1. Introduction
Fire is currently one of the most common and widespread major disasters that threaten the security and development of societies, and statistics from the European Forest Fire Information System (EFFIS) show that in 2021, forest fires covered 4260 hectares in Spain, more than 150,000 hectares in Italy, and 93,600 hectares in Greece [
1,
2,
3]. To mitigate the risks associated with fires, people have proposed numerous detection methods to minimize the damage caused by such accidents. These fire detection approaches can be broadly categorized into traditional fire alarm systems and visual sensor-based detection methods.
Traditional fire alarm detection systems commonly use sensors such as smoke, heat, and light detectors to detect fires. However, these systems often require human intervention to confirm fire information when triggering alarms. Due to the rapid spread and destructive nature of fires, as well as factors such as distance, affecting sensor performance, there can be delays in detection, leading to missed opportunities for early suppression [
4,
5,
6]. To overcome these limitations, researchers have explored several visual sensor-based detection methods. Initially, techniques were widely used to distinguish fire from the background and identify fire pixels. Various color spaces, including HSI (Hue, Saturation, Intensity) [
7], YCbCr [
8], and RGB (Red, Green, Blue) [
9,
10] have been utilized to represent fire pixels. However, these methods often struggle with accurately in detecting fire because they are highly sensitive to changes in lighting and it is challenging to precisely define the color range of fire pixels. To address these limitations, researchers have explored more robust vision-based approaches, which not only consider color but also incorporate additional features like texture and motion. Despite these advancements, one of the major challenges faced by vision-based detection methods is precisely identifying and analyzing the leading edge of surface fires, which denotes the boundary where the fire propagates across the ground [
11] due to the irregular shape, size, and complex background interference [
12]. In the early stages, Qiu et al. [
13] proposed a novel algorithm to clearly and continuously define the edges of flames and fire points. Experimental results obtained in the laboratory using various flame images and video frames demonstrated the effectiveness and robustness of the algorithm. However, further evaluation of the algorithm’s performance in real-life fire detection scenarios was not conducted. Chino et al. [
14] introduced “BoWFire” (Best of Both Worlds Fire detection), a method for fire detection that merges color and texture features to minimize false positives [
15]. Similarly, Jamali et al. [
16] utilized this combination of color and texture features to detect fire. Celik et al. [
17] proposed a real-time fire detector that combines foreground object information with statistical information on colored fire pixels. They then refined the classification of fire pixels using a general statistical model, achieving a final correct detection rate of 98.89%. Byoung et al. [
18] employed fuzzy finite automaton based on visual feature probability density functions to detect fire and non-fire videos. Their method outperformed other approaches tested in the experiment in terms of performance.
With the development of artificial intelligence in the field of computer vision, deep learning [
19] became a mainstream approach as soon as it appeared, with the advantage of automatically extracting the required features, and it has been used to analyze and extract information from images taken by drones [
20,
21,
22,
23,
24], autonomous vehicles [
25], pedestrian detectors [
26], and video surveillance equipment [
27,
28]. In 1998, Lecun first introduced LeNet [
29], which utilizes convolutional neural networks (CNNs). LeNet employs weight sharing to reduce the computational burden of neural networks, significantly advancing the application of deep learning in image recognition. Gonzalez et al. [
30] introduced the SFEwANSD (Simple Feature Extraction with FCN AlexNet, Single Deconvolution) technique for monitoring fires using UAVs (Unmanned Aerial Vehicles). This method utilizes two convolutional neural networks, namely AlexNet [
31] and a basic CNN, to effectively identify fire features. Muhammad et al. [
32] proposed an energy-efficient CNN approach using the SqueezeNet [
33] model for fire detection and localization in closed-circuit television (CCTV) networks. However, CNNs have their limitations. During the backpropagation process, they often suffer from slow parameter updates, convergence to local optima, information loss in pooling layers, and unclear interpretation of feature extraction, among other issues. The Transformer model [
34], initially proposed by the Google team in 2017, replaces the convolutional neural network components with self-attention modules. This model adopts multiple attention heads to process and capture different input data features, thereby enhancing feature extraction capabilities. However, Transformer has a high level of computational complexity in image processing. Therefore, the Microsoft team proposed Swin Transformer [
35], which divides the image into multiple uniformly sized windows and limits the computation of Transformer within the windows to reduce computational load. As the depth and complexity of models have increased, segmentation accuracy has comprehensively surpassed that of traditional methods such as machine learning to become mainstream. Many scholars have applied deep learning methods to fire detection, and various deep learning models have been applied to tasks in different fields. Jadon et al. [
36] constructed a lightweight neural network, FireNet, which occupies only 7.45M of disk space, and deployed it on Raspberry Pi 3B [
37] embedded devices to replace conventional physical sensors. It can stably operate at a frame rate of 24 frames per second and achieved an accuracy of over 93% on experimental datasets.
