


Federated Learning with Pareto Optimality for Resource Efficiency and Fast Model Convergence in Mobile Environments †


Abstract
1. Introduction
- Network Congestion: network congestion on a remote cloud server occurs when numerous user devices simultaneously send data to the server.
- Privacy Leak: private user experience data may be leaked due to malicious network attacks during transmission.
- Resource Constraints: the capacity of network resources (e.g., wireless channel subcarriers and bandwidth) and user devices (e.g., computing performances and battery life) is limited.
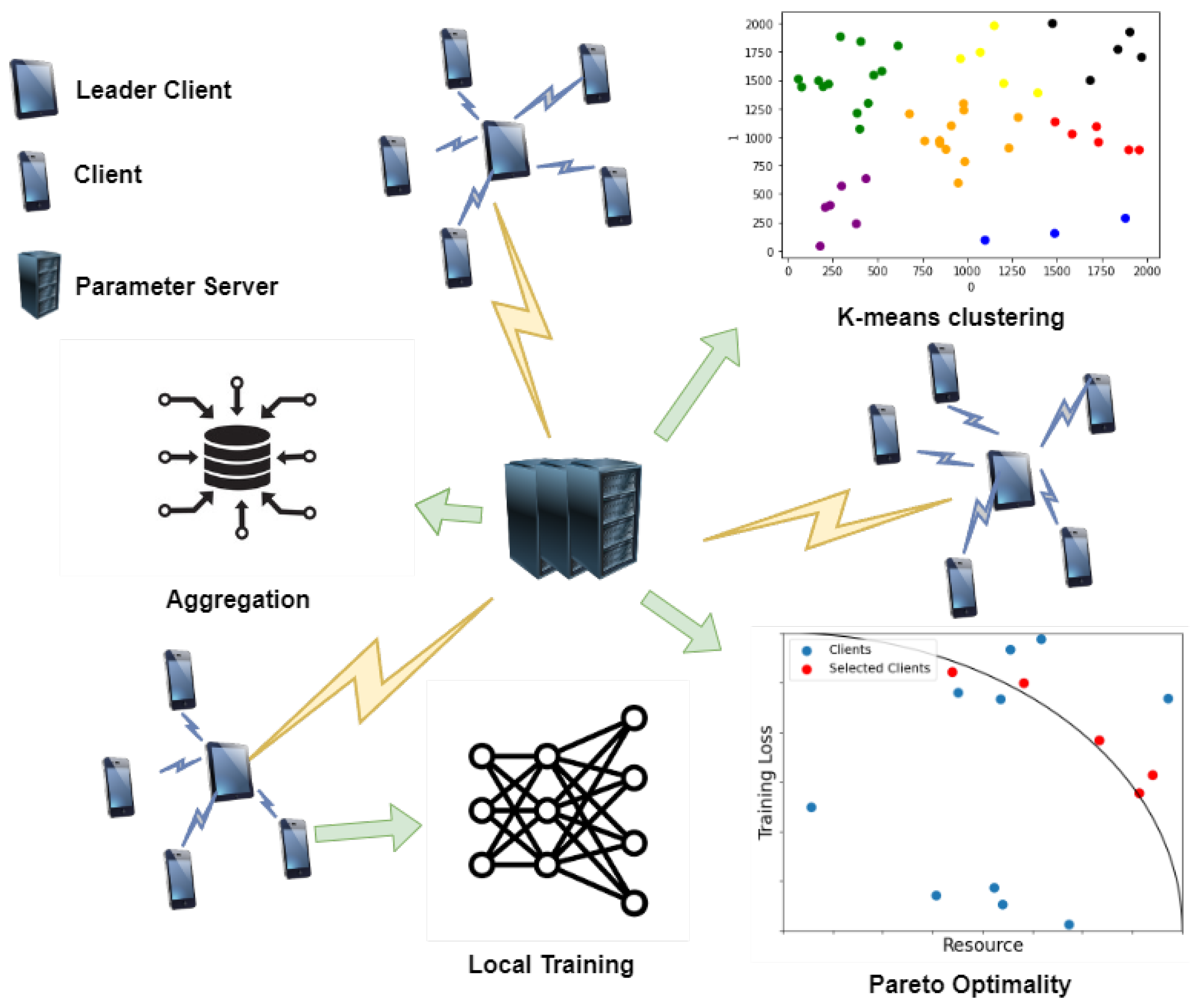
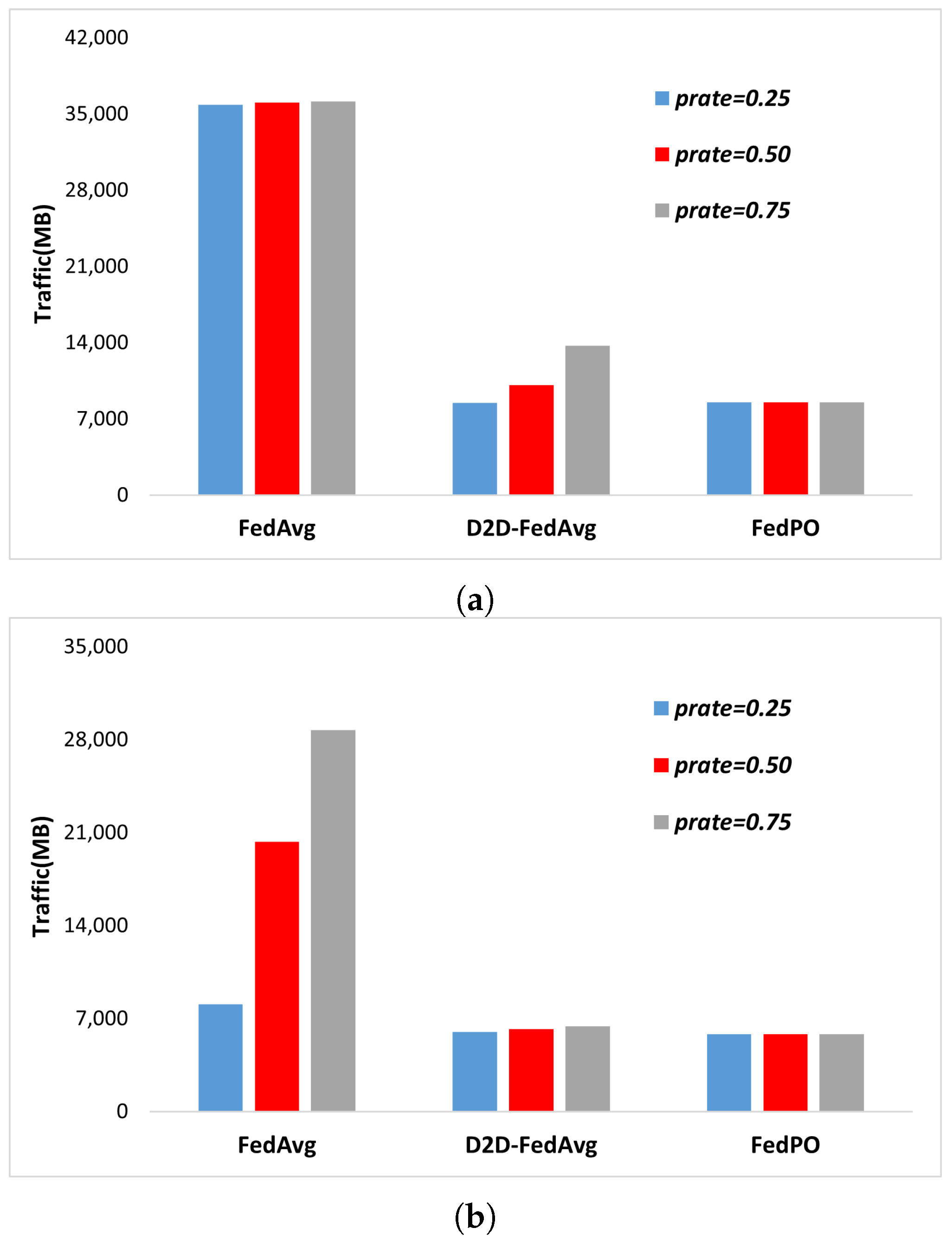
- We propose an FL mechanism with a hierarchical D2D structure by clustering clients on the basis of the location and communication range of each client. This mechanism can effectively reduce the wireless communication traffic generated when the FL model is updated for each client.
