
On the Kavya–Manoharan–Burr X Model: Estimations under Ranked Set Sampling and Applications


Abstract
:1. Introduction
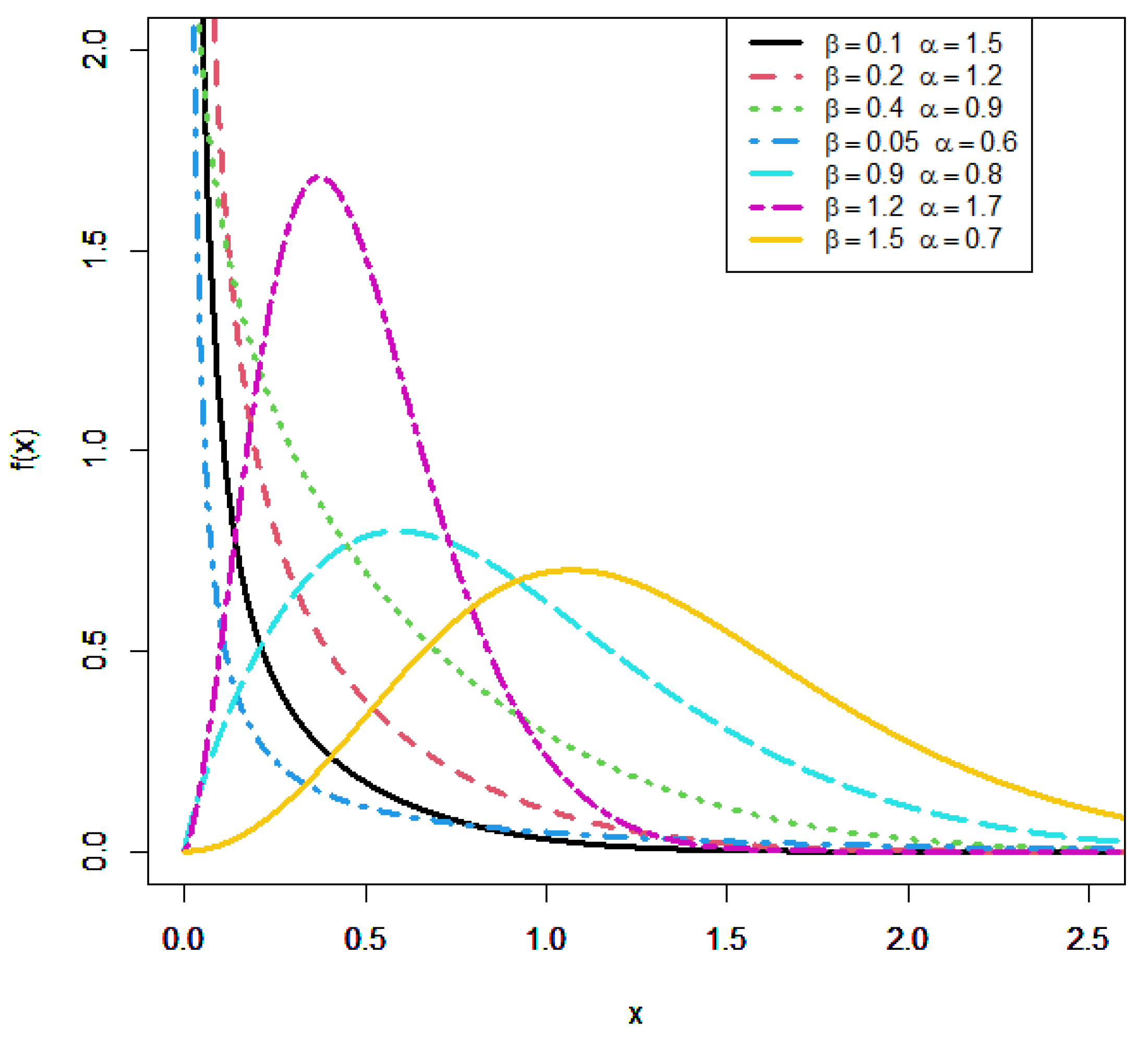
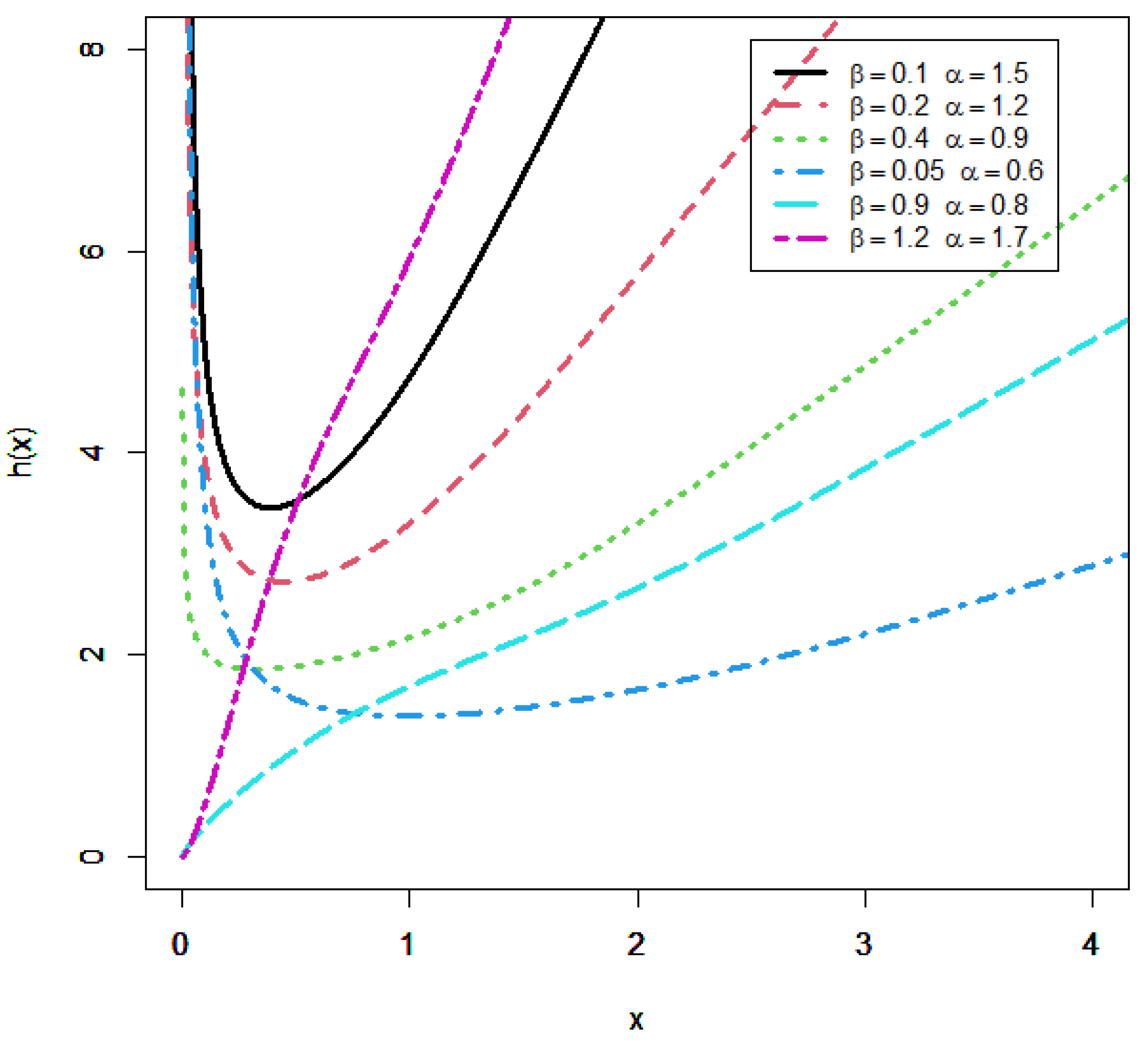
2. Kavya-Manoharan Burr X Distribution
3. Statistical Measures
3.1. Quantile Function
3.2. Moments and Incomplete Moments
3.3. Conditional Moments
3.4. Moment-Generating Functions
3.5. Rényi Entropy
4. Parameter Estimation
4.1. MLL Approach under SiRS
4.2. MLL Approach under RaSS
4.3. Numerical Outcomes
- The BIs and MSERs for the estimations depending on SiRS are greater than the comparable values depending on RaSS;
- In most scenarios, the BIs and MSER decrease as the n rises for both sampling strategies;
- In most cases, the efficiency of the estimates rises as the sample numbers grow;
- The MLLEs depending on RaSS have lower MSER values than the corresponding values depending on SiRS.
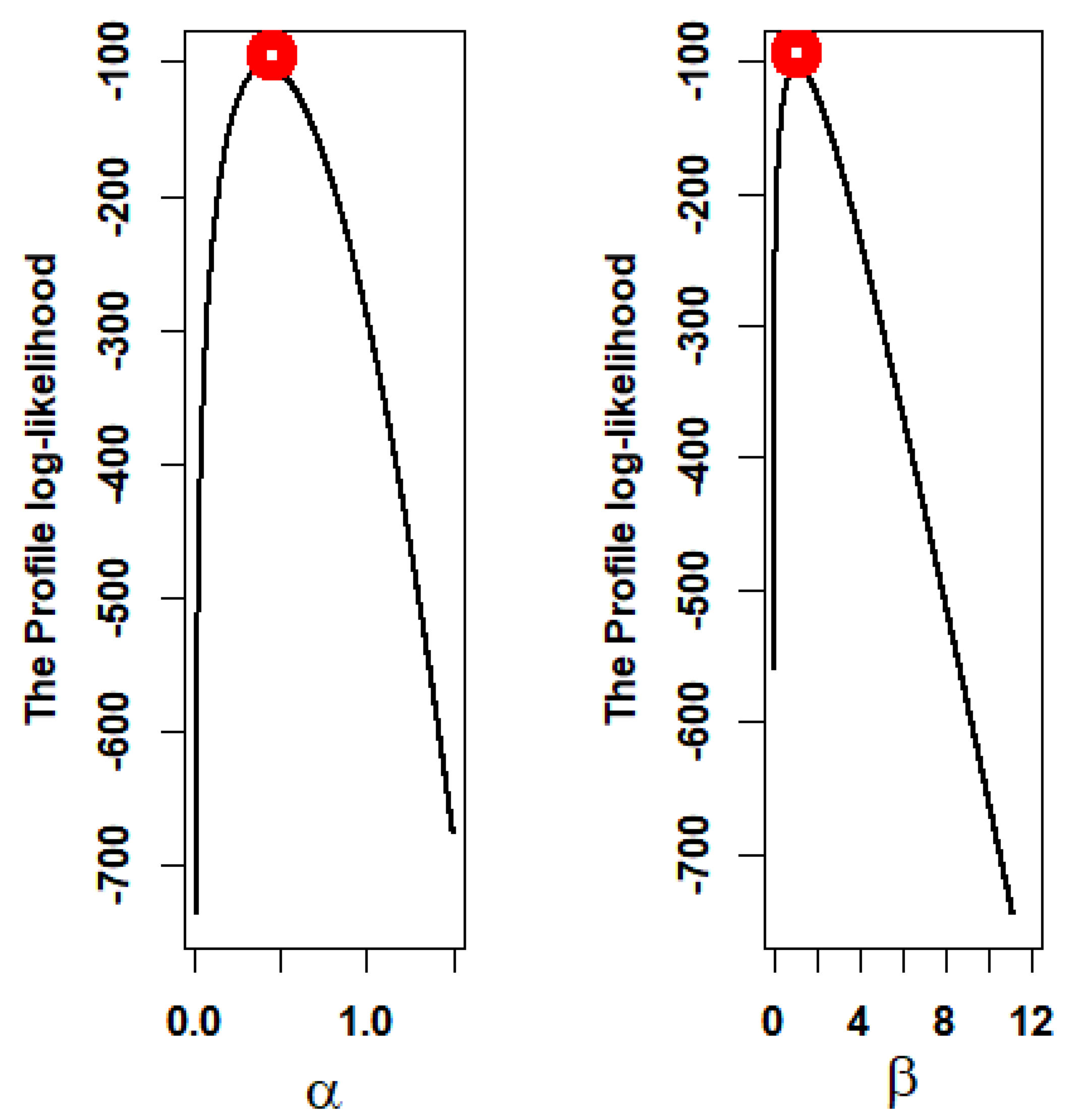
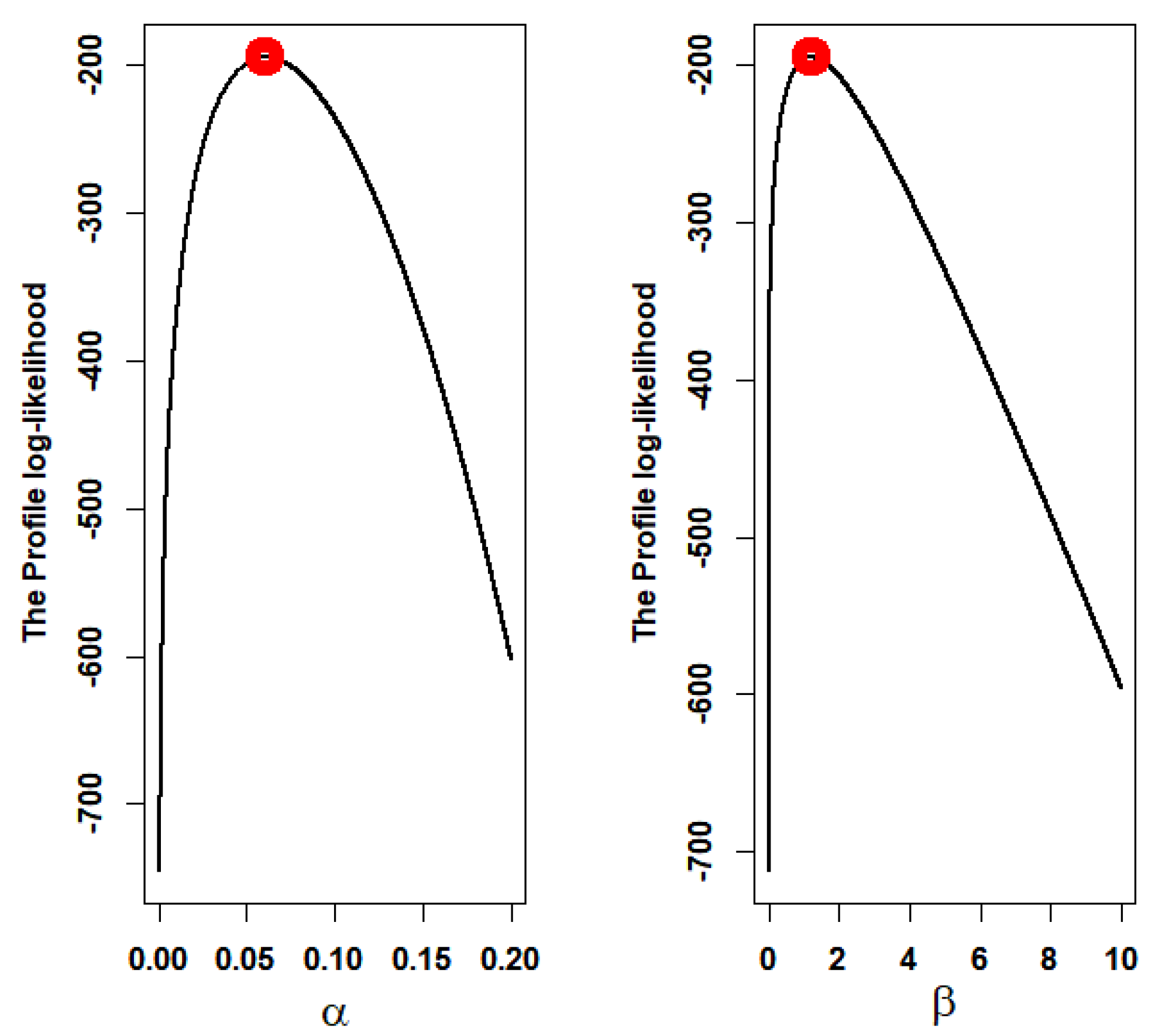
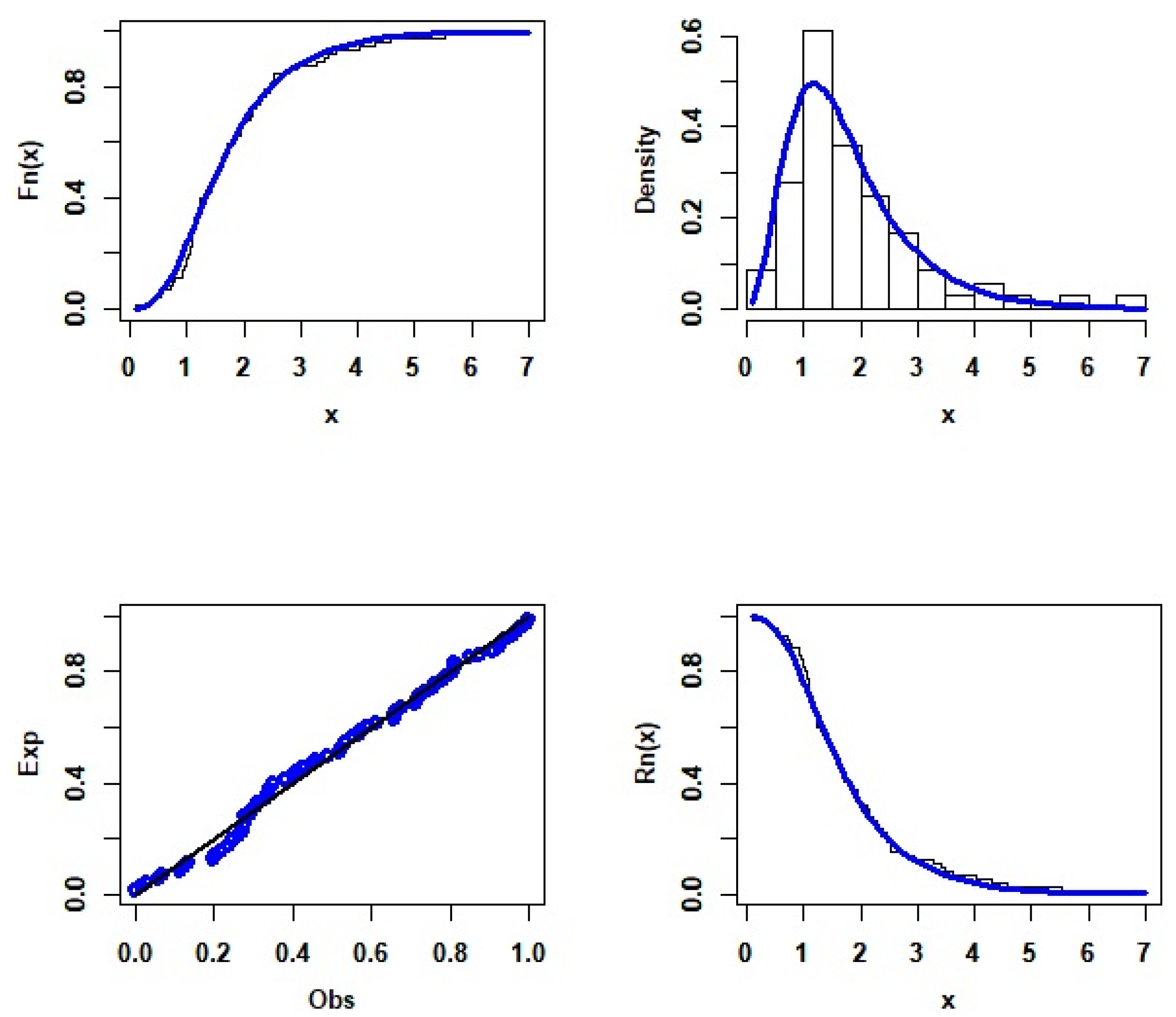
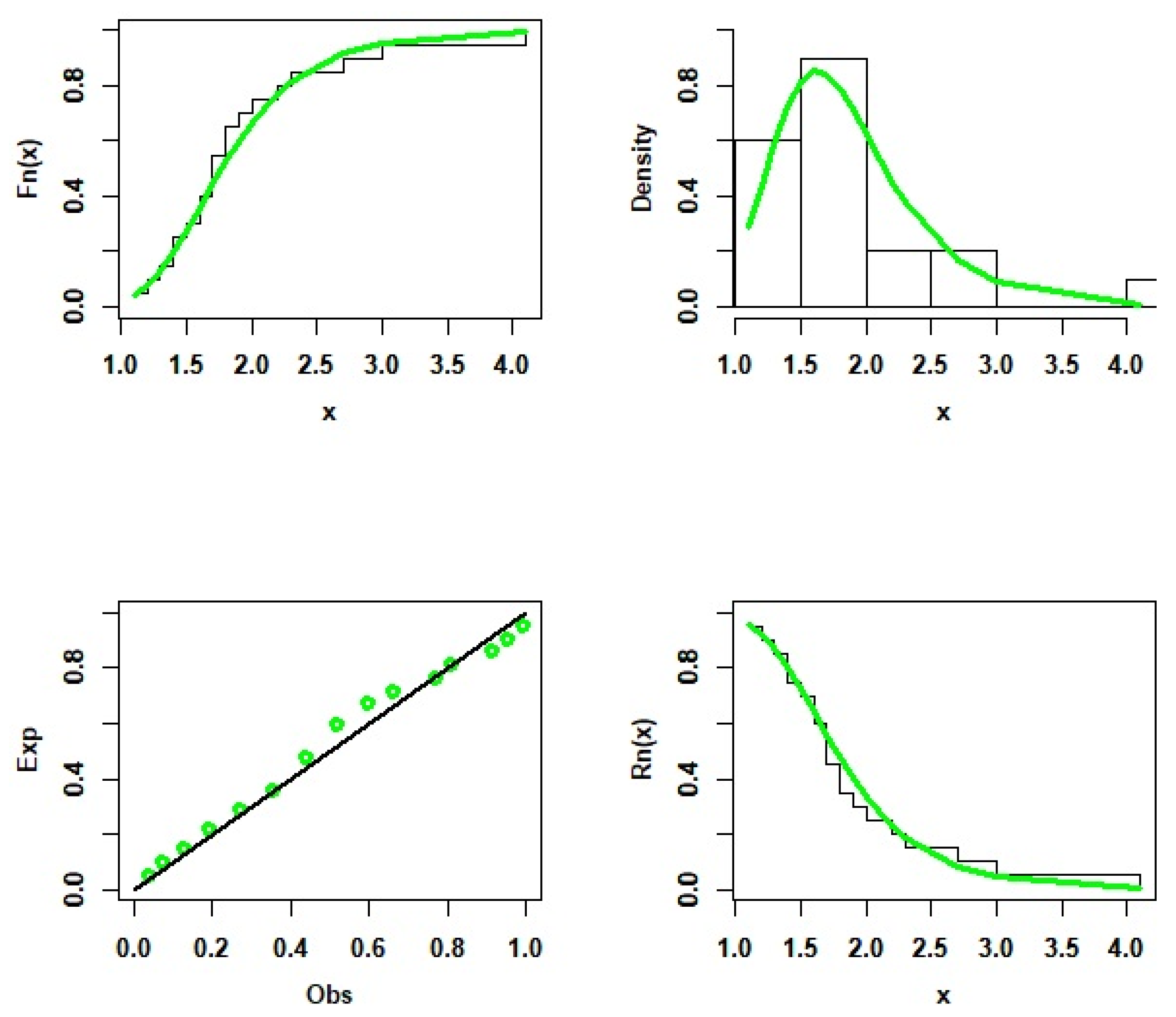
5. Application to Real Data Sets
- The First Data Set: Survival Times Data
- The Second Data Set: Relief Times Data
- The Third Data Set: Financial Data
6. Actuarial Measures
6.1. Value at Risk
6.2. Conditional Value at Risk
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Afify, Ahmed Z., Zohdy M. Nofal, and Nadeem Shafique Butt. 2014. Transmuted complementary Weibull geometric distribution. Pakistan Journal of Statistics and Operations Research 10: 435–54. [Google Scholar] [CrossRef] [Green Version]
- Afify, Ahmed Z., Zohdy M. Nofal, Haitham M. Yousof, Yehia M. El Gebaly, and Nadeem Shafique Butt. 2015. Transmuted Weibull Lomax distribution. Pakistan Journal of Statistics and Operations Research 11: 135–52. [Google Scholar] [CrossRef] [Green Version]
- Afify, Ahmed, Haitham Yousof, and Saralees Nadarajah. 2017. The beta transmuted-H family for lifetime data. Statistics and Its Interface 10: 505–20. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, Z., Zohdy M. Nofal, and N. Ebraheim Abd El Hadi. 2015. Exponentiated transmuted generalized Rayleigh distribution: A new four parameter Rayleigh distribution. Pakistan Journal of Statistics and Operations Research 11: 115–34. [Google Scholar]
- Aijaz, Ahmad, Afaq Ahmad, and Rajnee Tripathi. 2020. Inverse Analogue of Ailamujia Distribution with Statistical Properties and Applications. Asian Research Journal of Mathematics 16: 36–46. [Google Scholar] [CrossRef]
