Adopting Graph Neural Networks to Analyze Human–Object Interactions for Inferring Activities of Daily Living



Abstract
1. Introduction
- Designing a conceptual framework to construct graph-based data by image frames to infer the ADL within assisting at-home applications.
- Proposing a GNN architecture to jointly predict environmental objects and ADL by comprehending the relational data.
- Enhancing the prediction accuracy of ADL and environmental objects by aggregating the encoded information from the semantics of relational data.
2. Related Work
2.1. Background of GNN
2.2. GNN to Cope with HAR and ADL
2.3. Applying Relational Data to Scene Understanding
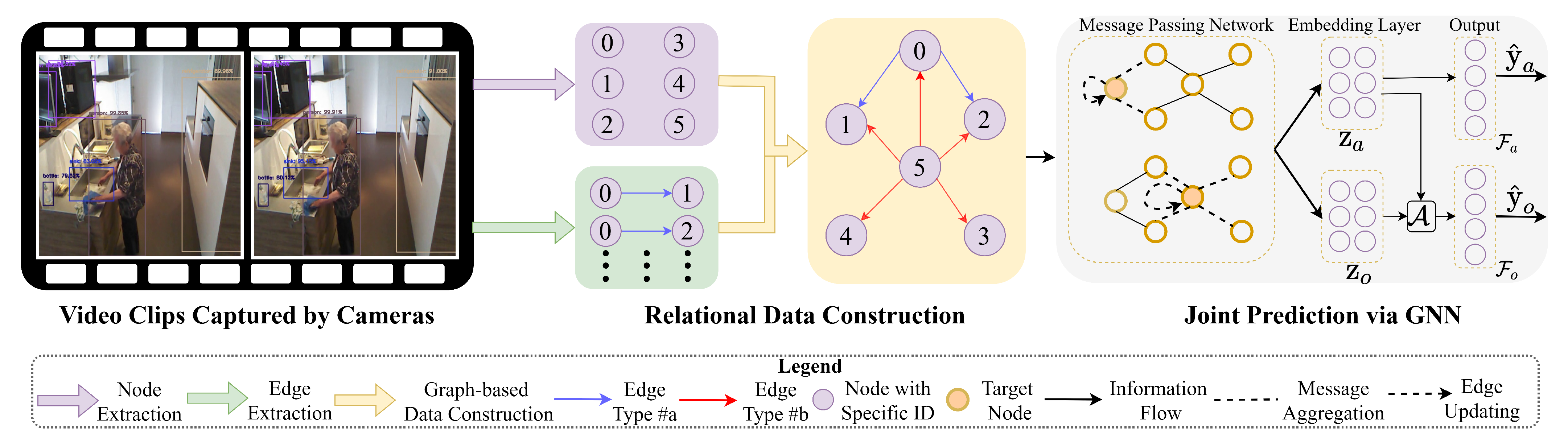
3. Methodology
3.1. Relational Data Construction
3.1.1. Node Extraction
3.1.2. Edge Extraction
3.2. Joint Prediction via GNN
3.2.1. Message-Passing Phase
3.2.2. Readout Phase
4. Case Study
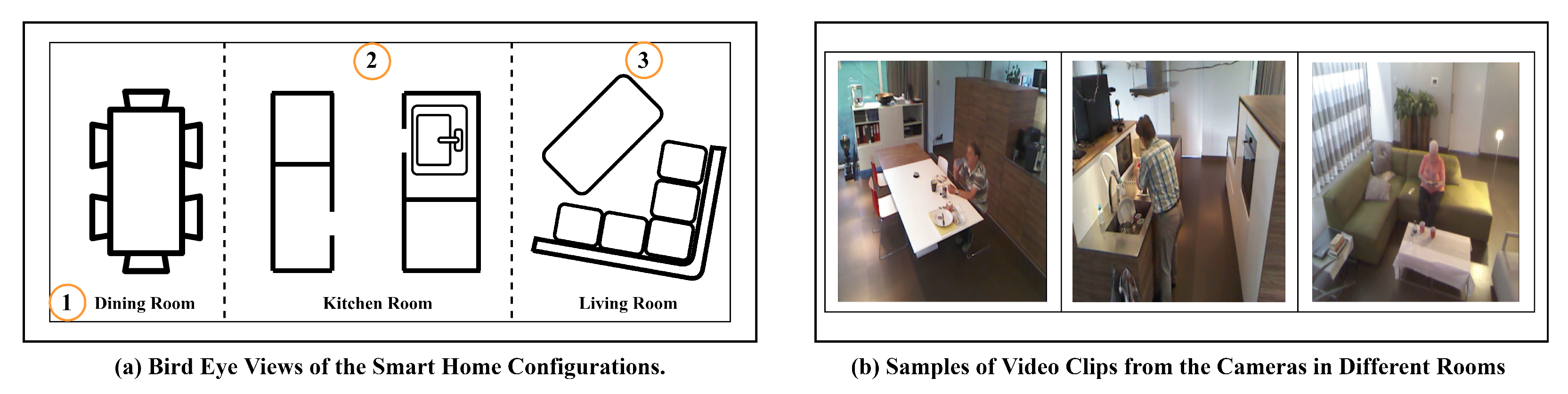
4.1. Overview of Toyota Dataset
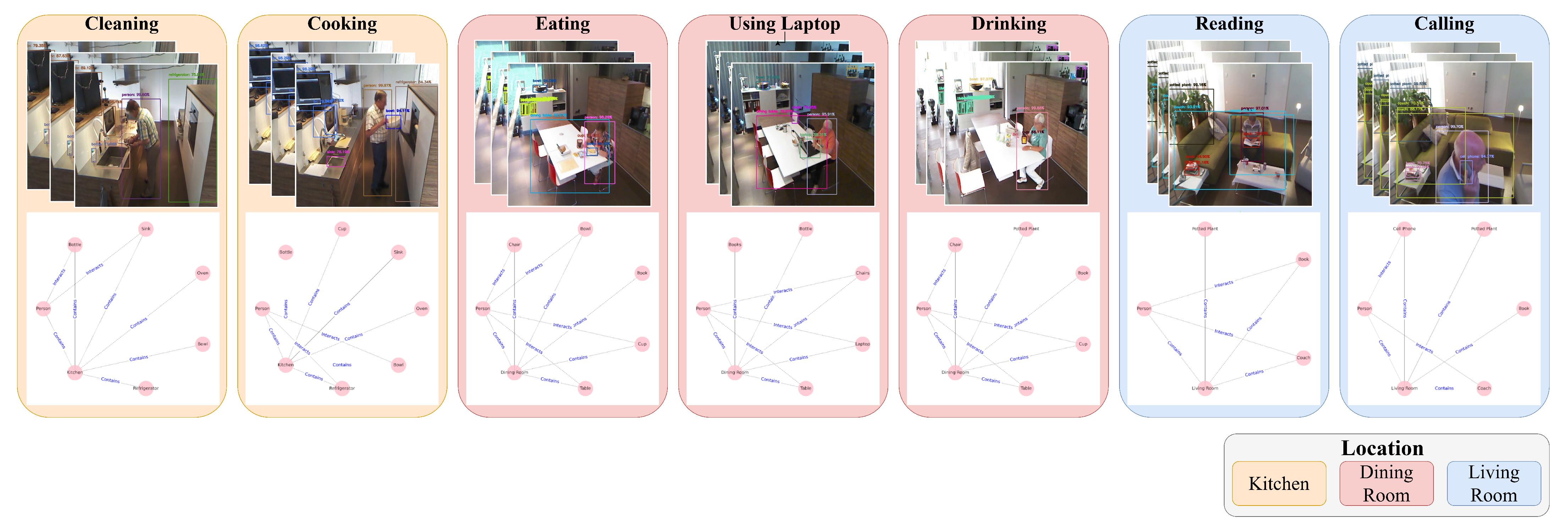
4.2. Constructing Relational Data
4.3. Implementing Joint Prediction via GNN
4.4. Ablation Study
5. Discussion and Future Work
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, S.; Li, Y.; Zhang, S.; Shahabi, F.; Xia, S.; Deng, Y.; Alshurafa, N. Deep learning in human activity recognition with wearable sensors: A review on advances. Sensors 2022, 22, 1476. [Google Scholar] [CrossRef]
- Petrich, L.; Jin, J.; Dehghan, M.; Jagersand, M. A quantitative analysis of activities of daily living: Insights into improving functional independence with assistive robotics. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; IEEE: Piscateville, NJ, USA, 2022; pp. 6999–7006. [Google Scholar]
- Masud, M.T.; Mamun, M.A.; Thapa, K.; Lee, D.; Griffiths, M.D.; Yang, S.H. Unobtrusive monitoring of behavior and movement patterns to detect clinical depression severity level via smartphone. J. Biomed. Inform. 2020, 103, 103371. [Google Scholar] [CrossRef]
- Johnson, D.O.; Cuijpers, R.H.; Juola, J.F.; Torta, E.; Simonov, M.; Frisiello, A.; Bazzani, M.; Yan, W.; Weber, C.; Wermter, S.; et al. Socially assistive robots: A comprehensive approach to extending independent living. Int. J. Soc. Robot. 2014, 6, 195–211. [Google Scholar] [CrossRef]
