
Six Days Ahead Forecasting of Energy Production of Small Behind-the-Meter Solar Sites


Abstract
:1. Introduction
2. Literature Review
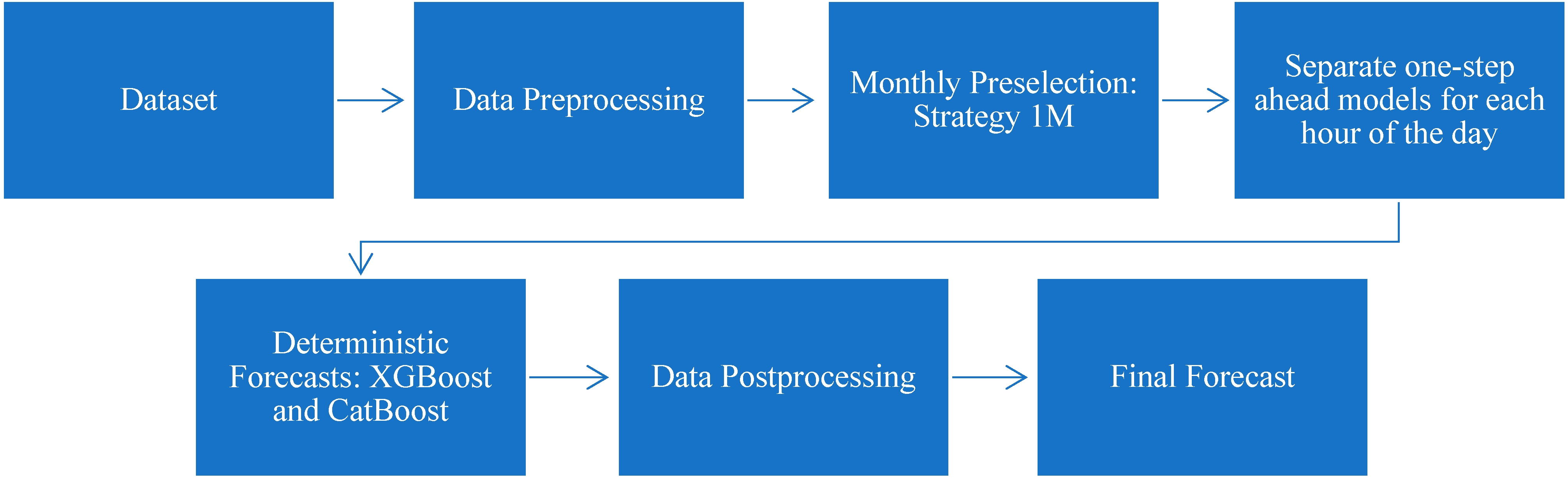
3. Proposed Solar Power Forecasting Methodology
3.1. Dataset
3.2. Data Preprocessing
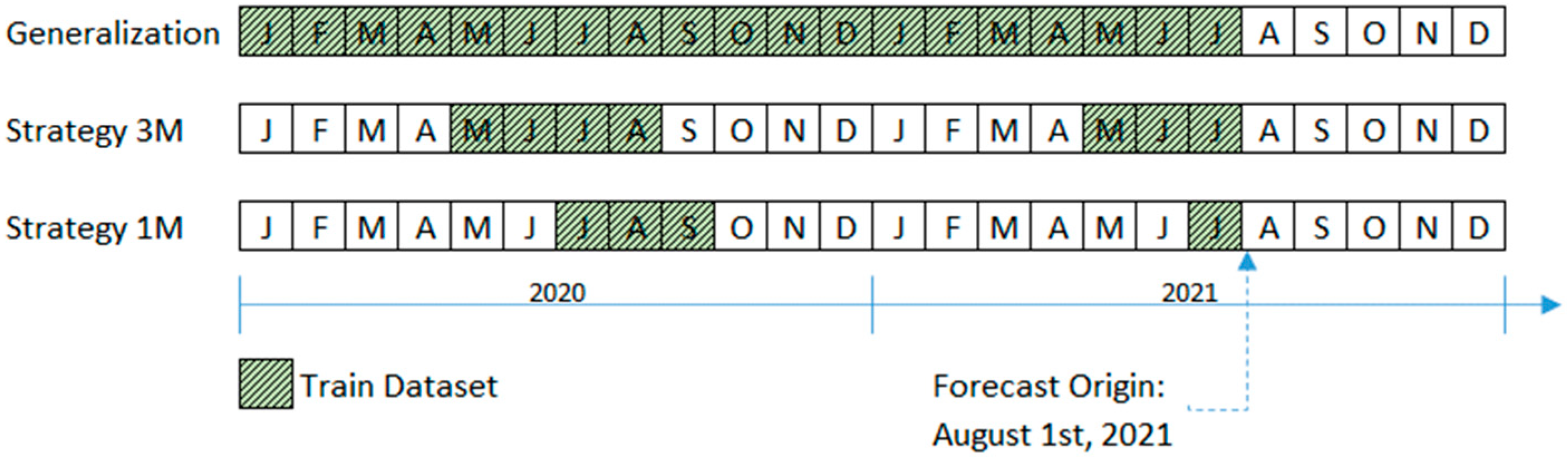
3.3. Monthly Preselection
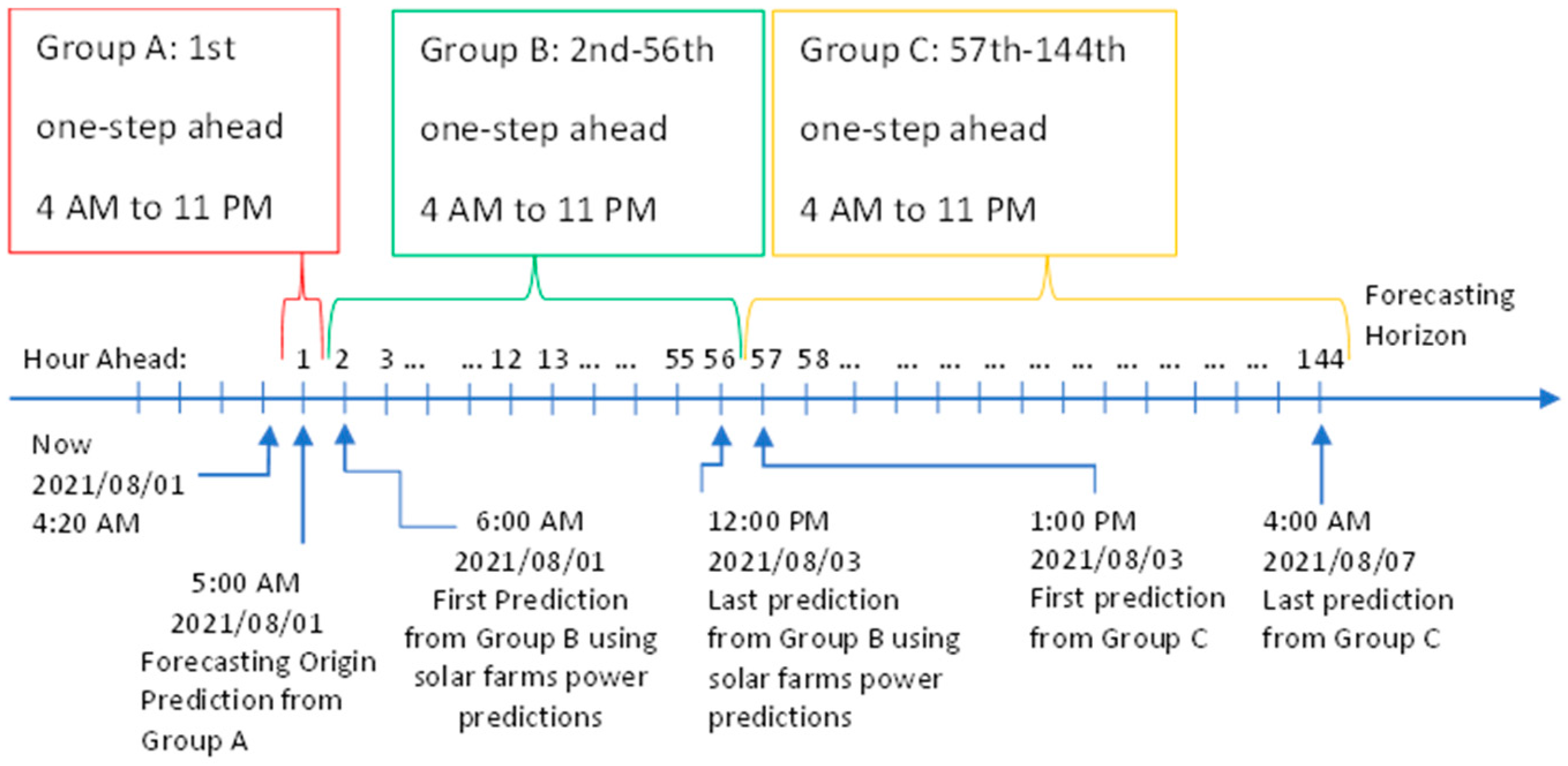
3.4. Separate One-Step Ahead Models for Each Hour of the Day
3.4.1. Group A: One-Step Ahead for the 1st Hour Ahead Framework
3.4.2. Group B: One-Step Ahead for 2nd to 56th Hour Ahead Framework
3.4.3. Group C: One-Step Ahead for 57th to 144th Hour Ahead Framework
3.5. Deterministic Forecast
- XGBoost (XGB) [32], or the eXtreme Gradient Boosting, is an evolution implementation of the gradient tree boosting (GB), which is a technique first introduced in 2000 by the authors of [33]. XGBoost gained recognition in several data mining challenges and machine learning competitions. For example, in 2017, one of the five best teams in The Global Energy Forecasting Competition 2017 (GEFCom2017) used XGBoost to solve a hierarchical probabilistic load forecasting problem. The technique is a gradient boosted tree algorithm, a supervised learning method capable of fitting generic nonparametric predictive models. For XGBoost, a search for the hyperparameters with RandomizedSearchCV class and GridSearchCV class from Scikitlearn is performed.
