
Eye-in-Hand Robotic Arm Gripping System Based on Machine Learning and State Delay Optimization †



Abstract
:1. Introduction
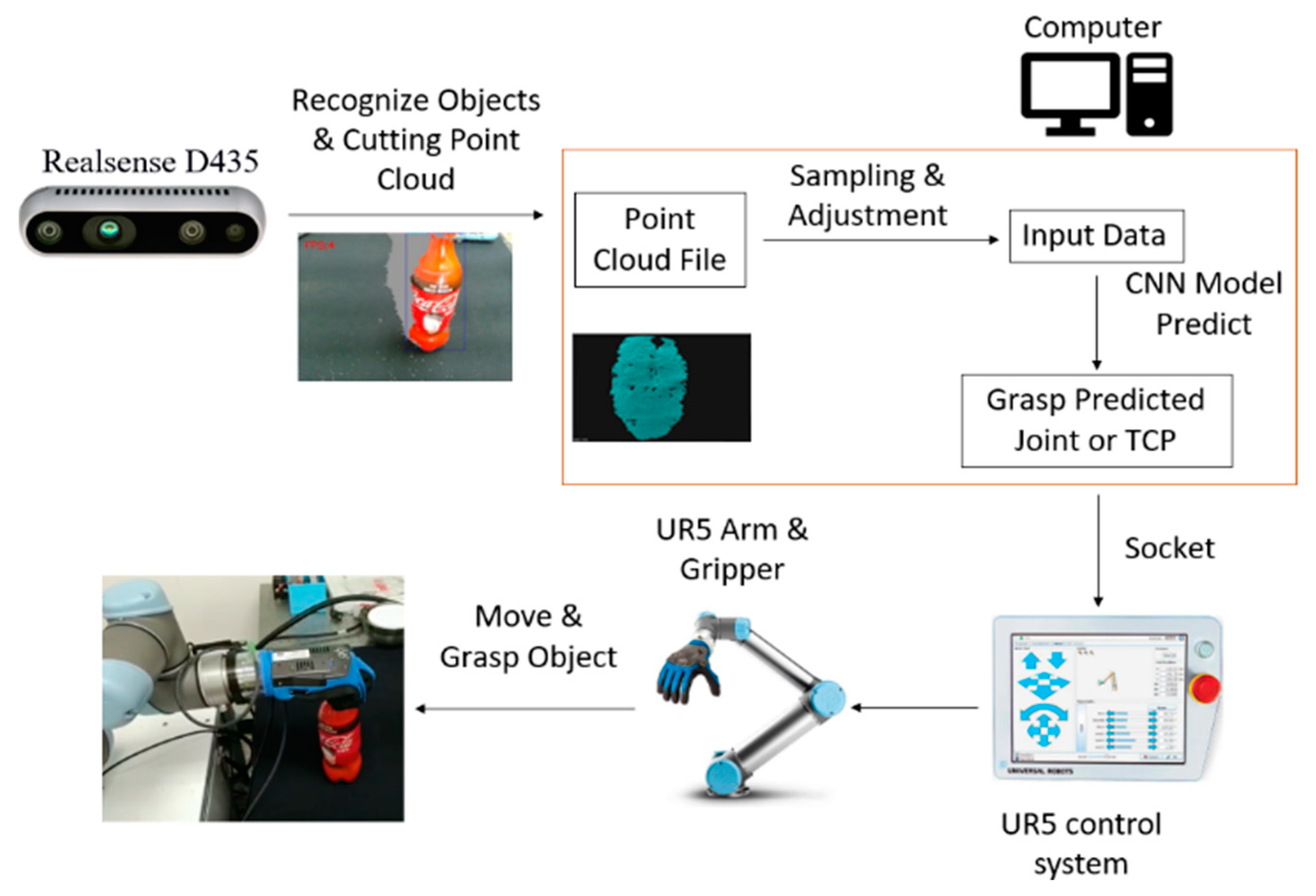
2. Control System Architecture
3. Point Cloud Data and Machine Learning Architecture
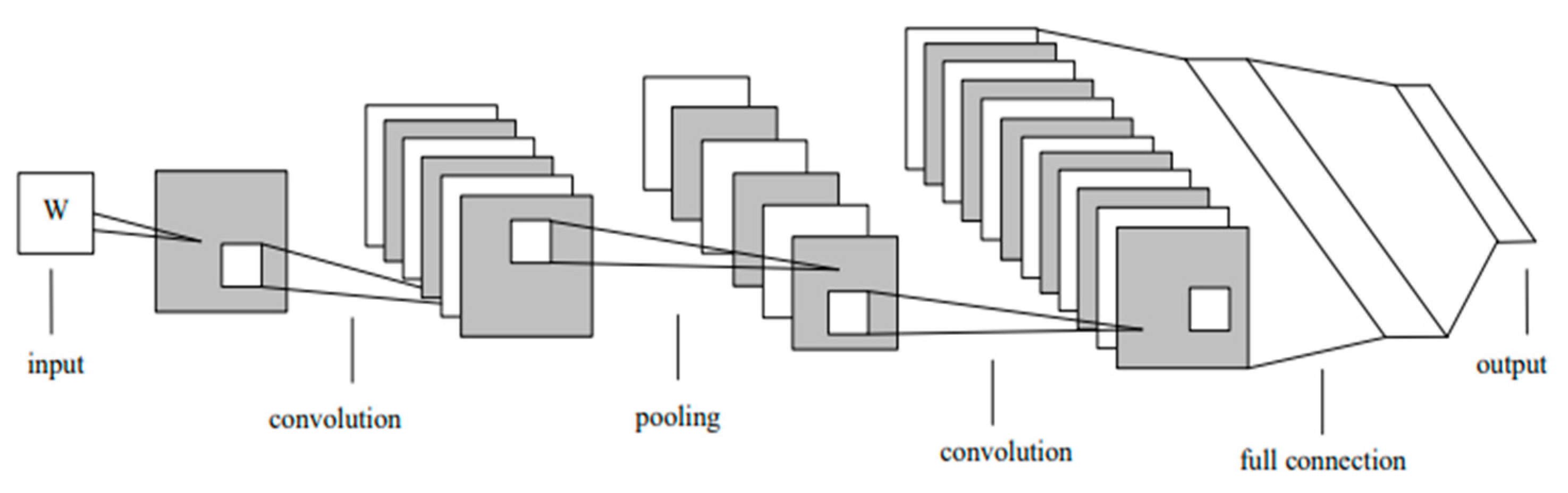
3.1. Convolutional Neural Network (CNN) Architecture
3.2. Min-Pnet Architecture
3.3. Input Point Cloud Data
3.4. Pooling Layer
3.5. Multi-Layer Perceptron (MLP)
4. State Delays Using Digital Redesign
5. Results
5.1. The Test of the Robot Manipulator










5.2. AI Training Results
5.3. Real Machine Grasping
5.3.1. Five-Finger and Two-Finger Claw Gripping Experiment
5.3.2. Comparison of CNN and Min-Pnet Networks
5.3.3. Out-of-Training Set Object Gripping
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, C.S.; Li, T.C.; Hu, N.T. The Gripping Posture Prediction of Eye-in-hand Robotic Arm Using Min-Pnet. In Proceedings of the 2022 International Conference on Advanced Robotics and Intelligent Systems (ARIS), Taipei, Taiwan, 24–27 August 2022; pp. 1–5. [Google Scholar]
- Kim, H.-S.; Park, J.; Bae, M.; Park, D.; Park, C.; Do, H.M.; Choi, T.; Kim, D.-H.; Kyung, J. Advanced 2-DOF Counterbalance Mechanism Based on Gear Units and Springs to Minimize Required Torques of Robot Arm. IEEE Robot. Autom. Lett. 2022, 7, 6320–6326. [Google Scholar] [CrossRef]
- Li, Z.; Li, S.; Luo, X. Using Quadratic Interpolated Beetle Antennae Search to Enhance Robot Arm Calibration Accuracy. IEEE Robot. Autom. Lett. 2022, 7, 12046–12053. [Google Scholar] [CrossRef]
- Yun, A.; Lee, W.; Kim, S.; Kim, J.-H.; Yoon, H. Development of a Robot Arm Link System Embedded with a Three-Axis Sensor with a Simple Structure Capable of Excellent External Collision Detection. Sensors 2022, 22, 1222. [Google Scholar] [CrossRef]
- Righi, M.; Magrini, M.; Dolciotti, C.; Moroni, D. A Case Study of Upper Limb Robotic-Assisted Therapy Using the Track-Hold Device. Sensors 2022, 22, 1009. [Google Scholar] [CrossRef]
