Abstract
Stock price prediction is a core challenge in quantitative finance. While machine learning has advanced the modeling of complex financial time series, existing methods often rely on single-target predictions, underutilize multidimensional market information, and are disconnected from practical trading systems. To address these gaps, this research develops a hybrid machine learning framework for flexible target forecasting and systematic trading of major American technology stocks. The framework integrates Ensemble Models (AdaBoost, Decision Tree, LightGBM, Random Forest, XGBoost) with Fusion Models (Voting, Stacking, Blending) and introduces a Transfer Learning method enhanced by Dynamic Time Warping to facilitate knowledge sharing across assets, improving robustness. Focusing on ten key stocks, we forecast three distinct momentum indicators: next-day Closing Price Difference, Moving Average Difference, and Exponential Moving Average Difference. Empirical results demonstrate that the proposed Transfer Learning approach achieves superior predictive performance and trading simulations confirm that strategies based on these predicted momentum signals generate substantial returns. This research demonstrates that the proposed hybrid machine learning framework can mitigate the high information entropy inherent in financial markets, offering a systematic and practical method for integrating machine learning with quantitative trading.
1. Introduction
Interdisciplinary research integrating finance and computer science is advancing rapidly, with growing applications in areas such as option pricing and default risk modeling [1,2,3]. In quantitative finance, stock price forecasting represents a central line of inquiry, serving both to mitigate trading risks and to pursue excess returns [4]. From an information theory perspective, financial markets can be viewed as high-entropy systems shaped by continuous information flows and inherent uncertainties reflected in price movements. Consequently, predicting stock prices entails the identification of temporary, localized low-entropy signals within a broadly high-entropy environment [5,6]. Driven by improvements in computational hardware and declining model training costs, methodological approaches in this field have evolved from traditional statistical models toward advanced artificial intelligence techniques, particularly machine learning and deep learning algorithms [7]. These methods provide greater flexibility in capturing complex nonlinear dynamics present in financial time-series data [8]. Recent empirical studies underscore the effectiveness of hybrid frameworks that combine established time-series models with data-driven machine learningtechniques. For example, Generalized Autoregressive Conditional Heteroskedasticity (GARCH), along with its variants such as Glosten-Jagannathan-Runkle GARCH (GJR-GARCH) and Exponential GARCH (EGARCH), have been integrated with Support Vector Machines (SVM) to forecast financial indicators [9]. Moreover, optimization algorithms like Particle Swarm Optimization (PSO) have been successfully coupled with SVM or deep learning architectures to predict movements in equity indices such as the S&P 500 index [10]. Convolutional Neural Networks (CNN), originally developed for computer vision tasks, have also been merged with Long Short-Term Memory (LSTM) to form CNN-LSTM models, which have been applied to forecast carbon prices in Chinese markets [11]. These hybrid methodologies demonstrate considerable potential for improving predictive accuracy, thereby supporting the development of more profitable automated trading systems.
However, a significant limitation persists in the extant literature on stock price prediction: current research efforts remain concentrated on forecasting univariate targets, such as future price levels or short-term directional movements like next-day price changes [12,13]. Although such studies possess academic value, this narrow focus inherently restricts the exploitation of multidimensional information embedded within price dynamics, thereby constraining the breadth of analytical inquiry. Empirical evidence indicates that predictive performance varies substantially across different target variables, model architectures, and temporal horizons [14,15,16]. More critically, single-target prediction frameworks are often inadequate for capturing the multidimensional uncertainties stemming from the market’s inherent entropy. For example, high-frequency trading strategies exhibit sensitivity to immediate momentum signals like Closing Price Returns, while trend-following approaches rely on smoothed indicators more heavily, such as Moving Average Crossovers. As a result, a model optimized for predicting next-day Closing Price Differences may yield divergent or even contradictory outcomes when applied to strategies based on Moving Average (MA) Differences [17]. This disconnect between predictive modeling and strategic implementation fundamentally undermines the adaptability and robustness of quantitative trading systems.
This research introduces an innovative flexible target machine learning framework designed to enhance quantitative trading by simultaneously forecasting three variables: the next-day Closing Price difference, MA difference, and the Exponential Moving Average (EMA) difference. This flexible target setup establishes a robust analytical foundation for evaluating algorithm strategies. By capturing distinct temporal dynamics of market momentum, these complementary predictors enable more resilient quantitative decision-making. The framework is designed to measure market behavior across multiple dimensions, thereby encoding information from different levels of the price series more completely and offering a finer depiction of the market’s complex entropy structure. While Ensemble Models such as LightGBM and XGBoost exhibit strong standalone predictive performance, they often underutilize latent information available in cross-stock datasets. To address this limitation, we incorporate Transfer Learning technology [18], which extracts domain knowledge from source domains containing structurally similar stocks, thereby mitigating the high noise and uncertainty inherent in single-stock data.
We propose and validate a hybrid machine learning framework for flexible target stock prediction designed to support quantitative trading decisions. The methodology consists of three interconnected stages. First, we construct an extensive feature set derived from historical price data and technical indicators for ten American technology stocks: Apple (AAPL), Advanced Micro Devices (AMD), Amazon (AMZN), Broadcom (AVGO), Google (GOOG), Meta Platforms (META), Microsoft (MSFT), NVIDIA (NVDA), Oracle Corporation (ORCL), and Tesla (TSLA), selected based on their significant index weights and market capitalization dominance. Second, we define three distinct prediction targets: the next-day Closing Price Difference, MA Difference, and EMA Difference. To capture complementary market signals, each target is modeled using Ensemble Models (AdaBoost, Decision Tree, LightGBM, Random Forest, and XGBoost), Fusion Models (Voting, Stacking, and Blending), and Transfer Learning. Finally, trading strategies are systematically constructed from model predictions across stock, model, and target dimensions, and rigorously evaluated via backtesting in a simulated environment. Performance is assessed based on profitability, risk-adjusted returns, and robustness under varying market regimes. This research makes contributions in the following three aspects:
- This research proposes a hybrid forecasting framework that integrates Ensemble Models, Fusion Models, and Transfer Learning for flexible target stock prediction, demonstrating superior performance compared to conventional single-target forecasting models. The framework offers investors a more comprehensive analytical foundation and yields predictions with broader practical applicability.
- We illustrate how predictions for distinct targets like Closing Price Difference, EMA Difference, and MA Difference can be systematically translated into quantitative trading strategies. This establishes a clear and reproducible pathway from model outputs to executable trading logic, thereby offering actionable insights for real world quantitative decision making.
- Through extensive empirical evaluation, we provide robust evidence on the comparative effectiveness of various machine learning models under flexible target settings and underscore the role of transfer learning in mitigating overfitting and enhancing predictive accuracy. These findings offer systematic support for employing machine learning techniques to better characterize and manage market uncertainties from an information theory standpoint.
The remainder of this paper is organized as follows: Section 2 reviews the relevant literature on stock prediction, machine learning techniques, and the application of Transfer Learning in finance. Section 3 delineates the methodological framework, encompassing data preprocessing, feature engineering, model specifications, prediction algorithms, and trading strategy design. Section 4 elucidates the experimental results derived from the model predictions, along with an analysis of the quantitative trading outcomes. Finally, Section 5 summarizes the key findings of the research and outlines potential directions for future research.
