Abstract
Autonomous decision-making is a hallmark of intelligent mobile robots and an essential element of autonomous navigation. The challenge is to enable mobile robots to complete autonomous navigation tasks in environments with mapless or low-precision maps, relying solely on low-precision sensors. To address this, we have proposed an innovative autonomous navigation algorithm called PEEMEF-DARC. This algorithm consists of three parts: Double Actors Regularized Critics (DARC), a priority-based excellence experience data collection mechanism, and a multi-source experience fusion strategy mechanism. The algorithm is capable of performing autonomous navigation tasks in unmapped and unknown environments without maps or prior knowledge. This algorithm enables autonomous navigation in unmapped and unknown environments without the need for maps or prior knowledge. Our enhanced algorithm improves the agent’s exploration capabilities and utilizes regularization to mitigate the overestimation of state-action values. Additionally, the priority-based excellence experience data collection module and the multi-source experience fusion strategy module significantly reduce training time. Experimental results demonstrate that the proposed method excels in navigating the unmapped and unknown, achieving effective navigation without relying on maps or precise localization.
1. Introduction
In unmapped and unknown environments, safe and effective autonomous decision-making and obstacle avoidance present significant challenges for the autonomous navigation of mobile robots. To address these challenges, the three main components of mobile robots—perception, localization, and decision-making—employ various effective methods to solve this problem. In particular, the unmapped environment, though structured, introduces unique difficulties in localization and navigation due to its narrow and monotonous layout, making it a complex environment for testing the robustness of autonomous systems. Autonomous decision-making in such an environment is a significant challenge for the safe and effective navigation of mobile robots. For mobile robots navigating indoor environments, Simultaneous Localization and Mapping (SLAM) [,,] is an essential component of an autonomous navigation system. The generated map enables precise robot localization, facilitating path planning and trajectory tracking applications. However, SLAM has the following limitations: (1) high computational resource demand for data processing and high-precision mapping; (2) sensor accuracy impacting mapping quality; (3). reduced map accuracy in sparse or non-structured environments; and (4) limited navigational accuracy over long distances and in unknown environments. Furthermore, when using low-cost 2D LiDAR sensors (TurtleBot3 LDS-01) in unmapped environments, challenges such as localization errors and multipath reflections can further complicate navigation.
To address these challenges, we utilize artificial intelligence technology to integrate data from low-cost, low-precision ranging sensors into the control system, enabling autonomous robotic decisions even in constrained environments. We employ a data-driven, end-to-end training approach for the agent to accomplish navigation tasks independent of high-precision maps. While there has been significant research on mapless navigation, existing algorithms that integrate traditional methods with deep learning still have limitations in mobile robot navigation []. Recently, deep reinforcement learning (DRL) has demonstrated considerable potential in various domains [,,,], notably in autonomous navigation, motion control, and pattern recognition for mobile robots. However, in unfamiliar and complex environments, the absence of map data can cause robots to converge on local optima, leading to task failures. Additionally, discrepancies between simulation and real environments can render trained strategies ineffective in practice. Visual navigation, although powerful, is sensitive to environmental changes, involves high computational complexity, and has limited generalizability, making the transition from simulation to real-world applications challenging.
In light of this, we propose a DRL algorithm for unmapped and unknown environments, as illustrated in Figure 1. This study validates the algorithm using the mobile robot “Turtlebot3”, which is equipped solely with a low-cost 2-D LiDAR in both simulation and real-world environments. Despite the lower map accuracy and significant localization errors inherent in such sensors, our approach offers increased versatility and robustness. This algorithm facilitates the completion of navigation tasks via real-time, effective, autonomous decision-making in unknown environments. The structure of the proposed algorithm is detailed in Figure 2. The figure illustrates the entire process, from data collection and prioritization to policy training. Initially, the robot generates initial strategies using the 2D lidar and DRL algorithm, interacting with the environment to produce experience data. The data are then stored and fed into the “Multi-source Experience Fusion Pool”, where they are prioritized based on reward values. Within the “Experience Collection Environment”, the data undergo further prioritization and categorization, contributing to the pool for subsequent strategy optimization. The DRL module continuously refines the strategy through experience replay, enhancing the robot’s performance in complex tasks. The contributions of this paper are in the following three aspects:

Figure 1.
Robot navigates through an Unknown Environment.
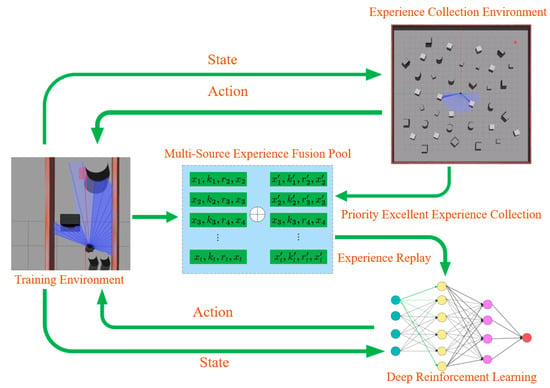
Figure 2.
Proposed algorithmic structural framework for autonomous navigation and autonomous obstacle avoidance.
- We propose an enhanced (DRL) algorithm based on [], which leverages low-cost, low-precision 2D LiDAR sensors for mapless navigation, enabling robust performance in complex environments without the need for high-precision maps.
- We propose a priority-based excellence experience collection mechanism and a multi-source experience fusion strategy. These strategies allow the agent to efficiently learn optimal policies from prior experiences, significantly reducing the training time required for effective navigation.
- Compared to other algorithms, our method can reach the destination quicker, safer, and more smoothly in unmapped and unknown environments, even when localization is inaccurate. Moreover, the strategies and hyperparameters in the simulation environment can be deployed in the real world without any adjustments.
- Additionally, our algorithm has been open-sourced, and the code repository is available at https://github.com/nfhe/darc_drl_nav (accessed on 28 August 2024).
