
Design of a Spark Big Data Framework for PM2.5 Air Pollution Forecasting




Abstract
:1. Introduction
2. Literature Review
2.1. Air Pollution
- Correlation of Air Pollutants
- Air quality prediction
- Sensor of Air quality
2.2. Input and Output Variables of PM2.5 Prediction Model
- Traffic
- Weather
- PMs
2.3. Machine Learning
2.3.1. Ensemble Learning
2.3.2. Spark MLlib
- (1)
- ML Algorithms: Provide machine learning algorithms such as classification, clustering, regression, and collaborative filtering.
- (2)
- Featurization: includes methods such as feature extraction, feature selection and dimension reduction.
- (3)
- Pipelines: Provide tools for constructing, evaluating and adapting ML Pipelines.
- (4)
- Persistence: Provides the ability to persist machine learning models, which means that machine learning models can be saved and loaded, making model development more convenient.
- (5)
- Utilities: Including data processing, statistics and other tools.
2.4. Google Cloud Platform
3. Methodology
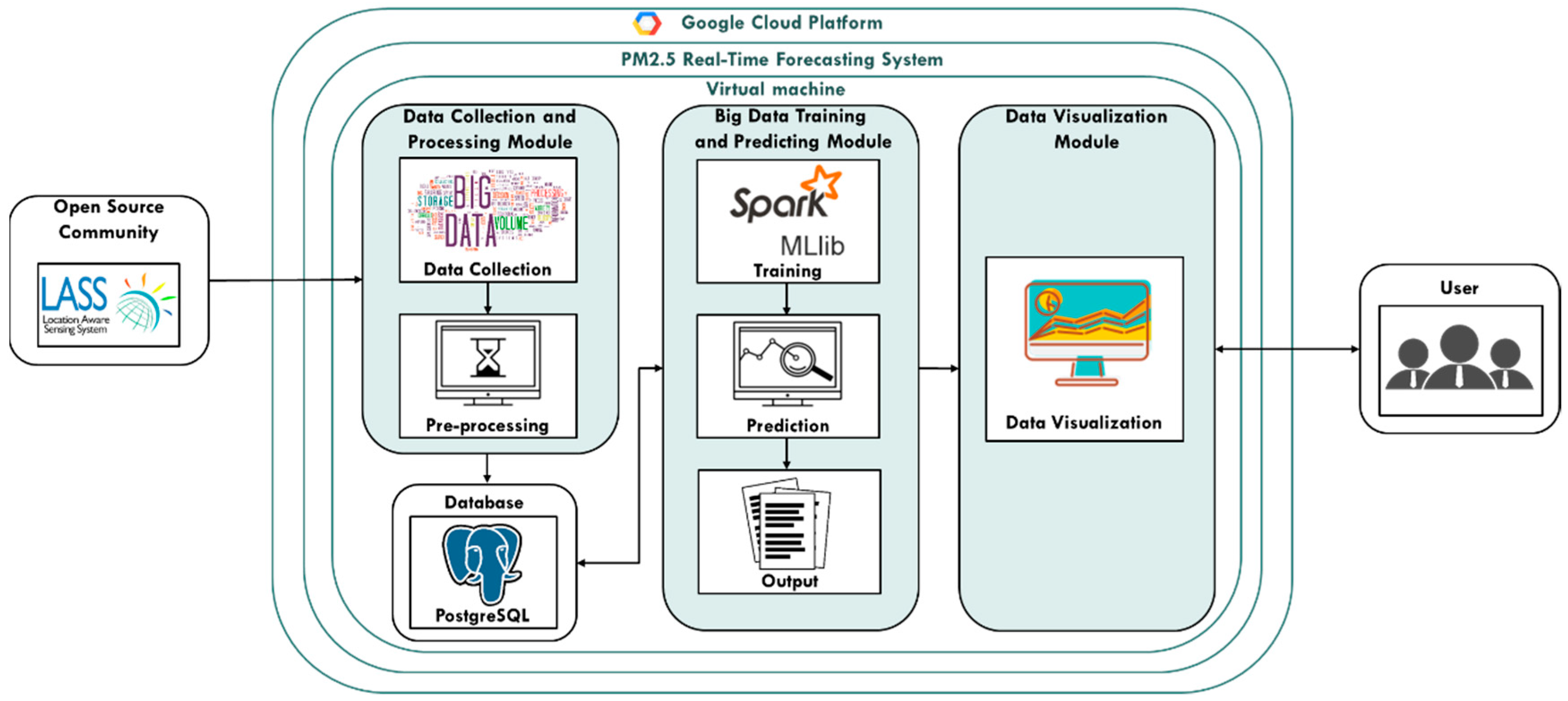
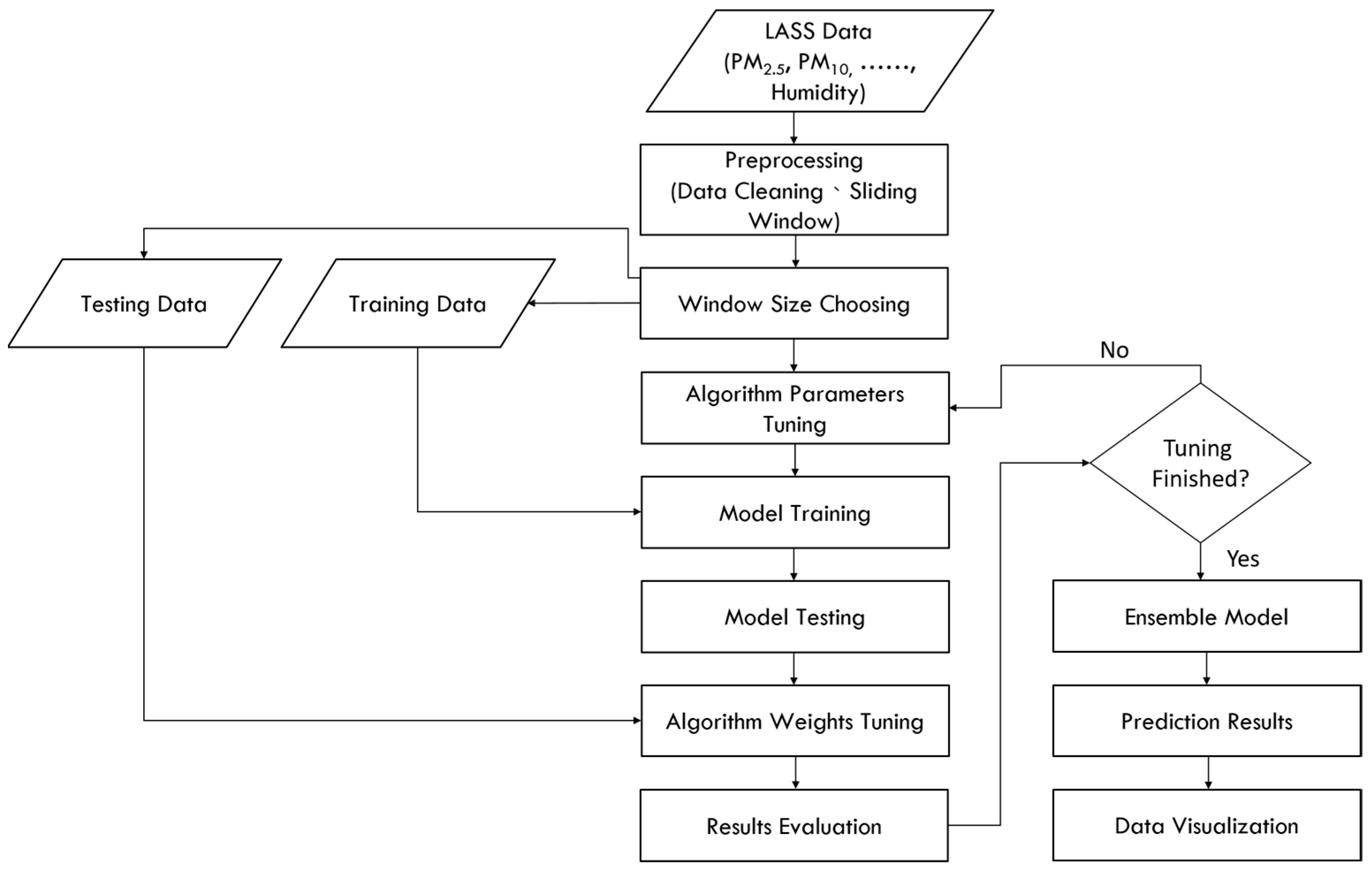
3.1. Spark Big Data Framework
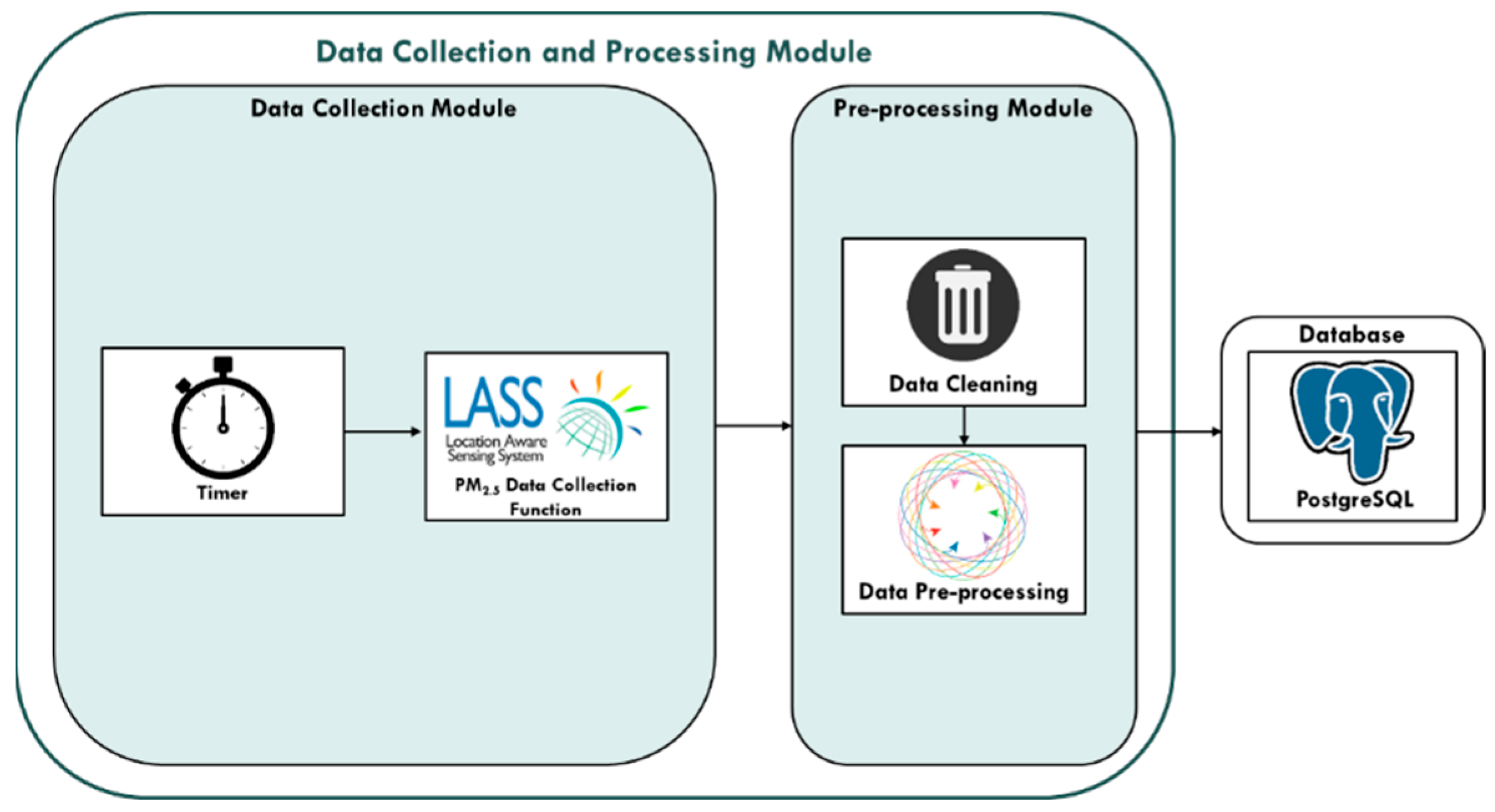
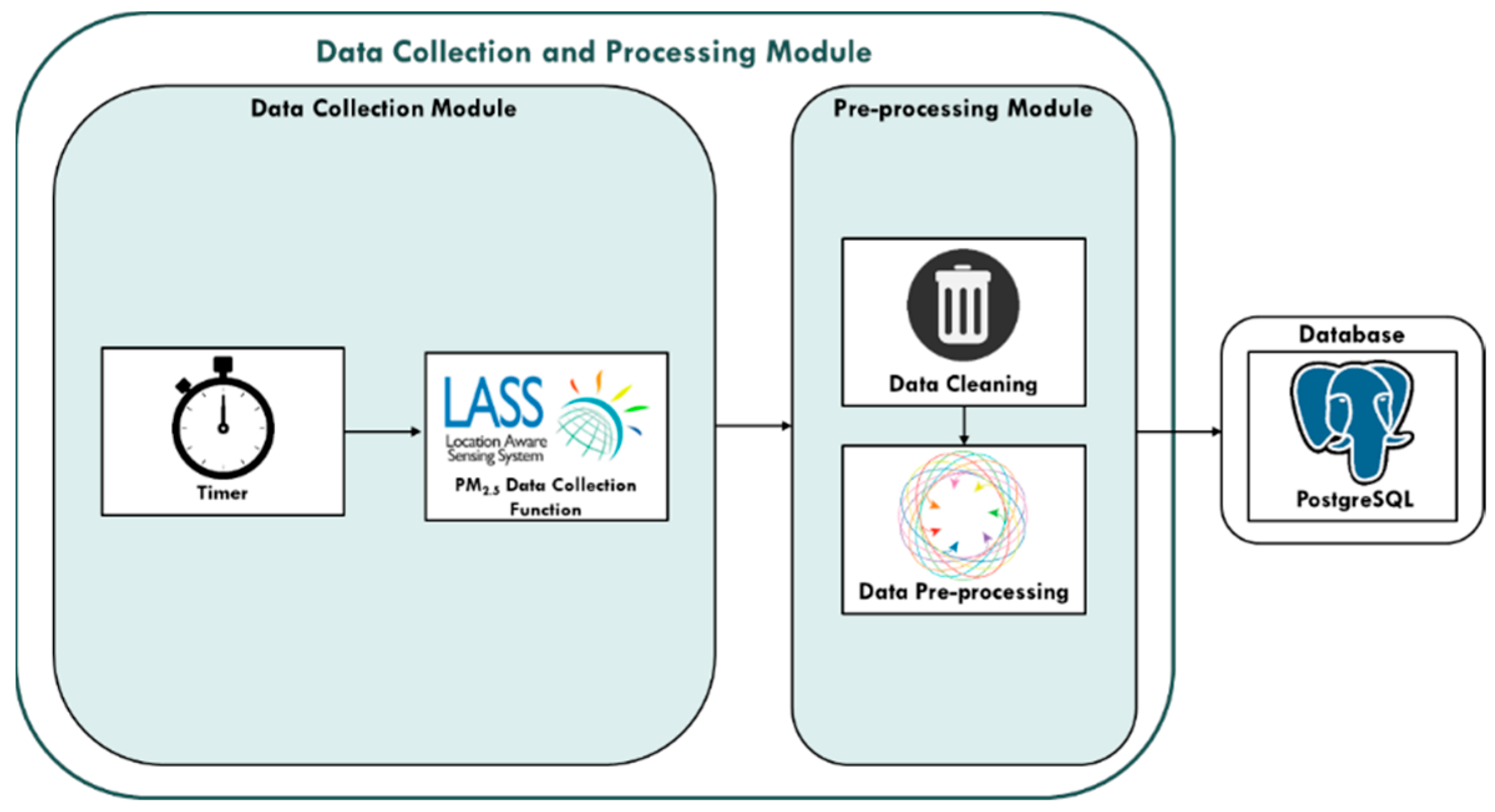
3.1.1. Data Collection and Processing Module
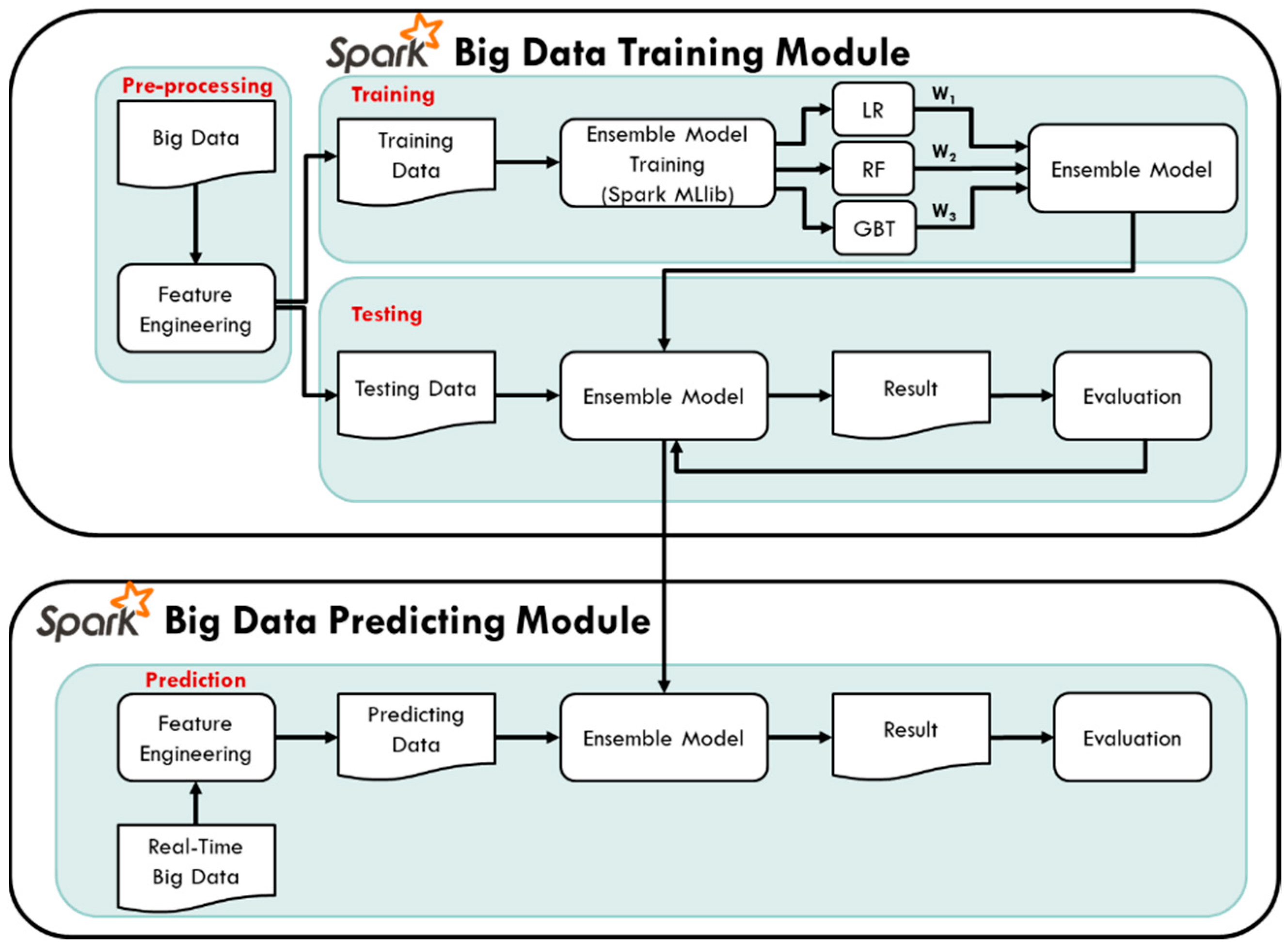
3.1.2. Big Data Training and Predicting Module
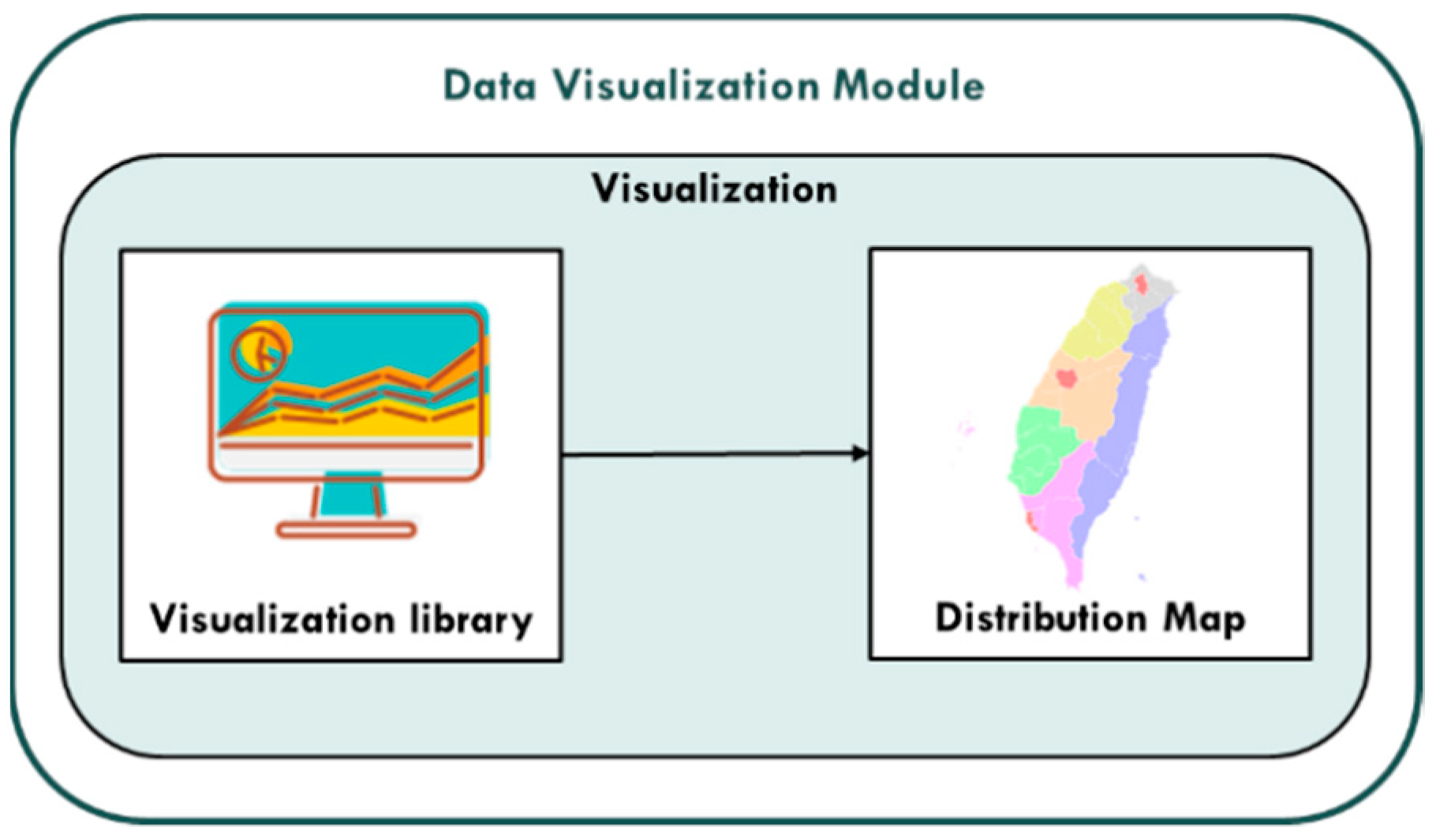
3.1.3. Data Visualization Module
