Abstract
The fusion of infrared and visible images provides complementary information from both modalities and has been widely used in surveillance, military, and other fields. However, most of the available fusion methods have only been evaluated with subjective metrics of visual quality of the fused images, which are often independent of the following relevant high-level visual tasks. Moreover, as a useful technique especially used in low-light scenarios, the effect of low-light conditions on the fusion result has not been well-addressed yet. To address these challenges, a decoupled and semantic segmentation-driven infrared and visible image fusion network is proposed in this paper, which connects both image fusion and the downstream task to drive the network to be optimized. Firstly, a cross-modality transformer fusion module is designed to learn rich hierarchical feature representations. Secondly, a semantic-driven fusion module is developed to enhance the key features of prominent targets. Thirdly, a weighted fusion strategy is adopted to automatically adjust the fusion weights of different modality features. This effectively merges the thermal characteristics from infrared images and detailed information from visible images. Additionally, we design a refined loss function that employs the decoupling network to constrain the pixel distributions in the fused images and produce more-natural fusion images. To evaluate the robustness and generalization of the proposed method in practical challenge applications, a Maritime Infrared and Visible (MIV) dataset is created and verified for maritime environmental perception, which will be made available soon. The experimental results from both widely used public datasets and the practically collected MIV dataset highlight the notable strengths of the proposed method with the best-ranking quality metrics among its counterparts. Of more importance, the fusion image achieved with the proposed method has over 96% target detection accuracy and a dominant high mAP@[50:95] value that far surpasses all the competitors.
1. Introduction
The images of visible sensors contain rich texture details, but they face limitations in low-light or night-time conditions. In contrast, infrared sensors capture the thermal radiation of a target for imaging, providing valuable information in dark environments. However, infrared images are often disturbed by noise. To fully leverage the complementary advantages of these two modalities, many infrared and visible image fusion (IVIF) methods have been developed to obtain comprehensive information about a target scene. The fusion of infrared and visible images (IVIs) has been widely applied in advanced visual tasks, such as target detection [1,2], tracking [3,4], and segmentation [5,6].
Over the past few decades, numerous IVIF methods have been designed, from traditional methods [7,8,9,10,11,12,13] gradually updating to deep-learning-based methods [14,15,16,17,18,19,20,21]. Traditional IVIF techniques can handle the fusion problem for scenes with idea imaging conditions, such as multi-scale transformation associated methods [7,8], sparse-representation-based approaches [9,10], methods depend on subspace clustering [11], saliency [12], and hybrid methods [13]. Nevertheless, the traditional methods mentioned above rely on manually set fusion rules and are unable to adapt to complex scenarios. Although one method [22] integrates multi-scale decomposition, sparse representation, and guided filtering techniques to improve the quality of fused images, it tends to have high computational complexity. In recent years, the advancement of deep learning has spurred the development of neural-network-based IVIF methods, which provide better results fonr IVIF tasks.
Deep-learning-based fusion approaches can be generally classified into three categories: auto-encoder (AE)-associated networks [14,15,16,17], convolutional neural networks (CNNs) [18,19], and generative adversarial networks (GAN) [20,21]. Specifically, AE-based IVIF methods reconstruct fused images through an encoder, feature fusion, and a decoder [14,15]. In fact, these methods also require manually designed fusion rules (concatenation, element-wise addition, etc.) [16,17] and cannot flexibly adjust the fusion content according to the input data characteristics. Therefore, the strategy for automatically adjusting fusion weights is of great importance for producing more robust fusion results. Additionally, some methods try to extract detailed information from the two modalities through different feature learning modules. For example, Qi et al. [18] guided the fusion process by learning sharp and blurry regions in the images. LRRNet constructs a learnable model by utilizing the low-rank and sparse coefficients [19]. However, these methods focus on enhancing the visual quality of the fused image, neglecting the guidance of semantic tasks. The acquired fused images also have difficulty in accommodating sophisticated visual challenges. Although some methods have tried to combine high-level visual tasks to guide fusion metrics, such as SeAFusion [23] and DetFusion [24], they do not account for the potential different feature representations between the fused image and the original images. This leads to artifacts in the fused image. So, some GAN-based methods, such as TGFuse [25] and AT-GAN [26], enhance the fusion effect by identifying specific features and removing redundant features. The discrimination between the fused image and the original images leads to the fused image containing more detailed information. However, the training of GAN is often unstable and requires careful loss adjustment to converge. In addition, the currently available public datasets for IVIF primarily contain terrestrial environments such as streets and roads, lacking diverse samples for special scenarios. As a result, the robustness and generalization of the related fusion methods are limited in practical applications.
To address the issues mentioned above, we propose an IVIF method based on a decoupled and semantic segmentation-driven network (DSSFusion). Firstly, we designed a cross-modality transformer fusion module (CMTFM) based on transformer cross-attention for learning rich hierarchical feature representations at multiple scales. Secondly, we explored a semantic-driven fusion module (SDFM), which incorporates semantic segmentation information to better preserve and enhance critical features of target objects. Thirdly, according to the characteristics of infrared and visible features, we adopted a weighted fusion approach that automatically adjusts fusion weights. This helps integrate the thermal features from infrared images with the structure and detail information from visible images. Subsequently, we designed a refined loss. In addition to the common gradient and pixel losses, we proposed an auxiliary loss via the decoupling network to constrain the pixel distribution between the fused image and the original images, resulting in more natural fused images. Based on the above design, our fused images maintain the texture of visible images while highlighting prominent targets regardless of lighting conditions. Finally, to validate the performance of the proposed method in complex scenes, we developed an aligned MIV dataset. The MIV dataset not only fills the gap in maritime scene datasets but also provides a new benchmark for evaluating fusion methods.
The main contributions of this paper are summarized as follows:
- We constructed an IVIF method based on a decoupled and semantic segmentation-driven network, which can automatically adjust the fusion weights and integrate meaningful information from the IVIs.
- We developed two fusion modules, namely, CMTFM and SDFM. These modules integrate information from different modalities by combining the transformer cross-attention mechanism with semantic segmentation, thus embedding semantic information into the fusion process.
- A refined loss function was designed to improve the quality of the fused images by importing auxiliary losses through the decoupling network to guide the training of the fusion network.
- We constructed a new benchmark dataset for evaluating infrared and visible image fusion in a special scenario called the Maritime Infrared and Visible (MIV) dataset. The benchmark dataset is available from https://github.com/xhzhang0377/MIV-Dataset (accessed on 19 April 2025).
2. Related Work
2.1. Deep-Learning-Based IVIF Method
Deep learning technology is commonly used in IVIF tasks and typically improves fusion quality by constructing more reasonable loss functions. For instance, Liu et al. [27] developed a coupled contrast constraint in the loss function that preserves the typical characteristics of IVIs. Zhang et al. created a general model [28] to perform various image fusion tasks by adjusting the weights of each intensity loss term. U2Fusion uses information measurement and feature extraction [29] to automatically assess the IVIs’ significance. To adjust to a range of image fusion tasks, MUFusion [30] utilizes the intermediate training outcomes as supplementary supervision signals. In recent years, the advancements in diffusion models [31,32] have brought new perspectives to image fusion. Zhao et al. [31] decomposed the fusion task into an unconditional generation component and a maximum likelihood estimation step. To enhance color fidelity, Yue et al. [32] utilized a diffusion-based model to generate the distribution of multi-channel input data. However, diffusion-based models require repeated iterative denoising processes, leading to a substantial computational burden and limiting their practical utility at the current stage. Static fusion methods [33,34] typically employ fixed fusion strategies, lacking adaptability. For different application scenarios or data distributions, manual adjustment of fusion parameters is required.
Additionally, some CNN-based IVIF methods focus on the impact of scene brightness on the quality of the fused images. For example, PIAFusion [35] incorporates illumination probability for developing an illumination perception loss function. Song et al. designed an illumination adjustment network [36] aimed at enhancing night-time visual image brightness. IAIFNet introduces a salient target-aware module alongside an adaptive differential fusion module to refine the IVIF process [37]. Meanwhile, MLFFusion [38] features a regional illumination preservation module specifically to boost fusion algorithm performance in low-light conditions. Although these methods yield impressive imaging results in dark environments, brightness adjustment inevitably leads to overexposure issues in daylight scenarios. The proposed network addresses this issue by employing gradient maximization and pixel value maximization losses to ensure excellent imaging in night-time environments. Simultaneously, the auxiliary loss generated by the decoupling network was designed to prevent brightness imbalance in daytime settings, thereby enhancing the overall performance of the image fusion process across diverse lighting conditions.
