
MambaOSR: Leveraging Spatial-Frequency Mamba for Distortion-Guided Omnidirectional Image Super-Resolution


Abstract
1. Introduction
- (1)
- We introduce state space models into ODISR and propose an efficient network named MambaOSR. By leveraging the strong global modeling capabilities of the Mamba architecture, our method effectively captures long-range dependencies, significantly improving reconstruction quality. Extensive experiments validate the superior performance of MambaOSR compared to existing methods.
- (2)
- To further enhance global context modeling, we propose an SF-VSSM. Specifically, the SF-VSSM integrates an FAM with the VSSM to adaptively exploit frequency-domain information beneficial to the ODISR task. This integration enhances the model’s ability to capture global structural features and improves the reconstruction accuracy.
- (3)
- To address the degradation of image quality caused by geometric distortions inherent in omnidirectional imaging, we introduce a DGM. The DGM leverages distortion map priors to adaptively fuse the information of geometric deformation, effectively suppressing distortion artifacts. Additionally, we design an MFFM to integrate features across multiple scales, further strengthening the model’s representation capability and enhancing reconstruction performance.
2. Related Works
2.1. Single-Image Super-Resolution
2.1.1. CNN-Based SISR Methods
2.1.2. GAN-Based SISR Methods
2.1.3. Transformer-Based SISR Methods
2.1.4. Diffusion-Based SISR Methods
2.2. Omnidirectional Image Super-Resolution (ODISR)
2.3. State Space Model (SSM)
2.4. Fourier Transform
3. Methodology
3.1. Overview of MambaOSR
3.2. Equirectangular Projection
3.3. Spatial-Frequency Visual State Space Model (SF-VSSM)
- (a)
- The Real FFT2d converts the feature tensor into the complex frequency domainand concatenates its real and imaginary parts
- (b)
- Then, a convolutional block with activation and normalization processes the frequency spectrum information
- (c)
- The processed result is inversely transformed to restore spatial structure
3.4. Distortion-Guided Module (DGM)
3.5. Multi-Scale Feature Fusion Module (MFFM)
3.6. Loss Function
4. Experiments
4.1. Experimental Configuration
4.2. Evaluation Under ERP Downsampling
4.3. Model Efficiency
4.4. Ablation Study
4.4.1. Effect of FAM
4.4.2. Effect of DGM
4.4.3. Effect of MFFM
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Deng, X.; Wang, H.; Xu, M.; Guo, Y.; Song, Y.; Yang, L. Lau-net: Latitude adaptive upscaling network for omnidirectional image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9189–9198. [Google Scholar]
