1. Introduction
Important techniques for mapping and monitoring Land Use and Land Cover (LULC) changes are based on Geographic Information Systems (GIS) and remote sensing products obtained by orbital platforms. In recent decades, remote sensing has become an important tool to monitor the Earth’s natural resources, since it provides data over large geographical extensions and in a temporal frequency that allows for the monitoring of the processes that occur in these areas [
1].
Remote sensing images have greatly expanded the horizons of their applications in recent years due to the improvement of several factors such as number of satellites, sensor quality (radiometric and spatial resolutions), computational capacity, and higher availability of images freely distributed, allowing us to observe the Earth’s surface in more detail and with higher frequency. The integration of these images with other spatial data sources (GIS) and the Geographic Database (GD) has significantly expanded the possibilities of spatial analysis of the Earth’s surface data [
2].
The mapping and monitoring of LULC are of great importance and there is an effort from the scientific community to provide and improve the accuracy of these products [
3,
4,
5]. These studies aim to understand changes due to natural and anthropic factors [
6,
7] and improve efficiency in the elaboration of natural resource management plans [
8,
9], as well as the delimitation of priority areas for conservation [
10]. LULC classification has a great impact on ecosystem management and has become an important base for much research into environmental hot topics worldwide [
11,
12,
13,
14].
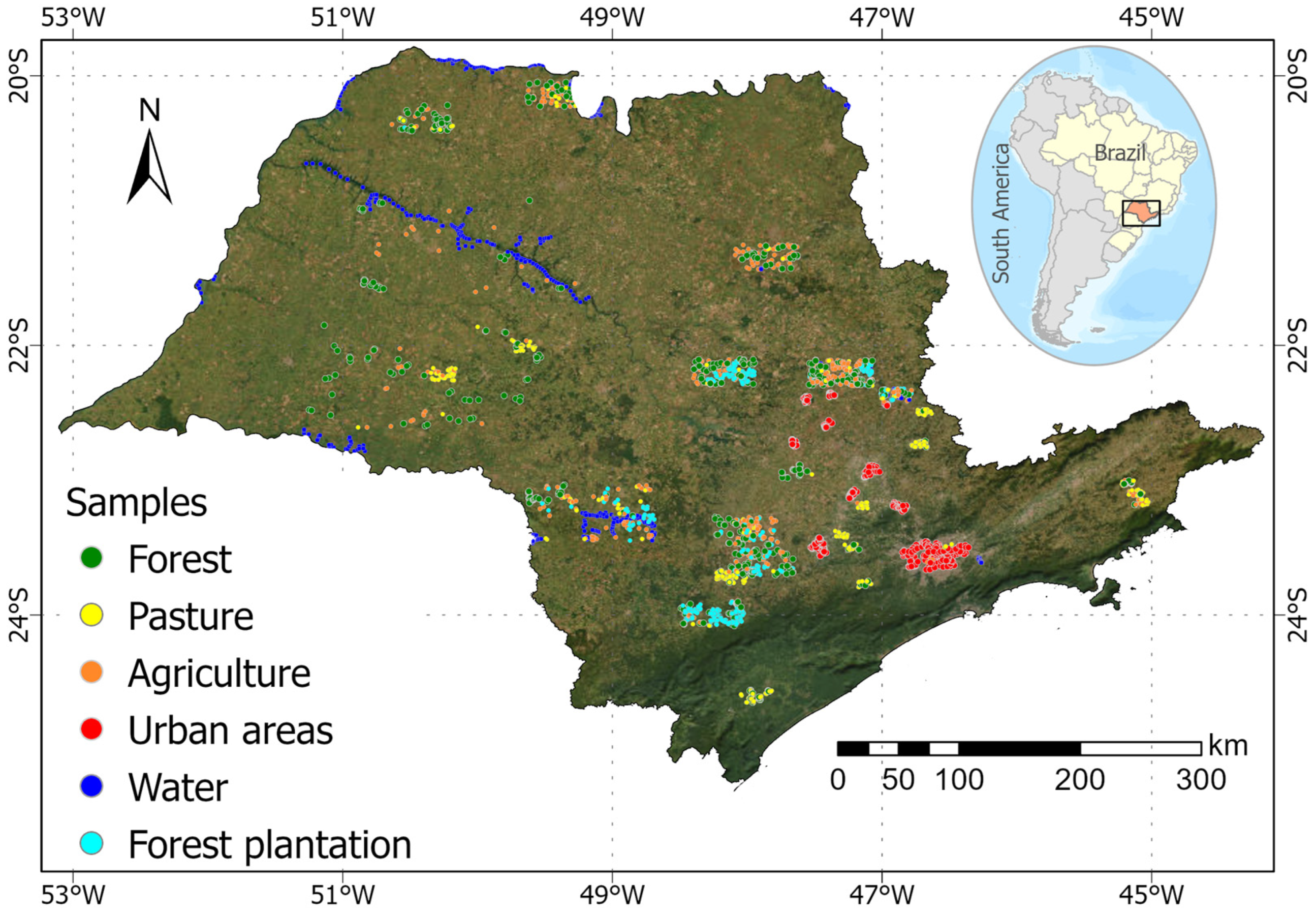
In Brazil, the state of São Paulo is widely known as the largest national economic and industrial hub. In addition, it is a global leader in agribusiness, accounting for 13.5% of Brazilian crop production, while maintaining the largest number of Atlantic forest remnants [
15,
16]. The natural vegetation of the São Paulo State is mainly defined by the Atlantic Forest and Cerrado biomes, which have been massively removed since 1500 but have increased again in the last two centuries [
16]. According to data from the Secretary of State for the Environment and Forest Inventory of São Paulo, it is estimated that São Paulo state has 24% remaining of the native vegetation of the Atlantic Forest and only 17% of the native vegetation of the Cerrado [
16,
17].
