
EEG Emotion Classification Network Based on Attention Fusion of Multi-Channel Band Features


Abstract
:1. Introduction
- (1)
- An EEG emotional classification network based on the attentional fusion (ECN-AF) of multi-channel band features is proposed, focusing on the relationship among the frequency bands, channels, and time series features.
- (2)
- An induction experiment of an online learning scenario is designed, resulting in the self-collected LE-EEG dataset with relatively large sample size (N = 45).
- (3)
- The cross-dataset validation demonstrates that the proposed ECN-AF model outperforms the baseline models, showing not only a good performance on the public data SEED, but also significant advantages on the self-collected LE-EEG dataset.
2. Related Works
3. Methodology
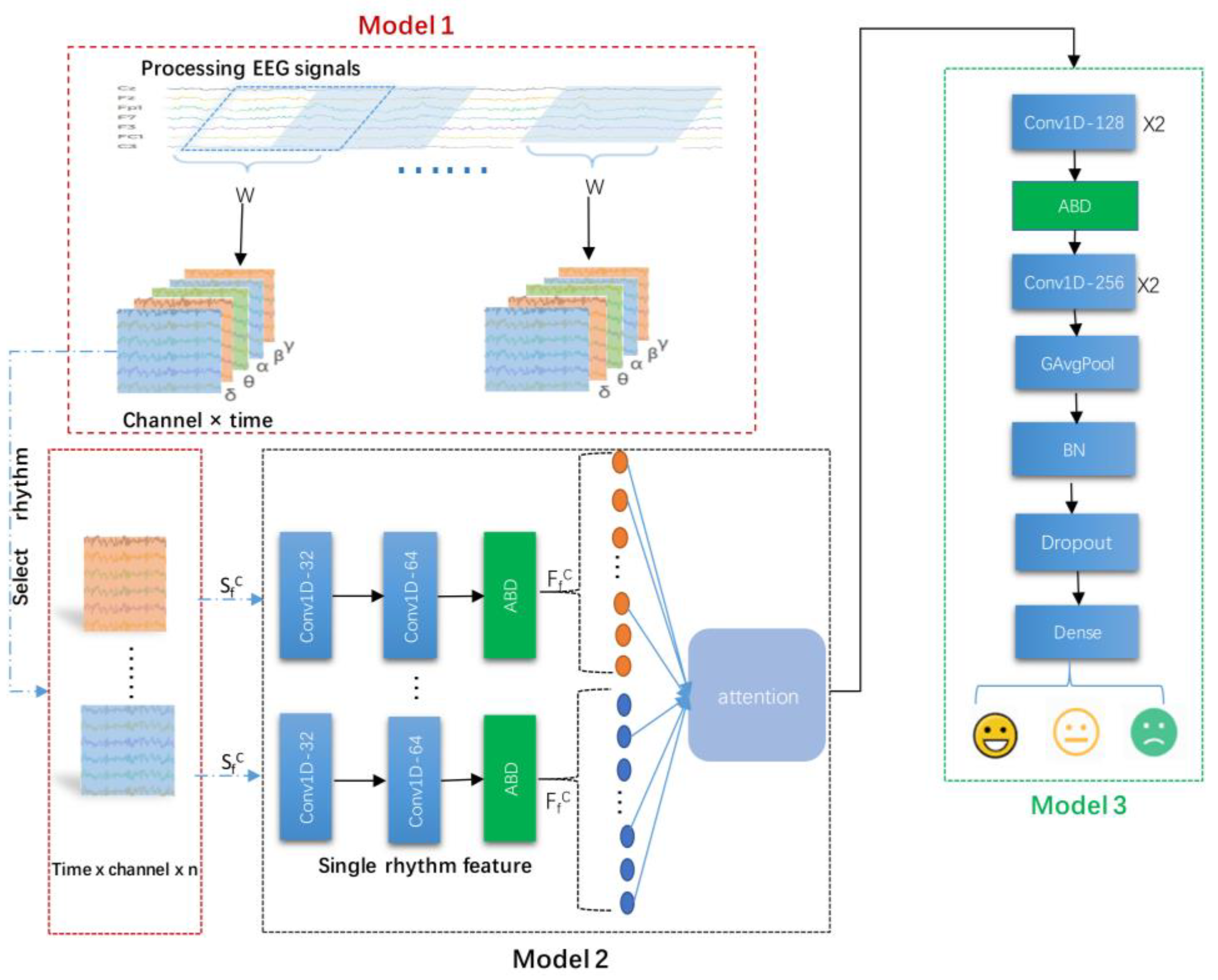
3.1. Model Framework
- (1)
- Module 1: frequency band division and channel selection module. In this module, first, the acquired EEG signal were divided into raw segments by a sliding window with a window size 10 s and a step size 2 s; second, five different frequency bands were extracted by passing the raw segments through bandpass filters; third, the final segments were generated, which were the optimal combinations of EEG channels obtained by multi-channel filtering operation.
