
Harnessing Machine Learning, a Subset of Artificial Intelligence, for Early Detection and Diagnosis of Type 1 Diabetes: A Systematic Review


 , and
, and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Aims and Research Questions
2.2. Search Strategy and Selection Criteria
2.3. Assessment of Methodological Quality and Risk of Bias
2.4. Data Extraction and Analysis
3. Results
3.1. Study Characteristics and Outcomes
3.2. Summary of the Quality Assessment
3.3. Comparative Performance of ML Models
3.4. ML for Predicting T1D in Children
3.5. Clinical and Trace Elements as Predictors of T1D Risk
3.6. Identifying Misdiagnosed Adult-Onset T1D
3.7. Early Detection of T1D Using Data from Electronic Health Records
3.8. Multi-Omic Biomarkers in T1D Progression
3.9. Stacking Ensemble Models for Diabetes Detection
3.10. CGM Data and ML for Early T1D Prediction
3.11. Plasma Proteins as Predictors of T1D
3.12. Islet Autoantibody Levels as Predictors of T1D
3.13. Multi-Modal AI for T1D Prediction
4. Discussion
5. Limitations
6. Perspectives for Clinical Practice
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- DiMeglio, L.A.; Evans-Molina, C.; Oram, R.A. Type 1 diabetes. Lancet 2018, 391, 2449–2462. [Google Scholar] [CrossRef] [PubMed]
- Gregory, G.A.; Robinson, T.I.G.; Linklater, S.E.; Wang, F.; Colagiuri, S.; de Beaufort, C.; Donaghue, K.C.; Magliano, D.J.; Maniam, J.; Orchard, T.J.; et al. Global incidence, prevalence, and mortality of type 1 diabetes in 2021 with projection to 2040: A modelling study. Lancet Diabetes Endocrinol. 2022, 10, 741–760. [Google Scholar] [CrossRef] [PubMed]
- Zimmermann, A.T.; Lanzinger, S.; Kummernes, S.J.; Lund-Blix, N.A.; Holl, R.W.; Fröhlich-Reiterer, E.; Maahs, D.M.; Ebekozien, O.; Rompicherla, S.; Warner, J.T.; et al. Treatment regimens and glycaemic outcomes in more than 100,000 children with type 1 diabetes (2013–22): A longitudinal analysis of data from paediatric diabetes registries. Lancet Diabetes Endocrinol. 2025, 13, 47–56. [Google Scholar] [CrossRef]
- Lizzo, J.M.; Goyal, A.; Gupta, V. Adult Diabetic Ketoacidosis. In StatPearls; StatPearls Publishing LLC: Treasure Island, FL, USA, 2025. [Google Scholar]
- Foti Randazzese, S.; La Rocca, M.; Bombaci, B.; Di Pisa, A.; Giliberto, E.; Inturri, T.; Militi, D.; Lombardo, F.; Gitto, E.; Salzano, G.; et al. Severe Diabetic Ketoacidosis in Children with Type 1 Diabetes: Ongoing Challenges in Care. Children 2025, 12, 110. [Google Scholar] [CrossRef]
- Shah, H.S.; McGill, J.B.; Hirsch, I.B.; Wu, C.; Galecki, A.; de Boer, I.H.; Mauer, M.; Doria, A. Poor Glycemic Control Is Associated With More Rapid Kidney Function Decline After the Onset of Diabetic Kidney Disease. J. Clin. Endocrinol. Metab. 2024, 109, 2124–2135. [Google Scholar] [CrossRef]
- Rossing, P.; Groop, P.H.; Singh, R.; Lawatscheck, R.; Tuttle, K.R. Prevalence of Chronic Kidney Disease in Type 1 Diabetes Among Adults in the U.S. Diabetes Care 2024, 47, 1395–1399. [Google Scholar] [CrossRef]
- Pavkov, M.E.; Harding, J.L.; Chou, C.F.; Saaddine, J.B. Prevalence of Diabetic Retinopathy and Associated Mortality Among Diabetic Adults With and Without Chronic Kidney Disease. Am. J. Ophthalmol. 2019, 198, 200–208. [Google Scholar] [CrossRef] [PubMed]
- Mantovani, A.; Morieri, M.L.; Aldigeri, R.; Palmisano, L.; Masulli, M.; Bonomo, K.; Baroni, M.G.; Cossu, E.; Cimini, F.A.; Cavallo, G.; et al. MASLD, hepatic steatosis and fibrosis are associated with the prevalence of chronic kidney disease and retinopathy in adults with type 1 diabetes mellitus. Diabetes Metab. 2024, 50, 101497. [Google Scholar] [CrossRef]
