1. Introduction
Amidst an energy crisis fueled by escalating energy costs and the specter of war, global interest in energy conservation and management has surged. In response, the government of the Republic of Korea has initiated various efforts to conserve energy. One such initiative involves the implementation of the Factory Energy Management System (FEMS), mandated by the Third Energy Master Plan for energy-intensive facilities consuming more than 100,000 tons of oil equivalent (TOE), effective from 2025 onward. Furthermore, the Korean government is actively promoting FEMS adoption among factories consuming less than 100,000 TOE [
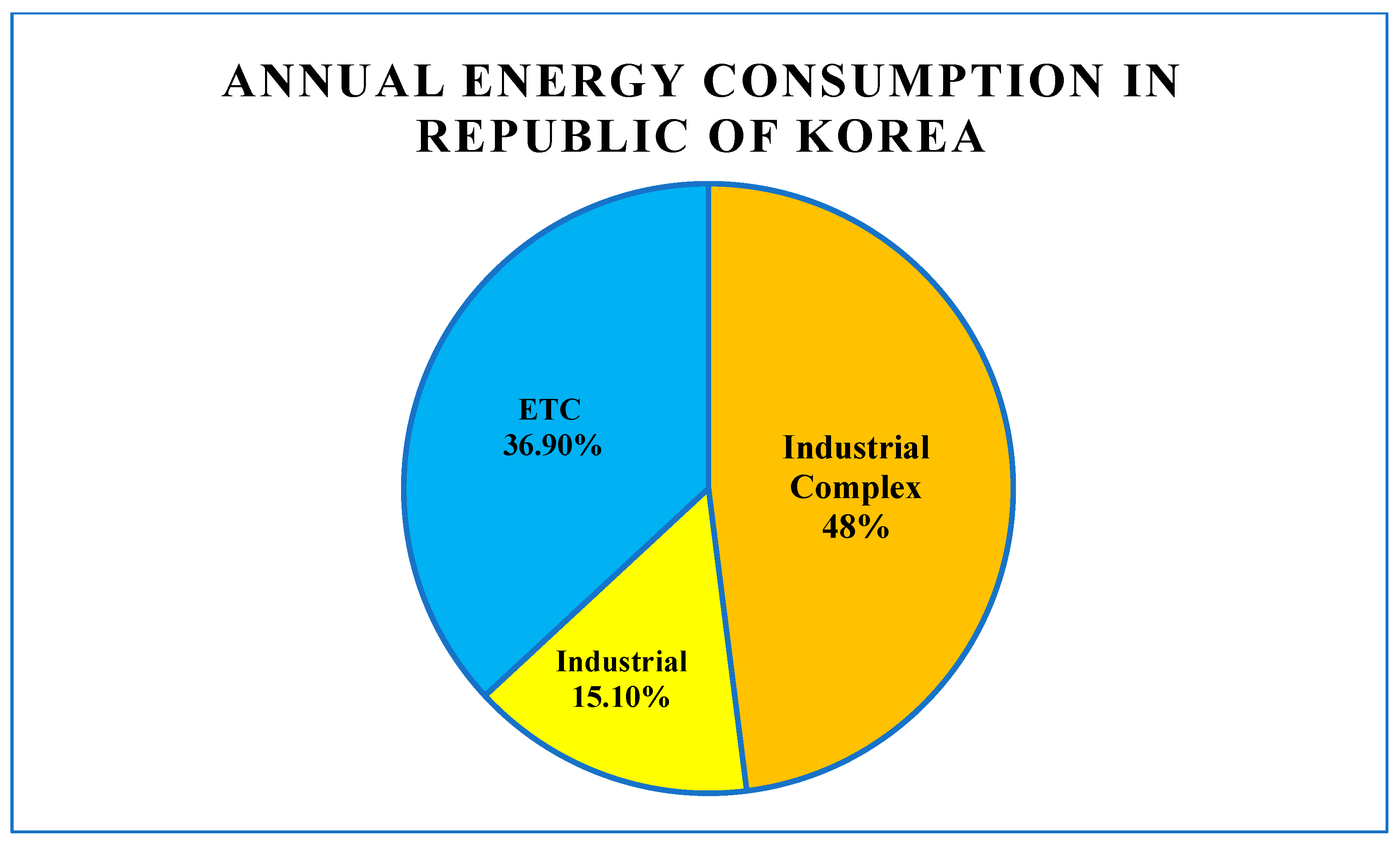
1]. Notably, energy-related policies in Korea are predominantly industry-centric, given that the industrial sector, particularly industrial complexes, accounts for a significant portion of the nation’s energy consumption. As shown in
Figure 1, industrial complexes alone contributed to approximately 48% of the Republic of Korea’s total energy consumption [
2]. Hence, it becomes imperative to implement energy-saving strategies and management protocols within these energy-intensive industrial complexes to bolster energy efficiency and conservation.
Within these industrial complexes, factories specializing in similar industries often coalesce. Despite this proximity, many factories fail to leverage shared energy utilities effectively. Instead, they resort to self-generation or individual contracts with energy production entities. This decentralized approach to energy procurement proves disadvantageous as it precludes the preparedness for potential issues arising from energy surpluses or shortages. Moreover, energy trade under such arrangements typically occurs through contracts with high unit prices [
3].
A network system has been devised to address these challenges by leveraging a virtual utility plant. Within this network system, factories within an industrial park that share the same energy utilities establish a stable supply chain, utilizing common facilities to stabilize the provision of energy utilities. Moreover, this concept facilitates energy trade between energy-producing companies and consumer companies by forecasting energy demand and supply and employing routing algorithms. This approach optimizes energy utilization and minimizes waste [
4].