Typical encoder-based IVIF technologies [14,15,39] exploit the results of each layer in the encoding network to build feature maps. Although some nested connections [15,39] are used in IVIF to help mitigate the loss of detailed information, the degradation of pixel information in the original input images is inevitable. To further improve fusion quality, Zhao et al. [40] constructed two optimization models from the iterative formulations of two conventional optimization models. Tang et al. proposed the DIVFusion [41] scene illumination decomposition network to remove deteriorated visible illumination features. Additionally, for pixel-level IVIF, SGFusion [42] creates a saliency-guided deep learning framework. CDDFuse processes low-frequency global features in IVIs by using long-range attention [43]. In addition, ResCC [44] uses the spatial cross-attention model, while GTMFuse [45] employs a group attention transformer mechanism, both achieving superior fusion effects for IVIs. Nonetheless, these methods fail to take into account the guidance provided by advanced visual tasks on the fusion outcomes and might not be well suited for real-world applications.
In the domain of GAN-based IVIF, FusionGAN [20] eliminates the need for manually designing complex activity-level measurements and fusion rules. GAN-FM features a full-scale jump-connected generator alongside two distinct Markovian discriminators [21]. Based on this, UMF-CMGR introduces a generative registration paradigm [46] designed to remove artifacts in fused images. Meanwhile, GANMcC simultaneously estimates the distributions of both the IVIs domains, employing a multi-classification discrimination mechanism to achieve a more balanced fusion result [47]. However, these methods face issues of training instability and poor robustness in practical applications. Subsequently, some approaches incorporate high-level visual task guidance into GAN networks, for instance, TarDAL [48] and AT-GAN [26], but these GAN-based fusion models lack the ability to perceive the typical feature regions of IVIs.
2.2. Transformer-Based IVIF
With the self-attention mechanism, transformer can establish long-distance dependencies and effectively acquire global contextual information. Consequently, IVIF strategies have made use of transformer. For instance, SwinFusion [49] integrates a self-attention-based intra-domain fusion unit and a cross-attention-based inter-domain fusion unit to effectively merge the complementary features of IVIs. This design allows for efficient feature integration across different domains. DATFuse [50] introduces a dual-attention residual module to identify the salient characteristics of both visible and infrared inputs. AcFusion [51] employs ACmix, which combines multi-head self-attention and convolution to improve the model’s global modeling ability. Following this, leveraging the advantage of transformer in reducing parameter quantities, transformer has been increasingly applied in IVIF. Mustafa et al. applied a transformer block to extract high-frequency domain-specific information from source IVIs [52]. CDDFuse uses a light transformer module [43] that processes the low-frequency global features of IVIs. GTMFuse [45] integrates a group attention transformer module into its encoder, which combines window, channel, and fixed-direction stripe attention seamlessly for better IVIF. Furthermore, TGFuse [25] learns the global relationships among IVIs in complex scenes using a transformer fusion module. Additionally, Wu et al. proposed a multi-source image fusion method based on a fully connected transformer [53], which enhances the interaction and information transfer between different modalities through a fully connected mechanism. Although these methods can reduce the impact of redundant information to some extent, they have limitations in reducing the number of parameters, making it difficult to adapt to real-time fusion and vision tasks.
2.3. Advanced Task-Guided IVIF
Some IVIF methods are driven by advanced visual tasks, thereby compelling the fused images to encompass richer semantic information. For example, a salient object mask was introduced into the loss function to guide the optimization of STDFusionNet [16] to achieve the goal of salient object detection. Segmentation results are used in SuperFusion [54] and SeAFusion [23] to constrain semantic loss, thus guiding the high-level semantic information to flow back to the IVIF model. Moreover, detection-driven loss is created in DetFusion [24], which uses a significant target enhancement method [55] to optimize the IVIF task. However, these methods overlook the characteristics of the underlying original images during the generation of fused images. Additionally, a GAN-based method, TarDAL [48], uses bilevel optimization for detection-oriented fusion. Through the semantic transformation module and instance attention module, AT-GAN [26] suppresses redundant visible and infrared features. Nevertheless, the single-discriminator GAN fusion network always leads to insufficient preservation of infrared target information in the fusion results. Other methods [56,57] take into account the requirements of downstream tasks, such as object detection and classification. The former combines rolling guidance filtering with gradient saliency maps to improve fusion performance, while the latter employs a pseudo-supervised generative adversarial network to enhance detail preservation and image quality. Additionally, the mask-guided Mamba fusion method [58] uses detection results from another modality to generate a mask map, which is then used to cover the intermediate feature maps of the current modality, focusing more on the target regions during the fusion process. However, the multiple convolutional layers and selective scanning involved in deep state–space models may increase the computational burden.
3. Proposed Method
3.1. Network Construction
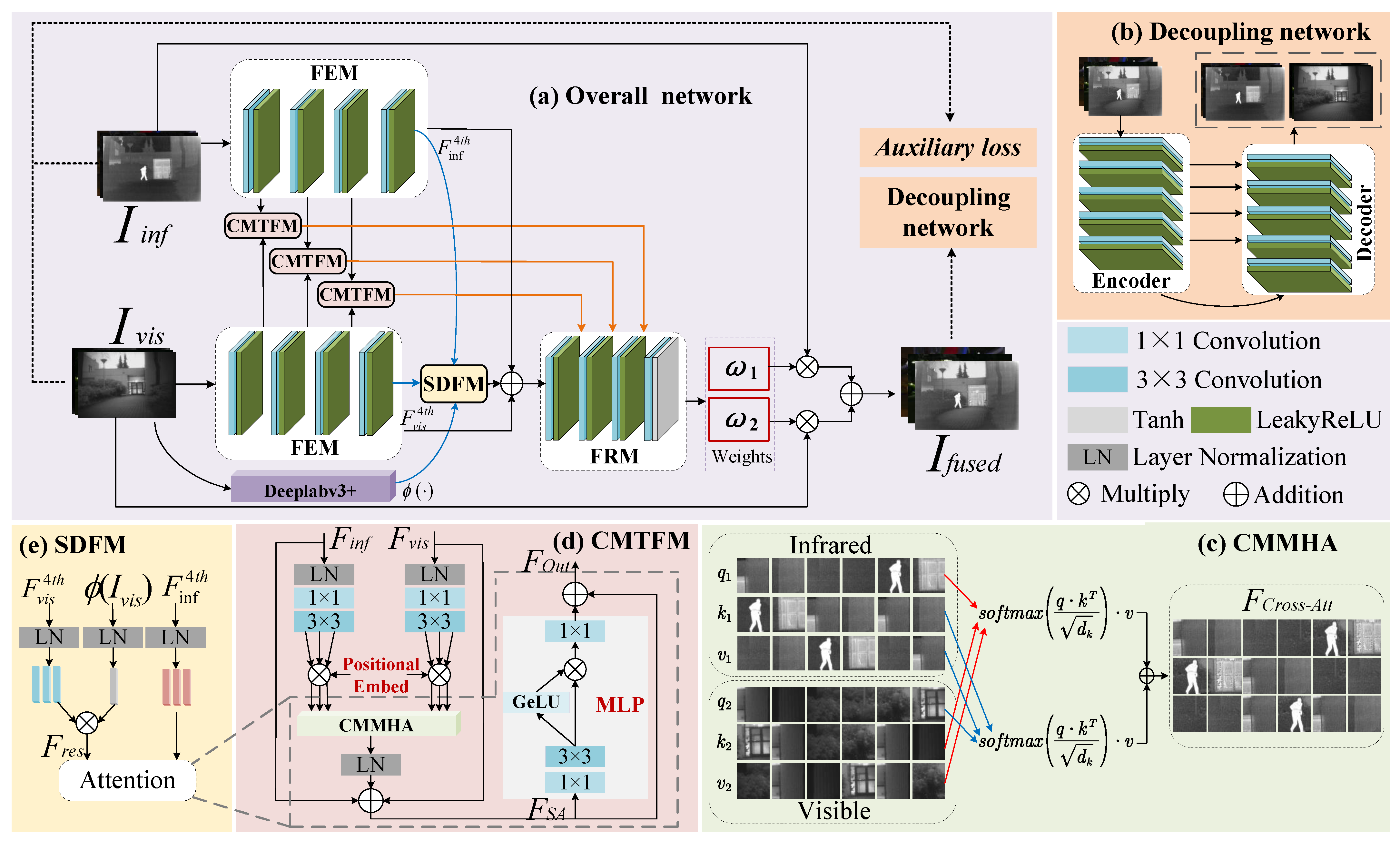
The framework overview of the proposed DSSFusion is shown in Figure 1a. Firstly, the IVIs are separately input into a feature extraction module (FEM), to extract the shallow and deep features of the source images. The FEM contains four feature extraction layers. Each feature extraction layer comprises a 3 × 3 convolution and a LeakyReLU activation layer. Then, the first three layers of features from both modalities are correspondingly input into the CMTFM for shallow feature fusion. As shown in Figure 1d, the CMTFM utilizes the cross-attention mechanism of transformer to facilitate the interactive fusion between infrared and visible features. Subsequently, the infrared and visible features from the fourth feature extraction layer, together with the segmentation feature mask generated by the Deeplabv3+ network [59], are input into the SDFM (Figure 1e) to guide deep feature fusion with the segmentation network. Furthermore, the output features of SDFM, along with the fourth-layer infrared and visible features extracted in the FEM module, are concatenated and then fed into the feature reconstruction module (FRM), to supplement detailed information and reconstruct the fused features. Specifically, the input of the last three feature reconstruction layers includes the features from the previous reconstruction layer as well as the corresponding shallow fusion features from the CMTFM.
