Abstract
Indoor fires may cause casualties and property damage, so it is important to develop a system that predicts fires in advance. There have been studies to predict potential fires using sensor values, and they mostly exploited machine learning models or recurrent neural networks. In this paper, we propose a stack of Transformer encoders for fire prediction using multiple sensors. Our model takes the time-series values collected from the sensors as input, and predicts the potential fire based on the sequential patterns underlying the time-series data. We compared our model with traditional machine learning models and recurrent neural networks on two datasets. For a simple dataset, we found that the machine learning models are better than ours, whereas our model gave better performance for a complex dataset. This implies that our model has a greater potential for real-world applications that probably have complex patterns and scenarios.
1. Introduction
There is an average of 358,300 home-based fires every year in the U.S. according to the Center for Disease Control, the U.S. Fire Administration, and the National Fire Protection Association (NFPA). Indoor fires cause many casualties and property damage, so it is important to prevent fire accidents in advance. Previous studies of the indoor fire prediction task can be divided into two groups: sensor-based and vision-based. The vision-based studies exploit video clips or image samples to detect fires or any clues of fire, whereas the sensor-based studies utilize time-series values collected from multiple sensors (e.g., CO2, humidity, and temperature). The images and video clips are usually much larger than the sensor values, so the sensor-based approach is preferable if it is given a limited computational resource or Internet bandwidth.
There have been sensor-based studies for indoor fire forecasting using machine learning (ML) models. The ML models require intensive feature engineering, so deep learning (DL) models have become more preferable. In particular, recurrent neural networks (RNNs) using long short-term memory (LSTM) [] or Gated Recurrent Unit (GRU) [] cells allow to effectively comprehend long-term dependencies within time-series values of multiple sensors.
Since Transformer [] has appeared, many Transformer-based language models have shown impressive power in learning linguistic patterns within documents. In particular, the Transformer encoder-based models (e.g., Bidirectional Encoder Representations from Transformer (BERT) []) are used not only for language comprehension tasks but also for other domains such as object detection in images [] and classification using time-series sensor data []. The multi-head self-attention mechanism of the Transformer allows it to better grasp the sequential patterns within the time-series data and contributes to performance improvement in down-stream tasks.
In this paper, we propose a new way of fire prediction using multiple sensors. The task is defined as the prediction of potential fires in advance given a certain amount of collected sensor data. To tackle the task, we design a stack of Transformer encoders where the Transformer architecture is known to be effective in analyzing sequence data. Our first contribution is that, as far as we know, this is the first study that employs the Transformer encoders to the fire prediction task. Our model takes the time-series values obtained from the sensors as input, and predicts fire accidents in advance. Our second contribution is that, by empirical results with two publicly available datasets, we demonstrate that our model has a strong potential in a complex fire prediction task.
2. Related Work
There are lots of studies that have utilized images or video clips for fire prediction. Such a vision-based approach takes the benefit from sufficient information beneath the images, but these studies have a common practical issue that they require a high-resolution camera and a sufficient amount of computational power. That is, big images are required to obtain better detection performance, and it takes a long time or requires expensive machines to train or run machine learning (ML) models with the big images. Therefore, using many cheaper sensors is a reasonable alternative way.
There are studies that have exploited multiple sensors for fire prediction, and they mostly employed the machine learning (ML) or data-driven models. In [], a data-fusion based on Dempster–Shafer theory was used to aggregate smoke, temperature, and light sensor values, and achieved 98% of accuracy. Chen et al. [] proposed a fast and cost-effective indoor fire alarm system using support vector machines (SVMs) []. They employed carbon monoxide, smoke, temperature and humidity sensor values, and accomplished 99.8% of F1 scores. Jana and Shome [] proposed an ensemble of ML models such as logistic regression, SVM, decision tree, and Naive Bayes, and obtained 97.52% precision. Dampage et al. [] utilized ML models to detect forest fires at initial stage using a wireless sensor network.
