
A Systematic Study on Reinforcement Learning Based Applications

 , ,
, , 


Abstract
:1. Introduction
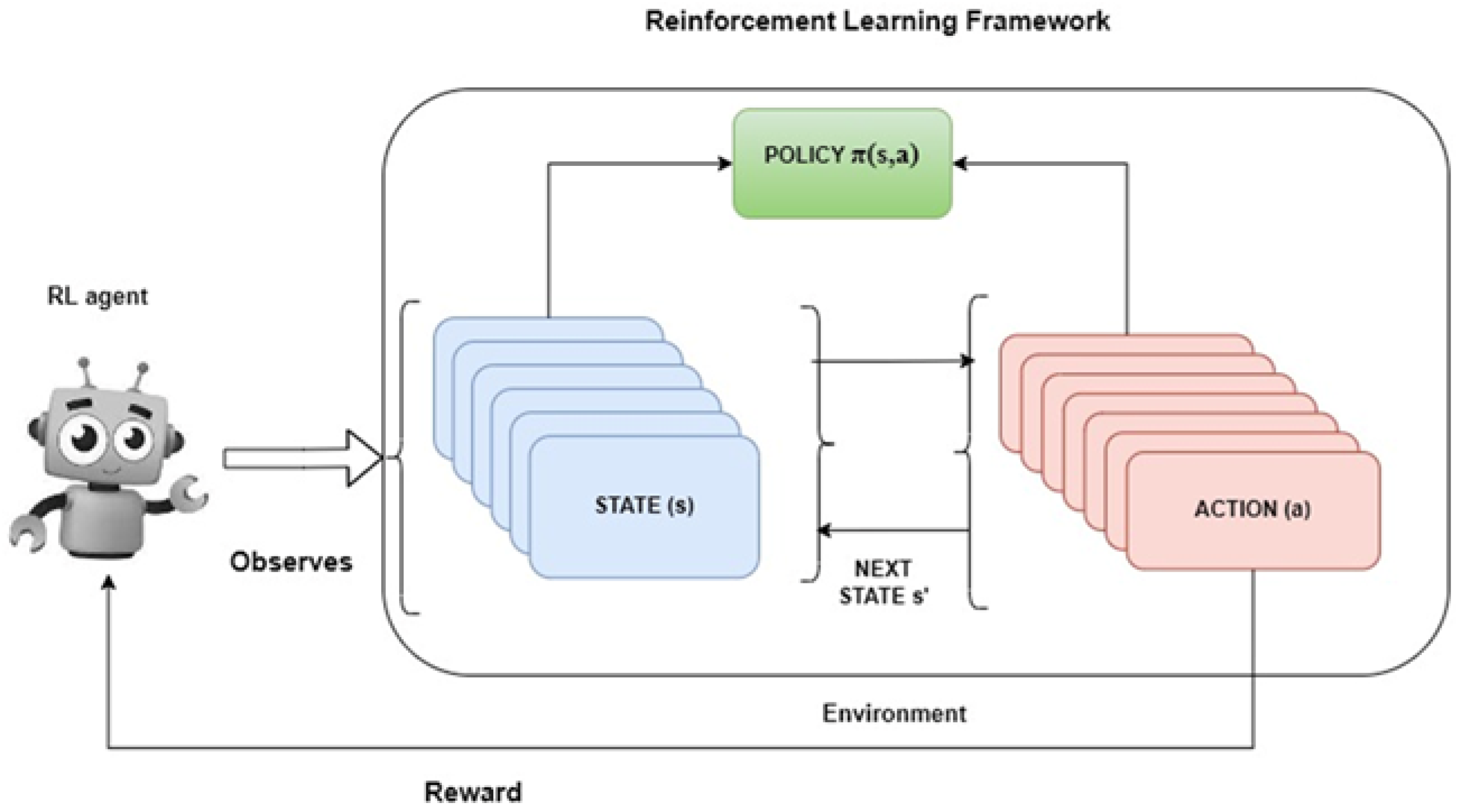
2. Reinforcement Learning Algorithms
2.1. Three Approaches to RL
2.2. Different Types of RL Algorithms
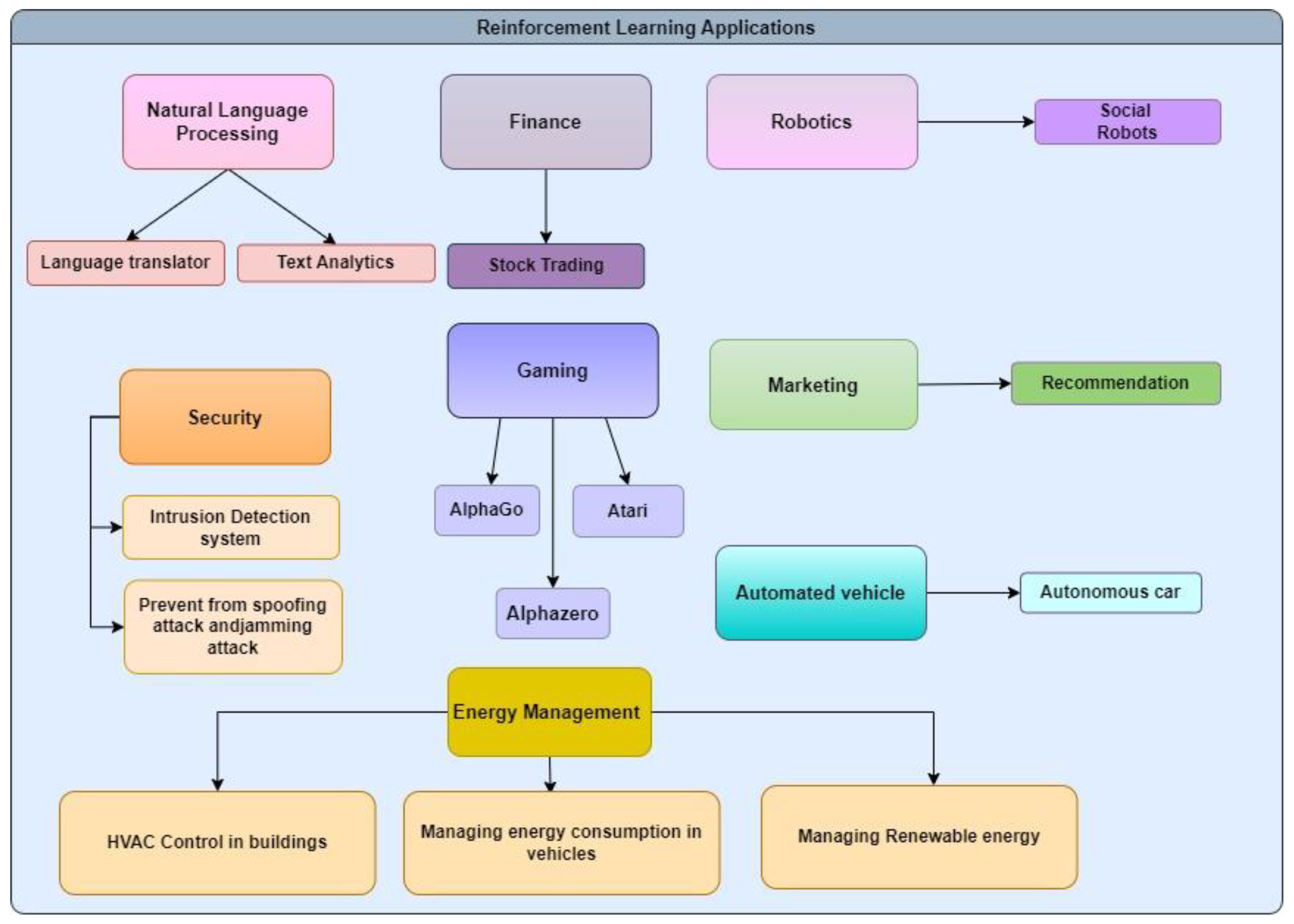
3. Reinforcement Learning Applications
3.1. Reinforcement Learning Applications in Recommendations
3.1.1. Deep Recommender Systems in Recommendations
3.1.2. Recommendation Using Contextual Bandits
3.2. Reinforcement Learning in Gaming
3.3. Reinforcement Learning in Automated Vehicles
3.4. Reinforcement Learning in Natural Language Processing (NLP)
3.5. Reinforcement Learning in the Internet of Things Security
3.6. Reinforcement Learning in Finance
3.6.1. Trading
3.6.2. Comparison between ML and RL in Credit Risk
3.7. Reinforcement Learning in Robotics
3.8. Reinforcement Learning in Healthcare
3.9. Inverse Reinforcement Learning (IRL)
3.10. Multi-Agent Reinforcement Learning (MARL)
3.11. Energy Management
3.11.1. HVAC Control in Buildings
3.11.2. Energy Management in Vehicles
3.11.3. Renewable Energy Management
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kadhim, A.I. Survey on Supervised Machine Learning Techniques. Artif. Intell. Rev. 2019, 52, 273–292. [Google Scholar] [CrossRef]
- Yau, K.A.; Elkhatib, Y.; Hussain, A.; Al-fuqaha, A.L.A. Unsupervised Machine Learning for Networking: Techniques, Applications and Research Challenges. IEEE Access 2019, 7, 65579–65615. [Google Scholar] [CrossRef]
- Singh, B.; Kumar, R.; Singh, V.P. Reinforcement Learning in Robotic Applications: A Comprehensive Survey. Artif. Intell. Rev. 2022, 55, 1–46. [Google Scholar] [CrossRef]
- Rao, S.; Verma, A.K.; Bhatia, T.A. Review on Social Spam Detection: Challenges, Open Issues, and Future Directions. Expert Syst. Appl. 2021, 186, 115742. [Google Scholar] [CrossRef]
- Sahil, S.; Zaidi, A.; Samar, M.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A Survey of Modern Deep Learning Based Object Detection Models. Digit. Signal Process. 2022, 126, 103514. [Google Scholar] [CrossRef]
- Bochenek, B.; Ustrnul, Z. Machine Learning in Weather Prediction and Climate Analyses—Applications and Perspectives. Atmosphere 2022, 13, 180. [Google Scholar] [CrossRef]
- Keerthana, S.; Santhi, B. Survey on Applications of Electronic Nose. J. Comput. Sci. 2020, 16, 314–320. [Google Scholar] [CrossRef]
- Razzaghi, P.; Tabrizian, A.; Guo, W.; Chen, S.; Taye, A.; Thompson, E.; Wei, P. A Survey on Reinforcement Learning in Aviation Applications. arXiv 2022, arXiv:2211.02147. [Google Scholar]
- Islek, I.; Gunduz, S. A Hierarchical Recommendation System for E-Commerce Using Online User Reviews. Electron. Commer. Res. Appl. 2022, 52, 101131. [Google Scholar] [CrossRef]
- Elangovan, R.; Vairavasundaram, S.; Varadarajan, V.; Ravi, L. Location-Based Social Network Recommendations with Computational Intelligence-Based Similarity Computation and User Check-in Behavior. Concurr. Comput. Pract. Exp. 2021, 33, 1–16. [Google Scholar] [CrossRef]
- Asik Ibrahim, N.; Rajalakshmi, E.; Vijayakumar, V.; Elakkiya, R.; Subramaniyaswamy, V. An Investigation on Personalized Point-of-Interest Recommender System for Location-Based Social Networks in Smart Cities. Adv. Sci. Technol. Secur. Appl. 2021, 275–294. [Google Scholar] [CrossRef]
- Afsar, M.M.; Crump, T.; Far, B. Reinforcement Learning Based Recommender Systems: A Survey. ACM Comput. Surv. 2022, 55, 1–38. [Google Scholar] [CrossRef]
- Adams, S.; Cody, T.; Beling, P.A. A Survey of Inverse Reinforcement Learning. Artif. Intell. Rev. 2022, 55, 4307–4346. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An introduction; Sutton Barto Second Book; MIT Press: Cambridge, MA, USA, 1998; Volume 258. [Google Scholar] [CrossRef]
- Liu, B.; Xie, Y.; Feng, L.; Fu, P. Engineering Applications of Artificial Intelligence Correcting Biased Value Estimation in Mixing Value-Based Multi-Agent Reinforcement Learning by Multiple Choice Learning. Eng. Appl. Artif. Intell. 2022, 116, 105329. [Google Scholar] [CrossRef]
- Yu, M.; Sun, S. Engineering Applications of Artificial Intelligence Policy-Based Reinforcement Learning for Time Series Anomaly Detection. Eng. Appl. Artif. Intell. 2020, 95, 103919. [Google Scholar] [CrossRef]
