1. Introduction
Bio-inspired computing, that is the study of computing paradigms inspired from biological systems, is a well-established field within AI that over the years has proposed several efficient computing models and algorithms [
1]. Membrane computing is a branch of bio-inspired computing that was initiated by Păun in 1998 [
2]. The goal of membrane computing is to perform computations by emulating nature at the
cellular level.
In the area of membrane computing, researchers have focused on developing new computational models that have parallel and distributed computation capability. The resulting membrane systems are called P systems. Moreover, P systems can be coupled with the biologically plausible firing mechanism observed in neurons, which enables processing and exchanging information through spikes. In this sense, Spiking Neural P (in short, SN P) systems [
3,
4] were proposed by incorporating the idea of spiking neurons (and spike trains) into P systems. One major difference with respect to other neural-like parallel computing systems [
5] is that SN P systems use
time as a source of information in the computation, similarly to what happens in brains.
Of note, it has been proved that SN P systems can simulate a Turing machine with a fairly small number of neurons [
6,
7,
8]. However, their application to real-world tasks is still limited, because it requires a remarkable expertise for humans to design such systems. Although few methods have been proposed for mitigating this problem [
9,
10], the lack of automatic design methodologies is still a
bottleneck in the development of the field.
Driven by this motivation, and following up on our previous work [
11], here we employ a well-known neuro-evolutionary algorithm, namely the Neuro-Evolution of Augmenting Topologies (NEAT) [
12], to automatically design SN P systems for a predictive maintenance (PdM) task. More specifically, we customize the vanilla NEAT algorithm to adjust the parameters of a specific type of SN P systems by increasing the number of parameters encoded in the genotype (i.e., the candidate solutions handled by NEAT) and adapting them to the parameters of the neurons in the SN P systems.
One important advantage of our proposal is that it requires little human knowledge on the design of SN P systemscompared to other approaches from the literature; for instance, the automatic design methods introduced in [
9,
10] need to fix either the topology or the parameters of the rules used in each neuron (see
Section 2). On the other hand, our approach allows us to optimize all the parameters simultaneously except for the number of rules. With this further automation, the need for experts capable of designing such systems is reduced; in turn, this may enhance the applicability of SN P systems.
To verify our approach applied to PdM, we evolve SN P systems as predictors for the remaining useful life (RUL) of industrial components. PdM is a growing trend in research and industry that has the potential to provide benefits in terms of costs and performance by optimizing maintenance. As a matter of fact, RUL prediction is one of the essential elements for efficient and robust PdM. Given the historical data of condition monitoring signals for a target component until its end-of-life, RUL prediction can be considered as solving a regression problem by leveraging the relation between the degradation patterns in the historical data and their RUL.
Various machine learning (ML)-based methods based on traditional backpropagation-neural networks (BPNNs) have been introduced for RUL prediction. One of the earliest approaches, discussed in [
13], uses a multi-layer perceptron (MLP) and a convolutional neural network (CNN) for performing RUL prediction in the case of aircraft engines. In [
14], instead of extracting convolutional features, recurrent neural networks (RNNs) such as long short-term memory (LSTM) have been used to directly recognize temporal patterns in the data used for prediction. Recently, Ref. [
15] applied an attention mechanism to improve the RUL prediction accuracy. Another recent work [
16] applied evolutionary computation to optimize the architecture of a multi-head CNN-LSTM model tailored to the RUL prediction task, which was previously handcrafted in [
17]. More recently, a combination of an auto-encoder (AE) with a DL architecture has been proposed to improve the RUL prediction accuracy [
18], whereas Extreme Learning Machines (ELMs) have been proposed in [
19].
While a few previous works proposing SN P systems for pattern recognition do exist, they all use handcrafted systems for classification tasks, such as English letter recognition [
1] or fingerprint recognition [
20]. SN P systems have been used also for fault diagnosis [
21,
22], but in most cases, these existing approaches require extensive domain knowledge for the design of the used SN P systems. Our work, instead, allows automatically designing SN P systems by using a neuro-evolutionary technique. Another novelty is that in our case, we apply SN P systems to a regression task, differently from the previous literature focused on classification tasks. To summarize, the main (to the best of our knowledge, novel) contributions of this work can be identified in the following elements:
We use a modified version of the NEAT algorithm to successfully evolve SN P systems applied to RUL prediction.