Although significant achievements have been made in fire detection using deep learning technology, there still exists a considerable gap in wildfire image segmentation [
20]. Compared to traditional fire detection, wildfire image segmentation techniques can provide more detailed fire information, including fire scale, flame-spreading speed, and precise fire location. This information is crucial for formulating effective prevention and control strategies and rational allocation of firefighting resources. Wang et al. [
38] combined an adaptive multi-scale attention mechanism and focal loss function based on Swin Transformer to segment forest fire images, achieving an IoU of 86.73%. This is a significant improvement compared to traditional models such as PSPNet [
39], SegNet [
40], DeepLabV3 [
41], and FCN [
42]. Bochkov et al. [
43] introduced wUUNet, an advanced U-Net variant with extended skip connections. It uses a two-step process. The first U-Net detects fire regions, and the second refines this result by segmenting fire colors like orange, red, and yellow.
Many scholars have also modified the YOLO series for flame recognition. Xue et al. [
44] modified the original Spatial Pyramid Pooling-Fast (SPPF) module in YOLOv5 to a Spatial Pyramid Pooling-Fast-Plus (SPPFP) module for fire detection. They observed a 10.1% improvement in
[email protected] on their dataset. Zhu et al. [
45] used an improved YOLOv7-tiny [
46] model to detect cabin fires, achieving a 2.6% increase in
[email protected] and a 10 fps speed improvement. Hojune Ann et al. [
47] developed a proactive fire risk detection system that performs object detection on images captured by surveillance cameras to determine whether both a fire source and combustible materials are present. The performance of two deep learning models, namely YOLOv5 [
48] and EfficientDet, was compared. Kuldoshbay Avazov et al. [
49] developed a novel convolutional neural network using an enhanced YOLOv4 [
50] to detect fire areas. Experiments demonstrated that the proposed method can successfully be used for urban fire monitoring. Soon-Young Kim et al. [
51] proposed an improved version of the YOLOv7 model, successfully detecting smoke from forest fires with an AP50 of 86.4%, which is 3.9% higher than previous single-stage and multi-stage object detectors.
Many scholars have utilized various CNNs or Swin Transformer networks for fire detection. CNNs can only capture local features; to capture global features, layer stacking is required. Similarly, Swin Transformer limits computations within windows and confines receptive fields within these windows. Consequently, Swin Transformer also requires layer stacking to expand receptive fields to cover the entire image. Moreover, in layers with large feature map sizes, Swin Transformer’s global feature-capturing ability is weak, diminishing the effectiveness of step-by-step decoding. Therefore, the main focus of this research is to address the issue of Swin Transformer’s window interactions being limited to adjacent windows and how to more efficiently integrate global and local features. The innovations of this paper are summarized as follows:
(1) We propose a non shift window Transformer module. Unlike Swin Transformer, which requires layer stacking to gradually expand the receptive field to cover the entire image, our method ensures that after each window Transformer operation, all pixels capture global features. This enhances the global feature-capturing capability of shallow layers of the network and strengthens the effectiveness of step-by-step decoding.
