
Bayesian Optimization-Based LSTM for Short-Term Heating Load Forecasting

Abstract
:1. Introduction
- Empirical equation-based method
- 2.
- Method based on physical models
- 3.
- Machine learning-based method
2. Data Set
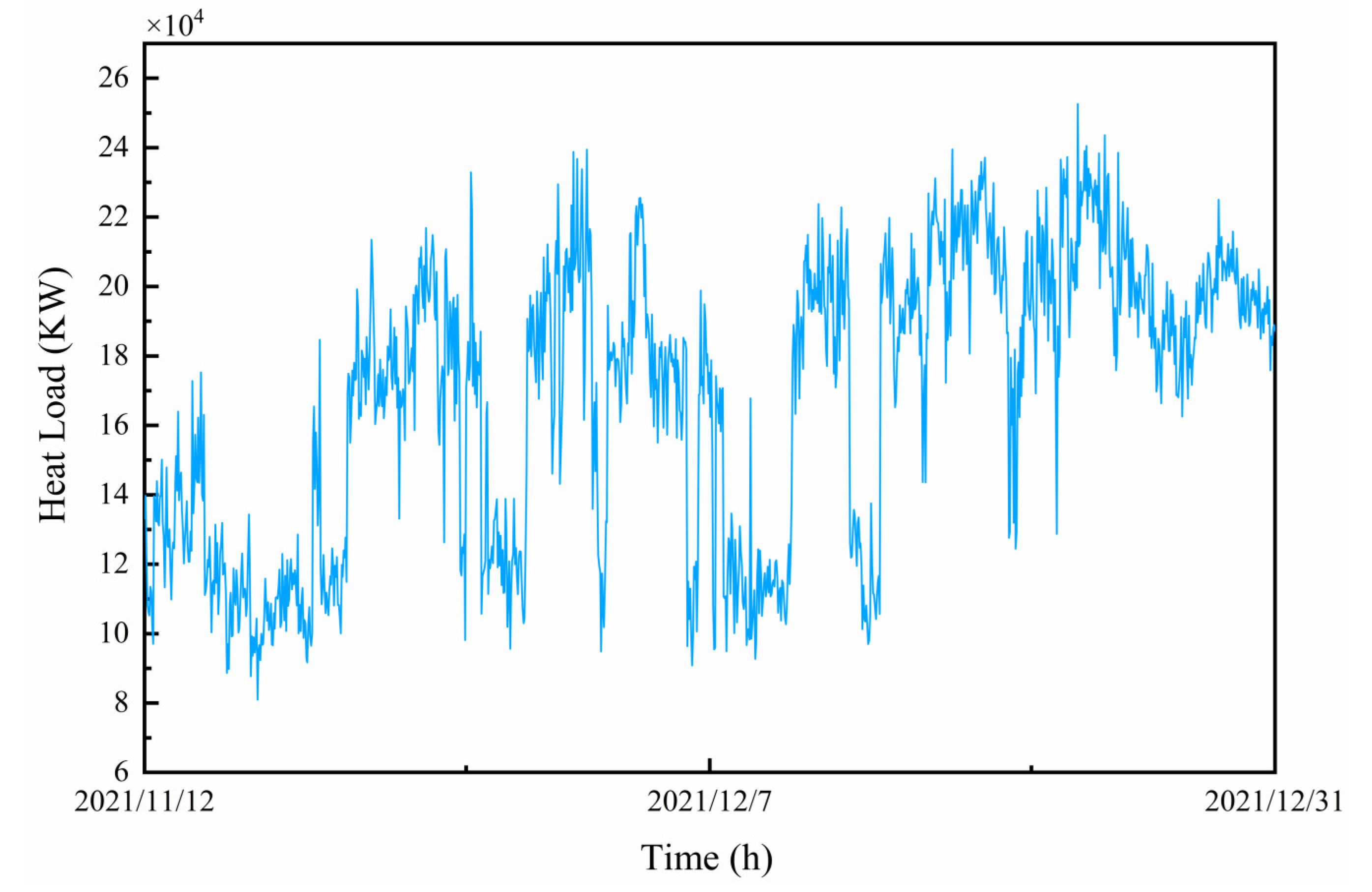
2.1. Data Sources and Composition
2.2. Abnormal Data Handling
2.3. Data Smoothing
2.4. Relevance Analysis
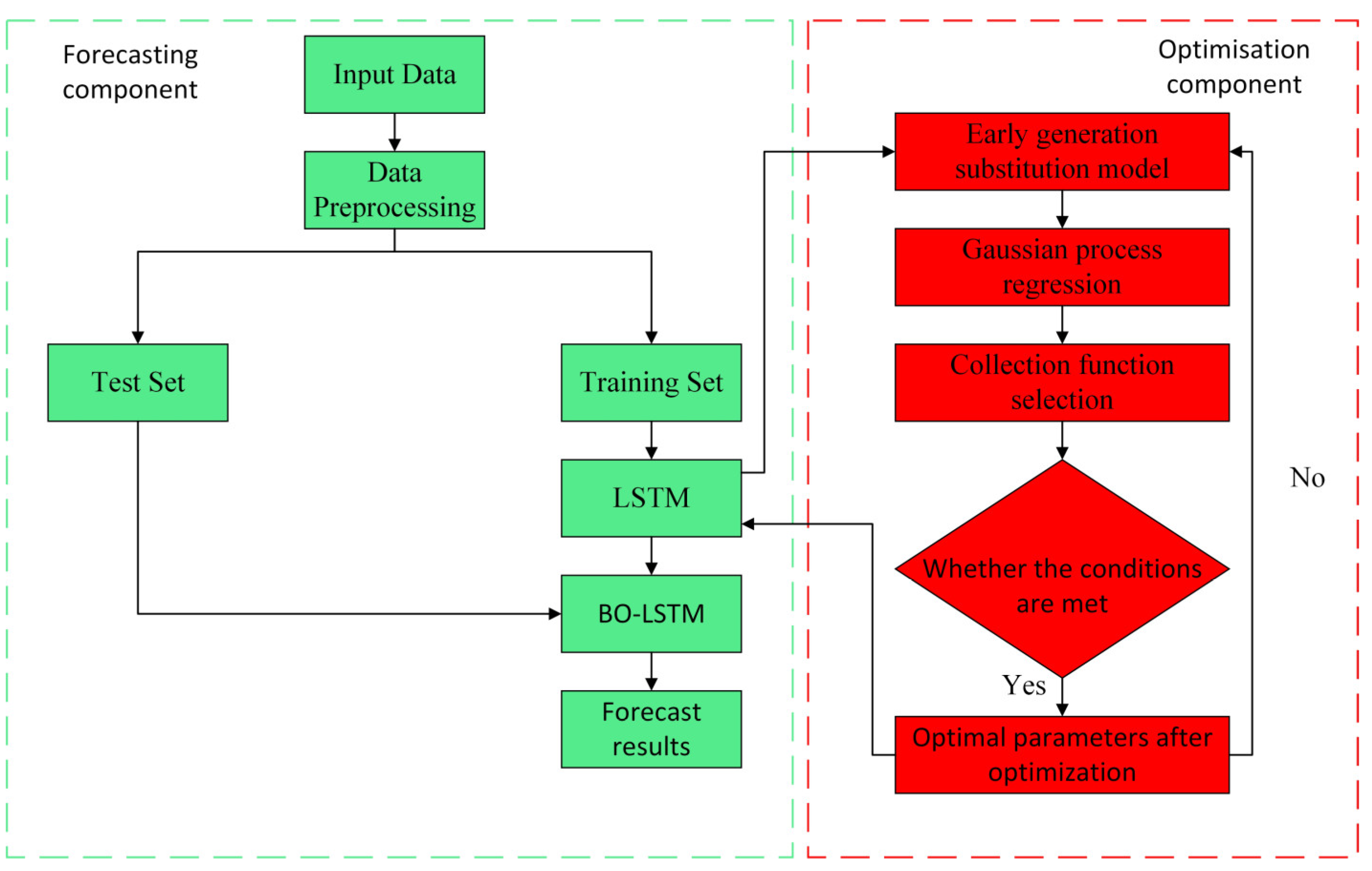
3. Forecasting Methodology
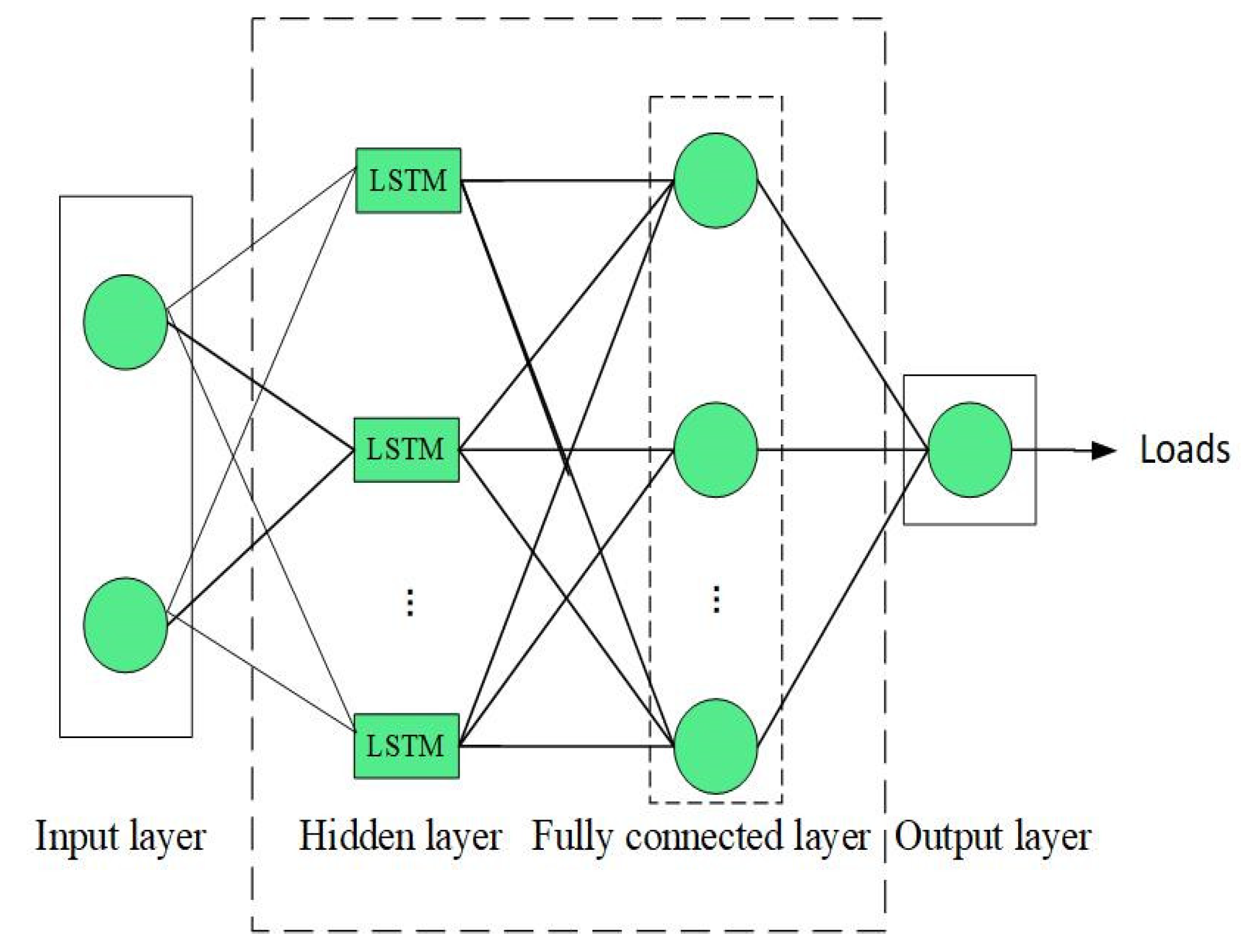
3.1. Basic Model
3.2. Loss Function
3.3. Model Parameters
3.4. Bayesian Optimization
3.5. Bayesian Optimization Parameters
4. Results of The Experiment
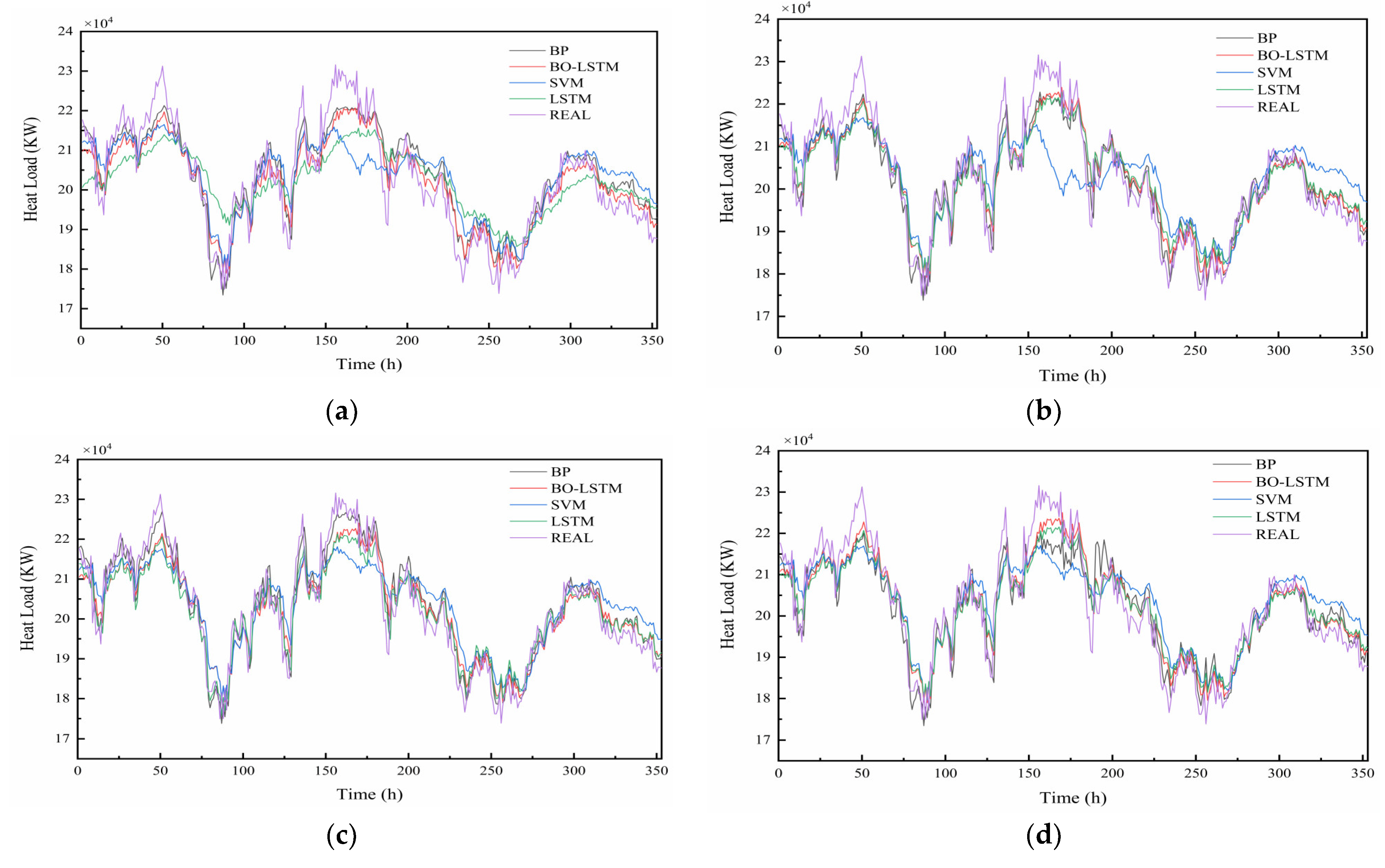
4.1. Forecast Results
4.2. Evaluation Indicators
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Stienecker, M.; Hagemeier, A. Developing Feedforward Neural Networks as Benchmark for Load Forecasting: Methodology Presentation and Application to Hospital Heat Load Forecasting. Energies 2023, 16, 2026. [Google Scholar] [CrossRef]
- Dahl, M.; Brun, A.; Andresen, G.B. Decision rules for economic summer-shutdown of production units in large district heating systems. Appl. Energy 2017, 208, 1128–1138. [Google Scholar] [CrossRef]
- Huang, Y.T.; Li, C. Accurate heating, ventilation and air conditioning system load prediction for residential buildings using improved ant colony optimization and wavelet neural network. J. Build. Eng. 2021, 35, 101972. [Google Scholar] [CrossRef]
- Yuan, J.J.; Zhou, Z.H.; Huang, K.; Han, Z.; Wang, C.D.; Lu, S.L. Analysis and evaluation of the operation data for achieving an on-demand heating consumption prediction model of district heating substation. Energy 2021, 214, 118872. [Google Scholar] [CrossRef]
