
Ambalytics: A Scalable and Distributed System Architecture Concept for Bibliometric Network Analyses



Abstract
:1. Introduction
- A technical description of the generation process of hybrid research fronts is presented, which can then be used as a development blueprint for other calculation opportunities of bibliometric analyses.
- A derivation of user stories and functional requirements based on interviews is provided to better show the needs of the interested users.
- A computing schema to support ad hoc as well as batch-oriented bibliometric analysis tasks is presented and discussed.
- A system architecture concept to support scalable and distributed bibliometric analyses is presented.
2. Bibliometric Analysis
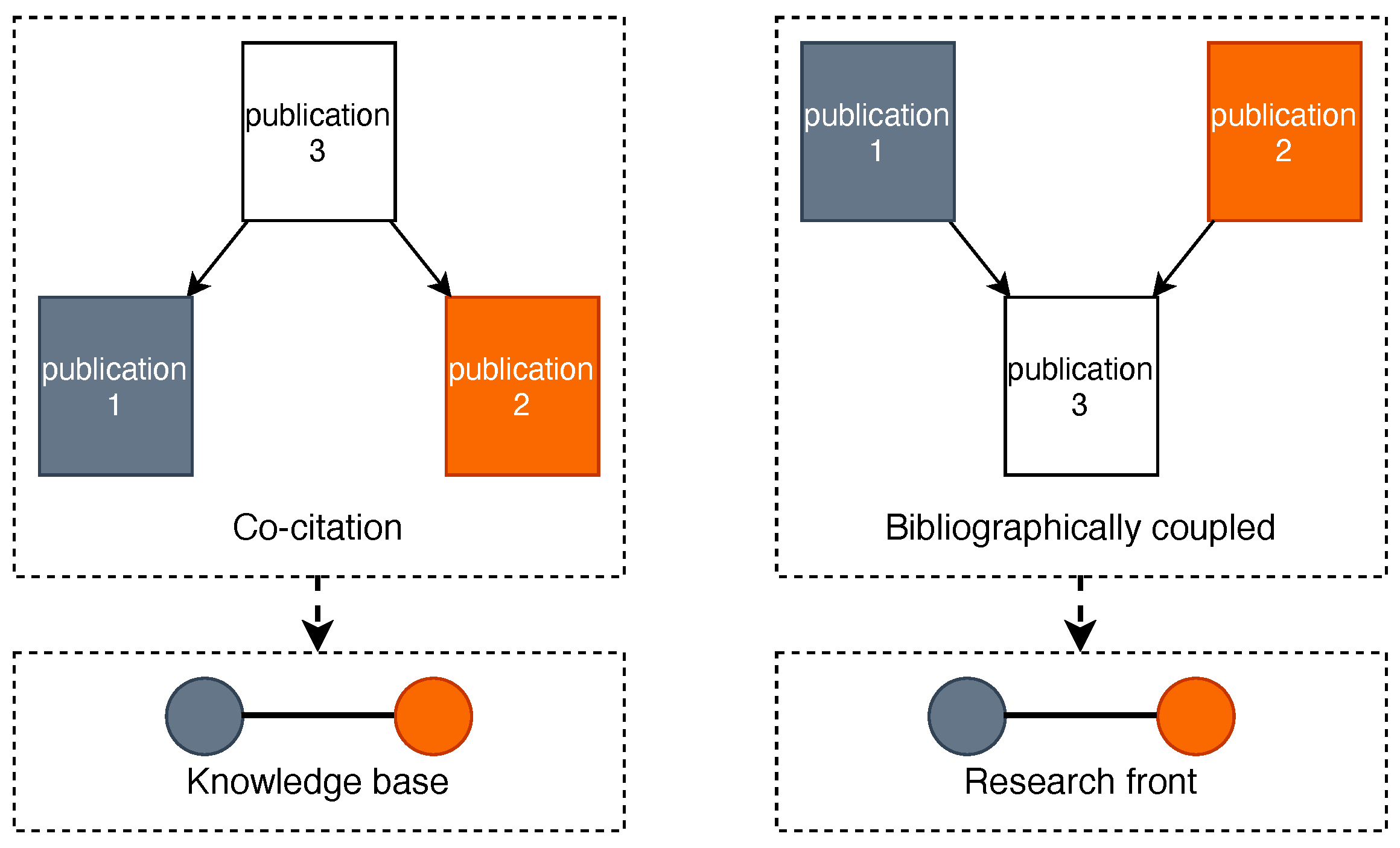
- Knowledge Bases: Groups of academic publications in a field of research on which the field is based on.
- Research Fronts: Groups of academic publications in a field of research that concern themselves with similar unsolved research problems.
- Classics: Academic publications that are outstanding and have a great impact on a field of research.
- Field Players: Authors, organizations, or countries significantly contributing to a field of research, and thereby their cooperation dynamics can be analyzed.
- Hidden Knowledge: Scientific knowledge is not always published in the form of academic publications or even published at all. Furthermore, qualitative findings, such as expert opinions, are often not taken into account by bibliometric analyses.
- Dataset Creation: Every bibliometric analysis is based on a dataset of documents that has to be acquired in some way. Typically, publication databases are queried, and the results are extracted. The query terms used for data collection affect bibliometric analyses results.
- Time Delay: The data available in publication databases is a snapshot of academic knowledge, which does not fully represent the current state of the art, as it takes up to two years for research findings to be published and listed in those databases.
- Publish or Perish: As the number of publications and citations have some influence on the evaluation of authors and institutions, a co-authorship might not reflect actual collaborations [1]. In addition, self-citations and citations in review publications may not be content-specific.