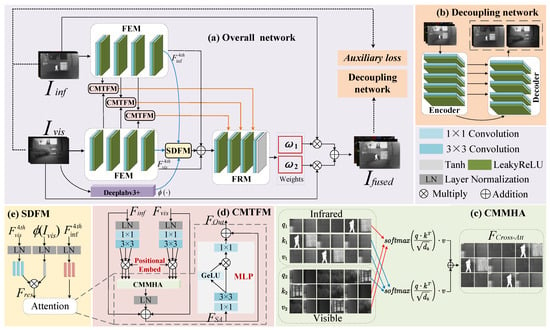
Figure 1.
The architecture of the proposed network and related modules. (a) The network architecture of the proposed DSSFusion, (b) the framework of the decoupling network, (c) the computation of CMMHA, (d) the architecture of CMTFM, and (e) the architecture of SDFM.
In the FRM, each of the first three feature reconstruction layers contains a 3 × 3 transposed convolutional layer and a LeakyReLU activation layer. The cross-modal fusion features after the first three layers of feature reconstruction are denoted as . In the fourth layer of feature reconstruction, is first passed through a 3 × 3 convolutional layer to achieve channel compression, generating a two-channel tensor . Then, the tensor values are constrained to the symmetric interval [−1, 1] through a Tanh activation function. A linear translation and scaling operation is introduced to adjust the dynamic range of the tensor to [0, 1], satisfying the probabilistic constraint for weight coefficients. Subsequently, is split along the channel dimension to obtain the infrared modality weight and the visible modality weight . Finally, the two weights are multiplied point-wise with their corresponding original images and then added together to produce the fused image . Dynamic adaptive weighting of cross-modal features helps achieve the optimal fusion of thermal radiation targets and visible image texture details.
In the training process, to further improve the quality of the fused image, is decomposed into new IVIs by the decoupling network (Figure 1b). The decoupled IVIs, along with the original images, are used to compute the auxiliary loss. Additionally, gradient loss and pixel loss are calculated between the fused image and the source images. These three types of losses are combined to jointly guide the training of DSSFusion.
3.2. Modules
3.2.1. Cross-Modality Transformer Fusion Module
The architecture of the CMTFM is shown in Figure 1d. After applying LayerNorm to the features of the IVIs, the obtained feature maps undergo a 1 × 1 convolution and a 3 × 3 convolution. After the above operations, the channel number of the infrared and visible features is three times larger. Then, each modal feature is split into three parts along the channel dimension, which are used as the query, key, and value vectors. Taking the visible feature as an example, the operation proceeds as follows:
where , , and are the query, key, and value of visible features, respectively. denotes the visible feature input to the CMTFM. and denote the layer normalization and split operation along the channel dimension, respectively. signifies a convolution with an input channel of C and an output channel of . implies a convolution, with input and output channels both being . Afterward, , , and are embedded with learnable positional encoding, and the resulting vectors are denoted as , , and , respectively. Note that the operation for the infrared feature input to the CMTFM is the same as that for , and the resulting vectors are named , , and after introducing learnable positional encoding.
Leveraging its strong ability to represent long-distance dependencies, the transformer module is adept at capturing global content information from original images. This makes it particularly suitable for extracting nuanced features from IVIs. Consequently, the infrared and visible feature vectors are fed to the cross-modal multi-head attention (CMMHA, as shown in Figure 1c) to compute the cross-attention of the infrared and visible features, which can be formulated as follows:
where denotes the cross-attention feature. , , and are the vectors from the infrared modality, and , , and are the vectors from the visible modality. represents the dimension of k.
Moreover, is reshaped to map back to the input feature of the CMTFM, followed by layer normalization for decrease dimensions and two residual additions with as well as for complementing the detailed information of the IVIs. The above operation is formulated as
where denotes the feature map.
Cross-attention is effective in SwinFusion [49], so two separate MLPs are used for each modality without deeply mixing the two modalities. To reduce the number of parameters and enhance the recombination of different modal features, we adopt a shared MLP to further transform the fused features. The shared MLP introduces non-linear factors in the hidden layers, enabling the network to learn complex patterns and enhance the model’s generalization ability. Specifically, after undergoing a 1 × 1 convolution and a 3 × 3 convolution, is split into two parts along the channel dimension, which can be formulated as
where and denote the features after splitting. means a convolution with an input channel of C and an output channel of . implies a convolution with input and output channels both being .
After that, feature is passed through a GeLU activation function and then multiplied element-wise with the other part, . Then, the channel dimension is adjusted using a 1 × 1 convolution. Finally, an addition is constructed among MLP and , and the output of the CMTFM can be formulated as
where and ⊙ denote the output feature of the CMTFM, and element-wise multiplication, respectively. means a convolution with an input channel of and an output channel of C. means the GeLU activation function.
3.2.2. Semantic-Driven Fusion Module
To assist the proposed method in understanding the boundaries and internal structures of different targets within images, a pre-trained semantic segmentation model Deeplabv3+ [59] is employed in the deep feature fusion process. The encoding structure of Deeplabv3+ consists of a ResNet-101 backbone and an atrous spatial pyramid pooling (ASPP) module. The ResNet-101 backbone extracts image features to generate high-level semantic features. The ASPP module captures multiscale semantic information using the high-level semantic feature maps generated by ResNet-101. In the tail of the encoder, the high-level semantic features of ASPP and the low-level features from ResNet-101 are combined along the channel dimension. Finally, in the decoding stage, the merged features undergo bilinear upsampling and mapping to produce the final segmentation feature map. The segmentation map is then used as a feature mask to further enhance the semantic information of the fused feature in SDFM (Figure 1e). As shown in Figure 1a, after the fourth feature extraction layer, the deep features of both modalities, along with the segmentation feature mask produced by Deeplabv3+, are input into the SDFM. The SDFM uses prior semantic knowledge to guide the fusion of deep features, which better preserves detailed information during the fusion. Specifically, we enhance the visible modality’s query with the segmentation features to ensure that semantic information is maximally preserved during the fusion process. This process can be formulated as
where is the visible feature extracted after the fourth feature extraction layer. , , and are the query, key, and value obtained from after undergoing layer normalization and split operation.
After the visible image undergoes semantic segmentation Deeplabv3+ and normalization, it is multiplied with query to enhance the feature representation of the target region. This operation is formulated as
where and denote the visible feature after embedding semantic segmentation and the source visible image, respectively. represents the pre-trained semantic segmentation operation Deeplabv3+.
After that, special visible features and the infrared feature extracted from the fourth feature extraction layer are fed into CMMHA and LN, followed by two residual connections, and then through an MLP. Finally, after another residual connection, the output of SDFM is obtained.
3.2.3. Decoupling Network
To ensure that the fused images generated by the proposed network contain rich multimodal information, we follow a key principle: if the fused image can recover the original multimodal information, then the fusion network demonstrates high-quality multimodal feature fusion capability. Therefore, we adopt a decoupling network based on the U-Net architecture. The decoupling network is devoted to decomposing the fused high-quality images into modality-specific features that closely resemble the distribution of the original image information. As illustrated in Figure 1b, the decoupling network comprises an encoder, a decoder, and multilayer skip connections. This decoupling network is used to evaluate and guide the fusion performance of the proposed CMTFM and SDFM.
The input of the decoupling network is fused images. As illustrated in Figure 1b, the encoder consists of five feature extraction layers. Each feature extraction layer is composed of a 3 × 3 convolutional layer and a LeakyReLU activation layer, with a convolutional stride of 1 and padding of 1. These five layers of feature extraction effectively compress the input fused images and extract deep features. Additionally, the decoder of the decoupling network is made up of five feature reconstruction layers. Each feature reconstruction layer is composed of a transposed convolutional layer with a kernel size of 3 and a LeakyReLU activation layer. Through five layers of feature reconstruction, the original size and number of channels of the images are gradually restored. In each feature reconstruction step, the feature from the encoder is skip-connected to the feature reconstruction layer. Finally, these features are reconstructed into a new pair of IVIs.