- Wei, Q.; Yang, Z.; Su, H.; Wang, L. Monte Carlo-Based Reinforcement Learning Control for Unmanned Aerial Vehicle Systems. Neurocomputing 2022, 507, 282–291. [Google Scholar] [CrossRef]
- Wang, Q.; Hao, Y.; Cao, J. Learning to Traverse over Graphs with a Monte Carlo Tree Search-Based Self-Play Framework. Eng. Appl. Artif. Intell. 2021, 105, 104422. [Google Scholar] [CrossRef]
- Ramicic, M.; Bonarini, A. Correlation Minimizing Replay Memory in Temporal-Difference Reinforcement Learning. Neurocomputing 2020, 393, 91–100. [Google Scholar] [CrossRef]
- Bertsekas, D. Results in Control and Optimization Multi-agent Value Iteration Algorithms in Dynamic Programming and Reinforcement Learning. Results Control Optim. 2020, 1, 100003. [Google Scholar] [CrossRef]
- van Eck, N.J.; van Wezel, M. Application of Reinforcement Learning to the Game of Othello. Comput. Oper. Res. 2008, 35, 1999–2017. [Google Scholar] [CrossRef]
- Maoudj, A.; Hentout, A. Optimal Path Planning Approach Based on Q-Learning Algorithm for Mobile Robots. Appl. Soft Comput. J. 2020, 97, 106796. [Google Scholar] [CrossRef]
- Aljohani, T.M.; Mohammed, O. A Real-Time Energy Consumption Minimization Framework for Electric Vehicles Routing Optimization Based on SARSA Reinforcement Learning. Vehicles 2022, 4, 1176–1194. [Google Scholar] [CrossRef]
- Lin, Y.; Feng, S.; Lin, F.; Zeng, W.; Liu, Y.; Wu, P. Adaptive Course Recommendation in MOOCs. Knowl.-Based Syst. 2021, 224, 107085. [Google Scholar] [CrossRef]
- Lin, Y.; Lin, F.; Zeng, W.; Xiahou, J.; Li, L.; Wu, P.; Liu, Y.; Miao, C. Hierarchical Reinforcement Learning with Dynamic Recurrent Mechanism for Course Recommendation. Knowl.-Based Syst. 2022, 244, 108546. [Google Scholar] [CrossRef]
- Tang, X.; Chen, Y.; Li, X.; Liu, J.; Ying, Z. A Reinforcement Learning Approach to Personalized Learning Recommendation Systems. Br. J. Math. Stat. Psychol. 2019, 72, 108–135. [Google Scholar] [CrossRef]
- Ke, G.; Du, H.L.; Chen, Y.C. Cross-Platform Dynamic Goods Recommendation System Based on Reinforcement Learning and Social Networks. Appl. Soft Comput. 2021, 104, 107213. [Google Scholar] [CrossRef]
- Chen, Y. Towards Smart Educational Recommendations with Reinforcement Learning in Classroom. In Proceedings of the IEEE International Conference on Teaching, Assessment, and Learning for Engineering (TALE), Wollongong, NSW, Australia, 4–7 December 2018; pp. 1079–1084. [Google Scholar] [CrossRef]
- Jiang, P.; Ma, J.; Zhang, J. Deep Reinforcement Learning Based Recommender System with State Representation. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; pp. 5703–5707. [Google Scholar] [CrossRef]
- Yuyan, Z.; Xiayao, S.; Yong, L. A Novel Movie Recommendation System Based on Deep Reinforcement Learning with Prioritized Experience Replay. In Proceedings of the 2019 IEEE 19th International Conference on Communication Technology (ICCT), Xi’an, China, 16–19 October 2019; pp. 1496–1500. [Google Scholar] [CrossRef]
- Fu, M.; Agrawal, A.; Irissappane, A.A.; Zhang, J.; Huang, L.; Qu, H. Deep Reinforcement Learning Framework for Category-Based Item Recommendation. IEEE Trans. Cybern. 2021, 52, 12028–12041. [Google Scholar] [CrossRef]
- Huang, L.; Fu, M.; Li, F.; Qu, H.; Liu, Y.; Chen, W. A Deep Reinforcement Learning Based Long-Term Recommender System. Knowl.-Based Syst. 2021, 213, 106706. [Google Scholar] [CrossRef]
- Zhao, X.; Xia, L.; Zhang, L.; Tang, J.; Ding, Z.; Yin, D. Recommendations with Negative Feedback via Pairwise Deep Reinforcement Learning. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1040–1048. [Google Scholar] [CrossRef]
- Gao, R.; Xia, H.; Li, J.; Liu, D.; Chen, S.; Chun, G. DRCGR: Deep Reinforcement Learning Framework Incorporating CNN and GAN-Based for Interactive Recommendation. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; pp. 1048–1053. [Google Scholar] [CrossRef]
- Zhou, F.; Luo, B.; Hu, T.; Chen, Z.; Wen, Y. A Combinatorial Recommendation System Framework Based on Deep Reinforcement Learning. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; pp. 5733–5740. [Google Scholar] [CrossRef]