To effectively utilize an energy utility-sharing network such as the VUP network system, artificial intelligence AI-based techniques are essential for predicting energy production and demand across common facilities, energy production, and trading entities. The conventional method for deploying these techniques involves each company utilizing its own on-premise servers.
However, deploying FEMS or VUP simulators in industrial complexes using conventional server systems necessitates additional equipment, such as air conditioners and dehumidifiers, to regulate temperature and humidity for server management. Nonetheless, this approach consumes a significant amount of energy. Moreover, given the spatial constraints inherent in many factories within industrial complexes, setting up these systems using conventional server infrastructure poses numerous limitations.
To address these challenges, a method such as Software-as-a-Service (SaaS) can be considered. While SaaS offers easy setup with low initial costs, it entails ongoing fixed expenses [
5]. Additionally, concerns about security may arise due to the sharing of operational and sensor data among factories [
6,
7].
For a more fundamental solution, ARM-based edge devices present a viable option. This approach entails replacing conventional server systems with ARM-based edge devices. Unlike conventional servers, which consume several thousand watts of power, each ARM-based device consumes only tens of watts. Their lower power consumption reduces the occurrence of overheating issues, thereby easing device management burdens. Furthermore, ARM-based devices occupy significantly less space, approximately 40 to 50 times less than conventional server systems, thus optimizing space utilization. However, ARM-based embedded devices typically offer lower performance than conventional server systems, impacting processing throughput. Additionally, they utilize ARM-based application processors (APs) rather than conventional x86- or AMD64-based central processing units (CPUs). This imposes constraints and limits the scope of support they can provide.
Notably, AI learning often requires high graphics processing unit (GPU) performance, which has historically posed challenges for embedded devices with lower performance capabilities.
Recent studies have been exploring methods to overcome various limitations, including constraints related to space, environment, and energy, using edge devices. A key focus of this research is leveraging the capabilities of low-performance edge devices, strategically positioned closer to data collection points [
8]. Related studies examine strategies for distributing data processing by relocating segments of existing AI systems to edge devices. However, these efforts primarily aim to complement existing systems rather than replace them entirely. Consequently, they neither operate autonomously nor fully resolve challenges such as external data access.
Additionally, the utilization of TinyML, which offers benefits such as low power consumption, real-time operation, and high accuracy, has been studied [
9,
10]. Nonetheless, these devices may struggle with processing large volumes of data in real time owing to their constrained specifications. Specifically, they may not be suitable for environments characterized by significant fluctuations in data production, necessitating frequent model updates.
Another avenue of research involves developing predictive systems by optimizing clustering algorithms on edge devices [
