
Non-Intrusive Load Monitoring Based on Multiscale Attention Mechanisms


Abstract
:1. Introduction
- We discuss the combination of smart home technology and non-intrusive load monitoring (NILM) technology under the development of smart grids and new power systems in order to provide users with a clear picture of the operating status of household electrical appliances based on NILM, reduce household energy loss, and save money.
- We propose a non-intrusive load disaggregation model with a parallel multiscale attention mechanism that has a high degree of readiness for load disaggregation and was validated on the publicly available UK-DALE dataset. First, the feature extraction network was formed using a four-layer, one-dimensional convolutional block and a pooling layer. This improved the model’s global perception of sequence data through the convolution of multiple layers. Subsequently, the feature extraction network was enhanced with a parallel multiscale attention mechanism and a parallel feature fusion network in order to extract deep load features. The PMAM model’s decomposition performance was validated using the publicly available UK-DALE dataset.
- In the case of load detection using the same dataset, other machine learning algorithms, such as the Long Short-Term Memory (LSTM) recurrent neural network, Time Pooling-Based Load Disaggregation Model (TPNILM), Extreme Learning Machine (ELM), and Load Disaggregation Model without Parallel Multi-scale Attention Mechanisms (UNPMAM), were applied, and the results were compared and analyzed. To verify the generalizability of the PMAM model, we trained the model using two different household users and compared its decomposition performance across households.
2. Load Characterization and Datasets
2.1. Load Characteristics
2.1.1. Homeostatic Characteristics
