence. arXiv 2020, arXiv:2002.06177. [Google Scholar]
- Liu, X.; Yin, D.; Feng, Y.; Wu, Y.; Zhao, D. Everything has a cause: Leveraging causal inference in legal text analysis. arXiv 2021, arXiv:2104.09420. [Google Scholar]
- Larson, J.; Kirchner, L.; Mattu, S.; Angwin, J. Machine Bias; CRC Press: Boca Raton, FL, USA, 2022. [Google Scholar]
- Simpson, E.H. The Interpretation of Interaction in Contingency Tables. J. R. Stat. Soc. Ser. B 1951, 13, 238–241. [Google Scholar] [CrossRef]
- Ash, E.; Morelli, M.; Vannoni, M. More Laws, More Growth? Evidence from US States; Evidence from US States (April 25, 2022); BAFFI CAREFIN Centre Research Paper; The University of Chicago Press: Chicago, IL, USA, 2022. [Google Scholar]
- Imbens, G.W.; Rubin, D.B. Causal Inference in Statistics, Social, and Biomedical Sciences; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar]
- Leins, K.; Lau, J.H.; Baldwin, T. Give me convenience and give her death: Who should decide what uses of NLP are appropriate, and on what basis? In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 2908–2913. [Google Scholar]
- Bommarito, M.J., II; Katz, D.M.; Detterman, E.M. LexNLP: Natural language processing and information extraction for legal and regulatory texts. In Research Handbook on Big Data Law; Edward Elgar Publishing: Cheltenham, UK, 2021. [Google Scholar]
- Sleimi, A.; Sannier, N.; Sabetzadeh, M.; Briand, L.; Dann, J. Automated extraction of semantic legal metadata using natural language processing. In Proceedings of the 2018 IEEE 26th International Requirements Engineering Conference (RE), Banff, AB, Canada, 20–24 August 2018; IEEE: New York, NY, USA, 2018; pp. 124–135. [Google Scholar]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. BMJ 2021, 372, n71. [Google Scholar] [PubMed]
- Peters, M.D.; Godfrey, C.M.; McInerney, P.; Soares, C.B.; Khalil, H.; Parker, D. The Joanna Briggs Institute Reviewers’ Manual 2015: Methodology for JBI Scoping Reviews; The Joanna Briggs Institute: Adelaide, Australia, 2015. [Google Scholar]
- Petticrew, M.; Roberts, H. Systematic Reviews in the Social Sciences: A Practical Guide; Blackwell Publishers: Malden, MA, USA, 2006. [Google Scholar]
- Haddaway, N.R.; Page, M.J.; Pritchard, C.C.; McGuinness, L.A. PRISMA2020: An R package and Shiny app for producing PRISMA 2020-compliant flow diagrams, with interactivity for optimised digital transparency and Open Synthesis. Campbell Syst. Rev. 2022, 18, e1230. [Google Scholar] [CrossRef] [PubMed]
- Critical Appraisal Skills Programme (CASP). CASP Systematic Review Checklist; Critical Appraisal Skills Programme: Oxford, UK, 2018. [Google Scholar]
- Braun, V.; Clarke, V. Using thematic analysis in psychology. Qual. Res. Psychol. 2006, 3, 77–101. [Google Scholar]
- Wu, L.; Wang, D.; Evans, J.A. Large teams develop and small teams disrupt science and technology. Nature 2019, 566, 378–382. [Google Scholar]
- Williams, S. Predictive Contracting. Columbia Bus. Law Rev. 2019, 2019, 621. [Google Scholar] [CrossRef]
- Kemper, C. Kafkaesque AI? Legal Decision-Making in the Era of Machine Learning. Intellect. Prop. Technol. Law J. 2019, 24, 251. [Google Scholar]
- Gastwirth, J.L. The role of statistical evidence in civil cases. Annu. Rev. Stat. Its Appl. 2020, 7, 39–60. [Google Scholar]
- Wood, J.; Matiasz, N.; Silva, A.; Hsu, W.; Abyzov, A.; Wang, W. OpBerg: Discovering causal sentences using optimal alignments. In Proceedings of the Big Data Analytics and Knowledge Discovery: 24th International Conference, DaWaK 2022, Vienna, Austria, 22–24 August 2022; Proceedings. Springer International Publishing: Berlin/Heidelberg, Germany, 2022; pp. 17–30. [Google Scholar]
- Rahali, A.; Akhloufi, M. End-to-end transformer-based models in textual-based NLP. AI 2023, 4, 54–110. [Google Scholar] [CrossRef]
- Sun, Z.; Xu, J.; Zhang, X.; Dong, Z.; Wen, J.R. Law Article-Enhanced Legal Case Matching: A Model-Agnostic Causal Learning Approach. arXiv 2022, arXiv:2210.11012. [Google Scholar]
