
High-Resolution Urban Air Quality Mapping for Multiple Pollutants Based on Dense Monitoring Data and Machine Learning


Abstract
:1. Introduction
2. Materials and Methods
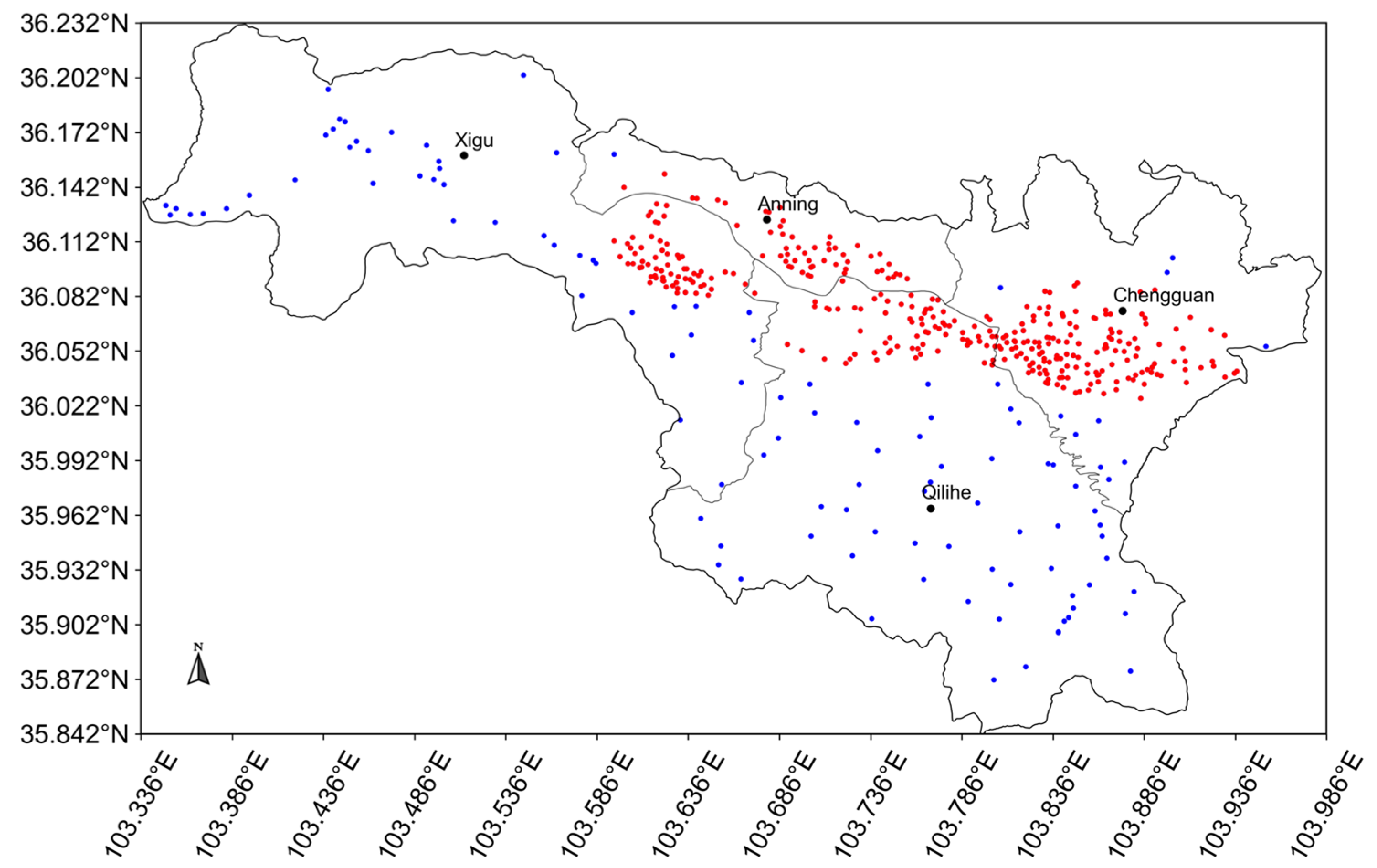
2.1. Study Area and Micro Stations Distribution
2.2. Data Collection
2.2.1. Air Quality Data
2.2.2. Meteorological and Land-Use Data
2.3. City Grid
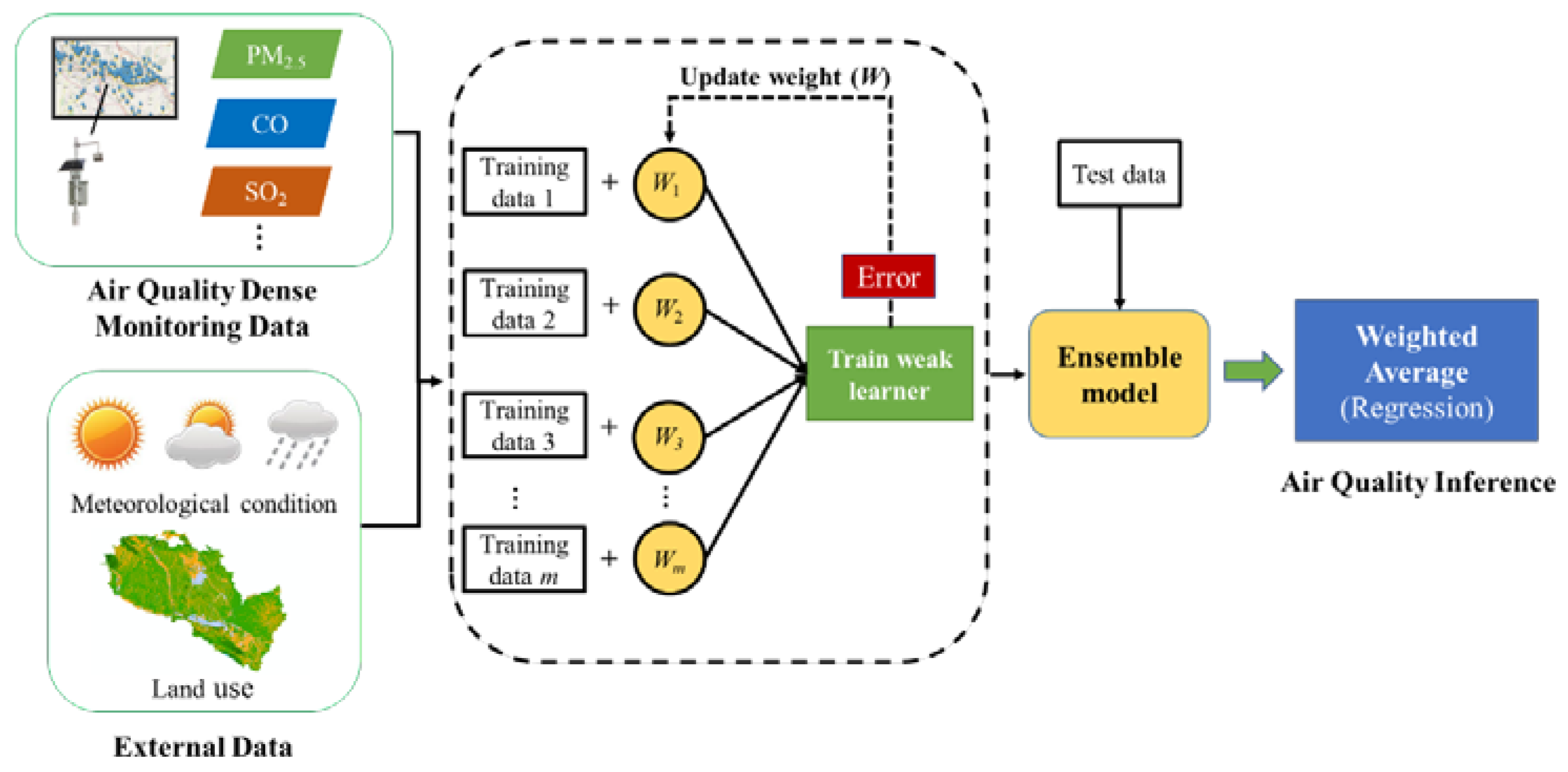
