
Modeling Funding for Industrial Projects Using Machine Learning: Evidence from Morocco


Abstract
1. Introduction
2. Literature Review
3. Data
4. Methodology
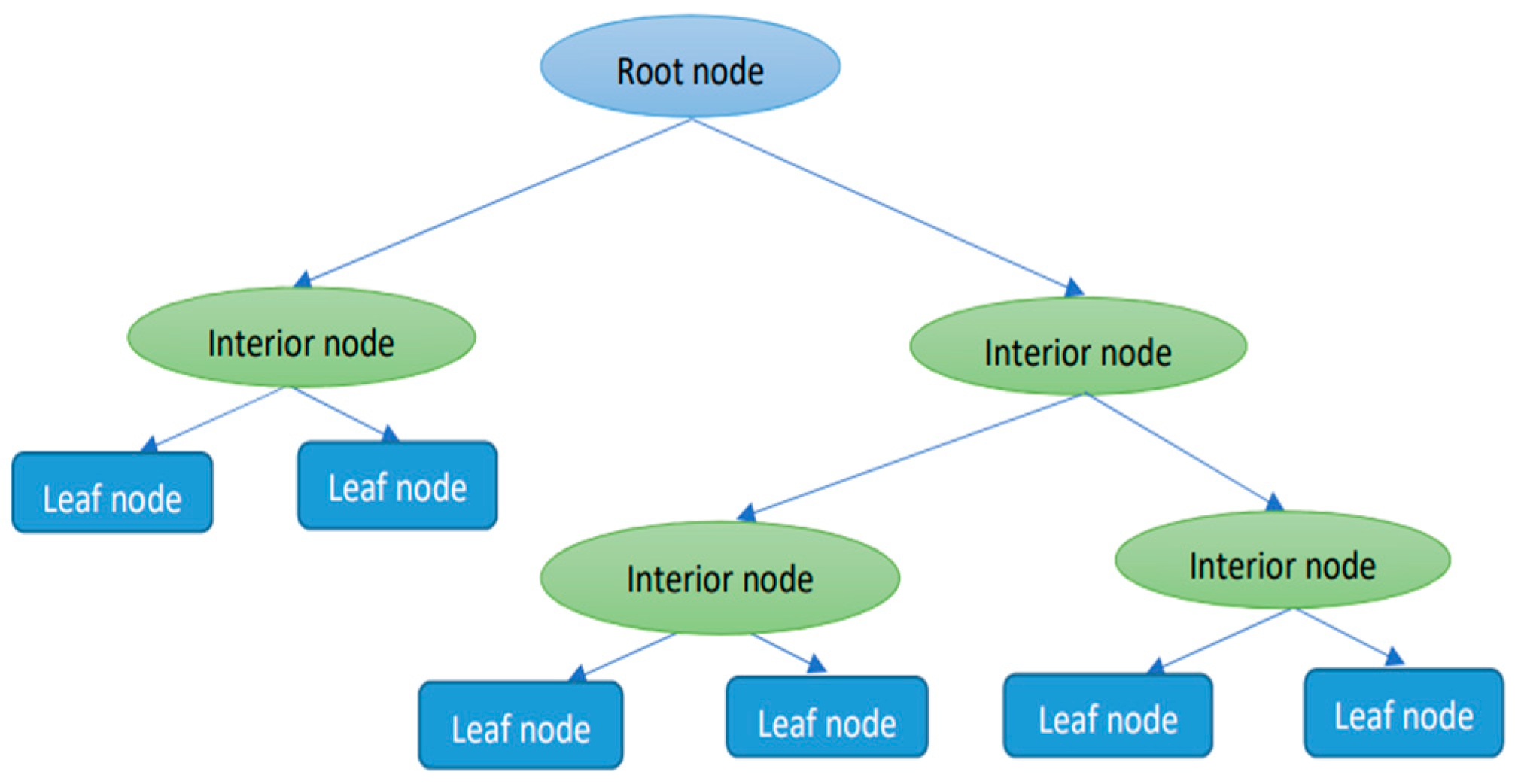
4.1. Machine Learning Methods to Predict Funding Method
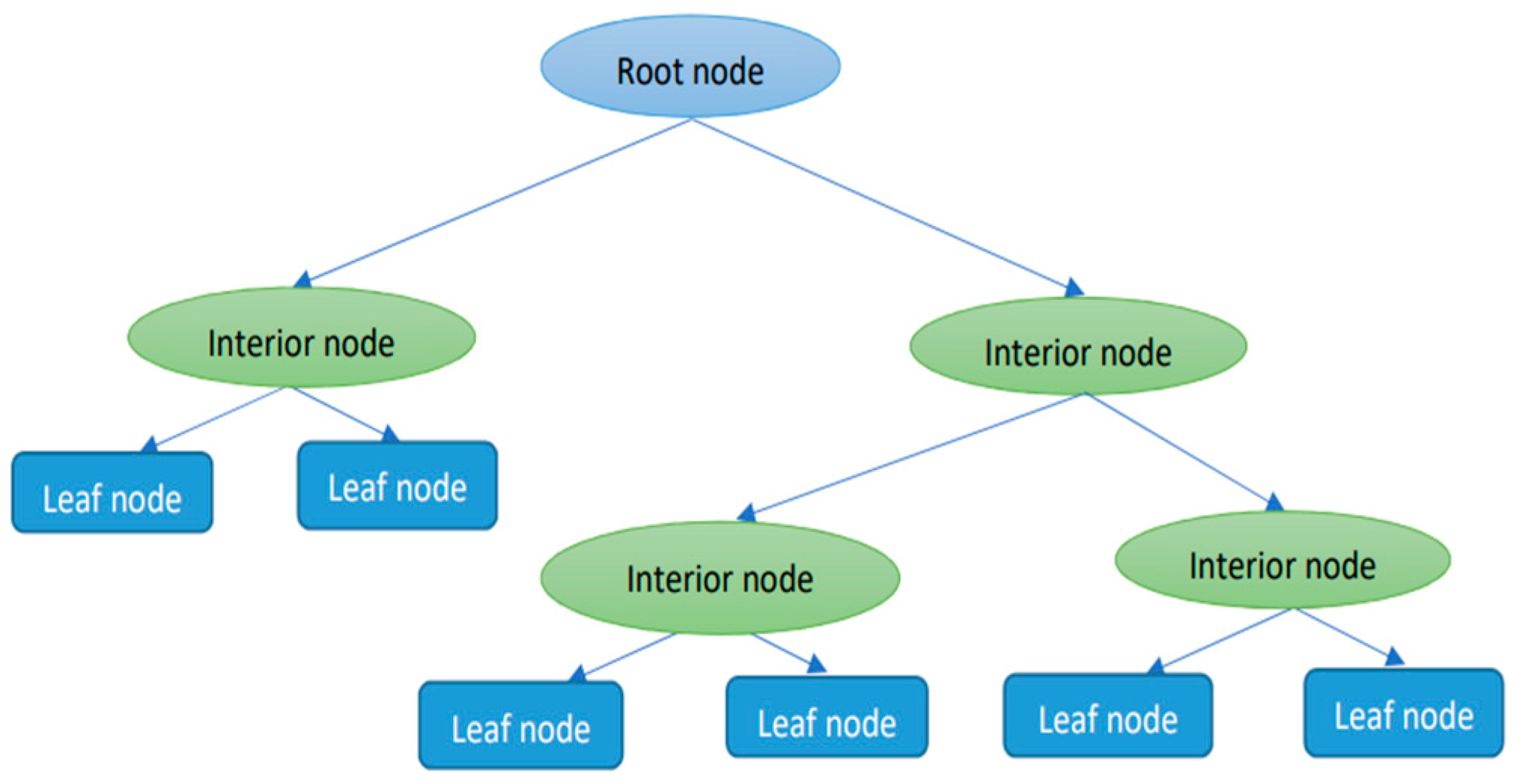
- Decision tree
- 2.