(2) We propose a network that integrates local and global features, where local features are captured using CNNs and global features are captured using non-shift window Transformer modules. These features are effectively fused in the network.
(3) We conducted experiments on a ground camera dataset and a drone camera dataset to analyze the generalization ability of the individual networks.
3. Method
3.1. Nswin Transformer
In processing images, transformers require significant computational overhead. To mitigate this, Liu from Microsoft Research Asia proposed Swin Transformer. Swin Transformer divides the image into several equally sized windows, constraining computations for each pixel to the pixels within its window, as illustrated in
Figure 1.
Figure 1b shows the ViT method, where the entire image undergoes Transformer operations together. In contrast,
Figure 1a depicts the Swin Transformer approach, where the image is divided into several equally sized patches according to the window size. Swin Transformer confines pixel computations to within the same window, hindering pixel interaction between windows. To address this, Swin Transformer employs a shifting-window mechanism, where windows are simultaneously shifted rightward and downward by half of the window width, ensuring different pixel coverage within each window, as shown in
Figure 2. By alternating stacking between window Transformer and window-shifting Transformer, each pixel gradually extends its receptive field to cover the entire image.
Swin Transformer restricts Transformer computations within windows, reducing computational complexity. However, Swin Transformer relies on layer stacking to gradually expand the receptive field of pixels to cover the entire image. Consequently, with sufficient layer stacking, deep feature maps possess a global receptive field, while shallow feature maps lack global context. Through research, it has been determined that decoding with multi-layer feature fusion yields better results than decoding with only deep feature maps. Hence, having a global receptive field in shallow feature maps is also crucial.
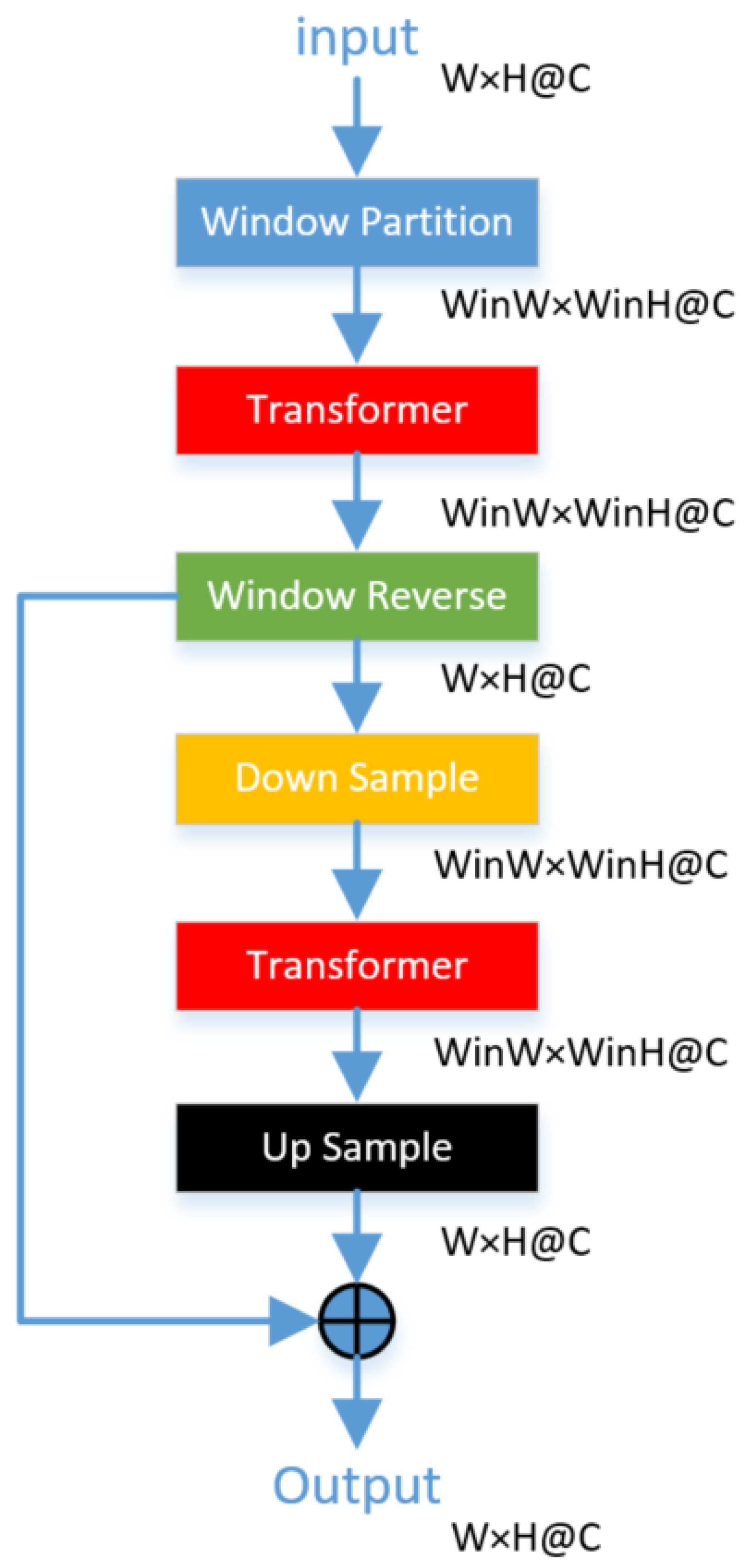
To address the limitation of Swin Transformer’s window-shifting method indirectly expanding the receptive field to cover the entire image, we propose a module called Nswin Transformer (Non shift window Transformer), as depicted in
Figure 3.
In
Figure 3, the input feature map has a size of H×W@C. Then, the feature map is partitioned into several patches according to the window size, with each patch’s size being the window’s H×window’s W@C. Each patch undergoes computation using the same transformer; then, these patches are stitched back to the original feature map size, resulting feature map B with a size of H×W@C. To facilitate pixel interaction between windows, feature map B is downsampled to the window size, resulting in feature map C with a size of the window’s H×window’s W@C. Feature map C undergoes Transformer operations, yielding feature map D with a global receptive field. To fuse the global features from D into each pixel, feature map D is upsampled to the size of the input feature map, then added to feature map B, which is computed by the window Transformer, resulting in feature map E with integrated global features. Feature map E retains the same size and channel number as the input feature map, ensuring that the Nswin Transformer module does not alter the feature map’s size or channel number. The pseudocode for the Nswin Trans-former module is shown in Algorithm 1.
