1. Introduction
Optimally allocating a collection of financial investments such as stocks, bonds and commodities has been a topic of concern to financial institutions and shareholders at least since the pioneering work of Markowitz’s mean-variance portfolio theory in 1952. People then realized the potential of diversification and their work laid the foundations for the development of portfolio analysis in both academia and industry. These initial results were in discrete-time, but it was not long before continuous-time portfolio decisions were produced in the alternative paradigm of expected utility theory, as can be seen in
Merton (
1969). The author assumed that the investor is able to continuously adjust their position, and the stock price process is modelled by a geometric Brownian motion (GBM). The optimal trading strategy and consumption policy that maximize the investor’s expected utility were obtained in closed-form by solving a Hamilton–Jacobi–Bellman equation.
The beauty and practicality of this continuous-time solution has led many researchers onto this path, producing optimal closed-form strategies for a wide range of models. For example,
Kraft (
2005) considered the stochastic volatility (SV) Heston model,
Heston (
1993).
Flor and Larsen (
2014) constructed a portfolio of stocks and fixed-income market products to hedge the interest rate risk. Explicit solutions in the presence of regime switching, stochastic interest rate and stochastic volatility was presented in
Escobar et al. (
2017), whilst the positive performance of their portfolio is confirmed by empirical study. For the commodities asset class,
Chiu and Wong (
2013) modelled a mean-reverting risky asset by an exponential Ornstein–Uhlenbeck (OU) process and solved the investment problem for an insurer subject to the random payment of insurance claim.
These models are particular cases of the quadratic-affine family (see
Liu (
2006)), one of the broadest models solvable in closed-form. The value function for a model in this family is the product of a function of wealth and an exponential quadratic function. Nonetheless, the complexity of financial markets has continued increasing every decade, with researchers detecting new stylized facts and proposing new models outside the quadratic-affine. Needless to say, investors must rely on these advanced models for better financial decisions, however. closed-form solutions are no longer guaranteed. One example of these advanced models is the GBM 4/2 model, introduced in
Grasselli (
2017). The model improves the Heston model in terms of the better fitting of implied volatility surfaces and historical volatilities patterns. The optimal portfolio problem with the GBM 4/2 model is solvable for certain types of market price of risk (MPR, see
Cheng and Escobar-Anel (
2021)), while the optimal trading strategy has not been found yet with an MPR proportional to the instantaneous volatility. More recently, an OU 4/2 model, which unifies the mean-reverting drift and stochastic volatility in a single model, was presented in
Escobar-Anel and Gong (
2020). The model targets two asset classes: commodities and volatility indexes. The optimal portfolio with the OU 4/2 model is not in closed form. This motivates approximation methods for dynamic portfolio choice.
Most approximation methods follow the idea from martingale method (see
Karatzas et al. (
1987)) or dynamic programming technique
Brandt et al. (
2005).
Cvitanić et al. (
2003) proposed a simulation-based method seeking the financial replication of the optimal terminal wealth given in the martingale method.
Detemple et al. (
2003) developed a comprehensive approach for the same investment problems, and the application of Malliavin calculus enhances its accuracy. The work in
Brandt et al. (
2005) led to the BGSS method, which was inspired by the popular least-square Monte Carlo method of
Longstaff and Schwartz (
2001). BGSS pioneered the recursive approximation method for dynamic portfolio choice.
Cong and Oosterlee (
2017) enhanced BGSS with the stochastic grid bundling method (SGBM) for conditional expectation estimation introduced in
Jain and Oosterlee (
2015). More recently, a polynomial affine method for constant relative risk aversion utility (PAMC) was recently developed in
Zhu et al. (
2020). The method takes advantage of the quadratic-affine structure, leading to superior accuracy and efficiency in the approximation of the optimal strategy and value function. In this paper, we extend the methodology in PAMC using neural networks.
The history of artificial neural networks goes back to
McCulloch and Pitts (
1943), where the author created the so-called “threshold logic” on the basis of the neural networks of the human brain in order to mimic human thoughts. Deep learning has since steadily evolved. Almost three decades later, back propagation, a widely used algorithm in neural network’s parameter fitting for supervised learning, was introduced, see
Linnainmaa (
1970). The importance of back propagation was only fully recognized when
Rumelhart et al. (
1986) showed that it can provide interesting distribution representations. The universal approximation theorem (see
Cybenko (
1989)) illustrated that every bounded continuous function can be approximated by a network with an arbitrarily small error, which further verifies the effectiveness of the neural network. Neural networks recently attracted a lot of attention of applied scientists, and were successful in fields such as image recognition and natural language processing because they are particular good at function approximation when the form of the target function is unknown. In the realm of dynamic portfolio analyses,
Lin et al. (
2006) first predicted portfolio covariance matrix with the Elman network and achieved the good estimation of the optimal mean-variance portfolio. More recently,
Li and Forsyth (
2019) proposed a neural network, representing the portfolio strategy at each rebalancing time, for a constrained defined contribution (DC) allocation problem.
