Abstract
The increasing adoption of artificial intelligence algorithms is redefining decision-making across various industries. In the financial sector, where automated credit granting has undergone profound changes, this transformation raises concerns about biases perpetuated or introduced by AI systems. This study investigates the methods used to identify and mitigate biases in AI models applied to credit granting. We conducted a systematic literature review using the IEEE, Scopus, Web of Science, and Science Direct databases, covering the period from 1 January 2013 to 1 October 2024. From the 414 identified articles, 34 were selected for detailed analysis. Most studies are empirical and quantitative, focusing on fairness in outcomes and biases present in datasets. Preprocessing techniques dominated as the approach for bias mitigation, often relying on public academic datasets. Gender and race were the most studied sensitive attributes, with statistical parity being the most commonly used fairness metric. The findings reveal a maturing research landscape that prioritizes fairness in model outcomes and the mitigation of biases embedded in historical data. However, only a quarter of the papers report more than one fairness metric, limiting comparability across approaches. The literature remains largely focused on a narrow set of sensitive attributes, with little attention to intersectionality or alternative sources of bias. Furthermore, no study employed causal inference techniques to identify proxy discrimination. Despite some promising results—where fairness gains exceed 30% with minimal accuracy loss—significant methodological gaps persist, including the lack of standardized metrics, overreliance on legacy data, and insufficient transparency in model pipelines. Future work should prioritize developing advanced bias mitigation methods, exploring sensitive attributes, standardizing fairness metrics, improving model explainability, reducing computational complexity, enhancing synthetic data generation, and addressing the legal and ethical challenges of algorithms.
1. Introduction
The widespread adoption of artificial intelligence (AI) algorithms, especially those based on Machine Learning (ML), is reshaping how many industries make crucial decisions. In the financial sector, automation has revolutionized lending processes, making it a standout area of change Tigges et al. (2024). Algorithms can process large amounts of data in record time, exceeding human cognitive capabilities. This efficiency sometimes leads to the belief that algorithms are more objective and fair in decision-making, especially when bank loan approvals (Bhatore et al., 2020). However, despite the efficiency of automated systems, significant concerns arise regarding the biases that can perpetuate or be introduced.
ML algorithms learn from historical data, often derived from financial institutions’ datasets. These data reflect past decisions that may carry biases towards groups defined by race, gender, sexual orientation, and other attributes. For instance, ML models can identify historical patterns, such as men being more likely to take out large loans solely in their own names rather than jointly with partners (de Castro Vieira et al., 2019).
Even when historical data appears unbiased, ML models can still produce unfair outcomes (Bircan & Ãzbilgin, 2025). Empirically detecting discrimination in these systems is a complex task, as they rely on records of past lender decisions. Historical data biases consolidate under the guise of precision and accuracy in the results, making bias detection a substantial challenge.
This issue raises a critical concern: Predictive models may, in fact, be inherently biased as they learn and perpetuate historical biases embedded in the data used for training the algorithms. Such issues have fueled growing concerns about algorithmic fairness and have sparked increasing interest in the academic literature on defining, evaluating, and improving fairness in ML algorithms (Pessach & Shmueli, 2022).
Concerns about algorithmic bias emerged with the seminal proposal of Fairness Through Awareness, which cast fairness as a distance-based constraint between individuals, as shown by Dwork et al. (2012). Soon after, Hardt et al. (2016) formalized group-level criteria of Equalized Odds and Equal Opportunity that equalize error rates across protected classes. Early work then explored how to enforce these criteria in practice: Pedreshi et al. (2008) and Calders and Verwer (2010) laid the groundwork for measuring and eliminating disparate impact; Zemel et al. (2013) introduced fair representation learning to achieve both accuracy and group parity; Feldman et al. (2015) developed preprocessing methods to certify and remove bias directly from the data; and Kamishima et al. (2012) proposed regularization techniques to penalize dependence on sensitive attributes. A series of follow-up studies exposed inherent trade-offs among those criteria (Corbett-Davies et al., 2023; Kleinberg, 2018) and showed how model parameters may encode cultural stereotypes—such as gender bias in word embeddings (Bolukbasi et al., 2016). Later advances pushed fairness into the causal domain with Counterfactual Fairness (Kusner et al., 2017). Comprehensive surveys now map this rich landscape of definitions, metrics, and mitigation pipelines (Y. Huang et al., 2023; Mehrabi et al., 2021; Pessach & Shmueli, 2022; Wang et al., 2022).
In credit decision-making, empirical evidence indicates that mortgage approval models can amplify historical disparities (Zou & Khern-am nuai, 2023) and even reinforce societal bias through seemingly neutral features (Hassani, 2021). Systematic reviews of discrimination in the credit domain highlight open challenges such as indirect (structural) bias and regulatory misalignment (Garcia et al., 2023). Recent methodological advances span information theoretic preprocessing that removes sensitive information while preserving utility (Kim & Cho, 2022) and stochastic multi-objective optimization that renders the accuracy versus fairness Pareto frontier explicit (S. Liu & Vicente, 2022).
The good news is that addressing algorithmic bias is considerably easier than tackling certain forms of human prejudice (Lobel, 2023). Researchers have broadly categorized several methods to mitigate biases and unfairness into three approaches: preprocessing, in-processing, and post-processing. However, defining fairness, which can vary widely, plays a crucial role in determining the effectiveness of programming fair algorithms (Garcia et al., 2023). In particular, in domains such as finance, the style of explanation plays a fundamental role in the perception of fairness by users. Different explanation styles can help them understand the role of various features and the reasoning behind a prediction, increasing their ability to distinguish between different motives and consequently enhancing their perception of fairness (Haque et al., 2023).
In addition, the literature has deeply explored the concepts of algorithmic fairness and the trade-off between fairness and accuracy. According to Wang et al. (2022), pursuing greater fairness can sometimes come at the expense of model accuracy. Therefore, the aspiration of a fairness-aware algorithm is to achieve a balance that allows greater fairness without significantly diminishing accuracy or other alternative notions of utility.
Given this context, this article seeks to answer the following research question: How have methods been used to identify and mitigate biases in AI models applied to credit granting, and what are the results and research gaps?
Thus, this article presents a comprehensive review of fairness in ML models, focusing on credit granting. The main objective is to investigate the state of the art in identifying and mitigating biases and unfairness in ML models for credit decisions. Unlike previous research (e.g., Garcia et al., 2023; Y. Huang et al., 2023; Pessach & Shmueli, 2022; Wang et al., 2022), this work covers algorithms, databases, measures, mechanisms and techniques, results, and effectiveness, challenges and limitations, future trends, and recommendations, all used in identifying and mitigating biases and unfairness in ML models for credit decision-making.
This review aims to make a meaningful contribution to understanding and improving fairness in automated lending decisions by highlighting the complexities inherent in the pursuit of fairness in the era of AI. Additionally, the study advances the Sustainable Development Goals (SDGs) established by the United Nations. Specifically, it aligns with SDG 10: Reduced Inequalities by addressing the need for algorithmic fairness in credit granting and proposing methods to identify and mitigate biases that can perpetuate social and economic disparities. By investigating effective methods to detect and mitigate bias in artificial intelligence models, this paper seeks to promote more responsible and ethical practices in the financial sector, contributing to fairer and more inclusive societies.
This article is organized as follows. The next section outlines the methodology used for the systematic literature review. This includes the databases searched, the search criteria, the inclusion and exclusion criteria for articles, as well as the process of selecting and coding the studies. Next, we present the characteristics of the selected studies through both quantitative and qualitative analyses. We then explore the trends in the literature, including the analysis of author networks, citation frequencies, and the coding of the articles. The discussion demonstrates the main findings, identifies research gaps, and proposes an agenda for future studies. Finally, the conclusion section addresses the challenges and limitations of the study, as well as offers recommendations for improving allegiance.
2. Method
This study was conducted in accordance with the PRISMA 2020 (Preferred Reporting Items for Systematic Reviews and Meta-Analyses) guidelines (Page et al., 2021), and we used the PRISMA checklist when writing our report. The PRISMA protocol provides a set of checkpoints designed to improve the transparency and reproducibility of systematic reviews. We have followed, including defining a straightforward research question, developing inclusion and exclusion criteria, conducting a comprehensive search across relevant databases, selecting studies based on predefined criteria, systematically extracting data, and synthesizing the results. The adoption of PRISMA aims to ensure rigorous and standardized conduct of the review, increasing the reliability of our findings.
The method is also consistent with Jabbour (2013); Junior and Godinho Filho (2010); Seuring (2013), which is based on Huisingh (2012), and proposes that a literature review should follow the following steps:
- First step: Conduct a comprehensive search for published articles on the topic in relevant databases.
- Second step: Develop a classification model, coded using a logical structure.
- Third step: Apply the classification model and develop a framework for the current discussion on the topic.
- Fourth step: Present the characteristics of the scientific literature and the main results, considering the coding system.
- Fifth step: Analyze the gaps and suggest opportunities for further studies.
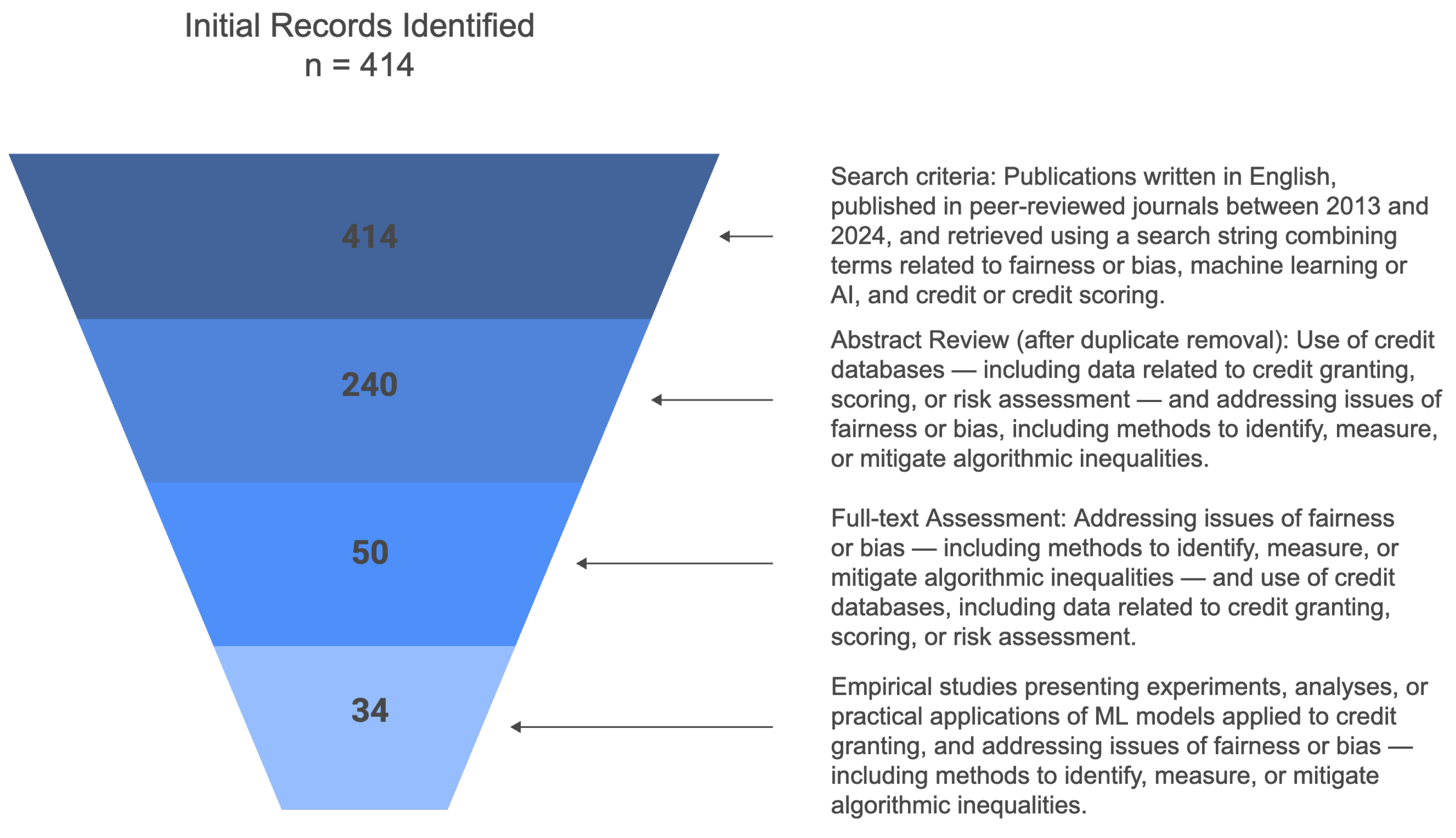
Thus, we conducted the study using the IEEE, Scopus, Web of Science, and Science Direct databases, with the search criteria defined as follows: (“bias” OR “fair” OR “fairness” OR “unfairness” OR “algorithmic discrimination” OR “algorithmic fairness” OR “discriminatory”) AND (“machine learning” OR “AI” OR “artificial intelligence”) AND (“credit” OR “mortgage” OR “loan” OR “credit scoring”). The search period spanned the range from 1 January 2013 to 1 October 2024, with the aim of obtaining a comprehensive and up-to-date view of scientific publications relevant to the topic.
