Abstract
Image-based ship detection is a critical function in maritime security. However, lacking high-quality training datasets makes it challenging to train a robust supervision deep learning model. Conventional methods use data augmentation to increase training samples. This approach is not robust because the data augmentation may not present a complex background or occlusion well. This paper proposes to use an information bottleneck and a reparameterization trick to address the challenge. The information bottleneck learns features that focus only on the object and eliminate all backgrounds. It helps to avoid background variance. In addition, the reparameterization introduces uncertainty during the training phase. It helps to learn more robust detectors. Comprehensive experiments show that the proposed method outperforms conventional methods on Seaship datasets, especially when the number of training samples is small. In addition, this paper discusses how to integrate the information bottleneck and the reparameterization into well-known object detection frameworks efficiently.
1. Introduction
Detecting and tracking vessels are routine and pressing tasks due to considerations related to security, safety, and environmental management. The regulation V/19-1 of the 1974 SOLAS convention requires specific ships must be equipped with a Long-Range Identification and Tracking (LRIT) system [1]. However, the information is only transmitted automatically every six hours from the LRIT equipment installed on the ship via the Inmarsat satellite. Another solution for tracking and identifying ships is the automatic identification system (AIS) [2]. An automatic identification system (AIS) is an automated tracking system that displays other vessels in the vicinity. The broadcast transponder system operates in the VHF mobile maritime band; hence, the transceiver range is limited and depends on weather conditions. Moreover, the system can be turned off manually and can be easily tampered with. For the aforementioned reasons, each country has established a radar-based monitoring system [3] for overseeing its maritime regions. This system is robust in various environments and can detect multiple objects at far distances. However, the system can provide only the distance and bearing of the object, not information about each vessel category. Modern naval observation stations have recently been equipped with high optical zoom cameras to supplement the traditional radar system. These systems can support day and night vision with outstanding image quality. This allows using image information for maritime border security.
Detecting and categorizing ships from images are applications of object detection [4] in computer vision. Recently, deep learning is the most successful solution for these applications by training a detector. The early deep-learning-based detectors RCNN [5] or FastRCNN [6] have a better accuracy compared with hand-crafted detectors [7], but they are not efficient enough to work in real-time. Later, one-stage detectors SDD [8] or YOLO [9] have been introduced to speed up the inference. These methods need anchor boxes and post-processing to detect objects. Recently, feature pyramid networks [10] and decoupled head [11] have been introduced to detect small objects with higher performance. In addition, the success of transformer [12] on natural language processing (NLP) also opens a new approach for object detection when transformer-based detectors [13,14] could obtain a comparable result with CNN-based detectors [8,11]. Transformer-based detectors do not require anchor boxes and post-processing for detection. Hence, it can work as an end-to-end training process.
Deep-learning-based detectors have reported many promising results. However, training a ship detector for maritime security is still an open question with several challenges. First, high-quality datasets may not be available for research. Satellite datasets such as [15,16,17] can provide many images for ship detection; however, cameras at naval observation stations are front-view cameras. The PASCAL VOC2012 database [18] provides front-view ship images, but the number of training samples is very limited. In the dataset, few ship objects are available, and all of them are categorized as a single “boat” class. Recently, a large-scale dataset [19] has been introduced. This dataset includes 31,455 images with six classes. However, only 7000 images are published for research purposes. The second challenge in ship detection is the complexity of environmental factors. The large-scale dataset [19] had reported several factors such as background selection, lighting environment, visible proportion, and occlusion have been reported. These above challenges raise a research question: Could we learn generalization features that focus on a ship and eliminate environmental factors based on small datasets?
Given a limited dataset, conventional methods use data argumentation to address these challenges by enriching the training dataset. In classification tasks, well-known data argumentation are listed as flipping, rotation, scaling, cropping, translation, and adding Gaussian noise have been integrated into training frameworks. In object detection tasks, Mosaic is a successful solution that has been introduced in YOLOv4 [20] and reused in later YOLO versions. However, these data argumentations may not model environmental factors such as background selection and visible proportion in an ocean scenario. Recently, Light_SDNet [21] enriched a large-scale ship dataset [19] by adding haze and rain to the original ship images.
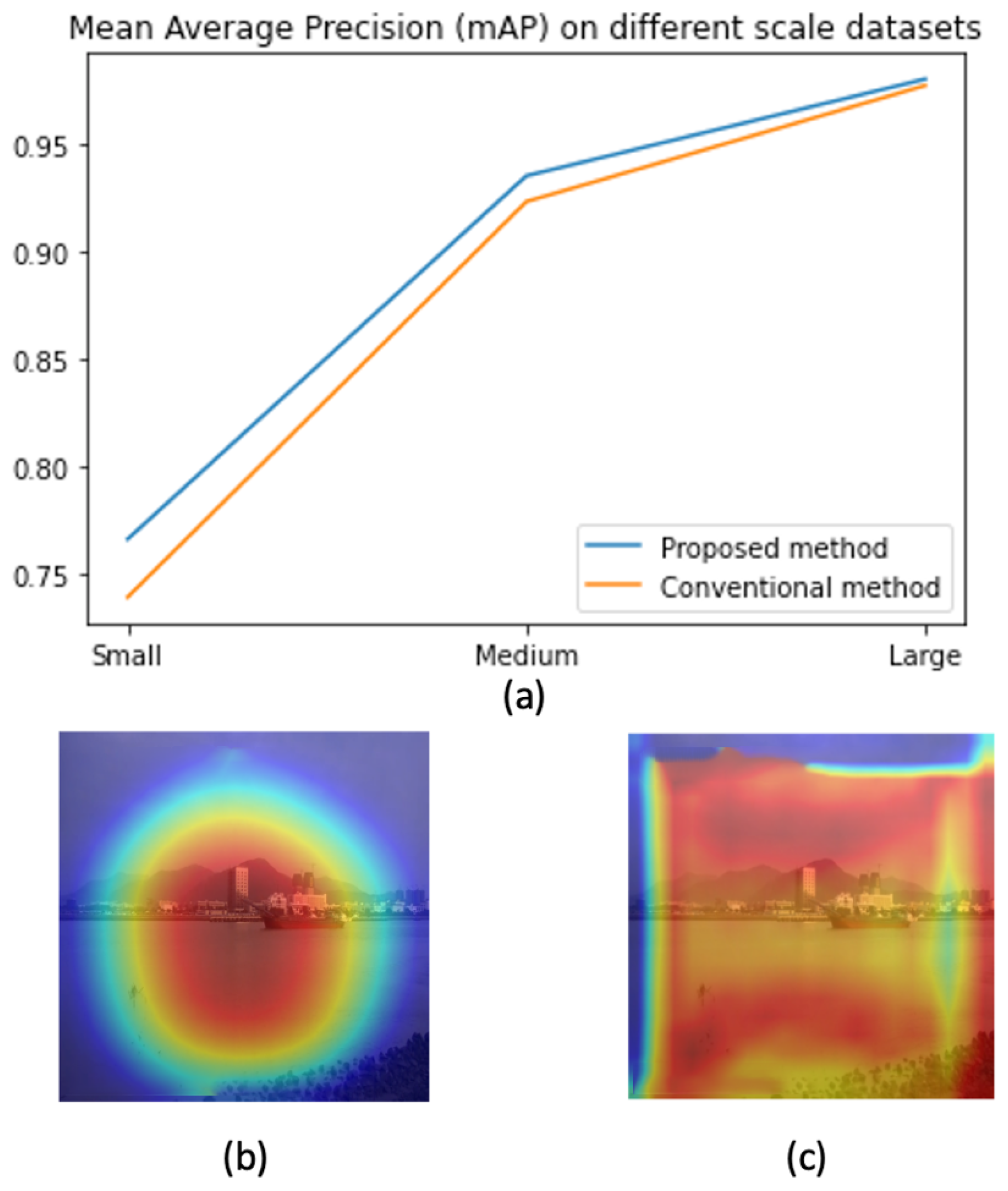
In this paper, we address the challenge by co-designing two factors. First, we aim to learn features that focus only on ships and skip all background information. This will help to address the background selection challenges. Second, a reparameterization is used to enrich the dataset in feature space. Unlike conventional methods where the training data are increased in the image domain, we aim to add some uncertainty in the feature domain. Hence, the classifier can work with noise from the environment. The variational information bottleneck (VIB) [22] is used to select features that focus only on objects and eliminate background information. Later, these features add some uncertainty before feeding to a classification head. This approach could be integrated into any well-known detectors; however, this paper uses YOLOX [11] as our baseline due to its outperforming on testing datasets. As shown in Figure 1, the proposed method help to have a better performance, especially on small datasets. Also, heatmaps in Figure 1 prove that learned features focus on objects. It means the model may work better in a practical environment.
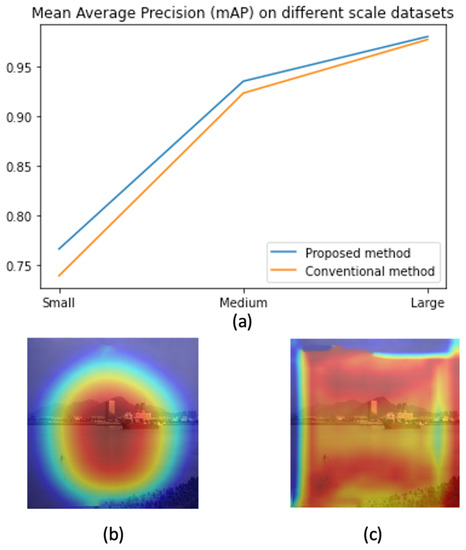
Figure 1.
The contribution of the proposed method. (a) Performance on different scale datasets (b) A heat map by the proposed method (c) A heat map by a baseline method.