- We propose a biased client-selection method for a clustered structure by using Pareto optimality. This client-selection method employs high training loss values to accelerate model convergence and reduce resource consumption.
2. Related Work
3. Preliminaries
3.1. A Brief Overview on Federated Learning
3.2. Pareto Principle and Pareto Optimality
3.2.1. Basic Definition
3.2.2. Pareto Front
4. FedPO: Federated Learning with Pareto Optimality
4.1. Problem Formulation
- 1.
- We assume an elliptic function to illustrate Pareto optimality.
- 2.
- Point is an ideal maximum point of A if for every and closest to the elliptic function.
4.2. FedPO Framework
- K-means clustering for D2D communication: Compared with short-distance wireless communication [9], D2D communication effectively reduces resource consumption and network delay. We use D2D communication for transmitting the model parameters, training loss, and resource state of clients to the LCs for HFL. The PS builds an intranetwork for D2D communication using k-means clustering, based on the locations of clients. is the average communication distance between intraclients according to the number of clusters j: , where j does not exceed as the pairing for D2D communication. Additionally, we consider that at least two clients exist in each cluster. Therefore, when the number of clusters is j, the average Euclidean communication distance from to the location of each client k belonging to cluster is expressed as follows:A threshold value is set for the communication distance. The average communication distance from each client in the clusters does not exceed the threshold, and the optimal j is the maximum value.
