Abstract
Permutations on a set, endowed with function composition, build a group called a symmetric group. In addition to their algebraic structure, symmetric groups have two metrics that are of particular interest to us here: the Cayley distance and the Kendall tau distance. In fact, the aim of this paper is to introduce the concept of distance in a general finite group based on them. The main tool that we use to this end is Cayley’s theorem, which states that any finite group is isomorphic to a subgroup of a certain symmetric group. We also discuss the advantages and disadvantage of these permutation-based distances compared to the conventional generator-based distances in finite groups. The reason why we are interested in distances on groups is that finite groups appear in symbolic representations of time series, most notably in the so-called ordinal representations, whose symbols are precisely permutations, usually called ordinal patterns in that context. The natural extension from groups to group-valued time series is also discussed, as well as how such metric tools can be applied in time series analysis. Both theory and applications are illustrated with examples and numerical simulations.
1. Introduction
Symbolic representation of real-valued times series is a usual and useful tool in data analysis, where numbers are replaced by discrete “symbols”, in order to gain more tools and insights []. So to speak, symbolic representations coarse-grain the data in such a way that the information retained is sufficient for the purposes of the analysis. From a mathematical point of view, this technique consists of partitioning the state space, both in statistics and nonlinear methods. Traditional examples include binning and thresholding. More recently, Bandt and Pompe [] proposed to use ordinal patterns, which are the rank vectors of sliding windows along a time series, the size of the windows being the length of the ordinal patterns. Since then, ordinal representations, i.e., symbolic representations with ordinal patterns, have become a popular technique among data analysts. Common applications of ordinal patterns include classification using ordinal pattern-based indices [,,], discrimination of chaotic signals from white noise [,], characterization of dynamics and couplings [,,] and nonparametric tests of serial dependence [,], to mention a few. For general overviews, see [,,].
More importantly for the topic of this paper, ordinal patterns of any given length can be interpreted as permutations (i.e., bijections) on any set of L elements, say, . In fact, the Shannon entropy of a probability distribution of ordinal patterns is called permutation entropy [], and the same happens with any other entropic functional based on ordinal pattern probability distributions, e.g., divergence, mutual information, or statistical complexity. A potential advantage of viewing ordinal patterns of length L as permutations is that the latter build a group, namely, the symmetric group of degree L, denoted by , where the binary operation is function composition. In fact, the algebraic structure of provides additional leverage to ordinal representations that can be harnessed in time series analysis. An example of this is the concept of transcript introduced in [].
More generally, symbolic representations whose symbols are elements of a group are called algebraic representations, an ordinal representation being an algebraic representation with alphabet . Actually, most results for ordinal representations can be readily generalized to algebraic representations whose alphabets are any other finite group . This is not surprising if no particular property of is used in a given proof or application. There may be another, more theoretical reason for this. According to Cayley’s theorem [], any finite group is isomorphic to a subgroup of a symmetric group. This means that permutations are a sort of universal symbol for discretizing time series by means of group elements; a different question is whether such a “canonical” embedding is always the best option in practice.
This being the case, in this paper, we extend two distances in , namely, the Cayley distance and the Kendall tau distance (henceforth called Kendall distance), to arbitrary finite groups via Cayley’s theorem. A possible advantage of the here-proposed distances compared to others (e.g., the conventional generator-based distances) is their expediency and acceptable computation time for groups of moderate cardinality, as happens in practice. By extension, we discuss also distances for group-valued time series, which include algebraic representations of time series. This issue raises naturally when comparing two time series to measure their “similarity” (think of classification or clustering) or studying coupled systems (think of different types of synchronization). The result is a suite of permutation-based (or ordinal pattern-based) distances for groups and group-valued time series.
In sum, this is a follow-up paper on the quest to exploit the algebraic structure of group-valued time series—a possibility rarely used in the literature. Remarkably, the Cayley and Kendall distances and, hence, their extensions to general groups, are actually norms of transcripts, which shows the potential of our algebraic approach. Since our interest in distances between group elements was motivated by the study of ordinal representations and transcripts, we will speak of both permutations and ordinal patterns.
To address the aforementioned topics, we begin in Section 2 by establishing the mathematical framework, which includes group actions and group representations. In particular, we will prove Cayley’s theorem and implement it in three different ways—one of them using transcripts. There and throughout this paper, our approach is formal, the theoretical concepts being illustrated with simple examples. Section 3 is dedicated to the symmetric group and its two standard metrics: the Cayley and Kendall distances. In Section 4, we transition from the symmetric group to general groups and propose a distance based on Cayley’s Theorem (Section 4.1). This distance is compared to the conventional string metric for finitely generated groups (Section 4.2) in Section 4.3. Possible extensions to distances between group-valued times series are discussed in Section 5 and illustrated with mathematical simulations in Section 6. This paper ends with the conclusions in Section 7.
2. Groups, Group Actions and Cayley’s Theorem
In this section, we set the mathematical framework of this paper—group actions and group representations [,,].
Definition 1.
A group is a nonempty set endowed with a binary operation “*", sometimes called composition law or product, satisfying the following properties.
- (G1)
- Associativity: For all , it is true that .
- (G2)
- Identity element: There exists an element , called the identity (or neutral) element, such that for all .
- (G3)
- Inverse element: For every , there exists an element , called the inverse element of a, such that .
It can be proved that the identity of a group and the inverse of each element are unique. Groups whose product is commutative (i.e., for all ) are called commutative or abelian. Examples of abelian groups are the real numbers endowed with addition and the nonzero real numbers endowed with multiplication. Invertible square matrices are examples of nonabelian groups under multiplication. If the binary operation is clear from the context, then is shortened to .
Definition 2.
If is a group and S a nonempty set, then a left group action of on S is a mapping such that it satisfies the following two axioms:
- (L1a)
- Identity: for all , where e is the identity element of .
- (L2a)
- Compatibility: for all and .
If F is a left action of on S, we can define the function , i.e.,
for each , for , the axioms L1a and L2a read as follows:
- (L1b)
- Identity: is the identity mapping for all .
- (L2b)
- Compatibility: for all .
Lemma 1.
(i) is a bijection for each .
- (ii)
- The set endowed with function composition is a group.
Proof.
(i) Since is defined from S into itself, it suffices to prove that every has an inverse. Indeed, because by axioms L2b and L1b.
- (ii)
- According to Definition 1, we have to prove three properties: (G1) associativity is a general property of the composition of functions; (G2) is the identity because of axiom L1b; (G3) for all mappings , as in (i).
□
Bijections from a finite set S onto itself are called permutations. So, according to Lemma 1(i), the mappings are permutations. The permutations on S, endowed with function composition, build a group called the symmetric group . In this paper, we consider only finite groups and finite sets S, so, if is the cardinality of S, then . Since the properties of the permutations on S do not depend on S but only on , we choose , unless otherwise stated, and also refer to as the symmetric group of degree , . As a historical note, the symmetric group goes back to Évariste Galois (1811–1832) and his work on the resolution of algebraic equations by means of radicals.
Furthermore, Lemma 1(ii) states that the set of permutations is a subgroup (of cardinality ) of . This result together with axiom L2b, which spells out that the mapping preserves the algebraic structure of , are merged in the following theorem.
Theorem 1.
Any (left) group action of a group on a finite set S defines a group homomorphism from into . Therefore, Φ is a representation of the group by means of permutations .
In other words, every group is isomorphic to a subgroup of , namely , hence, . In this formulation, Theorem 1 is known as Cayley’s theorem. Therefore, we will call Cayley’s homomorphism and, abusing notation, Cayley’s isomorphism. Below, we will discuss three different implementations of Cayley’s isomorphism.