By training the decoupling network and minimizing the loss function, the information distribution of the decoupled infrared and visible feature maps can be made to approximate that of the source images. Notably, during the training phase of DSSFusion, the decoupling network is used to decompose the images generated by DSSFusion. Moreover, the differences between the decoupled images and the original images are quantified through the auxiliary loss, which guides the training of DSSFusion to guarantee the fused images contain more multimodal information.
3.3. Loss Function
3.3.1. Loss Function of the Decoupling Network
The input of the decoupling network is fused images, and the output is the reconstructed IVIs. Since the input fused images are obtained from the source IVIs, the loss of the decoupling network is defined as
where and are the loss of training of the decoupling network and source infrared image, respectively. and denote the reconstructed IVIs obtained after the decoupling network decomposing . The symbol represents the norm. ∇ denotes the Sobel gradient operator, which forces the reconstructed images to contain more texture information with high fidelity. and are the balance weights.
3.3.2. Joint Loss of DSSFusion
To ensure that the fused images comprehensively reflect multimodal information and enhance the performance of the fusion strategies, we adopt a joint loss to train the DSSFusion network, which includes the gradient loss, pixel loss, and auxiliary loss as follows:
where , , and denote the gradient loss, the pixel loss, and the auxiliary loss generated by the decoupling network, respectively. These three losses are combined to form the joint loss, denoted as , to guide the training of the proposed network for retaining more details and information from the multimodal images. Additionally, , , and are weighting coefficients used to adjust the weight of each loss term in the joint loss.
Gradient loss helps to preserve more edge and texture information in the fused images, which is particularly important for multimodal image fusion. The gradient loss is expressed as
where is the fused image generated by DSSFusion.
Pixel loss directly compares the differences between the fused image and each source image at each pixel point, enabling the fused image to be close to the source images at the pixel level. The pixel loss is expressed as
where and N are the pixel loss and the total number of pixels in the image, respectively. , , and denote the intensity value at pixel i in the fused image, source visible image, and source infrared image, respectively. The symbol refers to absolute value calculation, which ensures the consideration of only positive magnitudes for preserving the fine details and texture patterns in the fused image.
Additionally, the fused images generated by DSSFusion are decomposed by the trained decoupling network. The differences between the decomposed images and the original images are quantified using the auxiliary loss, denoted as , which motivates the fused images to contain more multimodal information. The auxiliary loss is calculated as
where is the auxiliary loss. and denote the decomposed IVIs produced by the decoupling network.
4. Experiments
4.1. Experimental Setup
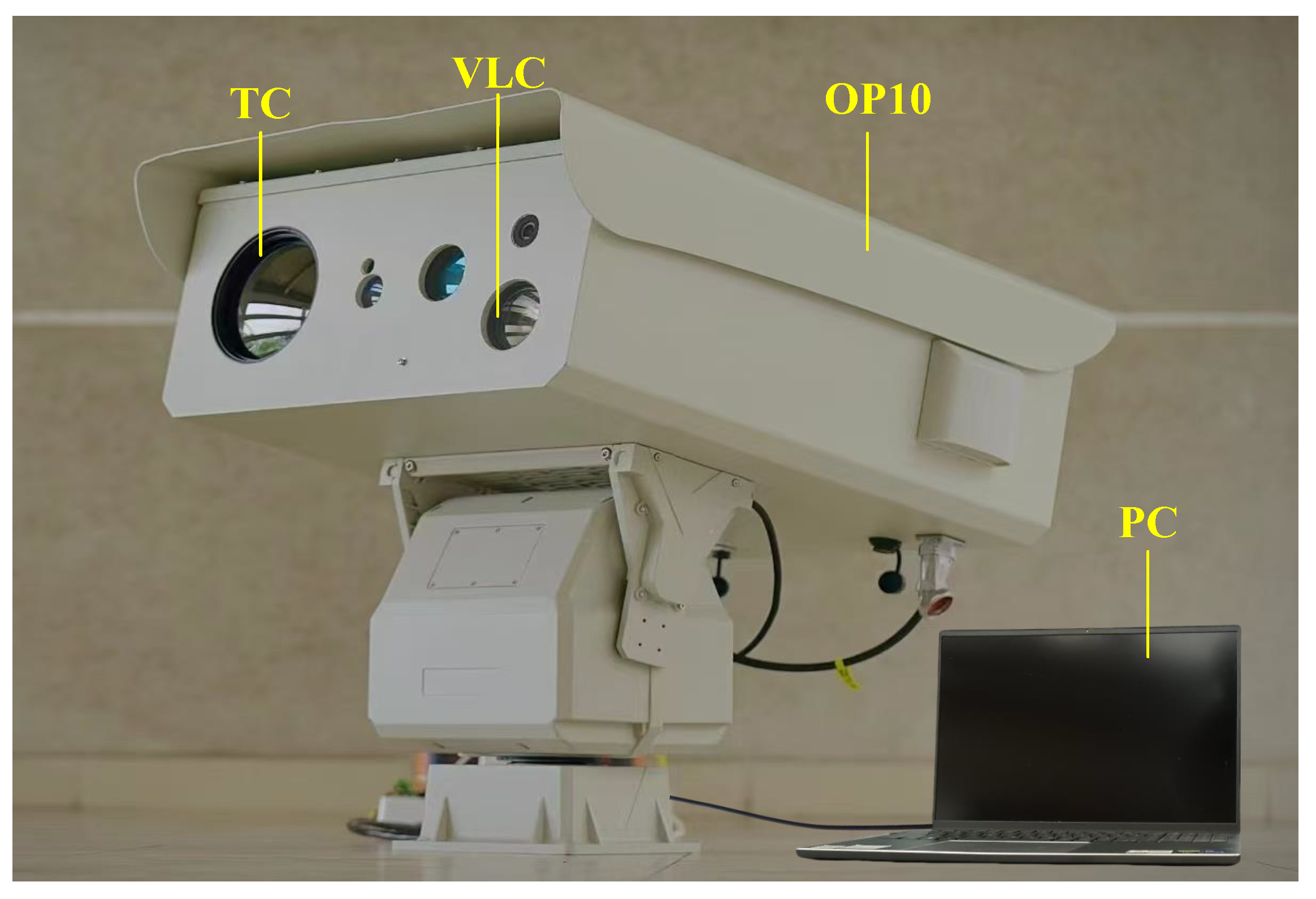
As shown in Figure 2, we built an infrared and visible imaging system using Optical Pod No.10 (OP10) developed by our team to capture paired IVIs in maritime scenes. The data acquisition system comprised a visible light camera (VLC) with a resolution of 1920 × 1080, a thermal camera (TC) with a resolution of 1280 × 720 and a wavelength range of 8–14 µm, as well as a high-performance personal computer (PC). Both cameras interfaced with the PC through USB connections. The PC was responsible for executing tasks such as image registration, model inference, and result visualization. The MIV dataset [60] we created in this study (available online: https://github.com/xhzhang0377/MIV-Dataset (accessed on 19 April 2025) contains IVIs of maritime scenes during both daytime and night-time. Note that the infrared and visible image pairs in the proposed MIV dataset are aligned. During the alignment process, the common region of the infrared and visible images captured at the same time was first cropped, and then feature registration was performed using the modality conversion and registration method proposed in the UMF-CMGR [46]. Finally, we manually inspected and selected 109 pairs of aligned images to form the MIV dataset, which was also used to assess the performance of the proposed method.
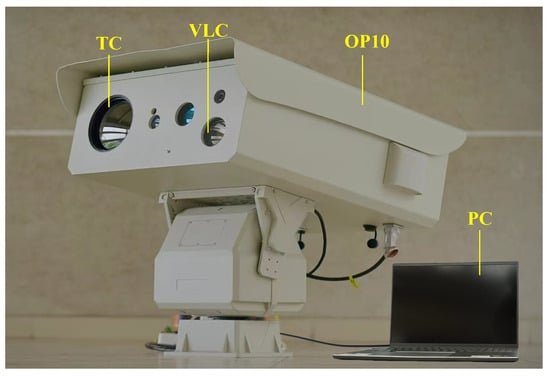
Figure 2.
The visible and infrared imaging system.
4.2. Dataset Preparation
We performed a series of both qualitative and quantitative tests across four datasets to thoroughly assess the effectiveness of our proposed method. These datasets included three public datasets containing IVIs, namely, LLVIP [61], MSRS [62], and TNO [63], as well as the maritime dataset MIV. Specifically, the LLVIP dataset comprises aligned IVIs captured in night-time road scenes, being ideal for evaluating low-light vision techniques. The MSRS dataset images, taken under extremely low-light conditions, provided a rigorous performance test of the proposed method in challenging environments. Additionally, the TNO dataset offers multi-spectral night-time images from various military-related scenes with multiple targets, facilitating the assessment of the effectiveness of the proposed method in intricate scenarios.