- Lu, Y.K.; Tian, Z.; Peng, P.; Niu, J.D.; Li, W.C.; Zhang, H.J. GMM clustering for heating load patterns in-depth identification and prediction model accuracy improvement of district heating system. Energy Build. 2019, 190, 49–60. [Google Scholar] [CrossRef]
- Gao, X.; Qi, C.; Xue, G.; Song, J.; Zhang, Y.; Yu, S.-A. Forecasting the Heat Load of Residential Buildings with Heat Metering Based on CEEMDAN-SVR. Energies 2020, 13, 6079. [Google Scholar] [CrossRef]
- Protić, M.; Shamshirband, S.; Petković, D.; Abbasi, A.; Kiah, M.L.M.; Unar, J.A.; Živković, L.; Raos, M. Forecasting of consumers heat load in district heating systems using the support vector machine with a discrete wavelet transform algorithm. Energy 2015, 87, 343–351. [Google Scholar] [CrossRef]
- Gong, M.; Zhou, H.; Wang, Q.; Wang, S.; Yang, P. District heating systems load forecasting: A deep neural networks model based on similar day approach. Adv. Build. Energy Res. 2020, 14, 372–388. [Google Scholar] [CrossRef]
- Sun, C.H.; Liu, Y.A.; Cao, S.S.; Gao, X.Y.; Xia, G.Q.; Qi, C.Y.; Wu, X.D. Research paper Integrated control strategy of district heating system based on load forecasting and indoor temperature measurement. Energy Rep. 2022, 8, 8124–8139. [Google Scholar] [CrossRef]
- Dahl, M.; Brun, A.; Andresen, G.B. Using ensemble weather predictions in district heating operation and load forecasting. Appl. Energy 2017, 193, 455–465. [Google Scholar] [CrossRef]
