1. Introduction
Population model-based (pharmacometric) approaches, through the usage of NLMEM, improve the power considerably when analyzing longitudinal data [
1,
2,
3,
4]. However, the assumptions involved in NLMEM, e.g., the absence of model misspecification or asymptotic conditions, can impact the performance of such approaches in terms of type I error, power, and accuracy of the treatment effect estimates [
5]. As the development of a reasonable model often implies a data-driven trial and error process across many models, type I error inflation related to multiple testing is a legitimate concern. Furthermore, despite all the efforts invested in the rationalization of the selection of one of the candidate models, it inevitably leads to selection bias, and relying on a unique selected model can hinder inference by discarding the model structure uncertainty and dismissing the inherent model misspecification [
6].
Over the recent years, multiple approaches have been developed to overcome these caveats. Model-averaging across drug models (MAD) weights the outcome of interest from a set of pre-selected models according to a goodness-of-fit based metric [
7,
8,
9,
10] to prevent selection bias and handle model structure uncertainty. Individual model averaging (IMA) [
11] uses mixture models to test for treatment effect, which mitigates consequences of both placebo and drug model misspecification and improves the conditions of application of the likelihood ratio test (LRT). combined-LRT (cLRT) [
12] combines an alternative cut-off value for the LRT and MAD to handle model structure uncertainty.
The pre-selection of a set of possible candidate models prior to the data analysis, recommended in the ICH E9 guidance [
13], is a common alternative to handle model selection bias and its consequences in terms of bias in the estimates. The restriction of the set of candidate models also inherently reduces the type I error inflation caused by multiple testing. MAD, IMA, and cLRT were assessed separately in different contexts of treatment effect or dose-response assessment using real or simulated data. This work aimed to assess MAD, IMA, and cLRT together with four other related approaches in the same framework: treatment effect assessment in balanced two-armed designs using real data. The additional approaches were standard model selection (STDs), structural similarity selection (SSs), randomized-cLRT (rcLRT), and model-averaging across placebo and drug models (MAPD).
Three evaluation aspects were considered: type I error, power, and accuracy of treatment effect estimate (assessed via the root mean squared error (RMSE)). The former aspect was assessed using real natural history data, while the two latter were assessed on the same natural history data modified by the addition of various simulated treatment effects. Model candidate pre-selection is an inherent part of the model-averaging approaches. In this work, it was generalized to all the approaches to provide a common scope to the seven NLMEM approaches for the evaluation. The AIC was used for selection and weighting according to previous recommendations [
8,
9].
2. Materials and Methods
For parameter estimation, NONMEM [
14] version 7.5.0 was used. The simulation or randomization and re-estimations were performed using PsN [
15,
16] version 5.2.1 through the Stochastic Simulation and Estimation or the randtest functions. The runs with failed minimization status or unreportable number of significant digits were removed from the analysis (see
Appendix A for more details). The first order with conditional estimates (FOCE) method was used for all models without the interaction option, as the residual error model was additive. The processing of the results was performed with the statistical software R [
17] version 4.1.2.
2.1. Data
Data used in the preparation of this article were obtained from the Alzheimer’s Disease Neuroimaging Initiative (ADNI) database (adni.loni.usc.edu). The ADNI was launched in 2003 as a public-private partnership, led by Principal Investigator Michael W. Weiner, MD. The primary goal of ADNI has been to test whether serial magnetic resonance imaging, positron emission tomography, other biological markers, and clinical and neuropsychological assessment can be combined to measure the progression of mild cognitive impairment and early Alzheimer’s disease. For up-to-date information, see
www.adni-info.org.
The real natural history data were longitudinal ADAS-cog scores ranging from 0 to 70, previously published and detailed elsewhere [
18]. Due to the high number of categories, the data were treated as continuous. In this work, we used 817 individuals (aged from 55 to 91 years old), with ADAS-cog evaluation at 0, 6, 12, 18, 24, and 36 months, for a total observation count of 3597. The Baseline Mini-Mental State (BMMS) was also collected at baseline for all the individuals and is used to describe the baseline ADAS-cog scores.
