
Semantic Guidance Fusion Network for Cross-Modal Semantic Segmentation

Abstract
1. Introduction
- We introduce a novel semantic guidance convolution (SGC) operation that calculates the similarity of adjacent pixels under the guidance of another modality to enhance the complementary cues and reduce the noise;
- We further propose a new general multimodal segmentation network named SGFN, which is built on the SDC. This network is adept at effectively integrating and fusing bi-modal features from any amalgamation of modalities;
- With comprehensive experiments on six datasets, our SGFN achieves state-of-the-art performance, covering RGB-D, RGB-T, RGB-P, RGB-E, and RGB-L tasks.
2. Related Works
2.1. Semantic Segmentation
2.2. Multimodal Semantic Segmentation
2.3. Central Difference Convolution
3. Proposed Method
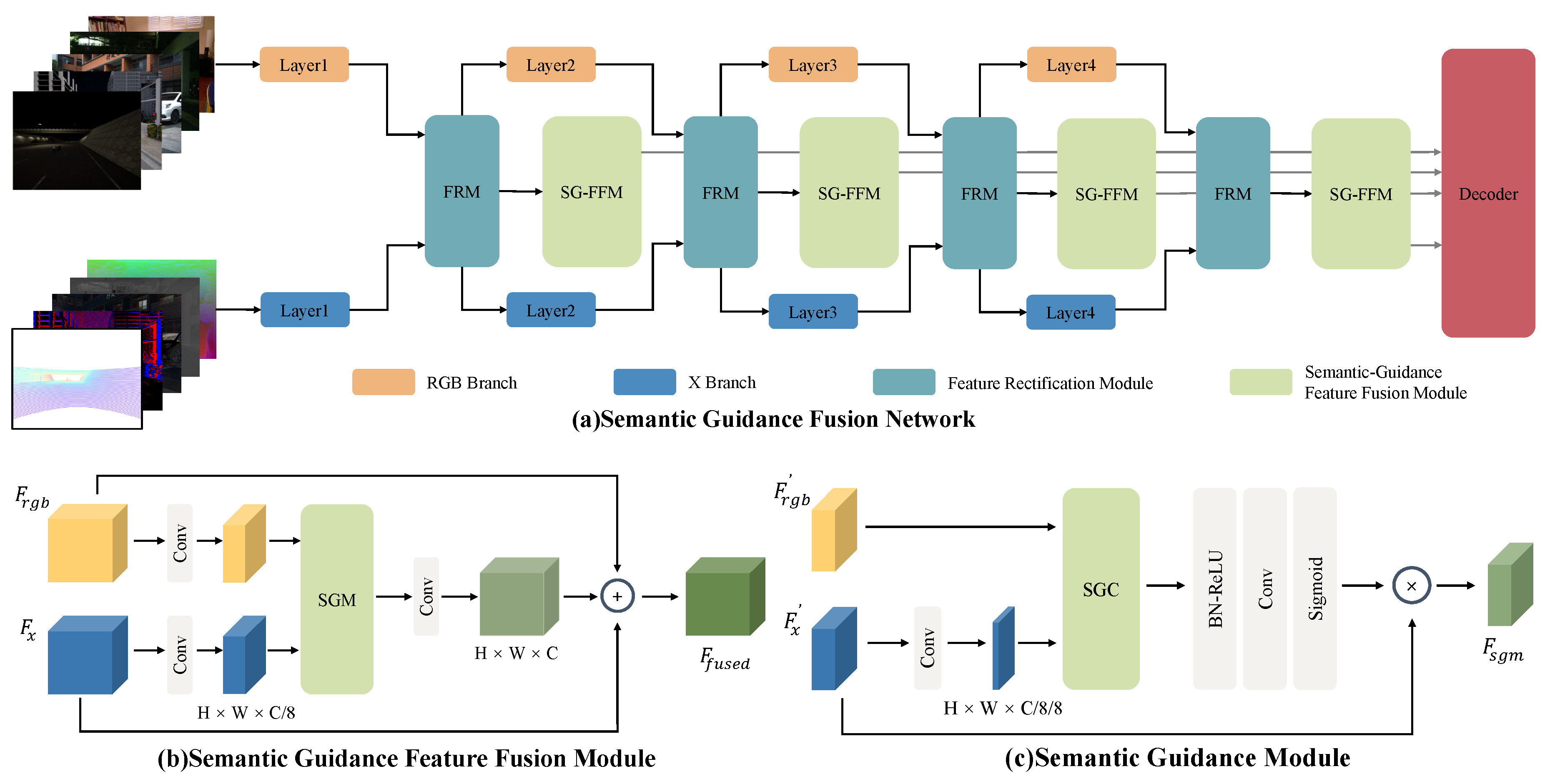
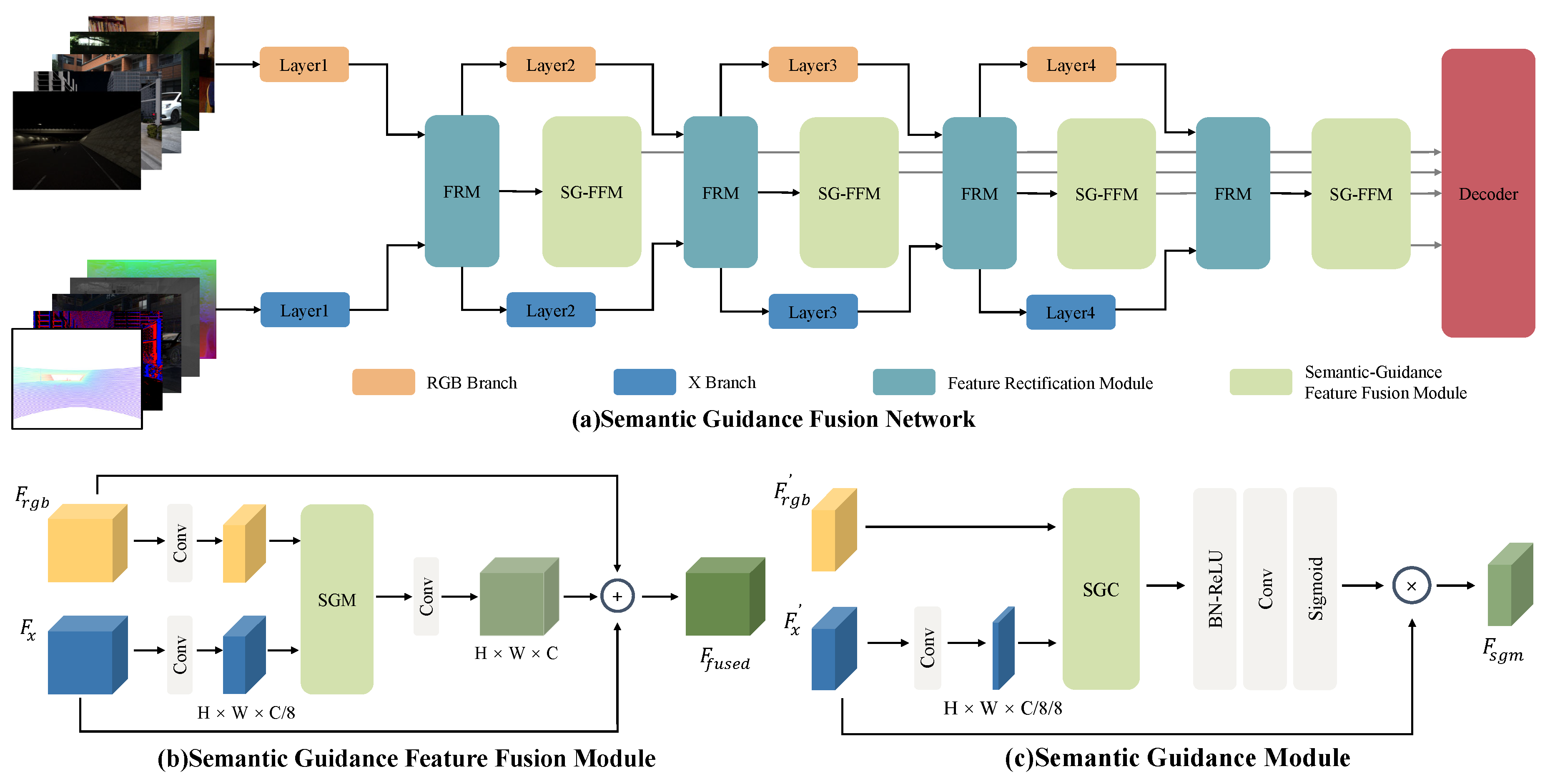
3.1. Framework Overview
3.2. Semantic Guidance Feature Fusion Module
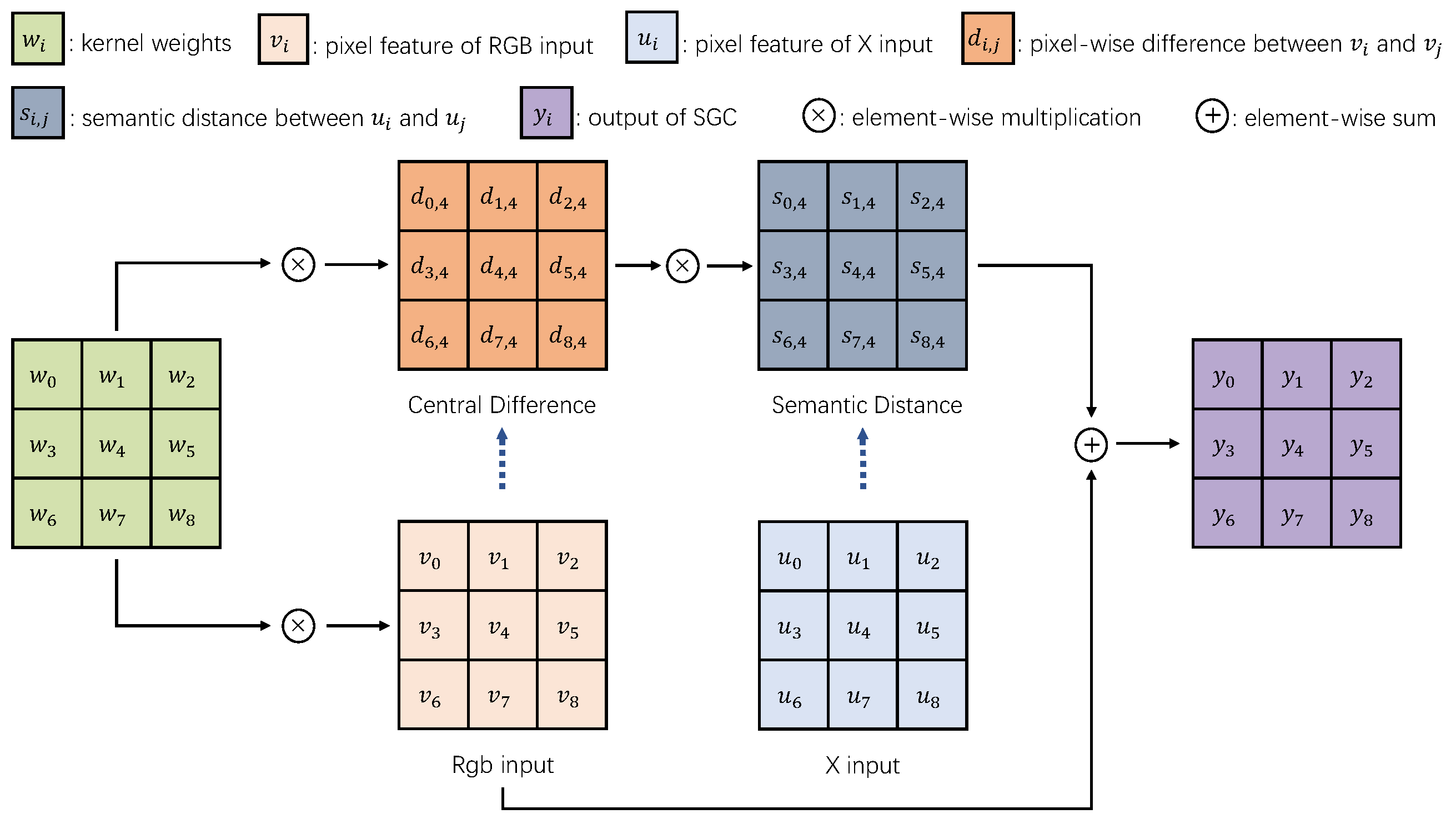
3.2.1. Semantic Guidance Convolution
3.2.2. Semantic Guidance Module
4. Experiments
4.1. Datasets
4.2. Implementation Details
5. Experiment Results and Analyses
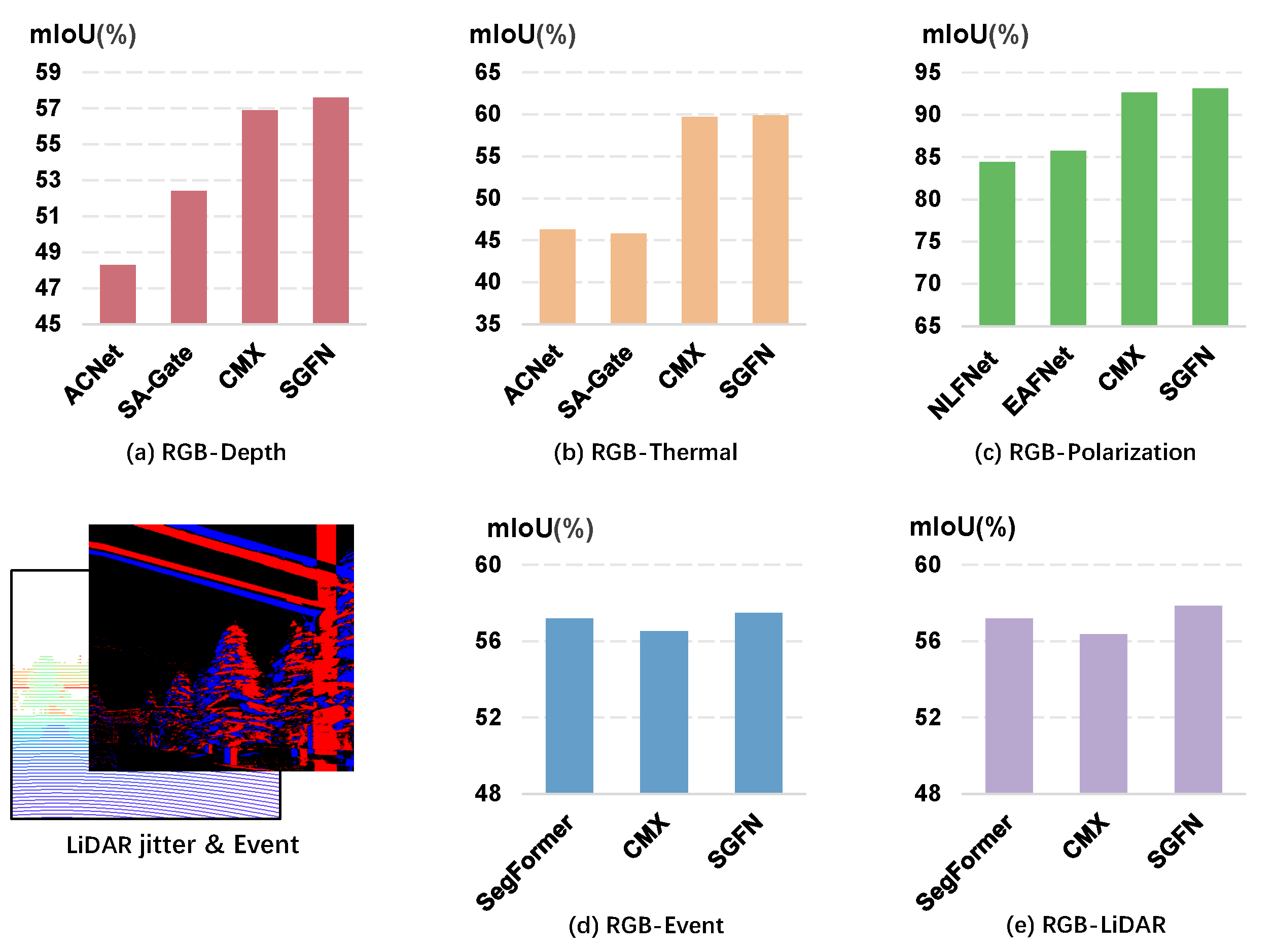
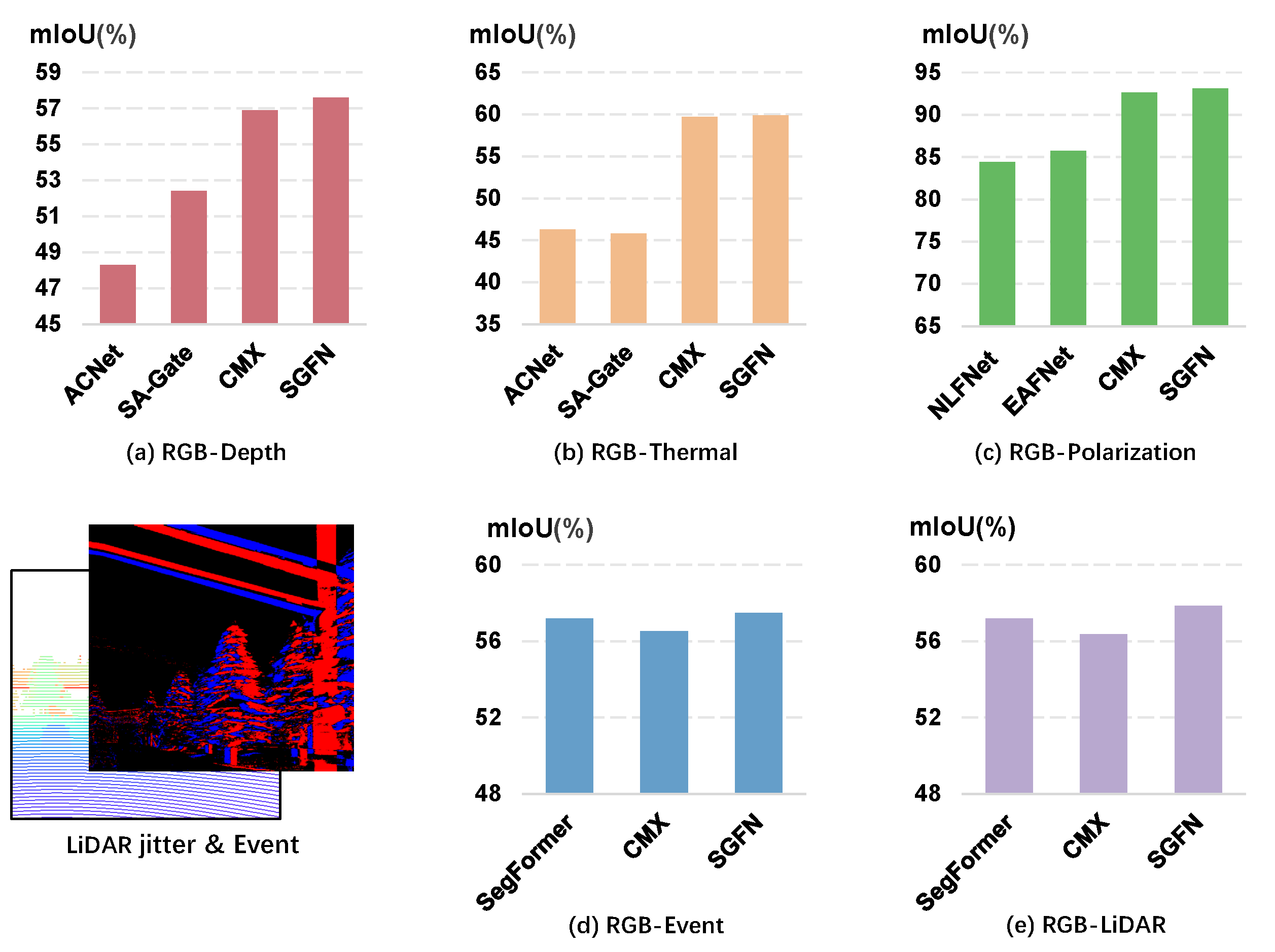
5.1. Results of the RGB-Depth Datasets
5.2. Results of the RGB-Thermal Dataset
5.3. Results of the RGB-Polarization Dataset
5.4. Results of the DELIVER Dataset
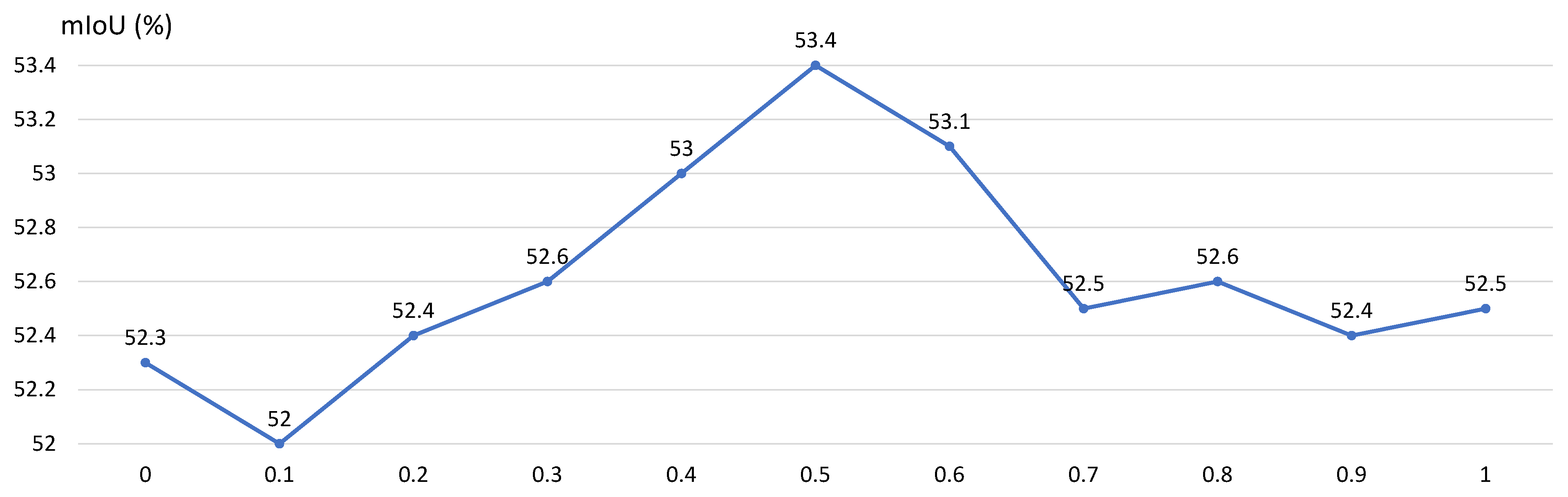
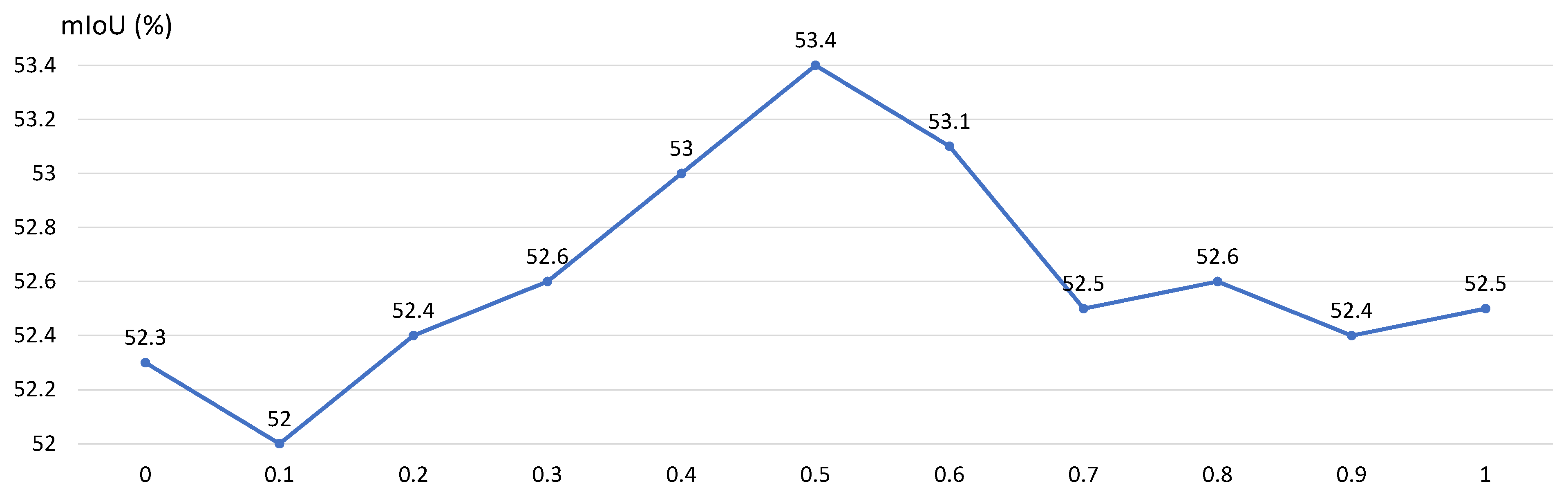
5.5. Ablation Study
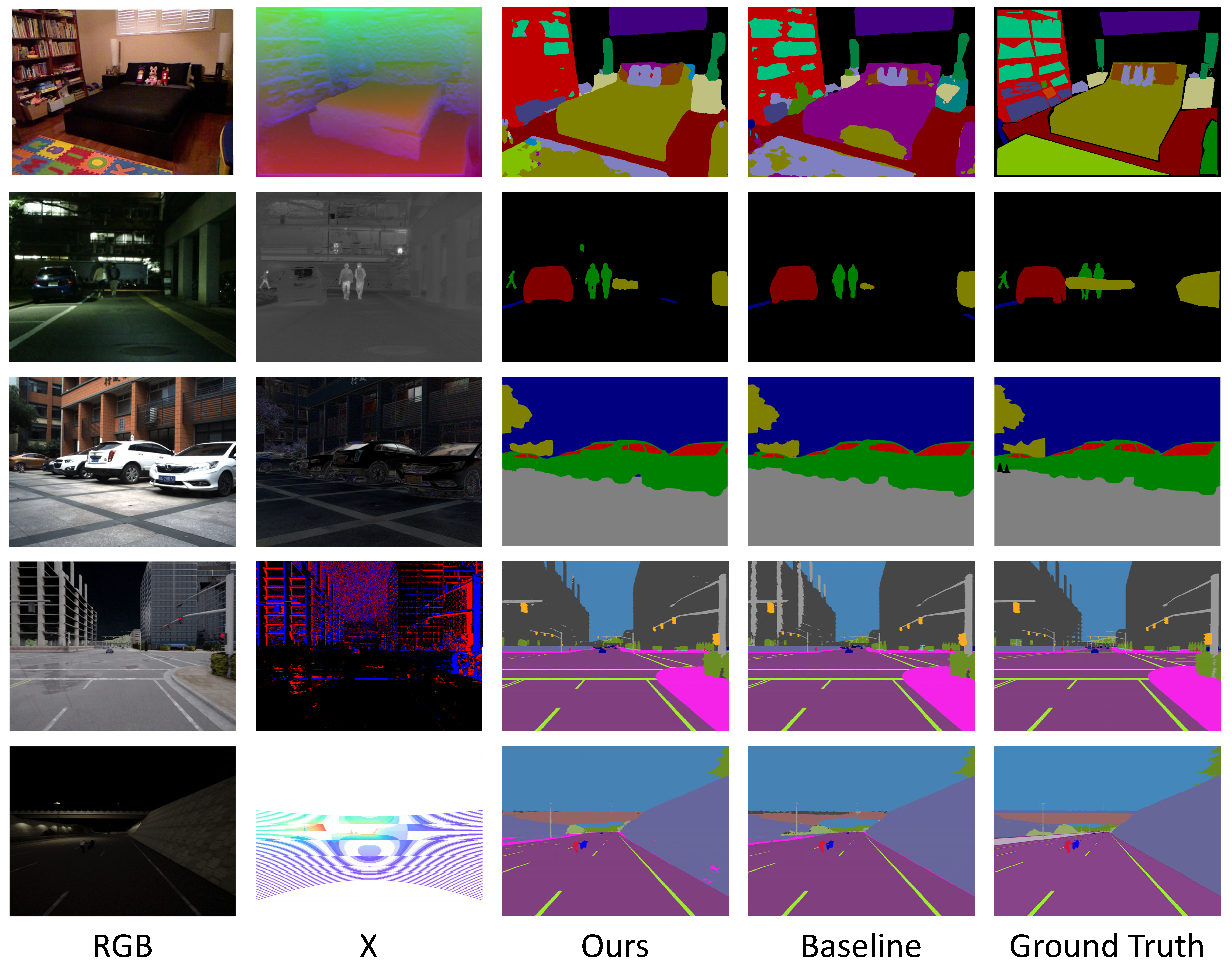
5.6. Qualitative Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Weng, X.; Yan, Y.; Chen, S.; Xue, J.H.; Wang, H. Stage-Aware Feature Alignment Network for Real-Time Semantic Segmentation of Street Scenes. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 4444–4459. [Google Scholar] [CrossRef]
- Sheng, H.; Cong, R.; Yang, D.; Chen, R.; Wang, S.; Cui, Z. UrbanLF: A Comprehensive Light Field Dataset for Semantic Segmentation of Urban Scenes. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 7880–7893. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar] [CrossRef]
- Brooks, F. What’s Real About Virtual Reality? In Proceedings of the IEEE Virtual Reality (Cat. No. 99CB36316), Virtual, 13–17 March 1999; pp. 2–3. [Google Scholar] [CrossRef]
- Liu, J.; Zhou, W.; Cui, Y.; Yu, L.; Luo, T. GCNet: Grid-like context-aware network for RGB-thermal semantic segmentation. Neurocomputing 2022, 506, 60–67. [Google Scholar] [CrossRef]