- Zhao, Q.; Guo, R.; Feng, X.; Hu, W.; Zhao, S.; Wang, Z.; Cao, Y. Research on a Decision Prediction Method Based on Causal Inference and a Multi-Expert FTOPJUDGE Mechanism. Mathematics 2022, 10, 2281. [Google Scholar] [CrossRef]
- Kenton, J.D.M.W.C.; Toutanova, L.K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the naacL-HLT, Minneapolis, MN, USA, 2–7 June 2019; Volume 1. [Google Scholar]
- Liu, Y. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Xiao, C.; Hu, X.; Liu, Z.; Tu, C.; Sun, M. Lawformer: A pre-trained language model for chinese legal long documents. AI Open 2021, 2, 79–84. [Google Scholar] [CrossRef]
- Dymitruk, M.; Markovich, R.; Liepiña, R.; El Ghosh, M.; van Doesburg, R.; Governatori, G.; Verheij, B. Research in progress: Report on the ICAIL 2017 doctoral consortium. Artif. Intell. Law 2018, 26, 69–76. [Google Scholar] [CrossRef]
- Ritov, Y.A.; Sun, Y.; Zhao, R. On conditional parity as a notion of non-discrimination in machine learning. arXiv 2017, arXiv:1706.08519. [Google Scholar]
- Keith, K.A. Social Measurement and Causal Inference with Text. Ph.D. Thesis, University of Massachusetts Amherst, Amherst, MA, USA, 2021. [Google Scholar]
- Cheng, L. Algorithmic Solutions for Socially Responsible AI. Ph.D. Thesis, Arizona State University, Tempe, AZ, USA, 2022. [Google Scholar]
- Xiao, C.; Liu, Z.; Lin, Y.; Sun, M. Legal knowledge representation learning. In Representation Learning for Natural Language Processing; Springer Nature: Singapore, 2023; pp. 401–432. [Google Scholar]
- Chen, W.; Tian, J.; Xiao, L.; He, H.; Jin, Y. Exploring logically dependent multi-task learning with causal inference. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Bangkok, Thailand, 16–20 November 2020; pp. 2213–2225. [Google Scholar]
- Zhang, Y.; Zhang, M.; Chen, H.; Chen, X.; Chen, X.; Gan, C.; Dong, X.L. The 1st International Workshop on Machine Reasoning: International Machine Reasoning Conference (MRC 2021). In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, Hong Kong, China, 8–12 March 2021; pp. 1161–1162. [Google Scholar]
- Wu, Y.; Kuang, K.; Zhang, Y.; Liu, X.; Sun, C.; Xiao, J.; Zhuang, Y.; Si, L.; Wu, F. De-biased court’s view generation with causality. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Bangkok, Thailand, 16–20 November 2020; pp. 763–780. [Google Scholar]
- Santosh, T.Y.S.; Xu, S.; Ichim, O.; Grabmair, M. Deconfounding Legal Judgment Prediction for European Court of Human Rights Cases Towards Better Alignment with Experts. arXiv 2022, arXiv:2210.13836. [Google Scholar]
- Henderson, P.; Chugg, B.; Anderson, B.; Ho, D.E. Beyond Ads: Sequential Decision-Making Algorithms in Law and Public Policy. In Proceedings of the 2022 Symposium on Computer Science and Law, Berkeley, CA, USA, 3–4 November 2022; pp. 87–100. [Google Scholar]
- Hassanzadeh, O.; Bhattacharjya, D.; Feblowitz, M.; Srinivas, K.; Perrone, M.; Sohrabi, S.; Katz, M. Causal knowledge extraction through large-scale text mining. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13610–13611. [Google Scholar]
- Cohen, M.C.; Dahan, S.; Rule, C. Conflict Analytics: When Data Science Meets Dispute Resolution. Manag. Bus. Rev. 2022, 2, 86–92. [Google Scholar] [CrossRef]
- Mamakas, D.; Tsotsi, P.; Androutsopoulos, I.; Chalkidis, I. Processing Long Legal Documents with Pre-trained Transformers: Modding LegalBERT and Longformer. arXiv 2022, arXiv:2211.00974. [Google Scholar]
- Cemri, M.; Çukur, T.; Koç, A. Unsupervised Simplification of Legal Texts. arXiv 2022, arXiv:2209.00557. [Google Scholar]
- Hassani, H.; Huang, X.; Ghodsi, M. Big data and causality. Ann. Data Sci. 2018, 5, 133–156. [Google Scholar] [CrossRef]
- Barale, C. Human-centered computing in legal NLP-An application to refugee status determination. In Proceedings of the Second Workshop on Bridging Human–Computer Interaction and Natural Language Processing, Dublin, Ireland, 11 July 2022; pp. 28–33. [Google Scholar]
- Lam, J.; Chen, Y.; Zulkernine, F.; Dahan, S. Detection of Similar Legal Cases on Personal Injury. In Proceedings of the 2021 International Conference on Data Mining Workshops (ICDMW), Virtual, 6–9 December 2021; IEEE: New York, NY, USA, 2021; pp. 639–646. [Google Scholar]