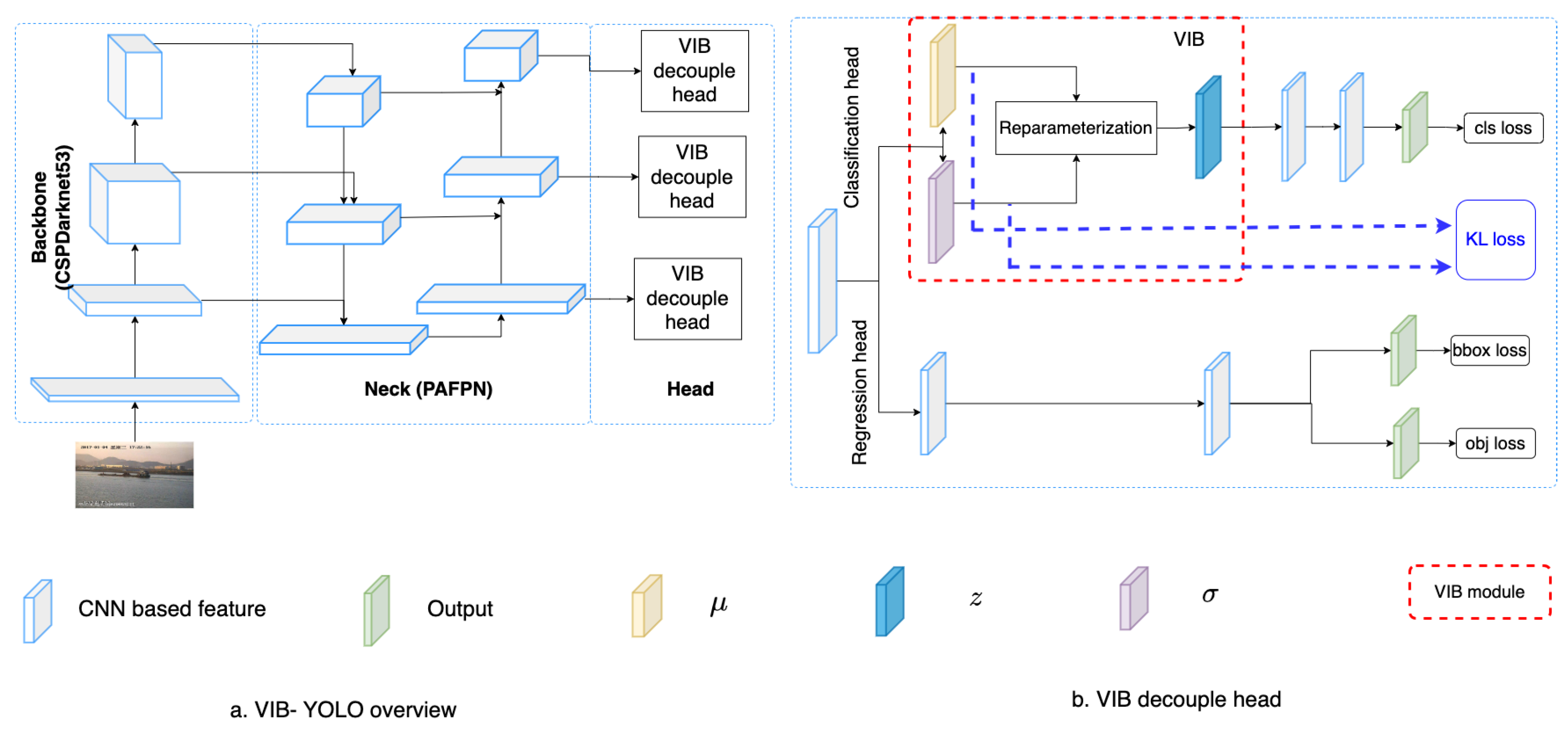
Conventionally, a detector includes a backbone, a neck, and a decoupled head that addresses regression and classification tasks. Given an input image x, the backbone extracts the feature at different scales ith. For each feature , the neck module connects the feature to the corresponding classification head and regression head as in YOLOX [11]. We found that box regression is a critical task to ensure the success of a detector in training; hence, the regression head in [11] is reused to make the network converge smoothly. The modification is on the classification head. On this head, an encoder extracts the mean , and the corresponding variance of features . As the classifier must work well with variant features, we sample latent features from the mean and variance. Then, the classification result is predicted from sampled feature by . A good feature z must represent fine-grained features of ship categories. Hence, the mutual information [23] should be maximized. Additionally, the background information from input x should be eliminated on feature space z. Hence, the mutual information should be minimized. Two constraints are optimized together in a variational information bottleneck (VIB) loss [22]. Since this loss could be integrated into any supervised learning framework, it could be accompanied by regression and object losses to train a detector.
In summary, the paper’s contributions are listed below:
- Regularly, VIB and the parameterization trick are used in classification tasks. However, this paper discusses integrating these techniques into object-detection frameworks. The method outperforms SoTA in detecting ship objects, especially in small-scale datasets.
- We carefully test the effect of VIB and parameterization at different positions in decoupled heads. The result shows that VIB can only work on the classification head and should not allow the VIB loss effect on the regression head.
- A feature analysis proves that the proposed method could learn feature focus on objects rather than the background.
2. Related Works
2.1. Object Detection
Deep learning-based object detection has been developed rapidly in recent years. Early works [5,6,24,25,26] are considered as two-stage detectors because two processes are needed in an inference. First, a region that may involve an object is selected. The region is considered the location of an object on the image. Second, the region is cropped and fed to a classifier to estimate its categories. To detect small objects, the feature pyramid [10] had been used to extract features in multiple levels. The FPN has two pathways: a bottom-up pathway which is a ConvNet computing feature hierarchy at several scales, and a top-down pathway that upsamples coarse feature maps from higher levels into high-resolution features. FPN is a region proposal network (RPN) in Faster R-CNN [25].
Another approach to solving the detection is single-state detectors [8,9,27,28,29,30,31]. These single-stage detectors directly predict the image pixels as objects and their bounding box attributes. YOLO [9] is the first representation of a single-stage detector. It can work very fast, but the accuracy is not high. Single Shot MultiBox Detector (SSD) [8] was the first method of single-stage detectors that matched the accuracy of contemporary two-stage detectors like Faster R-CNN [25]. RetinaNet [30] proposed a focal loss as the means to remedy the imbalance between background and foreground objects. The focal loss parameter reduces the loss contribution from easy examples. The authors demonstrate its efficacy with the help of a simple, single-stage detector. Later, CenterNet [29] models objects as points. As the predictions are points but not bounding boxes, non-maximum suppression (NMS) [9] is not required for post-processing. EfficientDet [31] introduces efficient multi-scale features (BiFPN) and model scaling. BiFPN is a bi-directional feature pyramid network with learnable weights for cross-connection input features at different scales. In addition, it jointly scales up all dimensions of the backbone network, BiFPN network, class/box network, and resolution. Therefore, this method achieves better efficiency and accuracy than previous detectors while being smaller and computationally cheaper.
The next generation of the YOLO family, such as YOLOv4 [20], and YOLOv5 [32], incorporated many exciting ideas to design a fast object detector that could work in existing production systems. Recently, YOLOX [11] has introduced the decouple head to separate the classification and regression tasks. It allows the detector to convert easily. Also, data arguments like Mosaic and Mixup have been introduced to increase accuracy.
Transformer [12] had been very successful in NLP [33]. Therefore, many works [13,14,34] have tried to apply the transformer concept to object detection. Transformers present a paradigm shift from CNN-based neural networks. While its application in vision is still nascent, its potential to replace convolution from these tasks is very real. The state-of-the-art transformer-based detectors have promising results on the COCO dataset [35], but utilize comparatively higher parameters than convolutional models.
2.2. Ship Detection
Several modifications of well-known object detection methods have been introduced to improve the performance of ship detectors. Liu_2022 [36] based on the SSD [8] framework and VGG backbone to detect a ship on small scales. The author [36] used a local attention network to fuse cross-features; also, a merge module combines features from different scales to improve detection results. The YOLO family is also used by many works to enhance the detection of ship datasets. Based on the YOLO framework, Biaohua_2022 [37] introduced a “Cross-level Attention and Ratio Consistency Network” (CARC) for ship detection. In this paper, the backbone was Resnet-34; the neck was a cross-level-attention module that used channel attention and spatial attention to extract features at different scales. The features were concatenated and fed to a head. Cui_2019 [38], Liu_2020 [39], and Li_2021 [40] based on YOLOV3 to detect ships. Cui_2019 [38] introduced YOLOv3-ship consisting of dimension clusters, network improvement, and Squeeze-and-Excitation(SE) module embedding. Liu_2020 [39] introduced two new anchor-setting methods and cross-feature fusion to enhance the performance of YOLOV3. Instead of using the FPN [10] to connect the backbone to a head, the method used a Cross PANet, which can combine the location information of the low-level feature maps with the semantic information of the high-level feature maps. Li_2021 [40] is based on YOLOV3 Tiny [28] to develop a two-training process. Here, CBAM attention [41] is used to detect large targets; later, a fine-tuning is made to detect small targets.
Recently, advanced versions of the YOLO framework were introduced for ship detection. Zhang_2021 [42] used YOLOV4 with a Reverse Depthwise Separable Convolution (RDSC) to detect ships. The proposed RDSC replaced the Depthwise Separable Convolution (DSC) [43] in the ResUnit of the YOLOV4 backbone. With the help of RDSC, the complexity of the network model is reduced while ensuring accuracy. Han_2021 [44] also uses the YOLOV4 backbone with an attention mechanism to improve performance. Light_SDNet [21] modified the YOLO5 backbone by a Gost Unit [45] and DepthWise Convolution (DWConv) [46] to reduce the number of parameters; also, data augmentations like haze generation and rain generation have been introduced to enrich the training set. Recently, YOLOX has been considered a robust and powerful method for object detection; Zhang_2022 [47] used the YOLOX framework to design a lightweight method. Instead of using a PANnet [48] for feature fusion, the paper used a Lightweight Adaptive Channel Feature Fusion (LACFF) to overcome the inconsistent scale of feature maps. The features of all other layers are adjusted to the same shape. Afterward, the channels are fused according to the learned weights. Similar to Zhang_2022 [47], our work is also based on YOLOX; however, we do not focus on feature fusion but introduce a loss that selects suitable features on the classification head.
