1. Introduction
Cybercriminal activities continue to pose significant threats to personal data, particularly amid an era of heightened technological advancements [
1,
2]. Each attacker, driven by the nature of target data, employs a distinct set of skills [
3], often targeting valuable information, especially private data encompassing economic, military, and celebrity—related content [
4]. These attackers carefully lead their attacks through using different techniques, such as data interruption, interception, modification, and manufacturing, to produce harm in the targets [
5,
6,
7]. They orchestrate different cybercriminal activities using their effective ways to provide malicious threats, namely data poisoning [
3].
To prevent such attacks, intrusion detection systems (IDSs) have been effectively introduced to play a crucial role in checking the data streams and give alerts to decision-makers once certain criteria are achieved [
8,
9,
10]. More specifically, IDSs transfer into Network Intrusion Detection Systems (NIDS) at the network flow stage, which necessitates training data to identify network flow records [
11]. Traditional retraining of NIDS is important to improve the flow behavior [
12].
Deep Learning (DL) is considered to be one of the best techniques in many domains, such as pattern recognition, spanning language, images, speech, and video content [
13,
14,
15,
16]. Its superiority over other techniques stems from its improved computational capabilities, cost-effectiveness of computing equipment, and breakthroughs in Machine Learning (ML) [
15]. However, poisoning cyberattacks targeting training datasets have emerged as a prominent concern among machine learning practitioners [
12]. These attacks aim to corrupt training data intentionally, leading to poor performance of ML systems [
12]. Yet, creating feasible poisoning attacks for cyber activities remains challenging, with limited understanding of mitigation strategies [
17].
Motivated by the discrepancy between proposed adversarial settings in NIDS studies and their actual feasibility [
18], our research aims to address this gap. Many studies often assume that threat models are without sufficient consideration of their practicality [
18,
19,
20]. Moreover, research on poisoning attempts in the cyber realm has been confined to specific applications, such as computer vision, tabular, and text data [
21,
22,
23]. However, reliance on outdated datasets like NSL-KDD (35%) [
24], fraught with flaws and unreflecting modern networks, underscores the necessity for updated datasets, such as CICIDS2017, CSECICIDS2018, and LITENT2020 [
25,
26,
27,
28].
Utilizing these updated datasets allows for accurate conclusions regarding modern technological challenges in networks [
27,
28]. Label manipulation attack techniques in training data, though limited in attacking power, present an evident drawback as it is incapable of achieving sophisticated adversarial goals [
29,
30]. Current hostile machine learning studies predominantly focus on evasion attacks during inference [
31]. Recent surveys highlight poisoning attacks as a primary concern among implementing ML organizations, necessitating a shift towards addressing poisoning attack during the training [
32]. This shift emphasizes the need for further research in this critical area.
While poisoning assault strategies have been extensively explored within conventional ML techniques, only few studies have been specifically tailored for DL [
33,
34]. To address these issues, we introduce a poisoning attack approach aimed at evaluating the performance of DL model. Our experimentation involves inserting varying quantities of harmful samples into the model. These poisoned samples, generated via the DeepFool method as an untargeted attack [
35], ensure minimal modifications to repeatedly deceive the model’s classification [
36]. This methodology strategically avoids large modifications that might drastically deviate samples from benign elements, resulting in diminished performance and rapid detection [
37].
Subsequently, these poisoned instances are introduced into the original training dataset with diverse poisoning rates ranging from 1% to 10%. The injection involves altering the distance among the injected poisoned samples, randomly placing them within the original training locations. Given the substantial data requirements for DL techniques and hyperparameter adjustment, our research leverages extensive datasets provided by the Canadian Institute of Cybersecurity (CIC), specifically the Communications Security and Establishment dataset (CIC2019 or CICIDS2019) [
38]. This choice showcases the efficacy of our proposed assault approach in a real-world context.
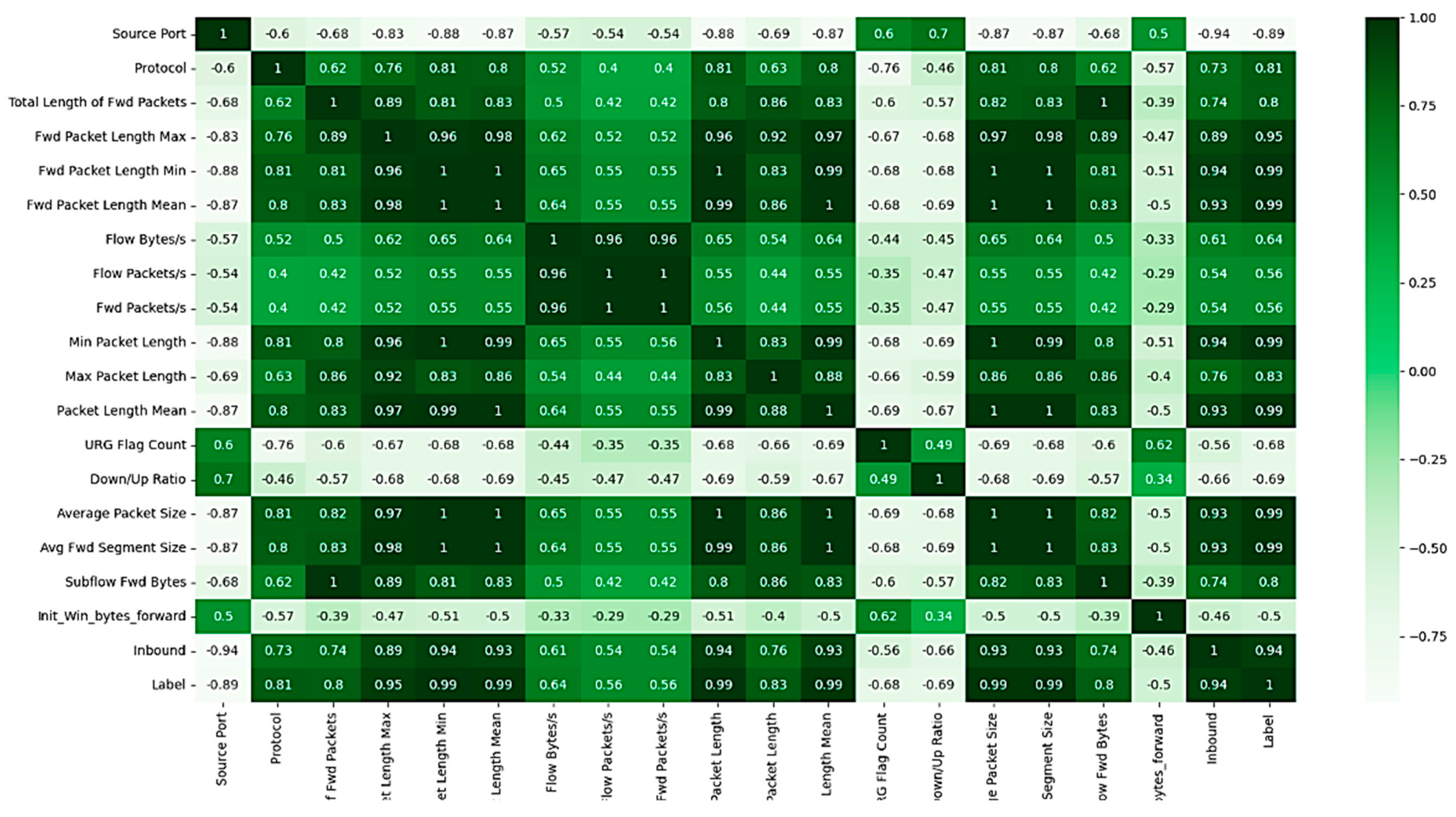
Feature selection crucially relied on Pearson’s Correlation technique to discern relationships between features, acknowledging the stability of associations in larger datasets compared to smaller ones [
39]. Leveraging a high-dimensional dataset encompassing recent network attacks, we rigorously assessed the robustness of the system and presented our findings based on multiple metrics, such as accuracy, True Positive Rate (TPR), and True Negative Rate (TNR). This comprehensive evaluation offers a comprehensive insight into the efficacy of the proposed approach.