2. Related Works
Autonomous navigation and obstacle avoidance remain prominent research areas in mobile robotics [,,,]. Technological advancements have led to the emergence of more high-performance sensors and computing devices. This has markedly enhanced the accuracy and operability of real-time SLAM. Ranging sensors encompass RGB cameras [,,], 2D lidar [], 3D lidar [], and multi-sensor fusion algorithms [,,]. Despite advancements, most mobile robots depend on SLAM for indoor navigation [,,]. This dependence presents a significant challenge for robots in unmapped and unknown environments.
The advancement of DRL algorithms, coupled with enhanced data processing capabilities, has broadened their application in autonomous navigation. One study [] introduced an autonomous navigation and obstacle avoidance algorithm, merging the Artificial Potential Field (APF) method with DRL. This method adaptively optimizes the two-parameter gains of the APF controller through the actor–critic approach, efficiently completing the navigation task. Surmann et al. [] developed a parallel acceleration algorithm that enhances learning strategies by integrating multi-sensor data fusion and relative positioning. Cimurs et al. [] introduced a DRL-based framework for autonomous navigation and exploration of unknown environments. This framework utilizes potential navigation information to select optimal path points, addressing the local optimum problem in real-time planning. Enrico et al. [] presented an algorithm based on Double Q-learning, employing parallel asynchronous training to expedite the learning of optimal control strategies. Lodel et al. [] proposed a navigation strategy that maximizes information collection rewards based on reference trajectory points and integrates it with a Model Predictive Control (MPC) local planner. The robot’s control strategy is optimized by generating trajectories with enhanced safety constraints guided by reference points. Lee et al. [] introduced a hierarchical reinforcement learning framework to streamline navigation strategy learning in agents. This approach minimizes the need for manual reward function selection and improves training convergence by using a broadly referenced collection reward instead of a fixed reward function. Murad et al. [] addressed the issue of sparse reward functions using MPC. Their strategy efficiently resolves the sparse reward problem in navigation tasks, reducing the need for expert intervention and extensive parameter adjustments. Cui et al. [] proposed an optimization algorithm using the control barrier function, enhancing the safety and flexibility of agents during navigation with lidar data. This algorithm leverages a large data model to perceive and predict the surrounding environment’s dynamics and the consequences of various agent behaviors. Shen et al. [] presented a navigation framework combining mixed-weight trust region optimization with active learning for inverse reinforcement learning. This method integrates expert-level navigation data and domain knowledge to refine navigation strategies through weight learning. Xiong et al. [] developed a navigation strategy that merges the twin neural Lyapunov function with a control strategy and DRL, focusing on safety in unknown, dynamic, and complex environments, an aspect often overlooked in traditional DRL strategies.
Although these strategies are effective in autonomous robot navigation, they exhibit limitations, including poor generalization, low learning efficiency, vulnerability to local optima, and challenges in transitioning from simulations to real-world applications. Consequently, we propose an enhanced DRL algorithm capable of completing navigation tasks autonomously, effective even in scenarios with mapless or low-accuracy mapping.
3. PEEMEEF-DARC Autonomous Navigation
To address mapless navigation in unmapped and unknown environments, we introduce a novel navigation framework, PEEMEEF-DARC. The framework consists of the following three key components: (1) an enhancement of the DDPG algorithm’s exploration capabilities, achieved by integrating an additional actor and a regularized critic to address low-value estimations in the critic; (2) a priority-based excellence experience collection, derived from the traditional navigation framework, which accelerates the agent’s learning of effective strategies; and (3) the integration of a multi-source experience fusion strategy module, further improving the agent’s learning efficiency and quality.
3.1. DARC Module
To enhance the autonomous navigation capabilities of robots in complex environments, we applied the DARC algorithm, as introduced in []. The core idea of the DARC algorithm is to reduce the bias in value estimation by employing two critics to estimate a weighted Q value. In traditional single-critic structures, the value estimation can often be overly optimistic or pessimistic, which negatively impacts the stability and effectiveness of policy learning. This bias is particularly problematic in complex and dynamic environments, where it can cause the robot to get stuck in local optima and fail to find the global optimum.
Accurately estimating values is crucial for agents to acquire strategic understanding. Double actors allow agents to choose from multiple control strategies in diverse environments instead of being limited to a single condition. As depicted in Figure 3, the single-factor policy could cause agents to settle for the local optimum , rather than the global optimum , due to insufficient exploration performance.
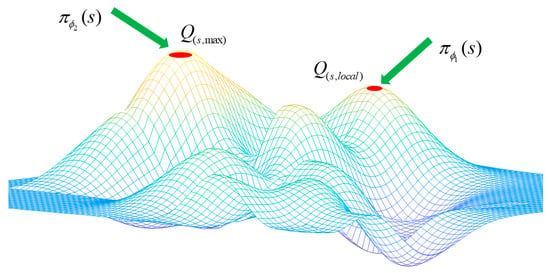
Figure 3.
Double agents can assist in overcoming local optima.
To address these challenges, the DARC algorithm introduces a dual-critic structure, where each critic independently estimates the Q value for a given state–action pair. By averaging the estimates from both critics, the algorithm mitigates the bias that can result from relying on a single critic, leading to more accurate and reliable value estimations. This dual-critic approach not only enhances the robustness of the value estimation but also provides a broader perspective for policy evaluation, which is critical in navigating complex and uncertain environments. We start by initializing two critic networks and , and two actor networks and , where and represent the parameters of the respective networks. During each training step, both critic networks are used to estimate the Q value []:
This approach is intended to provide a more conservative estimate by selecting the lower of the two Q-values, which may help avoid the risks associated with overestimation in policy updates.
Subsequently, we construct the critic network parameters on the double actors. To select the value function, the DARC algorithm employs a conservative approach by first selecting the minimum Q value estimated by the critic network for each strategy . This helps in reducing the risk of overestimation in policy updates. Then, among these minimum Q values, the algorithm selects the maximum value, ensuring a balanced estimation across different strategies and enhancing the stability of the learning process. Unlike traditional Double Q learning algorithms, it employs a value function for calibrating value estimation instead of independently updating the estimated target value through the actor–critic.