- Lei, Y.; Li, W. Interactive Recommendation with User-Specific Deep Reinforcement Learning. ACM Trans. Knowl. Discov. Data 2019, 13, 1–15. [Google Scholar] [CrossRef]
- Guo, D.; Ktena, S.I.; Myana, P.K.; Huszar, F.; Shi, W.; Tejani, A.; Kneier, M.; Das, S. Deep Bayesian Bandits: Exploring in Online Personalized Recommendations. In Proceedings of the 14th ACM Conference on Recommender Systems, Virtual Event, Brazil, 22–26 September 2020; pp. 456–461. [Google Scholar] [CrossRef]
- Gan, M.; Kwon, O.C. A Knowledge-Enhanced Contextual Bandit Approach for Personalized Recommendation in Dynamic Domains. Knowl.-Based Syst. 2022, 251, 109158. [Google Scholar] [CrossRef]
- Pilani, A.; Mathur, K.; Agrawal, H.; Chandola, D.; Tikkiwal, V.A.; Kumar, A. Contextual Bandit Approach-Based Recommendation System for Personalized Web-Based Services. Appl. Artif. Intell. 2021, 35, 489–504. [Google Scholar] [CrossRef]
- Yan, C.; Xian, J.; Wan, Y.; Wang, P. Modeling Implicit Feedback Based on Bandit Learning for Recommendation. Neurocomputting 2021, 447, 244–256. [Google Scholar] [CrossRef]
- Wang, L.; Wang, C.; Wang, K.; He, X. BiUCB: A Contextual Bandit Algorithm for Cold-Start and Diversified Recommendation. In Proceedings of the 2017 IEEE International Conference on Big Knowledge (ICBK), Hefei, China, 9–10 August 2017; pp. 248–253. [Google Scholar] [CrossRef]
- Intayoad, W.; Kamyod, C.; Temdee, P. Reinforcement Learning Based on Contextual Bandits for Personalized Online Learning Recommendation Systems. Wirel. Pers. Commun. 2020, 115, 2917–2932. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Wang, M.; Wang, L.; Yue, T. An Application of Continuous Deep Reinforcement Learning Approach to Pursuit-Evasion Differential Game. In Proceedings of the 2019 IEEE 3rd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chengdu, China, 15–17 March 2019; pp. 1150–1156. [Google Scholar] [CrossRef]
- Rajendran, D.; Santhanam, P. Towards Digital Game-Based Learning Content with Multi-Objective Reinforcement Learning. Mater. Today Proc. 2021, 2214–7853. [Google Scholar] [CrossRef]
- Liu, S.; Cao, J.; Wang, Y.; Chen, W.; Liu, Y. Self-Play Reinforcement Learning with Comprehensive Critic in Computer Games. Neurocomputing 2021, 449, 207–213. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the Game of Go with Deep Neural Networks and Tree Search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. A General Reinforcement Learning Algorithm That Masters Chess, Shogi, and Go through Self-Play. Science 2018, 362, 1140–1144. [Google Scholar] [CrossRef]
- Núñez-molina, C.; Fernández-olivares, J.; Pérez, R. Learning to Select Goals in Automated Planning with Deep-Q Learning. Expert Syst. Appl. 2022, 202, 117265. [Google Scholar] [CrossRef]
- Gong, X.; Yu, J.; Lü, S.; Lu, H. Actor-Critic with Familiarity-Based Trajectory Experience Replay. Inf. Sci. 2022, 582, 633–647. [Google Scholar] [CrossRef]
- Badue, C.; Guidolini, R.; Carneiro, R.V.; Azevedo, P.; Cardoso, V.B.; Forechi, A.; Jesus, L.; Berriel, R.; Paixão, T.M.; Mutz, F.; et al. Self-Driving Cars: A Survey. Expert Syst. Appl. 2021, 165, 113816. [Google Scholar] [CrossRef]
- Cao, Z.; Xu, S.; Peng, H.; Yang, D.; Zidek, R. Confidence-Aware Reinforcement Learning for Self-Driving Cars. IEEE Trans. Intell. Transp. Syst. 2022, 23, 7419–7430. [Google Scholar] [CrossRef]
- Kim, M.-S.; Eoh, G.; Park, T.-H. Decision Making for Self-Driving Vehicles in Unexpected Environments Using Efficient Reinforcement Learning Methods. Electronics 2022, 11, 1685. [Google Scholar] [CrossRef]
- Uc-Cetina, V.; Navarro-Guerrero, N.; Martin-Gonzalez, A.; Weber, C.; Wermter, S. Survey on Reinforcement Learning for Language Processing. Artif. Intell. Rev. 2022, 1–33. [Google Scholar] [CrossRef]
- Alomari, A.; Idris, N.; Qalid, A.; Alsmadi, I. Deep Reinforcement and Transfer Learning for Abstractive Text Summarization: A Review. Comput. Speech Lang. 2022, 71, 101276. [Google Scholar] [CrossRef]
- Cuayáhuitl, H.; Lee, D.; Ryu, S.; Cho, Y.; Choi, S.; Indurthi, S.; Yu, S.; Choi, H.; Hwang, I.; Kim, J. Ensemble-Based Deep Reinforcement Learning for Chatbots. Neurocomputing 2019, 366, 118–130. [Google Scholar] [CrossRef]