| Algorithm 1 Nswin Transformer |
- 1:
procedure NswinTransformer - 2:
Input: feature map - 3:
Output: feature map - 4:
The input feature map is partitioned into several patches by window to obtain the feature map A. - 5:
All patches undergo computation using the same window Transformer, and then these patches are stitched back to the original feature map size, resulting in feature map B. - 6:
Feature map B is downsampled to the window size, resulting in feature map C. - 7:
Feature map C undergoes Transformer operations, resulting in feature map D. - 8:
Feature map D is upsampled to the size of the input feature map and then added to feature map B, resulting in feature map E. - 9:
return feature map E. - 10:
end procedure
|
3.2. Nswin Transformer Net
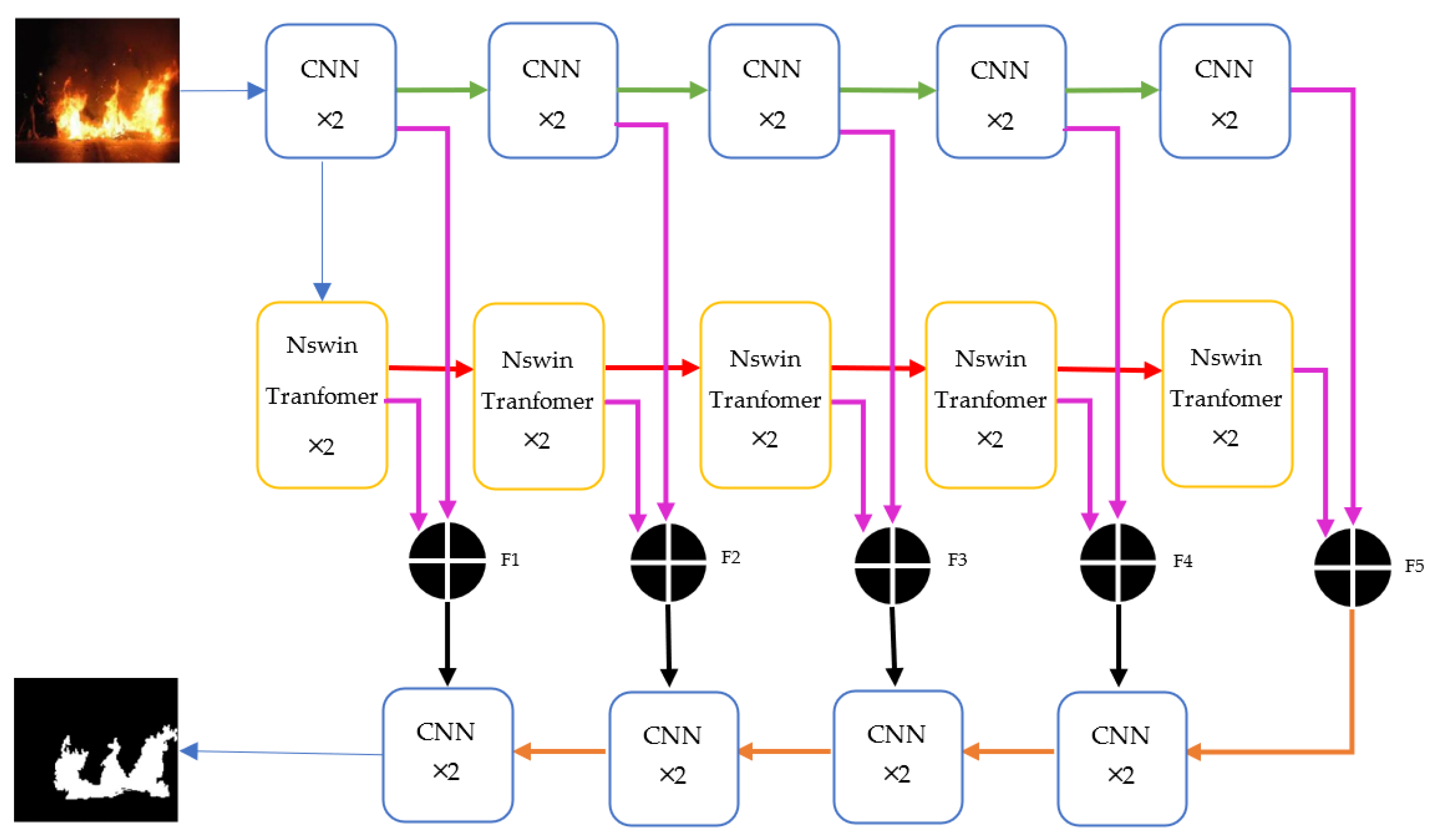
The Nswin Transformer module is adept at capturing global features. However, local features are also crucial, and an overemphasis on global information can obscure significant local details. To address this, we introduce the Nswin Transformer Network, which synergizes the strengths of convolutional neural networks (CNNs) and Nswin Transformer modules. In this network, CNNs are employed to effectively extract local features, while Nswin Transformer modules focus on global feature extraction. These two feature types are then integrated in each layer and gradually upsampled to match the input image size. The architecture of the Nswin Transformer Network is illustrated in
Figure 4.
The encoding part of the Nswin Transformer Network abandons the 4-layer structure of Swin Transformer and adopts the same 5-layer structure as UNet. The encoding part consists of the following two components: CNNs for capturing local features and Nswin Transformer blocks for capturing global features.
