
Spike-Weighted Spiking Neural Network with Spiking Long Short-Term Memory: A Biomimetic Approach to Decoding Brain Signals

 , and
, and
Abstract
1. Introduction
2. Methods
2.1. Datasets
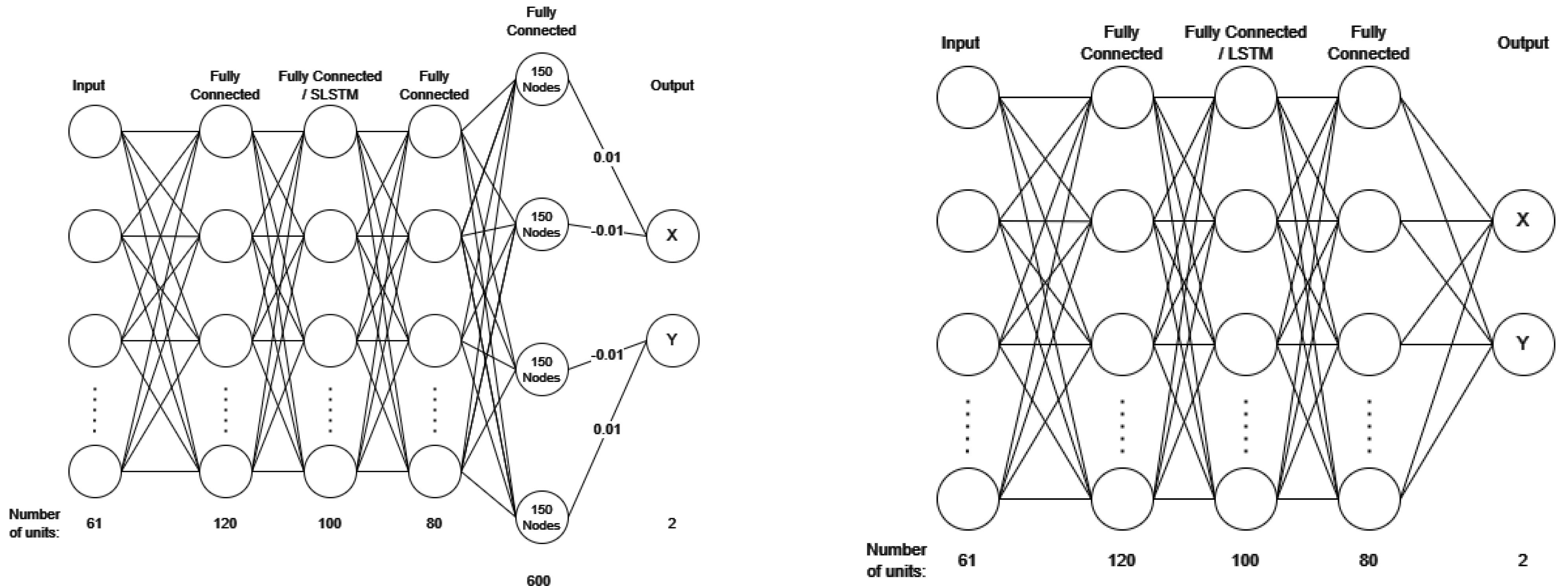
2.2. Decoder Architecture
2.2.1. Spiking Neural Networks
- (1)
- Conversion from ANNs to SNNs; however, this can cause issues, leading to the need to increase the time period for inference latency [35].
- (2)
- Using a biologically plausible approach called spike-timing-dependent plasticity (STDP) [36]. This, however, has exhibited problems in terms of performance.
- (3)
- Backpropagation through time (BPTT), which was the method we used. BPTT uses surrogate gradients in the backwards pass to allow for differentiability [34].