- Yang, J.; Bai, L.; Sun, Y.; Tian, C.; Mao, M.; Wang, G. Pixel Difference Convolutional Network for RGB-D Semantic Segmentation. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 1481–1492. [Google Scholar] [CrossRef]
- Ha, Q.; Watanabe, K.; Karasawa, T.; Ushiku, Y.; Harada, T. MFNet: Towards real-time semantic segmentation for autonomous vehicles with multi-spectral scenes. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 5108–5115. [Google Scholar] [CrossRef]
- Gupta, S.; Girshick, R.; Arbeláez, P.; Malik, J. Learning rich features from RGB-D images for object detection and segmentation. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Part VII. Springer: Berlin/Heidelberg, Germany, 2014; pp. 345–360. [Google Scholar]
- Cao, J.; Leng, H.; Lischinski, D.; Cohen-Or, D.; Tu, C.; Li, Y. ShapeConv: Shape-aware Convolutional Layer for Indoor RGB-D Semantic Segmentation. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 7068–7077. [Google Scholar] [CrossRef]
- Wang, J.; Wang, Z.; Tao, D.; See, S.; Wang, G. Learning common and specific features for RGB-D semantic segmentation with deconvolutional networks. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part V. Springer: Berlin/Heidelberg, Germany, 2016; pp. 664–679. [Google Scholar]
- Chen, X.; Lin, K.Y.; Wang, J.; Wu, W.; Qian, C.; Li, H.; Zeng, G. Bi-directional cross-modality feature propagation with separation-and-aggregation gate for RGB-D semantic segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 561–577. [Google Scholar]
- Zhang, Q.; Zhao, S.; Luo, Y.; Zhang, D.; Huang, N.; Han, J. ABMDRNet: Adaptive-weighted Bi-directional Modality Difference Reduction Network for RGB-T Semantic Segmentation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 2633–2642. [Google Scholar] [CrossRef]
- Hazirbas, C.; Ma, L.; Domokos, C.; Cremers, D. Fusenet: Incorporating depth into semantic segmentation via fusion-based cnn architecture. In Proceedings of the Computer Vision–ACCV 2016: 13th Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Revised Selected Papers, Part I. Springer: Berlin/Heidelberg, Germany, 2017; pp. 213–228. [Google Scholar]