- Yu, F.; Wang, X.; Cao, M.; Li, G.; Shan, Y.; Dong, C. Osrt: Omnidirectional image super-resolution with distortion-aware transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 13283–13292. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar]
- Guo, H.; Li, J.; Dai, T.; Ouyang, Z.; Ren, X.; Xia, S.T. Mambair: A simple baseline for image restoration with state-space model. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 222–241. [Google Scholar]
- Guo, H.; Guo, Y.; Zha, Y.; Zhang, Y.; Li, W.; Dai, T.; Xia, S.T.; Li, Y. MambaIRv2: Attentive State Space Restoration. arXiv 2024, arXiv:2411.15269. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef]
- Niu, B.; Wen, W.; Ren, W.; Zhang, X.; Yang, L.; Wang, S.; Zhang, K.; Cao, X.; Shen, H. Single image super-resolution via a holistic attention network. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 191–207. [Google Scholar]
- Zang, H.; Zhao, Y.; Niu, C.; Zhang, H.; Zhan, S. Attention network with information distillation for super-resolution. Entropy 2022, 24, 1226. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Chen, H.; Wang, Y.; Guo, T.; Xu, C.; Deng, Y.; Liu, Z.; Ma, S.; Xu, C.; Xu, C.; Gao, W. Pre-trained image processing transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12299–12310. [Google Scholar]
- Chen, X.; Wang, X.; Zhou, J.; Qiao, Y.; Dong, C. Activating more pixels in image super-resolution transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 22367–22377. [Google Scholar]
- Saharia, C.; Ho, J.; Chan, W.; Salimans, T.; Fleet, D.J.; Norouzi, M. Image super-resolution via iterative refinement. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 4713–4726. [Google Scholar] [CrossRef]
- Li, H.; Yang, Y.; Chang, M.; Chen, S.; Feng, H.; Xu, Z.; Li, Q.; Chen, Y. Srdiff: Single image super-resolution with diffusion probabilistic models. Neurocomputing 2022, 479, 47–59. [Google Scholar] [CrossRef]
- Yue, Z.; Wang, J.; Loy, C.C. Resshift: Efficient diffusion model for image super-resolution by residual shifting. Adv. Neural Inf. Process. Syst. 2023, 36, 13294–13307. [Google Scholar]
- Ozcinar, C.; Rana, A.; Smolic, A. Super-resolution of omnidirectional images using adversarial learning. In Proceedings of the 2019 IEEE 21st International Workshop on Multimedia Signal Processing (MMSP), Kuala Lumpur, Malaysia, 27–29 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Nishiyama, A.; Ikehata, S.; Aizawa, K. 360 single image super resolution via distortion-aware network and distorted perspective images. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1829–1833. [Google Scholar]