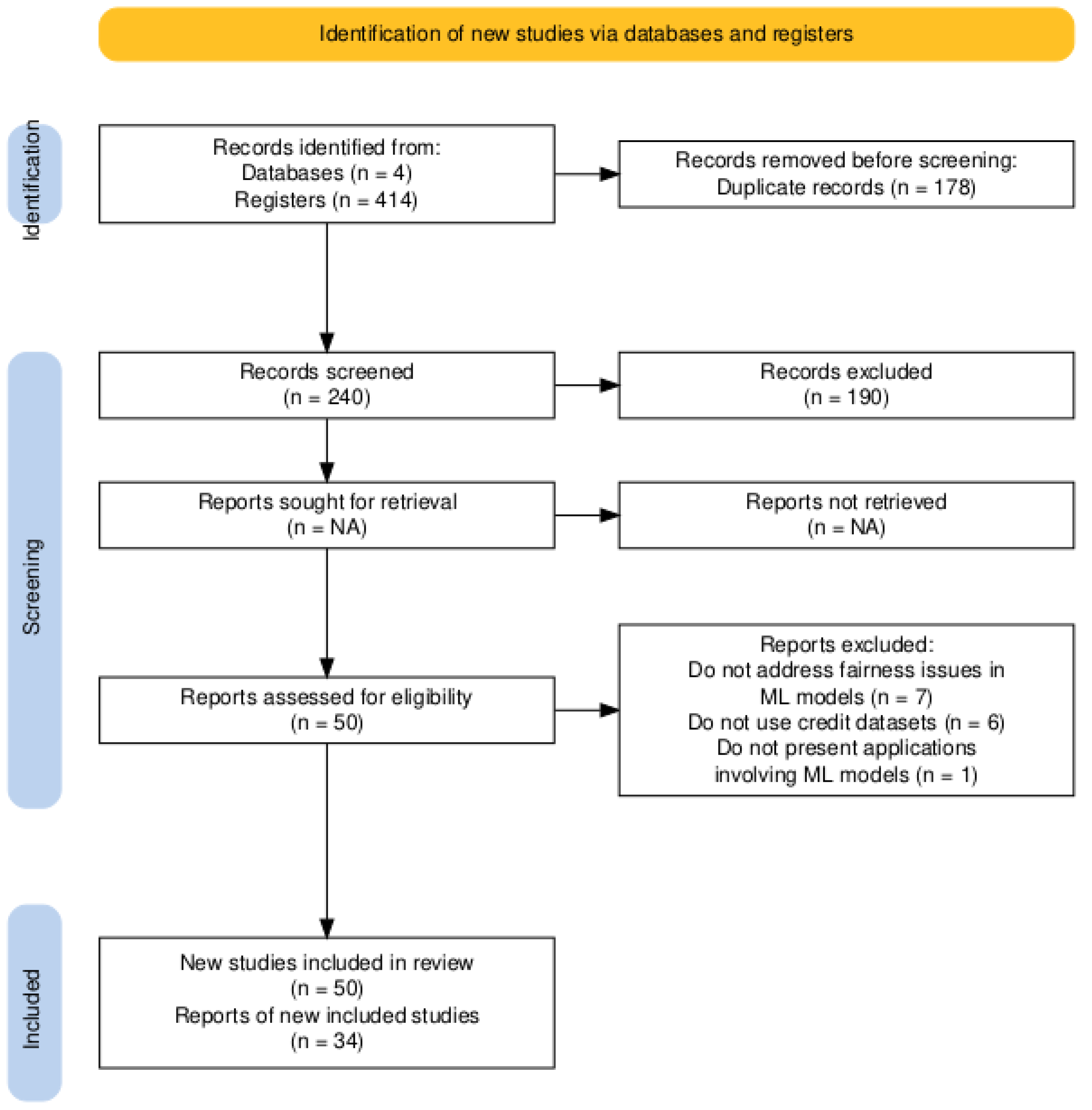
We define the inclusion criteria to ensure the review focuses on high-quality studies and is directly relevant to the proposed research question. By concentrating on peer-reviewed empirical studies that apply ML models to credit databases and that address algorithmic fairness, we ensure that the results are reliable and applicable to the current context of credit granting. The limitation to English aims to provide full comprehension of the studies, while the defined publication period captures the most recent advances in the field. The papers that did not address fairness issues in Machine Learning, did not use credit datasets, or did not present an application involving Machine Learning were excluded. Figure 1 shows the inclusion flowchart of the manuscripts. This approach, as highlighted by Stoll et al. (2019), allows for a critical and impartial evaluation of the research, increasing the results’ reliability. During the initial search, we identified 414 articles.
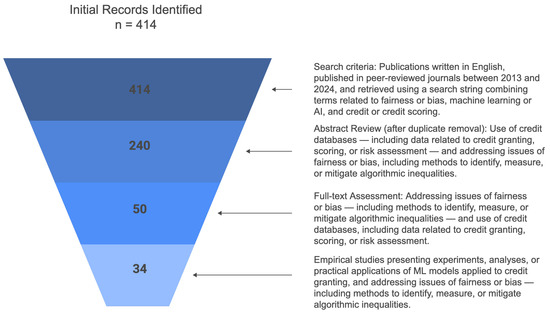
Figure 1.
Inclusion Flowchart.
The initial screening eliminated duplicate records from the 414 articles. We subsequently read the abstracts to verify whether the articles met the inclusion criteria. This approach is consistent with the methodology described by Peters et al. (2020), in which screening is a crucial step in selecting the most relevant studies that are aligned with the research objectives.
After the initial screening, we selected 50 articles for a more detailed analysis. At this stage, the articles were read in full, and the selection was based on the relevance of the content and suitability for the objectives of the study in question, observing the inclusion criteria. At the end of this stage, we selected 34 articles for the final research. Figure 2 shows the identification, screening, and eligibility of articles. This approach is corroborated by Leite et al. (2019), which highlights the importance of a detailed analysis of the selected articles to build a consistent and reliable literature review.
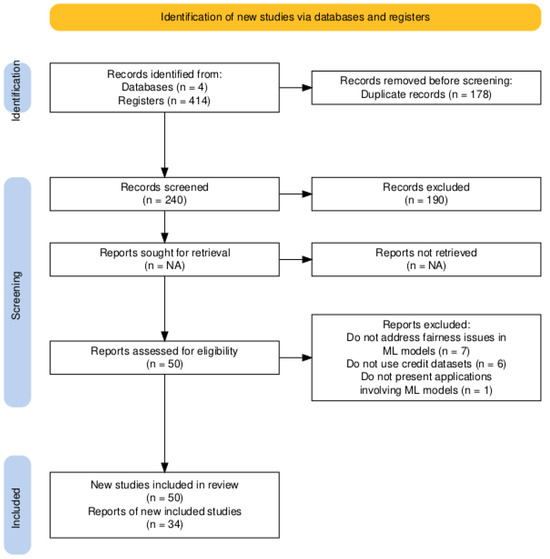
Figure 2.
Identification, Screening, and Eligibility of Articles.
This approach allowed us to obtain a set of relevant and reliable articles to support the literature review of the proposed topic.
Classification and Coding
We developed a standardized data extraction form to extract study characteristics. After completing the data extraction spreadsheet, one reviewer performed the initial data extraction for all included articles, and a second reviewer verified all procedures. We constructed the classification structure based on the method proposed by Jabbour (2013); Junior and Godinho Filho (2010); Seuring (2013). The classification scheme includes 11 categories, numbered from 1 to 11. We also code each classification with letters (A, B, C, etc.). Thus, this classification system involves an aggregation of numbers and letters. We should note that an article may be associated with multiple codes for a given item.
To develop the proposed coding, we referenced the review studies by Garcia et al. (2023); Y. Huang et al. (2023); Kim and Cho (2022). Table 1 presents the classification structure and the codes used, while Table 2 provides the complete list of articles that compose the sample and their classification across the various listed items.

Table 1.
Classification and coding used for data analysis.
Table 2.
Classification of Articles Using the Proposed Coding.
The Study Type indicates the method used, which may be empirical or theoretical. The methodological approach refers to the way in which data are collected and analyzed, and it can be classified as qualitative or quantitative. The Research Topic represents the central theme of the study. The Theory Background designates the theoretical framework that underpins the research. The Bias-Mitigation Method and Approach refer to the technique used in the research to mitigate biases and improve fairness in classification. Data Access specifies the form of access to the data used in the research, which may be public or private. The Data Source identifies the source of the data used in the study. The Loan Type indicates the type of credit analyzed in the research. The Biased Attribute identifies the attribute that may generate biases in credit decisions, which may be age, gender, race, or ethnicity. Fairness Metrics refer to the measures used to assess the fairness of Machine Learning algorithms in credit decisions. Performance Metrics indicate the measures used to evaluate the model’s performance.
To assess the risk of bias in the included studies, a double-check was performed by a reviewer using the main relevant methodological domains and based on the information available in the published articles.