2. Related Works
This section synthesizes the evolution of methodologies in financial time series prediction, tracing the progression from traditional statistical models to contemporary machine learning and deep learning algorithms. We then examine a critical yet frequently underemphasized factor in stock prediction literature: the significant influence of target variable selection on model performance. Subsequently, we analyze recent advances and persistent challenges associated with applying Fusion Models and Transfer Learning within financial contexts. Finally, we conclude by synthesizing the limitations of prior research to clearly delineate the novelty and contributions of our research.
Financial time series prediction is a core in quantitative finance. Early research mainly relied on linear statistical frameworks, including Autoregressive Moving Average (ARMA), Autoregressive Integrated Moving Average (ARIMA), and Generalized Autoregressive Conditional Heteroskedasticity (GARCH) models, to forecast price movements and volatility under specific stationarity assumptions [19,20]. However, the inherent stochasticity, nonlinear dynamics, and non-stationarity of financial markets fundamentally limit the efficacy of these parametric approaches, which often struggle to capture the complex, chaotic characteristics of asset prices [21]. The advent of high-performance computing and big data infrastructure has catalyzed a paradigm shift toward data-driven, non-linear modeling techniques. Machine learning and deep learning algorithms, such as Random Forests, Neural Networks, LSTM, and Transformer with attention mechanisms, have emerged as state-of-the-art solutions due to their superior capacity for learning complex market patterns from data without restrictive prior assumptions [22,23,24]. A significant trend in current research involves the development of hybrid modeling frameworks that integrate knowledge across methodological domains. For instance, combining GARCH-family models with machine learning algorithms has demonstrated enhanced volatility forecasting performance and improved profitability across different stocks [25]. More recently, multimodal fusion strategies leveraging Large Language Models (LLM), Transformers, and CNN have been pioneered to harness cross-architectural synergies and mitigate prediction errors [26,27].
Existing literature on stock price prediction has primarily focused on forecasting directional movements or next-day Closing prices. However, it is increasingly recognized that the specification of target variables critically shapes input feature engineering and predictive accuracy, thereby exerting a decisive influence on the efficacy of quantitative trading strategies. For instance, Lim et al. demonstrated substantial performance heterogeneity across different temporal windows and label formulations in both machine learning and deep learning [28]. To mitigate noise interference, our previous paper introduced MA as alternative predictive targets. Empirical evidence confirms that applying MA transformations to price data can substantially reduce daily prediction errors [29]. This research extends the predictive scope from MA to include the EMA, constructing a more practically valuable forecasting framework. While MA-based predictions help identify and confirm stable trends due to their smoother response, the incorporation of EMA differences leverages its heightened sensitivity to recent price changes, enabling earlier detection of trend shifts and supporting short-term trading signals. Nevertheless, most existing studies remain confined to singular target paradigms, lacking systematic comparative analyses among Closing Price Difference, MA Difference, and EMA Difference within a unified modeling framework. At the modeling level, the field has evolved from single model systems toward hybrid architectures that integrate base learners through Ensemble Models.
Machine learning algorithms, including Random Forest, Gradient Boosting, SVM, and XGBoost have demonstrated strong predictive performance in equity markets by effectively controlling overfitting and capturing complex nonlinear feature interactions [30]. These methods, however, often rely on isolated ensemble assumptions, where each base model is trained separately on the same dataset. While effective in certain settings, this approach can lead to substantial performance fluctuations under different market regimes, thereby limiting prediction consistency and stability. To address this issue, Fusion Models have been introduced as integrated frameworks that combine multiple base models to enhance robustness and generalization capability beyond what a single model can achieve.Empirical support for such approaches extends beyond finance; for instance, in medical prognostics such as renal cell carcinoma, Fusion Models have been shown to yield more consistent predictions while retaining interpretability [31]. In quantitative finance, Gul et al. validated these advantages through backtesting on META stock, confirming that fusion-based methods deliver significantly improved stability in trading performance [32]. Furthermore, Transfer Learning offers a promising pathway to mitigate distributional shifts and data scarcity in financial time series analysis. By leveraging knowledge from source domains, such as historical data of established stocks or correlated assets, this approach enhances model adaptability for target domains with limited samples, such as newly listed equities [33,34]. Although widely adopted in computer vision, natural language processing, and robotics, the application of Transfer Learning in quantitative trading remains nascent [35,36]. This research explores the transfer of knowledge learned from American technology stocks, with the aim of improving predictive accuracy.
A predominant focus in extant financial forecasting research has been on predicting univariate targets, such as equity prices or crude oil futures, with evaluation often confined to point-prediction accuracy metrics. However, such studies often neglect to systematically integrate the predicted labels or signals into a complete quantitative trading framework for closed-loop validation [37,38,39]. We contend that bridging predictive analytics with executable strategy implementation constitutes an essential test of validity for any financial machine learning model. Our previous work has established foundational methodologies in this domain, demonstrating the efficacy of integrating regression-classification techniques into trading systems [40], as well as achieving robust performance through volatility-informed strategy design [25]. Building upon these advances, the present research extends the prediction targets from volatility measures to a set of multi-dimensional difference indicators, thereby enhancing market regime adaptability. Furthermore, we develop a backtesting environment that incorporates real world transaction constraints. The framework enables a rigorous evaluation of algorithm label synergies through professional performance metrics, including Annualized Return and Maximum Drawdown, thus establishing an integrated pipeline from predictive signal generation to decision support.
3. Methodology
This research establishes a systematic comparative framework to evaluate the predictive performance of Ensemble Models, Fusion Models, and Transfer Learning techniques in a flexible target price diffusion modeling context, focusing on high-profile American technology stocks. The resulting predictive signals are systematically integrated into quantitative trading strategies and rigorously evaluated through backtesting procedures. The overall technical architecture, illustrated in Figure 1, consists of three interconnected phases: data preparation and feature engineering, model construction and training, and quantitative trading strategy.
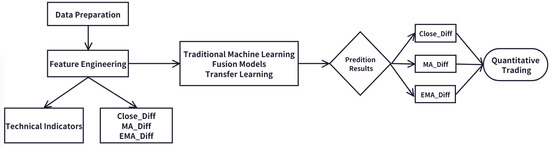
Figure 1.
Experimental Framework.
3.1. Data Preparation and Feature Engineering
This research selects a representative sample of ten leading technology stocks listed on the NASDAQ market: AAPL, AMD, AMZN, AVGO, GOOG, META, MSFT, NVDA, ORCL, and TSLA. These firms hold dominant positions in the global technology sector and exhibit high liquidity, substantial market capitalization, and pronounced sensitivity to market fluctuations, making them well-suited for evaluating predictive models. Daily market data spanning from January 2017 to December 2024 are obtained from official NASDAQ sources [41]. This period encompasses multiple market regimes, including periods of bullish momentum, high volatility, and sector-wide corrections, thereby providing a robust basis for model validation.