- Syed, F.Z. Type 1 Diabetes Mellitus. Ann. Intern. Med. 2022, 175, Itc33–Itc48. [Google Scholar] [CrossRef]
- Mittal, R.; McKenna, K.; Keith, G.; Lemos, J.R.N.; Mittal, J.; Hirani, K. A systematic review of the association of Type I diabetes with sensorineural hearing loss. PLoS ONE 2024, 19, e0298457. [Google Scholar] [CrossRef]
- Alazwari, A.; Johnstone, A.; Tafakori, L.; Abdollahian, M.; AlEidan, A.M.; Alfuhigi, K.; Alghofialy, M.M.; Albunyan, A.A.; Al Abbad, H.; AlEssa, M.H.; et al. Predicting the development of T1D and identifying its Key Performance Indicators in children; a case-control study in Saudi Arabia. PLoS ONE 2023, 18, e0282426. [Google Scholar] [CrossRef]
- Mitchell, D.M. Growth in patients with type 1 diabetes. Curr. Opin. Endocrinol. Diabetes Obes. 2017, 24, 67–72. [Google Scholar] [CrossRef]
- Insel, R.A.; Dunne, J.L.; Atkinson, M.A.; Chiang, J.L.; Dabelea, D.; Gottlieb, P.A.; Greenbaum, C.J.; Herold, K.C.; Krischer, J.P.; Lernmark, Å.; et al. Staging presymptomatic type 1 diabetes: A scientific statement of JDRF, the Endocrine Society, and the American Diabetes Association. Diabetes Care 2015, 38, 1964–1974. [Google Scholar] [CrossRef]
- Evans-Molina, C.; Oram, R.A. A Golden Hour and Golden Opportunity for β-Cell Preservation. Diabetes 2024, 73, 834–836. [Google Scholar] [CrossRef] [PubMed]
- Gubitosi-Klug, R.A.; Braffett, B.H.; Hitt, S.; Arends, V.; Uschner, D.; Jones, K.; Diminick, L.; Karger, A.B.; Paterson, A.D.; Roshandel, D.; et al. Residual β cell function in long-term type 1 diabetes associates with reduced incidence of hypoglycemia. J. Clin. Investig. 2021, 131, 143011. [Google Scholar] [CrossRef]
- Skyler, J.S.; Bakris, G.L.; Bonifacio, E.; Darsow, T.; Eckel, R.H.; Groop, L.; Groop, P.H.; Handelsman, Y.; Insel, R.A.; Mathieu, C.; et al. Differentiation of Diabetes by Pathophysiology, Natural History, and Prognosis. Diabetes 2017, 66, 241–255. [Google Scholar] [CrossRef] [PubMed]
- Sims, E.K.; Bundy, B.N.; Stier, K.; Serti, E.; Lim, N.; Long, S.A.; Geyer, S.M.; Moran, A.; Greenbaum, C.J.; Evans-Molina, C.; et al. Teplizumab improves and stabilizes beta cell function in antibody-positive high-risk individuals. Sci. Transl. Med. 2021, 13, eabc8980. [Google Scholar] [CrossRef] [PubMed]
- Sundheim, B.; Hirani, K.; Blaschke, M.; Lemos, J.R.N.; Mittal, R. Pre-Type 1 Diabetes in Adolescents and Teens: Screening, Nutritional Interventions, Beta-Cell Preservation, and Psychosocial Impacts. J. Clin. Med. 2025, 14, 383. [Google Scholar] [CrossRef]
- Chiang, J.L.; Maahs, D.M.; Garvey, K.C.; Hood, K.K.; Laffel, L.M.; Weinzimer, S.A.; Wolfsdorf, J.I.; Schatz, D. Type 1 Diabetes in Children and Adolescents: A Position Statement by the American Diabetes Association. Diabetes Care 2018, 41, 2026–2044. [Google Scholar] [CrossRef]
- Yoo, J.H.; Kim, J.H. Advances in Continuous Glucose Monitoring and Integrated Devices for Management of Diabetes with Insulin-Based Therapy: Improvement in Glycemic Control. Diabetes Metab. J. 2023, 47, 27–41. [Google Scholar] [CrossRef]
- Jendle, J.; Ericsson, Å.; Gundgaard, J.; Møller, J.B.; Valentine, W.J.; Hunt, B. Smart Insulin Pens are Associated with Improved Clinical Outcomes at Lower Cost Versus Standard-of-Care Treatment of Type 1 Diabetes in Sweden: A Cost-Effectiveness Analysis. Diabetes Ther. 2021, 12, 373–388. [Google Scholar] [CrossRef] [PubMed]