Meta-analyses could not be performed due to the heterogeneity of interventions, settings, study designs, and outcome measures. Graphs were created to provide a graphical overview of the data, and we developed summary tables of the findings.
3. Results
3.1. Study Selection
In the detailed analysis of the selected articles, it was possible to assess the eligibility criteria more precisely, resulting in the selection of 34 articles, as shown in Table 3, for the results of this investigation.
Table 3.
Papers Selected for the Study.
We did not select approximately 32% (16 articles) of the studies identified in the initial screening because they did not meet the eligibility criteria. For example, the papers S. Liu and Vicente (2022); Tang and Yuan (2023); Thuraisingham (2022) were excluded because they do not address credit issues or the use of credit datasets.
It is necessary to consider the risk of bias in the coding and categorization of the selected papers, keeping in mind that this process may be influenced by preconceptions, expectations, or research motivations. The subjectivity present in the classification procedure may contrast with the objectivity of the review. To mitigate this risk, double-checking strategies were adopted, along with the establishment of clear and distinct inclusion and exclusion policies, as well as the involvement of multiple independent reviewers.
3.2. General Characteristics of the Studies
The majority of studies (74%) are purely empirical and quantitative, reflecting the data-driven and experimental nature of the Machine-Learning field. However, there is also a significant share of theoretical work (18%) and a small percentage that combines theoretical and empirical approaches (7%). This highlights the importance of a solid theoretical foundation to understand and address fairness issues in Machine-Learning algorithms. Furthermore, the presence of qualitative (14%) and mixed-method studies (11%) indicates that there is value in approaches that transcend numbers, exploring fairness issues from a broader perspective that considers factors such as social context and human perceptions.
A greater number of published articles were observed in 2022 and 2023. Regarding the country of origin of these articles, as shown in Table 4, a significant dispersion was identified, with a higher incidence of publications in Germany, Italy, and the United States.
Table 4.
Distribution of the 34 Selected Articles by Country of the First Author’s Affiliation.
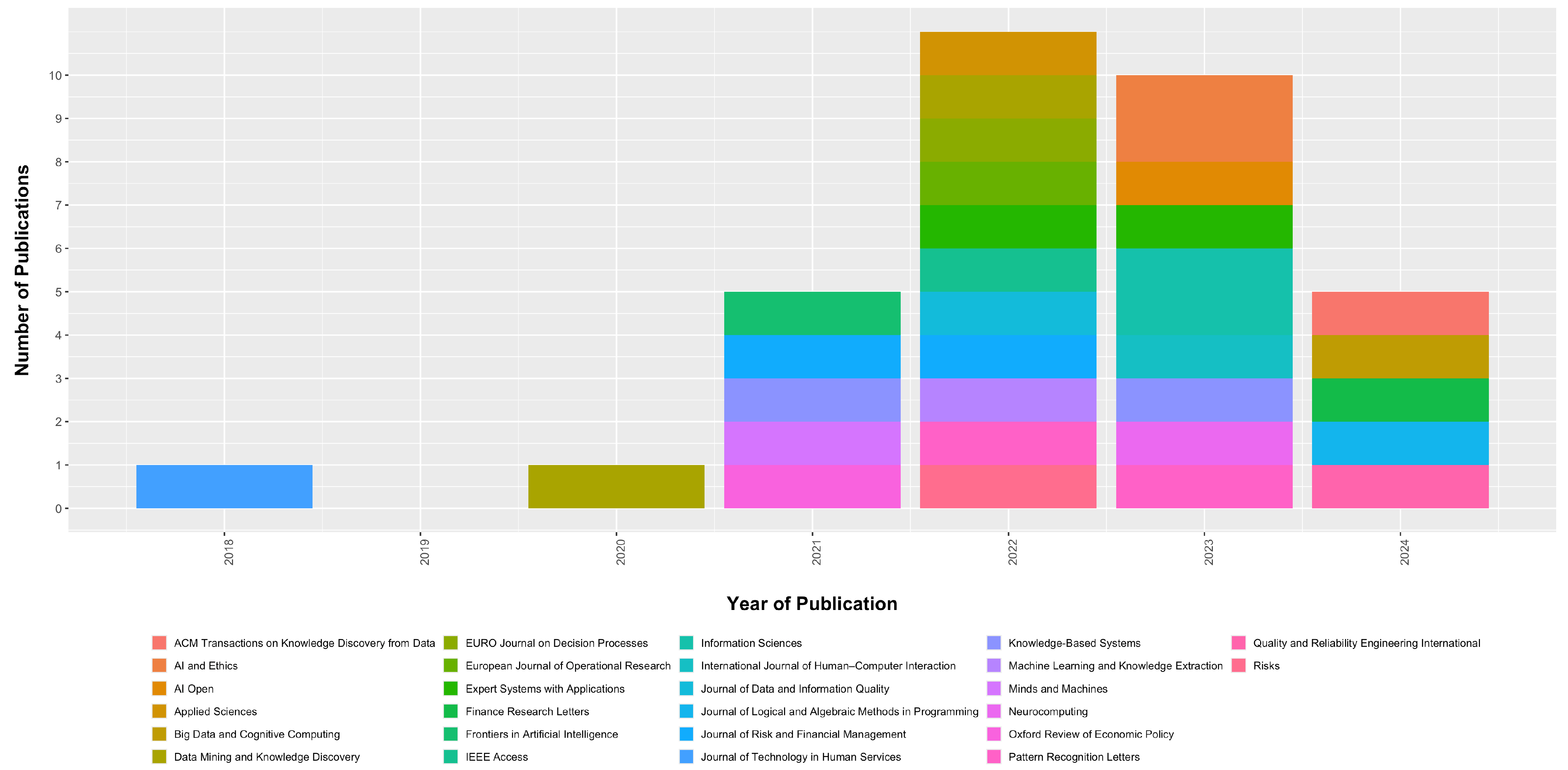
Figure 3 presents the result of our search, showing the number of publications in different academic journals over the years.
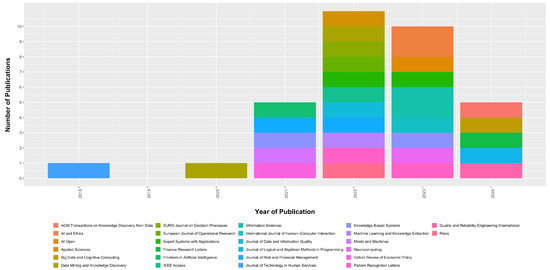
Figure 3.
Articles Published by Journal Year by Year.
The variety of colors represented in the graph indicates the participation of several academic journals in the dissemination of knowledge in this specific field. This suggests an interdisciplinary and multifaceted collaboration that is necessary to address the complexities associated with algorithmic fairness.
The graph reveals an interesting trend in scientific production published in academic journals over the years. A marked increase in publications starting in 2018 indicates a growing interest and research in this area. Since then, there has been a diversified expansion in literary production.
We attribute the increase to the growing awareness of the ethical and social implications of Machine-Learning algorithms in financial decisions. This growth in the number of publications suggests a recognition of the importance of the topic, with more researchers from different areas contributing to the advancement of knowledge at this intersection between justice, ML, and Finance. It also signals that the risks and implications of using biased models are gaining attention.
3.3. Citation of Articles
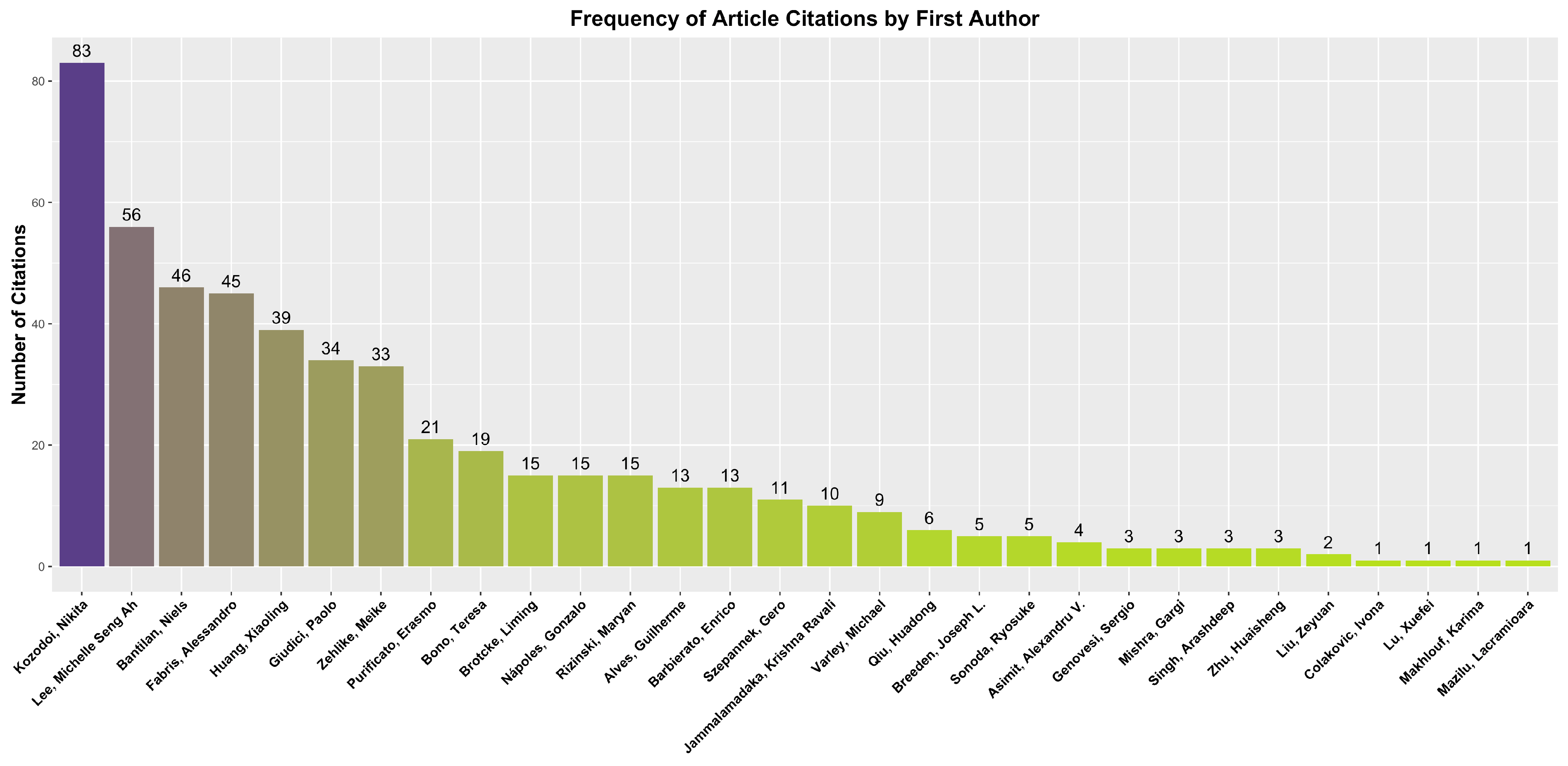
When analyzing the citations of the articles selected for the systematic review of fairness and bias in ML models applied to credit granting, a varied distribution in terms of academic impact is observed. The number of citations per article ranges from 0 to 83, with an approximate average of 15.14 and a standard deviation of 19.37. This pattern suggests that some works have established their influence in the field and receive extensive citations, while others are still gaining recognition or are recent in the literature. The figure below exemplifies these observations, presenting the number of citations per article associated with their respective first authors. Notably, articles by authors such as Kozodoi et al. (2022); Lee and Floridi (2021) stand out for having a higher number of citations, indicating a relevant contribution to the discussion on fairness in automated decision algorithms. The frequency of author citations can be better observed in Figure 4. This analysis reinforces the importance of continued research on methods that aim to mitigate bias in predictive models and their practical application in critical contexts such as finance.