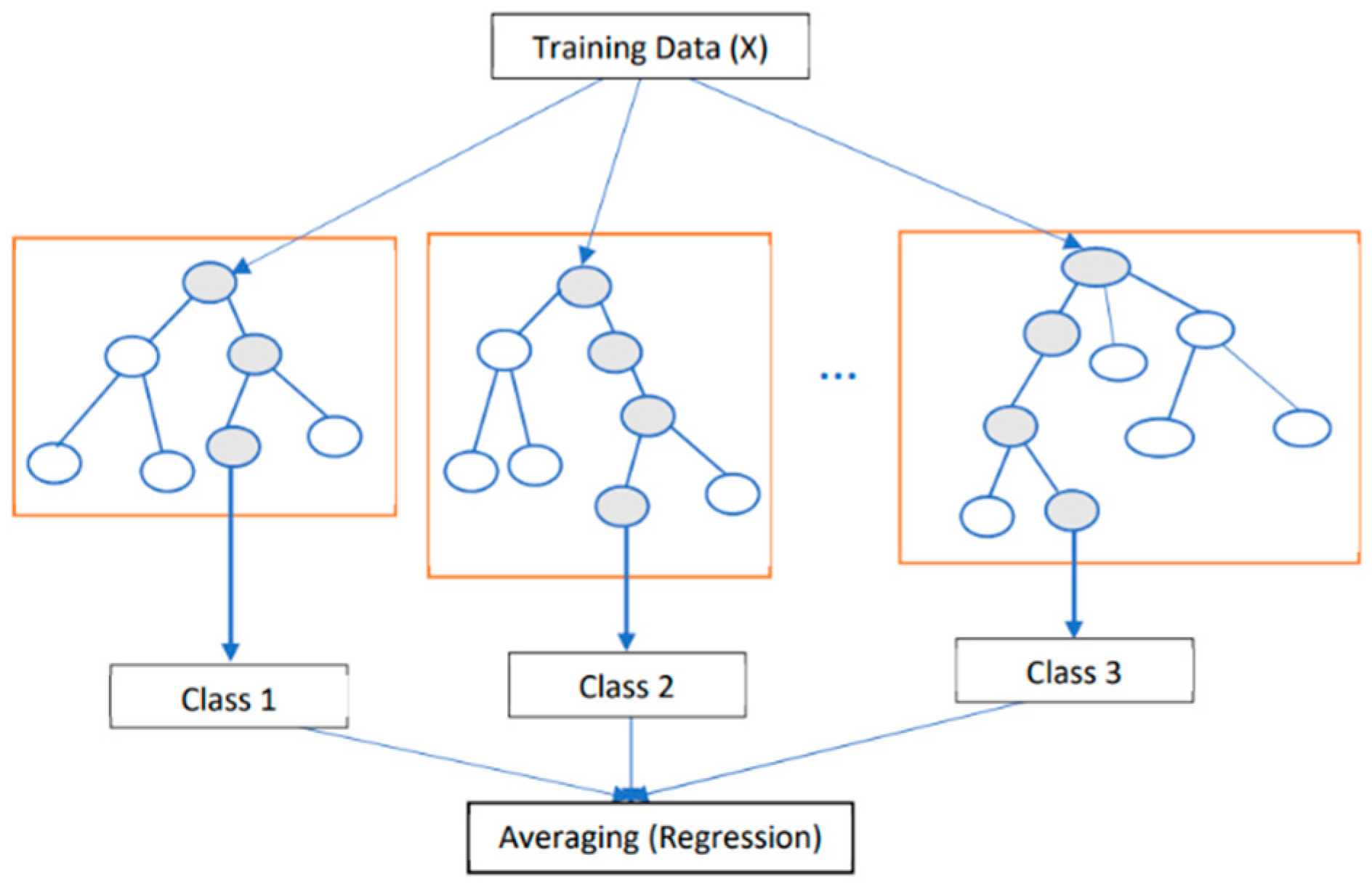
- Random forest
- 3.
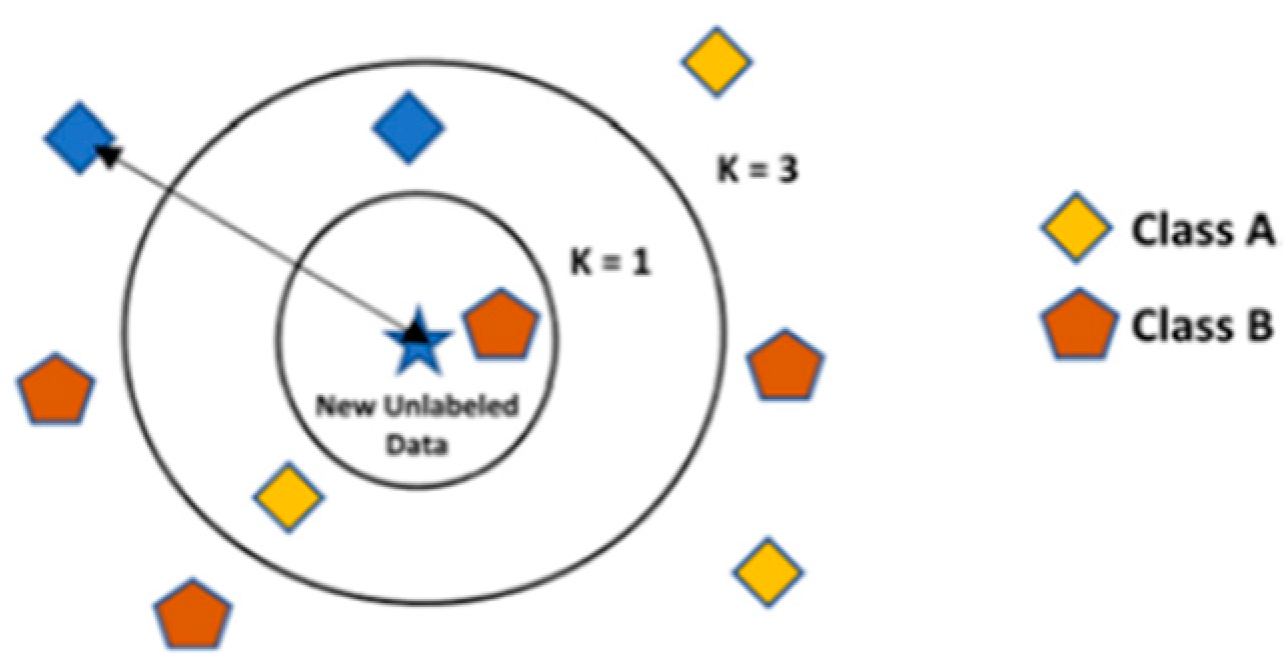
- KNN
- 4.
