Abstract
The threat posed by adversarial examples (AEs) to deep learning applications has garnered significant attention from the academic community. In response, various defense strategies have been proposed, including adversarial example detection. A range of detection algorithms has been developed to differentiate between benign samples and adversarial examples. However, the detection accuracy of these algorithms is significantly influenced by the characteristics of the adversarial attacks, such as attack type and intensity. Furthermore, the impact of image preprocessing on detection robustness—a common step before adversarial example generation—has been largely overlooked in prior research. To address these challenges, this paper introduces a novel adversarial example detection algorithm based on high-level feature differences (HFDs), which is specifically designed to improve robustness against both attacks and preprocessing operations. For each test image, a counterpart image with the same predicted label is randomly selected from the training dataset. The high-level features of both images are extracted using an encoder and compared through a similarity measurement model. If the feature similarity is low, the test image is classified as an adversarial example. The proposed method was evaluated for detection accuracy against four comparison methods, showing significant improvements over FS, DF, and MD, with a performance comparable to ESRM. Therefore, the subsequent robustness experiments focused exclusively on ESRM. Our results demonstrate that the proposed method exhibits superior robustness against preprocessing operations, such as downsampling and common corruptions, applied by attackers before generating adversarial examples. It is also applicable to various target models. By exploiting semantic conflicts in high-level features between clean and adversarial examples with the same predicted label, the method achieves high detection accuracy across diverse attack types while maintaining resilience to preprocessing, providing a valuable new perspective in the design of adversarial example detection algorithms.
1. Introduction
The opacity and vulnerability of deep learning models present significant risks, leading to various malicious attacks targeting these applications. The primary threats include model extraction, data poisoning, and adversarial example attacks. Adversarial examples [1,2], first introduced by Szegedy et al., involve the addition of carefully crafted, imperceptible perturbations to original samples, causing models to produce incorrect outputs. Notably, these adversarial examples can often transfer across different models, a phenomenon known as cross-model transferability. This issue arises not only in straightforward tasks, like image classification, but also in more complex applications, such as image segmentation [3] and autonomous driving [4], thus posing substantial challenges to the deployment of deep learning systems.
In response to these threats, a range of defense techniques has emerged. These include robust model architectures designed before the training phase, adversarial training during the training phase, and adversarial example purification and detection during inference [5]. While adversarial training enhances model robustness, it often compromises performance on clean images and may leave models vulnerable to subsequent attacks [6]. Adversarial example purification aims to eliminate adversarial noise but becomes less effective against stronger attacks [7]. Conversely, adversarial example detection offers a flexible solution that operates without modifying the original network architecture, ensuring both efficiency and time-saving benefits [8].
Adversarial example detection algorithms are broadly categorized into supervised and unsupervised methods, depending on their use of adversarial data [9]. Detection techniques include statistical differences, feature differences, input transformations, and reconstruction-based approaches.
Statistical-based detection: These methods often use supervised learning, as in Liu et al.’s steganalysis-based algorithm ESRM [10], which employs steganographic features and a binary classifier to detect adversarial perturbations. However, its detection accuracy declines significantly with lower-intensity attacks or optimization-based attacks.
Feature-based detection: By analyzing feature differences across network layers, both supervised [11,12] and unsupervised [13] approaches can classify adversarial examples. These methods [11,12] train binary classifiers using various metrics, like local intrinsic dimensionality (LID) and Mahalanobis distance (MD). However, LID estimation may introduce bias in sparse or high-dimensional spaces, while Mahalanobis distance is computationally intensive due to its dependence on training set statistics. In contrast, this method [13] clusters intermediate layer features within the network, allowing for more efficient unsupervised detection of diverse adversarial types.
Input transformation-based detection: This category identifies adversarial examples by applying transformations (e.g., denoising, compression, smoothing) and comparing model outputs for original and transformed inputs. These methods, often unsupervised, exploit adversarial sensitivity to such transformations [8,14]. For instance, the FS method [8] uses threshold-based distances between predictions pre- and post-transformation and is effective for lower-intensity attacks but less so for stronger ones. The DF method [14] applies scalar quantization and smoothing filters, adjusting parameters with image entropy, although its limited filter capacity can reduce the detection accuracy against high-intensity attacks.
Reconstruction-based detection: These methods typically rely on autoencoders or generative models to detect adversarial examples via reconstruction error analysis. For instance, CMAG [15] outperforms Fence FGAN [16] and UADD-GAN [17] by effectively identifying high-quality adversarial samples, though its basic autoencoder may struggle with complex data. ContraNet [18] leverages semantic inconsistencies between inputs and reconstructed images. Its architecture includes an encoder, conditional generator, and similarity measurement model to detect adversarial examples by comparing original images with generated reconstructions.
The field of adversarial example detection encompasses a variety of algorithms, stemming from the absence of a unified theoretical framework governing the generation mechanisms of adversarial examples. Approaches, such as ESRM, FS, and DF, concentrate on the pixel space of images, interpreting adversarial perturbations as forms of steganography or unique noise patterns. Consequently, these methods devise detection algorithms rooted in the analysis of the image space. In contrast, MD shifts its focus to the features extracted by deep neural networks, exploiting the discrepancies between clean images and adversarial counterparts within the feature space to identify adversarial examples. Meanwhile, ContraNet adopts a distinct strategy by leveraging the dissimilarity between an adversarial image and a clean image, where the clean image is generated by projecting the discriminative features of the adversarial image extracted by the DNN back into the input space. This diversity in methodological approaches underscores the complexity and multifaceted nature of adversarial example detection in the realm of deep learning.
While these detection methods have demonstrated promising results, their performance is critically constrained by the reliance on either meticulous parameter tuning or sophisticated feature selection, significantly limiting their scalability and practicality in real-world applications. Additionally, the robustness of detection algorithms against preprocessing operations has not received adequate attention, highlighting a critical gap in the current research. The primary objective of this study is to develop an adversarial example detection method that achieves high detection accuracy, exhibits strong robustness to diverse input corruptions, and demonstrates suitability for target models while eliminating the need for extensive manual optimization or complex feature engineering.