Transformer-based methods [13] are also a possible solution for ship detection. Yani_2022 [49] used distillation learning to train a DETR-based ship detector. A teacher model was trained based on a large-scale CoCo Dataset, and the student model was fine-tuned based on the Seaship dataset [19]. The method helps to reduce the FLOPs and number of parameters. However, its mAP is not improved compared with the conventional DETR framework.
3. Proposed Method
3.1. Overview System
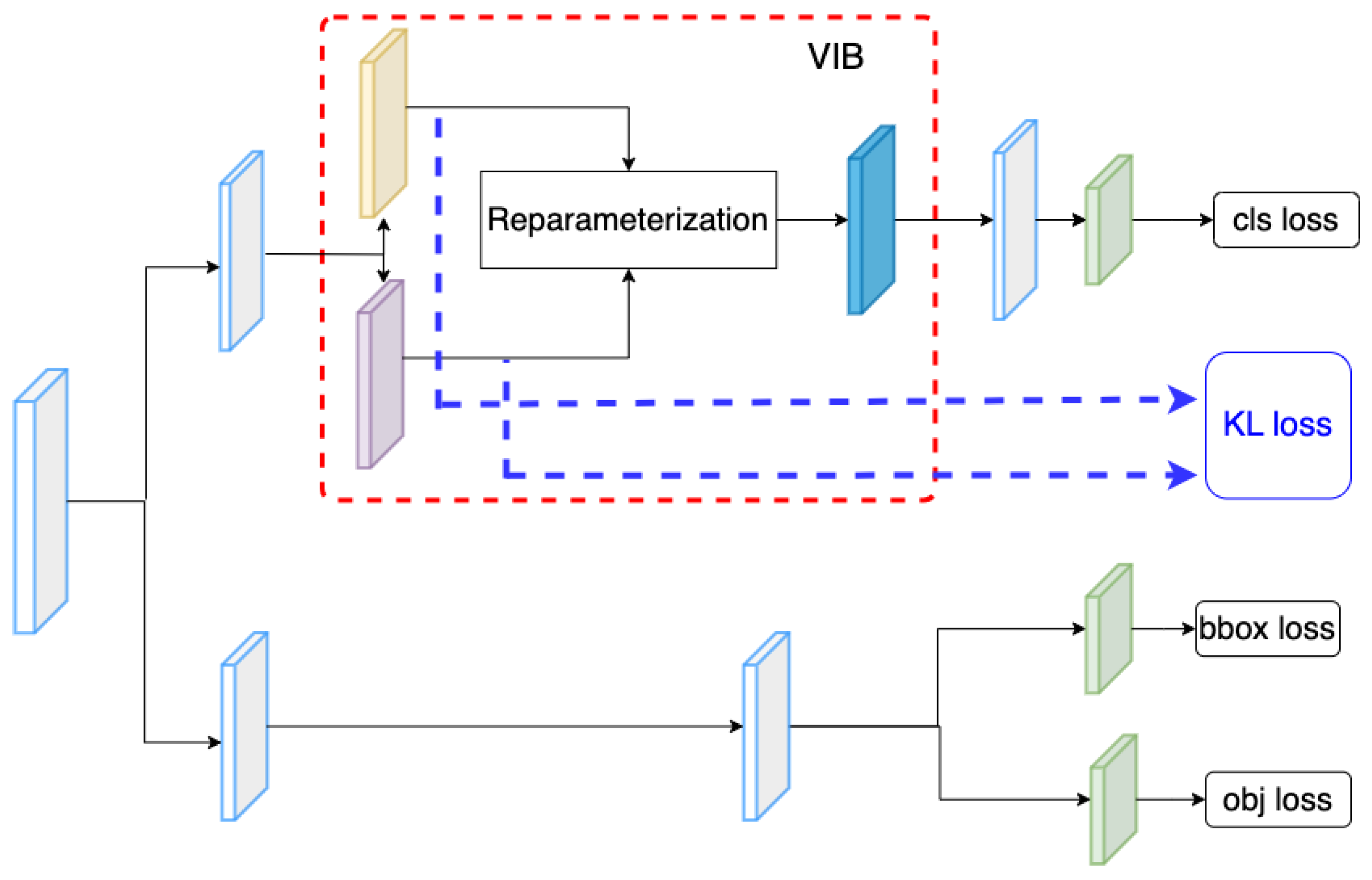
Table 1 summarizes mathematic notations in the paper, and Figure 2 introduces the concept of the proposed method. Given a backbone, features at different scales are extracted. Here, we use the Darknet53 backbone [28] to extract features at multiple scales. The PAFPN [48] serves as a neck that connects these features to a decoupled head. Detail of the backbone and the neck are introduced in Section 3.3. The decouple head includes a classification head and a regression head. While the classification head aims to classify a ship category, the regression head estimates a relative bounding box and the object ability for each cell. On the classification branch, we use kernels to extract the and at the position on a feature map. Using these kernels, tensors and are obtained. These tensors are used to estimate the VIB loss [22]; additionally, a reparameterization process samples a new latent for the position. A classifier takes the latent and predicts the vessel category . The detail of the VIB module is described in Table 2. The kernel size is means that the extracts cross exchange-feature but does not change the size of feature maps. It allows us to reuse the original classification head.

Table 1.
Mathematical Notation..
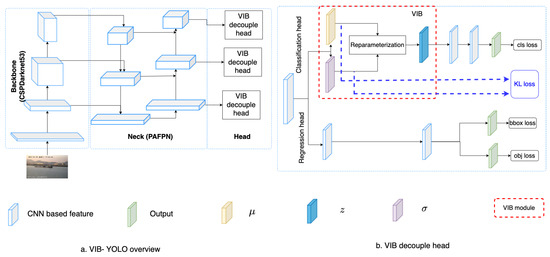
Figure 2.
Network structure. (a) The overview of proposed VIB-based object detection. (b) The proposed VIB-based classification head.
Table 2.
Network detail. Here, means the encoder to extract , means the encoder to extract , i is the index of the scale level, and is the number of channels in the input of the ith level.
A YOLO detector [11] addresses the bounding box regression, object classification, and category classification at the same time. In our work, the IoU loss () helps to train the bounding box regression, and the cross-entropy loss helps to train the object classification and the category classification. In addition, the VIB loss also helps to select features by introducing a feature selection loss . , , , are hyper-parameters that control the contribution of , , , and , respectively, the loss function in Equation (1) is used to train the detector.
Recently, the IoU loss () has been recognized by many researchers as a good solution to evaluate a predicted bounding box. The IoU loss helps the model to improve the quality of its bounding box predictions by penalizing boxes that do not closely match the ground truth in terms of overlap. It is crucial for achieving accurate object localization in object detection tasks. Equation (2) explains the concept of .
where:
- is the width and height of the output.
- is intersection over union between the predicted box and the ground-truth box at the position .
- is a mask that decides which locations will be used to compute the loss.
Object classification loss () is concerned with identifying whether there is any object present within a bounding box. It is a binary classification as in Equation (3), where the model predicts a probability score indicating whether an object is present or not in each bounding box. Category classification loss () is focused on determining the specific class or category of the object if one is found. Category classification is a multi-class classification problem, where the model predicts the probability distribution over different object categories for each bounding box as in Equation (4).
where:
- is the predicted objectness probability.
- is the ground-truth objectness label.
- is a mask that decides which locations will be used to compute the loss.
- C is the number of object classes.
- is the predicted class probability (usually obtained through softmax activation).
- is the ground-truth class label for the j-th location and the c-th class.
- is a mask that decides which locations will be used to compute the loss.
Finally, the feature selection loss is shown in Equation (5). A detailed explanation of the loss will be introduced in Section 3.2.
where:
- d is the dimension of latent features.
3.2. Feature Section Loss
Feature selection involves the process of choosing pertinent features tailored to a particular task. Drawing from the principles of information bottleneck theory [50], optimal features are concise representations that contain precisely the necessary information to address the task without redundancy. The necessity for this can be elucidated through the following two constraints:
- The latent z must help to well predict the output y (vessel categories);
- Given the latent z, we cannot infer input x very well.
In the realms of probability theory and information theory, the interrelation between two variables finds measurement through mutual information () [23]. Consequently, these dual constraints are formulated by maximizing the mutual information while minimizing the mutual information . The former constraint signifies that z aids in predicting vessel categories y, while the latter constraint signifies that z does not possess the capability to deduce the input image x.
Let represent a Lagrange multiplier; the optimization problem is depicted in Equation (6). A better solution makes have a greater value.
The mutual information [23] can gauge the information of one variable in relation to another variable by using Equation (7).
To maximize the mutual information , we approximate this term by a lower bound. When the lower bound obtains a greater value, the has a greater value. is a variational approximation of ; the lower bound is founded by Kullback–Leibler divergence as in Equation (10).
By incorporating the lower bound from Equation (10), the expression for in Equation (8) can be reformulated as Equation (11).
In this context, the entropy of the labels is considered independent and can be disregarded. As a result, the maximum value of is approximated as shown in Equation (12).
To minimize the mutual information , we approximate this term (Equation (9)) by an upper bound. When the upper bound obtains a smaller value, the has a smaller value. We denote as a variational approximation to the marginal . Using the KL divergence, the upper bound of is introduced as Equation (13).
Through the utilization of the lower bound for and the upper bound for , the Lagrangian function in Equation (6) can be approximated as represented in Equation (15).
In our application, the term is modeled by a classifier; and is a classification loss . In addition, the latent z could be sampled from a reparameterization trick where . Hence, z is estimated by Equation (16).