- Hu, X.; Yang, K.; Fei, L.; Wang, K. ACNET: Attention Based Network to Exploit Complementary Features for RGBD Semantic Segmentation. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1440–1444. [Google Scholar] [CrossRef]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from rgbd images. In Proceedings of the 12th European Conference on Computer Vision—ECCV 2012, Florence, Italy, 7–13 October 2012; Part V. Springer: Berlin/Heidelberg, Germany, 2012; pp. 746–760. [Google Scholar]
- Xiang, K.; Yang, K.; Wang, K. Polarization-driven semantic segmentation via efficient attention-bridged fusion. Opt. Express 2021, 29, 4802–4820. [Google Scholar] [CrossRef]
- Zhang, J.; Liu, R.; Shi, H.; Yang, K.; Reiß, S.; Peng, K.; Fu, H.; Wang, K.; Stiefelhagen, R. Delivering Arbitrary-Modal Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 1136–1147. [Google Scholar]
- Valada, A.; Mohan, R.; Burgard, W. Self-supervised model adaptation for multimodal semantic segmentation. Int. J. Comput. Vis. 2020, 128, 1239–1285. [Google Scholar] [CrossRef]
- Seichter, D.; Köhler, M.; Lewandowski, B.; Wengefeld, T.; Gross, H.M. Efficient RGB-D Semantic Segmentation for Indoor Scene Analysis. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 13525–13531. [Google Scholar] [CrossRef]
- Zhang, J.; Yang, K.; Stiefelhagen, R. ISSAFE: Improving Semantic Segmentation in Accidents by Fusing Event-based Data. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 1132–1139. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Part III. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Takikawa, T.; Acuna, D.; Jampani, V.; Fidler, S. Gated-SCNN: Gated Shape CNNs for Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5228–5237. [Google Scholar] [CrossRef]
- Ding, H.; Jiang, X.; Liu, A.Q.; Thalmann, N.M.; Wang, G. Boundary-Aware Feature Propagation for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6818–6828. [Google Scholar] [CrossRef]
- Yuan, Y.; Xie, J.; Chen, X.; Wang, J. Segfix: Model-agnostic boundary refinement for segmentation. In Proceedings of the 16th European Conference Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Part XII. Springer: Berlin/Heidelberg, Germany, 2020; pp. 489–506. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar] [CrossRef]
- Zhao, H.; Zhang, Y.; Liu, S.; Shi, J.; Loy, C.C.; Lin, D.; Jia, J. PSANet: Point-wise Spatial Attention Network for Scene Parsing. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. CCNet: Criss-Cross Attention for Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Ranftl, R.; Bochkovskiy, A.; Koltun, V. Vision Transformers for Dense Prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 12179–12188. [Google Scholar]