Fusing infrared and visible modalities can enhance the safety and precision of maritime missions, such as port management, patrol enforcement, search and rescue, and accurate target detection and recognition. However, there are currently no aligned IVIs for maritime scenarios. As the dynamic changes in maritime environments and complex lighting conditions impose higher demands on fusion algorithms, we created the MIV dataset to evaluate the robustness and adaptability of the proposed method in practical applications.
4.3. Comparison Method and Evaluation Metrics
We compared the experimental results of DSSFusion with nine advanced fusion methods from recent years, including FusionGAN [20], GANMcC [47], RFN-Nest [39], UMF-CMGR [46], SuperFusion [54], MLFFusion [38], LRRNet [19], DATFuse [50], and ResCCFusion [44], to evaluate the fusion performance. The aforementioned image fusion methods and datasets are publicly available, and we used the parameters set in the original papers.
For quantitative evaluation, we employed seven metrics [64] to objectively assess the fusion performance of the comparison methods. They included standard deviation (SD), mutual information (MI), visual information fidelity (VIF), average gradient (AG), entropy (EN), edge preservation (Qabf), and space-frequency (SF). Specifically, SD provides a statistical measure of the distribution and contrast within a fused image. MI quantifies the shared information between source images. VIF evaluates the fidelity of information transfer from a human visual system perspective. AG measures the texture richness in a fused image. EN assesses the information content in a fused image using information theory principles. Qabf gauges the accuracy of edge information preservation. SF captures the spatial frequency characteristics present in a fused image. Higher values for these metrics generally indicate superior fusion performance. It is worth noting that the VIF values in this paper are the sum of the VIF between the fused image and the visible image and the VIF between the fused image and the infrared image. The numerical range of the evaluation metric VIF is between 0 and 2.
4.4. Training Details
First-stage training: In this stage, high-quality fused images were fed into the decoupling network, which output reconstructed IVIs. These reconstructed images were then compared with the original IVIs using the loss introduced in Section 3.3.1 to train the decoupling network. Thereby, the decoupling network decomposed the fused images and obtained modal features similar to the information distribution of the original images.
In detail, the nine fusion methods used in the experiments were applied to fuse the IVIs from the MSRS dataset. Then, 752 high-quality fused images were selected from these fused images as input for the decoupling network, including 376 daytime scene images and 376 night-time scene images. The selected fused images not only effectively retained the thermal imaging characteristics of the infrared images but also included rich details and color information from the visible images. For this training, the input images were divided into patches of size 64 × 64. Adam was used as the optimizer for the decoupling network, and the weight decay of the optimizer was set as . The learning rate of the optimizer was initially set as and eventually decayed to . The batch size was set as 16, and the decoupling network was trained for epochs. The loss function parameters and were set as 50 and 20, respectively.
Second-stage training: We selected 752 pairs of IVIs from the MSRS dataset as input for the proposed DSSFusion, including 376 pairs of daytime scene images and 376 pairs of night-time scene images. The batch size was set as 8, and the input images were cropped into 64 × 64 patches for training. Additionally, all network parameters were updated using the Adam optimizer with a weight decay of , and the initial learning rate was set as . The loss function parameters , , and were set as 50, 20, and 0.1, respectively.
During the first and second stages of training, the experiments were conducted using a NVIDIA GTX 2080 Ti GPU. The programming environment was Python 3.8 and PyTorch 2.1.1.
4.5. Experimental Results on Public Datasets
During the testing phase, the decoupling network was no longer used. Instead, DSSFusion served as an end-to-end network for inference, and the model parameters and weights obtained from the second training phase were directly utilized for testing. In this study, we selected some images for testing from three public datasets, specifically, 50 pairs from LLVIP at a resolution of 1280 × 1024 pixels, 56 pairs from MSRS at a resolution of 640 × 480 pixels, and 41 pairs from TNO at various resolutions. Note that the selected images were not used for training. The average quantitative results of the experiments on the three datasets are shown in Table 1, Table 2 and Table 3, respectively. By conducting tests on a diverse set of datasets, we comprehensively evaluated the performance of DSSFusion and verified its generalization capabilities across different scenarios.

Table 1.
Comparative analysis of DSSFusion and nine advanced methods on the LLVIP dataset. The best is indicated in bold and the second best with underlining.
Table 2.
Comparative analysis of DSSFusion and nine advanced methods on the MSRS dataset. The best is indicated in bold and the second best with underlining.
Table 3.
Comparative analysis of DSSFusion and nine advanced methods on the TNO dataset. The best is indicated in bold and the second best with underlining.
4.5.1. Fusion Results on LLVIP Dataset
Table 1 provides the quantitative results of seven metrics on the LLVIP test dataset. As shown in Table 1, the proposed DSSFusion demonstrates top two rankings across all seven metrics. Moreover, DSSFusion achieves the best VIF, AG, SF, and Qabf, which means that the fused images have satisfactory visual effects, as well as contain more texture and edge information. These improvements are attributed to the proposed SDFM and auxiliary loss. The large SD and EN values of MLFFusion indicate that its fused images have high contrast and a rich information content. Additionally, the large value of DATFuse for MI suggests that its fused images more faithfully reflect the information relationships with the original images.
To showcase the proposed method’s performance in low-light settings visually, we chose two sets of night-time images for subjective evaluation. The visualization outcomes are presented in Figure 3. For enhanced comparison, two regions of interest within each image are magnified for detailed examination. From Figure 3, it is evident that while all methods preserve prominent targets, certain approaches exhibit limitations in detail preservation. Specifically, DATFuse, MLFFusion, and SuperFusion do not clearly delineate the texture of the paving tiles. GANMcC, LRRNet, and RFN-Nest struggle to distinctly reveal the bushes obscured by darkness. Meanwhile, FusionGAN, UMF-CMGR, and ResCCFusion result in blurred representations of the bushes and fences. DSSFusion effectively integrates the complementary information from IVIs, simultaneously retaining a clear representation of both the bushes and the fence.

Figure 3.
Qualitative comparison of DSSFusion with nine advanced methods on the LLVIP dataset.
4.5.2. Fusion Results on MSRS Dataset
The quantitative results for the different methods on 56 pairs of images from the MSRS dataset are shown in Table 2. DSSFusion still demonstrates the best performance across seven metrics, ranking second only on the SD metric, proving that the proposed method is effective in extremely dark scenes. Additionally, MLFFusion maintains high contrast and competitiveness even in extremely dark environments. The qualitative comparison is shown in Figure 4. It can be noted that all methods maintain the intensity distribution of significant target areas. However, FusionGAN and UMF-CMGR lose information on the bicycle lamp in the fusion results and introduce artifacts, reducing the visual quality of the fused images. The images from GANMcC, LRRNet, and RFN-Nest have unclear human contours. In addition, DATFuse, SuperFusion, MLFFusion, and ResCCFusion fail to retain sharp edges. Nevertheless, DSSFusion fully incorporates the complementary and common features of the source images by integrating the CMTFM and SDFM. Consequently, DSSFusion effectively circumvents challenges such as thermal target degradation and texture blurring, which are conspicuously absent in its fused images. The validation through experiments on the MSRS dataset underscores DSSFusion’s proficiency in exceedingly low-light scenarios.

Figure 4.
Qualitative comparison of DSSFusion with nine advanced methods on the MSRS dataset.
4.5.3. Fusion Results on TNO Dataset
The quantitative results of different methods on 41 pairs of images from the TNO dataset are shown in Table 3. The proposed DSSFusion performs quite well in multiple important aspects and can generate high-quality fused images. MLFFusion and LRRNet exhibit good contrast. ResCCFusion has advantages in terms of visual information fidelity and information content. The visual results are shown in Figure 5 and Figure 6. From the red boxes in Figure 5, FusionGAN and GANMcC blur the edges of thermal targets and exhibit severe spectral distortion in the background areas. LRRNet, MLFFusion, and RFN-Nest diminish the prominent targets. DATFuse, SuperFusion, and UMF-CMGR produce unclear trunk features. Only DSSFusion and ResCCFusion effectively retain the intensity of the prominent targets while preserving the texture details from the visible images. Comparable observations are evident in Figure 6. Note that, compared to other methods, DSSFusion effectively retains the texture details of visible images, as presented in the red and green boxes in Figure 5 and Figure 6.

Figure 5.
Qualitative comparison of DSSFusion with nine advanced methods on the field scene from
the TNO dataset.

Figure 6.