Using Equation (16), the term is estimated by Equation (17). , and the term is estimated by Equation (5). In addition, the term could serve as a feature selection loss in Equation (1). Hence, the parameter is replaced by the parameter . Equation (5) represents and it is applied at every scale level with classification loss, box loss, and object loss.
3.3. Backbone and Neck Module
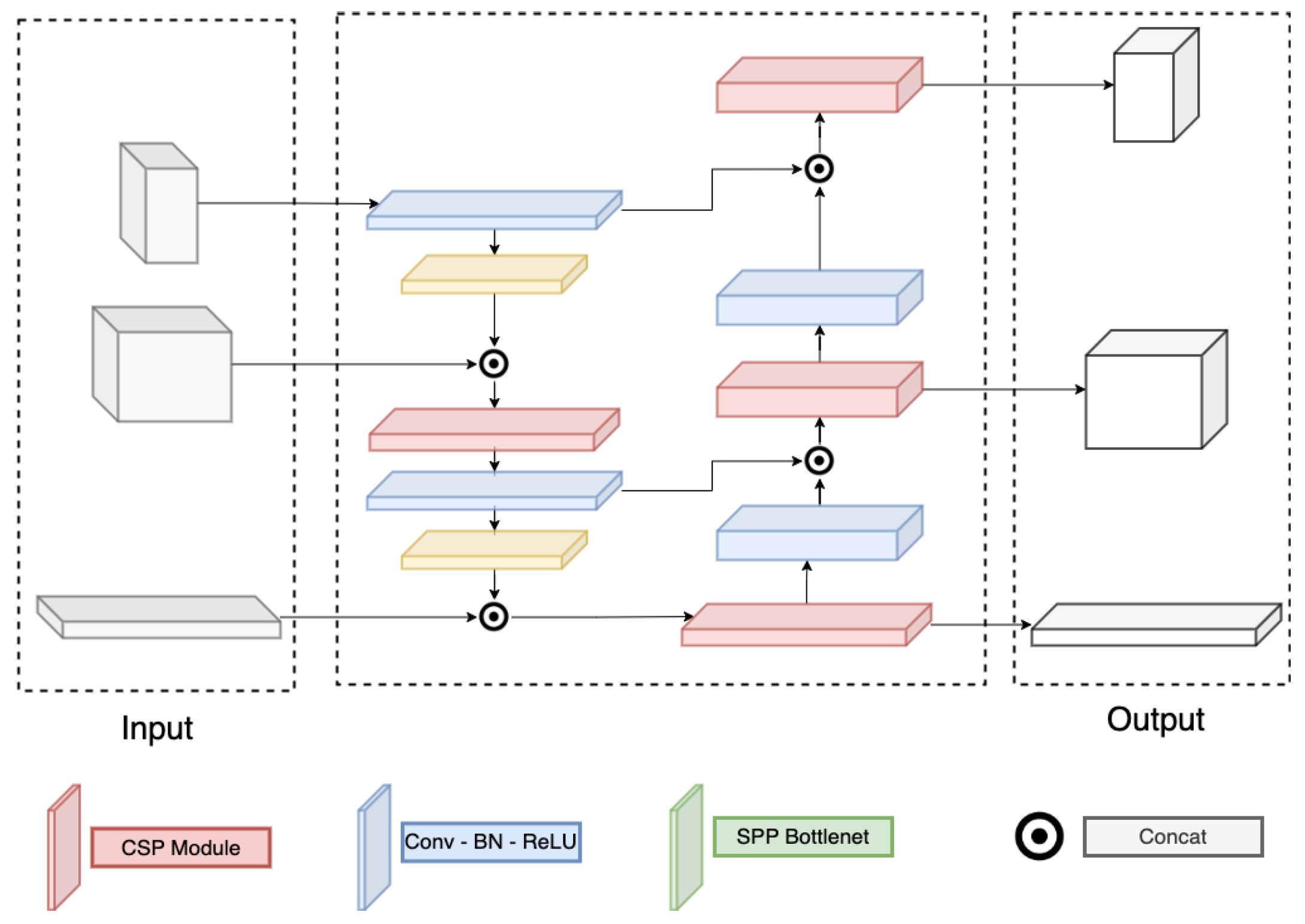
The proposed method could be integrated with any backbone. However, a modification is needed on the neck to match the selected backbone and the decoupled head. We have tried several backbones in Section 4.5 and pointed out that the Darknet backbone and PAFPN neck can perform better than others.
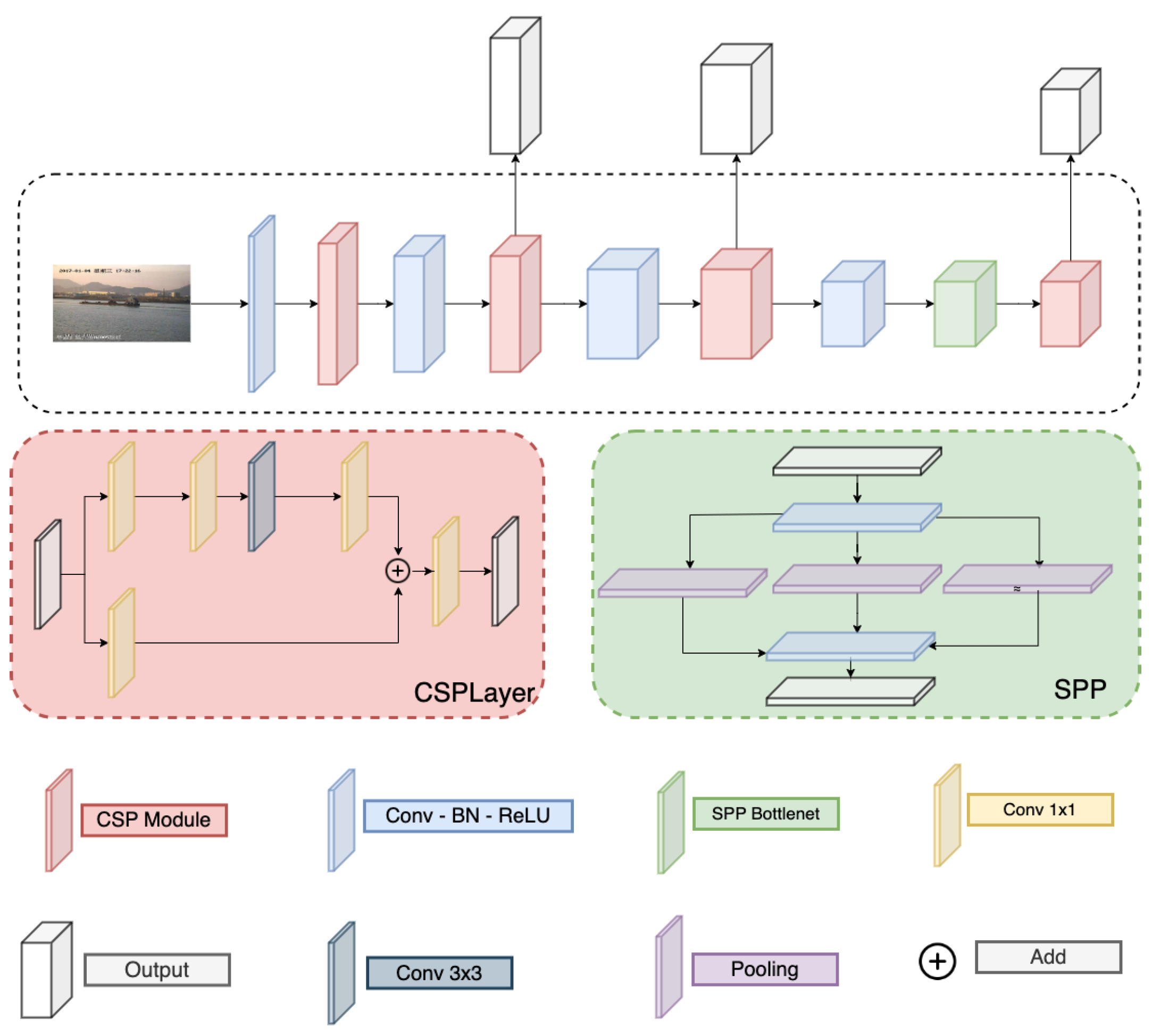
Detail of the Darknet and PAFPN are correspondingly in Figure 3 and Figure 4. Here, the Darknet backbone used CSPLayer to extract features. The features at 2nd, 3rd, and 4th CSPlayer are used in the PAFPN neck. Finally, output features are used with decoupled heads at different scales.
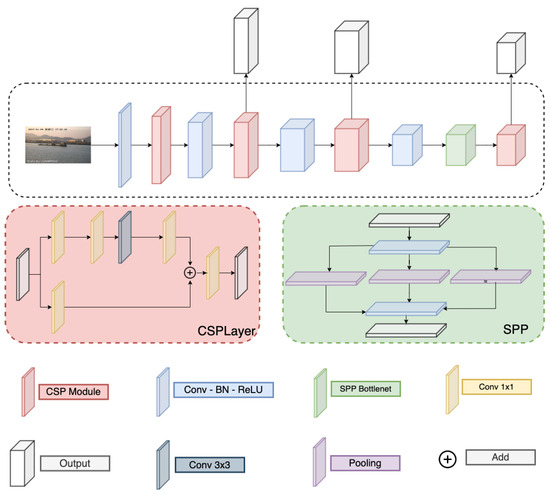
Figure 3.
Darknet structure.
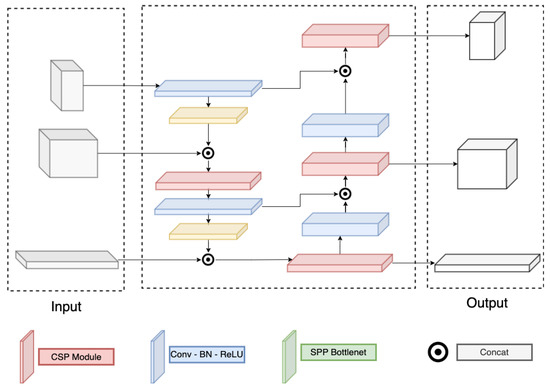
Figure 4.