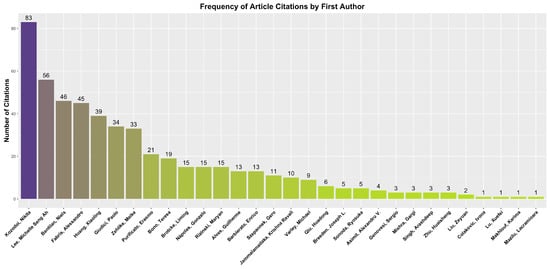
Figure 4.
Number of citations of articles.
3.4. Classification of Articles
The analysis of the data collected for the systematic literature review of fairness in the use of ML algorithms for credit decisions reveals a variety of approaches and research topics. The coding used to classify the articles covered several aspects, including study type, methodological approach, research topic, background theory, bias-mitigation method, approach, data access, data source, loan type, biased attribute, fairness metrics, and performance metrics.
For example, the article by Napoles and Koutsoviti Koumeri (2022) is an empirical and quantitative study that addresses bias in the dataset. The research is based on the theory of implicit discrimination. The study uses a post-processing approach with access to public and academic data. The loan type analyzed is a credit mix, and the biased attribute considered is gender.
On the other hand, the article by Barbierato et al. (2022) is also an empirical and quantitative study, but it focuses on the generation of synthetic data to control bias and fairness. The research is based on the same theory of implicit discrimination and uses the generation method to mitigate bias. The approach is preprocessing, with the study being carried out using public and synthetic data. The biased attributes considered are gender and race, and the fairness metric used is Fairness Through Awareness.
The complete analysis of the data reveals a diversity of approaches and research topics in the literature on fairness in the use of ML algorithms for credit decisions. This diversity reflects the complexity of the subject and the need for multiple approaches to understand and mitigate bias in ML algorithms.
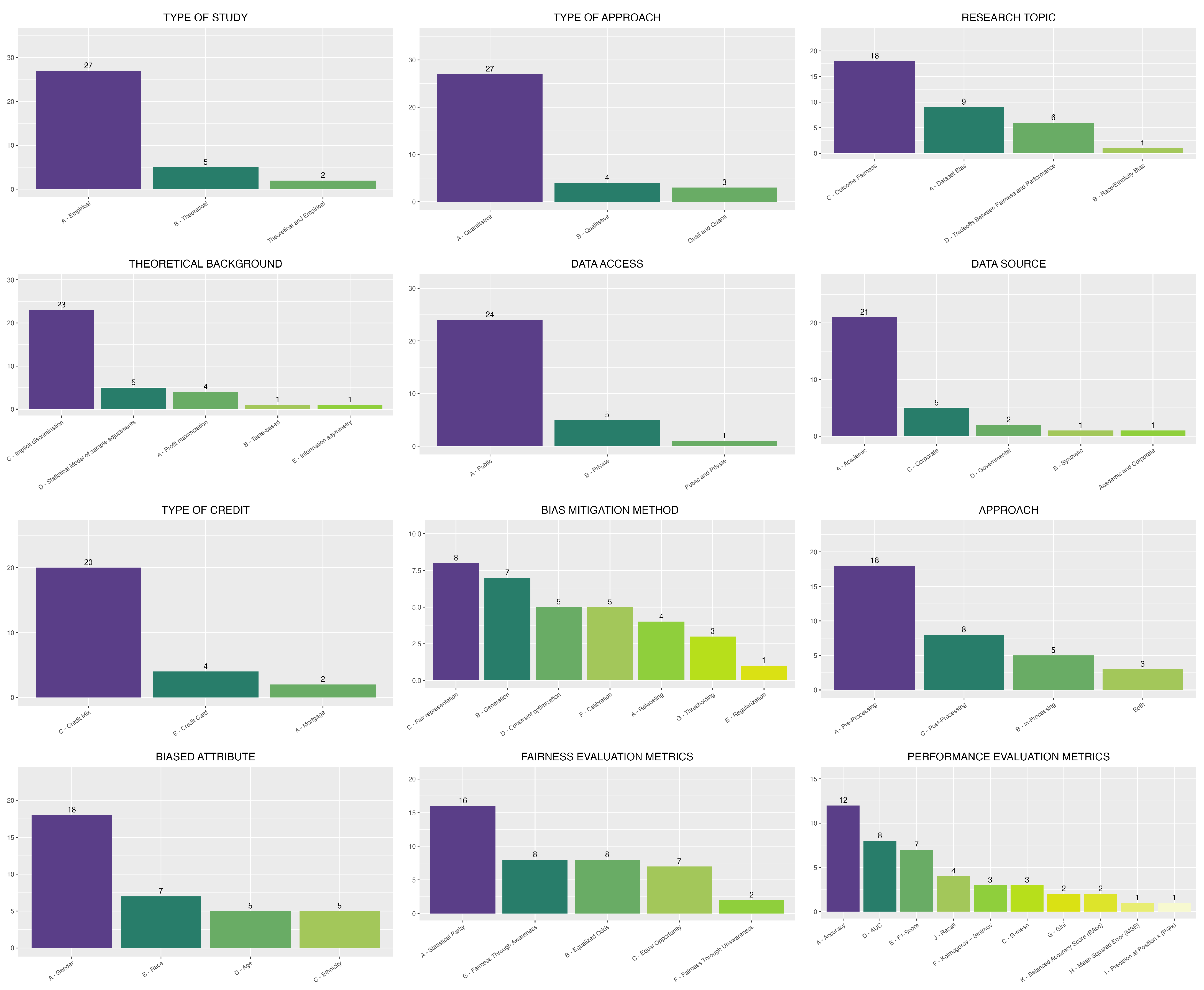
Furthermore, data analysis, considering the proposed classification, can reveal patterns and trends in research on fairness in the use of ML algorithms for credit decisions. For example, it is possible to observe the prevalence of empirical studies over theoretical ones, the importance of bias mitigation through preprocessing, and the popularity of the use of academic data and fairness metrics based on statistical parity. Figure 5 presents an illustration of the frequency of the reported results.
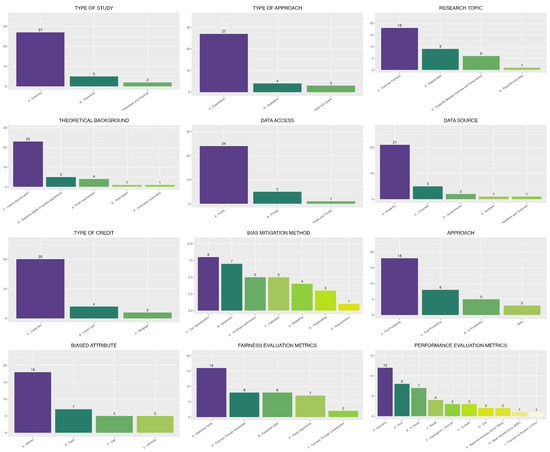
Figure 5.
Results Charts.
Most of the articles are empirical studies with a quantitative approach, focusing mainly on the themes of fairness of results and bias in datasets. The most frequently employed background theory is implicit discrimination, and the predominant bias-mitigation methods are fair representation and generation. Various studies perform bias mitigation at the preprocessing stage, using publicly available data from academic sources, with the most frequently analyzed loan type being credit mix. The most commonly investigated attributes for bias are gender and race, while the most commonly used fairness metric is statistical parity. Finally, the most frequently used performance metric is accuracy.
Table 5 reveals a correlation between the type of dataset, the chosen fairness metric, and the adopted mitigation stage. Most papers that use heterogeneous or synthetic credit-mix datasets (59%) diagnose unfairness through Statistical Parity and adopt low-cost preprocessing solutions such as re-sampling or the Disparate-Impact Remover (Jammalamadaka & Itapu, 2023). Studies using credit card data combine Statistical Parity with Equalized Odds, still prioritizing preprocessing fixes. In contrast, the two mortgage-related papers focus on Equal Opportunity, addressing false-negative disparities through post hoc threshold adjustments or adversarial representations (Qiu et al., 2023).
Table 5.
Credit-decision categories in the 34-paper corpus, prevailing sensitive attributes, fairness metrics, and mitigation stage. Counts reflect the classification codes in Table 2.
The distribution summarized in Table 5 mirrors the patterns documented in recent surveys on algorithmic fairness in finance. Mortgage studies—here only two, but both based on HMDA-like data— prioritize Equal Opportunity and resort to post-processing threshold shifts, a strategy recommended when regulatory or legacy constraints prevent retraining the model yet false-negative disparities are the main concern (Hardt et al., 2016; Mehrabi et al., 2021). Credit card papers continue to diagnose bias chiefly through Statistical Parity and, in a minority of cases, Equalized Odds while favoring low-cost preprocessing fixes such as re-sampling or the Disparate Impact Remover—exactly the workflow highlighted by Pessach and Shmueli (2022). The largest group (59%) relies on heterogeneous or synthetic “credit mix” datasets and therefore gravitates to model agnostic SP tests (14/20 papers) and simple preprocessing pipelines (15/20), in line with exploratory studies that need a metric applicable across tasks.
Table 6 cross-tabulates the sensitive attributes identified in our coding scheme (Code 10) with the fairness metrics actually reported (Code 11). Table 6 indicates that authors’ selection reflects both regulatory pressures and the theoretical suitability of each criterion to the protected attribute under scrutiny. For gender, the predominant reliance on Statistical Parity or Disparate Impact (10 out of 16 instances) aligns with the historical use of these ratio-based diagnostics in equal-treatment litigation and in early debiasing efforts involving word embeddings (Bolukbasi et al., 2016). When the protected attribute is race, researchers begin to prioritize error-rate metrics—Equalized Odds or Equal Opportunity—which appear jointly in nine papers, reflecting the argument by Hardt et al. (2016) that parity in approval rates can obscure disparities in false-negative risk. Overall, the observed co-occurrence pattern corroborates recent surveys (Mehrabi et al., 2021; Pessach & Shmueli, 2022): the field is gradually shifting from distribution-based parity toward error-rate or causal definitions, especially when the protected attribute or legal context calls for more nuanced criteria.
Table 6.
Co occurrence between sensitive attribute and fairness metric.