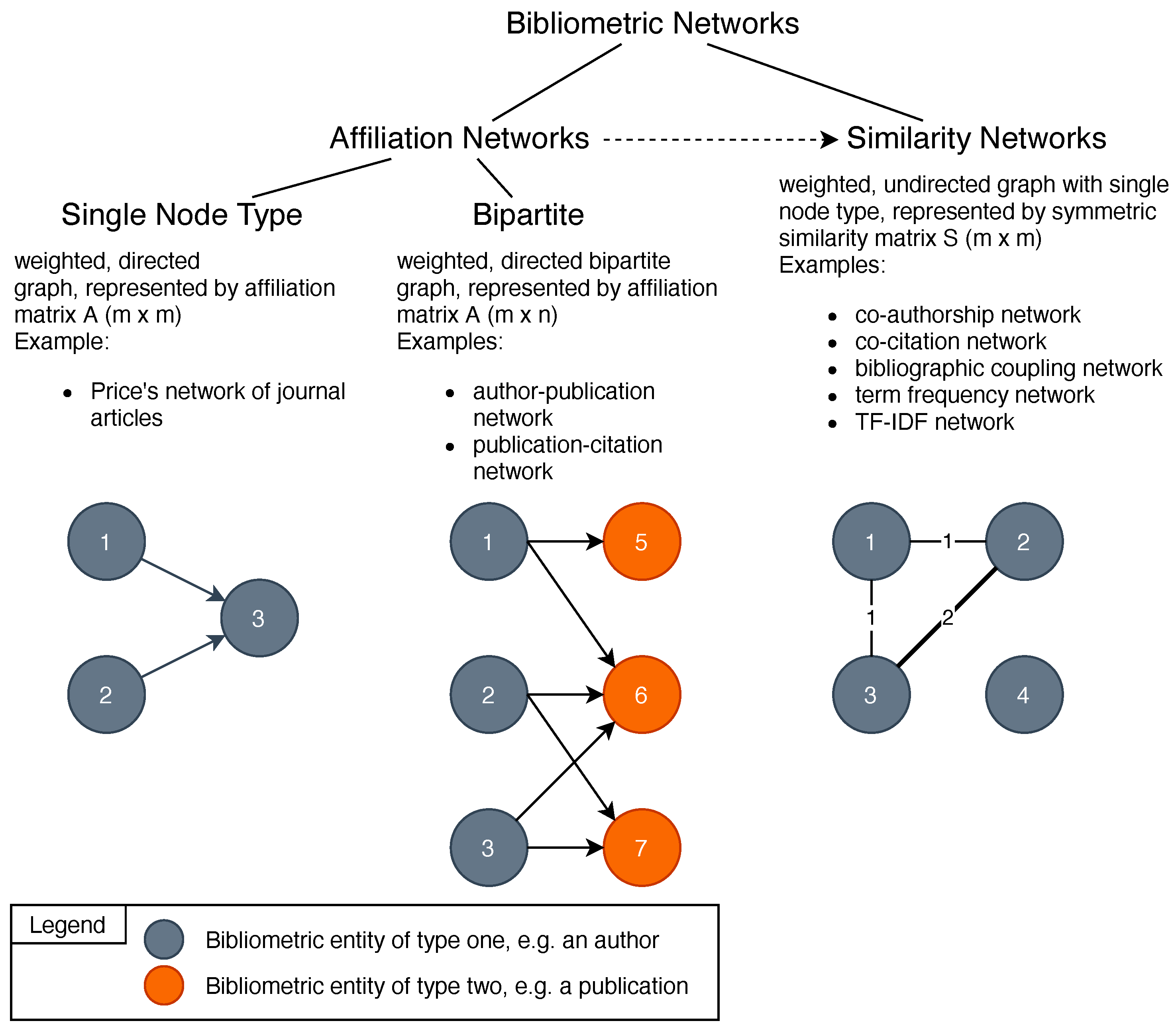
2.1. Bibliometric Networks
Publication Networks
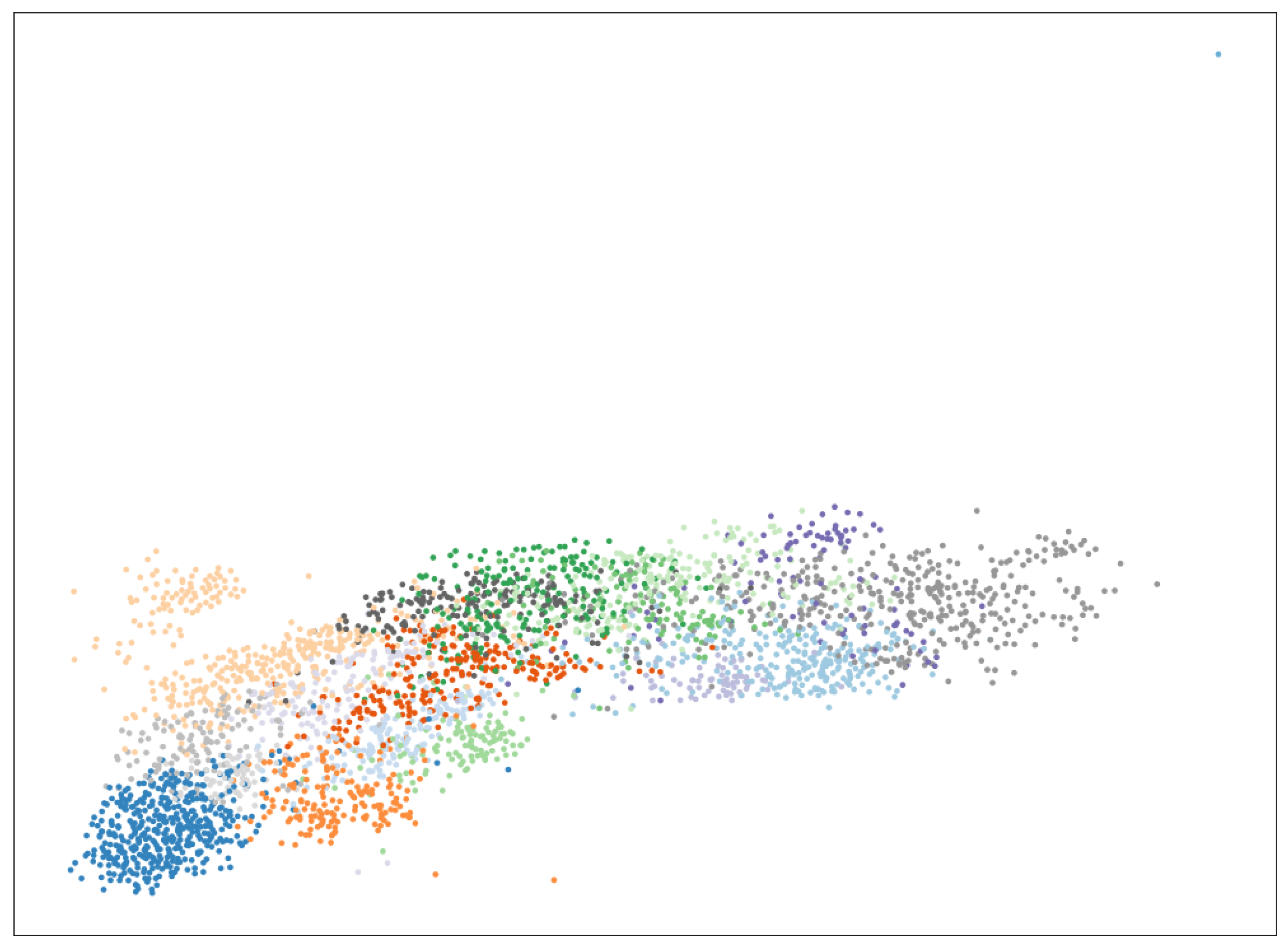
2.2. Computing Hybrid Research Fronts
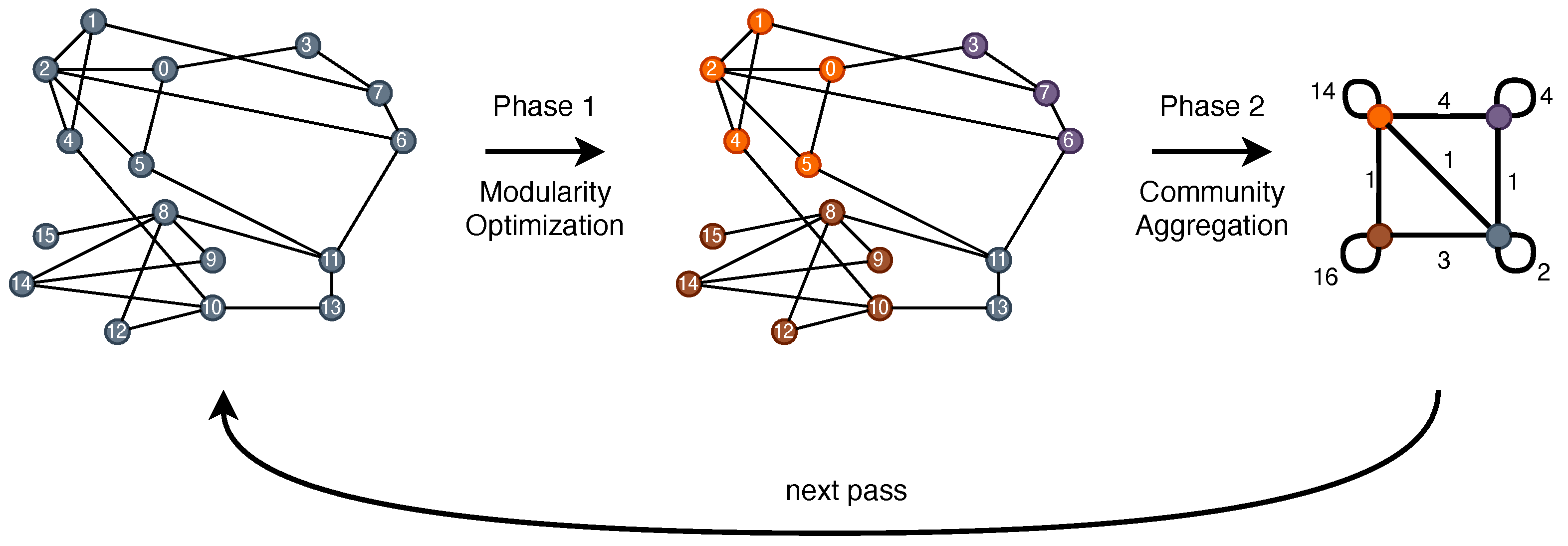
2.3. The Louvain Algorithm for Community Detection in Graphs
2.4. Bibliometric Analysis Process
3. Ambalytics Bibliometric Platform
3.1. Objectives and Challenges
3.2. User Stories
- A user searches for scientific publications and other bibliometric entities. For this purpose, they are able to search the entities in full text.
