3.2. Datasets
Four datasets are used in this research. The first dataset is the “Sign Language Digits Dataset” [
32] and the second dataset is the “American Sign Language Digit Dataset” [
33]. The third dataset is the “American Sign Language Dataset” [
34]. The last dataset is the validation dataset.
Table 1 exhibits the list of datasets that we use in our research.
The first dataset consists of hand images for the hand signs 0–9 in American Sign Language (ASL). Each image has a dimension of 100 × 100 pixels. Each class has more than 200 images, comprising 2062 images in 10 categories. Images in this dataset have good quality and are all taken with a uniform white-grey background color.
Figure 2 shows some example images from the dataset.
The second dataset contains 5000 raw images of hand signs 0–9 in ASL, 500 images per class. It also has the corresponding output image files, which were processed using Mediapipe to detect and show the hand landmarks. In addition, this dataset also includes the hand landmark detection results in the form of CSV files. In this research, the CSV files are used to train and test the model.
The third dataset consists of the whole digit and alphabet hand signs in ASL and some hand signs for simple sentences, but only the digit hand signs are used in this research. Images in this dataset have a dimension of 422 × 422 pixels. Similar to the first dataset, the images have good quality and are also taken in a uniform background color. The dataset’s author has already split the images into a train set and a test set. The train set contains 1000 images per class for 10,000 images, while the test set contains 200 images per class for a total of 2000 images.
Figure 3 shows some examples of the images in this dataset.
The last dataset is the validation dataset. The validation dataset is a collection of 300 images taken directly by researchers to test the models using images not part of the training and testing sets. These images are taken using webcams and are taken in good lighting conditions. The images in this dataset have some background variation, making them better when used to evaluate the accuracy of the trained models. The uncropped image is a half-body image with one hand showing a digit hand sign, while the cropped image is a 100x100 pixels image of the hand, cropped from the full image. The cropping is carried out programmatically by utilizing the hand-detection feature from Mediapipe. After adding some padding on the detected hand’s top, bottom, left, and right sides, the hand will be cropped. This dataset is only used to evaluate the models that have already been trained and tested using the other three datasets and will not be used for any model training.
3.5. Feature Selection Method
Recursive Feature Elimination (RFE) is implemented to reduce the number of features used to train the models. RFE is chosen since we can decide the number of features to be selected from the original features. RFE fits a learning model as a wrapper method and removes the less critical features [