2.2.2. Spiking Long Short-Term Memory (SLSTM) Architecture
2.2.3. Spiking Decoders
2.2.4. Variations of swSNN-SLSTM Models
2.2.5. Architecture of LSTM
| Algorithm 1. swSNN-SLSTM Forward Pass |
2.2.6. Kalman Filter
2.3. Evaluating Decoder Performance
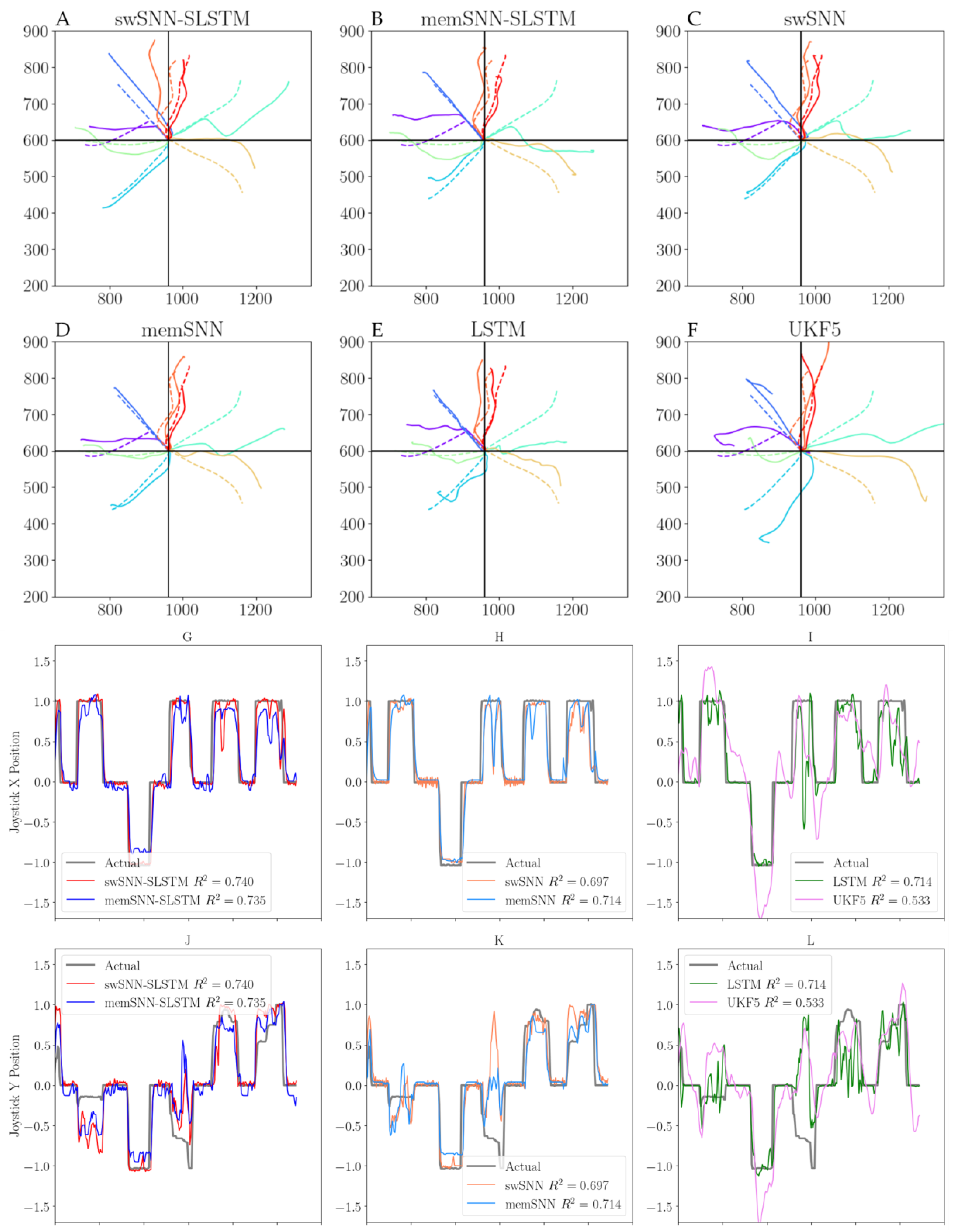
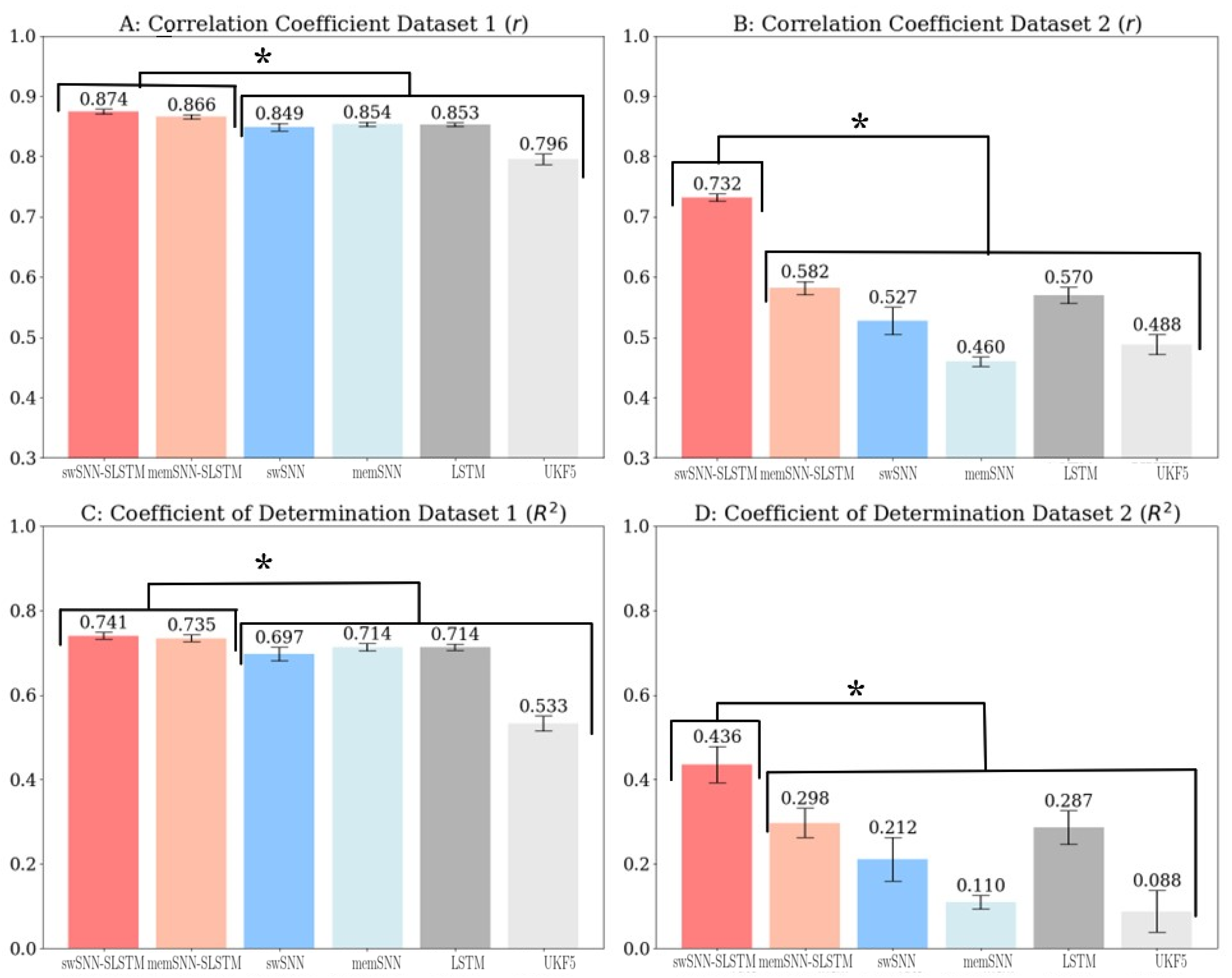
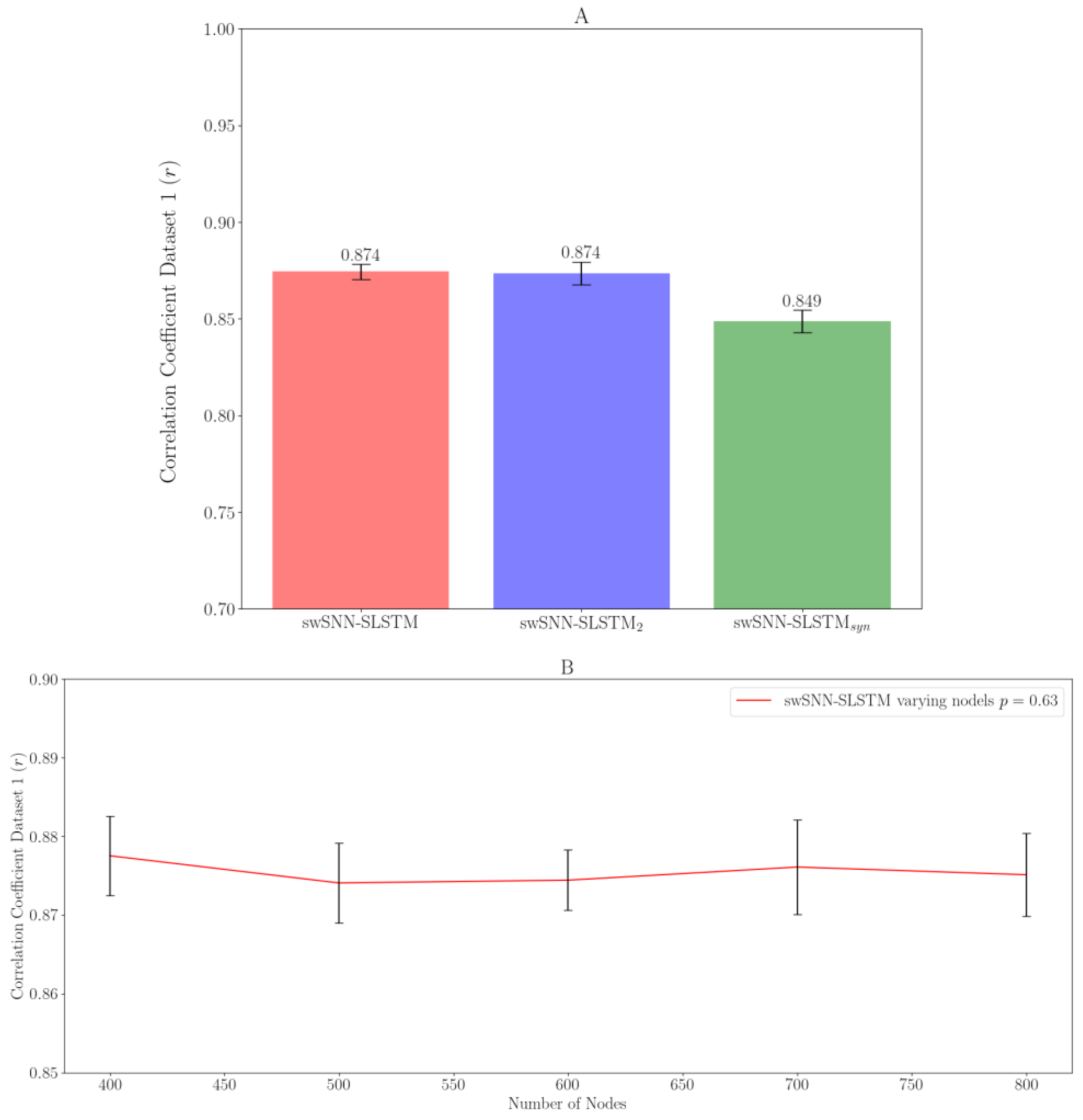
3. Results
3.1. Decoder Analysis
3.2. Variations of SLSTM Architecture
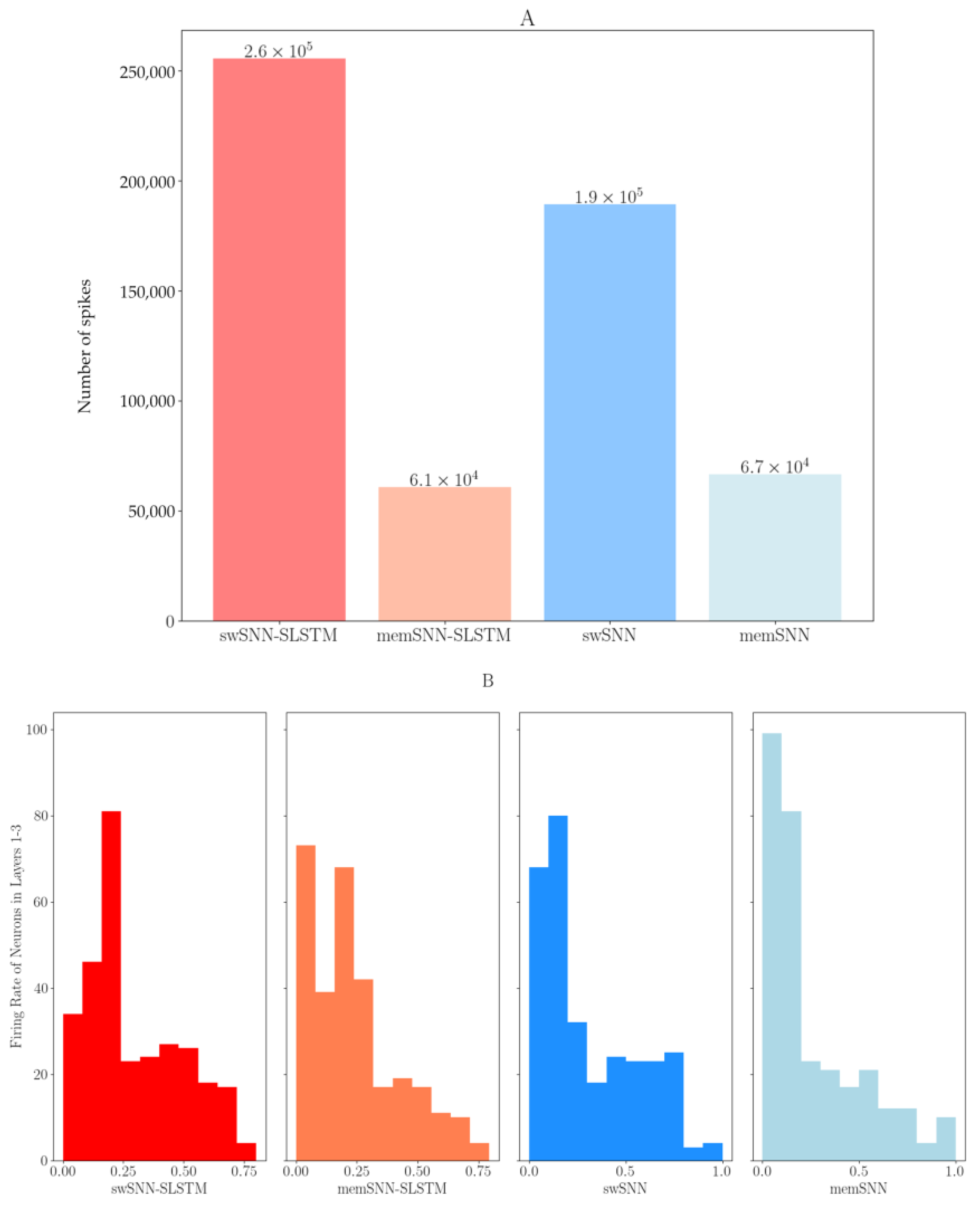
3.3. Firing Rate Analysis
4. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Aggarwal, V.; Mollazadeh, M.; Davidson, A.G.; Schieber, M.H.; Thakor, N.V. State-Based Decoding of Hand and Finger Kinematics Using Neuronal Ensemble and LFP Activity during Dexterous Reach-to-Grasp Movements. J. Neurophysiol. 2013, 109, 3067–3081. [Google Scholar] [CrossRef]
- Carmena, J.M.; Lebedev, M.A.; Crist, R.E.; O’Doherty, J.E.; Santucci, D.M.; Dimitrov, D.F.; Patil, P.G.; Henriquez, C.S.; Nicolelis, M.A.L. Learning to Control a Brain–Machine Interface for Reaching and Grasping by Primates. PLoS Biol. 2003, 1, e42. [Google Scholar] [CrossRef]
- So, R.; Xu, Z.; Libedinsky, C.; Toe, K.K.; Ang, K.K.; Yen, S.-C.; Guan, C. Neural Representations of Movement Intentions during Brain-Controlled Self-Motion. In Proceedings of the 2015 7th International IEEE/EMBS Conference on Neural Engineering (NER), Montpellier, France, 22–24 April 2015; pp. 228–231. [Google Scholar]
- Nason-Tomaszewski, S.R.; Mender, M.J.; Kennedy, E.; Lambrecht, J.M.; Kilgore, K.L.; Chiravuri, S.; Kumar, N.G.; Kung, T.A.; Willsey, M.S.; Chestek, C.A.; et al. Restoring Continuous Finger Function with Temporarily Paralyzed Nonhuman Primates Using Brain–Machine Interfaces. J. Neural Eng. 2023, 20, 036006. [Google Scholar] [CrossRef]