The study population was randomized to two study arms, representing placebo (
) and treatment (
). In the base scenario used to assess type I error, all subjects’ data were their natural disease progression. To assess the power and the accuracy of the treatment effect estimates, the original data were also modified by adding various treatment effect functions to the individual allocated to the treated arm. Offset (Equation (
2)) and time-linear (Equation (
3)) models were used to generate different treatment effect scenarios: with (30% CV) or without IIV on the treatment effect parameters, with a low (2-points increase) or a high (8-points increase) typical treatment effect at the end of the study. Eight treatment effect scenarios were generated, using both time-linear and offset drug models: (1) with or; (2) without IIV; (3) small treatment effect; and (4) large treatment effect.
2.2. Models
The published disease model is described extensively elsewhere [
18] and summarized in Equation (1). The corresponding NONMEM code is provided in
Appendix B. The disease model is time-linear (Equation (1a)), including covariates effects on the slope (Equation (1c)), and a slope model links the baseline value to BMMS (Equation (1b)).
where
describes fixed effect parameters,
are additive individual random effects, and
is the residual error for each observation. Four alternative disease models were considered for MAPD and are presented in
Table 1.
Offset with or without IIV (Equation (
2)) and disease-modifying with or without IIV (Equation (
4)) models were considered as treatment effect models for the type I error assessment. For the power and accuracy assessment, a time-linear model (Equation (
3)) was used instead of the disease-modifying model to avoid any disease model assumption in the simulation of the treatment effect.
With being the disease model slope.
2.3. Description of Modelling Approaches
For all the approaches, the Akaike information criteria (AIC) is used to compare the fit of the set of candidate models. The AIC is hence used to select the best-fitting candidate used as the alternative hypothesis (H1) in the statistical test, except for the model-averaging approaches, i.e., MAD and MAPD, for which no selection occurs, but an AIC-based weight is computed for each candidate model. The LRT is then used to conclude the presence of a treatment effect, except for the model averaging approaches, cLRT, and rcLRT for which the alternatives are described below.
In the STDs approach (Equation (5),
Figure 1a), the null hypothesis (H0) consists of a placebo model applied to all subjects, and H1 adds a drug model to the treated subjects. The LRT is used to discriminate between the best model selected and H0 to conclude the presence of a treatment effect, using
as the test statistic. The distribution of this test statistic under H0 is unknown. In the LRT, it is assumed to follow a
distribution with
degrees of freedom, with
, and
, the number of additional parameters estimated in H1 compared to H0. cLRT and rcLRT assumed a different distribution for that test statistic under H0, the alternative distribution being obtained by replicating the model selection procedure and the test statistic computation
times over
n different data sets. For cLRT (Equation (5),
Figure 1a), the distribution is obtained with
n data sets simulated under H0, for rcLRT (Equation (5),
Figure 1a) the distribution is obtained with
n randomized data set differing by the treatment allocation assignment.
In SSs (Equation (6),
Figure 1c), the drug model is fitted to all subjects in H0, but H1 allows different estimates for the treated individuals. The LRT is used to conclude on the presence of a treatment effect using the best model according to the AIC.
The two model averaging approaches, MAD and MAPD, have the H0 and H1 hypotheses constructed according to STDs (Equation (5) and
Figure 1b). Instead of selecting a unique best candidate model via a selection step, the model-averaging approaches assigned an AIC-based weight to each candidate model (Equation (
7)), with
being the minimum
of the candidate models. Hence, each model from the pre-defined set contributes to the computation of the metric of interest proportionally to its relative weight, contrary to the selection-based methods where only the best model candidate is used to draw conclusions. MAD considered a unique H0 and multiple H1 via the formulation of various drug models and a unique placebo model, while MAPD differed by also considering various placebo models in the set of pre-defined models. In that aspect, MAPD differed from MAD, and the other six approaches, by considering multiple disease models instead of only the published disease model.
In IMA (Equation (
8a),
Figure 1c), all subjects have, through a mixture feature, a probability
of being described by the drug model. This probability is fixed to the placebo allocation rate (0.5) in H0 but estimated based on the treatment allocation in H1. The LRT is used to conclude on the presence of a treatment effect using the best model according to the AIC.
where
is the published placebo model and
a drug model
d depending on the treatment allocation
.
where the same drug model
d is applied to all the individuals, allowing for different parameter estimates between the two arms in H1.
