
Security and Ownership in User-Defined Data Meshes


Abstract
:1. Introduction
2. Technical Background
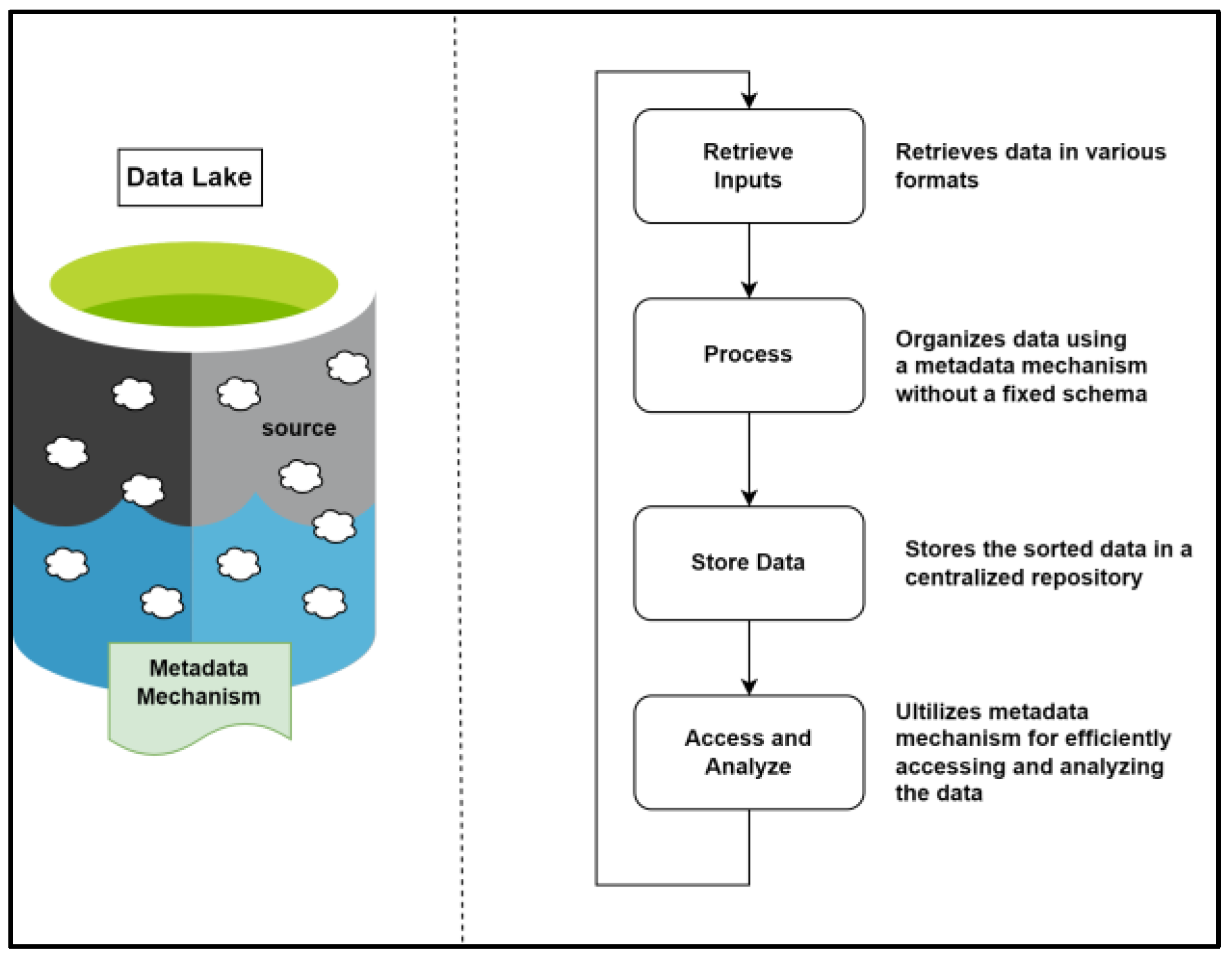
2.1. Understanding Data Lakes and Data Meshes
2.2. Understanding Blockchain and NFTs
3. Related Research
