
Deepfake-Image Anti-Forensics with Adversarial Examples Attacks


Abstract
:1. Introduction
2. Related Work
2.1. Adversarial Examples Generation Method
2.2. Adversarial Examples Attacks on Deepfake Detectors
3. Materials and Methods
3.1. Attacked Detector
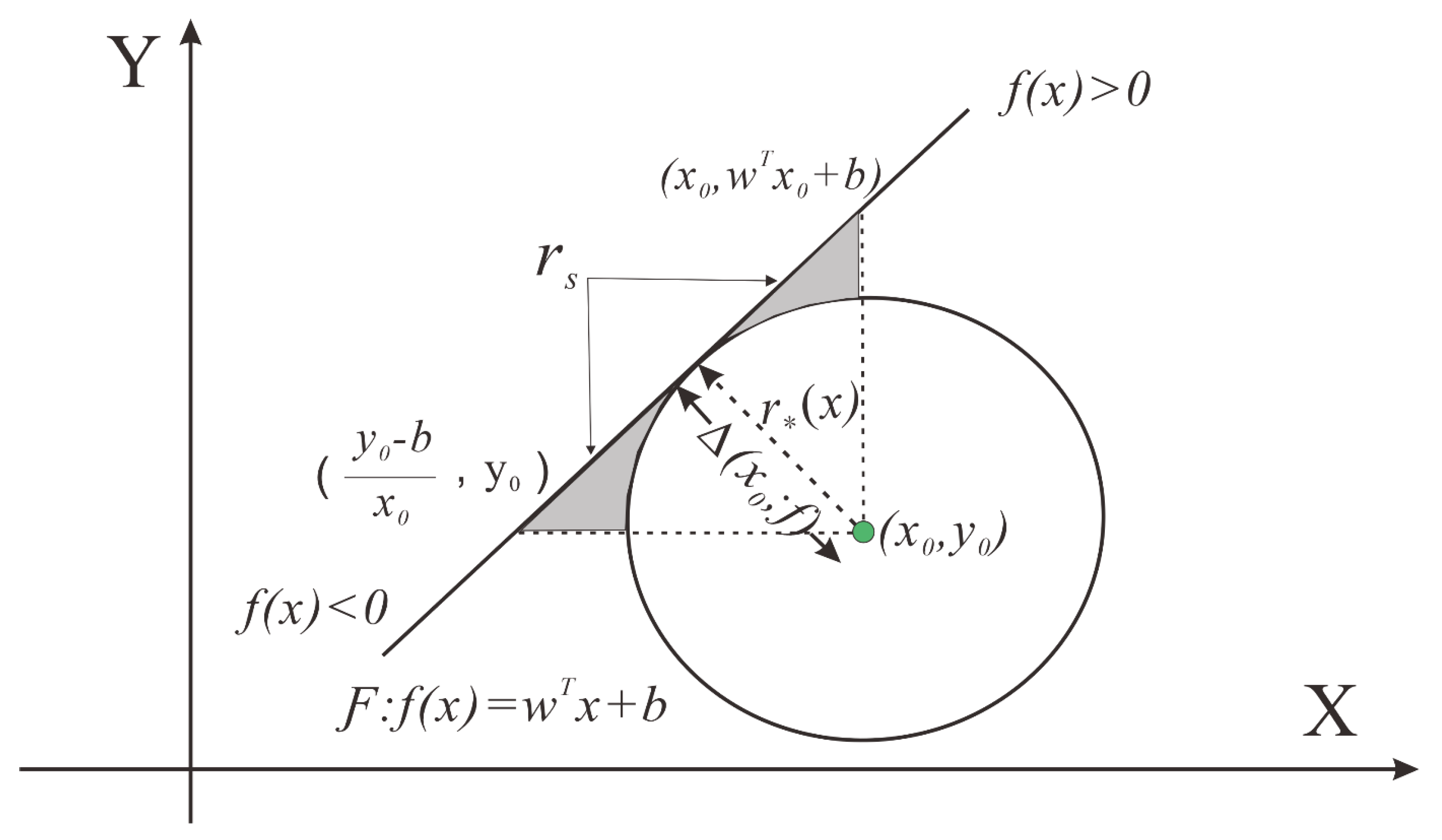
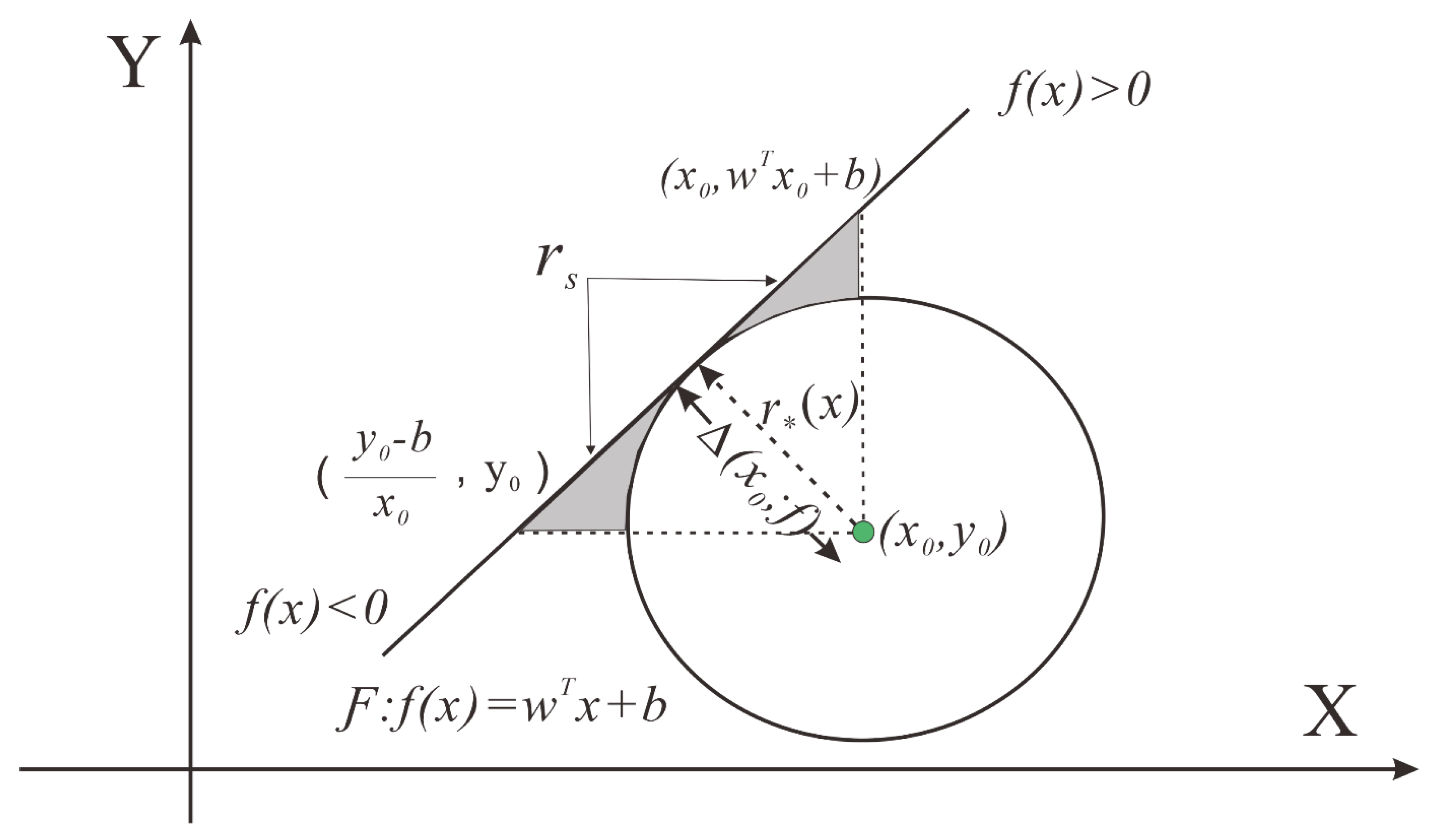
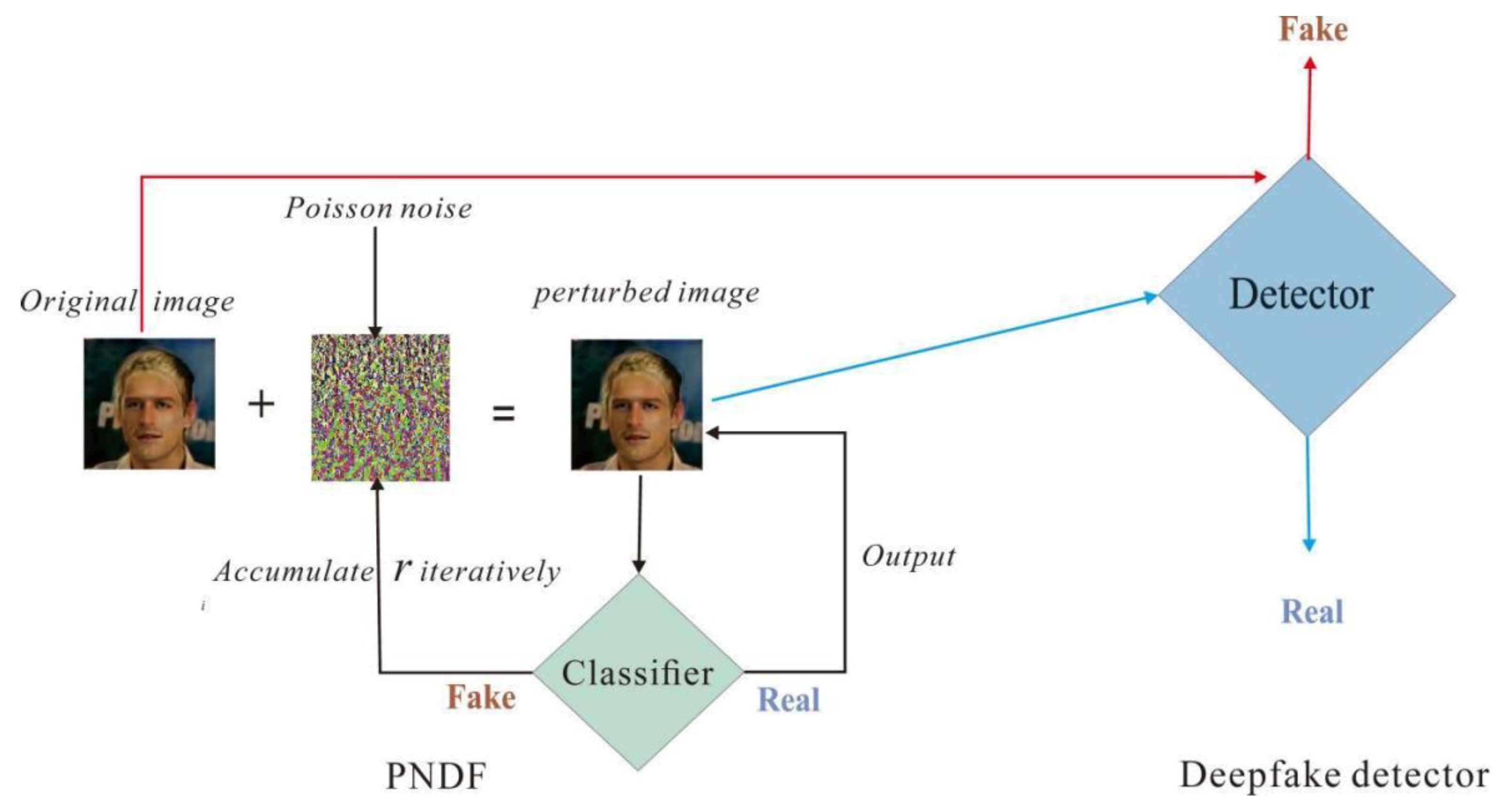
3.2. Adversarial Examples Attack
