Abstract
A multi-cut rearrangement of a string S is a string obtained from S by an operation called k-cut rearrangement, that consists of (1) cutting S at a given number k of places in S, making S the concatenated string , where and are possibly empty, and (2) rearranging the s so as to obtain , being a permutation on satisfying and . Given two strings S and T built on the same multiset of characters from an alphabet , the Sorting by Multi-Cut Rearrangements (SMCR) problem asks whether a given number ℓ of k-cut rearrangements suffices to transform S into T. The SMCR problem generalizes several classical genomic rearrangements problems, such as Sorting by Transpositions and Sorting by Block Interchanges. It may also model chromoanagenesis, a recently discovered phenomenon consisting of massive simultaneous rearrangements. In this paper, we study the SMCR problem from an algorithmic complexity viewpoint. More precisely, we investigate its classical and parameterized complexity, as well as its approximability, in the general case or when S and T are permutations.
1. Introduction
Genome rearrangements are large-scale evolutionary events that affect the genome of a species. They include among others reversals [1], transpositions [2], block interchanges [3] and many more [4]. Compared to small-scale evolutionary events such as the insertion, deletion or substitution of single DNA nucleotides, they are considered to be rare and, until recently, were assumed to happen one after the other. In the recent literature, however, a new type of event, called chromoanagenesis, has been shown to occur in genomes [5,6]. The term chromoanagenesis subsumes different types of rearrangements (namely, chromothripsis, chromoanasynthesis and chromoplexy) whose common ground is the following: in a single event, the genome is cut into many blocks, and then rearranged. As stated by Pellestor and Gatinois [6], these are “massive chromosomal rearrangements arising during single chaotic cellular events”. Chromoanagenesis, and notably chromothripsis, is suspected to play a role in cancer and congenital diseases [5]. In this paper, we introduce a new model for genome rearrangements that is general enough to encompass most of the previously described genome rearrangements [4], as well as chromoanagenesis. In view of providing fast and accurate algorithms for simulating chromoanagenesis, and following a long tradition of algorithmic developments in the genome rearrangements community [4,7], our goal here is to study its properties in terms of computational complexity.
The present article is an extended and enriched version of a paper published by the same authors in SOFSEM 2021 [8].
1.1. Notations and Definitions
Given an alphabet , let be the set of all strings over . We say that two strings are balanced if S and T are built on the same multiset of characters—in other words, each character in S also appears in T with the same number of occurrences. We denote by the length of a string S. Unless otherwise stated, we assume that . We denote by , , the i-th character of S. Given a string S in , we denote by d the maximum number of occurrences of any character of in S. In the special case where (i.e., when S and T are permutations), and for any , we say that there is a breakpoint at position i in S (or, equivalently, that is a breakpoint) if there is no position in T, such that the two consecutive characters and are consecutive in T, i.e., and . For the special cases and , we artificially set and , where and . Thus, there is a breakpoint at position 0 (resp. n) in S whenever (). We also denote by the number of breakpoints in S with respect to T.
Definition 1.
Given a string and an integer k, a k-cut rearrangement of S is an operation consisting of the two following steps: (1) cut S at k locations (thus S can be written as the concatenation of strings, i.e., , where any is possibly empty, and where a cut occurs between and , ) and (2) rearrange (i.e., permute) the s, so as to obtain , π being a permutation on the elements , such that and . Each of the s considered in a given k-cut rearrangement will be called a block.
In the above model, any block is only allowed to move whenever it is cut at both its left and right extremities. Hence, moving a prefix of S (resp. a suffix of S) comes at the cost of an “extra cut” to its left (resp. right), and this corresponds, in the above definition, to the case where (resp. ) is empty.
Note also that, although a k-cut rearrangement has been defined as a cut along S at k locations, it is always possible, if necessary, to perform only cuts, by cutting several times at the same location. Thus, one may mimic a k-cut rearrangement, while actually realizing a -cut rearrangement. Note finally that, in this model, each block can only be moved, thus no reversal of is allowed, and therefore the strings we consider are always unsigned. In this paper, we study the following problem.
- Sorting by Multi-Cut Rearrangements (SMCR)
- Instance: Two balanced strings S and T, two integers k and ℓ.
- Question: Is there a sequence of at most ℓ many k-cut rearrangements that transforms S into T?
Some examples of k-cut rearrangement scenarii are presented in Figure 1. For convenience, we may also refer to the SMCR problem with parameters k and ℓ as the -SMCR problem. Note that this notation shall not imply that k or ℓ are constants. Unless mentioned otherwise, input strings are considered to have an unbounded alphabet, although most hardness proofs also hold for constant-size alphabets, as detailed in the tables of results.
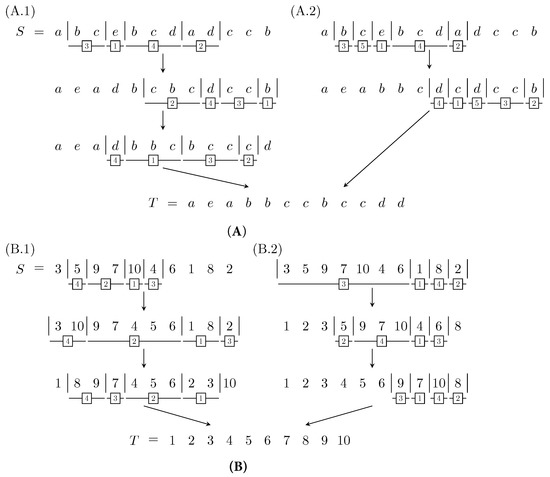
Figure 1.
Examples of k-cut rearrangement scenarii. Cuts are represented by vertical lines and the order of the rearranged blocks is indicated by the framed numbers. (A) Example on strings and . (A.1) shows a 5-cut rearrangement scenario with . (A.2) shows a 6-cut rearrangement scenario with . (B) Example on permutations and with . (B.1,B.2) show two alternative 5-cut rearrangement scenarii with .
1.2. Parameterized Algorithmics
Our goal in this paper is to study the algorithmic properties of SMCR. In particular, we aim to outline the effect of bounds on k and ℓ on the complexity of the problem. To carry out our studies, we use the framework of parameterized algorithmics [9,10] which has been applied to many hard string problems in the past [11].
An instance of a parameterized problem consists of the (classical) input instance I and a parameter . A parameterized problem is fixed-parameter tractable if every instance can be solved in time, where is the size of the input, and f is some computable function. An algorithm with such a running time is called an FPT-algorithm. Thus, an FPT -algorithm can be considered pratical if f does not grow too fast and takes on relatively small values, for example if and is upper-bounded by .
A particularly important technique for obtaining FPT-algorithms is kernelization, which is a framework for analyzing the power of data reduction rules for parameterized problems. A parameterized problem admits a kernelization, or simply a kernel, if there exists a polynomial-time algorithm that transforms every instance into an equivalent instance , such that The function g is called the kernel size. For any decidable parameterized problem L, the existence of a kernel implies that L has an FPT-algorithm with respect to , since the instance can be solved in time.
In our study, we consider the case that the parameter is one of k or ℓ, that is the combined parameter , or that k and ℓ are part of the input. Moreover, we consider some special cases where k or ℓ take on small constant values. Some of these cases correspond to well-studied problems, such as computing the transposition distance or the MCSP distance, as we discuss below. We will separately consider the case where S and T are strings (i.e., both in S and T) and the case where S and T are permutations (i.e., both in S and T), in Section 2 and Section 3, respectively.