Chen and Ge (
2021) introduced a differential equation-based method, where the value function with the Heston model is estimated by a deep neural network.
In this paper, motivated by the lack of knowledge on the correct expression for the portfolio value function for unsolvable models, we approximated the optimal portfolio strategy for any given stochastic process model with a neural network fitting the value function. Successful fitting relies on a suitable network architecture that captures the connection between input and output variables, as well as reasonable activation functions. We designed two architectures enriching an embedded quadratic-affine structure, and we considered three types of activation functions.
Given the lack of closed-form solutions for SV 4/2 models, we used them as our toy examples in the implementations. In particular, we first implemented our methodology in the solvable case (i.e., GBM 4/2 with solvable MPR), so the accuracy and efficiency were demonstrated before it is applied to the unsolvable cases of: GBM 4/2 model with stochastic jumps, GBM 4/2 model with proportional instantaneous volatility MPR, and the OU 4/2 model. Furthermore, we numerically show which network architecture is preferable in each case.
The paper is organized as follows.
Section 2 introduces the dynamic portfolio choice problem, and presents the neural network architectures, activation functions and parameter training details. The step-by-step algorithm of our methodology is provided in
Section 3.
Section 4 and
Section 5 apply the methodology to the GBM 4/2 and the OU 4/2 models.
Section 6 concludes.
2. Problem Setting and Architectures of the Deep Learning Model
We considered a frictionless market consisting of a money market account (cash,
M) and one stock (
S). We assume the stock price follows a generalized diffusion process incorporating a one-dimensional state variable
X. All the processes are defined on a complete probability space
with a right-continuous filtration
, summarized by the stochastic differential equations (SDE):
and
are Brownian motions with correlation
.
is the interest rate,
and
are the drift and diffusion coefficients for the stock price.
and
are measurable functions of state variable
.
is a pure-jump process independent of
and
with stochastic intensity
for constant
, and
denotes the jump size.
We consider an investor with risk preference represented by a constant relative risk aversion (CRRA) utility:
Investors can adjust their allocation at a predetermined set of rebalancing times
. The investors wish to derive a portfolio strategy
(percentage of wealth allocated to the stock) that maximizes their expected utility of terminal wealth, in other words,
. The value function, representing the investor’s conditional expected utility, has the following representation:
The value function is separated into a wealth factor and a state variable function f. The NNMC estimates the state variable function f with a neural network model and computes the optimal strategy with the Bellman principle.
2.1. Architectures of the Deep Learning Model
In this section, we present two neural network architectures to fit the value function. According to the separable property of the value function shown in (
3), the only unknown component is the state variable function
f, which is therefore the target function for the neural network. The architectures of the networks are built around exponential polynomial functions, which are the most common form of solvable investor’s value functions and used in the PAMC method (see
Zhu et al. (
2020)). This property of proposed networks ensures that the new method generalizes PAMC.
The neural network is expected to achieve a better fit than a polynomial regression if the true state variable function is significantly different from the exponential polynomial function. Furthermore, we designed an initialization method for networks, which is better than a random initialization in terms of portfolio value function fitting.