To enhance the accuracy of these estimates, DARC integrates a regularization mechanism that penalizes significant deviations between the two critics’ estimates. The regularized loss function for the critics is defined as:
where denotes reward, is the discount factor, and represents the target Q-value. The regularization term ensures that the estimates from the two critics remain close, thereby preventing large discrepancies that could destabilize the learning process.
Additionally, to facilitate a smoother convergence of the policy, a soft update mechanism is employed to combine the critics’ value estimates:
Here, serves as a parameter that adjusts the weight given to each Q-value estimation path. When approaches 0, the algorithm leans towards a more conservative estimate, minimizing potential overestimation. Conversely, as approaches 1, the algorithm becomes more optimistic in its value estimates. This mechanism allows the DARC algorithm to dynamically balance the exploration–exploitation trade-off during training, thereby improving the agent’s learning efficiency and robustness.
The DARC algorithm also leverages the interaction between the actor and critic networks to enhance policy learning. The policy is updated based on the critic’s evaluations, where the objective is to maximize the expected return:
To optimize this objective, we perform gradient ascent on the actor’s parameters:
Given that the policy’s effectiveness is directly influenced by the accuracy of the Q value estimates, the DARC algorithm’s dual-critic structure plays a crucial role in ensuring that these estimates are reliable, thereby stabilizing the entire learning process. Furthermore, the regularization applied to the critics not only reduces the underestimation bias but also ensures that the estimates remain consistent across different states and actions. This consistency is essential for maintaining the stability of the policy learning process, especially in environments where the state–action space is large and highly variable.
To further stabilize learning, DARC employs target networks for both the actors and critics. The target networks and are periodically updated with the parameters of the respective primary networks, ensuring that the target values used in updates do not change too rapidly. The target Q values are computed as:
The temporal difference error, which drives the learning process, is then calculated as:
By minimizing this temporal difference error, the critic networks can iteratively refine their Q-value estimates, potentially improving the accuracy of the value function over time.
The DARC algorithm, through its use of double critics, regularization, and soft updates, offers a structured approach to addressing the challenges of autonomous navigation. These mechanisms are intended to provide a more stable and accurate framework for policy learning, which could be particularly beneficial in complex and dynamic environments.
3.2. Priority Excellent Experience Date Collection Module
In this study, we introduced the use of the ROS move base package to facilitate automated data collection. Traditional experience collection methods often rely on manual configurations and predefined strategies. While these methods can be effective in controlled environments, they present several notable limitations when applied in real-world scenarios. Firstly, manual configurations are inherently subjective, leading to data that may lack the flexibility and adaptability required in complex and unknown environments. The fixed nature of these configurations often restricts the range of exploration, resulting in a dataset that may not be sufficiently diverse. This limitation can hinder the generalization of learned strategies, making them less effective when applied to a broader range of conditions. Moreover, manual configurations are prone to human bias, which can affect the objectivity of the collected data and ultimately reduce the effectiveness of the autonomous navigation tasks.
To overcome these limitations, we employed the move base package to enable autonomous data collection. As illustrated in Figure 4, the robot can autonomously navigate through various environments and collect critical navigation data in real time, including linear and angular velocities , laser scan data , the relative positions of goals , and the reward function value . This state is crucial for determining the appropriate action , which the robot will execute based on the current state.
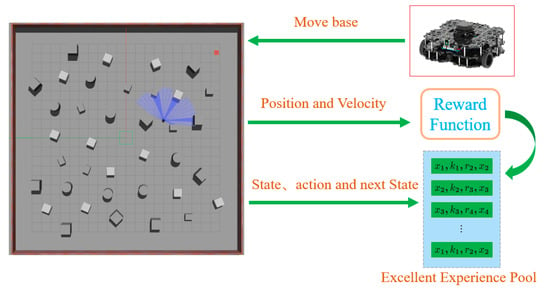
Figure 4.
Priority excellent experience data collection strategy.
This automated data collection approach not only minimizes human bias but also enhances the diversity of the dataset, ensuring that the collected data are comprehensive and representative of the operational environment. The actions , derived from state , lead to transitions to the next state , while a reward evaluates the effectiveness of the action. This interaction between states, actions, and rewards, as shown in Figure 4, forms the basis of the learning process, allowing the robot to refine its strategies over time.
Additionally, the move base package ensures that the data collection process is seamlessly integrated with the navigation tasks, thereby improving the relevance and effectiveness of the collected data. Compared to traditional methods, this autonomous approach provides a robust foundation for subsequent learning and strategy optimization, ultimately shortening training times and improving the generalization capabilities of the strategies.
All collected data are stored in a priority-based excellence experience pool. This experience pool allows the agent to prioritize learning from high-quality strategies, thereby enhancing training efficiency and better preparing the agent for autonomous navigation in unknown environments.
3.3. Multi-Source Experience Fusion Strategy Module
In this module, we propose a multi-source experience fusion strategy based on a reward value function. This strategy integrates prioritized excellent experience data into an excellent experience pool and combines this with ordinary experiences according to a predefined ratio during learning. This approach enables the agent to rapidly learn desired actions, thus efficiently speeding up the training process. Figure 2 illustrates the experience pool positioned at the framework’s core. Its primary function is to store the agent’s current actions, sensor data generated by environmental changes, and corresponding reward values. The implementation steps of this algorithm are as follows:
- (1)
- Real-time sorting of the data in the experience pool according to the reward value , and the data with the top reward values are divided into the excellent experience pool. In the process of data selection, samples are prioritized from this excellent experience pool.
- (2)
- In each iteration, the agent generates new data . If the reward value in this data exceeds the set excellent experience pool threshold, it is added to this pool.
- (3)
- For each training session, a total of data sets are chosen. are randomly selected from the excellent experience pool and from the ordinary pool. These are then randomly combined for training.
- (4)
- After training, the agent blends the excellent with the ordinary experience pool. The excellent pool and its reward threshold are reset based on the top in the experience pool.