We obtain better performance than an MLP on the CMAPSS dataset, reducing also the number of parameters.
We obtain better-than-random performance on the new CMAPSS dataset while significantly reducing the number of parameters w.r.t. the state-of-the-art.
The rest of the paper is organized as follows. The next section briefly presents the background concepts.
Section 3 introduces the proposed method to optimize SN P systems based on evolutionary computation. Then,
Section 4 and
Section 5 present the experimental setup and the numerical results, respectively. Finally,
Section 6 concludes this work.
5. Numerical Results
The aim of our experiments is to evaluate the SN P systems found with the proposed method described in
Section 3 by comparing their results with those obtained by the methods described in
Section 4.2. We evaluate our method in terms of prediction accuracy and computational simplicity. For the former, the comparison is mainly based on two metrics: the RMSE and the
s-score [
36] on the test set. For the latter, we use as proxy the number of trainable parameters and the execution time for the test.
When we define the error between the predicted and target RUL as
, the RMSE on the test set is given by:
where
N is the total number of test samples fed into the model during the test. The
s-score metric was proposed to differentiate between optimistic and pessimistic predictions by using an asymmetric function, and it is computed as follows:
i.e., it assigns a larger value to optimistic RUL predictions w.r.t. pessimistic RUL ones. This reflects the risk of predicting an RUL value higher than the real one. It should be noted that we use the
s-score solely for evaluating the methods on the test set; on the other hand, we perform the evolutionary optimization on the RMSE, since it provides more information from an optimization point of view w.r.t. the
s-score. In fact, based on our previous work [
16], networks optimized using the RMSE as fitness function provide better results in terms of both metrics compared to networks optimized based on the
s-score.
To obtain the number of trainable parameters in the SN P systems, we need to take into account all the connections between input and hidden neurons and between hidden and output neurons, as well as the four parameters for each neuron. Thus, the number of parameters in the SN P systems is , where , , and denote the number of input, hidden, and output neurons, respectively. It should be noted that this is the worst-case count; in fact, a structure produced by NEAT may not be fully connected. In addition to the above count, we measure the execution time of each method on the test set; it is the elapsed time to compute the predicted RUL for N test samples. This measurement helps compare the computational simplicity of each method intuitively.
Considering the stochasticity of the evolutionary search conducted by NEAT, to improve the reliability of the results, we execute 10 independent runs, each one with a different random seed. At the end of each run, we calculate the RMSE on the test set obtained by the best solution found in that run (note that during the evolutionary process, each solution is instead evaluated on the training set). We consider the mean of these 10 RMSE values as the final performance of the obtained SN P systems.