PAFPN structure.
4. Experimental Results
4.1. Datasets and Experiment Setting
This paper evaluates our proposed method using the SeaShips dataset [19]. The SeaShips dataset is built based on the images captured by an in-field video monitoring system deployed around Hengqin Island, Zhuhai City, China. Each camera records the scene from 6:00 a.m. to 8:00 p.m. every day. The images are obtained from one-minute video clips, resulting in 60 clips per hour. Each clip spans 60 s and contains approximately 1500 frames. For every 50 frames (approximately every two seconds), one image is extracted for inclusion in the dataset. This dataset encompasses six distinct ship types, namely bulk carriers, ore carriers, ordinary cargo ships, container ships, passenger ships, and fishing boats. It features a diverse background environment, characterized by varying light intensities to ensure dataset diversity. Additionally, the dataset incorporates numerous special scenarios, including instances of target occlusions. The SeaShips dataset is highly regarded within the research community for its professionalism, public availability, large-scale nature, and accuracy in ship labeling. It has earned a strong reputation for facilitating effective ship inspection procedures. While dataset [19] has 31,455 images, only 7000 images are published for research at [21,38]. Hence, we use the published dataset for our experiments.
Literature reviews show that many research works use 80% of the published data for training/validating and 20% for testing. Hence, we select , which includes 5600 images for training, and , which includes 1400 images for testing. In addition, recent works [37,49] also use a more challenging setting where 50% of the data are the training set, and the rest is the testing set. We also follow this setting to prepare and for comparison. To evaluate the performance on a very small dataset, we randomly select several subsets that include 30%, 70%, and 100% of samples from for training in later experiments.
Our experiment uses SGD optimizer, learning rate = 0.01, weight decay = 0.001, n_epoch = 200, and batch_size = 8. We use the reduce-mean operator on batch_size, and the reduce-sum operator on prediction output. The mAP is used to select the best model. The loss function in Equation (1) use and the .
4.2. Select the Hyper-Parameter
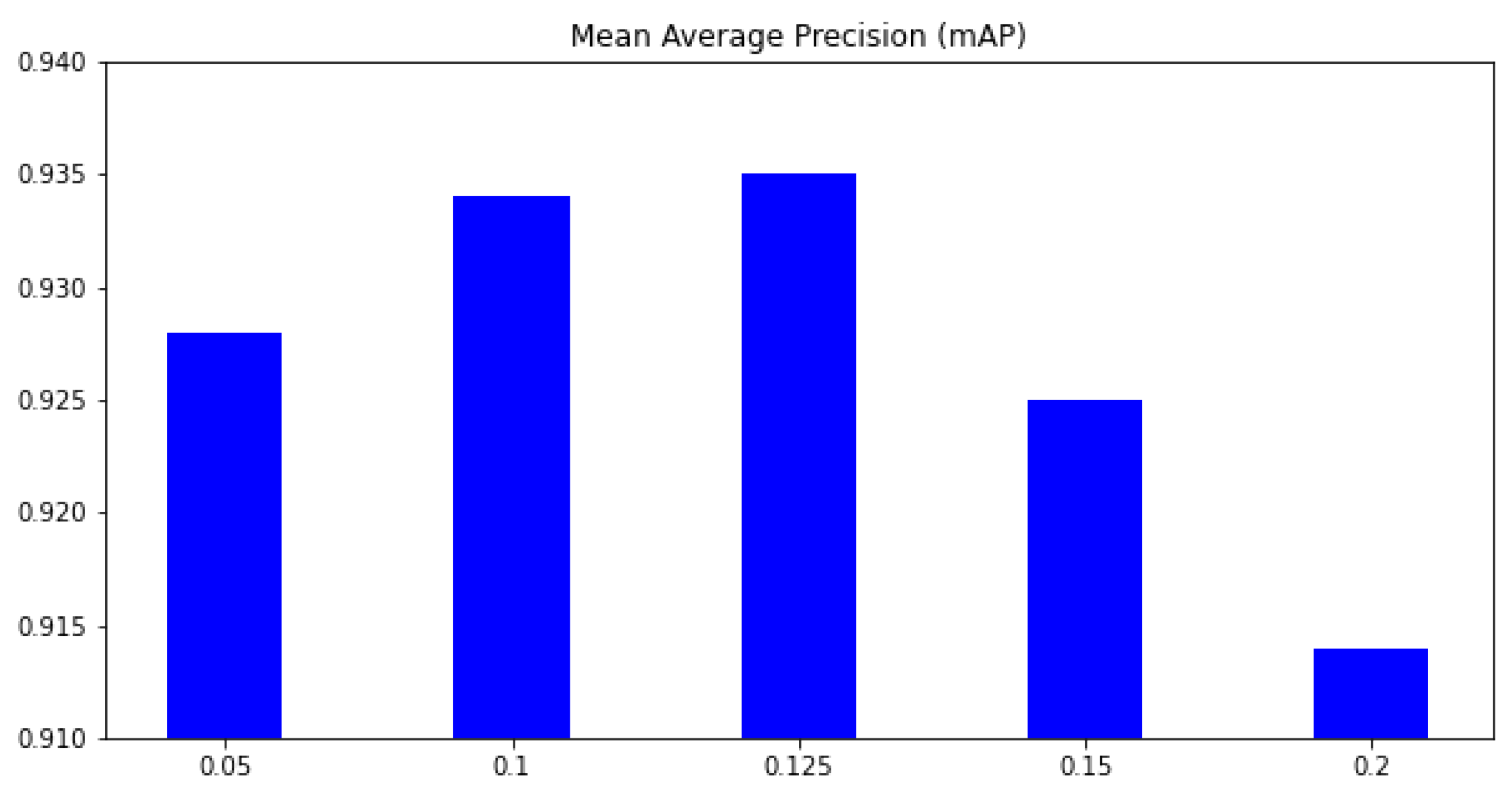
This section aims to select suitable hyperparameters for our training process. The major contribution of our work is introducing the feature selection loss to the YoloX framework. Therefore, our first experiment is selecting a suitable hyper-parameter in Equation (1). A small may not help to learn better features, whereas a large may focus too much on feature learning and forget the main task. In this experiment, the dataset is used for training, and the dataset is used for testing. The mAP metric on six classes is used for comparison. Figure 5 shows how the KL loss affects the result. Without the feature selection, the mAP is only 0.923; when is 0.05, the mAP increases to 0.928. The higher the , the higher our mAP. However, when , the mAP begins to be reduced; and if the mAP is 0.914. The mAP based on is smaller than when the mAP without feature loss. This phenomenon is because the feature loss reduces the features selected for the main task. When the feature is reduced too much, the classifier may not have enough information for the classification task. In the next experiments, we select the for our proposed method.
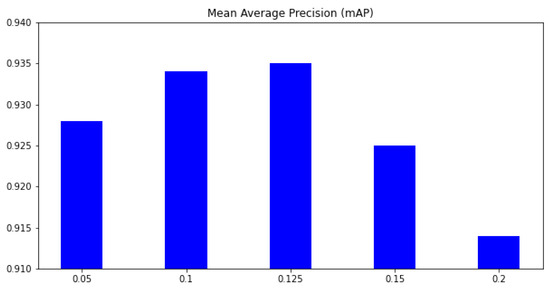
Figure 5.
The mean average precision (mAP) on different . x-axis means the parameter, and y-axis is the mean average precision (mAP) over all classes.
The next experiment aims to evaluate the contribution of other hyperparameters on the performance. In Equation (1), a hyper-parameter controls the contribution of its corresponding loss to the training process. Therefore, a greater hyperparameter will force the algorithm to learn this task first. By adjusting the hyper-parameter settings, we can control the steps of the learning process. For instance, if we want to train the category classification task before other tasks, the hyper-parameter setting should be and . Table 3 shows all settings in detail. The hyperparameter is not included in this table because the feature selection task is an auxiliary task and must be learned lastly after other tasks. By default, we set .
Table 3.
Hyperparameter settings that control the algorithm steps.
A comparison between the three scenarios is presented in Table 4. Here, the dataset is used for training, and the dataset is used for testing. The results show that changing steps of the learning process may not affect the performance too much. Because all component losses are combined into a unique loss by Equation (1), the algorithm will automatically focus on the task that may not work well and ensure all tasks can be learned at the end of a training process. However, in object detection, category classification is conditional on a predicted bounding box. Therefore, from literature reviews, a greater can provide better performance. As shown in Table 4, the mAP is 0.989 if we focus on first. This value is slightly greater than the performance by learning or first.
Table 4.
Performance comparisons of hyperparameter settings. The best results are marked in bold.
4.3. Compare with SoTA
This section compares our proposed method with SoTA on the mAP metric. There are several experiment settings from different works. Given 70,000 published images from SeaShip [19], Zhang_2022 [47], and Zhang_2021 [42] used 90% of data for training and validating; the other 10% of data are the testing dataset. Liu_2020 [39], Liu_2022 [36], Han_2021 [44], and Light_SDNet [21] use 80% of data for training and validating dataset, the other 20% is the testing dataset. To compare with these works, we use for training and for testing. The result in Table 5 shows that our method is better than other methods in terms of average precision. There are two reasons for this improvement. First, our method is based on the YOLOX framework, which is the recent SoTA frame for object detection. Light_SDNet is based on YOLO5, and its result is also promising. Liu_2020 [39] and Liu_2022 [36] are based on older versions in the YOLO family; hence, the performance is smaller than the SoTA framework as Light_SDNet and our method. Second, the parameterization adds some uncertainty to the training process. It allows the model to work with more data during the training phase. In comparison, Light_SDNet [21] also adds more haze and rain to the original image and gets a very good result (mAP = 0.988%). The major difference between our method and Light_SDNet [21] is how we add noise to training data. While Light_SDNet [21] adds noise to the image domain, our method adds noise to the feature domain. Last but not least, the VIB Loss learns features that focus on the object and remove redundant features in the background. Feature analysis in Section 4.4 will visualize feature maps in detail.