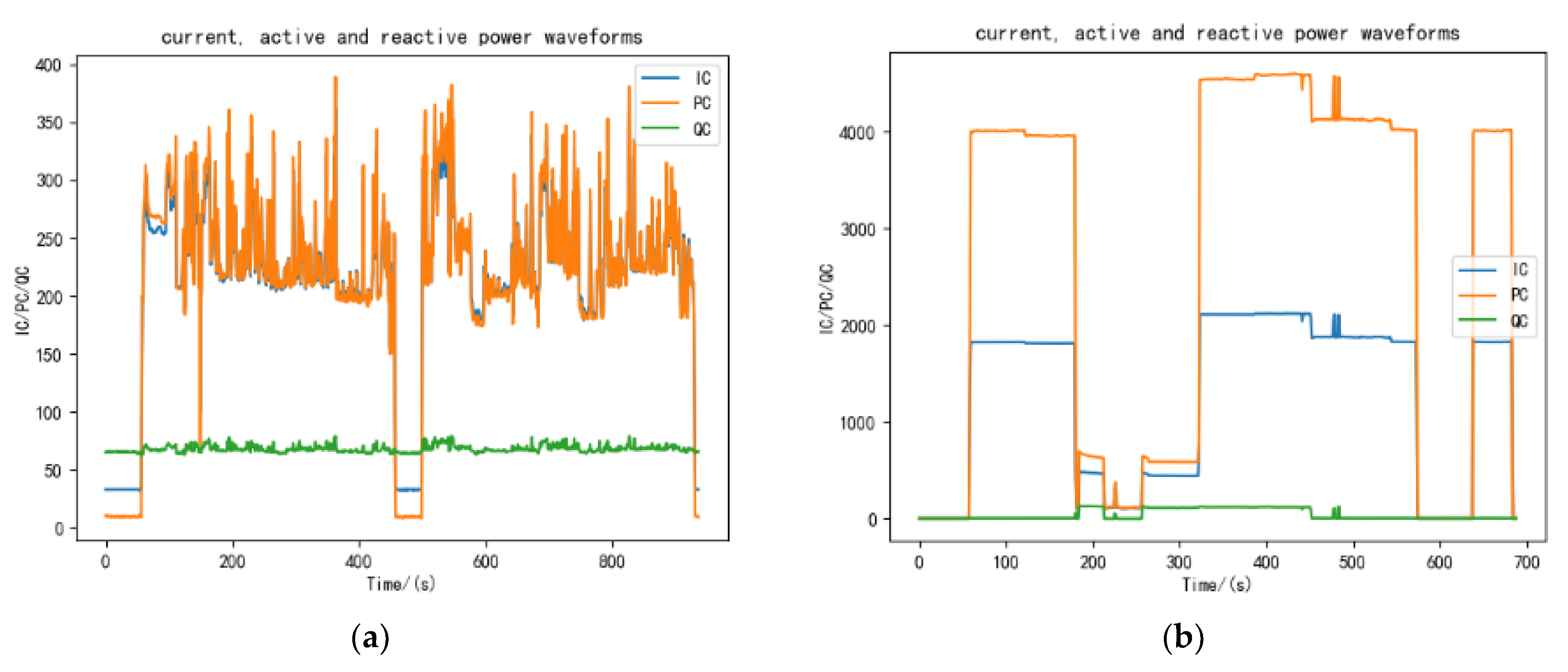
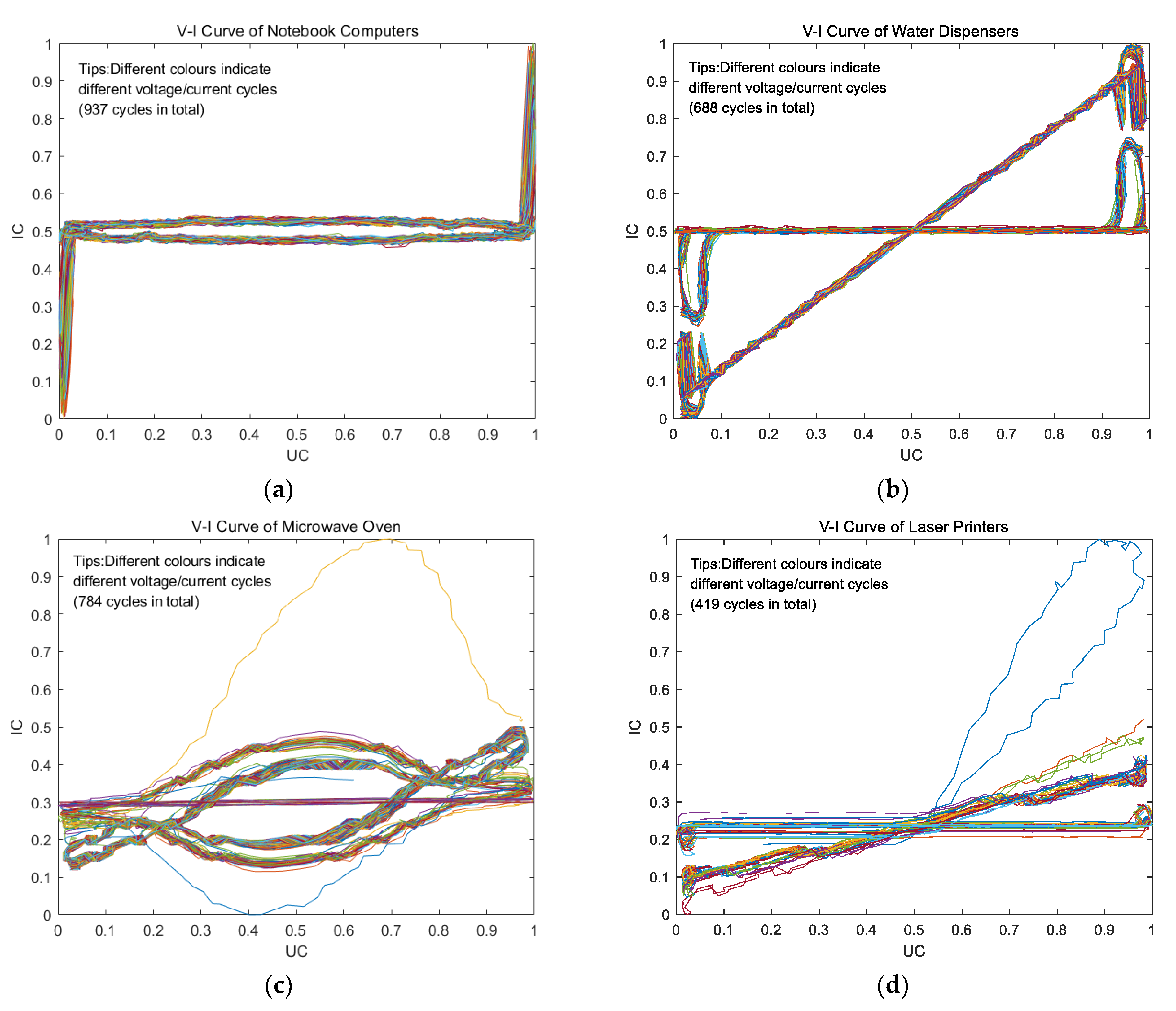
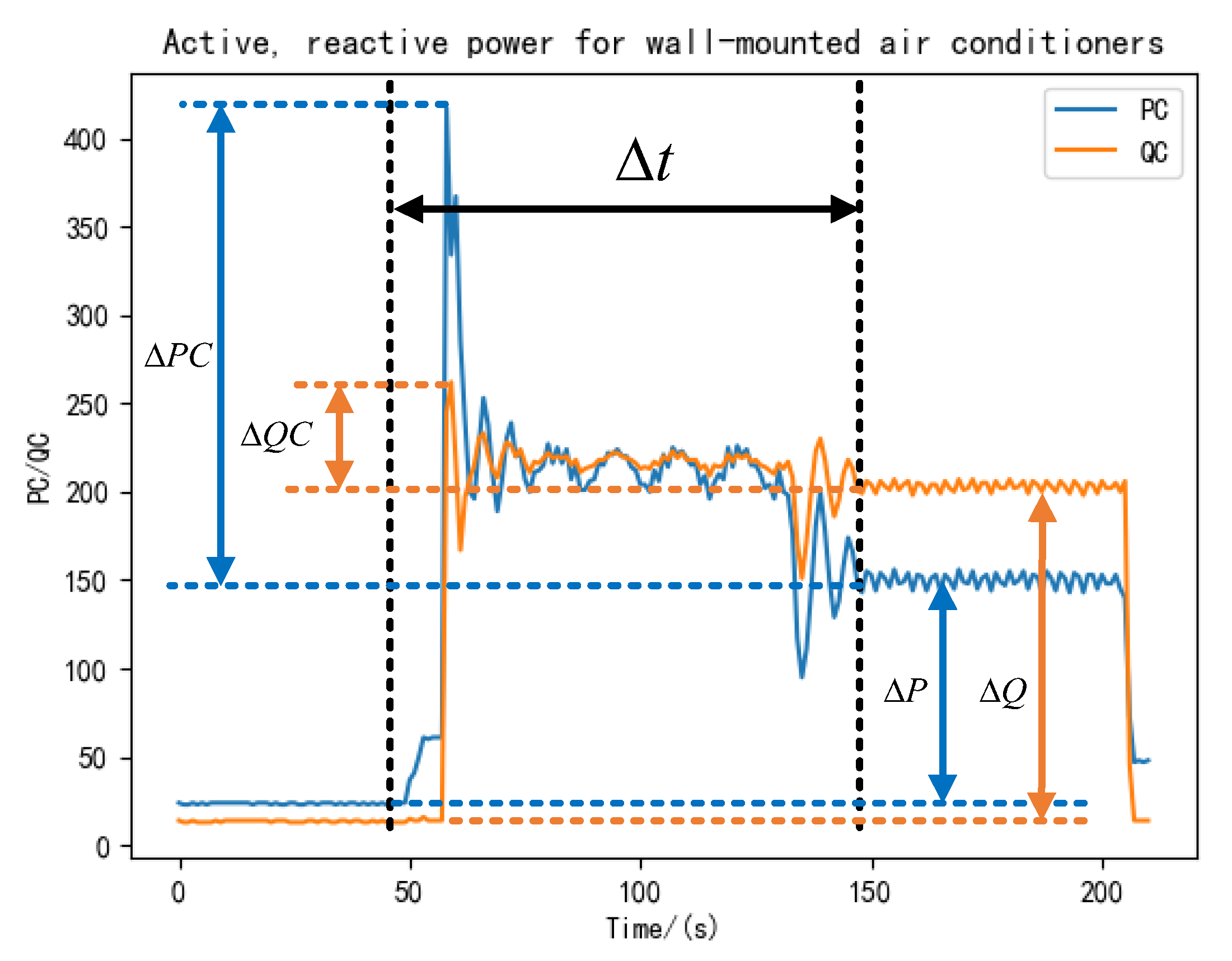
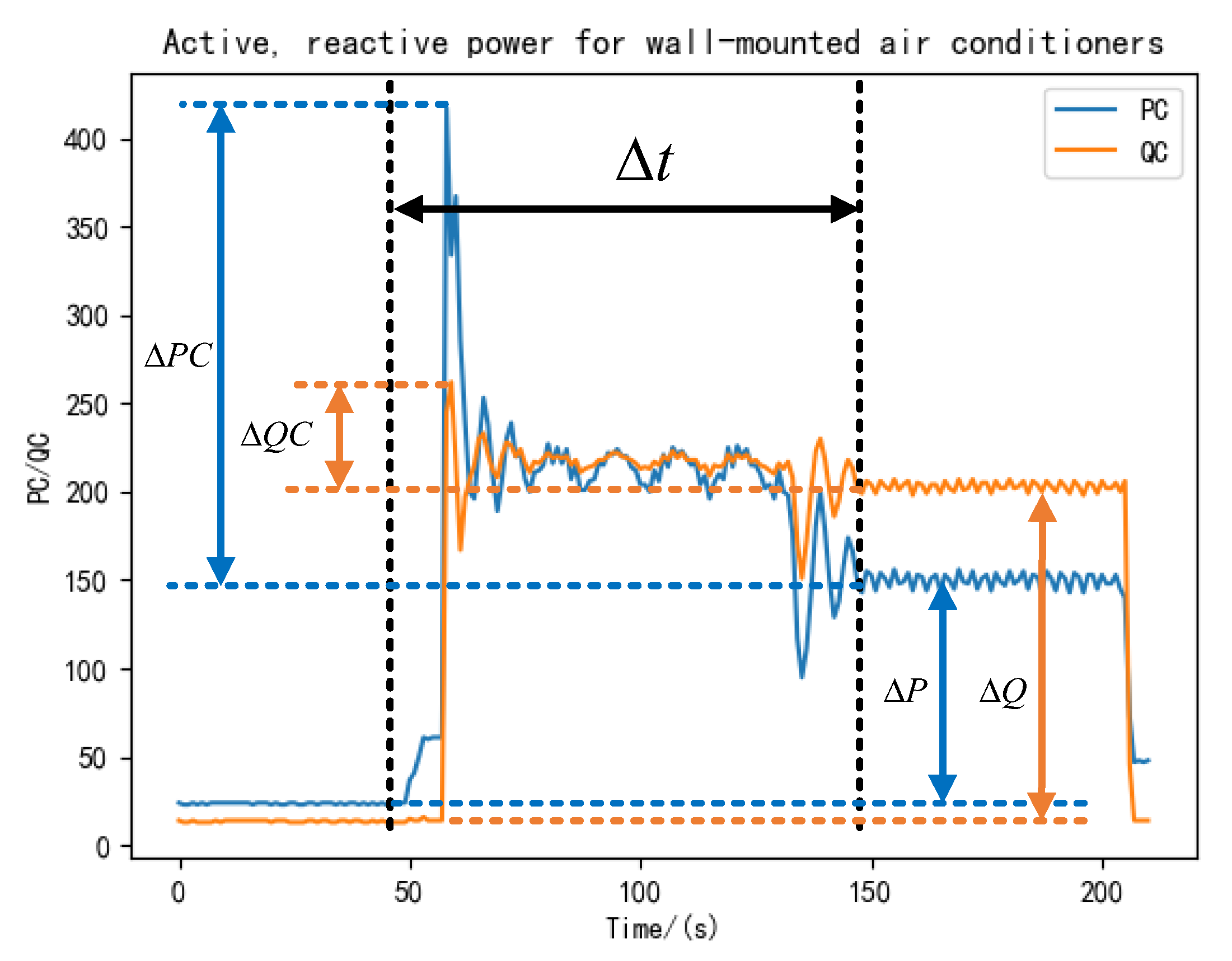
2.1.2. Transient Characteristics
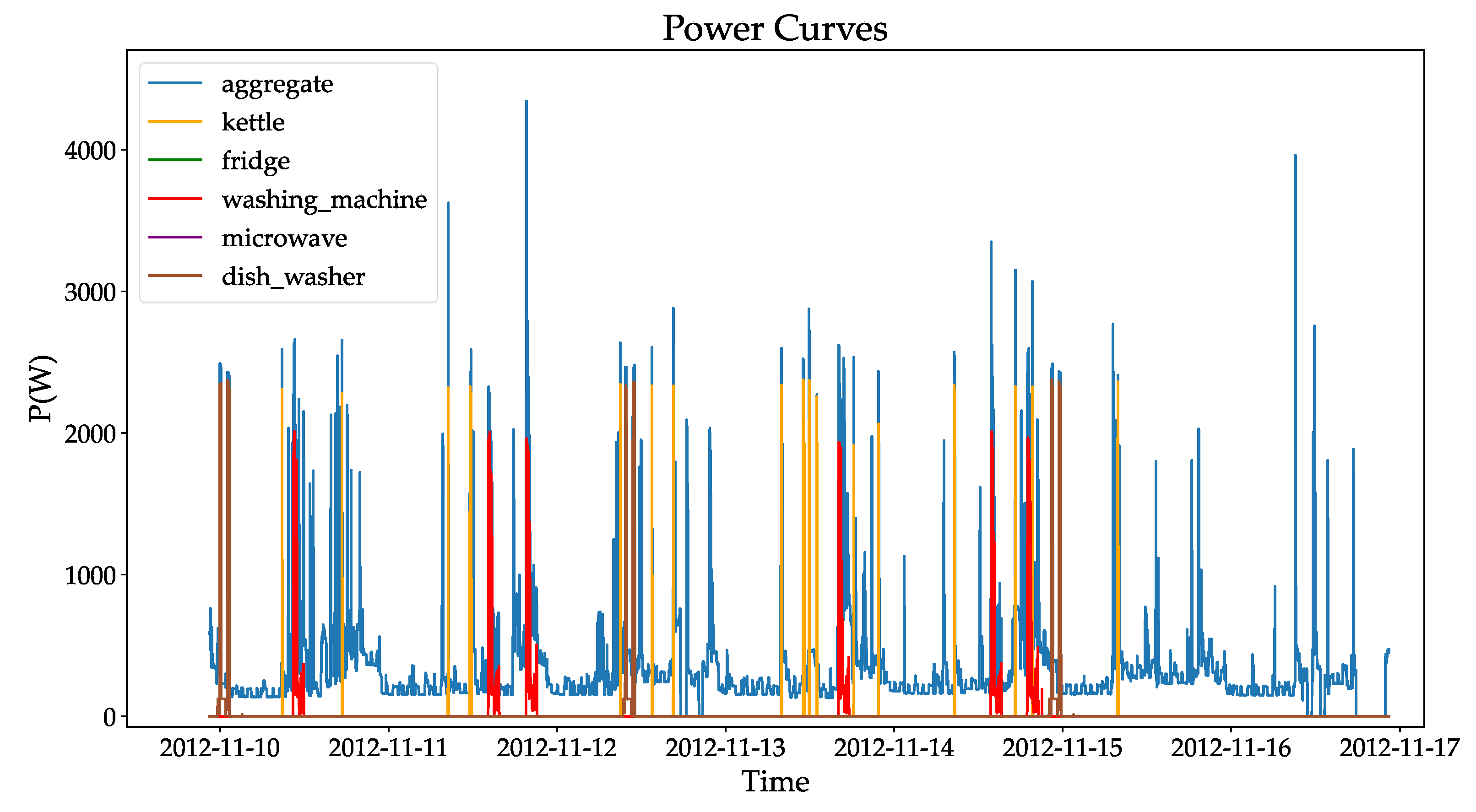
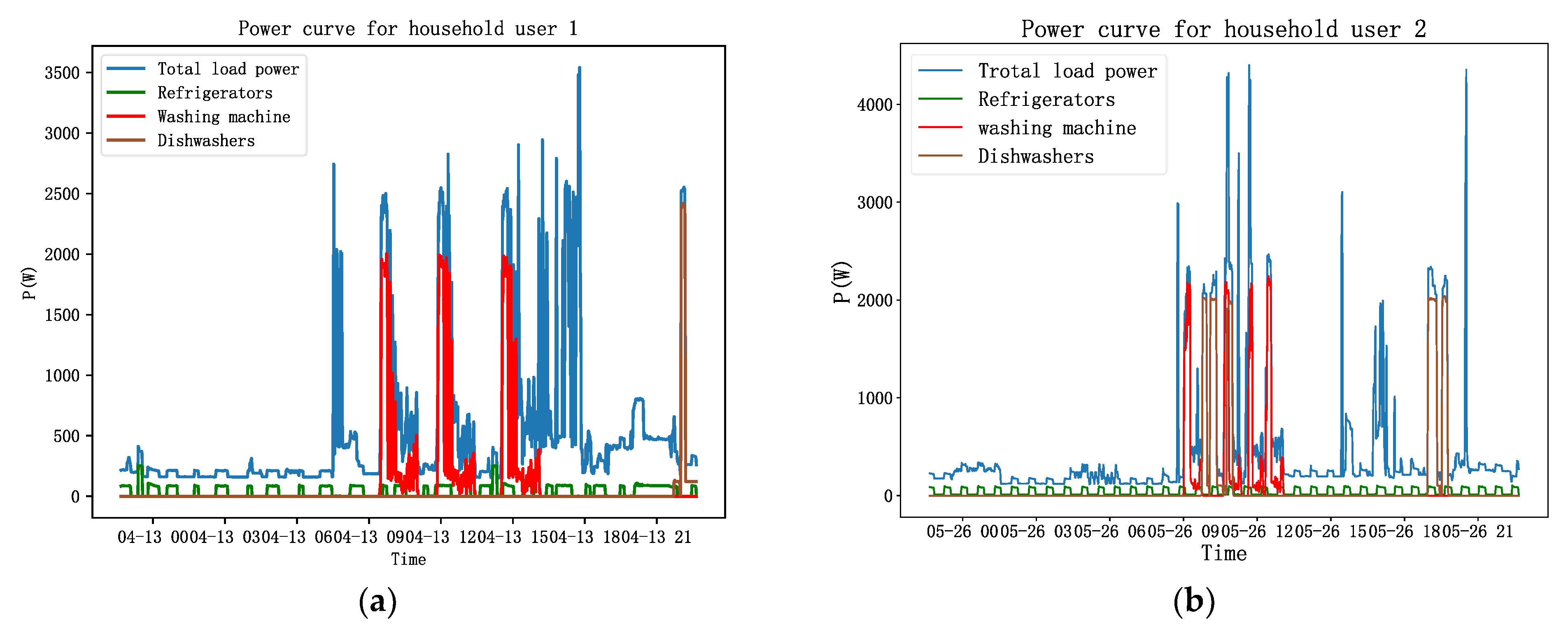
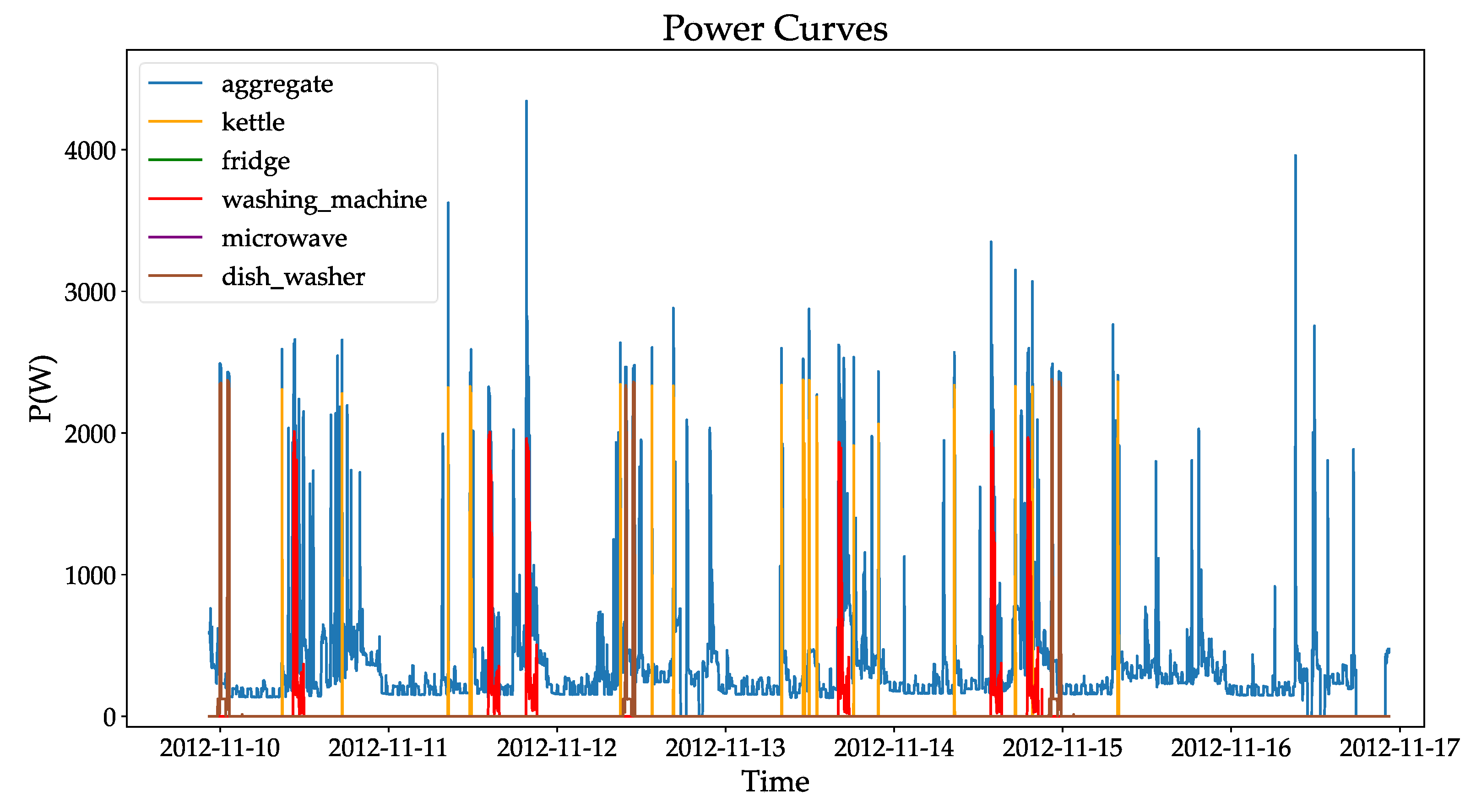
2.2. Dataset
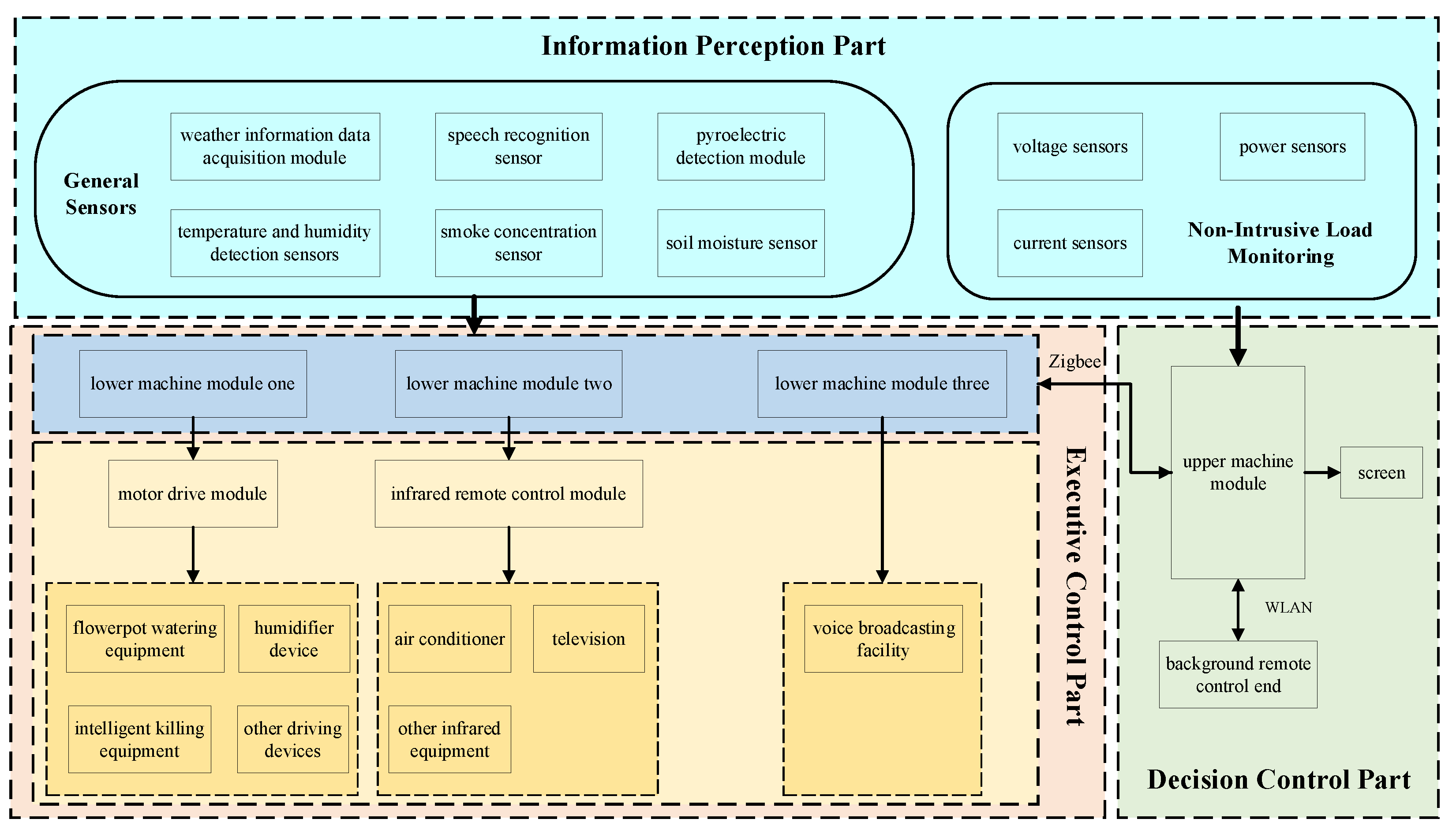
3. Smart Home Modeling Using Non-Intrusive Load Decomposition
3.1. Model Structure
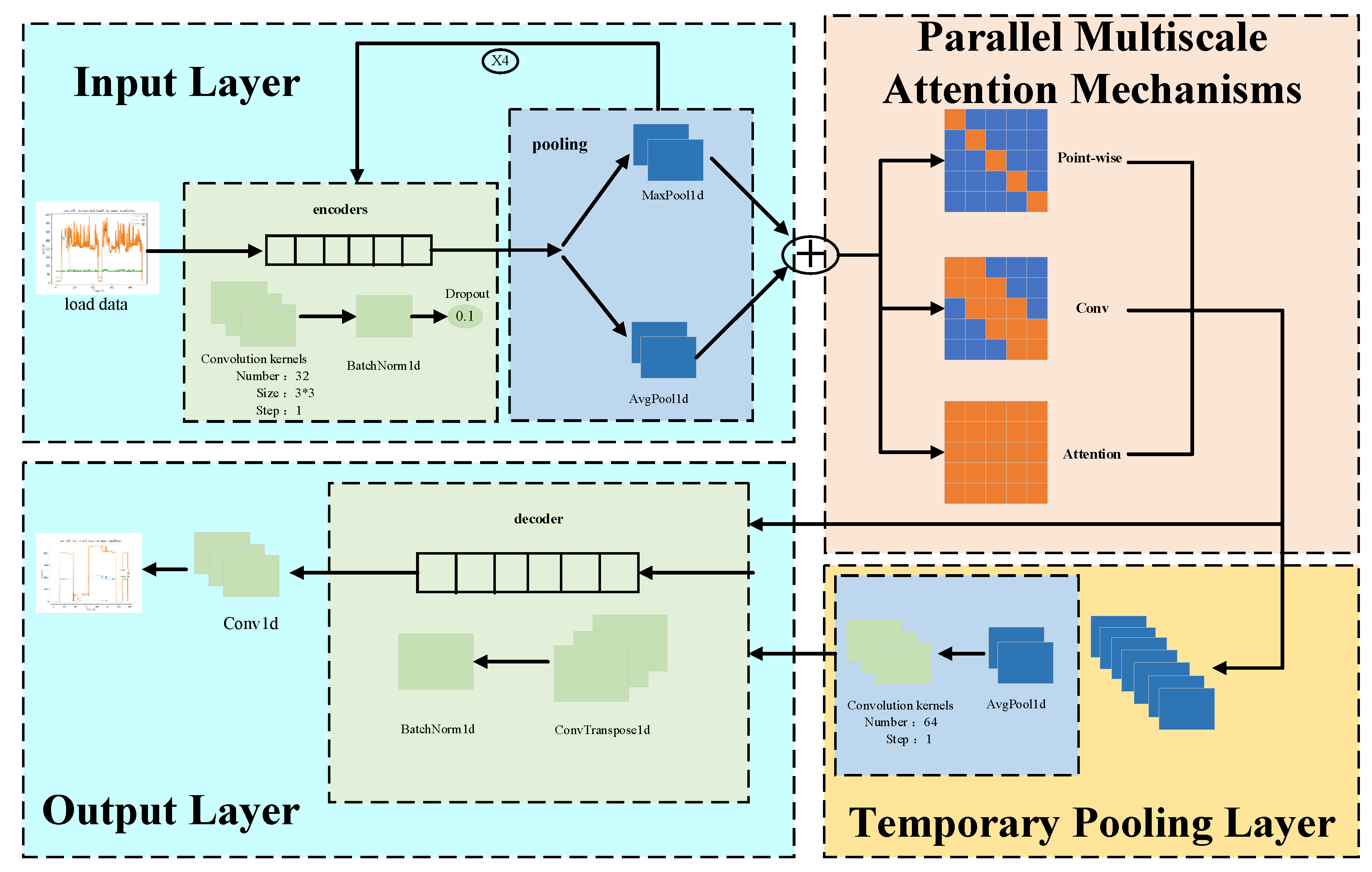
3.2. A Non-Intrusive Load Decomposition Model Based on a Parallel Multiscale Attention Mechanism
3.2.1. Sequence-to-Point Learning Model
3.2.2. Parallel Multiscale Attention Mechanism
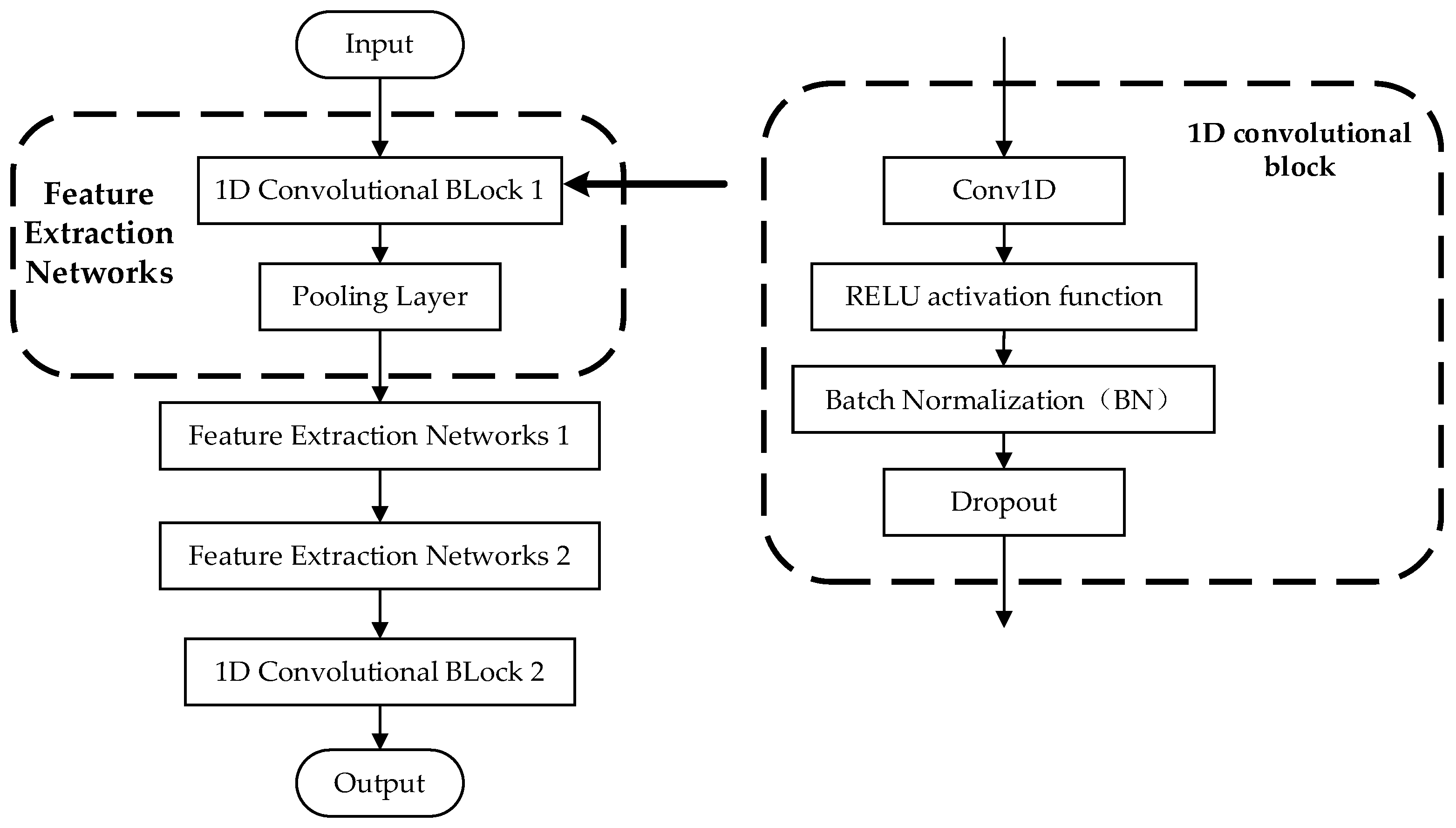
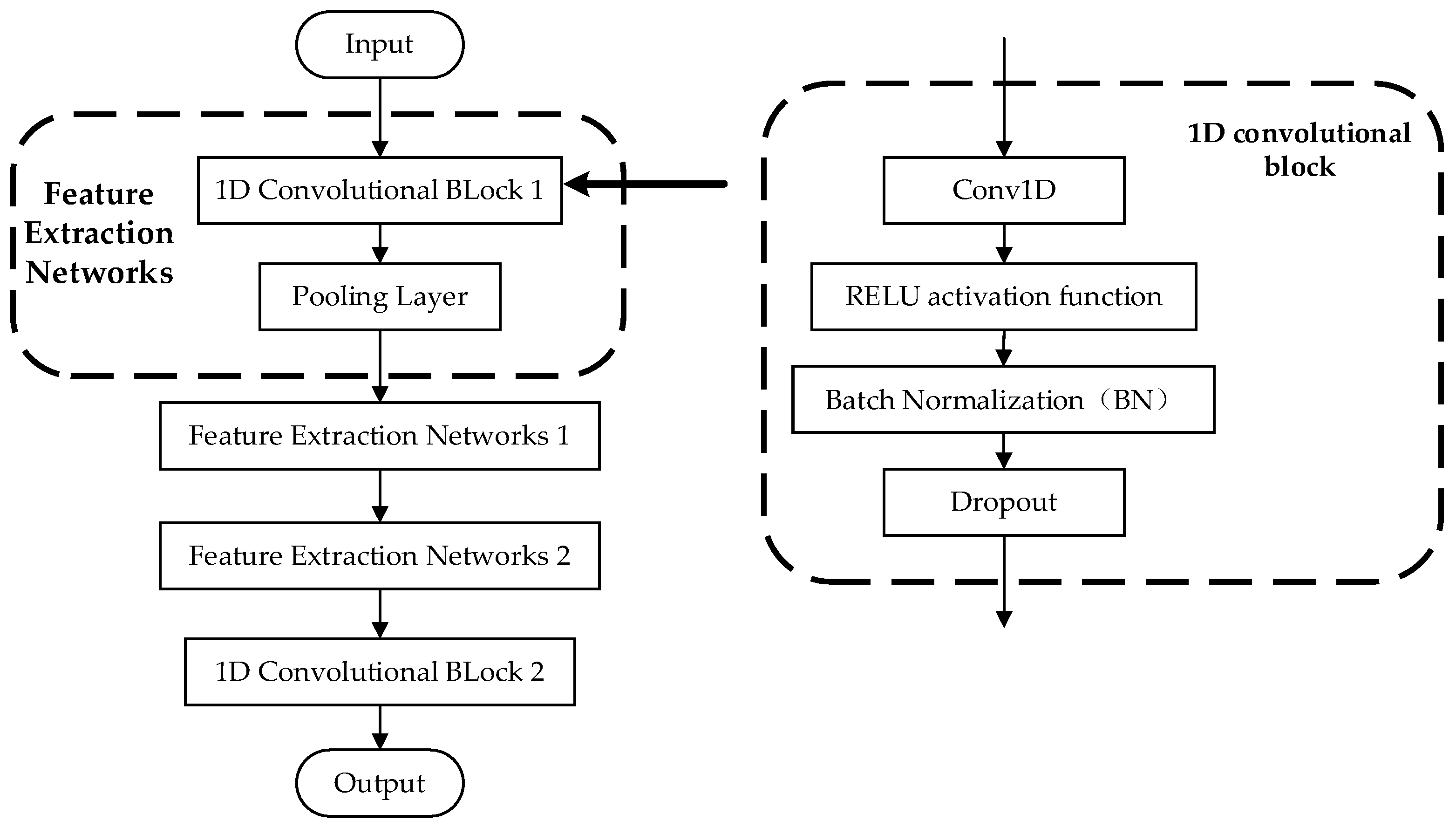
3.2.3. Feature Extraction Networks
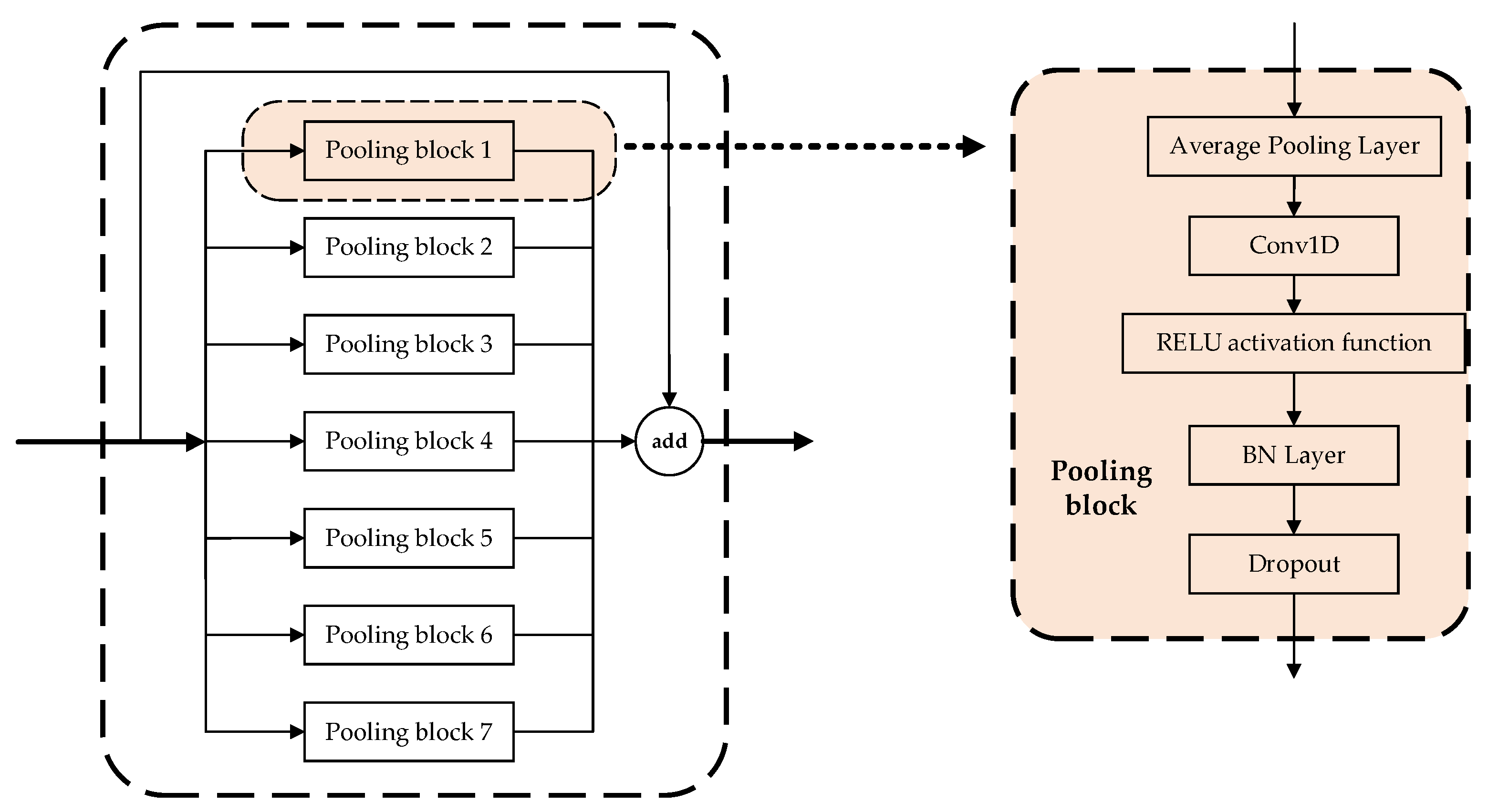
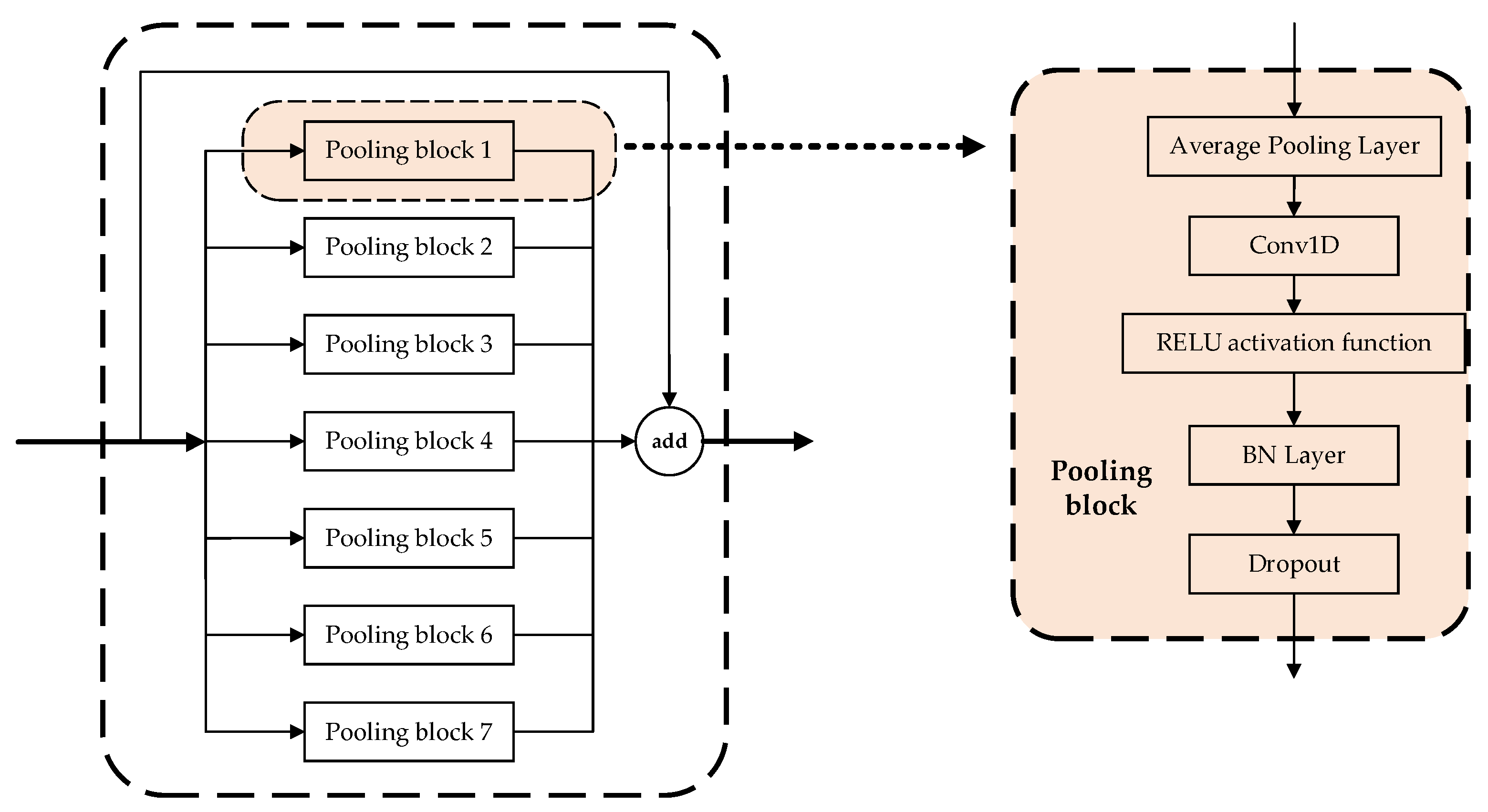
3.2.4. Parallel Multiscale Feature Fusion
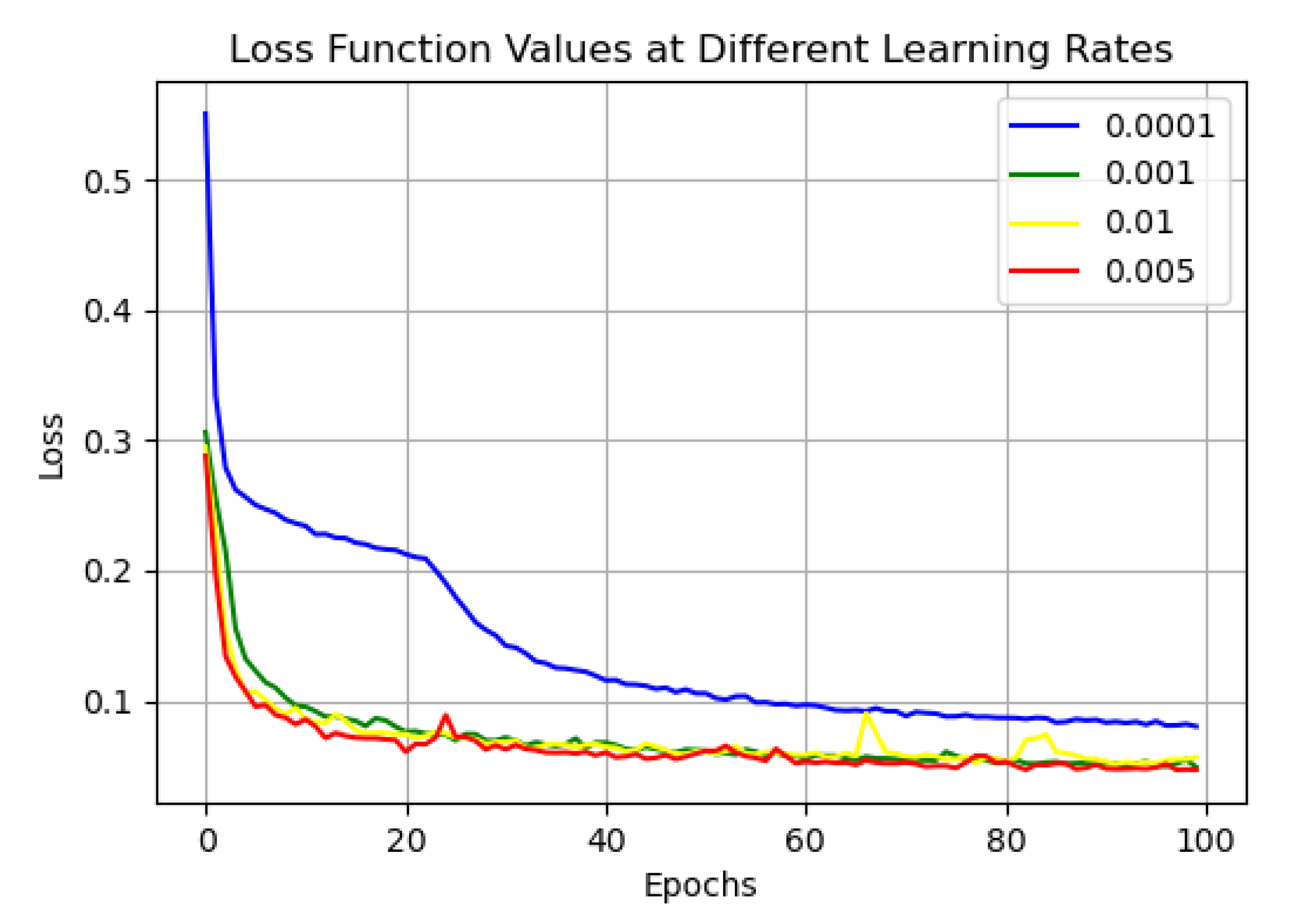
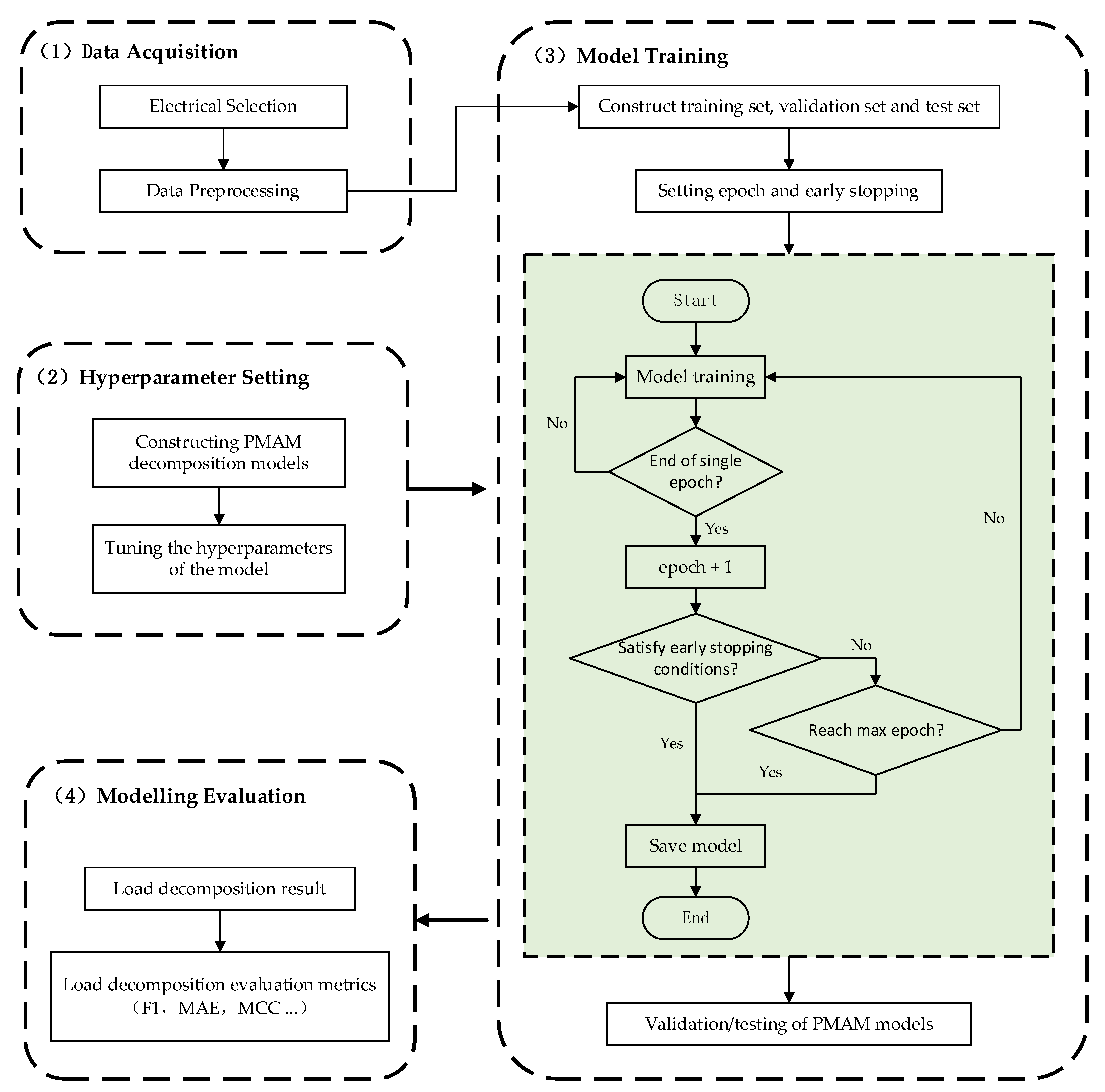
3.3. Model Parameter Selection
4. Algorithm Analysis
4.1. Hardware and Software Platform
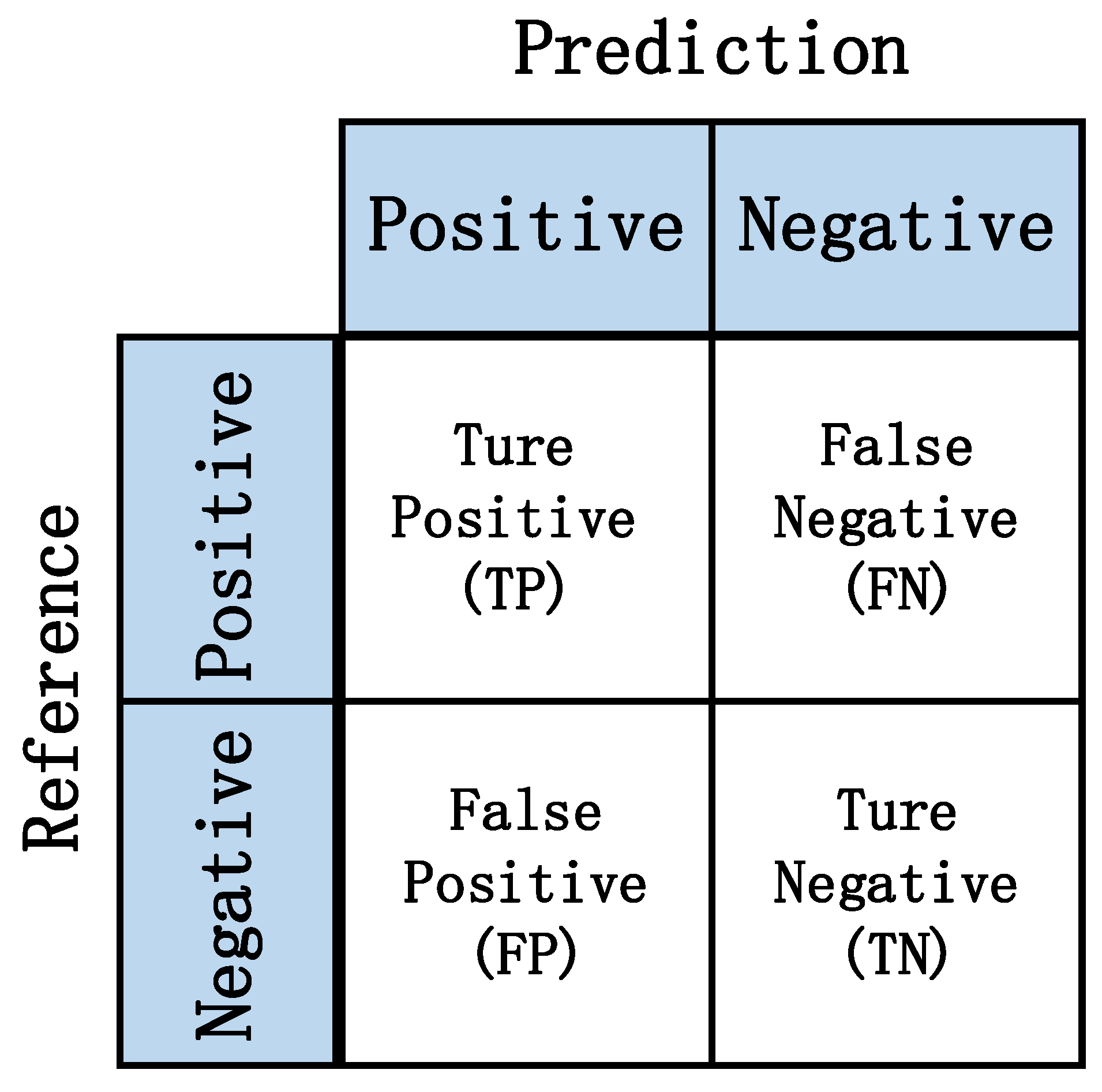
4.2. Load Decomposition Evaluation Metrics
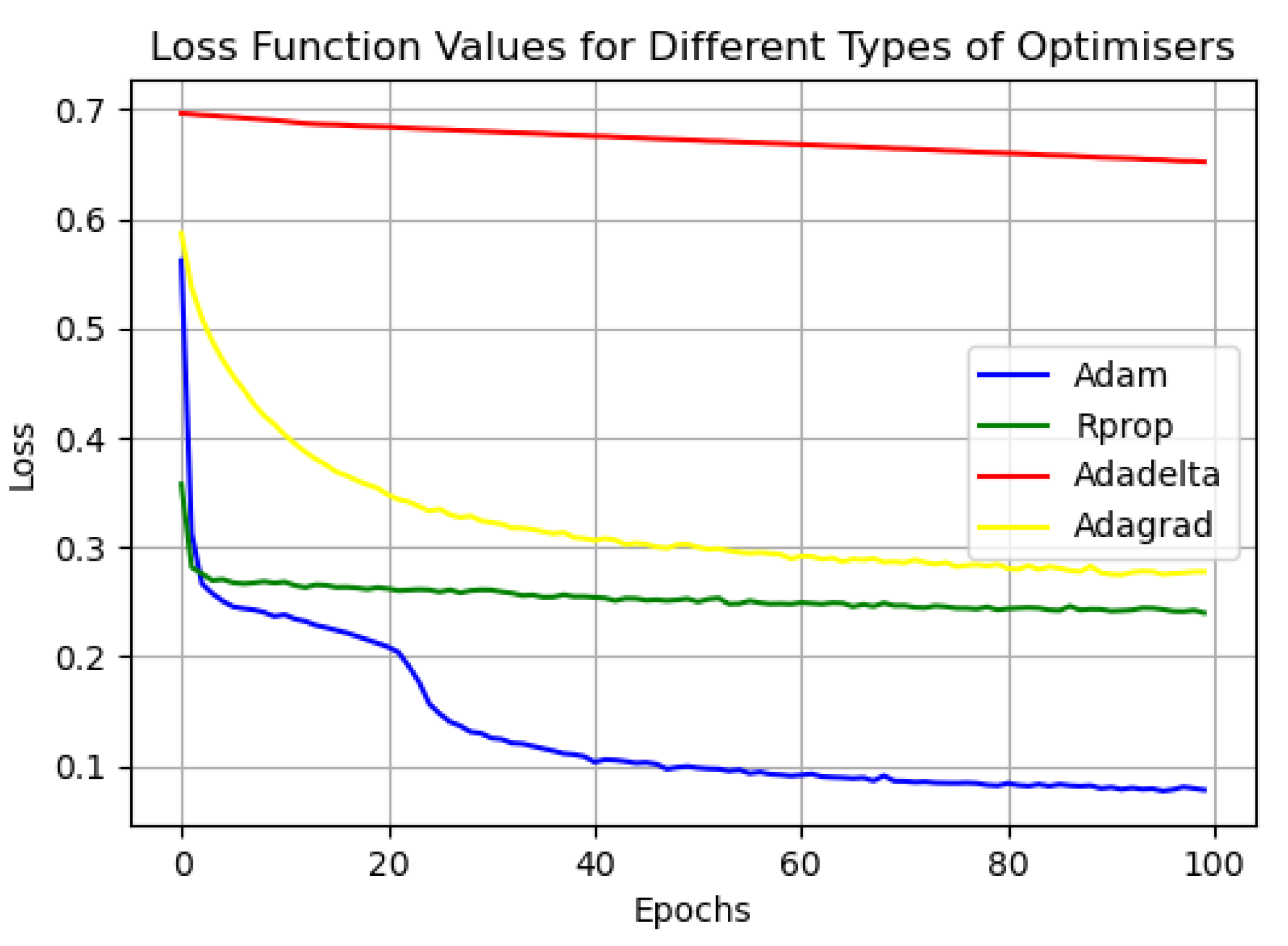
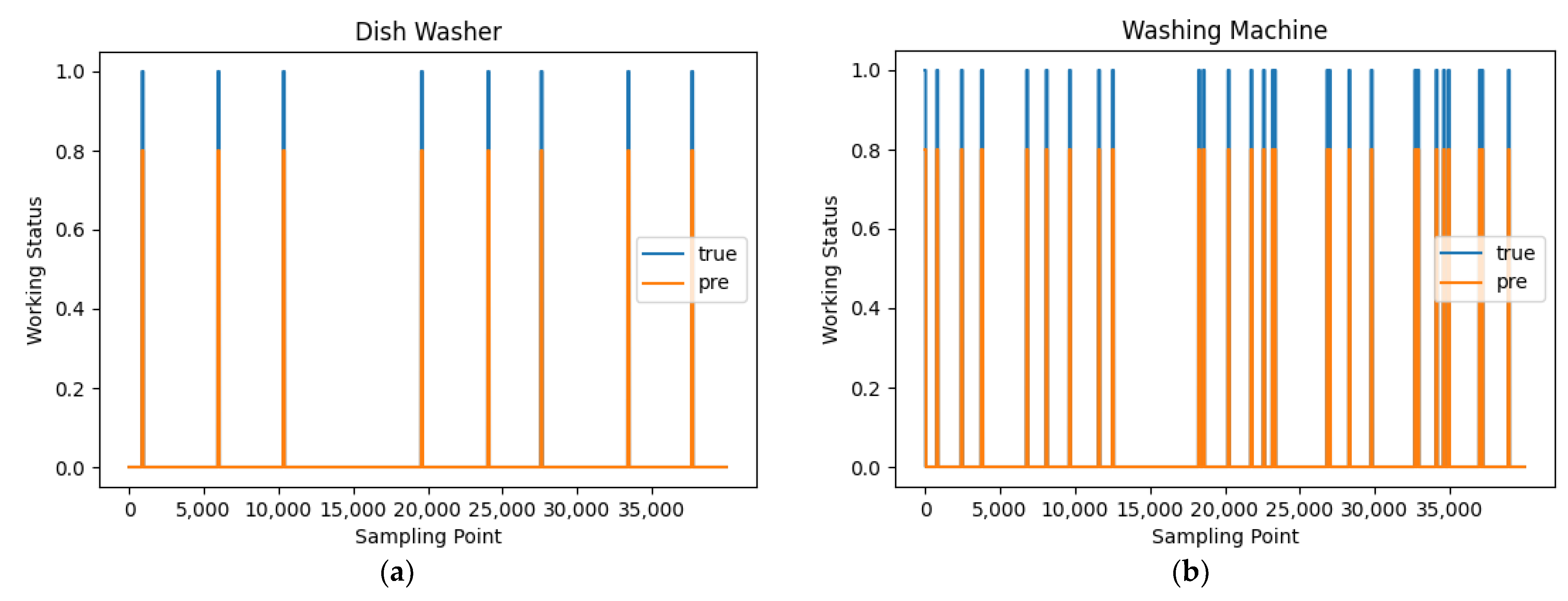
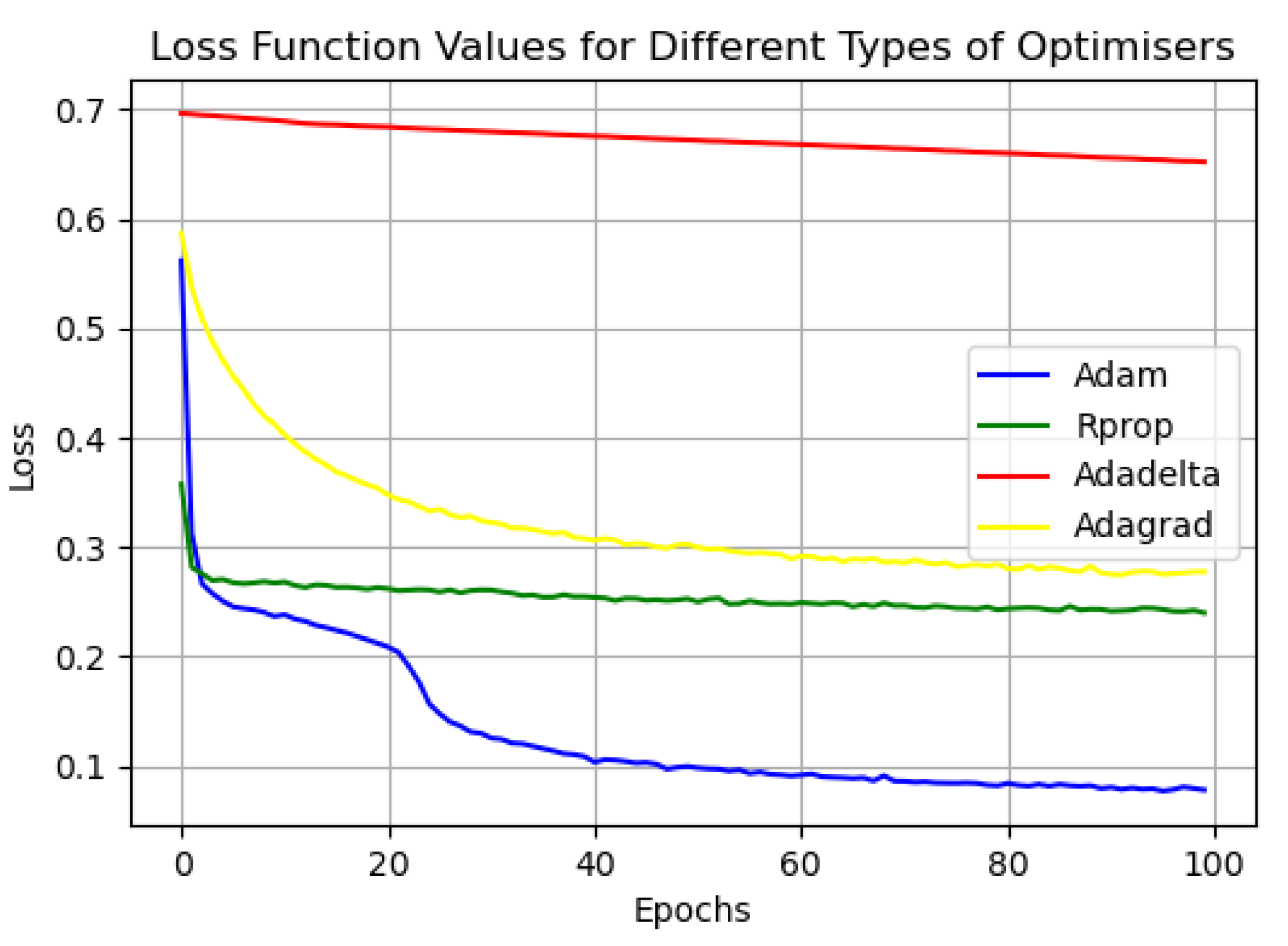
4.3. Experimental Results and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lu, J.; Zhao, R.; Liu, B.; Yu, Z.; Zhang, J.; Xu, Z. An Overview of Non-Intrusive Load Monitoring Based on VI Trajectory Signature. Energies 2023, 16, 939. [Google Scholar] [CrossRef]
- Aboulian, A.; Green, D.H.; Switzer, J.F.; Kane, T.J.; Bredariol, G.V.; Lindahl, P.; Donnal, J.S.; Leeb, S.B. NILM dashboard: A power system monitor for electromechanical equipment diagnostics. IEEE Trans. Ind. Inform. 2018, 15, 1405–1414. [Google Scholar] [CrossRef]