1.3. Basic Observations
Both in permutations and strings, the cases and are trivial, since they do not allow one to move any block, and thus we are in the presence of a Yes-instance if, and only if, . Additionally, the SMCR problem is a natural generalization and extension of several problems that have already been defined and studied in the literature before, as described hereafter.
When , each k-cut rearrangement is necessarily a transposition of blocks and (see Figure 2). Thus SMCR in that case is equivalent to the Sorting by Transpositions problem [2], which is NP-hard, even if S and T are permutations [12] or binary strings [13].
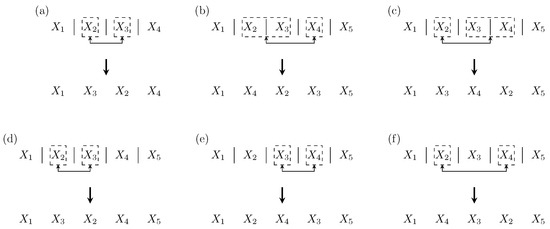
Figure 2.
Relationship between classical rearrangements and k-cut rearrangements. Cuts are represented by vertical lines, while dashed rectangles define blocks that are moved in classical rearrangements. (a) when , a k-cut rearrangement corresponds to a transposition (here of blocks and ). (b–f) are the 5 possible cases that we can get with a 4-cut rearrangement, all of them corresponding to a block interchange of dashed blocks.
When , each k-cut rearrangement allows one to move two blocks among , and , which exactly corresponds to the Sorting by Block Interchange problem (see Figure 2). This problem is known to be in P for permutations [3] and NP-hard for strings (an NP-hardness proof for binary strings is given in ([14], Theorem 5.7.2)).
It may come as a surprise that the case is polynomial on permutations, when the case —and all other non-trivial cases—are NP-hard. The original algorithm for is based on the cycle graph (see Section 3.1.1 for formal definitions): in this setting, the goal is to create as many cycles as possible at each step (a block interchange may create at most two cycles). The key intuition is that such an “efficient” block-interchange always exists and can be polynomially computed. In other words, efficient block-interchanges commute, so it is safe to greedily apply the best-available operation at any point. This is in contrast with , since transpositions may also create up to two new cycles, but such efficient transpositions are not always guaranteed to exist and cannot be chosen greedily (applying one may destroy another). In fact, finding a sequence of such efficient transpositions is at the core of the NP-hardness proof [12]. On a related note, Lin et al. [15] proposed an algebraic formulation of the Sorting by Block Interchange problem, translating the cycles into permutation orbits, leading to a linear-time algorithm.
When , the SMCR problem comes down to deciding whether k cuts are sufficient to rearrange S into T in one atomic move (i.e., one k-cut rearrangement). In permutations, the problem is trivially solved by counting the number of breakpoints between S and T, since we have a Yes-instance if and only if . In strings, the SMCR problem resembles the Minimum Common String Partition problem [16]. Both problems are indeed almost identical, and only differ in their optimum value, depending on whether S and T share the same prefix and/or suffix. This will be discussed in more detail in Theorems 5 and 6.
When k and ℓ are constant, SMCR is trivially polynomial-time solvable, since a brute-force algorithm, exhaustively testing all possible k-cut rearrangements at each of the ℓ permitted moves, has a running time of —the additional factor of n being needed to verify that the result corresponds to string T.
It is also natural to wonder whether -SMCR and -SMCR are equivalent. It can be easily seen that a Yes-instance for -SMCR is also a Yes-instance for -SMCR: it suffices for this to aggregate all cuts from the -SMCR solution (of which there are at most ), and rearrange accordingly. However, the reverse (i.e., from -SMCR to -SMCR) is not always true. For example, take , , , and . This is a Yes-instance for -SMCR: One 6-cut rearrangement on S with the cuts (symbolized as vertical segments) suffices to obtain T. In contrast, it is a No-instance for -SMCR: The number of breakpoints is equal to 6 and every 3-cut rearrangement is a transposition. In this instance, however, no transposition can decrease by 3. Thus, at least three 3-cut rearrangements are necessary to transform S into T.
2. Sorting by Multi-Cut Rearrangements in Strings
In this section, we provide algorithmic results concerning the Sorting by Multi-Cut Rearrangements problem, in the general case where S and T are strings. Our results are summarized in Table 1.

Table 1.
Summary of the results for Sorting by Multi-Cut Rearrangements in strings. Recall that d denotes the maximum number of occurrences of any character in the input string S.
As mentioned in the previous section, we know that SMCR is NP-hard in binary strings for [13,14]. In the following theorem, we extend this result to any value of k, however, in larger alphabet strings.
Theorem 1.
SMCRis NP-hard in k-ary strings for any fixed .
Proof.
By reduction from 3-Partition, a problem in which the input is a set of integers and an integer B, and the question is whether can be partitioned into triples such that the integers of each triple sum up to B. Observe that 3-Partition is strongly NP-hard, that is, it is NP-hard even if all integers are represented as unary numbers [17]. Given an instance of 3-Partition with and , we construct an instance of SMCR for any fixed as follows. By simple padding arguments, we may assume that each is a multiple of and that . This implies the following property: If for some subset I of and some with we have , then , , and . We use a size-k alphabet , we denote by X the string , and by the reverse of X, i.e., . Note that X and have length . We define
and
and set . This completes the construction. Before proving its correctness, let us group length-2 substrings of S and T (hereafter called duos) based on whether they are in excess in S, in T, or equal in both strings.
- Group 1 contains the duos , , and , which each occur times in S and which do not occur in T.
- Group 2 contains the duos , which occur times in S and times in T, and the duos which do not occur in S, and occur times each in T.
- Group 3 contains the duos and , which each occur m times in S and in T.
There are no further duos in S or T. To show the correctness of the reduction, we show that is a Yes-instance of 3-Partition if, and only if, there exists a sequence of at most many k-cut rearrangements transforming S into T.
Pick a solution of 3-Partition. For each triple of the solution, choose a unique substring of S and perform the following three k-cut rearrangements: first, cut S around and around the first copy of X in the chosen subsequence, and cut at every position inside X. Observe that the number of cuts is exactly k. Now reverse X into and exchange and . Perform a similar k-cut rearrangement with and the second occurrence of X and with and the third occurrence of X in the selected substring. The selected substring is transformed into and since each string is replaced by , the first part of the string is . Hence, the string obtained by the many k-cut rearrangements described above is T.
There are altogether duos in Group 1 which are in excess in S, and duos in Group 2 which are in excess in T. Since , each k-cut rearrangement cuts k duos in Group 1 (and no duo in Group 2 or 3). In particular, no 00 duo may be cut in a feasible solution, so each subsequence in T is obtained by concatenating a number of strips of the form , as well as some number of 0 singletons. Since S has of these singleton 0s, we have . By the constraint on the values of , each subsequence in T contains four singletons from S and three substrings of S whose lengths sum to B. Thus, the m substrings in T correspond to a partition of into m sets of three integers whose values sum up to B. □
Theorem 1 is improved by the following two theorems, which prove the NP-hardness of SMCR in ternary strings, but limited to odd values of k with . More precisely, Theorem 2 focuses on the specific case , while Theorem 3 extends the result to any odd .
Theorem 2.
SMCR isNP-hard for in ternary strings.
Proof.