- Suryanarayana, G.; Lago, J.; Geysen, D.; Aleksiejuk, P.; Johansson, C. Thermal load forecasting in district heating networks using deep learning and advanced feature selection methods. Energy 2018, 157, 141–149. [Google Scholar] [CrossRef]
- Thiangchanta, S.; Chaichana, C. The multiple linear regression models of heat load for air-conditioned room. Energy Rep. 2020, 6, 972–977. [Google Scholar] [CrossRef]
- Wang, L.; Lee, E.W.M.; Yuen, R.K.K. Novel dynamic forecasting model for building cooling loads combining an artificial neural network and an ensemble approach. Appl. Energy 2018, 228, 1740–1753. [Google Scholar] [CrossRef]
- Xu, H.-W.; Qin, W.; Sun, Y.-N.; Lv, Y.-L.; Zhang, J. Attention mechanism-based deep learning for heat load prediction in blast furnace ironmaking process. J. Intell. Manuf. 2023, 1–14. [Google Scholar] [CrossRef]
- Zhou, Y.; Liang, Y.; Pan, Y.; Yuan, X.; Xie, Y.; Jia, W. A Deep-Learning-Based Meta-Modeling Workflow for Thermal Load Forecasting in Buildings: Method and a Case Study. Buildings 2022, 12, 177. [Google Scholar] [CrossRef]
- Rusovs, D.; Jakovleva, L.; Zentins, V.; Baltputnis, K. Heat Load Numerical Prediction for District Heating System Operational Control. Latv. J. Phys. Tech. Sci. 2021, 58, 121–136. [Google Scholar] [CrossRef]
- Jahan, I.S.; Snasel, V.; Misak, S. Intelligent Systems for Power Load Forecasting: A Study Review. Energies 2020, 13, 6105. [Google Scholar] [CrossRef]
- Dahl, M.; Brun, A.; Kirsebom, O.S.; Andresen, G.B. Improving Short-Term Heat Load Forecasts with Calendar and Holiday Data. Energies 2018, 11, 1678. [Google Scholar] [CrossRef]
- Zhao, J.; Shan, Y. A Fuzzy Control Strategy Using the Load Forecast for Air Conditioning System. Energies 2020, 13, 530. [Google Scholar] [CrossRef]