2.4. Approaches Assessment
For each of the seven approaches, the type I error rate was assessed first using the raw natural history data modified to randomly allocate (1:1) each subject to an artificial placebo or treated arm. The allocation was repeated times to mimic N random trials without treatment effect. The type I error rate was computed over the N trials as the frequency with which H0 was rejected and assumed to be adequate when falling within the 2.5th–97.5th percentiles of a binomial distribution with a probability of success of 5% on N trial replicates.
When the type I error was controlled, power and accuracy were assessed using the data modified by the addition of a treatment effect to the subjects allocated to the treated arm. N simulations were performed for each of the eight treatment effect scenarios. The power was computed as the frequency with which H0 was rejected over N trials. Regarding the model-averaging approaches, the type I error and power were computed as the percentage of the weights allocated to any of the H1 considered in the set of the candidate models.
The accuracy in the treatment effect estimates was assessed only when using the data modified by the addition of simulated treatment effect, using the RMSE according to Equation (
9), where
is the true value used in the simulations and
is the estimated value of the
trial.
For IMA,
was computed according to Equation (
10), to account for the submodel allocation probability:
3. Results
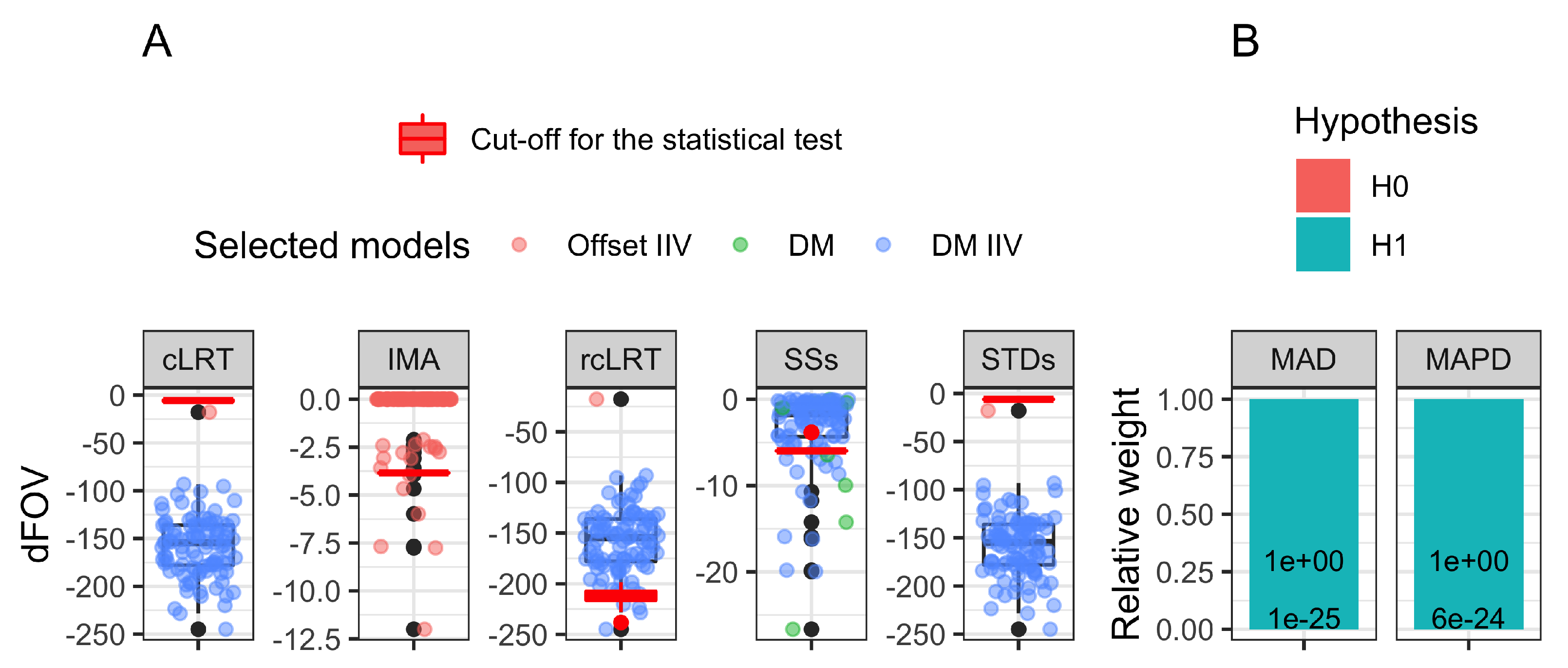
The type I error for each approach is available in
Table 2. Only IMA and rcLRT had controlled type I error (6%). All the other approaches had 100% type I error except SSs, for which the type I error was inflated to 17%. The model-averaging approaches had a very negligible total weight assigned to any H0 hypothesis,