Qualitative comparison of DSSFusion with nine advanced methods on the bench scene
from the TNO dataset.
4.6. Experimental Results on Actual Marine Datasets
Experimental system. The 109 pairs of images in the MIV dataset were used to validate the robustness of the proposed method in actual maritime scenarios. The average values measured across the seven evaluation metrics are shown in Table 4. SuperFusion has the greatest advantage in preserving the information relationship between the original images and fused images. MLFFusion exhibits excellent visual information fidelity. DSSFusion performs optimally in multiple key metrics, especially in terms of image contrast, detail preservation, and information content. The inference speed for image fusion on the MIV dataset is shown in Table 5, where DSSFusion has a faster inference speed than the nine methods.
Table 4.
Comparative analysis of DSSFusion and nine advanced methods on the MIV dataset. The best is indicated in bold and the second best with underlining.
Table 5.
Comparison of running speeds for ten fusion methods on the MIV dataset. The lowest and second-lowest values are labeled in bold and underline, respectively.
The fusion outcomes of the proposed method and compared methods are illustrated in Figure 7 and Figure 8. Notably, the MIV dataset was used exclusively for testing and did not participate in training. Figure 7 shows the fusion results in daytime maritime scenes. The images from FusionGAN, GANMcC, and LRRNet are generally darker and contain artifacts. RFN-Nest, UMF-CMGR, SuperFusion, and ResCCFusion overly integrate the intensity information from the infrared image while ignoring the detailed features of the visible image. MLFFusion and DATFuse fully integrate information from both modalities, but DSSFusion provides clearer details of the distant bridge and a more natural visual effect. Figure 8 shows the fusion results for night-time maritime scenes. FusionGAN, GANMcC, and RFN-Nest focus on the details of the visible image and fail to sufficiently fuse the infrared features, for example, losing the wire information in the top right corner of the infrared image. On the contrary, other methods (e.g., DATFuse, ResCCFusion, LRRNet, etc.) prioritize the intensity information in the infrared image, leading to incomplete feature integration of all targets in the image. The proposed DSSFusion generates higher-quality fused images, successfully integrating features such as the ships, buildings, and power lines in the image. Finally, the above experimental results indicate that DSSFusion has good target fusion performance under real-world conditions.

Figure 7.
Qualitative comparison of DSSFusion with nine advanced methods on the daytime scene
from the MIV dataset.

Figure 8.
Qualitative comparison of DSSFusion with nine advanced methods on the night-time scene
from the MIV dataset.
4.7. Ablation Study
To investigate the contribution and reliability of the proposed CMTFM, SDFM, weight fusion, and auxiliary loss, we conducted extensive ablation experiments on the TNO and MSRS datasets. The quantitative results are shown in Table 6. The best and suboptimal results are displayed in bold and underlined, respectively. In Exp. II, we eliminated weight fusion and directly obtained the fused image. In Exp. III, we replaced the CMTFM with an element-wise summation. In Exp. IV, we removed the auxiliary loss from Equation (9) by setting the hyperparameter of the last term to zero. In Exp. V, we removed the embedding DeepLabv3. The experiment where all the above elements were removed was recorded as Exp. I. On the contrary, the experiment with all modules added was the proposed DSSFusion (ours).
Table 6.
Average metric values of DSSFusion-component combinations on TNO and MSRS datasets. The activation status of individual components is represented as ✓ (included) and × (excluded). Bolded and underlined values indicate the best and second-best performance, respectively.
In Table 6, when the weight fusion is removed (Exp. II), most of the indicator values drop to suboptimal, indicating that some of the original information is partially compromised. Removing CMTFM leads to a decrease in the evaluation metrics (Exp. III), indicating that the absence of CMTFM results in insufficient fusion. In addition, it is validated that the auxiliary loss enables the fused image to contain more information from different modalities (Exp. IV), and the SDFM injects more semantic information into the network (Exp. V). Ours achieves the best and suboptimal performance across the seven evaluation metrics, indicating that DSSFusion combines the advantages of all designed modules.
4.8. Feature Visualization of Fusion Module
To visually demonstrate the feature selection capability of the proposed SDFM under low-light conditions, we provide some thermal feature maps after the feature fusion stage in night-time scenes. These heatmaps are visualizations with a channel dimension of 128, shown in Figure 9. The first column of Figure 9 shows the original infrared image, the original visible image, and the fused image after SDFM. The next three columns display the feature heatmaps of these three modalities across different channel dimensions. From Figure 9, we can see that without using the SDFM, the differences between the infrared and visible features are evident. After adding the SDFM, the features of the infrared and visible modalities are fused and become clearer, indicating that the SDFM has a strong feature integration ability.

Figure 9.
Visualization of feature maps learned from multi-modality image pairs in night-time
scenarios. The initial column displays a sequential array of infrared, visible, and fused images. The
subsequent three columns illustrate the feature maps associated with infrared, visible, and fused
modalities across various channel dimensions.
4.9. Visualization of the Decoupling Network
By visualizing the fused images, as well as reconstructed IVIs, we can better understand the working mechanism of the decoupling network and its ability to handle image details. As shown in Figure 10, the decoupling network is capable of effectively retaining and reconstructing important information from the input images.

Figure 10.
The fused image of night scenes from the MSRS dataset, along with visualizations of the
reconstructed IVIs after decomposition by the decoupling network.
5. Target Detection
On the Kaist dataset [65], we evaluate ddownstream tasks with the YOLOv8n [66] detector. We utilized the YOLOv8n model and fed the fusion results from different approaches straight into the detector for retraining to guarantee an equitable comparison. During the training phase of YOLO-v8n, the initial learning rate was set to 0.01, the batch size was configured to 16, the Adam optimizer was used, the number of epochs was set to 100, and the weight decay was set to 0.0005. The retrained models were then tested on a test set that was similarly randomly partitioned. Quantitative evaluations were obtained directly from the detector’s evaluation script, and all detector configurations remained true to their initial settings.
We used four common evaluation metrics [67] for objective detection (namely, Precision, Recall, mAP@50, and mAP@[50:95]) to assess the image quality of ten fused images and original images. Precision denotes the accuracy of positive predictions, and Recall means the proportion of actual positives correctly identified. The mAP@50 is average precision at an Intersection over Union (IoU) threshold of 0.5, and the mAP@[50:95] is the average mAP across IoU thresholds from 0.5 to 0.95 in steps of 0.05. The quantitative results of the experiments are presented in Table 7. Higher scores on these metrics reflect superior image quality for detection tasks. Notably, DSSFusion achieves the highest accuracy in target detection, indicating its superior image quality. To further demonstrate this advantage, Figure 11 and Figure 12 provide visual examples of pedestrian detection accuracy across different images, showcasing detection with confidence scores exceeding 0.5.
Table 7.
The pedestrian detection efficiency of the fused images generated by various fusion methods on the YOLOv8n model. Bold and underline denote the best and second-best, respectively.

Figure 11.
Qualitative comparison of target detection in daytime scenes on the Kaist dataset using
different fused images.

Figure 12.
Qualitative comparison of target detection from night-time scenes from the Kaist dataset
using different fused images.
Figure 11 shows the pedestrian detection results on daytime roads. By producing a high-contrast visual effect that is appropriate for the detection network, the fusion results from DSSFusion successfully highlight pedestrians, leading to improved detection performance. Conversely, methods like FusionGAN and MLFFusion have a tendency to blur pedestrian contours, which lowers detection confidence. Additionally, Figure 12 showcases night-time target detection, which better reflects DSSFusion’s ability to retain and utilize visible information. The pedestrian detection accuracy of the images generated by MLFFusion and ResCCFusion is lower in night scenes, which may be due to the impact of the lighting conditions on the model. In summary, the fused images produced by DSSFusion indicate optimal detection performance and the retention of rich visible information, meeting the requirements of the specific scenario.
6. Conclusions
We proposed and presented a decoupling and semantic segmentation-driven network for IVIF. To preserve informative features and avoid redundancy during the fusion process, we proposed CMTFM and SDFM, which learn rich hierarchical feature representations, better preserving and enhancing the key features of target objects. Additionally, a decoupling network was proposed to use auxiliary loss constraints to retain important features, achieving better visual effects. Unlike previous fusion methods, DSSFusion employs adaptive weight fusion to enable the automatic adjustment of fusion weights according to the data characteristics of different modalities. This successfully combines the structure and detail in visible images with the thermal properties of infrared photos. The results from both qualitative assessments and quantitative analyses demonstrated that DSSFusion markedly boosted the quality and utility of the fused images. Ablation experiments verified the effectiveness of the proposed method. Additionally, we extended the proposed network to maritime IVIF, which also achieved superior performance compared to other advanced methods. Furthermore, experiments on target detection demonstrated that the proposed method can be effectively applied to high-level visual tasks.