The proof is, as the proof of Theorem 1, by reduction from the strongly NP-hard 3-Partition problem, in which the input is a set of integers and an integer B, and the question is whether can be partitioned into triplets, such that the sum of the integers in each triplet is equal to B. Given an instance of 3-Partition with such that (i) for any and (ii) , we build the following instance of SMCR:
with and . Clearly, S and T are built on an alphabet of cardinality 3. Now, let us prove the correctness of our reduction.
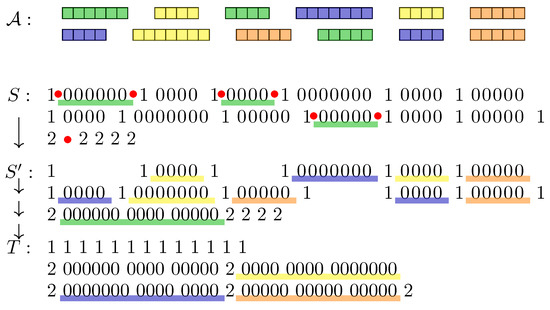
(⇒) Suppose the instance of 3-Partition is a Yes-instance. Thus, can be partitioned in sets , such that and for any . We now show how to reach T from S, using 7-cut rearrangements, in steps: at each step , cut in S to the right of the 1 preceding (resp. , ) and to the left of the 1 following (resp. , ), for a total of 6 cuts; the last cut is to the right of the j-th occurrence of 2. The 6 first cuts allow one to move blocks , , , which we concatenate so as to obtain (since by hypothesis). The 7th cut allows us to insert block between the j-th and the -th copy of 2. An illustration of the first step of the above described algorithm for solving SMCR is provided in Figure 3.
Figure 3.
Example of the proposed reduction starting from the following instance of 3-Partition: (thus ) and . Each is represented by a rectangle containing squares. Colors in describe a way to partition into triplets, each summing to . S and T are built as described in the reduction. Each vertical arrow corresponds to a 7-cut. The first one, which is the first step of the proposed 7-cut rearrangement scenario, going from S to , is detailed: each red bullet corresponds to a cut, and blocks of 0 that are rearranged are underlined in green (corresponding to the three “green s” summing to B).
After every step is achieved, three of the blocks (each one being surrounded by 1s) are removed, while a block is created between two occurrences of 2. Thus, after step m, we have produced sequence . Since every step uses cuts and T is obtained after steps, we conclude that is a Yes-instance for SMCR.
(⇐) Suppose that the instance that we have built is a Yes-instance. First, we note that S contains exactly duos (i.e., length-2 substrings) that are absent from T, while T contains duos that are absent from S, as shown in the exhaustive list of duos provided in Table 2.
Table 2.
Exhaustive list of duos present both in S and T, together with their occurrences.
Thus, starting from S, and in order to end in T, there are altogether duos to destroy, and to create. Since and , for each of the m allowed steps, 7 duos need to be destroyed (and never further created), while 7 duos need to be created (and never further destroyed). In particular, this implies that we never cut strictly inside a block of the form , otherwise a duo would be destroyed (whereas the goal is to create altogether of them). Since, in T, blocks containing 0s all are of the form , this implies that there is a way to arrange all blocks of the form from S, by concatenating them (and never cutting them), so that we obtain m blocks of the form . This shows that it is possible to partition into m sets, each achieving a sum equal to B. However, by hypothesis, each satisfies . Hence, the only way to partition in the above described manner is to group the s by triplets. Consequently, this shows that is a Yes-instance for 3-Partition. □
Proof of Theorem 2 above can be extended so as to prove NP-hardness of SMCR for any odd in ternary alphabets. This is the purpose of the following theorem.
Theorem 3.
SMCR isNP-hard for any odd in ternary strings.
The proof is heavily based on the arguments developed in proof of Theorem 2. The idea here is to reduce from a decision problem that we call p-Partition ( being an integer), which is an extension of 3-Partition; second, we slightly modify strings S and T according to this new problem. First, let us formally introduce p-Partition, and discuss its NP-hardness. The input of p-Partition is a set and an integer , such that , and the question is whether can be partitioned into sets , each of cardinality p, and such that, for any , . We call Balanced p-Partition the restriction where for all i.
Lemma 1.
For any ,Balanced p-Partitionis stronglyNP-hard.
Proof.
First, we show that for any , p-Partition is strongly NP-hard, by reduction from 3-Partition. Indeed, consider an instance of 3-Partition, with and . Let . We now construct an instance of p-Partition as follows: for any , , while for all . Let . Then, , that is . Note that .
(⇒) If is a Yes-instance for 3-Partition, then assume that can be partitioned into . Now, for any , take to be the union of and of any of the remaining elements among . The sum of the elements in is equal to , and sets together form a partition of . Hence, is a Yes-instance for p-Partition.
(⇐) If is a Yes-instance for p-Partition, then assume that can be partitioned into . Any contains at least three elements among , otherwise the sum of elements of would be at least . Since there are such elements, we conclude that each must contain exactly three elements of . Now, let . Let (resp. ) be the sum of the elements of (resp. ). Then, we have . Since , we conclude that . This shows that is a partition of for which each set is of cardinality 3 and sums to B. In other words, is a Yes-instance for 3-Partition.
Finally, the following argument shows that p-Partition remains strongly NP-hard in the balanced restriction. Indeed, take any instance of p-Partition and modify it as follows: every is increased by , and set . In that case, the sum of all elements from is , and if a partition exists, the sum of the elements of each is equal to . Since , we conclude that and we are done. Note that each remains bounded by a polynomial on the instance size (since each and B is polynomialy bounded in 3-Partition), hence preserving the strong NP-hardness. □
Proof of Theorem 3
Now, in order to prove that SMCR is NP-hard in ternary strings for any odd , it suffices to adapt the reduction provided in proof of Theorem 2.
Hence, starting from any instance of Balanced p-Partition, we build the following instance of SMCR:
with and . Clearly, S and T are built on an alphabet of cardinality 3.
Correctness of the reduction relies on the same type of arguments, as in proof of Theorem 2, and are only informally described here: if a partition of exists, this provides us with a rearrangement scenario where, at each step, cuts are applied. More precisely, of these cuts allow one to “disconnect” the p blocks of the form corresponding to a set (of cardinality p) of the partition, while the last cut allows one to insert the concatenated abovementioned blocks into a single block between two occurrences of character 2. The reverse direction is based on the number of duos that need to be deleted and created: there are duos in S which are not present in T, and duos in T which are not present in S; besides, is the total number of cuts we are allowed altogether in a rearrangement scenario from S to T. Consequently, no duo can be deleted during such a scenario, which shows that any block of the form in T must be the concatenation of blocks of the form . This in turn proves that can be partitioned in sets, each of which sums to . Moreover, since every , all sets in that partition are of cardinality at most p. However, since there are m sets and altogether elements to partition, we conclude that each set is necessarily of cardinality exactly p. Consequently, we are in the presence of a Yes-instance for p-Partition. □
Theorem 3 above shows that SMCR is NP-hard for ternary strings, for any odd . We conjecture that this result can be extended in two ways, i.e., that SMCR is NP-hard for any (both odd and even), even in the case of binary strings.
Theorems 1 to 3 are concerned with the complexity of SMCR relatively to parameter k. We now turn our attention to parameter ℓ.
Theorem 4.
SMCR isNP-hard for and any fixed .