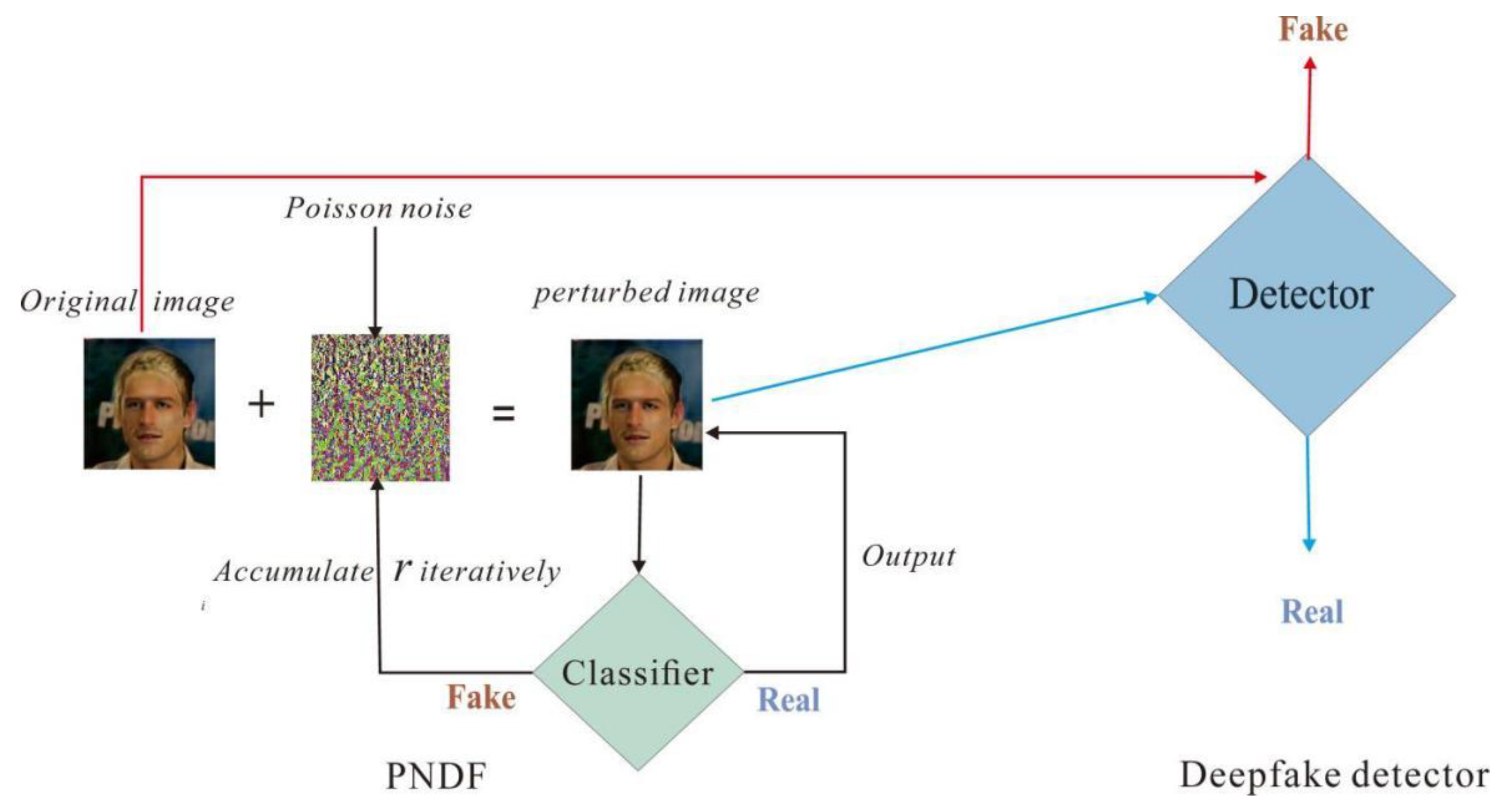
3.3. PNDF for Binary Classifier
| Algorithm 1 Poisson noise DeepFool (PNDF) for binary classifiers |
| Input: Image x, classifier f Output: Perturbation