In future research, we will optimize the decomposition loss to further enhance the network’s ability to retain semantic features from multi-source images. We will also explore methods such as continual learning to improve the generalization of the proposed model across different fusion tasks.
Author Contributions
X.Z. conceived the methodology, conducted the experiments, and wrote the original draft. Y.Y. conducted the validation and curated the data. Z.W., H.W., and G.Z. analyzed the results and edited this manuscript. L.C. and A.Y. provided supervision and resources. All authors reviewed this manuscript. All authors have read and agreed to the published version of this manuscript.
Funding
This work was supported by the Guangdong Provincial Marine Electronic Information Special Project (GDNRC[2024]19), National Natural Science Foundation of China (62173098), Guangdong Provincial Key Laboratory of Cyber-Physical System (2020B1212060069), University-Enterprise Cooperation Project 030000KC23040069 (GDKIXM20230381), and Guangdong Basic and Applied Basic Research Foundation (2024A1515010036 and 2025A1515012181).
Data Availability Statement
The data underlying the results presented in this paper are not publicly available at this time but may be obtained from the authors upon reasonable request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Jiang, C.; Ren, H.; Ye, X.; Zhu, J.; Zeng, H.; Nan, Y.; Sun, M.; Ren, X.; Huo, H. Object detection from UAV thermal infrared images and videos using YOLO models. Int. J. Appl. Earth Obs. Geoinform. 2022, 112, 102912. [Google Scholar] [CrossRef]
- Ma, W.; Wang, K.; Li, J.; Yang, S.X.; Li, J.; Song, L.; Li, Q. Infrared and visible image fusion technology and application: A review. Sensors 2023, 23, 599. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Xu, H.; Tian, X.; Jiang, J.; Ma, J. Image fusion meets deep learning: A survey and perspective. Inf. Fusion 2021, 76, 323–336. [Google Scholar] [CrossRef]
- Li, C.; Zhu, C.; Huang, Y.; Tang, J.; Wang, L. Cross-modal ranking with soft consistency and noisy labels for robust RGB-T tracking. Proc. Eur. Conf. Comput. Vis. (ECCV) 2018, 11217, 808–823. [Google Scholar]
- Zhou, W.; Liu, J.; Lei, J.; Yu, L.; Hwang, J.-N. GMNet: Graded-feature multilabel-learning network for RGB-thermal urban scene semantic segmentation. IEEE Trans. Image Process. 2021, 30, 7790–7802. [Google Scholar] [CrossRef]
- Lu, Y.; Wu, Y.; Liu, B.; Zhang, T.; Li, B.; Chu, Q.; Yu, N. Cross-modality person re-identification with shared specific feature transfer. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 13376–13386. [Google Scholar]
- Ma, J.; Zhou, Y. Infrared and visible image fusion via gradientlet filter. Comput. Vis. Image Underst. 2020, 197–198, 103016. [Google Scholar] [CrossRef]
- Chen, J.; Li, X.; Luo, L.; Mei, X.; Ma, J. Infrared and visible image fusion based on target-enhanced multiscale transform decomposition. Inform. Sci. 2020, 508, 64–78. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Ward, R.K.; Wang, Z.J. Image fusion with convolutional sparse representation. IEEE Signal Process. Lett. 2016, 23, 1882–1886. [Google Scholar] [CrossRef]
- Xing, C.; Wang, Z.; Ouyang, Q.; Dong, C.; Duan, C. Image fusion method based on spatially masked convolutional sparse representation. Image Vis. Comput. 2019, 90, 103806. [Google Scholar] [CrossRef]
- Kong, W.; Lei, Y.; Zhao, H. Adaptive fusion method of visible light and infrared images based on non-subsampled shearlet transform and fast non-negative matrix factorization. Infr. Phys. Technol. 2014, 67, 161–172. [Google Scholar] [CrossRef]
- Bavirisetti, D.P.; Dhuli, R. Two-scale image fusion of visible and infrared images using saliency detection. Infr. Phys. Technol. 2016, 76, 52–64. [Google Scholar] [CrossRef]
- Ma, J.; Zhou, Z.; Wang, B.; Zong, H. Infrared and visible image fusion based on visual saliency map and weighted least square optimization. Infr. Phys. Technol. 2017, 82, 8–17. [Google Scholar] [CrossRef]
- Li, H.; Wu, X. DenseFuse: A fusion approach to infrared and visible images. IEEE T. Image Process. 2018, 28, 2614–2623. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Wu, X.; Durrani, T. NestFuse: An infrared and visible image fusion architecture based on nest connection and spatial/channel attention models. IEEE T. Instrum. Meas. 2020, 69, 9645–9656. [Google Scholar] [CrossRef]
- Ma, J.; Tang, L.; Xu, M.; Zhang, H.; Xiao, G. STDFusionNet: An infrared and visible image fusion network based on salient target detection. IEEE Trans. Instrum. Meas. 2021, 70, 5009513. [Google Scholar] [CrossRef]
- Ram Prabhakar, K.; Sai Srikar, V.; Venkatesh Babu, R. DeepFuse: A deep unsupervised approach for exposure fusion with extreme exposure image pairs. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4714–4722. [Google Scholar]
- Qi, J.; Abera, D.E.; Fanose, M.N.; Wang, L.; Cheng, J. A deep learning and image enhancement based pipeline for infrared and visible image fusion. Neurocomputing 2024, 578, 127353. [Google Scholar] [CrossRef]
- Li, H.; Xu, T.; Wu, X.-J.; Lu, J.; Kittler, J. LRRNet: A novel representation learning guided fusion network for infrared and visible images. IEEE T. Pattern Anal. Mach. Intell. 2023, 45, 11040–11052. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inform. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Zhang, H.; Yuan, J.; Tian, X.; Ma, J. GAN-FM: Infrared and visible image fusion using GAN with full-scale skip connection and dual Markovian discriminators. IEEE Trans. Comput. Imaging 2021, 7, 1134–1147. [Google Scholar] [CrossRef]
- Li, L.; Shi, Y.; Lv, M.; Jia, Z.; Liu, M.; Zhao, X.; Zhang, X.; Ma, H. Infrared and visible image fusion via sparse representation and guided filtering in laplacian pyramid domain. Remote Sens. 2024, 16, 3804. [Google Scholar] [CrossRef]
- Tang, L.; Yuan, J.; Ma, J. Image fusion in the loop of high-level vision tasks: A semantic-aware real-time infrared and visible image fusion network. Inform. Fusion 2022, 82, 28–42. [Google Scholar] [CrossRef]
- Sun, Y.; Cao, B.; Zhu, P.; Hu, Q. Detfusion: A detection-driven infrared and visible image fusion network. In Proceedings of the 30th ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 4003–4011. [Google Scholar]
- Rao, D.; Xu, T.; Wu, X. TGFuse: An infrared and visible image fusion approach based on transformer and generative adversarial network. In IEEE Transactions on Image Processing; IEEE: New York, NY, USA, 2023. [Google Scholar] [CrossRef]
- Rao, Y.; Wu, D.; Han, M.; Wang, T.; Yang, Y.; Lei, T.; Zhou, C.; Bai, H.; Xing, L. AT-GAN: A generative adversarial network with attention and transition for infrared and visible image fusion. Inform. Fusion 2023, 92, 336–349. [Google Scholar] [CrossRef]
- Liu, J.; Lin, R.; Wu, G.; Liu, R.; Luo, Z.; Fan, X. Coconet: Coupled contrastive learning network with multi-level feature ensemble for multi-modality image fusion. Int. J. Comput. Vis. 2024, 132, 1748–1775. [Google Scholar] [CrossRef]
- Zhang, H.; Ma, J. SDNet: A versatile squeeze-and-decomposition network for real-time image fusion. Int. J. Comput. Vis. 2021, 129, 2761–2785. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Jiang, J.; Guo, X.; Ling, H. U2Fusion: A unified unsupervised image fusion network. IEEE T. Pattern Anal. 2020, 44, 502–518. [Google Scholar] [CrossRef]
- Cheng, C.; Xu, T.; Wu, X. MUFusion: A general unsupervised image fusion network based on memory unit. Inform. Fusion 2023, 92, 80–92. [Google Scholar] [CrossRef]