- Li, J.; Xu, W.; Zhang, X.; Feng, X.; Chen, Z.; Qiao, B.; Xue, H. Control method of multi-energy system based on layered control architecture. Energy Build. 2022, 261, 111963. [Google Scholar] [CrossRef]
- Koseleva, N.; Ropaite, G. Big data in building energy efficiency: Understanding of big data and main challenges. Procedia Eng. 2017, 172, 544–549. [Google Scholar] [CrossRef]
- He, X.; Dong, H.; Yang, W.; Hong, J. A Novel Denoising Auto-Encoder-Based Approach for Non-Intrusive Residential Load Monitoring. Energies 2022, 15, 2290. [Google Scholar] [CrossRef]
- Gopinath, R.; Kumar, M.; Joshua, C.P.C.; Srinivas, K. nergy management using non-intrusive load monitoring techniques—State-of-the-art and future research directions. Sustain. Cities Soc. 2020, 62, 102411. [Google Scholar] [CrossRef]
- Armel, K.C.; Gupta, A.; Shrimali, G.; Albert, A. Is disaggregation the holy grail of energy efficiency? The case of electricity. Energy Policy 2013, 52, 213–234. [Google Scholar] [CrossRef]
- Desley, V.; Laurie, B.; Peter, M. The effectiveness of energy feedback for conservation and peak demand: A literature review. Open J. Energy Effic. 2013, 2013, 28957. [Google Scholar]
- Bonfigli, R.; Principi, E.; Fagiani, M.; Severini, M.; Squartini, S.; Piazza, F. Non-intrusive load monitoring by using active and reactive power in additive Factorial Hidden Markov Models. Appl. Energy 2017, 208, 1590–1607. [Google Scholar] [CrossRef]
- Qu, L. Research and Application of Non-Intrusive Load Monitoring Technology Based on Event Detection. Ph.D. Thesis, Hangzhou University of Electronic Science and Technology, Hangzhou, China, 2023. [Google Scholar]
- Hart, G.W. Prototype Nonintrusive Appliance Load Monitor; Technical Report 2; MIT Energy Laboratory and Electric Power Research Institute: Concorde, MA, USA, 1985. [Google Scholar]