- (2)
- Module 2: frequency band attention feature extraction module. This module comprised a multi-channel convolutional backbone network with a frequency band attention fusion unit. First, the EEG sequences output from Module 1 were put into the multi-channel convolutional backbone network, which extracted not only the channel and time series features but also the features in different frequency bands. Second, the features extracted from different frequency bands were further put into a frequency band attention fusion unit, which performed the fusion of the channels and time series features across different frequency bands.
- (3)
- Module 3: feature fusion and classification module. In this module, the combined features obtained from the fusion unit were taken as the input to the classification network; subsequently, the fused features were extracted using the depth network and then input to the fully connected layer, giving the final classification results.
3.2. Module 1: Frequency Band Division and Channel Selection Module
3.3. Module 2: Frequency Band Attention Feature Extraction Module
3.3.1. Multi-Channel Convolutional Backbone Network
3.3.2. Frequency Band Attention Fusion Unit
3.4. Module 3: Feature Fusion and Classification Module
4. Experiments
4.1. Experimental Materials
4.1.1. Sources of Emotional Materials
4.1.2. Emotional Material Clipping
4.1.3. Evaluation of Emotional Materials
- ∘
- 0: really boring, I don’t want to listen at all;
- ∘
- 1: a little boring;
- ∘
- 2: average;
- ∘
- 3: not boring, can keep up with the teacher’s rhythm;
- ∘
- 4: not boring, very focused.
4.2. Experimental Procedure and Signal Pre-Processing
4.2.1. Experimental Procedure
4.2.2. Signal Pre-Processing
5. Results and Analysis
5.1. Ablation Study
5.1.1. Sub-Band Prediction and Combined Band Prediction
5.1.2. Comparison of the Results of Fusion Methods
5.2. Comparison
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Method | Type | Description |
|---|---|---|---|
| 1 | bogus or infrequency [52,53,54,55] | check items | Odd items placed in scale to solicit particular responses. |
| 2 | long-string analysis [52,53,54,55] | invariance | Length of longest sequential string of the same response |
| 3 | self-report data [52,53,54,55] | self-report | Items which ask the participant how much effort they applied or how they judge the quality of their data |
| 4 | semantic antonyms/synonyms [52,53,54,55] | consistency | Within-person correlations on sets of semantically matched pairs of items with opposite or similar meaning |
| 5 | instructional manipulation checks [52,53,54,55] | check items | Items with extended instructions which include instructing participant to answer in unique manner |
| 6 | polytomous guttman errors [52] | consistency | Count of the number of instances where a respondent broke the pattern of monotonically increasing response on the set of survey items ordered by difficulty. |
References