r 1: Initialize 2: While do 3: , 4: , 5: , 6: end while 7: return |
4. Experiment and Discussion
4.1. Datasets and Models
4.2. Attack Settings
4.3. Attack Results
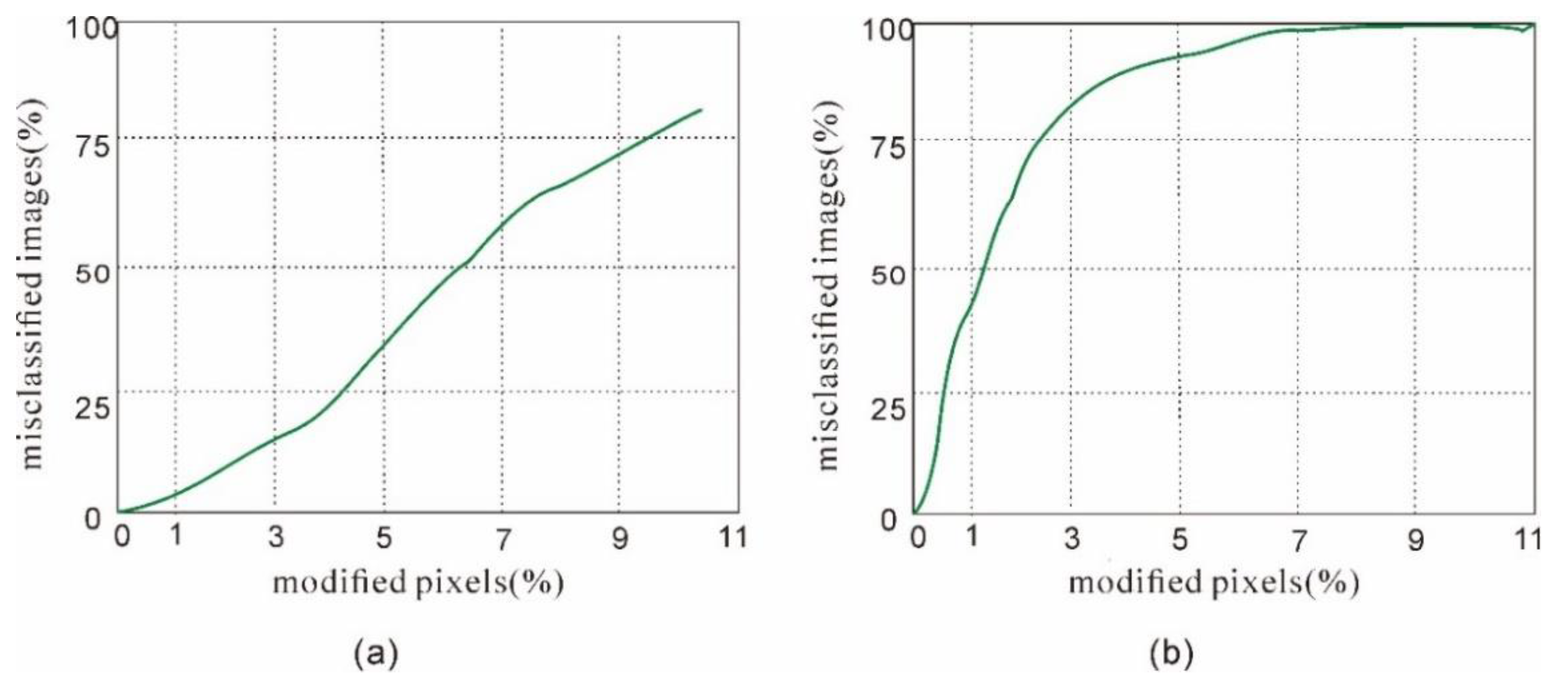