. Details about the drug models selected in the
N trials, their corresponding dOFV, and critical cut-off value for the LRT are presented in
Figure 2A for all but the model-averaging approaches. The model-averaging approaches results are presented in
Figure 2B, with the total relative weight allocated to any of the H0 or the H1 hypotheses. The minimization status is available in
Appendix A in
Figure A1 and
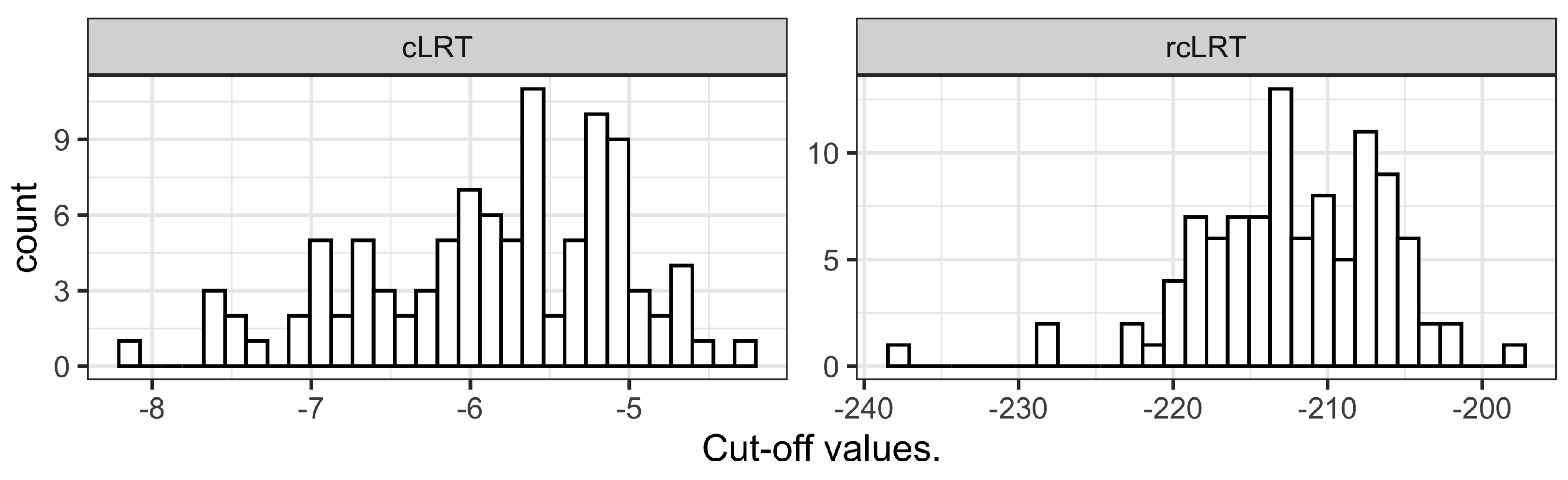
Figure A2. The cLRT and rcLRT alternative distributions used for the determination of the cut-off value in the statistical test are presented in
Figure A5 in
Appendix C. The summary of the model fits (number of estimated parameters and OFV) is provided in
Appendix D in
Table A1 for the models used in the type I error computation for all the approaches but MAPD, and in
Table A2 for the models used in MAPD, showing that the four proposed alternative disease models for MAPD improved the OFV significantly compared to the published disease model.
Power and accuracy in treatment effect estimates (RMSE) were investigated for IMA and rcLRT as they were the only two approaches with controlled type I error. The results (power and RMSE) for the eight investigated treatment effect scenarios are presented in
Table 3. The minimization status is available in
Appendix A.2 in
Figure A3 for rcLRT, and in
Figure A4 for IMA. For the high typical treatment effect scenarios (8-points), IMA and rcLRT had 100% power regardless of the simulated treatment effect model addition. For the low typical treatment effect scenarios (2-points), rcLRT had higher power than IMA when simulating the treatment effect with the offset models, whereas the opposite was true when simulating with the time-linear model. The RMSE was always higher for IMA for all eight scenarios tested.