This paper contributes significantly by bridging critical gaps in the field of network security. Specifically, this work presents a strong poisoning-based attacks method designed explicitly for DL to address a prominent deficiency in most recent literature that focuses on orthodox ML techniques. Our research provides an evaluation on the resilience and susceptibility of DNNs towards poisoning-based attacks via meticulous experiments leveraging the novel DeepFool method to create poisoned data. Furthermore, the study presents a comprehensive analysis of the attack’s influence on the performance of the system by injecting various amounts of such manipulated samples into the training datasets. Employing inclusive dataset provided by the Canadian Institute of Cybersecurity (CIC), notably as CIC2019 (CICIDS2019), offers real-world pertinence and validity to the findings of this study. Applying Pearson’s Correlation method to select features in datasets with high-dimensions further enhances the accuracy and depth of this investigation. Ultimately, the paper’s contribution lies in its meticulous exploration of data poisoning-based attacks on DNNs, shedding light on their implications for network security and offering insights into fortifying systems against such threats.
The article is structured into distinct sections, each dedicated for specific facets of the research.
Section 2 delves into a review of related work. Following this,
Section 3 elucidates the fundamental concepts introduced in this paper.
Section 4 intricately details the experimental setup. The methodological implementation is thoroughly outlined in
Section 5, providing insight into the research approach.
Section 6 examines and presents the findings derived from the study’s experimental cases. Finally,
Section 7 offers insightful concluding remarks and outlines potential avenues for future research endeavors.
4. Experimental Setup
Our experimental setup utilizes a computer server equipped with a powerful configuration, comprising a 16 GB NVIDIA Graphics Card RTX 4090 Ti, a 3.0 GHz multithread Core i9 CPU, and 64 GB of RAM. We employ Anaconda Python 3.6 software to execute our program and evaluate the effectiveness of the proposed technique.
4.1. Proposed System Framework
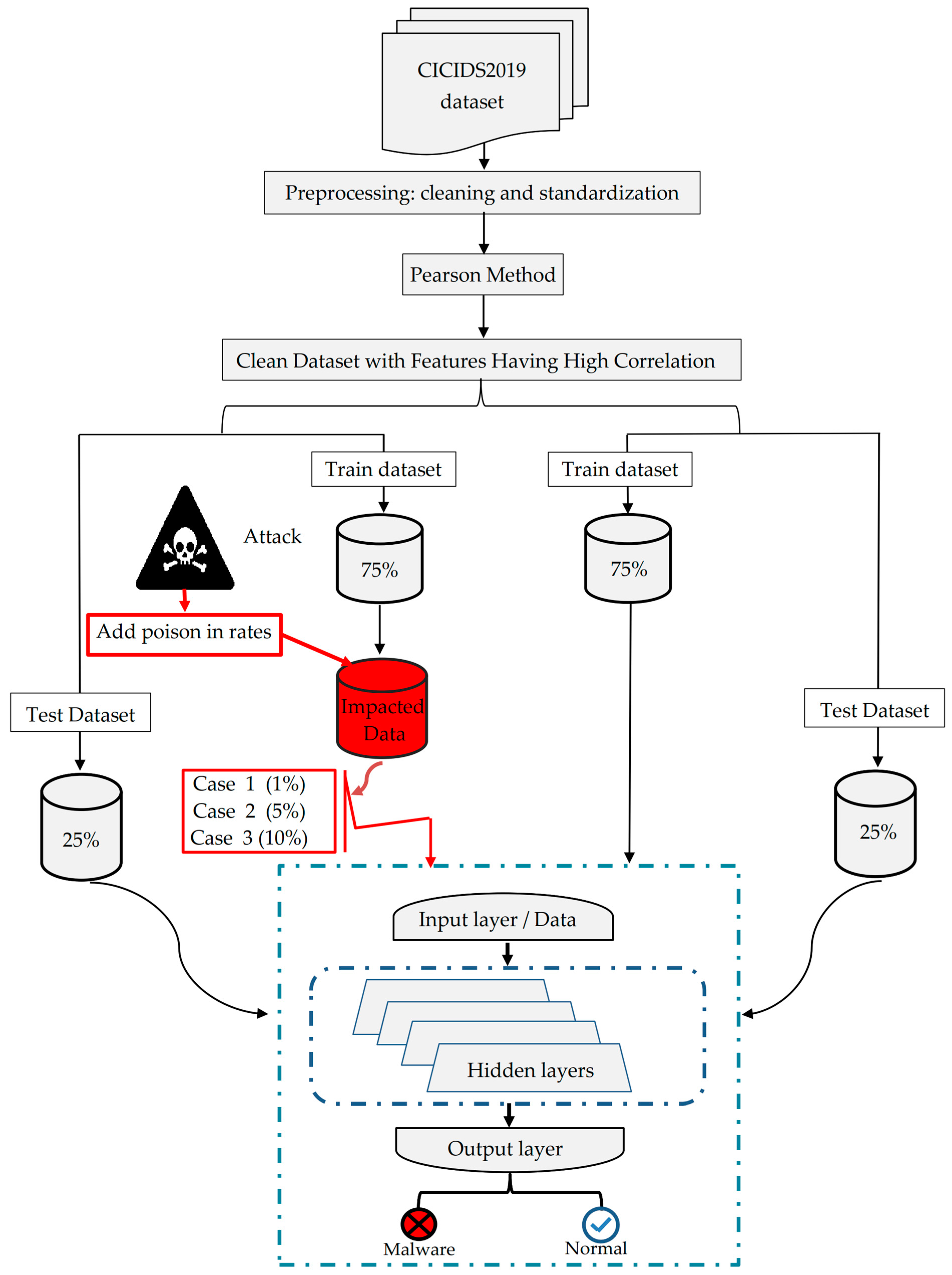
The proposed technique of this work, illustrated in
Figure 1, involves several phases. Initially, the system starts with fetching the network security dataset that contains various attacks, focusing on leveraging new and pertinent dataset for experimental purposes. Data preprocessing is considered as a critical step to treat the inherent noise, empty values, or inconsistencies of the collected data from different sources. The preprocessing includes refining and cleaning dataset, removing incorrect values, to futher enhance the accuracy of the next analyses. Afterwrds, feature selection method is used to remove redundant or inconsequential features that could significantly affect the model’s accuracy and complexity. Employing Pearson’s Correlation analysis is necessary to eliminate unrelated and undesirable features and to ensure that only essential pertinent features to the study’s objectives are retained.
As for the deep neural networks, models are usually classified into several layers that include interconnected neurons. Each neuron processes incoming data through weighted connections and activation functions to obtain the output. Ultimately, the framework produces poisoned data-based threat. In this study, the generation of such data has been achieved using the DeepFool as a white box attack methodology, in which these adversarial samples are injected into the training dataset at different rates to evaluate their impact on the model performance.
The final step of the framework contains an analysis of the model’s efficiency and resilience against these adversarial threats. Several evaluation metrics are leveraged to test the performance of the system, highlighting the strength of the system once adversarial instances are injected. A thorough investigation of the system’s behavior under adversarial attacks is achieved using our comprehensive framework, in order to reveal the vulnerabilities of the system and fortify its resilience in real-world applications.
4.2. Dataset Description and Preprocessing Procedures
The dataset leveraged in this work, namely CIC2019, has been recently produced by the Canadian Cyber Security Institute, to further fix flaws and address limitations that have been recorded in the two previous versions, CICIDS2017 and CICIDS2018 datasets [
38]. The new version of this dataset has been collected during a period of two days from a recording network flow, and then the recorded data instances are stored in a CSV format [
60]. The CIC2019 dataset involves eighty-seven features divided into normal and malware intrusion samples.
