
Bayesian Inference of Dwellings Energy Signature at National Scale: Case of the French Residential Stock



Abstract
:1. Introduction
1.1. Estimating Dwellings Consumption at District Scale
1.1.1. Context
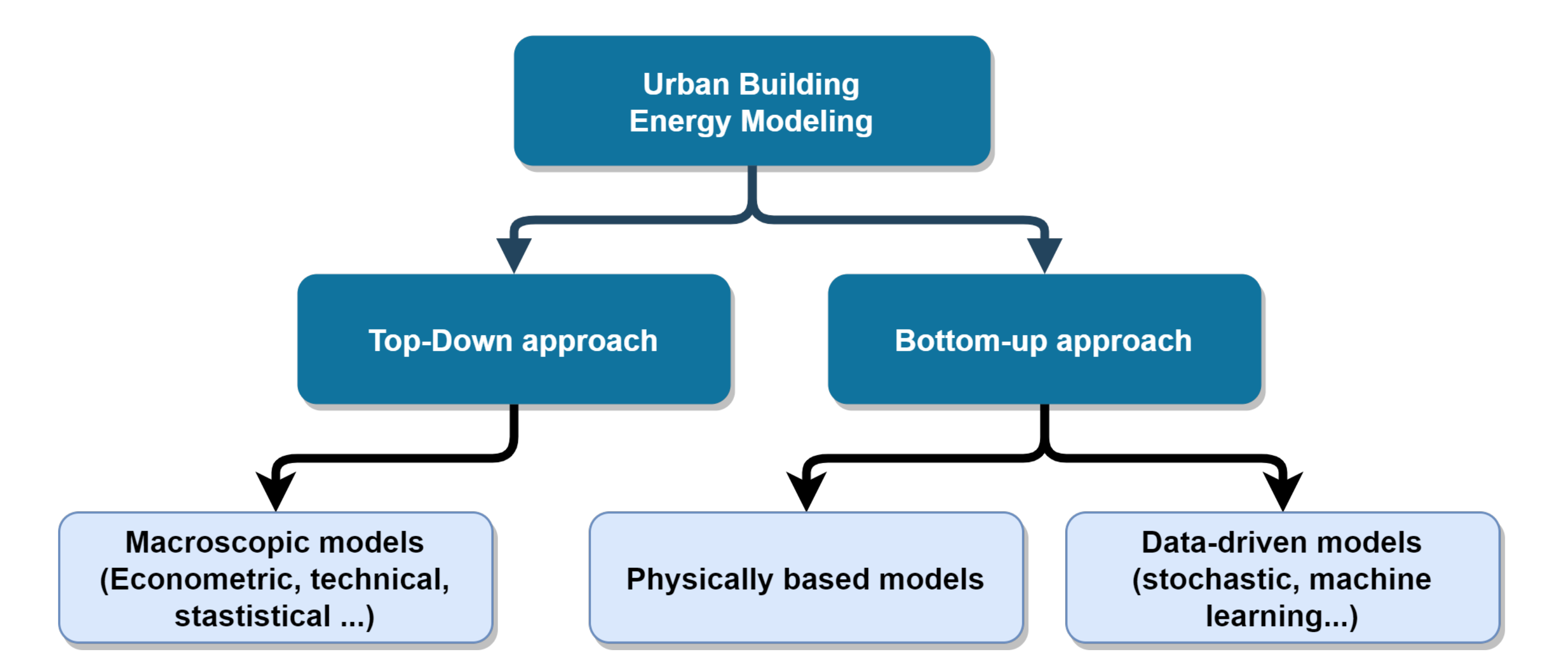
1.1.2. Approaches and Models for Urban Energy Assessment
1.2. Issues with District Energy Models Using Deterministic Archetypes
- From the authors experience, even when using archetypes with few input parameters, getting reliable data is still a challenge. Indeed, available data at district scale is generally sparse and heterogeneous, if not erroneous. Besides, open data is aggregated to comply with privacy requirements of citizens, it is therefore difficult to directly access detailed, individual data. Furthermore, most buildings don’t have an energy model available for reuse. Only most recent buildings used building energy simulation in the conception phase, and such models are most of the time not publicly available (e.g., proprietary). In [19], lack of data and underlying algorithms is also pointed out as an important issue in residential energy consumption estimation through bottom-up building stock models.
- The use of standard/default parameters and model structures may lead to accumulated biases. To give a simple example, if we consider a district with one dominant typology and architectural characteristics, initial bias on thermal parameters in buildings models may accumulate and lead to significant error in the total energy load. In a previous work, we study thermal flexibility at district scale with such approach and point out important errors between archetype models using the same data sources [25].