- Chen, K.; Zhang, D.; Yao, L.; Guo, B.; Yu, Z.; Liu, Y. Deep learning for sensor-based human activity recognition: Overview, challenges, and opportunities. ACM Comput. Surv. 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Ferrari, A.; Micucci, D.; Mobilio, M.; Napoletano, P. Deep learning and model personalization in sensor-based human activity recognition. J. Reliab. Intell. Environ. 2023, 9, 27–39. [Google Scholar] [CrossRef]
- Borkar, P.; Wankhede, V.A.; Mane, D.T.; Limkar, S.; Ramesh, J.; Ajani, S.N. Deep learning and image processing-based early detection of Alzheimer disease in cognitively normal individuals. Soft Comput. 2023. [Google Scholar] [CrossRef]
- Munea, T.L.; Jembre, Y.Z.; Weldegebriel, H.T.; Chen, L.; Huang, C.; Yang, C. The progress of human pose estimation: A survey and taxonomy of models applied in 2D human pose estimation. IEEE Access 2020, 8, 133330–133348. [Google Scholar] [CrossRef]
- Zheng, C.; Wu, W.; Chen, C.; Yang, T.; Zhu, S.; Shen, J.; Kehtarnavaz, N.; Shah, M. Deep learning-based human pose estimation: A survey. ACM Comput. Surv. 2023, 56, 1–37. [Google Scholar] [CrossRef]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3. 6m: Large scale datasets and predictive methods for 3d human sensing in natural environments. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1325–1339. [Google Scholar] [CrossRef]
- Mandery, C.; Terlemez, Ö.; Do, M.; Vahrenkamp, N.; Asfour, T. Unifying representations and large-scale whole-body motion databases for studying human motion. IEEE Trans. Robot. 2016, 32, 796–809. [Google Scholar] [CrossRef]
- Toshev, A.; Szegedy, C. Deeppose: Human pose estimation via deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1653–1660. [Google Scholar]
- Duan, H.; Zhao, Y.; Chen, K.; Lin, D.; Dai, B. Revisiting skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2969–2978. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 12026–12035. [Google Scholar]
- Ma, Y.; Wang, Y.; Wu, Y.; Lyu, Z.; Chen, S.; Li, X.; Qiao, Y. Visual knowledge graph for human action reasoning in videos. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 4132–4141. [Google Scholar]
- Das, S.; Dai, R.; Koperski, M.; Minciullo, L.; Garattoni, L.; Bremond, F.; Francesca, G. Toyota smarthome: Real-world activities of daily living. In Proceedings of the IEEE/CVF international Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 833–842. [Google Scholar]