- A user inspects a publication in the search results and uses additional information, such as the abstract, references and citations and their number, and a link to the publisher’s website.
- A user wants to compute and visualize a bibliometric network. For example, they want to find out emerging topics in research covered by the search result. Therefore, the user creates a publication similarity network.
- Having calculated a bibliometric network, a user is not satisfied with the result. He or she adjusts the search query, reruns the computation, and inspects the updated visualization.
- Calculation of a bibliometric network may take some time. Following this, a user starts the calculation of multiple networks, which are expected to be computed in parallel. Thus, they do not have to wait until they have been computed sequentially. While waiting for the calculations to finish, they explore the search results by inspecting some entities.
- A user interrupts his work on a bibliometric analysis in their office and continues their work at a later point in time with a different computer.
3.3. Requirements Analysis
3.4. Software Architecture
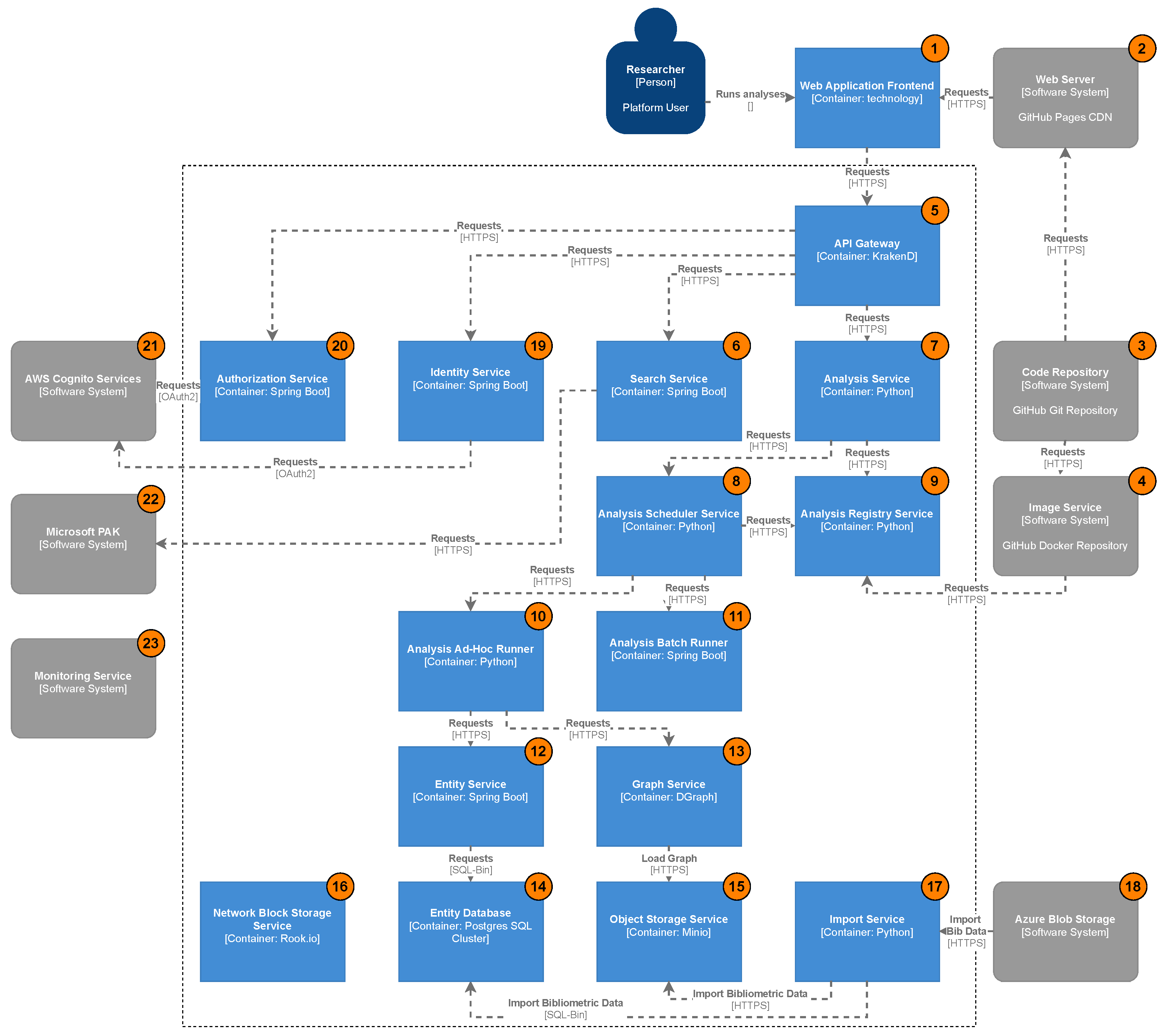
3.5. System Context
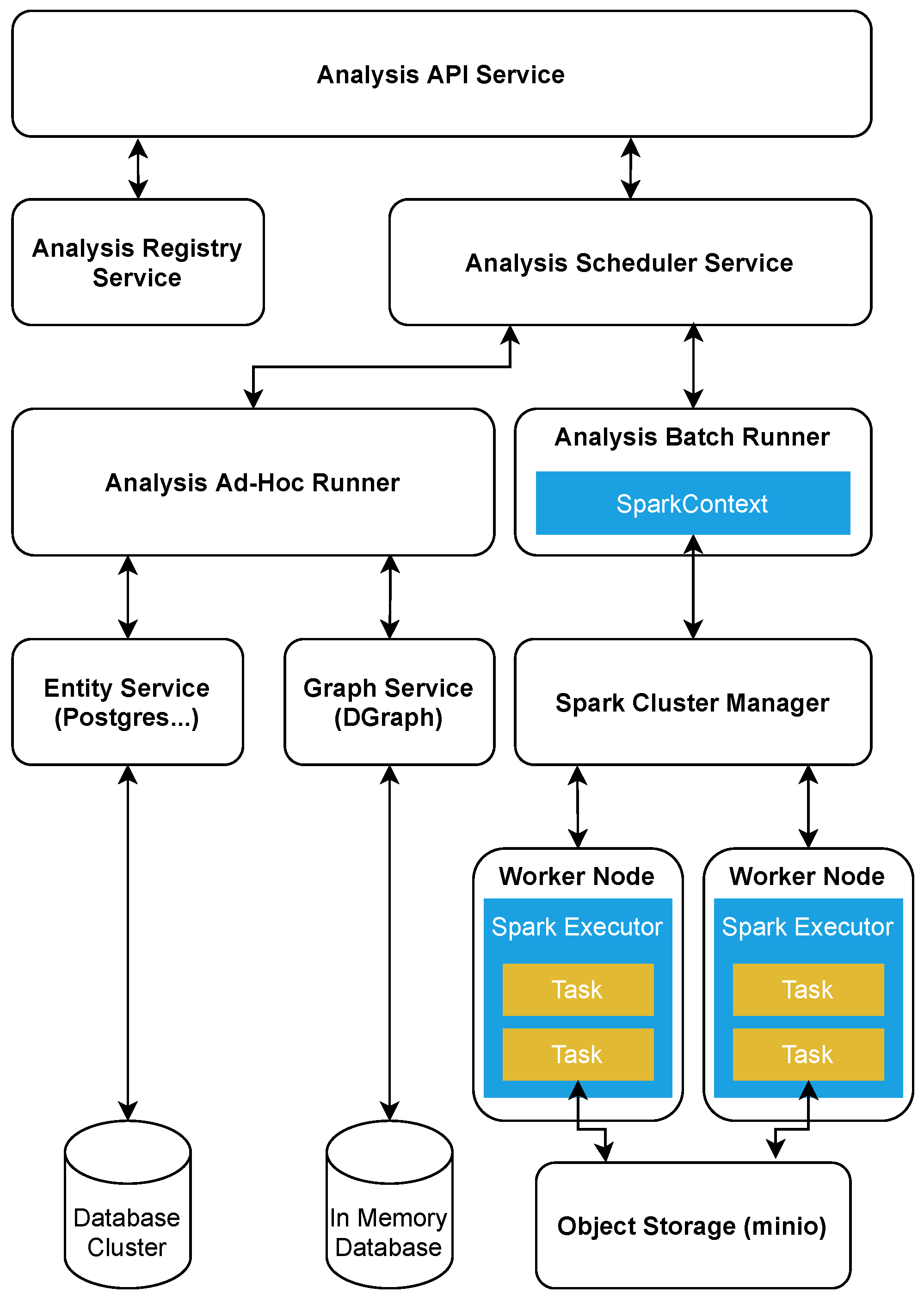
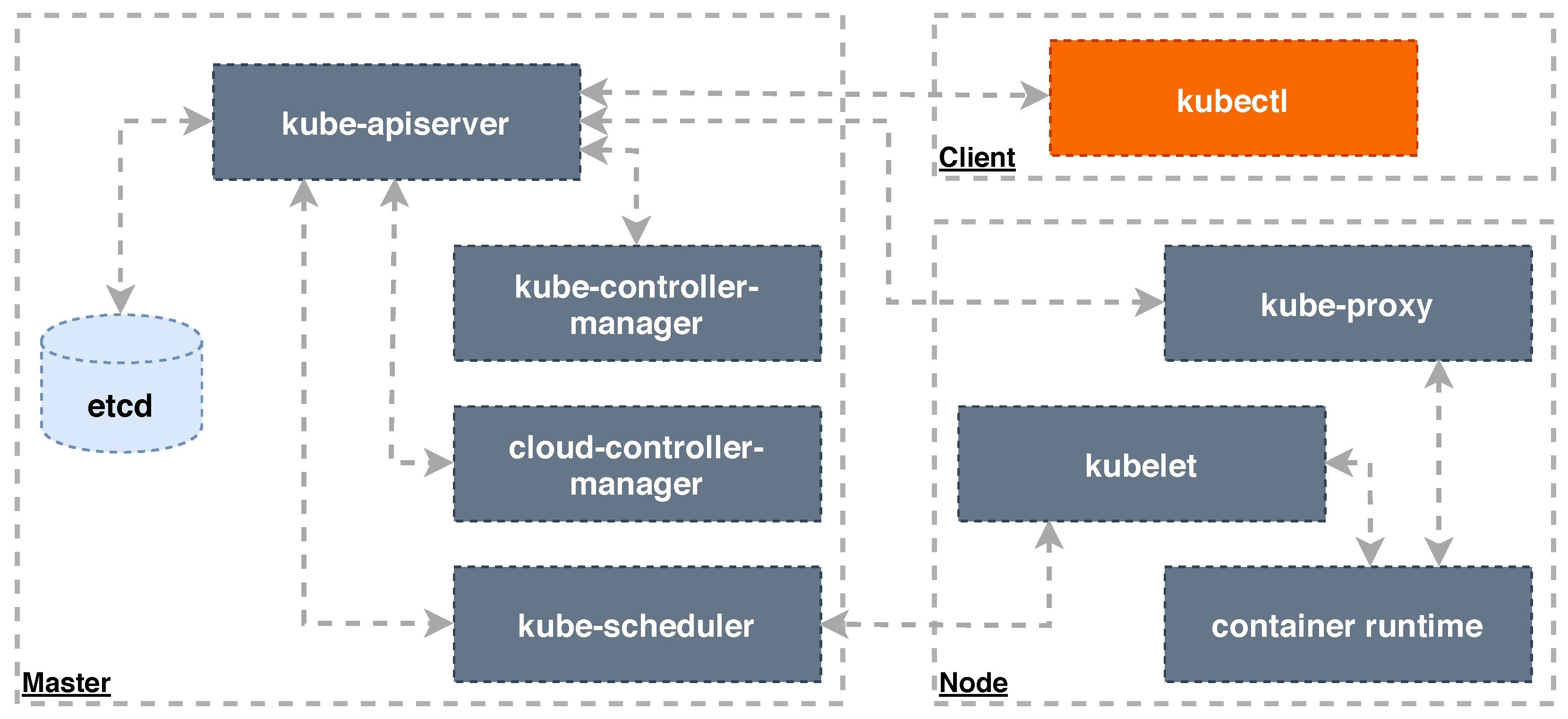
3.6. System Architecture
3.7. System Containers
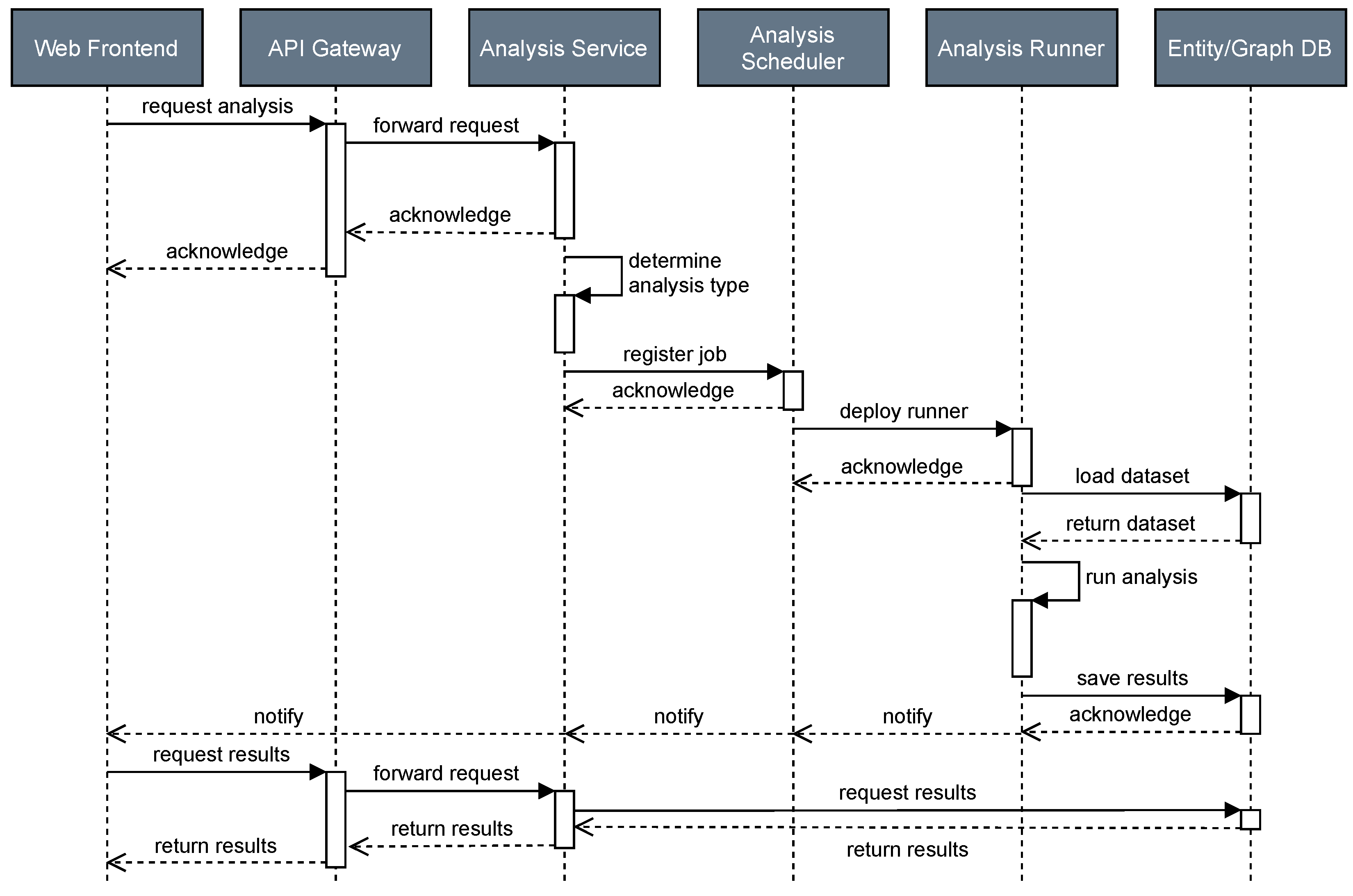
3.8. Process View
3.9. Infrastructure View
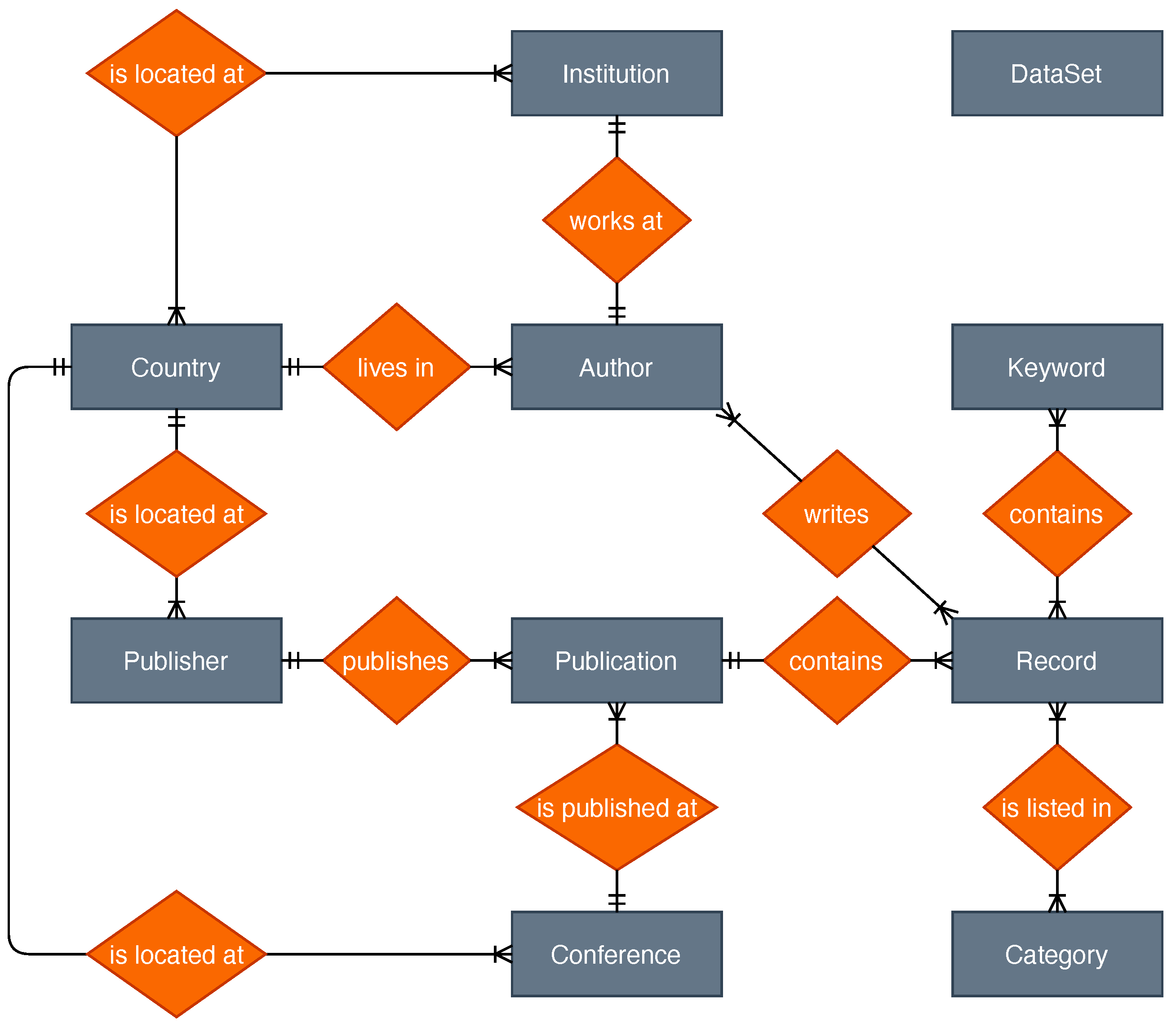
3.10. Data Model
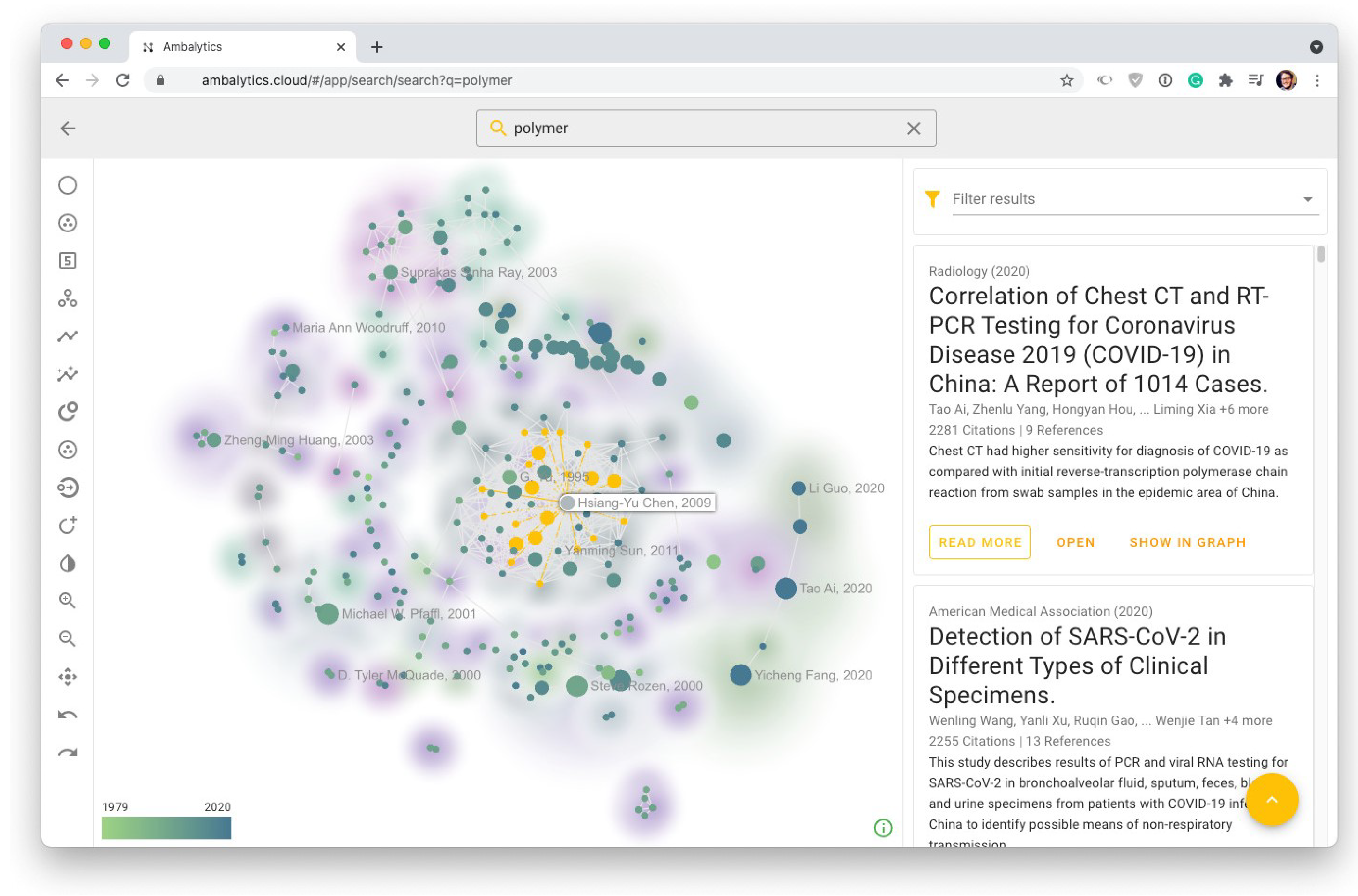
3.11. User Interface
4. Results and Discussion
4.1. Architectural Decisions
4.2. Technological Selection
4.3. Related Work
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| API | Application Programming Interface |
| CLI | Command Line Interface |
| DAG | Directed Acyclic Graph |
| DOI | Document Object Identifier |
| DFM | Document Feature Matrix |