- Hellman, J.; Hartvig, N.V.; Kaas, A.; Møller, J.B.; Sørensen, M.R.; Jendle, J. Associations of bolus insulin injection frequency and smart pen engagement with glycaemic control in people living with type 1 diabetes. Diabetes Obes. Metab. 2024, 26, 301–310. [Google Scholar] [CrossRef] [PubMed]
- MacLeod, J.; Im, G.H.; Smith, M.; Vigersky, R.A. Shining the Spotlight on Multiple Daily Insulin Therapy: Real-World Evidence of the InPen Smart Insulin Pen. Diabetes Technol. Ther. 2024, 26, 33–39. [Google Scholar] [CrossRef]
- Danne, T.P.A.; Joubert, M.; Hartvig, N.V.; Kaas, A.; Knudsen, N.N.; Mader, J.K. Association Between Treatment Adherence and Continuous Glucose Monitoring Outcomes in People With Diabetes Using Smart Insulin Pens in a Real-World Setting. Diabetes Care 2024, 47, 995–1003. [Google Scholar] [CrossRef] [PubMed]
- Schiaffini, R.; Lumaca, A.; Martino, M.; Rapini, N.; Deodati, A.; Amodeo, M.E.; Ciampalini, P.; Matteoli, M.C.; Pampanini, V.; Cianfarani, S. Time In Tight Range in children and adolescents with type 1 diabetes: A cross-sectional observational single centre study evaluating efficacy of new advanced technologies. Diabetes Metab. Res. Rev. 2024, 40, e3826. [Google Scholar] [CrossRef]
- Eviz, E.; Killi, N.E.; Karakus, K.E.; Can, E.; Gokce, T.; Yesiltepe Mutlu, G.; Hatun, S. Assessing the feasibility of time in tight range (TITR) targets with advanced hybrid closed loop (AHCL) use in children and adolescents: A single-centre real-world study. Diabet. Med. 2024, 41, e15333. [Google Scholar] [CrossRef]
- Bahillo-Curieses, P.; Fernández Velasco, P.; Pérez-López, P.; Vidueira Martínez, A.M.; Nieto de la Marca, M.O.; Díaz-Soto, G. Utility of time in tight range (TITR) in evaluating metabolic control in pediatric and adult patients with type 1 diabetes in treatment with advanced hybrid closed-loop systems. Endocrine 2024, 86, 539–545. [Google Scholar] [CrossRef]
- Pantanetti, P.; Cangelosi, G.; Palomares, S.M.; Ferrara, G.; Biondini, F.; Mancin, S.; Caggianelli, G.; Parozzi, M.; Sguanci, M.; Petrelli, F. Real-World Life Analysis of a Continuous GlucoseMonitoring and Smart Insulin Pen System in Type 1 Diabetes: A Cohort Study. Diabetology 2025, 6, 7. [Google Scholar] [CrossRef]
- Ogunpola, A.; Saeed, F.; Basurra, S.; Albarrak, A.M.; Qasem, S.N. Machine Learning-Based Predictive Models for Detection of Cardiovascular Diseases. Diagnostics 2024, 14, 144. [Google Scholar] [CrossRef]
- Sau, A.; Pastika, L.; Sieliwonczyk, E.; Patlatzoglou, K.; Ribeiro, A.H.; McGurk, K.A.; Zeidaabadi, B.; Zhang, H.; Macierzanka, K.; Mandic, D.; et al. Artificial intelligence-enabled electrocardiogram for mortality and cardiovascular risk estimation: A model development and validation study. Lancet Digit. Health 2024, 6, e791–e802. [Google Scholar] [CrossRef]
- Menzies, S.W.; Sinz, C.; Menzies, M.; Lo, S.N.; Yolland, W.; Lingohr, J.; Razmara, M.; Tschandl, P.; Guitera, P.; Scolyer, R.A.; et al. Comparison of humans versus mobile phone-powered artificial intelligence for the diagnosis and management of pigmented skin cancer in secondary care: A multicentre, prospective, diagnostic, clinical trial. Lancet Digit. Health 2023, 5, e679–e691. [Google Scholar] [CrossRef] [PubMed]
- Han, T.; Xiong, F.; Sun, B.; Zhong, L.; Han, Z.; Lei, M. Development and validation of an artificial intelligence mobile application for predicting 30-day mortality in critically ill patients with orthopaedic trauma. Int. J. Med. Inform. 2024, 184, 105383. [Google Scholar] [CrossRef] [PubMed]
