1. Introduction
In the late 1990s, researchers began investigating the information content of complex networks, [
1] and graphs based on Shannon’s entropy work [
2]. Numerous quantitative measures for analyzing complex networks have been proposed [
3,
4] spanning a wide range of issues in discrete mathematics, computer science, information theory, statistics, chemistry, biology, and other fields [
5,
6]. Graph entropy measures, for example, have been widely used to characterize the structure of graph-based systems [
7,
8] in mathematical chemistry, biology, and computer science-related areas. The concept of graph entropy [
9], developed by Rashevsky [
10] and Trucco [
11] has been used to quantify the structural complexity of graphs [
12,
13].
Chemical indices are important tools for studying different physico-chemical properties of molecules without having to conduct several tests. In the investigation of medicines, quantitative structure-activity relationships (QSAR) use mathematical computations to decipher the chemical properties [
14,
15]. Some researchers have analyzed the topological and
K-Banhatti indices in [
16,
17]. Mowshowitz [
18] introduced the entropy of a graph as an information-theoretic quantity. The complexity is evident here. The well-known Shannon’s entropy [
2] is used to calculate the entropy of a graph. Importantly, Mowshowitz interpreted his graph entropy measure as a graph’s structural information content and demonstrated that this quantity satisfies important properties when used with product graphs [
18]. Inspired by Dehmer and Kraus [
19], it was discovered that determining the minimal values of graph entropies is difficult due to a lack of analytical methods to address this specific problem.
The first-order valence-based
K-Banhatti indices [
17,
20,
21] are, respectively, as follows:
where
and
denote the atoms of a molecule,
and
represent the valency of each atom, and, if
and
are connected or have atom bonds, then we denote this by
. Accordingly, the second valence-based
K-Banhatti index [
22] and polynomial are as follows:
The hyper
K-Banhatti index and first and second polynomial types [
21] are as follows:
The Banhatti indices were proposed by the Indian mathematician Kulli as a result of Milan Randic’s 1972 Zagreb indices. With various techniques, such as modified and hyper-Banhatti indices, Kulli offered a number of studies on Banhatti indices. These indices have excellent associations with several chemical and nonchemical graph properties. The amount of thermal energy per unit temperature in a system that cannot be used for useful work is known as entropy [
23,
24]. In this article, we investigate the graphs of different molecules, namely the pyrene network, the circumnaphthalene series of benzenoid, and the honeycomb benzenoid network, to determine the
K-Banhatti entropies’ use of
K-Banhatti indices [
21,
25].
2. Definitions of Entropies via K-Banhatti Indices
Manzoor et al. in [
26] and Ghani et al. in [
27] recently offered another strategy that is a little bit novel in the literature: applying the idea of Shannon’s entropy [
28] in terms of topological indices. The following formula represents the valency-based entropy:
where
represents the atoms,
represents the edge set, and
represents the edge weight of edge
.
Let
. The first-order
K-Banhatti index (
1) is thus provided as
The use of (
5), the first
K-Banhatti entropy, is shown below:
Let
. Then, the second
K-Banhatti index (
2) is given by
The use of (
5), the second
K-Banhatti entropy, is shown below:
Let
. Then, the first
K-hyper Banhatti index (
3) is given by
The use of (
5), the first
K-hyper Banhatti entropy, is shown below:
Let
. Then, the second
K-hyper Banhatti index (
4) is given by
The use of (
5), the second
K-hyper Banhatti entropy, is shown below:
3. The Pyrene Network
The precise arrangement of rings in the benzenoid system offers a transformation within a sequence of benzenoid structures of the benzenoid graph, which changes the structure. The Pyrene network
is a collection of hexagons, and it is a simple, connected 2D planner graph, where
n represents the number of hexagons in any row of
(see
Figure 1). Accordingly, the Pyrene network is a series of benzenoid rings, and the total number of benzenoid rings is
in
. We sum up the Zagreb polynomial and topological indices of
in this section.