| DSL | Domain Specific Language |
| EER | Extended Entity Relationship |
| FR | Functional Requirement |
| HS | Hybrid Similarity Matrix |
| ID | Identifier |
| KDD | Knowledge Discovery in Databases |
| MAG | Microsoft Academic Graph |
| REST | REpresentational State Transfer |
| TF/IDF | Term Frequency/Inverse Document Frequency |
| UC | Use Case |
| US | User Story |
Appendix A. Overview of Bibliometric Tools

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Aspect | Citespace | CitNetExplorer | SciMAT | VOSViewer |
|---|---|---|---|---|
| Developer | College of Computing and Informatics, Drexel University | Centre for Science and Technology Studies, Leiden University | Research Group Soft Computing and Intelligent Information Systems, University of Granada | Centre for Science and Technology Studies, Leiden University |
| Primary Use Case | Trends Visualization with Bibliometric Analysis | Bibliometric Analysis and Visualization | Bibliometric Analysis and Visualization | Bibliometric Analysis and Visualization |
| Application Type/ Architecture | Desktop | Desktop | Desktop | Desktop |
| Programming Languages | Java | Java | Java | Java |
| Automatic Data Retrieval | − | − | − | − |
| Pre−Processing | Time slicing, data and networks reduction | Data reduction | De-duplication, time slicing, data reduction | − |
| Bibliometric Data Source | WoS, Scopus, CrossRef, Dimensions, PubMed, arXiv, custom | WoS, custom | WoS, Scopus, PubMed, custom | WoS, Scopus, PubMed |
| Initial Seed | Dataset | Dataset | Dataset | Dataset |
| Network Analysis | Citation, Co-citation, Bibliographic coupling | Citation | Citation, Co-citation, Bibliographic coupling | Citation, Co-citation, Bibliographic coupling |
| Community Detection | + | + | + | + |
| Lexical Analysis | + | − | − | + |
| GraphVisualization | + | + | + | + |
| Aspect | Tethne | Bibliometrix | Bibliotools | Metaknowledge |