- Hart, G.W. Nonintrusive appliance load monitoring. Proc. IEEE 1992, 80, 1870–1891. [Google Scholar] [CrossRef]
- Xu, X.H.; Zhao, S.T.; Cui, K.B. A non-intrusive load decomposition algorithm based on convolutional block attention model. Grid Technol. 2021, 45, 3700–3706. [Google Scholar]
- Kelly, J.; Knottenbelt, W. Neural nilm: Deep neural networks applied to energy disaggregation. In Proceedings of the 2nd ACM International Conference on Embedded Systems for Energy-Efficient Built Environments, New York, NY, USA, 4–5 November 2015; pp. 55–64. [Google Scholar]
- Batra, N.; Singh, A.; Whitehouse, K. Neighbourhood nilm: A big-data approach to household energy disaggregation. arXiv 2015, arXiv:1511.02900. [Google Scholar]
- Nalmpantis, C.; Vrakas, D. Machine learning approaches for non-intrusive load monitoring: From qualitative to quantitative comparation. Artif. Intell. Rev. 2019, 52, 217–243. [Google Scholar] [CrossRef]
- Yang, F.; Liu, B.; Luan, W.; Zhao, B.; Liu, Z.; Xiao, X.; Zhang, R. FHMM based industrial load disaggregation. In Proceedings of the 2021 6th Asia Conference on Power and Electrical Engineering (ACPEE), Chongqing, China, 8–11 April 2021; pp. 330–334. [Google Scholar]
- Jiao, X.; Chen, G.; Liu, J. A non-intrusive load monitoring model based on graph neural networks. In Proceedings of the 2023 IEEE 2nd International Conference on Electrical Engineering, Big Data and Algorithms (EEBDA), Changchun, China, 24–26 February 2023; pp. 245–250. [Google Scholar]
- Kang, J.S.; Yu, M.; Lu, L.; Wang, B.; Bao, Z. Adaptive non-intrusive load monitoring based on feature fusion. IEEE Sens. J. 2022, 22, 6985–6994. [Google Scholar] [CrossRef]
- Gao, Y.; Yang, H. Domestic load identification based on transient feature closeness matching. Power Syst. Autom. 2013, 37, 54–59. [Google Scholar]