The CNN consists of 2D convolutions with a kernel size of 3 × 3 and a stride of 1, followed by BatchNorm and ReLU activations. The input image passes through the first layer of 2 CNNs, resulting in a feature map size of 256 × 256@64. Subsequently, after max-pooling with a stride and window size of 2, both the length and width of the feature map are halved. Then, after two more CNN layers, the second layer’s feature map size becomes 128 × 128@128. Next, by continuing with the same max-pooling configuration as before, followed by 2 CNN layers, the third layer’s feature map size becomes 64 × 64@256. The max pooling, stride, window size, and CNN kernel size and stride for the fourth and fifth layers are all the same as those used in the previous layers. Consequently, we obtain a fourth-layer feature map size of 32 × 32@512 and a fifth-layer feature map size of 16 × 16@1024.
To effectively integrate global and local features in each layer, our global feature extraction part uses a 5-layer architecture. Each layer consists of 2 Nswin Transformer modules with a fixed window size of 8, and they all employ multi-head attention mechanisms. The number of attention heads increases progressively from 1 head for the first layer, to 2 heads for the second, 4 for the third, 8 for the fourth, and 16 for the fifth. Since the Nswin Transformer modules cannot alter the number of channels, the input to the global feature extractor is the feature map from the first layer of the CNN, with a size of 256 × 256@64. After processing through two Nswin Transformer modules in the first layer, the feature map retains its size of 256 × 256@64. Following this, a patch-merging module reduces the feature map’s dimensions by half. The output from the second layer, after passing through its two Nswin Transformer modules, results in a feature map of 128 × 128@128. This halving and processing pattern continues for the subsequent layers, producing feature maps of 64 × 64@256, 32 × 32@512, and 16 × 16@1024 for the third, fourth, and fifth layers, respectively.
Before decoding, the local features and global features of five layers are added separately in each layer to obtain feature maps F1, F2, F3, F4, and F5. Then, the same stepwise upsampling method is used as in UNet. The decoding part of the CNN is the same as the encoding part, consisting of 2D convolutions with a kernel size of 3 × 3 and a stride of 1, batch normalization, and ReLU activation. The upsampling module increases both the length and width of the feature maps by a factor of two, using an upsampling module, 2D convolutions with a kernel size of 3 × 3 and a stride of 1, batch normalization, and ReLU activation. After the feature map F5 is upsampled, its size becomes 32 × 32@512; then, it is concatenated with feature map F4, and after passing through two CNN modules, a feature map with a size of 32 × 32@512 is obtained. Subsequently, the same procedure is repeated to concatenate F3, F2, and F1, resulting in a feature map with a size of 256 × 256@64. Finally, after a 2D convolution with a kernel size of 1 and a stride of 1, the output size becomes 256 × 256@2.
3.3. Evaluation Metrics
We use the F1 score, consisting of precision and recall, as an evaluation metric, as well as mIoU (Mean Intersection over Union) and OA (Overall Accuracy). These three metrics are used to evaluate each deep learning model. They are calculated as shown in Equations (2)–(6).
The formula for mIoU is
where N is the number of foreground pixels;
TP is the abbreviation of true positives, that is, the number of pixels correctly predicted as the foreground;
FP is the abbreviation of false positives, that is, the number of background pixels misjudged as the foreground;
TN is the abbreviation of true negatives, that is, the number of pixels correctly predicted as the background; and
FN is the abbreviation of false negatives, that is, the number of foreground pixels misjudged as background.
The formula for the F1 score is.
where precision and recall are
In Equation (
3), fire and background are regarded as the foreground to obtain the IoU; then, the average value is taken as the mIoU. The foreground in Equations (4)–(6) is fire.
3.4. Hardware and Software for Experiments
The hardware and software configurations used in this experiment are shown in the
Table 1.
The hardware configuration of the computer used for the experiments is summarized as follows: CPU, is Intel i5-13600KF; RAM, SEIWHALE DDR4 16G × 2; and GPU, NVIDIA GeForce RTX 2080TI 22G. The version of Python is 3.10.12, and Pytorch is used as the deep learning framework for model training and evaluation.