|---|---|---|---|---|
| Developer | Digital Innovation Group, Arizona State University | Community-driven, Department of Economics and Management, Università della Campania Luigi Vanvitelli | Sébastian Grauwin | Netlab, University of Waterloo |
| Primary Use Case | Programming Library for Bibliometric Analysis | Programming Library for Bibliometric Analysis | Programming Library for Bibliometric Analysis | Programming Library for Bibliometric Analysis |
| Application Type/Architecture | Programming Library | Programming Library | Programming Library, Desktop (BiblioMaps) | Programming Library |
| Programming Languages | Python | R | Python | Python |
| Automatic Data Retrieval | − | − | − | − |
| Pre-Processing | − | + | Data and networks reduction | − |
| BibliometricData Source | WoS, JSTOR, Scopus | WoS, Scopus, Dimensions, Cochrane, PubMed | WoS, Scopus | WoS, Scopus, PubMed |
| Initial Seed | Dataset | Dataset | Dataset | Dataset |
| Network Analysis | Citation, Co-citation, Bibliographic coupling | Citation, Co-citation, Bibliographic coupling | Citation, Co-citation, Bibliographic coupling | Citation, Co-citation, Bibliographic coupling |
| CommunityDetection | − | + | + | − |
| Lexical Analysis | − | + | − | − |
| GraphVisualization | − | plot | − (with Bibliomaps) | - |
| Aspect | CoCites | ConnectedPapers | Inciteful | Ambalytics |
|---|---|---|---|---|
| Developer | Rollins School of Public Health of Emory University, Atlanta | Tel Aviv University | unknown | Institute of Databases and Information Systems, Ulm University and Institute of Clinical Epidemiology and Biometry, University of Würzburg |
| Primary Use Case | Discovery of related publications | Discovery of related publications | Discovery of related publications | Publication search, discovery of related publications, bibliometric analysis |