Table 2 provides more information regarding the dataset. It also includes an extensive collection of valuable samples that belong to the Distributed Denial of Service (DDOS)-based threats.
An important preliminary step involved initializing and preprocessing the dataset is required to remove common presence of undesirable data, including but not limited to noise, irregularities, outliers, and null values. The given dataset goes through two primary steps: cleaning and standardization. Initially, certain columns that involve “Flow ID”, “SimillarHTTP”, “Timestamp”, “Source IP”, and “Destination IP” have been eliminated to further reduce the complexity of the dataset and keep it with only eighty-two features. The “Flow Bytes” column has been standardized via replacing missing and infinite values with zeros to make the data consistent. In fact, real-world datasets usually include features with different units, magnitudes, and ranges to standardize the dataset and guarantee that the features are uniformed in ML models. During the scaling methods, the features have been rescaled to a range between zero and one in order to ensure homogeneity and enhance the performance of the ML algorithm. Note that some ML models, e.g., Neural Networks (NNs), assign standardized input data patterns for optimization purposes.
In this work, the dataset has been divided into 75% for training and 25% for testing through all levels to assure a comprehensive evaluation on the performance and generalizability of the ML model.
4.3. Performance Evaluation
To assess the performance of the model, we employ the Confusion Matrix (CM), a pivotal tool used for binary classification purposes to identify the differences between normal (benign) and malware (threat) data samples. CM provides a complete malfunction regarding the performance of the ML model, and it contains four primary elements: True Positive (True-P) refers to the accurate classification of normal instances, True Negative (True-N) denotes the correct identification of deceitful threats, False Positive (False-P) implies the misclassification of normal activity in the model as malware, and False Negative (False-N) represents the incorrect labeling of data attacks as normal tasks. Such elements are fundamental in order to successfully evaluate the accuracy of the ML model. Moreover, we incorporated different measurements, in which each has been designed for a specific task. Among these, the primary measurements utilized include:
Accuracy (Acc): Represents the percentage of successfully classified records in the whole dataset after training the algorithm.
Positive Predictive Value (PPV): Refers to the percentage of successfully recognized threat samples from all predicted threats.
False Positive Rate (FPR): Signifies the proportion of incorrect distinguished threat samples to the total number of actual threats.