AdamOptimizer was used for back propagation, the batch size was set to 4, and the learning rate was set to 0.0001 during training. Because the default EPS is too small, which can cause some models to have a LOSS of NAN during training, we set the EPS to 0.003. The sum of L2 regularization and binary cross entropy was used as the total loss to prevent overfitting. The total loss is shown in Formula (1). The maximum number of training epochs was set to 300. After each epoch, an evaluation was performed on the validation dataset. Unlike the stopping standard used in ShiftPoolingPSPNet [
54], in which training was stopped if the metrics in the validation set no longer increased for 10 consecutive epochs, our stopping standard was set such that if the loss in the test dataset no longer reduced for 20 consecutive epochs, then training was stopped.
The specific experimental steps are listed as follows:
(1) Set parameters;
(2) Read training sample data in batches;
(3) Train on all training data;
(4) Evaluate on the test set;
(5) Repeat steps (3) and (4) until the stopping condition is met;
(6) Segment the test-set images.
5. Discussion
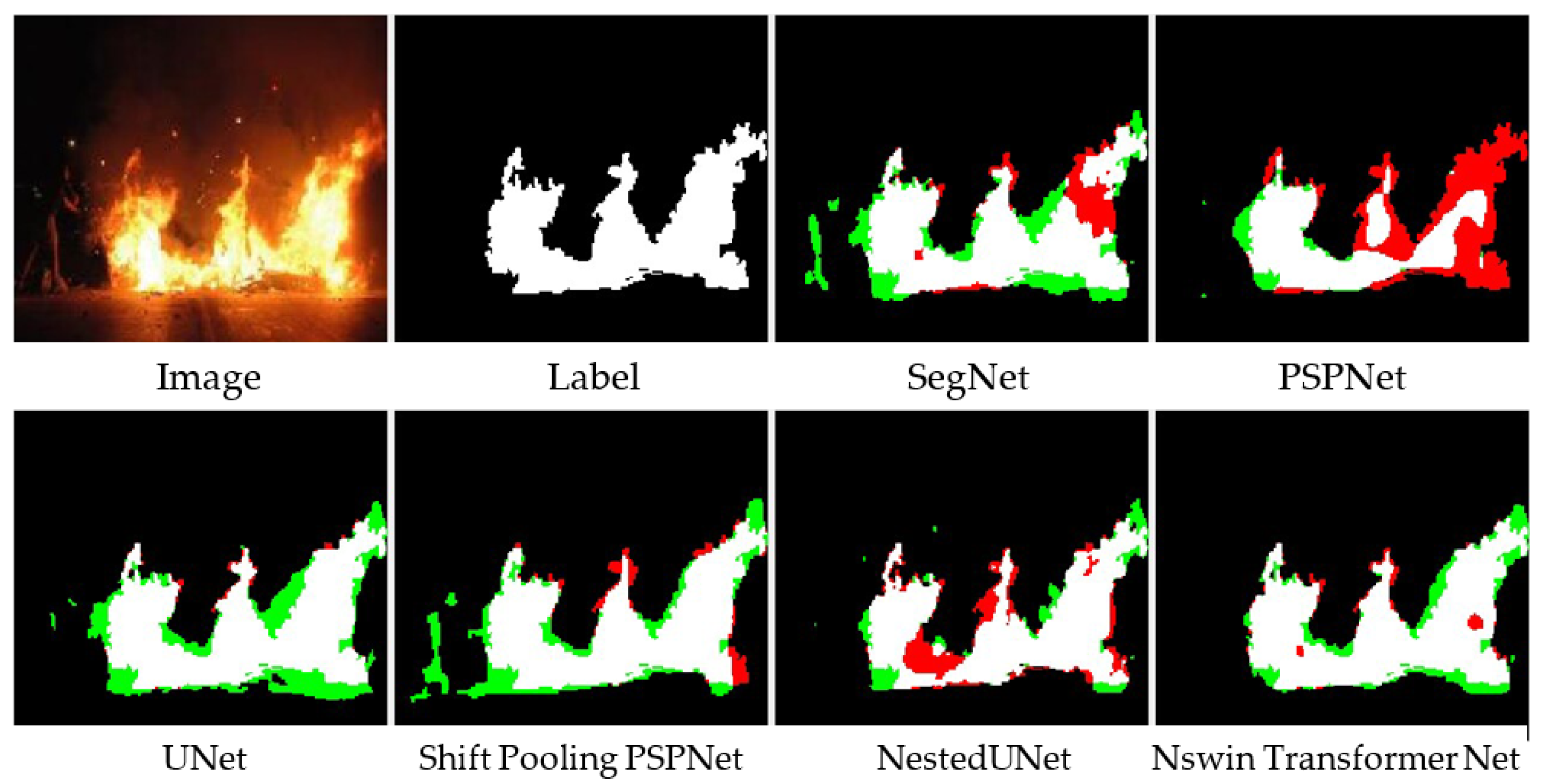
By introducing a transformer, Nswin Transformer Nets can capture global features in each layer after the window transformer. This significantly enhances the network’s feature-capturing ability. Experimental results on two datasets demonstrate that our proposed method performs the best in terms of mIoU, F1 score, and OA. Notably, on the Corsican Fire Dataset, our Nswin Transformer Net surpasses the second-best NestedUNet by 1.4% in mIoU, 2.1% in F1 score, and 0.2% in OA. This is a significant improvement, considering that the second-best NestedUNet only surpasses the third-best ShiftPoolingPSPNet by 0.6%, 1.1%, and 0.6% in mIoU, F1 score, and OA, respectively. Given that the proportion of fire pixels in the FLAME dataset is very small, achieving improvements in mIoU, F1 score, and OA is particularly challenging. However, our Nswin Transformer Net still outperforms the second-best NestedUNet by 0.5% in mIoU and 0.7% in F1 score.