2.4. Air Quality Inference Model
2.4.1. Model Construction
2.4.2. Variable Selection and Model Hyperparameters
2.4.3. Evaluation Metric
3. Results
3.1. Data Analysis
3.1.1. Spatio-Temporal Characteristics for Urban Air Pollutants
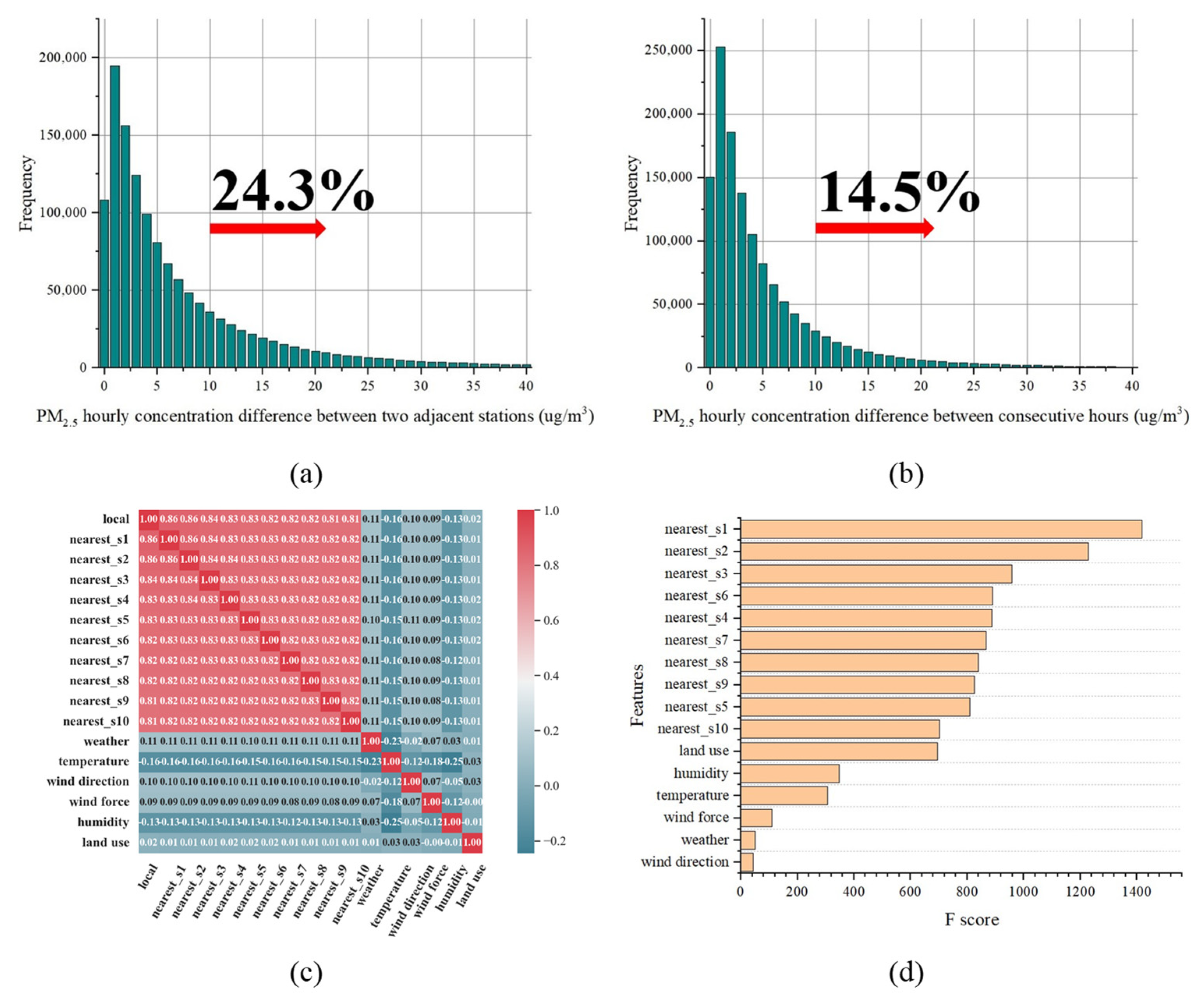
3.1.2. Correlation and Feature Importance
3.2. Performance on Air Quality Inference
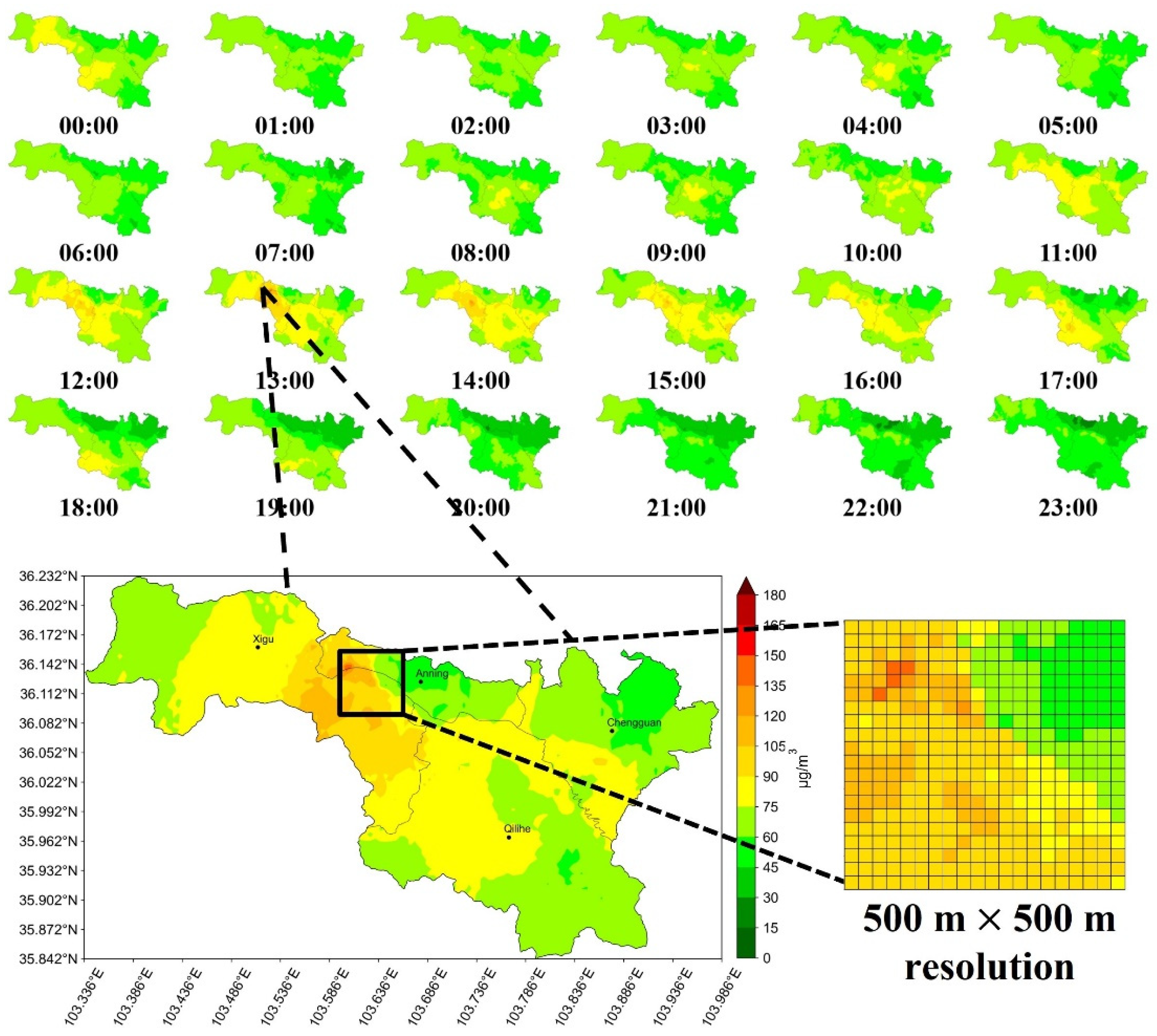
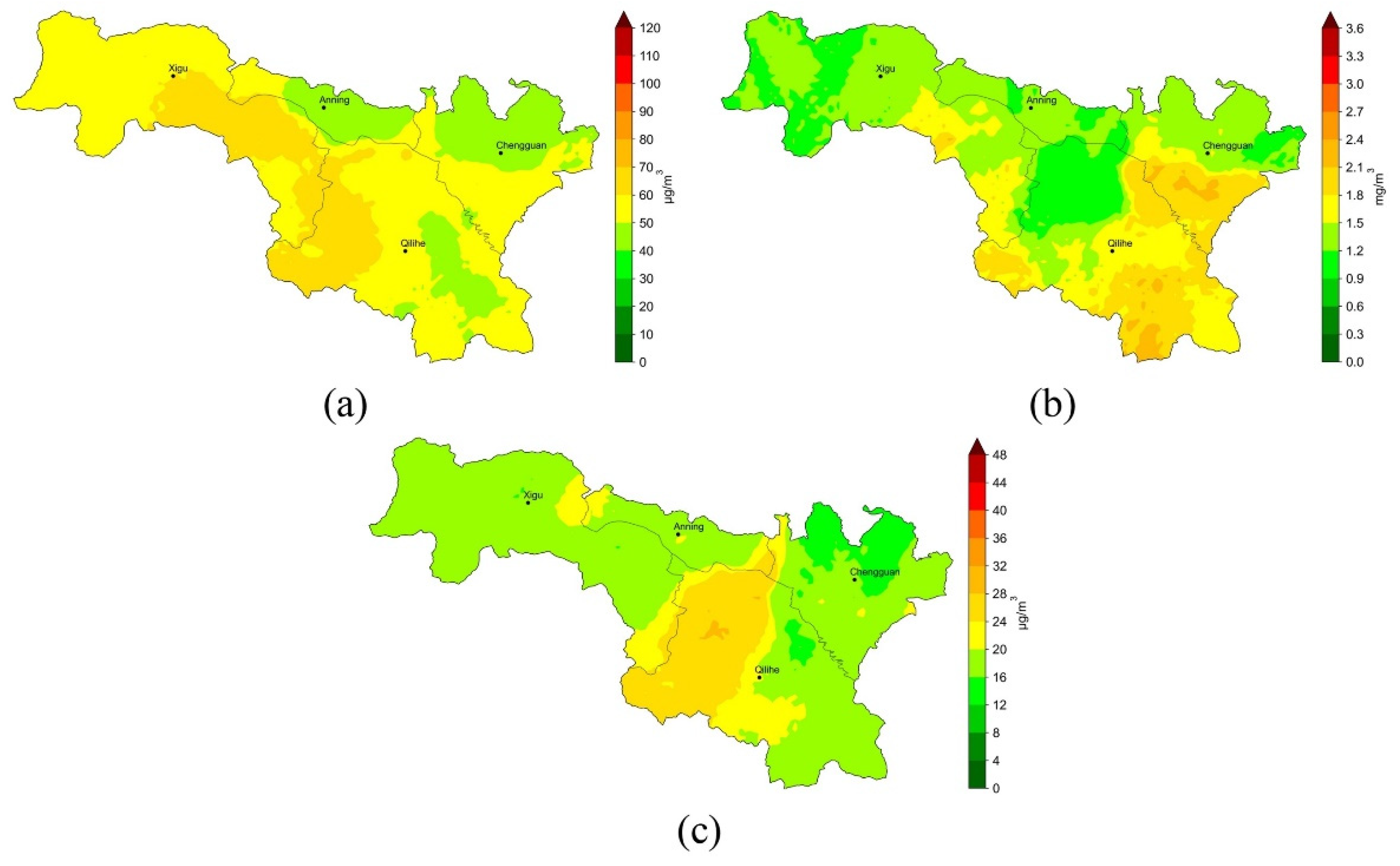