- Deng, X.; Wang, H.; Xu, M.; Li, L.; Wang, Z. Omnidirectional image super-resolution via latitude adaptive network. IEEE Trans. Multimed. 2022, 25, 4108–4120. [Google Scholar] [CrossRef]
- Yoon, Y.; Chung, I.; Wang, L.; Yoon, K.J. Spheresr: 360deg image super-resolution with arbitrary projection via continuous spherical image representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5677–5686. [Google Scholar]
- Sun, X.; Li, W.; Zhang, Z.; Ma, Q.; Sheng, X.; Cheng, M.; Ma, H.; Zhao, S.; Zhang, J.; Li, J.; et al. OPDN: Omnidirectional position-aware deformable network for omnidirectional image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 1293–1301. [Google Scholar]
- Wang, J.; Cui, Y.; Li, Y.; Ren, W.; Cao, X. Omnidirectional Image Super-resolution via Bi-projection Fusion. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 5454–5462. [Google Scholar]
- Cai, Q.; Li, M.; Ren, D.; Lyu, J.; Zheng, H.; Dong, J.; Yang, Y.H. Spherical pseudo-cylindrical representation for omnidirectional image super-resolution. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 873–881. [Google Scholar]
- Li, R.; Sheng, X.; Li, W.; Zhang, J. OmniSSR: Zero-shot Omnidirectional Image Super-Resolution using Stable Diffusion Model. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2025; pp. 198–216. [Google Scholar]
- Yang, C.; Dong, R.; Lam, K.M. Efficient Adaptation for Real-World Omnidirectional Image Super-Resolution. In Proceedings of the 2024 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Macau, China, 3–6 December 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–6. [Google Scholar]
- Yang, C.; Dong, R.; Xiao, J.; Zhang, C.; Lam, K.M.; Zhou, F.; Qiu, G. Geometric distortion guided transformer for omnidirectional image super-resolution. IEEE Trans. Circuits Syst. Video Technol. 2025. [Google Scholar] [CrossRef]
- Gu, A.; Goel, K.; Ré, C. Efficiently modeling long sequences with structured state spaces. arXiv 2021, arXiv:2111.00396. [Google Scholar]
- Shi, Y.; Xia, B.; Jin, X.; Wang, X.; Zhao, T.; Xia, X.; Xiao, X.; Yang, W. Vmambair: Visual state space model for image restoration. IEEE Trans. Circuits Syst. Video Technol. 2025. [Google Scholar] [CrossRef]