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.F.; Weiss, B. A database of German emotional speech. In Proceedings of the 9th European Conference on Speech Communication and Technology (INTERSPEECH2005), Lisbon, Portugal, 4–8 September 2005; pp. 1517–1520. [Google Scholar]
- Lim, W.; Jang, D.; Lee, T. Speech emotion recognition using convolutional and recurrent neural networks. In Proceedings of the Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA2016), Jeju, Korea, 13–16 December 2016; pp. 1–4. [Google Scholar]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.Y.; Potts, C. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing (EMNLP2013), Seattle, WA, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP2014), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Anderson, K.; Mcowan, P.W. A real-time automated system for the recognition of human facial expressions. IEEE Trans. Syst. Man. Cybern. B Cybern. 2006, 36, 96–105. [Google Scholar] [CrossRef] [PubMed]
- Kim, K.H.; Bang, S.W.; Kim, S.R. Emotion recognition system using short-term monitoring of physiological signals. Med. Biol. Eng. Comput. 2004, 42, 419–427. [Google Scholar] [CrossRef]
- Bulagang, A.F.; Weng, N.G.; Mountstephens, J.; Teo, J. A review of recent approaches for emotion classification using electrocardiography and electrodermography signals. Inform. Med. Unlocked 2020, 20, 100363. [Google Scholar] [CrossRef]
- Suzuki, K.; Laohakangvalvit, T.; Matsubara, R.; Sugaya, M. Constructing an emotion estimation model based on eeg/hrv indexes using feature extraction and feature selection algorithms. Sensors 2021, 21, 2910. [Google Scholar] [CrossRef] [PubMed]
- Fujii, A.; Murao, K.; Matsuhisa, N. disp2ppg: Pulse wave generation to PPG sensor using display. In Proceedings of the ACM International Symposium on Wearable Computers (ISWC2021), Virtual Event, 21–26 September 2021; pp. 119–123. [Google Scholar]
- Tong, Z.; Chen, X.X.; He, Z.; Kai, T.; Wang, X. Emotion Recognition Based on Photoplethysmogram and Electroencephalogram. In Proceedings of the IEEE 42nd Annual Computer Software and Applications Conference (COMPSAC2018), Tokyo, Japan, 23–27 July 2018; pp. 402–407. [Google Scholar]
- Coan, J.A.; Allen, J.J. Frontal EEG asymmetry as a moderator and mediator of emotion. Biol. Psychol. 2004, 67, 7–49. [Google Scholar] [CrossRef] [PubMed]
- Ekman, P. Expression and the nature of emotion. Approaches Emot. 1984, 3, 319–344. [Google Scholar]
- Petrantonakis, P.C.; Hadjileontiadis, L.J. Emotion recognition from brain signals using hybrid adaptive filtering and higher order crossings analysis. IEEE Trans. Affect. Comput. 2010, 1, 81–97. [Google Scholar] [CrossRef]
- Schaaff, K.; Schultz, T. Towards emotion recognition from electroencephalographic signals. In Proceedings of the Third International Conference and Workshops on Affective Computing and Intelligent Interaction(ACII2009), Amsterdam, The Netherlands, 10–12 September 2009; pp. 1–6. [Google Scholar]
- Duan, R.N.; Zhu, J.Y.; Lu, B.L. Differential entropy feature for EEG-based emotion classification. In Proceedings of the 6th International IEEE/EMBS Conference on the Neural Engineering (NER2013), San Diego, CA, USA, 6–8 November 2013; pp. 81–84. [Google Scholar]