11]. This line of inquiry explores the potential of employing GPUs such as the Jetson Nano to deploy AI systems on edge devices, as opposed to conventional predictive systems. However, implementing this approach on edge devices with limited GPU performance poses significant challenges. These studies predominantly focus on refining artificial intelligence algorithms and often overlook aspects such as data collection, thereby limiting the advancement of comprehensive systems exclusively utilizing edge devices.
Furthermore, active research is underway on refining AI models. By employing hyperparameter auto-tuning, opportunities for enhancing AI model performance can be identified [
12,
13]. However, owing to the necessity of frequent model reconstruction caused by significant production fluctuations, this method proves unsuitable for edge devices owing to the high computational burden. Self-adaptive deep learning techniques can more effectively accommodate production fluctuations [
14]. Nevertheless, self-adaptive deep learning is also unsuitable for edge devices with limited specifications owing to high computational demands and the potential for overfitting issues.
Additionally, studies have aimed at implementing a recommendation system using AWS as a backend platform for edge devices [
15]. However, this study also explores how to utilize edge devices as supplementary tools rather than directly addressing various limitations.
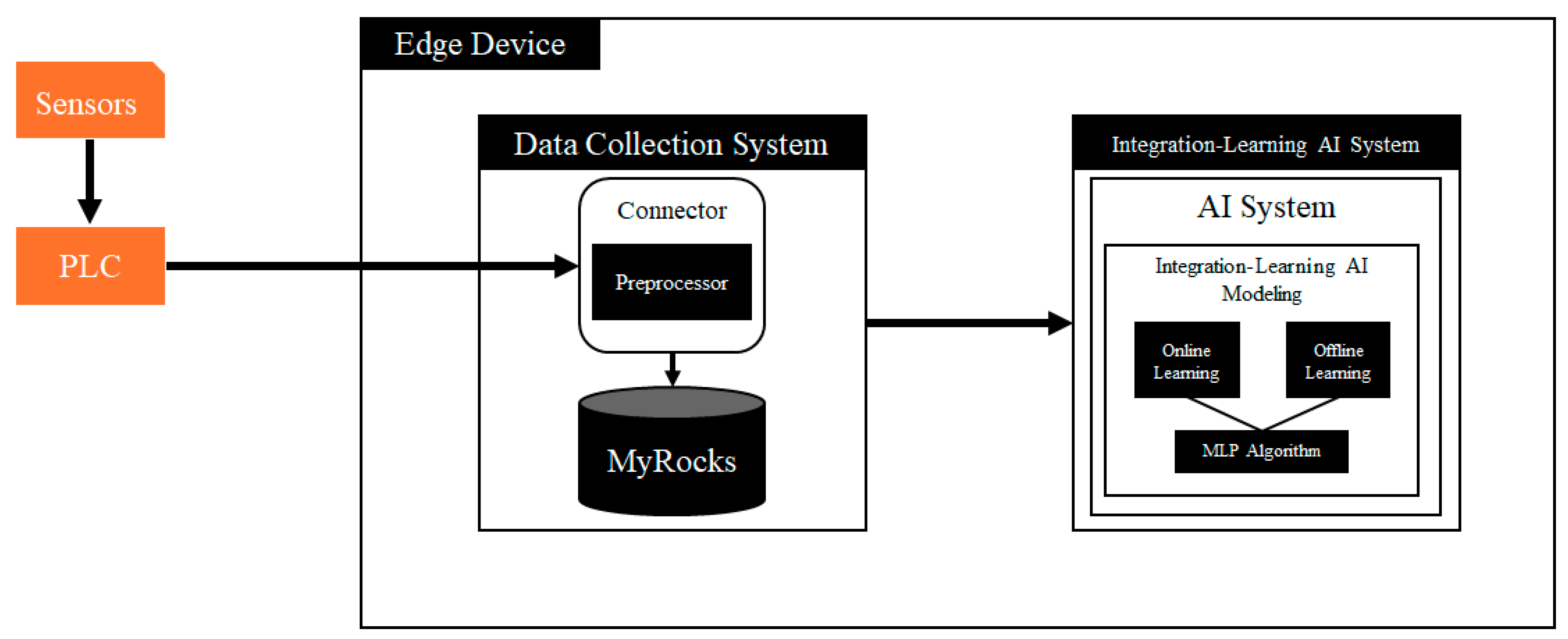
Herein, we introduce an integrated lightweight platform, as depicted in
Figure 2, aimed at addressing the limitations observed in prior studies. The integrated lightweight platform is designed to facilitate the independent operation of systems running on existing server infrastructure on edge devices. Sensor data collected within the platform were gathered using a programmable logic controller (PLC). This collected data underwent conversion and preprocessing utilizing the connector and preprocessor modules. Subsequently, the data were stored using a relational database management system known as MyRocks 5.6, which employs a key-value store as its backend storage engine [
16].
Utilizing the data stored in MyRocks, an AI system was constructed by employing integration-learning AI modeling techniques to forecast future supply and demand in factory settings. Integration-learning AI modeling utilizes online learning, characterized by lower computational costs compared to alternative algorithms, to adapt to changing data patterns in response to orders. If model retraining becomes necessary due to evolving conditions, the AI model can be retrained using offline learning techniques.
To alleviate the performance limitations of edge devices, delay techniques were employed to mitigate prediction-related load, facilitate data collection, and minimize platform interruptions, thereby enhancing stability.
To the best of our knowledge, no prior research has been conducted on developing a comprehensive system—from data collection to prediction—solely utilizing edge devices without reliance on networks or external devices.
This study conducted energy utility predictions using edge devices, aiming to develop a practical prediction system that can substitute conventional systems requiring high computing power. The reliability of edge devices was assessed by comparing their prediction duration with that of conventional systems. This research offers the potential to enhance conventional systems, which consume significant energy, by integrating edge devices. Moreover, this study contributes to the development of a lightweight platform and the improvement of edge device reliability.