Long-term LULC data for the state of São Paulo and consequently those to quantify changes are important to understand current patterns of LULC and to improve planning and management of state resources and governance [
3,
18]. In addition, in order to understand the patterns and phytophysionomic diversity of the remaining vegetation, it is paramount to identify historical patterns and which factors, including relief shapes and topography, it might be related. The removal of native vegetation, mainly for agricultural purposes, has well-known alteration patterns, as well as the relief, water availability, and soil fertility, among other factors. Urban expansion also shows characteristic expansion patterns, with future expansion arcs in regions that are already urbanized.
In this way, understanding the historical characteristics of each LULC and linking them with the spectral and temporal responses of satellite images on available machine learning methods are the key to gathering reliable information for LULC management on different scales. On the other hand, there are many classification algorithms available in the literature for LULC mapping [
19], from low computational costs such as machine learning [
20] to deep learning [
20,
21]. Among them, the Random Forest (RF) algorithm [
22] has been widely used in the context of LULC classification methods, favored for its robustness, the relatively low cost of the computational process, and because it does not require many parameters and data to obtain high-accuracy results [
23]. RF excels at handling complex datasets, mitigating overfitting with higher accuracy compared to other methods (e.g., Support Vector Machines and Artificial Neural Networks [
24]), and allows the use of a variety of datasets (e.g., vegetation indexes, fraction images, and spectral bands) to improve LULC classification. This algorithm does not consider a priori statistic distribution and it also combines a set of features randomly to create trees with bootstrapped samples of the training data [
25], also presenting the estimated importance of the variables for classification [
26,
27,
28]. Then, many decision trees are generated, and an unweighted selection is used to assign an unknown pixel to a specific class. With the advance of cloud computing platforms like Google Earth Engine (GEE) large datasets can be processed [
13,
29], especially with the addition of algorithms such as RF in the platform. For instance, large-scale data at state, country, or continental levels can have great results after a short processing time to combine the multiple datasets available on the GEE platform [
30].