2.1.1. Sum of Exponential Network
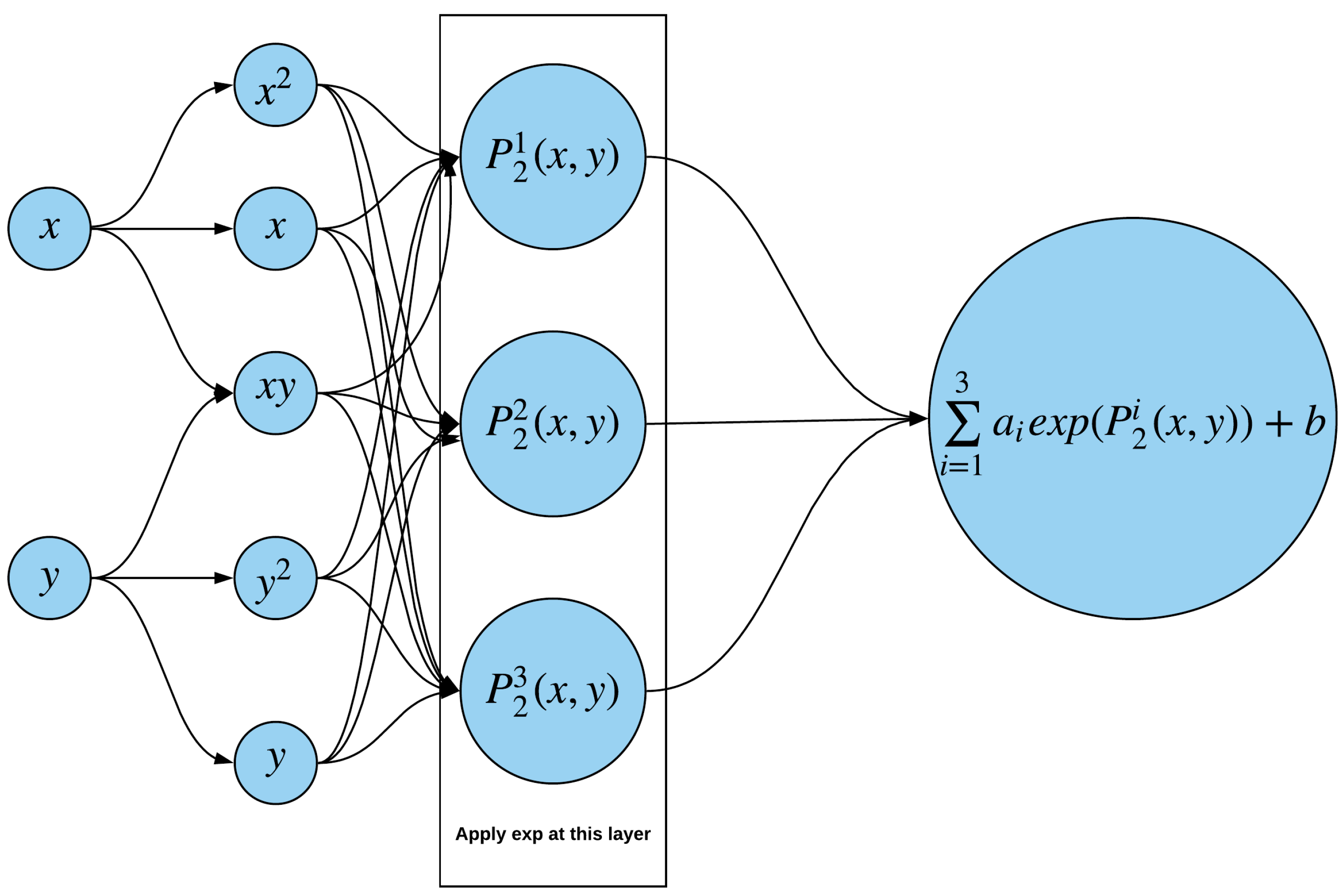
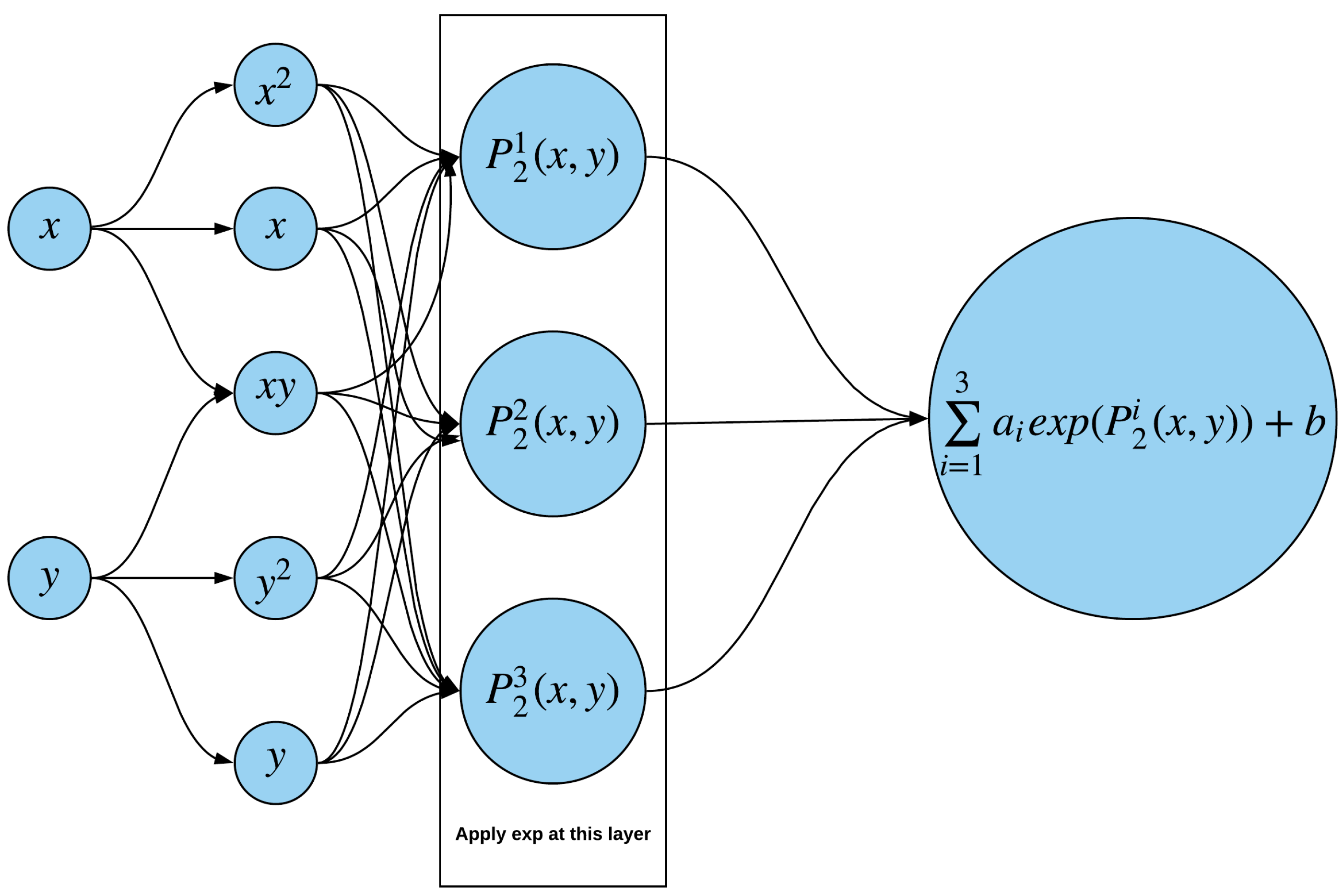
We first introduced the sum of the exponential polynomial neural network (SEN), as illustrated in
Figure 1. The amount of input depends on the number of state variables. For simplicity, we took two inputs as an example. The first hidden layer computes the monomial of inputs. The second hidden layer obtains the linear combinations of the neuron in the first layer, where the weights are fitted in NNMC. An exponential activation function is applied to the second layer. The final output calculates a linear combination of exponential polynomials, so the exponential polynomial is a specific case of this neural network.
We denote the sum of exponential network by ; the proposition next states the estimation of the corresponding optimal allocation.
Proposition 1. Given the SEN approximation of the value function at the next rebalancing time , (i.e., ), the optimal strategy at time t is given bywhich is the solution of:where:Notably, when follows a diffusion process, i.e., . when follows a jump process, i.e., . Proof. We substitute
with
and expand the right hand side of the equation with respect to
W,
S and
X, then