- Borst, C.; Fischer, M.; Hirzinger, G. Grasp Planning: How to Choose a Suitable Task Wrench Space. In Proceedings of the IEEE International Con-ference on Robotics and Automation (ICRA), New Orleans, LA, USA, 26 April–1 May 2004; pp. 319–325. [Google Scholar]
- Tang, T.; Lin, H.C.; Zhao, Y.; Chen, W.; Tomizuka, M. Autonomous alignment of peg and hole by force/torque measurement for robotic assembly. In Proceedings of the 2016 IEEE International Conference on Automation Science and Engineering (CASE), Fort Worth, TX, USA, 21–25 August 2016; pp. 162–167. [Google Scholar] [CrossRef]
- Luo, J.; Solowjow, E.; Wen, C.; Ojea, J.A.; Agogino, A.M. Deep Reinforcement Learning for Robotic Assembly of Mixed Deformable and Rigid Objects. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 2062–2069. [Google Scholar] [CrossRef]
- Klingbeil, E.; Rao, D.; Carpenter, B.; Ganapathi, V.; Ng, A.Y.; Khatib, O. Grasping with Application to an autonomous checkout robot. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011; pp. 2837–2844. [Google Scholar]
- Chen, N.; Westling, G.; Edin, B.B.; van der Smagt, P. Estimating Fingertip Forces, Torques, and Local Curvatures from Fingernail Images. Robotica 2020, 38, 1242–1262. [Google Scholar] [CrossRef] [Green Version]
- Cohen, Y.; Bar-Shira, O.; Berman, S. Motion Adaptation Based on Learning the Manifold of Task and Dynamic Movement Primitive Parameters. Robotica 2021, 39, 1299–1315. [Google Scholar] [CrossRef]
- Yao, S.; Ceccarelli, M.; Carbone, G.; Dong, Z. Grasp configuration planning for a low-cost and easy-operation underactuated three-fingered robot hand. Mech. Mach. Theory 2018, 129, 51–69. [Google Scholar] [CrossRef]
- Park, H.; Park, J.; Lee, D.-H.; Park, J.-H.; Bae, J.-H. Compliant Peg-in-Hole Assembly Using Partial Spiral Force Trajectory With Tilted Peg Posture. IEEE Robot. Autom. Lett. 2020, 5, 4447–4454. [Google Scholar] [CrossRef]