- Brandman, D.M.; Hosman, T.; Saab, J.; Burkhart, M.C.; Shanahan, B.E.; Ciancibello, J.G.; Sarma, A.A.; Milstein, D.J.; Vargas-Irwin, C.E.; Franco, B.; et al. Rapid Calibration of an Intracortical Brain–Computer Interface for People with Tetraplegia. J. Neural Eng. 2018, 15, 026007. [Google Scholar] [CrossRef] [PubMed]
- Soekadar, S.R.; Birbaumer, N.; Slutzky, M.W.; Cohen, L.G. Brain–Machine Interfaces in Neurorehabilitation of Stroke. Neurobiol. Dis. 2015, 83, 172–179. [Google Scholar] [CrossRef]
- Kalman, R.E. A New Approach to Linear Filtering and Prediction Problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Chen, Z.; Takahashi, K. Sparse Bayesian Inference Methods for Decoding 3D Reach and Grasp Kinematics and Joint Angles with Primary Motor Cortical Ensembles. In Proceedings of the 2013 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Osaka, Japan, 3–7 July 2013; pp. 5930–5933. [Google Scholar]
- Li, Z.; O’Doherty, J.E.; Hanson, T.L.; Lebedev, M.A.; Henriquez, C.S.; Nicolelis, M.A.L. Unscented Kalman Filter for Brain-Machine Interfaces. PLoS ONE 2009, 4, e6243. [Google Scholar] [CrossRef] [PubMed]
- Dangi, S.; Gowda, S.; Héliot, R.; Carmena, J.M. Adaptive Kalman Filtering for Closed-Loop Brain-Machine Interface Systems. In Proceedings of the 2011 5th International IEEE/EMBS Conference on Neural Engineering, Cancun, Mexico, 27 April–1 May 2011; pp. 609–612. [Google Scholar]
- Homer, M.L.; Harrison, M.T.; Black, M.J.; Perge, J.A.; Cash, S.S.; Friehs, G.; Hochberg, L.R. Mixing Decoded Cursor Velocity and Position from an Offline Kalman Filter Improves Cursor Control in People with Tetraplegia. In Proceedings of the 2013 6th International IEEE/EMBS Conference on Neural Engineering (NER), San Diego, CA, USA, 6–8 November 2013; pp. 715–718. [Google Scholar]
- Maksimenko, V.A.; Frolov, N.S.; Hramov, A.E.; Runnova, A.E.; Grubov, V.V.; Kurths, J.; Pisarchik, A.N. Neural Interactions in a Spatially-Distributed Cortical Network During Perceptual Decision-Making. Front. Behav. Neurosci. 2019, 13, 220. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Li, J.; Li, Z. An Improved Unscented Kalman Filter Based Decoder for Cortical Brain-Machine Interfaces. Front. Neurosci. 2016, 10, 587. [Google Scholar] [CrossRef] [PubMed]