To apply Theorem 1, label the elements of with the conventional set . For every , let
be the matrix (or two-line) form of the permutation , where is a shuffle of . Therefore, every element can be identified with the one-line form of . In the numerical examples below, we will juxtapose the components of and drop the parentheses for a compact notation.
Remark 1.
In addition to left actions of a group on a finite set S, there are also right actions , defined by (R1a) for all , and (R2a) , as well as the corresponding group homomorphism from to , such that (R1b) is the identity map for all , and (R2b) for all . The difference between left and right actions is that in the function composition (L2b), acts first on and second (as in the standard convention), whereas in (R2b), acts first on and second. Henceforth, we only consider left actions because the binary operation of the symmetric group, the main character of this paper, is precisely function composition and so we can use the standard convention.
There is a particular case of Theorem 1 that is of special interest here, namely, , i.e., when the group acts on itself. In this particular case, we are going to highlight three implementations of Cayley’s isomorphism via left actions.
- (A)
- Left translations: The mapping is a left action of on itself, sois a permutation on for every , called a left translation by a.
- (B)
- Right translations: The mapping is a left action of on itself, sois a permutation on for every , called a right translation by a. Let us mention that the operation is also called the transcription from the (source) symbol a to the (target) symbol b in []. Note that and .
- (C)
- Adjoint actions: The mapping is a left action of on itself, sois a permutation on for every , called the adjoint action of a.
Comparing Equations (3)–(5), we conclude that the implementation (3) of Cayley’s isomorphism is the most convenient in practice, since the (one-line form of the) permutations can be read immediately row by row in the multiplication table of . Indeed, if is an enumeration of the elements of , then is the i-th row of the multiplication table , i.e.,
Example 1.
Let . By Equation (3), the isomorphic copies of are given by the rows of the “multiplication" table of ,
 where stands for the composition of the permutation that labels a row with the permutation that labels a column. Therefore,
where stands for the composition of the permutation that labels a row with the permutation that labels a column. Therefore,
 For example,
or, in one-line form, . From
table (7) and Equation (4), we obtain similarly that the copies of via right translations are given by
For example,
or, in one-line form, . From
table (7) and Equation (4), we obtain similarly that the copies of via right translations are given by

Example 2.
Let endowed with the product where, in this example, the exponents are taken modulo 4. Hence, is the identity and . By definition, is a cyclic group generated by the element . Alternatively, can be identified with the additive group , where the sum is taken modulo 4.
(i) The four permutations , corresponding to Equation (3) under the isomorphism , are given in the following table:
 So, for instance, the second row of this table spells out
or .
So, for instance, the second row of this table spells out
or .

3. Ordinal Patterns and Distances
In the previous, section we have focused on group actions and the embedding of a group in a symmetric group. What is still missing is metric tools that can further boost applications in the realm of group-valued time series. Since the motivation and objective of this paper are the applications of such tools to symbolic representations of time series via group elements, we begin this section by briefly explaining how such symbolic representations arise in time series analysis. The choice of ordinal patterns (or permutations) responds to the popularity of these symbols among time series analysts. Then, we introduce the concept of distance in the symmetric group and, in the next section, we do the same for general groups.
3.1. Ordinal Patterns
Symmetric groups are very popular for symbolic representations since the concept of ordinal pattern was introduced in []. Given a real-valued time series , an ordinal representation of x is a symbolic time series whose alphabet is , the symmetric group of degree . How are the permutations obtained from x? Let be a window (segment, sequence, block, …) of size L. Then, is the rank vector of , that is, is the permutation of such that
In other words, the rank vector is viewed as the one-line form of the permutation , , …, , i.e., for . As a matter of fact, any total ranking can be viewed as a permutation. In case of a tie , one can apply the convention that if . Another possibility, more recommended in case of many ties, is to add a small-amplitude noise to and to undo the tie. As way of illustration, if and , then , or for short.
In [], the permutations were called order (or ordinal) patterns of length L, which is the usual name of the symbols in time series analysis. In addition to the length L of the patterns, ordinal representations depend also on a second parameter: a possible time delay in Equation (12). In this paper, the time delay is set equal to 1 throughout.
As a side note, the concept of ordinal pattern has been generalized in several directions. Thus, it has been extended to multivariate time series in [,]. Spatial ordinal patterns were introduced in [] to analyze two-dimensional images and applied in [,] to distinguish textures.
3.2. Distances for Ordinal Patterns
In this section, we introduce the Cayley and Kendall distances for the symmetric group ; see [] for a survey about distances on permutations. We remind first about the concept of distance.
Definition 3.
Given a nonempty set S, a distance is a function that satisfies the following three axioms for all points .
- (D1)
- Positivity: and if and only if
- (D2)
- Symmetry: .
- (D3)
- Triangular inequality: .
Following the notation in Section 3.1 for ordinal patterns, the permutations of will be written in the one-line form (possibly shortened to in numerical examples), where . If, furthermore, , then is the usual function composition , i.e.,
as exemplified in Equation (7) for . Due to the positivity and symmetry properties of a distance, the distance matrix is symmetric, with 0’s along the diagonal.
If , then denotes the permutation
called a cycle of length m, , or simply an m-cycle. The notation calls for a warning at this point: do not confuse the permutation with the cycle . Every permutation can be written as a product of disjoint cycles, which is unique except for the order of the factors. For example, the cycle factorization of the permutation 426135 is or if 1-cycles (“fixed elements”) are omitted.
Cycles of length 2 are called transpositions. That is, a transposition is a permutation such that , , and for all . If , then
If , then is called an adjacent transposition. Unlike the factorization of permutations into disjoint cycles, the factorization of permutations into adjacent transpositions (and, hence, into transpositions) is not unique, although the minimal number of factors is. For example, .
Definition 4
([,]). Let . (a) The Cayley distance between the two permutations and , denoted by , is defined as the minimum number of transpositions needed to transform into . (b) The Kendall distance (also known as the bubble-sort distance) between and , denoted by , is defined as the minimum number of adjacent transpositions needed to transform into .
The Cayley and Kendall distances are examples of edit distances between two strings of symbols, which measure the minimum cost sequence of allowed edit operations to transform one string into the other. The use of edit distances to measure distance between permutations was proposed in []. By definition,
for all .
The proofs of the positivity and symmetry (properties (D1) and (D2) in Definition 3) for and are straightforward. The triangular inequality can be easily proved by graph-based methods since the permutations of build a connected undirected graph where the nodes (or vertices) correspond to permutations and the links (or edges) to transpositions. For example, in the case of : (i) every node is connected to exactly nearest neighbors, namely, those permutations that differ from due to transpositions of the adjacent symbols for , and, hence, (ii) for any two nearest nodes and , . Therefore, counts the number of links of the shortest path connecting the nodes and . In other words, each node has degree and all its nearest neighbors (one link apart) are at distance 1. The diameter of the graph, i.e., the farthest distance between any two nodes, corresponds to and the order reversing permutation , hence
Such graphs are called adjacency graphs or networks.
Figure 1 and Figure 2 show the adjacency graphs of the groups (a cycle in this case) and , respectively. Unlike the adjacency graphs for the Kendall distance, the adjacency graphs for the Cayley distance are in general nonplanar, i.e., they have edge crossings (even for ), so we will not use them.
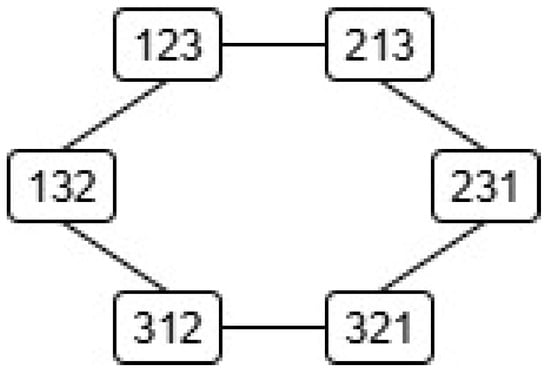
Figure 1.