- Xie, Y.; Hu, P.; Zhu, N.; Lei, F.; Xing, L.; Xu, L.; Sun, Q. A hybrid short-term load forecasting model and its application in ground source heat pump with cooling storage system. Renew. Energy 2020, 161, 1244–1259. [Google Scholar] [CrossRef]
- Bergsteinsson, H.G.; Møller, J.K.; Nystrup, P.; Pálsson, P.; Guericke, D.; Madsen, H. Heat load forecasting using adaptive temporal hierarchies. Appl. Energy 2021, 292, 116872. [Google Scholar] [CrossRef]
- Liu, G.; Kong, Z.; Dong, J.; Dong, X.; Jiang, Q.; Wang, K.; Li, J.; Li, C.; Wan, X. Influencing Factors, Energy Consumption, and Carbon Emission of Central Heating in China: A Supply Chain Perspective. Front. Energy Res. 2021, 9, 648857. [Google Scholar] [CrossRef]
- Kim, J.-H.; Seong, N.-C.; Choi, W. Cooling Load Forecasting via Predictive Optimization of a Nonlinear Autoregressive Exogenous (NARX) Neural Network Model. Sustainability 2019, 11, 6535. [Google Scholar] [CrossRef]
- Bujalski, M.; Madejski, P.; Fuzowski, K. Day-ahead heat load forecasting during the off-season in the district heating system using Generalized Additive model. Energy Build. 2023, 278, 112630. [Google Scholar] [CrossRef]
- Castellini, A.; Bianchi, F.; Farinelli, A. Generation and interpretation of parsimonious predictive models for load forecasting in smart heating networks. Appl. Intell. 2022, 52, 9621–9637. [Google Scholar] [CrossRef]
- Nigitz, T.; Gölles, M. A generally applicable, simple and adaptive forecasting method for the short-term heat load of consumers. Appl. Energy 2019, 241, 73–81. [Google Scholar] [CrossRef]