- Tseng, P.-H.; Urpi, N.A.; Lebedev, M.; Nicolelis, M. Decoding Movements from Cortical Ensemble Activity Using a Long Short-Term Memory Recurrent Network. Neural Comput. 2019, 31, 1085–1113. [Google Scholar] [CrossRef]
- Hosman, T.; Vilela, M.; Milstein, D.; Kelemen, J.N.; Brandman, D.M.; Hochberg, L.R.; Simeral, J.D. BCI Decoder Performance Comparison of an LSTM Recurrent Neural Network and a Kalman Filter in Retrospective Simulation. In Proceedings of the 2019 9th International IEEE/EMBS Conference on Neural Engineering (NER), San Francisco, CA, USA, 20–23 March 2019; pp. 1066–1071. [Google Scholar]
- Premchand, B.; Toe, K.K.; Wang, C.; Shaikh, S.; Libedinsky, C.; Ang, K.K.; So, R.Q. Decoding Movement Direction from Cortical Microelectrode Recordings Using an LSTM-Based Neural Network. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; pp. 3007–3010. [Google Scholar]
- Konstantakos, V.; Chatzigeorgiou, A.; Nikolaidis, S.; Laopoulos, T. Energy Consumption Estimation in Embedded Systems. Instrum. Meas. IEEE Trans. 2008, 57, 797–804. [Google Scholar] [CrossRef]
- Sze, V.; Chen, Y.-H.; Yang, T.-J.; Emer, J.S. Efficient Processing of Deep Neural Networks: A Tutorial and Survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef]
- Wolf, P.D. Thermal Considerations for the Design of an Implanted Cortical Brain–Machine Interface (BMI). In Indwelling Neural Implants: Strategies for Contending with the In Vivo Environment; Reichert, W.M., Ed.; Frontiers in Neuroengineering; CRC Press/Taylor & Francis: Boca Raton, FL, USA, 2008; ISBN 978-0-8493-9362-4. [Google Scholar]
- Ghosh-Dastidar, S.; Adeli, H. Spiking Neural Networks. Int. J. Neural Syst. 2009, 19, 295–308. [Google Scholar] [CrossRef] [PubMed]