Kendall adjacency graph of . A link between two nodes means that the corresponding permutations differ by an adjacent transposition, i.e., the Kendall distance between them is 1.
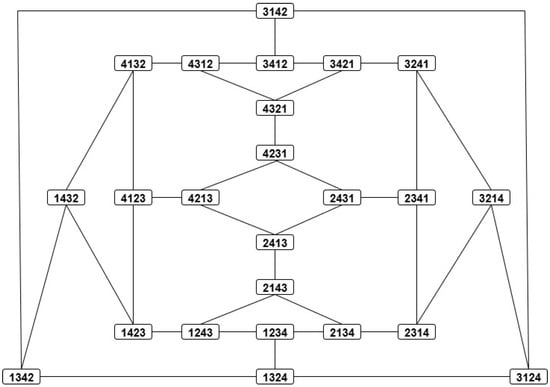
Figure 2.
Kendall adjacency graph of . A link between two permutations means that the Kendall distance between them is 1.
In the following, whenever convenient for economy of notation, we denote by both the Cayley and Kendall distances.
Proposition 1
(Invariance of under left translations). Given , then
for all .
Proof.
Suppose , i.e., k is the mimimum number of transpositions or adjacent transpositions such that
see Equation (15). Then,
which proves that □
Since , then Choose or in Equation (18) to prove:
Corollary 1.
For every ,
where is the identity permutation.
Remark 2.
Owing to Equation (19), all possible values of appear on the row of the distance matrix.
Equation (19) allows to define in an analogue to the concept of norm in a vector space.
Definition 5.
The norm of is defined as
Then, by Equation (19),
Remark 3.
Corollary 1 is instrumental for the computation of the Cayley and Kendall distances [].
Proposition 2.
(a) Let and the number of cycles (including 1-cycles) in the cycle factorization of the permutation . Then,
for all
(b) Let be the number of inversions in the permutation , i.e., the number of ordered pairs , , such that . Then,
for all .
Example 3.
We illustrate Proposition 2 with , and . Then,
so that
whose cycle factorization is
According to Equation (22),
As for Equation (23), the inversions of are
so that,
Let us check the results (26) and (27). First, the transpositions needed to transform into are the following:
where the elements being swapped in each transposition have been boldfaced. Therefore, . To check Equation (27), call the number of adjacent transpositions needed to move in the symbol 2 (the first or leftmost symbol of the target ) to the first position; call the result. Similarly, call the number of adjacent transpositions needed to move in the symbol 3 (the second symbol of the target ) to the second position. Proceed analogously until . The adjacent transpositions needed to transform into in this example are the following:
where the element of () being moved to the -position has been boldfaced. This shows that .
Example 4.
According to [], is the most common ordinal representation in data analysis. The Cayley and Kendall distance matrices for the group , Equation (7), are shown in the tables
 and
and
 As shown in Equations (16), (24) and (25), for all , and .
As shown in Equations (16), (24) and (25), for all , and .
Owing to their large size, the Cayley and Kendall distance matrices for have been moved to Appendix A. In this case, , and . Needless to say, the distances in table (29) and Table A2 can be easily checked in the corresponding adjacency graphs, Figure 1 and Figure 2, where each link stands for distance 1.
4. Distances for General Groups
In the first part of this section, we harness Cayley’s theorem to transport the Cayley and Kendall distances in (or, for that matter, any distance defined in ) to any finite group with . In the second part, we briefly introduce the distance with respect to a generating system. We also discuss the advantages of the first approach as compared to the second.
4.1. Permutation-Based Distance for Groups
Let be Cayley’s isomorphism, where is a subgroup of (namely, ) with ). This means:
- (i)
- , where e is the identity of .
- (ii)
- for all . Hence, .
To endow with a distance, we transport the distance from the group to and promote to an isometry.
Definition 6.
Let Φ be the Cayley isomorphism for a finite group . Then, is the distance in defined as
Therefore, has the same properties as . In particular:
- Norm-based definition: By Equation (21),where is the Cayley/Kendall norm in , i.e.,for all , being the identity of
From Equations (16) and (30), it follows
for all , since . Furthermore, by Equation (24),
and, by Equation (25),
Remark 4.
In the case of Section 3.2, the distances take on all integer values ranging from 0 to their respective maxima (Equation (24)), and (Equation (25)); think of the corresponding adjacency graphs. However, this does not happen with because is a subgroup of cardinality of the group , whose cardinality is , so not all possible distances can be realized (unless ). We call “forbidden distances for " the values in that are missing in the adjacency subgraph of ; otherwise, they are called allowed or admissible distances. By Equation (32) (or Remark 2), the admissible distances for can be read in the row of the distance matrix.
In general, the definition (30) depends on the implementation of Cayley’s isomorphism , e.g., whether is (i) a left translation (Equation (3)), (ii) a right translation (Equation (4)), or (iii) an adjoint action (Equation (5)). For simplicity, we mainly use the implementation (i), so that can be read row-wise in the multiplicaction table of (see Equation (6)), in which case we write for . In case (ii), we will write .
Example 5.
The only non-cyclic group of order 4 is the Klein four-group , defined by the multiplication table
 so that
so that
 According to Equations (36) and (37), and . From (39) it follows
According to Equations (36) and (37), and . From (39) it follows
 so the forbidden values of are and the forbidden values of are . Note that is abelian (as any group whose cardinality is the square of a prime number) since the multiplication table in Equation (38) is symmetric and every element other than the identity has order 2, i.e., every element is its own inverse. Therefore,
i.e., the isomorphic copies are the same for all , which implies . Labeling the elements as , one can locate the four copies of the group in the Kendall adjacency graph of , Figure 2, and read there the distances in the right table of Equation (40). For example,
so the forbidden values of are and the forbidden values of are . Note that is abelian (as any group whose cardinality is the square of a prime number) since the multiplication table in Equation (38) is symmetric and every element other than the identity has order 2, i.e., every element is its own inverse. Therefore,
i.e., the isomorphic copies are the same for all , which implies . Labeling the elements as , one can locate the four copies of the group in the Kendall adjacency graph of , Figure 2, and read there the distances in the right table of Equation (40). For example,
As a final remark, note that when , does not become , as one might think. The reason is that, in that event, is defined on , while , where is defined on . In other terms, the definition domain and the range of Cayley’s isomorphism are different also in the particular case , which prevents from becoming the identity (unless ). However, this does not prevent and from providing the same qualitative and even quantitative information, as shown in Example 6 below and Section 6. This fact supports the consistency of our approach to group metrics based on Cayley’s isomorphism.
Example 6.
Tables (41) and (42) below show the distances and for , and , , see table (8):

 For instance, if we encode the permutations of as
then
while
Note that if we replace 3 by 1 and 4 by 2 in Equation (41) for , then we obtain Equation (28) for . Furthermore, if we divide in Equation (42) by 3, then we obtain Equation (29) for , i.e.,
for all . We conclude that the results obtained using in and in are equivalent. According to Equations (41) and (42), the allowed distances for are out of , while the allowed distances for are out of .
For instance, if we encode the permutations of as
then
while
Note that if we replace 3 by 1 and 4 by 2 in Equation (41) for , then we obtain Equation (28) for . Furthermore, if we divide in Equation (42) by 3, then we obtain Equation (29) for , i.e.,
for all . We conclude that the results obtained using in and in are equivalent. According to Equations (41) and (42), the allowed distances for are out of , while the allowed distances for are out of .