- Yuan, Y.; Fu, R.; Huang, L.; Lin, W.; Zhang, C.; Chen, X.; Wang, J. HRFormer: High-Resolution Vision Transformer for Dense Predict. In Advances in Neural Information Processing Systems; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2021; Volume 34, pp. 7281–7293. [Google Scholar]
- Zhang, Y.; Pang, B.; Lu, C. Semantic Segmentation by Early Region Proxy. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 1248–1258. [Google Scholar] [CrossRef]
- He, H.; Cai, J.; Pan, Z.; Liu, J.; Zhang, J.; Tao, D.; Zhuang, B. Dynamic Focus-aware Positional Queries for Semantic Segmentation. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 11299–11308. [Google Scholar] [CrossRef]
- Gu, J.; Kwon, H.; Wang, D.; Ye, W.; Li, M.; Chen, Y.H.; Lai, L.; Chandra, V.; Pan, D.Z. Multi-Scale High-Resolution Vision Transformer for Semantic Segmentation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 12084–12093. [Google Scholar] [CrossRef]
- Shivakumar, S.S.; Rodrigues, N.; Zhou, A.; Miller, I.D.; Kumar, V.; Taylor, C.J. PST900: RGB-Thermal Calibration, Dataset and Segmentation Network. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 9441–9447. [Google Scholar] [CrossRef]
- Wu, W.; Chu, T.; Liu, Q. Complementarity-aware cross-modal feature fusion network for RGB-T semantic segmentation. Pattern Recognit. 2022, 131, 108881. [Google Scholar] [CrossRef]
- Zhou, W.; Liu, J.; Lei, J.; Yu, L.; Hwang, J.N. GMNet: Graded-Feature Multilabel-Learning Network for RGB-Thermal Urban Scene Semantic Segmentation. IEEE Trans. Image Process. 2021, 30, 7790–7802. [Google Scholar] [CrossRef]
- Sun, Y.; Zuo, W.; Liu, M. RTFNet: RGB-Thermal Fusion Network for Semantic Segmentation of Urban Scenes. IEEE Robot. Autom. Lett. 2019, 4, 2576–2583. [Google Scholar] [CrossRef]
- Kalra, A.; Taamazyan, V.; Rao, S.K.; Venkataraman, K.; Raskar, R.; Kadambi, A. Deep Polarization Cues for Transparent Object Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Mei, H.; Dong, B.; Dong, W.; Yang, J.; Baek, S.H.; Heide, F.; Peers, P.; Wei, X.; Yang, X. Glass Segmentation Using Intensity and Spectral Polarization Cues. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–20 June 2022; pp. 12622–12631. [Google Scholar]
- Alonso, I.; Murillo, A.C. EV-SegNet: Semantic segmentation for event-based cameras. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Zhang, J.; Yang, K.; Stiefelhagen, R. Exploring Event-Driven Dynamic Context for Accident Scene Segmentation. IEEE Trans. Intell. Transp. Syst. 2022, 23, 2606–2622. [Google Scholar] [CrossRef]