In this study, the term “multi-source” experience does not refer to data from multiple simulation environments but rather to the variety of experiences generated within a single simulation environment through iterative training. These experiences reflect the different scenarios and outcomes encountered by the agent during task execution. By integrating and sorting these diverse experience data based on reward values, the agent can more effectively identify and learn optimal strategies. To further evaluate the impact of different proportions of prioritized experience in the multi-source experience fusion strategy, we conducted ablation experiments. Specifically, we selected various proportions of prioritized experience (p-values of 50%, 60%, 70%, and 80%) for comparative analysis, aiming to assess how these proportions influence the convergence rate and final stability of the loss function during training. The experimental results, as shown in Figure 5, reveal the convergence trends of the loss function under different p-values. Analyzing these experimental data, we observe that as the proportion of prioritized experience increases, the algorithm’s convergence rate significantly improves. Notably, at p = 70%, the loss value reaches its lowest point, indicating that the model exhibits the best learning performance under this condition, with the most stable and smooth convergence of the loss function. Specifically, when the p-value is 50%, the loss function, although it decreases rapidly in the initial stages, exhibits considerable volatility in the later stages of training, resulting in poor convergence stability. In contrast, when the p-value is 70%, the loss function not only decreases rapidly in the initial stages but also shows the most stable convergence trend in the later stages. This suggests that the strategy provides the best support for model training at this proportion, reducing volatility during the training process.
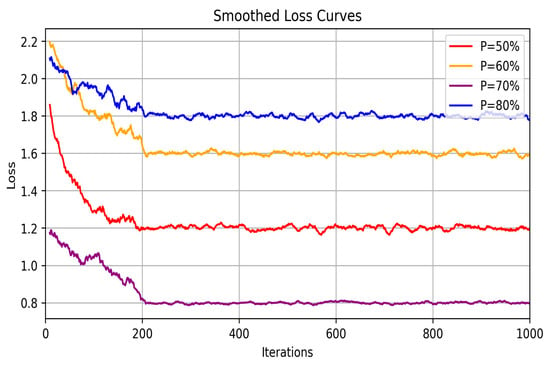
Figure 5.
Ablation study of multi-source experience fusion strategy.
The design of this multi-source experience fusion strategy enables the agent to learn the desired actions from better strategies. Especially in the early stages of training, this strategy helps the agent to learn more effectively, quickly escape from local optima, and accelerate the convergence process of the algorithm, thereby improving the efficiency and quality of the entire training.
3.4. Reinforcement Learning Setting Module
- (1)
- State Space and Action Space
State space: , where represents 2D lidar data, denotes the linear velocity of agents, stands for the angular velocity of agents, and denotes the relative position of the goal. Action space: , where the neural network provides the linear velocity and the angular velocity .
- (2)
- Reward Function Design
The goal of agent training is to achieve autonomous navigation in an unmapped and unknown environment. The agent aims to reach the goal in the shortest time, on the safest path, and with a smooth trajectory. To support this objective, we are developing a new reward function:
We hope that the agent moves towards the goal . and represent the positions of agents at two successive time intervals, respectively. To quantify our approach, we set a constant value . The reward is defined as follows:
We designed a reward function for angular velocity. If the angular velocity surpasses a specific limit, a significant penalty is applied. The reward is represented as follows:
If the agent is close to an obstacle or collides with it, a penalty is applied. We set as the distance between the agent and the obstacle, establish the collision threshold at , and assign . The expression is as follows:
To improve the flexibility and smoothness of agents, a penalty is applied when oscillations occur.
To accelerate the agent’s arrival, we set . The reward is defined as follows:
- (3)
- Network Structure
The DARC algorithm comprises three components, actor, critic, and their corresponding target networks, as illustrated in Figure 6. These target networks are structurally identical to the original networks. The actor network is composed of an input layer, three hidden layers, and an output layer. The input layer receives a 28-dimensional vector, which includes a 24-dimensional vector from the lidar, the distance to the goal, the heading angle deviation, and the agent’s linear and angular velocities. The hidden layers contain 300, 400, and 400 neurons, respectively, each employing a rectified linear unit (ReLU) for activation. The output layer utilizes the hyperbolic tangent function (Tanh) to determine the action space. This output from the action space is then fed into the critic network as input. The structure of the critic network closely mirrors that of the actor, with four hidden layers: the first containing 300 neurons and the remaining three, 400 each. All hidden layers in the critic network employ ReLU activation functions to compute the final Q value. Differing from the actor network, the critic’s input layer merges with the actor’s output after the first hidden layer and then continues through the second, third, and fourth hidden layers. This architecture enables the DARC algorithm to effectively handle complex decision-making tasks, particularly in scenarios involving high-dimensional input data and the requirement for precise outputs.
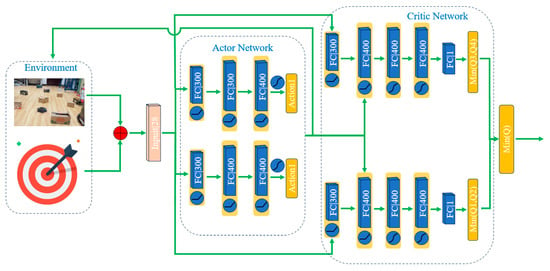
Figure 6.
The DRL algorithm comprises actors and critics, with each layer specifying its corresponding number of parameters.