- Levine, S.; Pastor, P.; Krizhevsky, A.; Ibarz, J.; Quillen, D. Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection. Int. J. Robot. Res. 2018, 37, 421–436. [Google Scholar] [CrossRef]
- Calli, B.; Wisse, M.; Jonker, P. Grasping of unknown objects via curvature maximization using active vision. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), San Francisco, CA, USA, 25–30 September 2011; pp. 995–1001. [Google Scholar]
- Yu, S.; Zhai, D.-H.; Wu, H.; Yang, H.; Xia, Y. Object recognition and robot grasping technology based on RGB-D data. In Proceedings of the 2020 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020. [Google Scholar] [CrossRef]
- Bae, J.-H.; Jo, H.; Kim, D.-W.; Song, J.-B. Grasping System for Industrial Application Using Point Cloud-Based Clustering. In Proceedings of the 2020 20th International Conference on Control, Automation and Systems (ICCAS), Busan, Republic of Korea, 13–16 October 2020. [Google Scholar] [CrossRef]
- Jeng, K.Y.; Liu, Y.C.; Liu, Z.Y.; Wang, J.W.; Chang, Y.L.; Su, H.T.; Hsu, W.H. GDN: A Coarse-To-Fine (C2F) Representation for End-To-End 6-DoF Grasp Detection. arXiv 2020, arXiv:2010.10695. [Google Scholar]
- Pas, A.T.; Platt, R. Using Geometry to Detect Grasp Poses in 3D Point Clouds. In Robotics Research; Springer: Cham, Switzerland, 2018; pp. 307–324. [Google Scholar] [CrossRef]
- Liang, H.; Ma, X.; Li, S.; Görner, M.; Tang, S.; Fang, B.; Zhang, J. PointNetGPD: Detecting Grasp Configurations from Point Sets. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 3629–3635. [Google Scholar]
- Mousavian, A.; Eppner, C.; Fox, D. 6-DOF GraspNet: Variational Grasp Generation for Object Manipulation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2901–2910. [Google Scholar]
- Varadarajan, K.M.; Zhou, K.; Vincze, M. Holistic Shape Detection and Analysis using RGB-D Range Data for Grasping. Available online: https://www.semanticscholar.org/paper/Holistic-Shape-Detection-and-Analysis-using-RGB-D-Varadarajan-Zhou/bf74c4e2453608042c23ab94a94edc1e68046e19 (accessed on 1 December 2022).