1.3. Objectives and Structure of the Paper
1.3.1. Contribution
1.3.2. Structure of the Paper
- In the first one, we introduce the Materials and Methods used in our work. More specifically, we present our test case of the French residential stock and the associated datasets. We explain how data is constituted and pre-treated to suit our needs. Then, we describe the model of energy signature used all along this work and the stochastic model and algorithms used to perform inference over our data.
- In the second one, we expose and interpret inference results for three variants of our inference model, each variant corresponding to an increase of the number of dwelling categories. Convergence and validation of the inference process is detailed and validated using state-of-the-art indicators.
- The third one is the comparative study with results from the TABULA project previously mentioned. This study relies on comparative box plots for heat loss coefficients and a Monte Carlo simulation from inferred models.
2. Materials and Methods
2.1. Case Study: Dwellings “Energy Signature” over Metropolitan FRANCE
2.1.1. Model of “Energy Signature” for a Building
2.1.2. Available Datasets
2.1.3. Preliminary Treatment of Available Data
- Thermo-energetic variables: , and (yearly sum of in Equation (1) aggregated for each IRIS).
- Census data: the number of dwellings and the ratios (i.e., fractions) of dwellings per type, surface, and construction date categories:
- −
- surface (m): [0, 30], [30, 40], [40, 60], [60, 80], [80, 100], [100, 120], [>120]
- −
- type and construction date ranges:
- *
- apartment: [<1919], [1919, 1945], [1945, 1970], [1970, 1990], [1990, 2005], [2005, 2013], [>2013]
- *
- house: same date ranges than for apartments
2.2. Models
2.2.1. General Framework for Studied Models
2.2.2. Models Description
2.3. Bayesian Inference of “Energy Signature” Parameters from Aggregated Data
2.3.1. A Primer on Bayesian Inference (BI) Methods
2.3.2. Convergence Assessment
- factor: Introduced by gelman and rubin in [47], it tests the discrepancy between several sampling chains. To solve an inference problem by sampling, one can try to solve the problem several times with different random seeds (e.g., solving the problem with two chains is equivalent to solving the problem two times). Resulting sets of samples, called the traces, may be significantly different if the convergence is wrong. A rule of thumb is to say that a between 1 and is a necessary but insufficient condition for convergence.
- The Effective Sample Size (ESS): This indicator gives an estimate of the quantity of independent samples. Indeed, autocorrelation between samples during the sampling process is undesired since it increases uncertainty in the estimated posterior [48]. A low ESS for a parameter means many samples for this parameter are auto-correlated. In our convergence summaries, we provide ess_bulk and ess_tail for the bulk and tails of posterior distributions.
- Monte Carlo Standard Error (MCSE): The standard error for the estimator of a parameter can be computed by the posterior standard deviation divided by the square root of the Effective Sample Size. This statistic can be extended to any functional of the parameter (mean, standard deviation or quantiles) [49]. If the MCSE is small, we can expect the estimate to be close to its true value. In our convergence summaries, we provide mcse_mean and mcse_sd for MCSE of mean and standard deviation of each parameter.
- Divergent transitions: This indicator is specific to HMC algorithms and NUTS. Its formulation is a bit technical and related with the algorithm’s implementation. During sampling, the algorithm can mark some divergent transitions to indicate that the sampler has issues in exploring the posterior around some points. Therefore, they can be indicators of a pathologic model or parameterization.
3. Inference Results
3.1. Separation by Type
3.1.1. Convergence Assessment
3.1.2. Physical Interpretation
3.2. Separation by Surface
3.2.1. Convergence Assessment
- values of with surfaces between 60 and 80 m.
- values of with surfaces between 60 and 80 m.
3.2.2. Physical Interpretation
3.3. Separation by Construction Date and Type
3.3.1. Convergence Assessment
- values of with dates between 1945 and 1970.
- values of for houses with dates between 1919 and 1945.
- values of with dates between 1919 and 1945, and between 1990 and 2005.
3.3.2. Physical Results
- Lowest values are observed for construction dates between 1919 and 1970, and for apartments built after 2005. If we can expect an effect of thermal regulations for recent apartments, it seems more likely for old buildings to be due to fossil fuel use or nonexistent thermal control.
- With both highest and base consumption, houses built since 1990 and before 1919 behave like energy drains. Even if we have a reduction from 1990 to 2013, we observe an increase right after. New studies targeting these categories for refurbishment could be very beneficial in the management of the winter electrical load.
- For apartments, base consumption values for are very close. This means the base consumption for apartments is not date sensitive, as opposed to houses.
- Distributions for houses built after 2013 are the wider. We therefore have a lot of uncertainty on the inferred values for this category. This point can be explained by the very low quantity of such dwellings in our dataset (see census data on Figure 5).