4. Experiments
4.1. Environment and Parameter Settings
Training the algorithm using Gazebo reduces reliance on environmental information. Additionally, the consistency of the robot model in the simulation with its real-world counterpart aids in a smoother transition from simulation to real-world application. To enhance the network’s generalization and robustness, Gaussian noise is added to sensor data and action values during training to improve the network’s generalization and robustness. First, to demonstrate the effectiveness of the improved algorithm, we conducted ablation experiments in unknown environments, as depicted in Figure 4. These ablation studies specifically analyzed the impact of each component of the PEEMEF-DARC framework, including the double actors regularized critics, the priority-based excellence experience data collection mechanism, and the multi-source experience fusion strategy mechanism. In the multi-source experience fusion strategy, the results of these experiments confirmed the significant contribution of each component to the overall performance of the algorithm, with particular emphasis on how varying the proportion of prioritized experiences affected the learning process. Second, the challenges of localization and stability in unmapped environments present a rigorous test for autonomous navigation systems. Evaluating the algorithm’s performance in these environments offers a stringent assessment of its robustness and generalization capabilities. Therefore, we performed a comprehensive comparison of our algorithm with other baseline methods in unmapped environments, as shown in Figure 7. In these experiments, the robots start at the position [0,0], with goals randomly generated and marked by red squares. The 24 sparse data points from the 2D lidar, depicted as blue laser lines, provide critical sensor information. This sensor has a 180° Field Of View (FOV) and a scanning range of 0.12 m to 3.5 m. These additional tests, including the variation in prioritized experience ratios, not only reinforce the algorithm’s versatility across various scenarios but also highlight its capacity to perform effectively in challenging environments where traditional SLAM-based methods might struggle with map inaccuracies.
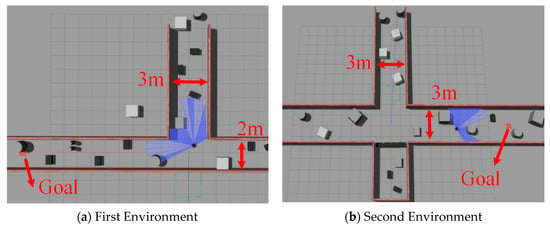
Figure 7.
Unmapped and unknown environment employed for the training of the robot.
For quantitative experiments and to enable comparisons with computationally constrained algorithms, the agent training was conducted on a computer system equipped with an NVIDIA GTX 2060 graphics card, 32 GB of memory, and an AMD R7 CPU. The actor–critic networks utilized an Adam optimizer with respective learning rates of and . The soft update factor is set to , and the regularization coefficient to . The threshold for advancing to the next round was determined by the performance outcomes of the preceding round. The buffer size is , comprising an excellent experience pool and an ordinary experience pool, each of size . The coefficient for the excellent experience pool is denoted by . The batch factor is set at . Training terminates under any of the following four conditions: (1) the agent reaches the goal; (2) collision between the agent and obstacles; (3) cumulative training steps reach 1000; (4) reward for a single training session exceeds −30.
To showcase the proposed algorithm’s superior performance, we conducted comparative experiments with various algorithms, including DDPG, DA-DDPG, PPO [], HYC-DDPG [], GD [], and CROP []. Notably, PPO is recognized by DeepMind as an important benchmark in assessing reinforcement learning algorithm performance. Additionally, three state-of-the-art autonomous navigation algorithms—HYC-DDPG, GD, and CROP—were selected for an in-depth comparative analysis.
4.2. Comparison of Experimental Results
In this study, we initially recorded 2000 sets of prioritized excellent experience data from the environment depicted in Figure 4. Subsequently, we conducted detailed ablation studies to verify the specific contributions of the improved DRL algorithm to performance. The aim of these studies was to analyze how each component of the algorithm affects overall performance, thereby deeply understanding the improved algorithm’s effectiveness.
- (1)
- Results of ablation experiment
To demonstrate the advantages of our improved DRL algorithm in autonomous navigation in unknown environments, experiments were conducted in the complex environment shown in Figure 4. Results in Figure 8 indicate that the improved DARC algorithm significantly outperforms the original DDPG algorithm. Additionally, the prioritized excellent experience strategy notably accelerates the algorithm’s convergence speed. Most notably, the multi-source experience fusion strategy module was observed to be crucial in enhancing the performance of autonomous navigation algorithms, particularly in terms of robustness and adaptability in diverse environments.
- (2)
- Simulation Environment Training
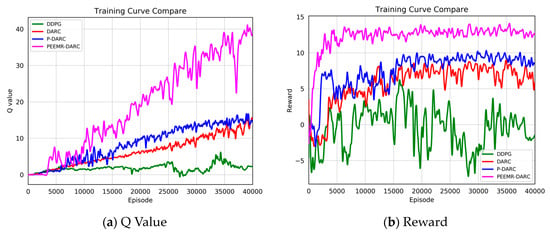
Figure 8.
Ablation study of an enhanced DRL algorithm in unmapped and unknown environments.
Figure 9 and Figure 10 present a comparison of training outcomes in two different unknown environments.
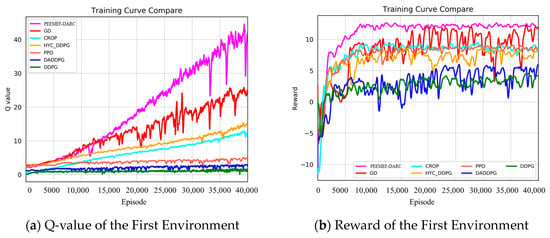
Figure 9.
Q value and reward value in the first environment.
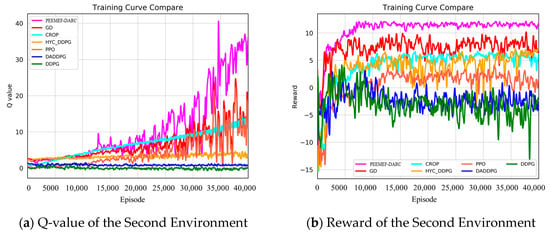
Figure 10.
Q value and reward value in the second environment.