In contrast to conventional approaches that primarily focus on univariate targets such as directional price movements or Closing Price Differences, this research introduces an innovative flexible target prediction framework. It is designed to simultaneously capture complementary aspects of price dynamics through the following predictive objectives: the next-day’s Closing price Difference (), the next-day’s MA Difference () and the next-day’s EMA Difference (). Among them, both MA and EMA are selected as the moving average values of the past five days. This flexible target design enables us to evaluate the relative performance of the model in predicting absolute price movements () and smoothing trend momentum (, ). The specific calculation formula for the dependent variable is as follows:
To quantify the uncertainties associated with the next-day , , and , we employ information entropy as the theoretical foundation for our calculations. Information entropy is a fundamental concept in information theory that measures the uncertainty inherent in a random variable [42]. For a discrete random variable X taking possible values with a corresponding probability distribution , the information entropy is defined as:
The information entropy is measured in bits. A higher entropy value indicates greater uncertainty associated with the variable, which corresponds to a larger amount of embedded information and increased difficulty in predicting its fluctuation pattern. Conversely, a lower entropy reflects a more stable time series with reduced uncertainty. Among the three difference variables examined in this research, we assign a value of −1 when the difference is negative and 1 when it is positive. Following this binary discretization, the probabilities and are derived, with their sum equaling 1. Based on the formal definition of information entropy, the entropy for each of the three price differences is computed, as summarized in Table 1. The results indicate that the entropy of the is higher than that of the and the , implying greater predictive uncertainty. In contrast, the smoothed EMA and MA differences exhibit lower entropy and reduced uncertainty, providing a empirical rationale for selecting appropriate forecasting schemes based on different MA types.

Table 1.
The Information Entropy for Dependent Variables.
The feature engineering framework employed in this research is designed to comprehensively capture information pertaining to market price trends, momentum, volatility, and trading volume. For each of the three dependent variables under consideration, we construct a set of trend and momentum attributes. These include Close, MA and EMA computed over multiple historical windows, which are widely adopted in financial forecasting to represent near-term, medium-term, and long-term price behaviors. While longer horizons such as the 50 days MA and 200 days MA are used as input variables [43,44], another recent paper incorporates averaged trading volumes as predictive features [45]. In our setup, the 5 days, 10 days, and 20 days MA or EMA are selected as inputs, corresponding to short-term, medium-term, and long-term trend signals commonly used in actual trading environments. Prior to feature construction, initial data cleaning is performed to remove missing values. In addition, to mitigate the influence of scale variation across variables, all numerical features are standardized using Z-score normalization, which enhances model stability and convergence during training.
- For the dependent variable, we construct the Closing prices for the past five days (, , …, ) and its daily price difference (, …, ).
- For the dependent variable , we construct the MA prices for the past five days (, , …, ) including the consecutive 5 days MA, 10 days MA, and 20 days MA, and its daily degree difference (, …, ).
- For the dependent variable , we construct the EMA prices for the past five days (, , …, ) including the consecutive 5 days EMA, 10 days EMA, and 20 days EMA, and its daily degree difference (, …, ).
To construct a predictive model capable of comprehensively capturing market dynamics, we construct a set of financial technical indicators spanning multiple dimensions, including price trends, momentum, volatility, trading volume, and market sentiment to provide a unified representation of market conditions for all models. The selected features include Bollinger Bands, Relative Strength Index (RSI), Average True Range (ATR), On-Balance Volume (OBV), trading volume over the past four days, trading volume difference, Commodity Channel Index (CCI), Stochastic Oscillator (SlowK and SlowD), and Moving Average Convergence Divergence (MACD).
Bollinger Bands, a widely recognized volatility indicator developed by John Bollinger, consist of a central MA line flanked by an upper band and a lower band. These bands are positioned at a distance determined by the standard deviation of price, allowing the indicator to adapt dynamically to changing market volatility conditions. In practice, when the price touches the upper band, it is often interpreted as an overbought signal; conversely, touching the lower band is generally viewed as an oversold signal [46]. We incorporate both the upper and lower Bollinger Bands as input features. The calculations are performed as follows:
The RSI is used to measure the speed of price changes. It assesses whether an asset is in an overbought or oversold state by comparing the average increase and average decrease of the Closing price within a certain period [47]. The RSI range is from 0 to 100. It is generally believed that a value above 70 indicates overbought conditions and a value below 30 indicates oversold conditions. It is calculated using the standard 14-days cycle.
The ATR indicator is used to measure the volatility of the market. It can be calculated based on the average difference of highest price and lowest price over a period of time, and can effectively capture the intensity of price fluctuations [48]. When the ATR value rises, it indicates increasing volatility; when the ATR value drops, it suggests that the market is calming down. It is calculated using a 14-days cycle.
OBV is a momentum indicator that combines trading volume with price changes. Its movement can be used to confirm the price trend or detect divergence. When the Closing price rises, the trading volume of the day will be added to the OBV. When the Closing price drops, the trading volume of the day will be reduced by OBV [49].
CCI is used to determine whether asset prices have deviated. It compares the current price with the average price over a period and divided by the average deviation during that period [50]. The range of CCI usually varies between −100 and 100. Beyond this range, it may indicate a change in the strength of the trend.
SlowK and SlowD are momentum indicators that determine the strength of a trend and potential turning points by comparing the Closing price with the price range within a specific period of time. It consists of two lines: the fast line %K, and the slow line %D, which is the MA of %K [51].
MACD shows the direction, momentum, duration and intensity of a trend by calculating the difference between two EMA lines of different periods [52].
3.2. Model Construction and Training
This section outlines the predictive modeling framework developed in this research, which is designed as a flexible target integrated learning system. The framework consists of three core components: Ensemble Models, Fusion Models, and Transfer Learning-enhanced methods. To ensure robust and comparable performance, five well-established machine learning algorithms: AdaBoost, Decision Tree, LightGBM, Random Forest, and XGBoost are selected as base models. These models span a range of structures from individual tree-based methods to ensemble techniques founded on distinct principles such as bagging and boosting, enabling the capture of a broad spectrum of potential linear and nonlinear patterns inherent in financial data [53]. To fully exploit the predictive capability of each model, hyperparameter optimization is systematically performed using a Grid Search strategy, with the principal objective of enhancing generalization performance. The detailed search spaces for the hyperparameters of each model are provided below.
- AdaBoost: n_estimators (50, 100, 200, 300), learning_rate (0.001, 0.01, 0.1, 1).
- Decision Tree: criterion (‘squared_error’, ‘friedman_mse’, ‘absolute_error’), max_depth (None, 10, 15, 20), max_features (None, ‘sqrt’, ‘log2’), min_samples_split (2, 5, 10), min_samples_leaf (2, 4, 8).
- LightGBM: learning_rate (0.01, 0.05, 0.1), n_estimators (100, 200, 300), max_depth (3, 5, 7), reg_alpha (0, 0.1, 0.5), reg_lambda (0, 0.1, 1), feature_fraction (0.8, 0.9, 1.0).
- Random Forest: n_estimators (50, 100, 200, 300), max_depth (None, 10, 20), max_features (‘auto’, ‘sqrt’, ‘log2’), min_samples_split (2, 5, 10).
- XGBoost: n_estimators (25, 50, 100, 200), max_depth (3, 5, 8), subsample (0.6, 0.8, 1.0), reg_alpha (0, 0.1, 0.5, 1), reg_lambda (0, 0.1, 0.5, 1).