Table 5.
Performance comparisons of SoTA methods. The best results are marked in bold.
In addition, Biaohua_2022 [37] and Yani_2022 [49] used 50% of published images for training and the rest 50% for testing. Hence, we use and for training and testing correspondingly. As shown in Table 5, the mAP on previous works is up to 0.965%. Our proposed method can achieve significantly better performance than previous works. It proves the benefit of our method when the number of training samples is reduced. The primary driving force behind this improvement is the adoption of our method, which builds upon the robust YoloX framework for object detection. It is worth noting that ship detection research typically leverages an object detection framework as its foundation, often with some custom modifications. Therefore, inheriting the capabilities of such a novel and powerful framework naturally leads to improved results.
4.4. Contribution of the VIB Loss on Small Datasets
In this section, we discuss the contribution of VIB loss on different scale datasets. The (525 images), (1225 images), and (3500 images) datasets are used for training. The testing dataset contains 3500 images. The results in Table 6 show that the VIB loss helps improve performance significantly on small datasets. If the training dataset is , the mAP improves 3%. When the number of training samples is increased, the improvement is reduced. The enhancement on mAP is 1.2% if is used for training, and if the training dataset is , the mAPs from both settings are quite equivalent. This phenomenon is reasonable because an unsupervised loss may help avoid overfitting on small datasets, and a reparameterization allows a classifier to be robust.
Table 6.
Performance on small datasets. means 30% training samples, means 70% training samples, means 100% training samples from . The best results are marked in bold.
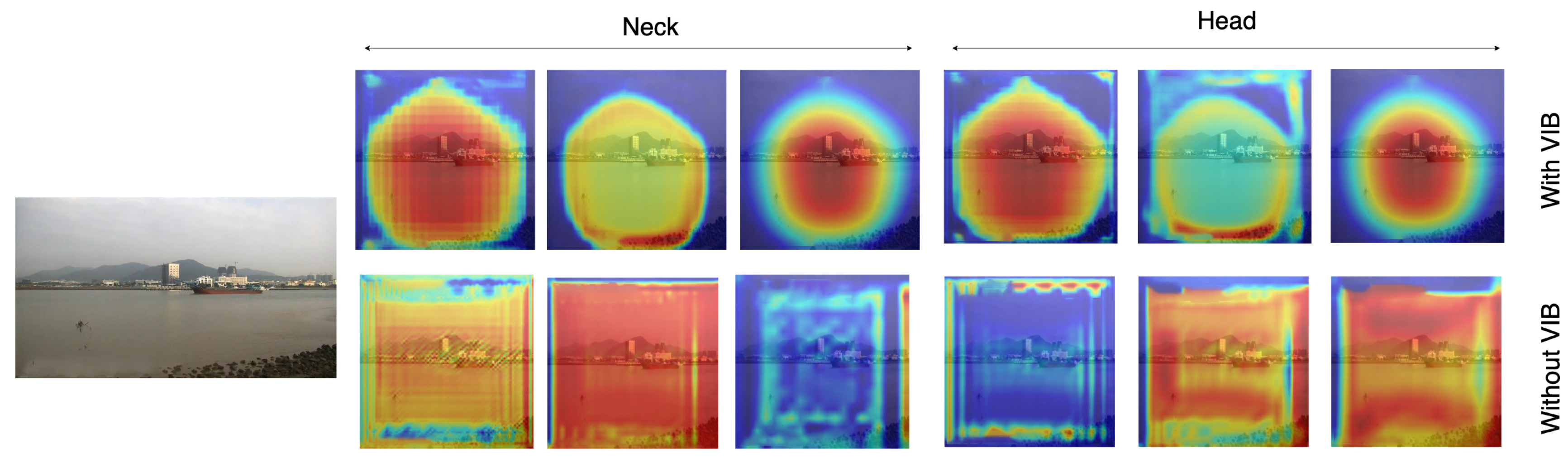
To clearly explain the benefit of the proposed method on feature learning, we compare the feature learned by our method (with VIB) and the baseline method (without VIB) using the dataset. Features before the last layer of necks and heads are extracted and visualized. We select 20 feature maps with the highest response scores for each scale level. We denote j as a pixel on a feature map F, which has size ; the score of the feature map is . These feature maps are accumulated together to formulate a unique response map. The result could represent important pixels on input images.
Figure 6 shows the heat map corresponding to an input image. The first row represents feature maps with VIB; the second row represents those without VIB. Since features are extracted at three scale levels, three responses are provided for head modules. The results show that VIB loss can learn features that focus on the object. Without VIB, the response likes a uniform distribution. With VIB, feature responses focus around the object but not all pixels. The phenomenon is also repeated at the neck module. It means the VIB loss can be backpropagated to the neck level and learn a better feature.
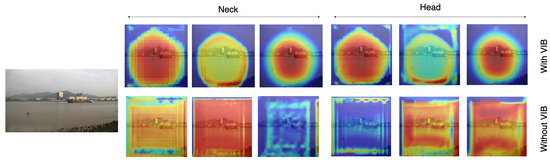
Figure 6.
Heatmaps on the classifier head and the neck.
In addition, we also evaluate the sparse level and the discriminate level of feature maps. A sparse feature map means many values in the feature map are close to zeros. If a feature map is more sparse, it means the learned filters are not responding to patterns that do not contribute to the prediction process. Also, a sparse feature map means we only select a few features. A discriminate level is the difference between the maximum value and the minimum value in a feature map. A greater discrimination level means some positions have a high response, whereas others have a low response. Hence, the learned filters can strongly respond to useful patterns rather than other patterns. Given a feature map where j is a position on the map, the sparse level is estimated by , and the discriminate level is .
Utilizing the input image depicted in Figure 6, we extract feature maps from the final layer of the classification head. The statistics regarding the sparsity and discriminative characteristics of these feature maps are presented in Table 7. The findings indicate that VIB generates feature maps with increased sparsity. This outcome can be attributed to the influence of the object function , which enforces a zero mean on the features. Furthermore, the higher discriminative level observed in the VIB-based results underscores the robustness of the learned features.
Table 7.
Statistics of sparse level and discriminate level on feature maps.
Behind the reasoning experiments, the computational cost has been introduced. Table 8 represents the frame per second (FPS), the Giga-Floating-Point Operations Per Second (GFlops), and the number of parameters of the model. Among them, FPS measures the speed of the model, GFlops evaluates the performance of hardware when running deep learning workloads, and the number of parameters represents the size of the model. The result in Table 8 shows that adding VIB to the network does not increase the computational cost too much. The number of parameters is slightly increased because the VIB module has been added to the network. However, the FPS and GFlops are quite similar in both cases. This means the additional VIB module did not increase the computational cost.
Table 8.
A comparison between computation cost with and without using VIB.
4.5. Effect of Backbone
This section discusses how the proposed method works with different backbones. ResNet, MobileNetv2, and DarkNet are used as backbones for comparison. The input channel of the necked is adapted to meet the output of these backbones. The average precisions (AP) for six classes are shown in Table 9. In this experiment, serves as a training dataset. The result shows that DarkNet is the best backbone among these pre-trained models. This is reasonable because DarkNet had been recognized as the best backbone in the YOLO family. In addition, the increment given by VIB loss on ResNet [51] is 5.9 %. It means VIB loss can help a lot with some particular backbone.
Table 9.
A mAP comparison with and without VIB on different backbones.
4.6. Effect of Pre-Processing Methods
Our approach enhances the classifier head by introducing a degree of uncertainty to the extracted features. However, it is worth noting that introducing uncertainty into the image domain has been explored in previous works [52,53,54]. For instance, in the Seg-based method [52], researchers trained their model using segmentation images. We have incorporated a similar approach into our ship dataset, generating segmentation images to create a new dataset for training our ship detector. Additionally, the NoiBased approach [53,54] method enriches datasets by introducing noise to input images and employing denoising techniques to bolster system robustness. Drawing inspiration from this observation, we conducted training sessions for our ship dataset both with and without the introduction of noise.
In this context, the dataset serves as the training dataset, while is designated as the testing dataset. The results presented in Table 10 reveal that applying a thresholding method for preprocessing the ship dataset may not yield optimal outcomes. The mean Average Precision (mAP) generated by this method falls short of the results achieved by alternative approaches. This disparity can be attributed to the inherent complexity of cluttered backgrounds within the dataset, making it challenging to identify a single segmentation method suitable for all images. Furthermore, in some instances, portions of ships may inadvertently be excluded, thus compromising the model’s overall performance.
Table 10.
Performance comparisons among pre-processing methods. The best results are marked in bold.
The NoiBased method [53,54] offers a potential remedy by augmenting the dataset through the introduction of noise into the input images. This augmentation leads to a modest performance improvement. Specifically, the mAP registers at 0.923 without the addition of noise, and it increases marginally to 0.925 when noise is incorporated. However, the incremental improvement is relatively slight, possibly because the feature extractor has already learned to filter out noise from the input images, resulting in similarities between the extracted features in both scenarios.
Our approach stands out as the most effective due to the deliberate introduction of uncertainty at the classifier head. In this configuration, the feature extractor is unable to eliminate the introduced uncertainty, placing a greater onus on the classifier to exhibit robustness in handling this uncertainty. This rationale has motivated the incorporation of uncertainty into the feature domain, a practice widely adopted in numerous research studies to enhance model performance.