- Liu, Y.; Tian, Y.; Zhao, Y.; Yu, H.; Xie, L.; Wang, Y.; Ye, Q.; Jiao, J.; Liu, Y. Vmamba: Visual state space model. Adv. Neural Inf. Process. Syst. 2025, 37, 103031–103063. [Google Scholar]
- Dong, W.; Zhu, H.; Lin, S.; Luo, X.; Shen, Y.; Liu, X.; Zhang, J.; Guo, G.; Zhang, B. Fusion-mamba for cross-modality object detection. arXiv 2024, arXiv:2404.09146. [Google Scholar]
- Xu, Q.; Zhang, R.; Zhang, Y.; Wang, Y.; Tian, Q. A fourier-based framework for domain generalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14383–14392. [Google Scholar]
- Yang, Y.; Soatto, S. Fda: Fourier domain adaptation for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4085–4095. [Google Scholar]
- Li, C.; Guo, C.L.; Zhou, M.; Liang, Z.; Zhou, S.; Feng, R.; Loy, C.C. Embedding fourier for ultra-high-definition low-light image enhancement. arXiv 2023, arXiv:2302.11831. [Google Scholar]
- Lee, J.H.; Heo, M.; Kim, K.R.; Kim, C.S. Single-image depth estimation based on fourier domain analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 330–339. [Google Scholar]
- Huang, J.; Liu, Y.; Zhao, F.; Yan, K.; Zhang, J.; Huang, Y.; Zhou, M.; Xiong, Z. Deep fourier-based exposure correction network with spatial-frequency interaction. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 163–180. [Google Scholar]
- Mao, X.; Liu, Y.; Liu, F.; Li, Q.; Shen, W.; Wang, Y. Intriguing findings of frequency selection for image deblurring. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 1905–1913. [Google Scholar]
- Chi, L.; Jiang, B.; Mu, Y. Fast fourier convolution. Adv. Neural Inf. Process. Syst. 2020, 33, 4479–4488. [Google Scholar]
- Suvorov, R.; Logacheva, E.; Mashikhin, A.; Remizova, A.; Ashukha, A.; Silvestrov, A.; Kong, N.; Goka, H.; Park, K.; Lempitsky, V. Resolution-robust large mask inpainting with fourier convolutions. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 2149–2159. [Google Scholar]
- Zhou, M.; Huang, J.; Yan, K.; Hong, D.; Jia, X.; Chanussot, J.; Li, C. A general spatial-frequency learning framework for multimodal image fusion. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 1–18. [Google Scholar] [CrossRef]
- Xiao, Y.; Yuan, Q.; Jiang, K.; Chen, Y.; Zhang, Q.; Lin, C.W. Frequency-assisted mamba for remote sensing image super-resolution. IEEE Trans. Multimed. 2024, 27, 1783–1796. [Google Scholar] [CrossRef]
- Wang, J.; Lu, Y.; Wang, S.; Wang, B.; Wang, X.; Long, T. Two-stage spatial-frequency joint learning for large-factor remote sensing image super-resolution. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–13. [Google Scholar] [CrossRef]
