

Secure and Transparent Banking: Explainable AI-Driven Federated Learning Model for Financial Fraud Detection


Abstract
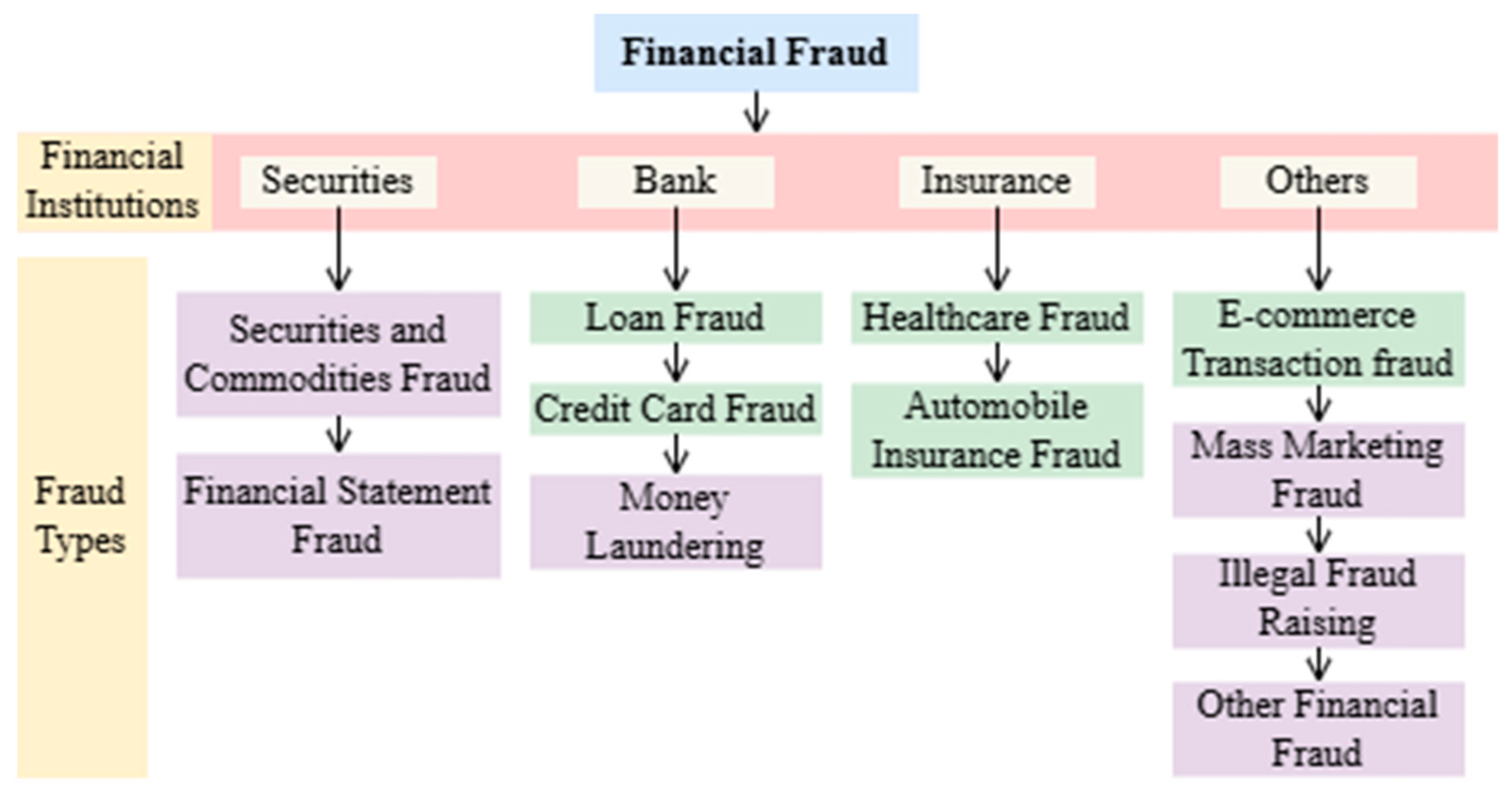
1. Introduction
2. Literature Review
3. Limitations of Previous Research Works
3.1. Lack of Privacy-Preserving Mechanisms
3.2. Lack of Model Transparency and Explainability
4. Contribution of the Proposed Work
4.1. Privacy-Preserving AI with FL
4.2. Enhancing Transparency with XAI
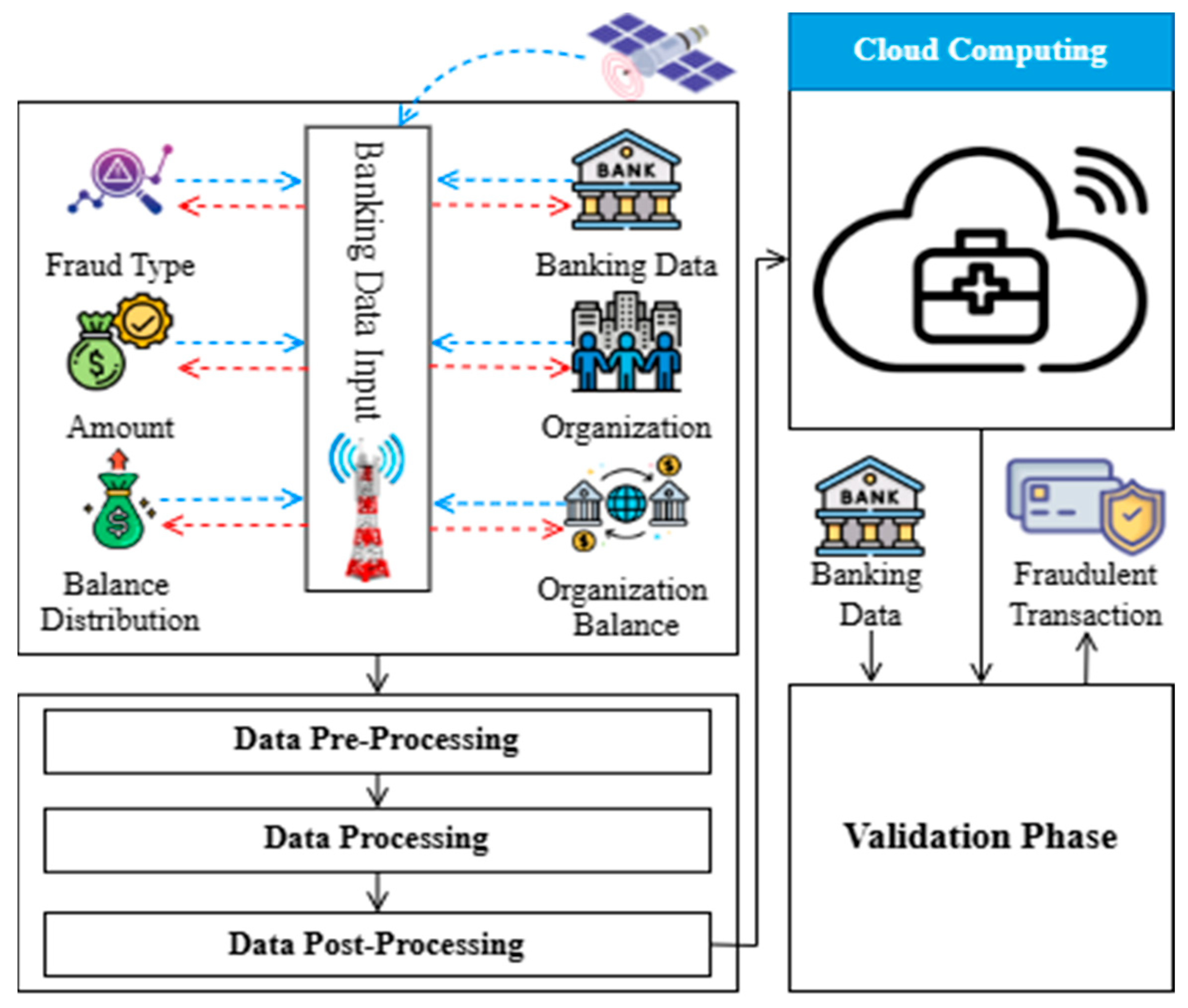
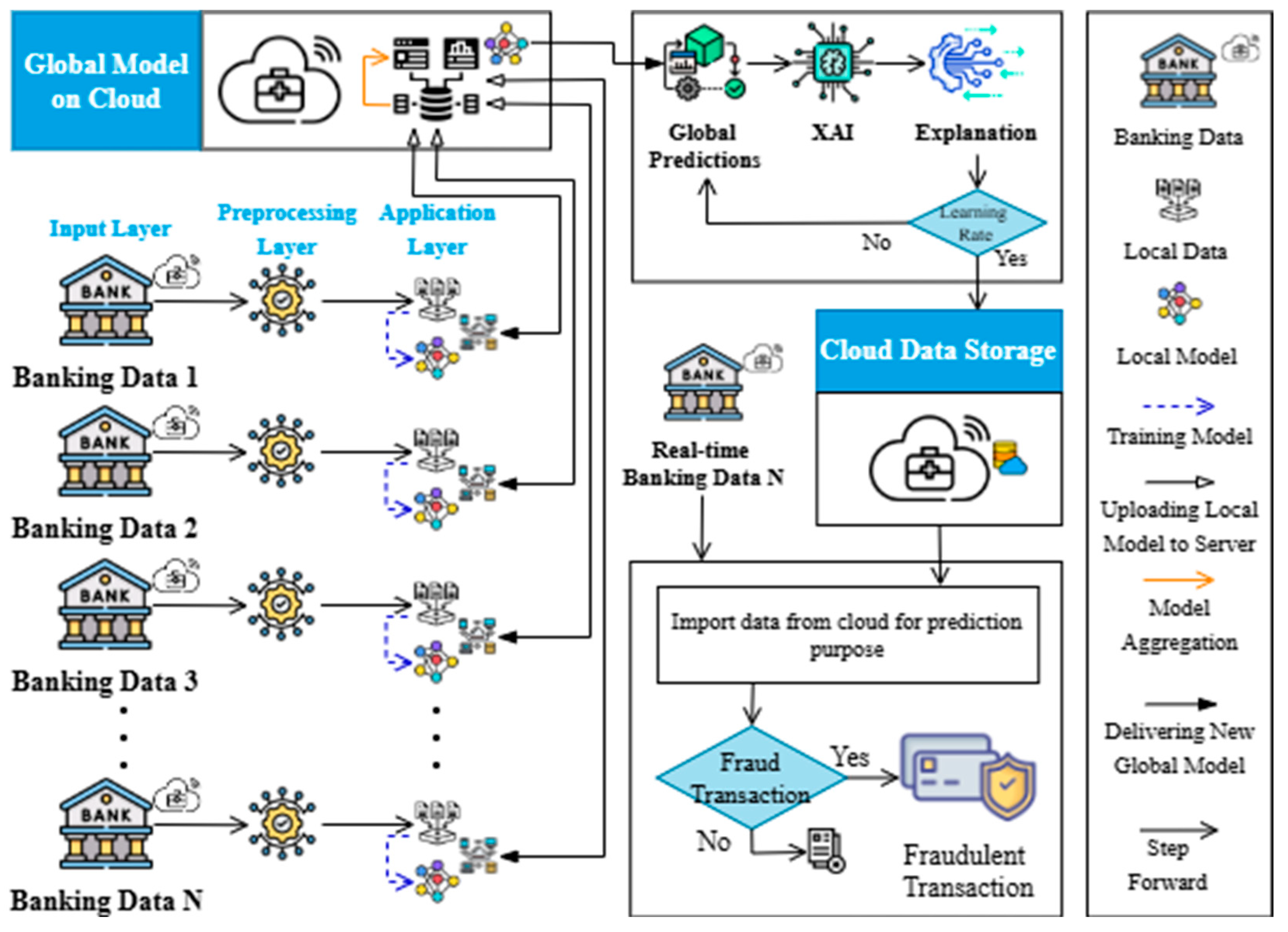
5. Proposed Methodology
5.1. Dataset Description
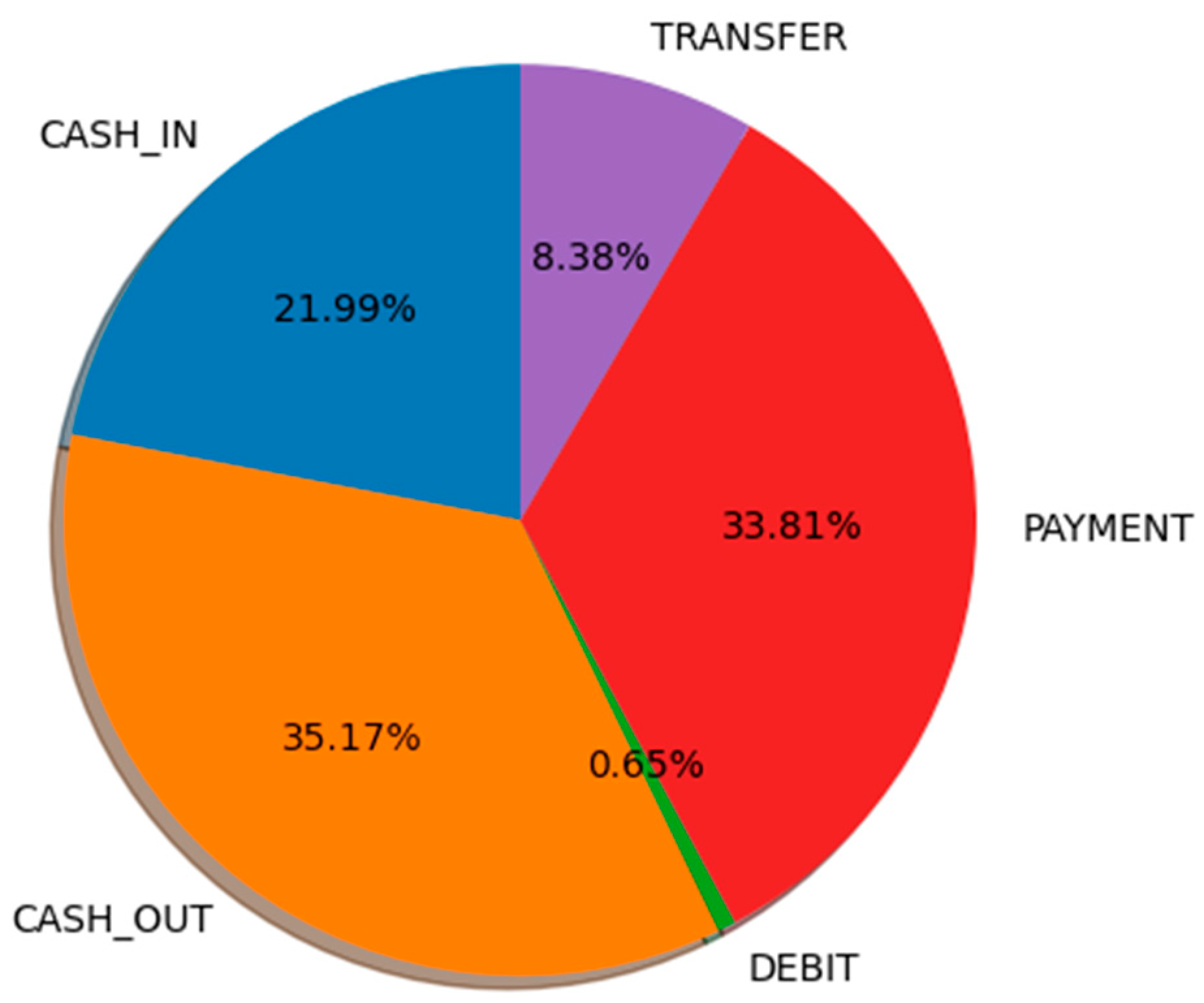
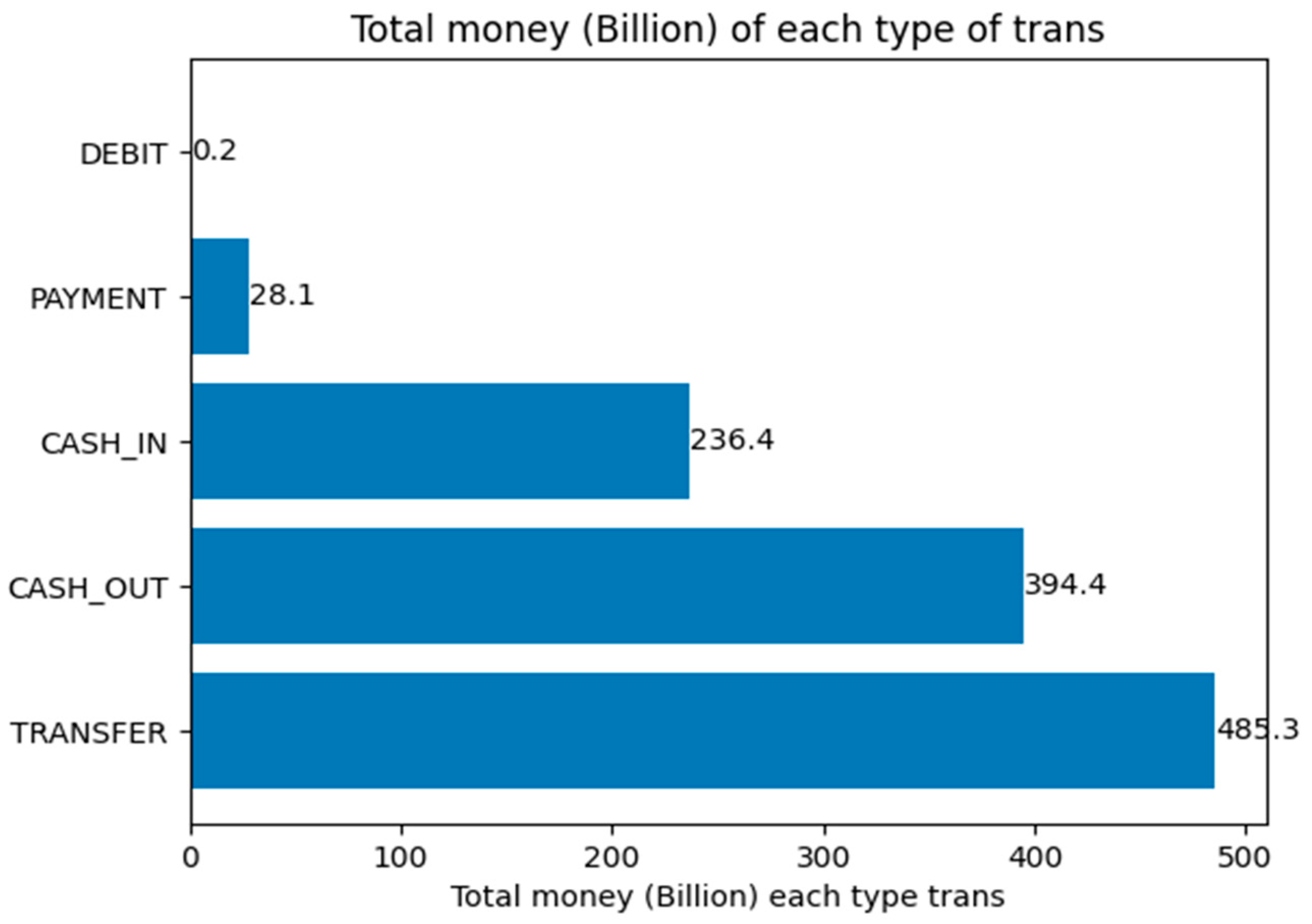
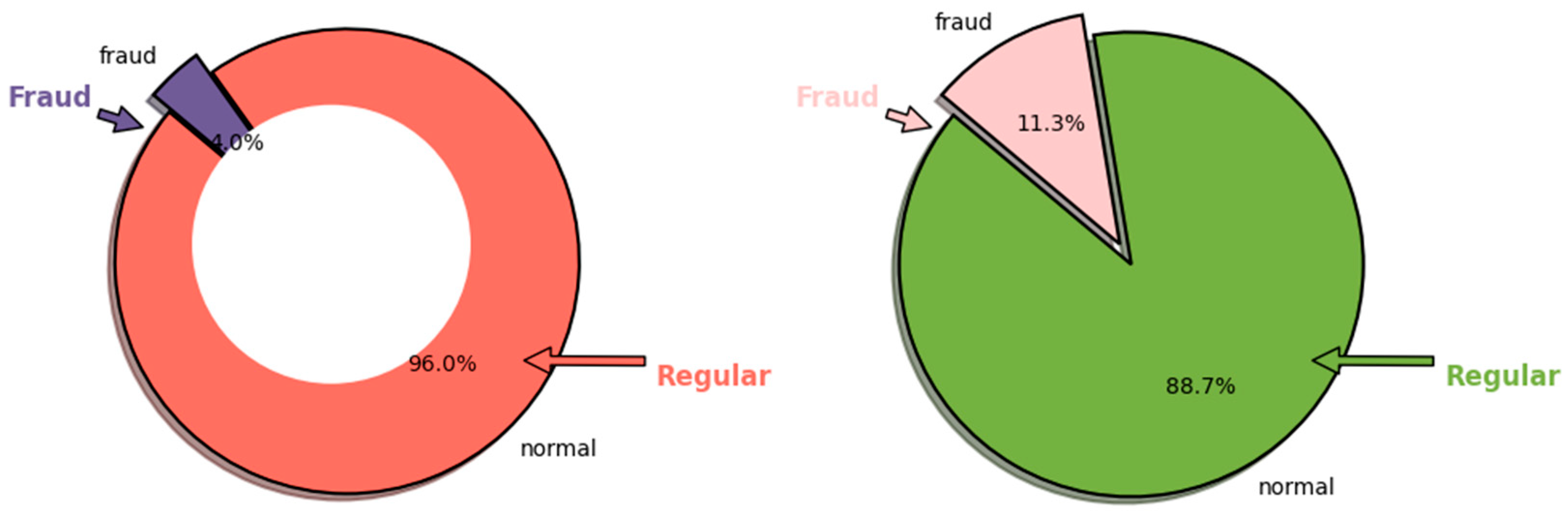
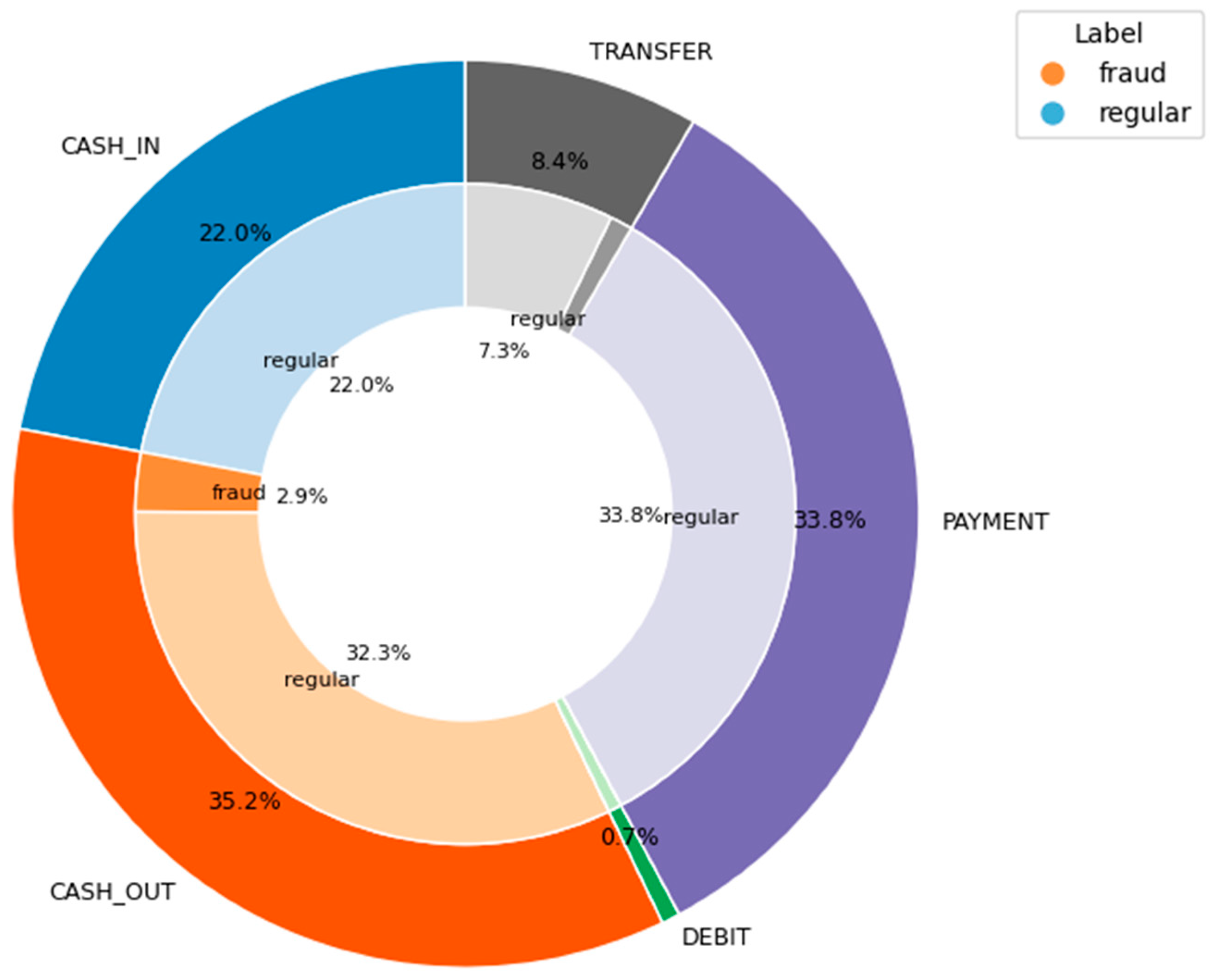
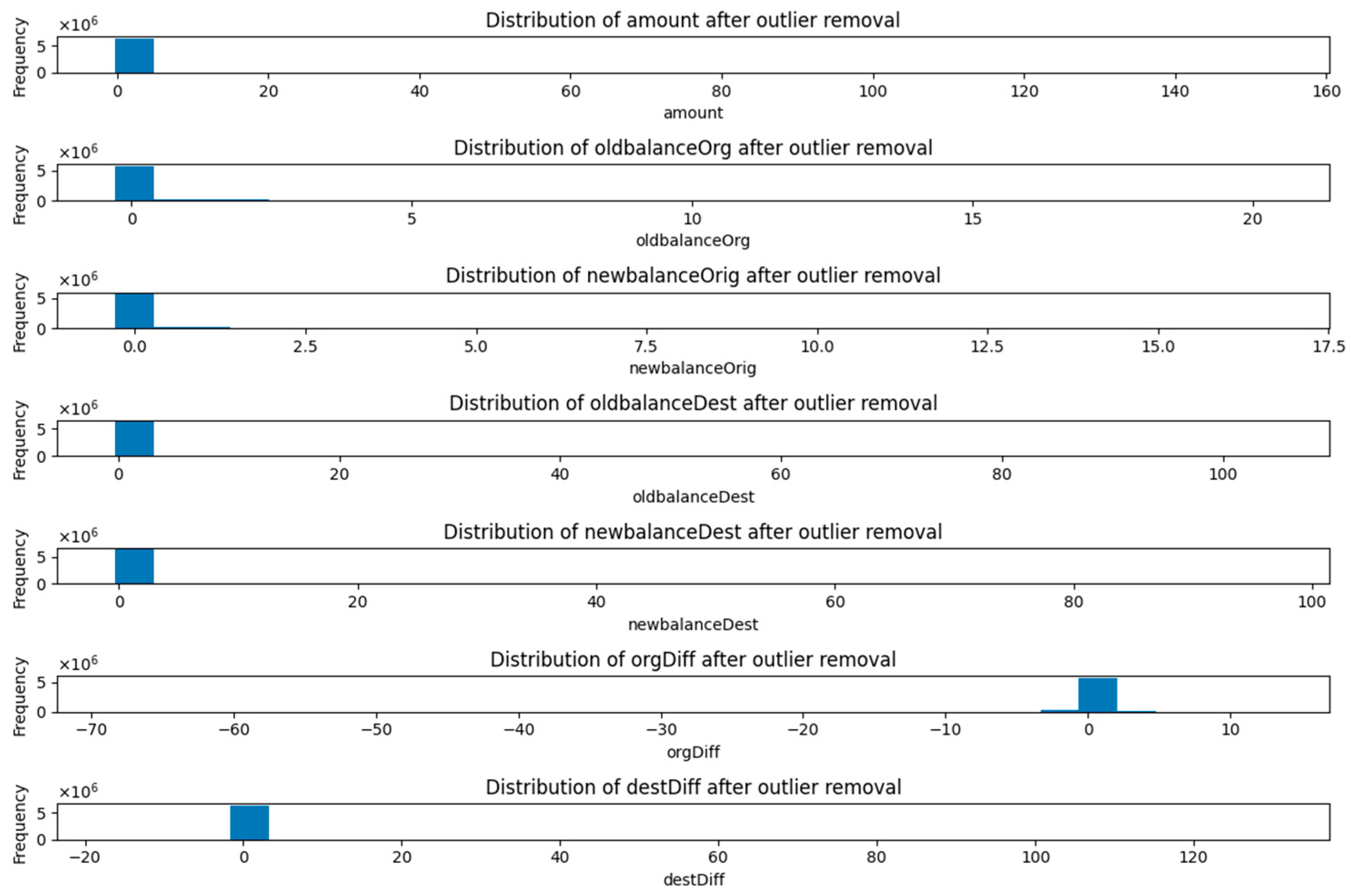
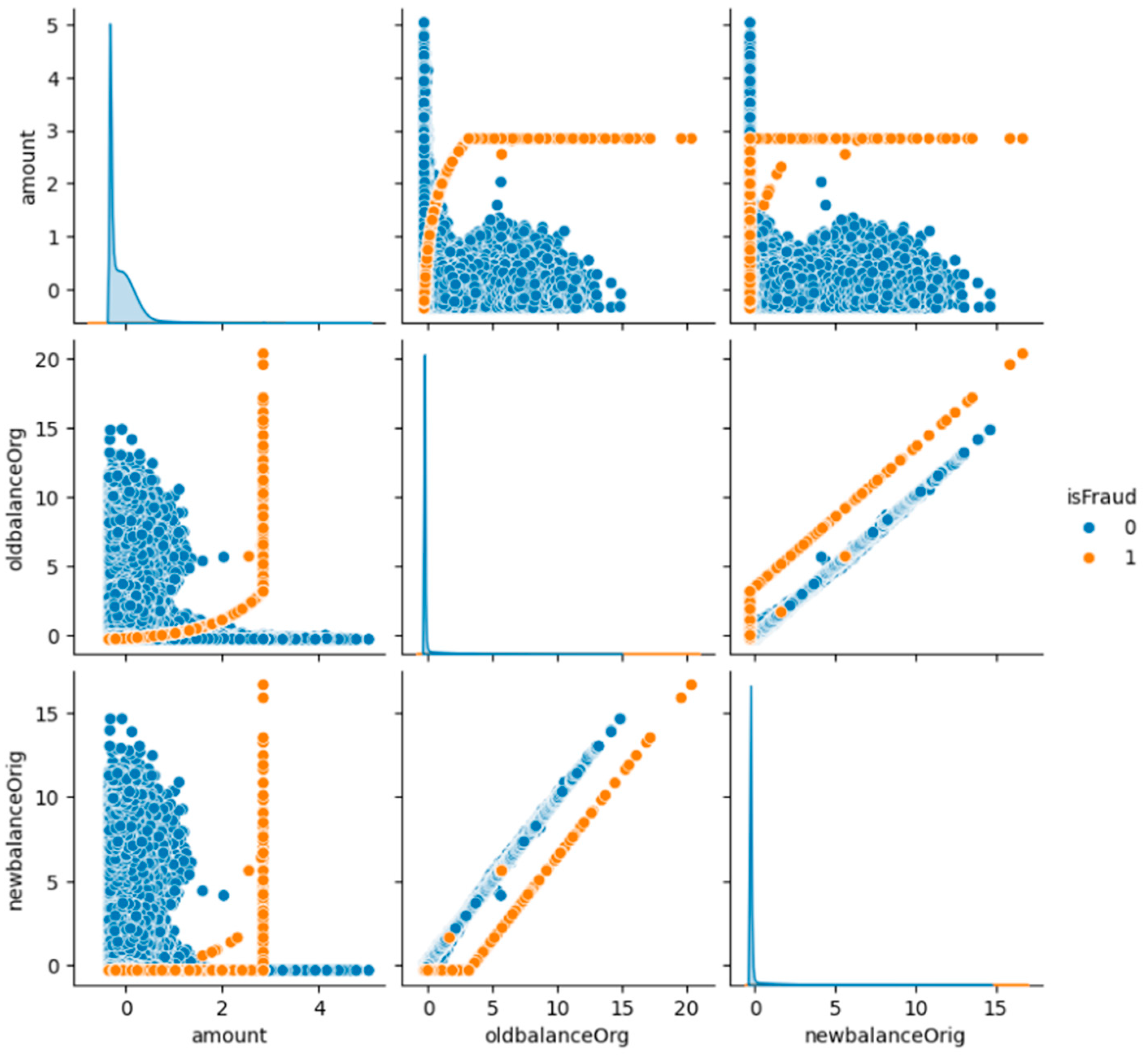
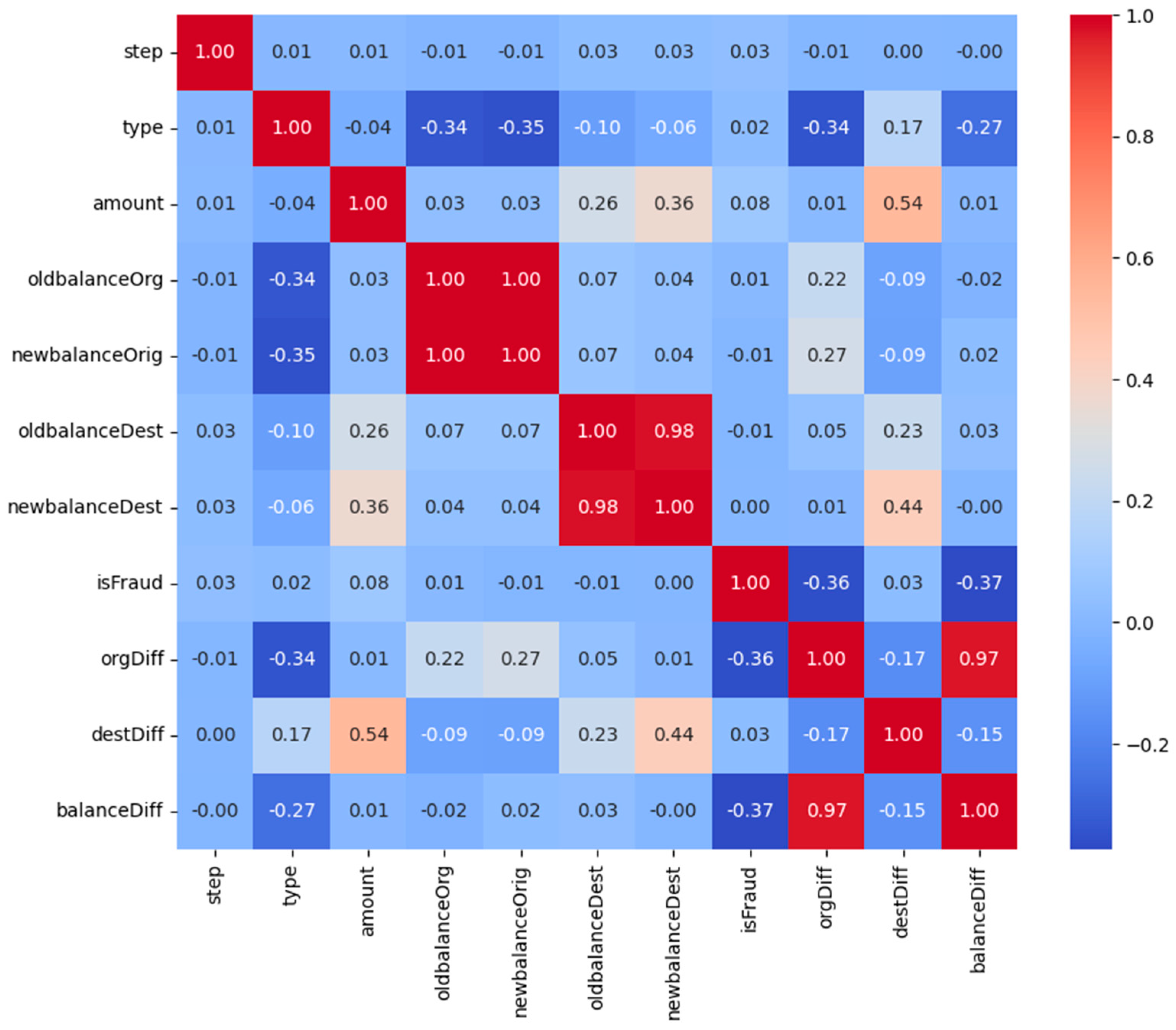
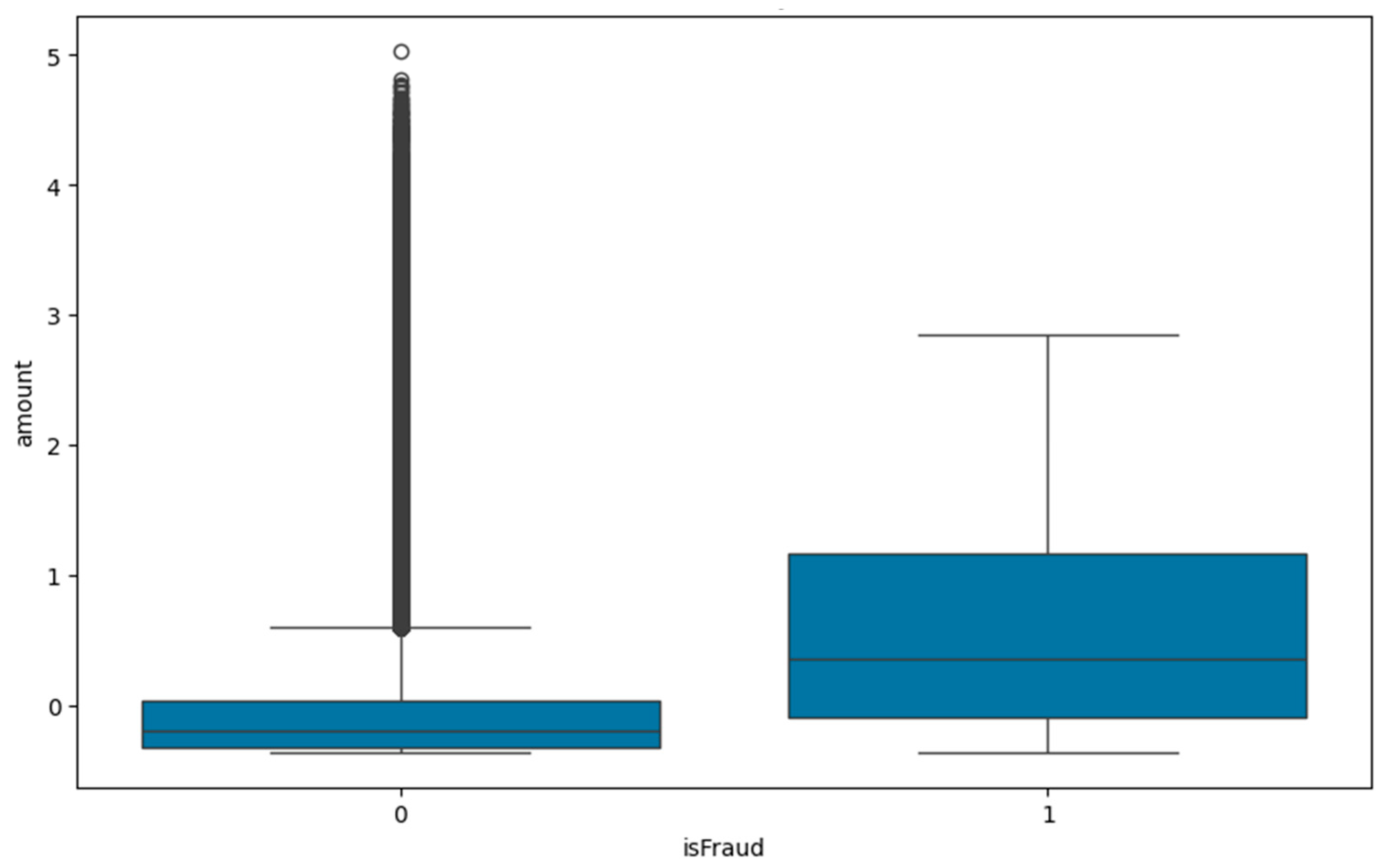