Our proposed method is inspired by ContraNet, but it differs in key aspects. Specifically, we leverage high-level feature differences in the examples instead of projecting the high-level feature back into images as in ContraNet. We compare a test example with a clean example selected from the training set with the same predicted label as the test sample, rather than comparing it with a reconstructed sample. This approach eliminates the need for a conditional generative network to reconstruct images, resulting in enhanced computational efficiency and real-time performance. To the best of our knowledge, this represents the first work in the field of adversarial example detection to leverage high-level features from image pairs sharing the same predicted label. In summary, the following contributions are presented:
- This study demonstrates that high-level feature distinctions are sufficient for detecting adversarial examples, providing a novel perspective on AE detection.
- This study proposes a new detection method utilizing a similarity measurement model trained on two types of concatenated high-level feature data, one is from an adversarial example and a clean example sharing the same predicted label, and the other from two clean examples with the same predicted label.
- This study validates the detector’s performance across various attack algorithms and neural network architectures, confirming its robustness against different preprocessing operations.
The remaining of this paper is organized as follows. Section 2 presents a systematic review of three key components integral to our experimental framework: (1) state-of-the-art attacking algorithms, (2) contemporary adversarial example detection methodologies, and (3) prevalent image corruption techniques applied prior to adversarial example generation. Section 3 presents our novel detection approach based on high-level feature differences (HFDs). Then, extensive experiments are conducted in Section 4 to systematically evaluate the performance of our method against different attack types, attack intensities, and preprocessing operations prior to adversarial example generation. Furthermore, the algorithm’s applicability to different target models has also been thoroughly examined. Finally, Section 5 concludes our research findings and outlines potential directions for future work in this domain.
2. Related Work
This section provides a brief overview of the algorithms for generating adversarial examples, existing detection algorithms, and image corruptions that may influence the accuracy of these detection methods.
2.1. Attacking Algorithms
Szegedy et al. [1] were the first to observe that deep neural network (DNN) models are vulnerable to adversarial perturbations. An adversarial example is an input crafted by an adversary to produce an incorrect output from a target machine learning model. Let x be a legitimate image, and y be the corresponding class label. For a well-trained DNN model , . An adversarial attack aims to find an adversarial for x such that . Several techniques have been proposed to find adversarial examples. Below, we present the adversarial attack algorithms employed in our experiments, which encompass a range of strengths and complexities, as well as both white-box and black-box attack scenarios. Specifically, BIM, MI-FGSM, and SINI-FGSM are primarily white-box attacks, with increasing strength and complexity. Among these, MI-FGSM and SINI-FGSM have good transferability, making them effective in black-box settings. AutoAttack is explicitly designed to address both white-box and black-box scenarios, establishing itself as a robust benchmark for evaluating adversarial robustness.
- Fast Gradient Sign Method: FGSM
Goodfellow et al. [2] proposed the fast gradient sign method (FGSM) to efficiently generate adversarial examples. FGSM finds an adversarial example as follows:
where is a constant controlling the maximum perturbation per pixel, denotes the symbolic function, denotes the loss function, and represents the gradient of the loss function with respect to the input .
- 2.
- Basic Iterative Method: BIM
Kurakin et al. [19] extended FGSM to an iterative algorithm, named the basic iterative method (BIM), which applies multiple small-step updates rather than a single-step update along the gradient direction.
- 3.
- Momentum Iterative Fast Gradient Sign Method: MI-FGSM
Dong et al. [20] introduced momentum-based iterative algorithms to improve the transferability of adversarial examples. The momentum iterative fast gradient sign method (MI-FGSM) incorporates a momentum term in each iteration to avoid poor local maxima.
- 4.
- Scale-Invariant Nesterov Iterative Fast Gradient Sign Method: SINI-FGSM
Lin et al. [21] proposed SINI-FGSM, which enhances the traditional iterative FGSM by combining a Nesterov accelerated gradient (NAG) and scale invariance. The NAG improves convergence speed, while scale invariance addresses sensitivity to input scaling, enhancing robustness against defenses that rely on gradient masking or input transformations.
- 5.
- AutoAttack: AA
AutoAttack [22] is an ensemble of parameter-free adversarial attacks designed to reliably assess model robustness. It combines several attacks, including white-box and black-box methods, providing a comprehensive evaluation tool.
2.2. Methods of Adversarial Example Detection Detecting Adversarial Examples
We discuss the adversarial example detection algorithms compared with our proposed algorithm in our experiments. These include two supervised algorithms, i.e., the Mahalanobis distance method and enhanced spatial rich model, and two unsupervised algorithms, i.e., feature squeezing and detection filter.
- Feature Squeezing method: FS
Xu et al. [8] proposed a strategy utilizing feature squeezing to detect adversarial examples. The detector considers an input adversarial if the difference between predictions on the original and squeezed samples exceeds a threshold. Two feature-squeezing methods, namely reducing color bit depth and spatial smoothing, allow effective detection of static adversarial examples.
- 2.
- Mahalanobis Distance method: MD
Lee et al. [12] proposed a method applicable to any pretrained softmax neural classifier, detecting abnormal test samples using a distance-based approach. Under the assumption that class-conditional distributions are Gaussian, the Mahalanobis distance is used to calculate confidence scores, and a two-class classifier is then trained to distinguish clean and adversarial examples.
- 3.
- Enhanced Spatial Rich Model: ESRM
Liu et al. [10] proposed a detection algorithm from the steganalysis point of view. Both adversarial attacks and steganography on images cause perturbations on the pixel values. By modeling the differences between adjacent pixels in natural images, it is possible to identify deviations due to adversarial attacks. The spatial rich model (SRM) with 34,671 features is a kind of steganalysis feature set recommended to detect adversarial examples. A detector was trained with enhanced SRM features to detect adversarial examples.
- 4.
- Detection Filter: DF
Liang et al. [14] treated perturbations as noise and applied scalar quantization and smoothing filters to mitigate their effects. An input is classified as adversarial if the label of the original input differs from the filtered version, without requiring prior knowledge of attack types.