Table 7 links the concrete mitigation methods (Code 5) to the stage of the modeling pipeline where they are implemented (Code 6). The distribution in Table 7 is aligned with the taxonomy of fairness interventions found in recent surveys (Mehrabi et al., 2021; Pessach & Shmueli, 2022). All relabeling, re-sampling, and fair representation papers appear predominantly in the preprocessing column, as expected for techniques that transform the data before training (Mehrabi et al., 2021). Methods that embed fairness directly in the loss function—constraint optimization and regularization—concentrate in the in-processing column, matching the paradigm inaugurated by Zafar et al. (2017). Conversely, post-processing is populated only by calibration and threshold-shifting approaches, echoing the “equalized odds post-processing” of Hardt et al. (2016). The few cross-column cases (e.g., a synthetic generation model trained adversarially or a convex score adjustment framed as constraint optimization) reflect recent hybrid pipelines.
Table 7.
Frequency of mitigation techniques by intervention stage.
It is important to consider that the evaluation conducted may present a risk of bias related to missing results, which arises when relevant data or outcomes are not fully reported or are selectively omitted in the original studies, potentially compromising the integrity of the scientific synthesis. To mitigate this risk, the completeness of the papers was examined, and maximum transparency was ensured in presenting the results and acknowledging any potential informational gaps that could distort the interpretation of the findings.
Moreover, the reduced number of eligible studies may compromise the robustness of the results, introducing potential inaccuracies in the conclusions.
4. Discussion
The literature review of fairness in ML algorithms applied to credit granting revealed some interesting trends. The most common research topics were “Fairness of Results” and “Dataset Bias”. This indicates that the academic community is concerned with the fairness of the results produced by ML models and the possibility of bias in the data used to train these models.
The implicit discrimination theory was the most widely used background theory. The preprocessing approach is predominant, being used in 68% of the studies. Attributes such as Gender and Race are often considered sensitive to bias. Regarding fairness assessment metrics, Statistical Parity was the most widely used, followed by Equalized Odds and Equal Opportunity. The most commonly used performance metrics were Accuracy, AUC, and F1-Score. Consumer credit assessment is the most studied context in terms of application, focusing on personal loans and credit cards. However, there are also applications in other domains, such as mortgage lending and small business lending.
It is notable that over 60% of the empirical studies use the Deutsche Credit database to support their results. This suggests that Deutsche Credit is a reliable and widely accepted data source in the academic community for studies in this area. However, it also raises questions about the diversity of the datasets used in the research and whether the results would be consistent across different contexts.
Several ML algorithms were used in the studies, mainly Logistic Regression, SVM, Neural Networks, and Ensemble Methods, such as Random Forest and XGBoost.
4.1. State of the Art in Fairness in Credit Decisions
Recent research on fairness in algorithmic decisions, especially in the financial context such as credit scoring and loan approval, has proposed several criteria and methods for implementing fairness, analyzing their adequacy and the trade-offs involved (Kozodoi et al., 2022; Lee & Floridi, 2021). Approaches range from seamless interpolation between definitions of fairness (Zehlike et al., 2020) to adapting algorithms, such as AdaBoost, for fair ranking (X. Huang et al., 2022).
Table 8 clarifies why authors gravitate toward particular notions of fairness. Statistical Parity still dominates the field—appearing in 16 of the 34 papers (47%) because it is trivial to compute and map directly onto disparate-impact regulation. However, its blindness to the distribution of errors has motivated a rapid uptake of error rate criteria: Equalized Odds (8 papers) and Equal Opportunity (7 papers) together now match Statistical Parity in absolute frequency.
Table 8.
Fairness definitions observed in the 34-paper corpus and their practical trade-offs.
A surprisingly large minority—eight studies—implement Fairness Through Awareness (FTA) by defining an explicit distance metric so that similar applicants receive similar outputs. Although FTA offers applicant-level guarantees, its reliance on a task-specific similarity function still limits broader deployment. By contrast, Fairness Through Unawareness (FTU)—simply dropping the sensitive attribute—appears in only two papers, reflecting the well-known risk that proxy features can leak protected information. No study in the corpus operationalizes Counterfactual Fairness, underscoring the practical difficulty of specifying a full causal graph in credit data.
Frameworks have been developed to measure the risks and trustworthiness of AI, considering principles of sustainability, accuracy, fairness, and explainability (Giudici et al., 2024). The use of explainability and fairness techniques has the potential to increase trust in AI systems (Purificato et al., 2023), although tensions persist between different notions of fairness and properties such as privacy and accuracy (Alves et al., 2023). Preprocessing, in-processing, and post-processing approaches have been explored to manage these trade-offs in practical contexts.
Researchers have proposed methods such as fuzzy-rough uncertainty measures (Napoles & Koutsoviti Koumeri, 2022) and causal inference techniques (Szepannek & Lübke, 2021) to measure and mitigate bias. Some approaches seek to develop fair models without the use of sensitive attributes (Zhu et al., 2023), while others focus on creating synthetic datasets with controlled bias (Barbierato et al., 2022). The relevance of assessing bias in automated credit decisions has been emphasized (Brotcke, 2022), creating frameworks for responsible AI in this context (Jammalamadaka & Itapu, 2023). Probabilistic models, such as sum-product networks, have also been proposed to analyze fairness in machine learning (Varley & Belle, 2021).
Other recent studies have also proposed methods to address fairness concerns, including robust support vector machines (Asimit et al., 2022), Cohort Shapley values (Lu & Calabrese, 2023), and causality-based fairness approaches (Makhlouf et al., 2024). Fairness in credit ratings (Chen et al., 2024), lending decisions Babaei and Giudici (2024), and SME financing (Lu & Calabrese, 2023) have been explored, with techniques such as propensity matching Babaei and Giudici (2024), multi-objective optimization Badar and Fisichella (2024), and microaggregation for privacy and fairness (González-Zelaya et al., 2024). Additionally, adversarial frameworks have been investigated to learn fair representations (Qiu et al., 2023), aiming to mitigate discrimination and bias while maintaining high predictive performance and transparency.
Several approaches have been suggested to mitigate bias and promote fairness, including standardizing fairness assessment procedures (Genovesi et al., 2023), developing fair oversampling techniques (Sonoda, 2023), and creating unbiased-by-design models (Breeden & Leonova, 2021). Innovative classifiers and pipelines have been designed to handle multiple sensitive attributes and improve both accuracy and fairness (Z. Liu et al., 2023; Singh et al., 2022). Other studies investigate fairness-aware data integration (Mazilu et al., 2022), individual-fairness-based outlier detection (Mishra & Kumar, 2023), and ensemble boosting methods for learning on multiple sensitive attributes (Colakovic & Karakatič, 2023). These studies address various aspects of justice, such as distributive, procedural, and intersectional justice, and the balance between fairness and utility in machine-learning models.
Contemporary Debate and Divergences in Algorithmic Fairness
There is a clear consensus across papers that fairness in machine learning and credit scoring is a critical issue that needs to be addressed (Barbierato et al., 2022; Bono et al., 2021; Brotcke, 2022; Jammalamadaka & Itapu, 2023; Napoles & Koutsoviti Koumeri, 2022; Zhu et al., 2023). Papers highlight the growing concern that algorithmic decision-making may reinforce discriminatory biases.
Papers agree that achieving fairness in machine-learning models is a complex challenge. There is no simple solution, and multiple approaches and definitions of fairness exist Bono et al. (2021); Brotcke (2022); Napoles and Koutsoviti Koumeri (2022); Szepannek and Lübke (2021); Zhu et al. (2023). There is consensus that solutions to promote fairness need to be tailored to specific domains and contexts. The papers agree that generalized or “one-size-fits-all” approaches are inadequate and that the appropriate notion of fairness can vary significantly across different applications (Szepannek & Lübke, 2021). The papers emphasize the need to consider multiple objectives when addressing fairness rather than focusing exclusively on a single metric. This includes balancing fairness with other important factors, such as model accuracy and business objectives (Kozodoi et al., 2022).
There is an agreement that historical biases embedded in training data pose a significant challenge to fair machine learning (Giudici et al., 2024). The papers consistently highlight the risk that algorithms may perpetuate or amplify social biases present in the data. Furthermore, there is a consensus that understanding how algorithms make decisions is crucial to identifying and addressing potential biases (Szepannek & Lübke, 2021).
Finally, there is a clear consensus that achieving fairness in machine learning is an ongoing challenge that requires continuing research and development (Badar & Fisichella, 2024; Chen et al., 2024; Y. Huang et al., 2023; Kozodoi et al., 2022; Lee & Floridi, 2021). The papers agree that although progress has been made, there is still much to be done to develop algorithmic decision-making systems that are robust, fair, and context-appropriate.
On the other hand, we can observe some divergences in the literature. Some papers suggest that simply removing protected attributes such as gender or race from training data is insufficient to ensure fairness (Jammalamadaka & Itapu, 2023; Lee & Floridi, 2021), while others propose this “justice by ignorance” as a basic approach (Szepannek & Lübke, 2021; Varley & Belle, 2021). A key challenge is that sensitive attributes like race or gender are often correlated with other features in the dataset, such as socioeconomic status or access to education. For instance, an individual’s educational background might be influenced by systemic inequalities linked to race. Simply removing the race attribute does not eliminate these indirect influences, which remain embedded in the data through correlated features.
The definition of fairness in algorithms is another area of debate, as some approaches suggest different definitions of fairness as potential solutions to problems of algorithmic bias. On the one hand, some papers argue that fairness should be defined by fixed and absolute mathematical criteria (X. Huang et al., 2022). However, some studies point out that many of these definitions are mathematically incompatible and, therefore, cannot be satisfied simultaneously (Kozodoi et al., 2022). This paradox challenges the universal applicability of fairness definitions, indicating that choosing a specific definition may imply giving up another. This incompatibility raises questions about which definitions should be prioritized in different contexts and applications, suggesting that a flexible and contextualized approach may be more appropriate to address algorithmic fairness.
Furthermore, there are contradictory results on how much the treatment of fairness impacts model performance. Some papers report only small drops in accuracy when implementing fairness techniques (Varley & Belle, 2021), while others observe significant performance reductions when optimizing for fairness.
We conducted a qualitative synthesis based on how predictive performance metrics (Accuracy, AUC, and F1-score) were reported in the original studies. Our review did not perform a meta-analysis, nor did it recalculate performance indicators; instead, we recorded the presence or absence of these metrics during the full-text review. When available, the reported values were noted to contextualize the trade-offs between fairness gains and predictive performance losses. Table 9 illustrates how selected studies addressed this balance, offering an indicative—rather than comparative—view of the dynamics between fairness and performance. This approach aims to provide transparency regarding how the literature jointly considers algorithmic fairness and predictive quality without attempting statistical aggregation.
Table 9.
Effect of bias-mitigation on predictive performance (Accuracy/AUC/F1) and fairness.
Table 9 shows that the five illustrative pipelines deliver sizeable fairness gains at a modest performance cost. In four cases, the drop in Accuracy, AUC, or F1 is under two percentage points, while the corresponding fairness improvement ranges from 31% (Statistical Parity ratio) to 100% (SP gap completely removed). The mortgage experiment of Lee and Floridi (2021) records the steepest fairness boost—78% reduction in Equal Opportunity gap—by shifting thresholds post hoc; as expected, this alters group-specific error rates (FNR ↓ 25%) rather than global accuracy. The pattern confirms a recurring result in credit analytics: when pre or post-processing is used, moderate fairness improvements seldom erode headline performance beyond one or two points, especially for tabular datasets with high signal-to-noise ratios.