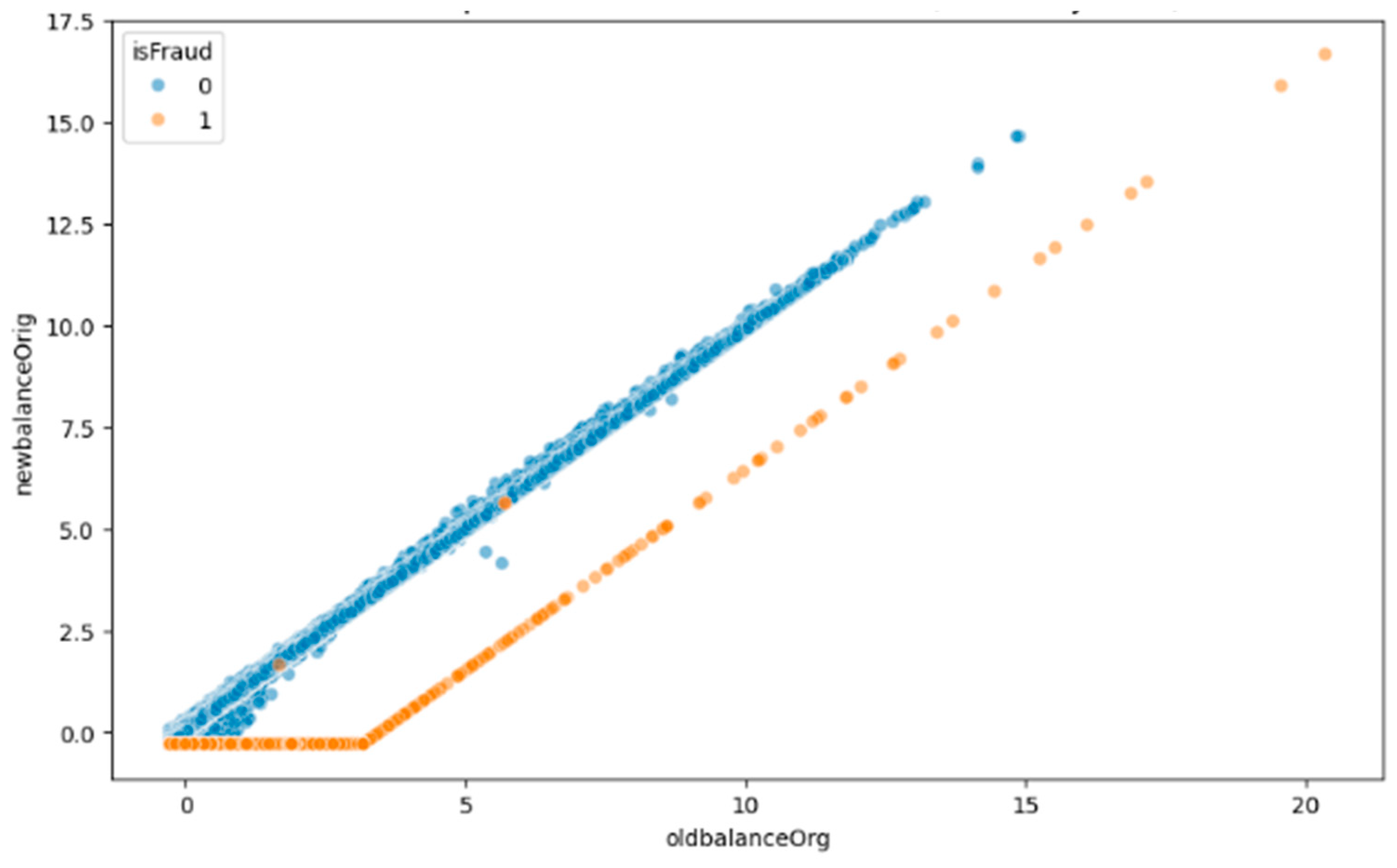
5.2. Exploratory Data Analysis (EDA)
5.3. Local Model Training and Validation Process
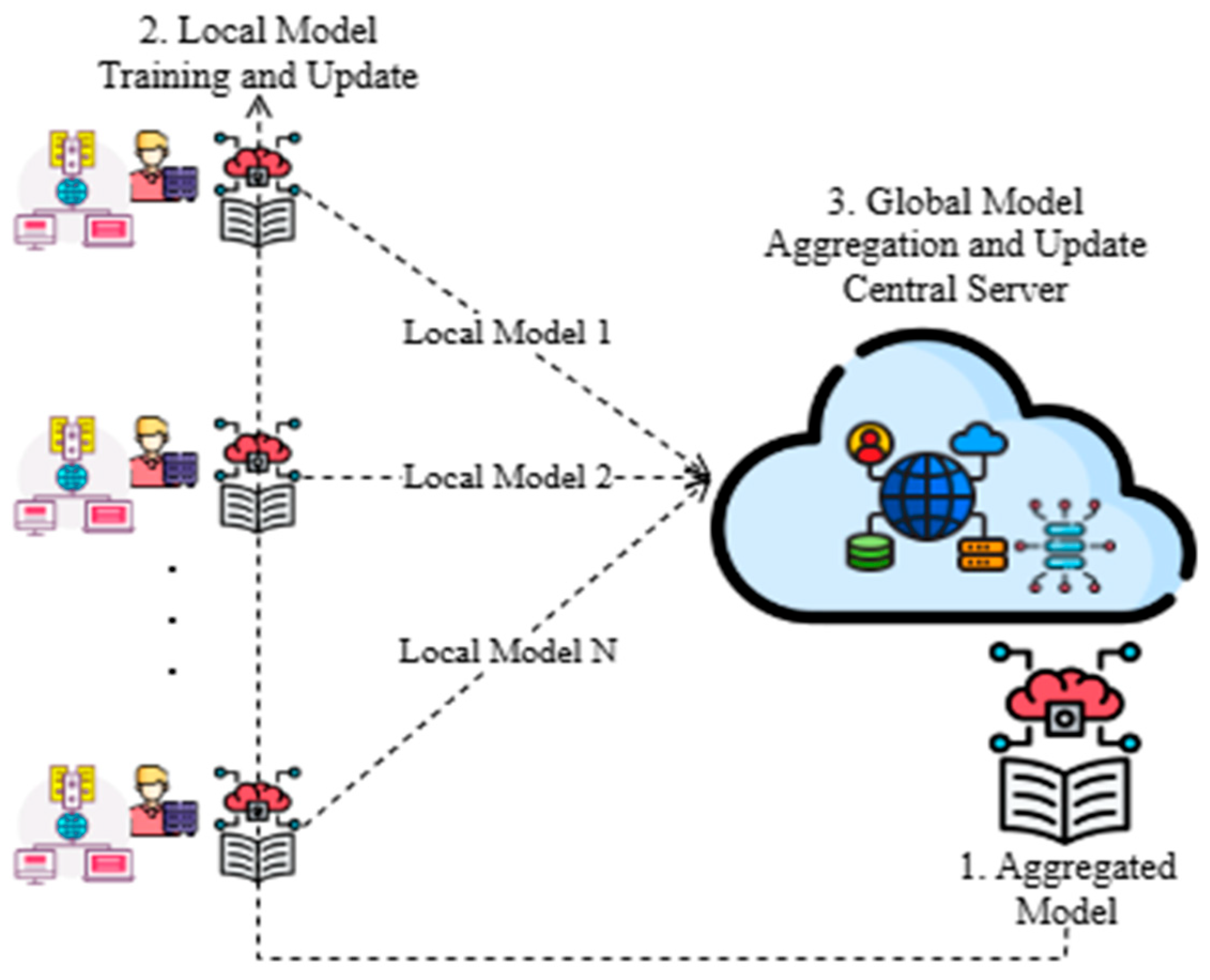
5.4. Federated Learning and Global Model Aggregation
6. Simulation Results
7. Conclusions
8. Limitations and Future Considerations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Abbas, S., Qaisar, A., Farooq, M. S., Saleem, M., Ahmad, M., & Khan, M. A. (2024). Smart vision transparency: Efficient ocular disease prediction model using explainable artificial intelligence. Sensors, 24(20), 6618. [Google Scholar] [CrossRef] [PubMed]
- Abolarin, J. (2025). Banking law and financial regulations: The imperatives for managing stability in the banking sector. Available online: https://books.google.com/books?hl=en&lr=&id=Ces9EQAAQBAJ&oi=fnd&pg=PP11&dq=Banking+Law+and+Financial+Regulations:+The+Imperatives+for+Managing+&ots=RYehI4bpju&sig=s0iGlQW9gEJHdyxk0yP5dScStCc (accessed on 2 November 2024).