- Algarni, Ali, Abdullah M. Almarashi, I. Elbatal, Amal S. Hassan, Ehab M. Almetwally, Abdulkader M. Daghistani, and Mohammed Elgarhy. 2021. Type I half logistic Burr XG family: Properties, Bayesian, and non-Bayesian estimation under censored samples and applications to COVID-19 data. Mathematical Problems in Engineering 2021: 5461130. [Google Scholar] [CrossRef]
- Almalki, Saad J., and Jingsong Yuan. 2013. A new modified Weibull distribution. Reliability Engineering and System Safety 111: 164–70. [Google Scholar] [CrossRef]
- Alotaibi, Naif, Atef F. Hashem, Ibrahim Elbatal, Salem A. Alyami, A. S. Al-Moisheer, and Mohammed Elgarhy. 2022a. Inference for a Kavya–Manoharan Inverse Length Biased Exponential Distribution under Progressive-Stress Model Based on Progressive Type-II Censoring. Entropy 24: 1033. [Google Scholar] [CrossRef]
- Alotaibi, Naif, Ibrahim Elbatal, Ehab M. Almetwally, Salem A. Alyami, A. S. Al-Moisheer, and Mohammed Elgarhy. 2022b. Bivariate Step-Stress Accelerated Life Tests for the Kavya–Manoharan Exponentiated Weibull Model under Progressive Censoring with Applications. Symmetry 14: 1791. [Google Scholar] [CrossRef]
- Aludaat, K. M., Moh’D Taleb Alodat, and Tareq Alodat. 2008. Parameter estimation of Burr type X distribution for grouped data. Applied Mathematical Sciences 2: 415–23. [Google Scholar]
- Alzaatreh, Ayman, Felix Famoye, and Carl Lee. 2014. The gamma-normal distribution: Properties and applications. Computational Statistics and Data Analysis 69: 67–80. [Google Scholar] [CrossRef]
- Artzner, Philippe. 1997. Thinking Coherently. Risk 10: 68–71. [Google Scholar]
- Artzner, Philippe. 1999. Application of coherent risk measures to capital requirements in insurance. North American Actuarial Journal 3: 11–25. [Google Scholar] [CrossRef]
- Bantan, Rashad A. R., Christophe Chesneau, Farrukh Jamal, Ibrahim Elbatal, and Mohammed Elgarhy. 2021. The Truncated Burr X-G Family of Distributions: Properties and Applications to Actuarial and Financial Data. Entropy 23: 1088. [Google Scholar] [CrossRef] [PubMed]
- Burr, Irving W. 1942. Cumulative frequency functions. The Annals of Mathematical Statistics 13: 215–32. [Google Scholar] [CrossRef]
- Cordeiro, Gauss M., Elizabeth M. Hashimoto, and Edwin M. M. Ortega. 2014. The McDonald Weibull model. Statistics 48: 256–78. [Google Scholar] [CrossRef]
- Elbatal, I., Yehia M. El Gebaly, and Essam A. Amin. 2017. The beta generalized inverse Weibull geometric distribution and its applications. Pakistan Journal of Statistics and Operation Research 13: 75–90. [Google Scholar] [CrossRef] [Green Version]