- Uprety, A.; Rawat, D.B. Reinforcement Learning for IoT Security: A Comprehensive Survey. IEEE Internet Things J. 2021, 8, 8693–8706. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Reddi, V.J. Deep Reinforcement Learning for Cyber Security. IEEE Trans. Neural Networks Learn. Syst. 2021, 1–17. [Google Scholar] [CrossRef]
- Hu, Y.J.; Lin, S.J. Deep Reinforcement Learning for Optimizing Finance Portfolio Management. In Proceedings of the 2019 Amity International Conference on Artificial Intelligence (AICAI), Dubai, United Arab Emirates, 4–6 February 2019; pp. 14–20. [Google Scholar] [CrossRef]
- Wu, X.; Chen, H.; Wang, J.; Troiano, L.; Loia, V.; Fujita, H. Adaptive Stock Trading Strategies with Deep Reinforcement Learning Methods. Inf. Sci. 2020, 538, 142–158. [Google Scholar] [CrossRef]
- Chen, Y.F.; Huang, S.H. Sentiment-Influenced Trading System Based on Multimodal Deep Reinforcement Learning. Appl. Soft Comput. 2021, 112, 107788. [Google Scholar] [CrossRef]
- Lei, K.; Zhang, B.; Li, Y.; Yang, M.; Shen, Y. Time-Driven Feature-Aware Jointly Deep Reinforcement Learning for Financial Signal Representation and Algorithmic Trading. Expert Syst. Appl. 2020, 140, 1–14. [Google Scholar] [CrossRef]
- Jeong, G.; Young, H. Improving Financial Trading Decisions Using Deep Q-Learning: Predicting the Number of Shares, Action Strategies, and Transfer Learning. Expert Syst. Appl. 2019, 117, 125–138. [Google Scholar] [CrossRef]
- Liu, F.; Bing, X. Bitcoin Transaction Strategy Construction Based on Deep Reinforcement Learning. Appl. Soft Comput. 2021, 113, 5–8. [Google Scholar] [CrossRef]
- Kanashiro, L.; Caio, F.; Paiva, L.; Vita, C.; De Yathie, E.; Helena, A.; Costa, R.; Del-moral-hernandez, E.; Brandimarte, P. Outperforming Algorithmic Trading Reinforcement Learning Systems: A Supervised Approach to the Cryptocurrency Market. Expert Syst. Appl. 2022, 202, 117259. [Google Scholar]
- Serrano, W. Deep Reinforcement Learning with the Random Neural Network. Eng. Appl. Artif. Intell. 2022, 110, 104751. [Google Scholar] [CrossRef]
- Shavandi, A.; Khedmati, M. A Multi-Agent Deep Reinforcement Learning Framework for Algorithmic Trading in Financial Markets. Expert Syst. Appl. 2022, 208, 118124. [Google Scholar] [CrossRef]
- Carta, S.; Ferreira, A.; Podda, A.S.; Recupero, D.R.; Sanna, A. Multi-DQN: An Ensemble of Deep Q-Learning Agents for Stock Market Forecasting. Expert Syst. Appl. 2021, 164, 113820. [Google Scholar] [CrossRef]
- Kang, Q. An Asynchronous Advantage Actor-Critic Reinforcement Learning Method for Stock Selection and Portfolio Management. In Proceedings of the 2nd International Conference on Big Data Research, Weihai, China, 27–29 October 2018; pp. 141–145. [Google Scholar] [CrossRef]
- Srinath, T.; Gururaja, H.S. Explainable Machine Learning in Identifying Credit Card Defaulters. Glob. Transit. Proc. 2022, 3, 119–126. [Google Scholar] [CrossRef]
- Addo, P.M.; Guegan, D.; Hassani, B. Credit Risk Analysis Using Machine and Deep Learning Models. Risks 2018, 6, 1–20. [Google Scholar] [CrossRef]
- Dastile, X.; Celik, T.; Potsane, M. Statistical and Machine Learning Models in Credit Scoring: A Systematic Literature Survey. Appl. Soft Comput. J. 2020, 91, 106263. [Google Scholar] [CrossRef]
- Leo, M.; Sharma, S.; Maddulety, K. Machine Learning in Banking Risk Management: A Literature Review. Risks 2019, 7, 29. [Google Scholar] [CrossRef] [Green Version]
- Milojević, N.; Redzepagic, S. Prospects of Artificial Intelligence and Machine Learning Application in Banking Risk Management. J. Cent. Bank. Theory Pract. 2021, 10, 41–57. [Google Scholar] [CrossRef]
- Sabri, A. Reinforcement Learning on the Credit Risk-Based Pricing. In Proceedings of the 2021 2nd International Conference on Computational Methods in Science & Technology (ICCMST), Mohali, India, 17–18 December 2021; pp. 233–236. [Google Scholar] [CrossRef]
- Wang, Y.; Jia, Y.; Tian, Y.; Xiao, J. Deep Reinforcement Learning with the Confusion-Matrix-Based Dynamic Reward Function for Customer Credit Scoring. Expert Syst. Appl. 2022, 200, 117013. [Google Scholar] [CrossRef]