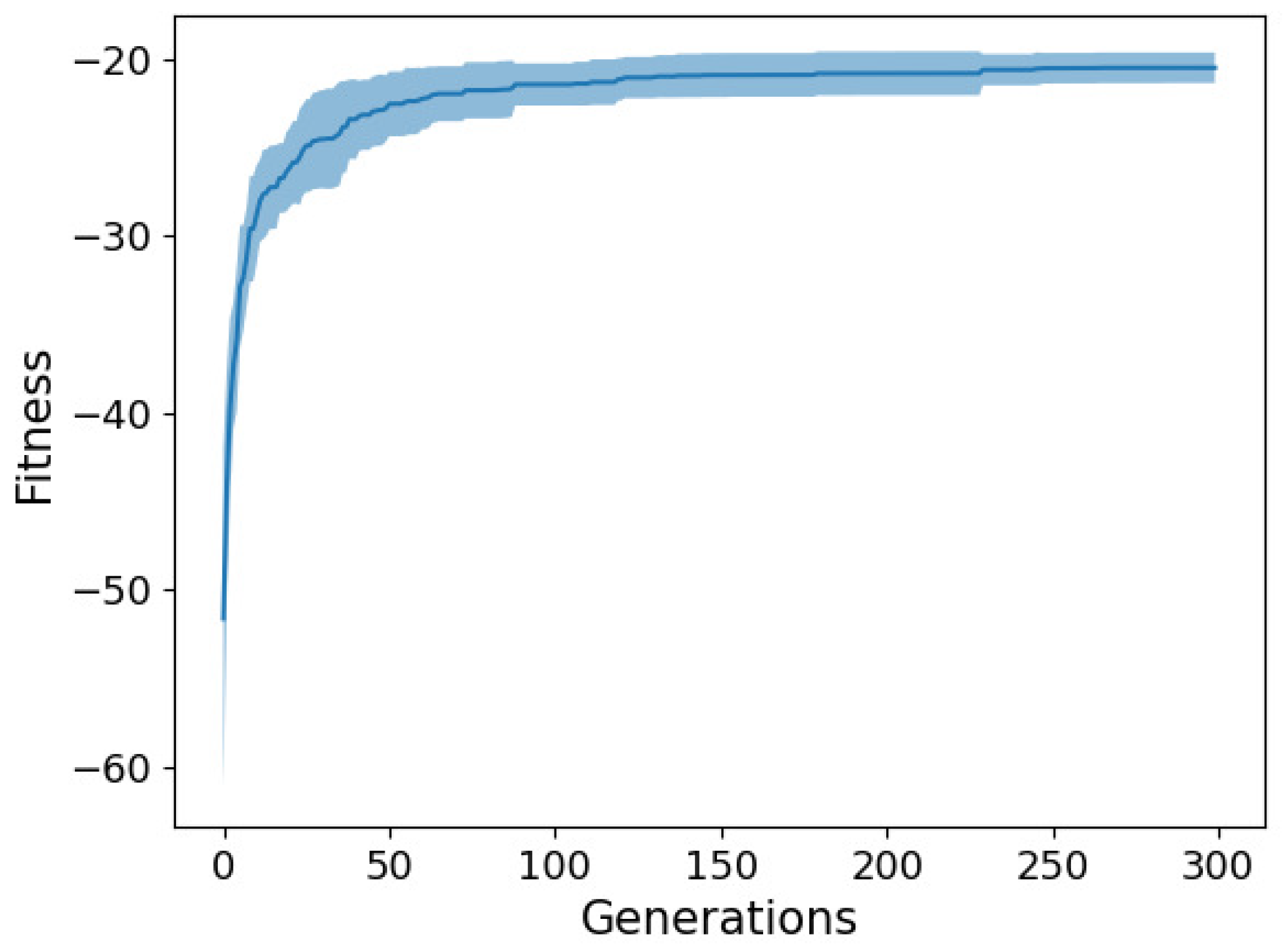
For illustration purposes,
Figure 3 and
Figure 4 show the fitness trend (i.e., the training RMSE trend), in terms of average (solid line) ± std. dev. (shaded area) across 10 independent runs, for the best solutions found across generations with two selected NEAT configurations on the two datasets, respectively. From the trends, we can conclude that the algorithm quickly converges in about one-third of the budget and then achieves minor improvements in the remaining part of the evolutionary process. Furthermore, we can observe that the method is quite robust across runs, since the std. dev. of the fitness trend is fairly small.
Concerning CMAPSS, the comparative results on the FD001 of all the considered methods are presented in
Table 7. SNPS (1) to (6) indicate the best SN P systems obtained with each of the six NEAT configurations reported in
Table 6. In terms of the test RMSE, all the six results are much better than the MLP, since we can achieve lower RMSE values with a smaller number of trainable parameters. In addition, we observe that the test RMSE of the SVM-based model taken from [
38] is placed between the result of the MLP and our best results. Furthermore, the test results of SNPS (4) and (6) are fairly comparable with those obtained by the CNN and the LSTM in terms of test RMSE, but our proposed method achieves these results by using a considerably smaller number of trainable parameters (1–2 orders of magnitude lower). In particular, we should note that the solution that gives the best RMSE, SNPS (5), contains only 232 parameters, while the most complex method in the table, the LSTM, has 14,681 parameters. The architecture of this SNPS is depicted in
Figure 5. It should be noted that this system was simplified by removing the nodes and edges that did not have an impact on the output.