3. AI System
The primary objective of an AI system based on edge devices for factories is to leverage AI for real-time predictions using collected data.
Hence, this section delves into the rationale behind selecting an AI model that operates on edge devices. Furthermore, it presents an architecture and methodology for integration-learning AI modeling as a benchmark for AI systems on edge devices.
3.1. AI Model
In this study, a previously researched AI algorithm served as the machine learning algorithm [
22].
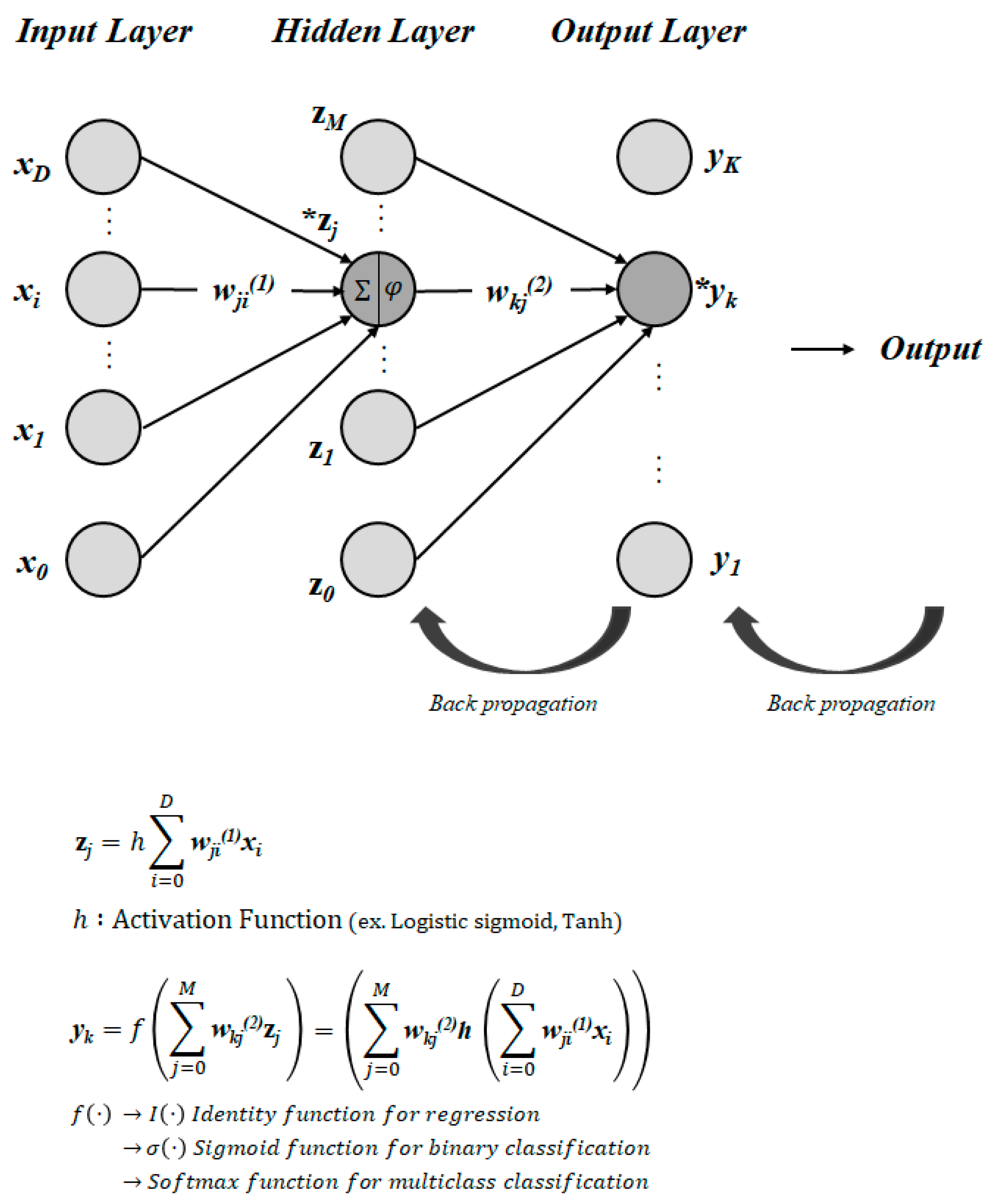
Two evaluation metrics, R2 and CvRMSE, were employed to assess the validity of the prediction models using the MLP and support vector regression (SVR) algorithms, respectively. For the SVR model, evaluation metrics were examined across three different kernels: linear, radial basis function network (RBF), and polynomial.
Based on the verification results of the models, the MLP demonstrated an R2 of 0.84 and CvRMSE of 17.35% for predicting electricity consumption, and an R2 of 0.88 and CvRMSE of 12.52% for predicting liquefied natural gas (LNG) consumption. The SVR model, when utilizing the linear kernel, exhibited an R2 of 0.72 and CvRMSE of 21.59% for predicting electricity consumption, and an R2 of 0.82 and CvRMSE of 21.59% for predicting LNG consumption. When employing the RBF kernel, the SVR model showed an R2 of 0.75 and CvRMSE of 20.52% for predicting electricity consumption, and an R2 of 0.88 and CvRMSE of 17.01% for predicting LNG consumption. Finally, with the polynomial kernel, the SVR model yielded an R2 of 0.71 and CvRMSE of 22.10% for predicting electricity consumption, and an R2 of 0.82 and CvRMSE of 21.58% for predicting LNG consumption.
Table 1 summarizes the results of the prediction models for each applied algorithm.
Based on the results, the model’s validity is highest when applying MLP for predicting both electricity and LNG consumption.
Furthermore, MLP is notable for its capacity to update weights. This study aimed to ensure the reliability of the AI system’s construction by reflecting real-time data weights and reconstructing the system when model retraining is necessary. Hence, the decision was made to utilize the MLP algorithm in this study.
The MLP model was developed and analyzed using Python 3.9.7, Tensorflow 2.3.0, Keras 2.4.3, Sklearn 1.0.2, Pandas 1.4.1, Numpy 1.19.5, and Matplotlib 3.5.1. The dataset was split into training and test data, with a ratio of 90% for training data and 10% for test data. Daily data spanning approximately 3 years were used for the electricity usage prediction model, and daily data covering around 3 months were utilized for the LNG usage prediction model. Data preprocessing involved the application of Minmax Scaling and Standard Scaling methods. Additionally, the previously developed predictive models served as base models before undergoing hyperparameter optimization. All hyperparameters were set to default settings and analyzed. Validation for each MLP-based prediction model was conducted by comparing predicted values with actual measured values over a 1-month period.
3.2. Integration-Learning AI Modeling
When employing AI models to predict energy management systems or demand and supply within an industrial complex, various factors such as process or task changes must be considered. Therefore, the AI model must be sensitive to data fluctuations and ensure the continual checking of the reliability and accuracy of predicted values.