- Posterior distributions of for parameters are quite wide and overlapping which means higher uncertainty on their inferred values. One can note than most extreme values are found for the two oldest categories of houses. It could be interesting to investigate why we have such discrepancy on these close categories.
4. Comparative Results
- TABULA Average Buildings: Archetype buildings per studied country provided for 4 structural typologies, declined in 10 construction date ranges and 3 refurbishment strategies (none, usual and advanced). This provides a total of 120 different archetypes, which can be used to perform heat load predictions at district scale. All archetypes are provided directly in the TABULA Webtool [7]. One must note that such archetypes doesn’t have any statistical sense despite the “average” term, but are built from on site general observations.
- Reports for countries buildings stocks: Each participating country performed a study on a defined building stock, and computed heat load for these stocks using the TABULA Average Building methodology. The TABULA Webtool provides links towards these reports and spreadsheets.
4.1. Comparisons with TABULA Average Buildings
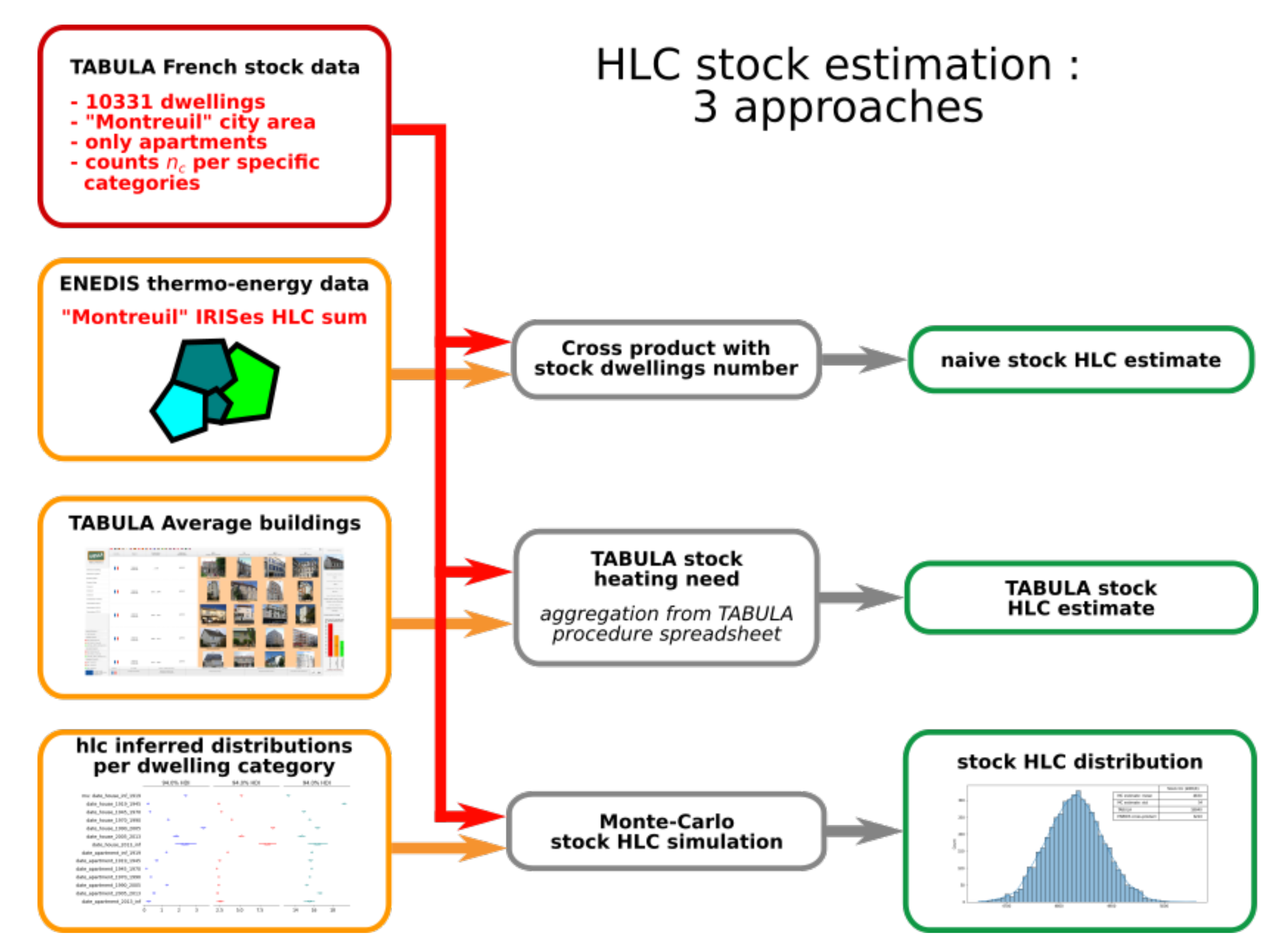
4.2. Monte Carlo Simulation for TABULA French Stock
- In a first place, we can naively estimate it from IRIS values in ENEDIS dataset. Under the hypothesis of uniformity of dwelling typologies in the considered area, we sum all IRIS values for the county of Montreuil and resize this sum by the fraction of dwellings in the considered stock (cross-product). The underlying hypothesis is strong, but gives a valuable order of magnitude of 6210 kWh/K.