- Mik, E. Caveat Lector: Large Language Models in Legal Practice. Rutgers Bus. Law Rev. 2023, 19, 70. [Google Scholar]
- Meneceur, Y.; Barbaro, C. Artificial intelligence and the judicial memory: The great misunderstanding. Cah. Justice 2019, 2, 277–289. [Google Scholar]
- Szilagyi, K. Artificial Intelligence & the Machine-Ation of the Rule of Law. Ph.D. Thesis, Université d’Ottawa/University of Ottawa, Ottawa, ON, Canada, 2022. [Google Scholar]
- Chalkidis, I.; Pasini, T.; Zhang, S.; Tomada, L.; Schwemer, S.F.; Søgaard, A. Fairlex: A multilingual benchmark for evaluating fairness in legal text processing. arXiv 2022, arXiv:2203.07228. [Google Scholar]
- Papaloukas, C.; Chalkidis, I.; Athinaios, K.; Pantazi, D.A.; Koubarakis, M. Multi-granular legal topic classification on greek legislation. arXiv 2021, arXiv:2109.15298. [Google Scholar]
- Cui, J.; Shen, X.; Nie, F.; Wang, Z.; Wang, J.; Chen, Y. A Survey on Legal Judgment Prediction: Datasets, Metrics, Models and Challenges. arXiv 2022, arXiv:2204.04859. [Google Scholar]
- Kirat, T.; Tambou, O.; Do, V.; Tsoukiàs, A. Fairness and Explainability in Automatic Decision-Making Systems. A challenge for computer science and law. arXiv 2022, arXiv:2206.03226. [Google Scholar] [CrossRef]
- Rubicondo, D.; Rosato, L. AI Fairness Addressing Ethical and Reliability Concerns in AI Adoption; Iason Consulting Ltd.: Milan, Italy, 2022. [Google Scholar]
- Balashankar, A. Enhancing Robustness Through Domain Faithful Machine Learning. Ph.D. Thesis, New York University, New York, NY, USA, 2022. [Google Scholar]
- Khetan, V.; Ramnani, R.; Anand, M.; Sengupta, S.; Fano, A.E. Causal bert: Language models for causality detection between events expressed in text. In Intelligent Computing: Proceedings of the 2021 Computing Conference; Springer International Publishing: Berlin/Heidelberg, Germany, 2022; Volume 1, pp. 965–980. [Google Scholar]
- Yao, F.; Xiao, C.; Wang, X.; Liu, Z.; Hou, L.; Tu, C.; Li, J.; Liu, Y.; Shen, W.; Sun, M. LEVEN: A large-scale Chinese legal event detection dataset. arXiv 2022, arXiv:2203.08556. [Google Scholar]
- Pryzant, R. Natural Language Processing for Computing the Influence of Language on Perception and Behavior. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2021. [Google Scholar]
- Ichim, O.; Grabmair, M. Zero Shot Transfer of Legal Judgement Prediction as Article-aware Entailment for the European Court of Human Rights. arXiv 2023, arXiv:2302.00609. [Google Scholar]
- Wang, S.; Liu, Z.; Zhong, W.; Zhou, M.; Wei, Z.; Chen, Z.; Duan, N. From lsat: The progress and challenges of complex reasoning. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 2201–2216. [Google Scholar]
- Kyriakakis, M.; Androutsopoulos, I.; Saudabayev, A. Transfer learning for causal sentence detection. arXiv 2019, arXiv:1906.07544. [Google Scholar]
- Mathur, P.; Morariu, V.I.; Garimella, A.; Dernoncourt, F.; Gu, J.; Sawhney, R.; Nakov, P.; Manocha, D.; Jain, R. DocScript: Document-level Script Event Prediction. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), Turin, Italy, 20–25 May 2024; pp. 5140–5155. [Google Scholar]
- Teney, D.; Abbasnedjad, E.; van den Hengel, A. Learning what makes a difference from counterfactual examples and gradient supervision. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part X 16. Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 580–599. [Google Scholar]
- Hundogan, O. CREATED: The Generation of viable Counterfactual Sequences using an Evolutionary Algorithm for Event Data of Complex Processes. Master’s Thesis, Utrecht University, Utrecht, The Netherlands, 2022. [Google Scholar]
- Arsenyan, V.; Shahnazaryan, D. Large Language Models for Biomedical Causal Graph Construction. arXiv 2023, arXiv:2301.12473. [Google Scholar]
- Singer, G.; Bach, J.; Grinberg, T.; Hakim, N.; Howard, P.R.; Lal, V.; Rivlin, Z. Thrill-K Architecture: Towards a Solution to the Problem of Knowledge Based Understanding. In Proceedings of the Artificial General Intelligence: 15th International Conference, AGI 2022, Seattle, WA, USA, 19–22 August 2022; Proceedings. Springer International Publishing: Berlin/Heidelberg, Germany, 2023; pp. 404–412. [Google Scholar]