- CatBoost (CTB), or categorical boosting [34], is an open-source machine learning tool developed in Germany in 2017. The authors claim that this updated method outperforms the existing state-of-the-art implementations of gradient-boosted decision trees XGBoost. CatBoost proposes ordered boosting, a modification of the standard gradient boosting algorithm that avoids both a target leakage and prediction shift, with a new algorithm for processing categorical features. It presents three main advantages: First, it can integrate data types, such as numerical, images, audio, and text features. Second, it can simplify the feature engineering process since it requires minimal categorical feature transformation. Finally, it has a built-in hyperparameter optimization, which simplifies the learning process while increasing the overall speed of the model.
4. Numerical Results
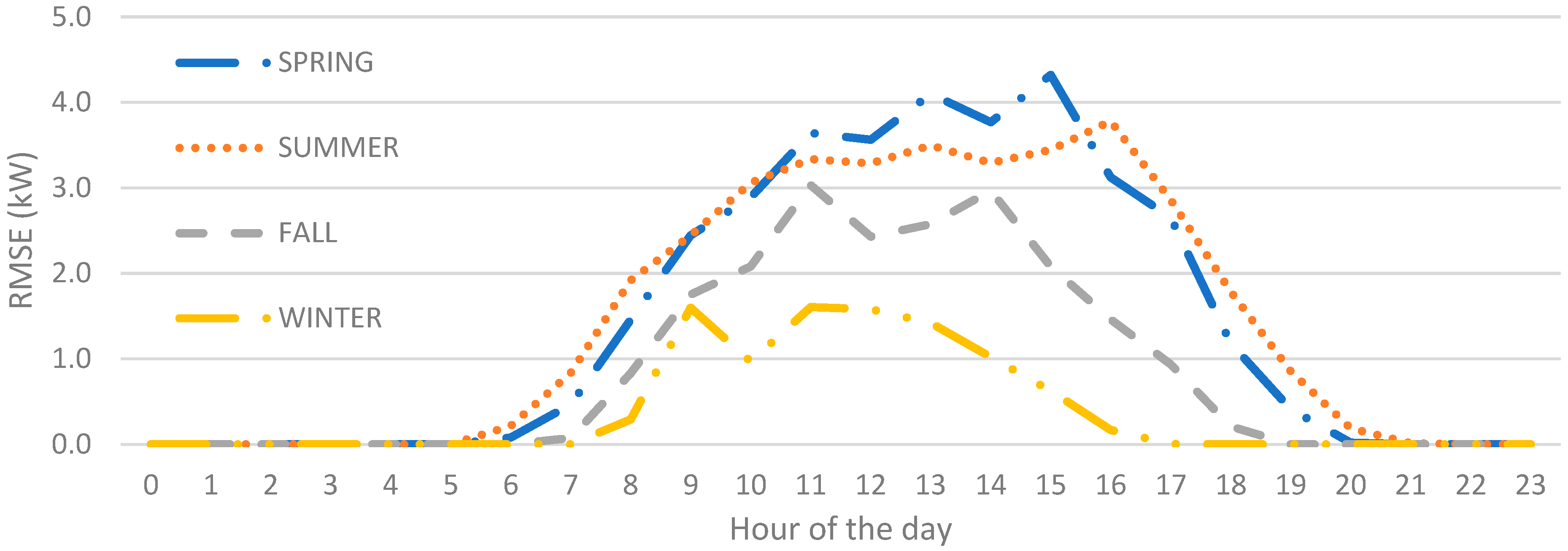
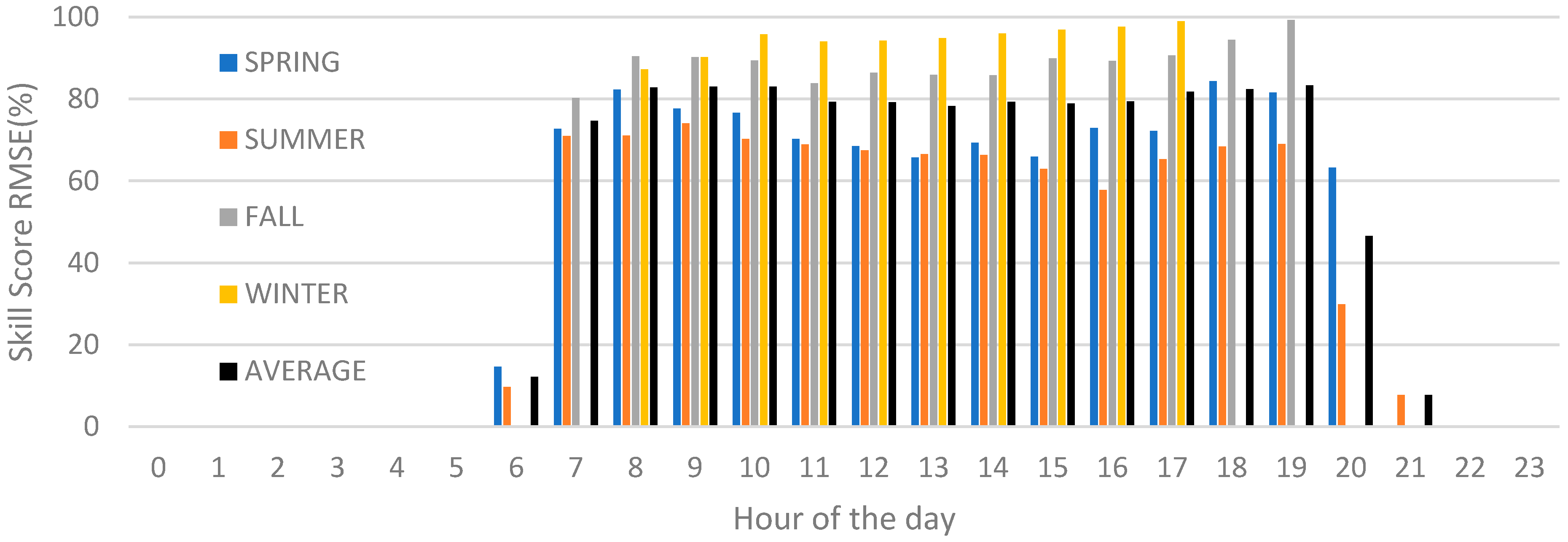
4.1. Evaluation Criteria
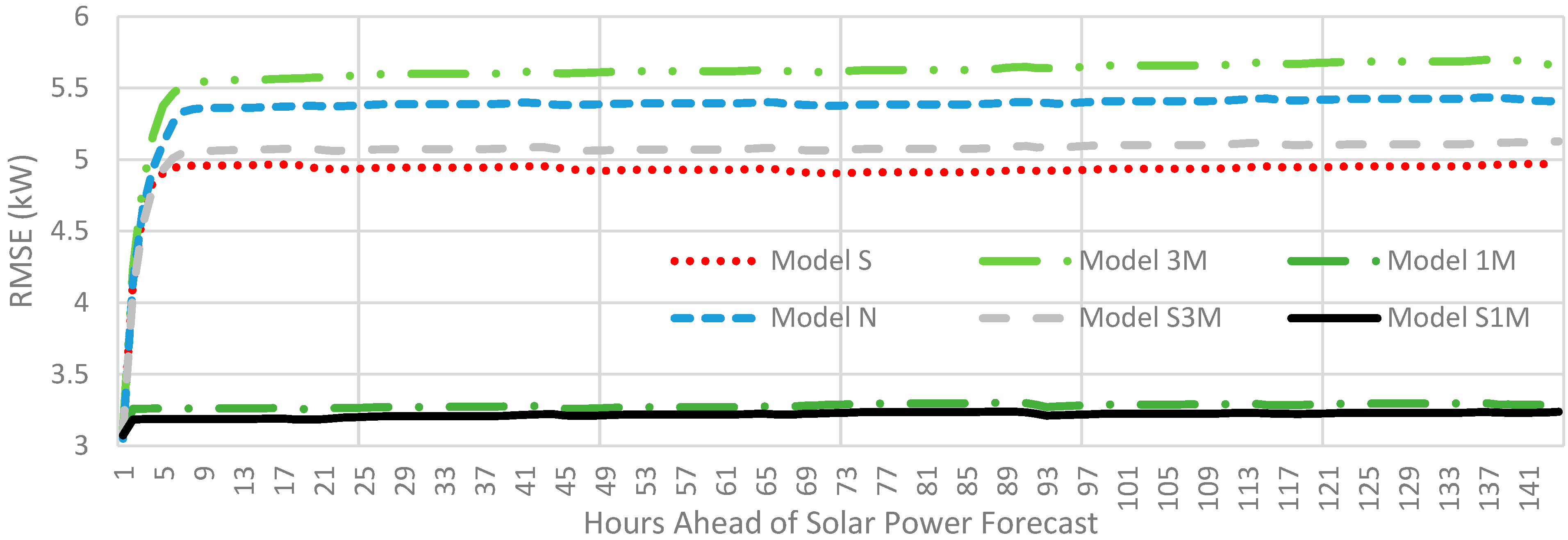
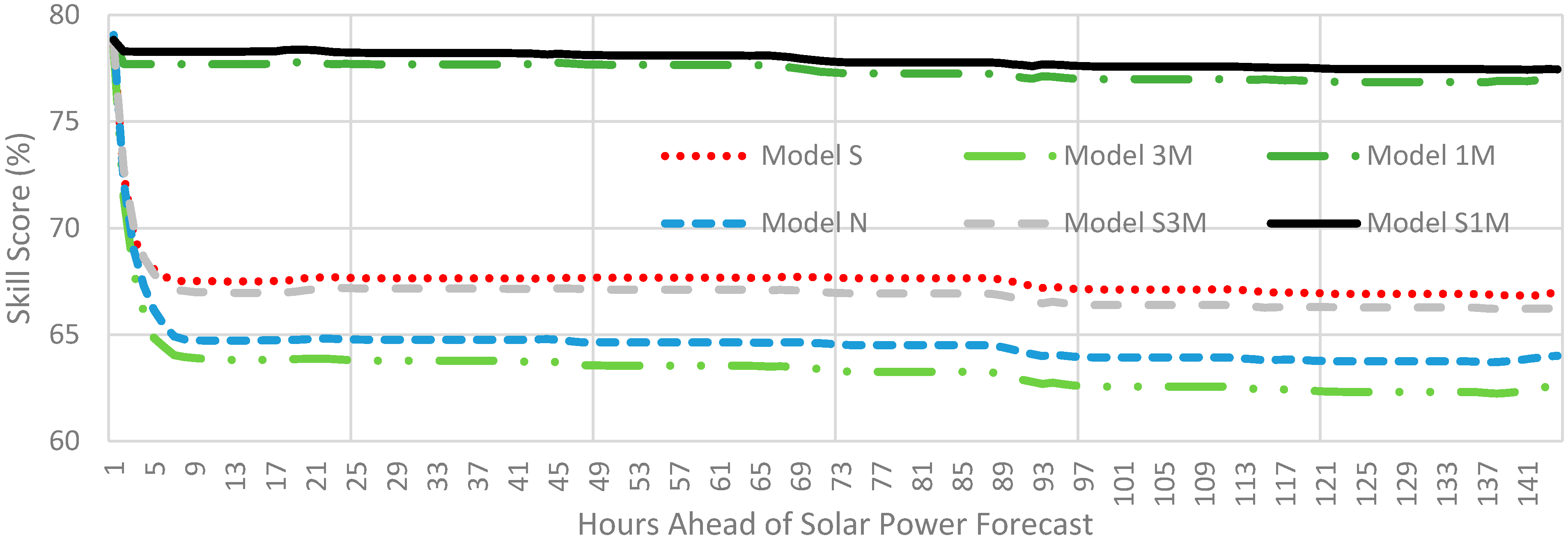
4.2. Benchmark
4.3. Test Design
5. Conclusions
Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Masson, G. International Energy Agency Snapshot. 2022. Available online: https://iea-pvps.org/snapshot-reports/snapshot-2022/ (accessed on 11 August 2022).