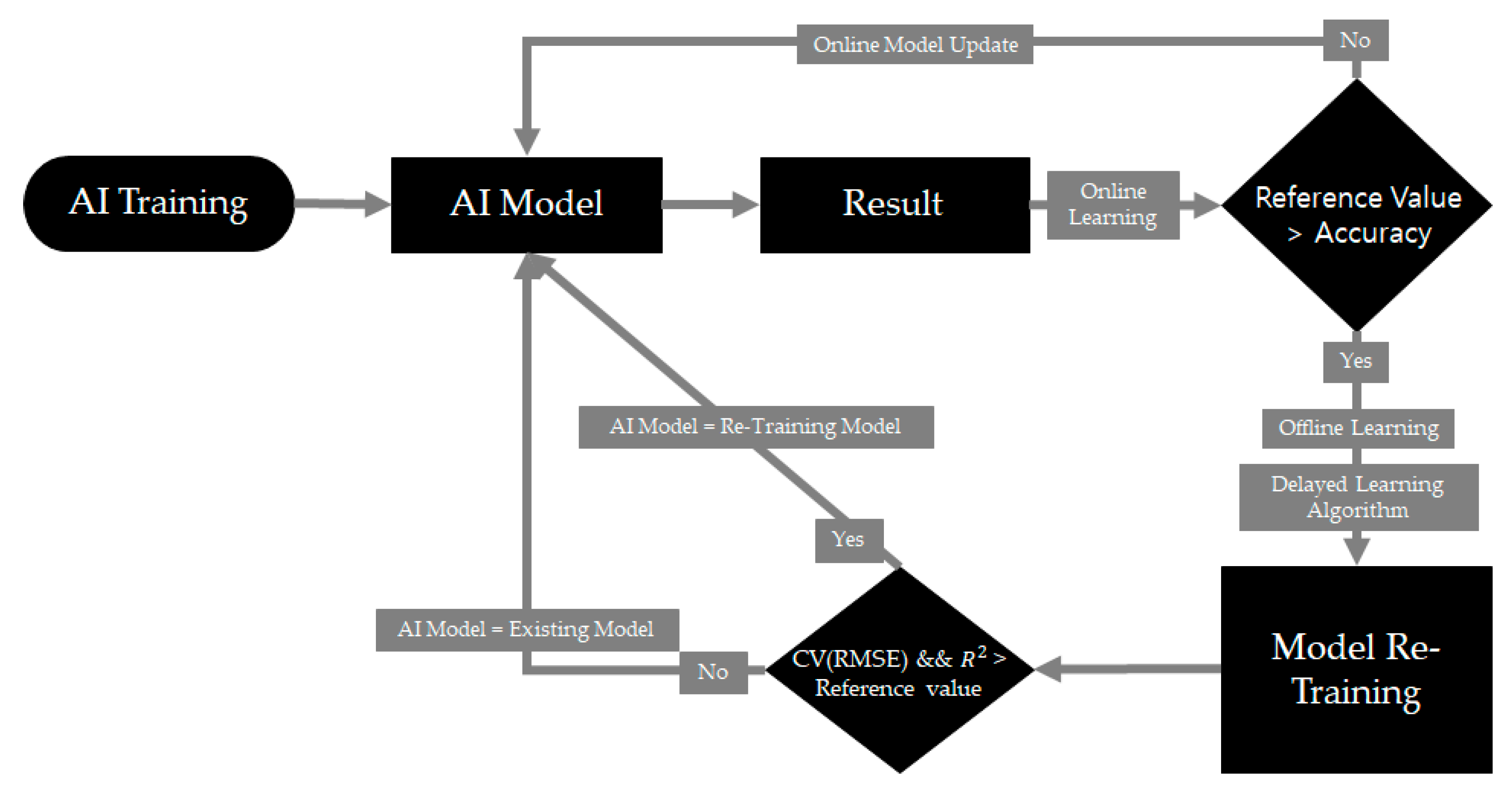
Many AI models currently utilized in systems requiring real-time data reflection often utilize online learning to manage real-time data streams or large datasets. Online learning offers the advantage of promptly reflecting changes as they occur. However, setting up large server systems in factories implementing online learning is challenging owing to spatial, cost, and energy constraints. To address these challenges, a solution has been devised: replacing large server systems with low-performance edge devices, known as integration-learning AI modeling. Integration-learning AI modeling combines online and offline learning. It primarily operates via online learning, which updates the AI model in real time. However, if overfitting or bias occurs due to continuous weight updates and the average accuracy of the AI model drops below a threshold value, offline learning is initiated to retrain the AI model using all collected data up to that point, thereby mitigating bias in the data. The proposed integration-learning AI modeling system is illustrated in
Figure 4.
Factory prediction systems must incorporate both online and offline learning because factory production is characterized not only by its time-series nature but also by its strong dependency on produced items. Thus, sensitivity to the most recent data is crucial, necessitating the use of online learning. However, past data can also provide valuable insights, and online learning tends to gradually favor more recent data, leading to bias. Therefore, offline learning should also be employed to counteract this drawback.
Several issues need to be addressed to effectively utilize integration-learning AI modeling, which combines online and offline learning, on edge devices. First, it may be challenging to implement integration-learning AI modeling on edge devices due to their limited computational performance. Additionally, there may be a latency issue where the prediction process extends beyond the completion of the next prediction due to high inference latency. Furthermore, there could be device-related issues during offline learning, potentially hindering model training.
To address these challenges, the model was optimized to be lightweight for online learning. Comparative analysis with an existing model revealed no significant difference in sensor data prediction. Although prediction speed was slower compared to a conventional server system, there were no bottlenecks observed in prediction and online learning for both the conventional server system and edge devices. However, bottlenecks occurred during data retrieval. Moreover, the CPU-based MLP model demonstrated low load during prediction, online learning, and backpropagation.
In the case of offline learning, there is a possibility of increased model training time as data accumulate. To mitigate this issue, the algorithm was enhanced by incorporating a technique to delay offline learning. This technique schedules training during non-operational time slots, such as idle periods, to prevent disruption to factory operations. Additionally, if a significant amount of data accumulates, potentially leading to high load conditions, offline learning is delayed accordingly.
6. Conclusions
In this study, we investigated the feasibility of operating data collection and AI systems on edge devices as standalone lightweight platforms in each factory.
The reliability of operation on the standalone edge device was assured through integration-learning AI modeling. Furthermore, even when the edge device was used independently, the load remained low, allowing for improvements to the AI model.