Results and discussion
The number of atoms and the total number of atomic bonds for
are now determined. Let us consider the line of symmetry that divides
into two symmetric parts, as shown in
Figure 1. Let us denote the number of atoms in one symmetric portion of
by
x and the number of layers by
l. In one symmetric part of
, there are
l layers of carbon atoms for
, as indicated in
Figure 1. Then, an
lth layer contains
carbon atoms. Accordingly, we have
The number of atoms in
is
because of the two symmetric parts in
. Furthermore, a
corner atom and an atom other than a corner atom have valencies two and three, respectively. Thus, out of
atoms,
atoms have valency two, and
atoms have valency three. So, by using Formula (1), the number of atomic bonds in
is
. According to the valencies (two and three) of the atoms, there are three types of atomic bonds, which are (2,2), (2,3), and (3,3) in
. On the basis of valency,
Table 1 provides the partition of the set of atomic bonds.
The edge partition of
is:
This partition provides:
Let
be the Pyrene network of
. The first
K-Banhatti polynomial is calculated using Equation (
1) and
Table 1.
Following the simplification of Equation (
10), we obtain the first
K-Banhatti index, which is given at
via differentiation.
Here, we calculate the first
K-Banhatti entropy of
using
Table 1 and Equation (
11) inside Equation (
6) in the following manner:
Let
be the Pyrene network of
. Then, using Equation (
2) and
Table 1, the second
K-Banhatti polynomial is
To differentiate (
34) at
, we obtain the second
K-Banhatti index:
Here, we calculate the second
K-Banhatti entropy of
using
Table 1 and Equation (
13) in Equation (
7) as described below:
Let
be the Pyrene network of