Even though the ML models exhibited quite successful performance on the fire prediction task, deep learning (DL) models have become more preferable for their superior robustness and performance without a heavy manual feature engineering. In [], given CO2, smoke, and temperature sensor values, they obtained 99.4% accuracy using a back-propagation neural network (BPNN). Nakip et al. [] proposed a recurrent trend predictive neural network (rTPNN) for multi-sensor fire detection, where the sensors include temperature, smoke, carbon monoxide, carbon dioxide, and oxygen sensors. Li et al. [] utilized a temporal convolutional network (TCN) to extract features, and generated prediction results using the SVM classifier. Jesubalan et al. [] designed a learning-based mechanism for forest fire prediction using deep learning models. Liu et al. [] adopted long short-term memory (LSTM) [] to analyze sequences of temperature, smoke, carbon dioxide, and carbon monoxide, and achieved 97% F1 score.
Since Transformer [] of the natural language processing (NLP) field has appeared, many of its variants including ChatGPT (https://chat.openai.com) have achieved state-of-the-art (SOTA) performance in various fields with different data types such as images, speeches, texts, and sensors. There are a few studies that have applied the self-attention mechanism of Transformer to fire prediction, but they have focused only on the image or video data. For example, FireFormer is a Transformer-based architecture dedicated to forest fire detection using surveillance cameras []. In Ref. [], a Transformer-based model for the detection of fire in videos was proposed, and showed that their model outperformed previous convolutional neural network (CNN) models.
In this paper, we propose a new model that is essentially a stack of Transformer encoders for fire prediction. It takes sequences of multiple sensor values, and predicts potential fire accidents. The ‘multi-head self-attention’ mechanism of Transformer captures various relations of all possible pairs in the sequence of sensor values, and the ‘multi-layer’ architecture allows it to comprehend high-level semantics and syntactic patterns. This enables it to better learn complex sequential patterns of the given sequences, contributing to performance improvements. As far as we know, this is the first study that proposes a Transformer-based architecture for fire prediction using multiple sensor values.
3. Method
3.1. Problem
The task of this paper is to predict fires in advance. Given a certain amount of collected data of multiple sensors, we predict whether the fire will break out in several minutes. Suppose we have a database (DB) system that collects time-series values from S sensors, where the sensor values are sampled using a particular sampling rate R (e.g., every 2 s). The collected dataset , where is the total number of instances (i.e., the total number of steps) within the dataset.
Figure 1 describes the input and output of the model M. Given the current step , the model takes the instances of window size as input (i.e., ). That is, the input matrix consists of [;;;] where indicates the S-dimensional feature vector at the step . The feature vector does not contain temporal information or any time-related feature values (e.g., timestamps). The model generates a prediction label (e.g., ‘fire’, ‘normal’) of the step which is steps ahead of the current step , where the is the output window size. The prediction label indicates whether the fire breaks out after steps from the current step . The model fails when its prediction is different from the actual label . More formally, the output (i.e., prediction label) generated from classifier f can be represented as Equation (1), where the input matrix :
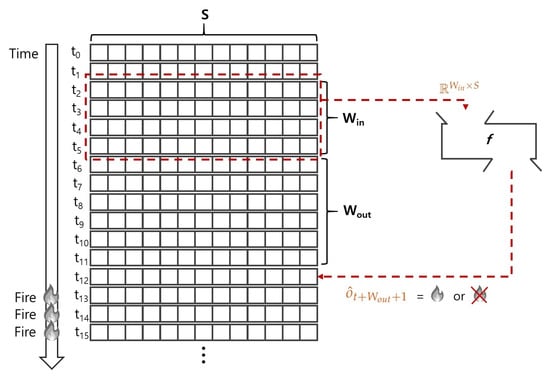
Figure 1.
Overview of the method, where the current step is , the input window size , and the output window size .
3.2. Solution
Transformer [] was originally designed for machine translation between languages. It has an encoder–decoder architecture, where the encoder converts a given input sequence into real-number vectors of distributed representation, and the decoder generates an output sequence based on the results of the encoder. The Transformer decoder was employed in the Generative Pre-trained Transformer (GPT) series [,,], where their most well-known product is ChatGPT. On the other hand, the Transformer encoder was adopted in Bidirectional Encoder Representations from Transformer (BERT) [] and its many variants. The encoder is designed to learn embeddings for various predictive tasks, so we take the Transformer encoder to address the task of fire prediction.