- Haupt, S.E.; Dettling, S.; Williams, J.K.; Pearson, J.; Jensen, T.; Brummet, T.; Kosovic, B.; Wiener, G.; McCandless, T.; Burghardt, C. Blending Distributed Photovoltaic and Demand Load Forecasts. Sol. Energy 2017, 157, 542–551. [Google Scholar] [CrossRef]
- Chu, Y.; Pedro, H.T.C.; Kaur, A.; Kleissl, J.; Coimbra, C.F.M. Net Load Forecasts for Solar-Integrated Operational Grid Feeders. Sol. Energy 2017, 158, 236–246. [Google Scholar] [CrossRef]
- Kaur, A.; Nonnenmacher, L.; Pedro, H.T.C.; Coimbra, C.F.M. Benefits of Solar Forecasting for Energy Imbalance Markets. Renew. Energy 2016, 86, 819–830. [Google Scholar] [CrossRef]
- Mellit, A.; Pavan, A.M.; Ogliari, E.; Leva, S.; Lughi, V. Advanced Methods for Photovoltaic Output Power Forecasting: A Review. Appl. Sci. 2020, 10, 487. [Google Scholar] [CrossRef]
- Dolara, A.; Grimaccia, F.; Leva, S.; Mussetta, M.; Ogliari, E. A Physical Hybrid Artificial Neural Network for Short Term Forecasting of PV Plant Power Output. Energies 2015, 8, 1138–1153. [Google Scholar] [CrossRef]
- Cervone, G.; Clemente-Harding, L.; Alessandrini, S.; Delle Monache, L. Short-Term Photovoltaic Power Forecasting Using Artificial Neural Networks and an Analog Ensemble. Renew. Energy 2017, 108, 274–286. [Google Scholar] [CrossRef]
- Yagli, G.M.; Yang, D.; Srinivasan, D. Automatic Hourly Solar Forecasting Using Machine Learning Models. Renew. Sustain. Energy Rev. 2019, 105, 487–498. [Google Scholar] [CrossRef]
- Zhang, X.; Li, Y.; Lu, S.; Hamann, H.F.; Hodge, B.M.; Lehman, B. A Solar Time Based Analog Ensemble Method for Regional Solar Power Forecasting. IEEE Trans. Sustain. Energy 2019, 10, 268–279. [Google Scholar] [CrossRef]
- Wolff, B.; Kühnert, J.; Lorenz, E.; Kramer, O.; Heinemann, D. Comparing Support Vector Regression for PV Power Forecasting to a Physical Modeling Approach Using Measurement, Numerical Weather Prediction, and Cloud Motion Data. Sol. Energy 2016, 135, 197–208. [Google Scholar] [CrossRef]
- Mellit, A.; Massi Pavan, A.; Lughi, V. Short-Term Forecasting of Power Production in a Large-Scale Photovoltaic Plant. Sol. Energy 2014, 105, 401–413. [Google Scholar] [CrossRef]
- Yang, C.; Xie, L. A Novel ARX-Based Multi-Scale Spatio-Temporal Solar Power Forecast Model. In Proceedings of the 2012 North American Power Symposium, NAPS 2012, Champaign, IL, USA, 9–11 September 2012. [Google Scholar] [CrossRef]
- Goncalves, C.; Bessa, R.J.; Pinson, P. Privacy-Preserving Distributed Learning for Renewable Energy Forecasting. IEEE Trans. Sustain. Energy 2021, 12, 1777–1787. [Google Scholar] [CrossRef]
- Antonanzas, J.; Osorio, N.; Escobar, R.; Urraca, R.; Martinez-de-Pison, F.J.; Antonanzas-Torres, F. Review of Photovoltaic Power Forecasting. Sol. Energy 2016, 136, 78–111. [Google Scholar] [CrossRef]
- Yang, D. Standard of Reference in Operational Day-Ahead Deterministic Solar Forecasting. J. Renew. Sustain. Energy 2019, 11, 053702. [Google Scholar] [CrossRef]
- Yang, D. A Universal Benchmarking Method for Probabilistic Solar Irradiance Forecasting. Sol. Energy 2019, 184, 410–416. [Google Scholar] [CrossRef]