- HFL: Similar to [17,22], we regard LCs as intermediate servers. In a cluster, the client located closest to the centroid is selected as the LC to minimize the distance between the LC and other clients in the cluster. The model parameters of the clients belonging to each cluster are transmitted to the LCs. The LCs aggregate the model parameters in round t and perform weighted averaging, as follows:Thereafter, each LC sends the averaged model parameters to the PS, which aggregates these model parameters. At time t, the global model parameters in the PS are .
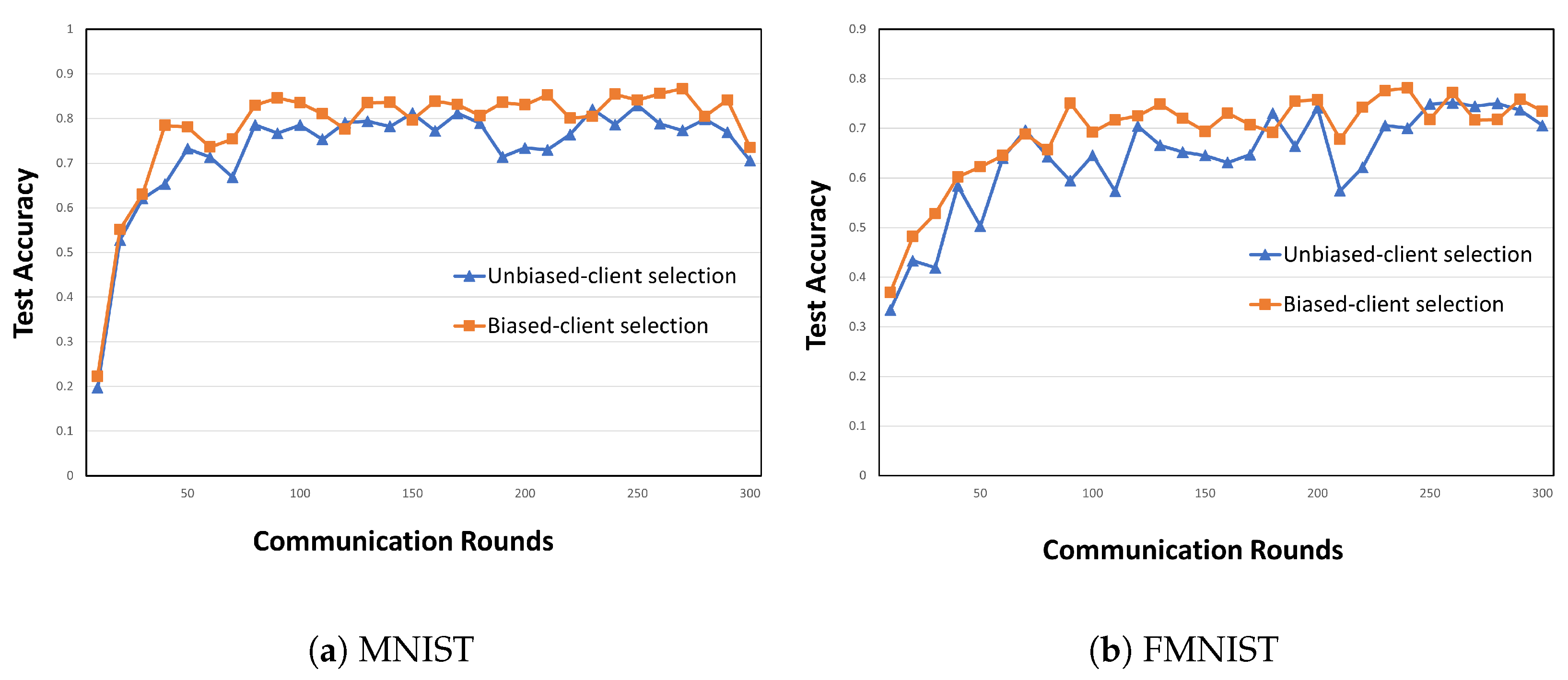