- Koelstra, S.; Muhl, C.; Soleymani, M.; Lee, J.; Yazdani, A.; Ebrahimi, T.; Pun, T.; Nijholt, A.; Patras, I. DEAP: A database for emotion analysis using physiological signals. IEEE Trans. Affect. Comput. 2012, 3, 18–31. [Google Scholar] [CrossRef] [Green Version]
- D’mello, S.; Graesser, A. Emotions during learning with AutoTutor. In Adaptive Technologies for Training and Education; Cambridge University Press: Cambridge, UK, 2012; pp. 117–139. [Google Scholar]
- Graesser, A.C.; D’mello, S. Emotions during the learning of difficult material. Psychol. Learn Motiv. 2012, 57, 183–225. [Google Scholar]
- Tonguc, G.; Ozkara, B.O. Automatic recognition of student emotions from facial expressions during a lecture. Comput. Educ. 2020, 148, 103797. [Google Scholar] [CrossRef]
- Sharma, P.; Joshi, S.; Gautam, S.; Maharjan, S.; Filipe, V.; Reis, M.J. Student engagement detection using emotion analysis, eye tracking and head movement with machine learning. arXiv 2019, arXiv:1909.12913. [Google Scholar]
- Jenke, R.; Peer, A.; Buss, M. Feature extraction and selection for emotion recognition from EEG. IEEE Trans. Affect. Comput. 2017, 5, 327–339. [Google Scholar] [CrossRef]
- Davidson, R.J. What does the prefrontal cortex “do” in affect: Perspectives on frontal EEG asymmetry research. Biol. Psychol. 2004, 67, 219–233. [Google Scholar] [CrossRef] [PubMed]
- Arnau-González, P.; Arevalillo-Herráez, M.; Ramzan, N. Fusing highly dimensional energy and connectivity features to identify affective states from EEG signals. Neurocomputing 2017, 244, 81–89. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Song, D.; Zhang, P.; Zhang, Y.; Hou, Y.; Hu, B. Exploring EEG features in cross-subject emotion recognition. Front. Neurosci. 2018, 12, 162. [Google Scholar] [CrossRef] [Green Version]
- Algumaei, M.; Hettiarachchi, I.T.; Veerabhadrappa, R.; Bhatti, A. Wavelet packet energy features for eeg-based emotion recognition. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics (SMC2021), Melbourne, Australia, 17–20 October 2021; pp. 1935–1940. [Google Scholar]
- Cui, F.; Wang, R.; Ding, W.; Chen, Y.; Huang, L. A Novel DE-CNN-BiLSTM Multi-Fusion Model for EEG Emotion Recognition. Mathematics 2022, 10, 582. [Google Scholar] [CrossRef]
- Xing, M.; Hu, S.; Wei, B.; Lv, Z. Spatial-Frequency-Temporal Convolutional Recurrent Network for Olfactory-enhanced EEG Emotion Recognition. J. Neurosci. Methods 2022, 376, 109624. [Google Scholar] [CrossRef]
- Li, J.; Wu, X.; Zhang, Y.; Yang, H.; Wu, X. DRS-Net: A spatial–temporal affective computing model based on multichannel EEG data. Biomed. Signal Process. Control. 2022, 76, 103660. [Google Scholar] [CrossRef]
- Toraman, S.; Dursun, Ö.O. GameEmo-CapsNet: Emotion Recognition from Single-Channel EEG Signals Using the 1D Capsule Networks. Traitement Signal 2021, 38, 1689–1698. [Google Scholar] [CrossRef]
- Zheng, W.L.; Lu, B.L. Investigating critical frequency bands and channels for EEG-based emotion recognition with deep neural networks. IEEE Trans. Auton. Ment. Dev. 2015, 7, 162–175. [Google Scholar] [CrossRef]