To integrate the strengths of diverse base models, this research implements three established Fusion Model strategies: Voting, Stacking, and Blending. For consistency and comparability, the same set of optimized Ensemble Models serves as the first-layer base models across all fusion approaches. In the Voting method, the regression predictions from all base models for future price differences are aggregated by computing their arithmetic mean, which is then adopted as the final fused output. The Stacking strategy employs a five-fold cross-validation procedure to generate out-of-fold predictions from the base models, which are subsequently used as meta-features. A Linear Regression model acts as the meta model to avoid overfitting problem, trained to optimally combine these predictions. For the Blending method, the training set is partitioned into a base model training subset and a held-out validation set. Predictions from the base models on this validation set form the meta-features used to train the meta model, reducing the risk of information leakage compared to Stacking.
The methodological innovation of this research lies in integrating Dynamic Time Warping (DTW) distance with Fusion Models, thereby introducing a Transfer Learning-enhanced ensemble approach for stock price prediction. In the context of time series prediction, DTW serves as a robust similarity measure that quantifies the alignment between sequences, even in the presence of nonlinear temporal distortions, thus enabling more informed knowledge transfer from source to target domains. By computing the optimal warping path between two sequences, DTW effectively captures similarities in shape, trend, and fluctuation patterns, which is critical for identifying suitable source domains from candidate datasets. Now DTW has been widely adopted in non-financial domains such as wind power prediction and energy forecasting [54,55,56]. And in stock prediction, DTW is also used to measure the similarity between different stocks for Transfer Learning [57]. In our research, DTW is employed to measure pairwise similarity among ten American technology stocks, all of which operate in related market segments and exhibit strong real world business linkages and correlated price movements. For each target stock, the DTW distances to the other nine stocks are computed based on their Closing sequences from 2017 to 2021. The resulting distance is used to assign a transfer weight , defined as the reciprocal of the distance:
We introduce three integrated variants of Fusion Models combined with Transfer Learning: Transfer Voting, Transfer Stacking, and Transfer Blending. For each source stock i, a distinct Fusion Model is independently trained to predict a target variable specific to that source domain. This process yields a set of source-specific models , each capturing domain-specific predictive characteristics. The final prediction for a target stock is obtained by computing a weighted aggregation of the predictions from all nine source-domain models. The weight assigned to each source model is determined by the inverse of the DTW distance between the source stock i and all the target stocks, thereby assigning greater influence to models originating from more similar market dynamics. The aggregated prediction is formally expressed as:
This approach ensures that predictions from models trained on source stocks exhibiting higher dynamic pattern similarity with lower DTW distance are assigned greater influence in the final aggregated forecast. To evaluate the effectiveness of the proposed modeling frameworks, we compare the Transfer Learning-enhanced variants against two baseline categories: Fusion Models trained solely on the target stock’s data, and Ensemble Models. Predictive performance is quantified using four widely adopted regression metrics: the coefficient of determination (R Squared), Mean Absolute Error (MAE), Mean Squared Error (MSE), and Root Mean Squared Error (RMSE). These metrics collectively assess the deviation between predicted and actual values from complementary perspectives. The R Squared metric measures the proportion of variance in the dependent variable that is predictable from the independent variables. A value closer to 1 indicates a better model fit, meaning the model more effectively explains the variability of the target output. The MAE, MSE, and RMSE reflect different aspects of prediction error, with values closer to zero signifying higher accuracy. MAE provides a linear score of the average error magnitude, offering an intuitive interpretation. In contrast, MSE and RMSE, by squaring the errors, assign a disproportionately higher penalty to large prediction errors, thereby highlighting the model’s robustness to outliers. The formulas for calculating these metrics are provided below:
3.3. Quantitative Trading Strategy
Quantitative trading represents a systematic investment approach that relies on computational systems to execute automated trading decisions. By analyzing historical market data and identifying statistical patterns, this methodology aims to minimize the impact of investors’ subjective emotions, thereby improving investment efficiency and stability through disciplined strategy implementation. The innovation of the flexible target machine learning quantitative trading strategy proposed in this research lies in its comprehensive integration of multiple technical indicators to forecast short-term price movements, followed by rule-based trading operations derived from these predictions.
Innovatively, we employs three distinct price-based indicators: , and as prediction targets to capture market momentum characteristics across multiple time horizons. Five Ensemble Models are utilized for prediction, and their outputs are integrated through Voting, Stacking, and Blending. To further enhance model robustness, Transfer Learning is incorporated to develop upgraded variants of each fusion approach. In total, eleven prediction models are constructed. Each model generates forecasts for the three target variables, yielding 33 distinct prediction results that collectively form a comprehensive quantitative trading signal. The trading strategy is designed as follows: a predicted positive difference for the next day is interpreted as a bullish signal, triggering a buy order when no position is held. Conversely, a predicted negative difference is treated as a bearish signal, prompting a sell order when a position exists. This logic is grounded in the assumption that a positive difference indicates strengthening momentum or an emerging uptrend, while a negative value suggests potential momentum decay or a trend reversal [58].
To evaluate the effectiveness of the trading strategy, we employ a backtesting framework to simulate real-market trading conditions. The simulation is implemented using the Backtrader platform, and the initial capital is $100,000, the commission for trading stocks is 0.025%, and slippage is also set. Annualized Return and Maximum Drawdown are selected as core performance metrics. The Annualized Return reflects the expected return of the strategy over a one-year horizon. A higher value indicates stronger profitability. It is calculated as follows:
Maximum Drawdown measures the largest peak-to-trough decline in portfolio value during the investment period, serving as a key indicator of strategy risk. A smaller Maximum Drawdown implies better capital preservation and lower downside risk.
4. Experimental Results and Discussion
This section conducts a systematic performance comparison among Ensemble Models, Fusion Models, and Transfer Learning approaches for forecasting flexible target prices of major American technology stocks (AAPL, AMD, AMZN, AVGO, GOOG, META, MSFT, NVDA, ORCL, and TSLA). Based on the prediction outputs, quantitative trading strategies are formulated and assessed through backtesting. Predictive accuracy is evaluated using multiple regression metrics: R Squared, MAE, MSE, and RMSE. The dataset covers the period from January 2017 to December 2024. Daily trading data from 2017 to 2021 are used to train all models, while data from 2022 to 2024 are reserved as the test set for evaluating predictive performance and conducting quantitative strategy backtesting.
4.1. Regression Prediction Results
This section conducts a systematic comparative analysis of all combinations between machine learning models and predictor variables for each target stock. Specifically, three predictor variables are evaluated using eleven distinct machine learning algorithms, resulting in a total of 33 unique model-variable configurations. To ensure the robustness of the regression predictions, performance metrics are aggregated and summarized as the Mean plus or minus the Standard Deviation (Mean ± SD), providing an integrated evaluation of predictive consistency and stability across all stocks.