- An, H.; Zhang, X.; Zhao, S.; Zhang, L. FATO: Frequency Attention Transformer for Omnidirectional Image Super-Resolution. In Proceedings of the 6th ACM International Conference on Multimedia in Asia, Auckland, New Zealand, 3–6 December 2024; pp. 1–7. [Google Scholar]
- Sun, Y.; Lu, A.; Yu, L. Weighted-to-spherically-uniform quality evaluation for omnidirectional video. IEEE Signal Process. Lett. 2017, 24, 1408–1412. [Google Scholar] [CrossRef]
- Xiao, J.; Ehinger, K.A.; Oliva, A.; Torralba, A. Recognizing scene viewpoint using panoramic place representation. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 2695–2702. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Yu, M.; Ma, H.; Shao, H.; Jiang, G. Weighted-to-spherically-uniform SSIM objective quality evaluation for panoramic video. In Proceedings of the 2018 14th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 12–16 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 54–57. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–22 June 2018; pp. 586–595. [Google Scholar]
- Latham, P.E.; Roudi, Y. Mutual information. Scholarpedia 2009, 4, 1658. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part IV 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 184–199. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Ahn, N.; Kang, B.; Sohn, K.A. Fast, accurate, and lightweight super-resolution with cascading residual network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 252–268. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. Memnet: A persistent memory network for image restoration. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4539–4547. [Google Scholar]
- Li, J.; Fang, F.; Mei, K.; Zhang, G. Multi-scale residual network for image super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 517–532. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Guo, Y.; Chen, J.; Wang, J.; Chen, Q.; Cao, J.; Deng, Z.; Xu, Y.; Tan, M. Closed-loop matters: Dual regression networks for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5407–5416. [Google Scholar]
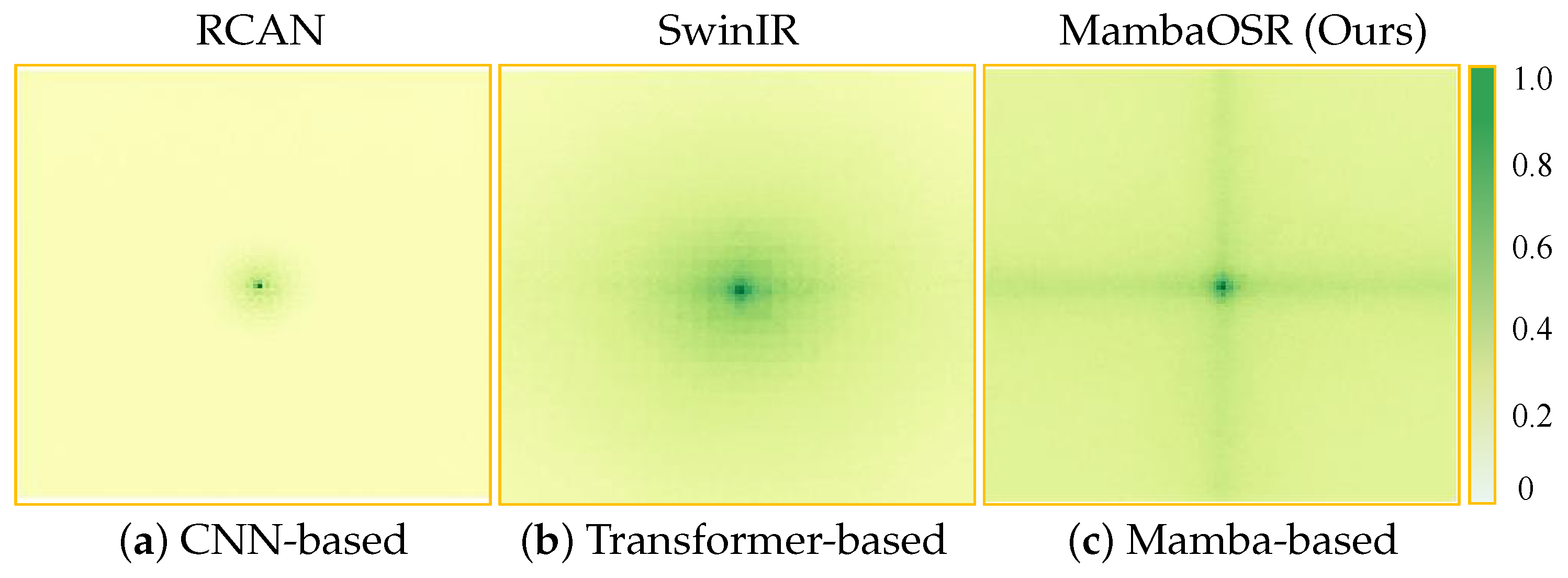






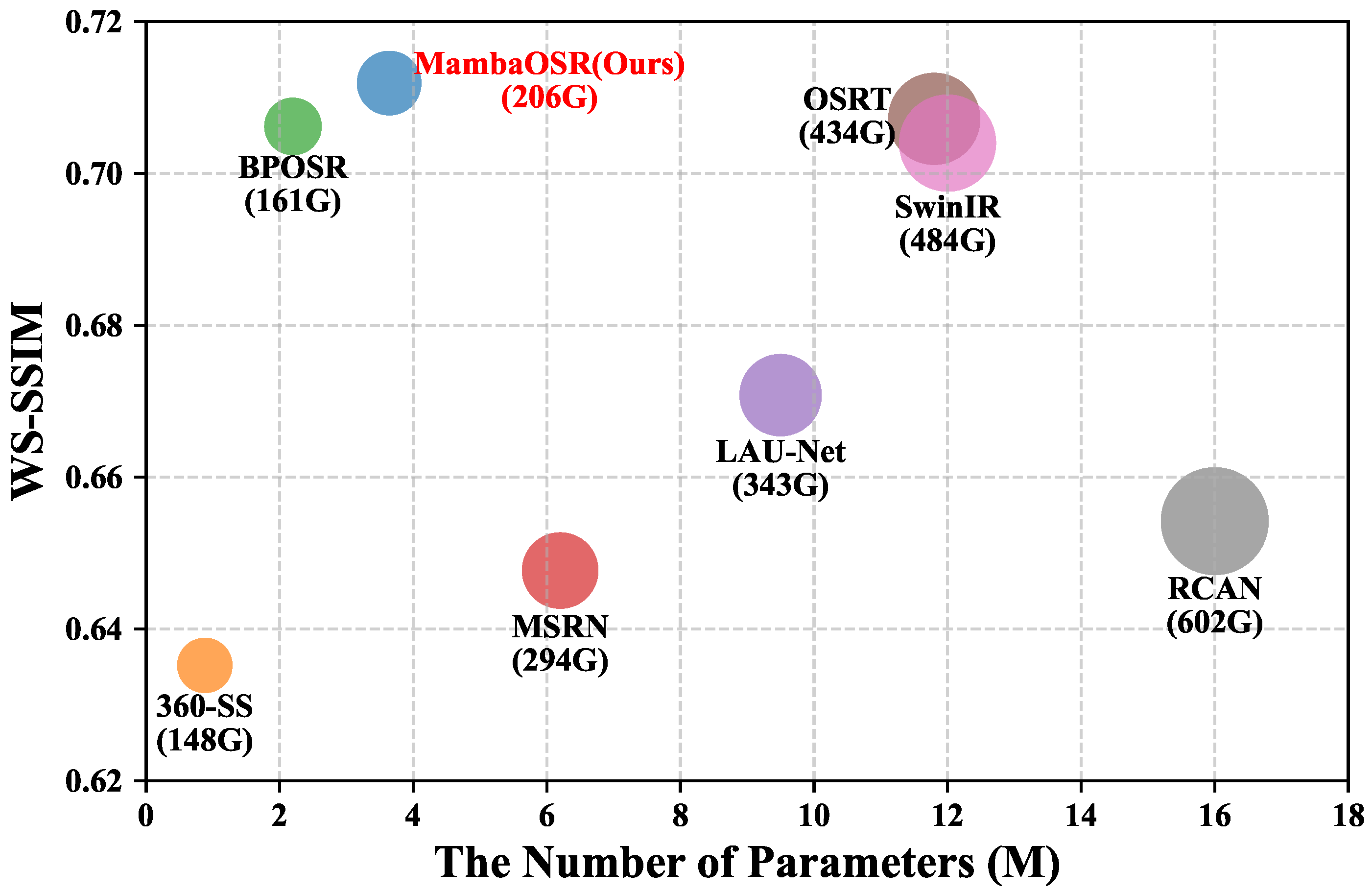
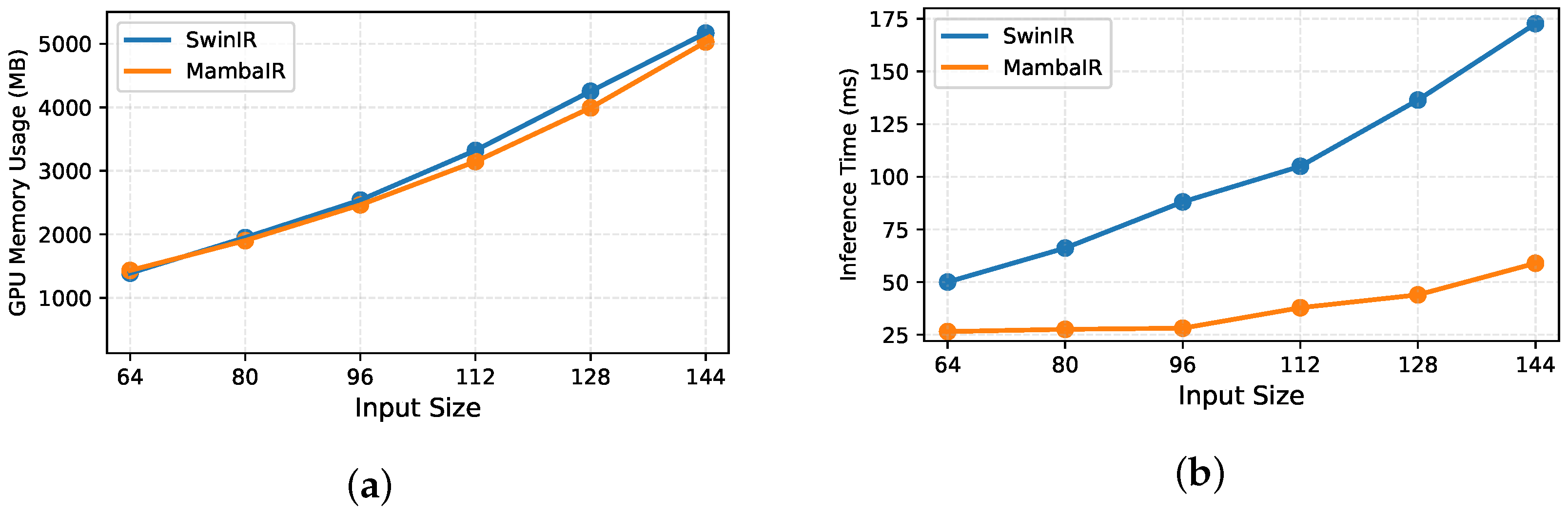


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| SFMG | Spatial-frequency Mamba group |
| SFMB | Spatial-frequency Mamba block |
| SF-VSSM | Spatial-frequency visual state space model |
| FAM | Frequency-aware module |
| DGM | Distortion-guided module |
| MFFM | Multi-scale feature fusion module |