Mean Squared Error (MSE): Represents the average squared dissimilarity between the predictions of the ML model and the original monitored outcomes. While MSE is traditionally used in regression problems rather than binary classification tasks, we employ MSE in our study for specific analytical purposes. Our objective is to analyze and monitor the changes in the system’s behavior when different ratios of poisoning data are applied. By utilizing MSE, we are able to quantify the deviations between the predicted and original outputs, providing valuable insights into the impact of poisoning attacks on model performance.
6. Results
The pursuit of enhancing DL-based NIDS has garnered considerable attention among researchers. Various methodologies have surfaced, encompassing diverse technologies, tools, algorithms, datasets, and benchmarks. Notably, many researchers have adopted DL algorithms in their investigations, each utilizing distinct datasets. The efficacy of our system can be readily gauged through its accuracy, when compared to previous works, which are detailed in
Table 5 below.
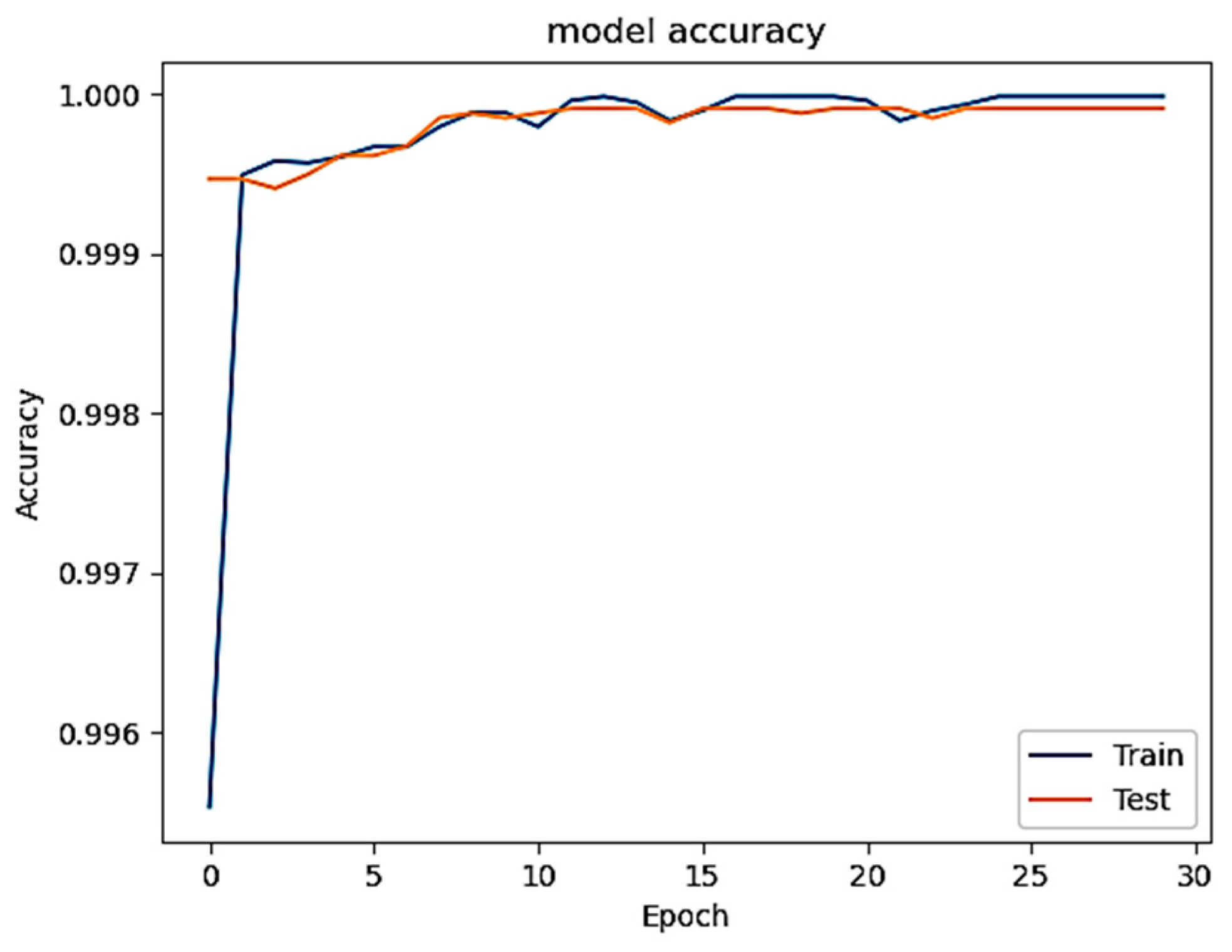
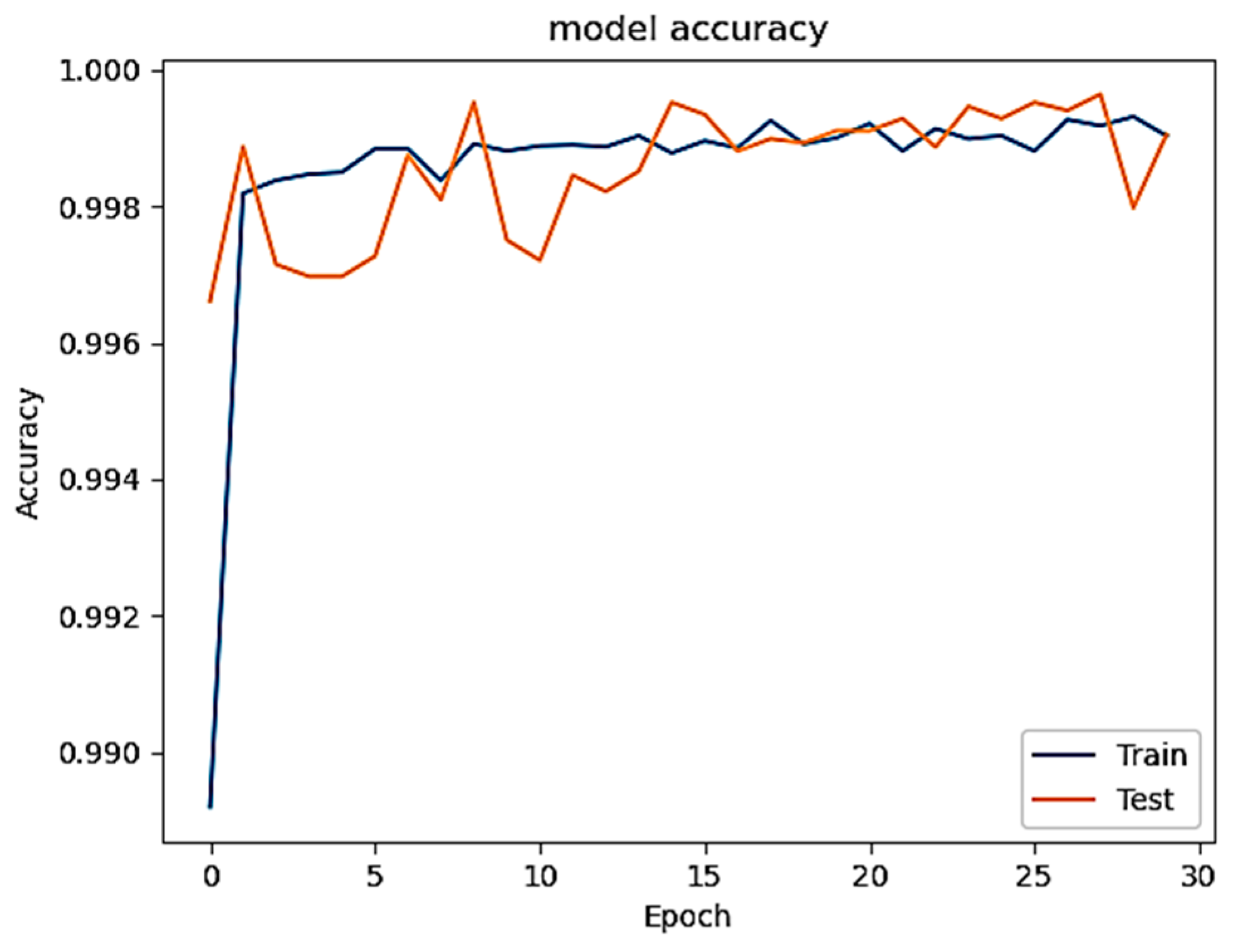
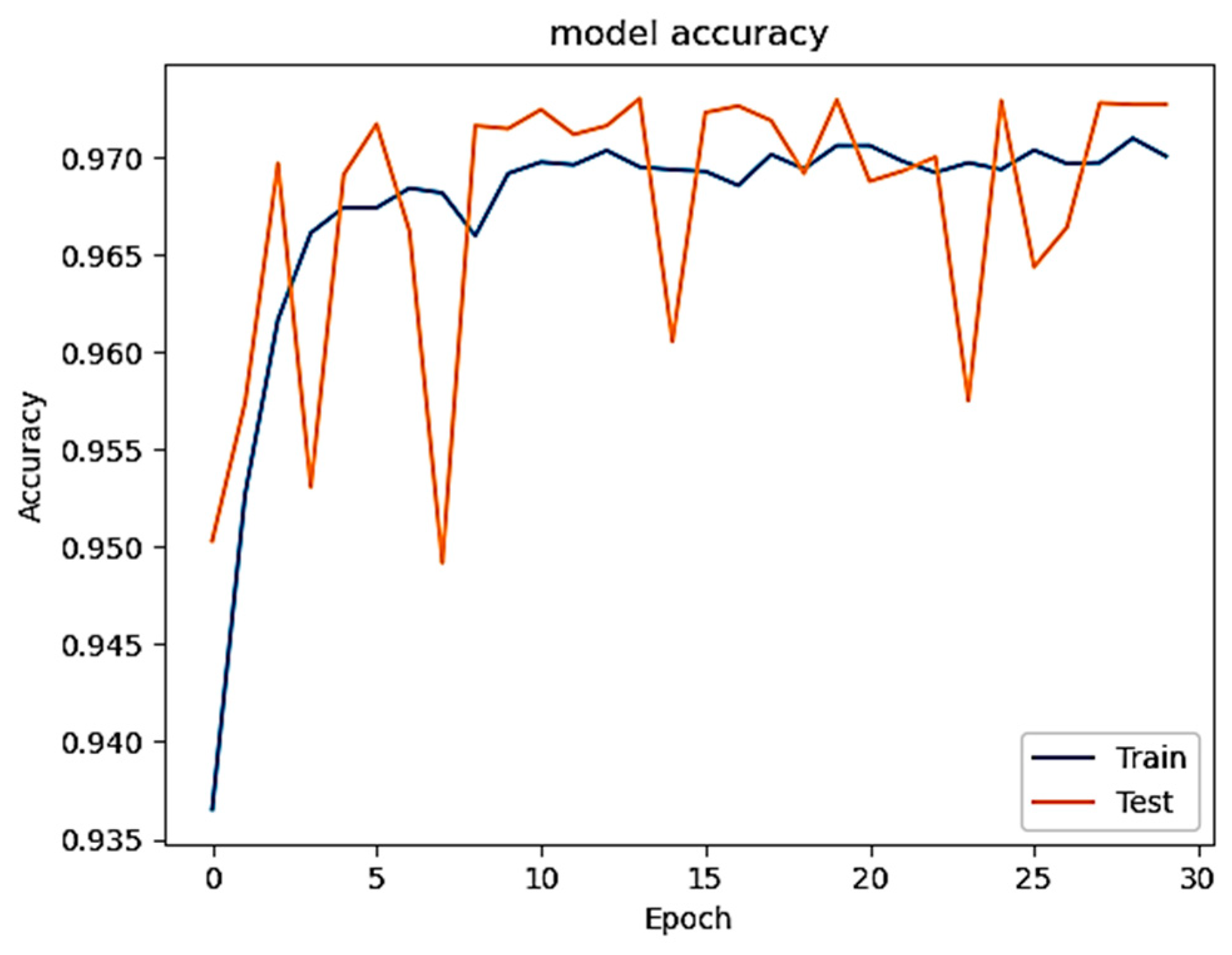
Figure 3 depicts the accuracy curve of our DL model after training on selected features in the first phase, in which the generated poisoned data are not included. The curve demonstrates a steady increase as epochs progress, indicating the suitability of the chosen features for training the system and the sufficiency of epochs in achieving high accuracy. Additionally,
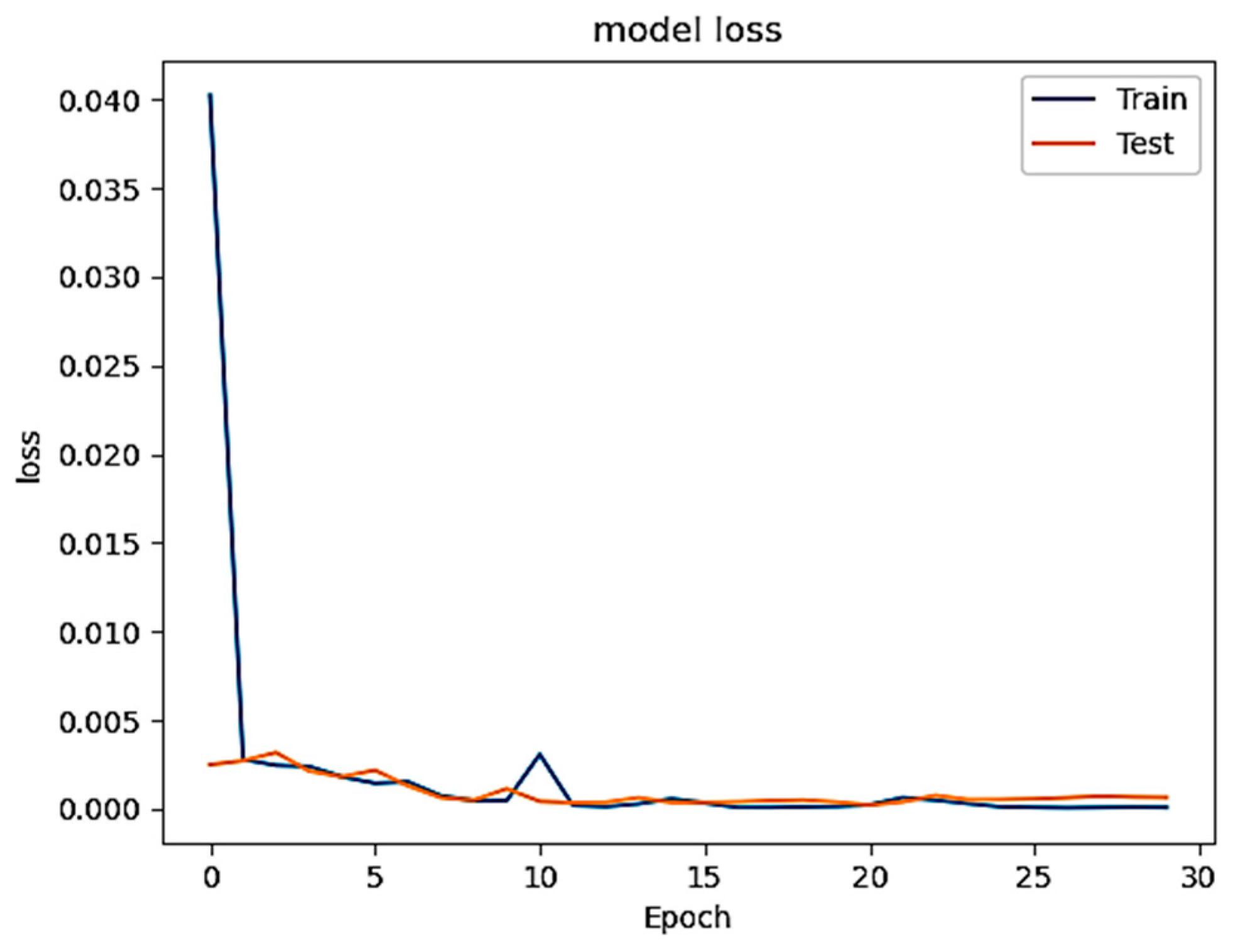
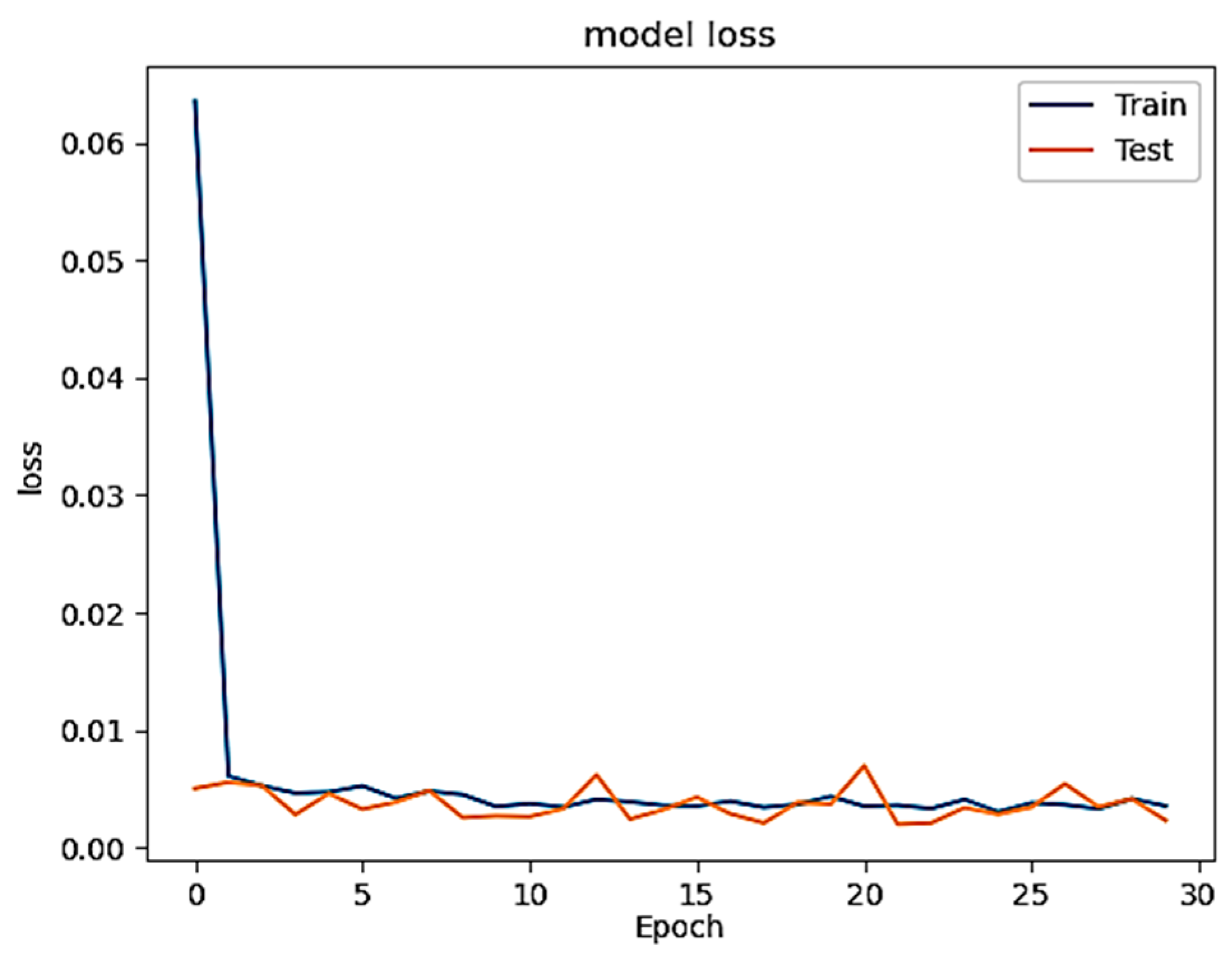
Figure 4 illustrates the model’s loss, indicating a consistent decrease with increasing epochs.