- Su, P.; Chen, D. Using fault injection for the training of functions to detect soft errors of dnns in automotive vehicles. In Proceedings of the International Conference on Dependability and Complex Systems, Wrocław, Poland, 27 June–1 July 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 308–318. [Google Scholar]
- Su, P.; Warg, F.; Chen, D. A simulation-aided approach to safety analysis of learning-enabled components in automated driving systems. In Proceedings of the 2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC), Bilbao, Spain, 24–28 September 2023; IEEE: Piscateville, NJ, USA, 2023; pp. 6152–6157. [Google Scholar]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Liu, Z.; Zhou, J. Introduction to Graph Neural Networks; Springer Nature: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Yang, Z.; Cohen, W.; Salakhudinov, R. Revisiting semi-supervised learning with graph embeddings. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 20–22 June 2016; pp. 40–48. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Berg, R.v.d.; Kipf, T.N.; Welling, M. Graph convolutional matrix completion. arXiv 2017, arXiv:1706.02263. [Google Scholar]
- Ahmad, T.; Jin, L.; Zhang, X.; Lai, S.; Tang, G.; Lin, L. Graph convolutional neural network for human action recognition: A comprehensive survey. IEEE Trans. Artif. Intell. 2021, 2, 128–145. [Google Scholar] [CrossRef]
- Elias, P.; Sedmidubsky, J.; Zezula, P. Understanding the gap between 2D and 3D skeleton-based action recognition. In Proceedings of the 2019 IEEE International Symposium on Multimedia (ISM), San Diego, CA, USA, 9–11 December 2019; IEEE: Piscateville, NJ, USA, 2019; pp. 192–1923. [Google Scholar]
- Liu, Y.; Zhang, H.; Xu, D.; He, K. Graph transformer network with temporal kernel attention for skeleton-based action recognition. Knowl.-Based Syst. 2022, 240, 108146. [Google Scholar] [CrossRef]
- Li, B.; Li, X.; Zhang, Z.; Wu, F. Spatio-temporal graph routing for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 29–31 January 2019; Volume 33, pp. 8561–8568. [Google Scholar]
