
Tracking Photovoltaic Power Output Schedule of the Energy Storage System Based on Reinforcement Learning

Abstract
:1. Introduction
2. Problem Formulation
- The capacity constraint of the ESS:
- 2.
- Charge/discharge power constraint of the ESS:
- (a)
- Charging:
- (b)
- Discharging:
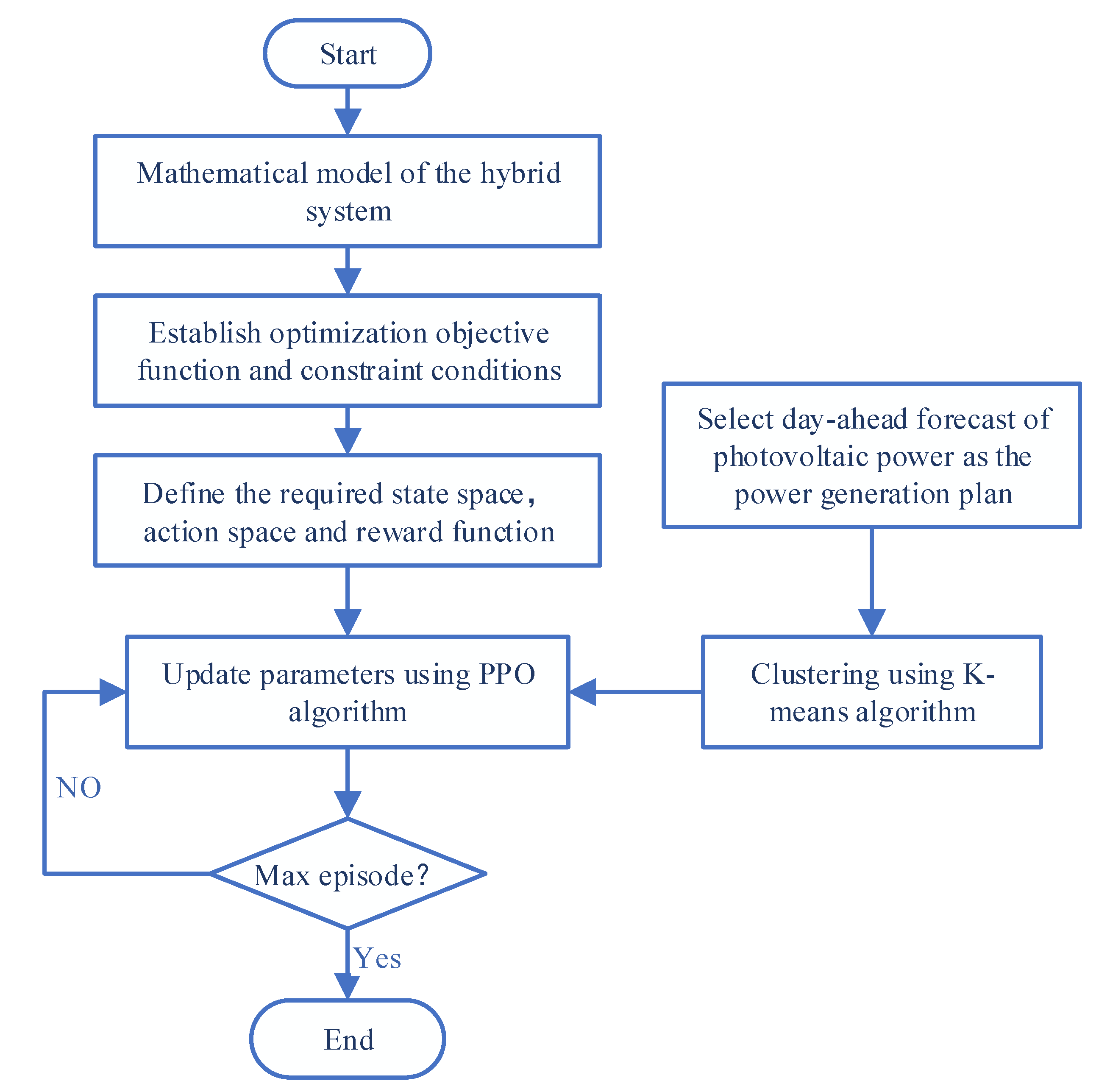
3. Power Generation Control Strategy Based on the PPO Algorithm
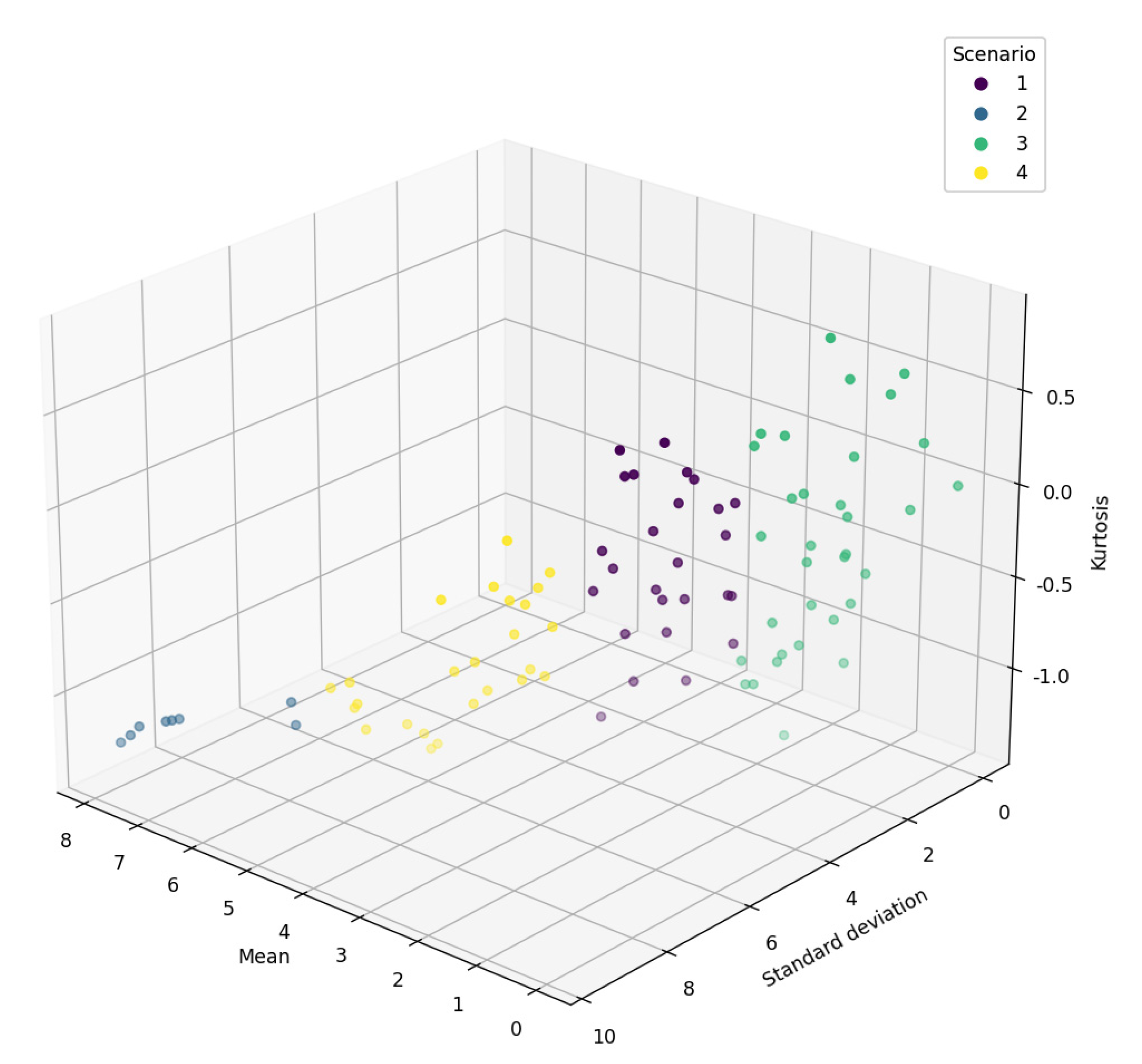
3.1. Scenario Clustering Based on the K-Means Algorithm
- (i)
- Determine the clustering features: The mean, standard deviation, and kurtosis of the power generation plan are taken as clustering features.
- (ii)
- Select cluster center: Select k objects from the data as the initial clustering center.
- (iii)
- Calculate the distances from each set of features to all cluster centers. Among the calculated distances, each feature that has the minimum distance with the cluster center would be classified into that cluster.