- Al-dahasi, E. M., Alsheikh, R. K., Khan, F. A., & Jeon, G. (2025). Optimizing fraud detection in financial transactions with machine learning and imbalance mitigation. Expert Systems, 42(2), e13682. [Google Scholar] [CrossRef]
- Al-Hashedi, K. G., & Magalingam, P. (2021). Financial fraud detection applying data mining techniques: A comprehensive review from 2009 to 2019. Computer Science Review, 40, 100402. [Google Scholar] [CrossRef]
- Askari, S. M. S., & Hussain, M. A. (2017, May 5–6). Credit card fraud detection using fuzzy ID3. IEEE International Conference on Computing, Communication and Automation, ICCCA 2017 (pp. 446–452), Greater Noida, India. [Google Scholar] [CrossRef]
- Baghdadi, P., Korukoglu, S., Bilici, M. A., & Onan, A. (2024). Ensemble learning approach using energy-based RBM and xLSTM for predictive analytics in credit card fraud detection. Authorea preprints. [Google Scholar] [CrossRef]
- Barker, L. (2024). Managing a company in an environment with significant corruption. Available online: https://www.proquest.com/openview/964c25d7eac52c3156f88664a095096f/1?cbl=18750&diss=y&pq-origsite=gscholar (accessed on 4 March 2025).
- Barnes, J. (2020). Fraud detection: Forensic accounting education and CFE designation impact on auditor’s confidence levels. Journal of Accounting and Finance, 20(4), 62–75. Available online: http://www.na-businesspress.com/JAF/JAF20-4/5_BarnesFinal.pdf (accessed on 4 March 2025).
- Behera, T. K., & Panigrahi, S. (2015, May 1–2). Credit card fraud detection: A hybrid approach using fuzzy clustering & neural network. 2015 2nd IEEE International Conference on Advances in Computing and Communication Engineering, ICACCE 2015 (pp. 494–499), Dehradun, India. [Google Scholar] [CrossRef]