Although the aforementioned adversarial example detection algorithms demonstrate considerable efficacy, it is imperative to underscore that their implementation and optimization constitute a non-trivial endeavor, as their performance critically relies on either meticulous parameter tuning or sophisticated feature selection. Specifically, FS necessitates precise selection of squeezing thresholds, MD demonstrates significant sensitivity to the feature space configuration for distance computation, ESRM demands rigorous feature engineering and feature selection, and DF requires dataset-specific parameter optimization to ensure robust performance.
2.3. Downsampling and Common Corruptions
Before generating adversarial examples, images are typically subjected to preprocessing steps, such as downsampling. Additionally, certain factors, including imaging conditions, image compression, and attacker-driven preprocessing operations, impact image quality. Collectively, these effects are referred to as “common corruptions”. Both downsampling and common corruptions may significantly influence the detection performance of adversarial example detectors. However, the impact of these factors has received limited attention in existing research.
Downsampling is a frequently applied operation in adversarial image generation. To conform to the smaller input dimensions required by neural networks, attackers often downsample images prior to launching an attack. Various adversarial attack frameworks incorporate specific downsampling algorithms, such as the bilinear interpolation utilized by Cleverhans [23] and the nearest-neighbor interpolation employed by EvadeML [8].
In this work, we select six types of corruption from the IMAGENET-C benchmark dataset [24], which is widely used to evaluate the corruption robustness of image classifiers. Gaussian noise, for example, commonly arises in low-lighting conditions, while zoom blur occurs when a camera moves rapidly toward an object. Frost artifacts can form when ice crystals accumulate on lenses or glass surfaces, impairing image clarity. Contrast changes, affected by lighting conditions and object color, may result in either high or low visibility. Elastic transformations deform small regions within an image through localized stretching or contraction. Lastly, JPEG compression, a lossy format, introduces visual artifacts that could influence the detection accuracy of adversarial examples.
3. HFD: Proposed Method
In this section, we detail the proposed HFD design. First, we introduce the motivation behind our design. Then, we depict an overview of HFD’s implementation. Next, we discuss the core component, i.e., the similarity measurement model, as well as its training process. Finally, we provide the detecting process for HFD.
3.1. Design Motivation
Following the common consensus that DNNs are feature extractors or encoders, we analyze adversarial examples from the feature perspective. Adversarial images are generated by adding small-norm perturbations (e.g., or ) that are imperceptible or negligible to humans. While these perturbations are minimal at the pixel level, they amplify as the image propagates through convolutional networks [25], hallucinating non-existent activations in feature maps. This amplification overwhelms true signal activations, causing incorrect predictions [26]. At the same time, revealed that image-dependent adversarial examples include not only the features of the target class, but also the original image features [27].
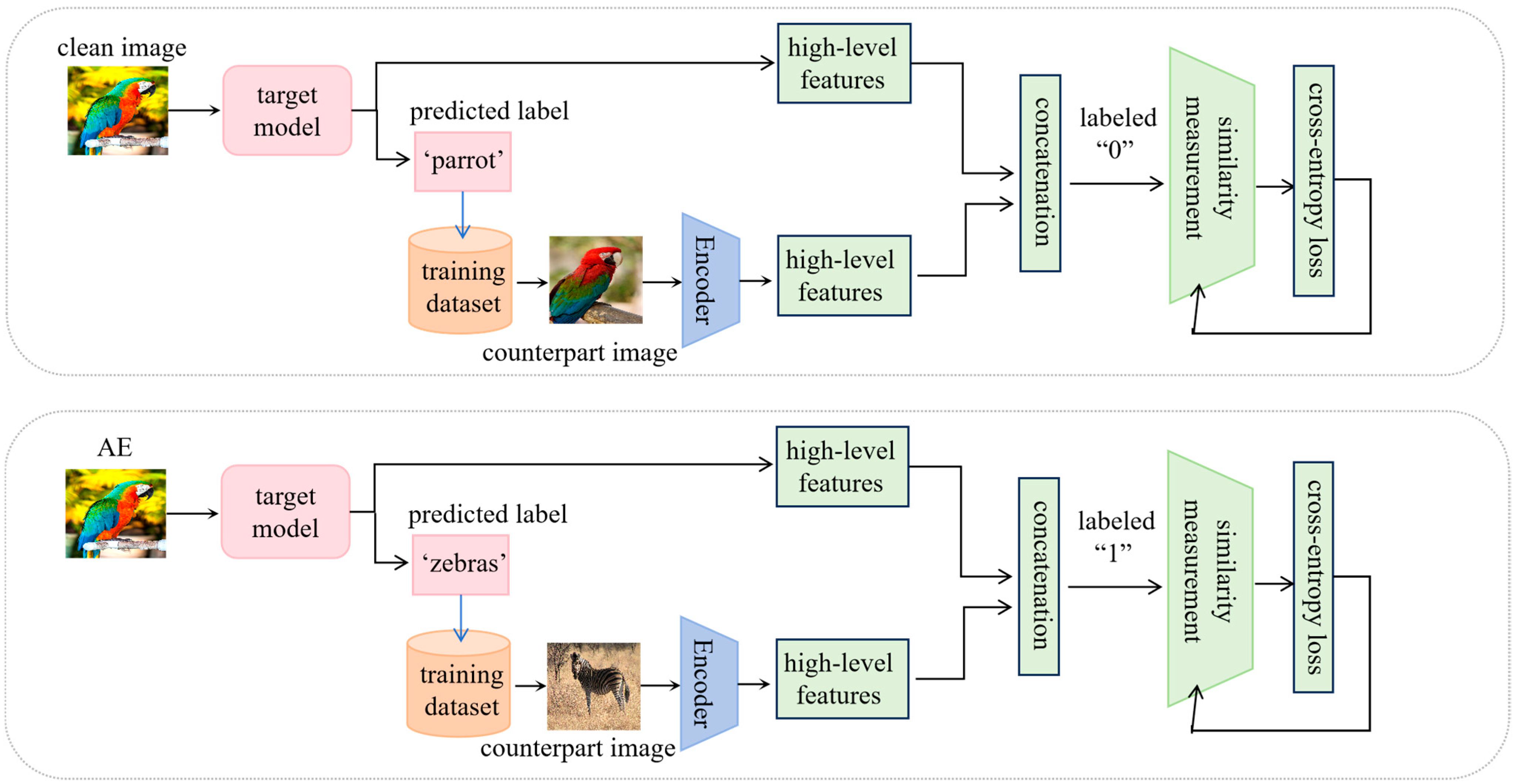
In our work, high-level features are utilized to detect adversarial examples. These features refer to the activations of the final convolutional layer, located just before the fully connected layer. Our design is motivated by the insight that high-level features of an adversarial example and a clean image sharing the same predicted class label exhibit lower similarity compared to a pair of clean images belonging to the same class, as illustrated by Figure 1. Specifically, for a clean image, the high-level features predominantly reflect the ground-truth class characteristics. In contrast, the high-level features of an adversarial example not only incorporate the target class features but also retain residual features from the original class. Consequently, the high-level features of two clean images belonging to the same class are more similar than that of an image pair composed of an adversarial example and a clean example sharing the same predicted label. This distinction enables the training of a binary classifier to differentiate between these two types of image pairs. Since this binary classifier operates based on the similarity of feature pairs, it is termed a similarity measurement model. Such a model could, thus, be utilized for adversarial example detection.