As illustrated in Table 2, the predictive performance exhibits considerable variation across individual stocks. Machine learning models achieve relatively high forecasting performance for AAPL, AMZN, AVGO, GOOG, NVDA, and ORCL, with MAE values consistently below 1.5, accompanied by comparatively low MSE and RMSE figures. In contrast, predictions for META, MSFT, and TSLA are associated with larger MAE values, exceeding 2.3. This performance disparity can be largely attributed to stock-level heterogeneity, wherein differences in market exposure, capitalization, liquidity, and firm-specific operational decisions collectively contribute to distinct price fluctuation patterns. Within the sample, stocks demonstrating smaller prediction errors, such as AAPL, AMZN, and GOOG, typically belong to well-established American technology giants characterized by substantial market capitalizations, and high liquidity. The price trends of these stocks tend to be relatively stable, less susceptible to singular unexpected events, and thus exhibit more consistent historical patterns that are more readily captured by machine learning algorithms. Conversely, each of the stocks associated with larger prediction errors presents unique challenges. TSLA is widely known for its high volatility and sensitivity to CEO commentary and shifts in market sentiment. These nonlinear and often difficult-to-quantify factors substantially increase forecasting difficulty. During the test period, META underwent a significant strategic transformation centered on its metaverse initiative, which introduced considerable valuation uncertainty and stock price fluctuations as the market reassessed its prospects. Although MSFT is generally regarded as a stable blue-chip stock, its price dynamics during the testing set were likely influenced by singular impactful events, such as its acquisition of Activision Blizzard. Such structural breaks can disrupt the statistical regularities present in historical data, thereby impairing the model’s ability to accurately capture subsequent price movements.
Table 2.
The Error Performance for Each Stock.
We further classifies the results according to the dependent variable under consideration. As illustrated in Figure 2 and Table 3, the predictive performance varies substantially across the three target variables. These results underscore that the choice of prediction target exerts a decisive influence on the performance of machine learning models in financial time series forecasting. Among the three targets, the model predicting the exhibits the weakest performance. This is evidenced by a negative R Squared values and a larger SD relative to the other two targets. In terms of error metrics, the MSE for is not only significantly higher but also demonstrates considerable volatility. From a technical perspective, the and incorporate smoothing that mitigates noise, thereby making underlying trends more discernible. In real market contexts, Closing prices are often susceptible to short-term noise and irrational trading behaviors, particularly during late trading sessions, which complicates trend extraction [59]. In contrast, EMA and MA offer a more robust representation of the genuine market trend by filtering out high-frequency fluctuations. Consistent with the entropy measures reported in Table 1, the higher entropy value associated with reflects greater underlying uncertainty, which in turn corresponds to the model’s inferior predictive performance.
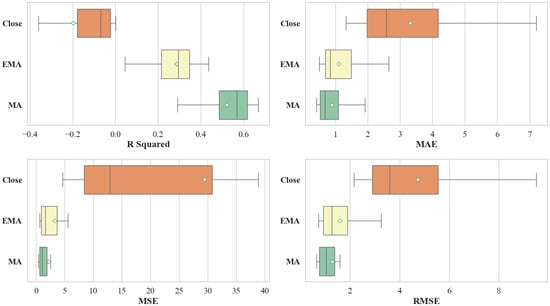
Figure 2.
Comparisons of Regression Results Based on Dependent Variables.
Table 3.
The Error Performance for Dependent Variables.
In evaluating the performance of the machine learning models, Significant differences are observed across the different model categories. Ensemble Models contain AdaBoost, Decision Tree, LightGBM, Random Forest, and XGBoost. Fusion Models contain Voting, Stacking, and Blending. Transfer Learning contains Transfer Voting, Transfer Stacking, and Transfer Blending. As summarized in Table 4, the Transfer Learning approach achieves the highest average R Squared value, alongside the lowest mean values for MAE, MSE, and RMSE, indicating its superior overall predictive accuracy among the evaluated methods. The Fusion Models also demonstrate robust performance, with its evaluation metrics closely trailing those of the Transfer Learning Technique. In contrast, the individual Ensemble Models exhibit greater performance dispersion and relatively lower average predictive accuracy. The outstanding results of the Fusion Models and Transfer Learning suggest that strategies which effectively combine multiple base learners or leverage DTW based weighting for cross-domain knowledge transfer are better equipped to capture the complex, nonlinear dynamics inherent in flexible target stock price forecasting. The comparatively larger SD associated with the individual Ensemble Models’ results points to higher instability in performance across different stocks and target variables.
Table 4.
The Error Performance of Machine Learning Models for Different Styles.
Table 5 provides a detailed breakdown of prediction errors for each model, based on the comparative framework established in Table 4. The results indicate that Ensemble Model, specifically AdaBoost and XGBoost exhibit moderate predictive performance, as reflected in their relatively low R Squared values and elevated MAE and RMSE. Furthermore, these models demonstrate considerable fluctuation across evaluation metrics, suggesting sensitivity to specific stock characteristics or market regimes. In contrast, Voting, Stacking, and Blending deliver more stable performance, with consistently lower error metrics and reduced variability. This aligns with the expectation that combining multiple base learners can mitigate individual model biases and enhance robustness. Notably, the Transfer Learning model achieves superior error control, slightly outperforming even the Fusion Models in terms of prediction accuracy. This improvement can be attributed to its ability to leverage shared patterns across related stocks, thereby reducing overfitting and strengthening generalization under market uncertainty. These findings are consistent with existing literature emphasizing the role of model integration and cross-domain knowledge transfer in improving forecast reliability in high entropy financial environments.
Table 5.
The Error Performance of Different Machine Learning Models.
4.2. Quantitative Trading Results
By classifying the trading performance at the individual stock level, we conduct a data analysis of strategy effectiveness. Figure 3 illustrates a simulated transaction sequence for NVDA using the Transfer Stacking method with the predictive target, where green markers indicate entry points and red markers denote exit points, visually reflecting profit and loss dynamics throughout the trading period. For each stock, we compute the Annualized Return and the Maximum Drawdown within a 95% confidence interval to ensure statistical robustness. Building on the prediction results outlined in the previous section, we select Fusion Models and Transfer Learning, representing the top-performing methodologies as the core engines for strategy construction. Correspondingly, the and , which demonstrated lower prediction errors, are adopted as the primary forecasting variables in the quantitative trading system.
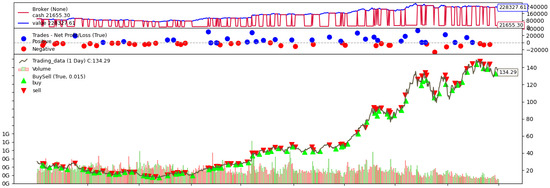
Figure 3.
Trading Simulation of NVDA.
As summarized in Table 6 and Figure 4, the machine learning driven strategies yield heterogeneous returns across the stock universe. Notably, AVGO, NVDA, and TSLA deliver the most pronounced profitability. In particular, AVGO and NVDA exhibit substantial cumulative gains, whereas TSLA, despite considerable fluctuations, also generates positive returns, a pattern conducive to buy-low-sell-high strategy modeling. Interestingly, although TSLA’s prediction accuracy was moderate in earlier evaluations, it achieves significant profitability in real world trading simulations, suggesting that prediction error alone does not fully capture trading potential. In contrast, other stocks such as AMD and META underperform. AMD consistently yields negative returns throughout the test period. Inspection of its historical price trajectory reveals that although its volatility is lower than that of high-momentum stocks like TSLA, it has largely oscillated within a bounded range without exhibiting a sustained upward trend, unlike NVDA. This limited directional movement likely explains the model’s inability to generate consistent profits in a volatile market regime. More critically, AMD contributes a relatively high Maximum Drawdown, which would substantially impact real world investor decision-making due to elevated risk exposure. While META’s returns within the 95% confidence band surpass those of AMD, its Maximum Drawdown level undermines its overall risk-adjusted performance, rendering it inferior to other technology equities.
Table 6.
Machine Learning Quantitative Trading Performance for Different Stocks.