- Akalin, N.; Loutfi, A. Reinforcement Learning Approaches in Social Robotics. Sensors 2021, 21, 1–37. [Google Scholar] [CrossRef] [PubMed]
- Bagheri, E.; Roesler, O.; Cao, H.L.; Vanderborght, B. A Reinforcement Learning Based Cognitive Empathy Framework for Social Robots. Int. J. Soc. Robot. 2021, 13, 1079–1093. [Google Scholar] [CrossRef]
- Cao, X.; Sun, C.; Yan, M. Target Search Control of AUV in Underwater Environment with Deep Reinforcement Learning. IEEE Access 2019, 7, 96549–96559. [Google Scholar] [CrossRef]
- Zhu, K.; Zhang, T. Deep Reinforcement Learning Based Mobile Robot Navigation: A Review. Tsinghua Sci. Technol. 2021, 26, 674–691. [Google Scholar] [CrossRef]
- Sun, H.; Zhang, W.; Yu, R.; Zhang, Y. Motion Planning for Mobile Robots-Focusing on Deep Reinforcement Learning: A Systematic Review. IEEE Access 2021, 9, 69061–69081. [Google Scholar] [CrossRef]
- Gao, J.; Ye, W.; Guo, J.; Li, Z. Deep Reinforcement Learning for Indoor Mobile Robot Path Planning. Sensors 2020, 20, 1–15. [Google Scholar] [CrossRef]
- Wang, W.; Wu, Z.; Luo, H.; Zhang, B. Path Planning Method of Mobile Robot Using Improved Deep Reinforcement Learning. J. Electr. Comput. Eng. 2022, 2022, 1–7. [Google Scholar] [CrossRef]
- Guo, N.; Li, C.; Gao, T.; Liu, G.; Li, Y.; Wang, D. A Fusion Method of Local Path Planning for Mobile Robots Based on LSTM Neural Network and Reinforcement Learning. Math. Probl. Eng. 2021, 2021, 1–21. [Google Scholar] [CrossRef]
- Luong, M.; Pham, C. Incremental Learning for Autonomous Navigation of Mobile Robots Based on Deep Reinforcement Learning. J. Intell. Robot. Syst. 2021, 101, 1–11. [Google Scholar] [CrossRef]
- Manuel, J.; Delgado, D.; Oyedele, L. Advanced Engineering Informatics Robotics in Construction: A Critical Review of the Reinforcement Learning and Imitation Learning Paradigms. Adv. Eng. Informatics 2022, 54, 101787. [Google Scholar] [CrossRef]
- Liu, Z.; Yao, C.; Yu, H.; Wu, T. Deep Reinforcement Learning with Its Application for Lung Cancer Detection in Medical Internet of Things. Futur. Gener. Comput. Syst. 2019, 97, 1–9. [Google Scholar] [CrossRef]
- Wang, L.; He, X.; Zhang, W.; Zha, H. Supervised Reinforcement Learning with Recurrent Neural Network for Dynamic Treatment Recommendation. Proc. ACM SIGKDD Int. Conf. Knowl. Discov. Data Min. 2018, 2447–2456. [Google Scholar] [CrossRef]
- Coronato, A.; Naeem, M.; Pietro, G.; De Paragliola, G. Reinforcement Learning for Intelligent Healthcare Applications: A Survey. Artif. Intell. Med. 2020, 109, 101964. [Google Scholar] [CrossRef]
- Wang, L.; Xi, S.; Qian, Y.; Huang, C. A Context-Aware Sensing Strategy with Deep Reinforcement Learning for Smart Healthcare. Pervasive Mob. Comput. 2022, 83, 101588. [Google Scholar] [CrossRef]
- Ho, S.; Jin, S.; Park, J. Knowledge-Based Systems Effective Data-Driven Precision Medicine by Cluster-Applied Deep Reinforcement Learning. Knowl.-Based Syst. 2022, 256, 109877. [Google Scholar] [CrossRef]
- Ho, S.; Park, J.; Jin, S.; Kang, S.; Mo, J. Reinforcement Learning-Based Expanded Personalized Diabetes Treatment Recommendation Using South Korean Electronic Health Records. Expert Syst. Appl. 2022, 206, 117932. [Google Scholar] [CrossRef]
- Liu, S.; Jiang, H. Personalized Route Recommendation for Ride-Hailing with Deep Inverse Reinforcement Learning and Real-Time Traffic Conditions. Transp. Res. Part E 2022, 164, 102780. [Google Scholar] [CrossRef]
- Self, R.; Abudia, M.; Mahmud, S.M.N.; Kamalapurkar, R. Model-Based Inverse Reinforcement Learning for Deterministic. Automatica 2022, 140, 110242. [Google Scholar] [CrossRef]
- Lian, B.; Xue, W.; Lewis, F.L.; Chai, T. Inverse Reinforcement Learning for Multiplayer Non-cooperative Apprentice Games. Automatica 2022, 145, 110524. [Google Scholar] [CrossRef]
- Lian, B.; Donge, V.S.; Member, G.S.; Lewis, F.L.; Fellow, L.; Chai, T.; Fellow, L.; Davoudi, A.; Member, S. Data-Driven Inverse Reinforcement Learning Control for Linear Multiplayer Games. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Jiang, H.; Chen, S.; Ye, J.; He, R.; Sun, Z. Integrating Dijkstra’ s Algorithm into Deep Inverse Reinforcement Learning for Food Delivery Route Planning. Transp. Res. Part E 2020, 142, 102070. [Google Scholar] [CrossRef]