- Biased client selection for Pareto principle and optimality: We use the Pareto principle and optimality to ensure model convergence and to optimize the resource consumption. Figure 2 shows the accuracy of biased and unbiased client-selection methods in FL. On the MNIST and FashionMNIST datasets, biased client selection leads to faster model convergence in the initial stage, and its accuracy is higher than that of unbiased client selection. This result can be interpreted considering the Pareto principle: a small number of clients selected through biased client selection can produce sufficient outcomes. Furthermore, we select clients in accordance with the Pareto optimality function based on two criteria: loss value and resource state. Therefore, according to the convergence analysis in [14], the loss value is adopted as the criterion for using Pareto optimality for client selection. The other criterion is the state of client resources because all clients have finite network and computational resources in actual environments.
4.3. Algorithm
| Algorithm 1: Federated Learning with Pareto Optimality |
|
| Algorithm 2: LocationBasedClustering |
|
| Algorithm 3: SelectClient |
|
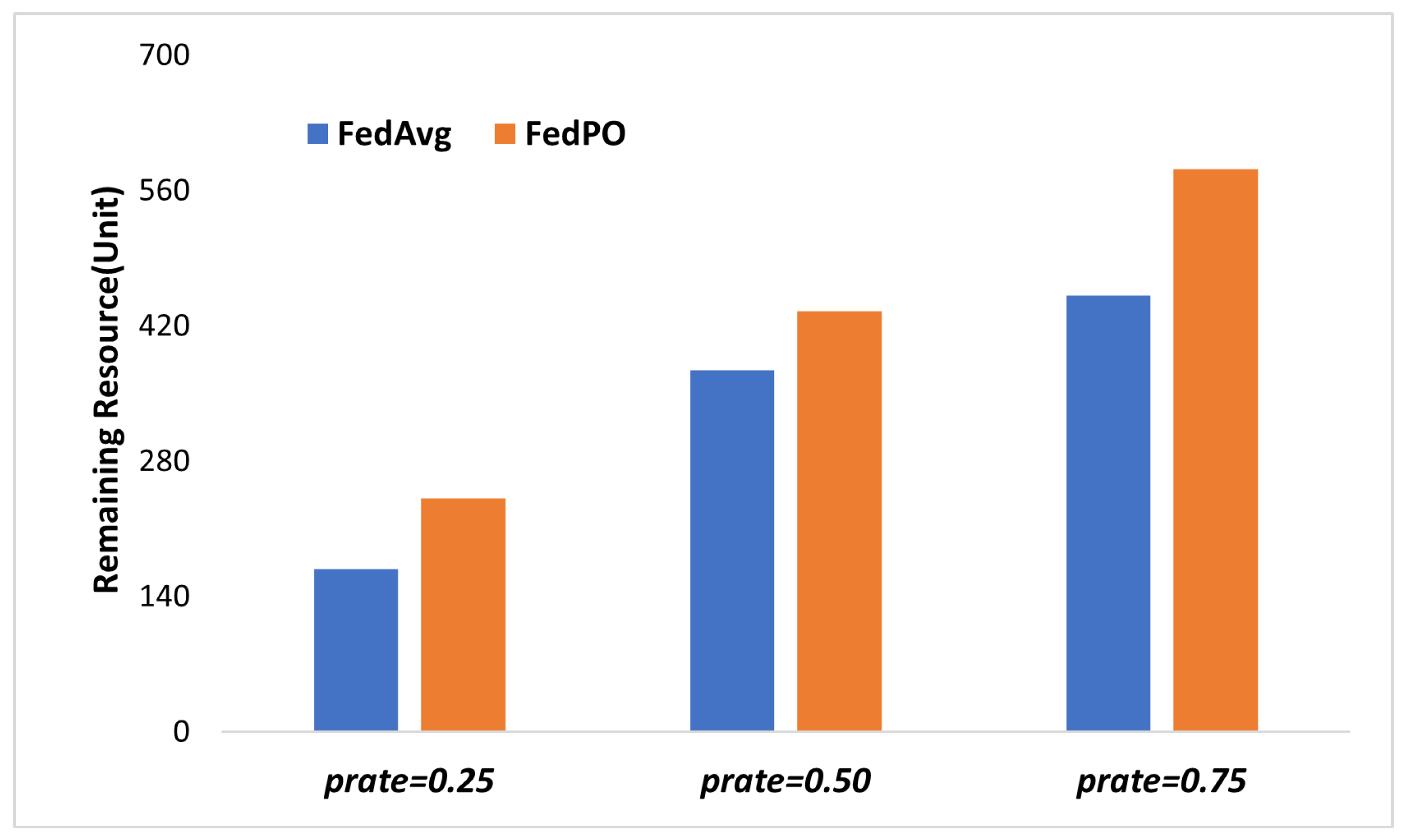
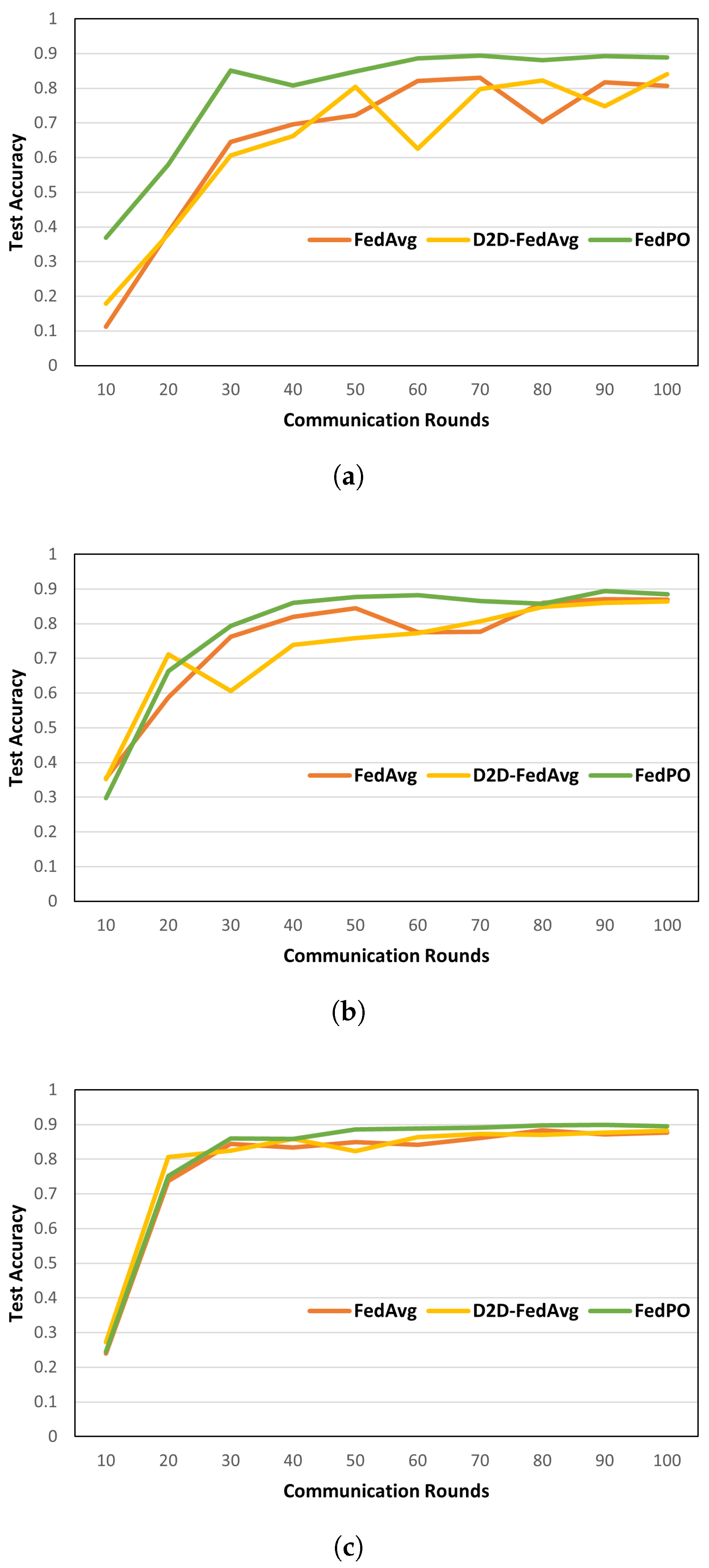
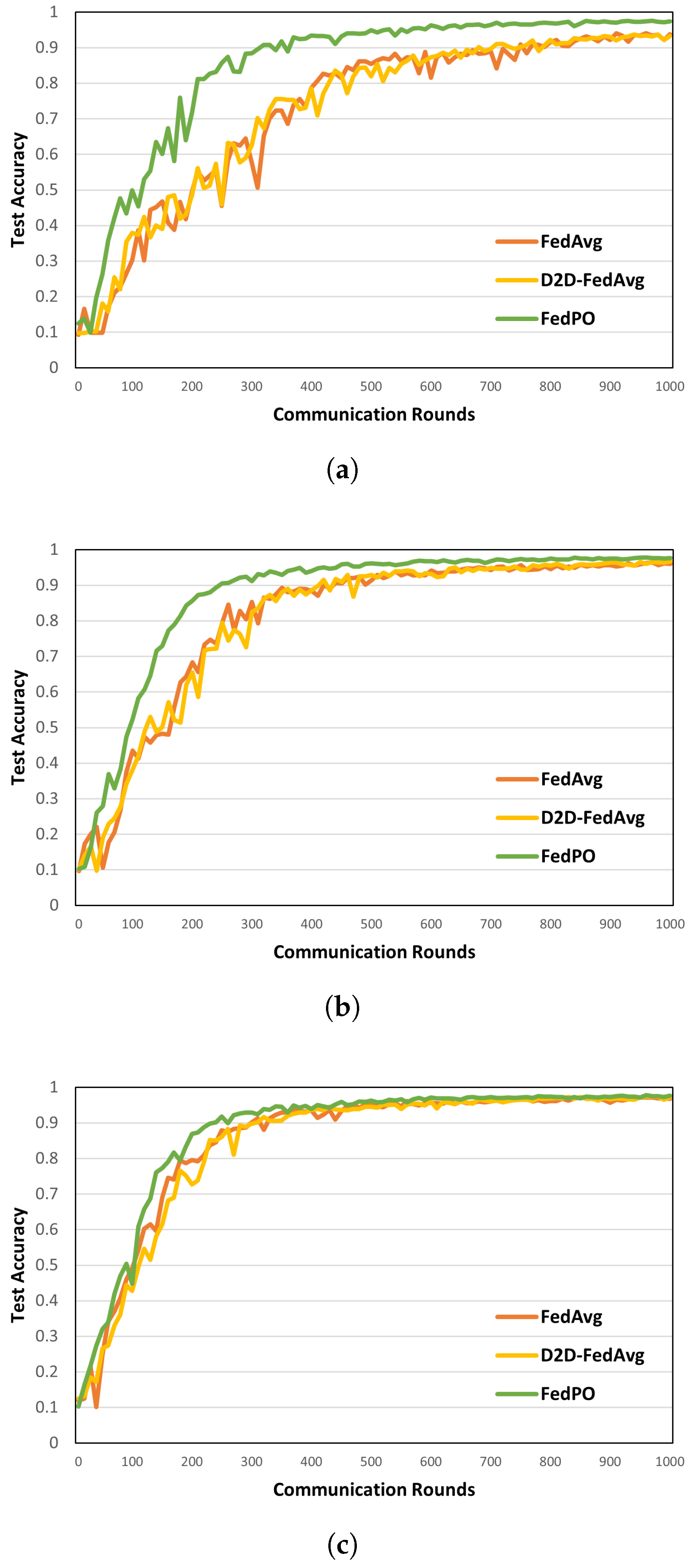
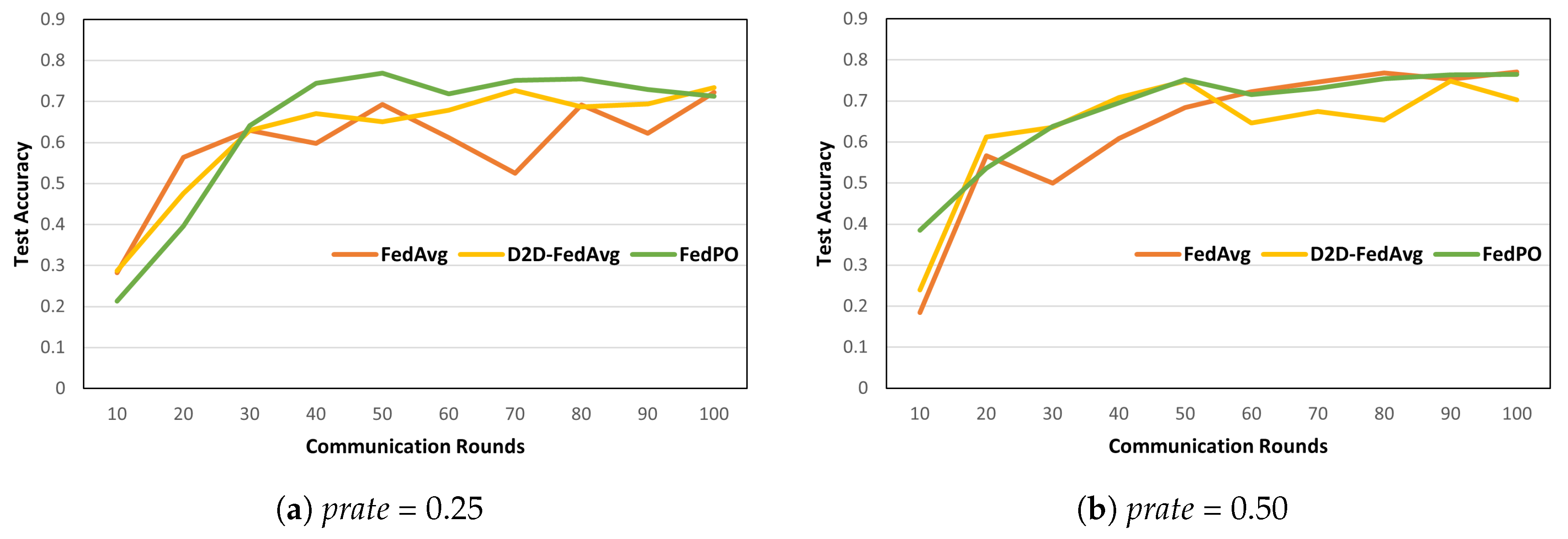
5. Performance Evaluation
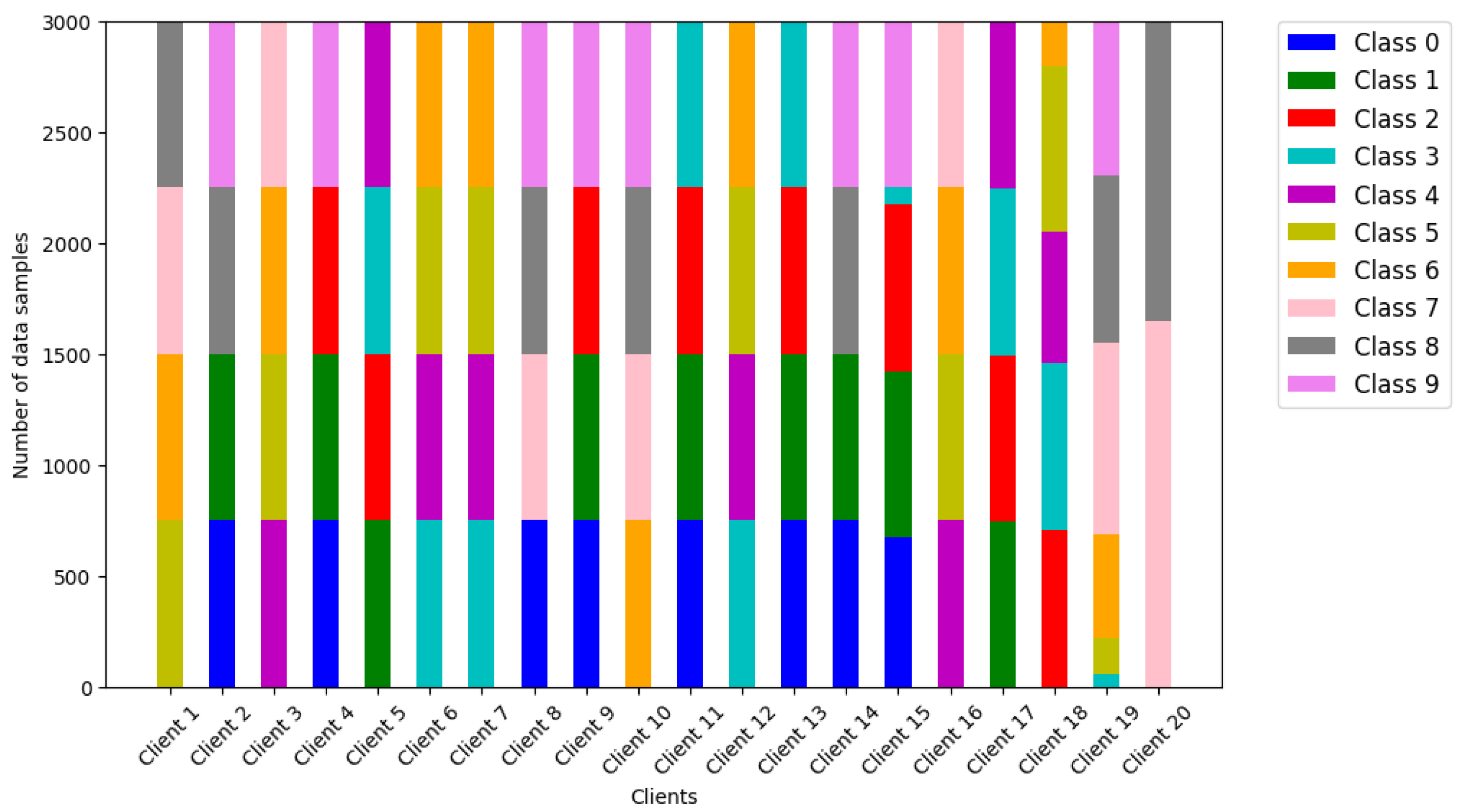
5.1. Simulation Settings
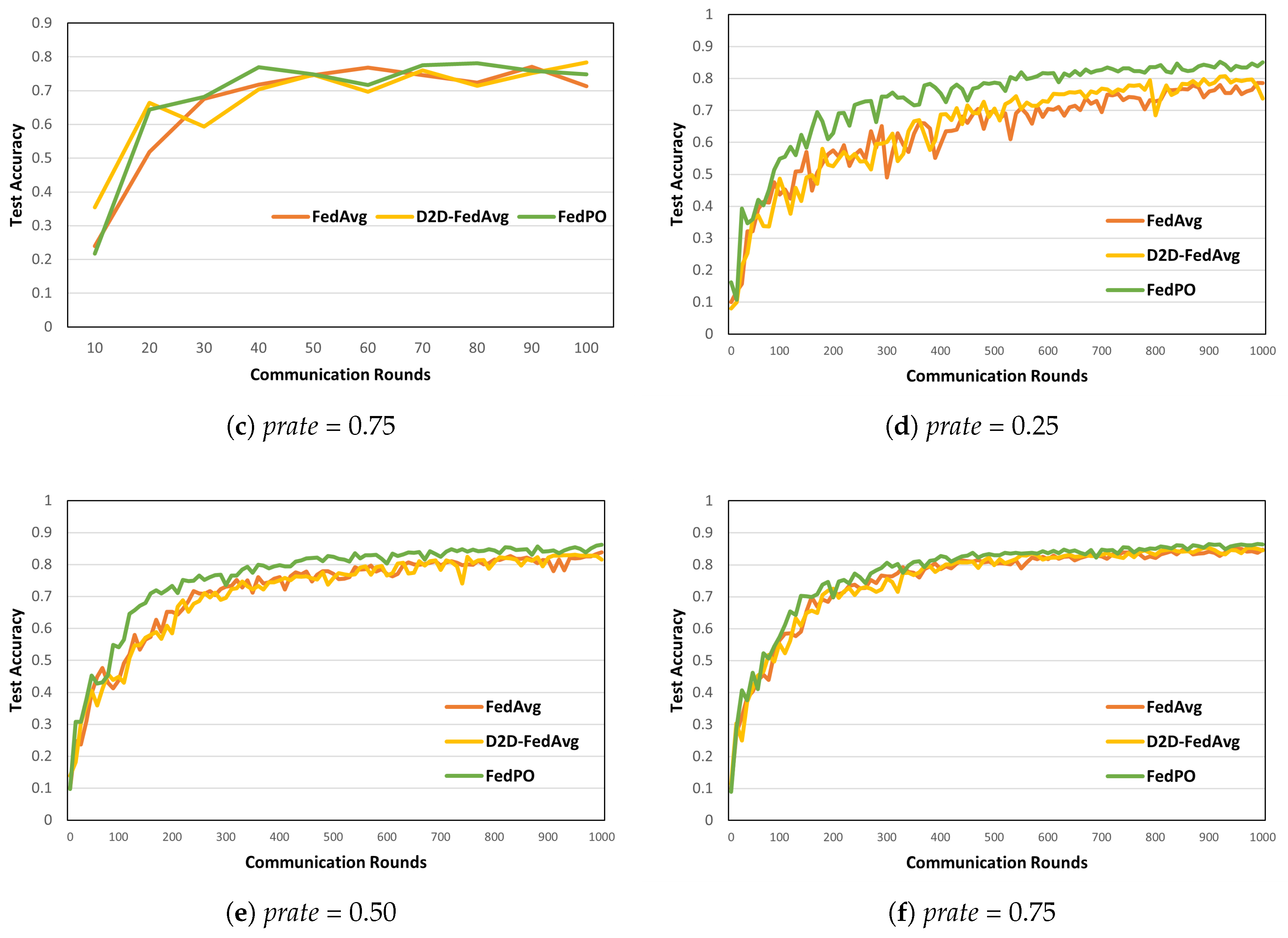
5.2. Simulation Results
6. Conclusions and Future Work
- Considering the effect of environmental factors on the FL performance: future work can be aimed at examining the effects of factors such as communication instability, network disconnection, and device heterogeneity on the FL performance.