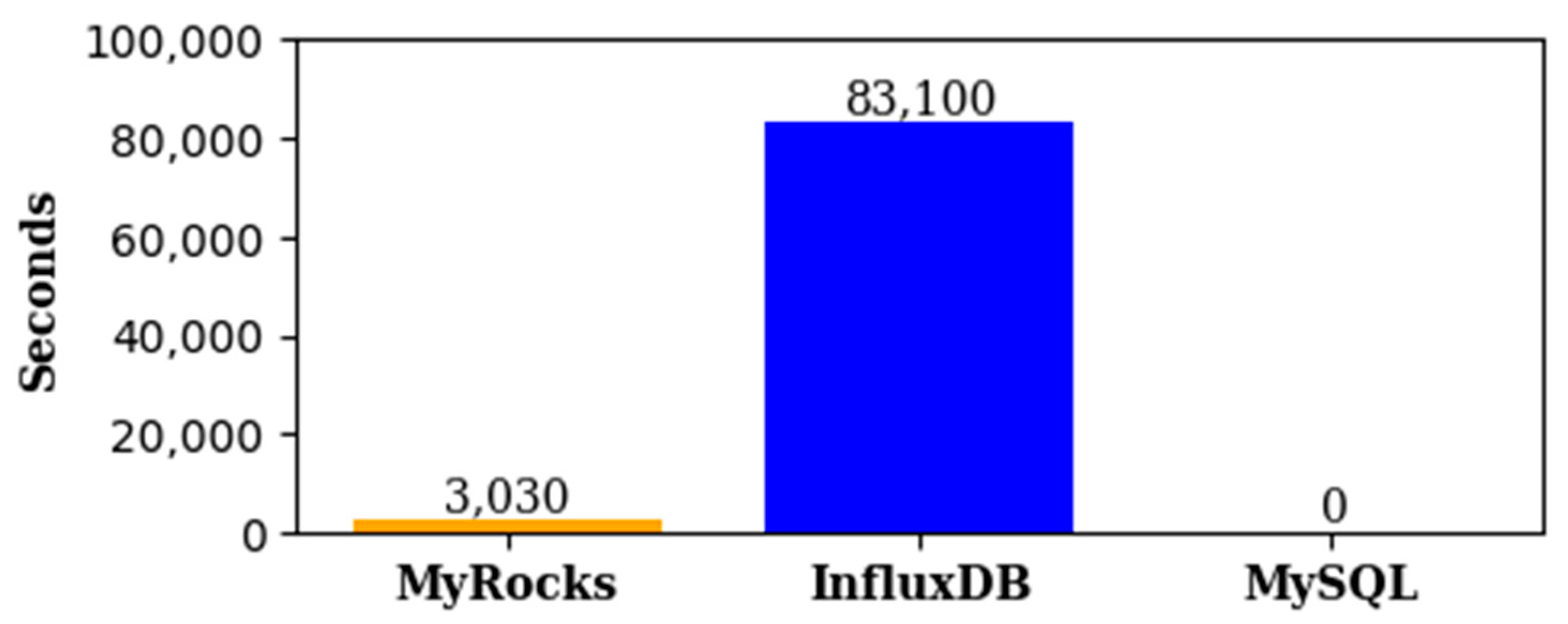
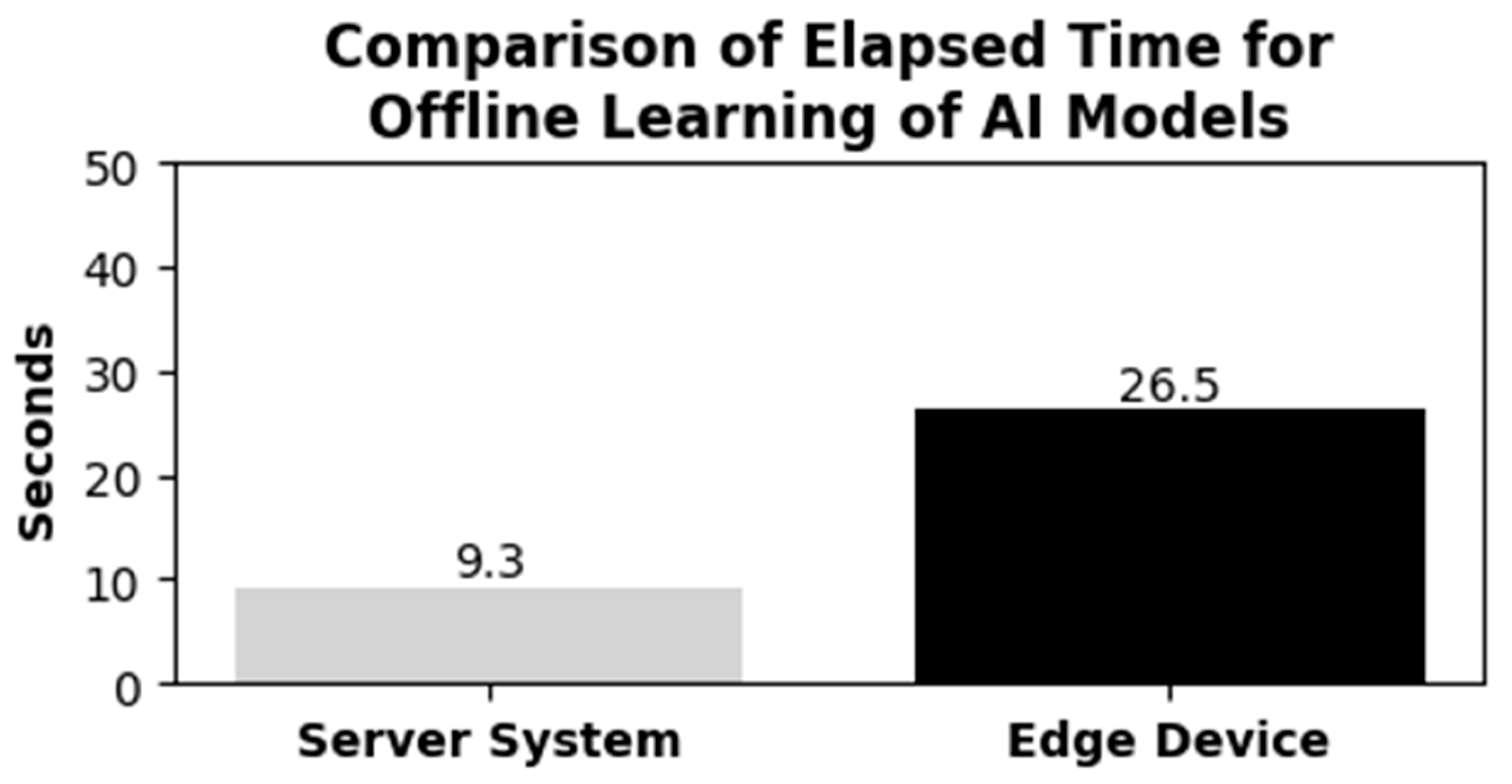
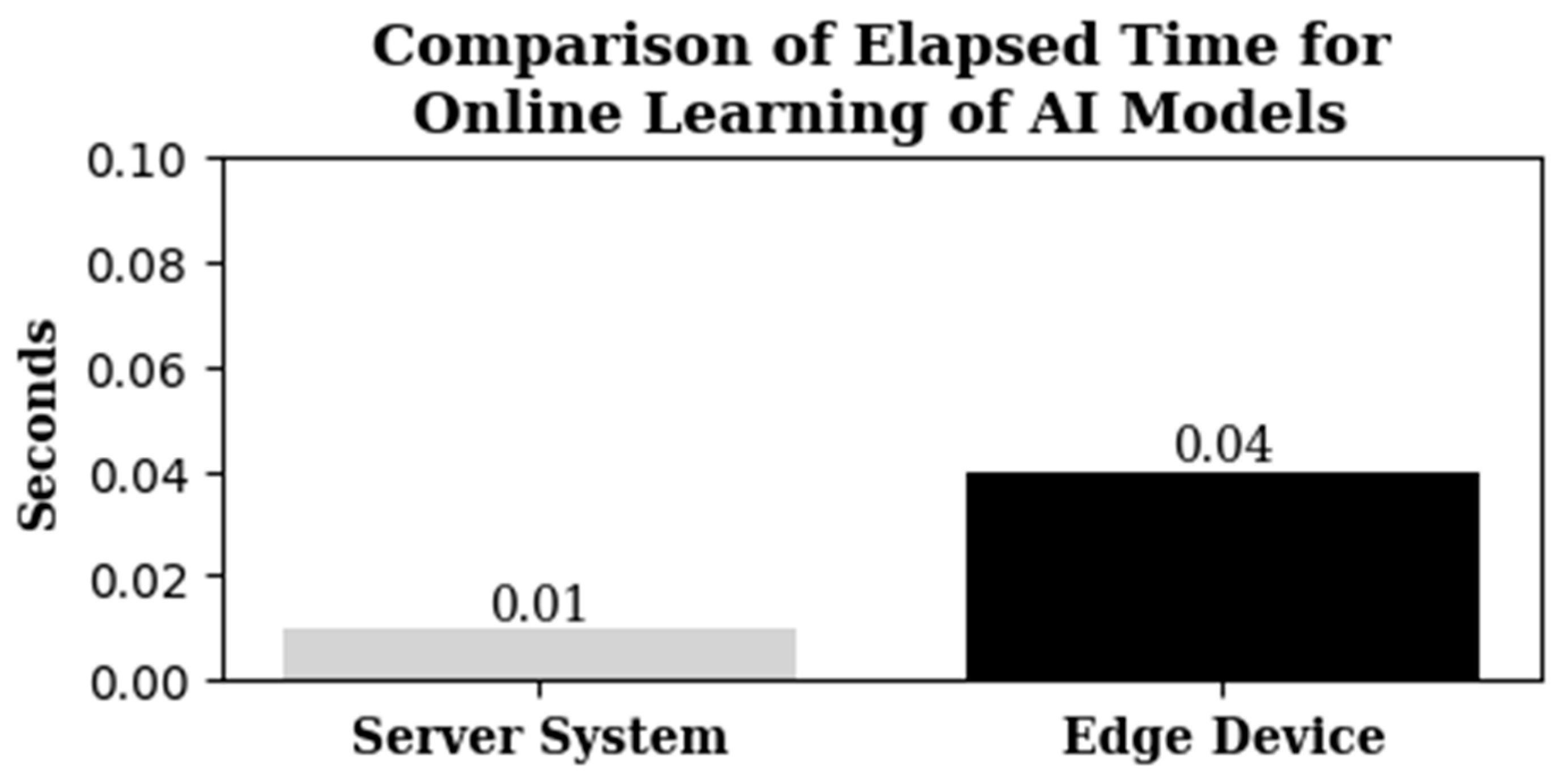
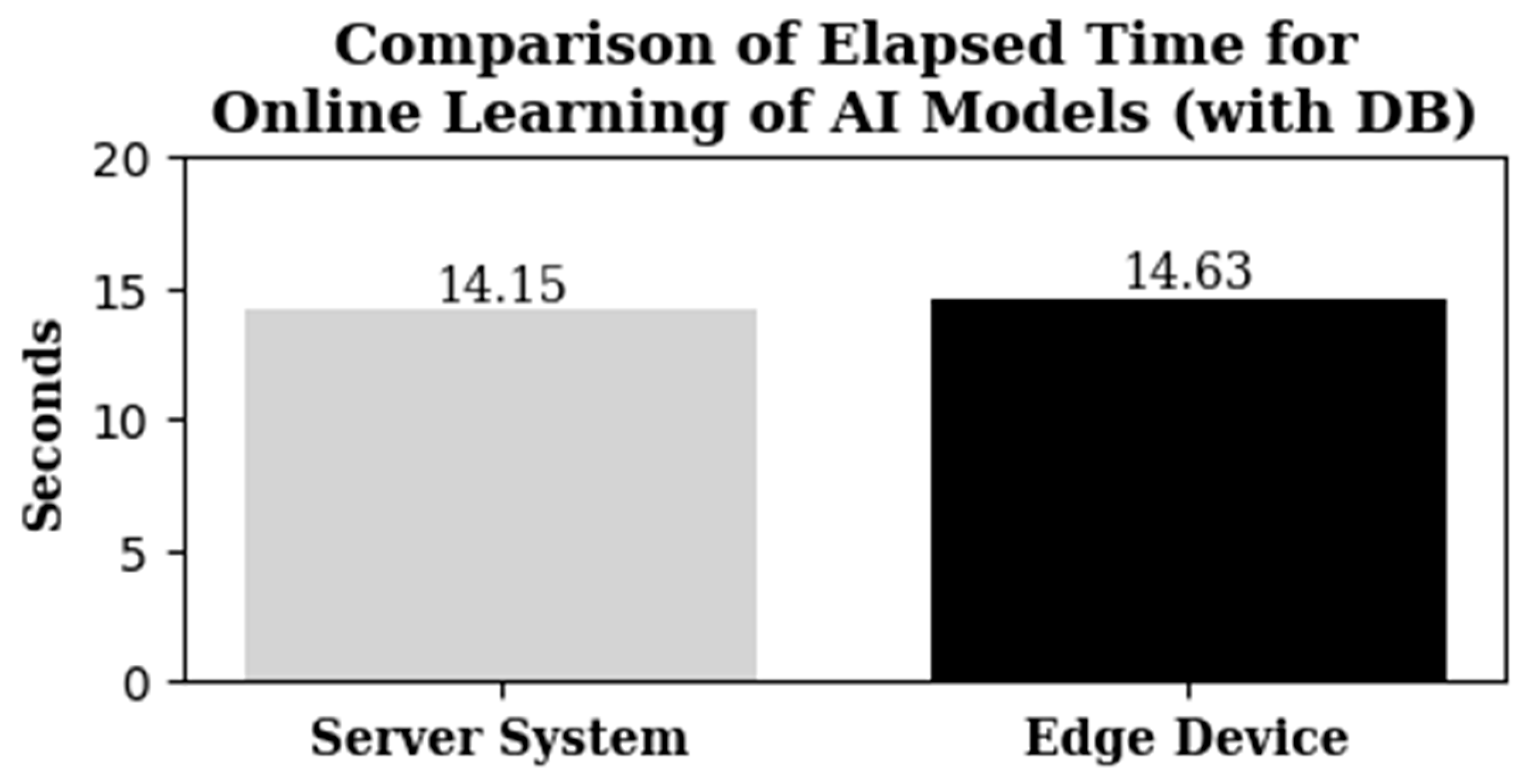
Additionally, although there was a performance difference of 2.8 times in offline learning and up to four times in online learning compared to the conventional system, predictions could be made without any issues on the edge device for a unit time of over 1 minute. In the database evaluation under high load conditions, reliable data collection was achieved when MyRocks was used.
This evaluation demonstrates the potential for replacing conventional server systems, which encounter issues such as high power consumption, inefficient space utilization, and management load. Moreover, it highlights the possibility of ensuring reliability in building edge devices as standalone systems in factories.
This study introduces an integrated lightweight platform by developing both a data collection system and the entire AI system cycle on an edge device. To the best of our knowledge, while there have been