- El-Morshedy, M., Ziyad Ali Alhussain, Doaa Atta, Ehab M. Almetwally, and M. S. Eliwa. 2020. Bivariate Burr X generator of distributions: Properties and estimation methods with applications to complete and type-II censored samples. Mathematics 8: 264. [Google Scholar] [CrossRef] [Green Version]
- Eugene, Nicholas, Carl Lee, and Felix Famoye. 2002. Beta-normal distribution and its applications. Communications in Statistics-Theory and Methods 31: 497–512. [Google Scholar] [CrossRef]
- Gross, Alan J., and Virginia Clark. 1975. Survival Distributions: Reliability Applications in the Biomedical Sciences. New York: John Wiley and Sons. [Google Scholar]
- Jose, K. K. 2011. Marshall-Olkin family of distributions and their applications in reliability theory, time series modeling and stress-strength analysis. Paper presented at ISI 58th World Statistics Congress International Statistical Institute, Dublin, Ireland, August 21–26; pp. 3918–23. [Google Scholar]
- Kavya, P., and M. Manoharan. 2020. On a Generalized lifetime model using DUS transformation. In Applied Probability and Stochastic Processes. Infosys Science Foundation Series. Edited by V. Joshua, S. Varadhan and V. Vishnevsky. Singapore: Springer, pp. 281–91. [Google Scholar]
- Kavya, P., and M. Manoharan. 2021. Some parsimonious models for lifetimes and applications. Journal of Statistical Computation and Simulation 91: 3693–708. [Google Scholar] [CrossRef]
- Khan, Muhammad Shuaib, Robert King, and Irene Hudson. 2013. A new three parameter transmuted Chen lifetime distribution with application. Journal of Applied Statistical Science 21: 239–59. [Google Scholar]
- Khan, Muhammad Shuaib, Robert King, and Irene Lena Hudson. 2016. Transmuted exponentiated Chen distribution with application to survival data. ANZIAM Journal 57: 268–90. [Google Scholar] [CrossRef] [Green Version]
- Kumar, Dinesh, Umesh Singh, and Sanjay Kumar Singh. 2015. A method of proposing new distribution and its application to bladder cancer patients data. Journal of Statistics Applications and Probability Letters 2: 235–45. [Google Scholar]
- Lee, Carl, Felix Famoye, and Olugbenga Olumolade. 2007. Beta-Weibull distribution: Some properties and applications to censored data. Journal of Modern Applied Statistical Methods 6: 173–86. [Google Scholar] [CrossRef]
- Lv, H. Q., L. H. Gao, and C. L. Chen. 2002. Ailamujia distribution and its application in support ability data analysis. Journal of Academy of Armored Force Engineering 16: 48–52. [Google Scholar]
- Raqab, Mohammad Z., and Debasis Kundu. 2006. Burr type X distribution: Revisited. Journal of Probability and Statistical Sciences 4: 179–93. [Google Scholar]