4. A Framework for Supporting the Transfer of Ownership in Data Meshes
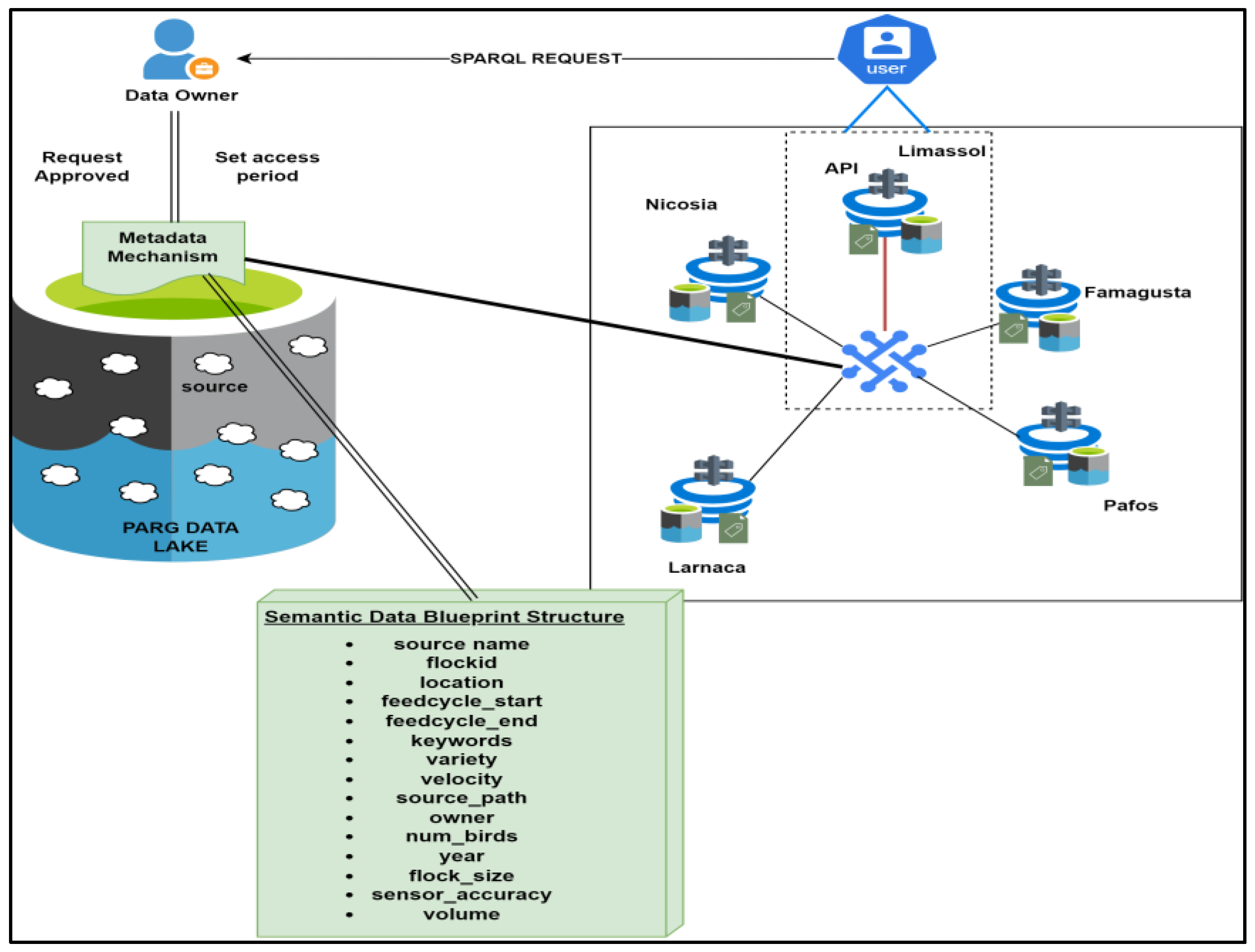
4.1. Semantically Enriched Creation of Data Lake Architecture and Data Mesh Products
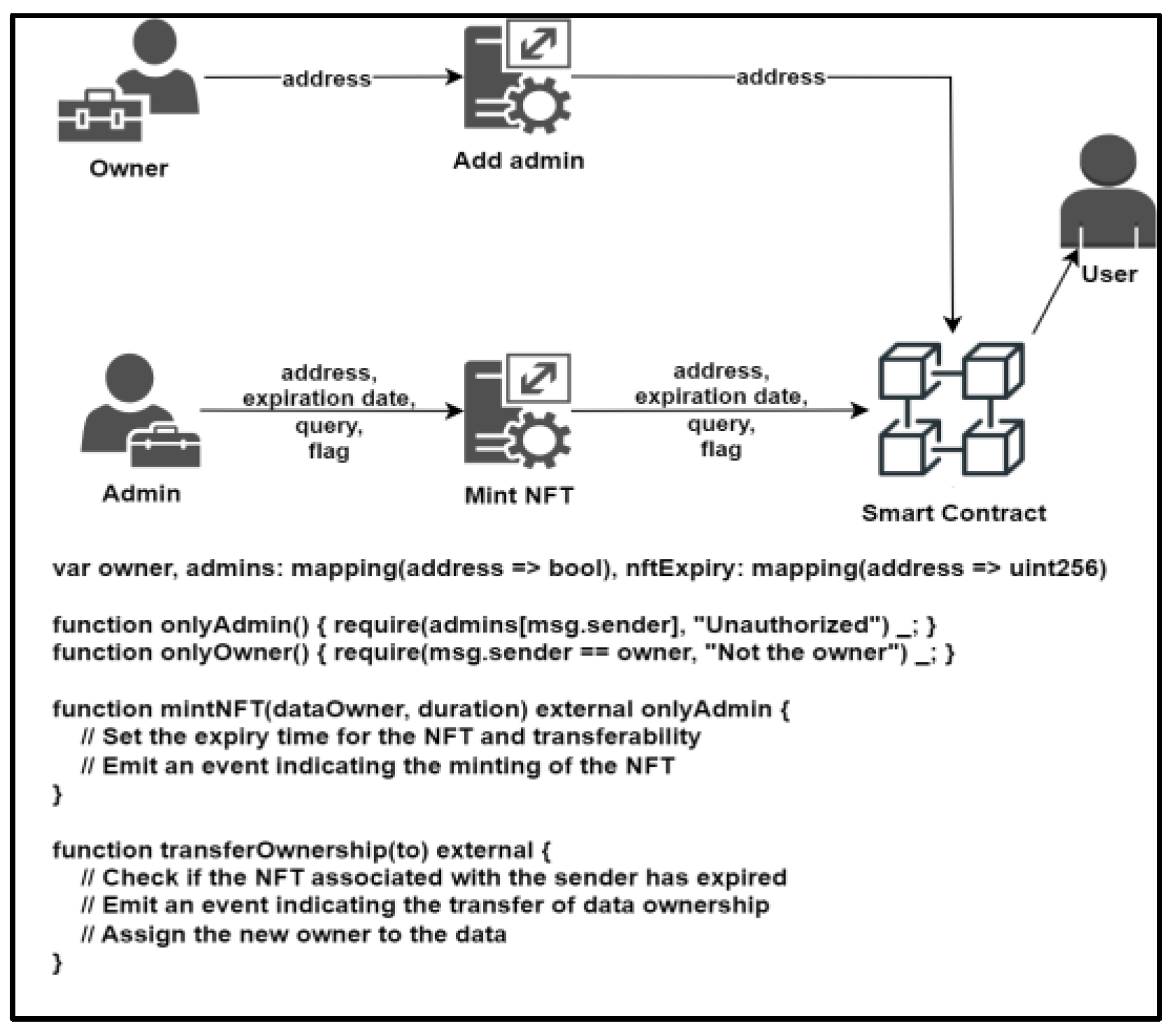
- The owner of the contract can add an administrator on the contract by calling the addAmin() function inserting an EVM-compatible address. Once an administrator is created, (s)he obtains access through her/his address to certain admin-only functions on the contract.