- Wang, K.; Zhong, H.; Yu, N.; Xia, Q. Non-intrusive load decomposition for residential users based on seq2seq and Attention mechanism. Chin. J. Electr. Eng. 2019, 39, 75–83+322. [Google Scholar]
- Shi, Y.T. Research and Application of Non-Intrusive Load Identification Method Based on Deep Learning. Ph.D. Thesis, Hangzhou University of Electronic Science and Technology, Hangzhou, China, 2023. [Google Scholar]
- De Baets, L.; Ruyssinck, J.; Develder, C.; Dhaene, T.; Deschrijver, D. Appliance classification using VI trajectories and convolutional neural networks. Energy Build. 2018, 158, 32–36. [Google Scholar] [CrossRef]
- Wang, S.; Chen, H.; Guo, L.; Xu, D. Non-intrusive load identification based on the improved voltage-current trajectory with discrete color encoding background and deep-forest classifier. Energy Build. 2021, 244, 111043. [Google Scholar] [CrossRef]
- Han, Y.; Li, K.; Feng, H.; Zhao, Q. Non-intrusive load monitoring based on semi-supervised smooth teacher graph learning with voltage–current trajectory. Neural Comput. Appl. 2022, 34, 19147–19160. [Google Scholar] [CrossRef]
- Mou, K.; Yang, H. A non-intrusive load monitoring method based on PLA-GDTW support vector machine. Grid Technol. 2019, 43, 4185–4193. [Google Scholar]
- Huber, P.; Ott, M.; Friedli, M.; Rumsch, A.; Paice, A. Residential power traces for five houses: The iHomeLab RAPT dataset. Data 2020, 5, 17. [Google Scholar] [CrossRef]
- Klemenjak, C.; Kovatsch, C.; Herold, M.; Elmenreich, W. A synthetic energy dataset for non-intrusive load monitoring in households. Sci. Data 2020, 7, 108. [Google Scholar] [CrossRef] [PubMed]
- Kelly, J.; Knottenbelt, W. The UK-DALE dataset, domestic appliance-level electricity demand and whole-house demand from five UK homes. Sci. Data 2015, 2, 150007. [Google Scholar] [CrossRef]