- Then, we can apply estimations from Building Archetypes and aggregate these estimates for the whole stock. This approach is performed in the TABULA-EPISCOPE French stock study and provides an estimate of net energy needed for heating of 54,353 MWh/year. From this value, we derive the stock by dividing the net heat need by the yearly accumulated difference between internal and external temperature, and get a value of 18,840 kWh/K. This value is computed considering no refurbishment for buildings.
- We can exploit inferred categories distributions for dwellings’ to perform a simple Monte Carlo estimation of the stock : Given the rough construction date ranges, we create an interpolated distribution to draw construction dates. For each category of drawn dates, we sample the corresponding number of values from related distributions. Summing-up these values gives an estimate for the whole stock. We repeat the process 5000 times to estimate a representative distribution (Figure 20). The mean result is about 4800 kWh/K, almost 4 times lower than the one from TABULA calculations.
- The ENEDIS dataset may not represent properly the considered stock. However, considered buildings are mostly heated by gas (60%) and electricity [50]. Therefore, if this is the case, errors may come from consumption measurement and estimations.
5. Discussion and Perspectives
- Since we recover parameter distributions, we have access to confidence intervals.
- We can use parameter distributions in stochastic models to perform Monte Carlo simulations from district to national scale, with uncertainty propagation.
- We perform here data mining while preserving physical sense. This enables critical analysis of resulting parameters, and new insights for energy planning at district or national scale. More generally, the approach can lead to the definition of building archetypes relying on statistical inference rather than parametric assumptions.
- Even if such stochastic models may be complicated to set up and the inference process is computationally intensive, there are no huge limitations in use and applicability. Indeed, on a valid model and dataset, the inference needs to be run only once, and inferred stochastic model can be reused at will in simulations/comparisons with a much lower computing cost. In our case, we use a yearly dataset, so our model can be inferred again once a year as new data is released by providers.
- In our model, output variables are considered as Gamma random variables. However, one can see in Figure 4 that they are not exactly Gamma distributions since there are some modalities. Indeed, the number of IRIS per dwelling can be only of few hundreds for some of them which reduces the smoothing effect of aggregations. A finer model involving Mixture Gamma distributions (hierarchical combination of Categorical and Gamma distributions) before an aggregating step could help improve the posterior predictive fit. However, such a model may involve much wider tensors and lead to memory and processing power issues (depending on implementation) since it could involve sampling for each dwelling instead of IRISes only.
- Using the provided census data as is, we cannot simply go towards a more detailed inference. One may want to infer the distribution for a specific dwelling type, surface and date range, but census for these joint categories are not in our original dataset. A naive approach would estimate joined ratios by simply multiplying marginal ratios. For example, if for an IRIS the ratio of houses built after 2005 is and the ratio of dwellings with surface between 100 and 120 is also , then the ratio of houses built after 2005 and with surface between 100 and 120 would be estimated as . However, this approach is only valid for independent variables, which is definitely not the case here. Moreover, some joint categories may have very few appearances in the whole national stock. For all these reasons, our trials with the naive approach failed consistently to converge or give interpretable results. If we want a more detailed model, we need here a better way to estimate all joint categories. This is a quite large and ill-posed problem, often found in literature under the terms of “population disaggregation”. For our case, we have numerous IRISes, therefore one can try to exploit the observed dependency between provided ratios to estimate joint ratios.
- MCMC sampling is computationally intensive and not very scalable: approaches of VI must be explored if one want to explore more detailed models. Since VI is more likely to provide biased results, one may have to define appropriate validation strategies when using this approach.
- In this study, we compared our inference results with average buildings from the TABULA-EPISCOPE projects. This comparison showed similar patterns for values in studied categories. However, TABULA values are generally higher, and with important differences for average buildings without refurbishment. It could be of great interest to pursue similar comparisons with other building archetypes and UBEM tools, such as TEASER or City Energy Analyst. Moreover, such comparisons can be done on a fully instrumented dwellings stock, to compare inferred signatures with the directly computed ones.
- Next studies should also focus on practicability, validation on detailed datasets, use in more complex models than energy signature (dynamic models). Stochastic models used in BI can be hard to set up and parameterize, since convergence is very sensitive to model formulation and parameterization. Hence, there is still large room for improvement towards ease of use in the urban energy planning community.