- Potočnik, P.; Škerl, P.; Govekar, E. Machine-learning-based multi-step heat demand forecasting in a district heating system. Energy Build. 2021, 233, 110673. [Google Scholar] [CrossRef]
- Bünning, F.; Heer, P.; Smith, R.S.; Lygeros, J. Improved day ahead heating demand forecasting by online correction methods. Energy Build. 2020, 211, 109821. [Google Scholar] [CrossRef]
- Eguizabal, M.; Garay-Martinez, R.; Flores-Abascal, I. Simplified model for the short-term forecasting of heat loads in buildings. Energy Rep. 2022, 8, 79–85. [Google Scholar] [CrossRef]
- Hofmeister, M.; Mosbach, S.; Hammacher, J.; Blum, M.; Röhrig, G.; Dörr, C.; Flegel, V.; Bhave, A.; Kraft, M. Resource-optimised generation dispatch strategy for district heating systems using dynamic hierarchical optimisation. Appl. Energy 2022, 305, 117877. [Google Scholar] [CrossRef]
- Shepero, M.; van der Meer, D.; Munkhammar, J.; Widén, J. Residential probabilistic load forecasting: A method using Gaussian process designed for electric load data. Appl. Energy 2018, 218, 159–172. [Google Scholar] [CrossRef]
- Kavitha, R.; Thiagarajan, C.; Priya, P.I.; Anand, A.V.; Al-Ammar, E.A.; Santhamoorthy, M.; Chandramohan, P. Improved Harris Hawks Optimization with Hybrid Deep Learning Based Heating and Cooling Load Prediction on residential buildings. Chemosphere 2022, 309, 136525. [Google Scholar] [CrossRef]
- Chen, Z.; Chen, Y.; Xiao, T.; Wang, H.; Hou, P. A novel short-term load forecasting framework based on time-series clustering and early classification algorithm. Energy Build. 2021, 251, 111375. [Google Scholar] [CrossRef]