Some papers propose preprocessing methods as a way to remove bias from data before model training Kozodoi et al. (2022). These techniques involve modifying the data so that it does not contain bias associated with protected features, with the aim of minimizing the perpetuation of bias during training. However, there are counterarguments that suggest that these methods may be impractical and ineffective, especially when predictors are strongly correlated with protected features (Lee & Floridi, 2021). This criticism indicates that preprocessing methods may not be able to completely remove bias since dependency between variables is not easily eliminated in real data.
With regard to in-processing methods, some researchers argue that these methods are more robust and effective in ensuring algorithmic fairness since they perform adjustments during model training to minimize bias (X. Huang et al., 2022). However, they warn that researchers designed many of these methods for specific types of classifiers, which limits their applicability across different models. This factor raises concerns about the generalizability of in-process methods, suggesting that new approaches need to be developed to deal with the diversity of models used in machine-learning applications.
4.2. Research Gaps
Although the literature on fairness in the use of ML algorithms for credit decisions has grown in recent years, researchers still need to explore several gaps. In particular, more research is needed on bias-mitigation methods, the use of real-world data, and the standardization of fairness and performance metrics.
In addition, the predominance of empirical and quantitative studies suggests that the literature could benefit from a greater diversity of methodological approaches. Theoretical and qualitative studies can offer new perspectives that complement data-driven results.
The prevalence of dataset bias as a research topic also suggests that the literature could benefit from a greater diversity of issues. Other aspects of fairness in the use of ML algorithms for credit decisions, such as transparency and accountability, could be fruitful areas for future research.
Other limitations and gaps identified in the studies reviewed include the lack of complete information in the datasets used, the need to balance the overall quality and fairness of the models, and the importance of considering different baseline estimators and algorithms.
The need for more work with multiple intersectional sensitive attributes, empirical studies in real-world contexts, research on causality, and verification of deployed models is highlighted. The gaps identified from the literature review are better described in Table 10.
Table 10.
Research Gaps Identified from the Literature Review.
4.3. Research Agenda
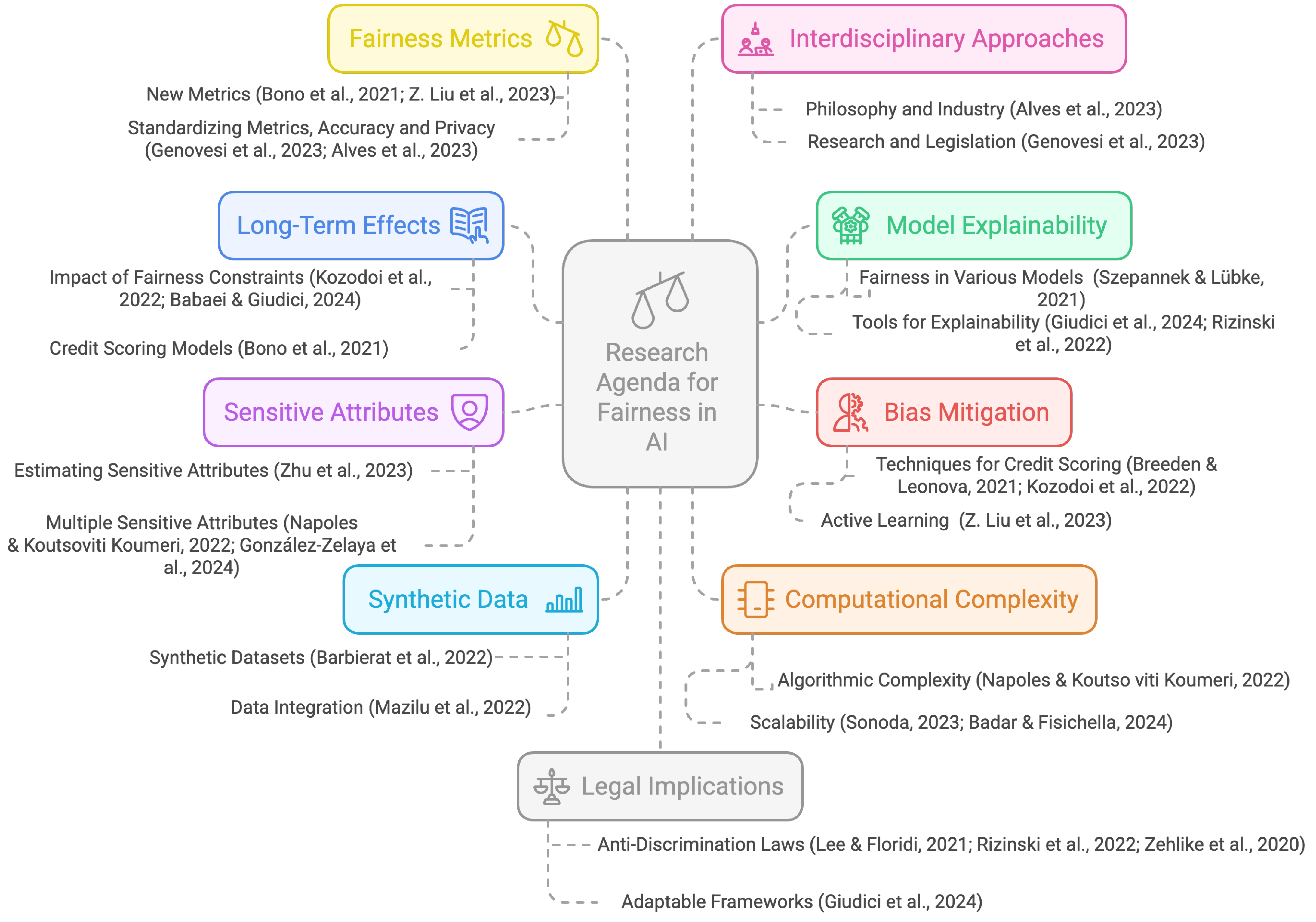
From the systematic review of the literature, several opportunities emerge for the continuation of scientific research in the area, as shown in Figure 6.
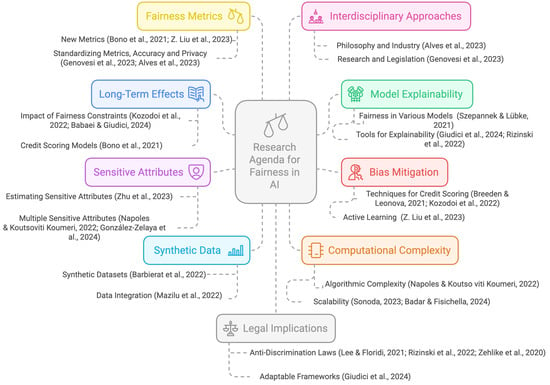
Figure 6.
Research agenda synthesized from the reviewed literature (e.g., Genovesi et al., 2023; Giudici et al., 2024; Kozodoi et al., 2022).
Assessing Long-Term Effects of Fairness Restrictions: Studying the long-term effects of implementing different fairness restrictions is necessary to assess whether the social goal of improving financial equality across demographic groups can be achieved with specific interventions Kozodoi et al. (2022). It is particularly important to note that algorithmic fairness is not a silver bullet. For instance, a fairness criterion suggests that credit should be granted to both protected and unprotected groups under the same conditions. However, if the economic situations of the protected and unprotected groups differ significantly, such credit concessions may worsen the economic condition of the protected group if they are unable to repay the loan. Researchers need to conduct more studies to understand how changes in credit assessment models impact real-world lending and pricing decisions and, ultimately, consumer outcomes. This involves studying the broader implications of algorithmic decisions on consumer welfare (Bono et al., 2021). Future work could also explore the integration of counterfactual frameworks to assess these long-term outcomes more rigorously (Babaei & Giudici, 2024).
Improving Explainability and Fairness of Models: It is important to investigate the effects of fairness correction on a broader range of ML models, including commonly used models such as random forests, gradient boosting, support vector machines, and neural networks. For model-agnostic approaches, the focus shifts to enhancing the fairness and interpretability of the outputs derived from these methods. Additionally, addressing the challenge of explaining fairness-corrected models to users remains a critical area of focus (Szepannek & Lübke, 2021). Developing methods to improve the explainability and transparency of machine-learning models, especially in high-stakes applications such as credit assessment and lending, is essential. This includes creating tools and frameworks that make model decisions more interpretable to stakeholders (Giudici et al., 2024; Rizinski et al., 2022). Future research is encouraged to extend explainability assessments to new sectors and explore statistical metrics for the trustworthiness and safety of AI systems (Giudici et al., 2024).
Developing Novel Bias-Mitigation Techniques in Credit Assessment: Research should focus on developing and evaluating bias-mitigation techniques in credit assessment, particularly in the context of regulatory requirements and the trade-off between fairness and profitability (Breeden & Leonova, 2021; Kozodoi et al., 2022). Investigating how researchers can use active learning to build fair models with limited labeled data, focusing particularly on the trade-off between informativeness and representativeness in sample selection, is a promising area for future research (Z. Liu et al., 2023). There is also a need to move beyond absolute mathematical conditions of fairness to more contextual and relational trade-offs. This involves understanding the ethical trade-offs and practical implications of different definitions of fairness in real-world applications (Lee & Floridi, 2021). Furthermore, extending fair representation learning approaches to applications beyond fairness, such as inferring counterfactual scenarios and considering continuous or discrete protected attributes with a large range of values, is a research frontier also highlighted in adversarial fairness learning frameworks (Badar & Fisichella, 2024; Qiu et al., 2023).
Exploring Sensitive Attributes and Implicit Bias: Researchers need to further explore how to estimate sensitive attributes from non-sensitive features and how to incorporate these estimates into the training of fair models (Zhu et al., 2023). Extending fairness considerations to multiple sensitive attributes and ensuring that models are fair across all possible intersections of these attributes is a critical area for future research. This includes developing methods that can handle the complexity of multiple sensitive attributes (Z. Liu et al., 2023). More research is needed to analyze implicit bias by considering all associations and correlations between protected and non-protected features. This includes understanding how implicit biases manifest themselves and how they can be mitigated (Napoles & Koutsoviti Koumeri, 2022). Future studies may also benefit from combining fairness with privacy-preserving techniques, particularly through data preprocessing strategies that jointly address bias and data protection (González-Zelaya et al., 2024).
Improving Synthetic Data Generation and Data Integration: There is a need to develop integrated tools to generate synthetic datasets with controlled bias and fairness to test discrimination mitigation techniques in machine-learning applications (Barbierato et al., 2022). Researchers need to conduct more studies to explore the trade-offs between different quality metrics in data integration processes and to apply fairness-aware data integration approaches to non-binary sensitive attributes (Mazilu et al., 2022). Recent work also suggests future directions that involve handling multi-class protected variables and evaluating fairness in multi-dimensional datasets (González-Zelaya et al., 2024).