Proof.
The reduction being very similar to the one of Theorem 1, we only highlight here the differences that allow us to have a fixed ℓ instead of fixed k. First assume that m is a multiple of ℓ (add up to ℓ triples of dummy elements otherwise), and let . Note that k is a multiple of 5. The reduction is the same as in proof of Theorem 1 using (i.e., with a size-5 alphabet). In other words, we have and .
In the forward direction, use the described scenario using 5-cut rearrangements, but combine a series of such rearrangements into a single k-cut rearrangement, as described at the end of Section 1.3. This gives a total of many k-cut rearrangements sorting S into T. In the reverse direction, the same breakpoint count as in proof of Theorem 1 holds, namely duos need to be broken using ℓ many k-cut rearrangements, with . So, again, no duo may be broken, and by the same argument, we obtain a valid 3-partition of . □
The previous theorem shows NP-hardness of SMCR for any fixed ℓ. However, a stronger result can be obtained in the specific case .
Theorem 5.
SMCR isNP-hard when , even when .
Proof.
The proof is obtained by reduction from the Minimum Common String Partition (MCSP) problem, which has been proven to be NP-hard in strings, even when [16]. Recall that the decision version of MCSP asks, given two balanced strings S and T, and an integer p, whether S can be written as the concatenation of p blocks and T can be written as , where is a permutation of . Note that here, we may have and/or .
Given an instance of MCSP, we build an instance of SMCR by setting , (with ), and . Clearly, if is a Yes-instance for MCSP, then is a Yes-instance for SMCR: the MCSP solution uses cuts, to which we add one before x, one after x, and one after S for solving SMCR. Conversely, if is a Yes-instance for SMCR, and since x occurs only once in , then 2 cuts are used to “isolate” x from . Besides, since ends with x, there must exist a cut after the last character of . Hence, since , at most cuts are used strictly within S, which in turns means that S has been decomposed in p blocks, which can be rearranged so as to obtain T, since . Thus, is a Yes-instance for MCSP. □
Note that MCSP has been proved to be in FPT with respect to the size of the solution [18]. It can be seen that this result can be adapted for the SMCR problem in the case .
Theorem 6.
When ,SMCRisFPTwith respect to parameter k.
Proof.
Assuming , let A (resp. B) be the length of the longest common prefix (resp. suffix) of S and T. For and , let and be the strings obtained from S and T by removing the first a and last b characters. Then, T can be obtained from S by one k-cut rearrangement if and only if, for some pair , and admit a common string partition into blocks. Indeed, this is easy to verify by matching the limits of the blocks in MCSP (including at the end of the strings) with the cuts of the rearrangement. So, SMCR when can be solved using calls to MCSP with parameter , each with a different pair , which itself is FPT for k [18]. □
Note that it is not sufficient to check only with the longest common prefix and suffix (i.e., and ), which can be seen in the following example. When and , then S can be transformed into T via the 3-cut rearrangement with the cuts . Moreover, we have , but only and have a common partition into two blocks, whereas and do not have such a partition.
3. Sorting by Multi-Cut Rearrangements in Permutations
In this section, we provide algorithmic results concerning the Sorting by Multi-Cut Rearrangements problem, in the specific case where S and T are permutations. Our results are summarized in Table 3.
Table 3.
Summary of the results for Sorting by Multi-Cut Rearrangements in permutations. Additionally, Opt-SMCR admits a 2-approximation algorithm (Theorem 10).
We start with showing the NP-hardness for constant k or ℓ (Theorems 7 and 8). Then, we show fixed-parameter tractability for the combined parameter in Theorem 9. Finally, we provide a 2-approximation result (Theorem 10).
3.1. Hardness for Constant Number of Cuts
We now show that SMCR is also hard in permutations.
Theorem 7.
For any ,SMCRin permutations isNP-hard.
Theorem 7 gives a complexity dichotomy with respect to the number of cuts in the rearrangement, since the case is known to be NP-hard [12] and the case is known to be polynomial-time solvable [3].
We show Theorem 7 by reduction from Sorting By Transpositions on 3-cyclic permutations [12]. Intuitively, in such permutations, it is straightforward to identify triples of breakpoints, called 3-cycles, that should be solved together in a transposition. The difficulty arises in selecting a correct order in which those 3-cycles should be solved. Our approach consists of extending these 3-cycles into k-cycles, such that any k-cut rearrangement solving the original cycle must solve all k breakpoints together, and still performs a simple transposition on the rest of the sequence (to this end, dummy elements are created in order to consume the extra blocks in k-cut rearrangements). We first recall the necessary definitions and properties for breakpoints and cyclic permutations, then show how to extend a single cycle by only two or three elements, and finally successively apply this method to extend all cycles to any size .
3.1.1. Breakpoints and Cycle Graph
See Figure 4 for an illustration of the definitions in this section. For a permutation S of length n, we assume that the alphabet of S is . We further write and (they are considered as implicit elements: they may not be part of rearrangements, but allow all other characters to have another element before and after). For a rearrangement r transforming S into , we write and . The cycle graph of strings S and T is the graph over vertices with arcs if . Every vertex has indegree and outdegree 1, so the graph is a disjoint union of cycles. Self-loops are called trivial cycles (when seen as a cycle) or adjacencies (when seen as an arc); other arcs are breakpoints. An element (or vertex) x is an adjacency (resp. breakpoint) according to its outgoing arc (we use transparently the bijection between a vertex and its outgoing arc). A k-cycle is a cycle of length k. The next breakpoint of breakpoint in is y (or equivalently, the outgoing arc of y). We write for the cycle of containing element x. A cycle graph (and, by extension, a pair of sequences generating this cycle graph) is k-cyclic if it contains only adjacencies and k-cycles. A rearrangement r applied to a permutation Scuts an element x, , if r cuts between and . Furthermore, rsolves breakpointx if r cuts x and x is an adjacency in . A rearrangement rsolves a cycle if it solves all breakpoints in it. We write for the number of breakpoints of . A k-cut rearrangement is efficient if it solves k breakpoints. A pair is k-efficiently sortable if there exists a sequence of efficient k-cut rearrangements transforming S into T. The following is a trivial generalization of a well-known lower bound for the transposition distance.
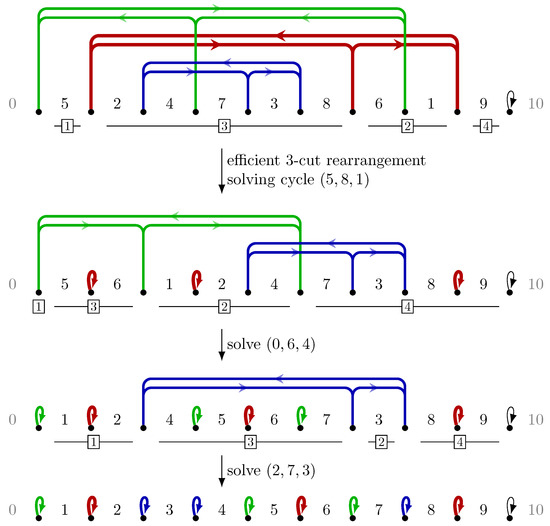
Figure 4.