Figure 2 depicts the structure of our encoder-based model. The model takes a sequence of S-dimensional vectors as an input, and the S-dimensional vectors are firstly mapped to another h-dimensional representation space through the linear layer. Note that is the input matrix in the Equation (1), where the is the input window size; please refer to Figure 1 for an example of window size. The positional encoding (PE) of the Transformer is applied to the vectors, and they are passed to the stack of encoders. If we regard the PE as a function, then it takes a position index as an input and generates a real-number vector that represents the positional information. The generated real-number vector (i.e., position vector) usually takes the same shape of the input embedding vectors; in this paper, the position vector will be the h-dimensional vector so that it can be combined with the h-dimensional embedding vector generated by the linear layer through arbitrary function (e.g., element-wise addition). The PE allows it to consider the positional information of the sensor values so that it grasps the sequential patterns of the sequence. The Transformer encoder has a ‘multi-head self-attention’ mechanism, where the self-attention analyzes pair-wise relations between any pairs of a given sequence, and the multi-head enables it to analyze various types of relations. Suppose the encoder takes h-dimensional vector as an input, then the encoder generates the h-dimensional vector as an output. This allows a stacked encoder architecture. The number of encoder layers L depends on the task complexity. The left-most representation generated from the last encoder layer is finally delivered to the output layer for the prediction. The output layer dimension depends on the number of classes. The output layer can be followed by a Softmax function for multi-class classification. The model structure is basically similar to the original Transformer encoder. The major difference is that our model takes the real-number feature vectors, so it does not have any embedding layer (i.e., look-up table) and just linearly converts the vectors into h-dimensional vectors. That is, the embedding layer of original Transformer takes tokens (i.e., categorical values) as input, whereas our model takes sensor values (i.e., numerical values) as input, and the linear layer projects the sensor values into the h-dimensional space. Another difference is that our model is designed for the classification task, so it has the output layer on top of the encoder stack.
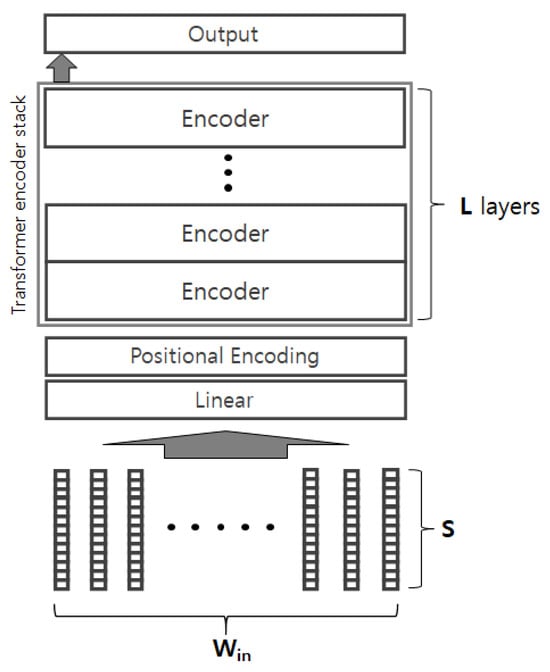
Figure 2.
Model structure.
One may ask why do we need to choose the Transformer encoder for the fire prediction using the time-series data (i.e., sequences of multiple sensor values). Instead of the Transformer, there are some alternatives for the sequence analysis; for example, long short-term memory (LSTM) [] and Gated Recurrent Unit (GRU) [] are known to be effective in analyzing sequential patterns, so they probably have a strong potential in the fire prediction task. Although these alternatives have shown quite successful performance on tasks of sequential data, the Transformer exhibited better performance in recent studies [,,,]. The reason is the multi-head self-attention mechanism of the Transformer, which enables to better comprehend contextual information in the input sequence and to model long-term dependencies. Some studies report that the RNN models (e.g., LSTM and GRU) outperform the Transformer []. However, we found that there are no studies that have exploited Transformer for the fire forecasting task, so we conduct experiments to compare the Transformer with other models, including RNNs.
4. Experiment
4.1. Dataset
Two datasets are used for experiments in this paper. The first dataset is obtained from NIST report of test FR 4016 (https://www.nist.gov/el/nist-report-test-fr-4016, accessed on 4 April 2024), where it provides 96∼130 feature values (i.e., ) collected in a manufactured house and a two-story house. The features correspond to various sensors of temperature, CO, CO2, O2, smoke, etc. The ‘NIST’ dataset contains several files, each of which has feature values collected from a distinct room. We utilized only 96 features that commonly appeared in all files. We observed that five files (e.g., sdc01, sdc03, sdc04, sdc05, and sdc06) have different sampling rates (e.g., 5 s), so we discarded them. The number of remaining files is 22, and their sampling rate is 2 s. The ‘TIME’ column of the dataset indicates the relative time based on the time of fire; for example, ‘TIME = −3’ means the corresponding instance is obtained 3 s before the fire, whereas ‘TIME = 5’ represents that the instance is obtained 5 s after the fire. We generated the ‘label’ column, and set to ‘normal’ for instances if TIME , whereas ‘fire’ when TIME ; the task of the NIST dataset is binary classification. Please refer to the official web page for more details.