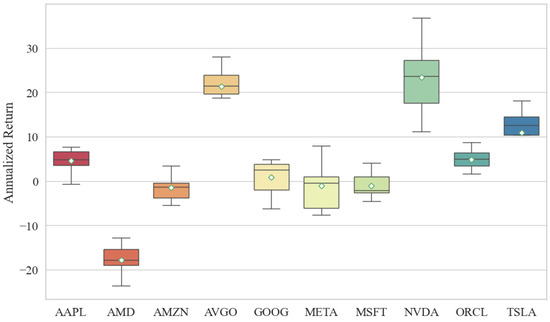
Figure 4.
Comparisons of Annualized Return Based on Different Stocks.
Similarly, we evaluate the profitability performance of all stocks from a modeling perspective, as summarized in Table 7. In general, the Transfer Voting and Transfer Stacking methods outperform their non-transfer counterparts Voting and Stacking respectively. However, the standard Blending model exhibits superior performance compared to the Transfer Blending. Among all models, Transfer Voting achieves the most notable Annualized Return. Notably, the lower bound of its 95% confidence interval exceeds that of all other models, while the upper bound is also significantly higher. In terms of risk exposure, as measured by the Maximum Drawdown, the Blending model demonstrates the narrowest drawdown range, albeit at the cost of a relatively modest profit margin. For the remaining five model categories, there is no statistically significant difference observed in their Maximum Drawdown intervals. Therefore, when jointly considering risk-adjusted returns and drawdown control, we recommend prioritizing the Transfer Voting model for practical applications in quantitative trading.
Table 7.
Quantitative Trading Performance for Machine Learning Models.
We further classifies the quantitative trading outcomes according to the dependent variable under investigation. As illustrated in the Table 8, the trading performance of the model exhibits notable variation between the two target variables. The machine learning model based on the demonstrates marginally superior performance compared to the , achieving an Annualized Return approximately 1–2% higher. In terms of risk control, the based model exhibits a Maximum Drawdown that is 1–3% lower, indicating better resilience under adverse market conditions. When considering the joint perspective of returns and risks, the focused strategy yields a more favorable risk-return profile.
Table 8.
Quantitative Trading Performance for Different Dependent Variables and Machine Learning Models.
Across both target variables, it is also observable that models incorporating Transfer Learning consistently outperform those relying solely on fusion techniques, with returns elevated by approximately 0.1–1%. This suggests that leveraging cross-stock knowledge transfer enhances predictive stability and profitability. In practical applications, investors may prioritize strategies built on , as they offer a more attractive trade-off between potential returns and risk exposure. Building on the insights from Table 7, investors are advised to consider adopting as the prediction target and employ Transfer Voting as the machine learning framework for stock forecasting, thereby constructing a robust and adaptive quantitative trading system.
5. Conclusions
This research presents a comprehensive evaluation of a hybrid forecasting framework that integrates Ensemble Models, Fusion Models, and Transfer Learning for flexible target stock price prediction and quantitative trading strategy generation in the American market. Through extensive experimentation and backtesting conducted on ten major American technology stocks, several key findings emerge. The proposed flexible target framework, simultaneously modeling the next-day , , and , captures market dynamics more comprehensively than conventional single target forecasting approaches. Empirical results indicate that models predicting smoothed trend indicators such as and achieve significantly lower forecasting errors compared to those targeting the raw series. This outcome underscores inherent differences among target variables in terms of noise resilience and trend representation. From an information theory perspective, the process of transforming raw price data into smoothed trends via technical indicators such as EMA and MA effectively filters out high-entropy market noise. The resulting sequences exhibit reduced complexity and a higher degree of temporal organization, which in turn enhances their predictability.
At the model level, Fusion Models consistently surpass individual traditional machine learning algorithms, underscoring the advantage of integrated Ensemble Models in enhancing prediction robustness and generalization capability. A key innovation introduced in this research, Transfer Learning further elevates performance by leveraging knowledge from stocks with analogous temporal patterns, thereby achieving the highest predictive accuracy in most situations. The results validate that Transfer Learning not only enhances target-stock forecasting by utilizing shared patterns from related equities but also effectively mitigates overfitting, particularly in high entropy market environments. Another major contribution lies in the direct translation of prediction outcomes into executable quantitative trading strategies, which are subsequently evaluated through rigorous backtesting simulations. The Transfer Learning models, particularly when applied to and , not only exhibits lower forecasting errors but also delivers superior trading performance, demonstrating a consistent ability to preserve capital and capture returns under American market.
Despite these results, several limitations should be considered. This research primarily relies on technical indicators derived from historical price and volume data. Future work can enhance the model’s robustness by incorporating more diverse data sources, such as macroeconomic indicators, fundamental corporate data, news sentiment, and social media analytics, to construct a more comprehensive representation of market conditions. The current Transfer Learning framework utilizes DTW as the core similarity measure; subsequent research can explore more advanced metrics based on sophisticated feature engineering or multimodal learning to better capture cross-asset relationships. Furthermore, the Transfer Learning architecture itself offers avenues for refinement. Investigating dynamic source stock selection mechanisms and cross-market knowledge transfer, rather than relying on a fixed set of technologically similar stocks, could improve adaptability to evolving market regimes. Extending the framework beyond individual stocks to model rotations among Exchange-Traded Funds across different sectors, represents another significant direction for developing more diversified strategic portfolios.
In terms of modeling, subsequent research may explore advanced deep learning architectures, such as Attention, Transformers, and Temporal Convolutional Networks (TCNs), to better capture long-range dependencies and complex, non-linear patterns inherent in financial time series. Finally, the application of LLM in interpreting market events, generating explanatory narratives for predictions, and even synthesizing trading logic presents a promising frontier for enhancing both the performance and interpretability of quantitative trading systems.
In summary, the proposed hybrid framework introduces a novel and effective methodology for integrating machine learning with quantitative trading. Its practical utility has been empirically validated through backtesting, demonstrating its ability to construct localized, dynamically adaptive structures within the prevailing high entropy market environment, ultimately yielding returns that consistently exceed the benchmark. Future research is expected to broaden the model’s applicability and enhance its robustness, thereby contributing to the advancement of intelligent quantitative investment systems.
Author Contributions
Conceptualization: K.Y., Z.Y. and Y.L.; methodology: Q.H. and Z.H.; data curation: C.C.W. and J.Z.; software: K.Y., Q.H., J.Z., Z.H. and Y.L.; investigation: K.Y., Z.Y. and C.C.W.; visualization: K.Y., Y.L. and Z.Y.; validation: Q.H., J.Z. and Z.H.; writing—original draft: K.Y. and Y.L.; writing—review & editing: K.Y., Z.Y., C.C.W., Q.H., J.Z., Z.H. and Y.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by grants from the Guangdong University of Finance Research Start-Up Fund, and 2024 Guangdong Province University Youth Innovation Talent Project (2024WQNCX123).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this research are available on request from the corresponding author.
Conflicts of Interest
The authors declare that there are no personal or organizational conflicts of interest with this research.