. Then, using Equation (
3) and
Table 1, the first
K-hyper Banhatti polynomial is
To differentiate (
15) at
, we obtain the first
K-hyper Banhatti index
Here, we calculate the first
K-hyper Banhatti entropy of
using
Table 1 and Equation (
16) in Equation (
9) as described below:
Let
be the Pyrene network of
. Then, using Equation (
4) and
Table 1, the second
K-hyper Banhatti polynomial is
To differentiate (
18) at
, we obtain the second
K-hyper Banhatti index
Here, we calculate the second
K-hyper Banhatti entropy of
using
Table 1 and Equation (
19) in Equation (
9) as described below:
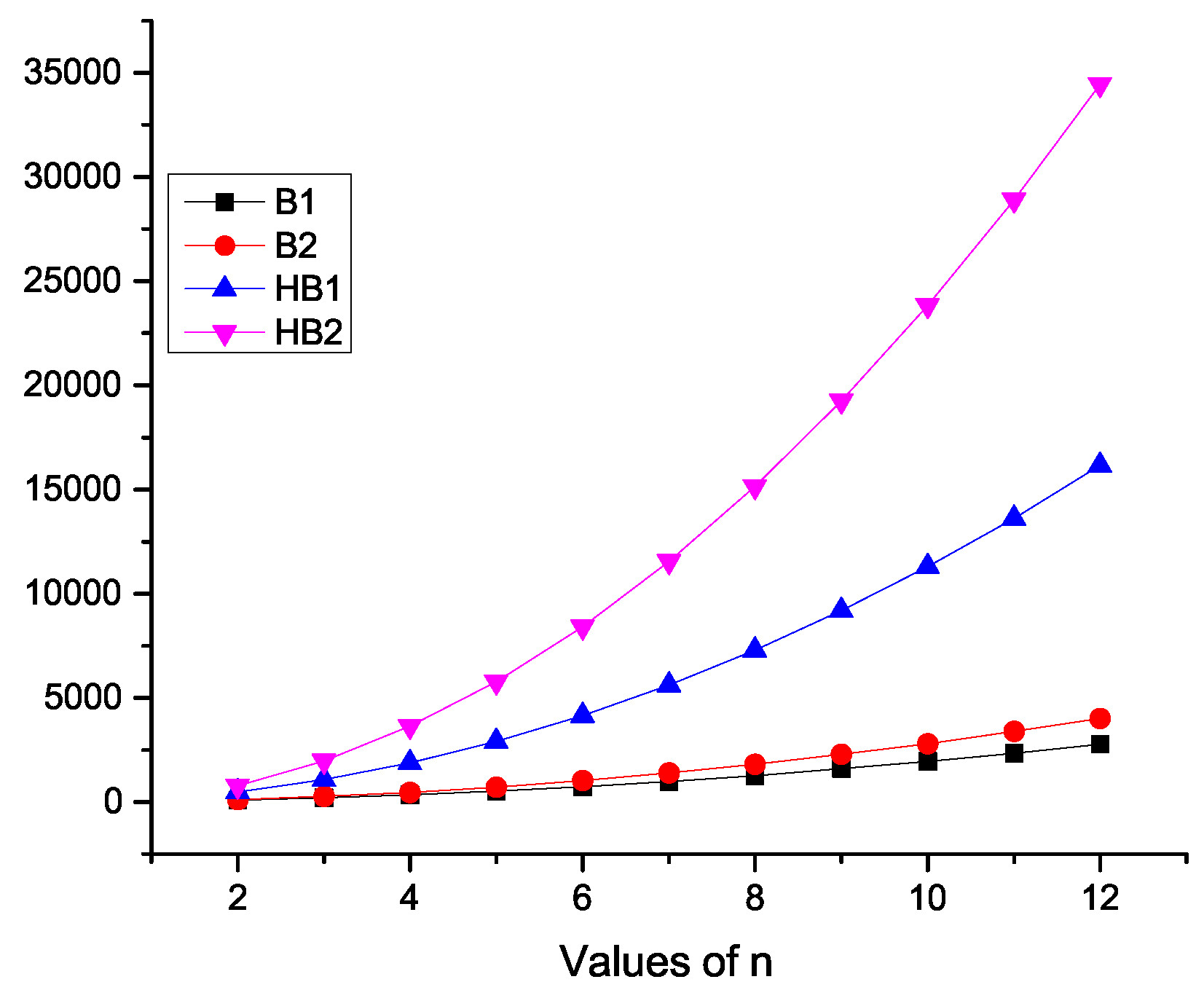
Characteristics of K-Banhatti Indices of
Here, we contrast the
K-Banhatti indices, namely
,
,
, and
for
quantitatively and visually in
Table 2 and
Figure 2, respectively.
4. Circumnaphthalene Series of Benzenoid
Circumnaphthalene is similar to the benzenoid polycyclic aromatic hydrocarbons with the formula
and the ten peri-fused six-member rings in figure
. Ovalene is a chemical that is reddish-orange in color. It is only slightly soluble in solvents, such as benzenoid, toluene, and dichloromethane. The circumnaphthalene series of benzenoids is designated by
, where “
n” is the number of benzenoid rings in the corner, as seen in
Figure 3.
Results and Discussion
In
Figure 3, we have the following three partitions of the carbon atoms in
:
These partitions provide us with the atomic bond partition of the
network (see
Table 3).
Let
be the circumnaphthalene series of benzenoid of
. Then, using Equation (
1) and
Table 3, the first
K-Banhatti polynomial is
Following the simplification of Equation (
21), we obtain the first
K-Banhatti index, which is given at
via differentiation.