- The BI approach can also be used on individual dwellings to infer energy signature from annual consumption measures and external temperature. Since we have the distribution of energy signature parameters per dwelling category, one may use them as priors for a specific dwelling to reduce the necessary amount of data for a reliable inference, and have a good estimation of the signature with only few weeks of data instead of at least one year.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Mean parameter of a distribution | |
| Variance parameter of a distribution | |
| Heat Loss Coefficient (kWh · K) | |
| Switch temperature of energy signature (C) | |
| Daily average external (outdoor) temperature | |
| Daily base consumption in energy signature | |
| Yearly base consumption (MWh) | |
| n_sites | Number of considered dwellings per IRIS |
| Vector of output variables for an IRIS , and ) | |
| ADVI | Automatic Differentiation Variational Inference |
| BI | Bayesian Inference |
| DJU | Degree days “Degrés Jours Unitaires” |
| ENEDIS | Power Grid Operator in France |
| ESS | Effective Sample Size, derived in ess_bulk, ess_tail variants |
| INSEE | National French Statistics and Economical Studies Institute |
| IRIS | Statistically significant geographic region in France (10,000 inhabitants max.) |
| MCSE | Monte Carlo Standard Error, derived in mcse_mean, mcse_sd variants |
| or r_hat, is the Gelman and Rubin factor | |
| NUTS | No U-Turns Sampler |
| PPD | Posterior Predictive Distribution |
| UBEM | Urban Buildings Energy Modeling |
| VI | Variational (Bayesian) Inference |
References
- Tavakoli, A.; Saha, S.; Arif, M.T.; Haque, M.E.; Mendis, N.; Oo, A.M.T. Impacts of grid integration of solar PV and electric vehicle on grid stability, power quality and energy economics: A review. IET Energy Syst. Integr. 2020, 2, 243–260. [Google Scholar] [CrossRef]
- Abergel, T.; Dean, B.; Dulac, J. Towards a Zero-Emission, Efficient, and Resilient Buildings and Construction Sector; Global Status Report; UN Environment and International Energy Agency: Brussels, Belgium, 2017; p. 48. [Google Scholar]
- Roth, J.; Lim, B.; Jain, R.K.; Grueneich, D. Examining the feasibility of using open data to benchmark building energy usage in cities: A data science and policy perspective. Energy Policy 2020, 139, 111327. [Google Scholar] [CrossRef]
- Fremouw, M.; Bagaini, A.; De Pascali, P. Energy Potential Mapping: Open Data in Support of Urban Transition Planning. Energies 2020, 13, 1264. [Google Scholar] [CrossRef] [Green Version]
- Urban Data Platform Plus. 2021. Available online: https://urban.jrc.ec.europa.eu/#/en (accessed on 1 June 2021).
- Institut Wohnen und Umwelt (IWU). EPISCOPE and TABULA Website. 2016. Available online: https://episcope.eu/welcome/ (accessed on 1 June 2021).
- TABULA WebTool. 2016. Available online: https://webtool.building-typology.eu/#bm (accessed on 1 June 2021).
- ENEDIS. Enedis Open Data. 2021. Available online: https://data.enedis.fr/explore/?sort=modified (accessed on 1 June 2021).
- ADEME. Portail Open Data de l’ADEME. Available online: https://data.ademe.fr (accessed on 1 June 2021).
- Plateforme Ouverte des Données Publiques Françaises: Environnement, Énergie, Logement. Available online: https://www.data.gouv.fr (accessed on 1 June 2021).
- Data MetropoleGrenoble: Saisissez vous des Données. Available online: https://data.metropolegrenoble.fr/ (accessed on 1 June 2021).
- Open data de la Métropole de Lyon. Available online: https://data.grandlyon.com/accueil (accessed on 1 June 2021).
- Paris Data Platform. Available online: https://opendata.paris.fr/pages/home/ (accessed on 1 June 2021).
- Hotmaps Project: TheOpen Source Mapping and Planning Tool for Heating and Cooling. Available online: https://www.hotmaps-project.eu/ (accessed on 6 June 2021).
- Pezzutto, S.; Croce, S.; Zambotti, S.; Kranzl, L.; Novelli, A.; Zambelli, P. Assessment of the Space Heating and Domestic Hot Water Market in Europe - Open Data and Results. Energies 2019, 12, 1760. [Google Scholar] [CrossRef] [Green Version]
- Planheat Project Website. 2021. Available online: http://planheat.eu/ (accessed on 7 June 2021).