Abbreviations
The following abbreviations are used in this manuscript:
| Generalized Autoregressive Conditional Heteroskedasticity | GARCH |
| Glosten-Jagannathan-Runkle GARCH | GJR-GARCH |
| Exponential GARCH | EGARCH |
| Support Vector Machines | SVM |
| Particle Swarm Optimization | PSO |
| Convolutional Neural Networks | CNN |
| Long Short-Term Memory | LSTM |
| Moving Average | MA |
| Exponential Moving Average | EMA |
| Autoregressive Moving Average | ARMA |
| Autoregressive Integrated Moving Average | ARIMA |
| Large Language Models | LLM |
| Relative Strength Index | RSI |
| Average True Range | ATR |
| On-Balance Volume | OBV |
| Commodity Channel Index | CCI |
| Moving Average Convergence Divergence | MACD |
| Mean Absolute Error | MAE |
| Mean Square Error | MSE |
| Root Mean Square Error | RMSE |
| Artificial Intelligence | AI |
| Temporal Convolutional Networks | TCNs |
References
- Liu, H.; Huang, S.; Wang, P.; Li, Z. A review of data mining methods in financial markets. Data Sci. Financ. Econ. 2021, 1, 362–392. [Google Scholar] [CrossRef]
- Li, Y.; Yan, K. Prediction of barrier option price based on antithetic Monte Carlo and machine learning methods. Cloud Comput. Data Sci. 2023, 4, 77–86. [Google Scholar] [CrossRef]
- Li, Y.; Yan, K. Prediction of bank credit customers churn based on machine learning and interpretability analysis. Data Sci. Financ. Econ. 2025, 5, 19–34. [Google Scholar] [CrossRef]
- Vishwakarma, V.K.; Bhosale, N.P. A survey of recent machine learning techniques for stock prediction methodologies. Neural Comput. Appl. 2025, 37, 1951–1972. [Google Scholar] [CrossRef]
- Papla, D.; Siedlecki, R. Entropy as a tool for the analysis of stock market efficiency during periods of crisis. Entropy 2024, 26, 1079. [Google Scholar] [CrossRef]
- Gupta, R.; Drzazga-Szczȩśniak, E.A.; Kais, S.; Szczȩśniak, D. Entropy corrected geometric Brownian motion. Sci. Rep. 2024, 14, 28384. [Google Scholar] [CrossRef]
- Zhang, C.; Sjarif, N.N.A.; Ibrahim, R. Deep learning models for price forecasting of financial time series: A review of recent advancements: 2020–2022. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2024, 14, e1519. [Google Scholar] [CrossRef]
- Elsegai, H.; Al-Mutawaly, H.S.; Almongy, H.M. Predicting the Trends of the Egyptian Stock Market Using Machine Learning and Deep Learning Methods. Comput. J. Math. Stat. Sci. 2025, 4, 186–221. [Google Scholar] [CrossRef]
- Karasan, A. Machine Learning for Financial Risk Management with Python, 1st ed.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2021. [Google Scholar]
- Kuo, R.J.; Chiu, T.H. Hybrid of jellyfish and particle swarm optimization algorithm-based support vector machine for stock market trend prediction. Appl. Soft Comput. 2024, 154, 111394. [Google Scholar] [CrossRef]
- Shi, H.; Wei, A.; Xu, X.; Zhu, Y.; Hu, H.; Tang, S. A CNN-LSTM based deep learning model with high accuracy and robustness for carbon price forecasting: A case of Shenzhen’s carbon market in China. J. Environ. Manag. 2024, 352, 120131. [Google Scholar] [CrossRef]
- Wang, Y.; Yan, K. Prediction of significant bitcoin price changes based on deep learning. In Proceedings of the 5th International Conference on Data Science and Information Technology (DSIT), Shanghai, China, 22–24 July 2022; pp. 1–5. [Google Scholar]
- Yang, C.Y.; Hwang, M.S.; Tseng, Y.W.; Yang, C.C.; Shen, V.R. Advancing financial forecasts: Stock price prediction based on time series and machine learning techniques. Appl. Artif. Intell. 2024, 38, 2429188. [Google Scholar] [CrossRef]
- Lee, H.; Kim, J.H.; Jung, H.S. Deep-learning-based stock market prediction incorporating ESG sentiment and technical indicators. Sci. Rep. 2024, 14, 10262. [Google Scholar] [CrossRef] [PubMed]
- Shirata, R.; Harada, T. A Proposal of a Method to Determine the Appropriate Learning Period in Stock Price Prediction Using Machine Learning. IEEJ Trans. Electr. Electron. Eng. 2024, 19, 726–732. [Google Scholar] [CrossRef]
- Htun, H.H.; Biehl, M.; Petkov, N. Forecasting relative returns for S&P 500 stocks using machine learning. Financ. Innov. 2024, 10, 118. [Google Scholar]
- Wang, Y.; Yan, K. Application of Traditional Machine Learning Models for Quantitative Trading of Bitcoin. Artif. Intell. Evol. 2023, 4, 34–48. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef]
- Minhaj, N.; Ahmed, R.; Khalique, I.A.; Imran, M. A comparative research of stock price prediction of selected stock indexes and the stock market by using arima model. Glob. Econ. Sci. 2023, 4, 1–19. [Google Scholar] [CrossRef]
- Ariyo, A.A.; Adewumi, A.O.; Ayo, C.K. Stock price prediction using the ARIMA model. In Proceedings of the UKSim-AMSS 16th International Conference on Computer Modelling and Simulation, Cambridge, UK, 26–28 March 2014; pp. 106–112. [Google Scholar]
- Bhattacharjee, I.; Bhattacharja, P. Stock price prediction: A comparative study between traditional statistical approach and machine learning approach. In Proceedings of the 4th International Conference on Electrical Information and Communication Technology (EICT), Khulna, Bangladesh, 20–22 December 2019; pp. 1–6. [Google Scholar]
- Gkonis, V.; Tsakalos, I. A hybrid optimized deep learning model via the Golden Jackal Optimizer for accurate stock price forecasting. Expert Syst. Appl. 2025, 278, 127287. [Google Scholar] [CrossRef]
- Akhtar, M.M.; Zamani, A.S.; Khan, S.; Shatat, A.S.A.; Dilshad, S.; Samdani, F. Stock market prediction based on statistical data using machine learning algorithms. J. King Saud Univ.-Sci. 2022, 34, 101940. [Google Scholar] [CrossRef]
- Oyewola, D.O.; Akinwunmi, S.A.; Omotehinwa, T.O. Deep LSTM and LSTM-Attention Q-learning based reinforcement learning in oil and gas sector prediction. Knowl.-Based Syst. 2024, 284, 111290. [Google Scholar] [CrossRef]
- Yan, K.; Li, Y. Machine learning-based analysis of volatility quantitative investment strategies for American financial stocks. Quant. Financ. Econ. 2024, 8, 364–386. [Google Scholar] [CrossRef]
- Yan, J.; Huang, Y. MambaLLM: Integrating Macro-Index and Micro-Stock Data for Enhanced Stock Price Prediction. Mathematics 2025, 13, 1599. [Google Scholar] [CrossRef]
- Zhou, L.; Zhang, Y.; Yu, J.; Wang, G.; Liu, Z.; Yongchareon, S.; Wang, N. Llm-augmented linear transformer–cnn for enhanced stock price prediction. Mathematics 2025, 13, 487. [Google Scholar] [CrossRef]