3.3. Mapping Citywide Air Quality at a High Resolution
3.3.1. Continuous Variations in the Short Term
3.3.2. Long-Term Distribution
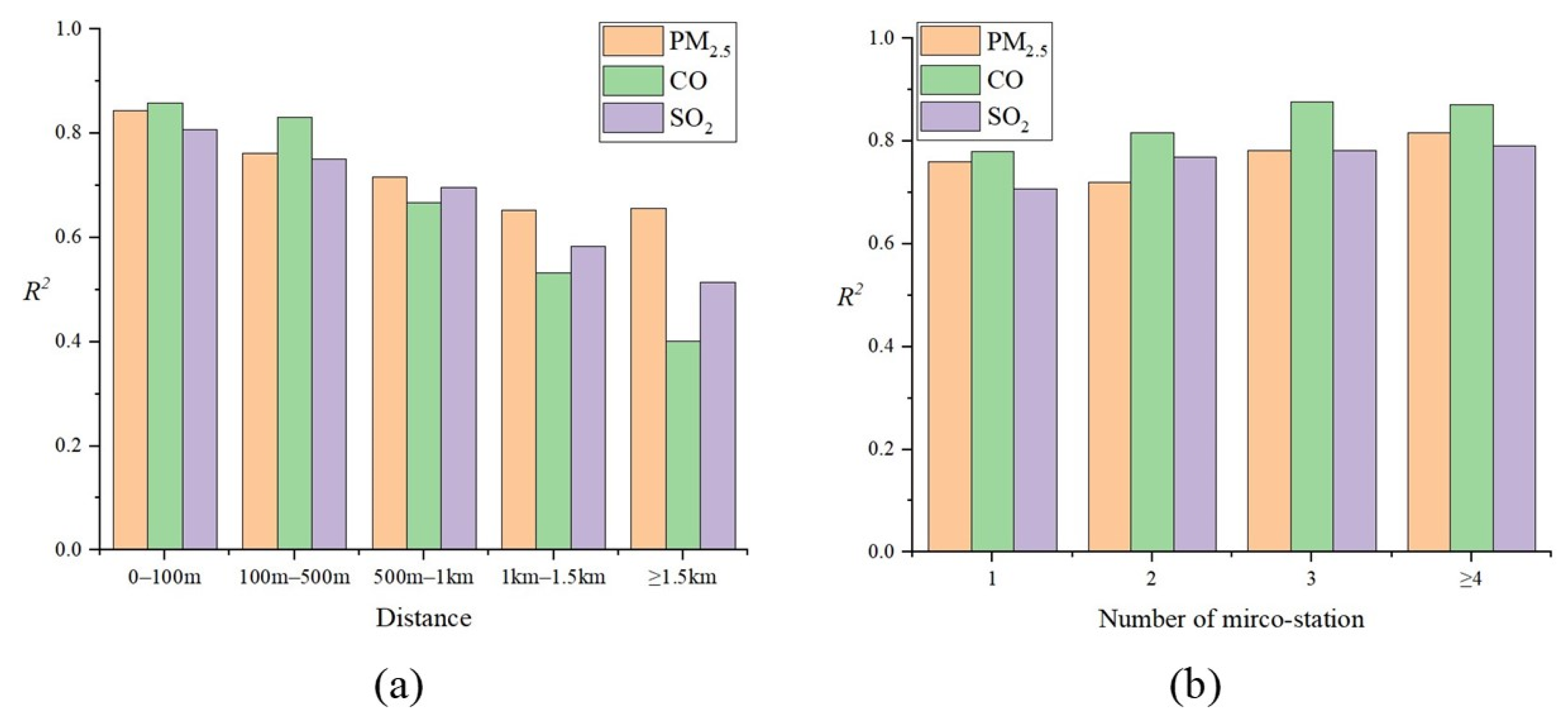
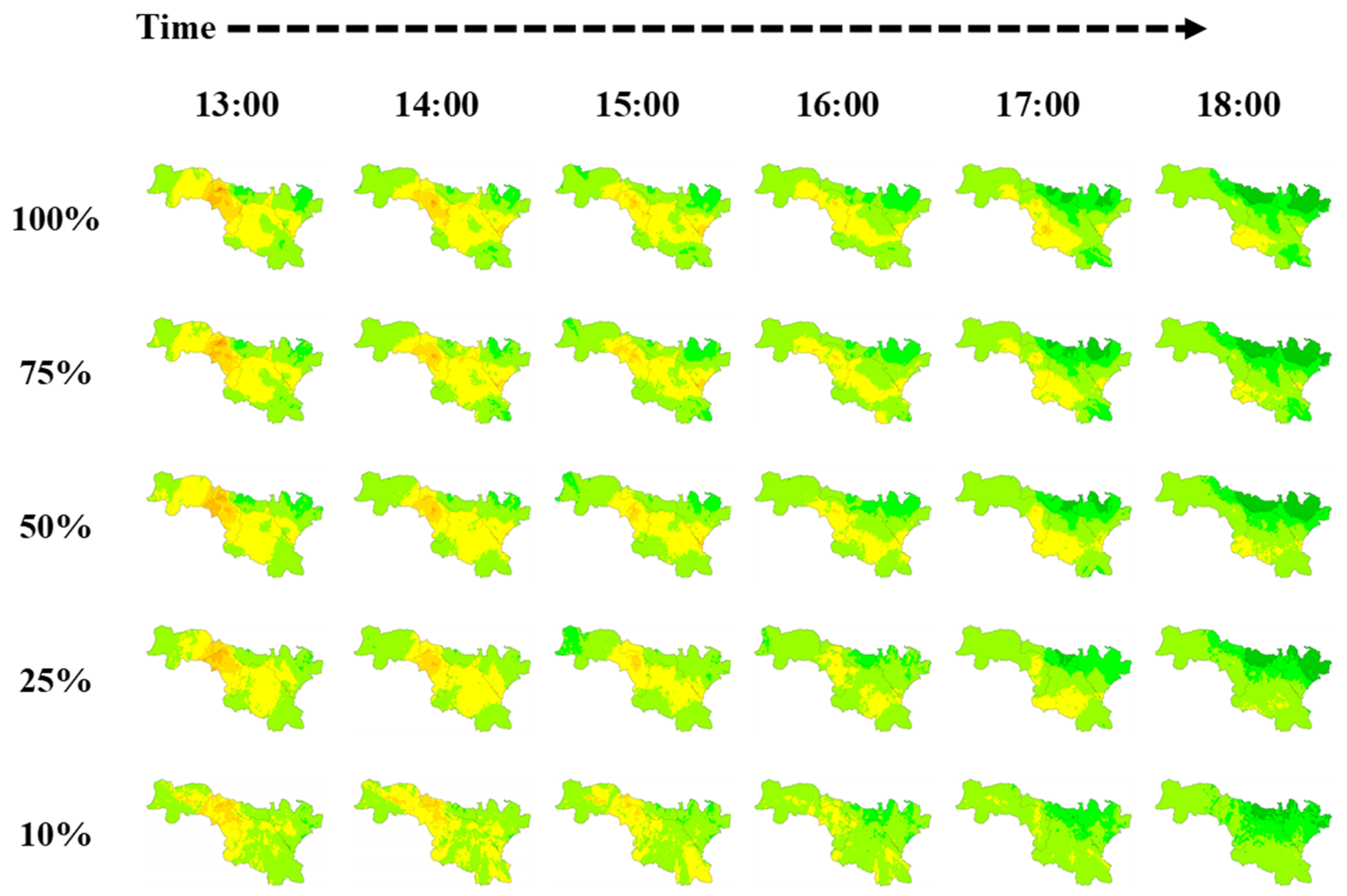
3.3.3. More Monitors Are Always Better?
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gharibvand, L.; Shavlik, D.; Ghamsary, M.; Beeson, W.L.; Soret, S.; Knutsen, R.; Knutsen, S.F. The Association between Ambient Fine Particulate Air Pollution and Lung Cancer Incidence: Results from the AHSMOG-2 Study. Environ. Health Perspect. 2017, 125, 378–384. [Google Scholar] [CrossRef] [PubMed]
- Lelieveld, J.; Pozzer, A.; Pöschl, U.; Fnais, M.; Haines, A.; Münzel, T. Loss of life expectancy from air pollution compared to other risk factors: A worldwide perspective. Cardiovasc. Res. 2020, 116, 1910–1917. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Jin, L.; Kan, H. Air pollution: A global problem needs local fixes. Nature 2019, 570, 437–439. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- World Bank. Urban Population (% of Total Population); The World Bank Group: Washington, DC, USA, 27 October 2019; Available online: https://data.worldbank.org/indicator/SP.URB.TOTL.in.zs (accessed on 10 April 2020).