4.2. Distances with Respect to a Generating Set
For the time being, let be a finite or infinite group. A finite set is a generating set (or generator) of if every can be written as a finite product of elements of S and their inverses. In particular, groups generated by a single element are called cyclic. For example, endowed with , where mod n is a cyclic group of order n with generator . The (edit) distance (or word metric) between the elements a and b of a finitely generated group (in particular of a finite group) is defined as the minimum number of elements from the generating set S needed to transform a into b. That is, if , where (or ), then is the smallest possible value of k. Therefore, the distance depends on the generating set S. In particular, if , then the Cayley distance of Section 3.2 is the distance with respect to the generating set of all transpositions, while the Kendall distance is the distance with respect to the generating set of all adjacent transpositions.
Example 7.
For the cyclic group of Example 2, the distances with respect to the generating set are the following:
 As for the distances , we find (see Equation (10)):
As for the distances , we find (see Equation (10)):
 For example,
If right translations (4) are used instead of left translations (3), then happens to be the same as in Equation (46). For example,
If the group elements are labeled , respectively, then the above distances can be read in the Kendall adjacency graph of , Figure 2. For example, distances (47) and (48) read and , respectively.
For example,
If right translations (4) are used instead of left translations (3), then happens to be the same as in Equation (46). For example,
If the group elements are labeled , respectively, then the above distances can be read in the Kendall adjacency graph of , Figure 2. For example, distances (47) and (48) read and , respectively.
4.3. Discussion
When comparing the distances and for finite groups, a possible advantage of the former is its expediency, in the sense that dispenses with generating sets and, hence, with the search for minimal descriptions of b as products of the form . In addition, there are algorithms (such as the bubble-sort algorithm) that compute in time and in time []. Computational issues are briefly discussed in Section 6.
On the other hand, a possible shortcoming of the distances in applications is the existence of forbidden values pointed out in Remark 4. For instance, the presence of such gaps in the distances between the algebraic representations of two coupled time series (see Section 5) might be misinterpreted as a dynamical characteristic of the underlying systems, e.g., full or generalized synchronization. So, the forbidden values for must be identified in advance, which can be easily done by calculating the row of the distance matrix (Remark 4). Alternatively, they can be identified using independent white noises. We come back to this point in Section 6.
In sum, when embedding a group in via Cayley’s isomorphism , we are encoding the elements as the permutations , where is a shuffle of ; see Equation (6) for being the left translation . The penalty for doing so is a more complex representation of the elements of . The pay-off is a general and computationally efficient metric . In principle, there may be symmetric groups with in which can be embedded, but finding such symmetric groups, in particular, the minimum-order one, is rather difficult in general [,]. In any case, note that in the practice of symbolic representation of time series, the alphabets used have low cardinality.
5. Distances for Group-Valued Time Series and Algebraic Representations
In this section, we explore possible applications of permutation-based distances to group-valued time series. Examples of group-valued time series include binary and n-ary time series. In the first case, , endowed with the XOR operation (addition modulo 2); these time series arise in digital communications and cryptography. The second example is a generalization, also used in digital communications: endowed with addition modulo n.
The perhaps most familiar example of group-valued time series is the ordinal representation of real-value time series, introduced in Section 3.1. A generalization thereof is the concept of algebraic representation.
Definition 7.
We say that a symbolic representation of a time series is an algebraic time series if its elements belong to a finite group .
Since here we are interested in practical applications, consider two finite -valued time series and of length N. In time series analysis, and could be ordinal representations of two coupled real-valued time series and , respectively. To carry out a data-driven analysis of the coupled dynamics of the underlying systems (think of various types of synchronization), or to measure the similarity between and , there are a number of metrics that we review in Section 5.1. In Section 5.2, we discuss how to extract information with those metrics.
5.1. String Metrics for Group-Valued Time Series
Below, we mention perhaps the most common metrics. Each of them targets specific situations.
- (i)
- Some of the metrics to quantify the similarity of two symbolic time series such as and are based on the probability distributions of their symbols (estimated by their frequencies) []. This category includes the Kullback–Leibler (KL) divergence (usually symmetrized via an arithmetic or harmonic mean) [], the Jensen–Shannon (JS) divergence [], the JS distance (which is the square root of the JS divergence) [], the permutation JS distance [,], the Hellinger distance [], the Wasserstein distance [,], the total variation distance [,] and more. Since in this paper we are interested in harnessing the algebraic structure of the symbolic data (if any), we will dispense with entropic distances.
- (ii)
- One can also exploit the algebraic structure of and calculate the transcription of and [], that is, the time series , where (right translations by ) or (left translations by ), see Equations (4) and (3). Trancriptions of coupled time series in an ordinal representation have been used to study different aspects of coupled dynamics: complexity [,], synchronization [,], information directionality (or causality) [], features for classification [], etc. Interestingly, if , then the distance between the ordinal patterns and can be written as the norm of the transcript , see Equation (21). Otherwise, we embed into via Cayley’s isomorphism and, again, the distance between the ordinal patterns and can be written as the norm of the transcript , see Equation (33).
- (iii)
- Since a window of size W of any -valued time series can be viewed as a string of symbols of length W, we can borrow a number of string metrics from information theory, computer science and computational linguistics to compare and , where (unlike permutations) these strings can have repeated symbols. Thus, the Hamming distance between two strings of equal length is the number of positions at which the corresponding symbols differ []. The Damerau–Levenshtein distance considers insertions, deletions, substitutions and adjacent transpositions of symbols [,,]. Such metrics are also examples of edit distances. Finally, we also mention the Jaro–Winkler similarity coefficient (not a true distance) which, like the Hamming distance, is based on symbol matching [,].
5.2. Extracting Information with and
Next, we focus on the distances for the group (Section 3.2) and for other groups (Section 3.2) and their applications to the analysis of -valued time series and algebraic representations. The idea is to measure the distance between (A) simultaneous symbols and , or (B) concurrent windows and , and thereby characterize the similarity or dissimilarity of the symbolic time series and . To this end, we consider sliding windows and , , with the same size , where we allow in order to include distances between simultaneous symbols.
- CASE A:
- To unify the notation, we will write for the distance between the elements , with the understanding that if and otherwise. Therefore,wherewhere the inequalities in Equation (50) allow for the possibility that is a forbidden distance (Remark 4). As a result of calculating for , we obtain the integer-valued time seriesAccording to Equation (50), and , except for Therefore, and have greater differentiating power in applications than their Cayley counterparts due to their larger ranges.
- CASE B:
- . Consider now the windows and as W-dimensional vectors in the corresponding Cartesian product of the metric space . In this case, we have the whole family of distances, , at our disposal. Well-known instances include the so-called Manhattan distance,the Euclidean distance,and the Chebychev distance,As a result, we obtain the time serieswhich is integer-valued for , and real-valued otherwise.
6. Numerical Simulations
In this section, we illustrate the application of permutation-based distances to algebraic representations with numerical simulations. To this end, we revisit a model composed of two unidirectionally coupled, non-identical Henon systems, used in [] to study generalized synchronization. The equations of the driver X are
and the equations of the responder Y are
where is the coupling strength. It is numerically proved in [] that this system has generalized synchronization for C in a small interval around and for ([], [Figure 3]).
For a given coupling strength C, let and be two stationary time series of length composed of the first components of the states of the driver and of the responder, respectively, and generated with seeds and (after discarding the initial transient). Let and be the algebraic representations of x and y with ordinal patterns of length . The values chosen for the coupling strength are .
Next we computed different types of distances between and from those presented in Section 5.2. Here, we present only the results with the Kendall distances and because, as explained there, they have greater differentiating power than and . As for the distances , we used (Equations (52)–(54)). Irrational values of were rounded to the integer n if . To facilitate analysis, we transformed the data , and into (empirical) probability distributions for the distance values.
Figure 3 illustrates CASE A of Section 5.2, i.e., . Here, (top row) and (bottom row). The main conclusions can be summarized as follows.