- Pedro, H.T.C.; Coimbra, C.F.M.; David, M.; Lauret, P. Assessment of Machine Learning Techniques for Deterministic and Probabilistic Intra-Hour Solar Forecasts. Renew. Energy 2018, 123, 191–203. [Google Scholar] [CrossRef]
- van der Meer, D. Comment on “Verification of Deterministic Solar Forecasts”: Verification of Probabilistic Solar Forecasts. Sol. Energy 2020, 210, 41–43. [Google Scholar] [CrossRef]
- Pedro, H.T.C.; Coimbra, C.F.M. Assessment of Forecasting Techniques for Solar Power Production with No Exogenous Inputs. Sol. Energy 2012, 86, 2017–2028. [Google Scholar] [CrossRef]
- Panamtash, H.; Zhou, Q.; Hong, T.; Qu, Z.; Davis, K.O. A Copula-Based Bayesian Method for Probabilistic Solar Power Forecasting. Sol. Energy 2020, 196, 336–345. [Google Scholar] [CrossRef]
- Marquez, R.; Pedro, H.T.C.; Coimbra, C.F.M. Hybrid Solar Forecasting Method Uses Satellite Imaging and Ground Telemetry as Inputs to ANNs. Sol. Energy 2013, 92, 176–188. [Google Scholar] [CrossRef]
- Huang, J.; Perry, M. A Semi-Empirical Approach Using Gradient Boosting and k-Nearest Neighbors Regression for GEFCom2014 Probabilistic Solar Power Forecasting. Int. J. Forecast. 2016, 32, 1081–1086. [Google Scholar] [CrossRef]
- Pierro, M.; Gentili, D.; Liolli, F.R.; Cornaro, C.; Moser, D.; Betti, A.; Moschella, M.; Collino, E.; Ronzio, D.; van der Meer, D. Progress in Regional PV Power Forecasting: A Sensitivity Analysis on the Italian Case Study. Renew. Energy 2022, 189, 983–996. [Google Scholar] [CrossRef]
- Sun, M.; Feng, C.; Zhang, J. Probabilistic Solar Power Forecasting Based on Weather Scenario Generation. Appl. Energy 2020, 266. [Google Scholar] [CrossRef]
- Pinho, M.; Muñoz, M.; De, I.; Perpiñán, O. Comparative Study of PV Power Forecast Using Parametric and Nonparametric PV Models. Sol. Energy 2017, 155, 854–866. [Google Scholar] [CrossRef]
- Lonij, V.P.A.; Brooks, A.E.; Cronin, A.D.; Leuthold, M.; Koch, K. Intra-Hour Forecasts of Solar Power Production Using Measurements from a Network of Irradiance Sensors. Sol. Energy 2013, 97, 58–66. [Google Scholar] [CrossRef]
- Vaz, A.G.R.; Elsinga, B.; van Sark, W.G.J.H.M.; Brito, M.C. An Artificial Neural Network to Assess the Impact of Neighbouring Photovoltaic Systems in Power Forecasting in Utrecht, the Netherlands. Renew. Energy 2016, 85, 631–641. [Google Scholar] [CrossRef]
- Henze, J.; Schreiber, J.; Sick, B. Representation Learning in Power Time Series Forecasting; Springer International Publishing: Kassel, Germany, 2020; ISBN 9783030317607. [Google Scholar]
- Zhang, G.; Yang, D.; Galanis, G.; Androulakis, E. Solar Forecasting with Hourly Updated Numerical Weather Prediction. Renew. Sustain. Energy Rev. 2022, 154, 111768. [Google Scholar] [CrossRef]
- Persson, C.; Bacher, P.; Shiga, T.; Madsen, H. Multi-Site Solar Power Forecasting Using Gradient Boosted Regression Trees. Sol. Energy 2017, 150, 423–436. [Google Scholar] [CrossRef]
- ben Taieb, S.; Hyndman, R.J. Recursive and Direct Multi-Step Forecasting: The Best of Both Worlds. Int. J. Forecast. Available online: https://www.monash.edu/business/ebs/research/publications/ebs/wp19-12.pdf (accessed on 11 August 2022).