- (iv)
- The center of each cluster is the average of all the features in the corresponding cluster.
- (v)
- Calculate the clustering cost function.
- (vi)
- Stop the calculation if the cost function is below a certain threshold value or the improvement over the previous iteration is below a certain tolerance.
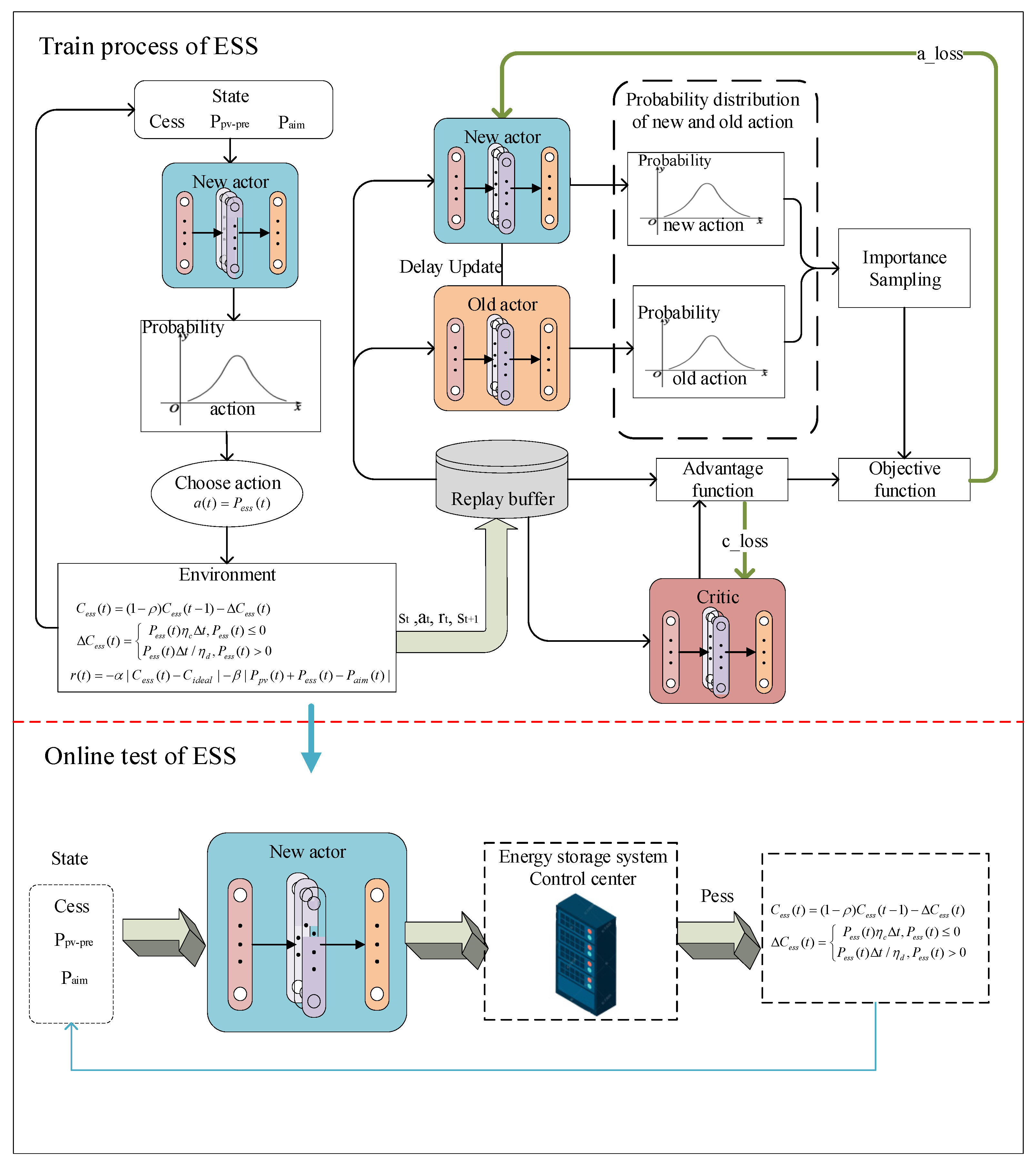
3.2. Tracking Control Based on Reinforcement Learning
- (1)
- State space
- (2)
- Action space
- (3)
- Reward function
| Algorithm 1. PPO algorithm. |
Train:
|
4. Simulation Analysis
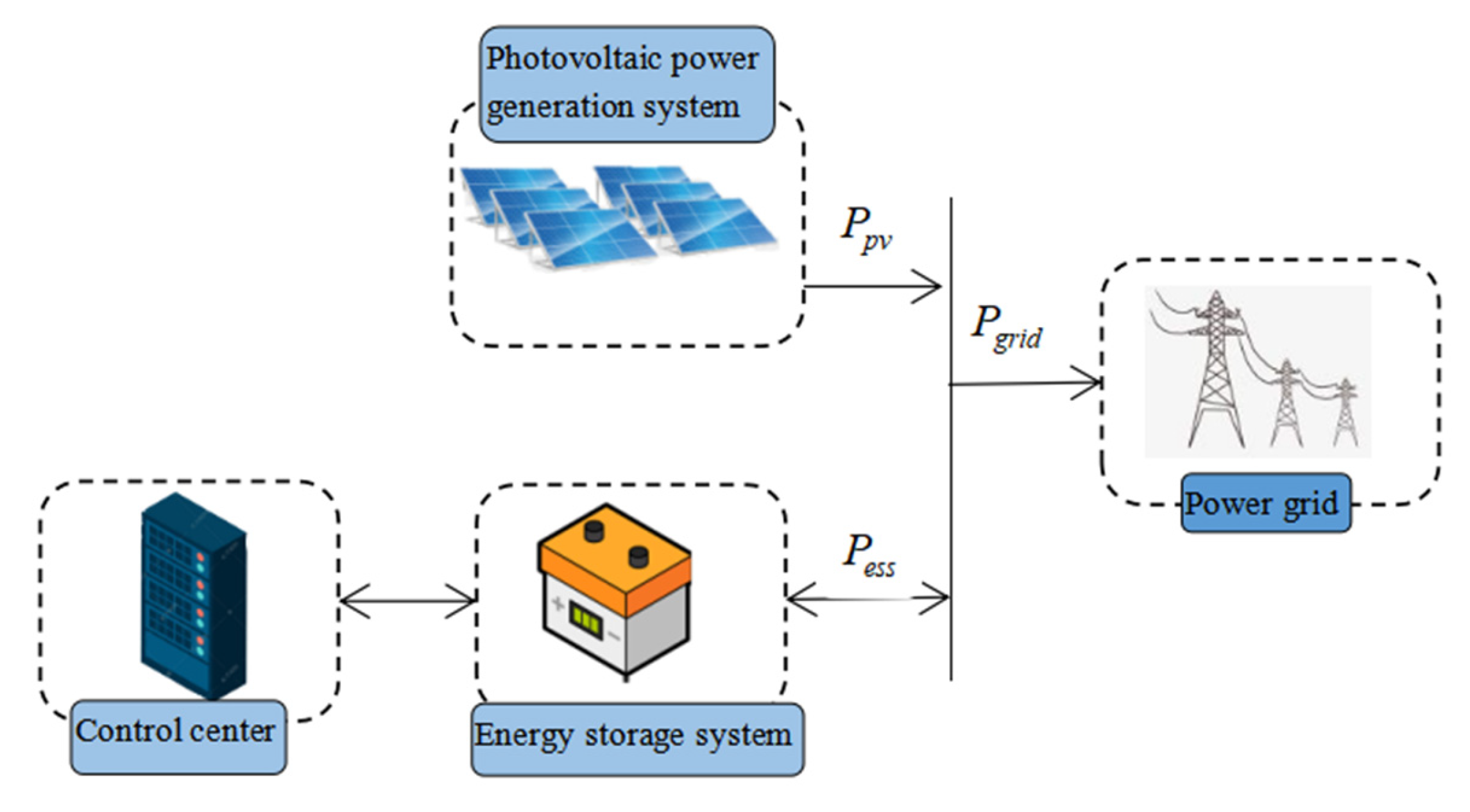
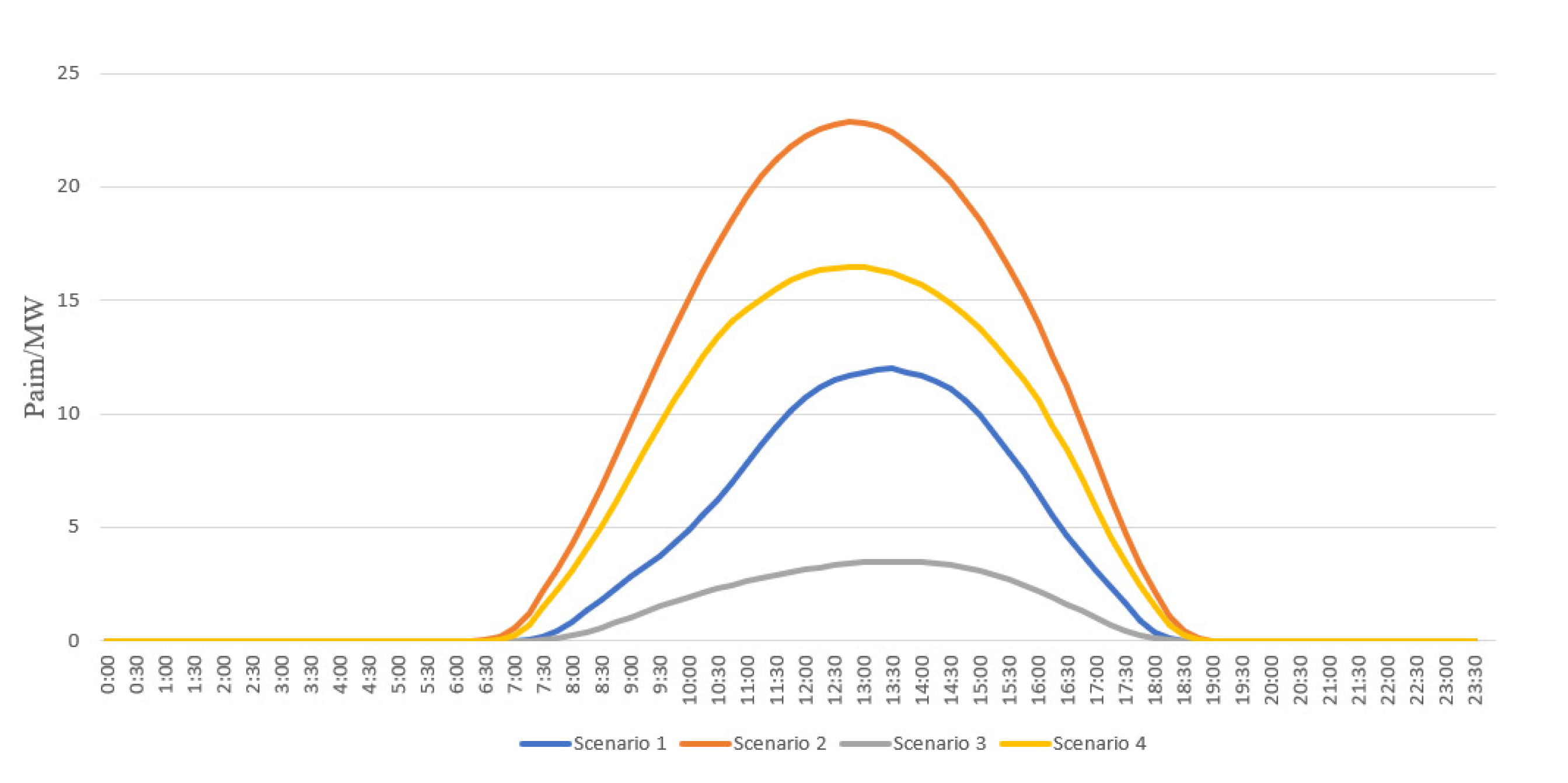
4.1. Description of Photovoltaic and Energy Storage Hybrid System
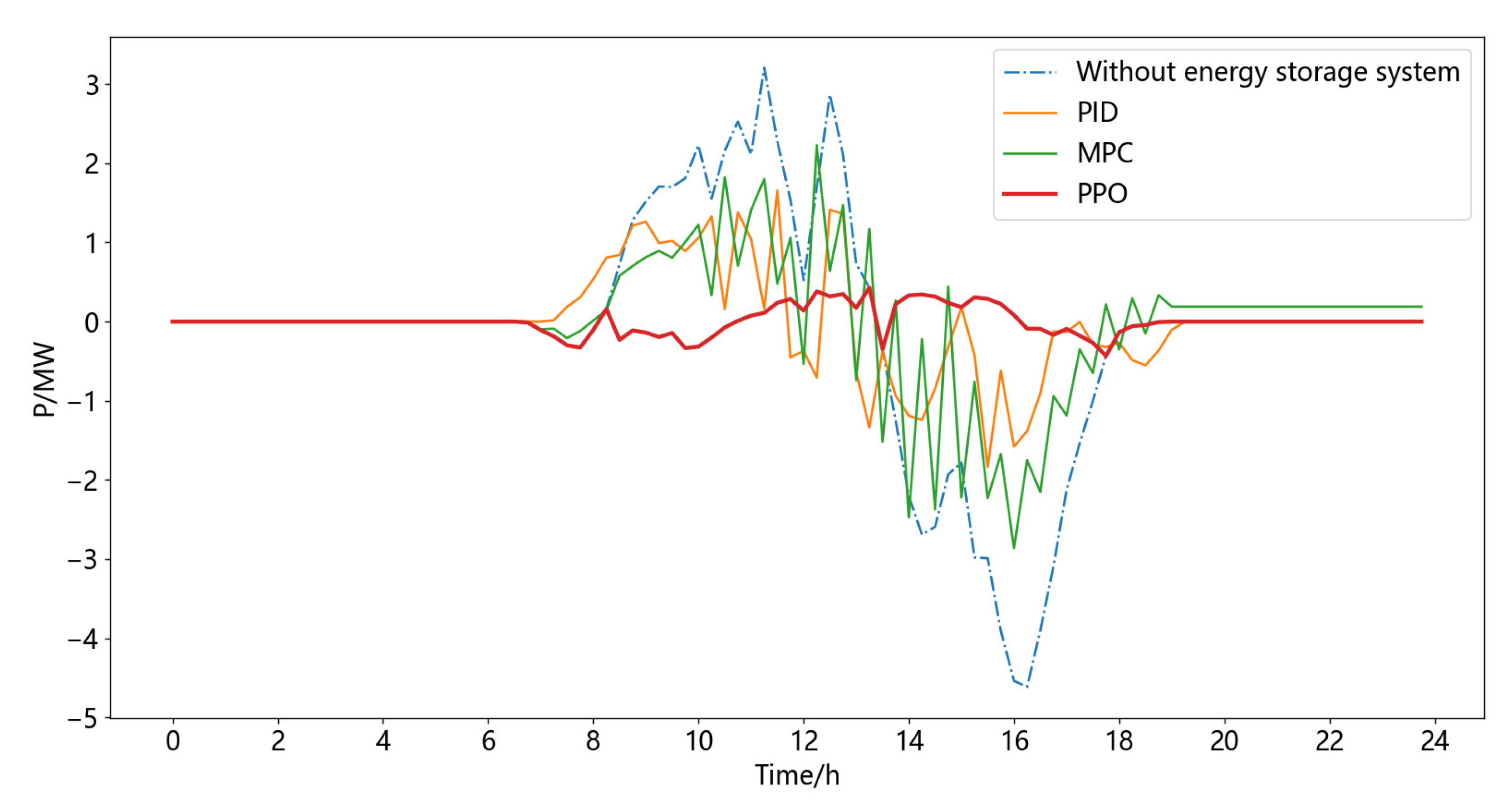
4.2. Results and Discussions
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dai, H.; Su, Y.; Kuang, L.; Liu, J.; Gu, D.; Zou, C. Contemplation on China’s Energy-Development Strategies and Initiatives in the Context of Its Carbon Neutrality Goal. Engineering 2021, 7, 1684–1687. [Google Scholar] [CrossRef]
- Hong, F.; Song, J.; Meng, H.; Wang, R.; Fang, F.; Zhang, G. A novel framework on intelligent detection for module defects of PV plant combining the visible and infrared images. Solar Energy 2022, 236, 406–416. [Google Scholar] [CrossRef]
- Qin, L.; Sun, N.; Dong, H.Y. Adaptive Double Kalman Filter Method for Smoothing Wind Power in Multi-Type Energy Storage System. Energies 2023, 16, 1856. [Google Scholar] [CrossRef]