To mitigate the effect of randomness on experimental outcomes, we averaged the Q-values and reward values over n consecutive steps. In a 3 m wide, unmapped, and unknown simulated environment, our algorithm demonstrated faster and more stable increases in Q-values and reward values. Notably, at 15,000 training steps, the Q-value of our algorithm significantly surpassed those of other algorithms. For instance, the Q-values for the GD, CROP, and HYC-DDPG algorithms were approximately 20, 14, and 11, respectively, compared to approximately 5, 3, and 1 for PPO, DA-DDPG, DDPG, and others. Similarly, the trend in reward values paralleled that of the Q-values, stabilizing at around 8000 steps and maintaining a level of about 15, whereas other algorithms’ rewards were around 7, 5, 5, 2, −2, and −3, respectively. In a more complex 2 m wide simulated environment, our algorithm consistently and rapidly attained higher Q-values and reward values. The heightened complexity of this environment increased the difficulty for the agent to navigate, resulting in generally lower Q-values and reward values for all algorithms. As Figure 10 illustrates, our algorithm’s Q-value reached 10 at 24,000 steps and continued to rise throughout subsequent training. The highest Q-value achieved by other algorithms at 40,000 steps was 25, markedly lower than that of our algorithm at the same stage. The reward values trended similarly to the Q-values, stabilizing after 10,000 training steps and remaining around 12 over the long term. These results demonstrate that our algorithm attains higher Q-values and reward values in unknown, complex, narrow environments, significantly shortening training duration and exhibiting superior performance.
- (3)
- Simulation Environment Results
To more comprehensively assess the adaptability of the algorithm, we conducted additional tests in two newly designed simulation environments. Figure 11a,b illustrates the configurations of these new test environments. These environments were specifically designed with varying obstacle positions to further challenge the algorithm’s ability to handle diverse scenarios. Through testing these environments, our aim is to evaluate the robustness and adaptability of the algorithm when faced with varying environmental conditions. These additional tests are intended to provide a more thorough evaluation of the algorithm’s performance in complex and unfamiliar settings.
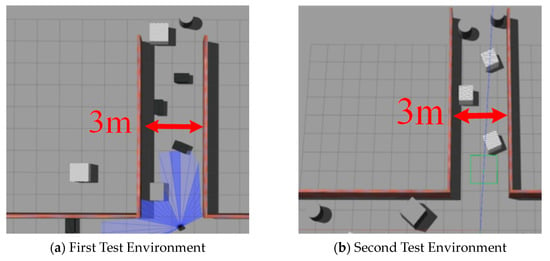
Figure 11.
The unmapped environment used for robot testing.
Upon completion of the initial training in two environments, we conducted 1000 random task tests to evaluate the trained models’ performance. To further validate the robustness and adaptability of the proposed algorithm, two additional testing environments were introduced, as shown in Figure 12c,d. These additional environments were designed to assess the algorithm’s generalization capability beyond the training scenarios. The results indicate that the success rates in the newly added environments were consistent with the trends observed in the initial training environments, demonstrating the effectiveness of the improved DRL algorithm in navigating unmapped and unknown environments. Moreover, this extended testing confirms that the proposed method maintains a higher success rate compared to other algorithms across different environments.
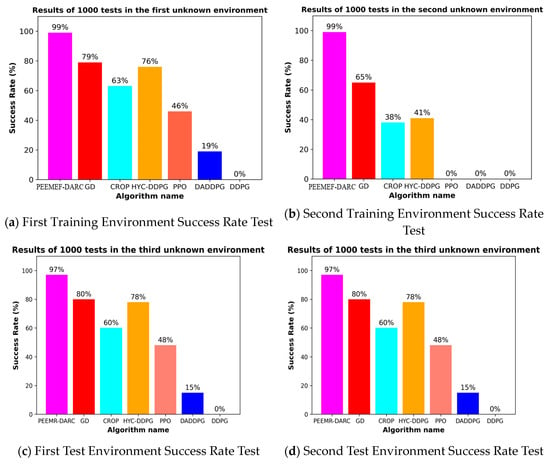
Figure 12.
Success rate of 1000 tests in unmapped and unknown environments.
The experimental results are summarized in Table 1. Across all four unmapped and unknown environments, the proposed PEEMEF-DARC algorithm consistently achieves the shortest average path length among the compared algorithms, particularly in Environment-1 and Environment-2. Even in the newly introduced Environment-3 and Environment-4, where the complexity was increased, our algorithm continued to demonstrate its efficiency by producing shorter average paths. This outcome indicates that the PEEMEF-DARC algorithm, while maintaining high success rates, also excels in real-time decision-making, effectively minimizing the total distance traveled by the robot from the start to the destination. The algorithm’s ability to generate efficient paths in real time underscores its robustness and adaptability across varying environmental conditions, making it a highly effective solution for autonomous navigation in complex settings.
- (4)
- Real–World Environment Results

Table 1.
Average length (m) of 1000 tests in four unmapped and unknown environments.
To further verify its applicability and effectiveness, the model was implemented in an actual robot for real-world testing. Tests were conducted in the laboratory and corridors of Block R at the Shenyang Institute of Automation, Chinese Academy of Sciences, featuring two randomly created unmapped and unknown environments, as shown in Figure 13. In these real-world experiments, the agent’s position was estimated using the AMCL algorithm. Figure 14 and Figure 15 display the robot’s trajectory in the actual environment. In these real-world experiments, the robot’s position was estimated using the Adaptive Monte Carlo Localization (AMCL) algorithm. However, it was observed that in Environment 2, the AMCL algorithm struggled with accurate positioning due to the long, narrow corridor, leading to occasional trajectory intersections with obstacles. Despite these challenges, our proposed PEEMEF-DARC algorithm demonstrated robust performance, effectively addressing the positioning inaccuracies and maintaining a high success rate.

Figure 13.
Unknown and complex experimental environments in real world.
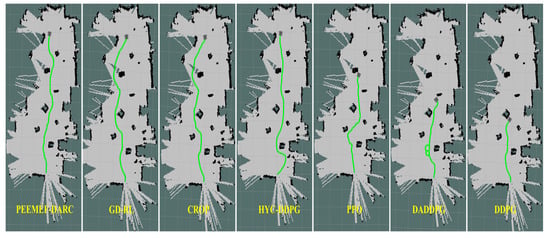
Figure 14.
Comparison of trajectories in the first environment.