Reducing Computational and Classifier Complexity: It is crucial to reduce the computational complexity of algorithms, especially in the context of large datasets. This is vital to make fairness-aware algorithms more practical and scalable (Napoles & Koutsoviti Koumeri, 2022). Further research should connect different concepts, such as maintainability and explainability, leveraging the principle of parsimony to alleviate the computational burden required to evaluate explainability and fairness (Giudici et al., 2024). Addressing the scalability and performance of fairness algorithms, especially when dealing with large datasets, while ensuring that the algorithms remain functional and efficient (Zehlike et al., 2020), is particularly important. Future work should explore how fairness-enhancing techniques can impact performance on more complex classifiers, such as deep learning classifiers and classifiers with fairness constraints (Sonoda, 2023), and optimize performance through strategies like multi-objective optimization in streaming environments (Badar & Fisichella, 2024).
Exploring Fairness Metrics and Trade-offs: Exploring the relationships and trade-offs between different fairness metrics and understanding how to balance them in practical applications is another important topic. This includes developing new metrics that can capture the nuances of fairness in various contexts (Bono et al., 2021; Z. Liu et al., 2023). In addition, it is important to develop and standardize specific fairness metrics for use cases, such as conditional demographic parity, through an independent consensus-driven platform involving multiple stakeholders (Genovesi et al., 2023). Future directions also call for a deeper exploration of how fairness metrics interact with accuracy and privacy guarantees, particularly in causal contexts (Alves et al., 2023).
Combining Interdisciplinary Approaches: It is critical to combine insights from philosophy, industry, research, and law to create comprehensive standards for fairness in AI systems (Alves et al., 2023; Genovesi et al., 2023). Future efforts may benefit from integrated frameworks capable of simultaneously addressing regulatory, ethical, and technical perspectives.
Assessing Legal, Ethical, and Policy Implications: Discussing fairness algorithms’ legal and policy implications in more detail, particularly in the context of anti-discrimination laws, remains an open research frontier. Developing comprehensive legal and ethical frameworks that guide the use of machine learning in sensitive applications while ensuring that these frameworks are adaptable to different cultural and legal contexts is crucial (Lee & Floridi, 2021; Rizinski et al., 2022; Zehlike et al., 2020). The SAFE framework proposed for financial AI applications exemplifies how fairness can be operationalized in risk regulation and policy (Giudici et al., 2024).
4.4. Conclusions
This systematic literature review investigated how researchers have used methods to identify and mitigate bias in artificial intelligence models applied to credit granting, what results they have achieved, and what research gaps remain. The analysis of 34 selected studies revealed a growing field of research characterized by a diversity of methodological and theoretical approaches and significant challenges that require attention.
The results showed that most studies focus on fairness in results and bias present in datasets, reflecting the academic community’s concern with the fairness of ML models and the quality of the data used for their training. The theory of implicit discrimination emerged as the main theoretical framework, indicating a trend toward exploring how algorithms can incorporate and perpetuate historical biases. Preprocessing approaches stood out as the most frequent bias-mitigation methods, suggesting a preference for techniques that act directly on the data before training the models.
Despite the advances observed, significant gaps remain in the literature. An overreliance on public and academic datasets, such as the German Credit, was identified, which may limit the generalizability of the results to real and diverse contexts. Furthermore, most studies focus on sensitive attributes such as gender and race, and there is a need to explore other attributes and their intersections for a more comprehensive understanding of algorithmic fairness. The lack of standardization in fairness and performance metrics was also noted, making it difficult to compare and evaluate consistently across studies.
Another crucial challenge is the balance between fairness and accuracy in ML models. Although some studies report small performance losses when implementing bias-mitigation techniques, others point to significant reductions in accuracy. This divergence indicates the need for research that deepens understanding of the inherent trade-offs between fairness and model effectiveness, seeking solutions that minimize performance losses without compromising equity.
Our review outlines practical guidelines to enhance bias mitigation in credit models. First, we observed a strong predominance of preprocessing techniques (68% of studies), often without sufficient traceability. To improve auditability, we recommend that institutions standardize the documentation and publication of data provenance records and versioned mitigation pipelines, ensuring a baseline level of transparency both before and after model deployment.
Second, only 25% of studies report more than one fairness criterion, which facilitates selective metric choice. To prevent such “cherry picking” and support consistent comparisons, we suggest that every fairness evaluation include simultaneously: (i) a parity metric (e.g., Statistical Parity), (ii) an error rate criterion (Equalized Odds or Equal Opportunity), and (iii) a global performance indicator (e.g., AUC or F1 score).
Moreover, reliance on legacy public datasets—such as German Credit and Adult Income—limits the external validity of findings. We recommend creating and using anonymized, up-to-date datasets drawn from current loan portfolios to better reflect today’s risk profiles and borrower demographics.
Finally, we identified an almost complete lack of robust causal assessments to uncover proxy biases during the design phase. We propose incorporating correlation analyses and counterfactual inference methods during model development, allowing biases to be anticipated and mitigated before production.
Although we must be cautious in interpreting these findings due to the small number of studies, they appear to be aligned with the studies by Garcia et al. (2023); Y. Huang et al. (2023); Pessach and Shmueli (2022); Wang et al. (2022).
The methodological limitations of this systematic review highlight challenges in consolidating scientific evidence. The scarcity of studies meeting the inclusion criteria restricts the scope of the investigation, making generalizations difficult and introducing risks of reporting bias. Methodological concerns, including potentially missing results, incomplete documentation, and heterogeneity among the selected studies, call for caution in interpreting the findings.
In conclusion, the search for fairness in AI models applied to credit granting is a complex challenge that requires multidisciplinary and continuous efforts. This study contributes to the field’s current understanding, highlighting advances, limitations, and opportunities for future research. The recommendations presented here are expected to encourage the development of more responsible and ethical practices in the financial sector, promoting the reduction of social and economic inequality and aligning with the Sustainable Development Goals established by the United Nations.
Author Contributions
Conceptualization, J.R.d.C.V. and H.K.; methodology, J.R.d.C.V. and F.B.; validation, D.C., F.B. and H.K.; formal analysis, J.R.d.C.V.; investigation, J.R.d.C.V.; writing—original draft preparation, J.R.d.C.V.; writing—review and editing, H.K., F.B. and D.C.; visualization, H.K.; supervision, H.K.; project administration, J.R.d.C.V. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
This review was not registered, but the research files and databases are available in the de Castro Vieira (2024) repository.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AI | Artificial intelligence |
| ML | Machine Learning |
References
- Alves, G., Bernier, F., Couceiro, M., Makhlouf, K., Palamidessi, C., & Zhioua, S. (2023). Survey on fairness notions and related tensions. EURO Journal on Decision Processes, 11, 100033. [Google Scholar] [CrossRef]
- Asimit, A. V., Kyriakou, I., Santoni, S., Scognamiglio, S., & Zhu, R. (2022). Robust classification via support vector machines. Risks, 10(8), 154. [Google Scholar] [CrossRef]
- Babaei, G., & Giudici, P. (2024). How fair is machine learning in credit lending? Quality and Reliability Engineering International, 40(6), 3452–3464. [Google Scholar] [CrossRef]
- Badar, M., & Fisichella, M. (2024). Fair-CMNB: Advancing fairness-aware stream learning with naïve bayes and multi-objective optimization. Big Data and Cognitive Computing, 8(2), 16. [Google Scholar] [CrossRef]
- Bantilan, N. (2018). Themis-ml: A fairness-aware machine learning interface for end-to-end discrimination discovery and mitigation. Journal of Technology in Human Services, 36(1), 15–30. [Google Scholar] [CrossRef]
- Barbierato, E., Vedova, M. L. D., Tessera, D., Toti, D., & Vanoli, N. (2022). A methodology for controlling bias and fairness in synthetic data generation. Applied Sciences, 12(9), 4619. [Google Scholar] [CrossRef]
- Bhatore, S., Mohan, L., & Reddy, Y. R. (2020). Machine learning techniques for credit risk evaluation: A systematic literature review. Journal of Banking and Financial Technology, 4, 111–138. [Google Scholar] [CrossRef]
- Bircan, T., & Ãzbilgin, M. F. (2025). Unmasking inequalities of the code: Disentangling the nexus of AI and inequality. Technological Forecasting and Social Change, 211, 123925. [Google Scholar] [CrossRef]
- Bolukbasi, T., Chang, K.-W., Zou, J. Y., Saligrama, V., & Kalai, A. T. (2016). Man is to computer programmer as woman is to homemaker? debiasing word embeddings. Advances in Neural Information Processing Systems, 29, 4356–4364. [Google Scholar]
- Bono, T., Croxson, K., & Giles, A. (2021). Algorithmic fairness in credit scoring. Oxford Review of Economic Policy, 37(3), 585–617. [Google Scholar] [CrossRef]
- Breeden, J. L., & Leonova, E. (2021). Creating unbiased machine learning models by design. Journal of Risk and Financial Management, 14(11), 565. [Google Scholar] [CrossRef]
- Brotcke, L. (2022). Time to assess bias in machine learning models for credit decisions. Journal of Risk and Financial Management, 15(4), 165. [Google Scholar] [CrossRef]
- Calders, T., & Verwer, S. (2010). Three naive bayes approaches for discrimination-free classification. Data Mining and Knowledge Discovery, 21, 277–292. [Google Scholar] [CrossRef]
- Chen, Y., Giudici, P., Liu, K., & Raffinetti, E. (2024). Measuring fairness in credit ratings. Expert Systems with Applications, 258, 125184. [Google Scholar] [CrossRef]
- Colakovic, I., & Karakatič, S. (2023). FairBoost: Boosting supervised learning for learning on multiple sensitive features. Knowledge-Based Systems, 280, 110999. [Google Scholar] [CrossRef]