- Li, S.; Xu, Q.; Huang, J. Research on the integrated application of battery energy storage systems in grid peak and frequency regulation. J. Energy Storage 2023, 59, 106459. [Google Scholar] [CrossRef]
- Ding, H.; Hu, Z.; Song, Y. Stochastic optimization of the daily operation of wind farm and pumped-hydro-storage plant. Renew. Energy 2012, 48, 571–578. [Google Scholar] [CrossRef]
- Mignoni, N.; Scarabaggio, P.; Carli, R.; Dotoli, M. Control frameworks for transactive energy storage services in energy communities. Control Eng. Pract. 2023, 130, 105364. [Google Scholar]
- Guo, X.; Xu, M.; Wu, L.; Liu, H.; Sheng, S. Review on Target Tracking of Wind Power and Energy Storage Combined Generation System. In Proceedings of the 2018 2nd International Conference on Power and Energy Engineering, Xiamen, China, 3–5 September 2018. [Google Scholar]
- Chunguang, T.; Li, T.; Dexin, L.; Xiangyu, L.; Xuefei, C. Control Strategy for Tracking the Output Power of Photovoltaic Power Generation Based on Hybrid Energy Storage System. Trans. China Electrotech. Soc. 2016, 31, 75–83. [Google Scholar]
- Yan, H.; Li, X.J.; Ma, X.F.; Hui, D. Wind power output schedule tracking control method of energy storage system based on ultra-short term wind power prediction. Power System Technol. 2015, 39, 432–439. [Google Scholar]