- Bharati, S., Mondal, M. R. H., Podder, P., & Prasath, V. B. S. (2022). Federated learning: Applications, challenges and future directions. International Journal of Hybrid Intelligent Systems, 18(1–2), 19–35. [Google Scholar] [CrossRef]
- Cecchini, M., Aytug, H., Koehler, G. J., & Pathak, P. (2010). Making words work: Using financial text as a predictor of financial events. Decision Support Systems, 50(1), 164–175. [Google Scholar] [CrossRef]
- Cho, Y. J., Wang, J., & Joshi, G. (2020). Client selection in federated learning: Convergence analysis and power-of-choice selection strategies. arXiv, arXiv:2010.01243. [Google Scholar]
- Choi, D., & Lee, K. (2018). An artificial intelligence approach to financial fraud detection under IoT environment: A survey and implementation. Security and Communication Networks, 2018(1), 5483472. [Google Scholar] [CrossRef]
- Damanik, N., & Liu, C. M. (2025). Advanced fraud detection: Leveraging K-SMOTEENN and stacking ensemble to tackle data imbalance and extract insights. IEEE Access, 13, 10356–10370. [Google Scholar] [CrossRef]
- Doshi-Velez, F., & Kim, B. (2017). Towards a rigorous science of interpretable machine learning. arXiv, arXiv:1702.08608. [Google Scholar]
- Farooq, M. S., Muhammad, M. H. G., Ali, O., Zeeshan, Z., Saleem, M., Ahmad, M., Abbas, S., Khan, M. A., & Ghazal, T. M. (2024). Developing a transparent anaemia prediction model empowered with explainable artificial intelligence. IEEE Access, 13, 1307–1318. [Google Scholar] [CrossRef]
- Financial Fraud Detection Dataset. (n.d.). Available online: https://www.kaggle.com/datasets/sriharshaeedala/financial-fraud-detection-dataset (accessed on 5 March 2025).