4. Experimental Design
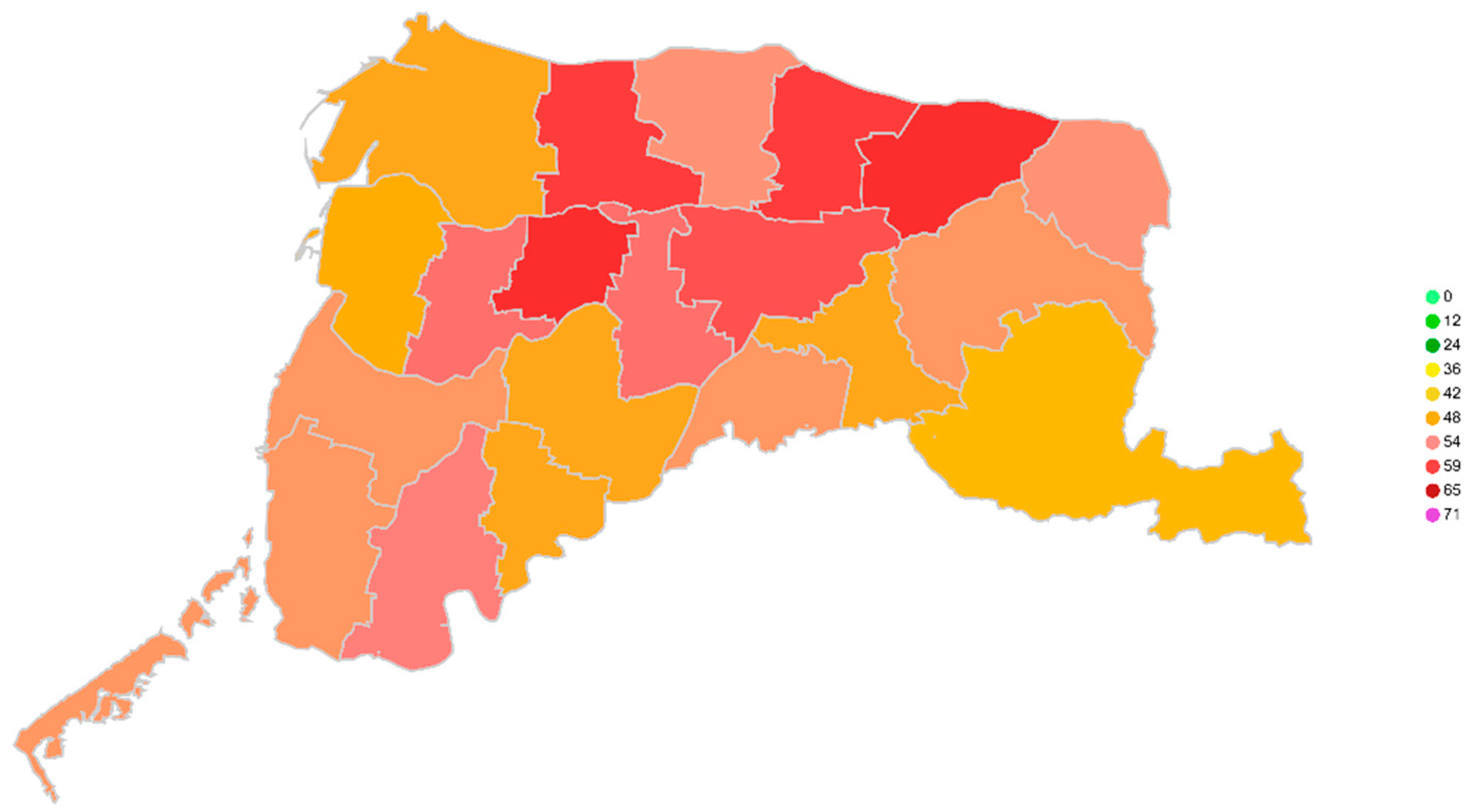
4.1. Data Source
4.1.1. Open Source Community
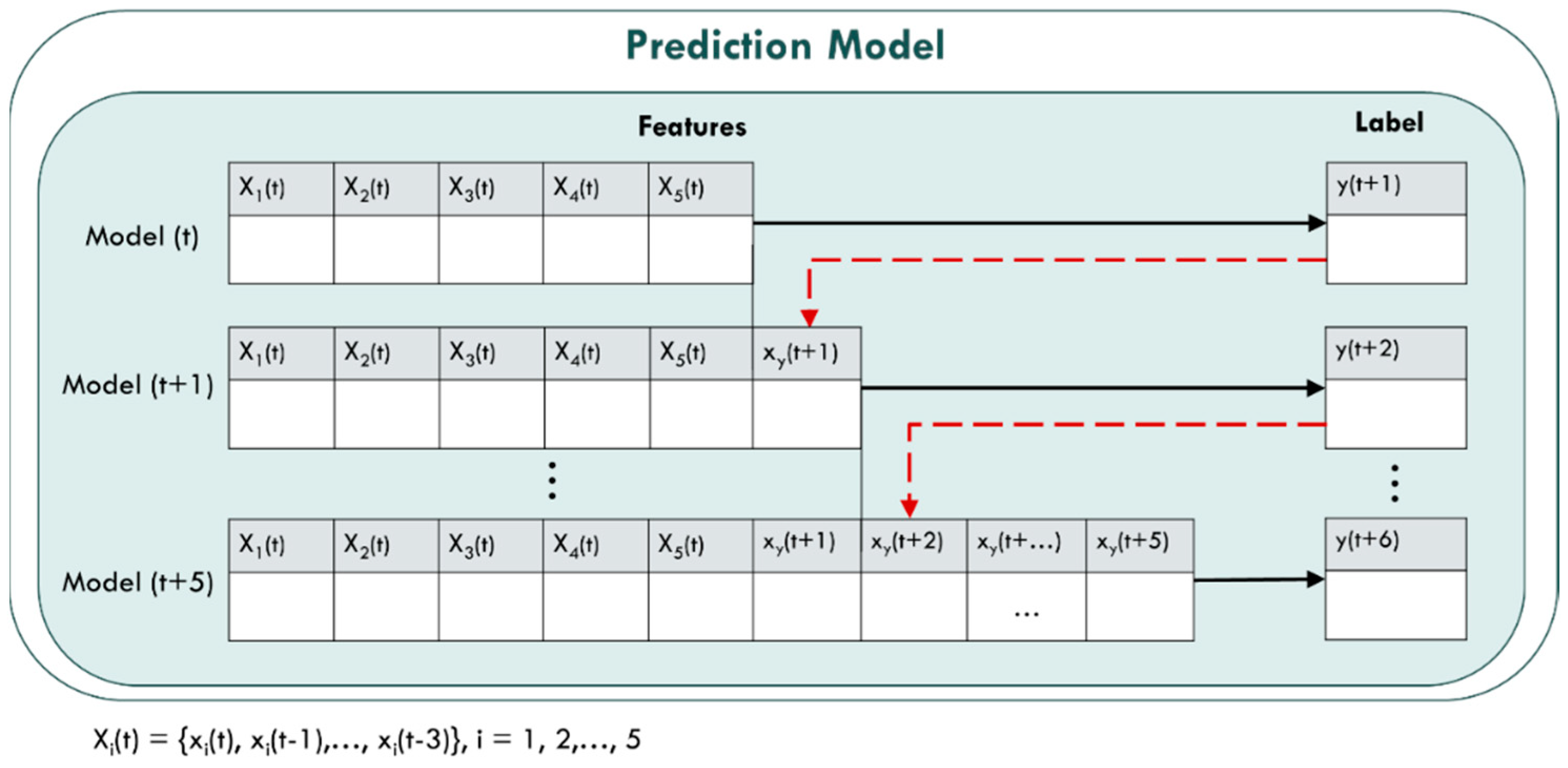
4.1.2. I/O Variables and Prediction Model
- Model(t): y(t + 1) = f [Xi(t)]
- Model(t + 1): y(t + 2) = f [Xi(t), xy(t + 1)]
- Model(t + 2): y(t + 3) = f [Xi(t), xy(t + 1), xy(t + 2)]
- Model(t + 3): y(t + 4) = f [Xi(t), xy(t + 1), xy(t + 2), xy(t + 3)]
- Model(t + 4): y(t + 5) = f [Xi(t), xy(t + 1), xy(t + 2), xy(t + 3), xy(t + 4)]
- Model(t + 5): y(t + 6) = f [Xi(t), xy(t + 1), xy(t + 2), xy(t + 3), xy(t + 4), xy(t + 5)]
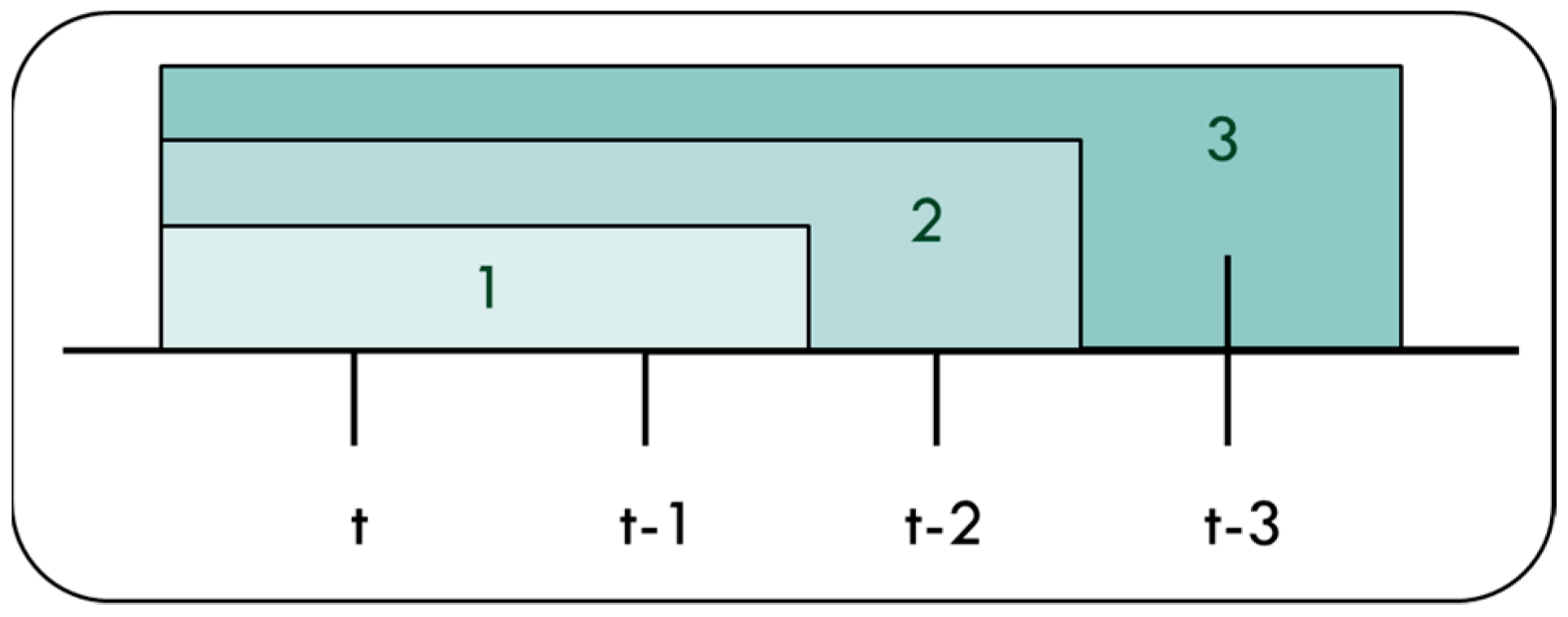
- where Xi(t) = {xi(t − 1), xi(t − 2), xi(t − 3), i = 1, 2, …, 5}
- and xy(t + j) = y(t + j), j = 1, 2, …, 5
4.2. Evaluation
4.2.1. Index of PM2.5
4.2.2. Performance Index
- (1)
- Root mean squared error (RMSE): is the sample standard deviation of the predicted value and the actual value. Its value can be used to measure the difference between the predicted value and the actual value. The smaller the value the better the prediction performance. The calculation formula is as Equation (1):
- (2)
- Coefficient of determination (R2): As in Equation (2), It measures the suitability of the model to the sample value and can test the predictive ability of the model. Its value is between 0 and 1. The closer to 1, the higher the suitability of the model, and the closer to 0 indicates the lower the model fitness.