- Venkatesan, K.; Govindarajan, U. Optimal power flow control of hybrid renewable energy system with energy storage: A WOANN strategy. J. Renew. Sustain. Energy 2019, 11, 015501. [Google Scholar]
- Qi, X.; He, S.; Wang, W.; Jiang, C.; Hao, L.; Zhu, W. FMPC based control strategy for tracking PV power schedule output of energy storage system. Renew. Energy Resour. 2019, 37, 354–360. [Google Scholar]
- Zhang, S.; Ma, C.; Yang, Z.; Yang, Z.; Wang, Y.; Wu, H.; Ren, Z. Joint dispatch of wind-photovoltaic-storage hybrid system based on deep deterministic policy gradient algorithm. Electric Power 2023, 56, 68–76. [Google Scholar]
- Yang, D.; Wang, L.; Yu, K.; Liang, J. A reinforcement learning-based energy management strategy for fuel cell hybrid vehicle considering real-time velocity prediction. Energy Convers. Manag. 2022, 274, 116453. [Google Scholar] [CrossRef]
- Zhou, K.; Zhou, K.; Yang, S. Reinforcement learning-based scheduling strategy for energy storage in microgrid. J. Energy Storage 2022, 51, 104379. [Google Scholar] [CrossRef]
- Kolodziejczyk, W.; Zoltowska, I.; Cichosz, P. Real-time energy purchase optimization for a storage-integrated photovoltaic system by deep reinforcement learning. Control Eng. Pract. 2021, 106, 104598. [Google Scholar] [CrossRef]
- Yang, T.; Zhao, L.; Li, W.; Zomaya, A.Y. Dynamic energy dispatch strategy for integrated energy system based on improved deep reinforcement learning. Energy 2021, 235, 121377. [Google Scholar] [CrossRef]