| Application Type/Architecture | Browser Plugin/unknown | Web-based/unknown | Web-based/unknown | Web-based/Micro-service architecture + Kubernetes |
| Programming Languages | unknown | unknown | Rust, React.js | Java, Python, Vue.js |
| Automatic Data Retrieval | + | + | + | + |
| Pre-Processing | N/A | unknown | unknown | De-duplication, data and networks reduction |
| BibliometricData Source | NIH Open Citation Collection (NIH-OCC) | SemanticScholar | Microsoft Academic, SemanticScholar | Microsoft Academic (WoS, Scopus, PubMed planned) |
| Initial Seed | Single Publication | Single Publication | Single Publication, extensible | Included keyword-based search: Single Publication, extensible |
| Network Analysis | Co-citation | Combination of Co-citation and bibliographic coupling | Citation, Co-citation | Citation, Co-citation, bibliographic coupling |
| CommunityDetection | − | − | − | + |
| Lexical Analysis | − | − | − | + |
| GraphVisualization | − | + | − | + |
References
- Havemann, F. Einführung in die Bibliometrie; Gesellschaft für Wissenschaftsforschung: Berlin, Germany, 2009. [Google Scholar]
- Ozdemir, S. Principles of Data Science; Packt Publishing: Birmingham, UK, 2016. [Google Scholar]
- Göster, M. Citarics—A Microservice Platform for Bibliometric Network Analysis and Visualization. Master’s Thesis, Ulm University, Ulm, Germany, 2020. [Google Scholar]
- Aria, M.; Cuccurullo, C. bibliometrix: An R-tool for Comprehensive Science Mapping Analysis. J. Informetr. 2017, 11, 959–975. [Google Scholar] [CrossRef]
- Van Eck, N.J.; Waltman, L. CitNetExplorer: A New Software Tool for Analyzing and Visualizing Citation Networks. J. Informetr. 2014, 8, 802–823. [Google Scholar] [CrossRef] [Green Version]
- Van Eck, N.J.; Waltman, L. VOSviewer Manual. Available online: https://www.vosviewer.com/documentation/Manual_VOSviewer_1.6.8.pdf (accessed on 11 June 2021).