- Chang, X.; Pan, H.; Sun, W.; Gao, H. A Multi-Phase Camera-LiDAR Fusion Network for 3D Semantic Segmentation With Weak Supervision. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 3737–3746. [Google Scholar] [CrossRef]
- Yuan, Z.; Song, X.; Bai, L.; Wang, Z.; Ouyang, W. Temporal-Channel Transformer for 3D Lidar-Based Video Object Detection for Autonomous Driving. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 2068–2078. [Google Scholar] [CrossRef]
- Rashed, H.; Yogamani, S.; El-Sallab, A.; Krizek, P.; El-Helw, M. Optical flow augmented semantic segmentation networks for automated driving. arXiv 2019, arXiv:1901.07355. [Google Scholar]
- Zhang, J.; Liu, H.; Yang, K.; Hu, X.; Liu, R.; Stiefelhagen, R. CMX: Cross-Modal Fusion for RGB-X Semantic Segmentation with Transformers. IEEE Trans. Intell. Transp. Syst. 2023, 24, 14679–14694. [Google Scholar] [CrossRef]
- Juefei-Xu, F.; Naresh Boddeti, V.; Savvides, M. Local binary convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 19–28. [Google Scholar]
- Zhang, X.; Liu, L.; Xie, Y.; Chen, J.; Wu, L.; Pietikainen, M. Rotation invariant local binary convolution neural networks. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 1210–1219. [Google Scholar]
- Yu, Z.; Qin, Y.; Zhao, H.; Li, X.; Zhao, G. Dual-cross central difference network for face anti-spoofing. arXiv 2021, arXiv:2105.01290. [Google Scholar]
- Yu, Z.; Wan, J.; Qin, Y.; Li, X.; Li, S.Z.; Zhao, G. NAS-FAS: Static-Dynamic Central Difference Network Search for Face Anti-Spoofing. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3005–3023. [Google Scholar] [CrossRef]
- Yu, Z.; Zhao, C.; Wang, Z.; Qin, Y.; Su, Z.; Li, X.; Zhou, F.; Zhao, G. Searching central difference convolutional networks for face anti-spoofing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5295–5305. [Google Scholar]
- Su, Z.; Liu, W.; Yu, Z.; Hu, D.; Liao, Q.; Tian, Q.; Pietikäinen, M.; Liu, L. Pixel Difference Networks for Efficient Edge Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 5097–5107. [Google Scholar] [CrossRef]
- Tan, H.; Wu, S.; Pi, J. Semantic diffusion network for semantic segmentation. Adv. Neural Inf. Process. Syst. 2022, 35, 8702–8716. [Google Scholar]