- Xinlei, C.; Cui, Y.; Kai, D.; Zijie, M.; Yuan, P.; Zhenfan, Y.; Jixing, W.A.; Xiangzhan, M.; Yang, Y. Day-ahead optimal scheduling approach of wind-storage joint system based on improved K-means and MADDPG algorithm. Energy Stor. Sci. Technol. 2021, 10, 2200–2208. [Google Scholar]
- Wang, Q.; Wang, C.; Feng, Z.; Ye, J.F. Review of K-means clustering algorithm. Electr. Design Eng. 2012, 20, 21–24. [Google Scholar]
- Feinberg, V.; Wan, A.; Stoica, I.; Jordan, M.I.; Gonzalez, J.E.; Levine, S. Model-Based Value Estimation for Efficient Model-Free Reinforcement Learning. arXiv 2018, arXiv:1803.00101. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347v2. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Minibatch size | 32 |
| Actor neural network size | (3,32,64,128,1) |
| Critic neural network size | (3,16,64,1) |
| Actor learning rate | 2 × 10−5 |
| Critic learning rate | 4 × 10−5 |
| Clipping parameter | 0.2 |
| Discount factor | 0.9 |
| Maximum episode | 1500 |
| The Evaluation Index | ||||
|---|---|---|---|---|
| Max Deviation/ MW | Mean Deviation/ MW | Probability of Deviation of Less than 3% | Time/s | |
| Without an ESS | 4.615 | 0.843 | 51.04% | |
| PID | 1.835 | 0.374 | 64.58% | 1.134 |
| MPC | 4.395 | 0.609 | 54.17% | 2.760 |
