1. Introduction
Three-fourth of global sedimentary rock are composed of shale, which plays a major role in hydrocarbon generation, migration, and then trapping the hydrocarbon either in other rock types (e.g., sandstone, or reservoir rock) or within the shale rock (acting as both source and reservoir rock). This self-produced and self-accumulated source–reservoir system is the unconventional rock. However, over the last twenty years significant interest has built-up on exploring unconventional shale gas reservoirs because of the massive demand for exploring more sustainable environmentally friendly gas-prone energy [
1,
2,
3]. In general, unconventional shale is constituted as having clay-sized fine-grained detrital, being organic-rich, and with low porosity and ultralow permeability (in order of nano-Darcy) [
4,
5,
6]. Rapid progress in technology, notably hydraulic fracturing and drilling in the horizontal direction, has made shale gas economically producible [
3,
7,
8]. Productive shale gas reservoirs have higher organic richness (for example USA’s Barnett, Eagle Ford shale). Organic richness is evaluated by total organic carbon (TOC) in the weight percentage (wt %) unit. TOC is one of the key parameters in assessing prospectively shale plays as well as identifying suitable sweet spots and estimation of in-place volumetric total hydrocarbon [
2,
9,
10,
11]. Holmes, et al. [
12] proposes another approach with triple combo logs to compute total in-place volumes of the unconventional shale reservoir. Organic matter within the rock matrix directly controls organic porosity and adsorbed gas [
2,
13,
14]. Additionally, TOC affects mechanical anisotropy (Sone and Zoback, 2013a), geomechanical properties [
15,
16,
17,
18,
19], and brittleness [
3,
4,
20]. In the global perspective, better gross estimation of shale reservoir requires the importance of a more precisely defined TOC model for future development activity. Despite the huge reserves, short production life cycle and lower recovery factor imply the reserve calculation, through total porosity with the inclusion of organic porosity, is being questionable [
21]. Therefore, accurate TOC estimations are essential for the development and production of an unconventional reservoir [
11,
13,
22,
23].
TOC is routinely measured on core cuttings, chips, or side-wall cores by a Rock-Eval pyrolysis analyzer in the laboratory (i.e., core TOC/laboratory TOC). This is the most reliable method as of now; however, because of the limitations of the core specimen, continuous TOC measurement is not possible. Schmoker [
24,
25] and Passey [
26] methods are industry standard, and they are routinely used to compute continuous TOC profiles from specific borehole-measured physical properties such as bulk density (RHOB), deep resistivity (LLD), and compressional sonic travel time (DT). Both traditional methods have limitations. Schmoker’s method solely depends upon the linear relationship of TOC with the inverse of density, which may not be always unique for different geological regimes. Passey’s method computes TOC from the combination of the porosity and resistivity log after the baseline curve has been identified. The uniformity of the method is questionable as baseline value varies from well to well and across the formations. Besides baseline identification, maturity is another constraint of this approach. Especially at higher maturity, the technique struggles to provide reliable TOC because the resistivity log does not increase with maturity level [
10].
In the case of an unconventional shale reservoir, the heterogeneity of the reservoir further adds more complexity [
22,
27]. Artificial intelligence (AI) techniques have overcome all the above-mentioned issues of the traditional process of TOC estimation. For example, Zhao, Verma, Devegowda, and Jayaram [
23] used support vector machine (SVM) to calculate TOC in Barnett Shale form commonly acquired well logs; Verma, Zhao, Marfurt, and Devegowda [
22] approached the probabilistic neural network to predict the TOC on Barnett Shale of the Fortworth Basin; Emelyanova, Pervukhina, Clennell, and Dewhurst [
27] carried out TOC prediction of the McArthur and Georgina basins of Australia by two non-parametric machine learning (ML) methods (an ensemble of Multi-layer Perceptrons—MLPs, and an ensemble of SVMs). Yu, Rezaee, Wang, Han, Zhang, Arif, and Johnson [
11] derived TOC with an ensemble of Gaussian Process Regressors (GPRs) through different kernel functions on an unconventional shale reservoir of the Ordos Basin; Johnson, et al. [
28] implemented the Levenberg–Marquardt ANN algorithm to predict geochemical logs of the unconventional reservoir at the Canning Basin; and Ritzer and Sperling [
29] tried to compute TOC from geochemical trace elements using the Random Forest (RF) method, an ensemble learning technique. These studies demonstrate the value of various AI methods in predicting TOC, but they do not advise how to choose a particular algorithm to perform best on a data set with different geology from another basin. In this study, we propose an ensemble learning approach that can integrate multiple models to build a predictive TOC model and improve the prediction performance of TOC.