- Hoiles, W.; Krishnamurthy, V.; Pattanayak, K. Rationally Inattentive Inverse Reinforcement Learning Explains Youtube Commenting Behavior. J. Mach. Learn. Res. 2020, 21, 1–39. [Google Scholar]
- Zhu, R.; Li, L.; Wu, S.; Lv, P.; Li, Y.; Xu, M. Multi-Agent Broad Reinforcement Learning for Intelligent Traffic Light Control. Inf. Sci. 2023, 619, 509–525. [Google Scholar] [CrossRef]
- Zhang, J.; He, Z.; Chan, W.; Chow, C. Knowledge-Based Systems DeepMAG: Deep Reinforcement Learning with Multi-Agent Graphs for Flexible Job Shop Scheduling. Knowl.-Based Syst. 2023, 259, 110083. [Google Scholar] [CrossRef]
- Shou, Z.; Chen, X.; Fu, Y.; Di, X. Multi-Agent Reinforcement Learning for Markov Routing Games: A New Modeling Paradigm for Dynamic Traffic Assignment. Transp. Res. Part C 2022, 137, 103560. [Google Scholar] [CrossRef]
- Luis, M.; Rodríguez, R.; Kubler, S.; Giorgio, A.D.; Cordy, M.; Robert, J.; Le, Y. Robotics and Computer-Integrated Manufacturing Multi-Agent Deep Reinforcement Learning Based Predictive Maintenance on Parallel Machines. Robot. Comput. Integr. Manuf. 2022, 78, 102406. [Google Scholar] [CrossRef]
- Hao, D.; Zhang, D.; Shi, Q.; Li, K. Entropy Regularized Actor-Critic Based Multi-Agent Deep Reinforcement Learning for Stochastic Games. Inf. Sci. 2022, 617, 17–40. [Google Scholar] [CrossRef]
- Kim, S.; Lim, H. Reinforcement Learning Based Energy Management Algorithm for Smart Energy Buildings. Energies 2019, 11, 2010. [Google Scholar] [CrossRef] [Green Version]
- Rocchetta, R.; Bellani, L.; Compare, M.; Zio, E.; Patelli, E. A Reinforcement Learning Framework for Optimal Operation and Maintenance of Power Grids. Appl. Energy 2019, 241, 291–301. [Google Scholar] [CrossRef]
- Fu, Q.; Han, Z.; Chen, J.; Lu, Y.; Wu, H.; Wang, Y. Applications of Reinforcement Learning for Building Energy Efficiency Control: A Review. J. Build. Eng. 2022, 50, 104165. [Google Scholar] [CrossRef]
- Duhirwe, P.N.; Ngarambe, J.; Yun, G.Y. ScienceDirect Energy-Efficient Virtual Sensor-Based Deep Reinforcement Learning Control of Indoor CO2 in a Kindergarten. Front. Archit. Res. 2022. [Google Scholar] [CrossRef]
- Ding, H.; Xu, Y.; Chew, B.; Hao, S.; Li, Q.; Lentzakis, A. A Safe Reinforcement Learning Approach for Multi-Energy Management of Smart Home. Electr. Power Syst. Res. 2022, 210, 108120. [Google Scholar] [CrossRef]
- Fu, Q.; Chen, X.; Ma, S.; Fang, N.; Xing, B.; Chen, J. Optimal Control Method of HVAC Based on Multi-Agent Deep Reinforcement Learning. Energy Build. 2022, 270, 112284. [Google Scholar] [CrossRef]
- Yu, L.; Sun, Y.; Xu, Z.; Shen, C.; Member, S. Multi-Agent Deep Reinforcement Learning for HVAC Control in Commercial Buildings. IEEE Trans. Smart Grid 2021, 12, 407–419. [Google Scholar] [CrossRef]
- Esrafilian-Najafabadi, M.; Haghighat, F. Towards Self-Learning Control of HVAC Systems with the Consideration of Dynamic Occupancy Patterns: Application of Model-Free Deep Reinforcement Learning. Build. Environ. 2022, 226, 109747. [Google Scholar] [CrossRef]
- Biemann, M.; Scheller, F.; Liu, X.; Huang, L. Experimental Evaluation of Model-Free Reinforcement Learning Algorithms for Continuous HVAC Control. Appl. Energy 2021, 298, 117164. [Google Scholar] [CrossRef]
- Deng, Z.; Chen, Q. Reinforcement Learning of Occupant Behavior Model for Cross-Building Transfer Learning to Various HVAC Control Systems. Energy Build. 2021, 238, 110860. [Google Scholar] [CrossRef]
- Du, Y.; Li, F.; Munk, J.; Kurte, K.; Kotevska, O.; Amasyali, K.; Zandi, H. Multi-Task Deep Reinforcement Learning for Intelligent Multi-Zone Residential HVAC Control. Electr. Power Syst. Res. 2021, 192, 106959. [Google Scholar] [CrossRef]
- Weinberg, D.; Wang, Q.; Timoudas, T.O.; Fischione, C. A Review of Reinforcement Learning for Controlling Building Energy Systems From a Computer Science Perspective. Sustain. Cities Soc. 2023, 89, 104351. [Google Scholar] [CrossRef]
- Lei, Y.; Zhan, S.; Ono, E.; Peng, Y.; Zhang, Z.; Hasama, T.; Chong, A. A Practical Deep Reinforcement Learning Framework for Multi-variate Occupant-Centric Control in Buildings. Appl. Energy 2022, 324, 119742. [Google Scholar] [CrossRef]