4. Discussion
Seven NLMEM approaches were compared in the same context of treatment effect assessment in balanced two-armed trials using real natural history data. The comparison scope was first the type I error using the natural history data observed without any treatment. For approaches with controlled type I error, power and accuracy in the drug estimates were evaluated using the natural history data modified by the addition of different simulated treatment effects. Among the seven approaches tested, only two (IMA and rcLRT) had controlled type I error and were consequently assessed on data with a simulated treatment effect. IMA and rcLRT had similar results in terms of power: 100% power in the presence of a high typical treatment effect but lower in the presence of a low typical treatment effect, except for rcLRT when an offset drug model was used to simulate the treatment effect (100% power). rcLRT had consistently better RMSE than IMA.
The STDs approach type I error results (100%) could be anticipated from the fit of the four drug models on one randomization of the treatment allocation (see
Table A1 in
Appendix D.1). Out of the four models, offset or disease-modifying with or without IIV, the two models with IIV had a significant drop in OFV, according to the LRT. The disease-modifying model with IIV had a drop of −133.54, compared to a critical value of −5.99 for the LRT, about 111 OFV points lower than the offset drug model with IIV, leaving no chance of selection for another candidate model even after the parameters-based penalty introduced by the AIC. Previous investigations [
11] of the STDs approach without the AIC selection step already outlined the uncontrolled type I error of the approach. Such uncontrolled type I error was attributed to the placebo model misspecification leaving room for additional model components and other possible violations of the standard LRT assumptions, such as not fulfilling the asymptotic properties. In this case, there was a pre-selection of H1 models using AIC. Another common way of model selection is to make multiple tests of different H1s against the H0 and then select the H1 associated with the lowest
p-value, given that it is below the predetermined cut-off. Both these procedures suffer from multiple testing and their greedy behavior.
The cLRT approach [
12] was introduced to account for the multiple testing of drug models and the structure model uncertainty in the computation of the critical value by using Monte Carlo simulation under H0. cLRT had controlled type I error in the context of simulated data [
12], but had a 100% type I error inflation with the real natural history data and the published disease model that was used in our study. The alternative computation of cut-off values for cLRT was unable to prevent the type I error inflation.
Even though cLRT accounts for multiple testing in the computation of the critical value via Monte Carlo simulations, it still assumes that the structure of the placebo model is adequate by simulating under the assumption of that model for the computation of an alternative cut-off value for the statistical test. By computing the critical value using randomization of the treatment allocation, rcLRT adds the uncertainty of the placebo model in the computation of the critical value by removing any placebo model assumption from the process. The success of this approach (controlled type I error with a rate of 6%) could also be anticipated from the fit of the drug model on the natural history data (see
Table A1 in
Appendix D.1), as the dOFV of the best drug model used to compute the critical value is the same as the one used to test for treatment effect. This ensures that the distribution used for the critical value computation is of the same magnitude as the model selected by the AIC step, which is critical to have a chance to limit the type I error inflation.
Appendix C illustrates the consequent difference in the typical value of the cut-off distribution obtained by cLRT and rcLRT, ranging, respectively, between −2 to −8 and −195 to −240. The success of this approach also validates the assumption that placebo model misspecification is the major factor involved in the type I error inflation of STDs and cLRT.
Aside from alternatives to the cut-off value used in the statistical test, SSs proposes another alternative to control the type I error inflation observed with STDs. SSs challenged the assumption of the main inflation factor being that the drug model tested is describing some features of the data that were not included in H0. Accordingly, SSs fits the drug model to all the subjects in H0 and allows for different estimates between the arms in H1. The expectation was that the drop in OFV observed in H1 for STDs, corresponding to an improvement of the placebo model rather than a treatment effect, would be included in the OFV of H0 and hence removed from the dOFV between H1 and H0. The results showed that the approach helped to decrease the type I error inflation (17% instead of 100%) but was not enough to control it. Further investigations would be necessary to decide whether and to which extent the remaining inflation should be attributed to multiple testing or the magnitude of the placebo model misspecification still present.