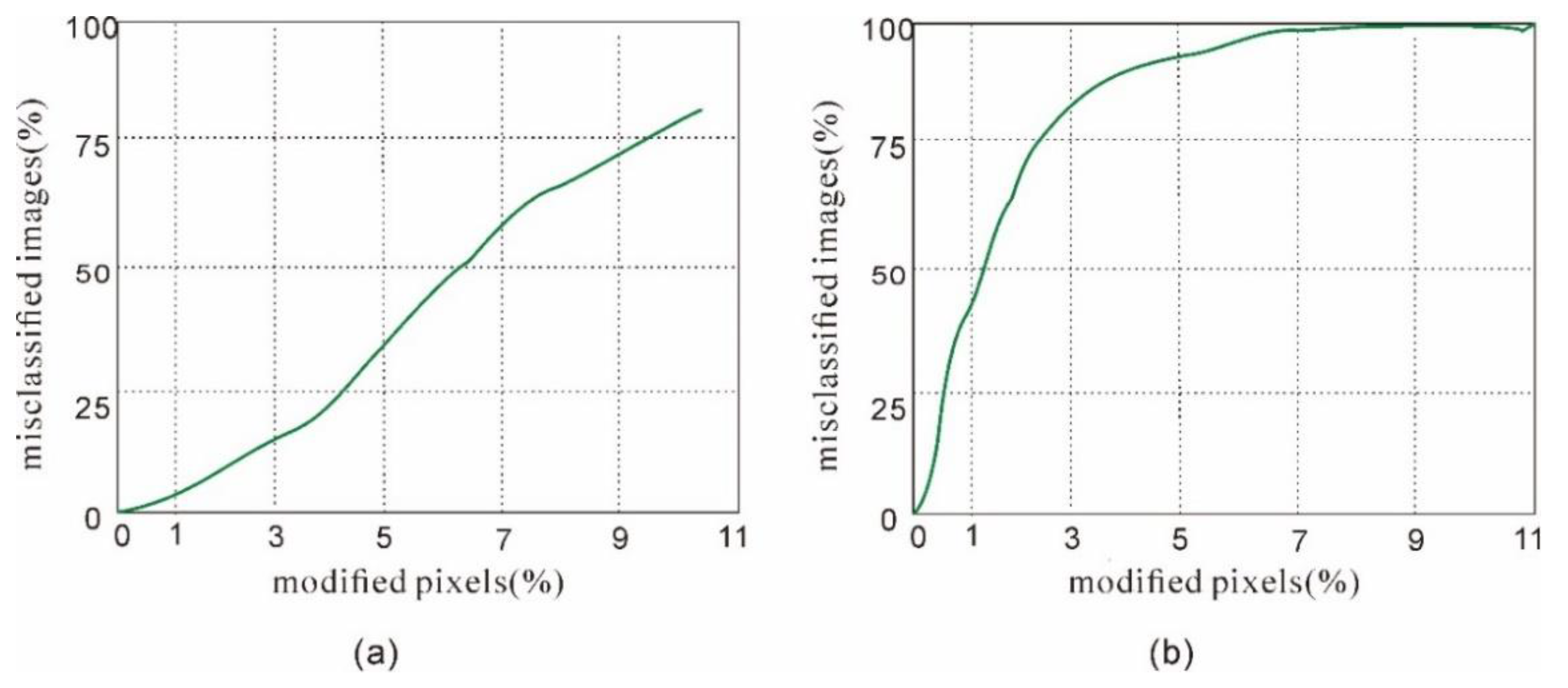
4.3.1. Attack Accuracy of the “General” Detector
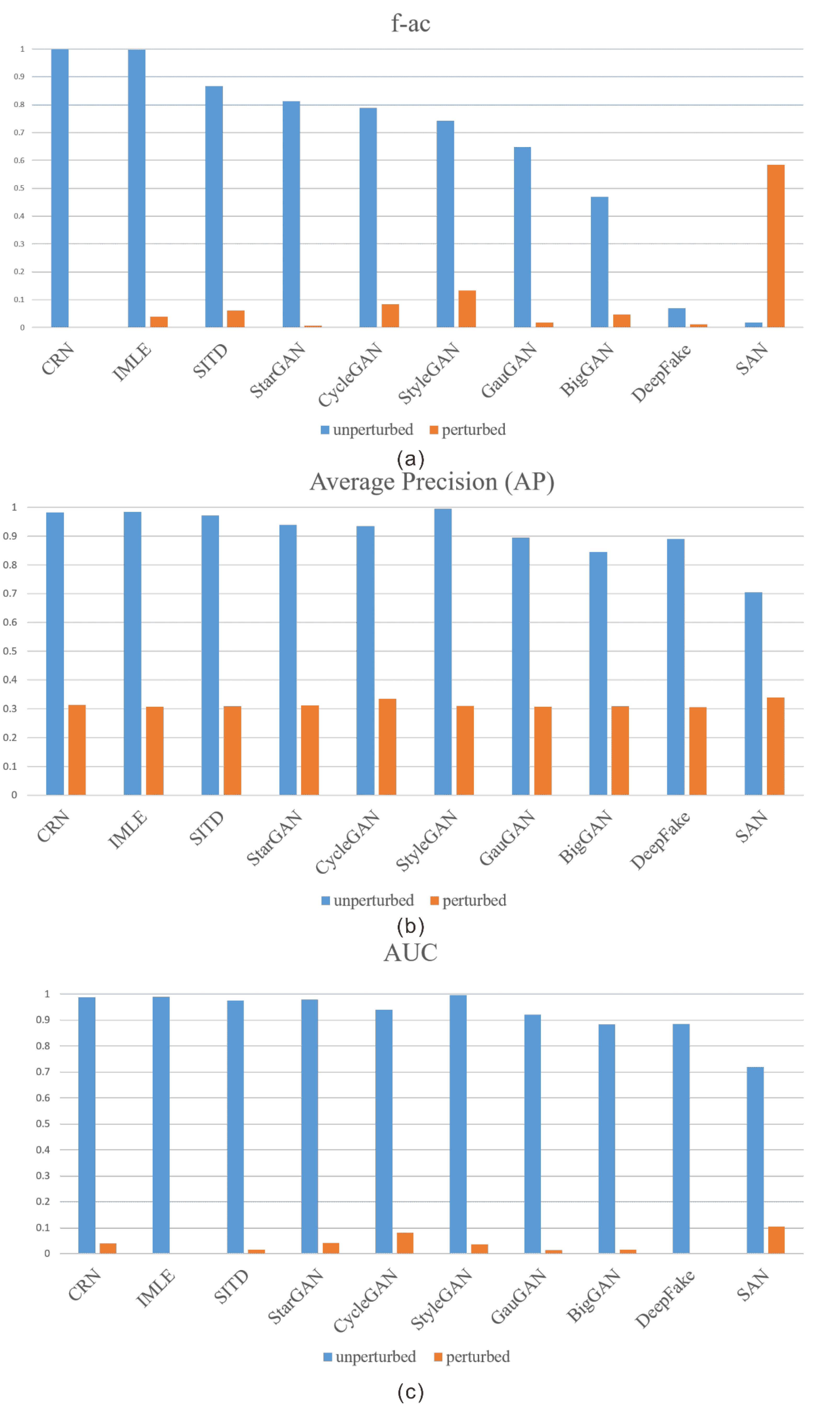
4.3.2. Attack Generalization of the “General” Detector
4.3.3. Attack of Zhang et al.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- DeepFakes Faceswap Github Repository. Available online: https://github.com/DeepFakes/faceswap. (accessed on 12 October 2021).