- Banerjee, A.; Dashtban, A.; Chen, S.; Pasea, L.; Thygesen, J.H.; Fatemifar, G.; Tyl, B.; Dyszynski, T.; Asselbergs, F.W.; Lund, L.H.; et al. Identifying subtypes of heart failure from three electronic health record sources with machine learning: An external, prognostic, and genetic validation study. Lancet Digit. Health 2023, 5, e370–e379. [Google Scholar] [CrossRef]
- Krittanawong, C.; Virk, H.U.H.; Kumar, A.; Aydar, M.; Wang, Z.; Stewart, M.P.; Halperin, J.L. Machine learning and deep learning to predict mortality in patients with spontaneous coronary artery dissection. Sci. Rep. 2021, 11, 8992. [Google Scholar] [CrossRef]
- Persson, I.; Macura, A.; Becedas, D.; Sjövall, F. Early prediction of sepsis in intensive care patients using the machine learning algorithm NAVOY® Sepsis, a prospective randomized clinical validation study. J. Crit. Care 2024, 80, 154400. [Google Scholar] [CrossRef]
- Howell, M.D.; Corrado, G.S.; DeSalvo, K.B. Three Epochs of Artificial Intelligence in Health Care. JAMA 2024, 331, 242–244. [Google Scholar] [CrossRef] [PubMed]
- Sun, J.; Feng, T.; Wang, B.; Li, F.; Han, B.; Chu, M.; Gong, F.; Yi, Q.; Zhou, X.; Chen, S.; et al. Leveraging artificial intelligence for predicting spontaneous closure of perimembranous ventricular septal defect in children: A multicentre, retrospective study in China. Lancet Digit. Health 2025, 7, e44–e53. [Google Scholar] [CrossRef]
- Rajkomar, A.; Dean, J.; Kohane, I. Machine Learning in Medicine. N. Engl. J. Med. 2019, 380, 1347–1358. [Google Scholar] [CrossRef]
- Liu, X.; Hu, P.; Yeung, W.; Zhang, Z.; Ho, V.; Liu, C.; Dumontier, C.; Thoral, P.J.; Mao, Z.; Cao, D.; et al. Illness severity assessment of older adults in critical illness using machine learning (ELDER-ICU): An international multicentre study with subgroup bias evaluation. Lancet Digit. Health 2023, 5, e657–e667. [Google Scholar] [CrossRef]
- Rasdall, M.A.; Cho, C.; Stahl, A.N.; Tovar, D.A.; Lavin, P.; Kerley, C.I.; Chen, Q.; Ji, X.; Colyer, M.H.; Groves, L.; et al. Primary Visual Pathway Changes in Individuals With Chronic Mild Traumatic Brain Injury. JAMA Ophthalmol. 2024, 143, 33. [Google Scholar] [CrossRef]
- Jackson, H.R.; Zandstra, J.; Menikou, S.; Hamilton, M.S.; McArdle, A.J.; Fischer, R.; Thorne, A.M.; Huang, H.; Tanck, M.W.; Jansen, M.H.; et al. A multi-platform approach to identify a blood-based host protein signature for distinguishing between bacterial and viral infections in febrile children (PERFORM): A multi-cohort machine learning study. Lancet Digit. Health 2023, 5, e774–e785. [Google Scholar] [CrossRef] [PubMed]
- Archer, D.B.; Bricker, J.T.; Chu, W.T.; Burciu, R.G.; McCracken, J.L.; Lai, S.; Coombes, S.A.; Fang, R.; Barmpoutis, A.; Corcos, D.M.; et al. Development and validation of the automated imaging differentiation in parkinsonism (AID-P): A multicentre machine learning study. Lancet Digit. Health 2019, 1, e222–e231. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Huang, G.; Zheng, K.; Lin, J.; Hu, S.; Zheng, S.; Du, G.; Zhang, G.; Bruni, C.; Matucci-Cerinic, M.; et al. Application of logistic regression and machine learning methods for idiopathic inflammatory myopathies malignancy prediction. Clin. Exp. Rheumatol. 2023, 41, 330–339. [Google Scholar] [CrossRef]
- Geeitha, S.; Prabha, K.P.R.; Cho, J.; Easwaramoorthy, S.V. Bidirectional recurrent neural network approach for predicting cervical cancer recurrence and survival. Sci. Rep. 2024, 14, 31641. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Du, R.; Xie, S.; Chen, C.; Lu, H.; Xiong, J.; Ting, D.S.W.; Uramoto, K.; Kamoi, K.; Ohno-Matsui, K. Machine Learning Models for Predicting Long-Term Visual Acuity in Highly Myopic Eyes. JAMA Ophthalmol. 2023, 141, 1117–1124. [Google Scholar] [CrossRef]