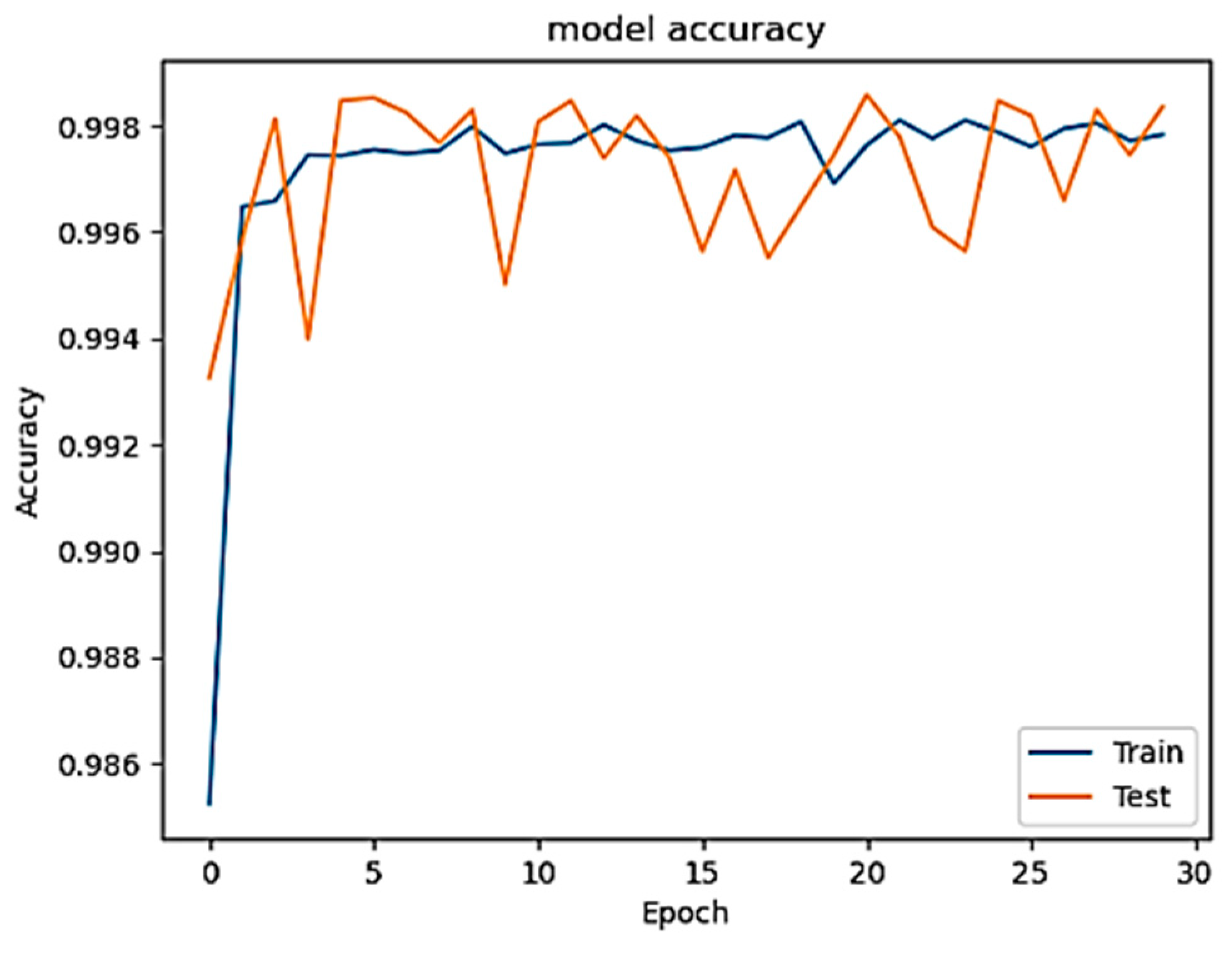
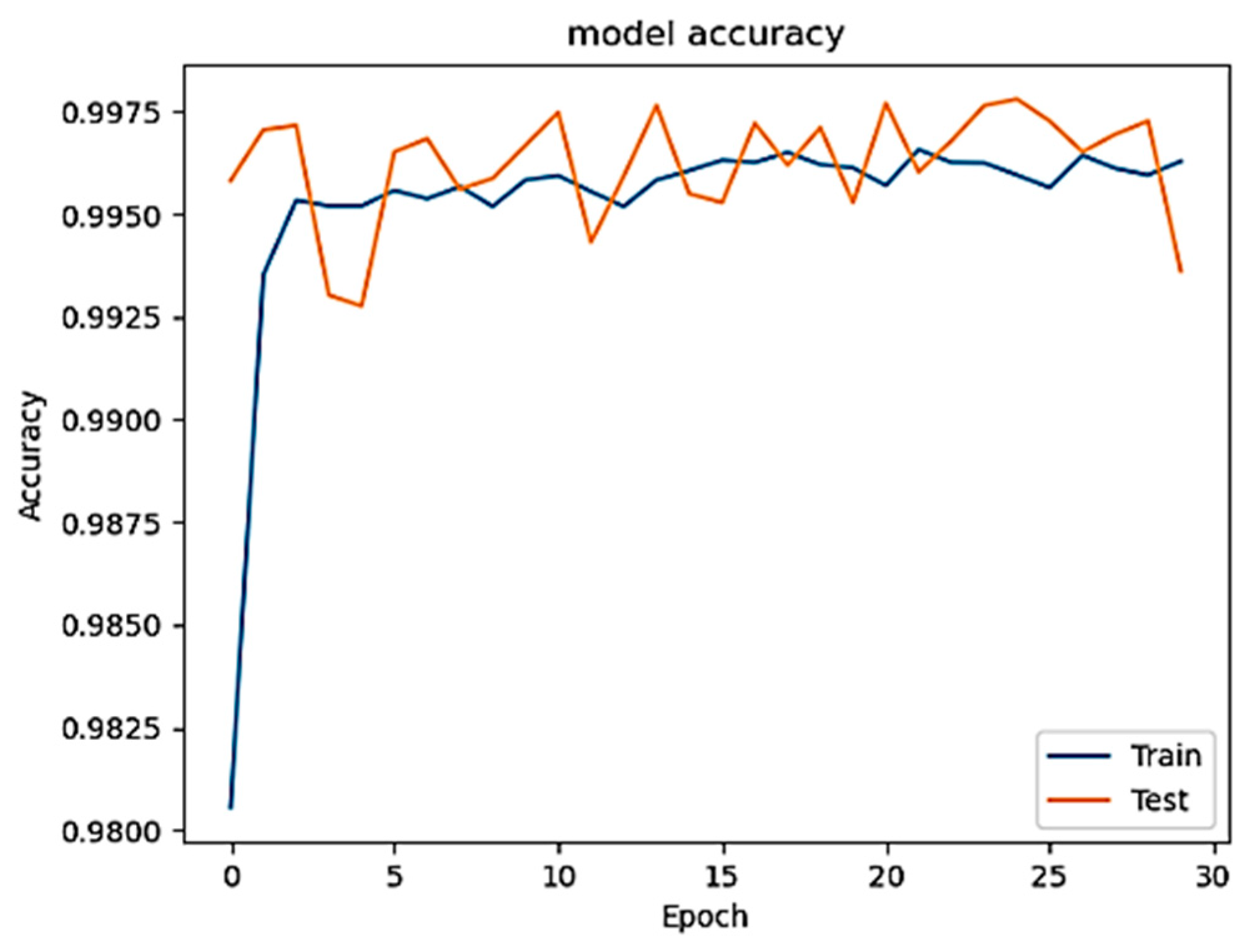
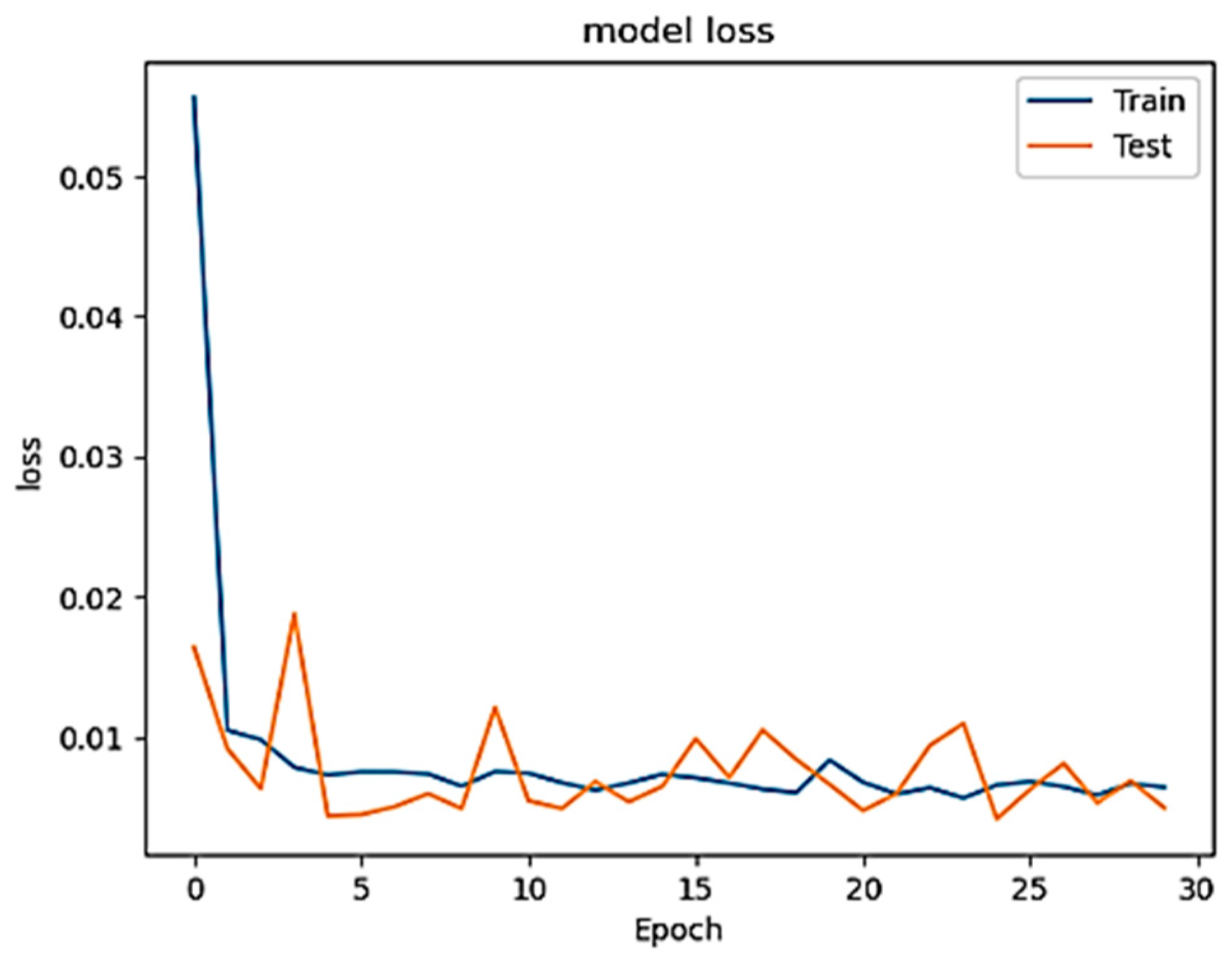
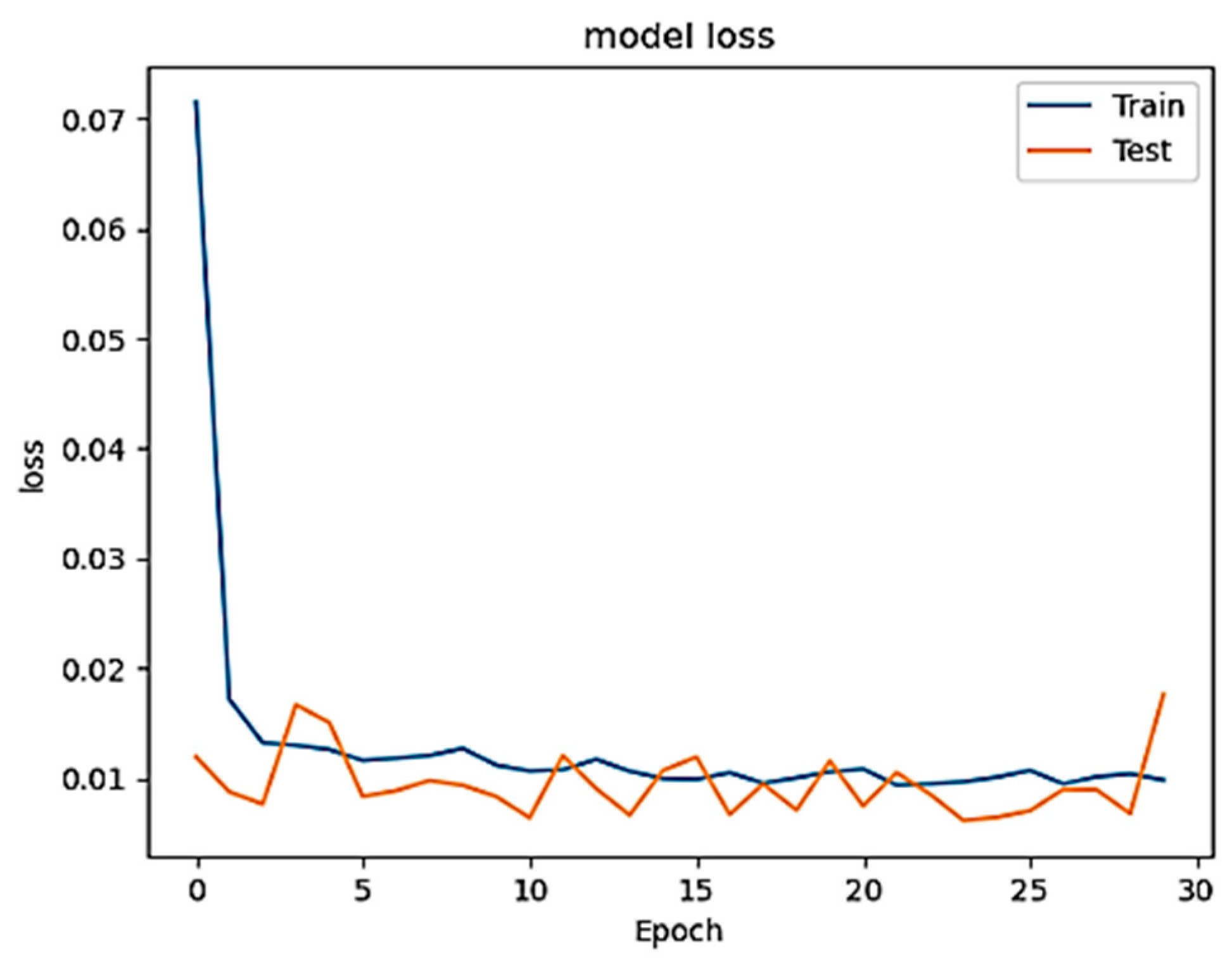
In the study’s second phase, we evaluated the performance of the model after injecting three different ratios, 1%, 5%, and 10%, of constructed poisoned patterns into the training set, where the inserting has been performed randomly to make the attack more realistic (closer to the real-world scenario) and render revealing the attack much harder once a traditional defense technique is employed. The main purpose of leveraging this technique is to appraise the effectiveness of the injected poisoned data to the model performance. Remarkably, even after injecting all three percentages of patterns into the original training set while isolating the test data, the accuracy remained relatively high.
Figure 5,
Figure 6 and
Figure 7 display the accuracy across these three cases, while
Figure 8,
Figure 9 and
Figure 10 visualize the corresponding model loss.