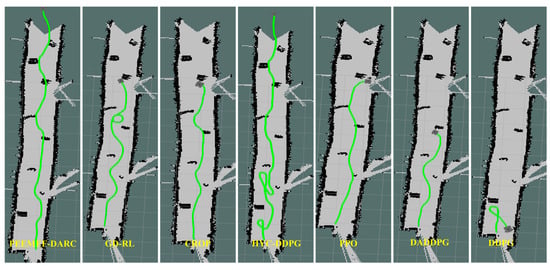
Figure 15.
Comparison of trajectories in the second environment.
To thoroughly evaluate our algorithm’s performance in autonomous navigation within unmapped and unknown environments, we executed 10 sets of repetitive tests. These tests specifically examined the agent’s navigation capability under challenging conditions, including the absence of prior map knowledge, incomplete map information, or inaccurate positioning. The experimental results, as depicted in Figure 16, demonstrate that our algorithm can make effective decisions under these challenging conditions, even while relying on low-precision sensors. This capability enables the agent to operate in a broader range of environments, transcending the limitations of known maps and precise positioning systems. Notably, our algorithm excelled in all test tasks, in contrast to comparative algorithms that failed to successfully complete them. This outcome underscores our algorithm’s substantial advantages in navigating unknown complex environments. These experiments show the efficiency, adaptability, and robustness of our algorithm, particularly in unmapped and unknown environments.
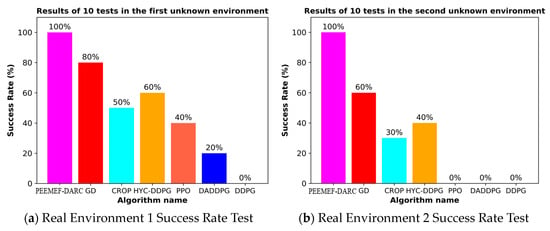
Figure 16.
Success rate of 10 tests in two environments.
Our experimental results are presented in Table 2. Under the condition of maintaining high success rates, the proposed algorithm achieves the shortest average path length in both real-world environments. This demonstrates that our algorithm not only guarantees high success rates but also significantly enhances path planning efficiency, effectively minimizing the total distance traveled by the robot from the start to the destination.
Table 2.
Average length (m) of 10 tests in two unmapped and unknown environments.
5. Conclusions
This study successfully developed an autonomous navigation and obstacle avoidance algorithm for mobile robots tailored for unmapped and unknown environments. Our enhanced DRL algorithm significantly improves exploration capacity, strategy learning speed, and overall learning efficiency in mobile robots compared to other algorithms. The implementation of regularization effectively addresses the overestimation problem often encountered in action-value predictions across varying states. Furthermore, the priority excellent experience collection and the multi-source experience fusion strategy developed in this study, significantly shorten the learning duration, allowing the agent to rapidly acquire effective strategies. Experimental results indicate that incorporating these strategic modules can reduce training time by approximately 60%. Our algorithm consistently shows superior performance in unmapped and unknown environments, particularly in scenarios such as narrow corridors approximately 2 m wide, compared to other DRL algorithms tested. In the future, we aim to apply our algorithm to indoor unmanned inspections, enhancing the autonomous decision-making capabilities of robots. Concurrently, we plan to further optimize the architecture to enable robots to predict the behavior of dynamic obstacles using multi-sensor fusion algorithms.
Author Contributions
Conceptualization, N.H., C.B. and Z.Y.; methodology, N.H.; software, X.F.; validation, N.H., Y.S. and X.F.; formal analysis, J.W.; investigation, Y.S.; resources, N.H.; data curation, N.H.; writing—original draft preparation, N.H.; writing—review and editing, N.H.; visualization, N.H.; supervision, Y.S.; project administration, W.Q.; funding acquisition, X.F. All authors have read and agreed to the published version of the manuscript.
Funding
Part of this research was funded by the Ministry of Science and Technology of China through Key Research and Development Project (Large Coal Mine Underground Roadway Auxiliary Demonstration of key technology and application of operation robot) under Grant (Number: 2022YFB4703600).
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
https://github.com/nfhe/darc_drl_nav (accessed on 29 August 2024).
Acknowledgments
Thanks to the Shenyang Institute of Automation and the Chinese Academy of Sciences for providing the experimental site and platform.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ismail, K.; Liu, R.; Athukorala, A.; Ng BK, K.; Yuen, C.; Tan, U.X. WiFi Similarity-Based Odometry. IEEE Trans. Autom. Sci. Eng. 2023, 21, 3092–3102. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, H.; Li, Y.; Nakamura, Y.; Zhang, L. Flowfusion: Dynamic dense rgb-d slam based on optical flow. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; IEEE: New York, NY, USA, 2020; pp. 7322–7328. [Google Scholar]
- Engel, J.; Koltun, V.; Cremers, D. Direct sparse odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 611–625. [Google Scholar] [CrossRef] [PubMed]
- Li, R.; Wang, S.; Gu, D. DeepSLAM: A Robust Monocular SLAM System With Unsupervised Deep Learning. IEEE Trans. Ind. Electron. 2021, 68, 3577–3587. [Google Scholar] [CrossRef]
- Lample, G.; Chaplot, D.S. Playing FPS games with deep reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science 2018, 362, 1140–1144. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Monroe, W.; Ritter, A.; Galley, M.; Gao, J.; Jurafsky, D. Deep reinforcement learning for dialogue generation. arXiv 2016, arXiv:1606.01541. [Google Scholar]
- Ismail, J.; Ahmed, A. Improving a sequence-to-sequence nlp model using a reinforcement learning policy algorithm. arXiv 2022, arXiv:2212.14117. [Google Scholar]
- Lyu, J.; Ma, X.; Yan, J.; Li, X. Efficient continuous control with double actors and regularized critics. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 7655–7663. [Google Scholar]