- An administrator can mint an NFT by executing the safeMint() function, providing the address of the recipient, an expiration date in UNIX epoch time, the query that is associated with the NFT, and its access level. If the value of the access level is set to 1, then the NFT grants read-only access to its new owner and the NFT is non-transferable, while, if the value is set to 2, the owner of the NFT, besides read access, is also able to transfer access, and thus can transfer the ownership of the NFT to a different user. At any given time, the current owner of the NFT can access and read the data.
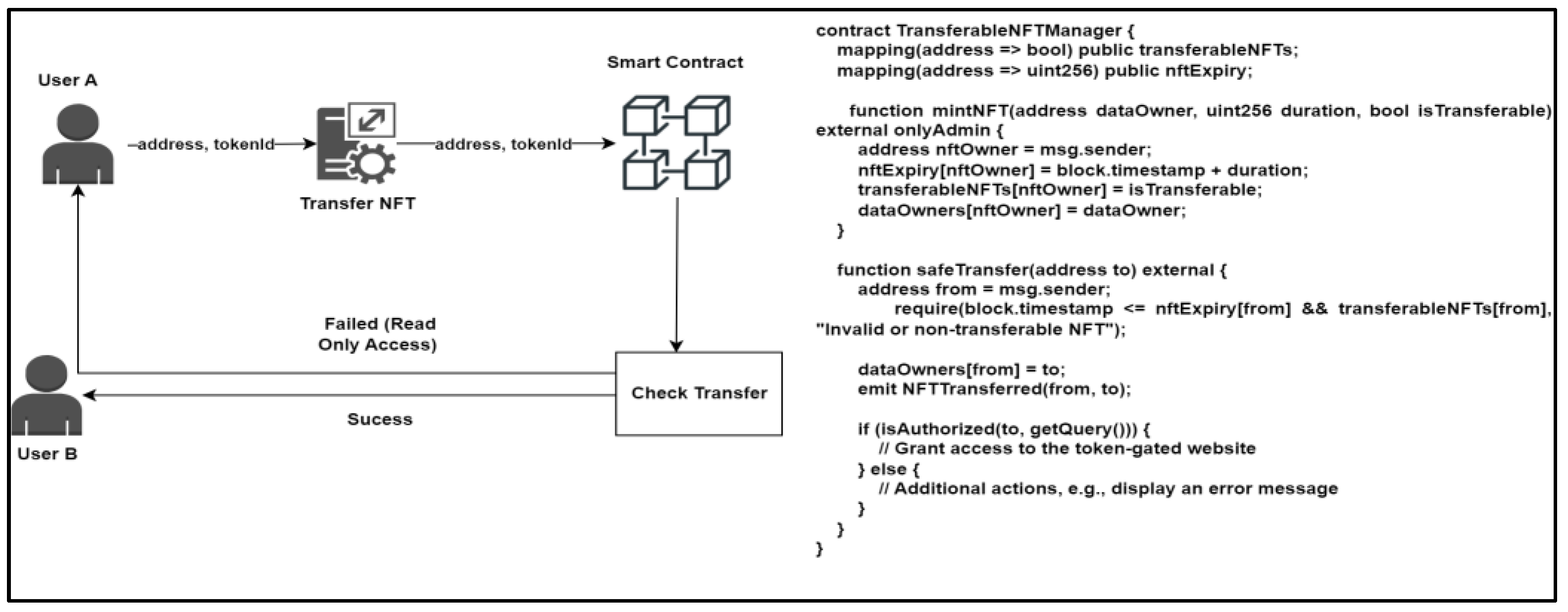
4.2. Smart Contract Architecture
5. Framework Demonstration through a Real-World Case Study
5.1. The PARADISIOTIS Group (PARG) Factory Case Study
5.2. Use Case Scenarios
5.2.1. Scenario 1—Minting
| Algorithm 1: First token process parameters |
| 1: Date of Expiration: 1706094000 (Wednesday, 24 January 2024 11:00:00 UTC) |
| 2: Query: |
| 3: PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> (accessed on 2 March 2024) |
| 4: PREFIX ex: <http://example.org/> |
| 5: SELECT ?location ?sourcePath |
| 6: WHERE { ?source rdf:type ex:Description; ex:location “Limassol”; } |
| 7: Transferrable: NO (flag is set to 1) |
| Algorithm 2: Second token process parameters |
| 1: Date of Expiration: 1706095000 (Wednesday, 24 January 2024 11:16:40 UTC) |
| 2: Query: |
| 3: PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> (accessed on 2 March 2024) |
| 4: PREFIX ex: <http://example.org/> |
| 5: SELECT ?location ?sourcePath |
| 6: WHERE { ?source rdf:type ex:Description; ex:location “Limassol”; } |
| 7: Transferrable: YES (flag is set to 2) |