- Gradient boosting
4.2. Evaluation of the Model’s Performance
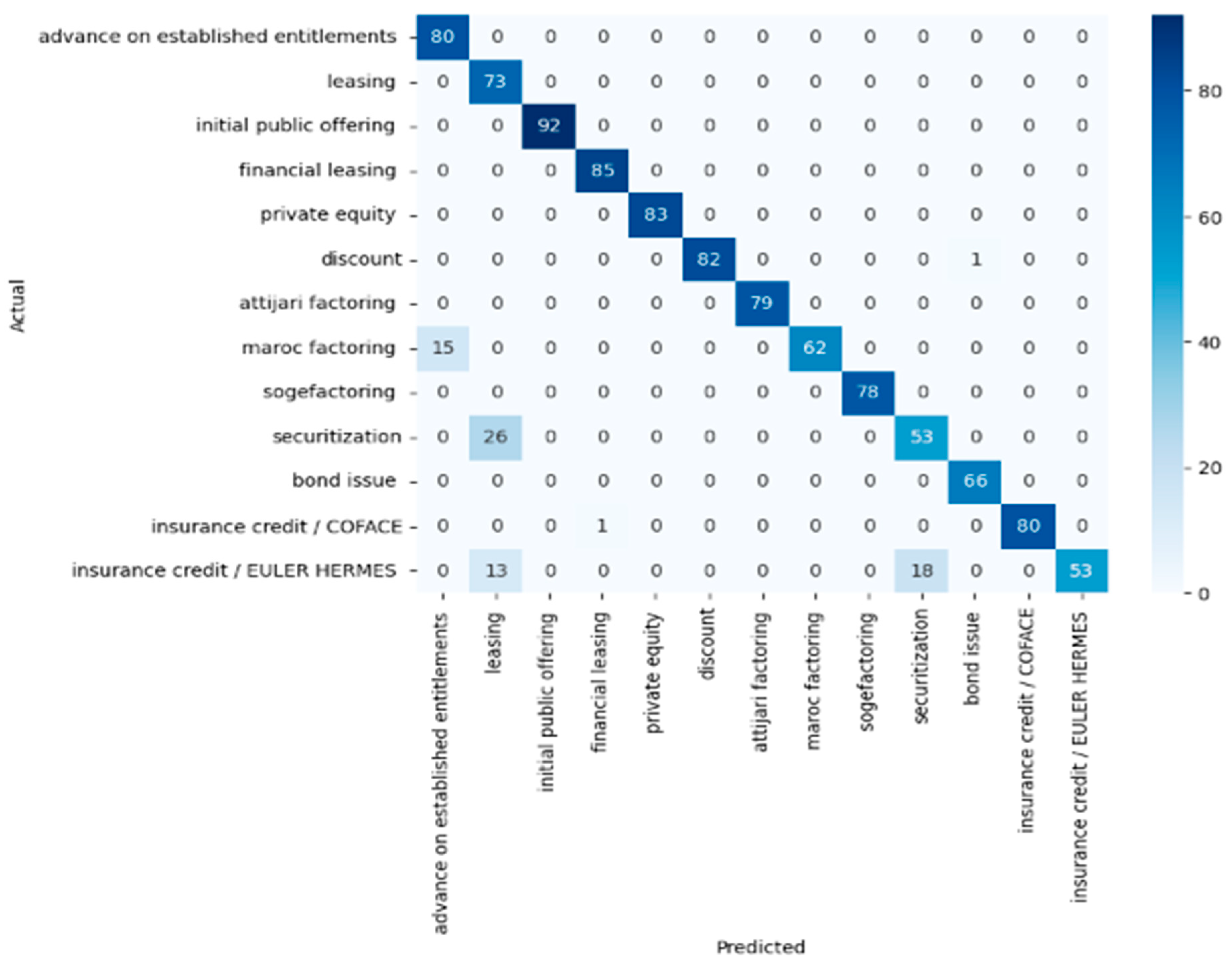
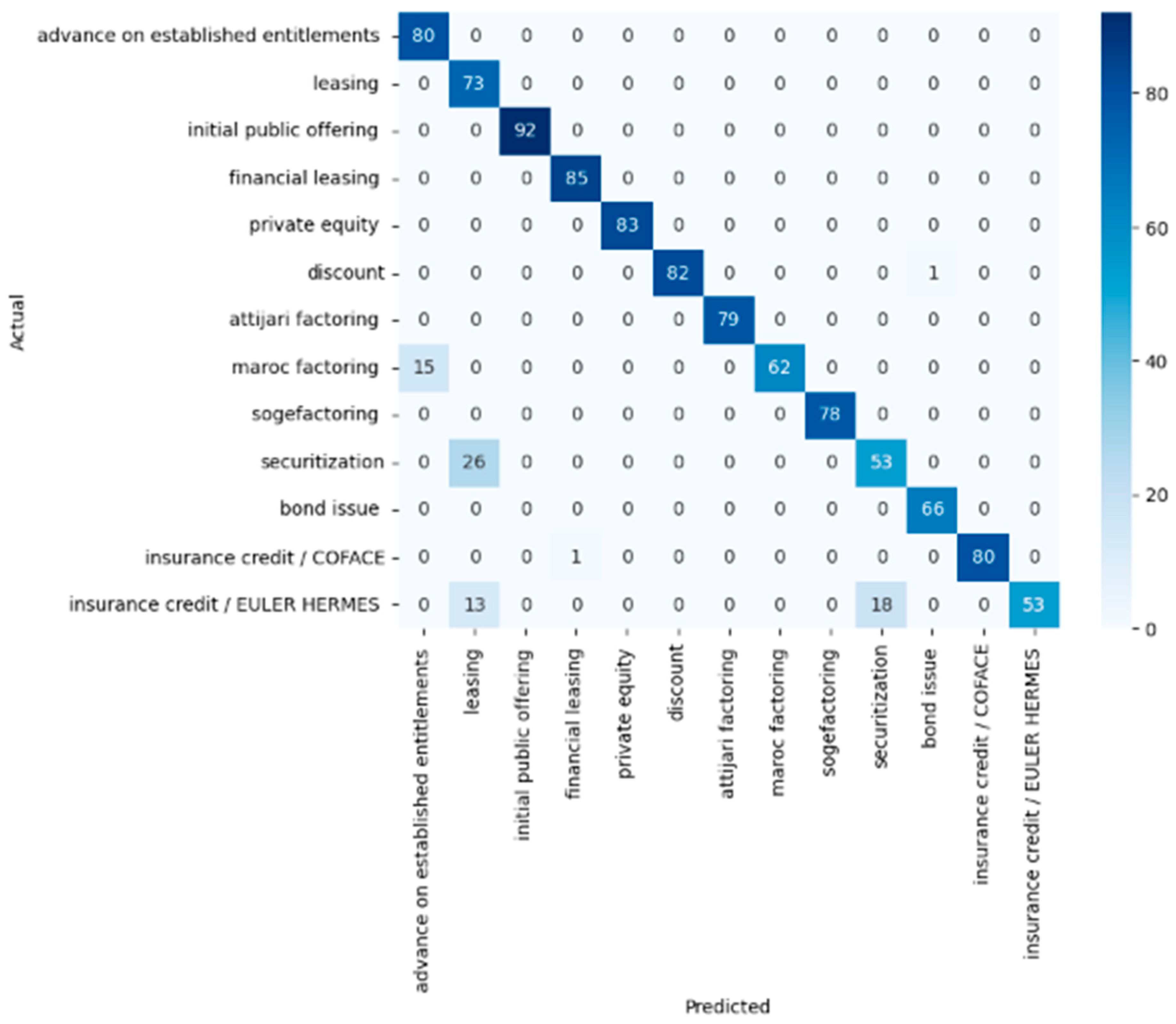
- Confusion Matrix
- 2.