- Sokhi, R.S.; Moussiopoulos, N.; Baklanov, A.; Bartzis, J.; Coll, I.; Finardi, S.; Friedrich, R.; Geels, C.; Grönholm, T.; Halenka, T.; et al. Advances in air quality research—current and emerging challenges. Atmos. Chem. Phys. 2022, 22, 4615–4703. [Google Scholar] [CrossRef]
- New York State Ambient Air Monitoring Program—2021 Monitoring Network Plan. Available online: https://www.dec.ny.gov/chemical/33276.html (accessed on 1 March 2022).
- Li, W.; Shao, L.; Wang, W.; Li, H.; Wang, X.; Li, Y.; Li, W.; Jones, T.; Zhang, D. Air quality improvement in response to intensified control strategies in Beijing during 2013–2019. Sci. Total Environ. 2020, 744, 140776. [Google Scholar] [CrossRef]
- Boogaard, H.; Kos, G.P.; Weijers, E.P.; Janssen, N.A.; Fischer, P.H.; van der Zee, S.C.; de Hartog, J.J.; Hoek, G. Contrast in air pollution components between major streets and background locations: Particulate matter mass, black carbon, elemental composition, nitrogen oxide and ultrafine particle number. Atmos. Environ. 2011, 45, 650–658. [Google Scholar] [CrossRef]
- Yi, X.; Zhang, J.; Wang, Z.; Li, T.; Zheng, Y. Deep distributed fusion network for air quality prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018. [Google Scholar]
- Simpson, D.; Benedictow, A.; Berge, H.; Bergström, R.; Emberson, L.D.; Fagerli, H.; Flechard, C.R.; Hayman, G.D.; Gauss, M.; Jonson, J.E.; et al. The EMEP MSC-W chemical transport model–technical description. Atmos.Chem. Phys. 2012, 12, 7825–7865. [Google Scholar] [CrossRef] [Green Version]
- Gibson, M.D.; Kundu, S.; Satish, M. Dispersion model evaluation of PM2.5, NOx and SO2 from point and major line sources in Nova Scotia, Canada using AERMOD Gaussian plume air dispersion model. Atmos. Pollut. Res. 2013, 4, 157–167. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Yin, Y.; Chen, S. Robust signal timing optimization with environmental concerns. Transp. Res. Part C Emerg. Technol. 2013, 29, 55–71. [Google Scholar] [CrossRef]
- Zheng, Y.; Liu, F.; Hsieh, H.-P. U-air: When urban air quality inference meets big data. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013. [Google Scholar]
- Lim, C.C.; Kim, H.; Vilcassim, M.R.; Thurston, G.D.; Gordon, T.; Chen, L.-C.; Lee, K.; Heimbinder, M.; Kim, S.-Y. Mapping urban air quality using mobile sampling with low-cost sensors and machine learning in Seoul, South Korea. Environ. Int. 2019, 131, 105022. [Google Scholar] [CrossRef]
- Qi, Z.; Wang, T.; Song, G.; Hu, W.; Li, X.; Zhang, Z.M. Deep Air Learning: Interpolation, Prediction, and Feature Analysis of Fine-Grained Air Quality. IEEE Trans. Knowl. Data Eng. 2018, 30, 2285–2297. [Google Scholar] [CrossRef] [Green Version]
- Schmitz, O.; Beelen, R.; Strak, M.; Hoek, G.; Soenario, I.; Brunekreef, B.; Vaartjes, I.; Dijst, M.J.; Grobbee, D.E.; Karssenberg, D. High resolution annual average air pollution concentration maps for the Netherlands. Sci. Data 2019, 6, 190035. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Di, Q.; Amini, H.; Shi, L.; Kloog, I.; Silvern, R.; Kelly, J.; Sabath, M.B.; Choirat, C.; Koutrakis, P.; Lyapustin, A.; et al. An ensemble-based model of PM2.5 concentration across the contiguous United States with high spatiotemporal resolution. Environ. Int. 2019, 130, 104909. [Google Scholar] [CrossRef]
- Shtein, A.; Kloog, I.; Schwartz, J.; Silibello, C.; Michelozzi, P.; Gariazzo, C.; Viegi, G.; Forastiere, F.; Karnieli, A.; Just, A.C.; et al. Estimating daily PM2.5 and PM10 over Italy using an ensemble model. Environ. Sci. Technol. 2019, 54, 120–128. [Google Scholar] [CrossRef]
- Apte, J.S.; Messier, K.P.; Gani, S.; Brauer, M.; Kirchstetter, T.W.; Lunden, M.M.; Marshall, J.D.; Portier, C.; Vermeulen, R.C.; Hamburg, S.P. High-Resolution Air Pollution Mapping with Google Street View Cars: Exploiting Big Data. Environ. Sci. Technol. 2017, 51, 6999–7008. [Google Scholar] [CrossRef]
- Christopher, S.A.; Gupta, P. Satellite Remote Sensing of Particulate Matter Air Quality: The Cloud-Cover Problem. J. Air Waste Manag. Assoc. 2010, 60, 596–602. [Google Scholar] [CrossRef]
- Stafoggia, M.; Bellander, T.; Bucci, S.; Davoli, M.; de Hoogh, K.; De’Donato, F.; Gariazzo, C.; Lyapustin, A.; Michelozzi, P.; Renzi, M.; et al. Estimation of daily PM10 and PM2.5 concentrations in Italy, 2013–2015, using a spatiotemporal land-use random-forest model. Environ. Int. 2019, 124, 170–179. [Google Scholar] [CrossRef]