Here, we calculate the first
K-Banhatti entropy of
using
Table 1 and Equation (
24) in Equation (
6) in the following manner:
Let
be the circumnaphthalene series of benzenoid of
. Then, using Equation (
2) and
Table 1, the second
K-Banhatti polynomial is
To differentiate (
23) at
, we obtain the second
K-Banhatti index
Here, we calculate the second
K-Banhatti entropy of
using
Table 3 and Equation (
24) in Equation (
7) as described below:
Let
be the circumnaphthalene series of benzenoid of
. Then, using Equation (
3) and
Table 3, the first
K-hyper Banhatti polynomial is
To differentiate (
26) at
, we obtain the first
K-hyper Banhatti index
Here, we calculate the first
K-hyper Banhatti entropy of
using
Table 1 and Equation (
27) in Equation (
9) as described below:
Let
be the circumnaphthalene series of benzenoid of
. Then, using Equation (
4) and
Table 3, the second
K-hyper Banhatti polynomial is
To differentiate (
29) at
, we obtain the second
K-hyper Banhatti index
Here, we calculate the second
K-hyper Banhatti entropy of
using
Table 3 and Equation (
30) in Equation (
9) as described below:
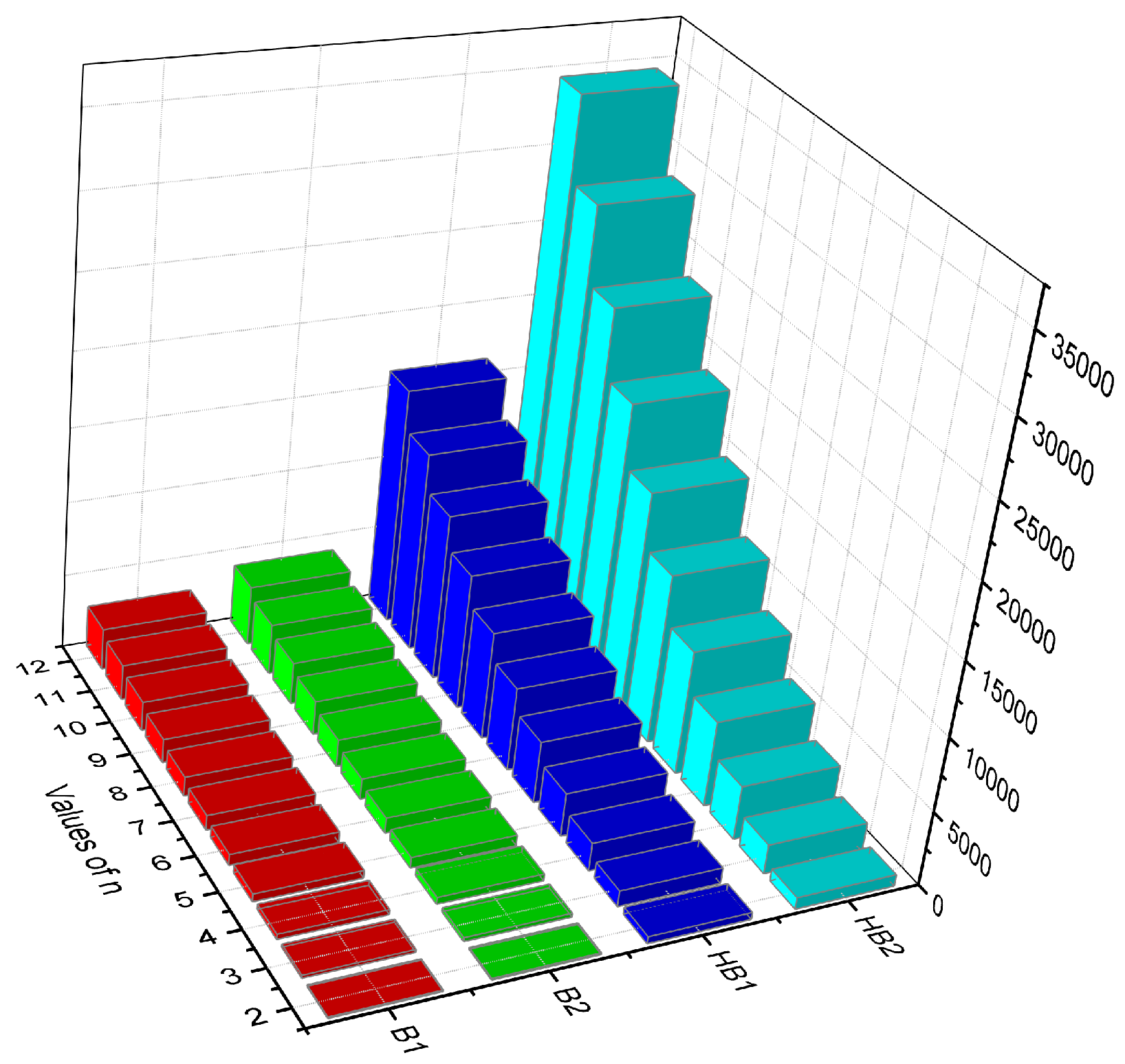
Characteristics of K-Banhatti Indices of
Here, we contrast the
K-Banhatti indices, namely
,
,
, and
for
quantitatively and visually in
Table 4 and
Figure 4, respectively.