- Li, J.; Li, S.; Pan, J.; Wang, F. Cross-subject EEG emotion recognition with self-organized graph neural network. Front. Neurosci. 2021, 15, 611653. [Google Scholar] [CrossRef] [PubMed]
- Song, T.Z.W.; Song, P.; Cui, Z. EEG emotion recognition using dynamical graph convolutional neural networks. IEEE Trans. Affect. Comput. 2020, 3, 532–541. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Wang, L.; Zheng, W.; Zong, Y.; Qi, L.; Cui, Z.; Zhang, T.; Song, T. A novel bi-hemispheric discrepancy model for EEG emotion recognition. IEEE Trans. Cogn. Dev. Syst. 2020, 13, 354–367. [Google Scholar] [CrossRef]
- Wang, Y.; Qiu, S.; Li, J.; Ma, X.; Liang, Z.; Li, H.; He, H. EEG-based emotion recognition with similarity learning network. In Proceedings of the 41st Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC2019), Berlin, Germany, 23–27 July 2019; pp. 1209–1212. [Google Scholar]
- Shen, F.; Dai, G.; Lin, G.; Zhang, J.; Kong, W.; Zeng, H. EEG-based emotion recognition using 4D convolutional recurrent neural network. Cogn. Neurodyn. 2020, 14, 815–828. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-excitation networks. IEEE Trans. Pattern. Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the 15th European Conference on Computer Vision (ECCV2018), Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland, 2018; Volume VII, pp. 3–19. [Google Scholar]
- Li, Y.; Fu, B.; Li, F.; Shi, G.; Zheng, W. A novel transferability attention neural network model for EEG emotion recognition. Neurocomputing 2021, 447, 92–101. [Google Scholar] [CrossRef]
- Wu, X.; Zheng, W.L.; Li, Z.; Lu, B.L. Investigating EEG-based functional connectivity patterns for multimodal emotion recognition. J. Neural Eng. 2022, 19, 016012. [Google Scholar] [CrossRef]
- Keelawat, P.; Thammasan, N.; Numao, M.; Kijsirikul, B. A comparative study of window size and channel arrangement on EEG-emotion recognition using deep CNN. Sensors 2021, 21, 1678. [Google Scholar] [CrossRef]
- Garg, N.; Garg, R.; Parrivesh, N.S.; Anand, A.; Abhinav, V.A.S.; Baths, V. Decoding the neural signatures of valence and arousal from portable EEG headset. bioRxiv 2021. [Google Scholar] [CrossRef]
- Kasim, Ö.; Tosun, M. Effective removal of eye-blink artifacts in EEG signals with semantic segmentation. Signal Image Video Processing 2022, 16, 1289–1295. [Google Scholar] [CrossRef]
- Zheng, W.L.; Liu, W.; Lu, Y.; Lu, B.L.; Cichocki, A. EmotionMeter: A multimodal framework for recognizing human emotions. IEEE Trans. Cybern. 2019, 49, 1110–1122. [Google Scholar] [CrossRef] [PubMed]
- Gross, J.J.; Levenson, R.W. Emotion elicitation using films. Cogn. Emot. 1995, 9, 87–108. [Google Scholar] [CrossRef]
- Delorme, A.; Makeig, S. EEGLAB: An open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J. Neurosci. Methods 2004, 134, 9–21. [Google Scholar] [CrossRef] [Green Version]