- For (no synchronization, panels (a) and (d)), all possible values of are realized.
- For (“weak synchronization”, panels (b) and (e)), only the greater values of are allowed.
- For (“strong synchronization”, panels (c) and (f)), only the smaller values of are allowed.
- So, detects that the generalized synchronizations at and are different: the former forbids the shorter distances between simultaneous ordinal patterns and , while the latter forbids large distances.
- The results for each C are consistently similar.

Figure 3.
Top row: Probability distributions of the Kendall distances for the algebraic representation of the time series x and y with the group (i.e., ordinal patterns of length ) and coupling strengths (left panel), (middle panel) and (right panel). Bottom row: Same as top row for the representation group (i.e., ordinal patterns of length ).
We conclude that the distance is sensitive to dynamical changes in coupled systems and robust with respect to the length of the ordinal patterns.
At this point, we draw on Figure 3 to, as in Example 6, check the consistency of the results obtained with and , this time using and . Figure 4 shows the probability distribution of the allowed distances for with (panel (a)) and (panel (b)). The coupling strength in both panels is , so that all allowed distances are realized. The allowed distances for , listed along the horizontal axes in Figure 4, happen to be for and for . Comparison of panels (a) and (b) of Figure 4 with panels (a) and (d) of Figure 3, respectively, shows that the probability distributions of and are exactly the same for and , except for the labeling of the distances; notice the change of scales. In fact, and similarly to Equation (44), numerical calculations show that (i)
for all , where , and (ii)
for all , where . For example, and . The same occurs for and (not shown).
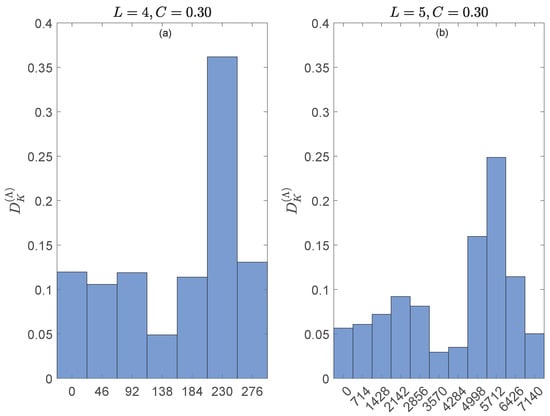
Figure 4.
Probability distributions of the allowed distances for for the algebraic representation of the time series x and y with the group (panel (a)) and (panel (b)). in both panels so that all allowed distances for (listed along the horizontal axes) are actually realized.
Figure 5 illustrates CASE B of Section 5.2, i.e., . Here, with , , and the distance is (i) in the top row, (ii) in the middle row and (iii) in the bottom row. The main conclusions can be summarized as follows.
- Due to the monotony property of the p-norms ( for ), the distances with smaller parameters p ( and in Figure 3) have greater differentiating power.

Figure 5.
Top row: Probability distributions of the distance for the algebraic representation of the time series x and y with the group (ordinal patterns of length ) and coupling strengths (left panel), (middle panel) and (right panel). Middle row: Same as top row for the distance . Bottom row: Same as top row for the distance .
We conclude that the distances are also sensitive to dynamical changes in coupled systems and robust with respect to the parameter .
To wrap up the previous discussion, we are also going to compare the computational times of (Section 4.1) and (Section 4.2), where , are -valued time series. Rather than using ad hoc groups and coupled time series, we take advange of the above ordinal representations and , and benchmark the computational cost of computing for , (the usual ordinal pattern lengths in applications), 10,000 and , against the computational cost of calculating for the same group and settings. We choose so that all allowed ordinal patterns are realized (see Figure 3 and Figure 4). Table 1 shows the times in seconds of the corresponding calculations with a laptop (Intel I9 processor, 8 cores, 64 GB of RAM, 8 GB of GPU memory) and a non-paralellized algorithm.

Table 1.
Computation time in seconds of and , 10,000.
Altogether, the above numerical results support the usefulness of distances , and in the analysis of group-valued time series.
7. Conclusions
The results presented in this paper are an outgrowth of the study of transcripts and their applications to time series analysis in algebraic representations (Section 5), which are a generalization of transcripts in ordinal representations []. Indeed, the concept of transcript from a group element to another or, for that matter, the right translation of b by a (Equation (4)) leads directly to the isomorphism from to a subgroup of the symmetric group (Cayley’s theorem). In turn, the elements of can be written as numerical or symbolic strings, which allows us to endow with any convenient edit distance, e.g., the Cayley distance or the Kendall distance of Section 3. This being the case, the isomorphism can be used to transport the distance in to , as we did in Section 4. The result is the ordinal pattern-based distance for groups proposed in Definition 6.
Metric properties of finite groups is an unsual tool in time series analysis in algebraic representations. Even in the ordinal representation, distances or similarities between time series are usually measured with functionals of probability distributions such as divergences or functions thereof. There are also distances defined in the groups themselves, based on generating sets, which were the subject of Section 4.2. Actually, the distances and in the permutations groups, discussed in Section 3, are examples of distances with respect to generating sets. A possible advantage of the ordinal pattern-based distance proposed in this paper for any group is its simplicity and generality, since it dispenses with generating sets and minimal descriptions of elements via generators. Furthermore, there are general-purpose algorithms to efficiently calculate the distances and in for the low and moderate group cardinalities used in practice, see Table 1.
In the previous sections we have presented the mathematical underpinnings of our approach, which include group actions, Cayley’s theorem, and group representations, as well as its practical implementation. It is remarkable that Cayley’s theorem gives permutations (or ordinal patterns) a certain universality in algebraic representations of time series, although other choices or isomorphisms can be more convenient in practice. For example, the Klein group (Example 5) is isomorphic to endowed with XOR addition and the cyclic group endowed with , where mod n, is isomorphic to equipped with addition modulo n. Some of these groups were used in the previous sections to illustrate the theory. In contrast to the specificities of each group, the group distance introduced in Definition 6 is completely general, since the only input it needs is the multiplication table of the group, and can be efficiently computed. Possible applications were only touched upon in Section 5 because they are the subject of ongoing research. The numerical simulations in Section 6 show the potential of the metric tools discussed in this paper in the analysis of group-valued time series.
Author Contributions
Conceptualization, J.M.A.; methodology, J.M.A.; software, R.D.; validation, J.M.A. and R.D.; formal analysis, J.M.A.; investigation, J.M.A.; resources, R.D.; data curation, J.M.A. and R.D.; writing—original draft preparation, J.M.A.; writing—review and editing, J.M.A. and R.D.; visualization, J.M.A. and R.D.; supervision, J.M.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The numerical data supporting the conclusions of this article will be made available by the authors on request.
Acknowledgments
The authors are very grateful to the Reviewers for their helpful comments.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Cayley and Kendall Distances for the Group Sym (4) (Example 4)
Table A1.
Distance for .
Table A1.