- van Schaik, A. Building Blocks for Electronic Spiking Neural Networks. Neural Netw. 2001, 14, 617–628. [Google Scholar] [CrossRef] [PubMed]
- Han, B.; Sengupta, A.; Roy, K. On the Energy Benefits of Spiking Deep Neural Networks: A Case Study. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 971–976. [Google Scholar]
- Henkes, A.; Eshraghian, J.K.; Wessels, H. Spiking Neural Networks for Nonlinear Regression. arXiv 2022, arXiv:2210.03515. [Google Scholar]
- Sorbaro, M.; Liu, Q.; Bortone, M.; Sheik, S. Optimizing the Energy Consumption of Spiking Neural Networks for Neuromorphic Applications. Front. Neurosci. 2020, 14, 662. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Deng, L.; Li, G.; Zhu, J.; Shi, L. Spatio-Temporal Backpropagation for Training High-Performance Spiking Neural Networks. Front. Neurosci. 2018, 12, 331. [Google Scholar] [CrossRef] [PubMed]
- Iakymchuk, T.; Rosado-Muñoz, A.; Guerrero-Martínez, J.F.; Bataller-Mompeán, M.; Francés-Víllora, J.V. Simplified Spiking Neural Network Architecture and STDP Learning Algorithm Applied to Image Classification. EURASIP J. Image Video Process. 2015, 2015, 4. [Google Scholar] [CrossRef]
- Liao, J.; Widmer, L.; Wang, X.; Di Mauro, A.; Nason-Tomaszewski, S.R.; Chestek, C.A.; Benini, L.; Jang, T. An Energy-Efficient Spiking Neural Network for Finger Velocity Decoding for Implantable Brain-Machine Interface. In Proceedings of the 2022 IEEE 4th International Conference on Artificial Intelligence Circuits and Systems (AICAS), Incheon, Republic of Korea, 13–15 June 2022; pp. 134–137. [Google Scholar]
- Nason, S.R.; Mender, M.J.; Vaskov, A.K.; Willsey, M.S.; Ganesh Kumar, N.; Kung, T.A.; Patil, P.G.; Chestek, C.A. Example Data and Code for “Real-Time Linear Prediction of Simultaneous and Independent Movements of Two Finger Groups Using an Intracortical Brain-Machine Interface”; University of Michigan: Ann Arbor, MI, USA, 2021. [Google Scholar] [CrossRef]