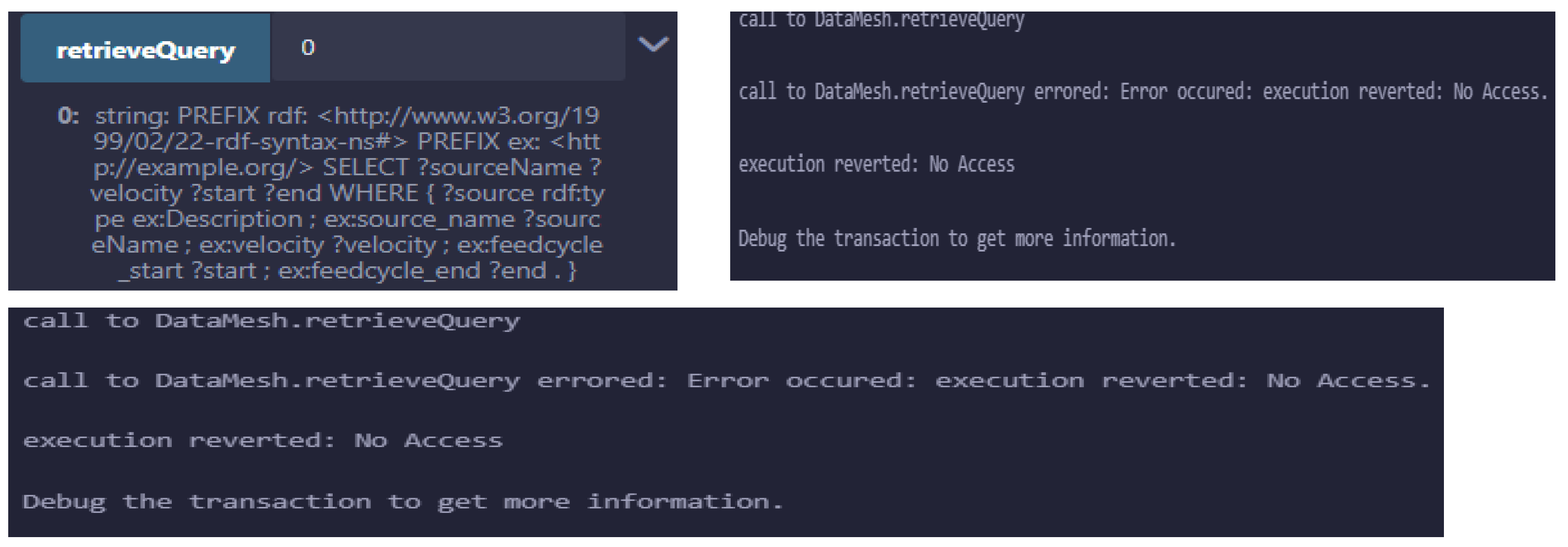
5.2.2. Scenario 2—Retrieving Data
5.2.3. Scenario 3—Applying Transfer Restrictions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gupta, S.; Kar, A.K.; Baabdullah, A.M.; Al-Khowaiter, W.A.A. Big Data with Cognitive Computing: A Review for the Future. Int. J. Inf. Manag. 2018, 42, 78–89. [Google Scholar] [CrossRef]
- Blazquez, D.; Domenech, J. Big Data Sources and Methods for Social and Economic Analyses. Technol. Forecast. Soc. Chang. 2017, 130, 99–113. [Google Scholar] [CrossRef]
- Al-Sai, Z.A.; Husin, M.H.; Syed-Mohamad, S.M.; Abdin, R.M.S.; Damer, N.A.; Abualigah, L.; Gandomi, A.H. Explore Big Data Analytics Applications and Opportunities: A Review. Big Data Cogn. Comput. 2022, 6, 157. [Google Scholar] [CrossRef]
- Khan, N.; Alsaqer, M.; Shah, H.; Badsha, G.; Abbasi, A.A.; Salehian, S. The 10 Vs, Issues and Challenges of Big Data. In Proceedings of the 2018 International Conference on Big Data and Education, New York, NY, USA, 9–11 March 2018. [Google Scholar] [CrossRef]
- Khine, P.P.; Wang, Z. A Review of Polyglot Persistence in the Big Data World. Information 2019, 10, 141. [Google Scholar] [CrossRef]
- Shahid, A.; Nguyen, T.-A.N.; Kechadi, M.-T. Big Data Warehouse for Healthcare-sensitive Data Applications. Sensors 2021, 21, 2353. [Google Scholar] [CrossRef] [PubMed]
- Driessen, S.; den Heuvel, W.J.V.; Monsieur, G. Promote: A Data Product Model Template for Data Meshes. In Proceedings of the International Conference on Conceptual Modeling, Lisbon, Portugal, 6–9 November 2023; Springer Nature: Cham, Switzerland, 2023; pp. 125–142. [Google Scholar]