Example of a 3-cut rearrangement scenario from to using cycle graphs. From top to bottom: The cycle graph for contains three non-trivial cycles and a trivial one (breakpoint u is depicted to the right of the label for u). Blocks 1 to 4 of a 3-cut rearrangement (cutting after 5, 8, and 1) are given: it solves cycle (denoted for short). Two other efficient rearrangements solve cycles and , thus reaching T in three steps. Note that some cycles do not admit efficient 3-cut rearrangement, e.g., in the original permutation S.
Proposition 1.
A k-cut rearrangement may not solve more than k breakpoints, so S needs at least k-cut rearrangements to be transformed into T. Furthermore, the bound is reached if, and only if, is k-efficiently sortable.
Proposition 2.
If r solves a breakpoint, it cuts the next breakpoint in the cycle graph.
Proof.
Let be an arc of the cycle graph, and let be the successor of x in T as well as the successor of y in S. If r solves x, then r joins a block ending in x with a block starting in , so is the first element of some block of r. Thus, y is the last element of some block of r, and r cuts the breakpoint y in . □
Proposition 3.
If r is efficient, it solves a cycle if, and only if, it solves any breakpoint in it. Furthermore, r solves all breakpoints in a union of cycles of total size k.
Proof.
If r is efficient, then it solves all breakpoints that it cuts (since it may not solve a breakpoint without cutting them, and it solves and cuts k breakpoints). Due to Proposition 2, if r solves a breakpoint in a cycle, then it must solve all subsequent arcs in the same cycle. Hence, r either solves all breakpoints of a cycle or none at all. The size constraint follows from the fact that all cycles are disjoint. □
Cycle is tied to another cycle through the pair of breakpoints if x is in , y is in , the permutation S has and for some i, and T has and for some y (for an illustration, see Figure 5). A breakpoint is without ties if no cycle is tied to the cycle containing it.
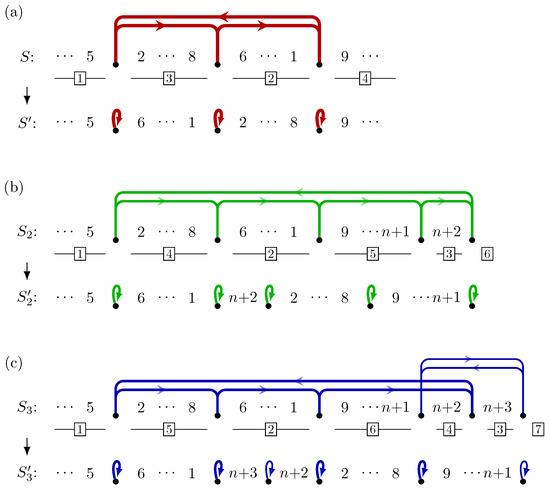
Figure 5.
(a) The cycle from Figure 4, and how solving it affects the rest of the sequence (substrings and , i.e., blocks  and
and  are swapped). (b) The 2-extension of S for breakpoint , giving cycle . This extended cycle can be solved with a 5-cut rearrangement having an equivalent effect on the sequence (substrings and are swapped). The resulting is the 2-extension of for adjacency . (c) The 3-extension of S for breakpoint , giving cycles and (the latter being tied to the former: there is no way of solving breakpoint without cutting ). These two cycles can be solved with a 6-cut rearrangement having an equivalent effect on the sequence (again, substrings and are swapped). The resulting is the 3-extension of for adjacency .
are swapped). (b) The 2-extension of S for breakpoint , giving cycle . This extended cycle can be solved with a 5-cut rearrangement having an equivalent effect on the sequence (substrings and are swapped). The resulting is the 2-extension of for adjacency . (c) The 3-extension of S for breakpoint , giving cycles and (the latter being tied to the former: there is no way of solving breakpoint without cutting ). These two cycles can be solved with a 6-cut rearrangement having an equivalent effect on the sequence (again, substrings and are swapped). The resulting is the 3-extension of for adjacency .
and are swapped). (b) The 2-extension of S for breakpoint , giving cycle . This extended cycle can be solved with a 5-cut rearrangement having an equivalent effect on the sequence (substrings and are swapped). The resulting is the 2-extension of for adjacency . (c) The 3-extension of S for breakpoint , giving cycles and (the latter being tied to the former: there is no way of solving breakpoint without cutting ). These two cycles can be solved with a 6-cut rearrangement having an equivalent effect on the sequence (again, substrings and are swapped). The resulting is the 3-extension of for adjacency .
Proposition 4.
If is tied to , then any efficient rearrangement solving must also solve .
Proof.
Let r be an efficient rearrangement solving and, in particular, x. Then, r must place y after x in , although y is before x in S, so r must have a cut somewhere between y and x, i.e., just after y. So, r cuts breakpoint y, and solves cycle . □
3.1.2. One-Cycle Extensions
We now introduce the central technical engine for the reduction of Theorem 7. Let be a pair of permutations. Let x be a vertex of with the following properties (we say that x is safe): x is either an adjacency or a breakpoint without ties in a cycle of length , and all 2-cycles in are tied. The p-extension of on x, with , denoted is the pair such that (see Figure 5 for an example):
- For :
- For :
Note that the implicit rightmost element is always inserted explicitly (indeed, is followed by in both and ), and becomes in the new permutations.
Lemma 2.
A p-extension on x has the following effects on the cycle graph:
- if x is an adjacency, it adds p trivial cycles;
- if x is a breakpoint and , it adds and to the cycle containing x;
- if x is a breakpoint and , it adds to the cycle containing x and a 2-cycle tied to the one containing x.
Other arcs and tied cycles are unchanged.
Proof.
If x is an adjacency, the p-extension inserts elements to in both strings in the same order after x, and they are followed by the same element in both strings, since x is an adjacency, so only trivial cycles are added.
Assume now that x is a breakpoint. Consider first an arc with in . Since no element is inserted after or , also appears in (the case is particular, as is explicitly introduced in both sequences, but it also yields the arc in ). If a cycle is tied to another one through a pair in S and in T, these duos cannot be broken by the p-extension (since x is safe, no cycle can be tied to ), so it is still tied after the extension. Similarly, a non-tied cycle cannot become tied because of the extension.
It remains to describe arcs going out from . Let y be the head of the outgoing arc from x.
For j such that , we have , so there exists an arc in (note, in particular, that y no longer has its incoming arc ).
For j such that , we have , so there exists an arc in .
For and j such that , we have , so there exists an arc in .
At this point, the outgoing arcs for all vertices except have been described, as well as incoming arcs for all vertices except y, so the last remaining arc is .
Overall, for , arc is replaced with the path . For , arc is replaced with and a 2-cycle is created. Note that this 2-cycle is tied to through . □
We now show how efficient rearrangements can be adapted through extensions. Let r be a k-cut rearrangement of . We write for the -cut rearrangement of defined as follows:
- if r does not cut x, then , cuts the same elements as r, and rearranges the blocks in the same order;
- if r cuts x, then , cuts the same elements as r, as well as , and (when ), and rearranges the blocks in the same way as r, with elements (when ) and inserted after x.
The following two lemmas show how efficient rearrangements of and those of are related through .
Lemma 3.
If r is an efficient k-cut rearrangement of , then is an efficient -cut rearrangement of . Furthermore, .
Proof.
If r does not cut x, then and solves in exactly the same breakpoints as r, so it is efficient. Furthermore, all elements in and are in the same order as in , except for , which are inserted, in both cases, at the end of S and in T as in (since r and do not edit the second string).