- Pion-Tonachini, L.; Kreutz-Delgado, K.; Makeig, S. ICLabel: An automated electroencephalographic independent component classifier, dataset, and website. NeuroImage 2019, 198, 181–197. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, H.; Zhao, M.; Wei, C.; Mantini, D.; Li, Z.; Liu, Q. Eegdenoisenet: A benchmark dataset for deep learning solutions of eeg denoising. J. Neural Eng. 2021, 18, 056057. [Google Scholar] [CrossRef]
- Klug, M.; Gramann, K. Identifying key factors for improving ICA-based decomposition of EEG data in mobile and stationary experiments. Eur. J. Neurosci. 2021, 54, 8406–8420. [Google Scholar] [CrossRef]
- Plechawska-Wójcik, M.; Tokovarov, M.; Kaczorowska, M.; Zapała, D. A three-class classification of cognitive workload based on EEG spectral data. Appl. Sci. 2019, 9, 5340. [Google Scholar] [CrossRef] [Green Version]
- Leach, S.C.; Morales, S.; Bowers, M.E.; Buzzell, G.A.; Debnath, R.; Beall, D.; Fox, N.A. Adjusting ADJUST: Optimizing the ADJUST algorithm for pediatric data using geodesic nets. Psychophysiology 2020, 57, e13566. [Google Scholar] [CrossRef]
- Zhong, P.; Wang, D.; Miao, C. EEG-based emotion recognition using regularized graph neural networks. IEEE. Trans. Affect. Comput. 2020. [Google Scholar] [CrossRef]
- Curran, P.G. Methods for the detection of carelessly invalid responses in survey data. J. Exp. Soc. Psychol. 2016, 66, 4–19. [Google Scholar] [CrossRef] [Green Version]
- DeSimone, J.A.; Harms, P.D.; DeSimone, A.J. Best practice recommendations for data screening. J. Organ. Behav. 2015, 36, 171–181. [Google Scholar] [CrossRef] [Green Version]
- DeSimone, J.A.; Harms, P.D. Dirty data: The effects of screening respondents who provide low-quality data in survey research. J. Bus. Psychol. 2018, 33, 559–577. [Google Scholar] [CrossRef]
- Murana, S.; Rahimin, R. Application of SPSS software in statistical learning to improve student learning outcomes. Indo-MathEdu Intellect. J. 2021, 2, 12–23. [Google Scholar] [CrossRef]
- Maison, M.; Kurniawan, D.A.; Anggraini, L. Perception, attitude, and student awareness in working on online tasks during the covid-19 pandemic. J. Pendidik. Sains Indones. 2021, 9, 108–118. [Google Scholar] [CrossRef]
- Chen, C. Research on teaching effect and course evaluation based on spss and analysis of influencing factors. In Proceedings of the 2021 4th International Conference on E-Business, Information Management and Computer Science, Hong Kong, China, 29–31 December 2021; pp. 229–234. [Google Scholar]






| Stage | Stage Setting | Output |
|---|---|---|
| Conv-1 | 32, strides = 2, activation = “relu” | (1000,32) |
| Conv-2 | 64, strides = 2, activation = “relu” | (498,64) |
| Pool_1 | 2, AvgPool | (249,64) |
| Batch_norm1 | BatchNormalization | (249,64) |
| Drop_1 | Dropout1D | (249,64) |
| Stage | Stage Setting | Output |
|---|---|---|
| Conv-1 | 128, strides = 2, activation = “relu” | (245,128) |
| Conv-2 | 128, strides = 2, activation = “relu” | (245,128) |
| Pool_1 | 2, AvgPool | (122,128) |
| Batch_norm1 | BatchNormalization | (122,128) |
| Drop_1 | Dropout | (122,128) |
| Conv-3 | 256, strides = 2, activation = “relu” | (118,256) |