- Kunigk, J.; Buss, I.; Wilkinson, P.; George, L. Architecting Modern Data Platforms: A Guide to Enterprise Hadoop at Scale; O’Reilly Media: Sebastopol, CA, USA, 2018. [Google Scholar]
- Derakhshannia, M.; Gervet, C.; Hajj-Hassan, H.; Laurent, A.; Martin, A. Data Lake Governance: Towards a Systemic and Natural Ecosystem Analogy. Future Internet 2020, 12, 126. [Google Scholar] [CrossRef]
- Pingos, M.; Andreou, A. A Data Lake Metadata Enrichment Mechanism via Semantic Blueprints. In Proceedings of the 17th International Conference on Evaluation of Novel Approaches to Software Engineering, Virtual, 25–26 April 2022; pp. 186–196. [Google Scholar] [CrossRef]
- Pingos, M.; Andreou, A.S. Exploiting Metadata Semantics in Data Lakes Using Blueprints. In Proceedings of the International Conference on Evaluation of Novel Approaches to Software Engineering, Virtual, 25–26 April 2022; Springer Nature: Cham, Switzerland, 2022; pp. 220–242. [Google Scholar] [CrossRef]
- Pingos, M.; Christodoulou, P.; Andreou, A. DLMetaChain: An IoT Data Lake Architecture Based on the Blockchain. In Proceedings of the 13th International Conference on Information, Intelligence, Systems & Applications (IISA), Corfu, Greece, 18–20 July 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Beheshti, A.; Benatallah, B.; Nouri, R.; Tabebordbar, A. CoreKG: A knowledge lake service. Proc. VLDB Endow. 2022, 11, 1942–1945. [Google Scholar] [CrossRef]
- Dehghani, Z. How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh. Available online: https://martinfowler.com/articles/data-monolith-to-mesh.html (accessed on 10 January 2024).
- Dehghani, Z. Data Mesh Principles and Logical Architecture. Available online: https://martinfowler.com/articles/data-mesh-principles.html (accessed on 10 January 2024).