- Swan, L.G.; Ugursal, V.I. Modeling of end-use energy consumption in the residential sector: A review of modeling techniques. Renew. Sustain. Energy Rev. 2009, 13, 1819–1835. [Google Scholar] [CrossRef]
- Zhuravchak, R.; Pedrero, R.A.; del Granado, P.C.; Nord, N.; Brattebø, H. Top-down spatially-explicit probabilistic estimation of building energy performance at a scale. Energy Build. 2021, 238, 110786. [Google Scholar] [CrossRef]
- Kavgic, M.; Mavrogianni, A.; Mumovic, D.; Summerfield, A.; Stevanovic, Z.; Djurovic-Petrovic, M. A review of bottom-up building stock models for energy consumption in the residential sector. Build. Environ. 2010, 45, 1683–1697. [Google Scholar] [CrossRef]
- Ferrando, M.; Causone, F.; Hong, T.; Chen, Y. Urban building energy modeling (UBEM) tools: A state-of-the-art review of bottom-up physics-based approaches. Sustain. Cities Soc. 2020, 62, 102408. [Google Scholar] [CrossRef]
- Fonseca, J.A.; Nguyen, T.A.; Schlueter, A.; Marechal, F. City Energy Analyst (CEA): Integrated framework for analysis and optimization of building energy systems in neighborhoods and city districts. Energy Build. 2016, 113, 202–226. [Google Scholar] [CrossRef]
- Remmen, P.; Lauster, M.; Mans, M.; Fuchs, M.; Osterhage, T.; Müller, D. TEASER: An open tool for urban energy modelling of building stocks. J. Build. Perform. Simul. 2018, 11, 84–98. [Google Scholar] [CrossRef]
- Hong, T.; Chen, Y.; Lee, S.H.; Piette, M. CityBES: A Web-based Platform to Support City-Scale Building Energy Efficiency. Urban Comput. 2016, 14. [Google Scholar] [CrossRef]
- Robinson, D.; Haldi, F.; Leroux, P.; Perez, D.; Rasheed, A.; Wilke, U. CitySim: Comprehensive micro-simulation of resource flows for sustainable urban planning. In Proceedings of the Eleventh International IBPSA Conference, Glasgow, Scotland, 27–30 July 2009; pp. 1083–1090. [Google Scholar]
- Pajot, C.; Artiges, N.; Delinchant, B.; Rouchier, S.; Wurtz, F.; Maréchal, Y. An Approach to Study District Thermal Flexibility Using Generative Modeling from Existing Data. Energies 2019, 12, 3632. [Google Scholar] [CrossRef] [Green Version]
- Kotzur, L. Future Grid Load of the Residential Building Sector. Ph.D. Thesis, RWTH Aachen University, Aachen, Germany, 2018. [Google Scholar]
- Lim, H.; Zhai, Z.J. Review on stochastic modeling methods for building stock energy prediction. Build. Simul. 2017, 10, 607–624. [Google Scholar] [CrossRef] [Green Version]
- Pasichnyi, O.; Wallin, J.; Kordas, O. Data-driven building archetypes for urban building energy modelling. Energy 2019, 181, 360–377. [Google Scholar] [CrossRef]
- Cerezo, C.; Sokol, J.; AlKhaled, S.; Reinhart, C.; Al-Mumin, A.; Hajiah, A. Comparison of four building archetype characterization methods in urban building energy modeling (UBEM): A residential case study in Kuwait City. Energy Build. 2017, 154, 321–334. [Google Scholar] [CrossRef]
- Wang, C.K. Urban Building Energy Modeling Using a 3D City Model and Minimizing Uncertainty through Bayesian Inference: A Case Study Focuses on Amsterdam Residential Heating Demand Simulation. Master’s Thesis, Delft University of Technology, Delft, The Netherlands, 2018. [Google Scholar]
- Sokol, J.; Cerezo Davila, C.; Reinhart, C.F. Validation of a Bayesian-based method for defining residential archetypes in urban building energy models. Energy Build. 2017, 134, 11–24. [Google Scholar] [CrossRef]
- ENEDIS. Consommation et Thermosensibilité Electriques par Secteur d’Activité à la Maille IRIS. 2017. Available online: https://data.enedis.fr/explore/dataset/consommation-electrique-par-secteur-dactivite-iris/information/?refine.annee=2017 (accessed on 27 May 2021).
- INSEE. Logement en 2016|Insee. 2016. Available online: https://www.insee.fr/fr/statistiques/4228432. (accessed on 27 May 2021).
- IGN. Géoservices|Accéder Au Téléchargement des Données Libres IGN. 2017. Available online: https://geoservices.ign.fr/documentation/diffusion/telechargement-donnees-libres.html#contoursiris. (accessed on 27 May 2021).