| Longitude and latitude | |
| Cartesian coordinates | |
| Coordinate transformation (sphere to 2D) | |
| Pixel stretching ratio at height h | |
| Height, width, and channel dimensions | |
| Learnable scaling factors | |
| Input and output features of the MFFM | |
| Channel-wise statistics | |
| Learnable weight matrices | |
| Feature height and width | |
| Branch weights in the MFFM | |
| Branch operation and total branches | |
| ReLU activation function |
| Dataset | ODI-SR | SUN360 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Scale | |||||||||||||
| Method | WS- | WS- | WS- | WS- | WS- | WS- | WS- | WS- | WS- | WS- | WS- | WS- | |
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | ||
| SISR | Bicubic | 24.62 | 0.6555 | 19.64 | 0.5908 | 17.12 | 0.4332 | 24.61 | 0.6459 | 19.72 | 0.5403 | 17.56 | 0.4638 |
| SRCNN | 25.02 | 0.6904 | 20.08 | 0.6112 | 18.08 | 0.4501 | 26.30 | 0.7012 | 19.46 | 0.5701 | 17.95 | 0.4684 | |
| VDSR | 25.92 | 0.7009 | 21.19 | 0.6334 | 19.22 | 0.5903 | 26.36 | 0.7057 | 21.60 | 0.6091 | 18.91 | 0.5935 | |
| LapSRN | 25.87 | 0.6945 | 20.72 | 0.6214 | 18.45 | 0.5161 | 26.31 | 0.7000 | 20.05 | 0.5998 | 18.46 | 0.5068 | |
| MemNet | 25.39 | 0.6967 | 21.73 | 0.6284 | 20.03 | 0.6015 | 25.69 | 0.6999 | 21.08 | 0.6015 | 19.88 | 0.5759 | |
| MSRN | 25.51 | 0.7003 | 23.34 | 0.6496 | 21.73 | 0.6115 | 25.91 | 0.7051 | 23.19 | 0.6477 | 21.18 | 0.5996 | |
| EDSR | 25.69 | 0.6954 | 23.97 | 0.6483 | 22.24 | 0.6090 | 26.18 | 0.7012 | 23.79 | 0.6472 | 21.83 | 0.5974 | |
| D-DBPN | 25.50 | 0.6932 | 24.15 | 0.6573 | 22.43 | 0.6059 | 25.92 | 0.6987 | 23.70 | 0.6421 | 21.98 | 0.5958 | |
| RCAN | 26.23 | 0.6995 | 24.26 | 0.6554 | 22.49 | 0.6176 | 26.61 | 0.7065 | 23.88 | 0.6542 | 21.86 | 0.5938 | |
| DRN | 26.24 | 0.6996 | 24.32 | 0.6571 | 22.52 | 0.6212 | 26.65 | 0.7079 | 24.25 | 0.6602 | 22.11 | 0.6092 | |
| HAT | 26.52 | 0.7494 | 24.42 | 0.6759 | 22.61 | 0.6284 | 26.93 | 0.7854 | 24.26 | 0.7063 | 22.02 | 0.6395 | |
| MambaIR | 26.91 | 0.7595 | 24.46 | 0.6737 | 22.59 | 0.6263 | 27.58 | 0.7997 | 24.32 | 0.6998 | 22.06 | 0.6404 | |
| ODISR | 360-SS | 25.98 | 0.6973 | 21.65 | 0.6417 | 19.65 | 0.5431 | 26.38 | 0.7015 | 21.48 | 0.6352 | 19.62 | 0.5308 |
| LAU-Net | 26.34 | 0.7052 | 24.36 | 0.6602 | 22.52 | 0.6284 | 26.48 | 0.7062 | 24.24 | 0.6708 | 22.05 | 0.6058 | |
| SphereSR | – | – | 24.37 | 0.6777 | 22.51 | 0.6370 | – | – | 24.17 | 0.6820 | 21.95 | 0.6342 | |
| OSRT | 26.89 | 0.7581 | 24.53 | 0.6780 | 22.69 | 0.6261 | 27.47 | 0.7985 | 24.38 | 0.7072 | 22.13 | 0.6388 | |