4.7. The Position of VIB Network
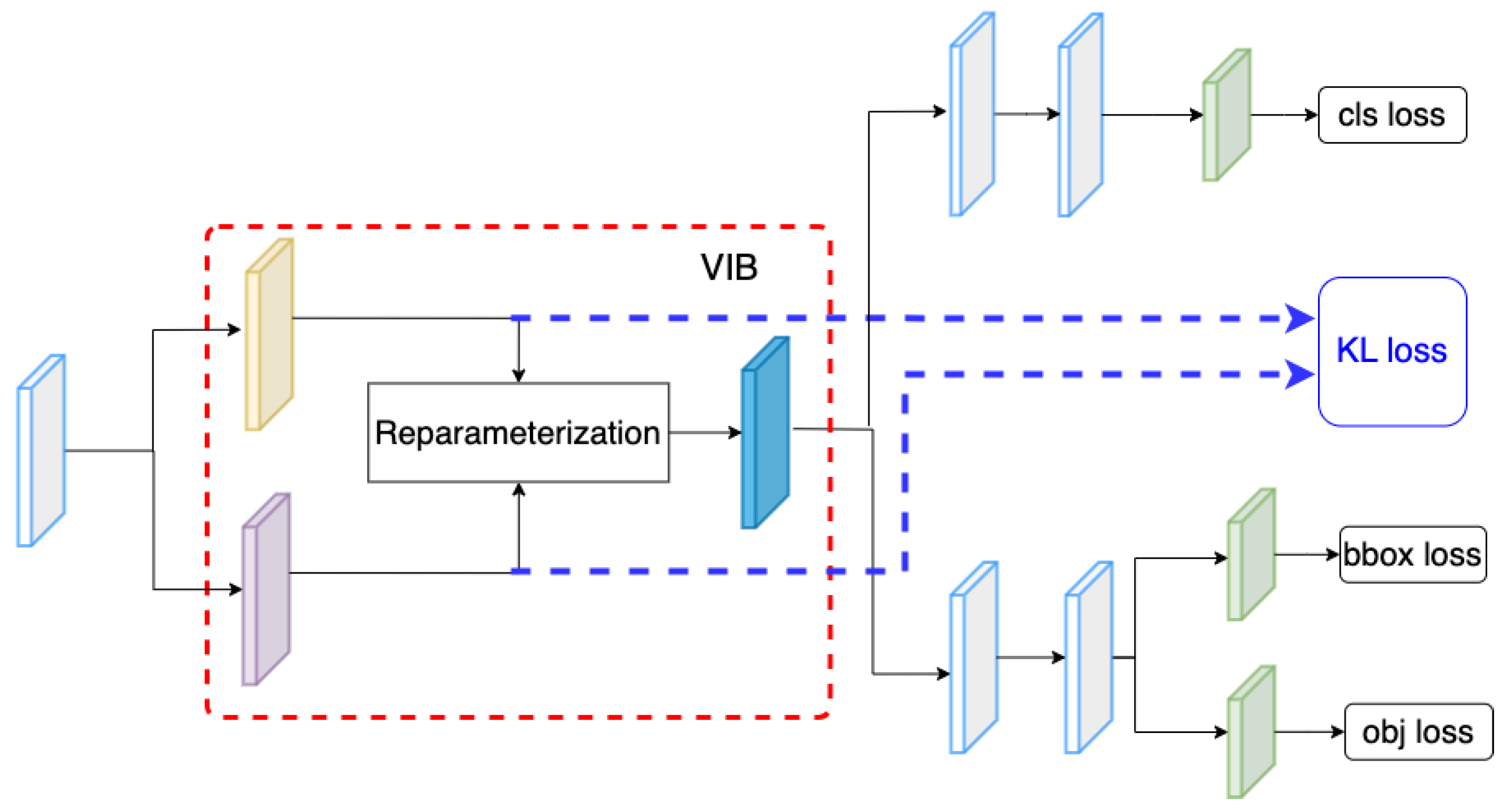
In the proposed method, we have inserted the VIB module at the beginning of the classification head. However, the VIB model could be inserted at any position of the network structure. Hence, in this section, we have tried several setups to evaluate how to use a VIB in an object detection task. In YOLOX, the classification head has two sequence convolution blocks. The proposed method inserts the VIB block at the beginning of the classification head, as in Figure 2. However, we can also set up the VIB module at the middle of the classification head as in Figure 7 or at the beginning of the decouple head as in Figure 8. Here, the dataset is used for training as in Section 4.5. The result in Table 11 shows that the VIB module is only suitable to be inserted on the classification branch. If the VIB module affects the regression branch, the network cannot converge.
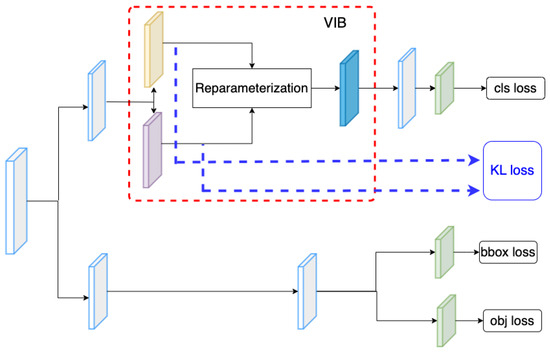
Figure 7.
VIB on the mid of classification head.
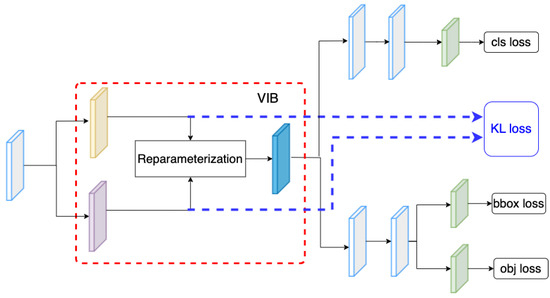
Figure 8.
VIB at the beginning of the decouple head.
Table 11.
Performance when the VIB module is inserted at different positions on the YOLOX framework.
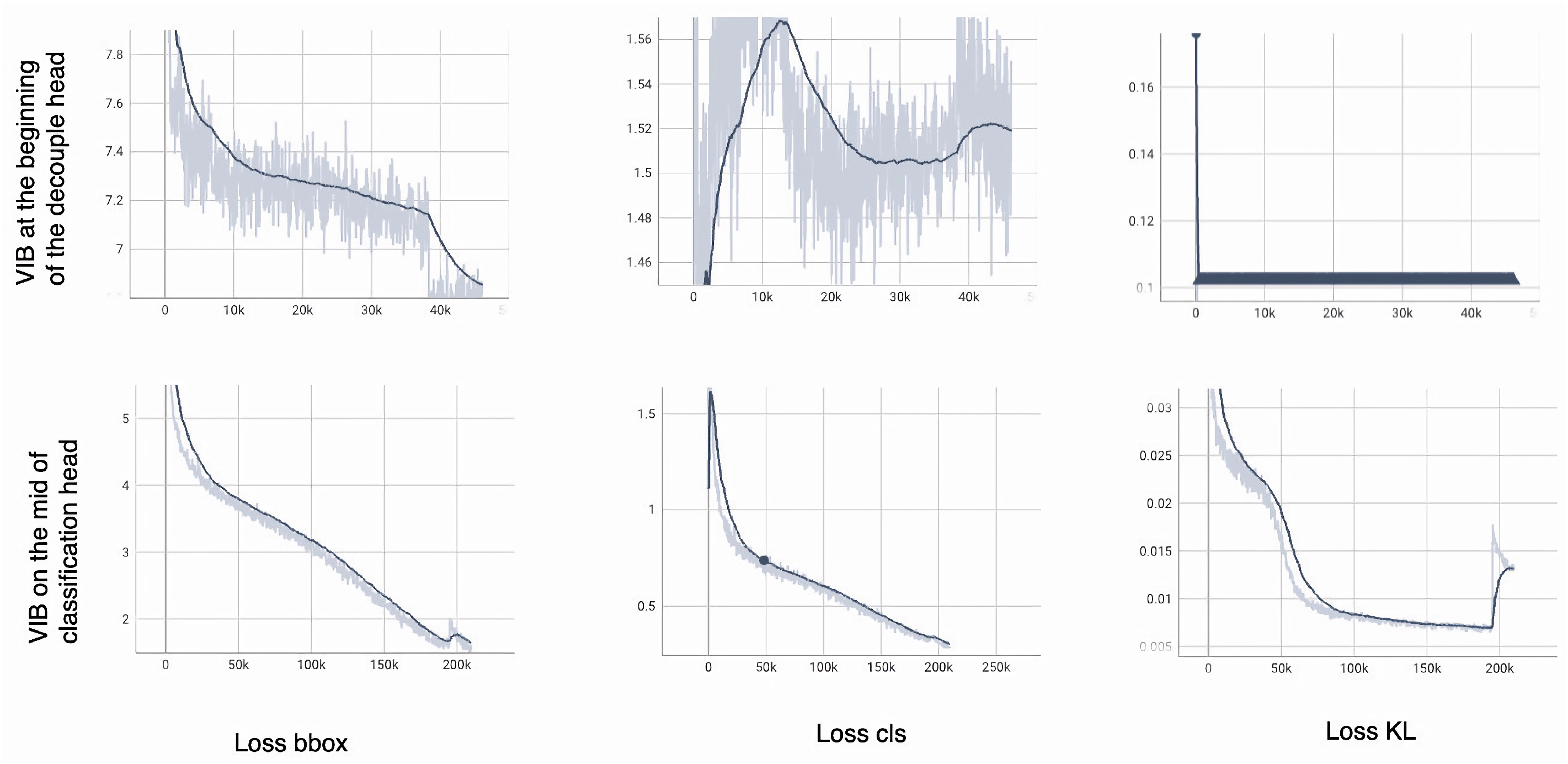
To explain the phenomenon, the , , and over a training phase are shown in Figure 9.
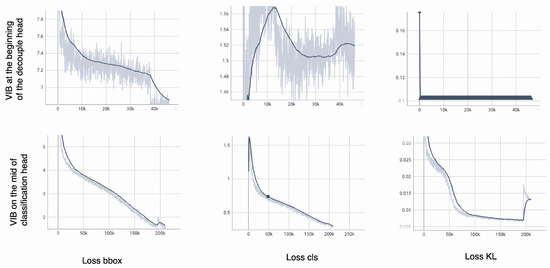
Figure 9.