- Refaie, Mohamed K. A. 2018. Burr X exponentiated exponential distribution. Journal of Statistics and Applications 1: 71–88. [Google Scholar]
- Surles, J. G., and W. J. Padgett. 2001. Inference for reliability and stress-strength for a scaled Burr type X distribution. Lifetime Data Analysis 7: 187–200. [Google Scholar] [CrossRef]
- Surles, J. G., and W. J. Padgett. 2005. Some properties of a scaled Burr type X distribution. Journal of statistical planning and inference 128: 271–80. [Google Scholar] [CrossRef]
- Tahir, Muhammad H., Gauss M. Cordeiro, M. Mansoor, and Muhammad Zubair. 2015. The Weibull-Lomax distribution: Properties and applications. Hacettepe Journal of Mathematics and Statistics 44: 455–74. [Google Scholar] [CrossRef]
- Tahir, Muhammad Hussain, Muhammad Mansoor, Muhammad Zubair, and Gholamhossein Hamedani. 2014. McDonald log logistic distribution with an application to breast cancer data. Journal of Statistical Theory and Applications 13: 65–82. [Google Scholar] [CrossRef] [Green Version]
- ZeinEldina, Ramadan A., and M. Elgarhyc. 2018. A new generalization of Weibull-exponential distribution with application. Journal of Nonlinear Science and Applications 11: 1099–112. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n | SiRS | RaSS | REEF | ||||
|---|---|---|---|---|---|---|---|
| MLLE | BI | MSER | MLLE | BI | MSER | ||
| 50 | 0.96494 | 0.06494 | 0.02302 | 0.91408 | 0.01408 | 0.00364 | 0.15794 |
| 0.56663 | 0.06663 | 0.02905 | 0.50424 | 0.00424 | 0.00272 | 0.09348 | |
| 150 | 0.92564 | 0.02564 | 0.01394 | 0.89715 | −0.00286 | 0.00096 | 0.06905 |
| 0.49715 | −0.00285 | 0.00801 | 0.49692 | −0.00308 | 0.00080 | 0.09998 | |
| 250 | 0.91592 | 0.01592 | 0.00439 | 0.90013 | 0.00013 | 0.00019 | 0.04265 |
| 0.50587 | 0.00587 | 0.00286 | 0.50162 | 0.00162 | 0.00015 | 0.05289 | |
| 500 | 0.90698 | 0.00698 | 0.00227 | 0.89978 | −0.00022 | 0.00017 | 0.07597 |
| 0.51065 | 0.01065 | 0.00179 | 0.49973 | −0.00027 | 0.00014 | 0.07568 | |
| 1000 | 0.89338 | −0.00662 | 0.00087 | 0.89998 | −0.00002 | 0.00003 | 0.03759 |
| 0.49586 | −0.00415 | 0.00052 | 0.50036 | 0.00036 | 0.00003 | 0.05376 | |
| n | SiRS | RaSS | REEF | ||||
|---|---|---|---|---|---|---|---|
| MLLE | BI | MSER | MLLE | BI | MSER | ||
| 50 | 0.71199 | 0.01198 | 0.01641 | 0.69496 | −0.00504 | 0.00204 | 0.12425 |
| 1.23371 | 0.03371 | 0.07765 | 1.18874 | −0.01126 | 0.01465 | 0.18867 | |
| 150 | 0.70128 | 0.00128 | 0.00412 | 0.70341 | 0.00341 | 0.00052 | 0.12526 |
| 1.21843 | 0.01843 | 0.05381 | 1.21744 | 0.01744 | 0.00486 | 0.09033 | |