5. The Honeycomb Benzenoid Network
In this section, we introduce a chemical compound that has received more and more attention in recent years, partly due to its applications in chemistry. Honeycomb networks are formed when hexagonal tiling is used recursively in a specific pattern.
denotes an
n-dimensional honeycomb network, where
n is the number of Benzene rings from center to top, center to bottom, or center to each corner of
, as shown in
Figure 5.
Results and Discussion
The honeycomb network
is created by adding a layer of hexagons around the boundary of
. In the honeycomb benzenoid network, a
amount of atoms has valency two, and
atoms have valency three. According to the valency of each atom in
, the atomic bonds are classified into three types:
,
, and
(see
Figure 5).
Thus, according to the above partition of the atomic bonds, there is
total number of atomic bonds used in the honeycomb benzenoid network. The atomic bond partition of
is shown in
Table 5.
Let
be the honeycomb benzenoid network of
. Then, using Equation (
1) and
Table 5, the first
K-Banhatti polynomial is
Following the simplification of Equation (
32), we obtain the first
K-Banhatti index given at
via differentiation.
Here, we calculate the first
K-Banhatti entropy of
using
Table 5 and Equation (
33) in Equation (
6) in the following manner:
Let
be the honeycomb benzenoid network of
. Then, using Equation (
2) and
Table 5, the second
K-Banhatti polynomial is
To differentiate (
34) at
, we obtain the second
K-Banhatti index
Here, we calculate the second
K-Banhatti entropy of
using
Table 5 and Equation (
35) in Equation (
7) as described below
Let
be the honeycomb benzenoid network of
. Then, using Equation (
3) and
Table 5, the first
K-hyper Banhatti polynomial is
To differentiate (
37) at
, we obtain the first
K-hyper Banhatti index
Here, we calculate the first
K-hyper Banhatti entropy of
using
Table 5 and Equation (
38) in Equation (