- Sapiro, G. Geometric partial differential equations in image analysis: Past, present, and future. In Proceedings of the International Conference on Image Processing, Washington, DC, USA, 23–26 October 1995; Volume 3, pp. 1–4. [Google Scholar] [CrossRef]
- Deng, F.; Feng, H.; Liang, M.; Wang, H.; Yang, Y.; Gao, Y.; Chen, J.; Hu, J.; Guo, X.; Lam, T.L. FEANet: Feature-Enhanced Attention Network for RGB-Thermal Real-time Semantic Segmentation. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 4467–4473. [Google Scholar] [CrossRef]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction Without Convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics—JMLR Workshop and Conference Proceedings, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Song, S.; Lichtenberg, S.P.; Xiao, J. SUN RGB-D: A RGB-D scene understanding benchmark suite. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 567–576. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified perceptual parsing for scene understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 418–434. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Gupta, S.; Arbeláez, P.; Malik, J. Perceptual Organization and Recognition of Indoor Scenes from RGB-D Images. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 564–571. [Google Scholar] [CrossRef]
- Qi, X.; Liao, R.; Jia, J.; Fidler, S.; Urtasun, R. 3D Graph Neural Networks for RGBD Semantic Segmentation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5209–5218. [Google Scholar] [CrossRef]
- Xu, D.; Ouyang, W.; Wang, X.; Sebe, N. Pad-net: Multi-tasks guided predictionand-distillation network for simultaneous depth estimation and scene parsing, in 2018 IEEE. In Proceedings of the CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 675–684. [Google Scholar]
- Zhang, Z.; Cui, Z.; Xu, C.; Yan, Y.; Sebe, N.; Yang, J. Pattern-Affinitive Propagation Across Depth, Surface Normal and Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4101–4110. [Google Scholar] [CrossRef]
- Yang, Y.; Xu, Y.; Zhang, C.; Xu, Z.; Huang, J. Hierarchical Vision Transformer with Channel Attention for RGB-D Image Segmentation. In Proceedings of the 4th International Symposium on Signal Processing Systems, Xi’an, China, 25–27 March 2022; pp. 68–73. [Google Scholar]
- Wu, Z.; Zhou, Z.; Allibert, G.; Stolz, C.; Demonceaux, C.; Ma, C. Transformer Fusion for Indoor rgb-d Semantic Segmentation. SSRN. 2022. Available online: https://ssrn.com/abstract=4251286 (accessed on 18 October 2022).