- Mongan, D.; Föcking, M.; Healy, C.; Susai, S.R.; Heurich, M.; Wynne, K.; Nelson, B.; McGorry, P.D.; Amminger, G.P.; Nordentoft, M.; et al. Development of Proteomic Prediction Models for Transition to Psychotic Disorder in the Clinical High-Risk State and Psychotic Experiences in Adolescence. JAMA Psychiatry 2021, 78, 77–90. [Google Scholar] [CrossRef]
- Jiang, Z.; Ren, W.; Liang, H.; Yan, J.; Yang, D.; Luo, S.; Zheng, X.; Lin, G.W.; Xian, Y.; Xu, W.; et al. HLA class I genes modulate disease risk and age at onset together with DR-DQ in Chinese patients with insulin-requiring type 1 diabetes. Diabetologia 2021, 64, 2026–2036. [Google Scholar] [CrossRef]
- Zhao, L.P.; Papadopoulos, G.K.; Lybrand, T.P.; Moustakas, A.K.; Bondinas, G.P.; Carlsson, A.; Larsson, H.E.; Ludvigsson, J.; Marcus, C.; Persson, M.; et al. The KAG motif of HLA-DRB1 (β71, β74, β86) predicts seroconversion and development of type 1 diabetes. EBioMedicine 2021, 69, 103431. [Google Scholar] [CrossRef]
- de Azevedo, J.C.V.; de Medeiros Fernandes, T.A.A.; Cavalcante, G.A.; de Medeiros, I.; Lanza, D.C.F.; de Araújo, J.M.G.; Bezerra, F.L.; Fernandes, J.V. Biology and Natural History of Type 1 Diabetes Mellitus. Curr. Pediatr. Rev. 2023, 19, 253–275. [Google Scholar] [CrossRef]
- Robertson, C.C.; Inshaw, J.R.J.; Onengut-Gumuscu, S.; Chen, W.M.; Santa Cruz, D.F.; Yang, H.; Cutler, A.J.; Crouch, D.J.M.; Farber, E.; Bridges, S.L., Jr.; et al. Fine-mapping, trans-ancestral and genomic analyses identify causal variants, cells, genes and drug targets for type 1 diabetes. Nat. Genet. 2021, 53, 962–971. [Google Scholar] [CrossRef]
- Kim, S.S.; Hudgins, A.D.; Yang, J.; Zhu, Y.; Tu, Z.; Rosenfeld, M.G.; DiLorenzo, T.P.; Suh, Y. A comprehensive integrated post-GWAS analysis of Type 1 diabetes reveals enhancer-based immune dysregulation. PLoS ONE 2021, 16, e0257265. [Google Scholar] [CrossRef] [PubMed]
- Nurminen, N.; Cerrone, D.; Lehtonen, J.; Parajuli, A.; Roslund, M.; Lönnrot, M.; Ilonen, J.; Toppari, J.; Veijola, R.; Knip, M.; et al. Land Cover of Early-Life Environment Modulates the Risk of Type 1 Diabetes. Diabetes Care 2021, 44, 1506–1514. [Google Scholar] [CrossRef]
- Tremblay, J.; Hamet, P. Environmental and genetic contributions to diabetes. Metabolism 2019, 100, 153952. [Google Scholar] [CrossRef]
- Mittal, R.; Camick, N.; Lemos, J.R.N.; Hirani, K. Gene-environment interaction in the pathophysiology of type 1 diabetes. Front. Endocrinol. 2024, 15, 1335435. [Google Scholar] [CrossRef]
- Kassani, P.H.; Lu, F.; Guen, Y.L.; Belloy, M.E.; He, Z. Deep neural networks with controlled variable selection for the identification of putative causal genetic variants. Nat. Mach. Intell. 2022, 4, 761–771. [Google Scholar] [CrossRef]
- van Hilten, A.; van Rooij, J.; Ikram, M.A.; Niessen, W.J.; van Meurs, J.B.J.; Roshchupkin, G.V. Phenotype prediction using biologically interpretable neural networks on multi-cohort multi-omics data. NPJ Syst. Biol. Appl. 2024, 10, 81. [Google Scholar] [CrossRef] [PubMed]
- Passemiers, A.; Folco, P.; Raimondi, D.; Birolo, G.; Moreau, Y.; Fariselli, P. A quantitative benchmark of neural network feature selection methods for detecting nonlinear signals. Sci. Rep. 2024, 14, 31180. [Google Scholar] [CrossRef] [PubMed]
- Ogutu, S.; Mohammed, M.; Mwambi, H. Cytokine profiles as predictors of HIV incidence using machine learning survival models and statistical interpretable techniques. Sci. Rep. 2024, 14, 29895. [Google Scholar] [CrossRef]