- Chen, J.; de Hoogh, K.; Gulliver, J.; Hoffmann, B.; Hertel, O.; Ketzel, M.; Bauwelinck, M.; van Donkelaar, A.; Hvidtfeldt, U.A.; Katsouyanni, K.; et al. A comparison of linear regression, regularization, and machine learning algorithms to develop Europe-wide spatial models of fine particles and nitrogen dioxide. Environ. Int. 2019, 130, 104934. [Google Scholar] [CrossRef]
- Chen, G.; Li, S.; Knibbs, L.D.; Hamm, N.A.S.; Cao, W.; Li, T.; Guo, J.; Ren, H.; Abramson, M.J.; Guo, Y. A machine learning method to estimate PM2.5 concentrations across China with remote sensing, meteorological and land use information. Sci. Total Environ. 2018, 636, 52–60. [Google Scholar] [CrossRef]
- Xiao, Q.; Geng, G.; Cheng, J.; Liang, F.; Li, R.; Meng, X.; Xue, T.; Huang, X.; Kan, H.; Zhang, Q.; et al. Evaluation of gap-filling approaches in satellite-based daily PM2.5 prediction models. Atmos. Environ. 2020, 244, 117921. [Google Scholar] [CrossRef]
- Xiao, Q.; Chang, H.; Geng, G.; Liu, Y. An Ensemble Machine-Learning Model to Predict Historical PM2.5 Concentrations in China from Satellite Data. ISEE Conf. Abstr. 2018, 2018. [Google Scholar] [CrossRef]
- Lyu, B.; Hu, Y.; Zhang, W.; Du, Y.; Luo, B.; Sun, X.; Sun, Z.; Deng, Z.; Wang, X.; Liu, J.; et al. Fusion method combining ground-level observations with chemical transport model predictions using an ensemble deep learning framework: Application in China to estimate spatiotemporally-resolved PM2.5 exposure fields in 2014–2017. Environ. Sci. Technol. 2019, 53, 7306–7315. [Google Scholar] [CrossRef] [PubMed]
- Gui, K.; Che, H.; Zeng, Z.; Wang, Y.; Zhai, S.; Wang, Z.; Luo, M.; Zhang, L.; Liao, T.; Zhao, H.; et al. Construction of a virtual PM2.5 observation network in China based on high-density surface meteorological observations using the Extreme Gradient Boosting model. Environ. Int. 2020, 141, 105801. [Google Scholar] [CrossRef]
- Hammer, M.S.; van Donkelaar, A.; Li, C.; Lyapustin, A.; Sayer, A.M.; Hsu, N.C.; Levy, R.C.; Garay, M.J.; Kalashnikova, O.V.; Kahn, R.A.; et al. Global estimates and long-term trends of fine par-ticulate matter concentrations (1998–2018). Environ. Sci. Technol. 2020, 54, 7879–7890. [Google Scholar] [CrossRef] [PubMed]
- Jiang, T.; Chen, B.; Nie, Z.; Ren, Z.; Xu, B.; Tang, S. Estimation of hourly full-coverage PM2.5 concentrations at 1-km resolution in China using a two-stage random forest model. Atmos. Res. 2020, 248, 105146. [Google Scholar] [CrossRef]
- Zaręba, M.; Danek, T. Analysis of Air Pollution Migration during COVID-19 Lockdown in Krakow, Poland. Aerosol Air Qual. Res. 2022, 22, 210275. [Google Scholar] [CrossRef]
- Zhao, B.; Yu, L.; Wang, C.; Shuai, C.; Zhu, J.; Qu, S.; Taiebat, M.; Xu, M. Urban Air Pollution Mapping Using Fleet Vehicles as Mobile Monitors and Machine Learning. Environ. Sci. Technol. 2021, 55, 5579–5588. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Los Angeles, CA, USA, 13–17 August 2016. [Google Scholar]
- Christidis, T.; Erickson, A.C.; Pappin, A.; Crouse, D.L.; Pinault, L.L.; Weichenthal, S.A.; Brook, J.R.; van Donkelaar, A.; Hystad, P.; Martin, R.V.; et al. Low concentrations of fine particle air pollution and mortality in the Canadian Community Health Survey cohort. Environ. Health 2019, 18, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Chen, R.; Yin, P.; Meng, X.; Wang, L.; Liu, C.; Niu, Y.; Liu, Y.; Liu, J.; Qi, J.; You, J.; et al. Associations between Coarse Particulate Matter Air Pollution and Cause-Specific Mortality: A Nationwide Analysis in 272 Chinese Cities. Environ. Health Perspect. 2019, 127, 017008. [Google Scholar] [CrossRef] [Green Version]
- Xing, Y.-F.; Xu, Y.-H.; Shi, M.-H.; Lian, Y.-X. The impact of PM2.5 on the human respiratory system. J. Thorac. Dis. 2016, 8, E69. [Google Scholar]
- Shi, L.; Zanobetti, A.; Kloog, I.; Coull, B.A.; Koutrakis, P.; Melly, S.L.; Schwartz, J.D. Low-concentration PM2.5 and mortality: Estimating acute and chronic effects in a population-based study. Environ. Health Perspect. 2016, 124, 46–52. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tobler, W.R. A Computer Movie Simulating Urban Growth in the Detroit Region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- Danek, T.; Zaręba, M. The Use of Public Data from Low-Cost Sensors for the Geospatial Analysis of Air Pollution from Solid Fuel Heating during the COVID-19 Pandemic Spring Period in Krakow, Poland. Sensors 2021, 21, 5208. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Cheng, Y.; Zhang, Y.; He, Y.; Gu, Z.; Yu, C. Impact of Air Humidity Fluctuation on the Rise of PM Mass Concentration Based on the High-Resolution Monitoring Data. Aerosol Air Qual. Res. 2017, 17, 543–552. [Google Scholar] [CrossRef] [Green Version]