- Gandomi, A. H., Abualigah, L., Saleh Alfaiz, N., & Fati, S. M. (2022). Enhanced credit card fraud detection model using machine learning. Electronics, 11(4), 662. [Google Scholar] [CrossRef]
- Ghazal, T. M., Iqbal Janjua, J., Abbas, S., Fatima, A., Saleem, M., Khan, M. A., & Alqarafi, A. (2024, May 3). Fuzzy-based weighted federated machine learning approach for sustainable energy management with IoE integration. 2024 Systems and Information Engineering Design Symposium, SIEDS 2024 (pp. 112–117), Charlottesville, VA, USA. [Google Scholar] [CrossRef]
- Glancy, F. H., & Yadav, S. B. (2011). A computational model for financial reporting fraud detection. Decision Support Systems, 50(3), 595–601. [Google Scholar] [CrossRef]
- Humpherys, S. L., Moffitt, K. C., Burns, M. B., Burgoon, J. K., & Felix, W. F. (2011). Identification of fraudulent financial statements using linguistic credibility analysis. Decision Support Systems, 50, 585–594. Available online: https://www.sciencedirect.com/science/article/pii/S0167923610001338 (accessed on 4 March 2025). [CrossRef]
- Ikemefuna, C. D., Okusi, O., Iwuh, A. C., & Yusuf, S. (2024). Adaptive fraud detection systems: Using ML to identify and respond to evolving financial threats. International Research Journal of Modernization in Engineering, 6, 2077–2092. Available online: https://www.researchgate.net/profile/Oluwatobiloba-Okusi/publication/384319231_Adaptive_Fraud_Detection_SystemsUsing_Machine_Learning_To_Identify_and_Respond_To_Evolving_Financial_Threat/links/66f3db50869f1104c6b488e2/Adaptive-Fraud-Detection-SystemsUsing-Machine-Learning-To-Identify-and-Respond-To-Evolving-Financial-Threat.pdf (accessed on 4 March 2025).
- Javadpour, A., Ja’fari, F., Taleb, T., Shojafar, M., & Benzaïd, C. (2024). A comprehensive survey on cyber deception techniques to improve honeypot performance. Computers & Security, 140, 103792. [Google Scholar] [CrossRef]
- Jessica, A., Raj, F. V., & Sankaran, J. (2023, October 29–31). Credit card fraud detection using machine learning techniques. ViTECoN 2023—2nd IEEE International Conference on Vision Towards Emerging Trends in Communication and Networking Technologies, Proceedings, Lagos, Nigeria. [Google Scholar] [CrossRef]
- Johnson, D. L. (2022). Demystifying the elusive quest for cyber insurance protection: The need for new contract language. Cardozo Law Review, 44, 2361. Available online: https://heinonline.org/HOL/Page?handle=hein.journals/cdozo44&id=2451&div=&collection= (accessed on 4 March 2025).
- Kazemi, Z., & Zarrabi, H. (2017, December 22). Using deep networks for fraud detection in credit card transactions. 2017 IEEE 4th International Conference on Knowledge-Based Engineering and Innovation, KBEI 2017 (pp. 630–633), Tehran, Iran. [Google Scholar] [CrossRef]
- Khan, M. A., Farooq, M. S., Saleem, M., Shahzad, T., Ahmad, M., Abbas, S., & Abu-Mahfouz, A. M. (2025). Smart buildings: Federated learning-driven secure, transparent, and smart energy management system using XAI. Energy Reports, 13, 2066–2081. [Google Scholar] [CrossRef]
- Khan, M. A., Sabahat, Z., Farooq, M. S., Saleem, M., Abbas, S., Ahmad, M., Mazhar, T., Shahzad, T., & Saeed, M. M. (2024). Optimizing smart home energy management for sustainability using machine learning techniques. Discover Sustainability, 5(1), 430. [Google Scholar] [CrossRef]
- Khetani, V., Gandhi, Y., Bhattacharya, S., Ajani, S. N., & Limkar, S. (2023). Cross-domain analysis of ML and DL: Evaluating their impact in diverse domains. International Journal of Intelligent Systems and Applications in Engineering, 11(7s), 253–262. Available online: https://www.ijisae.org/index.php/IJISAE/article/view/2951 (accessed on 4 March 2025).
- Kirkos, E., Spathis, C., & Manolopoulos, Y. (2007). Data mining techniques for the detection of fraudulent financial statements. Expert Systems with Applications, 32(4), 995–1003. [Google Scholar] [CrossRef]
- Kose, I., Gokturk, M., & Kilic, K. (2015). An interactive machine-learning-based electronic fraud and abuse detection system in healthcare insurance. Applied Soft Computing, 36, 283–299. [Google Scholar] [CrossRef]
- Lim, W. Y. B., Luong, N. C., Hoang, D. T., Jiao, Y., Liang, Y. C., Yang, Q., Niyato, D., & Miao, C. (2020). Federated learning in mobile edge networks: A comprehensive survey. IEEE Communications Surveys and Tutorials, 22(3), 2031–2063. [Google Scholar] [CrossRef]
- Mahboubi, A., Luong, K., Aboutorab, H., Bui, H. T., Jarrad, G., Bahutair, M., Camtepe, S., Pogrebna, G., Ahmed, E., Barry, B., & Gately, H. (2024). Evolving techniques in cyber threat hunting: A systematic review. Journal of Network and Computer Applications, 232, 104004. [Google Scholar] [CrossRef]
- Modi, K., & Dayma, R. (2018, June 23–24). Review on fraud detection methods in credit card transactions. 2017 International Conference on Intelligent Computing and Control, I2C2 2017 (pp. 1–5), Coimbatore, India. [Google Scholar] [CrossRef]
- Nicholls, J., Kuppa, A., & Le-Khac, N. A. (2021). Financial cybercrime: A comprehensive survey of deep learning approaches to tackle the evolving financial crime landscape. IEEE Access, 9, 163965–163986. [Google Scholar] [CrossRef]
- Nishio, T., & Yonetani, R. (2019, May 20–24). Client selection for federated learning with heterogeneous resources in mobile edge. IEEE International Conference on Communications, Shanghai, China. [Google Scholar] [CrossRef]
- Puh, M., & Brkić, L. (2019, May 20–24). Detecting credit card fraud using selected machine learning algorithms. 2019 42nd International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia. Available online: https://ieeexplore.ieee.org/abstract/document/8757212/ (accessed on 4 March 2025).
- Ramachandran, K., Kayathwal, K., Wadhwa, H., & Dhama, G. (2023, June 18–23). FraudAmmo: Large scale synthetic transactional dataset for payment fraud detection. International Joint Conference on Neural Networks, Gold Coast, Australia. [Google Scholar] [CrossRef]
- Randhawa, K., Loo, C. K., Seera, M., Lim, C. P., & Nandi, A. K. (2018). Credit card fraud detection using AdaBoost and majority voting. IEEE Access, 6, 14277–14284. [Google Scholar] [CrossRef]
- Rehman, A., & Hashim, F. (2020). Impact of Fraud Risk Assessment on Good Corporate Governance: Case of Public Listed Companies in Oman. Business Systems Research: International Journal of the Society for Advancing Innovation and Research in Economy, 11(1), 16–30. [Google Scholar] [CrossRef]
- Ruposky, T. J. (2022). The exponential rise of cybercrime. University of Central Florida Department of Legal Studies Law Journal, 5. Available online: https://heinonline.org/HOL/Page?handle=hein.journals/ucflaegs5&id=138&div=&collection= (accessed on 4 March 2025).
- Sabuhi, M., Musilek, P., & Bezemer, C. P. (2024). Micro-FL: A fault-tolerant scalable microservice-based platform for federated learning. Future Internet, 16(3), 70. [Google Scholar] [CrossRef]
- Saleem, M., Farooq, M. S., Shahzad, T., Hassan, A., Abbas, S., Ali, T., Aggoune, E. H. M., & Khan, M. A. (2024). Secure and transparent mobility in smart cities: Revolutionizing AVNs to predict traffic congestion using MapReduce, Private Blockchain and XAI. IEEE Access, 12, 131541–131555. [Google Scholar] [CrossRef]
- Shahzad, T., Saleem, M., Farooq, M. S., Abbas, S., Khan, M. A., & Ouahada, K. (2024). Developing a transparent diagnosis model for diabetic retinopathy using explainable AI. IEEE Access, 12, 149700–149709. [Google Scholar] [CrossRef]
- Sharma, M. A., Raj, B. R. G., Ramamurthy, B., & Bhaskar, R. H. (2022). Credit card fraud detection using deep learning based on auto-encoder. ITM Web of Conferences, 50, 01001. [Google Scholar] [CrossRef]
- Sweers, T., Heskes, T., & Krijthe, J. (2018). Autoencoding credit card fraud [Bachelor Thesis, Radboud University]. Available online: https://www.cs.ru.nl/bachelorscripties/2018/Tom_Sweers___4584325___Autoencoding_credit_card_fraude.pdf (accessed on 4 March 2025).