| The proposed PPO-based control method | 0.377 | 0.104 | 85.40% | 0.053 |
| The Evaluation Index | ||||
|---|---|---|---|---|
| Max Deviation/ MW | Mean Deviation/ MW | Probability of Deviation of Less than 3% | Time/s | |
| Without an ESS | 3.040 | 0.808 | 47.92% | |
| PID | 1.098 | 0.280 | 54.16% | 1.069 |
| MPC | 1.996 | 0.468 | 53.13% | 1.273 |
| The proposed PPO-based control method | 0.598 | 0.133 | 82.29% | 0.049 |
| The Evaluation Index | ||||
|---|---|---|---|---|
| Max Deviation/ MW | Mean Deviation/ MW | Probability of Deviation of Less than 3% | Time/s | |
| Without an ESS | 3.514 | 0.716 | 45.83% | |
| PID | 1.528 | 0.314 | 56.25% | 0.341 |
| MPC | 1.912 | 0.419 | 42.71% | 1.357 |
| The proposed PPO-based control method | 0.448 | 0.106 | 78.13% | 0.055 |
| The Evaluation Index | ||||
|---|---|---|---|---|
| Max Deviation/ MW | Mean Deviation/ MW | Probability Of Deviation of Less than 3% | Time/s | |
| Without an ESS | 3.005 | 0.690 | 50% | |
| PID | 1.666 | 0.498 | 58.33% | 0.331 |
| MPC | 2.831 | 0.591 | 55.83% | 1.389 |
| The proposed PPO-based control method | 0.481 | 0.131 | 83.33% | 0.047 |
| The Evaluation Index | ||||
|---|---|---|---|---|
| Max Deviation/ MW | Mean Deviation/ MW | Probability of Deviation of Less than 3% | Time/s | |
| Without an ESS | 5.102 | 0.571 | 65.63% | |
| PID | 3.237 | 0.432 | 66.67% | 0.334 |
| MPC | 4.112 | 0.816 | 54.17% | 2.150 |