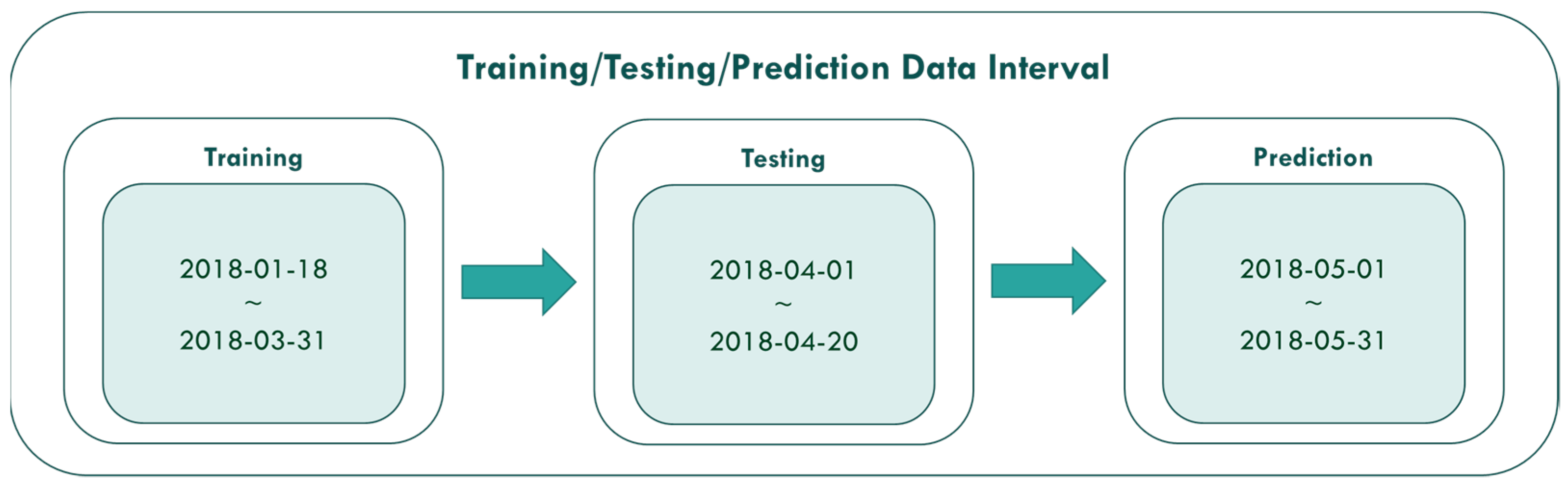
4.3. Experiment
5. Experimental Results and Discussion
5.1. Experimental Result
5.1.1. Model Training Results
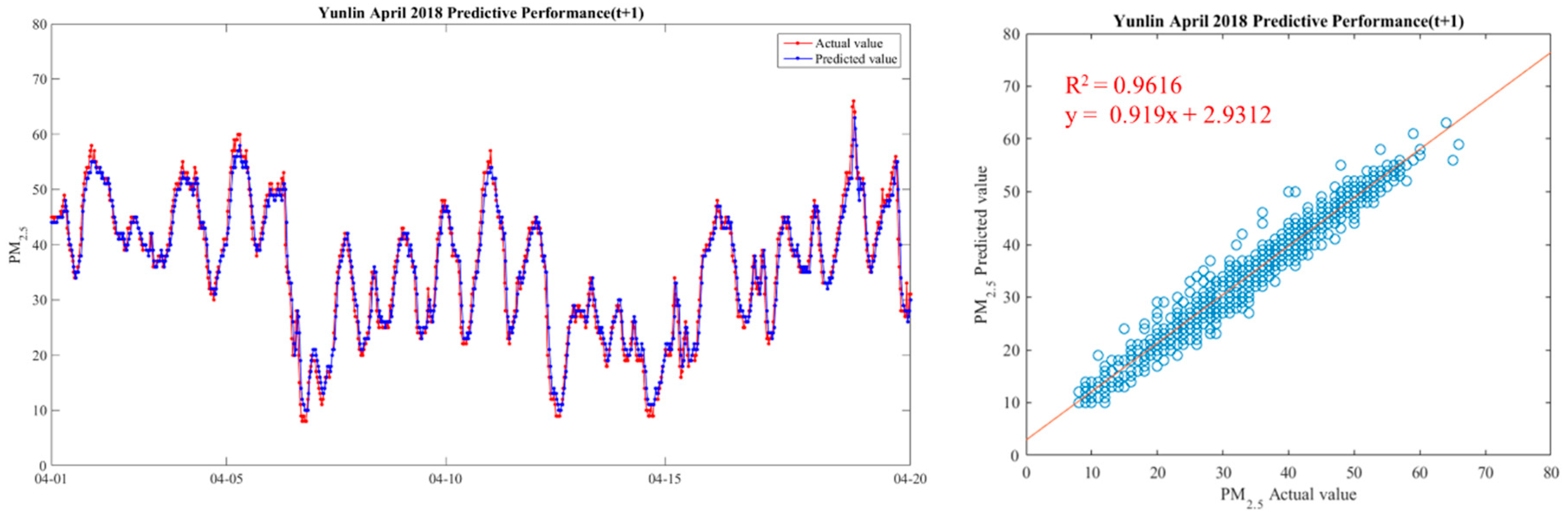
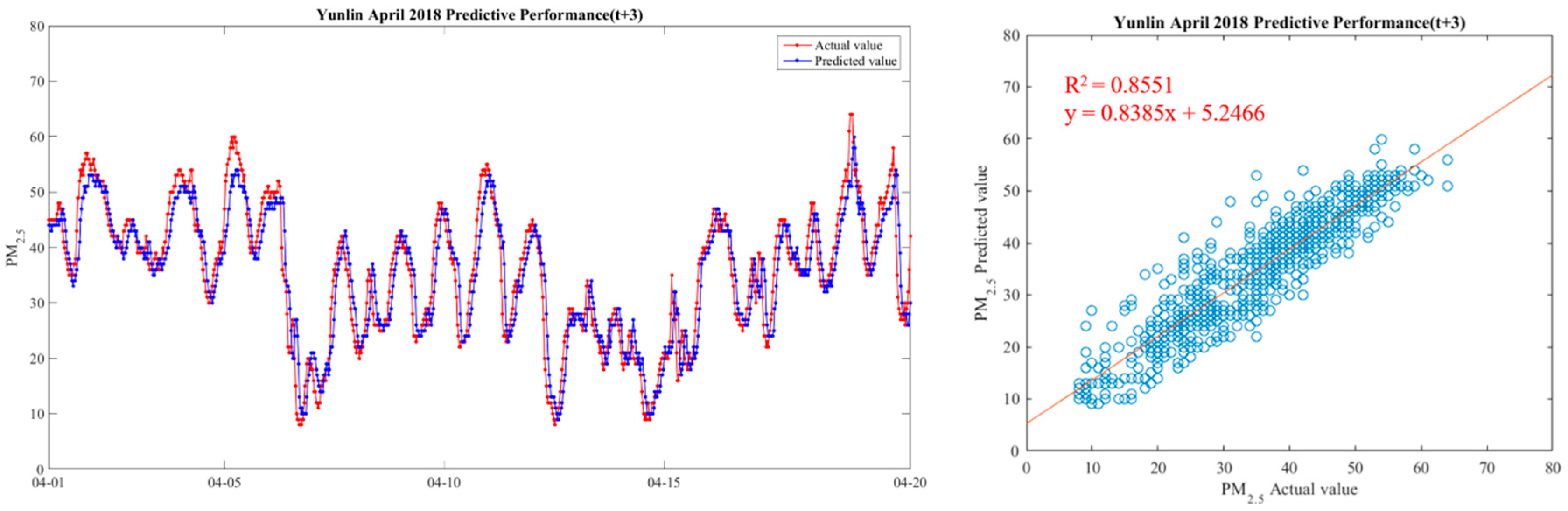
5.1.2. Model Testing Results
5.2. Discussion
5.2.1. Computation Time in Model Training
5.2.2. PM2.5 Concentration Category Prediction
5.2.3. Comparison with Other Studies
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- World Health Organization. Health in 2015: From MDGs, Millennium Development Goals to SDGs, Sustainable Development Goals; World Health Organization: Geneva, Switzerland, 2015. [Google Scholar]
- Martinelli, N.; Olivieri, O.; Girelli, D. Air particulate matter and cardiovascular disease: A narrative review. Eur. J. Intern. Med. 2013, 24, 295–302. [Google Scholar] [CrossRef] [PubMed]
- International Agency for Research on Cancer (IARC). Outdoor Air Pollution. IARC Monographs on the Evaluation of Carcinogenic Risks to Humans; IARC: Lyons, France, 2013; Volume 109. [Google Scholar]
- Hwang, S.L.; Guo, S.E.; Chi, M.C.; Chou, C.T.; Lin, Y.C.; Lin, C.M.; Chou, Y.L. Association between at-mospheric fine particulate matter and hospital admissions for chronic obstructive pulmonary disease in Southwestern Taiwan: A population-based study. Int. J. Environ. Res. Public Health. 2016, 13, 366. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, J.; Xin, J.; An, J.; Wang, Y.; Liu, Z.; Chao, N.; Meng, Z. Observation of aerosol optical properties and particulate pollution at background station in the Pearl River Delta region. Atmos. Res. 2014, 143, 216–227. [Google Scholar] [CrossRef]
- Kurt, A.; Oktay, A.B. Forecasting air pollutant indicator levels with geographic models 3days in advance using neural networks. Expert Syst. Appl. 2010, 37, 7986–7992. [Google Scholar] [CrossRef]
- Li, L.; Wu, A.H.; Cheng, I.; Chen, J.-C.; Wu, J. Spatiotemporal estimation of historical PM2.5 concentrations using PM10 meteorological variables, and spatial effect. Atmos. Environ. 2017, 166, 182–191. [Google Scholar] [CrossRef]
- Lee, M.; Lin, L.; Chen, C.-Y.; Tsao, Y.; Yao, T.-H.; Fei, M.-H.; Fang, S.-H. Forecasting air quality in Taiwan by using machine learning. Sci. Rep. 2020, 10, 1–13. [Google Scholar] [CrossRef]
- Devarakonda, S.; Sevusu, P.; Liu, H.; Liu, R.; Iftode, L.; Nath, B. Real-time air quality monitoring through mobile sensing in metropolitan areas. In Proceedings of the 2nd ACM SIGKDD International Workshop on Urban Computing -UrbComp ’13, Chicago, IL, USA, 11 August 2013; p. 15. [Google Scholar]
- Xu, Y.; Zhu, Y. When remote sensing data meet ubiquitous urban data: Fine-grained air quality inference. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 1252–1261. [Google Scholar]
- Chen, L.-J.; Ho, Y.-H.; Lee, H.-C.; Wu, H.-C.; Liu, H.-M.; Hsieh, H.-H.; Huang, Y.-T.; Lung, S.-C.C. An Open Framework for Participatory PM2.5 Monitoring in Smart Cities. IEEE Access 2017, 5, 14441–14454. [Google Scholar] [CrossRef]
- Liou, N.-C.; Luo, C.-H.; Mahajan, S.; Chen, L.-J. Why is Short-Time PM2.5 Forecast Difficult? The Effects of Sudden Events. IEEE Access 2019, 8, 12662–12674. [Google Scholar] [CrossRef]
- Brook, R.D.; Rajagopalan, S.; Pope, I.C.A.; Brook, J.R.; Bhatnagar, A.; Diez-Roux, A.V.; Holguin, F.; Hong, Y.; Luepker, R.V.; Mittleman, M.; et al. Particulate Matter Air Pollution and Cardiovascular Disease. Circulation 2010, 121, 2331–2378. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hwang, S.-L.; Lin, Y.-C.; Guo, S.-E.; Chi, M.-C.; Chou, C.-T.; Lin, C.-M. Emergency room visits for respiratory diseases associated with ambient fine particulate matter in Taiwan in 2012: A population-based study. Atmos. Pollut. Res. 2017, 8, 465–473. [Google Scholar] [CrossRef]
- World Health Organization. Global Health Risks: Mortality and Burden of Disease Attributable to Selected Major Risks; World Health Organization: Geneva, Switzerland, 2009. [Google Scholar]
- Pope, C.A., III; Dockery, D.W. Health Effects of Fine Particulate Air Pollution: Lines that Connect. J. Air Waste Manag. Assoc. 2006, 56, 709–742. [Google Scholar] [CrossRef]
- Pope, C.A., III; Burnett, R.T.; Thun, M.J.; Calle, E.E.; Krewski, D.; Ito, K.; Thurston, G.D. Lung cancer, car-diopulmonary mortality and long-term exposure to fine particulate air pollution. JAMA 2002, 287, 1132–1141. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, B.J.; Kim, B.; Lee, K. Air pollution exposure and cardiovascular disease. Toxicol. Res. 2014, 30, 71–75. [Google Scholar] [CrossRef] [PubMed]