Our study area is located inside the Canning Basin, which is a massive, intra-cratonic Paleozoic sedimentary basin with limited exploration activity because it is relatively less well drilled than the prospective Ordovician Goldwyer shale formation [
5,
28,
30]. The organic richness of Goldwyer shale is highly variable across the basin [
28,
31]. There is no guarantee that any of the above single ML methods are suitable for building the optimum TOC profile across the basin. This reflects our strategy of different ensemble learning considerations to provide an improved solution.
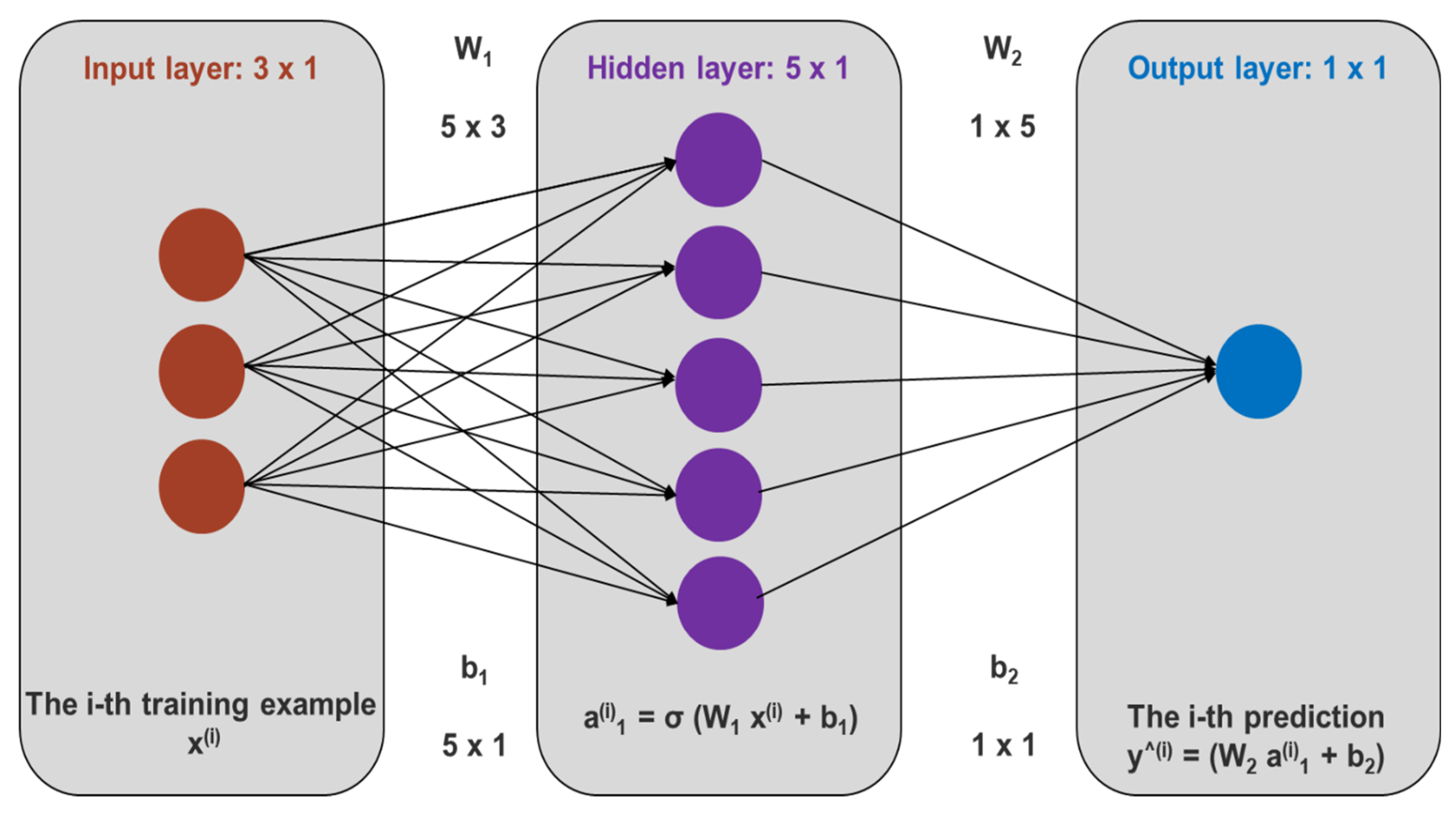
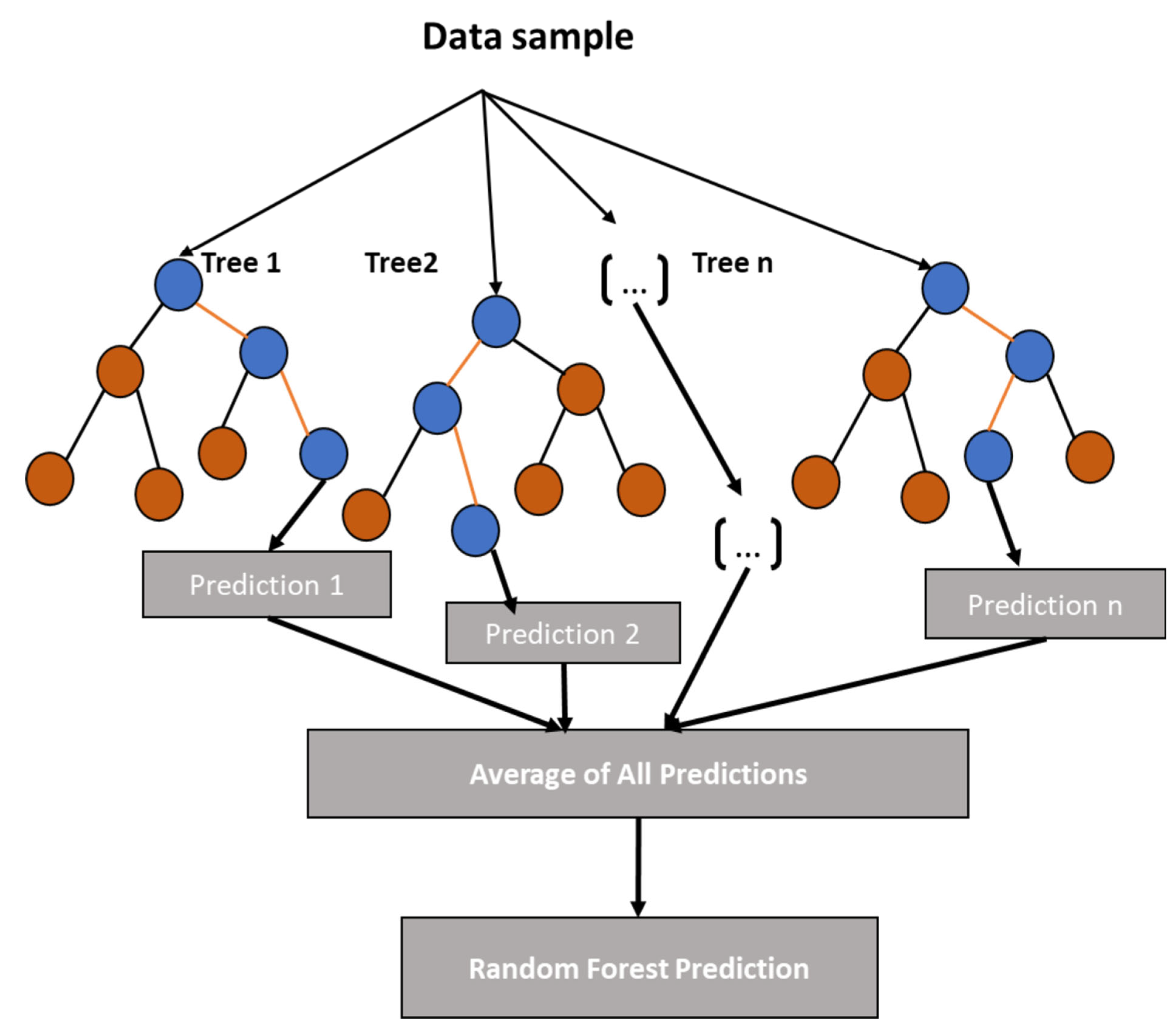
Due to the robustness, complex data handlining capacity, and consideration of bias-variance trade-off, we propose four ensemble learning methods [
32,
33] to obtain a generalized predictive TOC model from input well-logs in the heterogeneous Goldwyer shale reservoir such as: (i) running one algorithm many times with different initialization—Multi-layer Perceptron (MLP) an ANN algorithm [
34]; (ii) using different samples of the data set (sub-sampling) and feature selection, bootstrapping method—RF [