| 250 | 0.71035 | 0.01035 | 0.00281 | 0.69710 | −0.00290 | 0.00014 | 0.05060 |
| 1.21397 | 0.01397 | 0.01423 | 1.19018 | −0.00982 | 0.00157 | 0.11022 | |
| 500 | 0.70168 | 0.00168 | 0.00132 | 0.69931 | −0.00070 | 0.00005 | 0.04155 |
| 1.22349 | 0.02349 | 0.01004 | 1.19994 | −0.00006 | 0.00076 | 0.07581 | |
| 1000 | 0.70055 | 0.00055 | 0.00037 | 0.69965 | −0.00036 | 0.00003 | 0.08976 |
| 1.21896 | 0.01896 | 0.00504 | 1.20106 | 0.00106 | 0.00029 | 0.05743 | |
| n | SiRS | RaSS | REEF | ||||
|---|---|---|---|---|---|---|---|
| MLLE | BI | MSER | MLLE | BI | MSER | ||
| 50 | 1.23291 | 0.03291 | 0.04986 | 1.22258 | 0.02258 | 0.00777 | 0.15578 |
| 0.82114 | 0.02113 | 0.03598 | 0.82070 | 0.02070 | 0.00601 | 0.16693 | |
| 150 | 1.20390 | 0.00390 | 0.02785 | 1.18876 | −0.01124 | 0.00255 | 0.09166 |
| 0.79966 | −0.00034 | 0.01355 | 0.78934 | −0.01066 | 0.00161 | 0.11864 | |
| 250 | 1.23491 | 0.03491 | 0.00737 | 1.19494 | −0.00506 | 0.00047 | 0.06430 |
| 0.84220 | 0.04220 | 0.00967 | 0.79098 | −0.00902 | 0.00064 | 0.06587 | |
| 500 | 1.20088 | 0.00088 | 0.00600 | 1.19423 | −0.00577 | 0.00034 | 0.05708 |
| 0.79162 | −0.00838 | 0.00618 | 0.79611 | −0.00389 | 0.00029 | 0.04713 | |
| 1000 | 1.19978 | −0.00022 | 0.00228 | 1.19724 | −0.00276 | 0.00010 | 0.04262 |
| 0.81249 | 0.01249 | 0.00163 | 0.79893 | −0.00107 | 0.00009 | 0.05454 | |
| n | SiRS | RaSS | REEF | ||||
|---|---|---|---|---|---|---|---|
| MLLE | BI | MSER | MLLE | BI | MSER | ||
| 50 | 0.50285 | 0.00285 | 0.00512 | 0.50386 | 0.00386 | 0.00073 | 0.14321 |
| 0.49913 | −0.00087 | 0.01764 | 0.51884 | 0.01884 | 0.00570 | 0.32300 | |
| 150 | 0.50529 | 0.00529 | 0.00230 | 0.50698 | 0.00698 | 0.00031 | 0.13363 |
| 0.52127 | 0.02127 | 0.01639 | 0.51885 | 0.01885 | 0.00181 | 0.11041 | |
| 250 | 0.51010 | 0.01010 | 0.00172 | 0.49867 | −0.00133 | 0.00006 | 0.03632 |
| 0.52292 | 0.02292 | 0.00740 | 0.49353 | −0.00647 | 0.00037 | 0.04959 | |
| 500 | 0.50559 | 0.00559 | 0.00056 | 0.50038 | 0.00037 | 0.00004 | 0.06248 |
| 0.49469 | −0.00531 | 0.00275 | 0.50102 | 0.00102 | 0.00018 | 0.06560 | |
| 1000 | 0.50033 | 0.00033 | 0.00018 | 0.50046 | 0.00046 | 0.00001 | 0.06492 |
| 0.50108 | 0.00108 | 0.00064 | 0.50163 | 0.00163 | 0.00008 | 0.12523 | |
| n | SiRS | RaSS | REEF | ||||
|---|---|---|---|---|---|---|---|
| MLLE | BI | MSER | MLLE | BI | MSER | ||
| 50 | 1.59446 | 0.09446 | 0.11720 | 1.53348 | 0.03348 | 0.01638 | 0.13979 |
| 1.35838 | 0.15838 | 0.15340 | 1.22161 | 0.02161 | 0.01185 | 0.07722 | |
| 150 | 1.58630 | 0.08630 | 0.03646 | 1.47738 | −0.02262 | 0.00338 | 0.09269 |