If r cuts x, furthermore solves breakpoints , since it rearranges these elements in the same order as in . So, it is an efficient rearrangement as well. Finally, all elements in and are in the same order as in , except for (which are inserted after x in both strings) and (which is inserted as a last element). □
The following claim will be useful for proving Lemma 4.
Claim 1.
Either solves all breakpoints in , or none at all.
Proof.
For , this is a direct application of Proposition 3, since elements x, and are in the same cycle of .
For , by Lemma 2, is a -cycle containing x and , and also contains a cycle denoted with elements and . By Proposition 3, solves any element in (resp. ) if, and only if, it solves all elements in the same cycle (in particular, if cuts x, so ). Furthermore, is tied to , so if solves , it must also solve (by Proposition 4). Now, all that is left is to check the last direction: if solves , then it also solves . Indeed, is a -cycle and solves a total of breakpoints, so it must also solve some 2-cycle . Aiming at a contradiction, assume that . Then, is already a 2-cycle of , and it is tied to some other cycle (both in and ), so also solves . Since may not be equal to (x was chosen without ties), solves at least breakpoints, which yields a contradiction for a -cut rearrangement. □
Lemma 4.
If is an efficient -cut rearrangement of with , then there exists an efficient k-cut rearrangement r of such that , where if cuts x and otherwise. Furthermore, .
Proof.
We build r from using the converse operations of Lemma 3: mimicking the cuts and reordering of , but ignoring cuts after if cuts x. The relation between k and and the efficiency of r follow from the fact that solves either all of x, , or none at all, as proven in Claim 1. The ’furthermore’ part follows from Lemma 3, applied to r. □
3.1.3. Extending All Cycles
We use the natural order over integers as an arbitrary total order over the nodes. The representative of a cycle is its minimum node. We assume to be k-cyclic for some k. A sample for , where is k-cyclic is a list X containing the representative from each k-cycle, and an arbitrary number of adjacencies. The p-extensions of for sample and of a rearrangement r of are, respectively, and .
For in the sample, we write , i.e., is the size of the strings on which is applied. Note that the above definition requires each to be safe in . This is indeed the case by Lemma 2: either , there are no 2-cycles, and all breakpoints are without ties, or , all 2-cycles are tied to a single cycle with , which are all different from (since X is a sample and contains at most one element per cycle).
Proposition 5.
If is k-cyclic, then is -cyclic.
Proof.
This follows from Lemma 2, since the 2-extension adds 2 elements to each k-cycle, so is -cyclic. □
Lemma 5.
If r is an efficient k-cut rearrangement of , then is an efficient rearrangement of . Moreover, in this case, is k-cyclic with sample X, and .
Conversely, any efficient rearrangement of can be written as , where r is an efficient k-cut rearrangement of .
Proof.
Given an efficient k-cut rearrangement r, let
Since r is an efficient k-cut rearrangement of and is k-cyclic, Proposition 3 implies that r must solve a single cycle of . Let x be the representative of this cycle: x is the only breakpoint of X cut by r, and for some i. Furthermore, is also k-cyclic with sample X (with one cycle less than ).
By Lemma 3, we have that is an efficient -cut rearrangement of for each j, where if does not cut x (i.e., ) and otherwise. So, overall, is a an efficient -cut rearrangement of . The relationship also follows from Lemma 3.
The converse direction is proven similarly using Lemma 4, with a specific attention given to the size of the rearrangements: starting from (with cuts), the number of cuts remains constant, except for , where it drops to k and then remains constant again (so the condition in Lemma 4 is indeed satisfied). □
Lemma 6.
If is k-cyclic with sample X, then is k-efficiently sortable if, and only if, is k-efficiently sortable.
Proof.
This is a direct application of Lemma 5: a sequence of efficient k-cut rearrangements of translates into a sequence of efficient -cut rearrangements of through function (note that X remains a sample of throughout the sequence of rearrangements). □
Lemma 7.
For any odd , deciding whether a k-cyclic pair is k-efficiently sortable isNP-hard. For any even , deciding whether a pair is k-efficiently sortable isNP-hard.
Proof.
By induction on k. Deciding if a 3-cyclic pair is efficiently sortable is NP-hard (cf. [12], where it is shown that deciding if a permutation can be sorted with transpositions is NP-hard). For any , take if k is odd and otherwise, and consider a -cyclic instance and a sample X for (note that one always exists): is -efficiently sortable if, and only if, is k-efficiently sortable by Lemma 6, and is k-cyclic for by Proposition 5. This gives a polynomial reduction proving hardness for k (even when restricted to k-cyclic permutations when k is odd). □
Theorem 7 is a corollary of Lemma 7, since a k-cyclic pair is k-efficiently sortable if, and only if, S can be rearranged into T with at most k-cut rearrangements (Proposition 1).
3.2. Hardness for Constant Number of Rearrangements
By Theorem 7, SMCR is NP-hard for constant k. We now show that the case with constant ℓ is NP-hard for all . Since for SMCR is the same as computing the breakpoint distance between permutations, we thus obtain a complexity dichotomy with respect to ℓ.
Theorem 8.
SMCRin permutations isNP-hard for any constant .
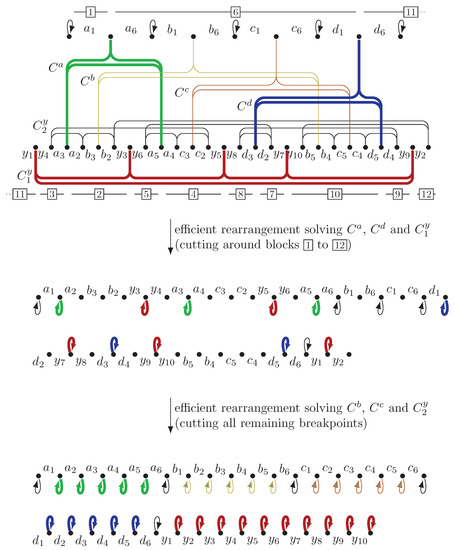
We refer to the notions of breakpoint graph, cycles and efficient rearrangements introduced in Section 3.1.1 of the proof of Theorem 7, as well as their first properties (Propositions 1 to 4). We first give an informal outline of our reduction for : we show that it is NP-hard to check if an input with breakpoints can be solved with two k-cut rearrangements (i.e., can be sorted efficiently). We build two permutations whose cycle graph can be decomposed into cycles of specific sizes, and we show that an efficient sorting scenario needs to satisfy two types of constraints: (i) each cycle must be solved entirely in the first or in the second rearrangement, so the sum of cycle size for each rearrangement must be exactly k, and (ii) some cycles must satisfy precedence constraints, i.e., we generalize the notion of ties by building tuples of cycles , where some must be solved before or during the same k-cut rearrangement as . We build an instance with a large cycle that needs to be solved during the first rearrangement by constraint (i), and that forces one to solve a non-trivial set of cycles in the same rearrangement by constraint (ii).
Proof.
We present a reduction from Exact 3-Set Cover, where we are given a collection of sets , all of size 3 over a universe U of size , and ask whether there are p sets in whose union is exactly U. Further assume that . This is without loss of generality: indeed, let . If , duplicate set times, so n increases by this quantity to become , and p is unchanged, so decreases by , and now . If , add new elements to the universe, and sets to , covering exactly those new elements, so both n and p increase by and become respectively and , yielding .