- Accuracy
- 3.
- F1 score
- 4.
- Precision
- 5.
- Recall
5. Results and Discussion
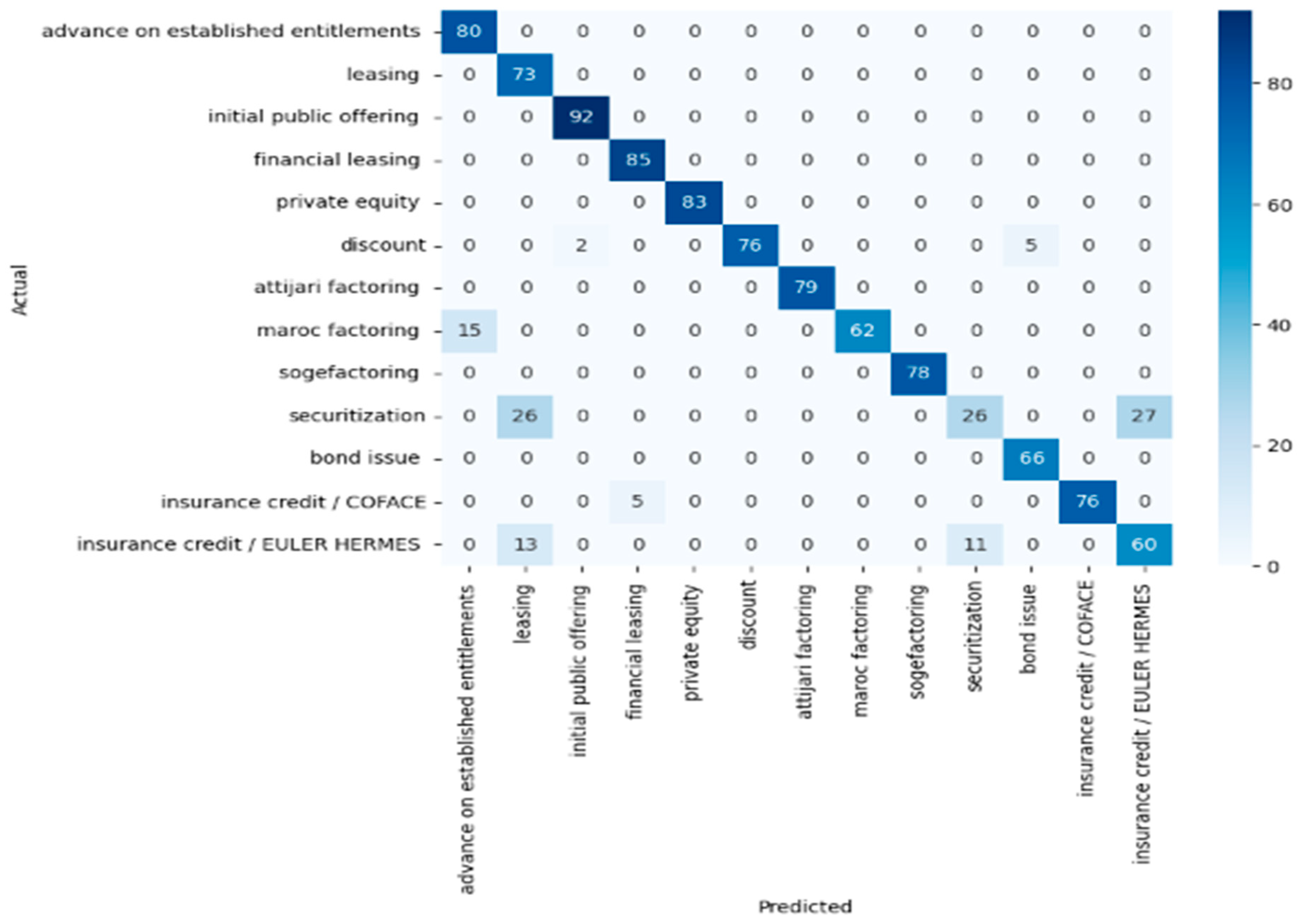
5.1. Comparison of Prediction Results of Classifiers
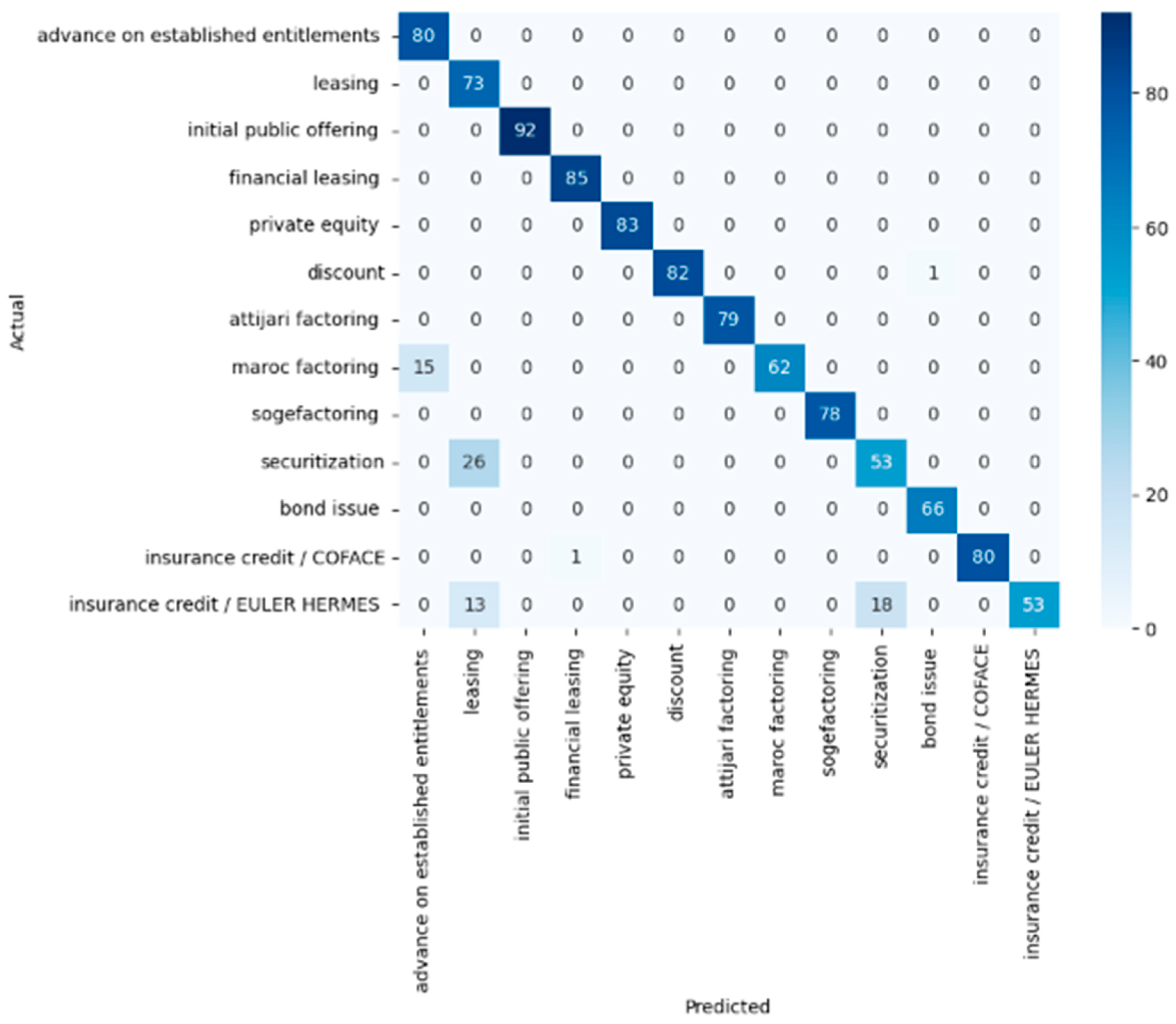
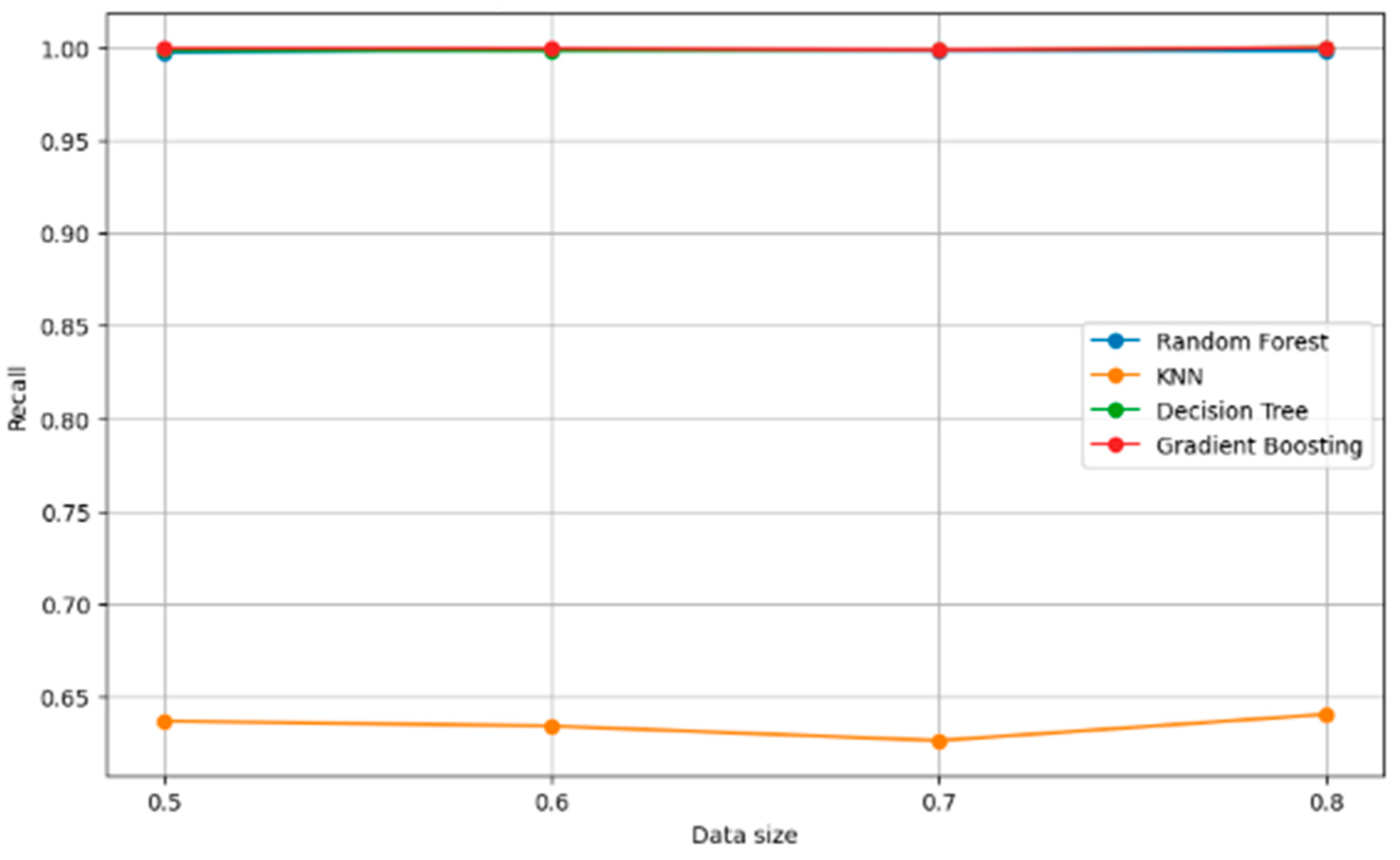
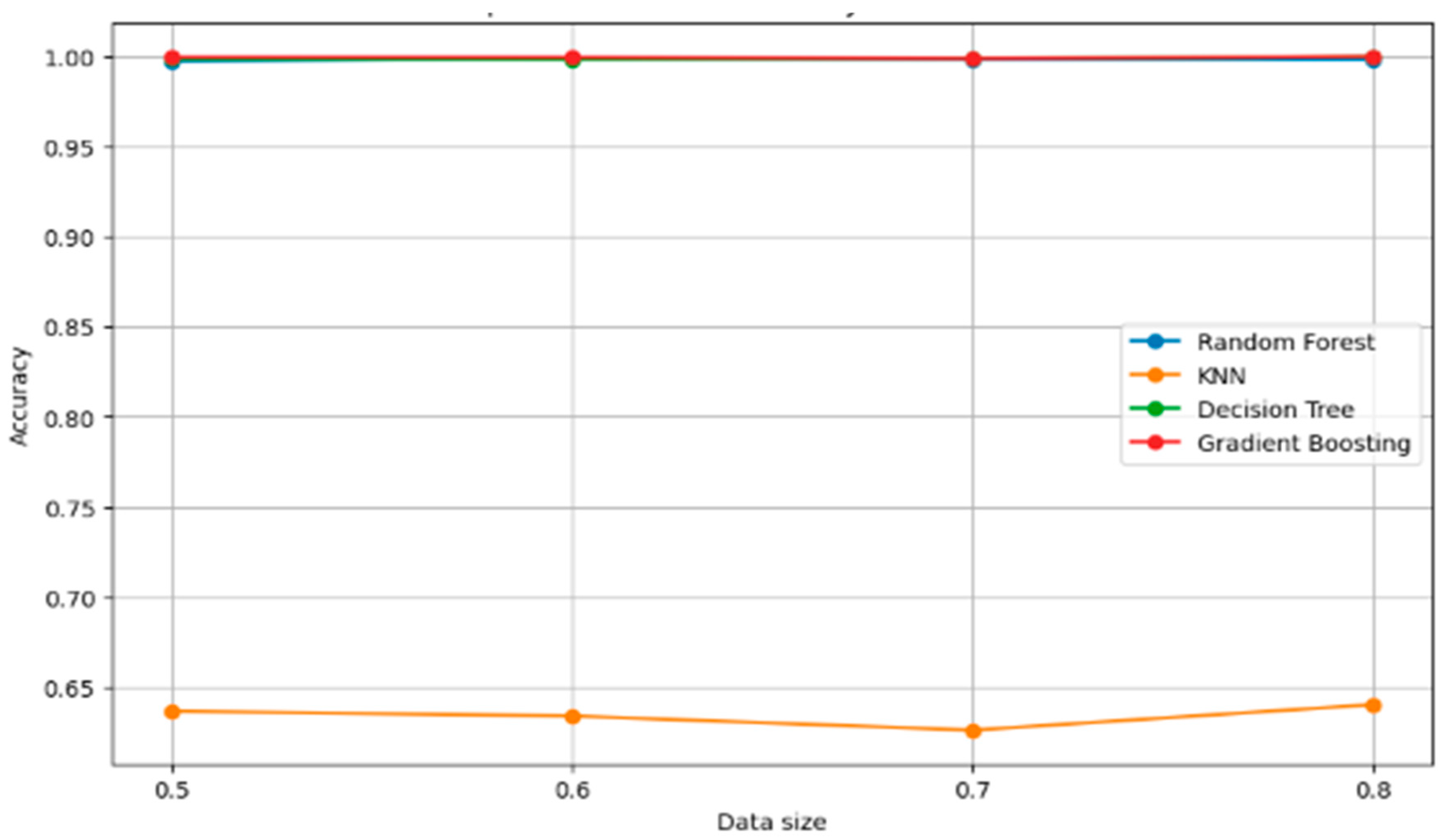
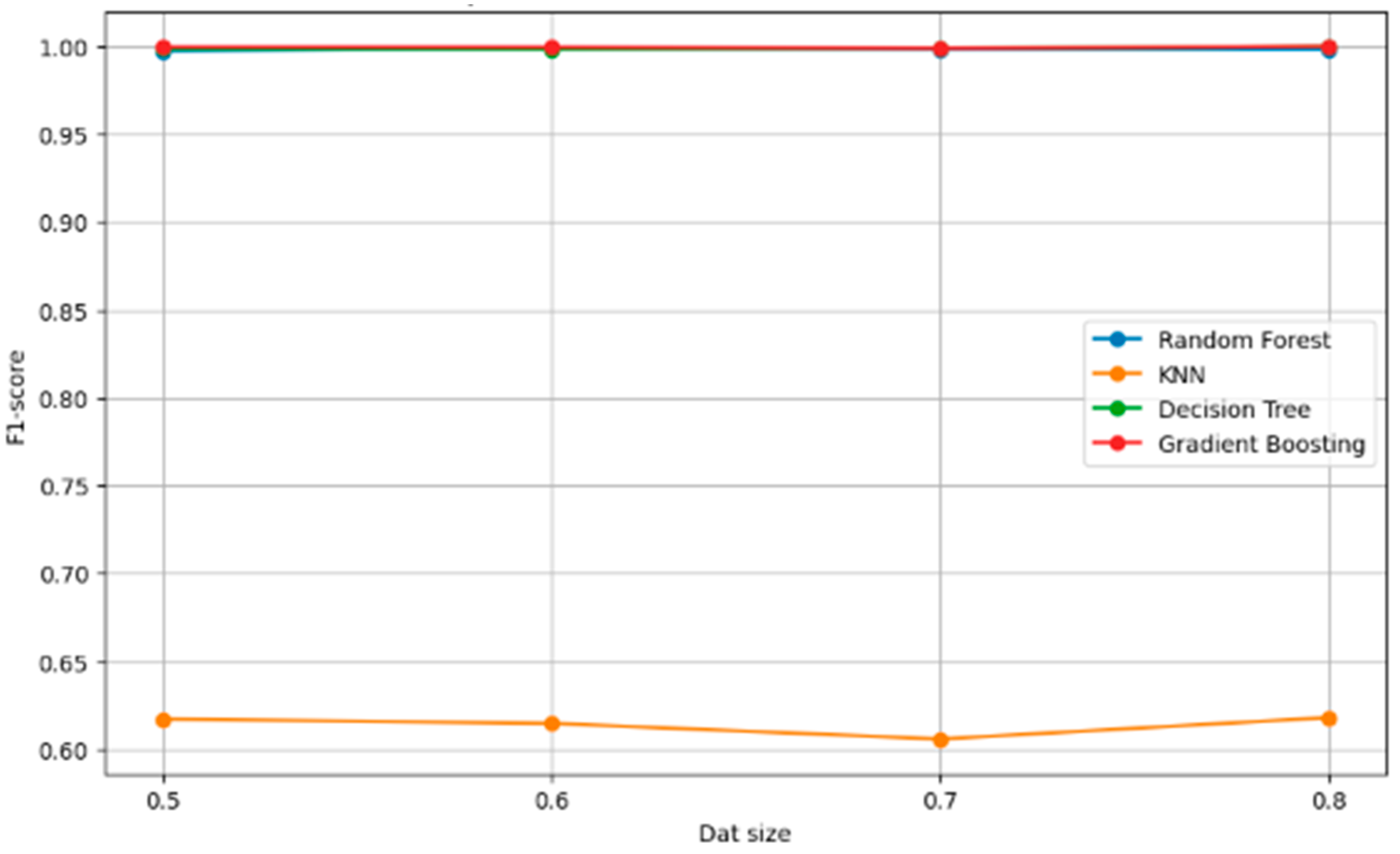
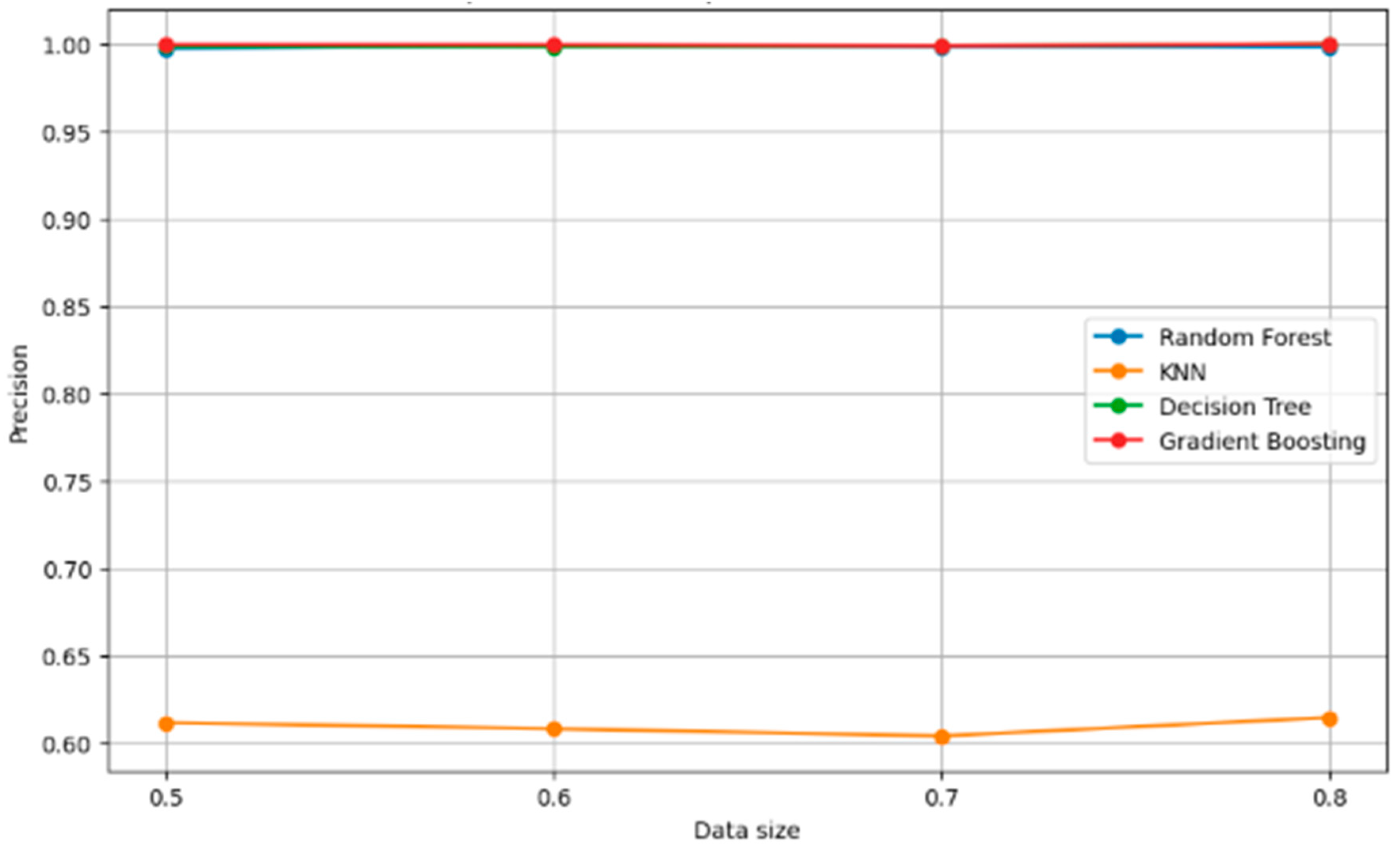
5.2. Robust Check of Classifiers
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Alami, Najia. 2022. Investment financing. Revue Internationale du Chercheur 3: 862–80. [Google Scholar]
- Amraoui, Mouna, Ye Jianmu, and Kenza Bouarara. 2018. Firm’s Capital Structure Determinants and Financing Choice by Industry in Morocco. International Journal of Management Science and Business Administration 4: 41–50. [Google Scholar] [CrossRef]
- Bauer, Markus, Clemens van Dinther, and Daniel Kiefer. 2020. Machine Learning in SME: An Empirical Study on Enablers and Success Factors. Paper presented at Americas Conference on Information Systems (AMCIS 2020), Online, August 10–14. [Google Scholar]
- Boushib, Kaoutar. 2020. Corporate Finance in Morocco: Econometrical Verification Tests based on data on Moroccan small and medium—Sized enterprises. Revue CCA 12: 180–91. [Google Scholar]
- Breiman, Leo. 2001. Random Forests. Machine Learning 45: 5–32. [Google Scholar] [CrossRef]
- Chung, Jinwook, and Kyumin Lee. 2015. A Long-Term Study of a Crowdfunding Platform: Predicting Project Success and Fundraising Amount. Paper presented at the 26th ACM Conference on Hypertext & Social Media, HT ‘15, Guzelyurt, Cyprus, September 1–4; New York: Association for Computing Machinery, pp. 211–20. [Google Scholar]
- Ciciana, Ciciana, Rahmawati Rahmawati, and Laila Qadrini. 2023. The Utilization of Resampling Techniques and the Random Forest Method in Data Classification. TIN: Terapan Informatika Nusantara 4: 252–59. [Google Scholar] [CrossRef]
- Duan, Tony, Anand Avati, Daisy Yi Ding, Khanh K. Thai, Sanjay Basu, Andrew Ng, and Alejandro Schuler. 2020. NGBoost: Natural Gradient Boosting for Probabilistic Prediction. Paper presented at the 37th International Conference on Machine Learning, Virtual Event, July 13–18. [Google Scholar]
- Fnitiz, Yassine. 2023. The contribution of participative banks to financing Moroccan SMEs. Research and Applications in Islamic Finance 7: 179–95. [Google Scholar]
- Friedman, Jerome H. 2001. Greedy Function Approximation: A Gradient Boosting Machine. The Annals of Statistics 29: 1189–232. [Google Scholar] [CrossRef]