Considering the s-score, the values obtained by our proposed method are better than the s-score of the MLP. Compared to the CNN, SNPS (5) gives a better s-score, although its RMSE is slightly worse. This indicates that the proposed method not only speeds up the RUL predictions with comparable accuracy, but also it can be robust to the risk of optimistic RUL predictions.
The importance of reducing the number of parameters can be highlighted by comparing the test execution time. For all the time measurements, we use the same GPU, and the time related to the initialization of the DL library is neglected. Although the test time is not linearly proportional to the number of trainable parameters, there is a positive correlation; our best SNPS in terms of test RMSE that has 232 parameters, i.e., SNPS (5), spends merely 25 ms to compute RUL predictions of the test samples, while a very simple one hidden layer MLP containing 801 parameters takes almost four times as much. Moreover, SNPS (3), which has only 60 parameters, spends only 7 ms to execute the test. In contrast, the CNN and LSTM, which contain a significantly larger number of parameters compared to our models, require a much longer time to complete the test. Thus, the small amount of parameters in our SN P systems represents the main advantage of the proposed method, since it is clear that reducing the number of parameters can reduce the time needed to predict the RUL.
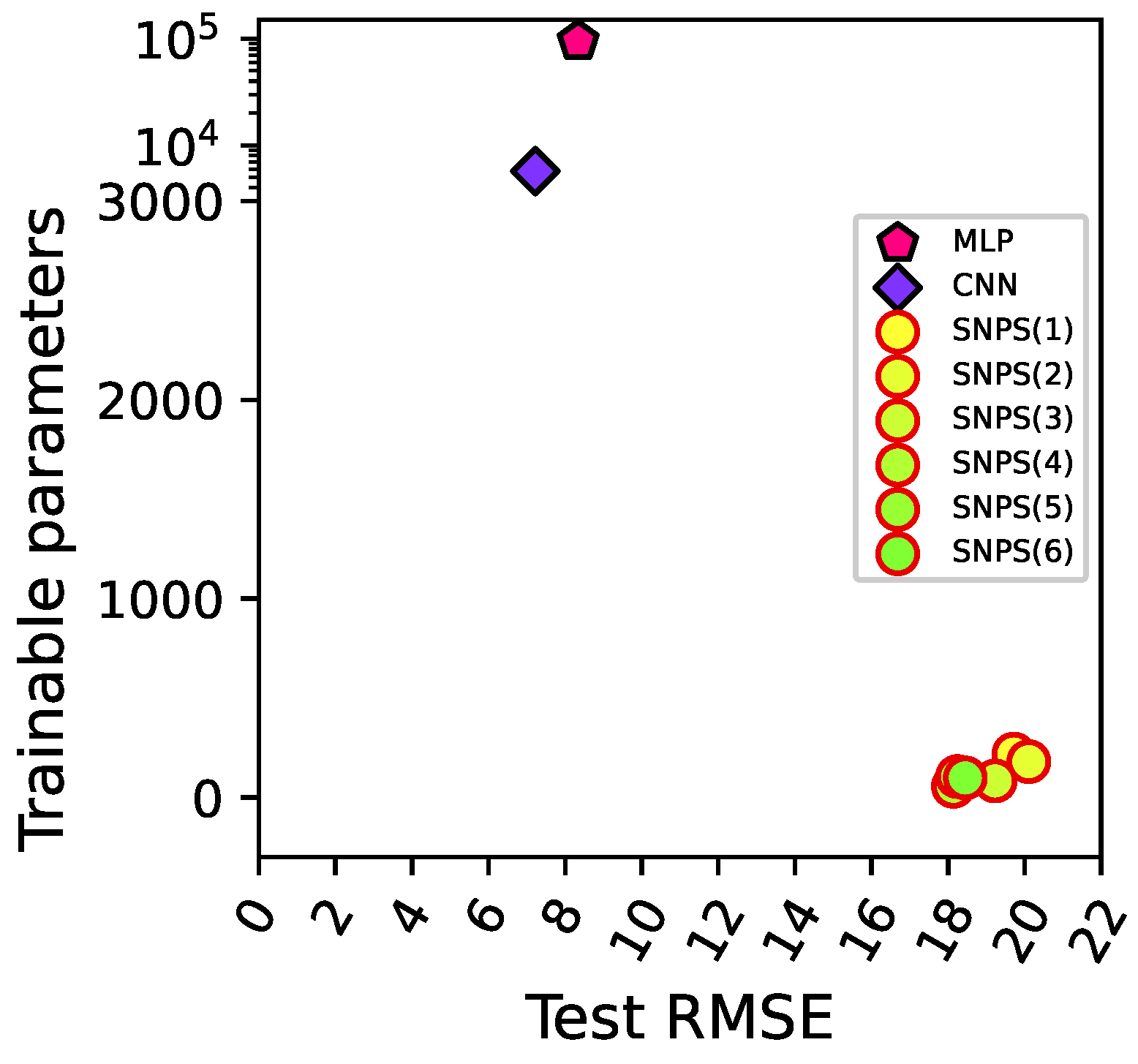
Figure 6 visualizes the trade-offs of the different methods (excluding SVM, for which the number of parameters is not available from [