- Kolter, J.Z.; Johnson, M.J. REDD: A public data set for energy disaggregation research. In Proceedings of the Workshop on Data Mining Applications in Sustainability (SIGKDD), San Diego, CA, USA, 21–24 August 2011; Volume 25, pp. 59–62. [Google Scholar]
- Filip, A. Blued: A fully labeled public dataset for event-based nonintrusive load monitoring research. In Proceedings of the 2nd Workshop on Data Mining Applications in Sustainability (SustKDD), Beijing, China, 12–16 August 2012. [Google Scholar]
- Cui, P.F. Research on Non-Intrusive Household Electric Load Decomposition and Application Based on Deep Learning. Ph.D. Thesis, Xi’an University of Architecture and Technology, Xi’an, China, 2023. [Google Scholar]
- Zhang, C.; Zhong, M.; Wang, Z.; Goddard, N.; Sutton, C. Sequence-to-point learning with neural networks for non-intrusive load monitoring. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Zhao, G.; Sun, X.; Xu, J.; Zhang, Z.; Luo, L. Muse: Parallel multi-scale attention for sequence to sequence learning. arXiv 2019, arXiv:1911.09483. [Google Scholar]
- Alhussein, M.; Aurangzeb, K.; Haider, S.I. Hybrid CNN-LSTM model for short-term individual household load forecasting. IEEE Access 2020, 8, 180544–180557. [Google Scholar] [CrossRef]
- Shao, X.; Kim, C.S.; Sontakke, P. Accurate deep model for electricity consumption forecasting using multi-channel and multi-scale feature fusion CNN–LSTM. Energies 2020, 13, 1881. [Google Scholar] [CrossRef]
- Xu, R.; Liu, D. Non-intrusive load monitoring based on multi-scale feature fusion and multi-head self-attention mechanism. Sci. Technol. Eng. 2024, 24, 2385–2395. [Google Scholar]
- Massidda, L.; Marrocu, M.; Manca, S. Non-intrusive load disaggregation by convolutional neural network and multilabel classification. Appl. Sci. 2020, 10, 1454. [Google Scholar] [CrossRef]