29,
35]; (iii) projection onto a higher dimension space with different kernel—SVM [
23,
27]; and (iv) handling of data heterogeneity and feature selection, bagging method—Gradient boosting regressor (GBR) [
35]. The standard multi-linear regression (MLR) statistical method is also considered for modelling a linear relationship between the log response and the core TOC. This study focused on the development of a workflow for generating a robust TOC prediction model using the ensemble learning approach so that the potential of the Goldwyer shale can be identified.
Python programming language and the scikit-learn machine learning platform [
33] are used to implement the workflow and build the predictive model. The workflow consists of two stages: (i) data preparation that includes data sanitation (QA/QC), input data accumulation, and synthetic well-log generation; (ii) model generation by ensemble learning and TOC prediction. We tested two different input attribute groups for optimization of the prediction. The champion model comes from the relative comparison of mean squared error (MSE) function and R
2 (the squared correlation coefficient) value of each ensemble learning model trough leave-one-out cross-validation (LOOCV). The obtained TOC from the ensemble learning approach is finally compared with traditional methods to show its effectiveness.
6. Discussion
The Goldwyer formation of the Canning Basin is highly complex in nature, which can be inferred from the large variety of core TOC value ranges from 0.16 wt % to 4.47 wt % with standard deviation of 1 wt % (
Table 3) and also from previous research publication on maturity index, lithology, and core description of the drilled wells [
5,
31,
59].
Figure 17 displayed the core plugs extracted from a well in the Goldwyer formation where it is very clear that the depositional environment is changing rapidly from shallow to deeper section. Due to the absence of NPHI and RHOB log on three studied wells we could not complete basic petrophysical evaluation nor estimate traditional TOC using Schmoker’s method. At the same time, the ensemble learning method with two different attribute groups could not be performed because of the shortage of those logs in Edgar Range-1, Mclarty-1, and Matches Spring-1.