The following reduction is for ; we show how to extend it to any larger ℓ at the end of the proof. See Figure 6 for an illustration. Given an instance of Exact 3-Set cover, we build an alphabet of size , with symbols for and , and for . Given , let be the indices, such that for all . Furthermore, let be the index of u in (i.e., 1, 2 or 3). Write for the following string:
Figure 6.
Illustration of the reduction from a simplified version of Exact Cover, with size-2 sets over a size-4 universe : , , , (for lighter indices we use instead of ; note also that we have for instead of because of the smaller sets). All six non-trivial cycles of are depicted on the top permutation: , , etc. In this example, admits an efficient 11-cut rearrangement corresponding to an exact set cover of U: cut all breakpoints in bold cycles , followed by an efficient 19-cut rearrangement solving the remaining breakpoints (in the actual reduction, we consider instances where to enforce that both efficient rearrangements have the same size k).
We now build permutations S and T:
where the suffix of S is the concatenation of for every , followed by . Finally, we set . Note that strings S and T have adjacencies (0, and each , ), so they have breakpoints. We compute the cycles of . To this end, we describe cycles (denoted , , and ), and check that their total size is indeed equal to the number of breakpoints.
For each , let be cycle . There are n such size-4 cycles, for a total size of breakpoints. Let be the cycle . It has size . The remaining arcs in substring are , for , and . Furthermore, , so all these arcs form a single cycle, of length ( for all , , plus for all , ). The total size of the cycles above is , so all breakpoints have been accounted for. Clearly, the reduction can be performed in polynomial time; we now prove that the reduction is correct, i.e.:
S can be transformed into T with 2 k-cut rearrangements has an exact cover of U.
Given an exact cover of U, we show that cutting all breakpoints in cycles and where is in the set cover yields a k-cut rearrangement solving k breakpoints in S. In other words, we first cut the following breakpoints: for each i such that is in the cover, cut between and , as well as between and for . Furthermore, cut after for each . There are indeed cuts. At this point, each substring is cut into two strings , and (where j is the index of the only set in the cover, such that ) merge them together in reverse order, i.e., create string (note that breakpoint is now solved). Furthermore, we merge the prefix ending in with , solving an additional breakpoint. Finally, for each j, such that is in the cover, insert strings , , between and . This step solves breakpoints and for each j in the cover, for a total of breakpoints solved. So, overall, k breakpoints of S can be solved with a single k-cut rearrangement. Note that the resulting thus has k remaining breakpoints with T: they can all be solved with a single k-cut rearrangement, so S can be sorted into T in only 2 steps.
Permutation S can be sorted into T with k-cut rearrangements if, and only if, it can be sorted using two efficient k-cut rearrangements (Proposition 1). Each of these solves a union of cycles of total size k (Proposition 3). In other words, some cycles (of total size k) are solved first (i.e., with the first rearrangement), the other cycles (of total size k as well) are solved second. Note that all cycles together have a size of , so at least one cycle among , is solved first. They are too large to be solved together, so in fact exactly one of them is solved first, the other second. We extend the notion of being solved first to breakpoints and arcs appearing in the cycles solved first. The following result adapts Proposition 4 to our setting.
Claim 2.
If an arc such that v occurs before u in S is solved first, then some breakpoint strictly between v and u in S is solved first as well.
Proof.
Let be the substring of S from v to u. Then, T has as a consecutive pair. Solving breakpoint u implies that the rearrangement puts just after u, which is only possible if there is at least one cut point between and u in S. □
Consider any , and element . This element appears in some substring of S (depending on the position of , z is either of the form or ), and has an arc . By the lemma above, if is solved first, then the only breakpoint between z and , (namely, ) must be solved first, and the cycle containing it as well. So, cannot be solved first, since otherwise, all cycles would be solved first as well, for a total size of .
Thus, is solved first, as well as cycles of the form . Write P for the size-p subset of , such that , if, and only if, is solved first. We show that , i.e., P is a solution to the set cover instance. Indeed, let . Recall that S contains substring , with arc in cycle . Thus, some other breakpoint z of this substring must be solved first. We have and , since otherwise , which is solved second. Thus for some i such that , and since z is solved first, we have , which concludes the hardness proof for .
For higher values of ℓ, the following is a reduction of SMCR for ℓ to SMCR for : given permutations and an integer k (assuming S and T have breakpoints), let and . Then, breakpoints form a size-k cycle: any efficient sorting of must use one step to exclusively sort the breakpoints in this cycle. Thus, can be solved with ℓ many k-cut rearrangements if, and only if, can be solved with many k-cut rearrangements. □
In many settings, we encounter a class of Center problems, which can be generally defined as follows: given a set of objects and a radius k, find an object at distance at most k from each . In particular, in the context of strings, depending on the distance measure, this problem is called Consensus String (using the Hamming distance) or Center String (using the Edit distance). Problems Longest Common Subsequence and Shortest Common Supersequence also fit in this setting, where (non-symmetrical) distances count 1 for deletions (resp. insertions), and forbid all other operations. See [11] for a review of results on these and related problems. Applying this framework to permutations, it is natural to consider the Breakpoint Center problem: given permutations and an integer k, find a permutation such that the breakpoint distance between each and is at most k. Note that this is slightly different from the Breakpoint Median problem [19], usually defined over permutations, which aims to minimize the sum of distances rather than the maximum. Clearly, for , have a breakpoint center at distance k if, and only if, can be obtained from using two k-cut rearrangements (using as an intermediary step). Thus, Theorem 8 can be restated as follows.
Corollary 1.
TheBreakpoint Centerproblem isNP-hard, even when restricted to two input permutations.
3.3. Fixed-Parameter Tractability and Approximability
We now show that input instances with bounded k and ℓ can be solved efficiently. More precisely, we show that SMCR in permutations is fixed-parameter tractable when parameterized by . In fact, SMCR admits a kernel with a polynomial size bound.
Theorem 9.
SMCRin permutations admits a kernel of size .
Proof.
The kernel is based on the following reduction rule: if there is a duo (i.e., a substring ) in both S and T, then remove b from S and T. Before we show the correctness, observe that the exhaustive application of the rule indeed gives the desired result: any Yes-instance that is reduced exhaustively with respect to the above rule has at most letters: we must cut inside every duo in S. Overall, we may create at most cuts via ℓ many k-cut rearrangements. Hence, if S has more than duos, then is a No-instance. Thus, after applying the rule exhaustively, we may replace any instance with more than letters in S (and thus in T) by a trivial No-instance of constant size. Thus, the correctness of the rule remains to be proven. Consider an instance consisting of the permutations S and T to which the rule is applied and let and denote the resulting instance. We show that is a Yes-instance if, and only if, is a Yes-instance.
If is a Yes-instance, then there is a sequence of permutations , such that can be obtained from via one k-cut rearrangement. Removing b from gives a sequence such that can be obtained from via one k-cut rearrangement.
If is a Yes-instance, then there is a sequence of permutations , such that can be obtained from via one k-cut rearrangement. Replacing a by in each permutation gives a sequence such that can be obtained from via one k-cut rearrangement. □
In addition, we show that for arbitrary values of k, SMCR has a polynomial-time approximation algorithm. Let Opt-SMCR be the optimisation version of SMCR, where we look for the smallest ℓ that is necessary to obtain T from S by k-cut rearrangements.
Theorem 10.
Opt-SMCRin permutations is 2-approximable.
Proof.