Distance for .
| 1234 | 1243 | 1324 | 1342 | 1423 | 1432 | 2134 | 2143 | 2314 | 2341 | 2413 | 2431 | 3124 | 3142 | 3214 | 3241 | 3412 | 3421 | 4123 | 4132 | 4213 | 4231 | 4312 | 4321 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1234 | 0 | 1 | 1 | 2 | 2 | 1 | 1 | 2 | 2 | 3 | 3 | 2 | 2 | 3 | 1 | 2 | 2 | 3 | 3 | 2 | 2 | 1 | 3 | 2 |
| 1243 | 1 | 0 | 2 | 1 | 1 | 2 | 2 | 1 | 3 | 2 | 2 | 3 | 3 | 2 | 2 | 1 | 3 | 2 | 2 | 3 | 1 | 2 | 2 | 3 |
| 1324 | 1 | 2 | 0 | 1 | 1 | 2 | 2 | 3 | 1 | 2 | 2 | 3 | 1 | 2 | 2 | 3 | 3 | 2 | 2 | 3 | 3 | 2 | 2 | 1 |
| 1342 | 2 | 1 | 1 | 0 | 2 | 1 | 3 | 2 | 2 | 1 | 3 | 2 | 2 | 1 | 3 | 2 | 2 | 3 | 3 | 2 | 2 | 3 | 1 | 2 |
| 1423 | 2 | 1 | 1 | 2 | 0 | 1 | 3 | 2 | 2 | 3 | 1 | 2 | 2 | 3 | 3 | 2 | 2 | 1 | 1 | 2 | 2 | 3 | 3 | 2 |
| 1432 | 1 | 2 | 2 | 1 | 1 | 0 | 2 | 3 | 3 | 2 | 2 | 1 | 3 | 2 | 2 | 3 | 1 | 2 | 2 | 1 | 3 | 2 | 2 | 3 |
| 2134 | 1 | 2 | 2 | 3 | 3 | 2 | 0 | 1 | 1 | 2 | 2 | 1 | 1 | 2 | 2 | 3 | 3 | 2 | 2 | 1 | 3 | 2 | 2 | 3 |
| 2143 | 2 | 1 | 3 | 2 | 2 | 3 | 1 | 0 | 2 | 1 | 1 | 2 | 2 | 1 | 3 | 2 | 2 | 3 | 1 | 2 | 2 | 3 | 3 | 2 |
| 2314 | 2 | 3 | 1 | 2 | 2 | 3 | 1 | 2 | 0 | 1 | 1 | 2 | 2 | 3 | 1 | 2 | 2 | 3 | 3 | 2 | 2 | 3 | 1 | 2 |
| 2341 | 3 | 2 | 2 | 1 | 3 | 2 | 2 | 1 | 1 | 0 | 2 | 1 | 3 | 2 | 2 | 1 | 3 | 2 | 2 | 3 | 3 | 2 | 2 | 1 |
| 2413 | 3 | 2 | 2 | 3 | 1 | 2 | 2 | 1 | 1 | 2 | 0 | 1 | 3 | 2 | 2 | 3 | 1 | 2 | 2 | 3 | 1 | 2 | 2 | 3 |
| 2431 | 2 | 3 | 3 | 2 | 2 | 1 | 1 | 2 | 2 | 1 | 1 | 0 | 2 | 3 | 3 | 2 | 2 | 1 | 3 | 2 | 2 | 1 | 3 | 2 |
| 3124 | 2 | 3 | 1 | 2 | 2 | 3 | 1 | 2 | 2 | 3 | 3 | 2 | 0 | 1 | 1 | 2 | 2 | 1 | 1 | 2 | 2 | 3 | 3 | 2 |
| 3142 | 3 | 2 | 2 | 1 | 3 | 2 | 2 | 1 | 3 | 2 | 2 | 3 | 1 | 0 | 2 | 1 | 1 | 2 | 2 | 1 | 3 | 2 | 2 | 3 |
| 3214 | 1 | 2 | 2 | 3 | 3 | 2 | 2 | 3 | 1 | 2 | 2 | 3 | 1 | 2 | 0 | 1 | 1 | 2 | 2 | 3 | 1 | 2 | 2 | 3 |
| 3241 | 2 | 1 | 3 | 2 | 2 | 3 | 3 | 2 | 2 | 1 | 3 | 2 | 2 | 1 | 1 | 0 | 2 | 1 | 3 | 2 | 2 | 1 | 3 | 2 |
| 3412 | 2 | 3 | 3 | 2 | 2 | 1 | 3 | 2 | 2 | 3 | 1 | 2 | 2 | 1 | 1 | 2 | 0 | 1 | 3 | 2 | 2 | 3 | 1 | 2 |
| 3421 | 3 | 2 | 2 | 3 | 1 | 2 | 2 | 3 | 3 | 2 | 2 | 1 | 1 | 2 | 2 | 1 | 1 | 0 | 2 | 3 | 3 | 2 | 2 | 1 |
| 4123 | 3 | 2 | 2 | 3 | 1 | 2 | 2 | 1 | 3 | 2 | 2 | 3 | 1 | 2 | 2 | 3 | 3 | 2 | 0 | 1 | 1 | 2 | 2 | 1 |
| 4132 | 2 | 3 | 3 | 2 | 2 | 1 | 1 | 2 | 2 | 3 | 3 | 2 | 2 | 1 | 3 | 2 | 2 | 3 | 1 | 0 | 2 | 1 | 1 | 2 |
| 4213 | 2 | 1 | 3 | 2 | 2 | 3 | 3 | 2 | 2 | 3 | 1 | 2 | 2 | 3 | 1 | 2 | 2 | 3 | 1 | 2 | 0 | 1 | 1 | 2 |
| 4231 | 1 | 2 | 2 | 3 | 3 | 2 | 2 | 3 | 3 | 2 | 2 | 1 | 3 | 2 | 2 | 1 | 3 | 2 | 2 | 1 | 1 | 0 | 2 | 1 |
| 4312 | 3 | 2 | 2 | 1 | 3 | 2 | 2 | 3 | 1 | 2 | 2 | 3 | 3 | 2 | 2 | 3 | 1 | 2 | 2 | 1 | 1 | 2 | 0 | 1 |
| 4321 | 2 | 3 | 1 | 2 | 2 | 3 | 3 | 2 | 2 | 1 | 3 | 2 | 2 | 3 | 3 | 2 | 2 | 1 | 1 | 2 | 2 | 1 | 1 | 0 |
Table A2.
Distance for .
Table A2.
Distance for .