NPHI is responsive to the variation of lithology, compaction, and hydrocarbon effect in the sub-surface. GR, DT, and log10_LLD are the most effective log to reflect the above variation. Therefore, our methodology of synthetic NPHI from these three input logs has clear physical significance in a petrophysical point of view. It is very common to generate a synthetic density log from the check shot or velocity-density transform [
39] function. Bailey and Henson [
36] predicted shallow bulk density profile from Gardner’s locally calibrated transform function on the Canning Basin but the prediction quality varies a lot. Here, synthetic RHOB log with Gardner’s transform and ML predictive modelling are compared on three wells. Lithology-specific velocity-density functions are not implemented because of the complex depositional history of Goldwyer shale formation [
5,
59]. It seems that the locally calibrated Gardner transform function does not follow the density data trend and was largely under-predicted (R
2 value of 0.40). This could be due to the variation in organic matter type and depositional environment, etc. [
30,
36]; however, the machine learning model’s prediction accuracy is meaningfully higher (R
2 value of 0.90) than Gardner’s empirical formula. The poorer performance of the Gardner empirical transform defended our decision to consider the ML application. Non-linearity, higher dimension, and overlapping nature of input–output features are the main factors of the ML model’s success [
22,
47,
61]. Therefore, the generation of NPHI and RHOB log with machine learning algorithms become effective in a highly variable depositional environment such as the Goldwyer formation. For both of their predictions, the random forest was the best estimator with the squared value of the correlation coefficient being 93% and 85%, respectively, on the validation data set. Synthetic log generation helped to increase more core TOC samples into our TOC database, which is an advantage for any machine learning prediction [
53].
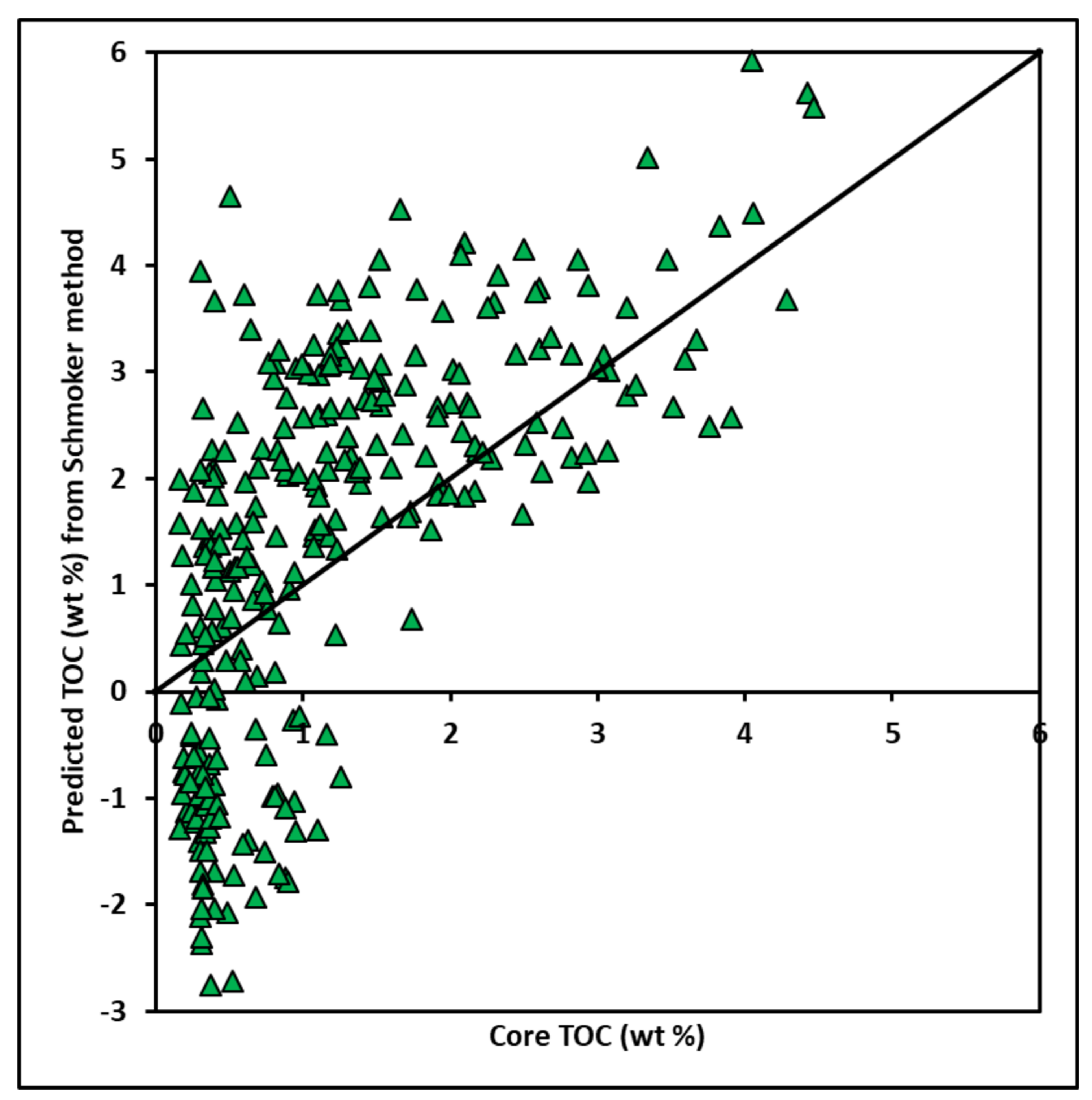
The formation’s complexity is responsive to poor correlation coefficients from traditional TOC techniques (Schmoker and Passey) with an R
2 value of 0.43 and 0.44 [
27]. Moreover, the MLR method, which builds TOC log with linear regression algorithm from wire-line logs can reach an average correlation of 0.77 on the studied wells, but it is difficult to generalize because of the difference in log response and proven non-linearity across the Goldwyer formation from previous work in the Canning Basin [
28,
31]. Due to the non-unique relationship of wire-line logs and core TOC (laterally as well as spatially) in shale gas reservoirs, data-driven techniques are more reliable to improve prediction not only in a well, but also across the reservoir interval. The authors in [