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; Volume 42, pp. 785–794. [Google Scholar]
- Friedman, J.; Tibshirani, R.; Hastie, T. Additive Logistic Regression: A Statistical View of Boosting (With Discussion and a Rejoinder by the Authors). Ann. Stat. 2000, 28, 337–407. [Google Scholar] [CrossRef]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. Catboost: Unbiased Boosting with Categorical Features. Adv. Neural Inf. Process. Syst. 2018, 6638–6648. [Google Scholar]
- Yang, D. A Guideline to Solar Forecasting Research Practice: Reproducible, Operational, Probabilistic or Physically-Based, Ensemble, and Skill (ROPES). J. Renew. Sustain. Energy 2019, 11. [Google Scholar] [CrossRef]
- Pedro, H.T.C.; Larson, D.P.; Coimbra, C.F.M. A Comprehensive Dataset for the Accelerated Development and Benchmarking of Solar Forecasting Methods. J. Renew. Sustain. Energy 2019, 11. [Google Scholar] [CrossRef]
- van der Meer, D.W.; Widén, J.; Munkhammar, J. Review on Probabilistic Forecasting of Photovoltaic Power Production and Electricity Consumption. Renew. Sustain. Energy Rev. 2018, 81, 1484–1512. [Google Scholar] [CrossRef]
- Nonnenmacher, L.; Kaur, A.; Coimbra, C.F.M. Day-Ahead Resource Forecasting for Concentrated Solar Power Integration. Renew Energy 2016, 86, 866–876. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| INDEX | 202108 | 202109 | 202110 | 202111 | 202112 | 202201 | 202202 | 202203 | 202204 | 202205 | 202206 | 202207 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S-XGBoost | 58 | 69 | 80 | 85 | 91 | 88 | 78 | 67 | 51 | 39 | 52 | 42 |
| S-CatBoost | 59 | 69 | 81 | 86 | 91 | 88 | 79 | 68 | 52 | 41 | 52 | 44 |
| 3M-XGBoost | 52 | 60 | 75 | 82 | 90 | 84 | 77 | 57 | 42 | 47 | 45 | 34 |
| 3M-CatBoost | 53 | 63 | 75 | 84 | 92 | 85 | 78 | 59 | 45 | 46 | 47 | 35 |
| 1M-XGBoost | 72 | 72 | 84 | 91 | 95 | 94 | 89 | 74 | 70 | 55 | 60 | 54 |
| 1M-CatBoost | 72 | 74 | 85 | 91 | 96 | 94 | 90 | 77 | 70 | 57 | 61 | 57 |
| N-XGBoost | 53 | 53 | 73 | 84 | 92 | 85 | 81 | 61 | 48 | 45 | 48 | 35 |
| N-CatBoost | 55 | 56 | 75 | 84 | 92 | 86 | 81 | 62 | 49 | 46 | 51 | 38 |
| S3M-XGBoost | 58 | 66 | 77 | 84 | 92 | 84 | 80 | 63 | 48 | 44 | 49 | 43 |
| S3M-CatBoost | 58 | 68 | 79 | 85 | 93 | 85 | 80 | 65 | 49 | 45 | 50 | 47 |
| S1M-XGBoost | 74 | 74 | 85 | 91 | 95 | 94 | 89 | 76 | 72 | 56 | 61 | 57 |
| S1M-CatBoost | 73 | 75 | 85 | 91 | 95 | 94 | 90 | 77 | 70 | 58 | 62 | 58 |
| INDEX | SPRING | SUMMER | FALL | WINTER | AVG Year | Ranking |
|---|---|---|---|---|---|---|
| S-XGBoost | 52 | 51 | 78 | 86 | 66.7 | 7 |
| S-CatBoost | 54 | 52 | 79 | 86 | 67.5 | 5 |
| 3M-XGBoost | 48 | 44 | 72 | 84 | 62.2 | 12 |
| 3M-CatBoost | 50 | 45 | 74 | 85 | 63.6 | 10 |
| 1M-XGBoost | 67 | 62 | 82 | 93 | 76.0 | 4 |
| 1M-CatBoost | 68 | 63 | 83 | 93 | 76.8 | 3 |
| N-XGBoost | 52 | 45 | 70 | 86 | 63.2 | 11 |
| N-CatBoost | 52 | 48 | 72 | 86 | 64.7 | 9 |
| S3M-XGBoost | 52 | 50 | 76 | 85 | 65.6 | 8 |
| S3M-CatBoost | 53 | 52 | 77 | 86 | 67.0 | 6 |
| S1M-XGBoost | 68 | 64 | 83 | 93 | 76.9 | 2 |
| S1M-CatBoost | 68 | 64 | 84 | 93 | 77.3 | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bezerra Menezes Leite, H.; Zareipour, H. Six Days Ahead Forecasting of Energy Production of Small Behind-the-Meter Solar Sites. Energies 2023, 16, 1533. https://doi.org/10.3390/en16031533
Bezerra Menezes Leite H, Zareipour H. Six Days Ahead Forecasting of Energy Production of Small Behind-the-Meter Solar Sites. Energies. 2023; 16(3):1533. https://doi.org/10.3390/en16031533
Chicago/Turabian StyleBezerra Menezes Leite, Hugo, and Hamidreza Zareipour. 2023. "Six Days Ahead Forecasting of Energy Production of Small Behind-the-Meter Solar Sites" Energies 16, no. 3: 1533. https://doi.org/10.3390/en16031533
APA StyleBezerra Menezes Leite, H., & Zareipour, H. (2023). Six Days Ahead Forecasting of Energy Production of Small Behind-the-Meter Solar Sites. Energies, 16(3), 1533. https://doi.org/10.3390/en16031533