- Czajewski, W.; Kołomyjec, K. 3D Object Detection and Recognition for Robotic Grasping Based on RGB-D Images and Global Features. Found. Comput. Decis. Sci. 2017, 42, 219–237. [Google Scholar] [CrossRef] [Green Version]
- Kingry, N.; Jung, M.; Derse, E.; Dai, R. Vision-Based Terrain Classification and Solar Irradiance Mapping for Solar-Powered Robotics. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 5834–5840. [Google Scholar] [CrossRef]
- Kang, H.; Zhou, H.; Wang, X.; Chen, C. Real-Time Fruit Recognition and Grasping Estimation for Robotic Apple Harvesting. Sensors 2020, 20, 5670. [Google Scholar] [CrossRef] [PubMed]
- Vignesh, T.; Karthikeyan, P.; Sridevi, S. Modeling and trajectory generation of bionic hand for dexterous task. In Proceedings of the 2017 IEEE International Conference on Intelligent Techniques in Control, Optimization and Signal Processing (INCOS), Srivilliputtur, India, 23–25 March 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Zhu, Q. Teleoperated Grasping Using an Upgraded Haptic-Enabled Human-Like Robotic Hand and a Cyber Touch Glove. Ph.D. Thesis, University of Ottawa, Ottawa, ON, Canada, 2020. [Google Scholar]
- Chen, X.; Li, Z.; Wang, Y.; Liu, J. Effect of fruit and hand characteristics on thumb–index finger power-grasp stability during manual fruit sorting. Comput. Electron. Agric. 2019, 157, 479–487. [Google Scholar] [CrossRef]
- Anzai, Y.; Sagara, Y.; Kato, R.; Mukai, M. Development of a foldable five-finger robotic hand for assisting in laparoscopic surgery. In Proceedings of the 2019 28th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), New Delhi, India, 14–18 October 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Chao, Y.; Chen, X.; Xiao, N. Deep learning-based grasp-detection method for a five-fingered industrial robot hand. IET Comput. Vis. 2019, 13, 61–70. [Google Scholar] [CrossRef]
- Wang, C.; Freer, D.; Liu, J.; Yang, G.-Z. Vision-based Automatic Control of a 5-Fingered Assistive Robotic Manipulator for Activities of Daily Living. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 627–633. [Google Scholar] [CrossRef]
- Ji, S.-Q.; Huang, M.-B.; Huang, H.-P. Robot Intelligent Grasp of Unknown Objects Based on Multi-Sensor Information. Sensors 2019, 19, 1595. [Google Scholar] [CrossRef] [Green Version]
- Xu, Z.; Yang, C.; Wu, W.; Wei, Q. Design of Underwater Humanoid Flexible Manipulator Motion Control System Based on Data Glove. In Proceedings of the 2020 6th International Conference on Mechatronics and Robotics Engineering (ICMRE), Barcelona, Spain, 12–15 February 2020; pp. 120–124. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zheng, S. Network Intrusion Detection Model Based on Convolutional Neural Network. In Proceedings of the 2021 IEEE 5th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 March 2021; Volume 5, pp. 634–637. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 24–29 July 2016; pp. 652–660. [Google Scholar]
- Rusu, R.B.; Cousins, S. 3d is here: Point cloud library (pcl). In Proceedings of the IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1–4. [Google Scholar]
- Tsai, J.S.-H.; Hu, N.T.; Yang, P.C.; Guo, S.M.; Shieh, L.-S. Modeling of decentralized linear observer and tracker for a class of unknown interconnected large-scale sampled-data nonlinear systems with closed-loop decoupling property. Comput. Math. Appl. 2010, 60, 541–562. [Google Scholar] [CrossRef] [Green Version]
- Hamzaoui, A.; Essounbouli, N.; Benmahammed, K.; Zaytoon, J. State Observer Based Robust Adaptive Fuzzy Controller for Nonlinear Uncertain and Perturbed Systems. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2004, 34, 942–950. [Google Scholar] [CrossRef] [PubMed]
- Shang, S.-Y. Eye-in-hand Robotic Arm Gripping System Based on Two Dimensional Object Recognition Using Machine Learning and Three Dimensional Object Posture Estimation. Available online: https://hdl.handle.net/11296/n9nqt6 (accessed on 1 December 2022).