- Nason, S.R.; Mender, M.J.; Vaskov, A.K.; Willsey, M.S.; Ganesh Kumar, N.; Kung, T.A.; Patil, P.G.; Chestek, C.A. Real-Time Linear Prediction of Simultaneous and Independent Movements of Two Finger Groups Using an Intracortical Brain-Machine Interface. Neuron 2021, 109, 3164–3177.e8. [Google Scholar] [CrossRef]
- Libedinsky, C.; So, R.; Xu, Z.; Kyar, T.K.; Ho, D.; Lim, C.; Chan, L.; Chua, Y.; Yao, L.; Cheong, J.H.; et al. Independent Mobility Achieved through a Wireless Brain-Machine Interface. PLoS ONE 2016, 11, e0165773. [Google Scholar] [CrossRef]
- Yang, H.; Libedinsky, C.; Guan, C.; Ang, K.; So, R. Boosting Performance in Brain-Machine Interface by Classifier-Level Fusion Based on Accumulative Training Models from Multi-Day Data. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Jeju, Republic of Korea, 11–15 July 2017; Volume 2017, pp. 1922–1925. [Google Scholar]
- Premchand, B.; Toe, K.K.; Wang, C.C.; Libedinsky, C.; Ang, K.K.; So, R.Q. Rapid Detection of Inactive Channels during Multi-Unit Intracranial Recordings. In Proceedings of the 2019 IEEE EMBS International Conference on Biomedical & Health Informatics (BHI), Chicago, IL, USA, 19–22 May 2019; pp. 1–4. [Google Scholar]
- Ludwig, K.A.; Miriani, R.M.; Langhals, N.B.; Joseph, M.D.; Anderson, D.J.; Kipke, D.R. Using a Common Average Reference to Improve Cortical Neuron Recordings From Microelectrode Arrays. J. Neurophysiol. 2009, 101, 1679–1689. [Google Scholar] [CrossRef] [PubMed]
- Eshraghian, J.K.; Ward, M.; Neftci, E.; Wang, X.; Lenz, G.; Dwivedi, G.; Bennamoun, M.; Jeong, D.S.; Lu, W.D. Training Spiking Neural Networks Using Lessons From Deep Learning. Proc. IEEE 2023, 111, 1016–1054. [Google Scholar] [CrossRef]
- Rathi, N.; Srinivasan, G.; Panda, P.; Roy, K. Enabling Deep Spiking Neural Networks with Hybrid Conversion and Spike Timing Dependent Backpropagation. arXiv 2020, arXiv:2005.01807. [Google Scholar]