- Chen, L.Z.; Lin, Z.; Wang, Z.; Yang, Y.L.; Cheng, M.M. Spatial Information Guided Convolution for Real-Time RGBD Semantic Segmentation. IEEE Trans. Image Process. 2021, 30, 2313–2324. [Google Scholar] [CrossRef] [PubMed]
- Zhang, G.; Xue, J.H.; Xie, P.; Yang, S.; Wang, G. Non-Local Aggregation for RGB-D Semantic Segmentation. IEEE Signal Process. Lett. 2021, 28, 658–662. [Google Scholar] [CrossRef]
- Zhou, H.; Qi, L.; Huang, H.; Yang, X.; Wan, Z.; Wen, X. CANet: Co-attention network for RGB-D semantic segmentation. Pattern Recognit. 2022, 124, 108468. [Google Scholar] [CrossRef]
- Oršic, M.; Krešo, I.; Bevandic, P.; Šegvic, S. In Defense of Pre-Trained ImageNet Architectures for Real-Time Semantic Segmentation of Road-Driving Images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12599–12608. [Google Scholar] [CrossRef]
- Sun, L.; Yang, K.; Hu, X.; Hu, W.; Wang, K. Real-time fusion network for RGB-D semantic segmentation incorporating unexpected obstacle detection for road-driving images. IEEE Robot. Autom. Lett. 2020, 5, 5558–5565. [Google Scholar] [CrossRef]
- Romera, E.; Álvarez, J.M.; Bergasa, L.M.; Arroyo, R. ERFNet: Efficient Residual Factorized ConvNet for Real-Time Semantic Segmentation. IEEE Trans. Intell. Transp. Syst. 2018, 19, 263–272. [Google Scholar] [CrossRef]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef]
- Xu, J.; Lu, K.; Wang, H. Attention fusion network for multi-spectral semantic segmentation. Pattern Recognit. Lett. 2021, 146, 179–184. [Google Scholar] [CrossRef]
- Yan, R.; Yang, K.; Wang, K. NLFNet: Non-Local Fusion Towards Generalized Multimodal Semantic Segmentation across RGB-Depth, Polarization, and Thermal Images. In Proceedings of the 2021 IEEE International Conference on Robotics and Biomimetics (ROBIO), Jinghong, China, 27–31 December 2021; pp. 1129–1135. [Google Scholar] [CrossRef]
- Broedermann, T.; Sakaridis, C.; Dai, D.; Van Gool, L. HRFuser: A multi-resolution sensor fusion architecture for 2D object detection. arXiv 2022, arXiv:2206.15157. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | mIoU (%) | Acc (%) |
|---|---|---|
| 3DGNN [70] | 43.1 | - |
| ACNet [14] | 48.3 | - |
| PADNet [71] | 50.2 | 62.3 |
| PAP [72] | 50.4 | 62.5 |
| Swin-RGBD [73] | 50.9 | 64.2 |
| TransD [74] | 55.5 | 69.4 |
| SGNet [75] | 51.1 | 76.8 |
| ShapeConv [9] | 51.3 | 76.4 |
| SA-Gate [11] | 52.4 | 77.9 |
| CMX (MiT-B2) * [52] | 54.4 | 79.9 |
| CMX (MiT-B5) * [52] | 56.9 | 80.1 |
| SGFN (Mit-B2) * | 53.4 | 78.5 |
| SGFN (Mit-B5) * | 57.6 | 80.5 |
| Method | mIoU (%) | Acc (%) |
|---|---|---|
| 3DGNN [70] | 45.9 | - |
| ACNet [14] | 48.1 | - |
| SGNet [75] | 48.6 | 82.0 |
| ShapeConv [9] | 48.6 | 82.2 |
| NANet [76] | 48.8 | 82.3 |
| PDCNet [6] | 49.2 | - |
| CANet [77] | 49.3 | 60.5 |
| TransD [74] | 51.9 | 64.1 |
| SA-Gate [11] | 49.4 | 82.5 |
| CMX (MiT-B2) * [52] | 49.7 | 82.8 |
| CMX (MiT-B5) * [52] | 52.4 | 83.8 |
| SGFN (Mit-B2) * | 50.8 | 83.0 |
| SGFN (Mit-B5) * | 53.1 | 84.1 |
| Method | Modal | Backbone | mIoU (%) |
|---|---|---|---|
| SwiftNet [78] | RGB | ResNet-18 | 70.4 |
| ESANet [19] | RGB | ResNet-50 | 79.2 |
| DANet [32] | RGB | ResNet-101 | 81.5 |
| SegFormer [21] | RGB | MiT-B2 | 81.0 |
| SegFormer [21] | RGB | MiT-B4 | 82.3 |
| RFNet [79] | RGB-D | ResNet-18 | 72.5 |
| PADNet [71] | RGB-D | ResNet-50 | 76.1 |
| ESANet [19] | RGB-D | ResNet-50 | 80.0 |
| SA-Gate [11] | RGB-D | ResNet-50 | 80.7 |
| SA-Gate [11] | RGB-D | ResNet-101 | 81.7 |
| CMX [52] | RGB-D | MiT-B2 | 81.6 |
| CMX [52] | RGB-D | MiT-B4 | 82.6 |
| SGFN | RGB-D | MiT-B2 | 81.6 |
| SGFN | RGB-D | MiT-B4 | 83.0 |
| Method | Modal | Unlabeled | Car | Person | Bike | Curve | Car Stop | Guardrail | Color Cone | Bump | mIoU |
|---|---|---|---|---|---|---|---|---|---|---|---|
| DANet [32] | RGB | 96.3 | 71.3 | 48.1 | 51.8 | 30.2 | 18.2 | 0.7 | 30.3 | 18.8 | 41.3 |
| SegNet [75] | RGB | 96.7 | 65.3 | 55.7 | 51.1 | 38.4 | 10.0 | 0.0 | 12.0 | 51.5 | 42.3 |
| UNet [23] | RGB | 96.9 | 66.2 | 60.5 | 46.2 | 41.6 | 17.9 | 1.8 | 30.6 | 44.2 | 45.1 |
| PSPNet [24] | RGB | 96.8 | 74.8 | 61.3 | 50.2 | 38.4 | 15.8 | 0.0 | 33.2 | 44.4 | 46.1 |
| ERFNet [80] | RGB | 96.7 | 67.1 | 56.2 | 34.3 | 30.6 | 9.4 | 0.0 | 0.1 | 30.5 | 36.1 |