- Lim, I.J.; Low, A.L.; Lim, K.Y. Evaluating the Effectiveness of Machine Learning Algorithms in Stock Price Prediction Across Different Time Frames. Hum. Interact. Emerg. Technol. 2025, 196, 33–42. [Google Scholar]
- Yan, K.; Wang, Y. Prediction of Bitcoin prices’ trends with ensemble learning models. In Proceedings of the 5th International Conference on Computer Information Science and Artificial Intelligence (CISAI 2022), Chongqing, China, 16–18 September 2022; pp. 900–905. [Google Scholar]
- Rai, B.; Soltanisehat, L. A Multi-Model Machine Learning Framework for Daily Stock Price Prediction. J. Abbr. 2025, 9, 248. [Google Scholar] [CrossRef]
- Yan, K.; Fong, S.; Li, T.; Song, Q. Multimodal machine learning for prognosis and survival prediction in renal cell carcinoma patients: A two-stage framework with model fusion and interpretability analysis. Appl. Sci. 2024, 14, 5658. [Google Scholar] [CrossRef]
- Gul, A. A Novel Hybrid Ensemble Framework for Stock Price Prediction: Combining Bagging, Boosting, Dagging, and Stacking. Comput. Econ. 2025, 1–31. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Yoon, S. A novel approach to short-term stock price movement prediction using transfer learning. J. Abbr. 2019, 9, 4745. [Google Scholar] [CrossRef]
- Pal, S.S.; Kar, S. Fuzzy transfer learning in time series forecasting for stock market prices. Soft Comput. 2022, 26, 6941–6952. [Google Scholar] [CrossRef]
- Gholizade, M.; Soltanizadeh, H.; Rahmanimanesh, M.; Sana, S.S. A review of recent advances and strategies in transfer learning. Int. J. Syst. Assur. Eng. Manag. 2025, 16, 1123–1162. [Google Scholar] [CrossRef]
- Jaquier, N.; Welle, M.C.; Gams, A.; Yao, K.; Fichera, B.; Billard, A.; Ude, A.; Asfour, T.; Kragic, D. Transfer learning in robotics: An upcoming breakthrough? A review of promises and challenges. Int. J. Robot. Res. 2025, 44, 465–485. [Google Scholar] [CrossRef]
- Wang, J.; Liu, J.; Jiang, W. An enhanced interval-valued decomposition integration model for stock price prediction based on comprehensive feature extraction and optimized deep learning. Expert Syst. Appl. 2024, 243, 122891. [Google Scholar] [CrossRef]
- Osman, E.G.A.; Otaibi, F.A. Integrating Deep Learning and Econometrics for Stock Price Prediction: A Comprehensive Comparison of LSTM, Transformers, and Traditional Time Series Models. Mach. Learn. Appl. 2025, 22, 100730. [Google Scholar] [CrossRef]
- Xu, Y.; Liu, T.; Fang, Q.; Du, P.; Wang, J. Crude oil price forecasting with multivariate selection, machine learning, and a nonlinear combination strategy. Eng. Appl. Artif. Intell. 2025, 139, 109510. [Google Scholar] [CrossRef]
- Wang, Y.; Yan, K. Machine learning-based quantitative trading strategies across different time intervals in the American market. Quant. Financ. Econ. 2023, 7, 569–594. [Google Scholar] [CrossRef]
- NASDAQ. Available online: https://www.nasdaq.com/ (accessed on 1 October 2025).
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Priyatno, A.M.; Ningsih, L.; Noor, M. Harnessing machine learning for stock price prediction with random forest and simple moving average techniques. J. Eng. Sci. Appl. 2024, 1, 1–8. [Google Scholar] [CrossRef]
- Anh, N.Q.; Son, H.X. Transforming stock price forecasting: Deep learning architectures and strategic feature engineering. In Proceedings of the International Conference on Modeling Decisions for Artificial Intelligence, Tokyo, Japan, 27–31 August 2024; pp. 237–250. [Google Scholar]
- Lu, M.; Xu, X. TRNN: An efficient time-series recurrent neural network for stock price prediction. Inf. Sci. 2024, 657, 119951. [Google Scholar] [CrossRef]
- Yan, K.; Wang, Y.; Li, Y. Enhanced Bollinger Band Stock Quantitative Trading Strategy Based on Random Forest. Artif. Intell. Evol. 2023, 4, 22–33. [Google Scholar] [CrossRef]
- Melda, M.; Mira, M.; Nurlina, N. Analysis of the effectiveness of rsi and macd indicators in addressing stock price volatility. Wiga J. Penelit. Ilmu Ekon. 2025, 15, 71–79. [Google Scholar] [CrossRef]
- Salkar, T.; Shinde, A.; Tamhankar, N.; Bhagat, N. Algorithmic trading using technical indicators. In Proceedings of the International Conference on Communication information and Computing Technology (ICCICT), Mumbai, India, 25–27 June 2021; pp. 1–6. [Google Scholar]
- Nti, I.K.; Adekoya, A.F.; Weyori, B.A. A systematic review of fundamental and technical analysis of stock market predictions. Artif. Intell. Rev. 2020, 53, 3007–3057. [Google Scholar] [CrossRef]
- Sharma, K.; Bhalla, R. A Comparative Analysis of Proposed and Existing Technical Indicators for Indian Stock Market. Procedia Comput. Sci. 2025, 259, 1619–1628. [Google Scholar] [CrossRef]
- Lai, C.Y.; Chen, R.C.; Caraka, R.E. Prediction stock price based on different index factors using LSTM. In Proceedings of the International Conference on Machine Learning and Cybernetics (ICMLC), Kobe, Japan, 7–10 July 2019; pp. 1–6. [Google Scholar]
- Wang, J.; Kim, J. Predicting stock price trend using MACD optimized by historical volatility. Math. Probl. Eng. 2018, 2018, 9280590. [Google Scholar] [CrossRef]
- Nti, I.K.; Adekoya, A.F.; Weyori, B.A. A comprehensive evaluation of ensemble learning for stock-market prediction. J. Big Data 2020, 7, 20. [Google Scholar] [CrossRef]
- Song, J.; Peng, X.; Song, J.; Yang, Z.; Wang, B.; Che, J. MTTLA-DLW: Multi-task TCN-Bi-LSTM transfer learning approach with dynamic loss weights based on feature correlations of the training samples for short-term wind power prediction. Wind Energy 2024, 27, 733–744. [Google Scholar] [CrossRef]
- Torres, M.V.; Shahid, Z.; Mitra, K.; Saguna, S.; Åhlund, C. A Transfer Learning Approach to Create Energy Forecasting Models for Building Fleets. In Proceedings of the IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids, Oslo, Norway, 17–20 September 2024; pp. 438–444. [Google Scholar]
- Lee, Y.; Jeong, J. TSMixer-and Transfer Learning-Based Highly Reliable Prediction with Short-Term Time Series Data in Small-Scale Solar Power Generation Systems. Energies 2025, 18, 765. [Google Scholar] [CrossRef]
- Abdulsahib, H.M.; Ghaderi, F. Cross-domain disentanglement: A novel approach to financial market prediction. IEEE Access 2024, 12, 16255–16265. [Google Scholar] [CrossRef]
- Berghorn, W. Trend momentum. Quant. Financ. 2015, 15, 261–284. [Google Scholar] [CrossRef]
- Mohammadi, S.; Mansourfar, G. The effect of financial data noise on the long-term co-movement of stock markets. Trans. Data Anal. Soc. Sci. 2022, 4, 9–21. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.