| 1234 | 1243 | 1324 | 1342 | 1423 | 1432 | 2134 | 2143 | 2314 | 2341 | 2413 | 2431 | 3124 | 3142 | 3214 | 3241 | 3412 | 3421 | 4123 | 4132 | 4213 | 4231 | 4312 | 4321 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1234 | 0 | 1 | 1 | 2 | 2 | 3 | 1 | 2 | 2 | 3 | 3 | 4 | 2 | 3 | 3 | 4 | 4 | 5 | 3 | 4 | 4 | 5 | 5 | 6 |
| 1243 | 1 | 0 | 2 | 3 | 1 | 2 | 2 | 1 | 3 | 4 | 2 | 3 | 3 | 4 | 4 | 5 | 5 | 6 | 2 | 3 | 3 | 4 | 4 | 5 |
| 1324 | 1 | 2 | 0 | 1 | 3 | 2 | 2 | 3 | 3 | 4 | 4 | 5 | 1 | 2 | 2 | 3 | 3 | 4 | 4 | 3 | 5 | 6 | 4 | 5 |
| 1342 | 2 | 3 | 1 | 0 | 2 | 1 | 3 | 4 | 4 | 5 | 5 | 6 | 2 | 1 | 3 | 4 | 2 | 3 | 3 | 2 | 4 | 5 | 3 | 4 |
| 1423 | 2 | 1 | 3 | 2 | 0 | 1 | 3 | 2 | 4 | 5 | 3 | 4 | 4 | 3 | 5 | 6 | 4 | 5 | 1 | 2 | 2 | 3 | 3 | 4 |
| 1432 | 3 | 2 | 2 | 1 | 1 | 0 | 4 | 3 | 5 | 6 | 4 | 5 | 3 | 2 | 4 | 5 | 3 | 4 | 2 | 1 | 3 | 4 | 2 | 3 |
| 2134 | 1 | 2 | 2 | 3 | 3 | 4 | 0 | 1 | 1 | 2 | 2 | 3 | 3 | 4 | 2 | 3 | 5 | 4 | 4 | 5 | 3 | 4 | 6 | 5 |
| 2143 | 2 | 1 | 3 | 4 | 2 | 3 | 1 | 0 | 2 | 3 | 1 | 2 | 4 | 5 | 3 | 4 | 6 | 5 | 3 | 4 | 2 | 3 | 5 | 4 |
| 2314 | 2 | 3 | 3 | 4 | 4 | 5 | 1 | 2 | 0 | 1 | 3 | 2 | 2 | 3 | 1 | 2 | 4 | 3 | 5 | 6 | 4 | 3 | 5 | 4 |
| 2341 | 3 | 4 | 4 | 5 | 5 | 6 | 2 | 3 | 1 | 0 | 2 | 1 | 3 | 4 | 2 | 1 | 3 | 2 | 4 | 5 | 3 | 2 | 4 | 3 |
| 2413 | 3 | 2 | 4 | 5 | 3 | 4 | 2 | 1 | 3 | 2 | 0 | 1 | 5 | 6 | 4 | 3 | 5 | 4 | 2 | 3 | 1 | 2 | 4 | 3 |
| 2431 | 4 | 3 | 5 | 6 | 4 | 5 | 3 | 2 | 2 | 1 | 1 | 0 | 4 | 5 | 3 | 2 | 4 | 3 | 3 | 4 | 2 | 1 | 3 | 2 |
| 3124 | 2 | 3 | 1 | 2 | 4 | 3 | 3 | 4 | 2 | 3 | 5 | 4 | 0 | 1 | 1 | 2 | 2 | 3 | 5 | 4 | 6 | 5 | 3 | 4 |
| 3142 | 3 | 4 | 2 | 1 | 3 | 2 | 4 | 5 | 3 | 4 | 6 | 5 | 1 | 0 | 2 | 3 | 1 | 2 | 4 | 3 | 5 | 4 | 2 | 3 |
| 3214 | 3 | 4 | 2 | 3 | 5 | 4 | 2 | 3 | 1 | 2 | 4 | 3 | 1 | 2 | 0 | 1 | 3 | 2 | 6 | 5 | 5 | 4 | 4 | 3 |
| 3241 | 4 | 5 | 3 | 4 | 6 | 5 | 3 | 4 | 2 | 1 | 3 | 2 | 2 | 3 | 1 | 0 | 2 | 1 | 5 | 4 | 4 | 3 | 3 | 2 |
| 3412 | 4 | 5 | 3 | 2 | 4 | 3 | 5 | 6 | 4 | 3 | 5 | 4 | 2 | 1 | 3 | 2 | 0 | 1 | 3 | 2 | 4 | 3 | 1 | 2 |
| 3421 | 5 | 6 | 4 | 3 | 5 | 4 | 4 | 5 | 3 | 2 | 4 | 3 | 3 | 2 | 2 | 1 | 1 | 0 | 4 | 3 | 3 | 2 | 2 | 1 |
| 4123 | 3 | 2 | 4 | 3 | 1 | 2 | 4 | 3 | 5 | 4 | 2 | 3 | 5 | 4 | 6 | 5 | 3 | 4 | 0 | 1 | 1 | 2 | 2 | 3 |
| 4132 | 4 | 3 | 3 | 2 | 2 | 1 | 5 | 4 | 6 | 5 | 3 | 4 | 4 | 3 | 5 | 4 | 2 | 3 | 1 | 0 | 2 | 3 | 1 | 2 |
| 4213 | 4 | 3 | 5 | 4 | 2 | 3 | 3 | 2 | 4 | 3 | 1 | 2 | 6 | 5 | 5 | 4 | 4 | 3 | 1 | 2 | 0 | 1 | 3 | 2 |
| 4231 | 5 | 4 | 6 | 5 | 3 | 4 | 4 | 3 | 3 | 2 | 2 | 1 | 5 | 4 | 4 | 3 | 3 | 2 | 2 | 3 | 1 | 0 | 2 | 1 |
| 4312 | 5 | 4 | 4 | 3 | 3 | 2 | 6 | 5 | 5 | 4 | 4 | 3 | 3 | 2 | 4 | 3 | 1 | 2 | 2 | 1 | 3 | 2 | 0 | 1 |
| 4321 | 6 | 5 | 5 | 4 | 4 | 3 | 5 | 4 | 4 | 3 | 3 | 2 | 4 | 3 | 3 | 2 | 2 | 1 | 3 | 2 | 2 | 1 | 1 | 0 |
References
- Hirata, Y.; Amigó, J.M. A review of symbolic dynamics and symbolic reconstruction of dynamical systems. Chaos 2023, 33, 052101. [Google Scholar] [CrossRef]
- Bandt, C.; Pompe, B. Permutation Entropy: A Natural Complexity Measure for Time Series. Phys. Rev. Lett. 2002, 88, 174102. [Google Scholar] [CrossRef] [PubMed]
- Keller, K.; Lauffer, H. Symbolic analysis of high dimensional time series. Int. J. Bifurc. Chaos 2003, 13, 2657–2668. [Google Scholar] [CrossRef]
- Graff, G.; Graff, B.; Kaczkowska, A.; Makowiecz, D.; Amigó, J.M.; Piskorski, J.; Narkiewicz, K.; Guzik, P. Ordinal pattern statistics for the assessment of heart rate variability. Eur. Phys. Spec. Top. 2013, 222, 525–534. [Google Scholar] [CrossRef]
- Schlemmer, A.; Berg, S.; Lilienkamp, T.; Luther, S.; Parlitz, U. Spatiotemporal permutation entropy as a measure for complexity of cardiac arrhythmia. Front. Phys. 2018, 6, 39. [Google Scholar] [CrossRef]
- Rosso, O.A.; Larrondo, H.A.; Martin, M.T.; Plastino, A.; Fuentes, M.A. Distinguishing noise from chaos. Phys. Rev. Lett. 2007, 99, 154102. [Google Scholar] [CrossRef] [PubMed]
- Amigó, J.M.; Zambrano, S.; Sanjuán, M.A.F. True and false forbidden patterns in deterministic and random dynamics. Europhys. Lett. 2007, 79, 50001. [Google Scholar] [CrossRef]
- Monetti, R.; Bunk, W.; Aschenbrenner, T.; Jamitzky, F. Characterizing synchronization in time series using information measures extracted from symbolic representations. Phys. Rev. E 2009, 79, 046207. [Google Scholar] [CrossRef]
- Parlitz, U.; Suetani, H.; Luther, S. Identification of equivalent dynamics using ordinal pattern distribution. Eur. J. Spec. Top. 2013, 222, 553–568. [Google Scholar] [CrossRef]
- Weiß, C.H. Non-parametric tests for serial dependence in time series based on asymptotic implementations of ordinal-pattern statistics. Chaos 2022, 32, 093107. [Google Scholar] [CrossRef]
- Weiß, C.H.; Ruiz Marín, M.; Keller, K.; Matilla-García, M. Non-parametric analysis of serial dependence in time series using ordinal patterns. Comput. Stat. Data Anal. 2022, 168, 107381. [Google Scholar] [CrossRef]
- Amigó, J.M.; Keller, K.; Kurths, J. Recent Progress in Symbolic Dynamics and Permutation Complexity. Eur. Phys. J. Spec. Top. 2013, 222, 241–247. [Google Scholar] [CrossRef][Green Version]
- Leyva, I.; Martinez, J.; Massoller, C.; Rosso, R.O.; Zanin, M. 20 Years of Ordinal Patterns: Perspectives and challenges. Eur. Phys. Lett. 2022, 138, 31001. [Google Scholar] [CrossRef]
- Amigó, J.M.; Rosso, O.A. Ordinal methods: Concepts, applications, new developments, and challenges. Chaos 2023, 33, 080401. [Google Scholar] [CrossRef]
- Herstein, I.N. Abstract Algebra; John Wiley: Hoboken, NJ, USA, 1996; ISBN 978-0471368793. [Google Scholar]
- Lang, S. Undergraduate Algebra, 3rd ed.; Undergraduate Texts in Mathematics; Springer: New York, NY, USA, 2005; ISBN 978-0387220253. [Google Scholar]
- Fraleigh, J.B. A First Course in Abstract Algebra; Pearson Education Limited: London, UK, 2013; ISBN 978-1292024967. [Google Scholar]
- Mohr, M.; Wilhelm, F.; Hartwig, M.; Möller, R.; Keller, K. New Approaches in Ordinal Pattern Representations for Multivariate Time Series. In Proceedings of the Thirty-Third International Artificial Intelligence Research Society Conference (FLAIRS 2020), North Miami Beach, FL, USA, 17–20 May 2020; pp. 124–129. Available online: https://aaai.org/papers/124-flairs-2020-18417 (accessed on 26 August 2025).