- Météo-France. Données Publiques de Météo-France: Données SYNOP Essentielles OMM. 2017. Available online: https://donneespubliques.meteofrance.fr/?fond=produit&id_produit=90&id_rubrique=32. (accessed on 27 May 2021).
- Chib, S.; Greenberg, E. Understanding the Metropolis-Hastings Algorithm. Am. Stat. 1995, 49, 327–335. [Google Scholar] [CrossRef] [Green Version]
- Betancourt, M. A Conceptual Introduction to Hamiltonian Monte Carlo. arXiv 2018, arXiv:1701.02434. [Google Scholar]
- Hoffman, M.D.; Gelman, A. The No-U-Turn sampler: Adaptively setting path lengths in Hamiltonian Monte Carlo. J. Mach. Learn. Res. 2014, 15, 1593–1623. [Google Scholar]
- Kucukelbir, A.; Tran, D.; Ranganath, R.; Gelman, A.; Blei, D.M. Automatic Differentiation Variational Inference. arXiv 2016, arXiv:1603.00788. [Google Scholar]
- Lee, D.; Carpenter, B.; Li, P.; Morris, M.; Betancourt, M.; Maverickg, M.; Brubaker, M.; Trangucci, R.; Inacio, M.; Kucukelbir, A.; et al. Stan software: V2.17.1. Zenodo 2017. [Google Scholar] [CrossRef]
- Bingham, E.; Chen, J.P.; Jankowiak, M.; Obermeyer, F.; Pradhan, N.; Karaletsos, T.; Singh, R.; Szerlip, P.; Horsfall, P.; Goodman, N.D. Pyro: Deep Universal Probabilistic Programming. J. Mach. Learn. Res. 2019, 20, 1–6. [Google Scholar]
- Salvatier, J.; Wiecki, T.V.; Fonnesbeck, C. Probabilistic programming in Python using PyMC3. PeerJ Comput. Sci. 2016, 2, e55. [Google Scholar] [CrossRef] [Green Version]
- Salvatier, J.; Wiecki, T.; Patil, A.; Kochurov, M.; Engels, B.; Lao, J.; Colin; Martin, O.; Seyboldt, A.; Rochford, A.; et al. PyMC3 software: V3.11.2. Zenodo 2021. [Google Scholar] [CrossRef]
- Davidson-Pilon, C. Bayesian Methods for Hackers: Probabilistic Programming and Bayesian Inference; Addison-Wesley: New York, NY, USA, 2016. [Google Scholar]
- Artiges, N.; Rouchier, S.; Delinchant, B. Bayesian Archetypes: Energy Signature Inference from National Data for Statistical Definition of Buildings Archetypes. 2021. Available online: https://gricad-gitlab.univ-grenoble-alpes.fr/districtmodeling/bayesian_archetypes (accessed on 1 September 2021). [CrossRef]
- Kumar, R.; Carroll, C.; Hartikainen, A.; Martin, O. ArviZ a unified library for exploratory analysis of Bayesian models in Python. J. Open Source Softw. 2019, 4, 1143. [Google Scholar] [CrossRef]
- Gelman, A.; Rubin, D.B. Inference from Iterative Simulation Using Multiple Sequences. Stat. Sci. 1992, 7, 457–472. [Google Scholar] [CrossRef]
- Geyer, C.J. Introduction to Markov Chain Monte Carlo. In Handbook of Markov Chain Monte Carlo; Chapman and Hall/CRC: London, UK, 2011. [Google Scholar]
- Vehtari, A.; Gelman, A.; Simpson, D.; Carpenter, B.; Bürkner, P.C. Rank-normalization, folding, and localization: An improved R for assessing convergence of MCMC. Bayesian Anal. 2021, 1, 1–28. [Google Scholar] [CrossRef]
- Pouget Consultants. National Report on Pilot Actions. Technical Report Deliverable D3.1. 2015. Available online: https://episcope.eu/fileadmin/episcope/public/docs/pilot_actions/FR_EPISCOPE_LocalCaseStudy_Pouget.pdf (accessed on 9 July 2021).
- TABULA Episcope Project. Average Buildings: Energy Need for Heating (French Case). Available online: https://s2.building-typology.eu/abpdf/FR_L_01_EPISCOPE_CaseStudy_TABULA_Local.pdf (accessed on 9 July 2021).