- Shah, A.; Langrish, J.P.; Nair, H.; McAllister, D.A.; Hunter, A.L.; Donaldson, K.; Newby, D.E.; Mills, N.L. Global association of air pollution and heart failure: A systematic review and meta-analysis. Lancet 2013, 382, 1039–1048. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Yin, Q.; Tong, S.; Ren, Z.; Hu, M.; Zhang, H. Prolonged continuous exposure to high fine particulate mat-ter associated with cardiovascular and respiratory disease mortality in Beijing, China. Atmos. Environ. 2017, 168, 1–7. [Google Scholar] [CrossRef]
- Brook, R.D.; Franklin, B.; Cascio, W.; Hong, Y.; Howard, G.; Lipsett, M.; Tager, I. Air pollution and cardiovascular disease. Circulation 2004, 109, 2655–2671. [Google Scholar] [CrossRef]
- Krämer, U.; Herder, C.; Sugiri, D.; Strassburger, K.; Schikowski, T.; Ranft, U.; Rathmann, W. Traffic-related air pol-lution and incident type 2 diabetes: Results from the SALIA cohort study. Environ. Health Perspect. 2010, 118, 1273. [Google Scholar] [CrossRef] [Green Version]
- VoPham, T.; Bertrand, K.A.; Tamimi, R.M.; Laden, F.; Hart, J.E. Ambient PM2.5 Air Pollution Exposure and Hepatocellular Carcinoma Incidence in the United States. Cancer Causes Control 2018, 29, 563–572. [Google Scholar] [CrossRef]
- Zhang, C.; Ni, Z.; Ni, L. Multifractal detrended cross-correlation analysis between PM2.5 and meteorological factors. Phys. A Stat. Mech. Appl. 2015, 438, 114–123. [Google Scholar] [CrossRef]
- Lu, D.; Xu, J.; Yang, D.; Zhao, J. Spatio-temporal variation and influence factors of PM2.5 concentrations in China from 1998 to 2014. Atmos. Pollut. Res. 2017, 8, 1151–1159. [Google Scholar] [CrossRef]
- Ni, X.; Huang, H.; Du, W. Relevance analysis and short-term prediction of PM2.5 concentrations in Beijing based on multi-source data. Atmos. Environ. 2017, 150, 146–161. [Google Scholar] [CrossRef]
- Voukantsis, D.; Karatzas, K.; Kukkonen, J.; Räsänen, T.; Karppinen, A.; Kolehmainen, M. Intercomparison of air quality data using principal component analysis, and forecasting of PM10 and PM2.5 concentrations using artificial neural networks, in Thessaloniki and Helsinki. Sci. Total Environ. 2011, 409, 1266–1276. [Google Scholar] [CrossRef] [PubMed]
- Yao, L.; Lu, N.; Jiang, S. Artificial Neural Network (ANN) for Multi-source PM2.5 Estimation Using Surface, MODIS, and Meteorological Data. In Proceedings of the 2012 International Conference on Biomedical Engineering and Biotechnology, Macau, Macao, 28–30 May 2012; pp. 1228–1231. [Google Scholar]
- Sun, W.; Zhang, H.; Palazoglu, A.; Singh, A.; Zhang, W.; Liu, S. Prediction of 24-hour-average PM2.5 con-centrations using a hidden Markov model with different emission distributions in Northern California. Sci. Total Environ. 2013, 443, 93–103. [Google Scholar] [CrossRef]
- Wang, P.; Liu, Y.; Qin, Z.; Zhang, G. A novel hybrid forecasting model for PM10 and SO2 daily concentrations. Sci. Total Environ. 2015, 505, 1202–1212. [Google Scholar] [CrossRef]
- Yeganeh, B.; Pour Motlagh, M.S.; Rashidi, Y.; Kamalan, H. Prediction of CO concentrations based on a hybrid Partial Least Square and Support Vector Machine model. Atmos. Environ. 2012, 55, 357–365. [Google Scholar] [CrossRef]
- Yu, R.; Yang, Y.; Yang, L.; Han, G.; Move, O.A. RAQ–A Random Forest Approach for Predicting Air Quality in Urban Sensing Systems. Sensors 2016, 16, 86. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Zhang, H.; Qin, Z.; Zhang, G. A novel hybrid-Garch model based on ARIMA and SVM for PM 2.5 concentrations forecasting. Atmos. Pollut. Res. 2017, 8, 850–860. [Google Scholar] [CrossRef]
- Wang, Y.-D.; Fu, X.-K.; Jiang, W.; Wang, T.; Tsou, M.-H.; Ye, X.-Y. Inferring urban air quality based on social media. Comput. Environ. Urban Syst. 2017, 66, 110–116. [Google Scholar] [CrossRef]
- Gao, Y.; Dong, W.; Guo, K.; Liu, X.; Chen, Y.; Liu, X.; Bu, J.; Chen, C. Mosaic: A low-cost mobile sensing system for urban air quality monitoring. In Proceedings of the IEEE INFOCOM 2016—The 35th Annual IEEE International Conference on Computer Communications, San Francisco, CA, USA, 10–14 April 2016; pp. 1–9. [Google Scholar]
- Russo, A.; Raischel, F.; Lind, P.G. Air quality prediction using optimal neural networks with stochastic variables. Atmos. Environ. 2013, 79, 822–830. [Google Scholar] [CrossRef] [Green Version]
- Shah, J.; Mishra, B. IoT-enabled low power environment monitoring system for prediction of PM2.5. Pervasive Mob. Comput. 2020, 67, 101175. [Google Scholar] [CrossRef]
- Dong, M.; Yang, D.; Kuang, Y.; He, D.; Erdal, S.; Kenski, D. PM2.5 concentration prediction using hidden semi-Markov model-based times series data mining. Expert Syst. Appl. 2009, 36, 9046–9055. [Google Scholar] [CrossRef]
- Pan, L.; Yao, E.; Yang, Y. Impact analysis of traffic-related air pollution based on real-time traffic and basic meteorological information. J. Environ. Manag. 2016, 183, 510–520. [Google Scholar] [CrossRef] [PubMed]