numerous endeavors to address energy, environmental, and space constraints, this study represents a significant milestone as the first to overcome these challenges by constructing a comprehensive system entirely on an edge device.
Our investigation devised an AI system capable of learning and predicting data with significant fluctuations on existing low-performance edge devices that are not specialized for AI tasks. This breakthrough addresses the constraints encountered with existing techniques, notably the high computational load, thereby enabling the utilization of low-performance edge devices in handling data with significant fluctuations through the AI system.
This research shows promise for various applications, including smart factories and smart homes, as well as in scenarios where network connectivity and physical locations are constrained due to security concerns or environmental characteristics.
Based on the insights gained from this study, we are currently involved in real-time prediction activities, having deployed our integrated lightweight platform in a demonstration factory. Additionally, we are investigating the enhancement of our capabilities by evolving the data collection system into an IIoT (Industrial Internet of Things) platform to enable control functionalities. Moreover, we have devised plans for a visualization project in response to requests from the demonstration factory.
For future research, our objectives include enhancing the performance of online learning and the edge device AI model by clustering edge devices and enhancing the data collection system. We also intend to explore the feasibility of utilizing edge devices as a lightweight platform for the entire prediction and data collection system cycle.
Moreover, we aim to expand our research beyond AI system development and delve into improving AI algorithms. Our plans entail exploring advanced AI algorithms, refining hyperparameter tuning techniques specifically designed for edge devices, and investigating self-adaptive methodologies to enhance the AI model itself.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}