The Brazilian Annual Land Use and Land Cover (LULC) Mapping Project (MapBiomas) initiative was formed in 2015 to develop an annual time series of the Brazil’s LULC maps from 1985 to present with a spatial resolution of 30 m. The project is organized by biomes (such as the Amazon, Atlantic Forest, Caatinga, Cerrado, Pampa, and Pantanal) and cross-cutting themes (such as pasture, agriculture, forest plantation, coastal zone, mining, and urban area). The imagery dataset used in the MapBiomas project for collections 1 to 7 is composed by the Landsat Thematic Mapper (TM), Enhanced Thematic Mapper Plus (ETM+), and the Operational Land Imager and Thermal Infrared Sensor (OLI-TIRS) sensors onboard of Landsat 5, Landsat 7 and Landsat 8, respectively, due to the long-term data available at medium spatial resolution (
https://mapbiomas-br-site.s3.amazonaws.com/ATBD_Collection_7_v2.pdf, accessed on 10 June 2023). Despite MapBiomas being widely used in Brazil, its complex data pre-processing and algorithms may hinder its full reproducibility in other areas. In contrast, the proposed method introduces a novel approach that enhances reproducibility and accuracy. By selecting images based on the spectral and temporal characteristics of the LULC classes and sorting them according to complexity, from the most uniform to the most complex, the classification process becomes more systematic and controlled. Classifying one LULC class at a time in that order allows for a more focused and accurate classification, reducing potential errors and ensuring better mapping results. This method promotes transparency and replicability, making it easier for researchers to apply the same approach to different regions with similar characteristics.