The second dataset, denoted as the ‘Pascal’ dataset in this paper, is collected in a standard EN 54 test room []. It contains a single file that has 16 columns, where the ‘ternary label’ ∈ {background(normal), nuisance, fire} is used as a label; the task of the Pascal dataset is ternary classification. The ‘nuisance’ indicates the activation of the fire alarm, caused by mechanical failure, malfunction, improper installation, lack of proper maintenance, or any other reason. It has 11 features (i.e., ) of several different sensors, including CO, CO2, H2, humidity, temperature, etc. We found that the sampling rate is 1.11200 s in average. Please refer to the official web page (https://data.mendeley.com/datasets/npk2zcm85h/1, accessed on 4 April 2024) of the dataset for more details.
For experiments, we defined the input as S-dimensional feature vectors for 60 s. The sampling rates of NIST and Pascal datasets are 2 s and nearly 1 s, respectively, so the is 30 and 60 for the NIST and Pascal datasets, respectively. The output is defined as a label after 300 s, so is 150 and 300 for the NIST and Pascal datasets, respectively. This setting is based on the report that the first 5 min is important to prevent severe fire damage []; it will be greatly helpful if we can secure another 5 min. From the two original datasets, we randomly extracted samples, and those are denoted as and , where . The input matrix of i-th sample . The i-th output {fire, normal} for the , whereas {fire, nuisance, normal} for the . Table 1 summarizes the statistics of the sampled datasets. The models learn from the training samples, and make a prediction for each test sample. For all experiments, we took 10% of the training set as a validation set for a grid searching.

Table 1.
Dataset statistics.
4.2. Result
We compared our model with other machine learning (ML) models such as support vector machine (SVM) [] and random forest (RF) []. For these models, we flattened the matrix into K-dimensional vector where . By the grid searching, we found no performance variation with different hyper-parameter settings of the SVM, so we followed the default setting (e.g., 1.0 for the regularization parameter C, RBF kernel with a scaled coefficient, and 1 × 10−3 tolerance for the stopping criterion). On the other hand, the RM gave the best performance when the number of estimators was 200, and the other remaining hyper-parameters followed the default setting (e.g., gini criterion, unlimited depth, and minimum samples of a leaf is 1). We also conducted experiments with multi-layered GRU, where the dimension of the hidden layer was 128. We used ‘Scikit-learn’ and ‘PyTorch’ packages to implement machine learning models and deep learning models, respectively.
Table 2 describes the performance of the models on , where the metric is the overall accuracy, false positive rate (FPR), true positive rate (TPR), and TPR-FPR. All results are averages of three independent runs. For our model, the Transformer encoder stack, we varied the number of encoder layers from 1 to 8. The dimension of hidden representation is 32, the embedding dimension is 128, and the number of heads is 4. The results in Table 2 demonstrate that our models generally outperform the ML models and the GRU. This is consistent with previous studies that have shown performance improvement by Transformers; the multi-head self-attention mechanism of Transformer allowed to better comprehend the sequential patterns underlying the time-series sensor values. In other words, the multi-head self-attention mechanism extracts pair-wise relations from the sequences, and the multi-layered encoder grasps high-level relations or semantics, contributing to the performance improvement. Our model gave the best results when the number of layers was four. For fair comparison, we made the GRU have the same number of layers. We employed the cross-entropy loss for training GRU and Transformer encoder stacks. Equation (2) represents the cross-entropy loss, where and indicate a predicted distribution and one-hot correct vector (i.e., gold vector), respectively. The number of epochs is 15 for 4-layered GRU, and 40∼55 for Transformer encoder stacks. We employed the Adam optimizer [] with an initial learning rate 0.0001, and early-stop strategy with five patience steps. The size of mini batches was 32. The four-layered GRU has 384 K trainable parameters, while the Transformer encoder stack of four layers has 312 K trainable parameters:
Table 2.