- Huang, S.; Ali, N.A.M.; Shaari, N.; Noor, M.S.M. Multi-scene design analysis of integrated energy system based on feature extraction algorithm. Energy Rep. 2022, 8, 466–476. [Google Scholar] [CrossRef]
- Gu, J.; Wang, J.; Qi, C.; Min, C.; Sundén, B. Medium-term heat load prediction for an existing residential building based on a wireless on-off control system. Energy 2018, 152, 709–718. [Google Scholar] [CrossRef]
- Shah, P.; Choi, H.-K.; Kwon, J.S.-I. Achieving Optimal Paper Properties: A Layered Multiscale kMC and LSTM-ANN-Based Control Approach for Kraft Pulping. Processes 2023, 11, 809. [Google Scholar] [CrossRef]
- Shibata, K.; Amemiya, T. How to Decide Window-Sizes of Smoothing Methods: A Goodness of Fit Criterion for Smoothing Oscillation Data. IEICE Trans. Electron. 2019, 102, 143–146. [Google Scholar] [CrossRef]
- Yager, R.R. Exponential smoothing with credibility weighted observations. Inf. Sci. 2013, 252, 96–105. [Google Scholar] [CrossRef]
- Schmid, M.; Rath, D.; Diebold, U. Why and How Savitzky–Golay Filters Should Be Replaced. ACS Meas. Sci. Au 2022, 2, 185–196. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification | Factor | Correlation Coefficient |
|---|---|---|
| External factors | outdoor temperature | −0.746 |
| solar radiation | −0.062 | |
| wind speed | −0.101 | |
| precipitation | 0.34 | |
| Internal factors | heat load at the previous moment | 0.883 |
| water supply pressure | 0.414 | |
| return water temperature | 0.539 |
| Parameters | Value |
|---|---|
| Input layer | 2 |
| Hidden unit | 50 |
| Fully connected layer | 1 |
| Output layer | 1 |
| Initial learning rate | 0.01 |
| Learning rate decline factor | 0.5 |