- Yu, L.; Xu, Z.; Zhang, T.; Guan, X.; Yue, D. Energy-Efficient Personalized Thermal Comfort Control in Office Buildings Based on Multi-Agent Deep Reinforcement Learning. Build. Environ. 2022, 223, 109458. [Google Scholar] [CrossRef]
- Naug, A.; Quinones-Grueiro, M.; Biswas, G. Deep Reinforcement Learning Control for Non-Stationary Building Energy Management. Energy Build. 2022, 277, 112584. [Google Scholar] [CrossRef]
- Lv, H.; Qi, C.; Song, C.; Song, S.; Zhang, R.; Xiao, F. Energy Management of Hybrid Electric Vehicles Based on Inverse Reinforcement Learning. Energy Rep. 2022, 8, 5215–5224. [Google Scholar] [CrossRef]
- Drungilas, D.; Kurmis, M.; Senulis, A.; Lukosius, Z.; Andziulis, A.; Januteniene, J.; Bogdevicius, M.; Jankunas, V.; Voznak, M. Deep Reinforcement Learning Based Optimization of Automated Guided Vehicle Time and Energy Consumption in a Container Terminal. Alexandria Eng. J. 2023, 67, 397–407. [Google Scholar] [CrossRef]
- Huo, W.; Chen, D.; Tian, S.; Li, J.; Zhao, T.; Liu, B. Lifespan-Consciousness and Minimum-Consumption Coupled Energy Management Strategy for Fuel Cell Hybrid Vehicles via Deep Reinforcement Learning. Int. J. Hydrog. Energy 2022, 47, 24026–24041. [Google Scholar] [CrossRef]
- Wang, J.; Zhou, J.; Zhao, W. Deep Reinforcement Learning Based Energy Management Strategy for Fuel Cell/Battery/Supercapacitor Powered Electric Vehicle. Green Energy Intell. Transp. 2022, 1, 100028. [Google Scholar] [CrossRef]
- Lee, H.; Kim, K.; Kim, N.; Cha, S.W. Energy Efficient Speed Planning of Electric Vehicles for Car-Following Scenario Using Model-Based Reinforcement Learning. Appl. Energy 2022, 313, 118460. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, Y.; Tang, Y.; Li, Q.; He, H. Cooperative Energy Management and Eco-Driving of Plug-in Hybrid Electric Vehicle via Multi-Agent Reinforcement Learning. Appl. Energy 2023, 332, 120563. [Google Scholar] [CrossRef]
- Gao, Y.; Matsunami, Y.; Miyata, S.; Akashi, Y. Operational Optimization for Off-Grid Renewable Building Energy System Using Deep Reinforcement Learning. Appl. Energy 2022, 325, 119783. [Google Scholar] [CrossRef]
- Yi, Z.; Luo, Y.; Westover, T.; Katikaneni, S.; Ponkiya, B.; Sah, S.; Mahmud, S.; Raker, D.; Javaid, A.; Heben, M.J.; et al. Deep Reinforcement Learning Based Optimization for a Tightly Coupled Nuclear Renewable Integrated Energy System. Appl. Energy 2022, 328, 120113. [Google Scholar] [CrossRef]
- Dreher, A.; Bexten, T.; Sieker, T.; Lehna, M.; Schütt, J.; Scholz, C.; Wirsum, M. AI Agents Envisioning the Future: Forecast-Based Operation of Renewable Energy Storage Systems Using Hydrogen with Deep Reinforcement Learning. Energy Convers. Manag. 2022, 258, 115401. [Google Scholar] [CrossRef]
- Fernandez-gauna, B.; Graña, M.; Osa-amilibia, J.; Larrucea, X. Actor-Critic Continuous State Reinforcement Learning for Wind-Turbine Control Robust Optimization. Inf. Sci. 2022, 591, 365–380. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| S. No | References | Product | Datasets | Model |
|---|---|---|---|---|
| 1 | [24] | Courses | MOOC | Dynamic attention and hierarchical reinforcement Learning (DARL) |
| 2 | [25] | Courses | MOOCCourse and MOOCCube | Hierarchical reinforcement learning with a dynamic recurrent mechanism |
| 3 | [29] | E-commerce items | Item-info, trainset, and track2_testset | Actor-critic with state representation |
| 4 | [30] | Movies | MovieLens | Deep Q network |
| 5 | [31] | Movies | MovieLens and Netflix | Deep Q network |
| 6 | [32] | Movies | MovieLens 100K, MovieLens 1M and Steam | Recurrent neural network |
| 7 | [33] | E-commerce items | JD.com(E-commerce website) | Deep Q network |
| 8 | [34] | E-commerce items | E-commerce website | Deep Q network with CNN and GAN |
| 9 | [35] | E-commerce items | E-commerce website | LSTM and DDPG |
| 10 | [36] | Movies and Music | ML100K, ML1M, and YMusic | User-specific deep Q-learning |
| 11 | [37] | Advertisements | ADS-16 | Deep bayesian bandits |
| 12 | [38] | E-commerce items | Amazon book and Yelp2018 | Knowledge-enhanced Ke-LinUCB |
| 13 | [39] | News and Movies | Yahoo Front Page Today Module, Lastfm, and MovieLens20M | LinUCB, Hybrid-LinUCB, and CoLin |