- Persson, O.; Danell, R.; Schneider, J.W. How to Use Bibexcel for Various Types of Bibliometric Analysis. In Celebrating Scholarly Communication Studies: A Festschrift for Olle Persson at his 60th Birthday; International Society for Scientometrics and Informetrics: Berlin, Germany, 2009; Volume 5, pp. 9–24. [Google Scholar]
- Knutas, A.; Hajikhani, A.; Salminen, J.; Ikonen, J.; Porras, J. Cloud-Based Bibliometric Analysis Service for Systematic Mapping Studies. In Proceedings of the 16th International Conference on Computer Systems and Technologies, Dublin, Ireland, 25–26 June 2015; pp. 184–191. [Google Scholar]
- Zammit, A.; Penza, K.; Haddod, F.; Abela, C.; Azzopardi, J. ACE: Big Data Approach to Scientific Collaboration Patterns Analysis. In Proceedings of the Scientometrics and Enabling Decentralised Scholarly Communication, Portorož, Slovenia, 28 May 2017; Volume 1878. [Google Scholar]
- Cyberinfrastructure for Network Science Center, Indiana University at Bloomington. Sci2 Tool. 2009. Available online: https://sci2.cns.iu.edu/ (accessed on 6 May 2021).
- Sinha, A.; Shen, Z.; Song, Y.; Ma, H.; Eide, D.; Hsu, B.J.; Wang, K. An Overview of Microsoft Academic Service (MAS) and Applications. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 243–246. [Google Scholar]
- Weber, B.; Reichert, M.; Rinderle-Ma, S. Change Patterns and Change Support Features—Enhancing Flexibility in Process-aware Information Systems. Data Knowl. Eng. 2008, 66, 438–466. [Google Scholar] [CrossRef] [Green Version]
- Hoppenstedt, B.; Pryss, R.; Stelzer, B.; Meyer-Brötz, F.; Kammerer, K.; Treß, A.; Reichert, M. Techniques and Emerging Trends for State of the Art Equipment Maintenance Systems—A Bibliometric Analysis. Appl. Sci. 2018, 8, 916. [Google Scholar] [CrossRef] [Green Version]
- Ellegaard, O.; Wallin, J.A. The Bibliometric Analysis of Scholarly Production: How Great is the Impact? Scientometrics 2015, 105, 1809–1831. [Google Scholar] [CrossRef] [Green Version]
- Manning, C.D.; Raghavan, P.; Schütze, H. An Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Stelzer, B.; Meyer-Brötz, F.; Schiebel, E.; Brecht, L. Combining the Scenario Technique With Bibliometrics for Technology Foresight: The Case of Personalized Medicine. Technol. Forecast. Soc. Chang. 2015, 98, 137–156. [Google Scholar] [CrossRef]
- Meyer-Brötz, F. A Bibliometric Technique for Quantitative Technology Foresight. Ph.D. Thesis, Universität Ulm, Ulm, Germany, 2019. [Google Scholar] [CrossRef]
- Price, D.J.D.S. Networks of Scientific Papers. Science 1965, 149, 510–515. [Google Scholar] [CrossRef] [PubMed]
- Tokunaga, T.; Makoto, I. Text Categorization Based on Weighted Inverse Document Frequency; Special Interest Groups and Information Process Society of Japan: Tokyo, Japan, 1994; pp. 33–39. [Google Scholar]
- Meyer-Brötz, F.; Schiebel, E.; Brecht, L. Experimental Evaluation of Parameter Settings in Calculation of Hybrid Similarities: Effects of First- and Second-order Similarity, Edge Cutting, and Weighting Factors. Scientometrics 2017, 111, 1307–1325. [Google Scholar] [CrossRef]
- Salton, G.; Buckley, C. Term-Weighting Approaches in Automatic Text Retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef] [Green Version]
- Glänzel, W.; Thijs, B. Using ‘Core Documents’ for the Representation of Clusters and Topics. Scientometrics 2011, 88, 297–309. [Google Scholar] [CrossRef]
- Herman, I.; Melancon, G.; Marshall, M.S. Graph Visualization and Navigation in Information Visualization: A Survey. IEEE Trans. Vis. Comput. Graph. 2000, 6, 24–43. [Google Scholar] [CrossRef] [Green Version]
- Cabena, P.; Hadjinian, P.; Stadler, R.; Verhees, J.; Zanasi, A. Discovering Data Mining: From Concept to Implementation; Prentice-Hall, Inc.: Hoboken, NJ, USA, 1998. [Google Scholar]
- Everitt, B.; Landau, S.; Leese, M.; Stahl, D. Cluster Analysis; Wiley Series in Probability and Statistics; Wiley: Hoboken, NJ, USA, 2011. [Google Scholar]
- Guidotti, R.; Coscia, M. On the Equivalence Between Community Discovery and Clustering. In Smart Objects and Technologies for Social Good; Springer: Cham, Switzerland, 2018; pp. 342–352. [Google Scholar]
- Fortunato, S. Community Detection in Graphs. Phys. Rep. 2010, 486, 75–174. [Google Scholar] [CrossRef] [Green Version]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast Unfolding of Communities in Large Networks. J. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef] [Green Version]
- Cobo, M.J.; López-Herrera, A.G.; Herrera-Viedma, E.; Herrera, F. Science Mapping Software tools: Review, Analysis, and Cooperative Study Among Tools. J. Am. Soc. Inf. Sci. Technol. 2011, 62, 1382–1402. [Google Scholar] [CrossRef]
- Kortgen, A.; Niederprüm, P.; Bauer, M. Implementation of an evidence-based “standard operating procedure” and outcome in septic shock. Crit. Care Med. 2006, 34, 943–949. [Google Scholar] [CrossRef]
- Stellman, A.; Greene, J. Applied Software Project Management; O’Reilly: Newton, MA, USA, 2006. [Google Scholar]
- Richards, M.; Ford, N. Fundamentals of Software Architecture: An Engineering Approach; O’Reilly: Newton, MA, USA, 2020. [Google Scholar]
- Brown, S. Software Architecture for Developers. Available online: http://static.codingthearchitecture.com/sddconf2014-software-architecture-for-developers-extract.pdf (accessed on 6 May 2021).