is written as a function of strategy
. Equation (
5) is obtained with the first order condition. □
2.1.2. Improving Exponential Network
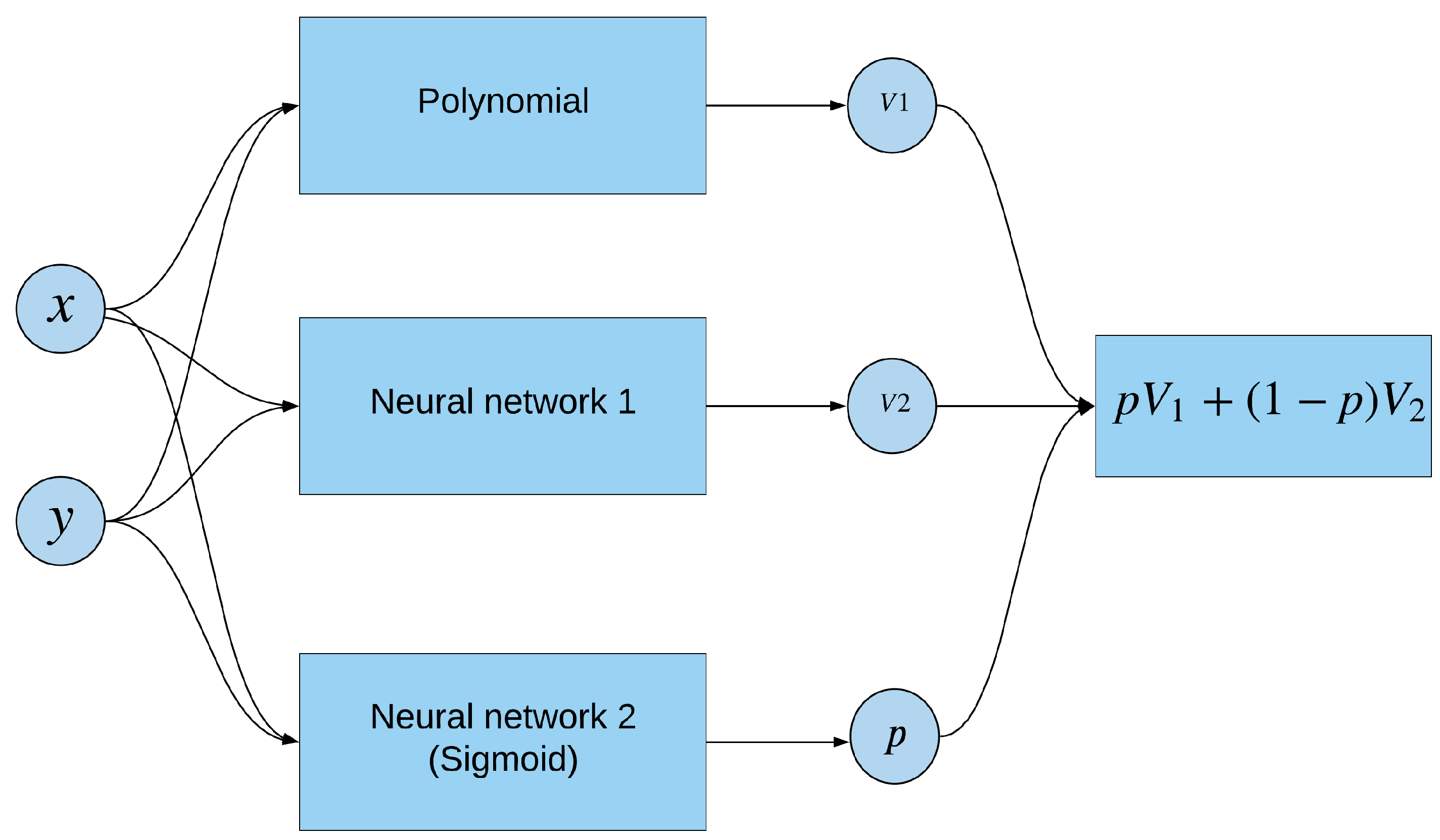
The architecture of an improving exponential network (IEN) is exhibited in
Figure 2.
The target function of IEN is the log of the state variable function
f (i.e.,
). The neural network consists of three parts. Node 1 is a polynomial with the output denoted by
. Node 2 is an artificial neural network with an arbitrary number of hidden layers and neurons; we denoted its output by
. Node 3 is a single-layer network with a Sigmoid function which computes a proportion
. The final output is the weighted average of the first two nodes
. The second node is the complement to the exponential polynomial function. Moreover, the similarity between the true value function and the exponential polynomial function is measured by
p, which is fitted into the NNMC methodology. Therefore, the network automatically adjusts the weights on the exponential polynomial function and its supplement according to the generated data. Finally, the state variable function
f is computed as
which is the geometric weighted average of nodes 1 and 2. Letting
denote the IEN, the estimation of the optimal strategy is given in the next proposition.
Proposition 2. Given the IEN approximation of the log value function at time (i.e., ), the optimal strategy at time t is given bywhich is the solution of:where: Notably, when follows a diffusion process, in other words, . when follows a jump process (i.e., ).
Proof. The proof follows similarly to Proposition 1. □
2.2. Initialization, Stopping Criterion and Activation Function
In this section, we disclose more details on training the neural networks. The initialization of weights is the first step of network training, which may significantly impact the goodness of fit. A good initialization prevents the network’s weights from converging to a local minimum and avoids slow convergence. Random initialization is mostly used as the interpretability of the network is usually weak. In contrast, both the SEN and the IEN are extensions of an exponential polynomial function; we suggest taking advantage of the results from the polynomial regression. Hence, the neural network searches the minimum near the exponential polynomial function used in the PAMC ensuring consistency. The polynomial regression initialization achieves superior results to the random initialization.