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference Inputs | Delay Parameters | Max. Output Error (Rad) | Tolerable Delay Time of Manipulator |
|---|---|---|---|
| Type 1 | |||
| Type 2 |
| Range | Joint 1 | Joint 2 | Joint 3 | Joint 4 | Joint 5 | Joint 6 |
|---|---|---|---|---|---|---|
| Max (1) | −160° | −80° | 140° | −10° | 120° | 0° |
| Min (0) | −220° | −120° | 80° | −40° | 40° | −50° |
| Range | X | Y | Z | α (Rx) | β (Ry) | γ (Rz) |
| Max (1) | 1.5 m | 1.5 m | 1.5 m | 1.5 m | 1.5 m | 1.5 m |
| Min (0) | −1.5 m | −1.5 m | −1.5 m | −1.5 m | −1.5 m | −1.5 m |
| Model | Bowl Loss | Bowl Val-Loss | Ball Loss | Ball Val-Loss | Time Consumed |
|---|---|---|---|---|---|
| CNN | 2.2469 × 10−5 | 0.0011 | 1.2599 × 10−5 | 1.7467 × 10−4 | 17 ms/epoch |
| Min-Pnet | 1.4181 × 10−4 | 0.0011 | 5.3420 × 10−5 | 3.6437 × 10−5 | 215 ms/epoch |
| OBB | 2.8651 × 10−4 | 0.0012 | 1.2412 × 10−4 | 2.4541 × 10−4 | 25 ms/epoch |
| Object and Model | Grasping Success Rate |
|---|---|
| 5-Fin CNN Bowl | 90.0% |
| 5-Fin CNN Ball | 80.0% |
| 5-finger CNN Bottle | 80.0% |
| 2-Fin CNN Bowl | 58.82% |
| 2-Fin CNN Ball | 52.94% |
| 2-finger CNN Bottle | 64.15% |
| Indoor [25] | 85% |
| Outdoor [25] | 80% |
| Object and Model | Grasping Success Rate |
|---|---|
| 2-Fin Min-Pnet Bowl | 82.60% |
| 2-Fin Min-Pnet Ball | 73.07% |
| 2-finger Min-Pnet Bottle | 69.01% |
| 2-Fin CNN Bowl | 58.82% |
| 2-Fin CNN Ball | 52.94% |
| 2-finger CNN Bottle | 64.15% |
| 2-Fin OBB Bowl | 60.00% |
| 2-Fin OBB Ball | 33.34% |
| 2-Fin OBB Bottle | 53.33% |
| Object and Model | Grasping Success Rate |
|---|---|
| 2-Fin Min-Pnet Ballobj | 75.00% |
| 2-Fin CNN Ballobj | 50.00% |
| 2-Fin OBB Ballobj | 25.00% |
| 2-Fin Min-Pnet Bottleobj | 73.33% |
| 2-Fin CNN Bottleobj | 60.00% |
| 2-Fin OBB Bottleobj | 53.33% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, C.-S.; Hu, N.-T. Eye-in-Hand Robotic Arm Gripping System Based on Machine Learning and State Delay Optimization. Sensors 2023, 23, 1076. https://doi.org/10.3390/s23031076
Chen C-S, Hu N-T. Eye-in-Hand Robotic Arm Gripping System Based on Machine Learning and State Delay Optimization. Sensors. 2023; 23(3):1076. https://doi.org/10.3390/s23031076
Chicago/Turabian StyleChen, Chin-Sheng, and Nien-Tsu Hu. 2023. "Eye-in-Hand Robotic Arm Gripping System Based on Machine Learning and State Delay Optimization" Sensors 23, no. 3: 1076. https://doi.org/10.3390/s23031076
APA StyleChen, C.-S., & Hu, N.-T. (2023). Eye-in-Hand Robotic Arm Gripping System Based on Machine Learning and State Delay Optimization. Sensors, 23(3), 1076. https://doi.org/10.3390/s23031076