- Rajagopalan, S.S.; Zhang, Y.; Yahia, A.; Tammimies, K. Machine Learning Prediction of Autism Spectrum Disorder From a Minimal Set of Medical and Background Information. JAMA Netw. Open 2024, 7, e2429229. [Google Scholar] [CrossRef]
- Park, Y.W.; Eom, S.; Kim, S.; Lim, S.; Park, J.E.; Kim, H.S.; You, S.C.; Ahn, S.S.; Lee, S.K. Differentiation of glioblastoma from solitary brain metastasis using deep ensembles: Empirical estimation of uncertainty for clinical reliability. Comput. Methods Programs Biomed. 2024, 254, 108288. [Google Scholar] [CrossRef]
- Wan, W.; Gu, Z.; Peng, C.K.; Cui, X. Beyond Frequency Bands: Complementary-Ensemble-Empirical-Mode-Decomposition-Enhanced Microstate Sequence Non-Randomness Analysis for Aiding Diagnosis and Cognitive Prediction of Dementia. Brain Sci. 2024, 14, 487. [Google Scholar] [CrossRef] [PubMed]
- Cai, G.; Huang, F.; Gao, Y.; Li, X.; Chi, J.; Xie, J.; Zhou, L.; Feng, Y.; Huang, H.; Deng, T.; et al. Artificial intelligence-based models enabling accurate diagnosis of ovarian cancer using laboratory tests in China: A multicentre, retrospective cohort study. Lancet Digit. Health 2024, 6, e176–e186. [Google Scholar] [CrossRef]
- Shen, X.; Wu, J.; Zhou, T.; Xu, Y.; Zhuo, S.; Zheng, F.; Tong, S.; Zhang, X.; Hu, L. Unsaturated fatty acid profiles and prognostic significance in epilepsy patients: A comprehensive analysis using UPLC-MS/MS and SVM algorithm. J. Pharm. Biomed. Anal. 2024, 255, 116610. [Google Scholar] [CrossRef] [PubMed]
- Liberati, A.; Altman, D.G.; Tetzlaff, J.; Mulrow, C.; Gøtzsche, P.C.; Ioannidis, J.P.; Clarke, M.; Devereaux, P.J.; Kleijnen, J.; Moher, D. The PRISMA statement for reporting systematic reviews and meta-analyses of studies that evaluate healthcare interventions: Explanation and elaboration. BMJ 2009, 339, b2700. [Google Scholar] [CrossRef] [PubMed]
- McHugh, M.L. Interrater reliability: The kappa statistic. Biochem. Med. 2012, 22, 276–282. [Google Scholar] [CrossRef]
- Mardan, M.; Mamat, M.; Yasin, P.; Cai, X.Y.; Fan, G.J.; Xu, T.; Li, B.; Chen, P.B.; Lu, Z.Y.; Sheng, W.B.; et al. An Inter- and Intra-Rater Agreement Assessment of Two Novel Classification Systems for Coronal Imbalance in Adult Scoliosis and Spine Deformity. Orthop. Surg. 2025, 17, 1075–1085. [Google Scholar] [CrossRef]
- Rushendran, R.; Singh, A.; Ankul Singh, S.; Chitra, V.; Ilango, K. A role of NLRP3 and MMP9 in migraine progression: A systematic review of translational study. Front. Neurol. 2024, 15, 1307319. [Google Scholar] [CrossRef]
- Wynn, M.; Stephens, M.; Pradeep, S.; Clarke-Cornwell, A.M.; Bianchi, J. Clinimetrics of the Lanarkshire Oximetry Index for patients with leg ulcers: A systematic review and meta-analysis. Int. Wound J. 2024, 21, e14519. [Google Scholar] [CrossRef]
- Bobos, P.; Pouliopoulou, D.V.; Harriss, A.; Sadi, J.; Rushton, A.; MacDermid, J.C. A systematic review and meta-analysis of measurement properties of objective structured clinical examinations used in physical therapy licensure and a structured review of licensure practices in countries with well-developed regulation systems. PLoS ONE 2021, 16, e0255696. [Google Scholar] [CrossRef]
- Campbell, J.M.; Klugar, M.; Ding, S.; Carmody, D.P.; Hakonsen, S.J.; Jadotte, Y.T.; White, S.; Munn, Z. Diagnostic test accuracy: Methods for systematic review and meta-analysis. Int. J. Evid. Based Healthc. 2015, 13, 154–162. [Google Scholar] [CrossRef]
- Chai, J.; Wang, Y.; Sun, Z.; Zhou, Q.; Xu, J. Evaluation among trace elements, clinical parameters and type 1 diabetes according to sex: A new sight of auxiliary prediction in negative insulin auto-antibodies population. J. Trace Elem. Med. Biol. 2023, 75, 127100. [Google Scholar] [CrossRef] [PubMed]