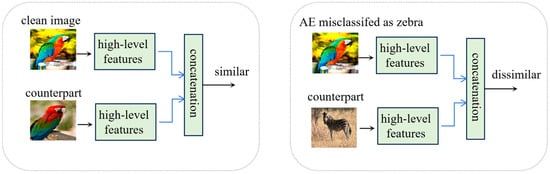
Figure 1.
Two types of high-level features of image pairs: (left) a pair of clean images belonging to the same class ‘parrot’; (right) an adversarial example and a clean image sharing the same predicted class label ‘zebra’.
We opt for high-level features over middle-level features due to the progressive amplification of perturbations as an adversarial image propagates through the network [1]. Specifically, the similarity between the features of an adversarial example and a clean image with the same predicted label increases with deeper layers, making it increasingly challenging to differentiate between the two types of image pairs at higher levels. Therefore, a similarity measurement model must be capable of distinguishing high-level features to effectively detect adversarial examples.
3.2. Implementation Overview
It can be inferred from Figure 1 that HFD should consist of two components, namely an encoder (E) and a similarity measurement model, which is a discriminator (D) to judge an input image is adversarial or not. To be more specific, the encoder E is the target model excluding the last fully connected layer and output layer and is in charge of extracting the high-level features of the input image. The similarity measurement model D measures the similarity of high-level features between the input image and its counterpart , which is randomly picked up from the training set with the same predicted label as .
During inference, given an input , we first obtain the predicted label from the target model and then pick up an image such that . In the following process, the encoder E will retrieve high-level features for the images and , respectively. Lastly, the similarity measurement model will evaluate the similarity between and , to identify AEs. Specifically, for a legitimate input that is correctly inferred, and are similar. Otherwise, for an AE, the high-level features would have low similarity.
3.3. The Similarity Measurement Model
The similarity measurement model D is essentially a binary classifier whose input is the concentrated features of an input image and its counterpart. The output of model D is 1 or 0, representing whether the input image is adversarial or not, respectively. We designed the similarity measurement model in the framework of an MLP (multilayer perception). There are 2 hidden layers, with 3000 and 500 neurons, respectively. The output layer has two neurons. The activation function for all the neurons is a sigmoid function.
The training procedure for the similarity measurement model is depicted in Algorithm 1 and illustrated by Figure 2.
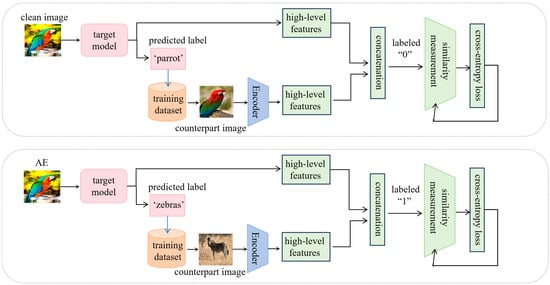
Figure 2.
Training of the similarity measurement model. The top panel shows the training sample of a similarity pair, and the bottom panel shows a difference pair.
| Algorithm 1: Training the similarity measurement model. |
| Input, selection operation Output: the parameters of model D 1: for t = 0 to T-1 do 2: 3: 4: 5: 6: 7: into the Encoder E: 8: construct feature pairs: , labeled as 0; , labeled as 1 9: to model D 10: optimize model D using cross-entropy loss 11: end for |
In this algorithm, the similarity measurement model is trained to measure semantic similarity based on feature pairs of an image and its counterpart. For each benign instance , the target model provides its predicted label . A counterpart image is selected from by the selection operation S, based on the criterion of sharing the same predicted label ; this counterpart is a benign instance and exhibits similar semantics with . An adversarial instance is then generated by perturbing . For , a benign counterpart is also selected by operation S, which shares the same label but has divergent semantics from .
The encoder, which is the target model excluding the last fully connected layer and output layer, extracts high-level features from each instance. Two types of feature pairs are created: (1) a similarity pair (two benign samples belonging to the same class, labeled as 0, top panel of Figure 2); and (2) a difference pair (one benign sample and one adversarial sample with the same predicted label, labeled as 1, bottom panel of Figure 2). These pairs are fed into the similarity measurement model D, which is optimized using cross-entropy loss. A dropout strategy is adopted for the two hidden layers during training. This training approach enables the model to effectively measure semantic similarity for a pair of images with the same predicted labels.
3.4. Detecting Adversarial Examples
The inference procedure is straightforward. Algorithm 2 describes the detecting process of the detector, which is composed of the similarity measurement model D and the encoder E. The process begins by passing the test image through the target model to obtain the predicted label . A counterpart benign image is selected from the training dataset using the selection operation , which ensures that shares the same predicted label as . High-level feature representations for both images and are extracted by the encoder E and then concatenated to form a combined feature vector . This concatenated feature vector is then fed into the similarity measurement model D to produce a binary output, where 1 indicates an adversarial instance and 0 indicates a benign instance.
| Algorithm 2: Detecting adversarial examples. |
| Input: , detector Output: is benign ) 6: if result = 1 7: is adversarial 8: else 9: is benign |
4. Verification
4.1. Experimental Settings
Attacks. Four popular attacks, namely BIM, MI-FGSM, SINI-FGSM, and AutoAttack, are employed to craft adversarial examples to evaluate the proposed detector. The magnitude of adversarial perturbations ϵ is set as 4, 8, and 16, while the other hyperparameters are consistent with the settings in the reference papers.