- Zhao, Z.; Bai, H.; Zhu, Y.; Zhang, J.; Xu, S.; Zhang, Y.; Zhang, K.; Meng, D.; Timofte, R.; Van Gool, L. DDFM: Denoising diffusion model for multi-modality image fusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 8082–8093. [Google Scholar]
- Yue, J.; Fang, L.; Xia, S.; Deng, Y.; Ma, J. Dif-fusion: Toward high color fidelity in infrared and visible image fusion with diffusion models. IEEE T. Image Process. 2023, 32, 5705–5720. [Google Scholar] [CrossRef]
- Heredia-Aguado, E.; Cabrera, J.J.; Jiménez, L.M.; Valiente, D.; Gil, A. Static Early Fusion Techniques for Visible and Thermal Images to Enhance Convolutional Neural Network Detection: A Performance Analysis. Remote Sens. 2025, 17, 1060. [Google Scholar] [CrossRef]
- Vivone, G.; Deng, L.-J.; Deng, S.; Hong, D.; Jiang, M.; Li, C.; Li, W.; Shen, H.; Wu, X.; Xiao, J.-L.; et al. Deep Learning in Remote Sensing Image Fusion: Methods, protocols, data, and future perspectives. IEEE Geosci. Remote Sens. Mag. 2025, 13, 269–310. [Google Scholar] [CrossRef]
- Tang, L.; Yuan, J.; Zhang, H.; Jiang, X.; Ma, J. PIAFusion: A progressive infrared and visible image fusion network based on illumination aware. Inform. Fusion 2022, 83, 79–92. [Google Scholar] [CrossRef]
- Song, W.; Gao, M.; Li, Q.; Guo, X.; Wang, Z.; Jeon, G. Optimizing Nighttime Infrared and Visible Image Fusion for Long-haul Tactile Internet. IEEE Trans. Consum. Electron. 2024, 70, 4277–4286. [Google Scholar] [CrossRef]
- Yang, Q.; Zhang, Y.; Zhao, Z.; Zhang, J.; Zhang, S. IAIFNet: An Illumination-Aware Infrared and Visible Image Fusion Network. IEEE Signal Process. Lett. 2024, 31, 1374–1378. [Google Scholar] [CrossRef]
- Wang, C.; Sun, D.; Gao, Q.; Wang, L.; Yan, Z.; Wang, J.; Wang, E.; Wang, T. MLFFusion: Multi-level feature fusion network with region illumination retention for infrared and visible image fusion. Infrared Phys. Techn. 2023, 134, 104916. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.; Kittler, J. RFN-Nest: An end-to-end residual fusion network for infrared and visible images. Inform. Fusion 2021, 73, 72–86. [Google Scholar] [CrossRef]
- Zhao, Z.; Xu, S.; Zhang, J.; Liang, C.; Zhang, C.; Liu, J. Efficient and model-based infrared and visible image fusion via algorithm unrolling. IEEE T. Circ. Syst. Vid. 2021, 32, 1186–1196. [Google Scholar] [CrossRef]
- Tang, L.; Xiang, X.; Zhang, H.; Gong, M.; Ma, J. DIVFusion: Darkness-free infrared and visible image fusion. Inform. Fusion 2023, 91, 477–493. [Google Scholar] [CrossRef]
- Liu, J.; Dian, R.; Li, S.; Liu, H. SGFusion: A saliency guided deep-learning framework for pixel-level image fusion. Inform. Fusion 2023, 91, 205–214. [Google Scholar] [CrossRef]
- Zhao, Z.; Bai, H.; Zhang, J.; Zhang, Y.; Xu, S.; Lin, Z.; Timofte, R.; Van Gool, L. CDDFuse: Correlation-driven dual-branch feature decomposition for multi-modality image fusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 5906–5916. [Google Scholar]
- Xiong, Z.; Zhang, X.; Han, H.; Hu, Q. ResCCFusion: Infrared and visible image fusion network based on ResCC module and spatial criss-cross attention models. Infrared Phys. Technol. 2024, 136, 104962. [Google Scholar] [CrossRef]
- Mei, L.; Hu, X.; Ye, Z.; Tang, L.; Wang, Y.; Li, D.; Liu, Y.; Hao, X.; Lei, C.; Xu, C. GTMFuse: Group-attention transformer-driven multiscale dense feature-enhanced network for infrared and visible image fusion. Knowl. Based Syst. 2024, 293, 111658. [Google Scholar] [CrossRef]
- Wang, D.; Liu, J.; Fan, X.; Liu, R. Unsupervised misaligned infrared and visible image fusion via cross-modality image generation and registration. In Proceedings of the International Joint Conference on Artificial Intelligence, Messe Wien, Austria, 23–29 July 2022; pp. 3508–3515. [Google Scholar]
- Ma, J.; Zhang, H.; Shao, Z.; Liang, P.; Xu, H. GANMcC: A generative adversarial network with multiclassification constraints for infrared and visible image fusion. IEEE T. Instrum. Meas. 2020, 70, 1–14. [Google Scholar] [CrossRef]
- Liu, J.; Fan, X.; Huang, Z.; Wu, G.; Liu, R.; Zhong, W.; Luo, Z. Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5802–5811. [Google Scholar]
- Ma, J.; Tang, L.; Fan, F.; Huang, J.; Mei, X.; Ma, Y. SwinFusion: Cross-domain long-range learning for general image fusion via swin transformer. IEEE/CAA J. Autom. Sin. 2022, 9, 1200–1217. [Google Scholar] [CrossRef]
- Tang, W.; He, F.; Liu, Y.; Duan, Y.; Si, T. DATFuse: Infrared and visible image fusion via dual attention transformer. IEEE T. Circuits Syst. Video Technol. 2023, 33, 3159–3172. [Google Scholar] [CrossRef]
- Zhu, H.; Wu, H.; He, D.; Lan, R.; Liu, Z.; Pan, X. AcFusion: Infrared and visible image fusion based on self-attention and convolution with enhanced information extraction. IEEE T. Cons. Electron. 2023, 70, 4155–4167. [Google Scholar] [CrossRef]
- Mustafa, H.T.; Shamsolmoali, P.; Lee, I.H. TGF: Multiscale transformer graph attention network for multi-sensor image fusion. Expert Syst. Appl. 2024, 238, 121789. [Google Scholar] [CrossRef]
- Wu, X.; Cao, Z.-H.; Huang, T.-Z.; Deng, L.-J.; Chanussot, J.; Vivone, G. Fully-Connected Transformer for Multi-Source Image Fusion. IEEE T. Pattern Anal. Mach. Intell. 2025, 47, 2071–2088. [Google Scholar] [CrossRef] [PubMed]
- Tang, L.; Deng, Y.; Ma, Y.; Huang, J.; Ma, J. SuperFusion: A versatile image registration and fusion network with semantic awareness. IEEE/CAA J. Autom. Sin. 2022, 9, 2121–2137. [Google Scholar] [CrossRef]
- Huo, X.; Deng, Y.; Shao, K. Infrared and Visible Image Fusion with Significant Target Enhancement. Entropy 2022, 24, 1633. [Google Scholar] [CrossRef]
- Li, L.; Lv, M.; Jia, Z.; Jin, Q.; Liu, M.; Chen, L.; Ma, H. An effective infrared and visible image fusion approach via rolling guidance filtering and gradient saliency map. Remote Sens. 2023, 15, 2486. [Google Scholar] [CrossRef]
- Qi, J.; Abera, D.E.; Cheng, J. PS-GAN: Pseudo Supervised Generative Adversarial Network With Single Scale Retinex Embedding for Infrared and Visible Image Fusion. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2024, 18, 766–1777. [Google Scholar] [CrossRef]
- Wang, S.; Wang, C.; Shi, C.; Liu, Y.; Lu, M. Mask-Guided Mamba Fusion for Drone-Based Visible-Infrared Vehicle Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 3452550. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, C.; Wu, H.; Chen, P. An improved Deeplabv3+ semantic segmentation algorithm with multiple loss constraints. PLoS ONE 2022, 17, e0261582. [Google Scholar] [CrossRef] [PubMed]
- MIV-Dataset. Available online: https://github.com/xhzhang0377/MIV-Dataset (accessed on 19 April 2025).
- Jia, X.; Zhu, C.; Li, M.; Tang, W.; Zhou, W. LLVIP: A visible-infrared paired dataset for low-light vision. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops, Montreal, BC, Canada, 11–17 October 2021; pp. 3489–3497. [Google Scholar]
- MSRS Dataset. Available online: https://github.com/Linfeng-Tang/MSRS (accessed on 19 April 2025).
- TNO Dataset. Available online: https://figshare.com/articles/dataset/TNO_Image_Fusion_Dataset/1008029 (accessed on 19 April 2025).
- Zhang, X.; Ye, P.; Xiao, G. VIFB: A visible and infrared image fusion benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 104–105. [Google Scholar]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; So Kweon, I. Multispectral pedestrian detection: Benchmark dataset and baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1037–1045. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLO. Software 2023, Version 8.0.0. Available online: https://github.com/ultralytics/ultralytics (accessed on 19 April 2025).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Geosci. Remote Sens. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).