| 1.26562 | 0.06562 | 0.03414 | 1.17926 | −0.02074 | 0.00304 | 0.08898 | |
| 250 | 1.52835 | 0.02836 | 0.01687 | 1.50914 | 0.00914 | 0.00086 | 0.05073 |
| 1.22796 | 0.02796 | 0.01695 | 1.21189 | 0.01189 | 0.00083 | 0.04872 | |
| 500 | 1.49492 | −0.00508 | 0.00549 | 1.50226 | 0.00226 | 0.00058 | 0.10633 |
| 1.18883 | −0.01117 | 0.00662 | 1.20171 | 0.00171 | 0.00045 | 0.06753 | |
| 1000 | 1.49477 | −0.00523 | 0.00323 | 1.50460 | 0.00460 | 0.00017 | 0.05218 |
| 1.20018 | 0.00018 | 0.00260 | 1.20380 | 0.00380 | 0.00015 | 0.05880 | |
| n | SiRS | RaSS | REEF | ||||
|---|---|---|---|---|---|---|---|
| MLLE | BI | MSER | MLLE | BI | MSER | ||
| 50 | 0.88857 | 0.08857 | 0.02169 | 0.80473 | 0.00472 | 0.00224 | 0.10323 |
| 0.85532 | 0.05532 | 0.03941 | 0.80765 | 0.00765 | 0.00443 | 0.11247 | |
| 150 | 0.80340 | 0.00340 | 0.00942 | 0.80461 | 0.00461 | 0.00067 | 0.07145 |
| 0.84545 | 0.04545 | 0.03142 | 0.80745 | 0.00745 | 0.00218 | 0.06927 | |
| 250 | 0.82881 | 0.02881 | 0.00474 | 0.80171 | 0.00171 | 0.00015 | 0.03126 |
| 0.82289 | 0.02289 | 0.01406 | 0.80072 | 0.00072 | 0.00064 | 0.04558 | |
| 500 | 0.79461 | −0.00539 | 0.00298 | 0.80089 | 0.00089 | 0.00008 | 0.02542 |
| 0.79290 | −0.00710 | 0.00643 | 0.80203 | 0.00203 | 0.00029 | 0.04512 | |
| 1000 | 0.79628 | −0.00372 | 0.00055 | 0.80068 | 0.00068 | 0.00005 | 0.09571 |
| 0.79694 | −0.00306 | 0.00153 | 0.79923 | −0.00077 | 0.00020 | 0.13225 | |
| Models | MLLEs and SErs | |||
|---|---|---|---|---|
| KMBX (α, β) | 0.443 (0.038) | 1.081 (0.153) | ||
| KMOLE (α, μ, τ, β) | 0.373 (0.136) | 3.478 (0.862) | 3.306 (0.781) | 0.299 (1.113) |
| BXE (θ, β) | 0.475 (0.06) | 0.206 (0.012) | ||
| GMOLE (λ, α, β) | 0.179 (0.07) | 47.640 (44.90) | 4.47 (1.33) | |
| BE (μ, τ, β) | 0.807 (0.70) | 3.461 (1.003) | 1.3311 (0.8551) | |
| KE (μ, τ, β) | 3.304 (1.1061) | 1.1 (0.76) | 1.037 (0.614) | |
| MOLKE (α, μ, τ, β) | 0.01 (0.002) | 2.7162 (1.3158) | 1.99 (0.784) | 0.099 (0.05) |
| MOLE (α, β) | 8.778 (3.555) | 1.3788 (0.1929) | ||
| ME (β) | 0.925 (0.077) | |||
| E (β) | 0.540 (0.06) | |||
| Models | ||||
|---|---|---|---|---|
| KMBX | 193.494 | 194.2 | 193.209 | 195.307 |
| KMOLE | 207.82 | 216.94 | 208.42 | 211.42 |
| BXE | 235.30 | 239.90 | 235.50 | 237.10 |
| GMOLE | 210.54 | 217.38 | 210.89 | 213.24 |
| BE | 207.38 | 214.22 | 207.73 | 210.08 |
| KE | 209.42 | 216.24 | 209.77 | 212.12 |
| MOLKE | 209.44 | 218.56 | 210.04 | 213.04 |
| MOLE | 210.36 | 214.92 | 210.53 | 212.16 |
| ME | 210.40 | 212.68 | 210.45 | 211.30 |
| E | 234.63 | 236.91 | 234.68 | 235.54 |
| Models | MLLEs and (SErs) | |||||