| Conv-4 | 256, strides = 2, activation = “relu” | (118,256) |
| Pool_2 | GlobalAvgPool | (256) |
| Drop_2 | Dropout | (256) |
| Dense | Activation = “softmax” | (3) |
| Frequency Band | SEED | LE-EEG | ||
|---|---|---|---|---|
| C1 | C2 | C3 | All_Band | |
| δ | 83.18/2.42 | 84.23/2.85 | 93.69/0.40 | 95.22/0.49 |
| θ | 67.05/7.71 | 69.88/7.52 | 93.06/0.45 | 94.64/1.15 |
| α | 77.55/6.82 | 82.68/5.58 | 93.09/1.11 | 94.64/0.63 |
| β | 81.46/7.27 | 87.09/4.17 | 93.56/0.44 | 94.97/0.51 |
| γ | 83.60/4.91 | 90.90/4.38 | 93.83/0.48 | 95.52/0.62 |
| β + γ | 84.14/6.12 | 92.10/4.02 | - | - |
| β × γ | 91.30/4.56 | 93.39/2.42 | - | - |
| Attention (β, γ) | 90.03/3.40 | 94.20/2.38 | - | - |
| Method | C1 | C2 | ||||
|---|---|---|---|---|---|---|
| Add | Mult | Attention | Add | Mult | Attention | |
| α, β | 72.34/10.70 | 72.54/11.50 | 72.75/7.54 | 83.16/4.84 | 87.63/7.67 | 89.80/4.13 |
| α, γ | 69.48/12.10 | 78.84/10.22 | 79.26/7.10 | 80.56/8.80 | 95.04/3.80 | 90.77/4.59 |
| δ, β | 94.81/2.20 | 77.62/11.56 | 93.77/2.27 | 94.68/3.45 | 95.36/3.96 | 87.40/4.41 |
| δ, γ | 95.03/2.45 | 82.41/8.30 | 95.63/1.92 | 92.00/2.26 | 95.60/2.75 | 95.70/3.67 |
| β, γ | 84.14/6.12 | 91.30/4.56 | 90.03/3.40 | 92.10/4.02 | 93.39/2.42 | 94.20/2.38 |
| δ, α, β | 94.79/3.22 | 95.11/3.60 | 94.95/2.73 | 94.24/3.32 | 96.09/3.00 | 95.87/4.17 |
| θ, β, γ | 94.10/4.50 | 92.23/4.99 | 92.46/6.92 | 95.44/2.35 | 95.77/3.90 | 94.89/4.06 |
| α, β, γ | 92.70/5.52 | 95.17/4.27 | 93.84/3.63 | 95.31/3.21 | 94.66/5.43 | 96.02/5.54 |
| δ, β, γ | 95.17/2.17 | 95.13/3.67 | 95.32/3.53 | 95.78/3.45 | 96.15/2.13 | 96.45/3.56 |
| δ, α, β, γ | 94.28/5.46 | 87.07/12.96 | 77.0/16.81 | 94.68/2.72 | 80.99/14.82 | 86.49/17.90 |
| Method | SEED | LE-EEG |
|---|---|---|
| SVM [24] | 83.30/--- | --- |
| DBN [30] | 86.08/--- | --- |
| SOGNN [31] | 86.81/5.79 | 74.38/1.50 |
| LDA [25] | 90.93/--- | --- |
| DGCNN [32] | 90.40/8.48 | --- |
| BiHDM [33] | 93.12/6.06 | --- |
| TANN [38] | 93.34/6.64 | --- |
| 3DCNN-BiLSTM [27] | 93.38/2.66 | --- |
| 4D_CRNN [35] | 94.08/2.55 | 67.48/0.39 |
| RGNN [51] | 94.24/5.95 | --- |
| DE-CNN-BiLSTM [26] | 94.82/--- | --- |
| DCCA [39] | 95.08/6.42 | --- |
| ECN-AF (C1) | 95.32/3.53 | --- |
| ECN-AF (C2) | 96.45/3.56 | --- |
| ECN-AF (C3) | --- | 94.80/0.57 |
| ECN-AF (All_band) | 95.7/4.71 | 95.87/0.38 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, X.; Rong, W.; Zhao, L.; He, Z.; Yang, Q.; Sun, J.; Liu, G. EEG Emotion Classification Network Based on Attention Fusion of Multi-Channel Band Features. Sensors 2022, 22, 5252. https://doi.org/10.3390/s22145252
Zhu X, Rong W, Zhao L, He Z, Yang Q, Sun J, Liu G. EEG Emotion Classification Network Based on Attention Fusion of Multi-Channel Band Features. Sensors. 2022; 22(14):5252. https://doi.org/10.3390/s22145252
Chicago/Turabian StyleZhu, Xiaoliang, Wenting Rong, Liang Zhao, Zili He, Qiaolai Yang, Junyi Sun, and Gendong Liu. 2022. "EEG Emotion Classification Network Based on Attention Fusion of Multi-Channel Band Features" Sensors 22, no. 14: 5252. https://doi.org/10.3390/s22145252