| Number of iterations | 10,200 |
| Ridge regularization coefficient | 0.001 |
| Step Size | Value |
|---|---|
| 24 | 204 |
| 48 | 178 |
| 72 | 314 |
| 168 | 255 |
| Parameter | Range |
|---|---|
| The optimal number of hidden layer nodes | [10, 200] |
| The optimal initial learning rate | [1 × 10−3, 1 × 10−2] |
| Optimal ridge regularization coefficient | [1 × 10−5, 1 × 10−3] |
| Classification | Hidden Unit | Initial Learning Rate | Time |
|---|---|---|---|
| 24 | 40 | 0.002017 | 3911 |
| 48 | 199 | 0.0033185 | 4041 |
| 72 | 103 | 0.0033282 | 4021 |
| 168 | 94 | 0.0033598 | 3872 |
| Classification | Ridge Regularization Coefficient | Observed Objective Function Value |
|---|---|---|
| 24 | 0.00015493 | 0.077476 |
| 48 | 0.00010084 | 0.077208 |
| 72 | 0.00024211 | 0.077196 |
| 168 | 0.000025777 | 0.077409 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, B.; Shao, Y.; Lian, Y.; Li, P.; Lei, Q. Bayesian Optimization-Based LSTM for Short-Term Heating Load Forecasting. Energies 2023, 16, 6234. https://doi.org/10.3390/en16176234
Li B, Shao Y, Lian Y, Li P, Lei Q. Bayesian Optimization-Based LSTM for Short-Term Heating Load Forecasting. Energies. 2023; 16(17):6234. https://doi.org/10.3390/en16176234
Chicago/Turabian StyleLi, Binglin, Yong Shao, Yufeng Lian, Pai Li, and Qiang Lei. 2023. "Bayesian Optimization-Based LSTM for Short-Term Heating Load Forecasting" Energies 16, no. 17: 6234. https://doi.org/10.3390/en16176234
APA StyleLi, B., Shao, Y., Lian, Y., Li, P., & Lei, Q. (2023). Bayesian Optimization-Based LSTM for Short-Term Heating Load Forecasting. Energies, 16(17), 6234. https://doi.org/10.3390/en16176234