- Nakayasu, E.S.; Bramer, L.M.; Ansong, C.; Schepmoes, A.A.; Fillmore, T.L.; Gritsenko, M.A.; Clauss, T.R.; Gao, Y.; Piehowski, P.D.; Stanfill, B.A.; et al. Plasma protein biomarkers predict the development of persistent autoantibodies and type 1 diabetes 6 months prior to the onset of autoimmunity. Cell Rep. Med. 2023, 4, 101093. [Google Scholar] [CrossRef]
- Webb-Robertson, B.M.; Nakayasu, E.S.; Frohnert, B.I.; Bramer, L.M.; Akers, S.M.; Norris, J.M.; Vehik, K.; Ziegler, A.G.; Metz, T.O.; Rich, S.S.; et al. Integration of Infant Metabolite, Genetic, and Islet Autoimmunity Signatures to Predict Type 1 Diabetes by Age 6 Years. J. Clin. Endocrinol. Metab. 2022, 107, 2329–2338. [Google Scholar] [CrossRef] [PubMed]
- Frohnert, B.I.; Webb-Robertson, B.J.; Bramer, L.M.; Reehl, S.M.; Waugh, K.; Steck, A.K.; Norris, J.M.; Rewers, M. Predictive Modeling of Type 1 Diabetes Stages Using Disparate Data Sources. Diabetes 2020, 69, 238–248. [Google Scholar] [CrossRef] [PubMed]
- Montaser, E.; Brown, S.A.; DeBoer, M.D.; Farhy, L.S. Predicting the Risk of Developing Type 1 Diabetes Using a One-Week Continuous Glucose Monitoring Home Test With Classification Enhanced by Machine Learning: An Exploratory Study. J. Diabetes Sci. Technol. 2024, 18, 257–265. [Google Scholar] [CrossRef]
- Cheheltani, R.; King, N.; Lee, S.; North, B.; Kovarik, D.; Evans-Molina, C.; Leavitt, N.; Dutta, S. Predicting misdiagnosed adult-onset type 1 diabetes using machine learning. Diabetes Res. Clin. Pract. 2022, 191, 110029. [Google Scholar] [CrossRef]
- Daniel, R.; Jones, H.; Gregory, J.W.; Shetty, A.; Francis, N.; Paranjothy, S.; Townson, J. Predicting type 1 diabetes in children using electronic health records in primary care in the UK: Development and validation of a machine-learning algorithm. Lancet Digit. Health 2024, 6, e386–e395. [Google Scholar] [CrossRef]
- Gollapalli, M.; Alansari, A.; Alkhorasani, H.; Alsubaii, M.; Sakloua, R.; Alzahrani, R.; Al-Hariri, M.; Alfares, M.; AlKhafaji, D.; Al Argan, R.; et al. A novel stacking ensemble for detecting three types of diabetes mellitus using a Saudi Arabian dataset: Pre-diabetes, T1DM, and T2DM. Comput. Biol. Med. 2022, 147, 105757. [Google Scholar] [CrossRef]
- Ng, K.; Anand, V.; Stavropoulos, H.; Veijola, R.; Toppari, J.; Maziarz, M.; Lundgren, M.; Waugh, K.; Frohnert, B.I.; Martin, F.; et al. Quantifying the utility of islet autoantibody levels in the prediction of type 1 diabetes in children. Diabetologia 2023, 66, 93–104. [Google Scholar] [CrossRef]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. BMJ 2021, 372, n71. [Google Scholar] [CrossRef]
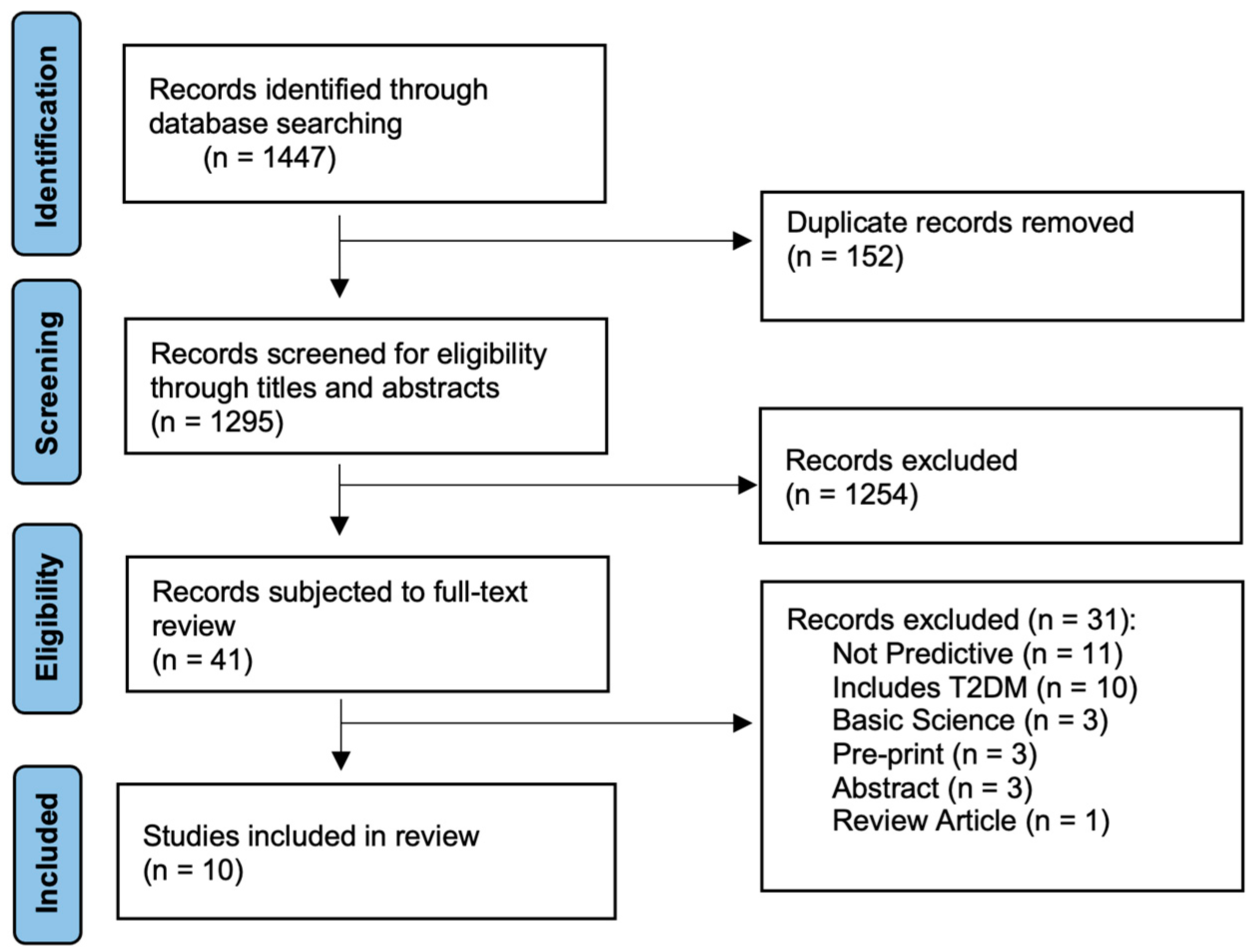
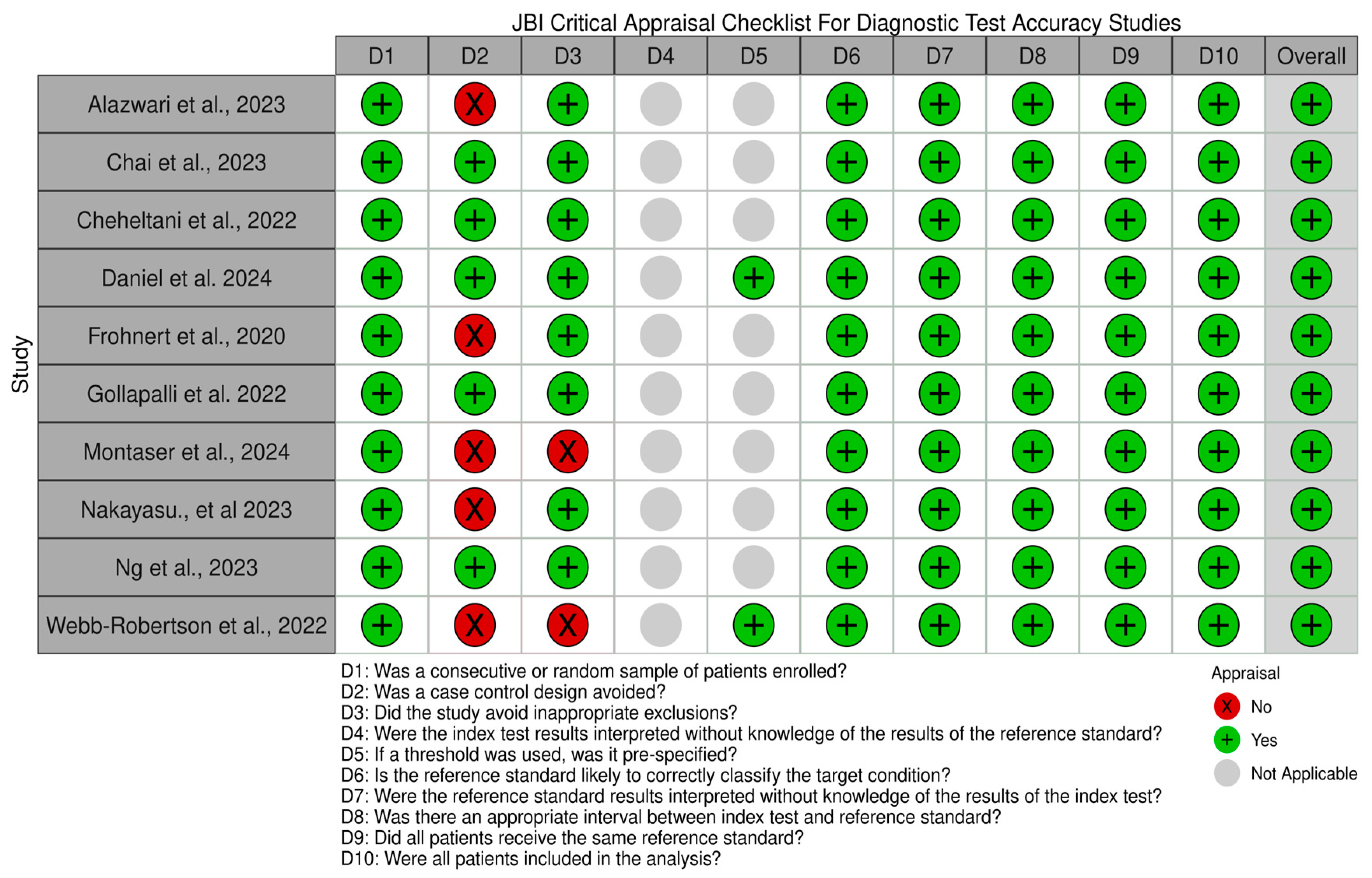


{kind=link}
{kind=link}
{kind=link}
| Inclusion Criteria | Exclusion Criteria |
|---|---|
| Clinical studies using ML or AI for early detection/diagnosis of T1D | Studies lacking predictive modeling |
| Studies reporting risk stratification and model performance metrics (such as accuracy, sensitivity, specificity, AUC-ROC) | Included T2D or other non-T1D diagnoses |
| Published in a peer-reviewed journal | Review articles |
| Involving human subjects | Animal and cadaveric studies |
| Written in English | Case reports |
| Reference | Study | Sample Size/Population | Comparison | Outcomes/Study Conclusions |
|---|---|---|---|---|