- Xu, B.; Luo, L.; Lin, B. A dynamic analysis of air pollution emissions in China: Evidence from nonparametric additive regression models. Ecol. Indic. 2016, 63, 346–358. [Google Scholar] [CrossRef]
- Du, L.; Wei, C.; Cai, S. Economic development and carbon dioxide emissions in China: Provincial panel data analysis. China Econ. Rev. 2012, 23, 371–384. [Google Scholar] [CrossRef]
- Dhyani, R.; Sharma, N.; Maity, A.K. Prediction of PM2.5 along urban highway corridor under mixed traffic conditions using CALINE4 model. J. Environ. Manag. 2017, 198, 24–32. [Google Scholar] [CrossRef] [PubMed]
- Kwiecień, J.; Szopińska, K. Mapping Carbon Monoxide Pollution of Residential Areas in a Polish City. Remote Sens. 2020, 12, 2885. [Google Scholar] [CrossRef]
- Walsh, M.P. PM2.5: Global progress in controlling the motor vehicle contribution. Front. Environ. Sci. Eng. 2014, 8, 1–17. [Google Scholar] [CrossRef]
- Hair, J.F.; Sarstedt, M.; Ringle, C.M.; Mena, J.A. An assessment of the use of partial least squares structural equation modeling in marketing research. J. Acad. Mark. Sci. 2012, 40, 414–433. [Google Scholar] [CrossRef]
- Pak, U.; Ma, J.; Ryu, U.; Ryom, K.; Juhyok, U.; Pak, K.; Pak, C. Deep learning-based PM2. 5 prediction considering the spatiotemporal correlations: A case study of Beijing, China. Sci. Total Environ. 2020, 699, 133561. [Google Scholar] [CrossRef]
- Xing, H.; Wang, G.; Liu, C.; Suo, M. PM2.5 concentration modeling and prediction by using temperature-based deep belief network. Neural Netw. 2021, 133, 157–165. [Google Scholar] [CrossRef]
- Polichetti, G.; Cocco, S.; Spinali, A.; Trimarco, V.; Nunziata, A. Effects of particulate matter (PM10, PM2.5 and PM1) on the cardiovascular system. Toxicology 2009, 261, 1–8. [Google Scholar] [CrossRef]
- Zhan, Y.; Luo, Y.Z.; Deng, X.F.; Grieneisen, M.L.; Zhang, M.H.; Di, B.F. Spatiotemporal prediction of daily ambient ozone levels across China using random forest for human exposure assessment. Environ. Pollut. 2018, 233, 464–473. [Google Scholar] [CrossRef]
- Dietterich, T.G. Ensemble Methods in Machine Learning. Trans. Petri Nets Models Concurr. XV 2000, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Kraska, T.; Talwalkar, A.; Duchi, J.C.; Griffith, R.; Franklin, M.J.; Jordan, M.I. MLbase: A Distributed Machine-learning System. CIDR 2013, 1, 2-1. [Google Scholar]
- Meng, X.; Bradley, J.; Yavuz, B.; Sparks, E.; Venkataraman, S.; Liu, D.; Xin, D. Mllib: Machine learning in apache spark. J. Mach. Learn. Res. 2016, 17, 1235–1241. [Google Scholar]
- Buczyńska, A.J.; Krata, A.; Van Grieken, R.; Brown, A.; Polezer, G.; De Wael, K.; Potgieter-Vermaak, S. Composition of PM2.5 and PM1 on high and low pollution event days and its relation to indoor air quality in a home for the elderly. Sci. Total Environ. 2014, 490, 134–143. [Google Scholar] [CrossRef] [PubMed]
- Kwon, S.-B.; Jeong, W.; Park, D.; Kim, K.-T.; Cho, K.H. A multivariate study for characterizing particulate matter (PM10, PM2.5, and PM1) in Seoul metropolitan subway stations, Korea. J. Hazard. Mater. 2015, 297, 295–303. [Google Scholar] [CrossRef]
- Zhou, Q.; Jiang, H.; Wang, J.; Zhou, J. A hybrid model for PM 2.5 forecasting based on ensemble empirical mode decomposition and a general regression neural network. Sci. Total Environ. 2014, 496, 264–274. [Google Scholar] [CrossRef]
- Zhang, Q.; Zheng, Y.; Tong, D.; Shao, M.; Wang, S.; Zhang, Y.; Hao, J. Drivers of improved PM2.5 air quality in China from 2013 to 2017. Proc. Natl. Acad. Sci. USA 2019, 116, 24463–24469. [Google Scholar] [CrossRef] [Green Version]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Field | Methods | Air Pollutants | Authors |
|---|---|---|---|
| Variables related to air pollution | Grey system correlation analysis, linear regression | PM2.5 | Lu et al. [25] |
| Back Propagation Neural Network | PM2.5 | Ni et al. [26] | |
| Multifractal descended cross-correlation analysis, (MF-DCCA) | PM2.5 | Zhang et al. [24] | |
| Air pollutant concentration prediction | Neural Network | CO\SO2\PM10 | Kurt & Oktay [6] |
| NO2 | Russo, Raischel, & Lind [36] | ||
| PM2.5\PM10 | Voukantsis et al. [27] | ||
| PM2.5 | Yao et al. [28] | ||
| PM2.5 | Shah et al. [37] | ||
| Hidden Markov Model | PM2.5 | Dong et al. [38] | |
| PM2.5 | Sun et al. [29] |
| Data Source | Input/Output Variables | Contents | Authors |
|---|---|---|---|
| LASS Community | y(t + 1) | PM2.5(t + 1) | Voukantsis et al. [27]; Sun et al. [29]; Polichetti et al. [48]; Li et al. [7] |
| y(t + 2) | PM2.5(t + 2) | ||
| y(t + 3) | PM2.5(t + 3) | ||
| y(t + 4) | PM2.5(t + 4) | ||
| y(t + 5) | PM2.5(t + 5) | ||
| y(t + 6) | PM2.5(t + 6) | ||
| xy(t + 1) | PM2.5 (t + 1) | ||