- Tasnim, N.; Baek, J.H. Dynamic edge convolutional neural network for skeleton-based human action recognition. Sensors 2023, 23, 778. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, H.; Li, Y.; He, K.; Xu, D. Skeleton-based human action recognition via large-kernel attention graph convolutional network. IEEE Trans. Vis. Comput. Graph. 2023, 29, 2575–2585. [Google Scholar] [CrossRef] [PubMed]
- Wu, L.; Zhang, C.; Zou, Y. SpatioTemporal focus for skeleton-based action recognition. Pattern Recognit. 2023, 136, 109231. [Google Scholar] [CrossRef]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.J.; Shamma, D.A.; et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef]
- Yang, J.; Lu, J.; Lee, S.; Batra, D.; Parikh, D. Graph r-cnn for scene graph generation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 670–685. [Google Scholar]
- Tang, K.; Niu, Y.; Huang, J.; Shi, J.; Zhang, H. Unbiased scene graph generation from biased training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3716–3725. [Google Scholar]
- Yu, S.Y.; Malawade, A.V.; Muthirayan, D.; Khargonekar, P.P.; Al Faruque, M.A. Scene-graph augmented data-driven risk assessment of autonomous vehicle decisions. IEEE Trans. Intell. Transp. Syst. 2021, 23, 7941–7951. [Google Scholar] [CrossRef]
- Jin, K.; Wang, H.; Liu, C.; Zhai, Y.; Tang, L. Graph neural network based relation learning for abnormal perception information detection in self-driving scenarios. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; IEEE: Piscateville, NJ, USA, 2022; pp. 8943–8949. [Google Scholar]
- Mylavarapu, S.; Sandhu, M.; Vijayan, P.; Krishna, K.M.; Ravindran, B.; Namboodiri, A. Understanding dynamic scenes using graph convolution networks. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; IEEE: Piscateville, NJ, USA, 2020; pp. 8279–8286. [Google Scholar]
- Chang, Y.; Zhou, W.; Cai, H.; Fan, W.; Hu, L.; Wen, J. Meta-relation assisted knowledge-aware coupled graph neural network for recommendation. Inf. Process. Manag. 2023, 60, 103353. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, F.; Zhang, M.; Leskovec, J.; Zhao, M.; Li, W.; Wang, Z. Knowledge-aware graph neural networks with label smoothness regularization for recommender systems. In Proceedings of the 25th International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 968–977. [Google Scholar]