The coefficients of the exponential polynomial were first obtained with a regression model. The output of the SEN is a linear combination of exponential polynomial functions , we substitute the coefficients from polynomial regression into and set . For the initialization of the IEN, we substitute the coefficients into the first node and artificially make .
The training process minimizes the mean squared error (MSE) between the network’s output and the simulated expected utility, and the sample data are split into a training set and a test set to reduce the overfitting problem. Adam is a back-propagation algorithm that combines the best properties of the AdaGrad and RMSProp algorithms to handle sparse gradients on noisy problems and provides excellent convergence speed. We applied the Adam on the training set for updating the network’s weights, and the test set MSE was computed and subsequently recorded. The test set MSE was expected to be convergent, so the training process was finished when the difference between the moving average of the recent 100 test set MSEs and the most recent test set MSE was less than a predetermined threshold, which was set at in the implementation.
The number of exponential polynomials is a hyperparameter in the SEN. We let the SEN be a sum of two exponential polynomial functions for simplicity. Node 2 in the IEN is an artificial neural network, which complements node 1 when the value function significantly deviates from an exponential polynomial function. The number of hidden layers and neurons, as well as the activation function of node 2, are freely determined before fitting the value function. We assume node 2 is a single layer network with 10 neurons and we implement several functions for comparison purposes, such as the logistic (sigmoid):