Therefore, this work aims to map the LULC in the state of São Paulo using the Landsat-8 Operational Land Imager (OLI) images acquired mainly during the year 2020, based on the classification of individual LULC classes: forest, forest plantation, pasture, agriculture, urban areas, and water. For forest plantation exclusively we also used images from Landsat-8 OLI from the years 2013 to 2020 due to its rotation age [
31]. First, we identified the individual classes and then we highlighted these classes by deriving synthetic images such as spectral indices and fraction images. Finally, we applied the RF algorithm, available on the GEE platform, to classify each LULC class separately, using the best set of visually selected images, and then compose the LULC map of São Paulo State.
3. Results
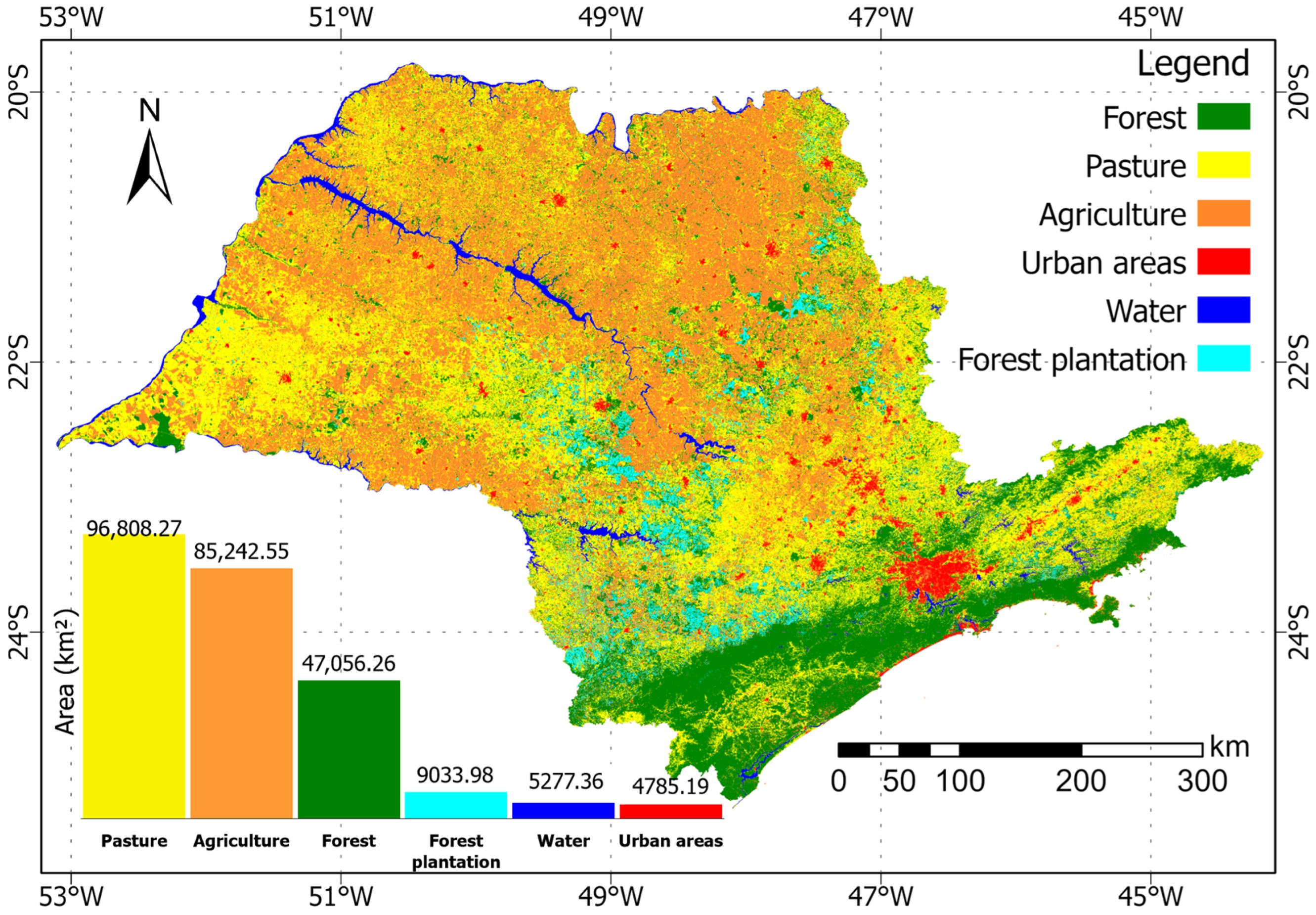
Figure 7 shows the LULC map of São Paulo State for the year 2020 produced by the method proposed in this work. We observed that most of the forest areas are in the eastern region of São Paulo, mostly linked to the steeper slopes. It covers 47,056 km
2 (18.96%), and most of it is in the Atlantic Rain Forest biome. Only small and sparse patches of Cerrado forests still remain as natural vegetation, mostly located in protected areas. Pasture is the class with the largest proportion of the study area, representing 96,808 km
2 (39%) of the total area. Pastures are found throughout the state, but the east and west are the two most representative regions. The agriculture class comprised 85,243 km
2 (34.34%), located around the Tiete river (the big river at the center), and the southern and central northern parts of São Paulo State. Forest plantation covers 9034 km
2 (3.64%) and is particularly located in the central south region. The São Paulo metropolitan area is the largest urban area in South America and the state has 4785 km
2 (1.93%) of its area classified as urban. Almost the same amount (5277 km