- Grandini, Margherita, Enrico Bagli, and Giorgio Visani. 2020. Metrics for Multi-Class Classification: An Overview. Available online: http://arxiv.org/abs/2008.05756 (accessed on 18 January 2024).
- Hefnaoui, Ahmed, and Zakaria Ben Darkawi. 2020. Moroccan SMEs and the difficulties in accessing external funding. The International Journal of the Researcher 1: 686–708. [Google Scholar]
- Hind, Tadjousti, and Zahi Jamal. 2023. Financing Constraints and Prospects for Innovative SMEs in Morocco. African Journal of Business and Economic Research 18: 299–312. [Google Scholar]
- Hossin, Mohammad, and Md Nasir Sulaiman. 2015. A Review on Evaluation Metrics for Data Classification Evaluations. International Journal of Data Mining & Knowledge Management Process 5: 1–11. [Google Scholar]
- Jalila, Bouanani El Idrissi, and Ladraa Salwa. 2020. Economic recovery during the state of health crisis COVID-19: Impact study on the activity of industrial companies in Morocco. French Journal of Economics and Management 1: 46–60. [Google Scholar]
- Kaoutar, Boushib. 2019. Financing of small and medium-sized enterprises in Morocco. International Journal of Social Sciences 2: 144–53. [Google Scholar]
- Kuzey, Cemil, Ali Uyar, and Dursun Delen. 2014. The impact of multinationality on firm value: A comparative analysis of machine learning techniques. Decision Support Systems 59: 127–42. [Google Scholar] [CrossRef]
- Laaouina, Soukaina, Sara El Aoufi, and Mimoun Benali. 2024. How Does Age Moderate the Determinants of Crowdfunding Adoption by SMEs’s: Evidences from Morocco? Journal of Risk and Financial Management 17: 18. [Google Scholar] [CrossRef]
- Lahmini, Hajar Mouatassim, and Abdelamajid Ibenrissoul. 2015. Impact of the financing decision on the performance of the Moroccan company: Case listed companies in the Real Estate and Construction materials. Paper presented at 4th International Conference and Doctoral Seminar on Research Methods, University of Jean Moulin Lyon 3, Lyon, France, June 10–11. [Google Scholar]
- Mahesh, Batta. 2018. Machine Learning Algorithms—A Review. International Journal of Science and Research 9: 381–86. [Google Scholar]
- Méndez, Manuel, Mercedes Merayo, and Manuel Núñez. 2023. Machine learning algorithms to forecast air quality: A survey. Artificial Intelligence Review 56: 10031–66. [Google Scholar] [CrossRef]