- Linux Foundation. Kubernetes. 2020. Available online: https://kubernetes.io/ (accessed on 6 May 2021).
- Linux Foundation. Cloud Native Computing Foundation. 2020. Available online: https://www.cncf.io/ (accessed on 6 May 2021).
- Linux Foundation. Kubernetes Documentation. 2020. Available online: https://kubernetes.io/docs/ (accessed on 6 May 2021).
- Ushio, T. Kubernetes in Three Diagrams. 2018. Available online: https://medium.com/@tsuyoshiushio/kubernetes-in-three-diagrams-6aba8432541c (accessed on 6 May 2021).
- Matsuda, K.; Lea, R. WebGL Programming Guide: Interactive 3D Graphics Programming with WebGL; Addison-Wesley: Boston, MA, USA, 2013. [Google Scholar]
- Moral Muñoz, J.A.; Herrera Viedma, E.; Santisteban Espejo, A.; Cobo, M.J. Software Tools for Conducting Bibliometric Analysis in Science: An up-to-Date Review. 2020. Available online: http://hdl.handle.net/10498/22857 (accessed on 7 July 2021).
- Hug, S.E.; Ochsner, M.; Brändle, M.P. Citation Analysis with Microsoft Academic. Scientometrics 2017, 111, 371–378. [Google Scholar] [CrossRef] [Green Version]
- Visser, M.; van Eck, N.J.; Waltman, L. Large-scale Comparison of Bibliographic Data Sources: Scopus, Web of Science, Dimensions, Crossref, and Microsoft Academic. Quant. Sci. Stud. 2021, 2, 20–41. [Google Scholar] [CrossRef]
- Vicknair, C.; Macias, M.; Zhao, Z.; Nan, X.; Chen, Y.; Wilkins, D. A Comparison of a Graph Database and a Relational Database: A Data Provenance Perspective. In Proceedings of the 48th Annual Southeast Regional Conference, Oxford, MS, USA, 15–17 April 2010. [Google Scholar] [CrossRef]
- Meyer, U.; Sanders, P. Algorithms for Memory Hierarchies: Advanced Lectures; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2003; Volume 2625. [Google Scholar]
- Apache Software Foundation. Apache Spark. 2020. Available online: https://spark.apache.org/ (accessed on 6 May 2021).
- White, C. Why Not Airflow? 2020. Available online: https://medium.com/the-prefect-blog/why-not-airflow-4cfa423299c4 (accessed on 6 May 2021).
- Aldinucci, M.; Danelutto, M.; Kilpatrick, P.; Meneghin, M.; Torquati, M. An Efficient Unbounded Lock-free Queue for Multi-core Systems. In European Conference on Parallel Processing; Springer: Berlin/Heidelberg, Germany, 2012; pp. 662–673. [Google Scholar]
- Bankar, R.S.; Lihitkar, S.R. Science Mapping and Visualization Tools used for Bibliometric and Scientometric Studies: A Comparative Study. J. Adv. Libr. Sci. 2019, 6, 382–394. [Google Scholar]
- Synnestvedt, M.B.; Chen, C.; Holmes, J.H. CiteSpace II: Visualization and Knowledge Discovery in Bibliographic Databases. In Proceedings of the AMIA Annual Symposium Proceedings. American Medical Informatics Association, Washington, DC, USA, 22–26 October 2005; Volume 2005, p. 724. [Google Scholar]
- Cobo, M.J.; López-Herrera, A.G.; Herrera-Viedma, E.; Herrera, F. SciMAT: A New Science Mapping Analysis Software Tool. J. Am. Soc. Inf. Sci. Technol. 2012, 63, 1609–1630. [Google Scholar] [CrossRef]
- Grauwin, S.; Jensen, P. Mapping Scientific Institutions. Scientometrics 2011, 89, 943–954. [Google Scholar] [CrossRef] [Green Version]
- McLevey, J.; McIlroy-Young, R. Introducing metaknowledge: Software for Computational Research in Information Science, Network Analysis, and Science of Science. J. Informetr. 2017, 11, 176–197. [Google Scholar] [CrossRef]
- Roberts, R.J. PubMed Central: The GenBank of the Published Literature. 2001. Available online: https://www.pnas.org/content/98/2/381.full (accessed on 6 May 2021).
- Ammar, W.; Groeneveld, D.; Bhagavatula, C.; Beltagy, I.; Crawford, M.; Downey, D.; Dunkelberger, J.; Elgohary, A.; Feldman, S.; Ha, V.; et al. Construction of the Literature Graph in Semantic Scholar. arXiv 2018, arXiv:1805.02262. [Google Scholar]
- Adamic, L.A.; Adar, E. Friends and Neighbors on the Web. Soc. Netw. 2003, 25, 211–230. [Google Scholar] [CrossRef] [Green Version]














| Name | Summary | Rationale |
|---|---|---|
| Search for Bibliometric Entities | Create a dataset by executing a search query. | In order to execute a bibliometric analysis, a dataset containing bibliometric entities is needed. |
| Provide Bibliometric Entities | Provide an interface to retrieve bibliometric entities. | The use of bibliometric entities and their attributes, such as the abstract of a publication, is a prerequisite for performing a full-text search and computing hybrid similarity networks. |
| Results Search and Sorting | Provide an interface to search for bibliographic entity attributes in search results. | It is essential to have a capable text search within search results as it typically consists of several hundred or thousand publications. |
| Descriptive Statistics | Compute descriptive metrics of the given search result. | Users are interested in search result descriptive metrics, such as a time-based distribution, to orient themselves and obtain an overview. |
| Bibliometric Networks Computation | Create bipartite or similarity graphs of bibliometric entities. | A user wants to use bibliometric networks to obtain a better overview of a research field, find related publications, or identify research trends. |
| Visualization of Analysis Results | Computed descriptive statistics and bibliometric networks have to be visualized. | Appropriate visualizations are appealing and provide fast insights to a user. |
| Parallel Execution of Computation-intensive Tasks | Distribute computation-intensive tasks, such as network calculations, across processes and computing hardware. | Parallel computations are required to ensure high speed in the creation of bibliometric networks. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kammerer, K.; Göster, M.; Reichert, M.; Pryss, R. Ambalytics: A Scalable and Distributed System Architecture Concept for Bibliometric Network Analyses. Future Internet 2021, 13, 203. https://doi.org/10.3390/fi13080203
Kammerer K, Göster M, Reichert M, Pryss R. Ambalytics: A Scalable and Distributed System Architecture Concept for Bibliometric Network Analyses. Future Internet. 2021; 13(8):203. https://doi.org/10.3390/fi13080203
Chicago/Turabian StyleKammerer, Klaus, Manuel Göster, Manfred Reichert, and Rüdiger Pryss. 2021. "Ambalytics: A Scalable and Distributed System Architecture Concept for Bibliometric Network Analyses" Future Internet 13, no. 8: 203. https://doi.org/10.3390/fi13080203
APA StyleKammerer, K., Göster, M., Reichert, M., & Pryss, R. (2021). Ambalytics: A Scalable and Distributed System Architecture Concept for Bibliometric Network Analyses. Future Internet, 13(8), 203. https://doi.org/10.3390/fi13080203