- Corbett-Davies, S., Gaebler, J. D., Nilforoshan, H., Shroff, R., & Goel, S. (2023). The measure and mismeasure of fairness. Journal of Machine Learning Research, 24(312), 14730–14846. [Google Scholar]
- de Castro Vieira, J. R. (2024). Replication data for: IA justa: Promovendo a justiça no crédito. Harvard Dataverse. [Google Scholar] [CrossRef]
- de Castro Vieira, J. R., Barboza, F., Sobreiro, V. A., & Kimura, H. (2019). Machine learning models for credit analysis improvements: Predicting low-income families’ default. Applied Soft Computing, 83, 105640. [Google Scholar] [CrossRef]
- Dwork, C., Hardt, M., Pitassi, T., Reingold, O., & Zemel, R. (2012, January 8–10). Fairness through awareness. 3rd Innovations in Theoretical Computer Science Conference (pp. 214–226), Cambridge, MA, USA. [Google Scholar]
- Fabris, A., Messina, S., Silvello, G., & Susto, G. A. (2022). Algorithmic fairness datasets: The story so far. Data Mining and Knowledge Discovery, 36(6), 2074–2152. [Google Scholar] [CrossRef]
- Feldman, M., Friedler, S. A., Moeller, J., Scheidegger, C., & Venkatasubramanian, S. (2015, August 10–13). Certifying and removing disparate impact. 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (pp. 259–268), Sydney, Australia. [Google Scholar]
- Garcia, A. C. B., Garcia, M. G. P., & Rigobon, R. (2023). Algorithmic discrimination in the credit domain: What do we know about it? AI & Society, 39, 2059–2098. [Google Scholar] [CrossRef]
- Genovesi, S., Mönig, J. M., Schmitz, A., Poretschkin, M., Akila, M., Kahdan, M., Kleiner, R., Krieger, L., & Zimmermann, A. (2023). Standardizing fairness-evaluation procedures: Interdisciplinary insights on machine learning algorithms in creditworthiness assessments for small personal loans. AI and Ethics, 4, 537–553. [Google Scholar] [CrossRef]
- Giudici, P., Centurelli, M., & Turchetta, S. (2024). Artificial intelligence risk measurement. Expert Systems with Applications, 235, 121220. [Google Scholar] [CrossRef]
- González-Zelaya, V., Salas, J., Megias, D., & Missier, P. (2024). Fair and private data preprocessing through microaggregation. ACM Transactions on Knowledge Discovery from Data, 18(3), 1–24. [Google Scholar] [CrossRef]
- Haque, A. B., Islam, A. N., & Mikalef, P. (2023). Explainable Artificial Intelligence (XAI) from a user perspective: A synthesis of prior literature and problematizing avenues for future research. Technological Forecasting and Social Change, 186, 122120. [Google Scholar] [CrossRef]
- Hardt, M., Price, E., & Srebro, N. (2016). Equality of opportunity in supervised learning. Advances in Neural Information Processing Systems, 29, 3323–3331. [Google Scholar]
- Hassani, B. K. (2021). Societal bias reinforcement through machine learning: A credit scoring perspective. AI and Ethics, 1(3), 239–247. [Google Scholar] [CrossRef]
- Huang, X., Li, Z., Jin, Y., & Zhang, W. (2022). Fair-AdaBoost: Extending AdaBoost method to achieve fair classification. Expert Systems with Applications, 202, 117240. [Google Scholar] [CrossRef]
- Huang, Y., Liu, W., Gao, W., Lu, X., Liang, X., Yang, Z., Li, H., Ma, L., & Tang, S. (2023). Algorithmic fairness in social context. BenchCouncil Transactions on Benchmarks, Standards and Evaluations, 3(3), 100137. [Google Scholar] [CrossRef]
- Huisingh, D. (2012). Call for comprehensive/integrative review articles. Journal of Cleaner Production, 29–30, 1–2. [Google Scholar]
- Jabbour, C. J. C. (2013). Environmental training in organisations: From a literature review to a framework for future research. Resources, Conservation and Recycling, 74, 144–155. [Google Scholar] [CrossRef]
- Jammalamadaka, K. R., & Itapu, S. (2023). Responsible AI in automated credit scoring systems. AI and Ethics, 3(2), 485–495. [Google Scholar] [CrossRef]
- Junior, M. L., & Godinho Filho, M. (2010). Variations of the kanban system: Literature review and classification. International Journal of Production Economics, 125(1), 13–21. [Google Scholar] [CrossRef]
- Kamishima, T., Akaho, S., Asoh, H., & Sakuma, J. (2012). Fairness-aware classifier with prejudice remover regularizer. In Machine learning and knowledge discovery in databases, European conference, ECML PKDD 2012, Bristol, UK, September 24–28 (pp. 35–50). Part II, LNCS 7524. Springer. [Google Scholar]
- Kim, J.-Y., & Cho, S.-B. (2022). An information theoretic approach to reducing algorithmic bias for machine learning. Neurocomputing, 500, 26–38. [Google Scholar] [CrossRef]
- Kleinberg, J. (2018, June 18–22). Inherent trade-offs in algorithmic fairness. 2018 ACM International Conference on Measurement and Modeling of Computer Systems (pp. 40–40), Irvine, CA, USA. [Google Scholar]
- Kozodoi, N., Jacob, J., & Lessmann, S. (2022). Fairness in credit scoring: Assessment, implementation and profit implications. European Journal of Operational Research, 297(3), 1083–1094. [Google Scholar] [CrossRef]
- Kusner, M. J., Loftus, J., Russell, C., & Silva, R. (2017). Counterfactual fairness. Advances in Neural Information Processing Systems, 30, 4069–4079. [Google Scholar]
- Lee, M. S. A., & Floridi, L. (2021). Algorithmic fairness in mortgage lending: From absolute conditions to relational trade-offs. Minds and Machines, 31(1), 165–191. [Google Scholar] [CrossRef]
- Leite, D. F., Padilha, M. A. S., & Cecatti, J. G. (2019). Approaching literature review for academic purposes: The literature review checklist. Clinics, 74, e1403. [Google Scholar] [CrossRef]
- Liu, S., & Vicente, L. N. (2022). Accuracy and fairness trade-offs in machine learning: A stochastic multi-objective approach. Computational Management Science, 19(3), 513–537. [Google Scholar] [CrossRef]
- Liu, Z., Zhang, X., & Jiang, B. (2023). Active learning with fairness-aware clustering for fair classification considering multiple sensitive attributes. Information Sciences, 647, 119521. [Google Scholar] [CrossRef]
- Lobel, O. (2023). The law of AI for good. Florida Law Review, 75, 1073. [Google Scholar] [CrossRef]
- Lu, X., & Calabrese, R. (2023). The Cohort Shapley value to measure fairness in financing small and medium enterprises in the UK. Finance Research Letters, 58, 104542. [Google Scholar] [CrossRef]
- Makhlouf, K., Zhioua, S., & Palamidessi, C. (2024). When causality meets fairness: A survey. Journal of Logical and Algebraic Methods in Programming, 141, 101000. [Google Scholar] [CrossRef]
- Mazilu, L., Paton, N. W., Konstantinou, N., & Fernandes, A. A. A. (2022). Fairness-aware Data Integration. Journal of Data and Information Quality, 14(4), 1–26. [Google Scholar] [CrossRef]
- Mehrabi, N., Morstatter, F., Saxena, N., Lerman, K., & Galstyan, A. (2021). A survey on bias and fairness in machine learning. ACM Computing Surveys (CSUR), 54(6), 1–35. [Google Scholar] [CrossRef]
- Mishra, G., & Kumar, R. (2023). An individual fairness based outlier detection ensemble. Pattern Recognition Letters, 171, 76–83. [Google Scholar] [CrossRef]
- Napoles, G., & Koutsoviti Koumeri, L. (2022). A fuzzy-rough uncertainty measure to discover bias encoded explicitly or implicitly in features of structured pattern classification datasets. Pattern Recognition Letters, 154, 29–36. [Google Scholar] [CrossRef]
- Page, M. J., McKenzie, J. E., Bossuyt, P. M., Boutron, I., Hoffmann, T. C., Mulrow, C. D., Shamseer, L., Tetzlaff, J. M., Akl, E. A., & Brennan, S. (2021). The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. BMJ, 372, n71. [Google Scholar] [CrossRef]
- Pedreshi, D., Ruggieri, S., & Turini, F. (2008, August 6–10). Discrimination-aware data mining. 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (pp. 560–568), Long Beach, CA, USA. [Google Scholar]
- Pessach, D., & Shmueli, E. (2022). A review on fairness in machine learning. ACM Computing Surveys (CSUR), 55(3), 1–44. [Google Scholar]
- Peters, M. D., Marnie, C., Tricco, A. C., Pollock, D., Munn, Z., Alexander, L., McInerney, P., Godfrey, C. M., & Khalil, H. (2020). Updated methodological guidance for the conduct of scoping reviews. JBI Evidence Synthesis, 18(10), 2119–2126. [Google Scholar] [CrossRef]
- Purificato, E., Lorenzo, F., Fallucchi, F., & De Luca, E. W. (2023). The use of responsible artificial intelligence techniques in the context of loan approval processes. International Journal of Humanâ Computer Interaction, 39(7), 1543–1562. [Google Scholar] [CrossRef]
- Qiu, H., Feng, R., Hu, R., Yang, X., Lin, S., Tao, Q., & Yang, Y. (2023). Learning fair representations via an adversarial framework. AI Open, 4, 91–97. [Google Scholar] [CrossRef]
- Rizinski, M., Peshov, H., Mishev, K., Chitkushev, L. T., Vodenska, I., & Trajanov, D. (2022). Ethically responsible machine learning in fintech. IEEE Access, 10, 97531–97554. [Google Scholar] [CrossRef]
- Seuring, S. (2013). A review of modeling approaches for sustainable supply chain management. Decision Support Systems, 54(4), 1513–1520. [Google Scholar] [CrossRef]
- Singh, A., Singh, J., Khan, A., & Gupta, A. (2022). Developing a novel fair-loan classifier through a multi-sensitive debiasing pipeline: DualFair. Machine Learning and Knowledge Extraction, 4(1), 240–253. [Google Scholar] [CrossRef]
- Sonoda, R. (2023). Fair oversampling technique using heterogeneous clusters. Information Sciences, 640, 119059. [Google Scholar] [CrossRef]
- Stoll, C. R., Izadi, S., Fowler, S., Green, P., Suls, J., & Colditz, G. A. (2019). The value of a second reviewer for study selection in systematic reviews. Research Synthesis Methods, 10(4), 539–545. [Google Scholar] [CrossRef] [PubMed]
- Szepannek, G., & Lübke, K. (2021). Facing the challenges of developing fair risk scoring models. Frontiers in Artificial Intelligence, 4, 681915. [Google Scholar] [CrossRef] [PubMed]
- Tang, S., & Yuan, J. (2023). Beyond submodularity: A unified framework of randomized set selection with group fairness constraints. Journal of Combinatorial Optimization, 45(4), 102. [Google Scholar] [CrossRef]
- Thuraisingham, B. (2022). Trustworthy machine learning. IEEE Intelligent Systems, 37(1), 21–24. [Google Scholar] [CrossRef]
- Tigges, M., Mestwerdt, S., Tschirner, S., & Mauer, R. (2024). Who gets the money? A qualitative analysis of fintech lending and credit scoring through the adoption of AI and alternative data. Technological Forecasting and Social Change, 205, 123491. [Google Scholar] [CrossRef]
- Varley, M., & Belle, V. (2021). Fairness in machine learning with tractable models. Knowledge-Based Systems, 215, 106715. [Google Scholar] [CrossRef]
- Wang, X., Zhang, Y., & Zhu, R. (2022). A brief review on algorithmic fairness. Management System Engineering, 1(1), 7. [Google Scholar] [CrossRef]
- Zafar, M. B., Valera, I., Rogriguez, M. G., & Gummadi, K. P. (2017). Fairness constraints: Mechanisms for fair classification. In Artificial intelligence and statistics (pp. 962–970). PMLR. [Google Scholar]
- Zehlike, M., Hacker, P., & Wiedemann, E. (2020). Matching code and law: Achieving algorithmic fairness with optimal transport. Data Mining and Knowledge Discovery, 34(1), 163–200. [Google Scholar] [CrossRef]
- Zemel, R., Wu, Y., Swersky, K., Pitassi, T., & Dwork, C. (2013). Learning fair representations. In International conference on machine learning (pp. 325–333). PMLR. [Google Scholar]
- Zhu, H., Dai, E., Liu, H., & Wang, S. (2023). Learning fair models without sensitive attributes: A generative approach. Neurocomputing, 561, 126841. [Google Scholar] [CrossRef]
- Zou, L., & Khern-am nuai, W. (2023). AI and housing discrimination: The case of mortgage applications. AI and Ethics, 3(4), 1271–1281. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).