- Talukder, M. A., Khalid, M., & Uddin, M. A. (2024). An integrated multistage ensemble machine learning model for fraudulent transaction detection. Journal of Big Data, 11(1), 1–25. [Google Scholar] [CrossRef]
- Wang, J., Liu, Q., Liang, H., Joshi, G., & Poor, H. V. (2020). Tackling the objective inconsistency problem in heterogeneous federated optimization. Advances in Neural Information Processing Systems, 33, 7611–7623. [Google Scholar]
- Yan, C., Li, Y., Liu, W., Li, M., Chen, J., & Wang, L. (2020). An artificial bee colony-based kernel ridge regression for automobile insurance fraud identification. Neurocomputing, 393, 115–125. [Google Scholar] [CrossRef]
- Yang, W., Zhang, Y., Ye, K., Li, L., & Xu, C. Z. (2019). FFD: A federated learning-based method for credit card fraud detection. In Lecture notes in computer science (including subseries lecture notes in artificial intelligence and lecture notes in bioinformatics), 11514 LNCS (pp. 18–32). Springer. [Google Scholar] [CrossRef]
- Zhu, X., Ao, X., Qin, Z., Chang, Y., Liu, Y., He, Q., & Li, J. (2021). Intelligent financial fraud detection practices in the post-pandemic era. Innovation, 2(4), 100176. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Model Used | Objective | Preprocessing Techniques | Predictive Model | Privacy- Preserving (FL) | Interpretability (XAI) | Scalability | Regulatory Compliance | Real-Time Fraud Detection | Strengths | Limitations |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Talukder et al. (2024) | IMEML (EIC, EBC, EMC) | Handling data imbalance | IHT+EMC, cluster centroids, RUS | Ensemble Learning | 🞫 | 🞫 | Moderate | 🞫 | 🞫 | Reduces false positives and balances data. | High computational cost; may not generalize well. |
| Baghdadi et al. (2024) Fraud detection while balancing speed and accuracy | Not explicitly mentioned | Ensemble Learning (RBM + LSTM) | 🞫 | 🞫 | High | 🞫 | ☑ | 🞫 | 🞫 | High fraud detection accuracy; real-time processing | Dataset sharing limitations; high model complexity |
| Puh and Brkić (2019) | Decision Trees, SVM, Neural Networks | Identify fraudulent transactions using ML techniques. | Feature selection; data preprocessing | ML (Supervised) | 🞫 | 🞫 | Moderate | 🞫 | 🞫 | Reduces false positives and false negatives; enhances financial security | Performance varies across models and potential data imbalance issues |
| Randhawa et al. (2018) | AdaBoost, Majority Voting, 12 ML algorithms | Enhance fraud detection using ensemble learning. | Not explicitly mentioned | Ensemble Learning | 🞫 | 🞫 | High | 🞫 | 🞫 | Robust against data noise; reduces false positives | Requires diverse datasets; performance depends on dataset quality |
| Sharma et al. (2022) | Autoencoder (AE) | Improve fraud detection using unsupervised DL | Not explicitly mentioned | DL (Unsupervised) | 🞫 | 🞫 | High | 🞫 | ☑ | Adapts to evolving fraud patterns; effective anomaly detection | High computational cost; lacks explainability |
| Bharati et al. (2022) | FL | Address privacy concerns in decentralized ML | Not explicitly mentioned | FL | ☑ | 🞫 | High | ☑ | 🞫 | Ensures data privacy; enables collaborative learning | High communication costs; system heterogeneity |
| Yang et al. (2019) | Federated Fraud Detection (FFD) | Enhance privacy-preserving fraud detection | Oversampling for class balancing | FL | ☑ | 🞫 | High | ☑ | ☑ | Improves fraud classification; preserves data privacy | High computational cost; potential network delays |
| Doshi-Velez and Kim (2017) | Interpretable ML | Improve ML transparency and trust | Not explicitly mentioned | XAI | 🞫 | ☑ | Moderate | ☑ | 🞫 | Enhances fairness, and accountability | Reduced accuracy; lack of standard evaluation metrics |
| Damanik and Liu (2025) | K-means SMOTEEN, Stacking Ensemble (XGBoost, Decision Trees) | Improve fraud detection accuracy by handling class imbalance | K-means SMOTEENN (resampling for data balancing) | Ensemble Learning | 🞫 | ☑ | High | 🞫 | 🞫 | High fraud detection accuracy; enhanced interpretability | Computationally expensive; dependency on feature quality |
| Proposed Model | XFL with SHAP and LIME | Enhance fraud detection with privacy-preserving and XAI | Not explicitly mentioned | FL + XAI | ☑ | ☑ | High | ☑ | ☑ | Ensures privacy; high fraud detection accuracy; improves interpretability | Higher computational cost; dependency on data quality; potential latency in federated updates |
| Sr. No. | Features | Description |
|---|---|---|
| 1 | step | int64 |
| 2 | type | object |
| 3 | amount | float64 |
| 4 | nameOrig | object |
| 5 | oldbalanceOrg | float64 |
| 6 | newbalanceOrig | float64 |
| 7 | nameDest | object |
| 8 | oldbalanceDest | float64 |
| 9 | newbalanceDest | float64 |
| 10 | isFraud | int64 |
| Step | Process |
|---|---|
| 1 | Start |
| 2 | (e.g., transaction type, amount, sender and receiver balance). |
| 3 | Preprocessing: ☑ Feature Selection ☑ Feature Engineering ☑ Handling Missing Values ☑ Feature Scaling (Standardization) ☑ Encoding Categorical Variables ☑ Outlier Detection and Removal ☑ Data Transformation ☑ Feature Reduction ☑ Fraud Labeling ☑ Data Aggregation for Insights ☑ Visualization and Data Exploration |
| 4 | . |
| 5 | for fraud classification. |
| 6 | . |
| 7 | , retrain the model. |
| 8 | to the local banking server. |
| 9 | to the global system for aggregation. |
| 10 | to banking professionals/clients. |
| 11 | Stop |
| Step | Process |
|---|---|
| 1 | Start |
| 2 | . |
| 3 | . |
| 4 | ). |
| 5 | |
| 6 | , proceed to model deployment. |
| 7 | If not converged: Request additional training from local clients with adjusted hyperparameters. |
| 8 | Apply XAI techniques (SHAP and LIME) for interpretability |
| 9 | values using the feature impact formula. |
| 10 | locally. |
| 11 | . |
| 12 | |
| 13 | |
| 14 | Securely store validated predictions in cloud storage. |
| 15 | Stop |
| Confusion Matrix | |||
|---|---|---|---|
| GBM | SVM | LR | |
| True Positive (TP) | 1,270,835 | 1,270,853 | 1,270,745 |
| True Negative (TN) | 997 | 147 | 719 |
| False Positive (FP) | 018 | 000 | 108 |
| False Negative (FN) | 647 | 1497 | 925 |
| Performance Matrices | Algorithms | ||
|---|---|---|---|
| GBM | SVM | LR | |
| Accuracy | 99.95 | 99.88 | 99.92 |
| Sensitivity (TPR) | 99.95 | 99.88 | 99.93 |
| Specificity (TNR) | 98.23 | 1 | 86.94 |
| Miss-rate (FNR) | 0.05 | 0.12 | 0.08 |
| Positive Predictive Value (PPV) | 1 | 1 | 99.99 |
| Negative Predictive Value (NPV) | 60.64 | 8.94 | 43.73 |
| References | Model | Accuracy (%) | Miss-Rate (%) |
|---|---|---|---|
| Behera and Panigrahi (2015) | FCM-MLP | 94 | 6 |
| Kazemi and Zarrabi (2017) | AE | 81.6 | 18.4 |
| Sweers et al. (2018) | VAE | 93.8 | 6.2 |
| Kirkos et al. (2007) | DT, NN, BNN | DT = 73.6, NN = 80, BNN = 90.3 | DT = 26.4, NN = 20, BNN = 9.7 |
| Cecchini et al. (2010) | Ontology + WN | 83.87 | 16.3 |
| Humpherys et al. (2011) | LR, NB, SVM, C4.5, LWL | LR = 63.4, NB = 67.3, SVM = 65.8, C4.5 = 67.3, LWL = 60.4 | LR = 36.6, NB = 32.7, SVM = 34.2, C4.5 = 32.7, LWL = 39.6 |
| Glancy and Yadav (2011) | CFDM | 90.9 | 9.1 |
| Askari and Hussain (2017) | FL+ID3 | 89 | 11 |
| Proposed XFL-based financial fraud detection model | XAI+FL | 99.95 | 0.05 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aljunaid, S.K.; Almheiri, S.J.; Dawood, H.; Khan, M.A. Secure and Transparent Banking: Explainable AI-Driven Federated Learning Model for Financial Fraud Detection. J. Risk Financial Manag. 2025, 18, 179. https://doi.org/10.3390/jrfm18040179
Aljunaid SK, Almheiri SJ, Dawood H, Khan MA. Secure and Transparent Banking: Explainable AI-Driven Federated Learning Model for Financial Fraud Detection. Journal of Risk and Financial Management. 2025; 18(4):179. https://doi.org/10.3390/jrfm18040179
Chicago/Turabian StyleAljunaid, Saif Khalifa, Saif Jasim Almheiri, Hussain Dawood, and Muhammad Adnan Khan. 2025. "Secure and Transparent Banking: Explainable AI-Driven Federated Learning Model for Financial Fraud Detection" Journal of Risk and Financial Management 18, no. 4: 179. https://doi.org/10.3390/jrfm18040179
APA StyleAljunaid, S. K., Almheiri, S. J., Dawood, H., & Khan, M. A. (2025). Secure and Transparent Banking: Explainable AI-Driven Federated Learning Model for Financial Fraud Detection. Journal of Risk and Financial Management, 18(4), 179. https://doi.org/10.3390/jrfm18040179