- Masquelier, T.; Thorpe, S.J. Unsupervised Learning of Visual Features through Spike Timing Dependent Plasticity. PLoS Comput. Biol. 2007, 3, e31. [Google Scholar] [CrossRef]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to Forget: Continual Prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef] [PubMed]
- Tan, P.-Y.; Wu, C.-W.; Lu, J.-M. An Improved STBP for Training High-Accuracy and Low-Spike-Count Spiking Neural Networks. In Proceedings of the 2021 Design, Automation & Test in Europe Conference & Exhibition (DATE), Virtual, 1–5 February 2021; pp. 575–580. [Google Scholar]
- Fang, W.; Yu, Z.; Chen, Y.; Huang, T.; Masquelier, T.; Tian, Y. Deep Residual Learning in Spiking Neural Networks. In Proceedings of the 34th Conference on Advances in Neural Information Processing Systems, Online, 6–14 December 2021; Curran Associates, Inc.: Red Hook, NY, USA, 2021; Volume 34, pp. 21056–21069. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving Neural Networks by Preventing Co-Adaptation of Feature Detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Ahmadi, N.; Constandinou, T.G.; Bouganis, C.-S. Robust and Accurate Decoding of Hand Kinematics from Entire Spiking Activity Using Deep Learning. J. Neural Eng. 2021, 18, 026011. [Google Scholar] [CrossRef]
- Gilja, V.; Nuyujukian, P.; Chestek, C.A.; Cunningham, J.P.; Yu, B.M.; Fan, J.M.; Churchland, M.M.; Kaufman, M.T.; Kao, J.C.; Ryu, S.I.; et al. A High-Performance Neural Prosthesis Enabled by Control Algorithm Design. Nat. Neurosci. 2012, 15, 1752–1757. [Google Scholar] [CrossRef]
- Wu, W.; Black, M.; Gao, Y.; Serruya, M.; Shaikhouni, A.; Donoghue, J.; Bienenstock, E. Neural Decoding of Cursor Motion Using a Kalman Filter. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2002; Volume 15. [Google Scholar]
- Frontiers|Deep Learning with Spiking Neurons: Opportunities and Challenges. Available online: https://www.frontiersin.org/articles/10.3389/fnins.2018.00774/full (accessed on 2 September 2023).