- Salerno, V.M.; Rabbeni, G. An extreme learning machine approach to effective energy disaggregation. Electronics 2018, 7, 235. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Type | Specific Characteristics | Feature Extraction Method |
|---|---|---|
| Homeostatic Characteristics | voltage/current characteristics | statistical analysis |
| active/reactive power characteristics | statistical analysis | |
| harmonic characteristic | Fast Fourier Transform (FFT) | |
| peripheral V-I characteristics | relevant indicators used to characterize trajectories | |
| Transient Characteristics | prompt power | power spectral envelope estimation, waveform vectors |
| instantaneous current | Fast Fourier Transform (FFT) | |
| voltage noise | spectral analysis |
| Electrical Equipment | Modeling | Evaluation Indicators | |||||
|---|---|---|---|---|---|---|---|
| F1 | Precision | Recall | Accuracy | MAE | MCC | ||
| Dishwasher | PMAM | 0.966 | 0.967 | 0.965 | 0.998 | 20.44 | 0.965 |
| UNPMAM | 0.933 | 0.908 | 0.959 | 0.997 | 21.37 | 0.932 | |
| LSTM | 0.06 | 0.03 | 0.63 | 0.35 | 130 | - | |
| TPNILM | 0.930 | 0.942 | 0.919 | 0.997 | 20.41 | 0.928 | |
| ELM | 0.93 | 0.89 | 0.99 | 0.98 | 19 | - | |
| Washing machine | PMAM | 0.989 | 0.987 | 0.991 | 0.998 | 41.48 | 0.988 |
| UNPMAM | 0.984 | 0.985 | 0.982 | 0.998 | 41.51 | 0.982 | |
| LSTM | 0.09 | 0.05 | 0.62 | 0.31 | 133 | - | |
| TPNILM | 0.978 | 0.975 | 0.982 | 0.997 | 41.97 | 0.977 | |
| ELM | 0.84 | 0.73 | 0.99 | 0.76 | 27 | - | |
| Refrigerators | PMAM | 0.900 | 0.903 | 0.898 | 0.910 | 12.66 | 0.818 |
| UNPMAM | 0.867 | 0.879 | 0.856 | 0.881 | 15.09 | 0.760 | |
| LSTM | 0.06 | 0.03 | 0.63 | 0.35 | 130 | - | |
| TPNILM | 0.867 | 0.875 | 0.859 | 0.880 | 15.25 | 0.759 | |
| ELM | 0.83 | 0.88 | 0.80 | 0.88 | 20 | - | |
| Electrical Equipment | Modeling | Evaluation Indicators | |||||
|---|---|---|---|---|---|---|---|