35]. Random Forest (RF) is the learning model chosen for this research. Random Forest uses Gini importance to calculate the feature importance. The feature importance of a binary tree decision tree can be denoted by Equation (3):
where
nij is the importance of node
j;
wj is the weighted number of samples reaching node
j;
Cj is the impurity value of node
j;
left (j) is the child node from left split on node
j;
right (j) is the child node from right split on node
j.
Then the importance of each feature on a decision tree is based on Equation (4):
where
fii is the importance of feature
I;
nij is the importance of node
j.
These values then can be normalized by dividing them by the sum of all feature importance values with Equation (5):
Finally, the feature importance of a feature in the random forest level is the average over all the trees as in Equation (6):
RF fii is the importance of a feature I in the random forest model; norm fiij is the normalized feature importance of feature I in tree j; T is the total number of trees in the random forest.
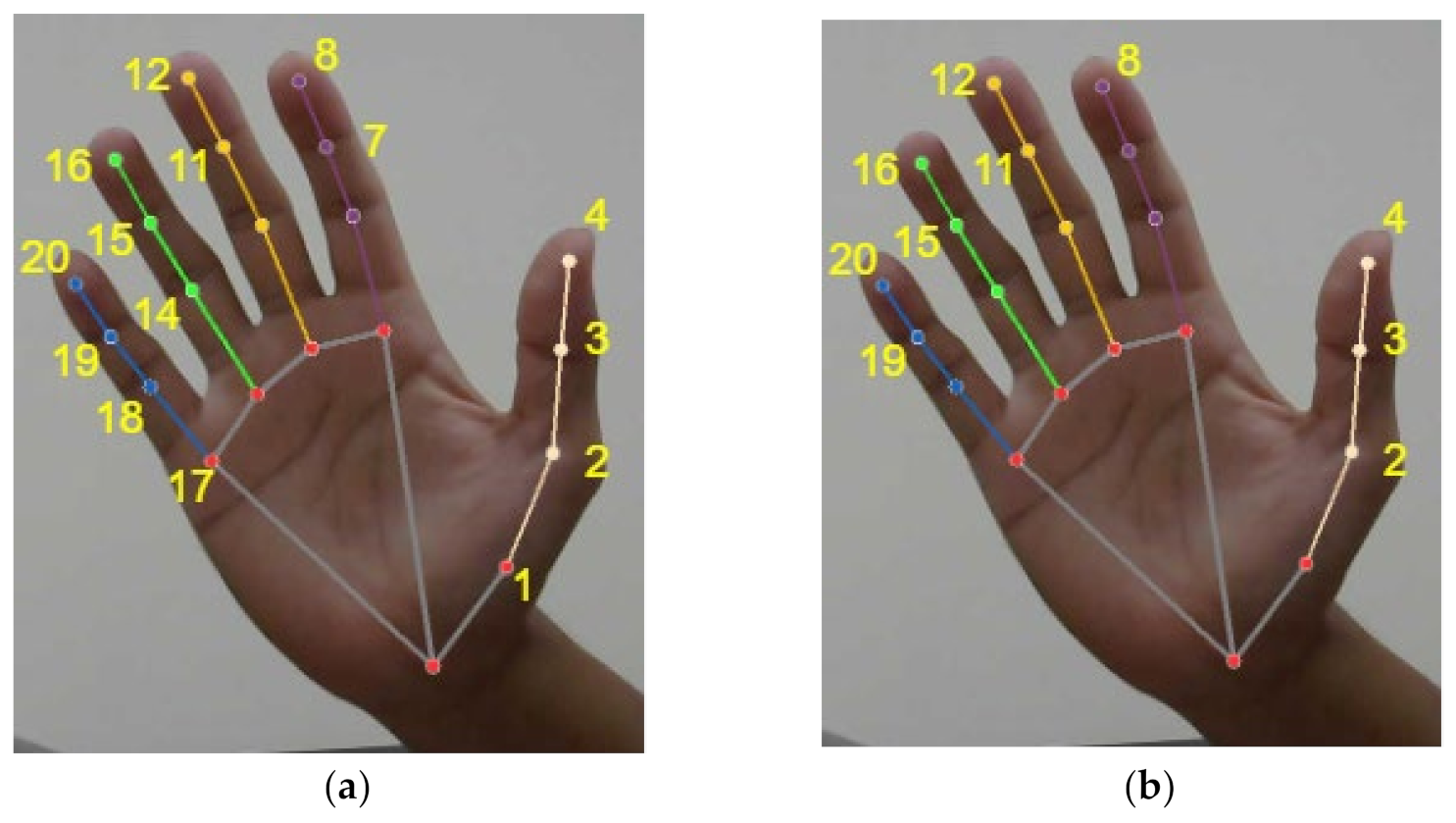
Before making the feature selection, the hand landmark data need to be converted from coordinates to distance between points because the feature selection methods currently available in Python cannot accept a 2D array as the input feature. We choose not to flatten the input into 1D because doing so will destroy the relationship between the
x and
y coordinate of each point and RFE will treat each
x and
y value of a point as a separate feature. In this research, we propose using a novel distance between the hand landmark to the hand palm centroid. The distance is calculated as a Euclidean distance from the hand landmarks to an anchor point
Pa which is in the center of the palm. The point
Pa is calculated as a centroid of a triangle formed by the coordinates
P0,
P5, and
P17. This coordinate can be represented by Equations (7) and (8):
Pax is the x coordinate for Pa; Pnx is the x coordinate of the n landmark point; Pay is Pa’s y coordinate; and Pny is the y coordinate of the n landmark point.
Euclidean distance between
Pa and
Pn is indicated in Equation (9):
where (
x1,
y1) is the coordinate of the first point, which is the anchor point; (
x2,
y2) is the coordinate of the second point; and
d is the Euclidean distance between the 2 points.
Using RFE, the number of features is reduced from the original 21 features to 15 and 10 features. The algorithm of RFE can be described in Algorithm 1:
| Algorithm 1: Random Forest-Recursive Feature Elimination. |
![Futureinternet 14 00352 i001]() |
RFE will take an input of the number of desired features and also the dataset containing the original number of features. Then it will build and fit a random forest model and calculate the feature importance. The next step is to remove the least important feature from the dataset. If there is still a feature in the dataset, it will recursively repeat this until there are no more features in the dataset. Finally, it will return the top-n most important features for digit hand-sign classification.