- Tani, J. Model-based learning for mobile robot navigation from the dynamical systems perspective. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 1996, 26, 421–436. [Google Scholar] [CrossRef] [PubMed]
- Zhu, A.; Yang, S.X. Neurofuzzy-based approach to mobile robot navigation in unknown environments. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2007, 37, 610–621. [Google Scholar] [CrossRef]
- Liu, B.; Xiao, X.; Stone, P. A lifelong learning approach to mobile robot navigation. IEEE Robot. Autom. Lett. 2021, 6, 1090–1096. [Google Scholar] [CrossRef]
- Liu, Z.; Zhai, Y.; Li, J.; Wang, G.; Miao, Y.; Wang, H. Graph Relational Reinforcement Learning for Mobile Robot Navigation in Large-Scale Crowded Environments. IEEE Trans. Intell. Transp. Syst. 2023, 24, 8776–8787. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Hess, W.; Kohler, D.; Rapp, H.; Andor, D. Real-time loop closure in 2D LIDAR SLAM. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; IEEE: New York, NY, USA, 2016; pp. 1271–1278. [Google Scholar]
- Shan, T.; Englot, B. Lego-loam: Lightweight and ground-optimized lidar odometry and mapping on variable terrain. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; IEEE: New York, NY, USA, 2018; pp. 4758–4765. [Google Scholar]
- Kim, G.; Kim, A. LT-mapper: A modular framework for lidar-based lifelong mapping. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; IEEE: New York, NY, USA, 2022; pp. 7995–8002. [Google Scholar]
- Wang, J.; Rünz, M.; Agapito, L. DSP-SLAM: Object oriented SLAM with deep shape priors. In Proceedings of the 2021 International Conference on 3D Vision (3DV), London, UK, 1–3 December 2021; IEEE: New York, NY, USA, 2021; pp. 1362–1371. [Google Scholar]
- Yue, J.; Wen, W.; Han, J.; Hsu, L.T. LiDAR data enrichment using deep learning based on high-resolution image: An approach to achieve high-performance LiDAR SLAM using Low-cost LiDAR. arXiv 2020, arXiv:2008.03694. [Google Scholar]
- Taketomi, T.; Uchiyama, H.; Ikeda, S. Visual SLAM algorithms: A survey from 2010 to 2016. IPSJ Trans. Comput. Vis. Appl. 2017, 9, 1–11. [Google Scholar] [CrossRef]
- Henein, M.; Zhang, J.; Mahony, R.; Ila, V. Dynamic SLAM: The need for speed. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; IEEE: New York, NY, USA, 2020; pp. 2123–2129. [Google Scholar]
- Helmberger, M.; Morin, K.; Berner, B.; Kumar, N.; Cioffi, G.; Scaramuzza, D. The hilti slam challenge dataset. IEEE Robot. Autom. Lett. 2022, 7, 7518–7525. [Google Scholar] [CrossRef]
- Bektaş, K.; Bozma, H.I. Apf-rl: Safe mapless navigation in unknown environments. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; IEEE: New York, NY, USA, 2022; pp. 7299–7305. [Google Scholar]
- Surmann, H.; Jestel, C.; Marchel, R.; Musberg, F.; Elhadj, H.; Ardani, M. Deep reinforcement learning for real autonomous mobile robot navigation in indoor environments. arXiv 2020, arXiv:2005.13857. [Google Scholar]
- Cimurs, R.; Suh, I.H.; Lee, J.H. Goal-driven autonomous exploration through deep reinforcement learning. IEEE Robot. Autom. Lett. 2021, 7, 730–737. [Google Scholar] [CrossRef]
- Marchesini, E.; Farinelli, A. Enhancing deep reinforcement learning approaches for multi-robot navigation via single-robot evolutionary policy search. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 5525–5531. [Google Scholar]
- Lodel, M.; Brito, B.; Serra-Gómez, A.; Ferranti, L.; Babuška, R.; Alonso-Mora, J. Where to look next: Learning viewpoint recommendations for informative trajectory planning. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; IEEE: New York, NY, USA, 2022; pp. 4466–4472. [Google Scholar]
- Lee, K.; Kim, S.; Choi, J. Adaptive and Explainable Deployment of Navigation Skills via Hierarchical Deep Reinforcement Learning. arXiv 2023, arXiv:2305.19746. [Google Scholar]
- Dawood, M.; Dengler, N.; de Heuvel, J.; Bennewitz, M. Handling Sparse Rewards in Reinforcement Learning Using Model Predictive Control. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; IEEE: New York, NY, USA, 2023; pp. 879–885. [Google Scholar]
- Cui, Y.; Lin, L.; Huang, X.; Zhang, D.; Wang, Y.; Jing, W.; Chen, J.; Xiong, R.; Wang, Y. Learning Observation-Based Certifiable Safe Policy for Decentralized Multi-Robot Navigation. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; IEEE: New York, NY, USA, 2022; pp. 5518–5524. [Google Scholar]
- Shen, Y.; Li, W.; Lin, M.C. Inverse reinforcement learning with hybrid-weight trust-region optimization and curriculum learning for autonomous maneuvering. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; IEEE: New York, NY, USA, 2022; pp. 7421–7428. [Google Scholar]
- Xiong, Z.; Eappen, J.; Qureshi, A.H.; Jagannathan, S. Model-free neural lyapunov control for safe robot navigation. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; IEEE: New York, NY, USA, 2022; pp. 5572–5579. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Marchesini, E.; Farinelli, A. Discrete deep reinforcement learning for mapless navigation. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; IEEE: New York, NY, USA, 2020; pp. 10688–10694. [Google Scholar]
- Niu, H.; Ji, Z.; Arvin, F.; Lennox, B.; Yin, H.; Carrasco, J. Accelerated sim-to-real deep reinforcement learning: Learning collision avoidance from human player. In Proceedings of the 2021 IEEE/SICE International Symposium on System Integration (SII), Iwaki, Fukushima, Japan, 11–14 January 2021; IEEE: New York, NY, USA, 2021; pp. 144–149. [Google Scholar]
- Marzari, L.; Marchesini, E.; Farinelli, A. Online Safety Property Collection and Refinement for Safe Deep Reinforcement Learning in Mapless Navigation. arXiv 2023, arXiv:2302.06695. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).