During the first injection of the poisoned data with the ratio of 1% (1000) into the training set, there is no much difference in the result of the Acc when comparing the trained model with and without injecting poisoned data, but the MSE has increased and PPV has decreased. When the 5% ratio dataset is injected, the MSE and PPV have been further impacted, and the Acc has slightly affected. When the poisoned data ratio is increased to 10%, the MSE and PPV have been more affected while still the Acc has barely changed. In general, the effectiveness of the injected poisoned data to the model is summarized in
Table 6, in which the impact of the Acc, PPV, FPR and MSE are reported when the ratio of the injected poisoned samples is elevated. This explains the effect of the randomly injected points within the training group, and how the rate of misclassification increases as the injection rate elevates.
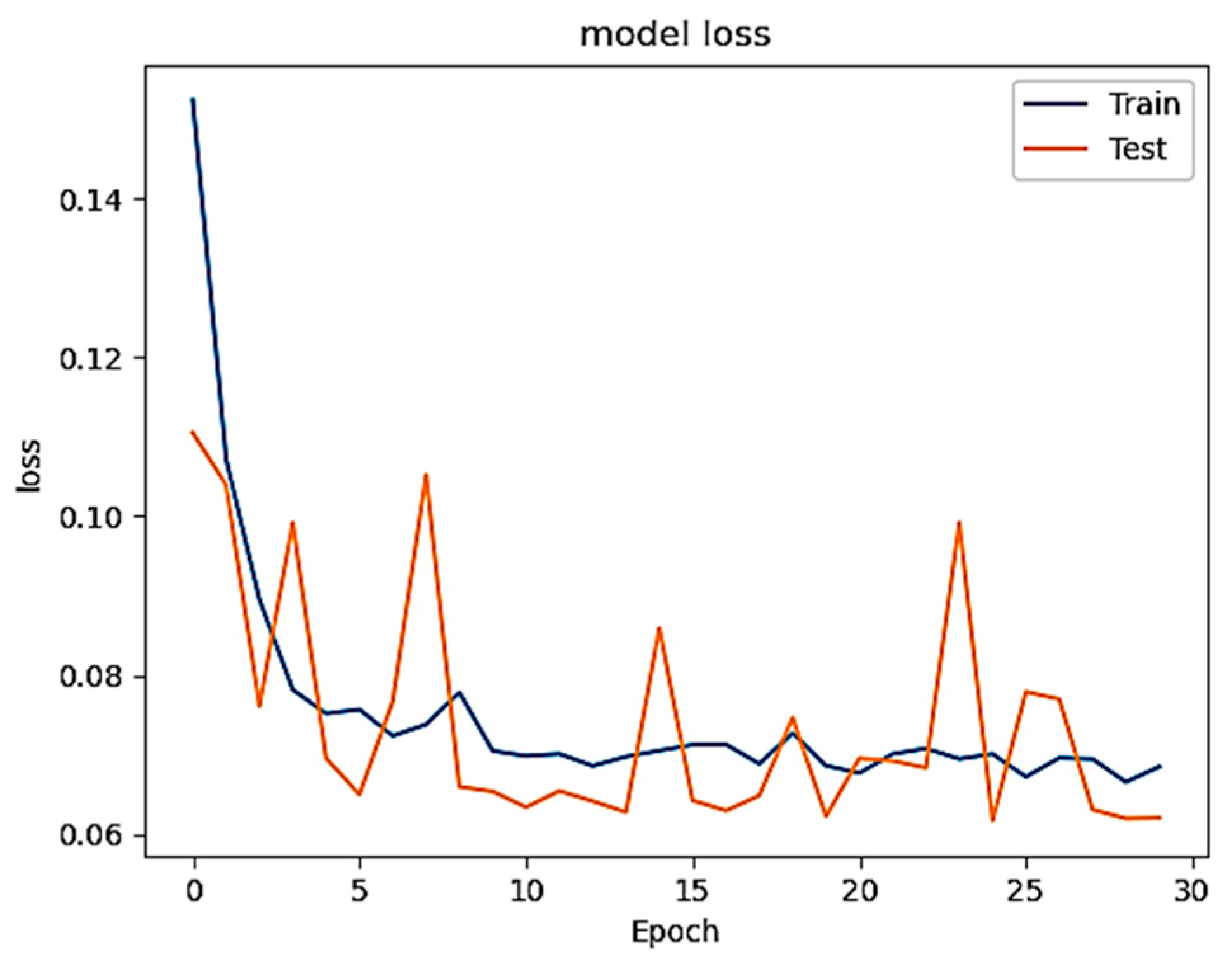
To provide an additional proof, we injected half of the training set with the generated poisoned data (50%) to further show the effectiveness of the injected poisoned data on the model performance. The result indicates a significant drop in accuracy, as shown in
Figure 11 and
Figure 12 and also in the prediction, as summarized in
Table 6. To sum up, the poisoned data are considered strong if the PPV, FPR, and MSE are significantly impacted while the accuracy is slightly influenced, and this is clearly shown in
Table 6. In other words, the injected poisoned data, that are carefully constructed from highly correlated features and randomly distributed into the training data, cause deluding the model and ensuring that these generated patterns are highly concealed since the model fails to detect such poisoned data. Unlike other techniques, e.g., Flipping Label method, in which the accuracy has dramatically decreased and resulted in exposing the attack and the position of the enemy. This type of attack poses a significant threat as it directly manipulates the data, rendering it invisible to traditional detection methods. Its insidious nature demands highly skilled defenders capable of promptly processing and validating data to mitigate potential damage to system outputs. While these attacks may not immediately impact the accuracy of the system, other metrics utilized in this study revealed their detrimental effects. Additionally, deep learning-based systems exhibit inherent weaknesses, rendering them particularly vulnerable to such attacks unless robust preventive measures are implemented.
Considering the overall performance of our proposed technique shown in
Table 6, we can conclude that deep learning model can be considered as a reliable system for detecting intrusion tasks on network field. However, defense techniques against strong poisoned data that are carefully generated leveraging highly correlated features with large data volume are required, especially for sensitive information that are pertinent to medical healthcare field [
65]. Also, analyzing the model’s performance of deep neural networks using other types of generation methods, particularly when the target is to attack the model, not just the data should be taken into consideration during the evaluation. Moreover, it is not enough to say that the model is strong when only the accuracy is high. As shown in this work, an attacker can inject poisoned data into the training set and such data cannot be detected since the accuracy is still high, where the impact of such attack is shown on other metrics, e.g., precision.
7. Conclusions and Future Works
In this study, we investigate the robustness of a DL model employed for the detection of computer network attacks. Our research is centered on examining the susceptibility of the model towards adversarial attacks, particularly focusing on the impact of such attacks on its performance and resilience. Experiments were conducted utilizing the widely recognized CICIDS2019 network dataset. Employing Pearson correlation coefficient method for feature deduction, we meticulously identified relevant features crucial for effective attack detection. The DeepFool white-box attacks has been included to carefully evaluate the resilience of the model against strong poisoning-based threats, which are designed to evade the system’s detection and significantly affect the performance of the model. Our analysis, supported by experimental results, indicates that the generated poisoned data is highly concealed and hard to be detected, which is shown in accurate results that range from 0.99 to 0.93, which indicates the significant concealment achieved by the proposed threats. It also has a significant impact on the performance of the model to correctly recognize normal from malignant instances in the network, as evidenced by variations in Positive Predictive Value (PPV) ranging from 0.99 to 0.082, False Positive Rate (FPR) from 1.00 to 0.29, and Mean Squared Error (MSE) from 0.000008 to 0.67. Also, our proposal aims to explore alternative techniques to further improve the robustness of the system, including but not limited to the selection of more distinguished features, experimenting different features, and exploring alternative deep learning architectures. Furthermore, future attempts will include multiclass classification tasks and investigating various feature selection methods to generate better defense mechanisms and efficient strategies against complicated network threats. This holistic approach underscores our commitment to advance the state-of-the-art in network security, with a keen focus on developing resilient and adaptive defense mechanisms capable of mitigating emerging threats effectively.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}