- Amigó, J.M.; Keller, K. Permutation entropy: One concept, two approaches. Eur. Phys. J. Spec. Top. 2013, 222, 263–274. [Google Scholar] [CrossRef]
- Ribeiro, H.V.; Zunino, L.; Lenzi, E.K.; Santoro, P.A.; Mendes, R.S. Complexity-entropy causality plane as a complexity measure for twodimensional patterns. PLoS ONE 2012, 7, e40689. [Google Scholar] [CrossRef]
- Zunino, L.; Ribeiro, H.V. Discriminating image textures with the multiscale two-dimensional complexity-entropy causality plane. Chaos Solitons Fractals 2016, 91, 679–688. [Google Scholar] [CrossRef]
- Bandt, C.; Wittfeld, K. Two new parameters for the ordinal analysis of images. Chaos 2023, 33, 043124. [Google Scholar] [CrossRef] [PubMed]
- Deza, M.; Huang, T. Metrics on permutations: A survey. J. Comb. Inf. Syst. Sci. 1998, 23, 173–185. [Google Scholar]
- Nguyen, T. Improving the Gilbert-Varshamov bound for permutation Codes in the Cayley metric and Kendall τ-Metric. arXiv 2024, arXiv:2404.15126v2. [Google Scholar]
- Kendall, M.G. A new measure of rank correlation. Biometrika 1938, 30, 81–93. [Google Scholar] [CrossRef]
- Sörensen, K. Distance measures based on the edit distance for permutation-type representations. J. Heuristics 2007, 13, 35–47. [Google Scholar] [CrossRef]
- Bandt, C. Small Order Patterns in Big Time Series: A Practical Guide. Entropy 2019, 21, 613. [Google Scholar] [CrossRef] [PubMed]
- Cicirello, V.A. Kendall tau sequence distance: Extending Kendall tau from ranks to sequences. arXiv 2019, arXiv:1905.02752v3. [Google Scholar] [CrossRef]
- Johnson, D.L. Minimal Permutation Representations of Finite Groups. Am. J. Math. 1971, 93, 857–866. [Google Scholar] [CrossRef]
- Grechkoseeva, M.A. On Minimal Permutation Representations of Classical Simple Groups. Sib. Math. J. 2003, 44, 443–462. [Google Scholar] [CrossRef]
- Rachev, S.T.; Klebanov, L.; Stoyanov, S.V.; Fabozzi, F. The Methods of Distances in the Theory of Probability and Statistics; Springer: New York, NY, USA, 2013; ISBN 978-1461448686. [Google Scholar]
- Lin, J. Divergence measures based on the Shannon entropy. IEEE Trans. Inf. Theory 1991, 37, 145–151. [Google Scholar] [CrossRef]
- Endres, D.; Schindelin, J. A new metric for probability distributions. IEEE Trans. Inf. Theory 2003, 49, 1858–1860. [Google Scholar] [CrossRef]
- Zunino, L.; Olivares, F.; Ribeiro, H.V.; Rosso, O.A. Permutation Jensen-Shannon distance: A versatile and fast symbolic tool for complex time-series analysis. Phys. Rev. E 2022, 105, 045310. [Google Scholar] [CrossRef]
- Zunino, L. Revisiting the Characterization of Resting Brain Dynamics with the Permutation Jensen–Shannon Distance. Entropy 2024, 26, 432. [Google Scholar] [CrossRef]
- Hellinger, E. Neue Begründung der Theorie quadratischer Formen von unendlichvielen Veränderlichen. J. Fürdie Reine Angew. Math. 1909, 136, 210–271. Available online: http://eudml.org/doc/149313 (accessed on 26 August 2025). [CrossRef]
- Kantorovich, L.V. On the translocation of masses. Dokl. Akad. Nauk SSSR 1942, 37, 227–229, Reprinted in J. Math. Sci. 2006, 133, 1381–1382. [Google Scholar] [CrossRef]
- Figalli, A.; Glaudo, F. An Invitation to Optimal Transport, Wasserstein Distances, and Gradient Flows. In EMS Textbooks in Mathematics, 23rd ed.; European Mathematical Society: Berlin, Germany, 2021; ISBN 978-3985470105. [Google Scholar]
- Pinsker, M.S. Information and Information Stability of Random Variables and Processes; Holden-Day: San Francisco, CA, USA, 1964; ISBN 978-0816268047. [Google Scholar]
- Bhattacharyya, A.; Gayen, S.; Meel, K.S.; Myrisiotis, D.; Pavan, A.; Vinodchandran, N.V. On Approximating Total Variation Distance. arXiv 2023, arXiv:2206.07209v2. [Google Scholar] [PubMed]
- Amigó, J.M.; Monetti, R.; Aschenbrenner, T.; Bunk, W. Transcripts: An algebraic approach to coupled time series. Chaos 2012, 22, 013105. [Google Scholar] [CrossRef]
- Monetti, R.; Bunk, W.; Aschenbrenner, T.; Springer, S.; Amigó, J.M. Information directionality in coupled time series using transcripts. Phys. Rev. E 2013, 88, 022911. [Google Scholar] [CrossRef][Green Version]
- Pilarczyk, P.; Graff, G.; Amigó, J.M.; Tessmer, K.; Narkiewicz, K.; Graff, B. Differentiating patients with obstructive sleep apnea from healthy controls based on heart rate-blood pressure coupling quantified by entropy-based indices. Chaos 2023, 33, 103140. [Google Scholar] [CrossRef]
- Hamming, R.W. Error detecting and error correcting codes. Bell Syst. Tech. J. 1950, 29, 147–160. [Google Scholar] [CrossRef]
- Damerau, F.J. A technique for computer detection and correction of spelling errors. Commun. ACM 1964, 7, 171–176. [Google Scholar] [CrossRef]
- Levenshtein, V.I. Binary codes capable of correcting deletions, insertions, and reversals. Sov. Phys. Dokl. 1966, 10, 707–710. [Google Scholar]
- Cormen, T.H.; Leiserson, C.E.; Rivest, R.L.; Stein, C. Introduction to Algorithms, 3rd ed.; The MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Jaro, M.A. Advances in record-linkage methodology as applied to matching the 1985 census of Tampa, Florida. J. Am. Stat. Assoc. 1989, 84, 414–420. [Google Scholar] [CrossRef]
- Winkler, W.E. String Comparator Metrics and Enhanced Decision Rules in the Fellegi-Sunter Model of Record Linkage. In Proceedings of the Section on Survey Research Methods, American Statistical Association, Anaheim, CA, USA, 6–9 August 1990; pp. 354–359. [Google Scholar]
- Amigó, J.M.; Dale, R.; King, J.C.; Lehnertz, K. Generalized synchronization in the presence of dynamical noise and its detection via recurrent neural networks. Chaos 2024, 34, 123156. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).