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Mirsky, Y.; Lee, W. The Creation and Detection of Deepfakes: A Survey. arXiv. 2020. Available online: https://arxiv.org/abs/2004.11138 (accessed on 12 October 2021).
- Tolosana, R.; Vera-Rodriguez, R.; Fierrez, J.; Morales, A.; Ortega-Garcia, J. Deepfakes and beyond: A Survey of face manipulation and fake detection. Inf. Fusion. 2020, 64, 131–148. [Google Scholar] [CrossRef]
- Tran, L.Q.; Yin, X.; Liu, X. Representation Learning by Rotating Your Faces. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 3007–3021. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schwartz, O. You Thought Fake News Was Bad? The Guardian. Available online: https://www.theguardian.com/technology/2018/nov/12/deep-fakes-fake-news-truth (accessed on 12 October 2021).
- Samuel, S. A Guy Made a Deepfake App to Turn Photos of Women into Nudes. It didnfit Go Well. 2019. Available online: https://www.vox.com/2019/6/27/18761639/ai-deepfake-deepnude-app-nude-women-porn (accessed on 12 October 2021).
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Proces. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Zhu, J.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar] [CrossRef] [Green Version]
- Nataraj, L.; Mohammed, T.M.; Manjunath, B.S.; Chandrasekaran, S.; Flenner, A.; Bappy, J.H.; Roy-Chowdhury, A. Detecting GAN generated Fake Images using Co-occurrence Matrices. Electron. Imaging 2019, 2019, 532-1–532-7. [Google Scholar] [CrossRef] [Green Version]
- Cozzolino, D.; Thies, J.; Rssler, A.; Riess, C. Forensic Transfer: Weakly-Supervised Domain Adaptation for Forgery Detection. 2018. Available online: https://arxiv.org/abs/1812.02510 (accessed on 12 October 2021).
- Guarnera, L.; Giudice, O.; Battiato, S. Fighting Deepfake by Exposing the Convolutional Traces on Images. IEEE Access 2020, 8, 165085–165098. [Google Scholar] [CrossRef]
- Odena, A.; Dumoulin, V.; Olah, C. Deconvolution and Checkerboard Artifacts. Distill 2016, 1, e3. [Google Scholar] [CrossRef]
- Zhang, X.; Karaman, S.; Chang, S.-F. Detecting and Simulating Artifacts in GAN Fake Images. In Proceedings of the 2019 IEEE International Workshop on Information Forensics and Security (WIFS), Delft, The Netherlands, 9–12 December 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Wang, S.-Y.; Wang, O.; Zhang, R.; Owens, A.; Efros, A.A. CNN-Generated Images Are Surprisingly Easy to Spot… for Now. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 8692–8701. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I. Intriguing properties of neural networks. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Gandhi, A.; Jain, S. Adversarial Perturbations Fool Deepfake Detectors. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 June 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Hussain, S.; Neekhara, P.; Jere, M.; Koushanfar, F.; McAuley, J. Adversarial Deepfakes: Evaluating Vulnerability of Deepfake Detectors to Adversarial Examples. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 3347–3356. [Google Scholar]
- Zhang, W. Generating Adversarial Examples in One Shot with Image-to-Image Translation GAN. IEEE Access 2019, 7, 151103–151119. [Google Scholar] [CrossRef]
- Akhtar, N.; Mian, A. Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey. IEEE Access 2018, 6, 14410–14430. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Moosavi-Dezfooli, S.; Fawzi, A.; Fawzi, O. Universal adversarial perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Carlini, N.; Farid, H. Evading Deepfake-Image Detectors with White- and Black-Box Attacks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 2804–2813. [Google Scholar]
- Marra, F.; Gragnaniello, D.; Cozzolino, D.; Verdoliva, L. Detection of GAN-Generated Fake Images Over Social Networks. In Proceedings of the 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Miami, FL, USA, 10–12 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 384–389. [Google Scholar]
- Yu, N.; Davis, L.; Fritz, M. Attributing Fake Images to GANs: Learning and Analyzing GAN Fingerprints. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 7555–7565. [Google Scholar]