- Rezk, N.M.; Purnaprajna, M.; Nordström, T.; Ul-Abdin, Z. Recurrent Neural Networks: An Embedded Computing Perspective. IEEE Access 2020, 8, 57967–57996. [Google Scholar] [CrossRef]
- Horowitz, M. 1.1 Computing’s Energy Problem (and What We Can Do about It). In Proceedings of the 2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), San Francisco, CA, USA, 9–13 February 2014; pp. 10–14. [Google Scholar]
- Lü, S.; Zhang, R. Two Efficient Implementation Forms of Unscented Kalman Filter. Control Intell. Syst. 2011, 39, 761–764. [Google Scholar] [CrossRef]
- Golub, M.D.; Yu, B.M.; Schwartz, A.B.; Chase, S.M. Motor Cortical Control of Movement Speed with Implications for Brain-Machine Interface Control. J. Neurophysiol. 2014, 112, 411–429. [Google Scholar] [CrossRef] [PubMed]
- Eshraghian, J.K.; Lammie, C.; Azghadi, M.R.; Lu, W.D. Navigating Local Minima in Quantized Spiking Neural Networks. In Proceedings of the 2022 IEEE 4th International Conference on Artificial Intelligence Circuits and Systems (AICAS), Incheon, Republic of Korea, 13–15 June 2022. [Google Scholar]
- Buhrmester, V.; Münch, D.; Arens, M. Analysis of Explainers of Black Box Deep Neural Networks for Computer Vision: A Survey. arXiv 2019, arXiv:1911.12116. [Google Scholar] [CrossRef]
- Premchand, B.; Toe, K.K.; Wang, C.; Libedinsky, C.; Ang, K.K.; So, R.Q. Information Sparseness in Cortical Microelectrode Channels While Decoding Movement Direction Using an Artificial Neural Network. In Proceedings of the 2022 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Glasgow, UK, 11–15 July 2022; pp. 3534–3537. [Google Scholar]
- Olshausen, B.; Field, D. Sparse Coding of Sensory Inputs. Curr. Opin. Neurobiol. 2004, 14, 481–487. [Google Scholar] [CrossRef]
- Cai, H.; Ao, Z.; Tian, C.; Wu, Z.; Liu, H.; Tchieu, J.; Gu, M.; Mackie, K.; Guo, F. Brain Organoid Reservoir Computing for Artificial Intelligence. Nat. Electron. 2023, 6, 1032–1039. [Google Scholar] [CrossRef]
- Willsey, M.S.; Nason-Tomaszewski, S.R.; Ensel, S.R.; Temmar, H.; Mender, M.J.; Costello, J.T.; Patil, P.G.; Chestek, C.A. Real-Time Brain-Machine Interface in Non-Human Primates Achieves High-Velocity Prosthetic Finger Movements Using a Shallow Feedforward Neural Network Decoder. Nat. Commun. 2022, 13, 6899. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Name | Dropout | Learning Rate | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| swSNN | 0.047 | 0.014 | 0.158 | 0.1 | 0.1 | 0.216 | 0.276 | 0.239 | 0.427 | 0.009 |
| swSNN-SLSTM | 0.014 | 0.147 | 0.218 | 0.1 | 0.1 | 0.208 | 0.203 | N/A | 0.518 | 0.007 |
| memSNN | 0.103 | 0.014 | 0.158 | 0.1 | 0.2 | 0.192 | 0.276 | 0.239 | 0.427 | 0.009 |
| memSNN-SLSTM | 0.103 | 0.149 | 0.025 | 0.1 | 0.26 | 0.134 | 0.193 | N/A | 0.496 | 0.006 |
| Models | LIF Spikes | SLSTM Spikes | MAC | ADD | Total Operations |
|---|---|---|---|---|---|
| UKF5 | 0 | 0 | 1.74 × 107 | 0 | 1.74 × 107 |
| LSTM | 0 | 0 | 5.25 × 105 | 0 | 5.25 × 105 |
| swSNN | 1.89 × 105 | 0 | 900 | 1.89 × 105 | 6.4 × 104 |
| memSNN | 6.7 × 104 | 0 | 300 | 6.7 × 104 | 2.7 × 104 |
| swSNN-SLSTM | 2.4 × 105 | 1.4 × 104 | 1000 | 2.96 × 105 | 1.0 × 105 |
| memSNN-SLSTM | 5.3 × 104 | 1.4 × 104 | 400 | 1.09 × 105 | 3.7 × 104 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
McMillan, K.; So, R.Q.; Libedinsky, C.; Ang, K.K.; Premchand, B. Spike-Weighted Spiking Neural Network with Spiking Long Short-Term Memory: A Biomimetic Approach to Decoding Brain Signals. Algorithms 2024, 17, 156. https://doi.org/10.3390/a17040156
McMillan K, So RQ, Libedinsky C, Ang KK, Premchand B. Spike-Weighted Spiking Neural Network with Spiking Long Short-Term Memory: A Biomimetic Approach to Decoding Brain Signals. Algorithms. 2024; 17(4):156. https://doi.org/10.3390/a17040156
Chicago/Turabian StyleMcMillan, Kyle, Rosa Qiyue So, Camilo Libedinsky, Kai Keng Ang, and Brian Premchand. 2024. "Spike-Weighted Spiking Neural Network with Spiking Long Short-Term Memory: A Biomimetic Approach to Decoding Brain Signals" Algorithms 17, no. 4: 156. https://doi.org/10.3390/a17040156
APA StyleMcMillan, K., So, R. Q., Libedinsky, C., Ang, K. K., & Premchand, B. (2024). Spike-Weighted Spiking Neural Network with Spiking Long Short-Term Memory: A Biomimetic Approach to Decoding Brain Signals. Algorithms, 17(4), 156. https://doi.org/10.3390/a17040156