- Optimizing the clustering approach: when selecting the threshold for k-means clustering, other factors affecting the model convergence, such as the data distribution and number of clusters, can be considered.
- Evaluating the performance of the proposed approach in real-world scenarios: The experiments in this study are conducted in simulated environments. In future work, the performance of the proposed approach can be evaluated in real-world settings to assess its practicality and effectiveness.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Taylor, R.; Baron, D.; Schmidt, D. The world in 2025-predictions for the next ten years. In Proceedings of the 2015 10th International Microsystems, Packaging, Assembly and Circuits Technology Conference (IMPACT), Taipei, Taiwan, 21–23 October 2015; IEEE: Piscateville, NJ, USA, 2015; pp. 192–195. [Google Scholar]
- Chiang, M.; Zhang, T. Fog and IoT: An overview of research opportunities. IEEE Internet Things J. 2016, 3, 854–864. [Google Scholar] [CrossRef]
- Gaff, B.M.; Sussman, H.E.; Geetter, J. Privacy and big data. Computer 2014, 47, 7–9. [Google Scholar] [CrossRef]
- Wang, S.; Tuor, T.; Salonidis, T.; Leung, K.K.; Makaya, C.; He, T.; Chan, K. When edge meets learning: Adaptive control for resource-constrained distributed machine learning. In Proceedings of the IEEE INFOCOM 2018-IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; IEEE: Piscateville, NJ, USA, 2018; pp. 63–71. [Google Scholar]
- Konečnỳ, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- Duan, Q.; Huang, J.; Hu, S.; Deng, R.; Lu, Z.; Yu, S. Combining Federated Learning and Edge Computing Toward Ubiquitous Intelligence in 6G Network: Challenges, Recent Advances, and Future Directions. IEEE Commun. Surv. Tutor. 2023, 25, 2892–2950. [Google Scholar] [CrossRef]
- Bonawitz, K.; Eichner, H.; Grieskamp, W.; Huba, D.; Ingerman, A.; Ivanov, V.; Kiddon, C.; Konečnỳ, J.; Mazzocchi, S.; McMahan, B.; et al. Towards federated learning at scale: System design. Proc. Mach. Learn. Syst. 2019, 1, 374–388. [Google Scholar]
- Chilimbi, T.; Suzue, Y.; Apacible, J.; Kalyanaraman, K. Project adam: Building an efficient and scalable deep learning training system. In Proceedings of the 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI 14), Broomfield, CO, USA, 6–8 October 2014; pp. 571–582. [Google Scholar]
- Jameel, F.; Hamid, Z.; Jabeen, F.; Zeadally, S.; Javed, M.A. A survey of device-to-device communications: Research issues and challenges. IEEE Commun. Surv. Tutor. 2018, 20, 2133–2168. [Google Scholar] [CrossRef]
- Jung, J.P.; Ko, Y.B.; Lim, S.H. Resource Efficient Cluster-Based Federated Learning for D2D Communications. In Proceedings of the 2022 IEEE 95th Vehicular Technology Conference: (VTC2022-Spring), Helsinki, Finland, 19–22 June 2022; IEEE: Piscateville, NJ, USA, 2022; pp. 1–5. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A.Y. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, PMLR, Ft. Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Xie, C.; Koyejo, S.; Gupta, I. Asynchronous Federated Optimization. arXiv 2019, arXiv:1903.03934. [Google Scholar] [CrossRef]
- Li, X.; Huang, K.; Yang, W.; Wang, S.; Zhang, Z. On the convergence of fedavg on non-iid data. arXiv 2019, arXiv:1907.02189. [Google Scholar]
- Cho, Y.J.; Wang, J.; Joshi, G. Client selection in federated learning: Convergence analysis and power-of-choice selection strategies. arXiv 2020, arXiv:2010.01243. [Google Scholar]
- Nishio, T.; Yonetani, R. Client selection for federated learning with heterogeneous resources in mobile edge. In Proceedings of the ICC 2019-2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; IEEE: Piscateville, NJ, USA, 2019; pp. 1–7. [Google Scholar]
- Reisizadeh, A.; Tziotis, I.; Hassani, H.; Mokhtari, A.; Pedarsani, R. Straggler-resilient federated learning: Leveraging the interplay between statistical accuracy and system heterogeneity. IEEE J. Sel. Areas Inf. Theory 2022, 3, 197–205. [Google Scholar] [CrossRef]
- Wang, Z.; Xu, H.; Liu, J.; Huang, H.; Qiao, C.; Zhao, Y. Resource-efficient federated learning with hierarchical aggregation in edge computing. In Proceedings of the IEEE INFOCOM 2021-IEEE Conference on Computer Communications, Vancouver, BC, Canada, 10–13 May 2021; IEEE: Piscateville, NJ, USA, 2021; pp. 1–10. [Google Scholar]
- Lim, W.Y.B.; Ng, J.S.; Xiong, Z.; Niyato, D.; Miao, C.; Kim, D.I. Dynamic edge association and resource allocation in self-organizing hierarchical federated learning networks. IEEE J. Sel. Areas Commun. 2021, 39, 3640–3653. [Google Scholar] [CrossRef]
- De Rango, F.; Guerrieri, A.; Raimondo, P.; Spezzano, G. HED-FL: A hierarchical, energy efficient, and dynamic approach for edge Federated Learning. Pervasive Mob. Comput. 2023, 92, 101804. [Google Scholar] [CrossRef]
- Gong, W.; Pang, L.; Wang, J.; Xia, M.; Zhang, Y. A social-aware K means clustering algorithm for D2D multicast communication under SDN architecture. AEU-Int. J. Electron. Commun. 2021, 132, 153610. [Google Scholar] [CrossRef]