Datasets. We conduct experiments on subsets of ILSVRC 2012 [28]. The training dataset for the similarity measurement model D is composed of 10,000 images, with 10 randomly selected from each class of the ILSVRC 2012 training set. The clean images to test are chosen from the ILSVRC 2012 test set, with 10 for each class and 10,000 images altogether. Adversarial examples are generated from correctly classified clean images, resulting in 10,000 image pairs for testing the detector.
Target models. For target models, we consider classical convolutional neural networks, including ResNet-50, Inception V3, EfficientNet B0, and ConvNeXt. ResNet-50 [29] is widely adopted due to its balance of depth and efficiency, achieving strong performance across various computer vision tasks. ConvNeXt [30] is a recently proposed advanced convolutional neural network classification model built upon ResNet, incorporating techniques from vision transformers. Inception V3 [31] employs multi-scale feature extraction with parallel convolutional filters. Although it is more computationally intensive, it achieves higher accuracy than ResNet-50. EfficientNet B0 [32] is designed for high accuracy with minimal resources and is highly efficient for mobile and edge devices, featuring only 18 convolutional layers.
Threat model. The defender has access only to information about the target model, with no knowledge of the attacker’s strategy. The adversarial examples used for training the detector are generated exclusively using the BIM algorithm, with the perturbation strength set to ϵ = 4. Retraining of the detector is required only when the target model undergoes changes.
Evaluation metric. The metric should evaluate a detector from two perspectives: (1) the impact on classification accuracy on legitimate samples, and (2) the ability of AE detection. We conventionally denote the adversarial example as the Positive sample and the clean sample as the Negative sample. We define acc as the evaluation metric for the detector. Equation (2) is as follows:
where is the number of the negative samples, is the number of the positive samples, denotes the number of negative samples that passed the detector, and represents the number of positive samples which are rejected by the detector. It is reasonably straightforward to deduce that the acc metric serves as an integral indicator, encapsulating both the true positive rate (TPR) and the false positive rate (FPR). Furthermore, in our experimental setup, we employ the configuration of . Consequently, a high accuracy value inherently implies an elevated TPR coupled with a diminished FPR.
Baselines. We choose four high cited detection-based defense methods as the baselines, including the ESRM (enhanced spatial rich model), FS (feature squeezing), MD (Mahalanobis distance method) and DF (detection filter) approaches. Thanks to their authors, we reproduce their work with officially open-source codes. FS combines three types of squeezers, where the threshold is set for FPR = 5%. For ESRM and MD, 5000 image pairs randomly picked from the test dataset are used to train the binary classifiers, while the remaining pairs are used to evaluate the detectors.
4.2. Detection Accuracy
We evaluate the performance of our method and the baseline detectors on subsets of ILSVRC 2012 with the ResNet-50 classifier. The detector is trained with BIM adversarial examples where ϵ = 4, and it is then used to detect adversarial examples generated from four typical attacks with different magnitudes of disturbance, including BIM, MI-FGSM, SINI-FGSM, and AutoAttack. The experimental settings are listed in Table 1.

Table 1.
Experimental settings for the detection accuracy experiment.
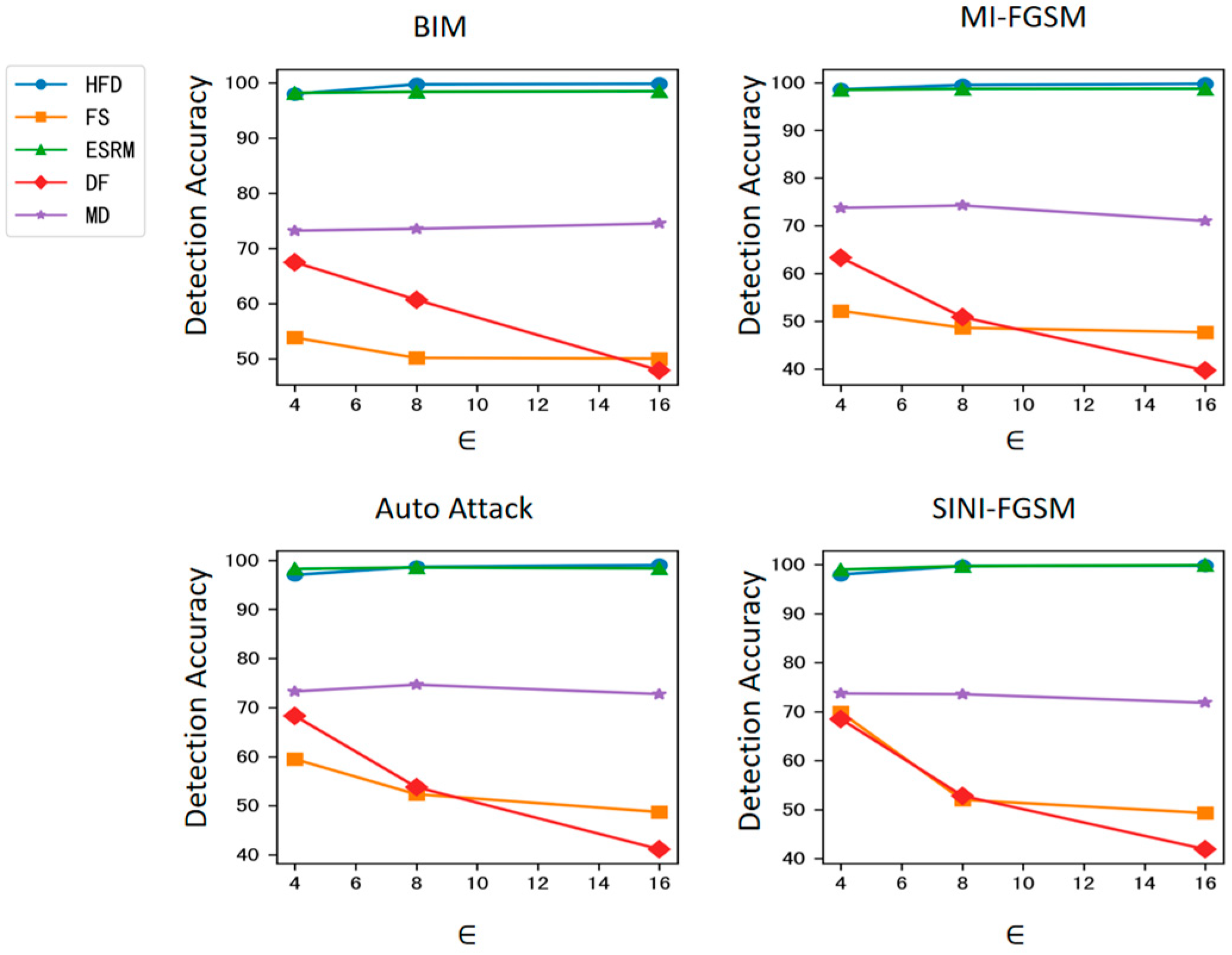
The results are shown in Table 2 and Figure 3. It can be seen that the proposed method significantly outperforms the FS, DF, and MD detection algorithms in detection accuracy and achieves comparable accuracy to the ESRM detection algorithm on the target model ResNet-50. Notably, as the intensity of adversarial attacks increases, the detection accuracy of the FS, DF, and MD algorithms shows a clear downward trend, with the maximum drop reaching 27.17%. In contrast, the detection accuracy of the proposed method remains relatively stable, indicating strong robustness against varying attack intensities. Furthermore, as can be observed from Table 2 and Figure 3, although the detector is trained with BIM adversarial examples with ϵ = 4, the detection accuracy of the proposed method remains relatively stable across different attack types and different magnitudes of disturbance, demonstrating good robustness against attacks.