3.6. Training Steps
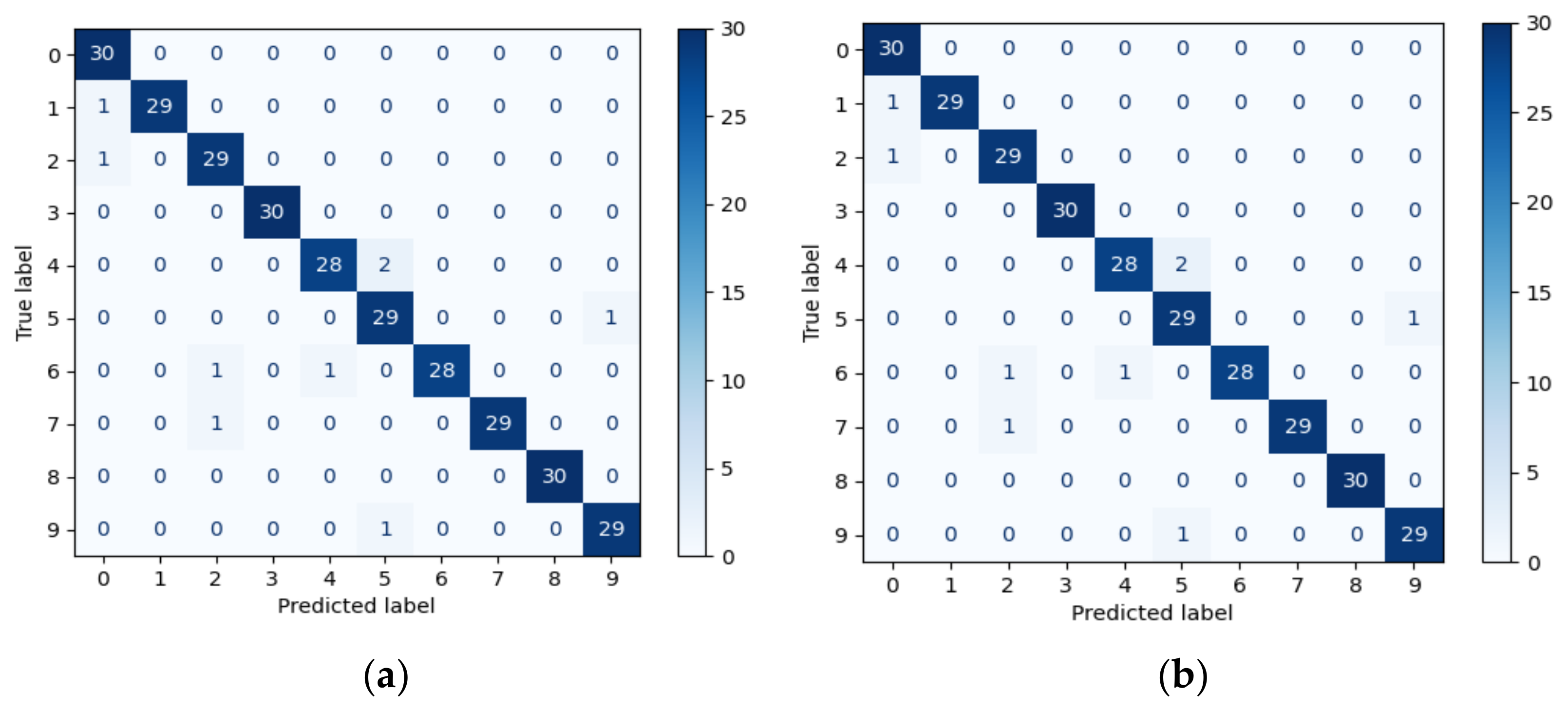
Neural networks are used as the classifier in this research. The type of neural network used is a sequential neural network. The number of input nodes will be the number of features used for training, while the number of output nodes will be ten, corresponding to the digit 0–9. Dataset 1, Dataset 2, and Dataset 3 are used to train three models, totaling nine trained models. Dataset 4 is used to evaluate the performance of the models and not for training. This study’s training and evaluation algorithm is depicted in Algorithm 2.
| Algorithm 2: Model Training Steps. |
| inputs: training, testing, and validation set |
| The selected feature sets Fs15 and Fs10 |
| Initialization: initialize untrained model m1, m2, and m3 |
| output: trained model m1, m2, and m3 |
| 1 train m1 using the original training and testing set |
| 2 evaluate m1 performance using the original validation set |
| 3 reduce the number of features in the dataset to follow Fs15 |
| 4 train m2 using the Fs15 training and testing set |
| 5 evaluate m2 performance using the Fs15 validation set |
| 6 reduce the number of features in the dataset to follow Fs10 |
| 7 train m3 using the Fs10 training and testing set |
| 8 evaluate m3 performance using the Fs10 validation set |
For the model training and evaluation, it will need the training, testing, and validation set. We will also need the feature selection result. Fs15 is the top 15 important features and Fs10 is the top 10 important features. First 3 untrained models m1, m2, and m3 will be initialized. Model m1 will be trained using the original 21 features, m2 will use 15 features in Fs15, while m3 will use 10 features in Fs10. First, we will train and test the model m1 using the original training and testing data. Then model m1 will be evaluated using the validation dataset. Next, we will reduce the number of features in the training, testing and validation sets to follow Fs15 features. Then model m2 will be trained and tested using the already feature-reduced dataset. After that, model m2 will be evaluated for its performance. The features in the training, testing, and validation will then be reduced once more to conform with Fs10. Finally, model m3 will be trained, tested, and also validated using the dataset having 10 features only. This procedure will be conducted for Dataset 1, Dataset 2, and Dataset 3 to produce three trained models per dataset.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}