- Mohamed, Habachi, Abdelilah Jebbari, and Salim EL Haddad. 2021. Impact of digitalization on the financing performance of Moroccan companies. International Journal of Economic Studies and Management (IJESM) 1: 338–53. [Google Scholar] [CrossRef]
- Ouafy, Sakina EL Ouafy, and Ahmed Chakir. 2015. Financing Micro Businesses in Morocco: Case Studies. European Journal of Business and Social Sciences 4: 170–79. [Google Scholar]
- Oudgou, Mohamed, and Mohamed Zeamari. 2018. The Contribution of Capital Markets to the Financing of Moroccan SMEs. European Scientific Journal 14: 350–72. [Google Scholar]
- Voyant, Cyril, Gilles Notton, Soteris Kalogirou, Marie-Laure Nivet, Christophe Paoli, Fabrice Motte, and Alexis Fouilloy. 2017. Machine Learning Methods for Solar Radiation Forecasting: A Review. Renewable Energy 105: 569–82. [Google Scholar] [CrossRef]
- Xiong, Lei, and Ye Yao. 2021. Study on an Adaptive Thermal Comfort Model with K-Nearest-Neighbors (KNN) Algorithm. Building and Environment 202: 108026. [Google Scholar] [CrossRef]
- Zamazal, Ondřej. 2019. Machine Learning Support for EU Funding Project Categorization. The Computer Journal 62: 1684–94. [Google Scholar] [CrossRef]
- Zhang, Chuqing, Han Zhang, and Xiaoting Hu. 2019. A Contrastive Study of Machine Learning on Funding Evaluation Prediction. IEEE Access 7: 106307–15. [Google Scholar] [CrossRef]
- Zhang, Chuqing, Jiangyuan Yao, Guangwu Hu, and Xingcan Cao. 2023. A Machine Learning Based Funding Project Evaluation Decision Prediction. Computer Systems Science and Engineering 45: 2111–24. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Article | Year of Publication | Journal | Authors | Methodology | Sample |
|---|---|---|---|---|---|
| How Does Age Moderate the Determinants of Crowdfunding Adoption by SMEs’s: Evidences from Morocco? (Laaouina et al. 2024) | 2024 | Journal of risk and financial management | Soukaina Laaouina, Sara el Aoufi, Mimoun Benali | Qualitative study based on structural equation modelling | 241 respondents |
| Financing Constraints and Prospects for Innovative SMEs in Morocco (Hind and Jamal 2023) | 2023 | African Journal of Business and Economic Research | Tadjousti Hind and Zahi Jamal | A literature review and qualitative analysis | 12 case studies through interviews |
| The contribution of participative banks to financing Moroccan SMEs (Fnitiz 2023) | 2023 | Research and Applications in Islamic Finance | Yassine Fnitiz | Quantitative study | 392 Moroccan SMEs |
| Investment financing (Alami 2022) | 2022 | The International Journal of the Researcher | Najia Alami | Literature review | |