| 14 | [40] | Item | Yoochoose, IJCAI-15 Retailrocket | Thompson sampling |
| 15 | [41] | Movies | MovieLens | BiUCB (Binary upper confidence bound) |
| S. No | References | Application | Algorithm |
|---|---|---|---|
| 1 | [21] | Othello game | Q-learning |
| 2 | [43] | Atari 2600 games | Convolutional neural network with Q-learning |
| 3 | [44] | Pursuit-Evasion differential game | Deep deterministic policy gradient |
| 4 | [47] | AlphaGo | Deep neural network and Monte Carlo |
| 5 | [48] | AlphaZero | Monte Carlo tree search |
| 6 | [49] | Boulder Dash game | Deep Q network |
| S. No | References | Datasets Source | Model | Performance Measures |
|---|---|---|---|---|
| 1 | [62] | Yahoo Finance | Time-driven feature-aware jointly deep reinforcement learning model | Total profit, transaction times, the annualized rate of return, and sharp ratio |
| 2 | [63] | Thomson Reuters and Yahoo Finance | Deep neural network regressor and DQN (Deep Q network) | Total profit |
| 3 | [64] | Cryptodatadownload | LSTM and PPO | Profit rate |
| 4 | [66] | UK house prices, Gold, Bitcoin, FTSE, and Brent oil Market Validation | DRL with random neural network | Accuracy, RSME, MAE, MAPE |
| 5 | [67] | Forex | Multi-agent DQN | Sharp ratio, average cumulative return, maximum cumulative return, minimum cumulative return, etc. |
| 6 | [68] | Standard & Poor’s 500 (S&P500) and the German stock index (DAX) | Q-learning | Equity curve, accuracy, coverage, maximum drawdown, and Sortino ratio |
| S. No | References | Applications | Algorithms |
|---|---|---|---|
| 1 | [109] | Water cooling system | Multi-agent DRL |
| 2 | [110] | HVAC control in commercial buildings | Multi-agent DRL with actor attention critic |
| 3 | [111] | Control of HVAC considering dynamic occupant patterns | Double deep Q networks |
| 4 | [112] | HVAC control by maintaining the thermal stability | Actor-critic |
| 5 | [113] | HVAC control based on occupant behaviour for different buildings | Q-learning |
| 6 | [114] | Multi-zone HVAC control | Deep deterministic policy gradient |
| 7 | [116] | Multi-variant occupant-centric HVAC | Branching dueling Q-network |
| 8 | [117] | HVAC control in office buildings | Attention-based multi-agent DRL |
| 9 | [118] | HVAC control for non-stationary buildings | A deep reinforcement learning model |
| S. No | References | Applications | Algorithms |
|---|---|---|---|
| 1 | [120] | Automated guided vehicle | Actor-critic and DDPG |
| 2 | [121] | Reducing the fuel consumption in hybrid vehicles | Deep Q-learning and DDPG |
| 3 | [122] | Energy management strategy for logistic trucks | TD3 |
| 4 | [123] | Energy-efficient eco-driving by controlling the speed in electric vehicles | Q-learning |
| 5 | [124] | Eco-driving in hybrid electric vehicles | MARL using SAC |
| S. No | References | Applications | Algorithms |
|---|---|---|---|
| 1 | [125] | Off-grid optimization of renewable energy | TD3 and DDPG |
| 2 | [126] | Nuclear renewable integrated energy system optimization | TD3, PPO, SAC |
| 3 | [127] | Storage systems of renewable energy | PPO |
| 4 | [128] | Control of wind turbines | Actor-Critic |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sivamayil, K.; Rajasekar, E.; Aljafari, B.; Nikolovski, S.; Vairavasundaram, S.; Vairavasundaram, I. A Systematic Study on Reinforcement Learning Based Applications. Energies 2023, 16, 1512. https://doi.org/10.3390/en16031512
Sivamayil K, Rajasekar E, Aljafari B, Nikolovski S, Vairavasundaram S, Vairavasundaram I. A Systematic Study on Reinforcement Learning Based Applications. Energies. 2023; 16(3):1512. https://doi.org/10.3390/en16031512
Chicago/Turabian StyleSivamayil, Keerthana, Elakkiya Rajasekar, Belqasem Aljafari, Srete Nikolovski, Subramaniyaswamy Vairavasundaram, and Indragandhi Vairavasundaram. 2023. "A Systematic Study on Reinforcement Learning Based Applications" Energies 16, no. 3: 1512. https://doi.org/10.3390/en16031512
APA StyleSivamayil, K., Rajasekar, E., Aljafari, B., Nikolovski, S., Vairavasundaram, S., & Vairavasundaram, I. (2023). A Systematic Study on Reinforcement Learning Based Applications. Energies, 16(3), 1512. https://doi.org/10.3390/en16031512