- Grimmond, S.; Bouchet, V.; Molina, L.T.; Baklanov, A.; Tan, J.; Schlünzen, K.H.; Mills, G.; Golding, B.; Masson, V.; Ren, C.; et al. Integrated urban hydrometeorological, climate and envi-ronmental services: Concept, methodology and key messages. Urban Clim. 2020, 33, 100623. [Google Scholar] [CrossRef]
- Guan, Q.; Li, F.; Yang, L.; Zhao, R.; Yang, Y.; Luo, H. Spatial-temporal variations and mineral dust fractions in particulate matter mass concentrations in an urban area of northwestern China. J. Environ. Manag. 2018, 222, 95–103. [Google Scholar] [CrossRef]
- Filonchyk, M.; Yan, H.; Li, X. Temporal and spatial variation of particulate matter and its correlation with other criteria of air pollutants in Lanzhou, China, in spring-summer periods. Atmos. Pollut. Res. 2018, 9, 1100–1110. [Google Scholar] [CrossRef]
- Yan, C.; Wang, L.; Zhang, Q. Study on Coupled Relationship between Urban Air Quality and Land Use in Lanzhou, China. Sustainability 2021, 13, 7724. [Google Scholar] [CrossRef]
- Kumar, P.; Morawska, L.; Martani, C.; Biskos, G.; Neophytou, M.K.-A.; DI Sabatino, S.; Bell, M.; Norford, L.; Britter, R. The rise of low-cost sensing for managing air pollution in cities. Environ. Int. 2015, 75, 199–205. [Google Scholar] [CrossRef] [Green Version]
- Coker, E.S.; Amegah, A.K.; Mwebaze, E.; Ssematimba, J.; Bainomugisha, E. A land use regression model using machine learning and locally developed low cost particulate matter sensors in Uganda. Environ. Res. 2021, 199, 111352. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Range | Interval |
|---|---|---|
| n_estimators | 100~500 | 100 |
| learning_rate | 0.05~0.1 | 0.01 |
| max_depth | 3~10 | 1 |
| min_child_weight | 1~6 | 1 |
| colsample_bytree | 0.7~1 | 0.1 |
| Subsample | 0.7~1 | 0.1 |
| PM2.5 | CO | SO2 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Methods | RMSE | R2 | COR | RMSE | R2 | COR | RMSE | R2 | COR |
| KNN | 12.710 | 0.653 | 0.814 | 0.524 | 0.659 | 0.816 | 6.426 | 0.618 | 0.794 |
| SVR | 11.666 | 0.708 | 0.851 | 0.518 | 0.668 | 0.858 | 6.135 | 0.652 | 0.844 |
| DNN | 11.171 | 0.732 | 0.860 | 0.452 | 0.747 | 0.865 | 5.607 | 0.709 | 0.842 |
| Random Forest | 11.188 | 0.731 | 0.856 | 0.455 | 0.743 | 0.862 | 5.645 | 0.705 | 0.840 |
| XGBoost | 10.999 | 0.740 | 0.861 | 0.445 | 0.754 | 0.869 | 5.537 | 0.716 | 0.846 |
| PM2.5 | CO | SO2 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Predictors | RMSE | R2 | COR | RMSE | R2 | COR | RMSE | R2 | COR |
| 1 station | 12.820 | 0.647 | 0.806 | 0.567 | 0.602 | 0.784 | 6.806 | 0.571 | 0.763 |
| 3 stations | 11.414 | 0.721 | 0.849 | 0.469 | 0.727 | 0.853 | 5.879 | 0.680 | 0.825 |
| 5 stations | 11.183 | 0.732 | 0.856 | 0.458 | 0.740 | 0.861 | 5.649 | 0.705 | 0.840 |
| 7 stations | 11.093 | 0.736 | 0.858 | 0.452 | 0.747 | 0.864 | 5.569 | 0.713 | 0.844 |
| 10 stations | 11.055 | 0.738 | 0.859 | 0.449 | 0.750 | 0.866 | 5.550 | 0.715 | 0.846 |
| 10 s + m 1 | 11.045 | 0.738 | 0.859 | 0.449 | 0.750 | 0.866 | 5.545 | 0.715 | 0.846 |
| 10 s + l 2 | 11.021 | 0.739 | 0.860 | 0.447 | 0.753 | 0.868 | 5.538 | 0.716 | 0.846 |
| 10 s + m + l | 10.999 | 0.740 | 0.861 | 0.445 | 0.754 | 0.869 | 5.537 | 0.716 | 0.846 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, R.; Qi, Y.; Zhao, B.; Pei, Z.; Wen, F.; Wu, S.; Zhang, Q. High-Resolution Urban Air Quality Mapping for Multiple Pollutants Based on Dense Monitoring Data and Machine Learning. Int. J. Environ. Res. Public Health 2022, 19, 8005. https://doi.org/10.3390/ijerph19138005
Guo R, Qi Y, Zhao B, Pei Z, Wen F, Wu S, Zhang Q. High-Resolution Urban Air Quality Mapping for Multiple Pollutants Based on Dense Monitoring Data and Machine Learning. International Journal of Environmental Research and Public Health. 2022; 19(13):8005. https://doi.org/10.3390/ijerph19138005
Chicago/Turabian StyleGuo, Rong, Ying Qi, Bu Zhao, Ziyu Pei, Fei Wen, Shun Wu, and Qiang Zhang. 2022. "High-Resolution Urban Air Quality Mapping for Multiple Pollutants Based on Dense Monitoring Data and Machine Learning" International Journal of Environmental Research and Public Health 19, no. 13: 8005. https://doi.org/10.3390/ijerph19138005
APA StyleGuo, R., Qi, Y., Zhao, B., Pei, Z., Wen, F., Wu, S., & Zhang, Q. (2022). High-Resolution Urban Air Quality Mapping for Multiple Pollutants Based on Dense Monitoring Data and Machine Learning. International Journal of Environmental Research and Public Health, 19(13), 8005. https://doi.org/10.3390/ijerph19138005