|---|---|---|---|---|---|---|
| KMBX (α, β) | 0.655 (0.085) | 3.563 (2.431) | - | - | - | |
| BGIWG (α, γ, θ, p, μ, τ) | 19.187 (33.03) | 20.597 (43.24) | 1.435 (0.84) | 9.85 (2.001) | 39.231 × 10−5 (63.25) | 5.802 (4.35) |
| MOLE (α, β) | 54.474 (35.581) | 2.32 (0.374) | ||||
| BXE (θ, β) | 1.164 (0.33) | 0.321 (0.030) | ||||
| KE (μ, τ, β) | 83.76 (42.361) | 0.57 (0.326) | 3.333 (1.188) | |||
| GMOLE (λ, α, β) | 0.52 (0.256) | 89.462 (66.28) | 3.169 (0.772) | |||
| BE (μ, τ, β) | 81.633 (120.41) | 0.542 (0.327) | 3.514 (1.410) | |||
| KMOLE (α, μ, τ, β) | 8.87 (9.15) | 34.83 (22.31) | 0.299 (0.24) | 4.90 (3.18) | ||
| A (β) | 0.95 (0.15) | |||||
| IA (β) | 3.45 (0.55) | |||||
| E (β) | 0.53 (0.12) | |||||
| KWE (μ, τ, α, β, λ) | 7.820 (3.992) | 21.52 (0.10) | 1.47 (1.022) | 0.402 (0.362) | 0.005 (0.002) | |
| BTRW(α, β, μ, τ, λ) | 5.619 (9.35) | 0.531 (0.15) | 53.344 (111.45) | 3.568 (4.27) | −0.772 (3.894) | - |
| MCLOL (α, β, μ, τ, c) | 0.881 (0.11) | 2.07 (3.69) | 19.23 (22.34) | 32.03 (43.08) | 1.93 (5.17) | - |
| MCW (α, β, μ, τ, c) | 2.7738 (6.38) | 0.3802 (0.188) | 79.108 (119.131) | 17.8976 (39.511) | 3.0063 (13.968) | - |
| TRECH (α, β, μ, τ) | 300.01 (587.04) | 0.50 (0.56) | 2.43 (1.08) | 0.34 (0.11) | ||
| TRCWG (α, β, γ, λ) | 43.663 (45.46) | 5.127 (0.814) | 0.282 (0.042) | −0.271 (0.66) | - | - |
| CH (μ, τ) | 0. 14 (0.05) | 0.95 (0.09) | - | - | ||
| ETRGR(α, β, λ, δ) | 0.103 (0.44) | 0.692 (0.09) | −0.342 (1.97) | 23.54 (105.37) | - | - |
| TRWL(μ, τ, β, θ, λ) | 8.619 (42.83) | 6.215 (4.501) | 0.248 (0.67) | 0.226 (0.202) | 0.697 (0.338) | |
| WL(μ, τ, θ, λ) | 14.74 (64.67) | 5.585 (3.84) | 0.263 (0.67) | 0.22 (0.184) | ||
| BXII (λ, θ) | 0.016 (0.038) | 103.60 (245.14) | ||||
| NMW (α, β, γ, δ, θ) | 0.122 (0.06) | 2.784 (20.37) | 8.23 × 10−5(0.151) | 0.0003 (0.025) | 2.79 (0.43) | - |
| W (λ, θ) | 0.0021 (0.0004) | 1.435 (0.0602) | ||||
| GCH (α, β, μ, τ) | 7.59 (2.09) | 1.99 (0.46) | 5.00 (1.07) | 0.53 (0.003) | ||
| BW (α, β, μ, τ) | 0.831 (0.954) | 0.613 (0.34) | 29.95 (40.413) | 11.632 (21.9) | ||
| BCH (α, β, μ, τ) | 85.87 (103.13) | 0.48 (0.51) | 2.01 (0.69) | 0.55 (0.20) | ||
| MOLCH (α, μ, τ) | 400.01 (488.06) | 2.32 (0.64) | 0.43 (0.08) | |||
| TRCH (α, μ, τ) | 0.75 (0.28) | 0.07 (0.03) | 1.02 (0.09) | |||
| Model | ||||
|---|---|---|---|---|
| KMBX | 39.283 | 39.989 | 37.885 | 39.671 |
| BGIWG | 43.854 | 48.14 | 40.359 | 44.826 |
| MOLE | 43.51 | 45.51 | 44.22 | 43.90 |
| BXE | 48.10 | 50.10 | 48.80 | 48.50 |
| KE | 41.78 | 44.75 | 43.28 | 42.32 |
| GMOLE | 42.75 | 45.74 | 44.25 | 43.34 |