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Contents | References |
|---|---|---|
| European Urban Data Platform Plus | Provides access to information on the status and trends of cities and regions and to EU supported urban and territorial development strategies. This application enables studies up to regional scales. | [5] |
| TABULA/EPISCOPE | Launched in 2012, European projects EPISCOPE and TABULA aggregate results of detailed studies for the residential stock of 16 European countries. The database offers two main products: the TABULA Webtool as an endpoint for representing typical buildings per country and categories, and all technical reports from consultants implied in the project. | [6,7] |
| ENEDIS Open Data platform | Electric and Gas consumption data aggregated at various scales from ENEDIS (ex-ERDF), the Power Grid Operator in France. | [8] |
| ADEME Open Data platform | ADEME—The French Agency for Ecological Transition, provides about 112 datasets as of 2021 related to the energy transition in France | [9] |
| Open Platform of French public data | The French Government gathers in this platform most data issued from public services and affiliated companies. Most datasets are released under the “Licence Ouverte/Open License” licensing. | [10] |
| Data portals for major cities | Most important urban areas in Europe provide open data related to urban space use and major local events. | Examples: city of Grenoble [11], Lyon [12] and Paris [13] |
| Name | Features | References |
|---|---|---|
| City Energy Analyst | This stand-alone open-source tool aims to target several aspects of district modeling and energy demand forecasts. It provides a “data helper” to leverage some included datasets (mostly concerning Switzerland) and helps to generate building models using 15 typologies. | [21] |
| TEASER | TEASER is an open-source Python package to generate Modelica models of buildings based on “Buildings” and “AixLib” Modelica libraries. A building model can be generated with few parameters such as the construction date and the net leased area, using pre-defined typologies and default values partially issued from TABULA. | [22] |
| City BES | City Building Energy Saver is web-based tool leveraging GIS and building datasets (CityGML) to generate EnergyPlus models at district scale, themselves used for benchmarking and energy load prediction. | [23] |
| City SIM | City SIM helps the user to model 3D buildings and various flows at district scale. It features a specific focus on radiative modeling and use of climate boundary conditions. | [24] |
| Dataset | Description | Variables | Provider |
|---|---|---|---|
| Thermosensitivity 2017—CSV file [32] | Yearly aggregated consumption and heat demand of electricity and gas per category (residential, agriculture, industry) over IRIS areas considered statistically significant (i.e., about half of IRISes). | hlc and base consumption (yearly sum of in Equation (1)aggregated for each IRIS). “degree-days”—sum of daily degrees under for the whole year. | ENEDIS (ex-ERDF) is the Power Grid Operator in France. |
| Dwellings survey 2016—CSV file [33] | 2016 French dwellings survey at IRIS geographic scale. | Census data for dwellings categories per IRIS. | INSEE is the National French Statistics and Economical Studies Institute. |
| Geographical definitions 2017—Shapefile [34] | Precise polygons for IRIS borders, as they where at the year of 2017. | Borders as polygon coordinates. | IGN (Institut Géographique National) is the French National Geographic Institute. |
| weather stations data 2017—CSV file [35] | Data of main French weather stations (42 in metropolitan area), with a 3 h time-step. | Temperature measurements suitable to help finding back the missing parameter in ENEDIS’ data. | Meteo-France is the main French organization dedicated to meteorological studies. |
| mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|
| mean | 0 | 0 | 2.72 × 103 | 1.81 × 103 | 1 |
| std | 0 | 0 | 1.19 × 103 | 346 | 0.00289 |
| min | 0 | 0 | 594 | 936 | 1 |
| max | 0 | 0 | 3.89 × 103 | 2.1 × 103 | 1.01 |
| mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|
| mean | 0.00224 | 0.00162 | 1.91 × 103 | 1.49 × 103 | 1 |
| std | 0.00161 | 0.00129 | 670 | 562 | 0.00216 |
| min | 0 | 0 | 295 | 326 | 1 |
| max | 0.009 | 0.007 | 2.62 × 103 | 2.24 × 103 | 1.01 |
| mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|
| mean | 0.00232 | 0.00156 | 2.12 × 103 | 1.69 × 103 | 1 |
| std | 0.00253 | 0.00179 | 579 | 562 | 0.00187 |
| min | 0 | 0 | 352 | 230 | 1 |
| max | 0.013 | 0.009 | 2.74 × 103 | 2.32 × 103 | 1.01 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Artiges, N.; Rouchier, S.; Delinchant, B.; Wurtz, F. Bayesian Inference of Dwellings Energy Signature at National Scale: Case of the French Residential Stock. Energies 2021, 14, 5651. https://doi.org/10.3390/en14185651
Artiges N, Rouchier S, Delinchant B, Wurtz F. Bayesian Inference of Dwellings Energy Signature at National Scale: Case of the French Residential Stock. Energies. 2021; 14(18):5651. https://doi.org/10.3390/en14185651
Chicago/Turabian StyleArtiges, Nils, Simon Rouchier, Benoit Delinchant, and Frédéric Wurtz. 2021. "Bayesian Inference of Dwellings Energy Signature at National Scale: Case of the French Residential Stock" Energies 14, no. 18: 5651. https://doi.org/10.3390/en14185651