Table 2.
Comparison of detection accuracy against attacks with different magnitudes of disturbance on ResNet-50.
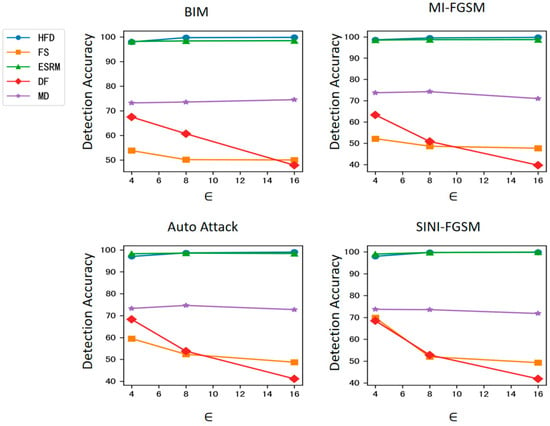
Figure 3.
Detection accuracy against attacks with different magnitudes of disturbance on ResNet-50.
Since only ESRM among the four baseline methods achieves comparable accuracy to the proposed method, ESRM continues to serve as the baseline in the following robustness experiments.
4.3. Robustness to Downsampling
To analyze the impact of downsampling on detection accuracy, we take the detection of BIM attacks as an example and select ESRM as the baseline for comparison. The experimental settings are listed in Table 3.
Table 3.
Experimental settings for downsampling robustness.
The primary factor in downsampling algorithms is the interpolation kernel. In the experiments, we used the nearest, bilinear, and Lanczos interpolation kernels in the Resize function in PyTorch 2.6.0 for downsampling. The nearest interpolation kernel selects the value of the nearest original image pixel as the value of the target pixel after downsampling. This method is simple and fast to implement, but it can result in jagged edges or distortions in the image. The bilinear interpolation kernel calculates the pixel value after downsampling by taking a weighted average of the four nearest pixels surrounding the target pixel. Compared to the nearest interpolation kernel, the bilinear interpolation kernel can reduce jagged edges and distortions. The Lanczos interpolation kernel is based on a sine function and takes more pixels into account when calculating new pixel values, producing a smoother image.
The experimental results in Table 4 indicate that the proposed method’s detection accuracy remains stable across different downsampling techniques. Specifically, the maximum fluctuation in detection accuracy across the nearest, bilinear, and Lanczos downsampling methods is 0.31%, 0.13%, and 0.13% for ϵ = 4, ϵ = 8, and ϵ = 16, respectively. In contrast, the ESRM detection algorithm, which is based on steganalysis, is more sensitive to downsampling, with a variation in detection accuracy exceeding 2%.
Table 4.
Comparison of detection accuracy (%) between HFD and ESRM under different downsampling operations.
4.4. Robustness to Common Corruptions
To evaluate the robustness of the proposed method against image preprocessing before generating adversarial examples, we conducted experiments to measure detection accuracy under various preprocessing operations. Assuming that the defender is unaware of the preprocessing operations, the detector was trained solely with clean samples and adversarial examples without any preprocessing. The target model used was ResNet-50, with the BIM attack method. Consistent with the downsampling experiment, ESRM was selected as the baseline for comparison. The experimental settings in Table 3 are adopted for this experiment.
Considering that the adversarial examples are required to be imperceptible to human eyes, we select the preprocessing operations that have a minimal impact on image quality, including Gaussian noise, zoom blur, frost, contrast enhancement, elastic transform, and JPEG compression. The parameters for these operations are set to ensure the corruption’s imperceptibility to human eyes. Specifically, the mean of the Gaussian noise is set to 0, and the standard deviation is set to 0.02. The JPEG compression factor is set to 95. The other parameter settings follow the work of Hendrycks et al. [24].
The experimental results are presented in Table 5. It can be observed that the proposed HFD method exhibits strong robustness against six different types of corruptions, while the performance of ESRM is comparatively weaker. Specifically, for adversarial examples subjected to these six corruptions, the detection accuracy of HFD deviates by no more than 1% compared to that of uncorrupted adversarial examples. In contrast, the detection accuracy of ESRM drops by over 47% when dealing with adversarial examples preprocessed with Gaussian noise, and it also experiences a decline of more than 1% for adversarial examples corrupted with Frost and JPEG preprocessing.