| F1 | Precision | Recall | Accuracy | MAE | MCC | ||
| Dishwasher | PMAM | 0.899 | 0.907 | 0.892 | 0.994 | 30.84 | 0.896 |
| UNPMAM | 0.740 | 0.679 | 0.813 | 0.984 | 35.91 | 0.735 | |
| LSTM | 0.08 | 0.04 | 0.87 | 0.30 | 168 | - | |
| TPNILM | 0.809 | 0.788 | 0.835 | 0.989 | 33.07 | 0.805 | |
| ELM | 0.55 | 0.35 | 1.00 | 1.00 | 22 | - | |
| Washing machine | PMAM | 0.973 | 0.977 | 0.969 | 0.999 | 9.32 | 0.972 |
| UNPMAM | 0.955 | 1.00 | 0.915 | 0.999 | 9.50 | 0.956 | |
| LSTM | 0.03 | 0.01 | 0.73 | 0.23 | 109 | - | |
| TPNILM | 0.863 | 0.858 | 0.869 | 0.997 | 8.31 | 0.862 | |
| ELM | 0.43 | 0.10 | 1.00 | 0.84 | 21 | - | |
| Refrigerators | PMAM | 0.874 | 0.829 | 0.924 | 0.908 | 15.87 | 0.805 |
| UNPMAM | 0.847 | 0.785 | 0.919 | 0.886 | 17.53 | 0.763 | |
| LSTM | 0.74 | 0.72 | 0.77 | 0.81 | 36 | - | |
| TPNILM | 0.871 | 0.892 | 0.851 | 0.905 | 17.03 | 0.796 | |
| ELM | 0.89 | 0.90 | 0.92 | 0.94 | 23 | - | |
| Model | Number of Modeling Parameters | Training Time/(s/epoch) |
|---|---|---|
| PMAM | 549,902 | 3.17 |
| UNPMAM | 496,259 | 0.76 |
| TPNILM | 327,619 | 1.62 |
| ELM | - | 2.46 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, L.; Wang, J.; Zhao, C. Non-Intrusive Load Monitoring Based on Multiscale Attention Mechanisms. Energies 2024, 17, 1944. https://doi.org/10.3390/en17081944
Yao L, Wang J, Zhao C. Non-Intrusive Load Monitoring Based on Multiscale Attention Mechanisms. Energies. 2024; 17(8):1944. https://doi.org/10.3390/en17081944
Chicago/Turabian StyleYao, Lei, Jinhao Wang, and Chen Zhao. 2024. "Non-Intrusive Load Monitoring Based on Multiscale Attention Mechanisms" Energies 17, no. 8: 1944. https://doi.org/10.3390/en17081944
APA StyleYao, L., Wang, J., & Zhao, C. (2024). Non-Intrusive Load Monitoring Based on Multiscale Attention Mechanisms. Energies, 17(8), 1944. https://doi.org/10.3390/en17081944