Let be an instance of Opt-SMCR. We first rewrite S and T into and in such a way that , where denotes the identity permutation of . Let . The algorithm consists of iterating the following three steps, starting from :
- (a)
- rewrite , by contracting adjacencies so as to obtain a permutation containing no adjacencies,
- (b)
- cut around (i.e., right before and right after) the first elements of that permutation, and
- (c)
- rearrange it so as to obtain followed by the rest of the permutation.
Steps (b) and (c) above are presented for the case where k is even. If k is odd, (b) and (c) are slightly modified, since we are left with an unused cut:
- (b’)
- do as (b) and additionally cut to the left of
- (c’)
- do as (c) but rearrange in such a way that and are consecutive.
Clearly, the optimal value ℓ for Opt-SMCR satisfies . Our algorithm removes at least (at least ) breakpoints at each iteration when k is even (when k is odd), and thus requires () many k-cut rearrangements. Altogether, we have if k is even and if k is odd. Since , we conclude that . □
4. Conclusions
We introduced Sorting by Multi-Cut Rearrangements, a generalization of usual genome rearrangement problems that, however, does not include reversals. We discussed its classical computational complexity (P vs. NP-hard) and its membership in FPT with respect to the parameters k and ℓ. For this, we distinguished the case where S and T are permutations from the case where S and T are strings.
The obvious remaining open problem is the one indicated in Table 1, namely the FPT status of SMCR with respect to parameter in strings (including cases where one of k or ℓ is constant, with ). Another question is whether the approximation factor of 2 of Theorem 10 can be improved. We also recall that we conjecture SMCR to be NP-hard for any in binary strings. It would also be interesting to better understand the comparative roles of k and ℓ in SMCR, for instance by studying the following question: assuming k is increased by some constant c, what impact does this have on the optimal distance?
Extensions or variants of SMCR could also be studied, notably the one allowing reversals (and thus applicable to signed strings/permutations), or the one where T is the lexicographically ordered string derived from S, as studied, for instance, by Radcliffe et al. [13] in the case of reversals.
Author Contributions
Conceptualization, L.B., G.F., G.J. and C.K.; methodology, L.B., G.F., G.J. and C.K.; validation, L.B., G.F., G.J. and C.K.; formal analysis, L.B., G.F., G.J. and C.K.; writing—original draft preparation, L.B., G.F., G.J. and C.K.; writing—review and editing, L.B., G.F., G.J. and C.K.; supervision, G.F. All authors have read and agreed to the published version of the manuscript.
Funding
This research was partially funded and supported by the PHC Procope grant number 17746PC (G.F. and G.J.), and by the DAAD Procope grant number 57317050 (C.K.).
Data Availability Statement
Not Applicable, the study does not report any data.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| SMCR | Sorting by Multi-Cut Rearrangements |
| MCSP | Minimum Common String Partition |
| FPT | Fixed-Parameter Tractable |
References
- Bafna, V.; Pevzner, P.A. Genome Rearrangements and Sorting by Reversals. SIAM J. Comput. 1996, 25, 272–289. [Google Scholar] [CrossRef]
- Bafna, V.; Pevzner, P.A. Sorting by Transpositions. SIAM J. Discret. Math. 1998, 11, 224–240. [Google Scholar] [CrossRef]
- Christie, D.A. Sorting Permutations by Block-Interchanges. Inf. Process. Lett. 1996, 60, 165–169. [Google Scholar] [CrossRef]
- Fertin, G.; Labarre, A.; Rusu, I.; Tannier, E.; Vialette, S. Combinatorics of Genome Rearrangements; Computational Molecular Biology; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Stephens, P.J.; Greenman, C.D.; Fu, B.; Yang, F.; Bignell, G.R.; Mudie, L.J.; Pleasance, E.D.; Lau, K.W.; Beare, D.; Stebbings, L.A.; et al. Massive Genomic Rearrangement Acquired in a Single Catastrophic Event during Cancer Development. Cell 2011, 144, 27–40. [Google Scholar] [CrossRef] [PubMed]
- Pellestor, F.; Gatinois, V. Chromoanagenesis: A piece of the macroevolution scenario. Mol. Cytogenet. 2020, 13, 3. [Google Scholar] [CrossRef] [PubMed]
- Hannenhalli, S.; Pevzner, P.A. Transforming Cabbage into Turnip: Polynomial Algorithm for Sorting Signed Permutations by Reversals. J. ACM 1999, 46, 1–27. [Google Scholar] [CrossRef]
- Bulteau, L.; Fertin, G.; Jean, G.; Komusiewicz, C. Sorting by Multi-cut Rearrangements. In Proceedings of the SOFSEM 2021: Theory and Practice of Computer Science—47th International Conference on Current Trends in Theory and Practice of Computer Science, Bolzano-Bozen, Italy, 25–29 January 2021; pp. 593–607. [Google Scholar]
- Downey, R.; Fellows, M.R. Fundamentals of Parameterized Complexity; Springer: London, UK, 2013. [Google Scholar]
- Cygan, M.; Fomin, F.V.; Kowalik, L.; Lokshtanov, D.; Marx, D.; Pilipczuk, M.; Pilipczuk, M.; Saurabh, S. Parameterized Algorithms; Springer: London, UK, 2015. [Google Scholar]
- Bulteau, L.; Hüffner, F.; Komusiewicz, C.; Niedermeier, R. Multivariate algorithmics for NP-hard string problems. Bull. Eur. Assoc. Theor. Comput. Sci. 2014, 114. Available online: https://hal.archives-ouvertes.fr/hal-01260610/document (accessed on 27 May 2021).
- Bulteau, L.; Fertin, G.; Rusu, I. Sorting by Transpositions Is Difficult. SIAM J. Discret. Math. 2012, 26, 1148–1180. [Google Scholar] [CrossRef]
- Radcliffe, A.J.; Scott, A.D.; Wilmer, E.L. Reversals and transpositions over finite alphabets. SIAM J. Discret. Math. 2005, 19, 224–244. [Google Scholar] [CrossRef]
- Christie, D.A. Genome Rearrangement Problems. Ph.D. Thesis, University of Glasgow, Glasgow, UK, 1998. [Google Scholar]
- Lin, Y.C.; Lu, C.L.; Chang, H.Y.; Tang, C.Y. An efficient algorithm for sorting by block-interchanges and its application to the evolution of vibrio species. J. Comput. Biol. 2005, 12, 102–112. [Google Scholar] [CrossRef] [PubMed]
- Kolman, P.; Goldstein, A.; Zheng, J. Minimum Common String Partition Problem: Hardness and Approximations. Electron. J. Comb. 2005, 12. [Google Scholar] [CrossRef]
- Garey, M.R.; Johnson, D.S. Computers and Intractability: A Guide to the Theory of NP-Completeness; W. H. Freeman & Co.: New York, NY, USA, 1979. [Google Scholar]
- Bulteau, L.; Komusiewicz, C. Minimum Common String Partition Parameterized by Partition Size Is Fixed-Parameter Tractable. In Proceedings of the Twenty-Fifth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2014, Portland, OR, USA, 5–7 January 2014; pp. 102–121. [Google Scholar]
- Sankoff, D.; Blanchette, M. The Median Problem for Breakpoints in Comparative Genomics. In Proceedings of the Computing and Combinatorics, Third Annual International Conference, COCOON ’97, Shanghai, China, 20–22 August 1997; Springer: London, UK, 1997; Volume 1276, pp. 251–264. [Google Scholar]








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).