38]) in terms of test RMSE vs. number of parameters. We can observe that the proposed method Pareto dominates the MLP. Among the compared algorithms, the proposed method is clearly the best one in terms of number of trainable parameters. Moreover, compared to the LSTM, the best SNPS architecture we found has an approximately
shorter test execution time, with around
less parameters, while its test RMSE is only about
larger.
Table 8 presents the comparative results on the N-CMAPSS dataset of the two deep neural networks taken from [
39] and the solutions obtained by our proposed method. It should be noted that compared to the shallow MLP used on the CMAPSS dataset, the number of parameters of the MLP used here is more than two orders of magnitude larger (
vs. 801). On the other hand, the CNN has a comparable number of parameters. We can see that the two deep networks can reach a very low RMSE. However, the CNN shows a better prediction accuracy with a lower number of parameters, although the computation for training this DL architecture is still considerably large [
19]. Differently from the results on CMAPSS, the
s-score performance of the proposed method is better than that of MLP, but it cannot reach the performance of the CNN. As illustrated in
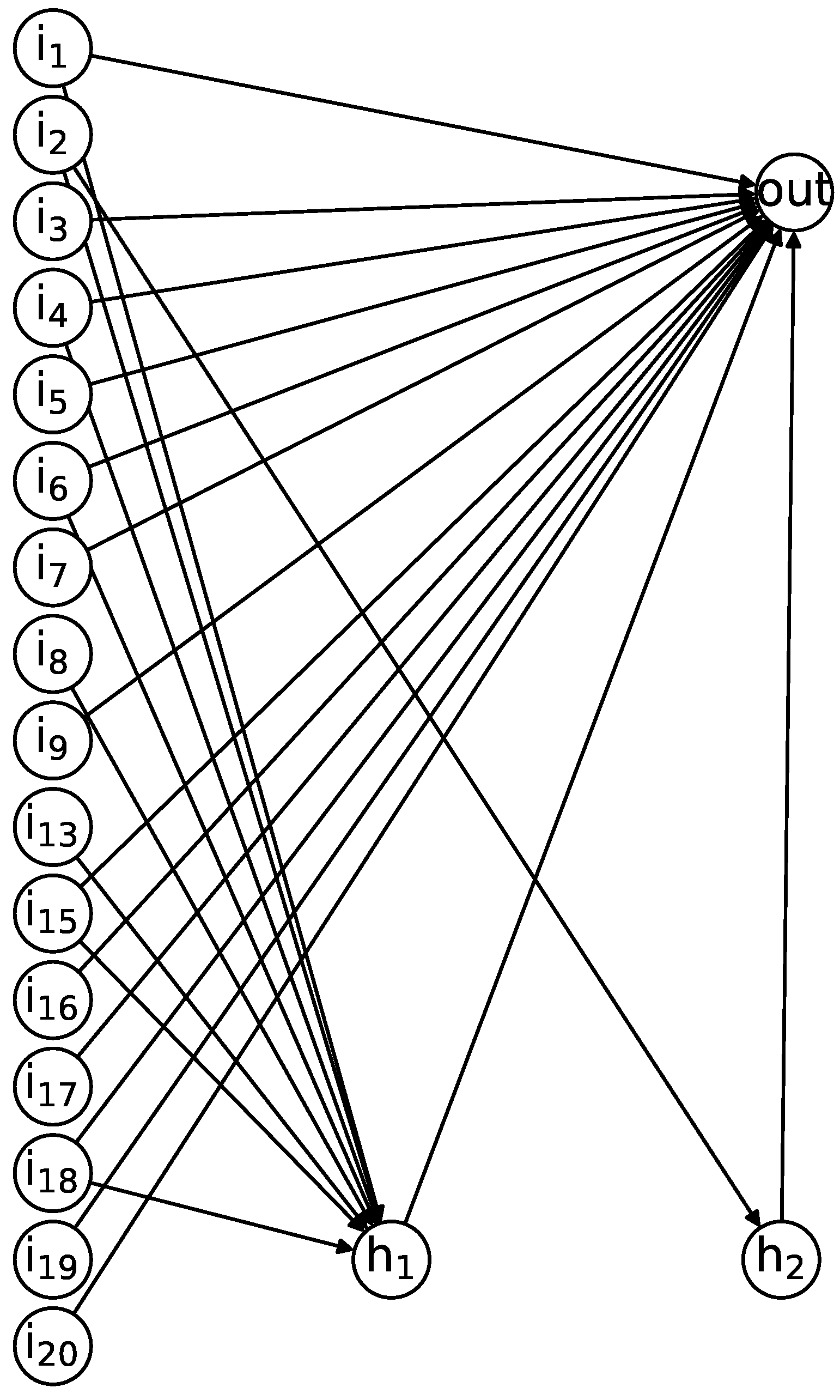
Figure 7, our SN P systems do not outperform the CNN in terms of RMSE, but they have a clear advantage in terms of number of trainable parameters. Especially the best solution in terms of test RMSE, SNPS (4) illustrated in
Figure 8, has 56 parameters, and this remarkably simple structure enables predicting RUL very quickly. In fact, the execution time on the test set reported in