2) is covered by water, representing 2.12% of the state’s area.
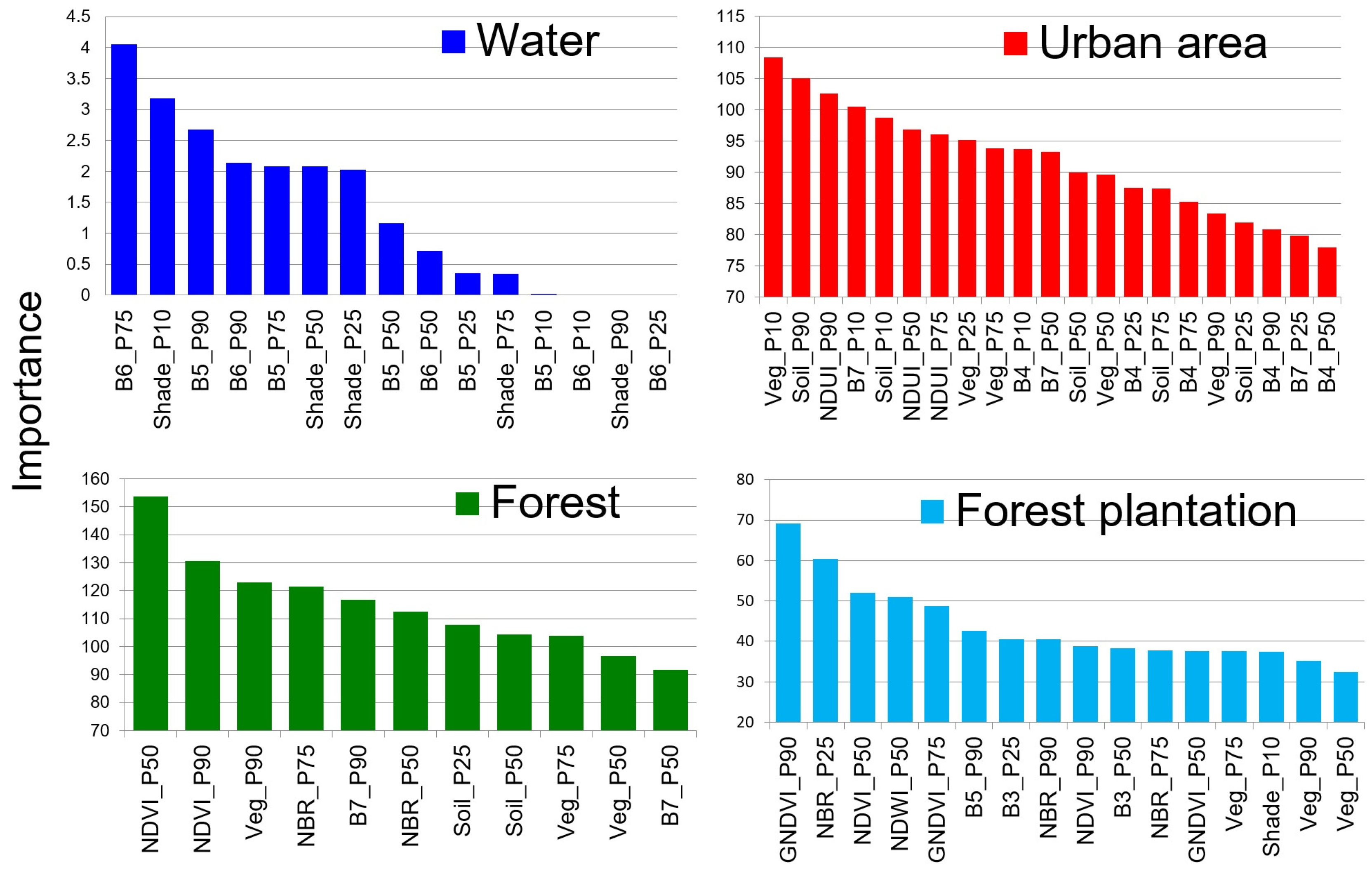
The importance variables obtained from the RF algorithm can be used to identify which variables were most important for classifying each class after our visual pre-selection. For the water class, band 6 (SWIR), shade fraction, and band 5 (NIR) in specific percentiles represented the three most important variables for RF with the input data used (
Figure 8). The urban area class’s three most important variables were based on image fractions (vegetation and soil) and spectral index (NDUI). The forest class had as its most important input the NDVI, vegetation fraction, and NBR index. For the forest plantation class, the spectral indices (GNDVI, NBR, and NDVI) presented a higher importance. The importance variables for the agriculture class were not obtained because the class was classified by a combination of cultures. Also, there are no importance variables for pasture since it was considered the remaining area of São Paulo State after classifying the other LULCs.
Table 5 shows the confusion matrix of the LULC classification, based on the collected samples, to evaluate the accuracy of the classification (prediction). The user and producer accuracies for each LULC class varied from 77% to 100% and 84% to 98%, respectively. The kappa value was 0.891 and the overall accuracy was 89.10%. The agriculture class presented the highest omission error since it is often misclassified as pasture and forest plantation due to the spectral similarities of these classes depending on the phenological response, and their spatial attributes (e.g., landscape fragmentation). On the other hand, the highest commission error was presented in the pasture class, which is often misclassified with other classes due to its heterogeneity, and temporal and spatial complexities.