The loss over a training process. The bold line is smooth values over iterations. The light line is the actual value in an iteration.
The model can converge smoothly if the VIB module is on the classification head (the second row of Figure 9). The quickly degrades to range [4–5] with only 3000 iterations. Box prediction’s success is a critical requirement to train the classification head. At the beginning of the training process, increases when is large; then, it degrades smoothly when the is smaller. The should contribute later in the training process because it is an auxiliary loss but not a major task.
The model cannot converge if the VIB module is at the beginning of the decoupled head (the first row of Figure 9). The degrades but is still higher than 7 after 40,000 iterations. While the box prediction is unsuccessful, the classification head may be unable to learn. The increases and reduces over a training process. The classification head cannot be learned if is still large. This phenomenon shows that the KL loss and the reparameterization make the regression more challenging. Consequently, the classification head cannot be learned, and the model fails to converge.
5. Conclusions
In this paper, we proposed a novel method for ship detection. Based on the YOLOX framework, we introduce a VIB module on the classification head of the network. Comprehensive experiments prove that our method is beneficial on small training datasets. The learned features will focus on the object rather than distribute uniformly over images. Our method also provides promising results in comparison with SoTA ship detection.
Author Contributions
Conceptualization, resources, investigation, writing-original draft, analysis, D.-D.N.; software, V.-L.V.; validation, T.N.; methodology, M.-H.N.; writing—review and editing, M.-H.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by HCMC University of Technology and Education, VietNam.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are openly available in [Zhang] at [https://doi.org/10.1109/ACCESS.2022.3199352], reference number [21].
Conflicts of Interest
The authors declare no conflict of interest.
References
- Szeto, A.; Pelot, R. The use of long range identification and tracking (LRIT) for modelling the risk of ship-based oil spills. In Proceedings of the AMOP Technical Seminar on Environmental Contamination and Response 2011, Banff, AB, Canada, 4–6 October 2011. [Google Scholar]
- Mao, S.; Tu, E.; Zhang, G.; Rachmawati, L.; Rajabally, E.; Huang, G. An Automatic Identification System (AIS) Database for Maritime Trajectory Prediction and Data Mining. arXiv 2016, arXiv:1607.03306. [Google Scholar]
- Paterniani, G.; Sgreccia, D.; Davoli, A.; Guerzoni, G.; Di Viesti, P.; Valenti, A.C.; Vitolo, M.; Vitetta, G.M.; Boriani, G. Radar-Based Monitoring of Vital Signs: A Tutorial Overview. Proc. IEEE 2023, 111, 277–317. [Google Scholar] [CrossRef]
- Zhou, X.; Gong, W.; Fu, W.; Du, F. Application of deep learning in object detection. In Proceedings of the 2017 IEEE/ACIS 16th International Conference on Computer and Information Science (ICIS), Wuhan, China, 24–26 May 2017; pp. 631–634. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv 2013, arXiv:1311.2524. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Girshick, R.; Iandola, F.; Darrell, T.; Malik, J. Deformable Part Models are Convolutional Neural Networks. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 July 2015. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; Available online: https://www.computer.org/csdl/proceedings-article/iccv/2021/281200j992/1BmGKZoEzug (accessed on 10 July 2023).
- Lee, S.H.; Park, H.G.; Kwon, K.H.; Kim, B.H.; Kim, M.Y.; Jeong, S.H. Accurate Ship Detection Using Electro-Optical Image-Based Satellite on Enhanced Feature and Land Awareness. Sensors 2022, 22, 9491. [Google Scholar] [CrossRef]
- Patel, K.; Bhatt, C.; Mazzeo, P.L. Deep Learning-Based Automatic Detection of Ships: An Experimental Study Using Satellite Images. J. Imaging 2022, 8, 182. [Google Scholar] [CrossRef]
- Stofa, M.M.; Zulkifley, M.A.; Zaki, S.Z.M. A deep learning approach to ship detection using satellite imagery. IOP Conf. Ser. Earth Environ. Sci. 2020, 540, 012049. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2012 (VOC2012) Results. 2012. Available online: http://www.pascal-network.org/challenges/VOC/voc2012/workshop/index.html (accessed on 10 July 2023).
- Zhang, Z.; Zhang, L.; Wang, Y.; Feng, P.; He, R. ShipRSImageNet: A Large-Scale Fine-Grained Dataset for Ship Detection in High-Resolution Optical Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8458–8472. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhang, M.; Rong, X.; Yu, X. Light-SDNet: A Lightweight CNN Architecture for Ship Detection. IEEE Access 2022, 10, 86647–86662. [Google Scholar] [CrossRef]
- Alemi, A.A.; Fischer, I.; Dillon, J.V.; Murphy, K. Deep Variational Information Bottleneck. arXiv 2016, arXiv:1612.00410. [Google Scholar]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. arXiv 2019, arXiv:1904.08189. [Google Scholar]
- Chen, W.; Shah, T. Exploring Low-light Object Detection Techniques. arXiv 2021, arXiv:cs.CV/2107.14382. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. arXiv 2020, arXiv:cs.CV/1911.09070. [Google Scholar]
- Grekov, A.N.; Shishkin, Y.E.; Peliushenko, S.S.; Mavrin, A.S. Application of the YOLOv5 Model for the Detection of Microobjects in the Marine Environment. arXiv 2022, arXiv:cs.CV/2211.15218. [Google Scholar]
- Katz, D.M.; Hartung, D.; Gerlach, L.; Jana, A.; Bommarito, M.J., II. Natural Language Processing in the Legal Domain. arXiv 2023, arXiv:cs.CL/2302.12039. [Google Scholar] [CrossRef]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.J.; Bourdev, L.D.; Girshick, R.B.; Hays, J.; Perona, P.; Ramanan, D.; Doll’a r, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In ECCV; Springer International Publishing: Cham, Switzerland, 2014; Volume 8693. [Google Scholar] [CrossRef]
- Zheng, J.; Liu, Y. A Study on Small-Scale Ship Detection Based on Attention Mechanism. IEEE Access 2022, 10, 77940–77949. [Google Scholar] [CrossRef]
- Ye, B.; Qin, T.; Zhou, H.; Lai, J.; Xie, X. Cross-level Attention and Ratio Consistency Network for Ship Detection. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 4644–4650. [Google Scholar] [CrossRef]
- Cui, H.; Yang, Y.; Liu, M.; Shi, T.; Qi, Q. Ship Detection: An Improved YOLOv3 Method. In Proceedings of the OCEANS 2019, Marseille, France, 17–20 June 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Liu, T.; Pang, B.; Ai, S.; Sun, X. Study on Visual Detection Algorithm of Sea Surface Targets Based on Improved YOLOv3. Sensors 2020, 20, 7263. [Google Scholar] [CrossRef]
- Li, H.; Deng, L.; Yang, C.; Liu, J.; Gu, Z. Enhanced YOLO v3 Tiny Network for Real-Time Ship Detection From Visual Image. IEEE Access 2021, 9, 16692–16706. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I. CBAM: Convolutional Block Attention Module. In Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Liu, T.; Pang, B.; Zhang, L.; Yang, W.; Sun, X. Sea Surface Object Detection Algorithm Based on YOLO v4 Fused with Reverse Depthwise Separable Convolution (RDSC) for USV. J. Mar. Sci. Eng. 2021, 9, 753. [Google Scholar] [CrossRef]
- Guo, J.; Li, Y.; Lin, W.; Chen, Y.; Li, J. Network Decoupling: From Regular to Depthwise Separable Convolutions. arXiv 2018, arXiv:cs.CV/1808.05517. [Google Scholar]
- Han, X.; Zhao, L.; Ning, Y.; Hu, J. ShipYOLO: An Enhanced Model for Ship Detection. J. Adv. Transp. 2021, 2021, 1060182. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features from Cheap Operations. arXiv 2020, arXiv:cs.CV/1911.11907. [Google Scholar]
- Ye, R.; Liu, F.; Zhang, L. 3D Depthwise Convolution: Reducing Model Parameters in 3D Vision Tasks. arXiv 2018, arXiv:cs.CV/1808.01556. [Google Scholar]
- Zhang, Q.; Huang, Y.; Song, R. A Ship Detection Model Based on YOLOX with Lightweight Adaptive Channel Feature Fusion and Sparse Data Augmentation. In Proceedings of the 2022 18th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Madrid, Spain, 29 November–2 December 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar] [CrossRef]
- Zhang, Y.; Er, M.J.; Gao, W.; Wu, J. High Performance Ship Detection via Transformer and Feature Distillation. In Proceedings of the 2022 5th International Conference on Intelligent Autonomous Systems (ICoIAS), Dalian, China, 23–25 September 2022; pp. 31–36. [Google Scholar] [CrossRef]
- Tishby, N.; Pereira, F.C.; Bialek, W. The information bottleneck method. In Proceedings of the 37-th Annual Allerton Conference on Communication, Control and Computing, Monticello, IL, USA, 22–24 September 1999; pp. 368–377. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Ashwani Kumar Aggarwal, P.J. Segmentation of Crop Images for Crop Yield Prediction. Int. J. Biol. Biomed. 2022, 7, 40–44. [Google Scholar]
- Thukral, R.; Arora, A.; Kumar, A.; Kumar, G. Denoising of Thermal Images Using Deep Neural Network; Springer: Singapore, 2022; pp. 827–833. [Google Scholar] [CrossRef]
- Thukral, R.; Kumar, A.; Arora, A.; Gulshan. Effect of Different Thresholding Techniques for Denoising of EMG Signals by using Different Wavelets. In Proceedings of the 2019 2nd International Conference on Intelligent Communication and Computational Techniques (ICCT), Jaipur, India, 28–29 September 2019; pp. 161–165. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).