| BE | 43.48 | 46.45 | 44.98 | 44.02 |
| KMOLE | 42.80 | 46.84 | 45.55 | 43.60 |
| A | 54.32 | 55.31 | 54.54 | 54.50 |
| IA | 53.653 | 53.888 | 52.954 | 53.847 |
| E | 67.67 | 68.67 | 67.89 | 67.87 |
| KWE | 41.8619 | 46.1476 | 42.8337 | 46.8405 |
| BTRW | 43.662 | 50.124 | 39.468 | 44.828 |
| MCLOL | 43.051 | 47.337 | 39.556 | 44.023 |
| MCW | 43.854 | 48.14 | 40.359 | 44.826 |
| TRECH | 39.56 | 42.227 | 36.764 | 40.338 |
| TRCWG | 51.173 | 55.459 | 47.678 | 52.145 |
| CH | 53.14 | 53.846 | 51.742 | 53.529 |
| ETRGR | 42.396 | 45.063 | 39.6 | 43.174 |
| TRWL | 47.804 | 52.09 | 44.309 | 48.776 |
| WL | 47.261 | 49.928 | 44.465 | 48.039 |
| BXII | 46.414 | 47.12 | 45.016 | 46.803 |
| NMW | 43.907 | 48.193 | 40.412 | 44.879 |
| W | 45.1728 | 45.8786 | 45.5615 | 47.1642 |
| GCH | 46.35 | 49.017 | 43.554 | 47.128 |
| BW | 41.607 | 44.274 | 38.811 | 42.385 |
| BC | 40.51 | 43.177 | 37.714 | 41.288 |
| MOLCH | 44.88 | 46.38 | 42.783 | 45.463 |
| TRCH | 53.63 | 55.13 | 51.533 | 54.213 |
| Models | MLLEs and SErs | ||
|---|---|---|---|
| KMBX (α, β) | 0.061 (0.006) | 1.204 (0.195) | |
| BX (α, β) | 0.0644 (0.006) | 1.0310 (0.184) | |
| EW (α, β, a) | 1.548 (0.913) | 0.471 (0.131) | 88.690 (8.407) |
| OWE (α, a, b) | 0.016 (0.019) | 6.616 (5.444) | 1.547 (1.563) |
| MOLE (α, a) | 0.209 (0.031) | 11.565 (5.202) | |
| W (α, β) | 0.007 (0.003) | 1.822 (0.134) | |
| E (β) | 0.074 (0.010) | ||
| Models | ||||
|---|---|---|---|---|
| KMBX | 394.464 | 394.678 | 394.006 | 396.086 |
| BX | 399.393 | 399.607 | 403.548 | 401.015 |
| EW | 538.535 | 538.979 | 544.716 | 540.942 |
| OWE | 404.876 | 405.313 | 411.109 | 407.309 |
| MOLE | 552.738 | 552.956 | 556.859 | 554.343 |
| W | 398.593 | 398.808 | 402.749 | 400.215 |
| E | 611.935 | 612.006 | 613.995 | 612.737 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hassan, O.H.M.; Elbatal, I.; Al-Nefaie, A.H.; Elgarhy, M. On the Kavya–Manoharan–Burr X Model: Estimations under Ranked Set Sampling and Applications. J. Risk Financial Manag. 2023, 16, 19. https://doi.org/10.3390/jrfm16010019
Hassan OHM, Elbatal I, Al-Nefaie AH, Elgarhy M. On the Kavya–Manoharan–Burr X Model: Estimations under Ranked Set Sampling and Applications. Journal of Risk and Financial Management. 2023; 16(1):19. https://doi.org/10.3390/jrfm16010019
Chicago/Turabian StyleHassan, Osama H. Mahmoud, Ibrahim Elbatal, Abdullah H. Al-Nefaie, and Mohammed Elgarhy. 2023. "On the Kavya–Manoharan–Burr X Model: Estimations under Ranked Set Sampling and Applications" Journal of Risk and Financial Management 16, no. 1: 19. https://doi.org/10.3390/jrfm16010019