| The proposed PPO-based control method | 1.109 | 0.137 | 84.37% | 0.051 |
| The Evaluation Index | ||||
|---|---|---|---|---|
| Max Deviation/ MW | Mean Deviation/ MW | Probability of Deviation of Less than 3% | Time/s | |
| Without an ESS | 2.873 | 0.293 | 60.41% | |
| PID | 0.827 | 0.135 | 58.33% | 0.355 |
| MPC | 1.540 | 0.162 | 61.46% | 2.321 |
| The proposed PPO-based control method | 0.460 | 0.063 | 69.79% | 0.049 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, M.; Ren, M.; Chen, J.; Cheng, L.; Yang, Z. Tracking Photovoltaic Power Output Schedule of the Energy Storage System Based on Reinforcement Learning. Energies 2023, 16, 5840. https://doi.org/10.3390/en16155840
Guo M, Ren M, Chen J, Cheng L, Yang Z. Tracking Photovoltaic Power Output Schedule of the Energy Storage System Based on Reinforcement Learning. Energies. 2023; 16(15):5840. https://doi.org/10.3390/en16155840
Chicago/Turabian StyleGuo, Meijun, Mifeng Ren, Junghui Chen, Lan Cheng, and Zhile Yang. 2023. "Tracking Photovoltaic Power Output Schedule of the Energy Storage System Based on Reinforcement Learning" Energies 16, no. 15: 5840. https://doi.org/10.3390/en16155840
APA StyleGuo, M., Ren, M., Chen, J., Cheng, L., & Yang, Z. (2023). Tracking Photovoltaic Power Output Schedule of the Energy Storage System Based on Reinforcement Learning. Energies, 16(15), 5840. https://doi.org/10.3390/en16155840