Pre-selection of the set of candidate drug models prior to the data analysis is a recommended practice to limit the type I error inflation [
13]. Previous publications showed its application with NLMEM in combination with model-averaging techniques, which was helpful to integrate drug model misspecification in the prediction of key metrics to plan better later stages of drug development [
8,
9,
12]. To our knowledge, in the NLMEM context, the averaging step was in these studies performed over a set of multiple drug model candidates and not over a set of both placebo and drug model candidates. In this work, the MAD approach illustrates the former, and MAPD the latter. MAD showed type I error control in previous publications on simulated data (method 3 from [
8]) which was not the case with the real natural history data used in our study (type I error rate of 100%). For the model-averaging approaches, the type I error was computed as the percentage of the relative weights assigned to any H1, as the weights are usually used to favor the output of the respective models in the computation of an effect metric. Because the weights were AIC based, the favored models among the set of candidates were also the model with the lowest OFV (disease-modifying model with IIV), and because of the significant gap between this lowest and the second lowest OFV model (111 points), the total relative weight assigned to any H0 was very negligible (
). This result was also predictable from the model fit on a single allocation randomization (see
Table A1 in
Appendix D.1). The addition of multiple placebo models in the set of candidate models did not help to reduce the type I error inflation and also resulted in a 100% type I error rate, even though the four alternative placebo models proposed all significantly improved the OFV (between −23.62 and −60.15 decrease in OFV). For the Boxcox transformation, the t-distribution, and the time-exponential model, the dOFV pattern across the four drug models was the same as with the published drug model. The drug models with IIV had significant dOFV, with the disease-modifying model with IIV being the best one, with a dOFV of about −100 points. The model with IIV on RUV had only the disease-modifying model with IIV as a significant treatment effect model with a drop of −68.84 points. The maximum difference between the model with the lowest OFV (13,585.26 for the t-distribution placebo model with disease-modifying with IIV model) and the model with the highest OFV (13,768.66 for the published model without treatment effect), i.e., 183.40 points, also lead to a very negligible total relative weight (
) assigned to any H0. We can note that the multiplicity of H0 increased the total weight assigned to the H0 by less than
. Both MAD and MAPD suffered from the gap in OFV between the published model without treatment effect and the model with the best treatment effect, even though the set of pre-selected drug model candidates is restricted to only four models.
Power and bias in treatment effect estimates were assessed for IMA and rcLRT on the natural history data modified by the addition of offset or disease-modifying treatment effects with or without IIV, with a low or a high typical treatment effect. Both approaches had similar power performances and reasonably good RMSE in the presence of a high typical treatment effect. However, in the presence of a low typical treatment effect simulated with an offset model, only rcLRT had good power and RMSE. When using time-linear treatment effect models with a low typical treatment effect, both IMA and rcLRT had unsatisfactory power and poor RMSE. These poor performances can be explained by the combination of two main factors: (1) a difficulty to distinguish the drug model from the placebo model as the added treatment effect was simulated with the same mathematical function as the placebo model; (2) the magnitude of the treatment effect (2 ADAS-cog score points at 36 months) which might be of the same magnitude as the model misspecification. The performances of IMA in the low typical treatment effect scenarios can be explained by the additional degree of freedom brought by the mixture model, allowing some over-fitting associated with a much lower OFV, misleading the AIC selection process.
Aside from these two specific simulation scenarios, the RMSE was overall better for rcLRT. This loss in accuracy for IMA can be explained by the fact that the formula used to compute the final treatment effect combines two parameters estimates: the treatment effect estimate and the mixture proportion, contrary to rcLRT, where the treatment effect is only in the treatment effect estimate (see Equation (
10)).
Overall the performances of the approaches were well aligned with the OFV obtained for each approach with a single fit of the different model (results presented in
Appendix D). The usage of real data together with a model that was developed, assessed, and published using the same data frames, this work in an interestingly realistic context with real-life model misspecifications. In contrast, the addition of a simulated treatment effect to create scenarios for power and accuracy assessment might lack some real-life complexity. Nonetheless, it allowed the highlighting of the dangerous combination between described features of the natural history data by the placebo model and greedy behavior of the test statistic (dOFV) and/or selection criteria (AIC).
The scope of this work was restricted to treatment effects for balanced two-armed designs. While it is difficult to extrapolate the results further for most of the approaches, IMA and the standard approach without the selection step were assessed regarding type I error in unbalanced designs with respect to treatment effect and dose-response elsewhere [
19]. The results were consistent with the ones presented here.



 on behalf of the Alzheimer’s Disease Neuroimaging Initiative
on behalf of the Alzheimer’s Disease Neuroimaging Initiative 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