- Son, D.J.; Yu, C.H.; Kim, D.I. Resource allocation based on clustering for D2D communications in underlaying cellular networks. In Proceedings of the 2014 International Conference on Information and Communication Technology Convergence (ICTC), Busan, Republic of Korea, 22–24 October 2014; IEEE: Piscateville, NJ, USA, 2014; pp. 232–237. [Google Scholar]
- Zhang, X.; Liu, Y.; Liu, J.; Argyriou, A.; Han, Y. D2D-assisted federated learning in mobile edge computing networks. In Proceedings of the 2021 IEEE Wireless Communications and Networking Conference (WCNC), Nanjing, China, 29 March–1 April 2021; IEEE: Piscateville, NJ, USA, 2021; pp. 1–7. [Google Scholar]
- Sun, Y.; Shao, J.; Mao, Y.; Wang, J.H.; Zhang, J. Semi-Decentralized Federated Edge Learning for Fast Convergence on Non-IID Data. In Proceedings of the 2022 IEEE Wireless Communications and Networking Conference (WCNC), Austin, TX, USA, 10–13 April 2022; pp. 1898–1903. [Google Scholar] [CrossRef]
- Lin, F.P.C.; Hosseinalipour, S.; Azam, S.S.; Brinton, C.G.; Michelusi, N. Semi-Decentralized Federated Learning With Cooperative D2D Local Model Aggregations. IEEE J. Sel. Areas Commun. 2021, 39, 3851–3869. [Google Scholar] [CrossRef]
- Xing, H.; Simeone, O.; Bi, S. Decentralized federated learning via SGD over wireless D2D networks. In Proceedings of the 2020 IEEE 21st International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Virtual, 26–29 May 2020; IEEE: Piscateville, NJ, USA, 2020; pp. 1–5. [Google Scholar]
- Meng, Z.; Xu, H.; Chen, M.; Xu, Y.; Zhao, Y.; Qiao, C. Learning-driven decentralized machine learning in resource-constrained wireless edge computing. In Proceedings of the IEEE INFOCOM 2021-IEEE Conference on Computer Communications, Vancouver, BC, Canada, 10–13 May 2021; IEEE: Piscateville, NJ, USA, 2021; pp. 1–10. [Google Scholar]
- Cui, S.; Pan, W.; Liang, J.; Zhang, C.; Wang, F. Addressing algorithmic disparity and performance inconsistency in federated learning. Adv. Neural Inf. Process. Syst. 2021, 34, 26091–26102. [Google Scholar]
- Hu, Z.; Shaloudegi, K.; Zhang, G.; Yu, Y. Federated learning meets multi-objective optimization. IEEE Trans. Netw. Sci. Eng. 2022, 9, 2039–2051. [Google Scholar] [CrossRef]
- Chinchuluun, A.; Karakitsiou, A.; Mavrommati, A. Pareto optimality. In Pareto Optimality, Game Theory and Equilibria; Springer: Berlin/Heidelberg, Germany, 2008; pp. 481–512. [Google Scholar]
- Van Veldhuizen, D.A.; Lamont, G.B. Evolutionary computation and convergence to a pareto front. In Proceedings of the Late Breaking Papers at the Genetic Programming 1998 Conference, Madison, WI, USA, 22–25 July 1998; Citeseer: Pittsburgh, PA, USA, 1998; pp. 221–228. [Google Scholar]
- Wang, S.; Tuor, T.; Salonidis, T.; Leung, K.K.; Makaya, C.; He, T.; Chan, K. Adaptive federated learning in resource constrained edge computing systems. IEEE J. Sel. Areas Commun. 2019, 37, 1205–1221. [Google Scholar] [CrossRef]
- Ding, H.; Ma, S.; Xing, C. Feasible D2D communication distance in D2D-enabled cellular networks. In Proceedings of the 2014 IEEE International Conference on Communication Systems, Macau, China, 19–21 November 2014; IEEE: Piscateville, NJ, USA, 2014; pp. 1–5. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Communication Method | Hierarchical Architecture | Client Selection |
|---|---|---|---|
| FedAvg [11] | central | ||
| FedAsync [12] | central | ||
| POWER-OF-CHOICE Strategy [14] | central | ✓ | |
| FedCS [15] | central | ✓ | |
| HFL [17,18,19] | ✓ | ||
| D2D-assisted hierarchical FL [22] | D2D | ✓ | |
| SD-FEEL [23] | Edge Server | ||
| TT-HF [24] | D2D | ||
| P2P FL [26] | P2P | ||
| FedPO | D2D | ✓ | ✓ |
| Parameter | Value |
|---|---|
| Number of clients | 100 |
| Max. transmit power of the client, | 23 dBm |
| Noise power level | −174 dBm/Hz |
| Transmit power of the parameter server | 43 dBm |
| Maximum distance between LC and clients | 200 m |
| Schemes | Prate | Transmitted (%) | Received (%) |
|---|---|---|---|
| FedAvg | 0.25 | 100 | 28.12 |
| 0.50 | - | 70.65 | |
| 0.75 | - | 100 | |
| D2D-FedAvg | 0.25 | 23.57 | 20.94 |
| 0.50 | 28.05 | 21.63 | |
| 0.75 | 37.99 | 22.37 | |
| FedPO | 0.25 | 23.73 | 21.09 |
| 0.50 | 23.67 | 21.23 | |
| 0.75 | 24.11 | 21.27 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jung, J.-P.; Ko, Y.-B.; Lim, S.-H. Federated Learning with Pareto Optimality for Resource Efficiency and Fast Model Convergence in Mobile Environments. Sensors 2024, 24, 2476. https://doi.org/10.3390/s24082476
Jung J-P, Ko Y-B, Lim S-H. Federated Learning with Pareto Optimality for Resource Efficiency and Fast Model Convergence in Mobile Environments. Sensors. 2024; 24(8):2476. https://doi.org/10.3390/s24082476
Chicago/Turabian StyleJung, June-Pyo, Young-Bae Ko, and Sung-Hwa Lim. 2024. "Federated Learning with Pareto Optimality for Resource Efficiency and Fast Model Convergence in Mobile Environments" Sensors 24, no. 8: 2476. https://doi.org/10.3390/s24082476
APA StyleJung, J.-P., Ko, Y.-B., & Lim, S.-H. (2024). Federated Learning with Pareto Optimality for Resource Efficiency and Fast Model Convergence in Mobile Environments. Sensors, 24(8), 2476. https://doi.org/10.3390/s24082476