the Rectified linear unit (ReLU):
and the Exponential linear unit (ELU):
5. Application to the OU 4/2 Model
Motivated by the 4/2 stochastic volatility model and mean-reverting price pattern popular among various asset classes (e.g., commodities, exchange rates, volatility indexes),
Escobar-Anel and Gong (
2020) defined an Ornstein–Uhlenbeck 4/2 (OU 4/2) stochastic volatility model for volatility index option and commodity option valuation. Equation (
22) presents the dynamics involved in the OU 4/2 model, which is a specific case of (
1) given
,
,
and
. The parameters used in this section are reported in
Table 6, which is estimated from the data of gold Exchange-traded fund (ETF) and the volatility index of gold ETF in
Escobar-Anel and Gong (
2020). There are two state variables in the OU 4/2 model; hence, the input in both the SEN and the IEN are 2. Furthermore, the degree of polynomial in PAMC and NNMC is 2:
SEN performs worse than IEN when fitting the value function with the OU 4/2 model. Sometimes, SEN significantly deviates from the true value function, which results in poor portfolio performances and the occurrence of negative terminal wealth. Therefore, we excluded the results from NNMC-SEN in this section.
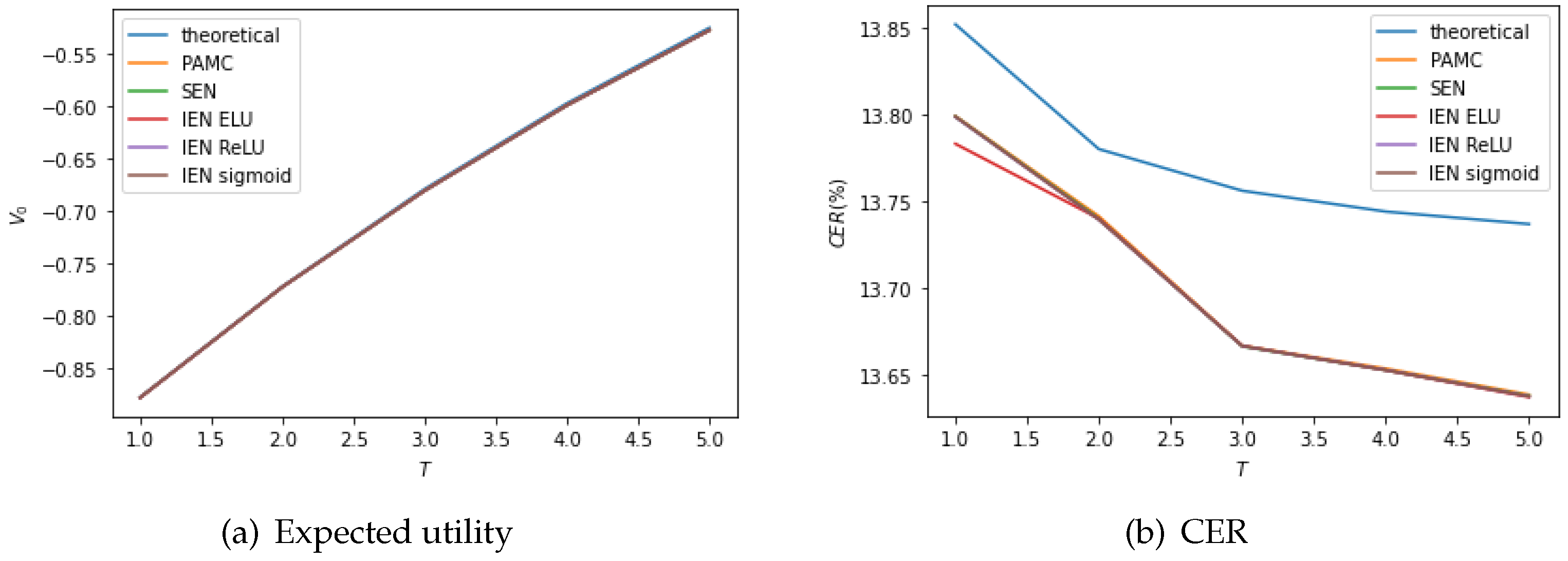
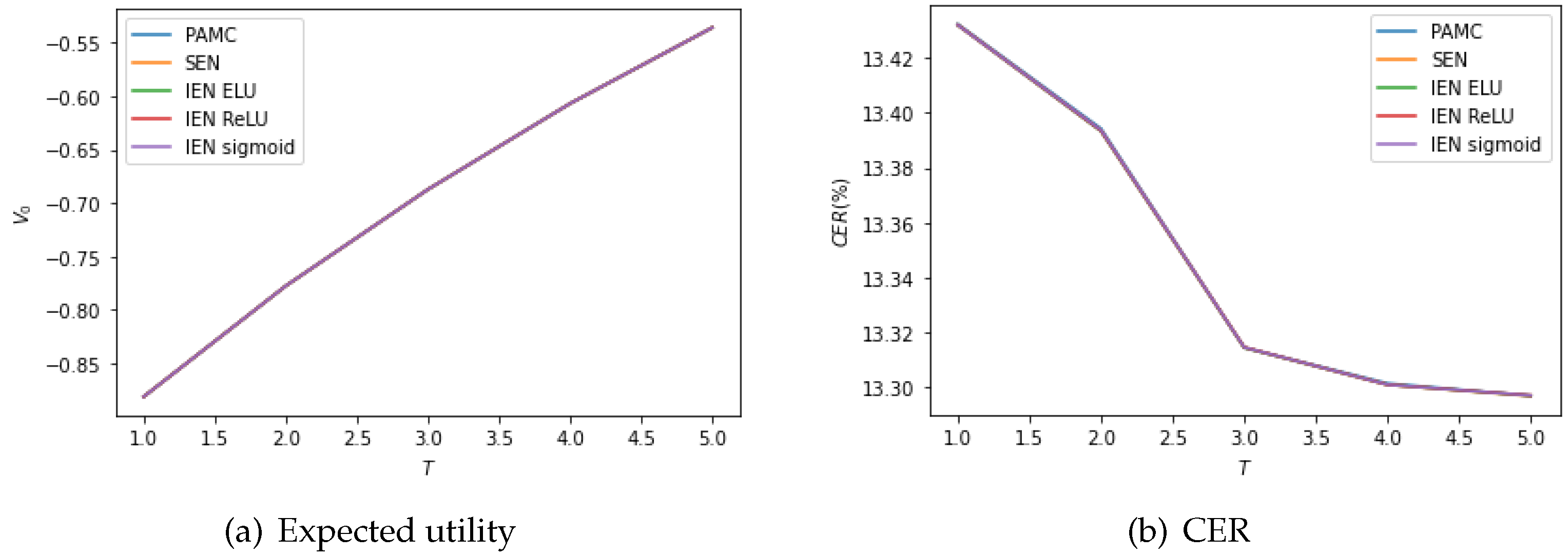
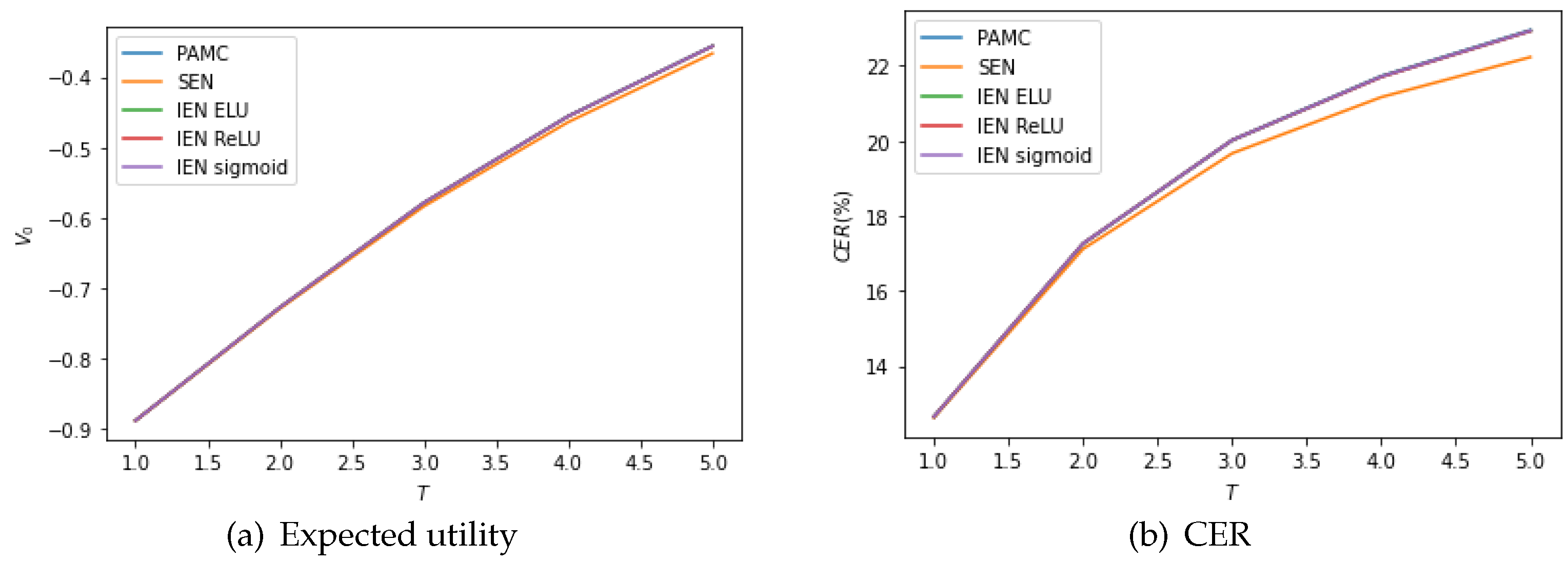
Table 7 compares the optimal allocation, expected utility and CER obtained for the OU 4/2 model. PAMC and NNMC-IEN produce similar optimal allocations, both outperforming NNMC-SEN. Furthermore, we also estimated the standard deviation of expected utility and CER, which demonstrates that NNMC leads to a less volatile estimation of expected utility and CER than PAMC in most cases. In contrast to the results for the 4/2 model, IEN is more efficient than SEN. We conclude that IEN is suitable for the model with a complex structure and multiple state variables. The expected utility and CER as a function of the maturity