| Impact of digitalization on the financing performance of Moroccan companies (Mohamed et al. 2021) | 2021 | International Journal of Economic Studies and Management | Mohamed Habachi, Abdelilah Jebbari, Salim El Haddad | Structural equation models estimated using the PLS approach | 74 companies |
| Moroccan SMEs and the difficulties in accessing external funding (Hefnaoui and Darkawi 2020) | 2020 | The International Journal of the Researcher | Ahmed Hefnaoui, Zakaria Ben Darkawi | Literature review | |
| Corporate Finance in Morocco: Econometrical Verification Tests based on data on Moroccan small and medium-sized enterprises (Boushib 2020) | 2020 | Journal of Control, Accounting and Auditing | Kaoutar Boushib | Multivariate analysis: logistic regression | 50 SMEs |
| Economic recovery during the state of health crisis COVID-19: Impact study on the activity of industrial companies in Morocco (Jalila and Salwa 2020) | 2020 | French Journal of Economics and Management | Jalila Bouanani El Idrissi, Salwa Ladraa | An exploratory study | 5 industrial companies |
| Financing of small and medium-sized enterprises in Morocco (Kaoutar 2019) | 2019 | International Journal of Social Sciences | Kaoutar Boushib | An empirical survey | 418 SMEs |
| The Contribution of Capital Markets to the Financing of Moroccan SMEs (Oudgou and Zeamari 2018) | 2018 | European Scientific Journal | Mohamed Oudgou, Mohamed Zeamari | Literature review | |
| Firm’s Capital Structure Determinants and Financing Choice by Industry in Morocco (Amraoui et al. 2018) | 2018 | International Journal of Management Science and Business Administration | Mouna Amraoui, Ye Jianmu, Kenza Bouarara | Panel regression approach | 52 Moroccan companies |
| Financing micro businesses in Morocco: case studies (Ouafy and Chakir 2015) | 2015 | European Journal of Business and Social Sciences | Sakina EL Ouafy, Ahmed Chakir | Multiple case studies | A total of 8 very micro businesses |
| Impact of the financing decision on the performance of the Moroccan company: Case listed companies in the Real Estate and Construction materials (Lahmini and Ibenrissoul 2015) | 2015 | Conference paper, 4th International Conference and Doctoral Seminar on Research Methods, University of Jean Moulin Lyon 3, France | Hajar Mouatassim Lahmini, Abdelamajid Ibenrissoul | Multiple linear regression | 8 companies |
| Columns/Variable Name | Type | Predictor/Response |
|---|---|---|