- Viriyasitavat, W.; Da Xu, L.; Bi, Z.; Hoonsopon, D. Blockchain technology for applications in internet of things—Mapping from system design perspective. IEEE Internet Things J. 2019, 6, 8155–8168. [Google Scholar] [CrossRef]
- Alam, T. Blockchain-based Internet of Things: Review, Current Trends, Applications, and Future Challenges. Computers 2022, 12, 6. [Google Scholar] [CrossRef]
- Di Angelo, M.; Salzer, G. Tokens, types, and standards: Identification and utilization in Ethereum. In Proceedings of the 2020 IEEE International Conference on Decentralized Applications and Infrastructures (DAPPS), Oxford, UK, 3–6 August 2020; pp. 1–10. [Google Scholar]
- Yildiz, H.; Küpper, A.; Thatmann, D.; Göndör, S.; Herbke, P. Towards Interoperable Self-Sovereign Identities. IEEE Access 2023, 11, 114080–114116. [Google Scholar] [CrossRef]
- Rehman, W.; e Zainab, H.; Imran, J.; Bawany, N.Z. NFTs: Applications and challenges. In Proceedings of the 2021 22nd International Arab Conference on Information Technology (ACIT), Muscat, Oman, 21–23 December 2021; pp. 1–7. [Google Scholar]
- Phuc, N.T.; Khanh, H.V.; Khoa, T.D.; Khiem, H.G.; Huong, H.L.; Ngan, N.T.; Triet, N.M.; Kha, N.H.; Anh, N.T.; Bang, L.K.; et al. An Enhanced CoD System Leveraging Blockchain, Smart Contracts, and NFTs: A New Approach for Trustless Transactions. Int. J. Adv. Comput. Sci. Appl. 2023, 14. [Google Scholar] [CrossRef]
- Shae, Z.Y.; Tsai, J.J. On the Design of Medical Data Ecosystem for Improving Healthcare Research and Commercial Incentive. In Proceedings of the IEEE 3rd International Conference on Cognitive Machine Intelligence (CogMI), Atlanta, GA, USA, 13–15 December 2021. [Google Scholar]
- Borovits, N.; Kumara, I.; Tamburri, D.A.; Van Den Heuvel, W.J. Privacy Engineering in the Data Mesh: Towards a Decentralized Data Privacy Governance Framework. In Proceedings of the International Conference on Service-Oriented Computing, Rome, Italy, 28 November–1 December 2023; Springer Nature: Singapore, 2023; pp. 265–276. [Google Scholar]
- Bode, J.; Kühl, N.; Kreuzberger, D.; Hirschl, S.; Holtmann, C. Towards Avoiding the Data Mess: Industry Insights from Data Mesh Implementations. arXiv 2023, arXiv:2302.01713. [Google Scholar]
- Hummel, P.; Braun, M.; Dabrock, P. Own data? Ethical reflections on data ownership. Philos. Technol. 2021, 34, 545–572. [Google Scholar] [CrossRef]
- Dorota, O. Securing Stakeholder Buy-In for Data Mesh: A Strategic Guide for Moving Forward with Data Mesh Implementation. Available online: https://nexocode.com/blog/posts/securing-data-mesh-stakeholder-buy-in/ (accessed on 3 March 2024).
- Dolhopolov, A.; Castelltort, A.; Laurent, A. Implementing a Blockchain-Powered Metadata Catalog in Data Mesh Architecture. In Proceedings of the International Congress on Blockchain and Applications, Guimaraes, Portugal, 12–14 July 2023; Springer Nature: Cham, Switzerland, 2023; pp. 348–360. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pingos, M.; Christodoulou, P.; Andreou, A.S. Security and Ownership in User-Defined Data Meshes. Algorithms 2024, 17, 169. https://doi.org/10.3390/a17040169
Pingos M, Christodoulou P, Andreou AS. Security and Ownership in User-Defined Data Meshes. Algorithms. 2024; 17(4):169. https://doi.org/10.3390/a17040169
Chicago/Turabian StylePingos, Michalis, Panayiotis Christodoulou, and Andreas S. Andreou. 2024. "Security and Ownership in User-Defined Data Meshes" Algorithms 17, no. 4: 169. https://doi.org/10.3390/a17040169
APA StylePingos, M., Christodoulou, P., & Andreou, A. S. (2024). Security and Ownership in User-Defined Data Meshes. Algorithms, 17(4), 169. https://doi.org/10.3390/a17040169