Experimental results with , where FPR and TPR represent the false positive rate and true positive rate of the ‘fire’ class, respectively.
Table 3 summarizes the experimental results on . In this table, the RF gives the best performance, and the two-layered GRU shows a comparable performance to the Transformer encoder stacks. The reason for this result is the complexity of the dataset. That is, the feature dimensions of and are 96 and 11, respectively, meaning that the has more complex sequential patterns. Such a complexity gap between the datasets caused the performance gap; the overall performance on is much lower than that of . The Transformer encoder stack gave its best performance when the number of layers was two, which implies that the two-layered structure was enough to analyze the sequential patterns of . In other words, the complexity of is relatively low, so the shallow structure (i.e., two-layered) was enough to analyze such simple sequential patterns of the dataset. To summarize, for a simple and easy task, the ML models may outperform the deep learning (DL) models, including Transformers. On the other hand, the Transformer-based model has a strong potential for the dataset of high complexity.
Table 3.
Experimental results with , where FPR and TPR represent the false positive rate and true positive rate of the ‘fire’ class, respectively.
We also examined the inference time of the proposed model because it would not be applicable to real-world applications if it takes too long to predict potential fires. We found that the eight-layered Transformer encoder took 0.54 s for 503 data instances, meaning that it will work for predicting fires in five minutes.
5. Conclusions
We introduced a new way that exploits the Transformer encoders to address the fire prediction task using time-series values collected from multiple sensors. By empirical results, we showed that the traditional machine learning models are better than deep learning models if the given dataset is simple. Our model exhibited better performance for the complex dataset (i.e., NIST dataset), which indicates that it has a greater potential for real-world applications that probably have complex patterns and scenarios. Nevertheless, there is big room for performance improvement, especially in the NIST dataset. We believe that our work contributes to not only fire prediction but also other various prediction tasks, such as risk prediction for patients or health-care services. We also believe that this work may contribute to developing fire surveillance system using autonomous vehicles or drones. We are working on collecting more data from sensors, and the dataset will be manually annotated for the fire prediction task. We will also develop pre-trained Transformer-based models with a large dataset, and investigate the combination of Transformer and other models for more performance improvement.
Author Contributions
Conceptualization, Y.-S.J., Y.K., and J.-I.K.; methodology, Y.-S.J., J.H. and S.L.; software, Y.-S.J.; validation, Y.-S.J., J.H., and S.L.; formal analysis, Y.-S.J.; investigation, J.-I.K.; resources, J.-I.K.; data curation, Y.K.; writing—original draft preparation, Y.-S.J.; writing—review and editing, Y.-S.J., J.H. and S.L.; visualization, G.E.N.; supervision, Y.K.; project administration, Y.K. and J.-I.K.; funding acquisition, Y.-S.J. and J.-I.K. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (No. NRF-2023R1A2C1003355). This research was supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (No. 2020R1A6A1A12047945).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All datasets are publicly available on Web through links provided in Section 4.1 (accessed on 4 April 2024).
Conflicts of Interest
Author Youngjin Kim was employed by the company Frugal Solution. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Correction Statement
This article has been republished with a minor correction to the Data Availability Statement. This change does not affect the scientific content of the article.