T when
is plotted in
Figure 6. Both the expected utility and CER increase with
T. The expected utility and CER obtained from PAMC and NNMC-IEN visually overlap and are slightly higher than that of NNMC-SEN. Moreover, the selection of activation function in IEN makes little difference.
6. Conclusions
This paper investigated fitting the value function in an expected utility, dynamic portfolio choice using a deep learning model. We proposed two architectures for the neural network, which extends the broadest solvable family of value functions (i.e., the exponential polynomial function). We measured the accuracy and efficiency of various types of NNMC methods on the 4/2 model and the OU 4/2 model. The difference in optimal allocation, expected utility and CER is insignificant when the stock price follows the 4/2 model. The embedded PAMC is superior to NNMC due to the lower parametric space, hence its efficiency. Furthermore, when considering the OU 4/2 model, NNMC-SEN is inferior to a polynomial regression (PAMC) and to the NNMC-IEN in terms of expected utility and CER.
In summary, NNMC benefits from the popular exponential polynomial representation (embedded PAMC method) to propose a network architecture flexible enough to reach beyond affine models. Although the best setting, NNMC-IEN (ELU), is not as efficient as PAMC, neural networks demonstrate the way to tackle more advanced models along the lines of Markov switching, Lévy processes and fractional Brownian processes.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}