| DUC [81] | RGB | 97.7 | 82.5 | 69.4 | 58.9 | 40.1 | 20.9 | 3.4 | 42.1 | 40.9 | 50.7 |
| HRNet [82] | RGB | 98.0 | 86.9 | 67.3 | 59.2 | 35.3 | 23.1 | 1.7 | 46.6 | 47.3 | 51.7 |
| SegFormer-B2 [21] | RGB | 97.9 | 87.4 | 62.8 | 63.2 | 31.7 | 25.6 | 9.8 | 50.9 | 49.6 | 53.2 |
| SegFormer-B4 [21] | RGB | 98.0 | 88.9 | 64.0 | 62.8 | 38.1 | 25.9 | 6.9 | 50.8 | 57.7 | 54.8 |
| MFNet [7] | RGB-T | 96.9 | 65.9 | 58.9 | 42.9 | 29.9 | 9.9 | 0.0 | 25.2 | 27.7 | 39.7 |
| SA-Gate [11] | RGB-T | 96.8 | 73.8 | 59.2 | 51.3 | 38.4 | 19.3 | 0.0 | 24.5 | 48.8 | 45.8 |
| ACNet [14] | RGB-T | 96.7 | 79.4 | 64.7 | 52.7 | 32.9 | 28.4 | 0.8 | 16.9 | 44.4 | 46.3 |
| RTFNet [44] | RGB-T | 98.5 | 87.4 | 70.3 | 62.7 | 45.3 | 29.8 | 0.0 | 29.1 | 55.7 | 53.2 |
| AFNet [83] | RGB-T | 98.0 | 86.0 | 67.4 | 62.0 | 43.0 | 28.9 | 4.6 | 44.9 | 56.6 | 54.6 |
| ABMDRNet [12] | RGB-T | 98.6 | 84.8 | 69.6 | 60.3 | 45.1 | 33.1 | 5.1 | 47.4 | 50.0 | 54.8 |
| FEANet [61] | RGB-T | 98.3 | 87.8 | 71.1 | 61.1 | 46.5 | 22.1 | 6.6 | 55.3 | 48.9 | 55.3 |
| GMNet [43] | RGB-T | 97.5 | 86.5 | 73.1 | 61.7 | 44.0 | 42.3 | 14.5 | 48.7 | 47.4 | 57.3 |
| CMX (MiT-B2) [52] | RGB-T | 98.3 | 89.4 | 74.8 | 64.7 | 47.3 | 30.1 | 8.1 | 52.4 | 59.4 | 58.2 |
| CMX (MiT-B4) [52] | RGB-T | 98.3 | 90.1 | 75.2 | 64.5 | 50.2 | 35.3 | 8.5 | 54.2 | 60.6 | 59.7 |
| SGFN (MiT-B2) | RGB-T | 98.3 | 89.4 | 76.0 | 66.1 | 49.3 | 32.7 | 10.9 | 52.4 | 56.1 | 59.0 |
| SGFN (MiT-B4) | RGB-T | 98.4 | 90.9 | 76.7 | 66.1 | 49.2 | 35.7 | 7.5 | 55.1 | 59.1 | 59.9 |
| Method | Modal | Daytime mIoU (%) | Nighttime mIoU (%) |
|---|---|---|---|
| SegFormer-B2 [21] | RGB | 48.6 | 49.2 |
| SegFormer-B4 [21] | RGB | 49.4 | 52.4 |
| GMNet [43] | RGB-T | 49.0 | 57.7 |
| MFNet [7] | RGB-T | 36.1 | 36.8 |
| RTFNet [44] | RGB-T | 45.8 | 54.8 |
| ABMDRNet [12] | RGB-T | 46.7 | 55.5 |
| CMX (MiT-B2) [52] | RGB-T | 51.3 | 57.8 |
| CMX (MiT-B4) [52] | RGB-T | 52.5 | 59.4 |
| SGFN (MiT-B2) | RGB-T | 52.0 | 58.7 |
| SGFN (MiT-B4) | RGB-T | 52.5 | 60.0 |
| Method | Modal | mIoU (%) |
|---|---|---|
| SwiftNet [78] | RGB | 80.3 |
| SegFormer-B2 [21] | RGB | 89.6 |
| NLFNet [84] | RGB-P | 84.4 |
| EAFNet [16] | RGB-P | 85.7 |
| CMX (SegFormer-B2) [52] | RGB-AoLP | 92.0 |
| CMX (SegFormer-B4) [52] | RGB-AoLP | 92.6 |
| CMX (SegFormer-B2) [52] | RGB-DoLP | 92.2 |
| CMX (SegFormer-B4) [52] | RGB-DoLP | 92.5 |
| SGFN (SegFormer-B2) | RGB-DoLP | 92.8 |
| SGFN (SegFormer-B4) | RGB-DoLP | 93.2 |
| Method | Modal | Backbone | mIoU (%) |
|---|---|---|---|
| HRFuser [85] | RGB | HRFormer-T | 47.95 |
| SegFormer [21] | RGB | MiT-B2 | 57.20 |
| HRFuser [85] | RGB-Event | HRFormer-T | 42.22 |
| CMX [52] | RGB-Event | MiT-B2 | 56.52 |
| CMNeXt [17] | RGB-Event | MiT-B2 | 57.48 |
| SGFN | RGB-Event | MiT-B2 | 57.48 |
| HRFuser [85] | RGB-LiDAR | HRFormer-T | 43.13 |
| CMX [52] | RGB-LiDAR | MiT-B2 | 56.37 |
| CMNeXt [17] | RGB-LiDAR | MiT-B2 | 58.04 |
| SGFN | RGB-LiDAR | MiT-B2 | 57.70 |
| Structure | mIoU (%) |
|---|---|
| SGFN (MiT-B2) | 53.4 |
| -without SGM | 51.6 (−1.8) |
| -without FRM | 50.6 (−2.8) |
| -with CDC instead of SGC | 51.4 (−2.0) |
| -with vanilla instead of SGC | 52.3 (−1.1) |
| -with SDC instead of SGC | 52.6 (−0.8) |
| Kernel Size | Dilation Rate | Pixel Acc. (%) | mIoU (%) |
|---|---|---|---|
| 3 × 3 | 1 | 78.5 | 53.4 |
| 3 × 3 | 3 | 78.2 | 53.1 |
| 3 × 3 | 5 | 77.9 | 52.7 |
| 5 × 5 | 1 | 78.4 | 53.3 |
| 7 × 7 | 1 | 78.2 | 52.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, P.; Chen, M.; Gao, M. Semantic Guidance Fusion Network for Cross-Modal Semantic Segmentation. Sensors 2024, 24, 2473. https://doi.org/10.3390/s24082473
Zhang P, Chen M, Gao M. Semantic Guidance Fusion Network for Cross-Modal Semantic Segmentation. Sensors. 2024; 24(8):2473. https://doi.org/10.3390/s24082473
Chicago/Turabian StyleZhang, Pan, Ming Chen, and Meng Gao. 2024. "Semantic Guidance Fusion Network for Cross-Modal Semantic Segmentation" Sensors 24, no. 8: 2473. https://doi.org/10.3390/s24082473
APA StyleZhang, P., Chen, M., & Gao, M. (2024). Semantic Guidance Fusion Network for Cross-Modal Semantic Segmentation. Sensors, 24(8), 2473. https://doi.org/10.3390/s24082473