9) as described below:
Let
be the honeycomb benzenoid network of
. Then, using Equation (
4) and
Table 5, the second
K-hyper Banhatti polynomial is
To differentiate (
40) at
, we obtain the second
K-hyper Banhatti index
Here, we calculate the second
K-hyper Banhatti entropy of
using
Table 5 and Equation (
41) in Equation (
9), as described below:
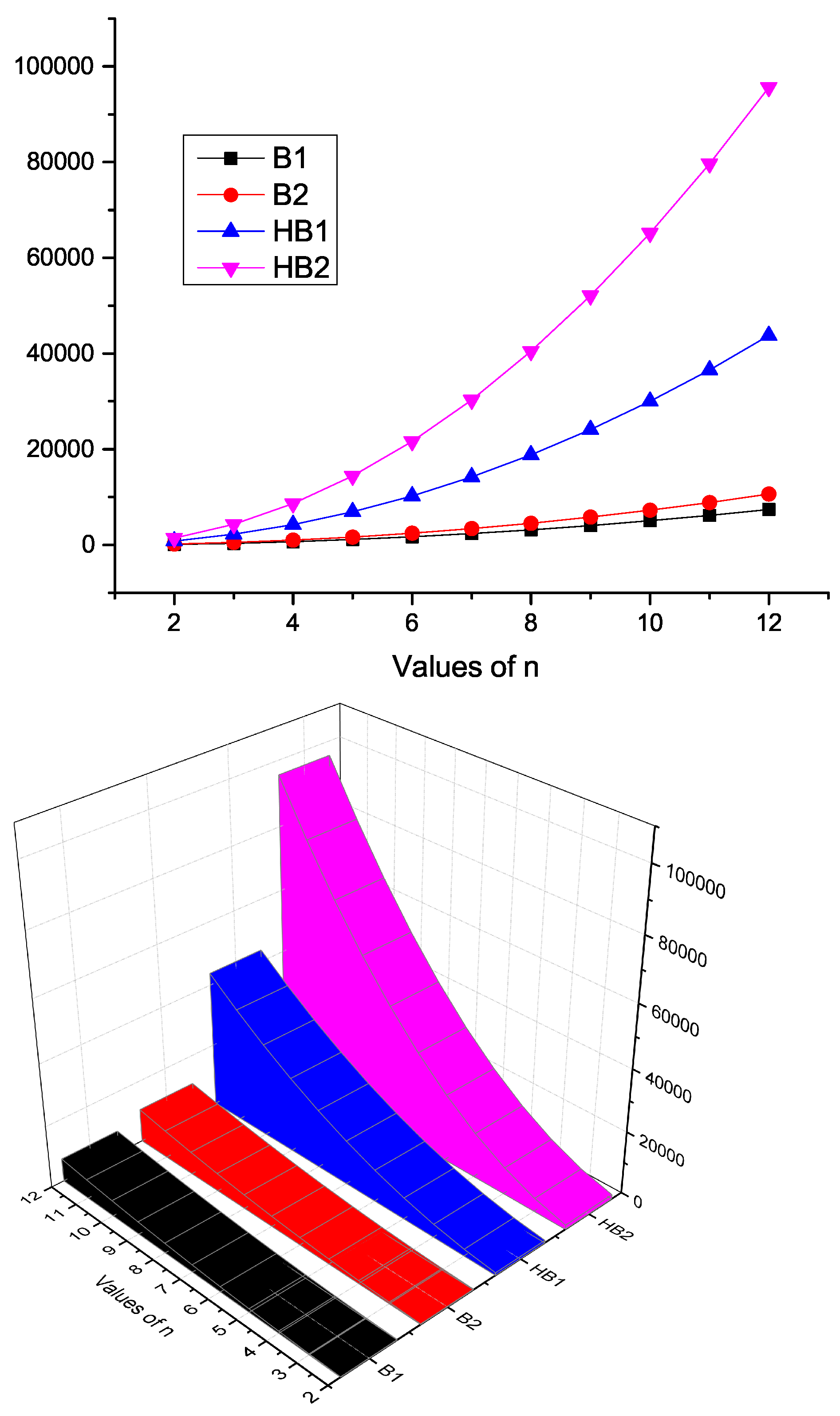
Characteristics of K-Banhatti Indices of
Here, we contrast the
K-Banhatti indices, namely
,
,
, and
for
quantitatively and visually in
Table 6 and
Figure 6, respectively.
6. Conclusions
By using Shannon’s entropy and the entropy definitions of Chen et al., we looked into the graph entropies connected to a novel information function and assessed the link between degree-based topological indices and degree-based entropies in this work. Industrial chemistry has a strong foundation in the concept of distance-based entropy. The Pyrene network, ; the circumnaphthalene series of benzenoid, ; and the honeycomb benzenoid network, were studied, and their valency-based K-Banhatti indices were estimated using four K-Banhatti polynomials with a set partition and an atom bonds approach. The acquired results are valuable for anticipating numerous molecular features of chemical substances, such as boiling point, electron energy, pharmaceutical configuration, and many more concepts. Our results can be applied to determine the electronic structure, signal processing, physicochemical reactions, and complexity of molecules and molecular ensembles for , , and . Together with chemical structure, thermodynamic entropy, energy, and computer sciences, the K-Banhatti entropy can be crucial to linking different fields and serving as the basis for future interdisciplinary research. We intend to extend this idea to different chemical structures in the future, opening up new directions for study in this area.



 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}