| Activity Nature Strategic business area Country Client Amount Funding method adopted | Categorical Categorical Categorical Categorical Categorical Numeric Categorical | Predictor Predictor Predictor Predictor Predictor Predictor Response |
| Algorithms | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Random forest | 0.93 | 0.94 | 0.93 | 0.93 |
| KNN | 0.64 | 0.61 | 0.64 | 0.61 |
| Decision tree | 0.93 | 0.94 | 0.93 | 0.94 |
| Gradient boosting | 0.93 | 0.94 | 0.93 | 0.93 |
| Train Size | Model | Precision | Recall | F1 Score | Accuracy |
|---|---|---|---|---|---|
| 0.5 | Random forest | 0.997718 | 0.997691 | 0.99769 | 0.997691 |
| 0.5 | KNN | 0.611504 | 0.636783 | 0.617148 | 0.636783 |
| 0.5 | Decision tree | 0.99848 | 0.998461 | 0.998461 | 0.998461 |
| 0.5 | Gradient boosting | 0.999617 | 0.999615 | 0.999615 | 0.999615 |
| 0.6 | Random forest | 0.998573 | 0.998558 | 0.998555 | 0.998558 |
| 0.6 | KNN | 0.608065 | 0.634135 | 0.614706 | 0.634135 |
| 0.6 | Decision tree | 0.998107 | 0.998077 | 0.998077 | 0.998077 |
| 0.6 | Gradient boosting | 0.999522 | 0.999519 | 0.999519 | 0.999519 |
| 0.7 | Random forest | 0.998104 | 0.998077 | 0.998071 | 0.998077 |
| 0.7 | KNN | 0.603909 | 0.626282 | 0.605805 | 0.626282 |
| 0.7 | Decision tree | 0.998729 | 0.998718 | 0.998718 | 0.998718 |
| 0.7 | Gradient boosting | 0.998729 | 0.998718 | 0.998718 | 0.998718 |
| 0.8 | Random forest | 0.998101 | 0.998077 | 0.998071 | 0.998077 |
| 0.8 | KNN | 0.614476 | 0.640385 | 0.617979 | 0.640385 |
| 0.8 | Decision tree | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.8 | Gradient boosting | 1.0 | 1.0 | 1.0 | 1.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Laaouina, S.; Benali, M. Modeling Funding for Industrial Projects Using Machine Learning: Evidence from Morocco. J. Risk Financial Manag. 2024, 17, 173. https://doi.org/10.3390/jrfm17040173
Laaouina S, Benali M. Modeling Funding for Industrial Projects Using Machine Learning: Evidence from Morocco. Journal of Risk and Financial Management. 2024; 17(4):173. https://doi.org/10.3390/jrfm17040173
Chicago/Turabian StyleLaaouina, Soukaina, and Mimoun Benali. 2024. "Modeling Funding for Industrial Projects Using Machine Learning: Evidence from Morocco" Journal of Risk and Financial Management 17, no. 4: 173. https://doi.org/10.3390/jrfm17040173
APA StyleLaaouina, S., & Benali, M. (2024). Modeling Funding for Industrial Projects Using Machine Learning: Evidence from Morocco. Journal of Risk and Financial Management, 17(4), 173. https://doi.org/10.3390/jrfm17040173