| Alazwari et al., 2023 [12] | Case–control study | A total of 1142 children <15 years with a confirmed diagnosis of T1D between 2010 and 2020 | Non-diabetic controls | Significant KPIs included the following:
|
| Chai et al., 2023 [72] | Retrospective cohort (EMRs) | A total of 105 T1D patients with negative insulin autoantibodies (zinc transporter8, anti-islet cell antibody, anti-glutamate decarboxylase antibody, anti-tyrosine phosphatase antibody, anti-insulin antibody, islet antigen-2 autoantibodies), 2019–2020 | Non-diabetic controls |
|
| Cheheltani et al., 2022 [77] | Retrospective cohort (AEMRs) | A total of 15,881 patients with type 1 | Patients misdiagnosed as type 2 cohort |
|
| Daniel et al., 2024 [78] | Retrospective cohort (EHRs) | A total of 1829 children younger than 15 years with type 1 DM development | Non-diabetic controls |
|
| Frohnert et al., 2020 [75] | Case–control study | A total of 2547 children in the DAISY cohort at increased DM risk, first-degree relatives of patients with type 1 diabetes (FDRs), and general-population children with type 1 diabetes susceptibility HLA DR-DQ genotypes identified by newborn screening, recruited between 1993 and 2004 | Non-diabetic control family vs. children with increased DM risk |
|
| Gollapalli et al., 2022 [79] | Retrospective cohort (EMRs) | A total of 2067 patients with cancer (n = 93), dementia (n = 152), and diabetes (n = 1822) | Non-diabetic controls |
|
| Montaser set al., 2024 [76] | Case–control study | A total of 56 individuals without a history of diabetes and fasting plasma glucose < 126 mg/dL classified as normoglycemia (n = 33) or pre-diabetes (n = 21) | Non-diabetic controls |
|
| Nakayasu et al., 2023 [73] | Case–control study (TEDDY study) | Untargeted proteomics of 2252 samples from 184 individuals identifying 376 regulated proteins | Non-diabetic controls |
|
| Ng et al., 2023 [80] | Prospective cohort studies | A total of 24,662 children at increased genetic or familial risk of developing islet autoimmunity and diabetes | Non-diabetic controls |
|
| Webb-Robertson et al., 2022 [74] | Case–control study (TEDDY study) | A total of 702 children with all data sources measured at ages 3, 6, and 9 months, 11.4% of whom progressed to T1D by age 6 years | Non-diabetic controls |
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mittal, R.; Weiss, M.B.; Rendon, A.; Shafazand, S.; Lemos, J.R.N.; Hirani, K. Harnessing Machine Learning, a Subset of Artificial Intelligence, for Early Detection and Diagnosis of Type 1 Diabetes: A Systematic Review. Int. J. Mol. Sci. 2025, 26, 3935. https://doi.org/10.3390/ijms26093935
Mittal R, Weiss MB, Rendon A, Shafazand S, Lemos JRN, Hirani K. Harnessing Machine Learning, a Subset of Artificial Intelligence, for Early Detection and Diagnosis of Type 1 Diabetes: A Systematic Review. International Journal of Molecular Sciences. 2025; 26(9):3935. https://doi.org/10.3390/ijms26093935
Chicago/Turabian StyleMittal, Rahul, Matthew B. Weiss, Alexa Rendon, Shirin Shafazand, Joana R N Lemos, and Khemraj Hirani. 2025. "Harnessing Machine Learning, a Subset of Artificial Intelligence, for Early Detection and Diagnosis of Type 1 Diabetes: A Systematic Review" International Journal of Molecular Sciences 26, no. 9: 3935. https://doi.org/10.3390/ijms26093935
APA StyleMittal, R., Weiss, M. B., Rendon, A., Shafazand, S., Lemos, J. R. N., & Hirani, K. (2025). Harnessing Machine Learning, a Subset of Artificial Intelligence, for Early Detection and Diagnosis of Type 1 Diabetes: A Systematic Review. International Journal of Molecular Sciences, 26(9), 3935. https://doi.org/10.3390/ijms26093935