- Mathis, B. Extracting proceedings information and legal references from court decisions with machine-learning. SSRN Electron. J. 2021. [Google Scholar] [CrossRef]
- Niklaus, J.; Matoshi, V.; Rani, P.; Galassi, A.; Stürmer, M.; Chalkidis, I. Lextreme: A multi-lingual and multi-task benchmark for the legal domain. arXiv 2023, arXiv:2301.13126. [Google Scholar]
- Guha, N.; Nyarko, J.; Ho, D.; Ré, C.; Chilton, A.; Chohlas-Wood, A.; Peters, A.; Waldon, B.; Rockmore, D.; Zambrano, D.; et al. Legalbench: A collaboratively built benchmark for measuring legal reasoning in large language models. Adv. Neural Inf. Process. Syst. 2024, 36, 44123–44279. [Google Scholar] [CrossRef]
- Nicholas, N. The black swan: The impact of the highly improbable. J. Manag. Train. Inst. 2008, 36, 56. [Google Scholar]



| Challenge Category | Key Challenges | Sources |
|---|---|---|
| Technical & Computational | Long-range dependency handling, Document-level temporal reasoning, Bidirectional context processing limitations, Computational complexity in counterfactuals, Integration with correlational systems, Implicit causal relationship handling, Cross-domain performance consistency | Mathur et al. [74]; Rahali and Akhloufi [36]; So [8]; Khetan et al. [68] |
| Data-Related | Limited labeled data availability, Small annotation budgets, Settlement data integration, Intervention data scarcity | Keith [44]; Cohen et al. [53] |
| Implementation | Batched/delayed feedback handling, Distribution shift adaptation, Model interpretability, Unstructured data complexity | Henderson et al. [51]; Cohen et al. [53] |
| Legal Domain-Specific | Context-dependent meaning, Multiple objective optimization, Predictability-flexibility balance, Legal expertise requirements | So [8]; Henderson et al. [51] |
| Method | Key Strengths | Limitations | Best Use Case |
|---|---|---|---|
| Causal-BERT [68] | Handles explicit/implicit causality; Strong contextual understanding; Minimal feature engineering | High computational requirements; Large training data needed; Complex model architecture | Complex legal texts with subtle causal relationships |
| Evolutionary Algorithms [76] | Sophisticated counterfactual generation; Preserves structural relationships; Outperforms baseline methods | Computationally intensive; Requires significant training data; Complex parameter tuning | Generating counterfactual scenarios in legal reasoning |
| Two-Side Scoring [77] | Clear directional causality assessment; Probabilistic framework; Simple implementation | May oversimplify relationships; Requires domain-specific training; Limited to binary relationships | Determining causal direction in legal arguments |
| OpBerg [35] | Works with limited training data; Efficient POS-based matching; complexity | Limited to pattern-based causality; May miss complex relationships; Requires POS accuracy | Quick causal analysis with limited training data |
| Thrill-K [78] | Structured knowledge organization; Multiple knowledge tiers; Strong domain integration | Complex architecture; Resource intensive; Requires knowledge engineering | Complex legal reasoning with multiple knowledge sources |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Prince Tritto, P.; Ponce, H. Causal Artificial Intelligence in Legal Language Processing: A Systematic Review. Entropy 2025, 27, 351. https://doi.org/10.3390/e27040351
Prince Tritto P, Ponce H. Causal Artificial Intelligence in Legal Language Processing: A Systematic Review. Entropy. 2025; 27(4):351. https://doi.org/10.3390/e27040351
Chicago/Turabian StylePrince Tritto, Philippe, and Hiram Ponce. 2025. "Causal Artificial Intelligence in Legal Language Processing: A Systematic Review" Entropy 27, no. 4: 351. https://doi.org/10.3390/e27040351
APA StylePrince Tritto, P., & Ponce, H. (2025). Causal Artificial Intelligence in Legal Language Processing: A Systematic Review. Entropy, 27(4), 351. https://doi.org/10.3390/e27040351