| BPOSR | 26.95 | 0.7598 | 24.62 | 0.6770 | 22.72 | 0.6285 | 27.59 | 0.7997 | 24.47 | 0.7062 | 22.16 | 0.6433 | |
| FATO | 26.78 | 0.7589 | 24.54 | 0.6784 | 22.73 | 0.6314 | 27.59 | 0.8035 | 24.42 | 0.7120 | 22.18 | 0.6449 | |
| MambaOSR | 27.01 | 0.7616 | 24.62 | 0.6792 | 22.66 | 0.6293 | 27.75 | 0.8042 | 24.49 | 0.7119 | 22.12 | 0.6452 | |
| Method | Scale | ODISR | SUN360 | ||||
|---|---|---|---|---|---|---|---|
| PSNR↑ | SSIM↑ | LPIPS↓ | PSNR↑ | SSIM↑ | LPIPS↓ | ||
| 360-SS [19] | 25.545 | 0.7251 | 0.3871 | 25.483 | 0.7123 | 0.4113 | |
| BPOSR [24] | 27.774 | 0.7812 | 0.3064 | 28.289 | 0.7966 | 0.2754 | |
| Ours | 27.875 | 0.7839 | 0.2969 | 28.512 | 0.8021 | 0.2561 | |
| LAU-Net [1] | 25.136 | 0.6953 | 0.4990 | 24.957 | 0.6967 | 0.4949 | |
| 360-SS [19] | 22.762 | 0.6564 | 0.5541 | 22.452 | 0.6366 | 0.6061 | |
| BPOSR [24] | 25.453 | 0.7078 | 0.4631 | 25.339 | 0.7133 | 0.4596 | |
| Ours | 25.450 | 0.7097 | 0.4442 | 25.359 | 0.7183 | 0.4245 | |
| Method | MI↑ | |||
|---|---|---|---|---|
| MambaOSR | BPOSR [24] | LAU-Net [1] | 360-SS [19] | |
| ODI-SR | 2.6419 | 2.6019 | 2.4884 | 2.0607 |
| SUN360 | 2.5568 | 2.5068 | 2.3952 | 1.8534 |
| Model | FAM | DGM | MFFM | ODI-SR | SUN360 | Params. | ||
|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | (M) | ||||
| Baseline | × | × | × | 23.95 | 0.6650 | 23.82 | 0.6792 | 2.57 |
| Model-1 | × | ✓ | ✓ | 24.33 | 0.6639 | 24.15 | 0.6859 | 2.59 |
| Model-2 | ✓ | × | ✓ | 24.17 | 0.6508 | 23.99 | 0.6766 | 2.62 |
| Model-3 | ✓ | ✓ | × | 24.39 | 0.6637 | 24.19 | 0.6860 | 2.60 |
| MambaOSR | ✓ | ✓ | ✓ | 24.53 | 0.6747 | 24.38 | 0.7023 | 2.60 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wen, W.; Zhao, Q.; Shao, X. MambaOSR: Leveraging Spatial-Frequency Mamba for Distortion-Guided Omnidirectional Image Super-Resolution. Entropy 2025, 27, 446. https://doi.org/10.3390/e27040446
Wen W, Zhao Q, Shao X. MambaOSR: Leveraging Spatial-Frequency Mamba for Distortion-Guided Omnidirectional Image Super-Resolution. Entropy. 2025; 27(4):446. https://doi.org/10.3390/e27040446
Chicago/Turabian StyleWen, Weilei, Qianqian Zhao, and Xiuli Shao. 2025. "MambaOSR: Leveraging Spatial-Frequency Mamba for Distortion-Guided Omnidirectional Image Super-Resolution" Entropy 27, no. 4: 446. https://doi.org/10.3390/e27040446
APA StyleWen, W., Zhao, Q., & Shao, X. (2025). MambaOSR: Leveraging Spatial-Frequency Mamba for Distortion-Guided Omnidirectional Image Super-Resolution. Entropy, 27(4), 446. https://doi.org/10.3390/e27040446