The confusion matrix for the MapBiomas LULC classification was cross-validated with the same collected samples shown in
Table 6. Although this data is already published and has an overall accuracy for level 2 data of 87.4% [
15,
18], we used the same collected samples to validate and resemble our results with the same reference data. The user and producer accuracies for each mapped class varied from 78% to 100% and 79% to 100%, respectively. The kappa value was 0.926 and the overall accuracy was 93.90%, based on the validation using our collected samples. For this data, the highest errors are in the agriculture and pasture classes (
Table 6).
In this manner, we performed the confusion matrix using the same sample points to evaluate the agreement of our result with the MapBiomas product that uses more a complex method (
Table 7). The user and producer accuracies for each mapped class varied from 62% to 100% and 63% to 98%, respectively. The kappa value was 0.83 and the overall accuracy was 85.47% showing an excellent agreement [
52]. Again, the agriculture class presented the highest omission error, and was often misclassified as pasture, forest plantation, and forest. For the commission error here, the pasture also presented the highest error.
4. Discussion
The aim of this study was to generate a LULC map for the state of São Paulo for the year 2020, based on 13 variables and their respective attributes derived from remote sensing indices, fraction images, and spectral bands used in RF models. The novelty of the proposed method is the performance of a preliminary analysis to select the features that enhance the individual LULC classes in the OLI images. In addition, it defines the period of production of the cloud-free image mosaics to be processed. Then, the LULC classes were classified individually using specific spectral bands, spectral indices, and fraction images. Another factor that was considered was the temporal resolution. For example, for agriculture classification the image mosaic was composed of images acquired during the rainy season; for forest and forest plantation classifications, the image mosaic was composed of images acquired during the dry season. Multiannual mosaics were also used for the forest plantation class, taking into account the forest rotation age; we used mosaics from 2013 to 2020 [
31]. These pre-processing steps highlighted the LULC classes for the classification step. In this study we used an RF classifier that is available in the GEE platform. RF is commonly used for LULC classification, due to its efficiency in achieving higher accuracy compared to other algorithms, and as the cost of the computational process is relatively low and does not require many parameters or much data to obtain high-accuracy results [
23,
53].
Classification errors between the agriculture and pasture classes occur mainly in areas of managed pasture. The rural producers who aim to increase the amount of food for cattle invest in pasture management destined for animal feeding [
54,
55]. In this sense, the vegetation indices and spectral responses from the satellite images could be similar between pasture and agricultural areas, with a significant gain in vegetation vigor at the beginning of the rains and a sudden loss of vegetation vigor at the end of the rainy season. For the selection of training points for the agriculture class, we selected images that consider the agriculture patterns based on the development of crops throughout the time series. In São Paulo State, the main crops are soybeans, sugarcane, corn, and beans [
15,
48,
49].
Classification errors between agriculture and forest plantation classes occurred, in most cases, in areas with teak (Tectona grandis) and rubber tree (Hevea brasiliensis) plantations. These species lose their leaves during the dry period leading to a drop in the vegetation indices and consequently the spectral response is influenced by the soil spectral mixture, which can lead to confusion in the classifier. The RF classifier interprets this behavior as the beginning and end of a cycle, but it is the seasonality of the vegetation itself. The reference dataset used to assess the mapping accuracy was collected based on the visual interpretation of Sentinel-2 color composites and ancillary spectral indices.
The results obtained by the proposed method were compared to the existing LULC products from MapBiomas, which performs a more complex classification procedure [
15,
18]. In general, MapBiomas classification presented better results (
Table 6) compared to our method (
Table 5). However, our proposed method presented lower omission error for the pasture class (84%) compared to MapBiomas (79%) and lower inclusion error for the agriculture class (84%) in comparison (78%). The differences observed between the results of the proposed method and the MapBiomas project can be attributed to several factors, for example, the classification algorithm, the variables and training dataset used in the classification process, and the data processing are some of the main factors that impact the classification results between the LULC maps analyzed. Our proposed method was trained and applied specifically for the state of São Paulo and achieved an overall accuracy of 89% based on the 13 variables and their respective attributes used in the classification. The pre-selection of variables can reduce data volume without losing important information, supporting the discrimination of classes and also improving classification accuracy. This study also analyzed the importance of the variables in the RF models, however, further investigation is necessary to understand the characteristics of each class of LULC in the study area.





 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}