- Gilmer, J.; Schoenholz, S.S.; Riley, P.F.; Vinyals, O.; Dahl, G.E. Neural message passing for quantum chemistry. In Proceedings of the International conference on machine learning. PMLR, Sydney, Australia, 6–11 August 2017; pp. 1263–1272. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017. [Google Scholar]
- Zhu, Z.; Su, P.; Zhong, S.; Huang, J.; Ottikkutti, S.; Tahmasebi, K.N.; Zou, Z.; Zheng, L.; Chen, D. Using a vae-som architecture for anomaly detection of flexible sensors in limb prosthesis. J. Ind. Inf. Integr. 2023, 35, 100490. [Google Scholar] [CrossRef]
- Su, P.; Lu, Z.; Chen, D. Combining Self-Organizing Map with Reinforcement Learning for Multivariate Time Series Anomaly Detection. In Proceedings of the 2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Hyatt Regency Maui, HI, USA, 1–4 October 2023; IEEE: Piscateville, NJ, USA, 2023; pp. 1964–1969. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| MLP | GNN-Based Methods | ||||
|---|---|---|---|---|---|
| Our Method | Att-GNN | JP-GNN | S-GNN | ||
| Activities Inference | 0.49 | 0.88 | 0.82 | 0.83 | 0.86 |
| Objects Inference | 0.56 | 0.77 | 0.65 | 0.71 | 0.68 |
| Reading | Cooking | Cleaning | Eating | Drinking | Using Laptop | Calling | Wathcing TV | Average | |
|---|---|---|---|---|---|---|---|---|---|
| Precision | 0.94 | 0.71 | 0.75 | 0.89 | 0.78 | 0.95 | 0.90 | 0.92 | 0.86 |
| Recall | 0.66 | 0.63 | 0.67 | 0.72 | 0.84 | 0.91 | 0.91 | 0.83 | 0.77 |
| F1-Score | 0.77 | 0.67 | 0.71 | 0.85 | 0.81 | 0.93 | 0.90 | 0.87 | 0.81 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, P.; Chen, D. Adopting Graph Neural Networks to Analyze Human–Object Interactions for Inferring Activities of Daily Living. Sensors 2024, 24, 2567. https://doi.org/10.3390/s24082567
Su P, Chen D. Adopting Graph Neural Networks to Analyze Human–Object Interactions for Inferring Activities of Daily Living. Sensors. 2024; 24(8):2567. https://doi.org/10.3390/s24082567
Chicago/Turabian StyleSu, Peng, and Dejiu Chen. 2024. "Adopting Graph Neural Networks to Analyze Human–Object Interactions for Inferring Activities of Daily Living" Sensors 24, no. 8: 2567. https://doi.org/10.3390/s24082567
APA StyleSu, P., & Chen, D. (2024). Adopting Graph Neural Networks to Analyze Human–Object Interactions for Inferring Activities of Daily Living. Sensors, 24(8), 2567. https://doi.org/10.3390/s24082567