From the ablation experiments, it can be observed that under the same network architecture and convolutional modules, our proposed Nswin Transformer module performs better than the original Swin Transformer module, with improvements of 1.3%, 1.8%, and 0.3% in mIoU, F1 score, and OA, respectively. This highlights the importance of enhancing global feature capture at each scale. Although this leads to a slight increase of 2.15 GMac in FLOPs, it is negligible compared to the 14.55 GMac increase caused by using only CNNs.
6. Conclusions
In this paper, we propose a network called Nswin Transformer Net aimed at addressing the limitations of Swin Transformer, which requires multiple layers to capture global features. Through detailed experimental validation and comparative analysis, we demonstrate that this network achieves significant performance improvements across multiple datasets.
Specifically, on the Corsican Fire Dataset, our Nswin Transformer Net achieved mIoU, F1-score, and OA values of 79.4, 76.6, and 96.9, respectively, surpassing the second-best NestedUNet by 1.4% in mIoU, 2.1% in F1 score, and 0.2% in OA. On the FLAME dataset, Nswin Transformer Net still outperforms the second-best NestedUNet by 0.5% in mIoU and 0.7% in F1 score. These results indicate that our the design of our Nswin Transformer model eliminates the limitation of Swin Transformer requiring multiple layers to capture global features, enabling the network to capture global features in each layer, thereby enhancing the global feature-capturing ability of the shallow network. This significantly improves the accuracy of fire image segmentation.
Furthermore, we conducted an in-depth analysis of the impact of each module in the Nswin Transformer network on accuracy and computational load. With other conditions unchanged, replacing Swin Transformer with Nswin Transformer improves mIoU, F1 score, and OA by 1.3%, 1.8%, and 0.3%, respectively, while increasing the computational load by only 2.15 GMac. Therefore, Nswin Transformer can significantly improve fire image segmentation accuracy with a minimal increase in computational load.
In conclusion, our proposed Nswin Transformer Net further improves upon the Swin Transformer. In our future work, we will further explore methods to maintain the capability of capturing global features in each layer of the window transformer while reducing computational complexity to improve processing speed.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}