Table 8 clearly demonstrates this advantage. On this notably larger dataset, the proposed method only takes less than 20 ms to predict the RUL, while the other methods take more than 1 s.
Another advantage of our method relates to memory consumption (which correlates to the number of parameters). Considering that in all the experiments we used the standard 32-bit floating point precision (so that each parameter takes 4 bytes), we can see that the method with the largest number of parameters, the MLP, consumes roughly 370 KB, while our SN P systems take much less than 1 KB. This difference may be crucial for some industrial environments characterized by stringent memory constraints, e.g., due to the use of embedded systems.
Finally, as a further reference, we include in
Table 8 two additional RMSE values, namely
and
. The test RMSE value of
indicates the performance that may be obtained by randomly choosing an RUL value from the test labels and considering it as an RUL prediction. Therefore, the random performance can be calculated by the RMSE between the test labels and the randomly chosen values. In the case of
, we take instead all the RUL values from the test labels and compute their mean. Then, the mean performance is computed by the RMSE between the test labels and their mean. We can see that our results are better than the result of
, but only three NEAT configurations perform slightly better than
. One additional note is that the test RMSE values of the BPNNs reported in
Table 8 are different from those reported in [
39], which are based on an early version of DS02 that has a lower noise level on the sensor readings and a sampling rate of
Hz.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}