References
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. In Proceedings of the NIPS 2014 Deep Learning and Representation Learning Workshop, Montreal, QC, Canada, 12–13 December 2014; pp. 1–9. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Li, Y.; Miao, N.; Ma, L.; Shuang, F.; Huang, X. Transformer for object detection: Review and benchmark. Eng. Appl. Artif. Intell. 2023, 126, 107021. [Google Scholar] [CrossRef]
- Luptáková, I.D.; Kubovčík, M.; Pospíchal, J. Wearable Sensor-Based Human Activity Recognition with Transformer Model. Sensors 2022, 22, 1911. [Google Scholar] [CrossRef] [PubMed]
- Ting, Y.Y.; Hsiao, C.W.; Wang, H.S. A Data Fusion-Based Fire Detection System. IEICE Trans. Inf. Syst. 2018, E101-D, 977–984. [Google Scholar]
- Chen, S.; Ren, J.; Yan, Y.; Sun, M.; Hu, F.; Zhao, H. Multi-sourced sensing and support vector machine classification for effective detection of fire hazard in early stage. Comput. Electr. Eng. 2022, 101, 108046. [Google Scholar] [CrossRef]
- Burges, C.J.C. A Tutorial on Support Vector Machines for Pattern Recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Jana, S.; Shome, S.K. Hybrid Ensemble Based Machine Learning for Smart Building Fire Detection Using Multi Modal Sensor Data. Fire Technol. 2023, 59, 473–496. [Google Scholar] [CrossRef]
- Dampage, U.; Bandaranayake, L.; Wanasinghe, R.; Kottahachchi, K.; Jayasanka, B. Forest fire detection system using wireless sensor networks and machine learning. Sci. Rep. 2022, 12, 46. [Google Scholar] [CrossRef] [PubMed]
- Wu, L.; Chen, L.; Hao, X. Multi-Sensor Data Fusion Algorithm for Indoor Fire Early Warning Based on BP Neural Network. Information 2021, 12, 59. [Google Scholar] [CrossRef]
- Nakip, M.; Güzelíş, C.; Yildiz, O. Recurrent Trend Predictive Neural Network for Multi-Sensor Fire Detection. IEEE Access 2021, 9, 84204–84216. [Google Scholar] [CrossRef]
- Li, Y.; Su, Y.; Zeng, X.; Wang, J. Research on Multi-Sensor Fusion Indoor Fire Perception Algorithm Based on Improved TCN. Sensors 2022, 22, 4550. [Google Scholar] [CrossRef]
- Jesubalan, A.; Nallasamy, S.; Anbukaruppusamy, S.; Upreti, K.; Dubey, A.K. Forest fire prediction using IoT and deep learning. Int. J. Adv. Technol. Eng. Explor. 2022, 9, 246–256. [Google Scholar]
- Liu, P.; Xiang, P.; Lu, D. A new multi-sensor fire detection method based on LSTM networks with environmental information fusion. Neural Comput. Appl. 2023, 35, 25275–25289. [Google Scholar] [CrossRef]
- Qiao, Y.; Jiang, W.; Wang, F.; Su, G.; Li, X.; Jiang, J. FireFormer: An efficient Transformer to identify forest fire from surveillance cameras. Int. J. Wildland Fire 2023, 32, 1364–1380. [Google Scholar] [CrossRef]
- Mardani, K.; Vretos, N.; Daras, P. Transformer-Based Fire Detection in Videos. Sensors 2023, 23, 3035. [Google Scholar] [CrossRef] [PubMed]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. Preprint. 2018. Available online: https://paperswithcode.com/paper/improving-language-understanding-by (accessed on 11 February 2024).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Unsupervised Multitask Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Pettersson, J.; Falkman, P. Comparison of LSTM, Transformers, and MLP-mixer neural networks for gaze based human intention prediction. Front. Neurorobot. 2023, 17, 1157957. [Google Scholar] [CrossRef] [PubMed]
- Dandwate, P.; Shahane, C.; Jagtap, V.; Karande, S.C. Comparative study of Transformer and LSTM Network with attention mechanism on Image Captioning. In Proceedings of the International Conference on Information and Communication Technology for Intelligent Systems, Ahmedabad, India, 27–28 April 2023; pp. 527–539. [Google Scholar]
- Kusumawardani, S.S.; Alfarozi, S.A.I. Transformer Encoder Model for Sequential Prediction of Student Performance Based on Their Log Activities. IEEE Access 2023, 11, 18960–18971. [Google Scholar] [CrossRef]
- Wass, D. Transformer Learning for Traffic Prediction in Mobile Networks. Master’s Thesis, KTH Royal Institute of Technology, Stockholm, Sweden, 2021. [Google Scholar]
- Bilokon, P.; Qiu, Y. Transformers versus LSTMs for electronic trading. arXiv 2023, arXiv:2309.11400. [Google Scholar] [CrossRef]
- Pascal, V. Indoor Fire Dataset with Distributed Multi-Sensor Nodes. Mendeley Data 2023. V1. Available online: https://data.mendeley.com/datasets/npk2zcm85h/1 (accessed on 11 February 2024).
- Jang, K.; Cho, S.B.; Cho, Y.S.; Son, S. Development of Fire Engine Travel Time Estimation Model for Securing Golden Time. J. Korea Inst. Intell. Transp. Syst. 2020, 19, 1–13. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).