- Moosavi-Dezfooli, S.-M.; Fawzi, A.; Frossard, P. DeepFool: A Simple and Accurate Method to Fool Deep Neural Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: New York, NY, USA, 2016; pp. 2574–2582. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S. Progressive growing of gans for improved quality, stability, and variation. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large Scale GAN Training for High Fidelity Natural Image Synthesis. In Proceedings of the International Conference on Learning Representations, Vancouver, Canada, 30 April–3 May 2018. [Google Scholar]
- Park, T.; Liu, M.-Y.; Wang, T.-C.; Zhu, J.-Y. Semantic Image Synthesis with Spatially-Adaptive Normalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2332–2341. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M. Stargan: Unified generative adversarial networks for multi-domain image-to-image transla-tion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 8789–8797. [Google Scholar]
- Chen, C.; Chen, Q.; Xu, J.; Koltun, V. Learning to See in the Dark. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition; Institute of Electrical and Electronics Engineers (IEEE), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3291–3300. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.-T.; Zhang, L. Second-Order Attention Network for Single Image Super-Resolution. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 11057–11066. [Google Scholar]
- Chen, Q.; Koltun, V. Photographic Image Synthesis with Cascaded Refinement Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1520–1529. [Google Scholar]
- Li, K.; Zhang, T.; Malik, J. Diverse Image Synthesis from Semantic Layouts via Conditional IMLE. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 4220–4229. [Google Scholar]
- Rossler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. Faceforensics++: Learning to detect manipulated facial images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Li, W.; Ding, W.; Sadasivam, R.; Cui, X.; Chen, P. His-GAN: A histogram-based GAN model to improve data generation quality. Neural Netw. 2019, 119, 31–45. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Models | Fake Images | Real Images | Image Source |
|---|---|---|---|---|
| Conditional GANs | CycleGAN | 1321 | 1321 | Style/object transfer |
| StarGAN | 1999 | 1999 | Celebes | |
| GauGAN | 5000 | 5000 | COCO | |
| Unconditional GANs | ProGAN | 4000 | 4000 | LSUN |
| StyleGAN | 5991 | 5991 | LSUN | |
| Bagan | 2000 | 2000 | ImageNet | |
| Low-level vision | SITD | 180 | 180 | Raw camera |
| SAN | 219 | 219 | Standard SR benchmark | |
| Perceptual loss | CRN | 6382 | 6382 | GTA |
| IMLE | 6382 | 6382 | GTA | |
| DeepFakes | FaceForensics++ | 2700 | 2700 | Videos of faces |
| f-ac | AP | AUC | |
|---|---|---|---|
| unperturbed | 0.9997 | 0.9999 | 0.9999 |
| Perturbed by DF | 0.0923 | 0.3356 | 0.0430 |
| Perturbed by PNDF | 0.0731 | 0.3212 | 0.0331 |
| Models | f-ac | AP | AUC | |||
|---|---|---|---|---|---|---|
| Unperturbed | Perturbed | Unperturbed | Perturbed | Unperturbed | Perturbed | |
| CRN | 0.9987 | 0.0007 | 0.9823 | 0.3135 | 0.9877 | 0.0394 |
| IMLE | 0.9976 | 0.0393 | 0.9840 | 0.3069 | 0.9884 | 0.0024 |
| SITD | 0.8666 | 0.0611 | 0.9723 | 0.3068 | 0.9756 | 0.0156 |
| StarGAN | 0.8129 | 0.0065 | 0.9400 | 0.3126 | 0.9780 | 0.0417 |
| CycleGAN | 0.7887 | 0.0832 | 0.9246 | 0.3346 | 0.9384 | 0.0799 |
| StyleGAN | 0.7426 | 0.1330 | 0.9959 | 0.3100 | 0.9958 | 0.0354 |
| GauGAN | 0.6480 | 0.0180 | 0.8948 | 0.3077 | 0.9206 | 0.0130 |
| BigGAN | 0.4690 | 0.0465 | 0.8450 | 0.3087 | 0.8819 | 0.0160 |
| DeepFake | 0.0685 | 0.0111 | 0.8902 | 0.3063 | 0.8844 | 0.0000 |
| SAN | 0.0182 | 0.5844 | 0.7046 | 0.3400 | 0.7185 | 0.1049 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, L.; Li, W.; Cui, X. Deepfake-Image Anti-Forensics with Adversarial Examples Attacks. Future Internet 2021, 13, 288. https://doi.org/10.3390/fi13110288
Fan L, Li W, Cui X. Deepfake-Image Anti-Forensics with Adversarial Examples Attacks. Future Internet. 2021; 13(11):288. https://doi.org/10.3390/fi13110288
Chicago/Turabian StyleFan, Li, Wei Li, and Xiaohui Cui. 2021. "Deepfake-Image Anti-Forensics with Adversarial Examples Attacks" Future Internet 13, no. 11: 288. https://doi.org/10.3390/fi13110288
APA StyleFan, L., Li, W., & Cui, X. (2021). Deepfake-Image Anti-Forensics with Adversarial Examples Attacks. Future Internet, 13(11), 288. https://doi.org/10.3390/fi13110288