Table 5.
Comparison of detection accuracy (%) between HFD and ESRM under different common corruptions. The corruptions resulting in maximum deviation are shown in bold.
4.5. Suitability for Target Models
We selected three neural network structures in addition to ResNet-50 to verify the suitability for different target model structures, including Inception V3, EfficientNet B0, and ConvNeXt. Specifically, for each target model, the encoder needs to be updated accordingly, and the similarity measurement model needs to be retrained. The experimental settings for the target model, Inception V3, are detailed in Table 6. For EfficientNet B0 and ConvNeXt, the experimental setup remains consistent with that of Table 6, with the exception being that the models used in both the design phase and the detection phase are replaced by EfficientNet B0 and ConvNeXt, respectively.
Table 6.
Experimental settings for the target model of Inception V3.
The experimental results for the four target models are presented in Table 7. Among them, the results for ResNet50 are repeated from Table 2 to ensure a comprehensive presentation of all results. From Table 7, it is evident that the proposed adversarial example detection method achieves high detection accuracy across different target models, demonstrating its broad applicability. Among these, ConvNeXt has the highest detection accuracy, likely due to its encoder’s superior feature extraction capability, which improves the similarity measurement model’s ability to distinguish between clean and adversarial samples. The proposed method is also effective against various attack algorithms, with AutoAttack being the most difficult to detect across different target models.
Table 7.
Detection accuracy (%) of HFD for different target models against different attacks.
5. Discussions
The effectiveness of HFD is somewhat surprising, given its simplicity and low computational cost compared to other detection algorithms. Although developing a comprehensive theory of adversarial examples detection remains an elusive goal, the success of HFD provides a valuable insight: even subtle differences in high-level feature representations between adversarial examples and clean images—despite their shared predicted label—can be leveraged for effective detection. This finding highlights the potential of exploiting minor feature discrepancies for robust detection, regardless of the adversarial example generation mechanism.
Although our experiments have thus far been confined to image classification models, the HFD approach, which leverages feature representations rather than raw image data, holds promise for broader applicability across various domains where deep learning is employed. For instance, in speech recognition systems, HFD could potentially be adapted to defend against adversarial voice commands by analyzing the semantic features of audio data. This versatility underscores the potential of HFD as a generalizable defense mechanism against adversarial attacks in diverse deep learning applications, contributing to the development of more reliable and trustworthy AI systems.
The HFD method, while effective, has several potential limitations. First, because the encoder shares the same structure as the classifier, the detector must be retrained for different classifier architectures, which could limit its practicality in diverse deployment scenarios. Second, the method relies on differences in feature representations, making it potentially less effective against adversarial examples generated with low-magnitude perturbations (i.e., weak attack strength). Finally, the detector itself is implemented as a neural network, introducing a vulnerability: if the detection strategy is exposed to attackers, the detector could become a target of adversarial attacks, compromising its effectiveness. These limitations highlight areas for future research, such as improving robustness against weak adversarial attacks, developing architecture-agnostic detectors, and enhancing the security of the detector itself against adversarial targeting.
6. Conclusions
To strengthen the defense capability of CNN classification networks against adversarial examples, this study presents a novel detection method that leverages semantic conflicts in high-level features between adversarial and clean examples sharing the same predicted label. Importantly, our approach does not require the adversarial example to be generated from the corresponding clean example; instead, the only prerequisite is that both examples yield the same prediction.
In detection accuracy experiments, 12 attack scenarios were designed by applying 4 attack algorithms (BIM, MI-FGSM, AutoAttack, and SINI-FGSM) to the ResNet50 target model, each with 3 intensity levels. The results (Table 2 and Figure 2) show that the proposed method significantly outperforms FS, DF, and MD, while achieving accuracy comparable to ESRM.
Robustness to downsampling and corruptions tests were performed under three BIM attack intensities, comparing the proposed method with ESRM. The proposed method showed a maximum accuracy fluctuation of 0.31%, far lower than ESRM’s 2.18–3.57% across three downsampling operations (Table 4). Against six common corruptions, the proposed method remained stable with a maximum deviation of 0.87%, while ESRM’s accuracy dropped by over 47% under Gaussian noise.
To evaluate generalizability, the method was tested on three additional target models (Inception V3, EfficientNet B0, and ConvNeXt) under four attack algorithms with three intensity levels each. Across these 48 scenarios, the proposed method consistently achieved a detection accuracy above 89% (Table 7), demonstrating its applicability to diverse target models.
In future work, we plan to explore scenarios in which the HFD method is exposed to adaptive attacks, where adversarial examples are crafted not only to deceive the target model but also to bypass the detection mechanism. This challenge could be addressed by retraining the similarity measurement model with updated adversarial examples, enhancing its robustness against such adaptive strategies.
Author Contributions
Conceptualization, H.M. and A.P.; methodology, H.M.; software, C.L.; validation, C.L. and A.P.; writing—original draft preparation, H.M.; writing—review and editing, H.M.; visualization, Z.L.; project administration, Y.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by Hefei Comprehensive National Science Center and the Scientific Research Project of National University of Defense Technology under Grant 22-ZZCX-07.