22,
23] applied a non-parametric single ML model to organic-rich North America’s Barnett shale (TOC value reaches a maximum value range from 10 to 15 wt %), whereas Yu et al., 2017, adopted the GPR ML model with different kernel functions on the organic-rich Ordos Basin and poorly distributed organic matter content of Goldwyer shale (TOC is confined within 0 to 2 wt %). So, it is not practicable to obtain a unique predictor with any of the single ML models on the randomly varying organic matter content of the Goldwyer shale formation covering low to moderate TOC ranges (See
Table 3;
Figure 14). At the same time, optimization of the input feature weighting factor is necessary and is dealt with two different attribute groups. The effective attribute selection is followed by several researchers in their ML application. In the final TOC model building stage, neutron porosity log (NPHI) was dropped due to its poor relationship with core TOC, and it did not improve the model’s performance in any way (
Table 8). So, this justified the selection of group-2 attributes for building the final TOC model.
In a given scenario of different well-logs (such as basic conventional logs, geochemical logs, and ECS log), the ensemble learning method automatically chooses the relevant input features when building more decision trees to improve its prediction power. This makes the application easier in any geological environment. Because of the capacity of generalizability in prediction, ensemble learning is relevant in the heterogeneous Goldwyer formation (see
Figure 17) to improve prediction power compared to any single ML model. Each of the ensemble learning models reveals similar prediction accuracy. Henceforth, an average regressor is our choice as the final predictor model, which combines four ensemble learning models. The advantage is such a model balances out the weakness of each equally well-performing individual model. After a hundred realizations, we can still predict TOC on the validation data set with the same value of error function relative to each ensemble learning model. This combined regressor model is able to capture heterogeneity and non-linear interactions between features better than a single ML model. It also handles smaller data set size, and under- and overfitting problem by combining many estimators compared to any single GPR, SVM, or ANN model. All the above points make the ensemble learning model a robust predictor compared to either empirical or multi-linear regression, as can be seen from
Figure 15.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


