| xy(t + 2) | PM2.5(t + 2) | ||
| xy(t + 3) | PM2.5(t + 3) | ||
| xy(t + 4) | PM2.5(t + 4) | ||
| xy(t + 5) | PM2.5(t + 5) | ||
| x1(t) | PM2.5(t) | ||
| x1(t − 1) | PM2.5(t − 1) | ||
| x1(t − 2) | PM2.5(t − 2) | ||
| x1(t − 3) | PM2.5(t − 3) | ||
| x2(t) | PM10(t) | Voukantsis et al. [27]; Polichetti et al. [48]; Li et al. [7] | |
| x2(t − 1) | PM10(t − 1) | ||
| x2(t − 2) | PM10(t − 2) | ||
| x2(t − 3) | PM10(t − 3) | ||
| x3(t) | PM1(t) | Buczyńska et al. [53]; Kwon, Jeong, Park, Kim, Cho, [54] | |
| x3(t − 1) | PM1(t − 1) | ||
| x3(t − 2) | PM1(t − 2) | ||
| x3(t − 3) | PM1(t − 3) | ||
| x4(t) | Temp.(t) | Voukantsis et al. [27]; Sun et al. [29] | |
| x4(t − 1) | Temp.(t − 1) | ||
| x4(t − 2) | Temp.(t − 2) | ||
| x4(t − 3) | Temp.(t − 3) | ||
| x5(t) | Humidity(t) | Voukantsis et al. [27]; Sun et al. [29]; Polichetti et al. [48]; | |
| x5(t − 1) | Humidity(t − 1) | ||
| x5(t − 2) | Humidity(t − 2) | ||
| x5(t − 3) | Humidity(t − 3) |
| Index Classification | Low | Medium, High | High | Very High |
|---|---|---|---|---|
| PM2.5 (μg/m3) | 0–35 | 36–53 | 54–70 | ≥71 |
| Activity suggestion for General public | Can go out normally | Can go out normally | If feel unwell, should consider reducing outdoor activities | If feel unwell, should reduce outdoor activities and physical exertion |
| 1 | 2 | 3 | ||
|---|---|---|---|---|
| RMSE | 10.65 | 10.63 | 10.27 | |
| R2 | 0.80 | 0.80 | 0.81 | |
| Evaluation Index | ||
|---|---|---|
| Algorithm | RMSE | R2 |
| linear regression | 11.40 | 0.83 |
| Random Forest | 10.90 | 0.85 |
| Gradient Boost | 11.12 | 0.84 |
| Ensemble | 10.63 | 0.85 |
| Evaluation Index | ||
|---|---|---|
| Time segment | RMSE | R2 |
| y(t + 1) | 10.63 | 0.85 |
| y(t + 2) | 12.18 | 0.81 |
| y(t + 3) | 13.41 | 0.77 |
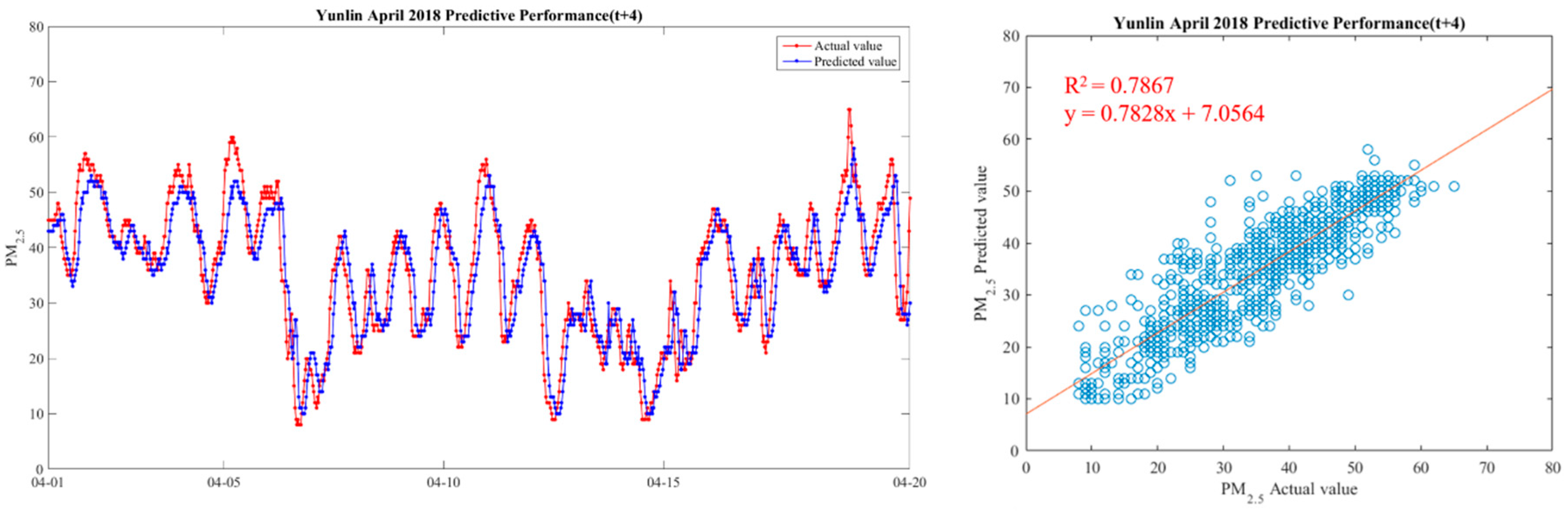
| y(t + 4) | 14.77 | 0.73 |
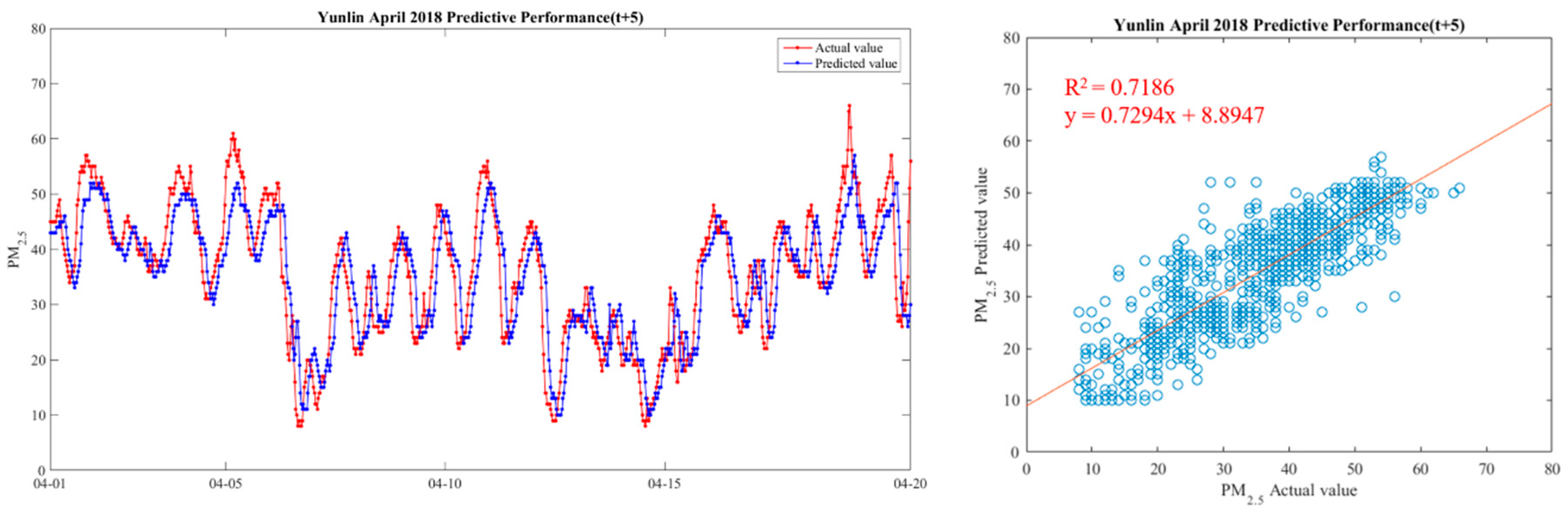
| y(t + 5) | 15.46 | 0.70 |
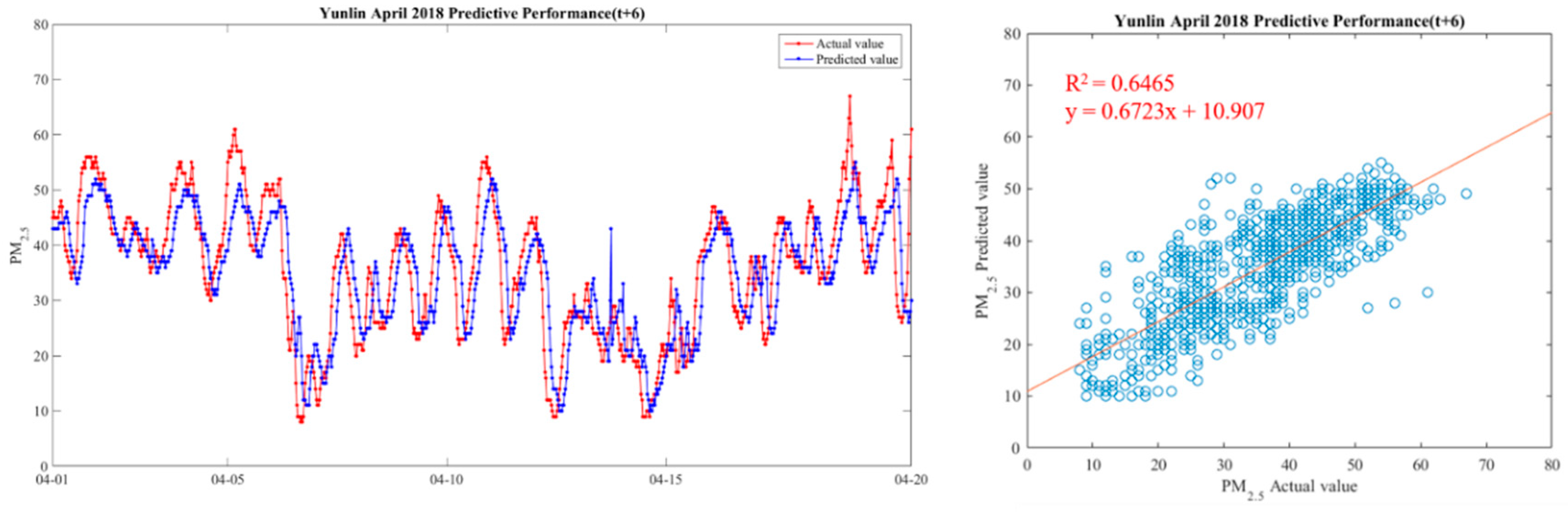
| y(t + 6) | 16.32 | 0.67 |
| Evaluation Index | ||
|---|---|---|
| Algorithm | RMSE | R2 |
| Linear regression | 9.18 | 0.75 |
| Random Forest | 9.38 | 0.73 |
| Gradient Boost | 11.82 | 0.58 |
| Ensemble Model | 9.14 | 0.75 |
| Evaluation Index | ||
|---|---|---|
| Time segment | RMSE | R2 |
| y(t + 1) | 9.14 | 0.75 |
| y(t + 2) | 10.01 | 0.68 |
| y(t + 3) | 10.76 | 0.64 |
| y(t + 4) | 11.88 | 0.56 |
| y(t + 5) | 12.97 | 0.50 |
| y(t + 6) | 13.79 | 0.41 |
| Time Segment | Training Time (s) |
|---|---|
| y(t + 1) | 1998.43 |
| y(t + 2) | 3226.57 |
| y(t + 3) | 6755.18 |
| y(t + 4) | 10,066.60 |
| y(t + 5) | 15,564.86 |
| y(t + 6) | 21,876.73 |
| Predictive Value | ||||||
|---|---|---|---|---|---|---|
| Actual value | Low | Medium | High | Extremely high | total | |
| Low | 332,951 | 19,195 | 185 | 12 | 352,343 | |
| Medium | 17,599 | 110,262 | 5318 | 119 | 133,298 | |
| High | 426 | 10,636 | 15,990 | 328 | 27,380 | |
| Extremely high | 310 | 1590 | 6697 | 669 | 9266 | |
| total | 351,286 | 141,683 | 28,190 | 1128 | 522,287 | |
| Author | Method | Time Seg. | Station | Parti. | Index | Value |
|---|---|---|---|---|---|---|
| Dong et al. [38] | Hidden semi-Markov | Next 24 h | 12 | PM2.5 | R2 | - |
| RMSE | - | |||||
| Kurt & Oktay [6] | neural networks (GFM_NN) | 3 days in advance | 10 | SO2, CO, PM10 | R2 | - |
| RMSE | - | |||||
| Kwon et al. [54] | Universal kriging models | Annual average | 277 | NO2, PM10 | R2 | 0.46 |
| RMSE | 6.31 | |||||
| Pak et al. [46] | CNN-LSTM model | Next 24 h | 384 | PM2.5 | RMSE | 2.875 |
| MAE | 2.117 | |||||
| MAPE | 0.037 | |||||
| Ours | Ensemble Big data | Next 30 to 180 min. | 2000 up | PM2.5 | R2 | 0.75 |
| RMSE | 9.14 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shih, D.-H.; To, T.H.; Nguyen, L.S.P.; Wu, T.-W.; You, W.-T. Design of a Spark Big Data Framework for PM2.5 Air Pollution Forecasting. Int. J. Environ. Res. Public Health 2021, 18, 7087. https://doi.org/10.3390/ijerph18137087
Shih D-H, To TH, Nguyen LSP, Wu T-W, You W-T. Design of a Spark Big Data Framework for PM2.5 Air Pollution Forecasting. International Journal of Environmental Research and Public Health. 2021; 18(13):7087. https://doi.org/10.3390/ijerph18137087
Chicago/Turabian StyleShih, Dong-Her, Thi Hien To, Ly Sy Phu Nguyen, Ting-Wei Wu, and Wen-Ting You. 2021. "Design of a Spark Big Data Framework for PM2.5 Air Pollution Forecasting" International Journal of Environmental Research and Public Health 18, no. 13: 7087. https://doi.org/10.3390/ijerph18137087
APA StyleShih, D.-H., To, T. H., Nguyen, L. S. P., Wu, T.-W., & You, W.-T. (2021). Design of a Spark Big Data Framework for PM2.5 Air Pollution Forecasting. International Journal of Environmental Research and Public Health, 18(13), 7087. https://doi.org/10.3390/ijerph18137087