Data Availability Statement
The datasets applied in this paper are all open-source datasets. The open source URL is shown below. https://image-net.org/challenges/LSVRC/2012/2012-downloads.php, accessed on 31 October 2024.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing Properties of Neural Networks. In Proceedings of the International Conference on Learning Representations, Scottsdale, Arizona, 20 December 2013. [Google Scholar]
- Goodfellow, I.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 19 December 2014. [Google Scholar]
- Xie, C.; Wang, J.; Zhang, Z.; Zhou, Y.; Xie, L.; Yuille, A. Adversarial Examples for Semantic Segmentation and Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2016; IEEE: Piscataway, NJ, USA, 2017; pp. 1378–1387. [Google Scholar]
- Wu, H.; Yunas, S.; Rowlands, S.; Ruan, W.; Wahlström, J. Adversarial Driving: Attacking End-to-End Autonomous Driving. In Proceedings of the 2023 IEEE Intelligent Vehicles Symposium (IV), Anchorage, AK, USA, 4–7 June 2023; pp. 1–7. [Google Scholar] [CrossRef]
- Bountakas, P.; Zarras, A.; Lekidis, A.; Xenakis, C. Defense Strategies for Adversarial Machine Learning: A Survey. Comput. Sci. Rev. 2023, 49, 100573. [Google Scholar] [CrossRef]
- Shafahi, A.; Najibi, M.; Ghiasi, A.; Xu, Z.; Dickerson, J.; Studer, C.; Davis, L.S.; Taylor, G.; Goldstein, T. Adversarial Training for Free! In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates Inc.: Red Hook, NY, USA, 2019; pp. 3358–3369. [Google Scholar]
- Nie, W.; Guo, B.; Huang, Y.; Xiao, C.; Vahdat, A.; Anandkumar, A. Diffusion Models for Adversarial Purification. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 1 July 2022. [Google Scholar]
- Xu, W.; Evans, D.; Qi, Y. Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks. In Proceedings of the 2018 Network and Distributed System Security Symposium, San Diego, CA, USA, 18–21 February 2018. [Google Scholar]
- Aldahdooh, A.; Hamidouche, W.; Fezza, S.A.; Déforges, O. Adversarial Example Detection for DNN Models: A Review and Experimental Comparison. Artif. Intell. Rev. 2022, 55, 4403–4462. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, W.; Zhang, Y.; Hou, D.; Liu, Y.; Zha, H.; Yu, N. Detection Based Defense Against Adversarial Examples from the Steganalysis Point of View. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 4820–4829. [Google Scholar]
- Ma, X.; Li, B.; Wang, Y.; Erfani, S.; Wijewickrema, S.; Houle, M.E.; Schoenebeck, G.; Song, D.; Bailey, J. Characterizing Adversarial Subspaces Using Local Intrinsic Dimensionality. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 8 January 2018. [Google Scholar]
- Lee, K.; Lee, K.; Lee, H.; Shin, J. A Simple Unified Framework for Detecting Out-of-Distribution Samples and Adversarial Attacks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Curran Associates, Inc.: Newry, UK, 2018; Volume 31. [Google Scholar]
- Choi, S.-H.; Bahk, T.; Ahn, S.; Choi, Y.-H. Clustering Approach for Detecting Multiple Types of Adversarial Examples. Sensors 2022, 22, 3826. [Google Scholar] [CrossRef] [PubMed]
- Liang, B.; Li, H.; Su, M.; Li, X.; Shi, W.; Wang, X. Detecting Adversarial Image Examples in Deep Neural Networks with Adaptive Noise Reduction. IEEE Trans. Dependable Secur. Comput. 2021, 18, 72–85. [Google Scholar] [CrossRef]
- Han, K.; Li, Y.; Xia, B. A Cascade Model-Aware Generative Adversarial Example Detection Method. Tsinghua Sci. Technol. 2021, 26, 800–812. [Google Scholar] [CrossRef]
- Ngo, P.C.; Winarto, A.A.; Kou, C.K.L.; Park, S.; Akram, F.; Lee, H.K. Fence GAN: Towards Better Anomaly Detection. In Proceedings of the 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, 4–6 November 2019; pp. 141–148. [Google Scholar]
- Xie, C.; Yang, K.; Wang, A.; Chen, C.; Li, W. A Mura Detection Method Based on an Improved Generative Adversarial Network. IEEE Access 2021, 9, 68826–68836. [Google Scholar] [CrossRef]
- Yang, Y.; Gao, R.; Li, Y.; Lai, Q.; Xu, Q. What You See Is Not What the Network Infers: Detecting Adversarial Examples Based on Semantic Contradiction. In Proceedings of the 2022 Network and Distributed System Security Symposium, San Diego, CA, USA, 24–28 April 2022. [Google Scholar] [CrossRef]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial Examples in the Physical World. In Proceedings of the International Conference on Learning Representations, San Juan, PR, USA, 2–4 May 2016; Yampolskiy, R.V., Ed.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2016. [Google Scholar]
- Dong, Y.; Liao, F.; Pang, T.; Su, H.; Zhu, J.; Hu, X.; Li, J. Boosting Adversarial Attacks with Momentum. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 9185–9193. [Google Scholar]
- Lin, J.; Song, C.; He, K.; Wang, L.; Hopcroft, J.E. Nesterov Accelerated Gradient and Scale Invariance for Adversarial Attacks. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 17 August 2019. [Google Scholar]
- Croce, F.; Hein, M. Reliable Evaluation of Adversarial Robustness with an Ensemble of Diverse Parameter-Free Attacks. In Proceedings of the 37th International Conference on Machine Learning, Vienna, Austria, 21 November 2020; pp. 2206–2216. [Google Scholar]
- Papernot, N.; Faghri, F.; Carlini, N.; Goodfellow, I.; Feinman, R.; Kurakin, A.; Xie, C.; Sharma, Y.; Brown, T.B.; Roy, A.; et al. Technical Report on the CleverHans v2.1.0 Adversarial Examples Library. arXiv 2016, arXiv:1610.00768. [Google Scholar]
- Hendrycks, D.; Dietterich, T. Benchmarking Neural Network Robustness to Common Corruptions and Perturbations. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Liao, F.; Liang, M.; Dong, Y.; Pang, T.; Hu, X.; Zhu, J. Defense Against Adversarial Attacks Using High-Level Representation Guided Denoiser. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1778–1787. [Google Scholar] [CrossRef]
- Xie, C.; Wu, Y.; van der Maaten, L.; Yuille, A.; He, K. Feature Denoising for Improving Adversarial Robustness. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 501–509. [Google Scholar] [CrossRef]
- Ilyas, A.; Santurkar, S.; Tsipras, D.; Engstrom, L.; Tran, B.; Madry, A. Adversarial Examples Are Not Bugs, They Are Features. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8 December 2019; pp. 125–136. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2014, 115, 211–252. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June 2016–1 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 770–778. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11966–11976. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 24 May 2019. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).